
Brain Hemorrhage Classification in CT Scan Images Using Minimalist Machine Learning

 ,
,  ,
, 
Abstract
:1. Introduction
- -
- Epidural Hemorrhage (HED);
- -
- Subdural Hemorrhage (SDH);
- -
- Subarachnoid Hemorrhage (SAH);
- -
- Intracerebral Hemorrhage (ICH); and
- -
- Intraventricular Hemorrhage (IVH).
- -
- Interpretability means providing explanations to end users for a particular decision or process.
- -
- Transparency quantitatively measures the ease or accessibility of a model or algorithm.
- -
- Explainability allows an explanation to be given of how a particular model has taken a particular solution.
- -
- Contestability means that any XAI user can affirm or reject a decision taken.
- -
- Justifiability indicates an understanding of the case to support a particular outcome.
2. Materials and Methods
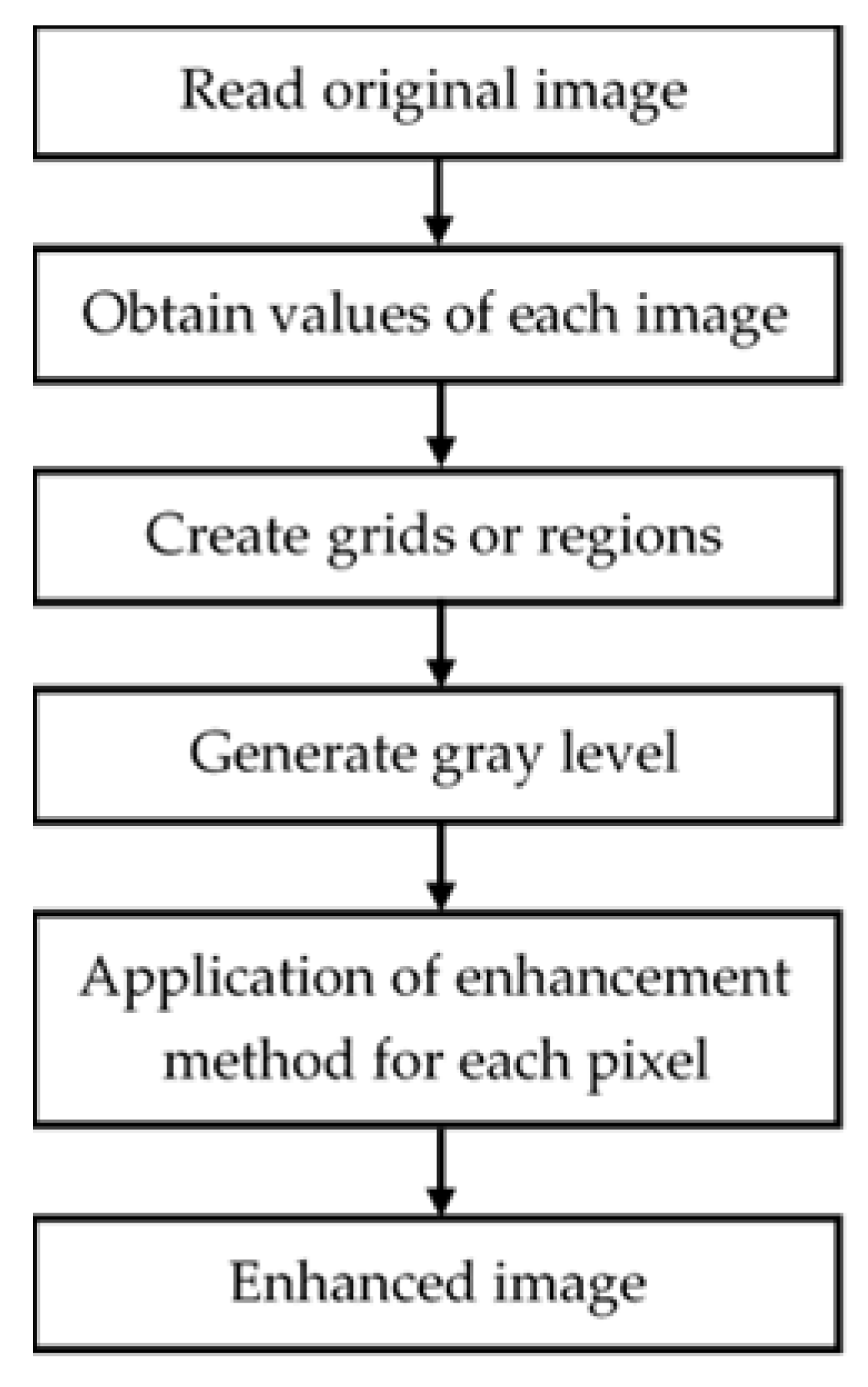
2.1. Image Processing
2.1.1. Contrast Limited Adaptive Histogram Equalization (CLAHE)
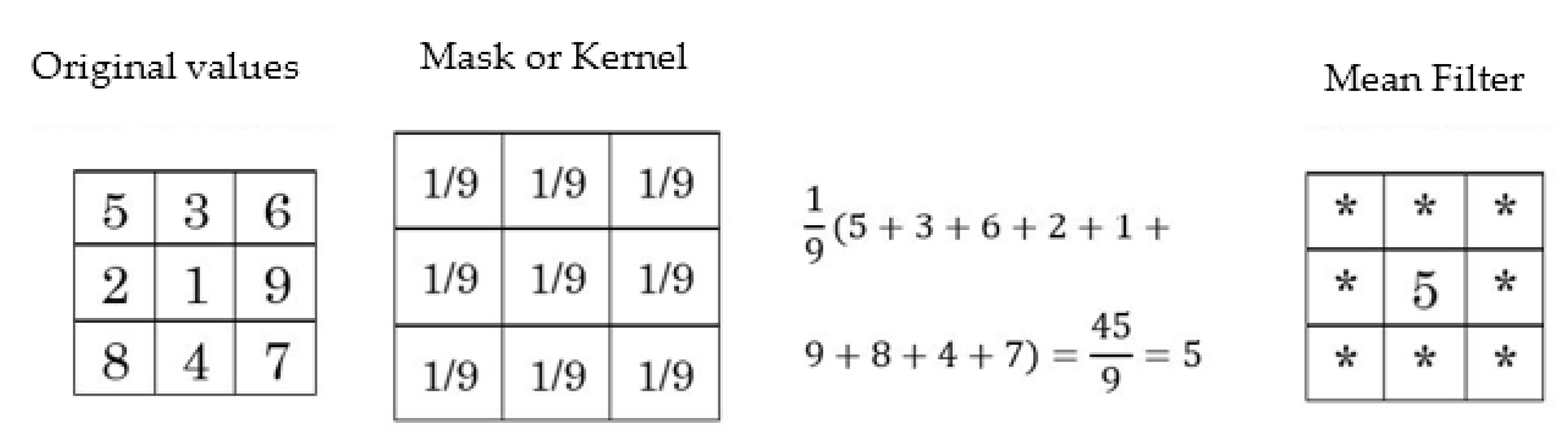
2.1.2. Mean Filter
2.2. Morphological Operations
2.2.1. Erosion
2.2.2. Dilation
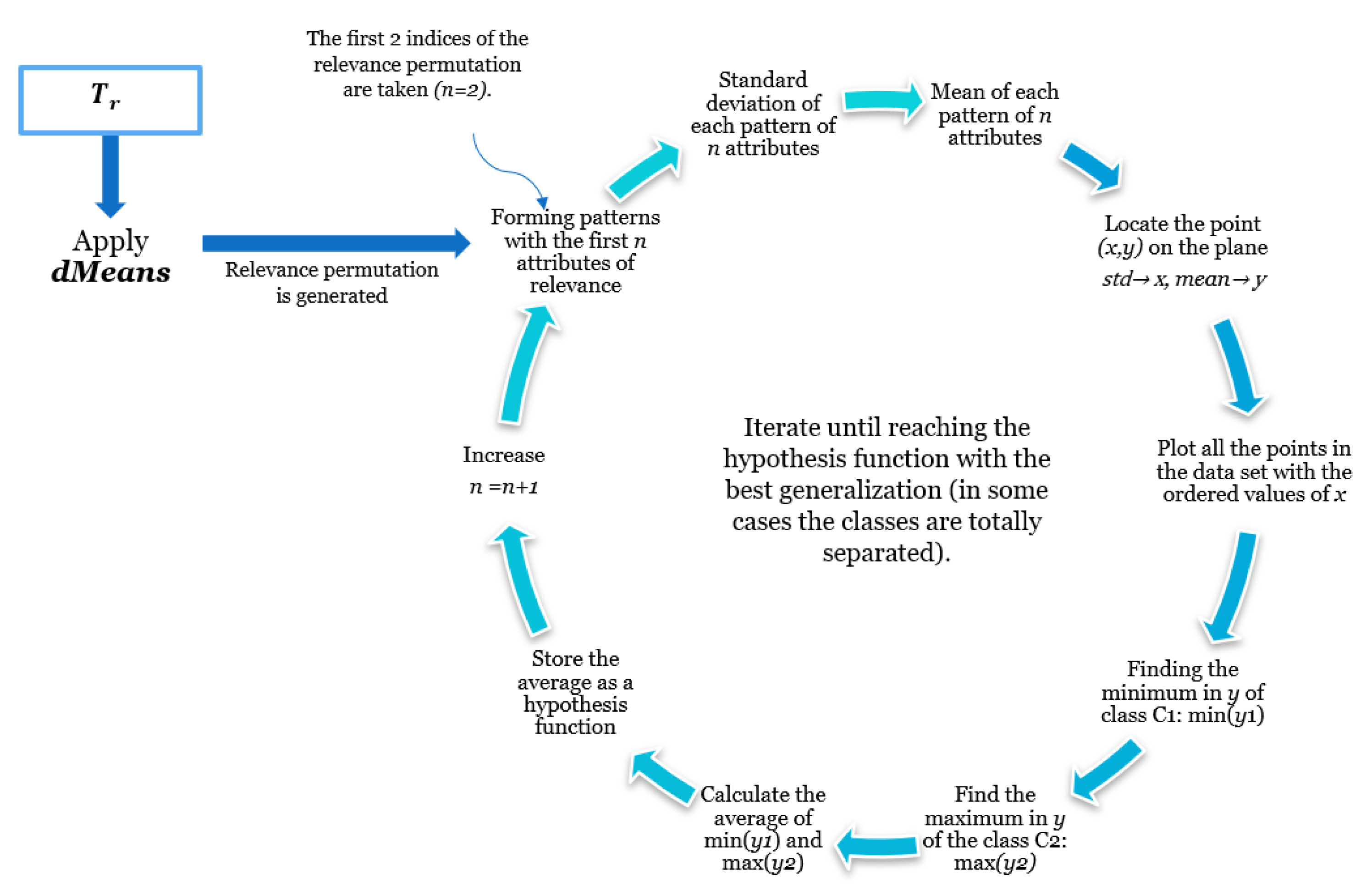
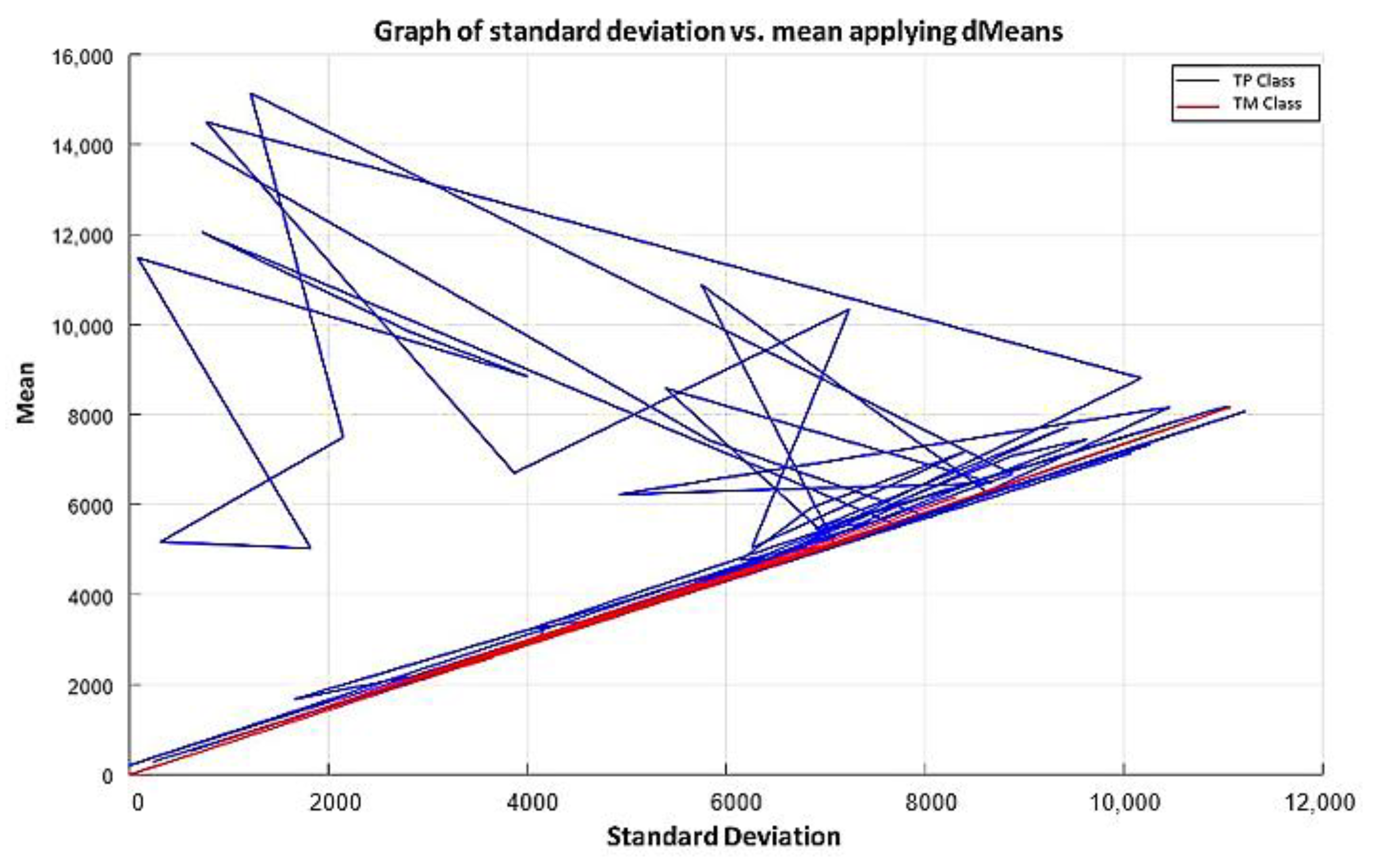
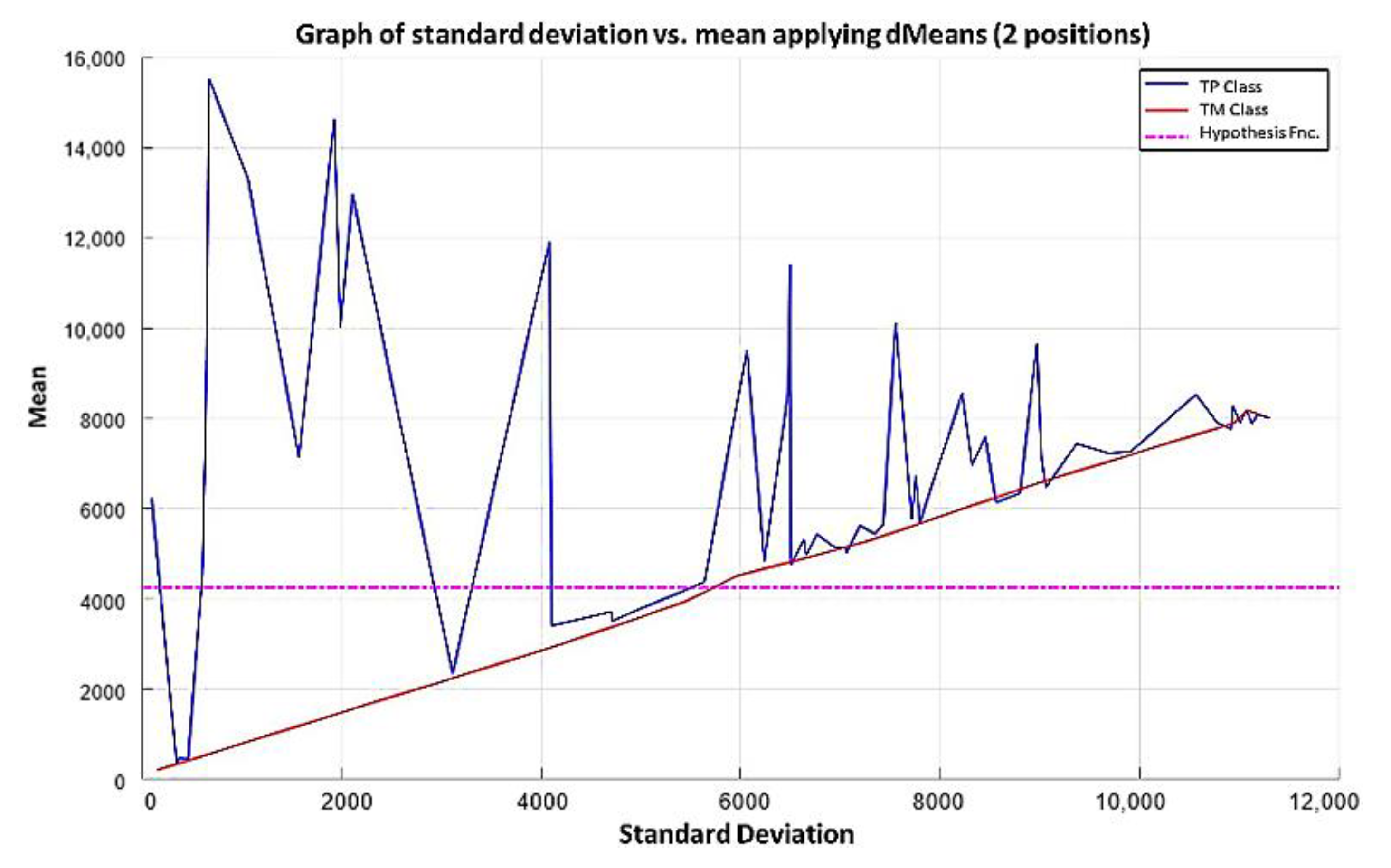
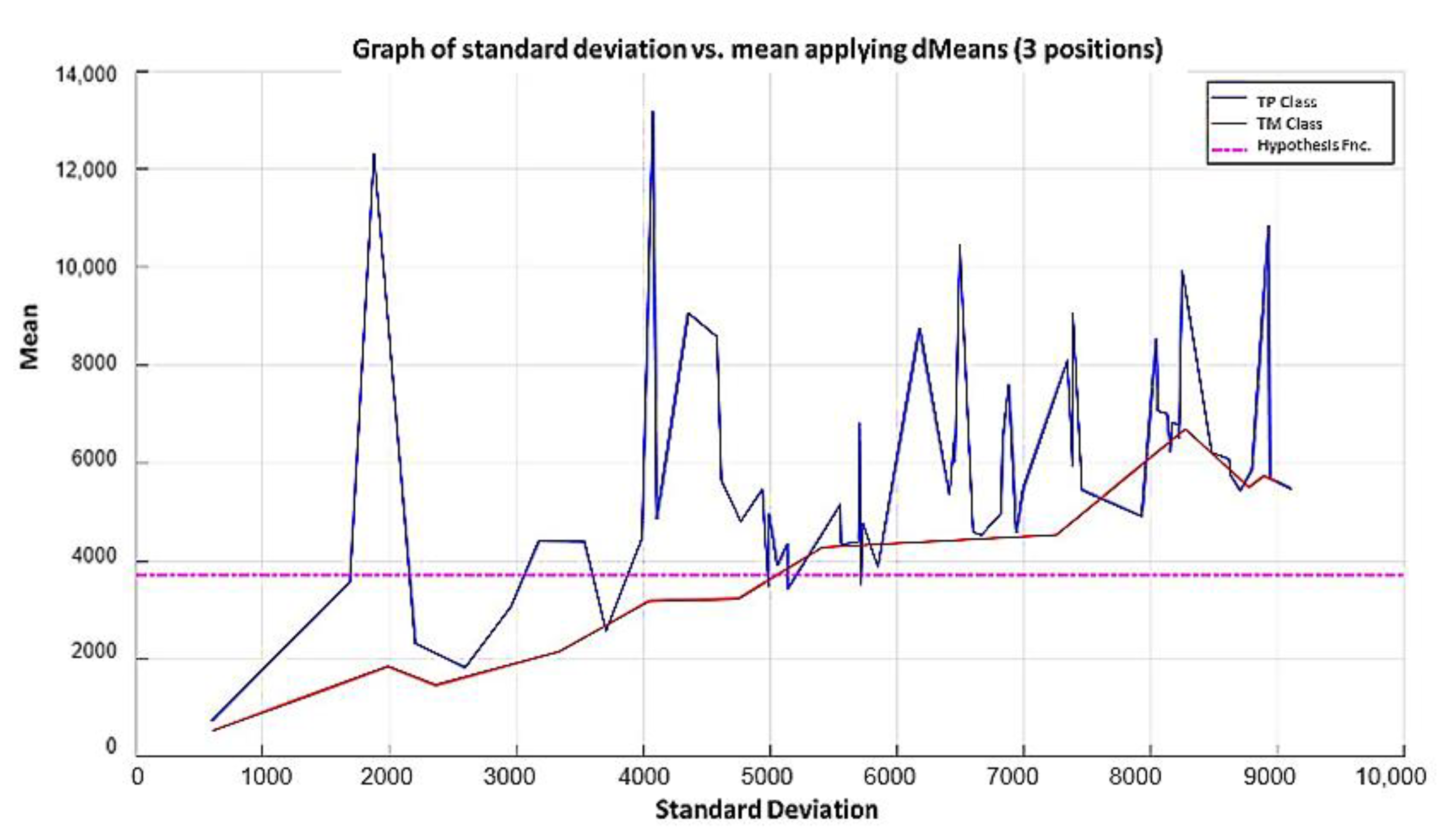
2.3. dMeans
| Algorithm 1:dMeans algorithm. |
Input: training set, with two mutually exclusive classes . The attributes are formed by a set of attributes
|
2.4. Minimalist Machine Learning
3. Proposed Methodology
3.1. Image Enhancement
3.1.1. Contrast Limited Adaptive Histogram Equalization (CLAHE)
3.1.2. Mean Filter
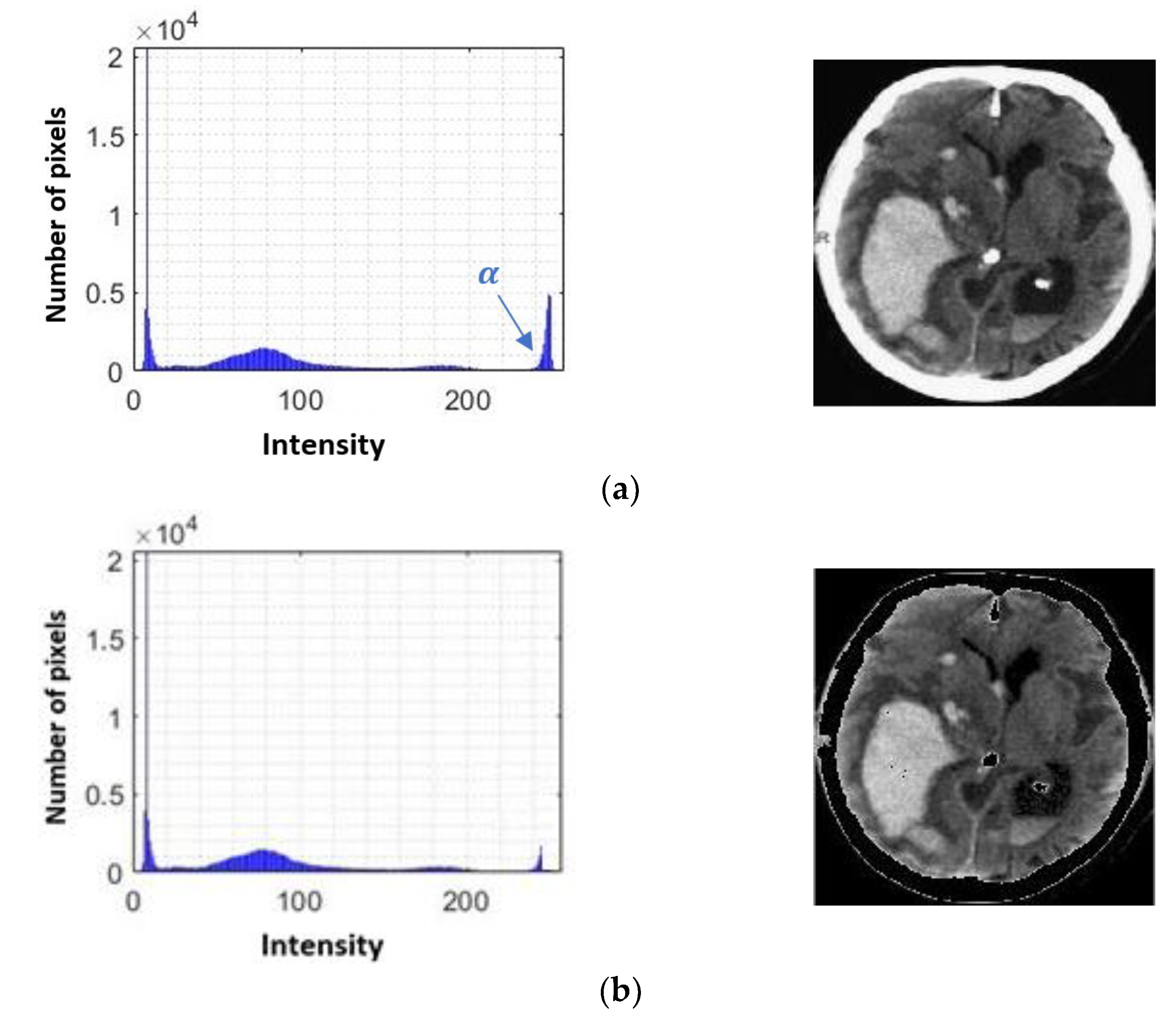
3.1.3. Removing the Skull
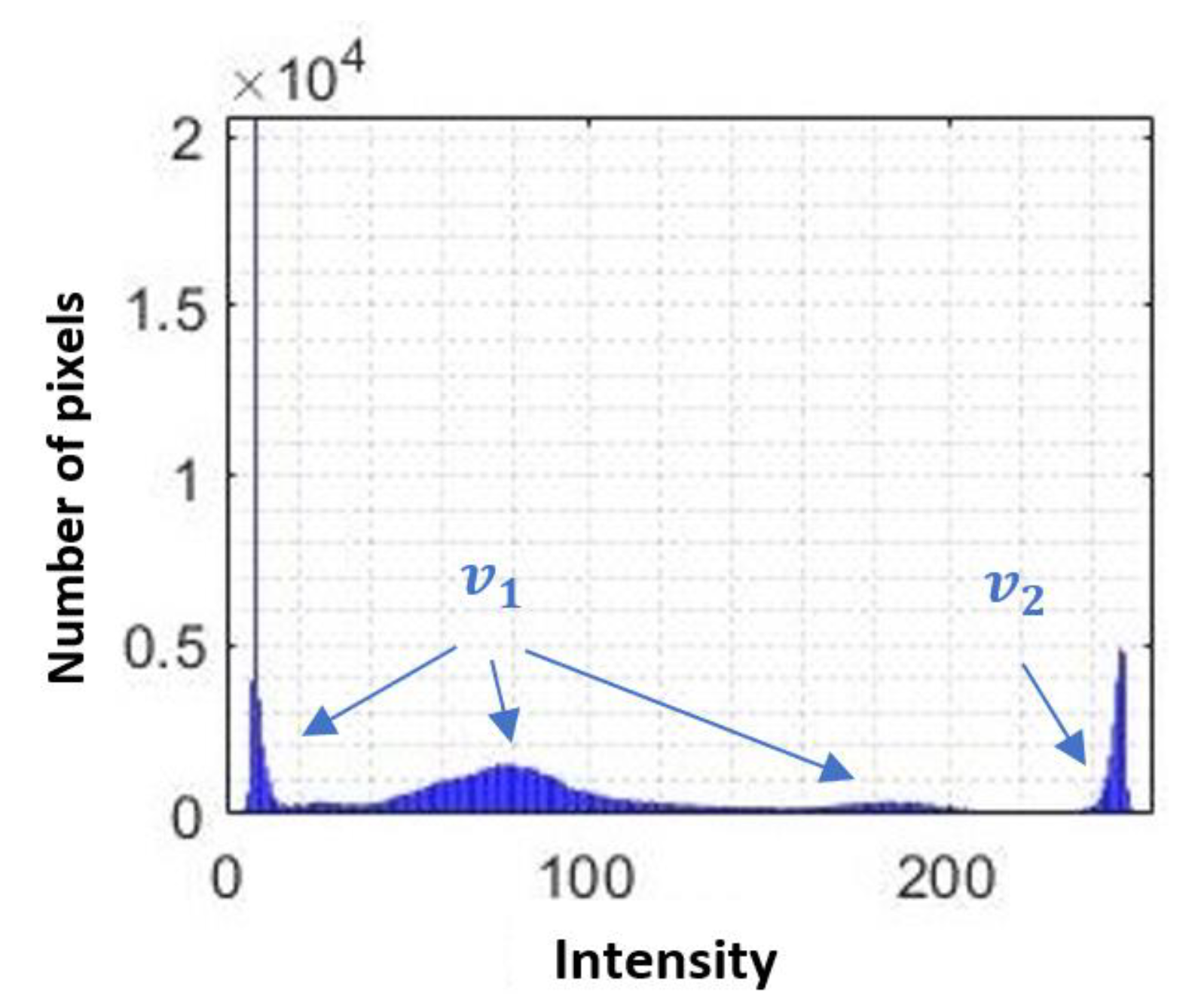
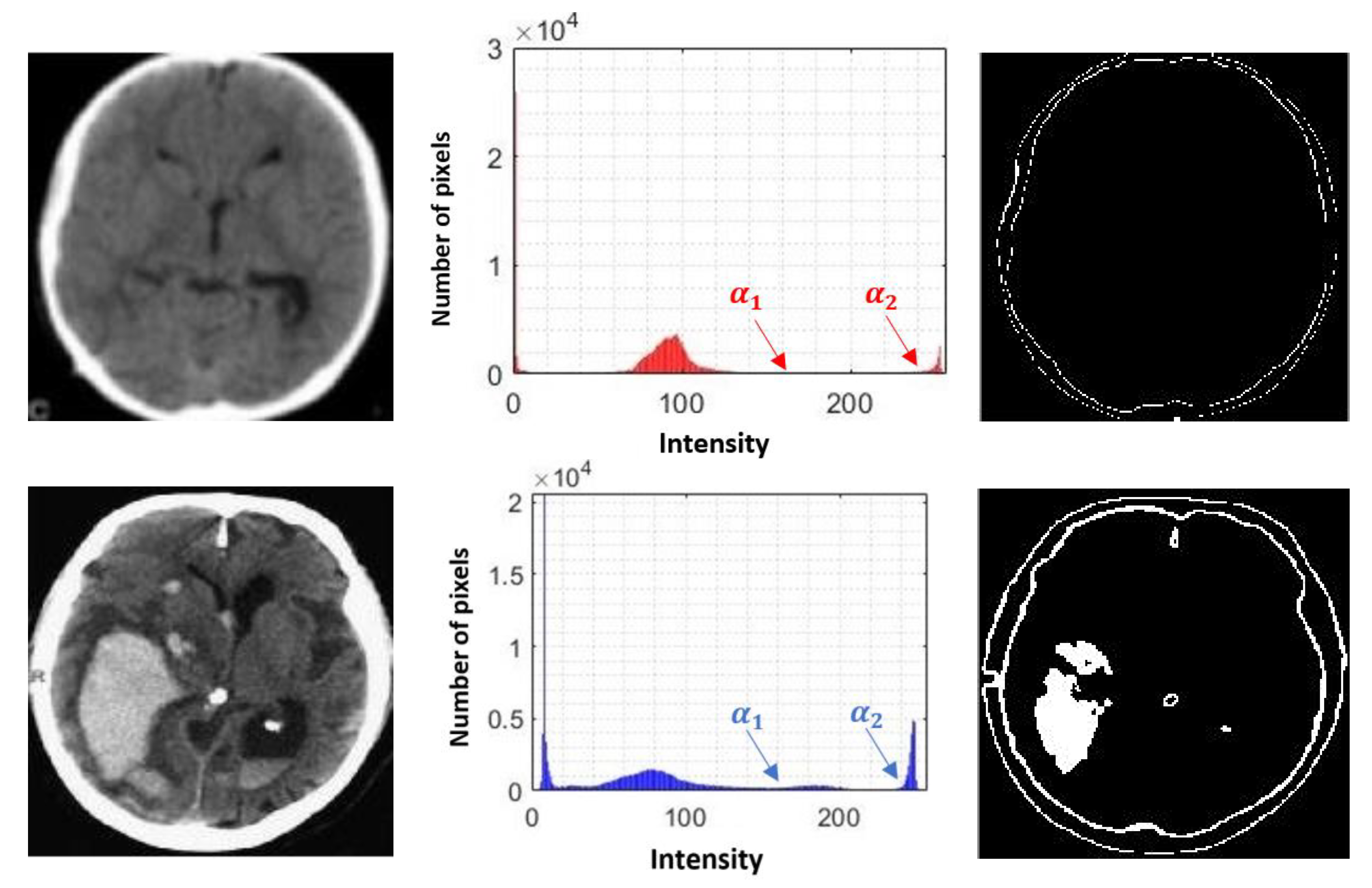
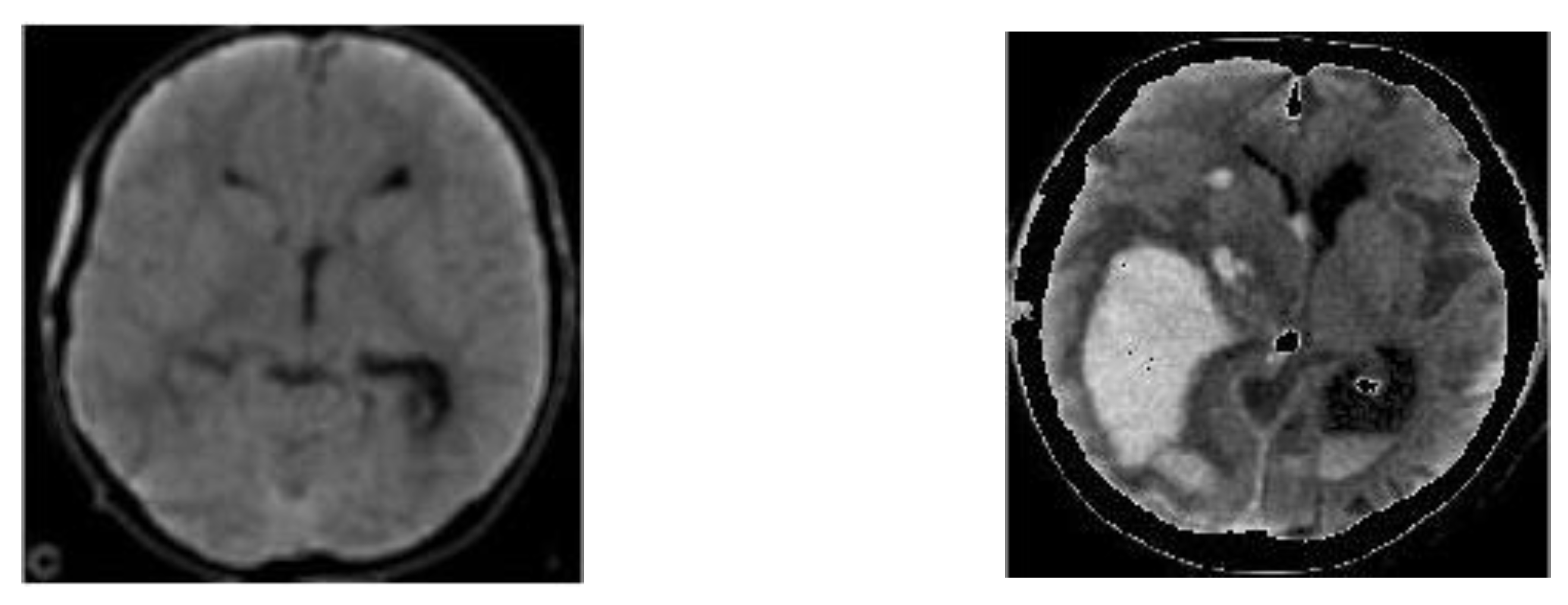
3.1.4. Segmentation of Possible Hemorrhages
3.1.5. Superimposition
3.2. Minimalist Machine Learning
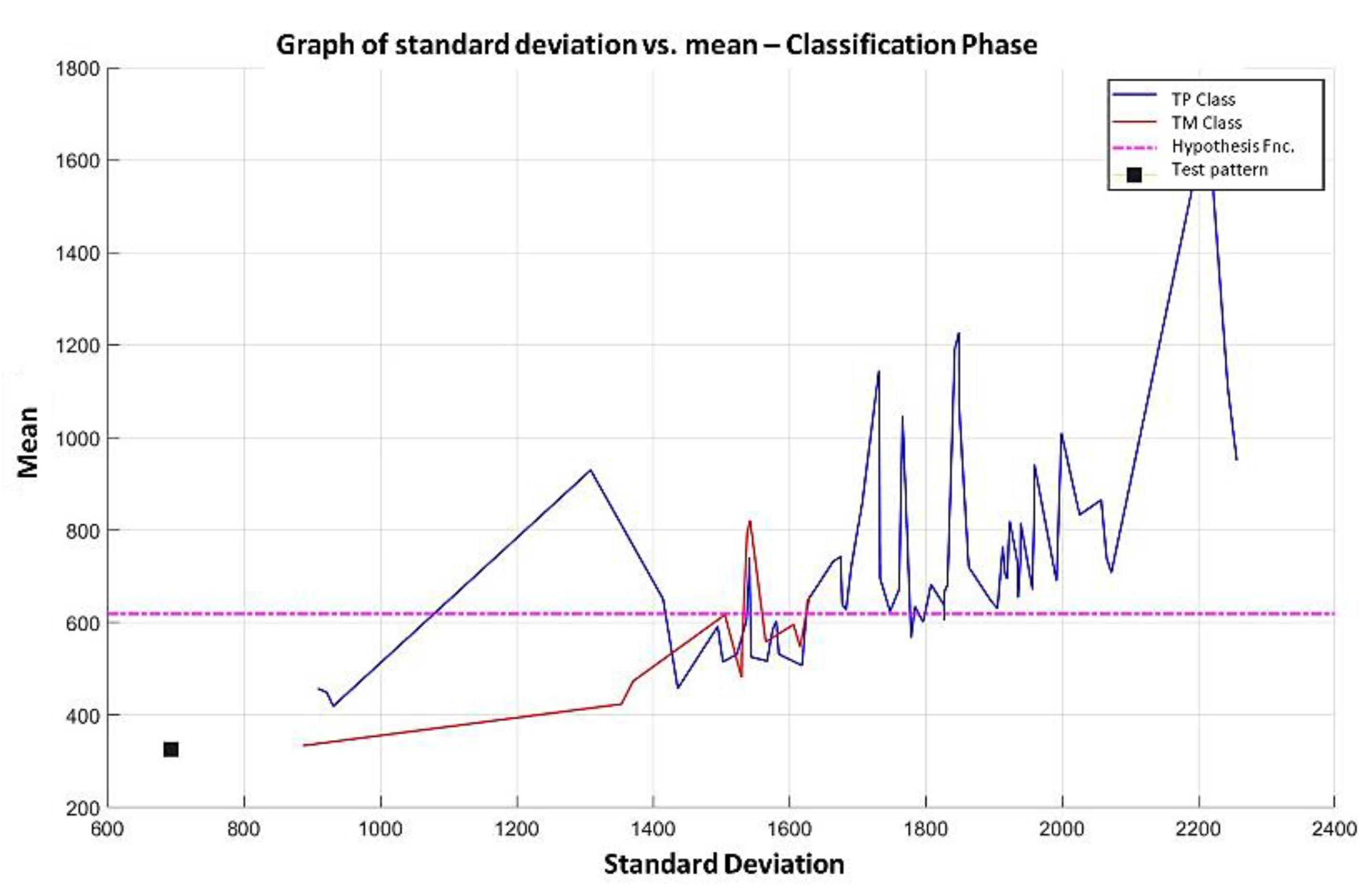
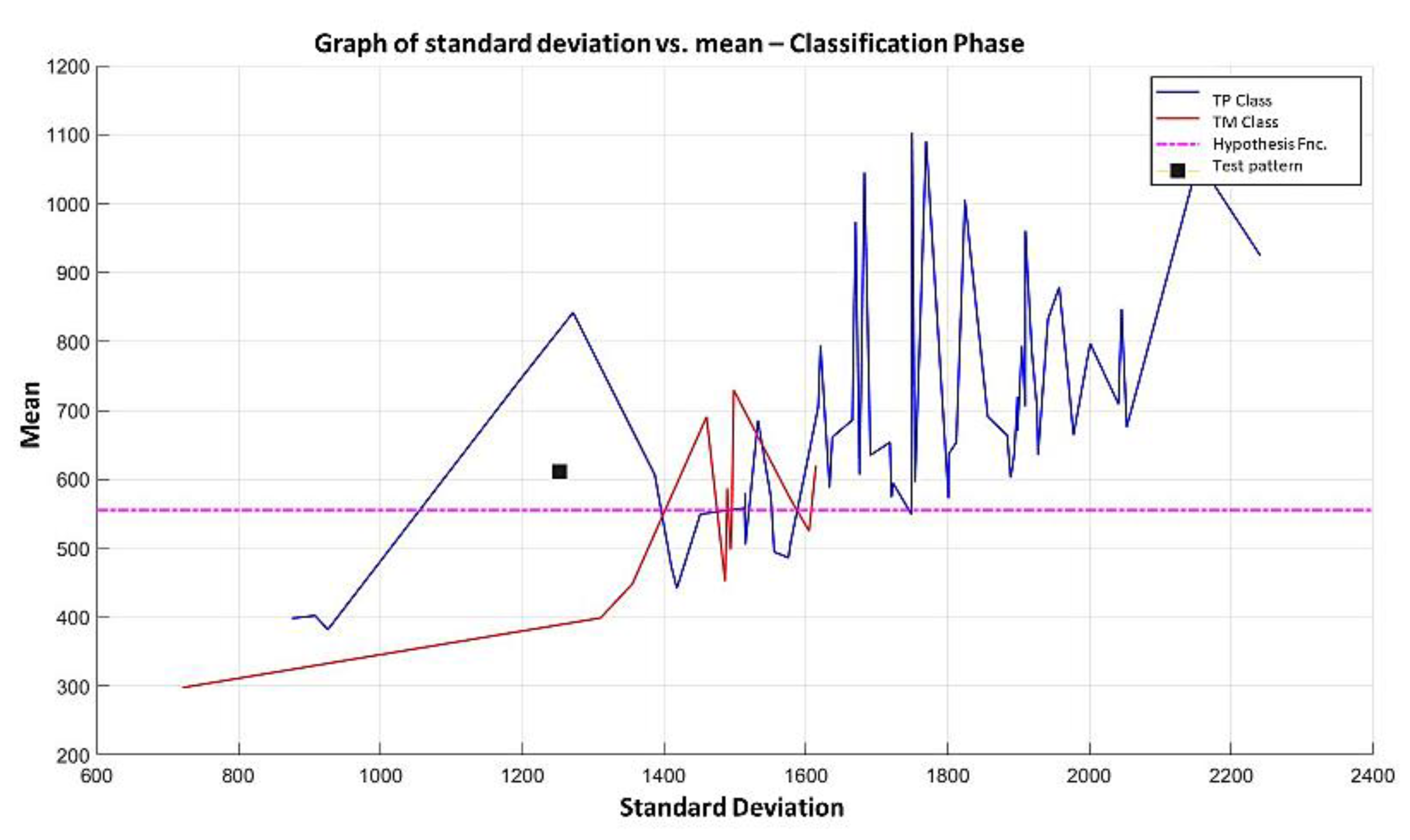
3.2.1. Learning Phase
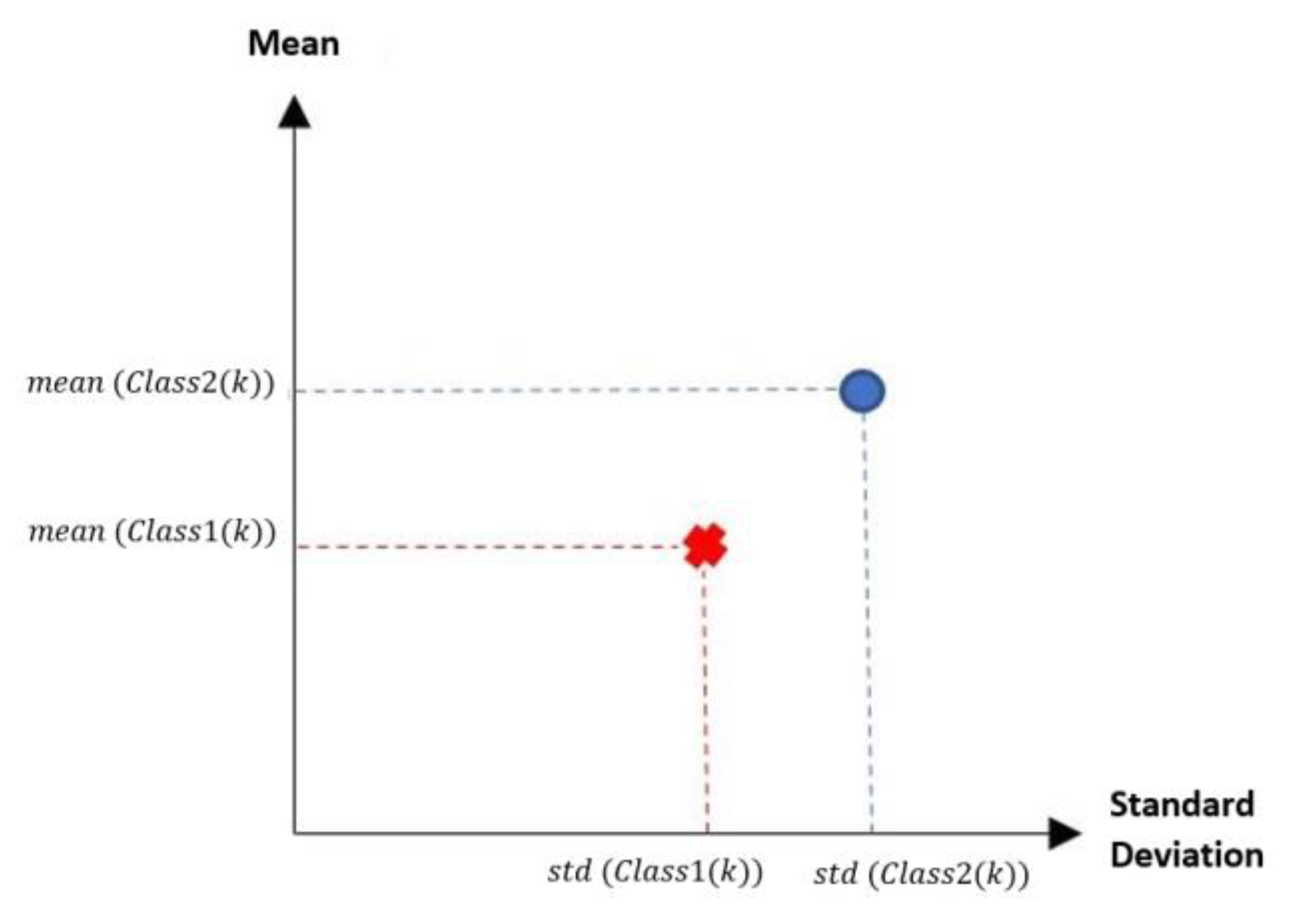
3.2.2. Hypothesis Function
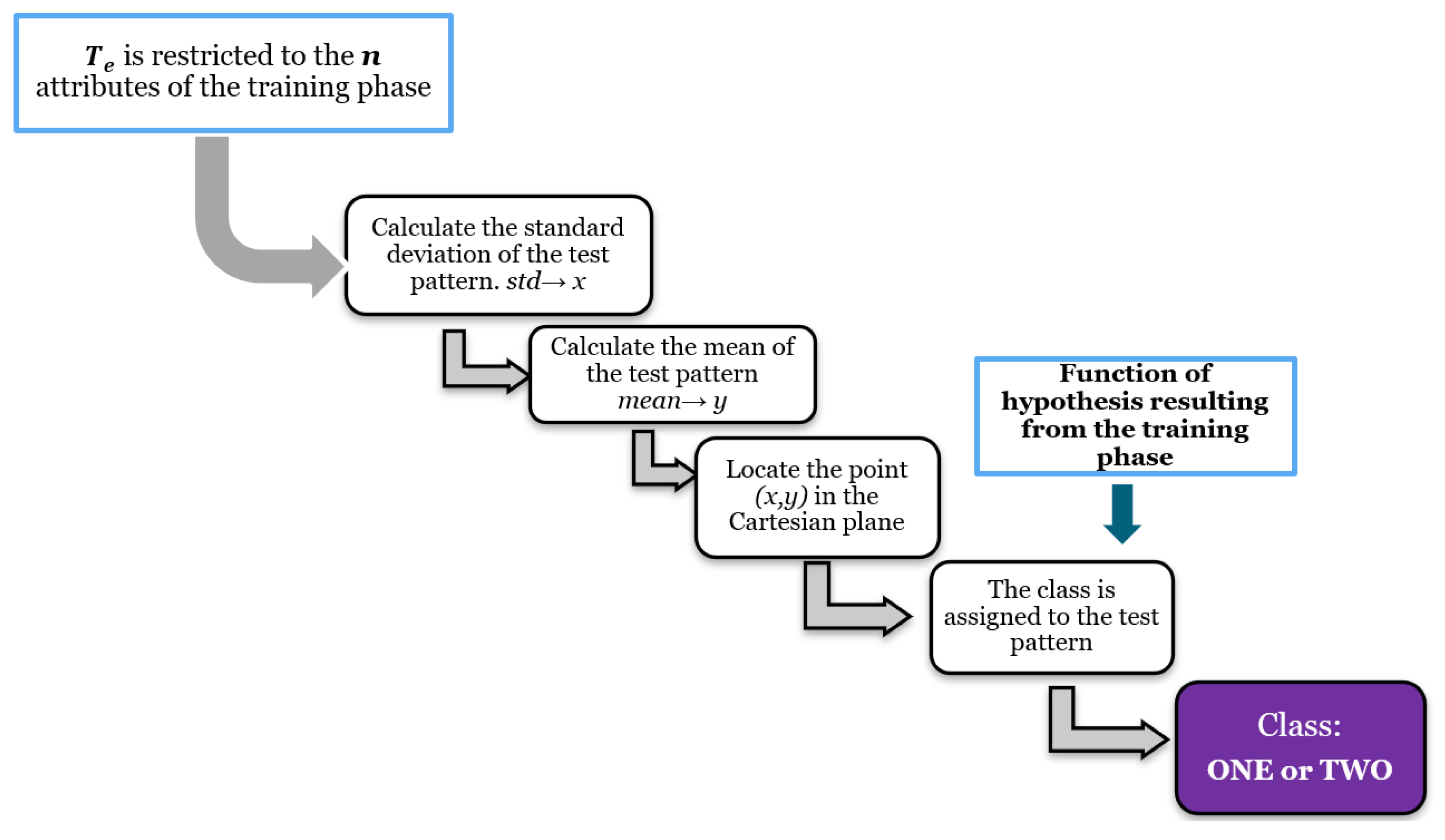
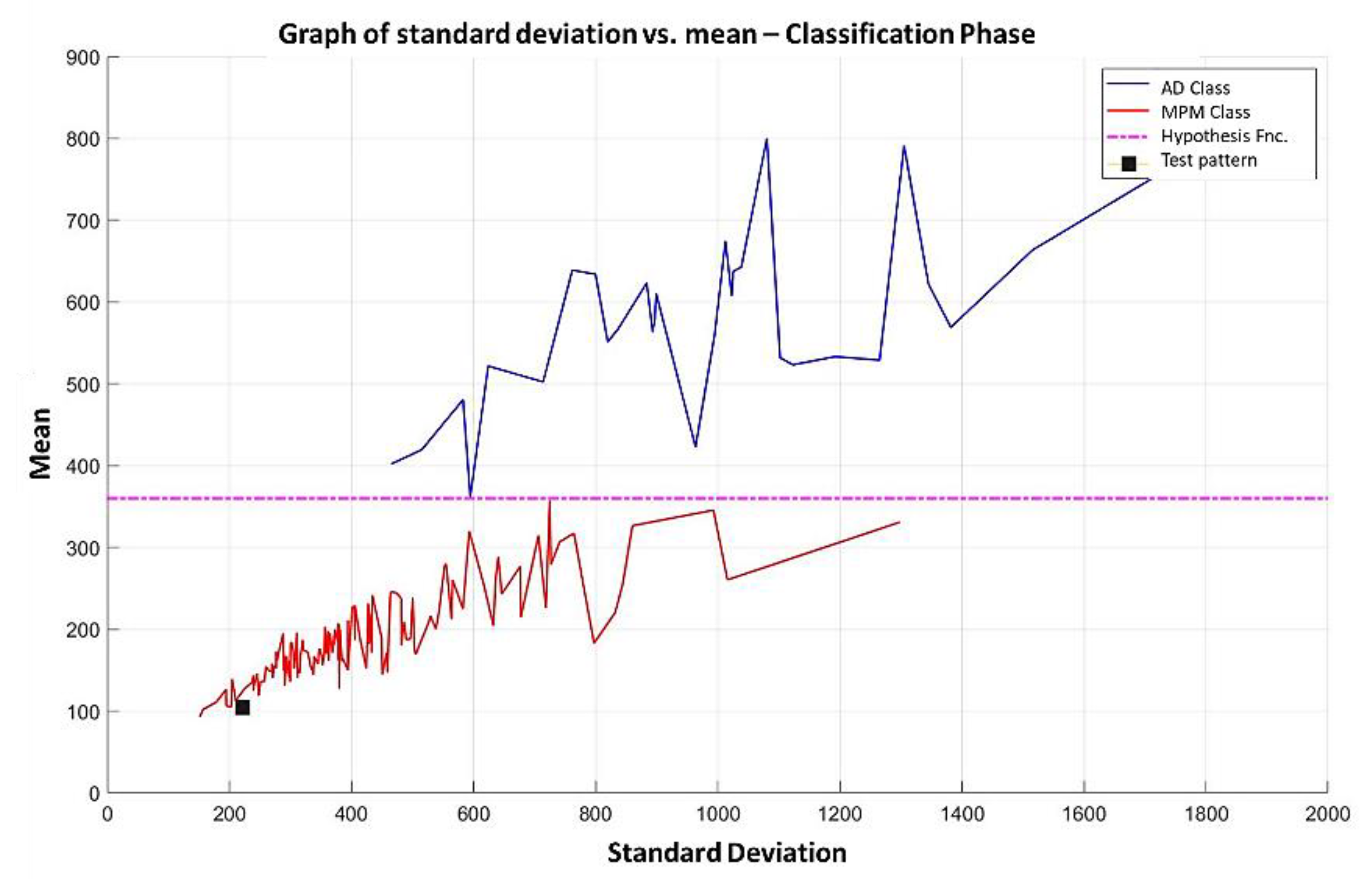
3.2.3. Test Phase
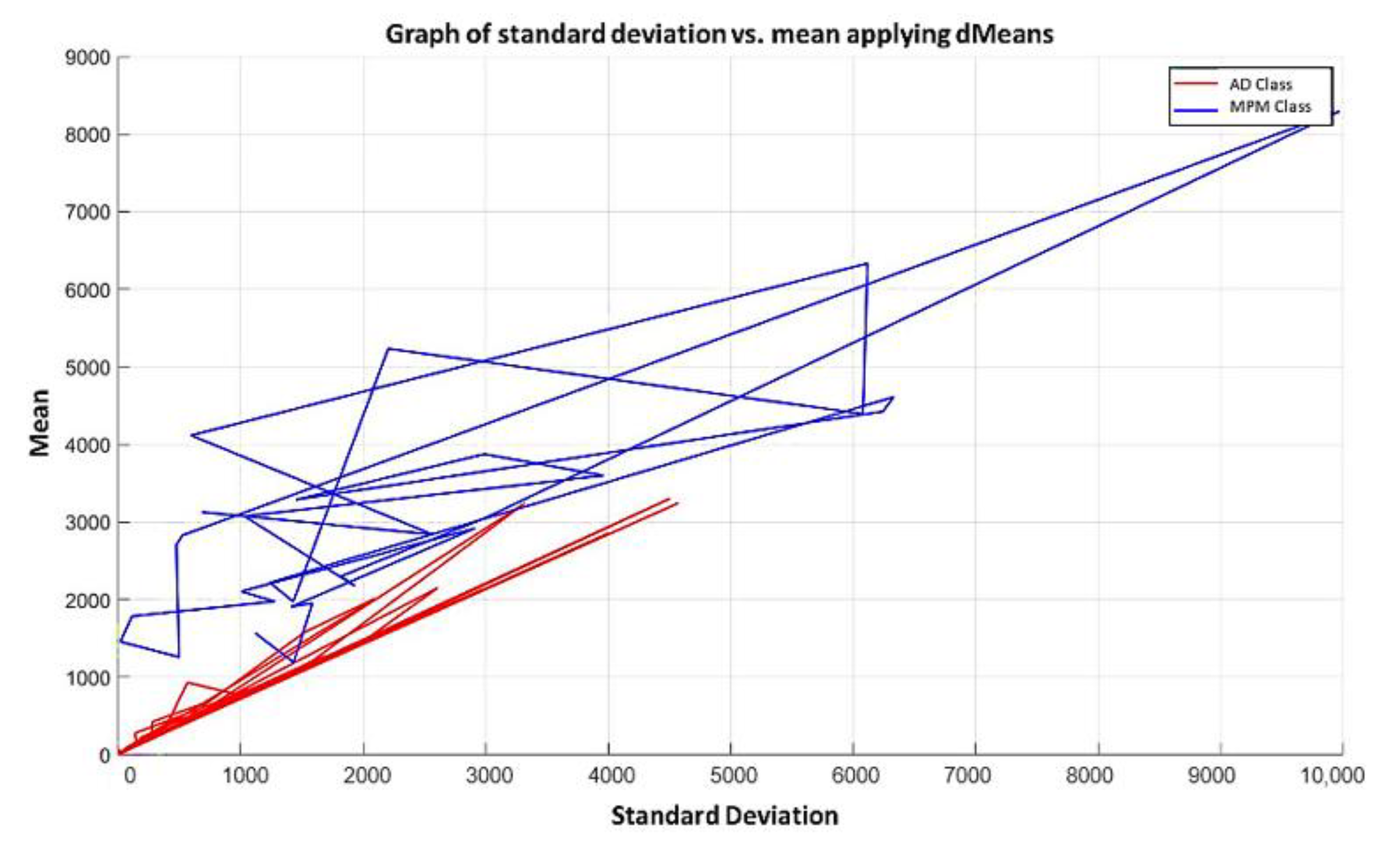
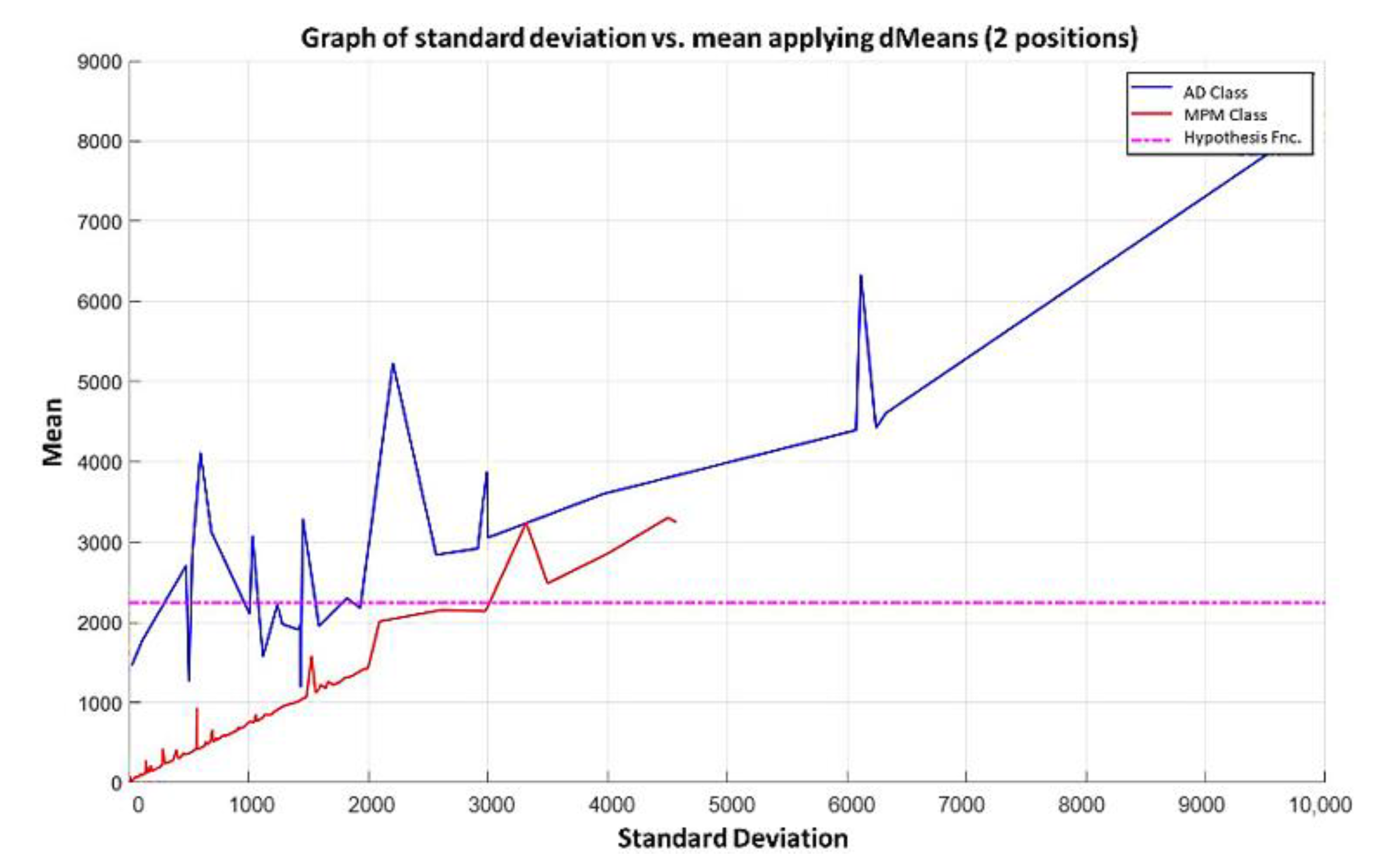
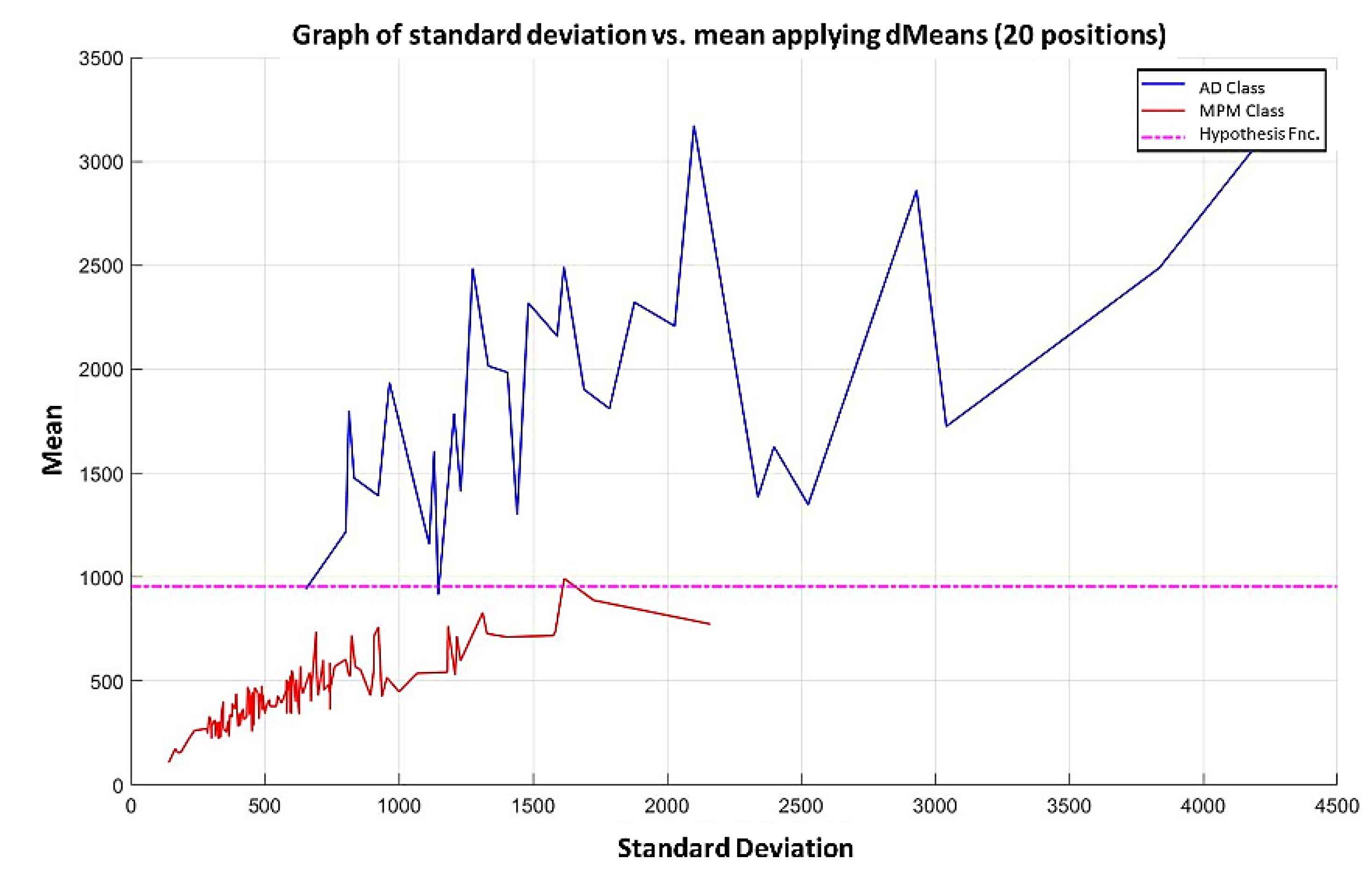
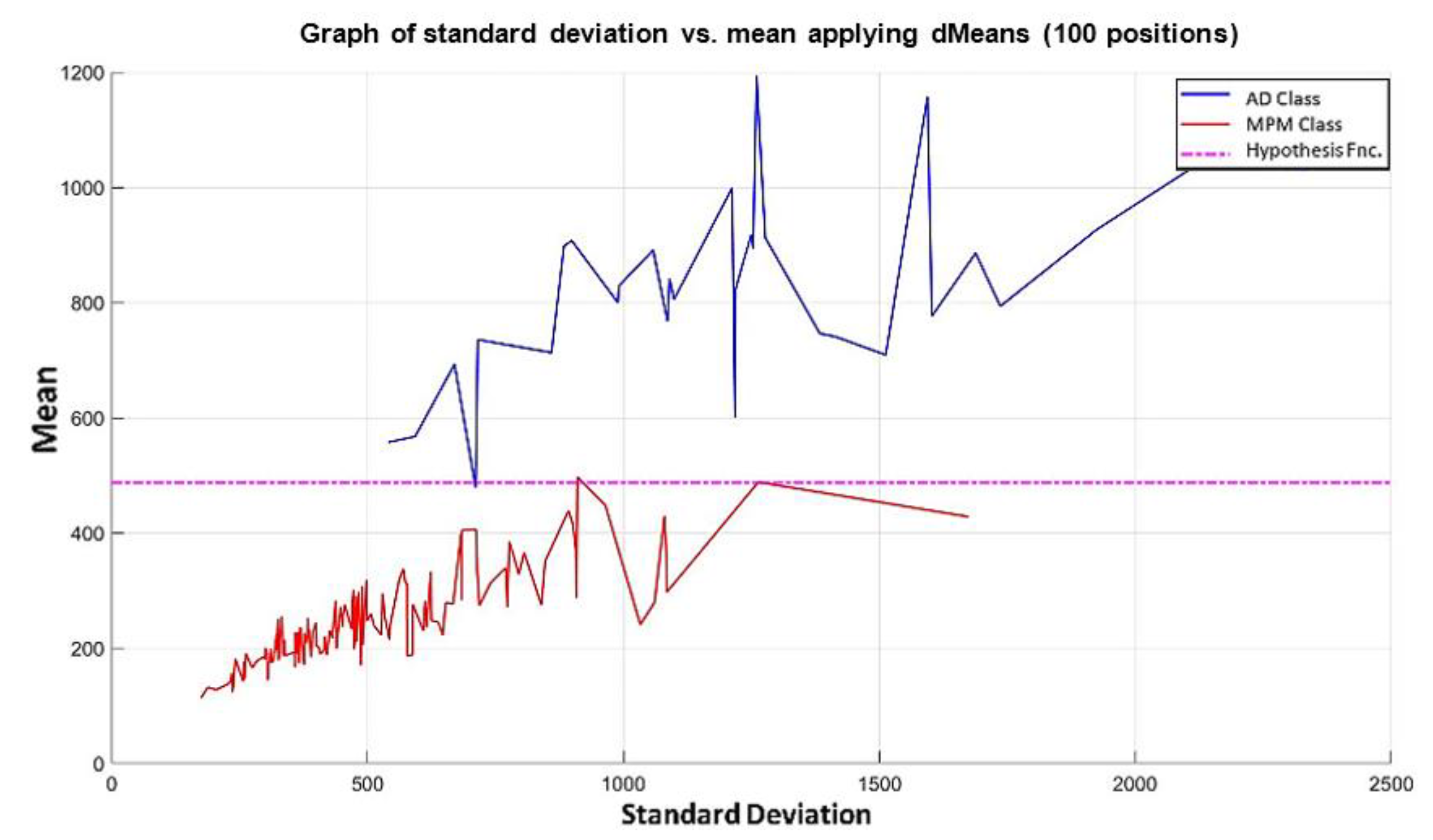
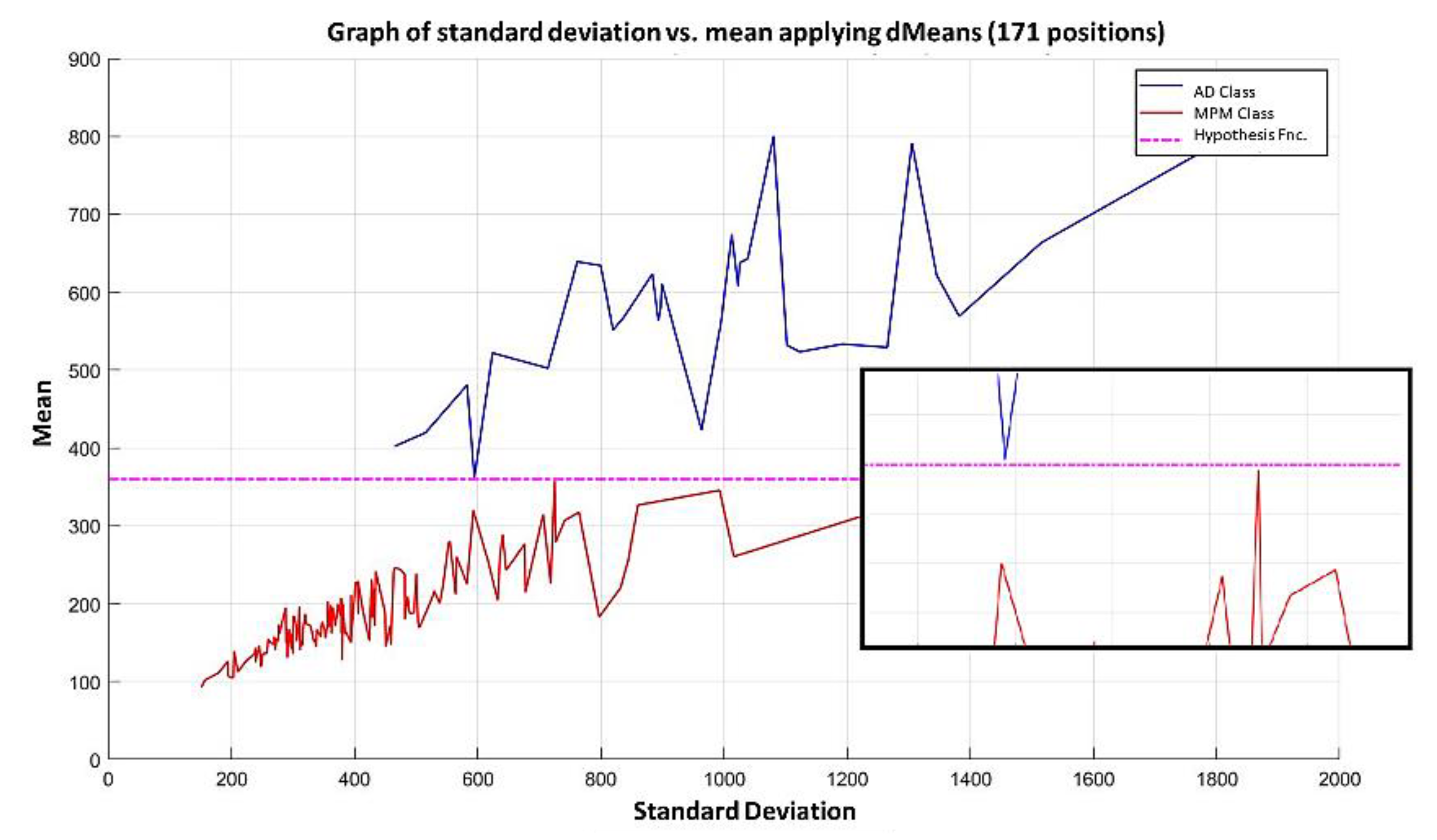
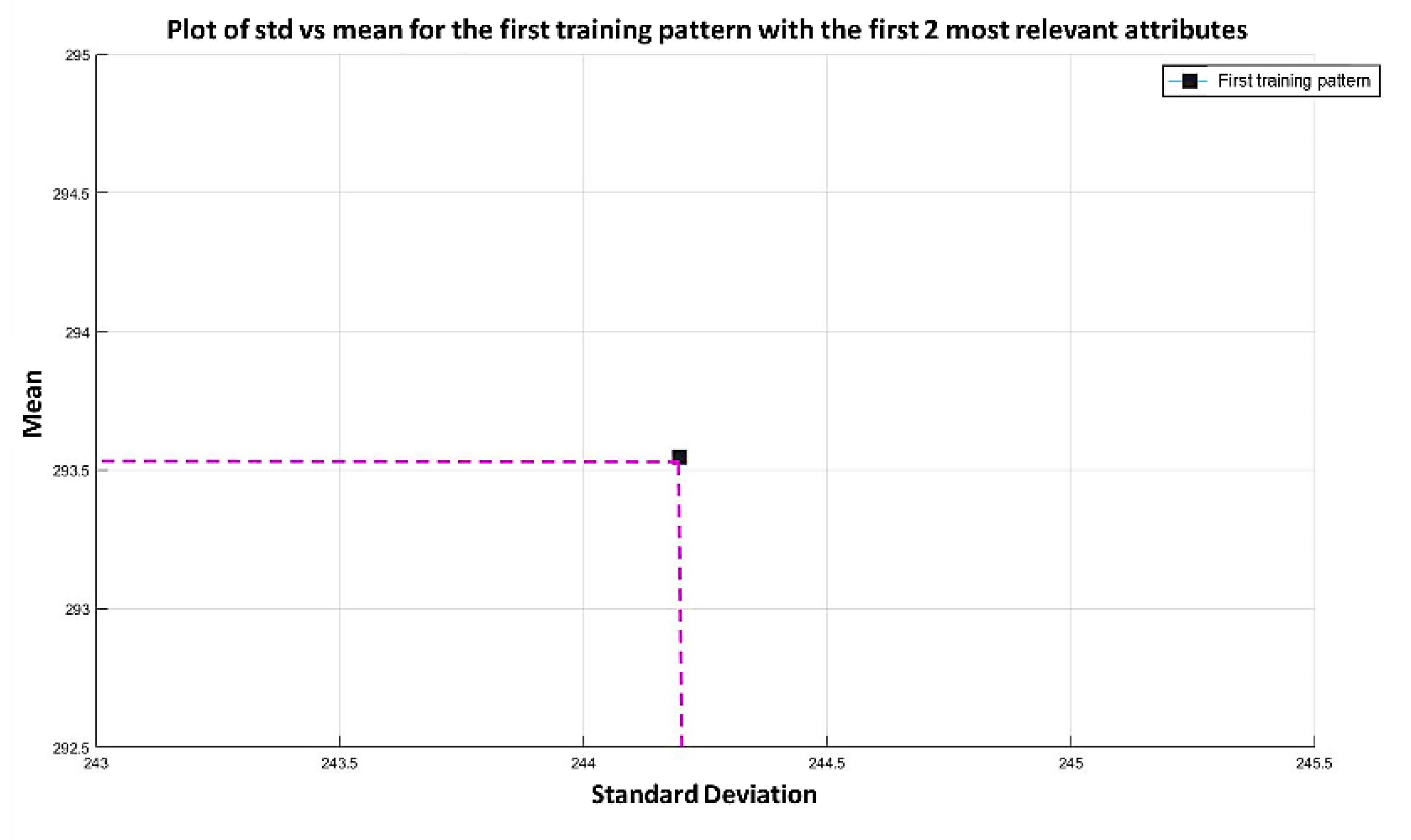
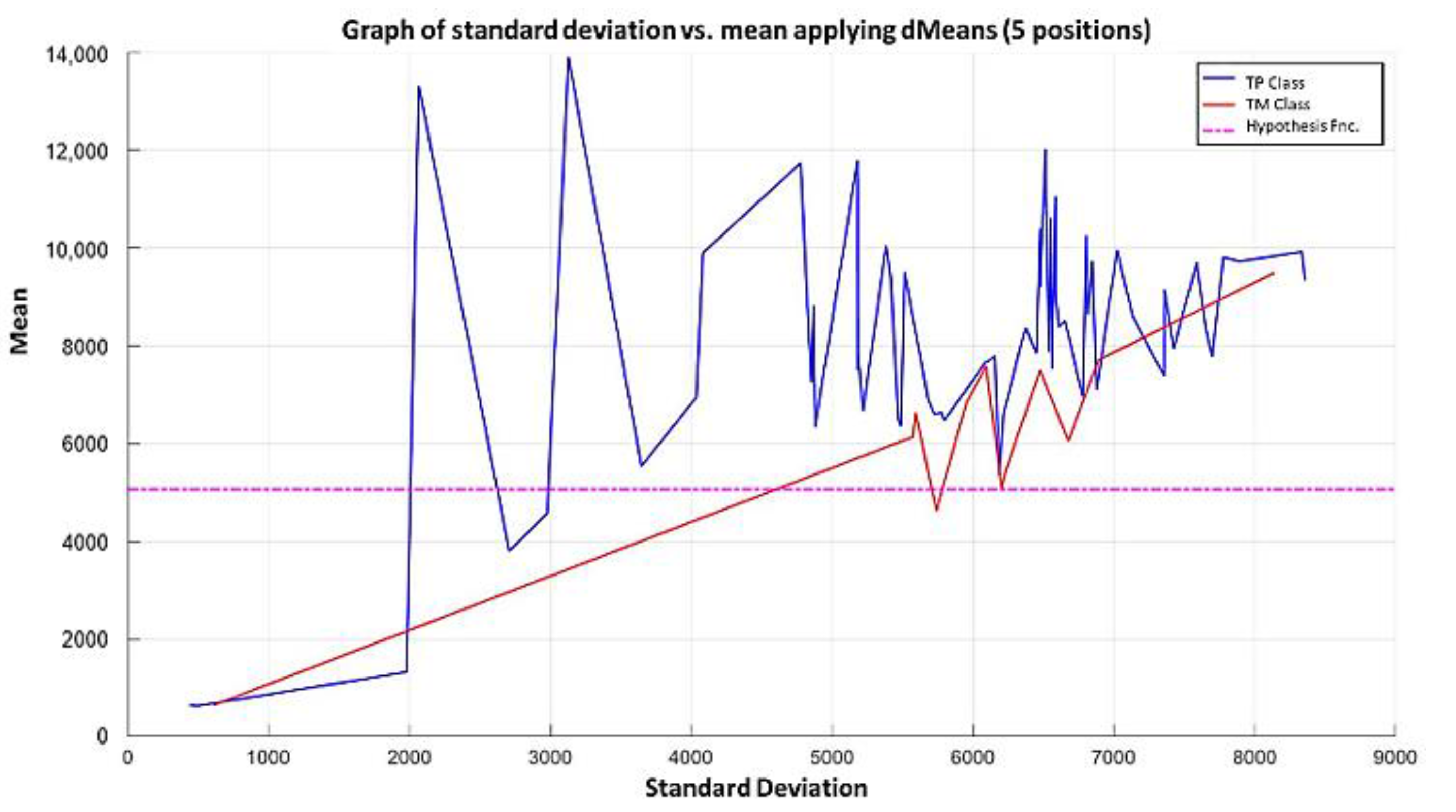
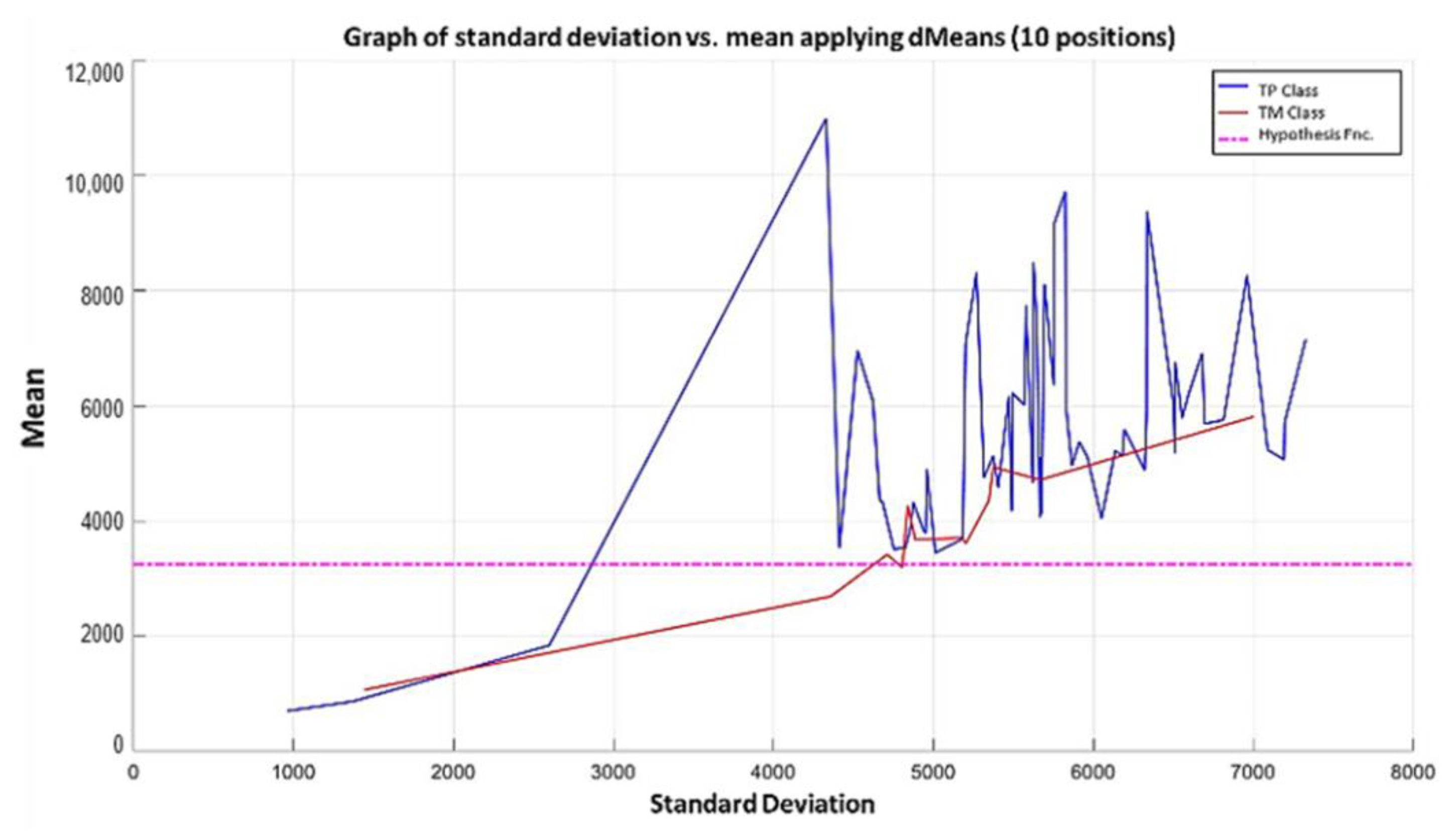
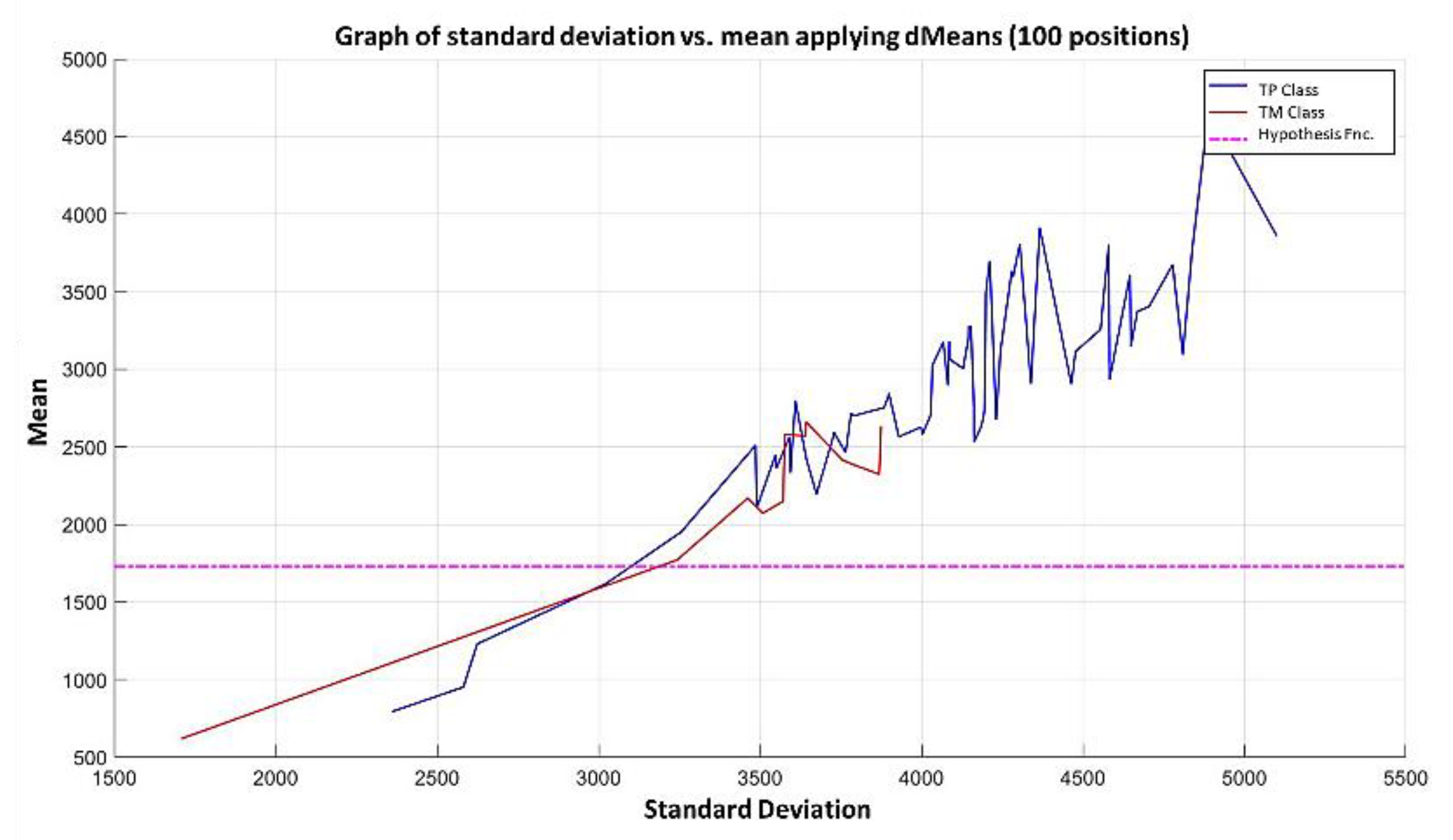
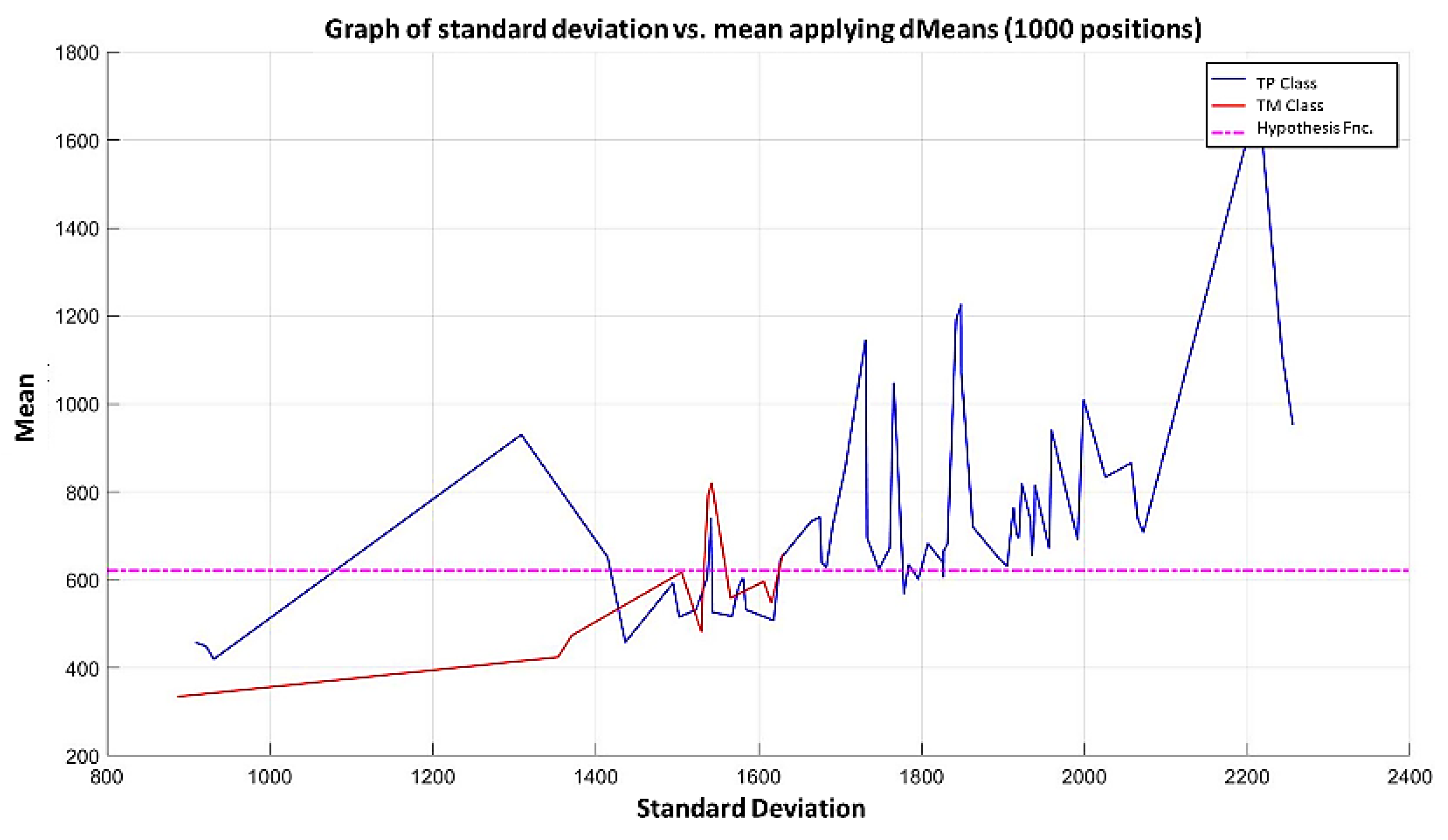
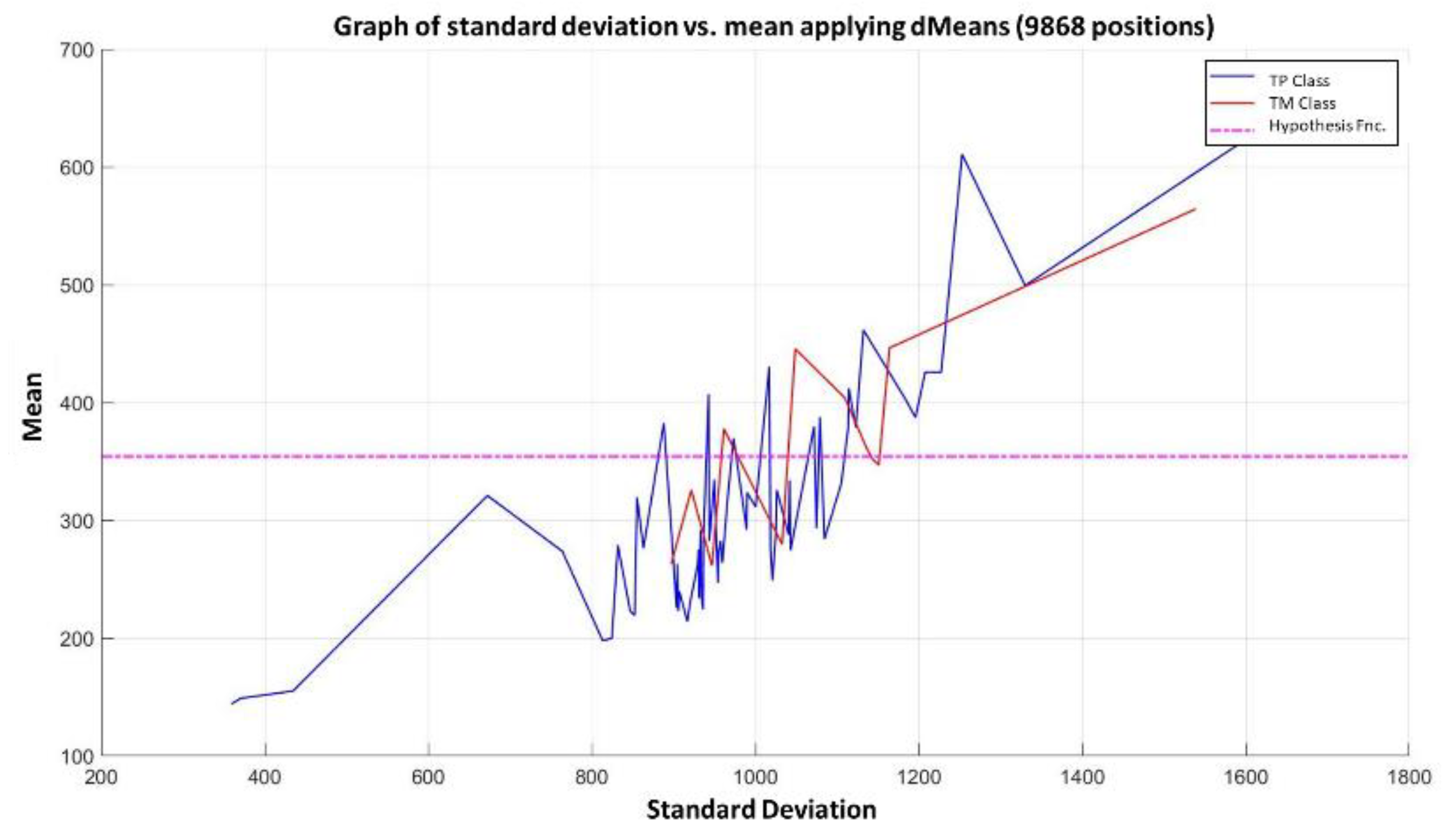
3.3. Illustrative Examples of Minimalist Machine Learning
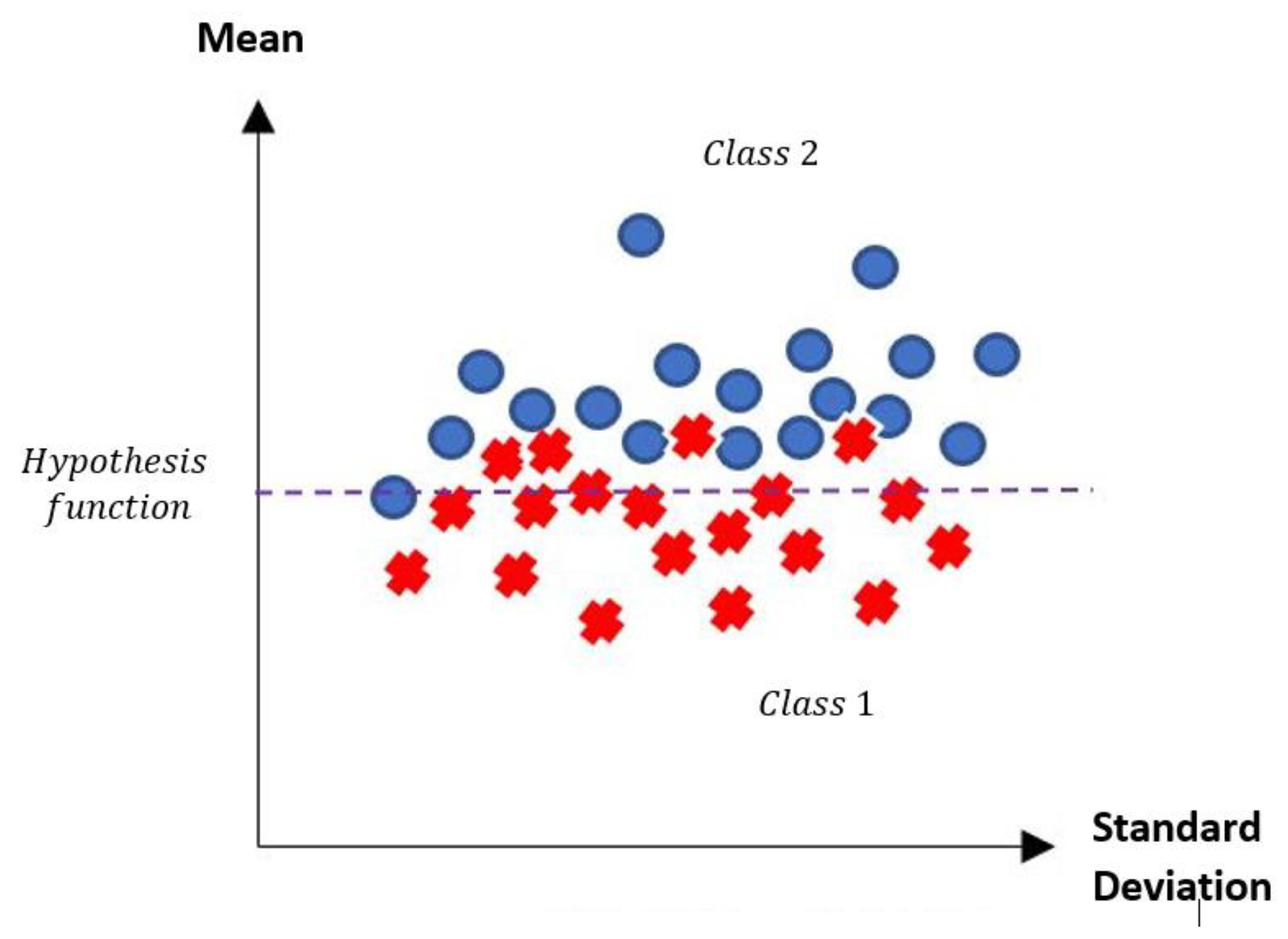
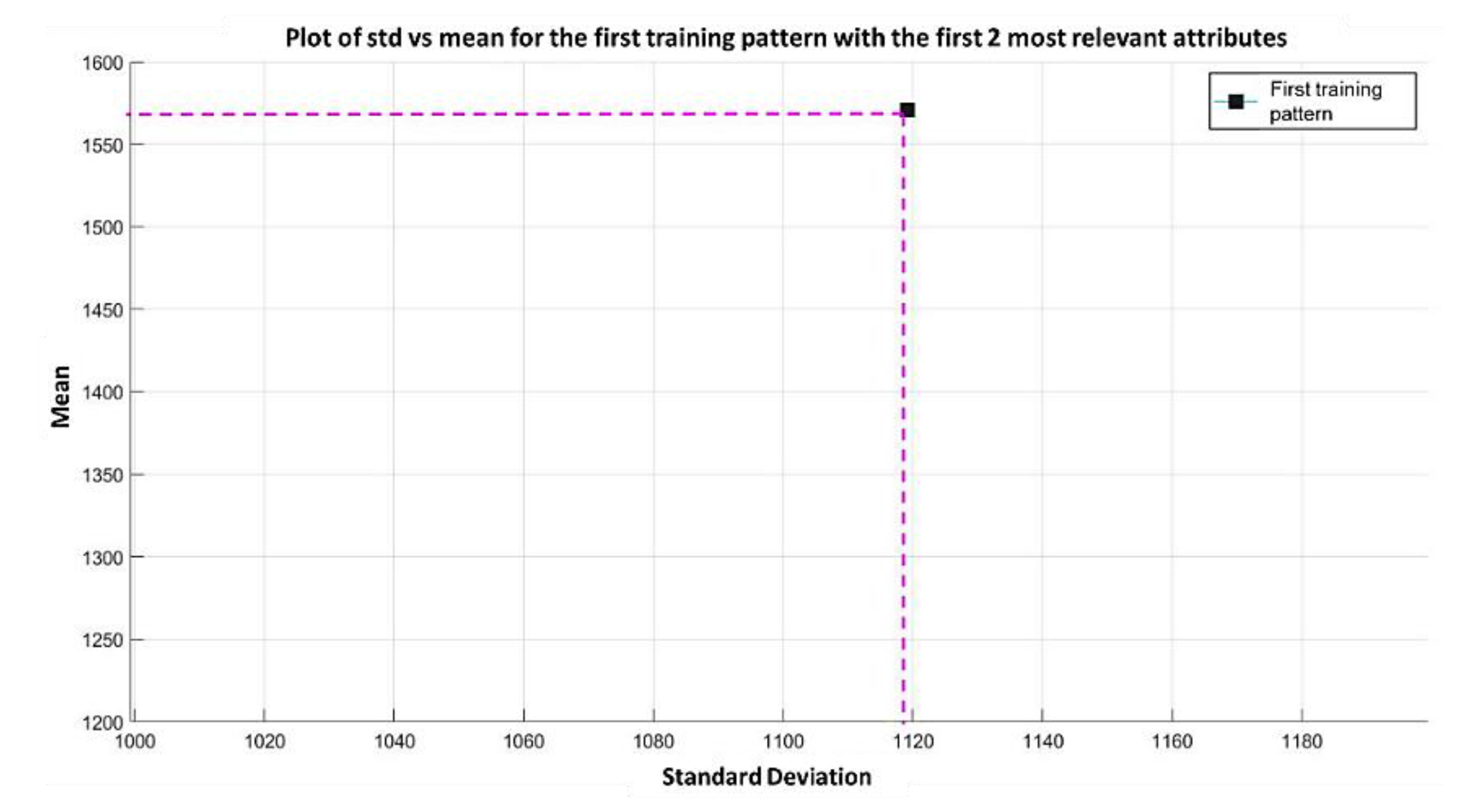
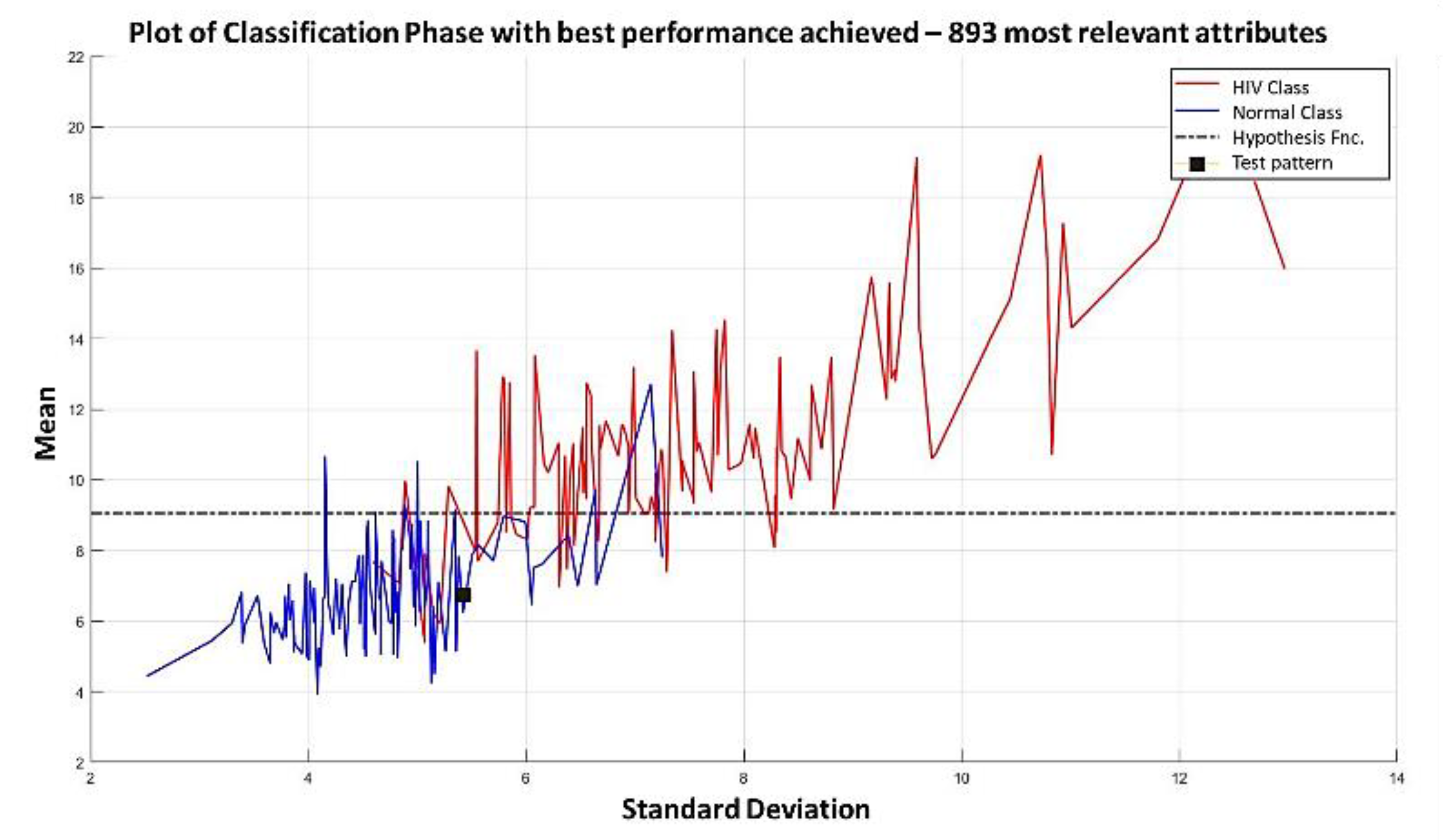
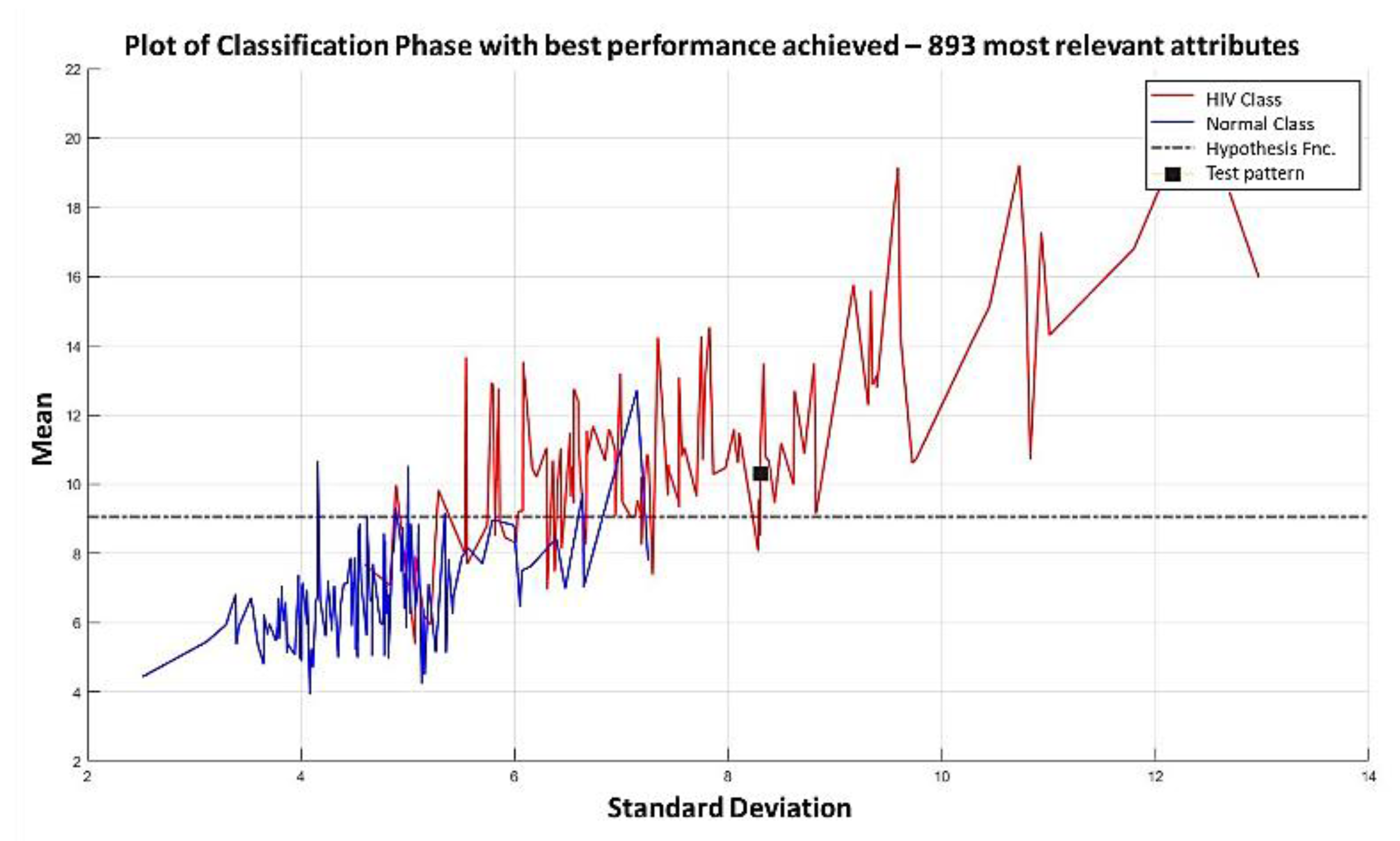
Example 1: Gordon Dataset
- The positions of the first 171 most relevant attributes.
- The line representing the hypothesis function, which in this case is the value 359.63 on the y-axis. This value was calculated using expression 3.3.
- This third piece of data is very important for the classification phase: the AD class (blue) is above the hypothesis line, while the MPM class (red) is below the hypothesis line.
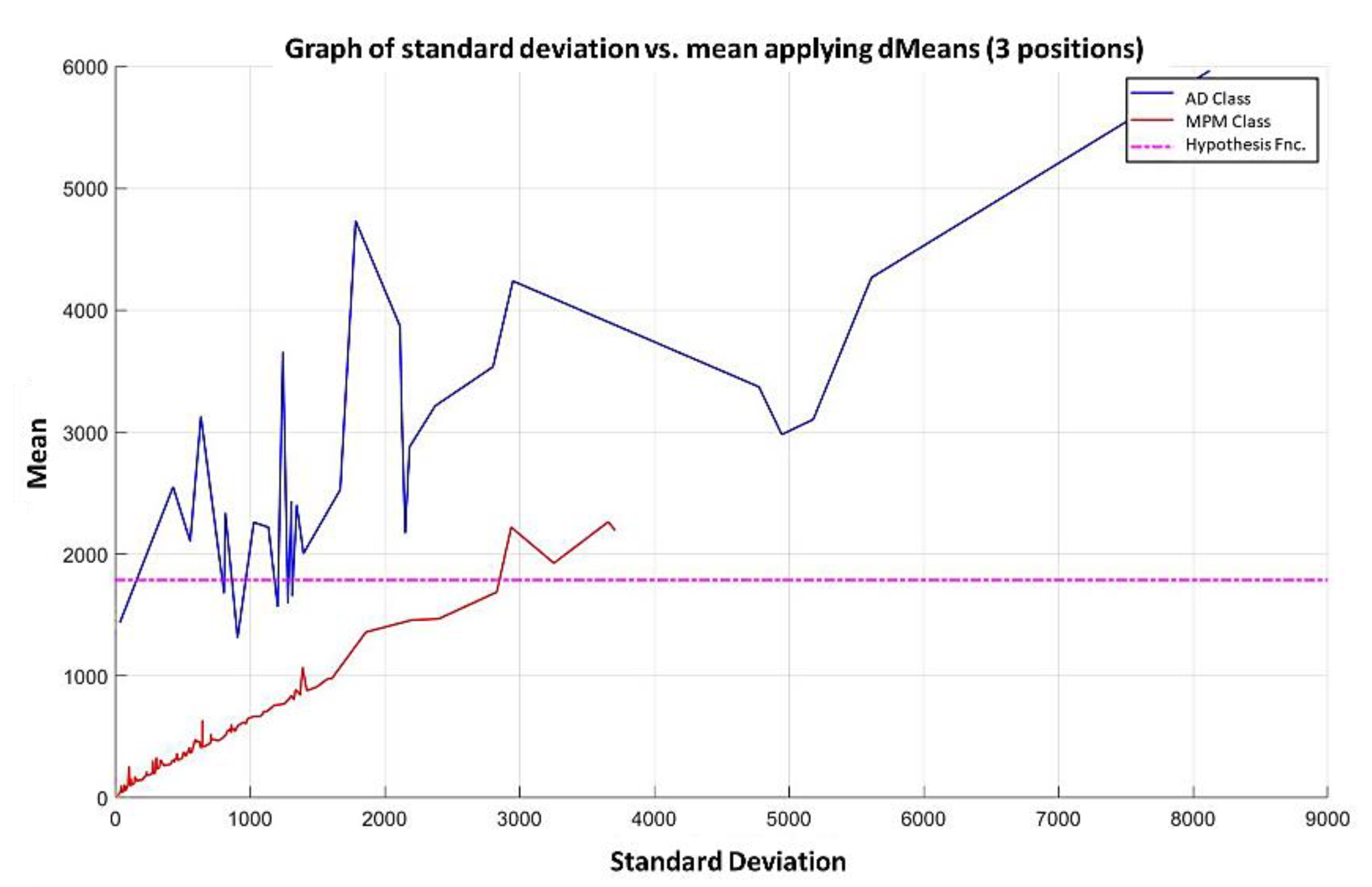
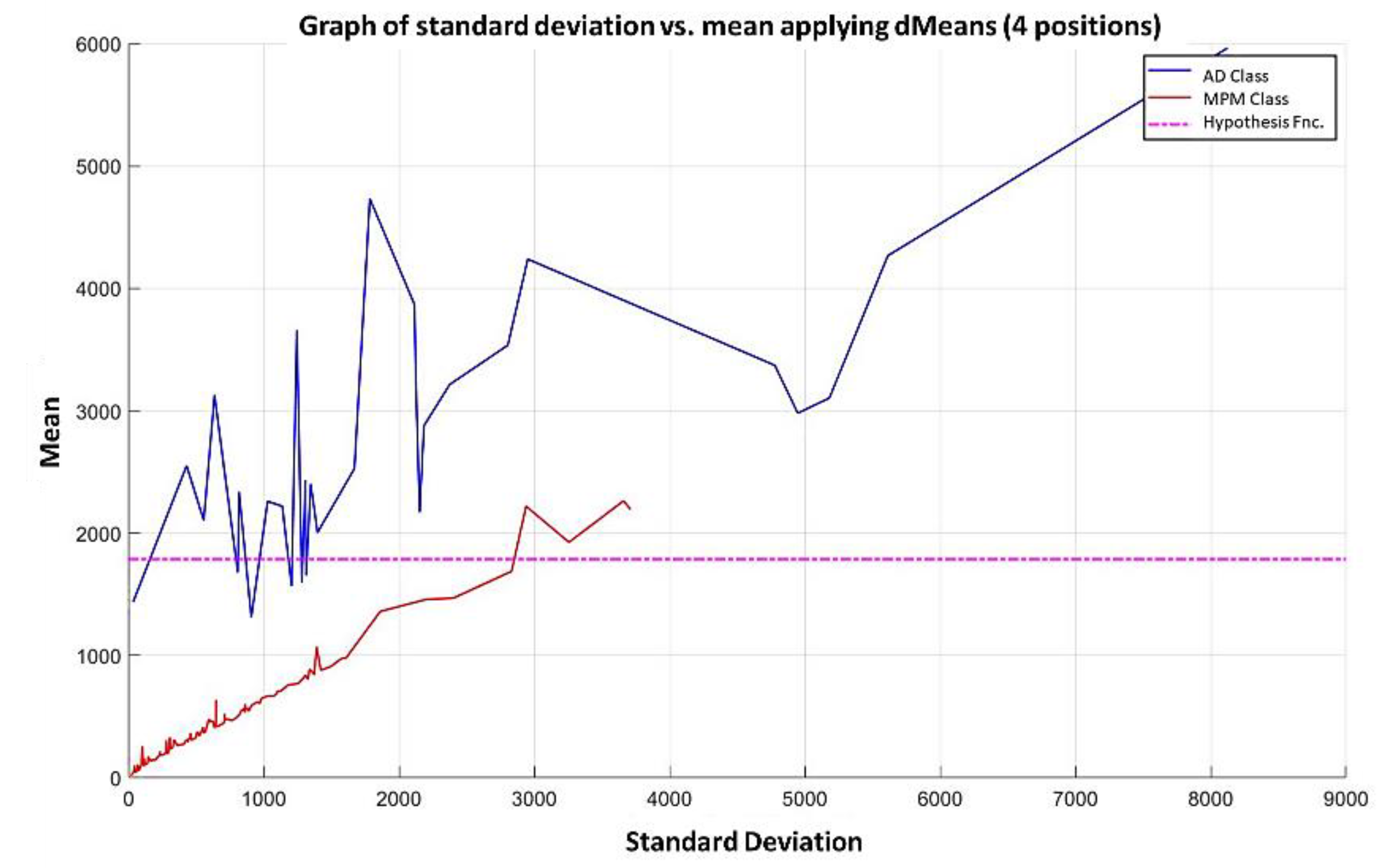
Example 2: Adenocarcinoma Dataset
4. Results and Discussion
4.1. Dataset
DS: Brain Hemorrhage CT Dataset
4.2. State of the Art Classifiers for Comparison
4.2.1. K-Nearest Neighbors (K-NN)
| Algorithm 2: K-NN Classification algorithm. |
| Input: |
| Training set, with defined classes |
| 1. Training set with classes included. |
| 2. Examine the elements close to the pattern to be classified. |
| 3. A new element is placed in the class with the highest number of nearby elements. |
| 4. The process is repeated for each tuple to be classified (depending on the size of the training set). |
| Output: Class label for the test pattern. |
4.2.2. Multi-Layer Perceptron (MLP)
| Algorithm 3: MLP Classification Algorithm. |
| Input: |
| training set, with classes desired outputs . |
| 1. Choose a vector of initial weights . |
| 2. Initialize the approximation to cost minimization. |
| while the error does not converge do |
| for all patterns do |
| 1. Apply the patterns to the network and compute the network output. |
| 2. Calculate . |
| 3. For all weights, sum over all training patterns. |
| 4. Update the weights in each error minimization approximation pattern. |
| end while |
| Output: Approximate class label for the test pattern. |
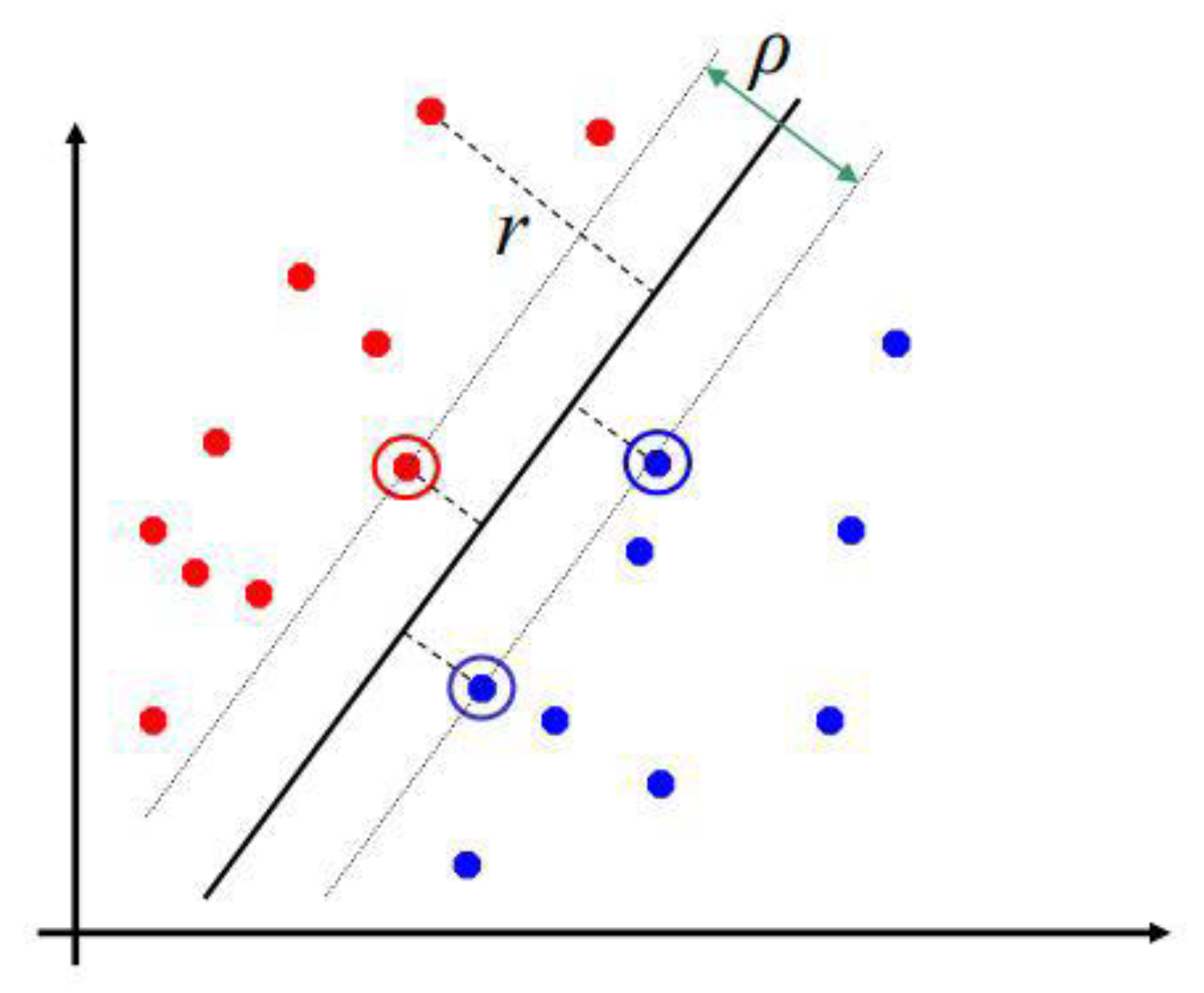
4.2.3. Support Vector Machine
- Non-linear representation of an input vector in a higher dimensional feature space.
- Construction of an optimal hyperplane to separate the attributes [47].
4.2.4. Adaboost
4.2.5. Random Forest
4.2.6. Naïve Bayes
4.2.7. Hierarchical Classifier
4.3. Performance and Comparative Analysis
- Training set: data that are shown to the model to be trained.
- Test set: data that the model has never observed and under which the performance of the classifier will be obtained.
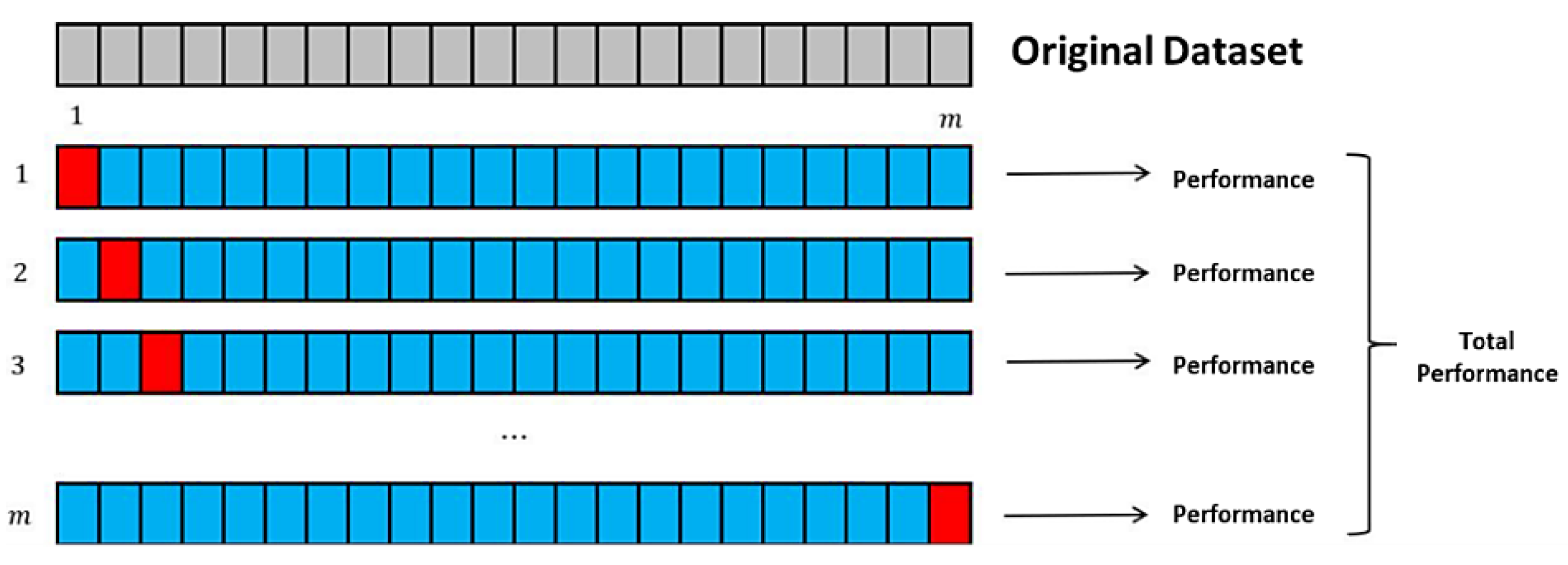
4.3.1. Leave-One-Out Cross-Validation (LOOCV)
4.3.2. Performance Metrics
- TP is the number of correct classifications of a positive pattern.
- TN is the number of correct classifications of a negative pattern.
- FP is the number of incorrect classifications of a positive pattern.
- FN is the number of incorrect classifications of a negative pattern.
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Tobacco Responsible for 20% of Deaths from Coronary Heart Disease. Available online: https://www.who.int/news-room/fact-sheets/detail/the-top-10-causes-of-death (accessed on 9 September 2020).
- Beul, D.S. Stroke in the diabetic patient. Diabetes Care 1994, 17, 213–219. [Google Scholar] [CrossRef]
- Verson, G.L.; Lange, R.T. Moderate and severe traumatic brain injury. In The Little Black Book of Neuropsychology; Springer: Boston, MA, USA, 2011; pp. 663–696. [Google Scholar]
- Pezzini, A.; Grassi, M.; Paciaroni, M.; Zini, A.; Silvestrelli, G.; Iacoviello, L.; Padovani, A. Obesity and the risk of intracerebral hemorrhage: The multicenter study on cerebral hemorrhage in Italy. Stroke 2013, 44, 1584–1589. [Google Scholar] [CrossRef] [Green Version]
- Coles, J.P. Imaging after brain injury. Br. J. Anaesth. 2007, 99, 49–60. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garnett, M.R.; Cadoux-Hudson, T.A.; Styles, P. How useful is magnetic resonance imaging in predicting severity and outcome in traumatic brain injury? Curr. Opin. Neurol. 2001, 14, 753–757. [Google Scholar] [CrossRef]
- Mohsen, H.; El-Dahshan, E.S.A.; El-Horbaty, E.S.M.; Salem, A.B.M. Classification using deep learning neural networks for brain tumors. Future Comput. Inform. J. 2018, 3, 68–71. [Google Scholar] [CrossRef]
- Abiwinanda, N.; Hanif, M.; Hesaputra, S.T.; Handayani, A.; Mengko, T.R. Brain tumor classification using convolutional neural network. In IFMBE Proceedings; Springer Science and Business Media LLC: Berlin, Germany, 2019; pp. 183–189. [Google Scholar]
- Bahadure, N.B.; Ray, A.K.; Thethi, H.P. Image analysis for MRI based brain tumor detection and feature extraction using biologically inspired BWT and SVM. Int. J. Biomed. Imaging 2017, 2017, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Landi, I.; Glicksberg, B.S.; Lee, H.-C.; Cherng, S.; Landi, G.; Danieletto, M.; Dudley, J.T.; Furlanello, C.; Miotto, R. Deep representation learning of electronic health records to unlock patient stratification at scale. NPJ Digit. Med. 2020, 3, 96. [Google Scholar] [CrossRef]
- Yang, G.; Ye, Q.; Xia, J. Unbox the black-box for the medical explainable ai via multi-modal and multi-centre data fusion: A mini-review, two showcases and beyond. Inf. Fusion 2021, 2102, 01998. [Google Scholar]
- Wang, Y.; Yue, W.; Li, X.; Liu, S.; Guo, L.; Xu, H.; Yang, G. Comparison study of radiomics and deep learning-based methods for thyroid nodules classification using ultrasound images. IEEE Access 2020, 8, 52010–52017. [Google Scholar] [CrossRef]
- Yang, M.; Xiao, X.; Liu, Z.; Sun, L.; Guo, W.; Cui, L.; Yang, G. Deep RetinaNet for dynamic left ventricle detection in multiview echocardiography classification. Sci. Program. 2020, 2020, 1–6. [Google Scholar] [CrossRef]
- Ye, Q.; Xia, J.; Yang, G. Explainable AI For COVID-19 CT Classifiers: An Initial Comparison Study. arXiv 2021, arXiv:2104.14506. [Google Scholar]
- Wang, S.; Sun, J.; Mehmood, I.; Pan, C.; Chen, Y.; Zhang, Y.D. Cerebral micro-bleeding identification based on a nine-layer convolutional neural network with stochastic pooling. Concurr. Comput. Pract. Exp. 2020, 32, e5130. [Google Scholar] [CrossRef]
- Doke, P.; Shrivastava, D.; Pan, C.; Zhou, Q.; Zhang, Y.D. Using CNN with Bayesian optimization to identify cerebral micro-bleeds. Mach. Vis. Appl. 2020, 31, 36. [Google Scholar] [CrossRef]
- Yáñez-Márquez, C. Toward the bleaching of the black boxes: Minimalist machine learning. IT Prof. 2020, 22, 51–56. [Google Scholar] [CrossRef]
- Shahangian, B.; Pourghassem, H. Automatic brain hemorrhage segmentation and classification in CT scan images. In Proceedings of the 2013 8th Iranian Conference on Machine Vision and Image Processing (MVIP), Zanjan, Iran, 10–12 September 2013; pp. 467–471. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Strok, D.G. Pattern Classification; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Kuncheva, L.I. Combining Pattern Classifiers: Methods and Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- De Sa, J.M. Pattern Recognition: Concepts, Methods and Applications; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; Romeny, B.T.H.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Muniyappan, S.; Allirani, A.; Saraswathi, S. A novel approach for image enhancement by using contrast limited adaptive histogram equalization method. In Proceedings of the Fourth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Tiruchengode, India, 4–6 July 2013; pp. 1–6. [Google Scholar]
- Mohan, P.; Vallikannu, A.L.; Devi, B.R.S.; Kavitha, B.C. Intelligent based brain tumor detection using ACO. Int. J. Innov. Res. Comput. Commun. Eng. 2013, 1, 2143–2150. [Google Scholar]
- James, R.M.; Sunyoto, A. Detection Of CT-Scan Lungs COVID-19 Image Using Convolutional Neural Network And CLAHE. In Proceedings of the 2020 3rd International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 24–25 November 2020; pp. 302–307. [Google Scholar]
- Gonzalez, R.C.; Eddins, S.L.; Woods, R.E. Digital Image Processing, 4th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2004; pp. 154–155. [Google Scholar]
- Diwakar, M.; Kumar, M. A review on CT image noise and its denoising. Biomed. Signal Process. Control. 2018, 42, 73–88. [Google Scholar] [CrossRef]
- Giraldo, J.C.R.; Kelm, Z.S.; Guimaraes, L.S.; Yu, L.; Fletcher, J.G.; Erickson, B.J.; McCollough, C.H. Comparative study of two image space noise reduction methods for computed tomography: Bilateral filter and nonlocal means. In Proceedings of the 2009 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 2–6 September 2009; pp. 3529–3532. [Google Scholar]
- Vijaykumar, V.R.; Vanathi, P.T.; Kanagasabapathy, P. Fast and efficient algorithm to remove gaussian noise in digital images. IAENG Int. J. Comput. Sci. 2010, 37, 300–302. [Google Scholar]
- Jamil, N.; Sembok, T.M.T.; Bakar, Z.A. Noise removal and enhancement of binary images using morphological operations. In Proceedings of the 2008 International Symposium on Information Technology, Kuala Lumpur, Malaysia, 26–28 August 2008; pp. 1–6. [Google Scholar]
- Schonfeld, D.; Goutsias, J. Optimal morphological pattern restoration from noisy binary images. IEEE Comput. Archit. Lett. 1991, 13, 14–29. [Google Scholar] [CrossRef] [Green Version]
- De Natale, F.G.; Boato, G. Detecting morphological filtering of binary images. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1207–1217. [Google Scholar] [CrossRef]
- Shahangian, B.; Pourghassem, H. Automatic brain hemorrhage segmentation and classification algorithm based on weighted grayscale histogram feature in a hierarchical classification structure. Biocybern. Biomed. Eng. 2016, 36, 217–232. [Google Scholar] [CrossRef]
- Mittal, N. Automatic Contrast Enhancement of Low Contrast Images using MATLAB. Int. J. Adv. Res. Comput. Sci. 2012, 3, 333–338. [Google Scholar]
- Song, Q.; Ma, L.; Cao, J.; Han, X. Image denoising based on mean filter and wavelet transform. In Proceedings of the 4th International Conference on Advanced Information Technology and Sensor Application (AITS), Washington, DC, USA, 21–23 August 2015; pp. 39–42. [Google Scholar]
- Fernández, A.; López, V.; Galar, M.; del Jesus, M.J.; Herrera, F. Analysing the classification of imbalanced data-sets with multiple classes: Binarization techniques and ad-hoc approaches. Knowl. Based Syst. 2013, 42, 97–110. [Google Scholar] [CrossRef]
- Malgouyres, R.; Fourey, S. Strong surfaces, surface skeletons, and image superimposition. In Proceedings of the Vision Geometry VII, International Society for Optics and Photonics, 2 October 1998; SPIE: San Diego, CA, USA, 1998; Volume 3454, pp. 16–27. [Google Scholar]
- Barreno, M.; Nelson, B.; Sears, R.; Joseph, A.D.; Tygar, J.D. Can machine learning be secure? In Proceedings of the 2006 ACM Symposium on Information, computer and communications security, Taipei, Taiwan, 21–24 March 2006; pp. 16–25. [Google Scholar]
- Rätsch, G. A Brief Introduction into Machine Learning; Friedrich Miescher Laboratory of the Max Planck Society: Tübingen, Germany, 2004. [Google Scholar]
- Gordon, G.J.; Jensen, R.V.; Hsiao, L.L.; Gullans, S.R.; Blumenstock, J.E.; Ramaswamy, S.; Bueno, R. Translation of microarray data into clinically relevant cancer diagnostic tests using gene expression ratios in lung cancer and mesothelioma. Cancer Res. 2002, 62, 4963–4967. [Google Scholar] [PubMed]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Ramaswamy, S.; Ross, K.N.; Lander, E.S.; Golub, T.R. A molecular signature of metastasis in primary solid tumors. Nat. Genet. 2003, 33, 49–54. [Google Scholar] [CrossRef]
- Díaz-Uriarte, R.; De Andrés, S.A. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006, 7, 3. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Baxt, W.G. Use of an artificial neural network for data analysis in clinical decision-making: The diagnosis of acute coronary occlusion. Neural Comput. 1990, 2, 480–489. [Google Scholar] [CrossRef]
- Karlik, B.; Olgac, A.V. Performance analysis of various activation functions in generalized MLP architectures of neural networks. Int. J. Artif. Intell. Expert Syst. 2011, 1, 111–122. [Google Scholar]
- Vanitha, L.; Venmathi, A.R. Classification of medical images using support vector machine. In Proceedings of the International Conference on Information and Network Technology (ICINT 2011), Chennai, India, 29–30 April 2011. [Google Scholar]
- Vedaldi, A.; Gulshan, V.; Varma, M.; Zisserman, A. Multiple kernels for object detection. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 606–613. [Google Scholar]
- Prajapati, G.L.; Patle, A. On performing classification using SVM with radial basis and polynomial kernel functions. In Proceedings of the 3rd International Conference on Emerging Trends in Engineering and Technology, Washington, DC, USA, 19–21 November 2010; pp. 512–515. [Google Scholar]
- Schapire, R.E. Explaining adaboost. In Empirical Inference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- He, Y.L.; Zhao, Y.; Hu, X.; Yan, X.N.; Zhu, Q.X.; Xu, Y. Fault diagnosis using novel AdaBoost based discriminant locality preserving projection with resamples. Eng. Appl. Artif. Intell. 2020, 91, 103631. [Google Scholar] [CrossRef]
- Ahmmed, B.; Mudunuru, M.K.; Karra, S.; James, S.C.; Vesselinov, V.V. A comparative study of machine learning models for predicting the state of reactive mixing. J. Comput. Phys. 2021, 432, 110147. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Andrejiova, M.; Grincova, A. Classification of impact damage on a rubber-textile conveyor belt using Naïve-Bayes methodology. Wear 2018, 414, 59–67. [Google Scholar] [CrossRef]
- Evgeniou, T.; Pontil, M.; Elisseeff, A. Leave one out error, stability, and generalization of voting combinations of classifiers. Mach. Learn. 2004, 55, 71–97. [Google Scholar] [CrossRef] [Green Version]
- Altman, D.G.; Bland, J.M. Diagnostic tests. 1: Sensitivity and specificity. BMJ Br. Med. J. 1994, 308, 1552. [Google Scholar] [CrossRef] [Green Version]
- Susmaga, R. Confusion matrix visualization. In Intelligent Information Processing and Web Mining; Springer: Berlin/Heidelberg, Germany, 2004; pp. 107–116. [Google Scholar]
- Livingston, S.A.; Lewis, C. Estimating the consistency and accuracy of classifications based on test scores. J. Educ. Meas. 1995, 32, 179–197. [Google Scholar] [CrossRef]
- Parikh, R.; Mathai, A.; Parikh, S.; Sekhar, G.C.; Thomas, R. Understanding and using sensitivity, specificity and predictive 7values. Indian J. Ophthalmol. 2008, 56, 45. [Google Scholar] [CrossRef]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Bauer, S.; Wiest, R.; Nolte, L.P.; Reyes, M. A survey of MRI-based medical image analysis for brain tumor studies. Phys. Med. Biol. 2013, 58, R97. [Google Scholar] [CrossRef] [Green Version]
- Raschke, F.; Barrick, T.R.; Jones, T.L.; Yang, G.; Ye, X.; Howe, F.A. Tissue-type mapping of gliomas. NeuroImage Clin. 2019, 21, 101648. [Google Scholar] [CrossRef] [PubMed]













































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
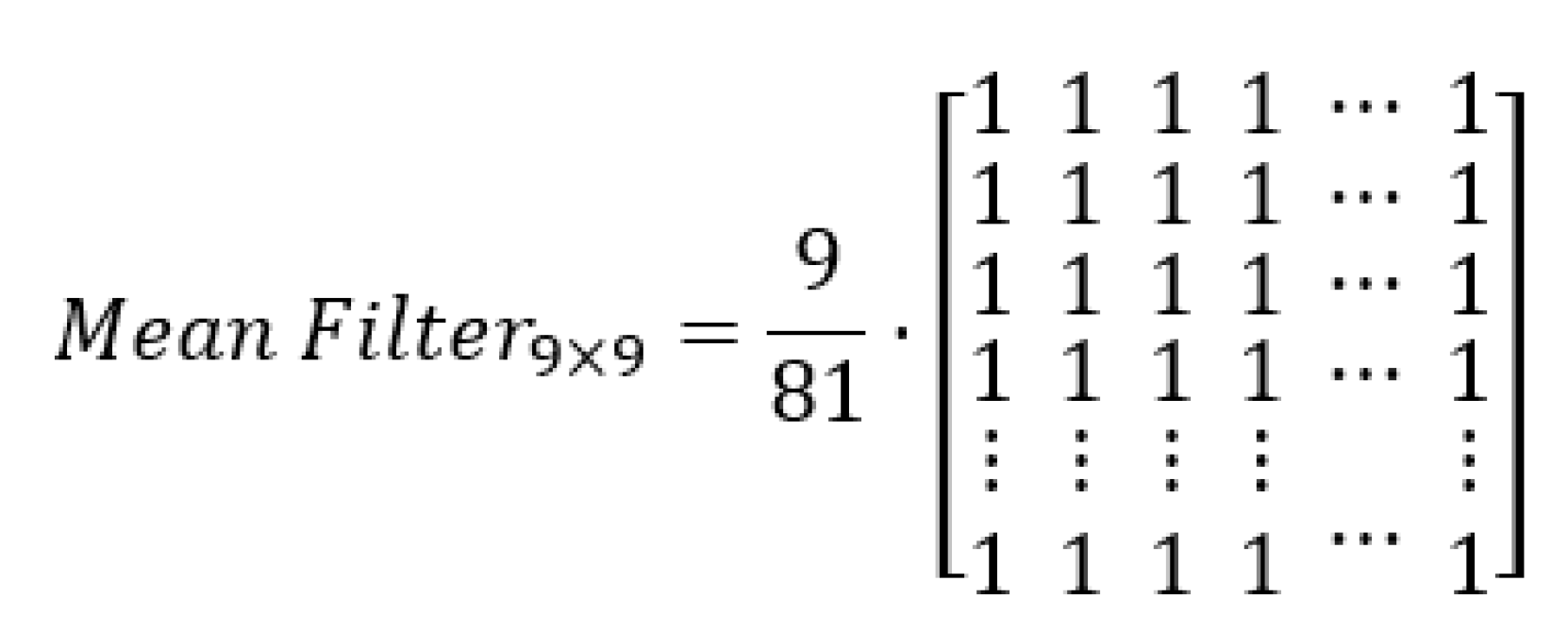{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameters |
|---|---|
| K-NN | K = 1; Distance Function = Euclidean Distance; Batch size = 100. |
| RF | Iterations = 100; Batch size = 100; Features = ; Depth = Unlimited. |
| MLP | Batch size = 100; Hidden Layers = 2; Learning rate = 0.3; momentum = 0.2; Epochs = 500. |
| Naïve Bayes | Batch size = 100. |
| SVM | Kernel = RBF; Batch size = 100; Kernel degree = 3; . |
| Adaboost | Batch size = 100; Classifier = Decision Stump; Iterations = 10. |
| Hierarchical | Defined by the authors in [33]. |
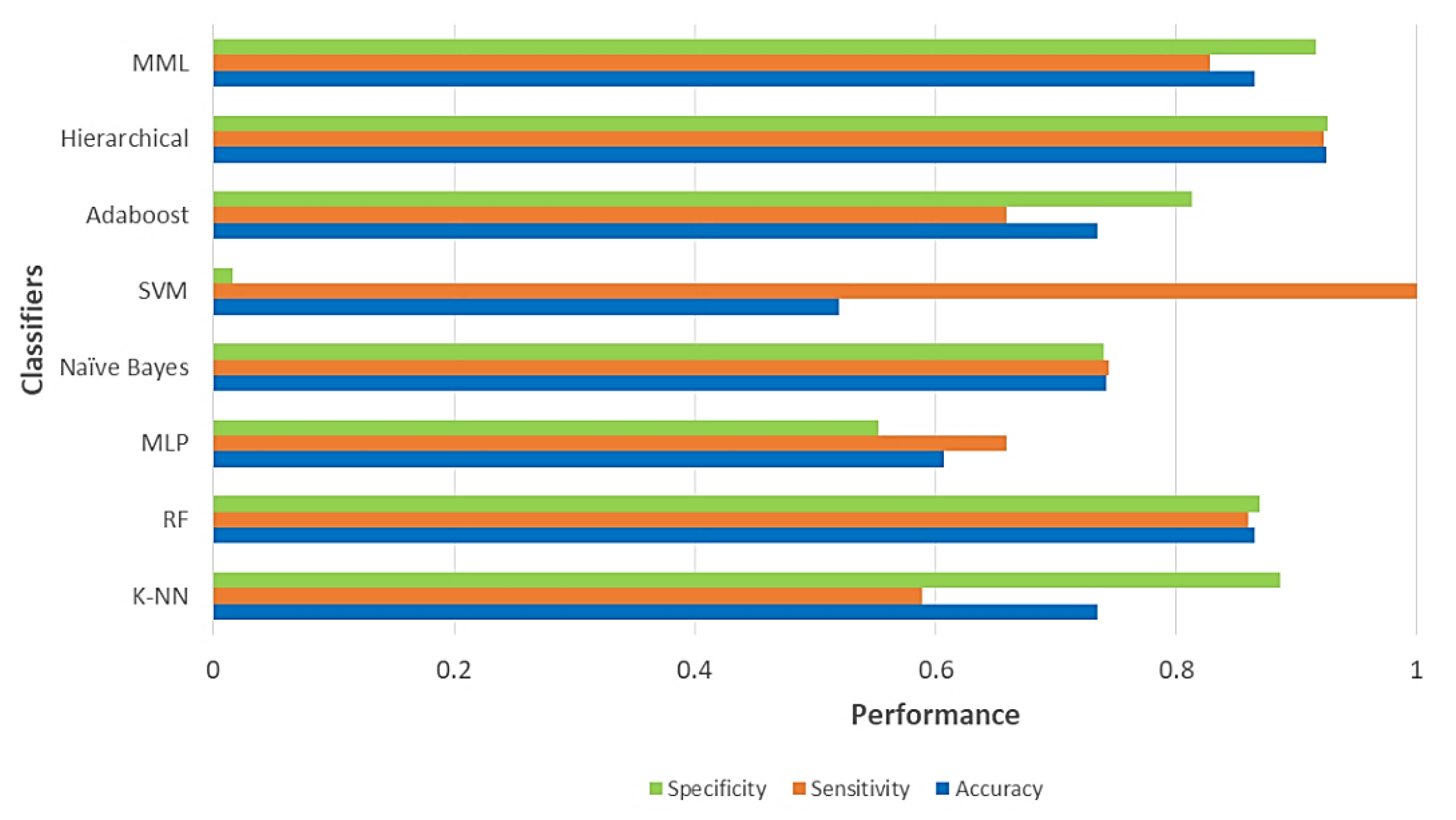
| Algorithm | Accuracy | Sensitivity | Specificity | Training Time 1 |
|---|---|---|---|---|
| K-NN | 0.7341 | 0.5890 | 0.8862 | 6.07 |
| RF | 0.8650 | 0.8600 | 0.8700 | 203.11 |
| MLP | 0.6071 | 0.6590 | 0.5528 | 100.73 |
| Naïve Bayes | 0.7420 | 0.7440 | 0.7400 | 115.77 |
| SVM | 0.5198 | 1.0000 | 0.0162 | 752.23 |
| Adaboost | 0.7341 | 0.6590 | 0.8130 | 623.45 |
| Hierarchical | 0.9246 | 0.9231 | 0.9262 | 60.57 |
| MML | 0.8650 | 0.8280 | 0.9160 | 252.04 |
| Algorithm | Mean Ranks 2 |
|---|---|
| Hierarchical | 2.34 |
| MML | 3.83 |
| RF | 4.16 |
| Naïve Bayes | 6.00 |
| K-NN | 6.50 |
| SVM | 6.66 |
| Adaboost | 6.66 |
| MLP | 7.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Solorio-Ramírez, J.-L.; Saldana-Perez, M.; Lytras, M.D.; Moreno-Ibarra, M.-A.; Yáñez-Márquez, C. Brain Hemorrhage Classification in CT Scan Images Using Minimalist Machine Learning. Diagnostics 2021, 11, 1449. https://doi.org/10.3390/diagnostics11081449
Solorio-Ramírez J-L, Saldana-Perez M, Lytras MD, Moreno-Ibarra M-A, Yáñez-Márquez C. Brain Hemorrhage Classification in CT Scan Images Using Minimalist Machine Learning. Diagnostics. 2021; 11(8):1449. https://doi.org/10.3390/diagnostics11081449
Chicago/Turabian StyleSolorio-Ramírez, José-Luis, Magdalena Saldana-Perez, Miltiadis D. Lytras, Marco-Antonio Moreno-Ibarra, and Cornelio Yáñez-Márquez. 2021. "Brain Hemorrhage Classification in CT Scan Images Using Minimalist Machine Learning" Diagnostics 11, no. 8: 1449. https://doi.org/10.3390/diagnostics11081449
APA StyleSolorio-Ramírez, J.-L., Saldana-Perez, M., Lytras, M. D., Moreno-Ibarra, M.-A., & Yáñez-Márquez, C. (2021). Brain Hemorrhage Classification in CT Scan Images Using Minimalist Machine Learning. Diagnostics, 11(8), 1449. https://doi.org/10.3390/diagnostics11081449