
Performance Evaluation of Different Object Detection Models for the Segmentation of Optical Cups and Discs

 ,
,  , ,
, ,  , and
, and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Foundation in Object Detection with Deep Learning
2.1.1. R-CNN
2.1.2. Fast R-CNN
2.1.3. Faster R-CNN
2.1.4. Mask R-CNN
2.2. Common Components in Object Detection Architectures
- Backbone: The network takes an image as input and extracts the feature map without the last fully connected layer. The backbone can be a pre-trained neural network.
- Neck: Following the backbone, the neck layer extracts more elaborate feature maps from different stages.
- DenseHead: This works on dense locations of feature maps. An example is RPN, where anchor boxes are generated from anchor points founding it in feature maps. Scales and aspect ratios are crucial elements used to make candidate boxes.
- RoIExtractor: This component extracts RoI-wise features using RoI Pooling techniques and RoI Aling allowing transform non-uniform target cells to the same size.
- RoIHead: This takes RoI features into a specific task such as bounding-box classification/regression and mask prediction in instance segmentation.
2.3. Instance Segmentation Models
2.3.1. Cascade R-CNN
2.3.2. Mask Scoring R-CNN
2.3.3. PointRend: Image Segmentation as Rendering
2.3.4. CARAFE
2.3.5. GCNet
2.3.6. SOLO
2.4. Materials
2.4.1. Device and Databases
- (a)
- REFUGE [47]: The Retinal Fundus Glaucoma Challenge was the first challenge on glaucoma assessment from retinal fundus photography and is one of the most extensive public datasets available for cup/disc segmentation. It consists of 1200 retinal images in JPEG format. Two devices were used: a Zeiss Visucam 500 fundus camera with a resolution of 2124 × 2056 pixels (400 images) and a Canon CR-2 with a resolution of 1634 × 1634 pixels (800 images). The macula and optic disc are visible in each image, centered at the posterior pole.
- (b)
- G1020 [48]: A new public dataset for cup/disc segmentation and images was collected at a private clinical practice in Kaiserslautern, Germany, between 2005 and 2017, with a 45-degree field of view after dilation drops. Experts marked optic-disc and cup boundaries and bounding-box annotations using labelme [49], a free, open-source tool for annotations. Images are stored in JPG format with sizes between 1944 × 2108 and 2426 × 3007 pixels.
2.4.2. Experimentation
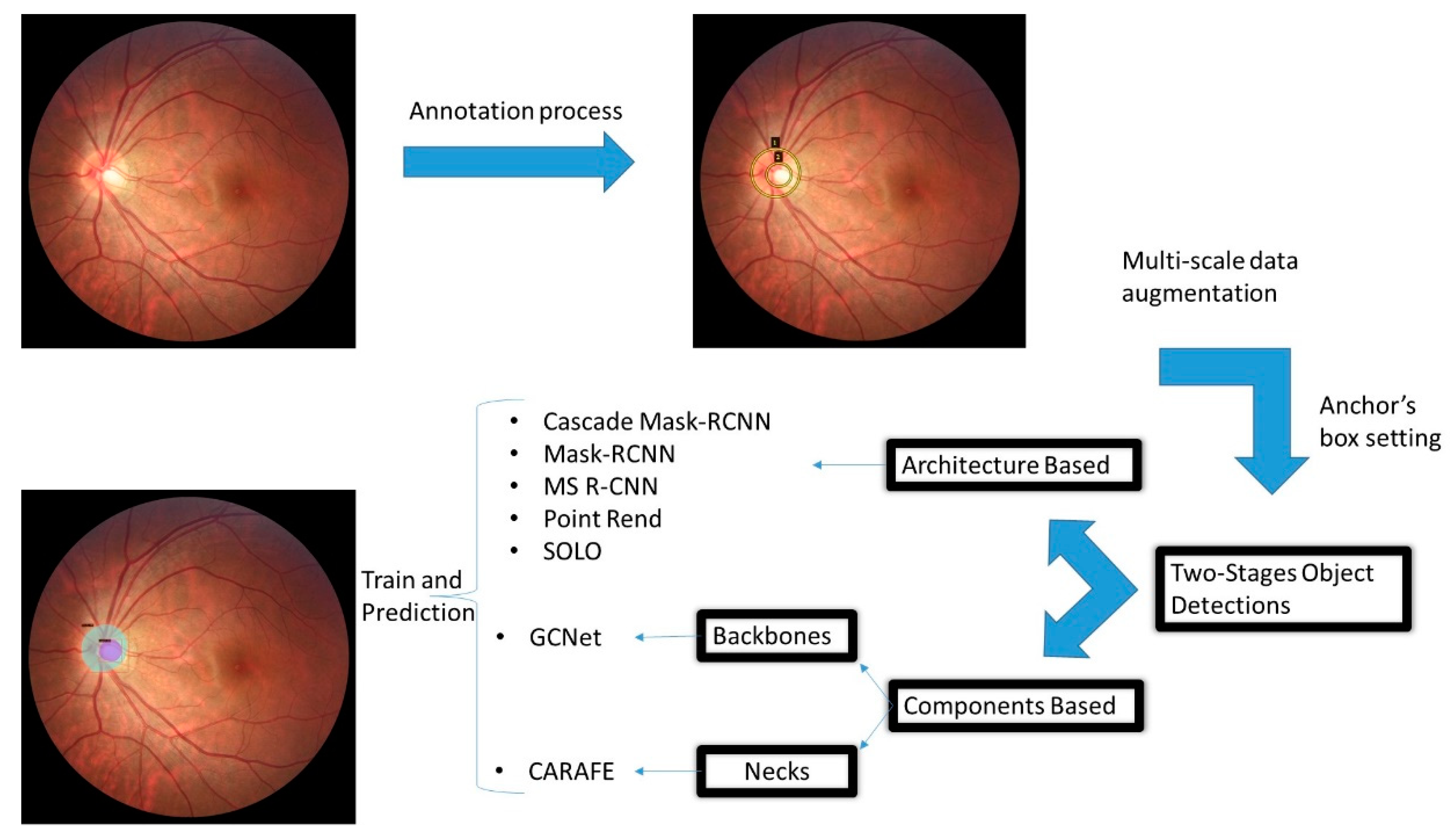
Annotations and Pre-Processing
Training Setting
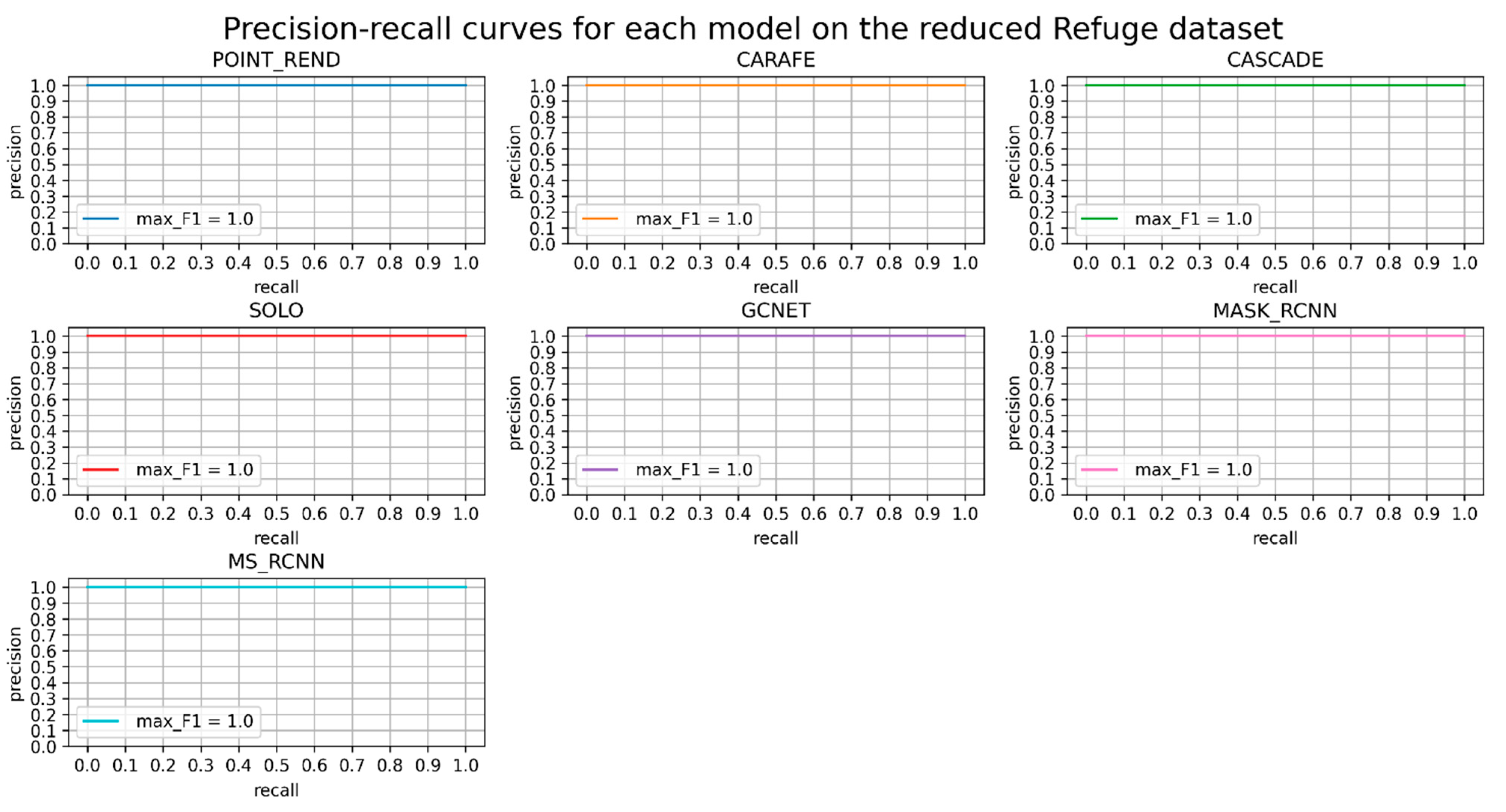
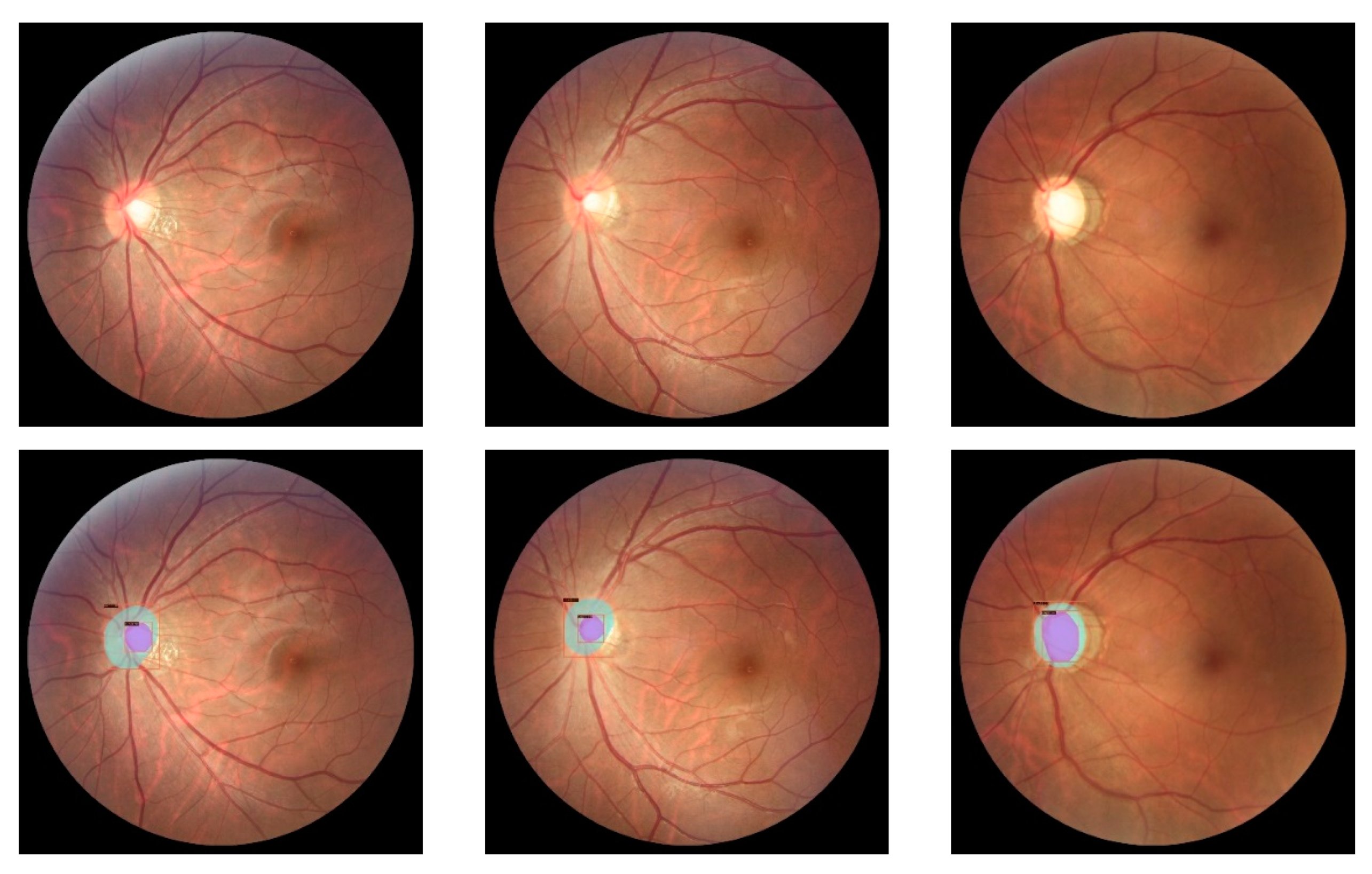
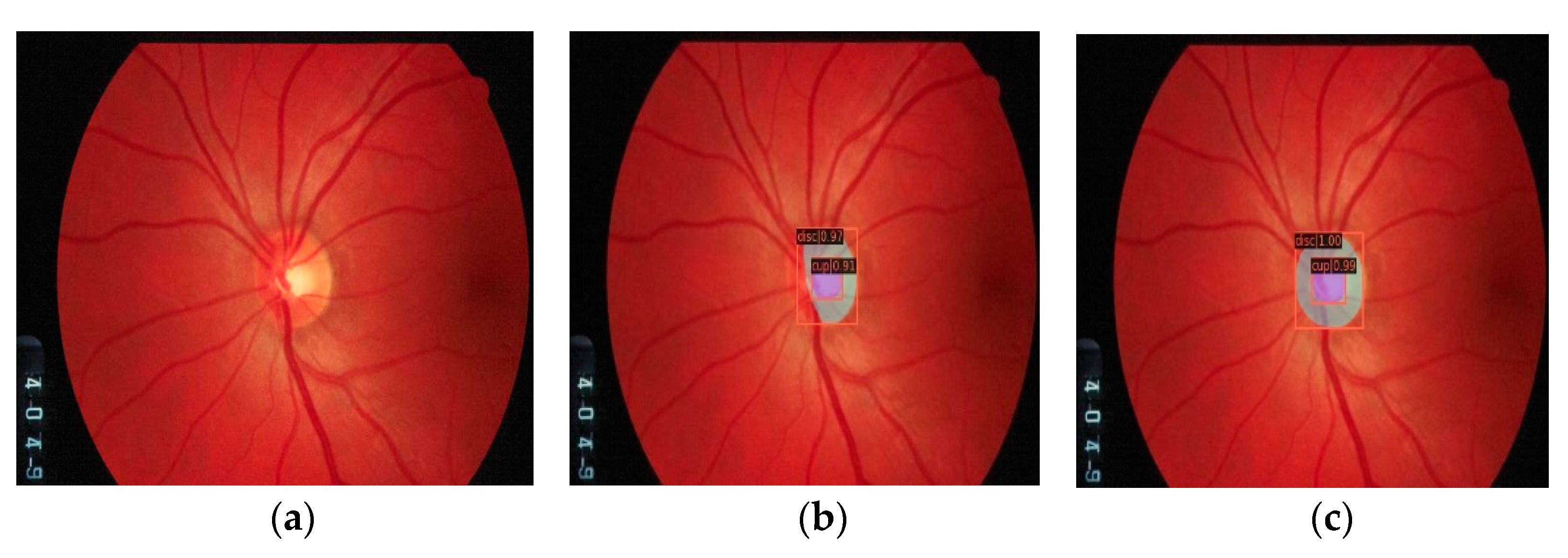
3. Evaluations and Results
- C75: area under the curve corresponds to AP[IoU=0.75] metric.
- C50: area under the curve corresponds to AP[IoU=0.50] metric.
- Loc: localization errors are ignored, but not duplicate detections.
- Sim: PR after supercategory false positives (fps) are removed.
- Oth: PR after all class confusions are removed.
- BG: PR after all background (and class confusion) fps are removed.
- FN: PR after all remaining errors are removed (trivially AP = 1).
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organisation. World Report on Vision; World Health Organisation: Geneva, Switzerland, 2019; Volume 214, ISBN 9789241516570. [Google Scholar]
- Giaconi, J.A.; Law, S.K.; Coleman, A.L.; Caprioli, J.; Nouri-Mahdavi, K. (Eds.) Pearls of Glaucoma Management, 2nd ed.; Springer: Berlin, Germany, 2016. [Google Scholar]
- Swathy, R.V. A Survey on Glaucoma Detection Methods. Imp. J. Interdiscip. Res. 2017, 3. [Google Scholar]
- Kanski, J.J.; Bowling, B. Kanski’s Clinical Ophthalmology E-Book: A Systematic Approach; Elsevier Health Sciences: Amsterdam, The Netherlands, 2015; ISBN 9780702055744. [Google Scholar]
- Abramoff, M.D.; Garvin, M.K.; Sonka, M. Retinal Imaging and Image Analysis. IEEE Rev. Biomed. Eng. 2010, 3, 169–208. [Google Scholar] [CrossRef] [Green Version]
- Veena, H.N.; Muruganandham, A.; Kumaran, T.S. A Review on the optic disc and optic cup segmentation and classification approaches over retinal fundus images for detection of glaucoma. SN Appl. Sci. 2020, 2, 1476. [Google Scholar] [CrossRef]
- Alawad, M.; Aljouie, A.; Alamri, S.; Alghamdi, M.; Alabdulkader, B.; Alkanhal, N.; Almazroa, A. Machine Learning and Deep Learning Techniques for Optic Disc and Cup Segmentation–A Review. Clin. Ophthalmol. 2022, 16, 747–764. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Xu, Y.; Zhao, W.; You, T.; Liu, J. Optic Disc Segmentation from Retinal Fundus Images via Deep Object Detection Networks. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 17–21 July 2018; pp. 5954–5957. [Google Scholar]
- Chakravarty, A.; Sivaswamy, J. A Deep Learning based Joint Segmentation and Classification Framework for Glaucoma Assesment in Retinal Color Fundus Images. arXiv 2018, arXiv:1808.01355. [Google Scholar] [CrossRef]
- Al-Bander, B.; Williams, B.M.; Al-Nuaimy, W.; Al-Taee, M.A.; Pratt, H.; Zheng, Y. Dense Fully Convolutional Segmentation of the Optic Disc and Cup in Colour Fundus for Glaucoma Diagnosis. Symmetry 2018, 10, 87. [Google Scholar] [CrossRef] [Green Version]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. CE-Net: Context Encoder Network for 2D Medical Image Segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [Green Version]
- Fu, H.; Cheng, J.; Xu, Y.; Zhang, C.; Wong, D.W.K.; Liu, J.; Cao, X. Disc-Aware Ensemble Network for Glaucoma Screening From Fundus Image. IEEE Trans. Med. Imaging 2018, 37, 2493–2501. [Google Scholar] [CrossRef] [Green Version]
- Singh, V.K.; Rashwan, H.A.; Akram, F.; Pandey, N.; Sarker, M.M.K.; Saleh, A.; Abdulwahab, S.; Maaroof, N.; Barrena, J.T.; Romani, S.; et al. Retinal Optic Disc Segmentation using Conditional Generative Adversarial Network. Front. Artif. Intell. Appl. 2018, 308, 373–380. [Google Scholar] [CrossRef]
- Sreng, S.; Maneerat, N.; Hamamoto, K.; Win, K.Y. Deep Learning for Optic Disc Segmentation and Glaucoma Diagnosis on Retinal Images. Appl. Sci. 2020, 10, 4916. [Google Scholar] [CrossRef]
- Wang, S.; Yu, L.; Yang, X.; Fu, C.-W.; Heng, P.-A. Patch-Based Output Space Adversarial Learning for Joint Optic Disc and Cup Segmentation. IEEE Trans. Med. Imaging 2019, 38, 2485–2495. [Google Scholar] [CrossRef] [PubMed]
- Son, J.; Park, S.J.; Jung, K.-H. Towards Accurate Segmentation of Retinal Vessels and the Optic Disc in Fundoscopic Images with Generative Adversarial Networks. J. Digit. Imaging 2019, 32, 499–512. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Pan, D.; Song, H. Joint optic disc and cup segmentation based on densely connected depthwise separable convolution deep network. BMC Med. Imaging 2021, 21, 14. [Google Scholar] [CrossRef] [PubMed]
- Tian, Z.; Zheng, Y.; Li, X.; Du, S.; Xu, X. Graph convolutional network based optic disc and cup segmentation on fundus images. Biomed. Opt. Express 2020, 11, 3043–3057. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Zhang, X.; Xu, X.; Tian, Z.; Du, S. Deep level set method for optic disc and cup segmentation on fundus images. Biomed. Opt. Express 2021, 12, 6969–6983. [Google Scholar] [CrossRef]
- Zhang, J.; Zheng, Y.; Hou, W.; Jiao, W. Leveraging non-expert crowdsourcing to segment the optic cup and disc of multicolor fundus images. Biomed. Opt. Express 2022, 13, 3967–3982. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [Green Version]
- Sadhukhan, S.; Ghorai, G.K.; Maiti, S.; Sarkar, G.; Dhara, A.K. Optic Disc Localization in Retinal Fundus Images using Faster R-CNN. In Proceedings of the 2018 Fifth International Conference on Emerging Applications of Information Technology (EAIT), Kolkata, India, 12–13 January 2018; pp. 1–4. [Google Scholar]
- Ajitha, S.; Judy, M. V Faster R-CNN classification for the recognition of glaucoma. J. Phys. Conf. Ser. 2020, 1706, 012170. [Google Scholar] [CrossRef]
- Li, G.; Li, C.; Zeng, C.; Gao, P.; Xie, G. Region Focus Network for Joint Optic Disc and Cup Segmentation. Proc. AAAI Conf. Artif. Intell. 2020, 34, 751–758. [Google Scholar] [CrossRef]
- Kakade, P.; Kale, A.; Jawade, I.; Jadhav, R.; Kulkarni, N. Optic Disc Detection using Image Processing and Deep Learning. Int. J. Comput. Digit. Syst. 2016, 3, 1–8. [Google Scholar]
- Nazir, T.; Irtaza, A.; Starovoitov, V. Optic Disc and Optic Cup Segmentation for Glaucoma Detection from Blur Retinal Images Using Improved Mask-RCNN. Int. J. Opt. 2021, 2021, 6641980. [Google Scholar] [CrossRef]
- Guo, Y.; Peng, Y.; Zhang, B. CAFR-CNN: Coarse-to-fine adaptive faster R-CNN for cross-domain joint optic disc and cup segmentation. Appl. Intell. 2021, 51, 5701–5725. [Google Scholar] [CrossRef]
- Almubarak, H.; Bazi, Y.; Alajlan, N. Two-Stage Mask-RCNN Approach for Detecting and Segmenting the Optic Nerve Head, Optic Disc, and Optic Cup in Fundus Images. Appl. Sci. 2020, 10, 3833. [Google Scholar] [CrossRef]
- Wang, Z.; Dong, N.; Rosario, S.D.; Xu, M.; Xie, P.; Xing, E.P. Ellipse Detection Of Optic Disc-And-Cup Boundary In Fundus Images. In Proceedings of the 2019 IEEE 16th Int. Symp. Biomed. Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 601–604. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 3686–3693. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury Google, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, Oregon, USA, 23–28 June 2013. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; Volume 2015, pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. Proc. IEEE Int. Conf. Comput. Vis. 2017, 2017, 2980–2988. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2015, 2016, 770–778. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, VN, USA, 27–30 June 2016. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High Quality Object Detection and Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask Scoring R-CNN. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; Volume 2019, pp. 6402–6411. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. PointRend: Image Segmentation as Rendering. arXiv 2019, arXiv:1912.08193. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. CARAFE: Content-Aware ReAssembly of FEatures. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. SOLO: Segmenting Objects by Locations. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Contributors, M. MMCV: OpenMMLab Computer Vision Foundation 2018. Available online: https://github.com/open-mmlab/mmcv (accessed on 31 October 2022).
- Orlando, J.I.; Fu, H.; Barbosa Breda, J.; van Keer, K.; Bathula, D.R.; Diaz-Pinto, A.; Fang, R.; Heng, P.-A.; Kim, J.; Lee, J.; et al. REFUGE Challenge: A unified framework for evaluating automated methods for glaucoma assessment from fundus photographs. Med. Image Anal. 2020, 59, 101570. [Google Scholar] [CrossRef] [PubMed]
- Bajwa, M.N.; Singh, G.A.P.; Neumeier, W.; Malik, M.I.; Dengel, A.; Ahmed, S. G1020: A Benchmark Retinal Fundus Image Dataset for Computer-Aided Glaucoma Detection. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A Database and Web-Based Tool for Image Annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Dutta, A.; Zisserman, A. The VIA annotation software for images, audio and video. MM 2019-Proc. 27th ACM Int. Conf. Multimed. 2019, 2276–2279. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar] [CrossRef]
- Norouzi, S.; Ebrahimi, M. A Survey on Proposed Methods to Address Adam Optimizer Deficiencies. Available online: https://www.cs.toronto.edu/~sajadn/sajad_norouzi/ECE1505.pdf (accessed on 31 October 2022).
- COCO-Common Objects in Context.
- Müller, D.; Soto-Rey, I.; Kramer, F. Towards a Guideline for Evaluation Metrics in Medical Image Segmentation. arXiv 2022, arXiv:2202.05273. [Google Scholar] [CrossRef]
- Carmona, E.J.; Rincón, M.; García-Feijoó, J.; Martínez-de-la-Casa, J.M. Identification of the optic nerve head with genetic algorithms. Artif. Intell. Med. 2008, 43, 243–259. [Google Scholar] [CrossRef]
- Zhang, Z.; Yin, F.S.; Liu, J.; Wong, W.K.; Tan, N.M.; Lee, B.H.; Cheng, J.; Wong, T.Y. ORIGA-light: An online retinal fundus image database for glaucoma analysis and research. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology, Buenos Aires, Argentina, 31 August–4 September 2010; Volume 2010, pp. 3065–3068. [Google Scholar]
- Shahinfar, S.; Meek, P.; Falzon, G. “How many images do I need?” Understanding how sample size per class affects deep learning model performance metrics for balanced designs in autonomous wildlife monitoring. Ecol. Inform. 2020, 57, 101085. [Google Scholar] [CrossRef]
- Hoiem, D.; Chodpathumwan, Y.; Dai, Q. Diagnosing Error in Object Detectors. In Proceedings of the Computer Vision–ECCV 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 340–353. [Google Scholar]
- Gao, L.; He, Y.; Sun, X.; Jia, X.; Zhang, B. Incorporating Negative Sample Training for Ship Detection Based on Deep Learning. Sensors 2019, 19, 684. [Google Scholar] [CrossRef]
- Grill, J.-B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap your own latent: A new approach to self-supervised Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem |
|
| What is Already Known |
|
| What This Paper Adds |
|
| Model Architecture | AP [IoU = 0.50:0.95] | AP [IoU = 0.5] | AP [IoU = 0.75] | |||
|---|---|---|---|---|---|---|
| WM | M | WM | M | WM | M | |
| CARAFE | 0.657 | 0.607 | 0.979 | 0.965 | 0.771 | 0.621 |
| Cascade Mask-RCNN | 0.618 | 0.608 | 1.000 | 0.980 | 0.661 | 0.646 |
| SOLO | 0.555 | 0.530 | 0.886 | 0.886 | 0.613 | 0.586 |
| GCNET | 0.584 | 0.595 | 0.980 | 0.960 | 0.608 | 0.638 |
| MASK-RCNN | 0.671 | 0.616 | 1.000 | 0.962 | 0.743 | 0.635 |
| MS-RCNN | 0.604 | 0.627 | 0.980 | 0.978 | 0.649 | 0.676 |
| POINT_REND | 0.582 | 0.607 | 1.000 | 0.965 | 0.564 | 0.621 |
| Model Architecture | AP [IoU = 0.50:0.95] | AP [IoU = 0.50] | AP [IoU = 0.75] | F1-Score | |||
|---|---|---|---|---|---|---|---|
| WM | M | WM | M | WM | M | ||
| CARAFE | 0.650 | 0.636 | 0.990 | 0.995 | 0.710 | 0.685 | 1.0 |
| Cascade Mask-RCNN | 0.644 | 0.661 | 0.985 | 0.990 | 0.716 | 0.739 | 0.997 |
| SOLO | 0.610 | 0.647 | 0.989 | 0.984 | 0.676 | 0.703 | 1.0 |
| GCNET | 0.631 | 0.656 | 0.990 | 0.995 | 0.712 | 0.729 | 1.0 |
| MASK-RCNN | 0.595 | 0.629 | 0.948 | 0.988 | 0.662 | 0.701 | 1.0 |
| MS-RCNN | 0.654 | 0.658 | 0.995 | 1.000 | 0.766 | 0.738 | 1.0 |
| POINT_REND | 0.632 | 0.661 | 0.990 | 0.994 | 0.670 | 0.735 | 1.0 |
| Model Architecture | AP [IoU = 0.50:0.95] | AP [IoU = 0.50] | AP [IoU = 0.75] | F1-Score |
|---|---|---|---|---|
| M | M | M | ||
| CARAFE | 0.624 | 0.948 | 0.632 | 0.963 |
| Cascade Mask-RCNN | 0.631 | 0.947 | 0.662 | 0.963 |
| SOLO | 0.568 | 0.909 | 0.583 | 0.916 |
| GCNET | 0.628 | 0.943 | 0.646 | 0.957 |
| MASK-RCNN | 0.613 | 0.941 | 0.621 | 0.963 |
| MS-RCNN | 0.638 | 0.944 | 0.664 | 0.963 |
| POINT_REND | 0.617 | 0.956 | 0.648 | 0.969 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alfonso-Francia, G.; Pedraza-Ortega, J.C.; Badillo-Fernández, M.; Toledano-Ayala, M.; Aceves-Fernandez, M.A.; Rodriguez-Resendiz, J.; Ko, S.-B.; Tovar-Arriaga, S. Performance Evaluation of Different Object Detection Models for the Segmentation of Optical Cups and Discs. Diagnostics 2022, 12, 3031. https://doi.org/10.3390/diagnostics12123031
Alfonso-Francia G, Pedraza-Ortega JC, Badillo-Fernández M, Toledano-Ayala M, Aceves-Fernandez MA, Rodriguez-Resendiz J, Ko S-B, Tovar-Arriaga S. Performance Evaluation of Different Object Detection Models for the Segmentation of Optical Cups and Discs. Diagnostics. 2022; 12(12):3031. https://doi.org/10.3390/diagnostics12123031
Chicago/Turabian StyleAlfonso-Francia, Gendry, Jesus Carlos Pedraza-Ortega, Mariana Badillo-Fernández, Manuel Toledano-Ayala, Marco Antonio Aceves-Fernandez, Juvenal Rodriguez-Resendiz, Seok-Bum Ko, and Saul Tovar-Arriaga. 2022. "Performance Evaluation of Different Object Detection Models for the Segmentation of Optical Cups and Discs" Diagnostics 12, no. 12: 3031. https://doi.org/10.3390/diagnostics12123031
APA StyleAlfonso-Francia, G., Pedraza-Ortega, J. C., Badillo-Fernández, M., Toledano-Ayala, M., Aceves-Fernandez, M. A., Rodriguez-Resendiz, J., Ko, S.-B., & Tovar-Arriaga, S. (2022). Performance Evaluation of Different Object Detection Models for the Segmentation of Optical Cups and Discs. Diagnostics, 12(12), 3031. https://doi.org/10.3390/diagnostics12123031