
Hierarchical Boosting Dual-Stage Feature Reduction Ensemble Model for Parkinson’s Disease Speech Data

 ,
, 
Abstract
:1. Introduction
- The instance space of the hierarchy is built by an iterative deep extraction mechanism.
- The manifold feature extraction method embeds the nearest neighbor feature preference method to form a dual-stage feature reduction pair module.
- The dual-stage feature reduction pair (D-Spair) module is iteratively performed by the AdaBoost mechanism to obtain higher quality features, thus achieving a substantial improvement in model diagnosis accuracy.
- The deep hierarchy instance space is integrated into the original instance space to enhance the generalization ability of the model.
2. Materials and Methods
2.1. Symbol Description
2.2. The Proposed Algorithm
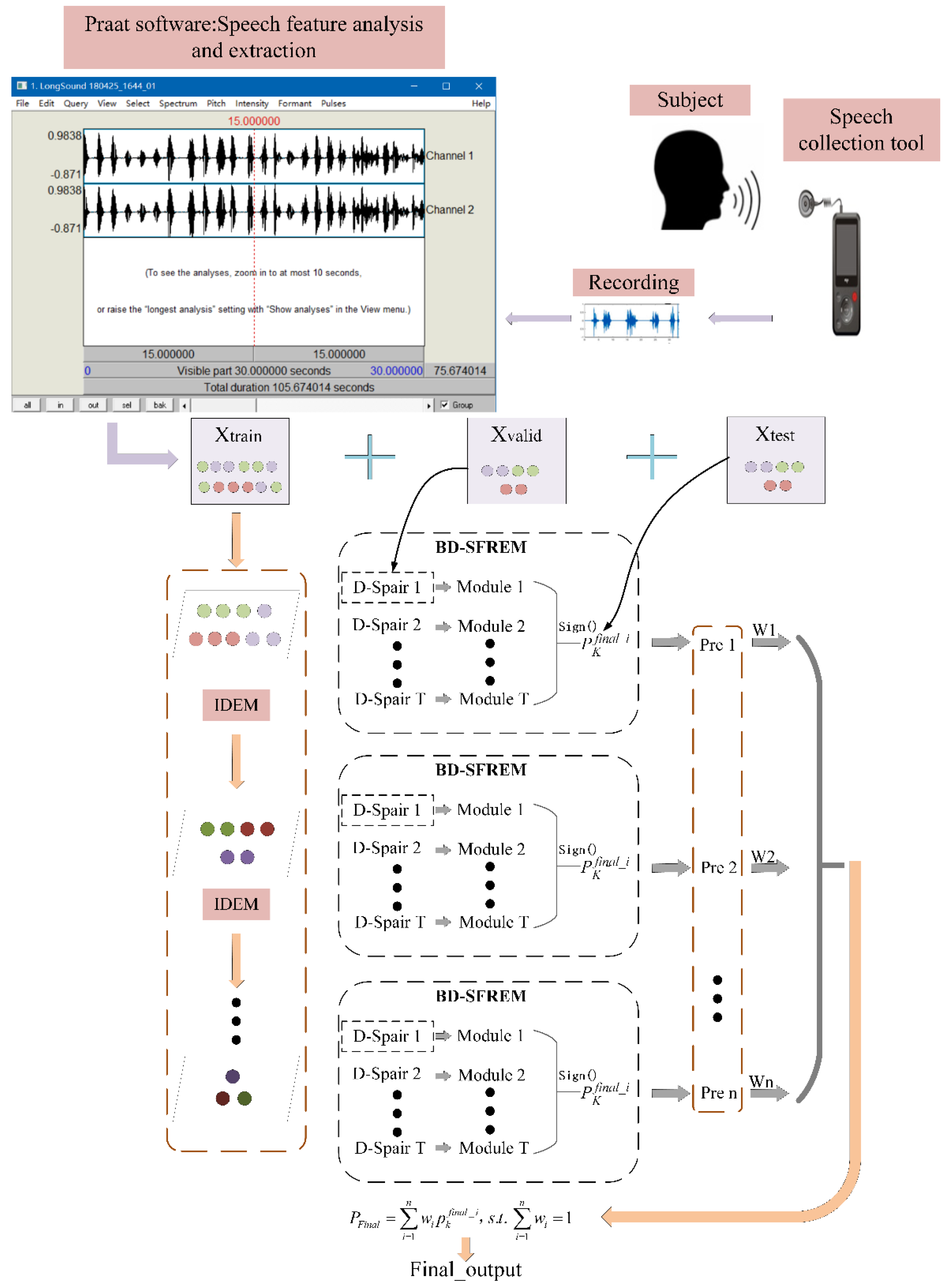
2.2.1. Construction of the Different Hierarchy Instance Space
2.2.2. Boosting Dual-Stage Feature Reduction Pair Ensemble Module
- D-Spair module;
- 2.
- Boosting ensemble module;
| BD-SFREM |
| Input: : training dataset (an matrix) and the corresponding labels (an matrix) : valid dataset (an matrix) and the corresponding labels (an matrix) : test data (an matrix) and the corresponding labels (an matrix) : boosting module usage times Threshold: flag of boosting module end Output: Final Prediction of the independent instance space |
| Begin 1: Given the data: . 2: Initial weights of : 3: while <= Threshold (where is error calculated from misclassified instances, ) do 4: Use the D-Spair module to obtain dual-stage features. 5: Obtain weakclassifier, use dual-stage features: . 6: Obtain misclassification instances rate: use , and obtain the misclassification instances. 7: Obtain weight of weak hypothesis 8: Add misclassified instances to form a new training set. 9: End while 10: Obtain the final prediction use : End |
2.2.3. Hierarchical Space Instance Learning Mechanism
| Hierarchical space instance learning mechanism |
| Begin 1: For = 1: do 2: ; //get the dimension information of . 3: The number of output instance clusters: . 4: Define the size of the cluster: , where stands for the number of centroid samples of cluster and the dimensionality of the centroid samples. where is the labels of the output samples after IDEM, and represents the labels that belong to the same category. 5: Obtain the hierarchy: . End for 6: Obtain the different hierarchy space construct by IDEM: . 7: Apply BD-SFREM on . 8: Obtain the of the different hierarchy space. End |
2.2.4. Overall Description of the Proposed Model
3. Results
3.1. Datasets
3.2. Experimental Environment
3.3. Evaluation Criteria
- ;
- ;
- ;
- ;
- ;
3.4. Results and Analysis
3.4.1. Verification of the Effectiveness of HBD-SFREM
- Verification of the BD-SFREM;
- 2.
- Verification of the hierarchical space instance learning mechanism;
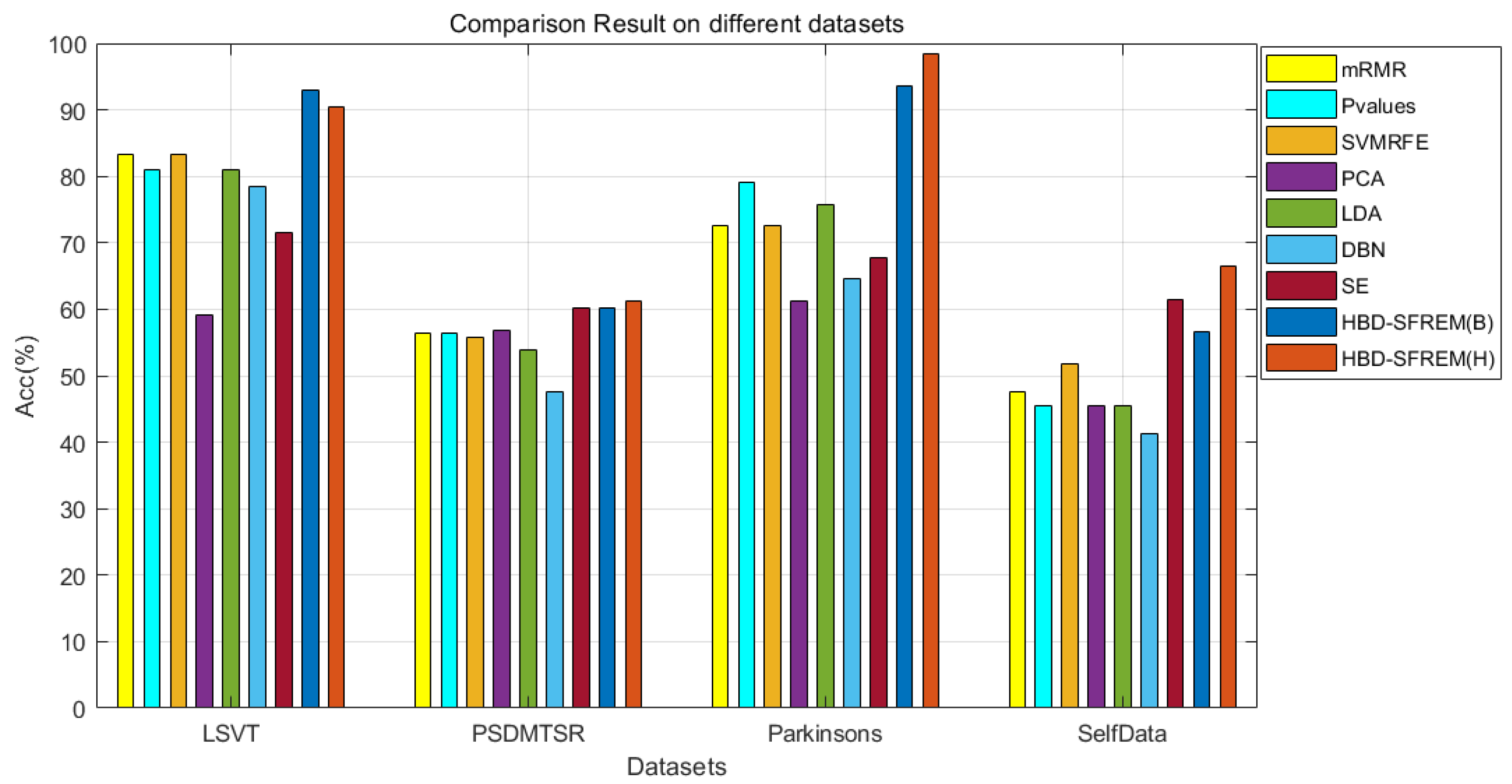
3.4.2. Comparison with the Representative Feature Processing Model
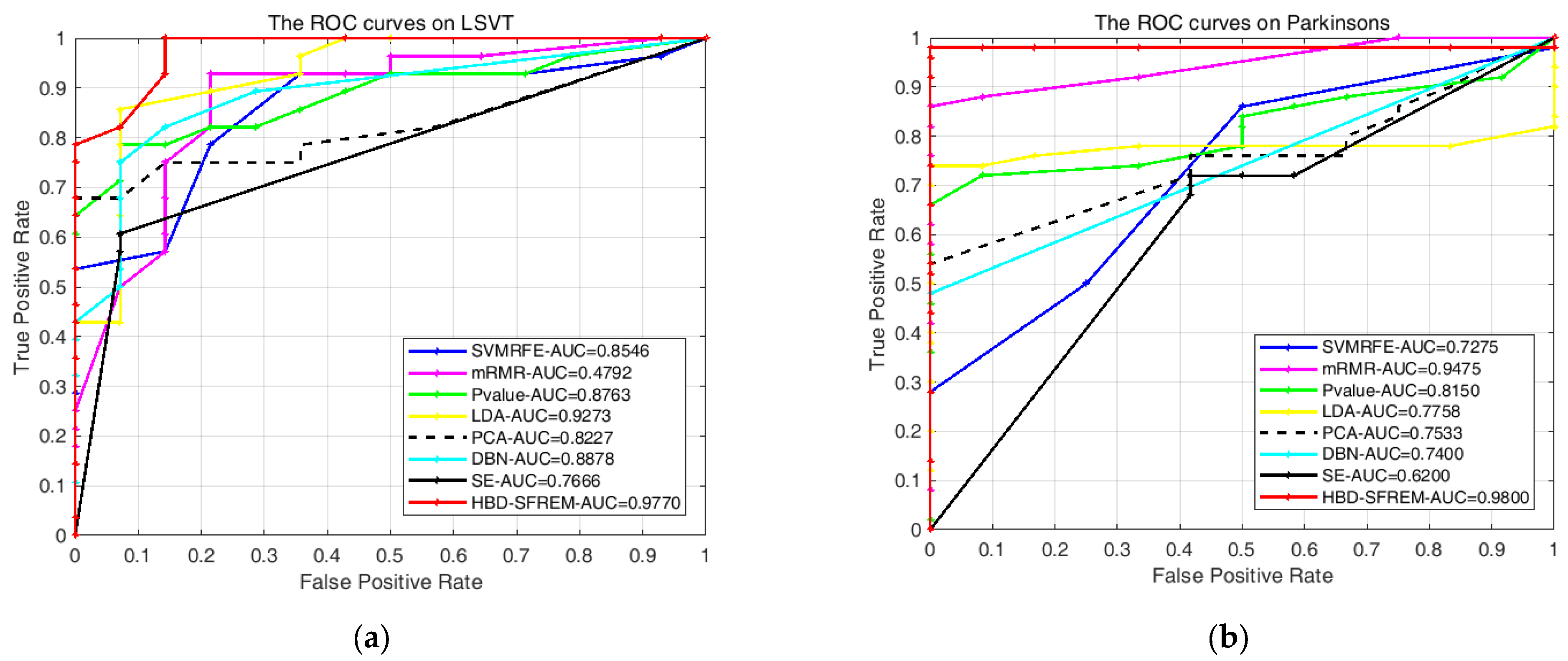
3.4.3. Comparison with Relevant PD Speech Recognition Methods
- (1)
- Relief-SVM [4]: Little used method in 2012, it involves first selecting four feature processing methods to process the features of the dataset, and then using Relief and SVM classifier with linear kernel function model (Relief-SVM) to learn to obtain a model.
- (2)
- (3)
- LDA-NN-GA [20]: This algorithm was proposed by L Ali and C Zhu in 2019. In [20]. The dataset is partitioned into a training set and a test set using the leave-one-out method (LOSO). Since each subject in the dataset contains multiple samples, the leave-one-out method here actually leaves all samples from one subject. Then, the feature dimension of the dataset is reduced using the LDA dimension reduction algorithm, and the BP neural network with genetic algorithm optimization is used to train the optimal prediction model (LDA-NN-GA).
- (4)
- FC-SVM [6]: This algorithm was proposed by Cigdem O in 2018. In [6], the Fisher criterion (FC)-based feature selection method is used to rank feature weights, finally, the first K useful features are selected based on a threshold to input the classifier (SVM with RBF) for training to obtain the model.
- (5)
- SFFS-RF [40]: This algorithm was proposed by Galaz Z in 2016. In this study, the sequential floating feature selection algorithm (SFFS) is adopted to process the data features, followed by inputting the processed results into the RF classifier to learn the prediction model.
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arkinson, C.; Walden, H. Parkin function in Parkinson’s disease. Science 2018, 360, 267–268. [Google Scholar] [CrossRef] [Green Version]
- Tsanas, A.; Little, M.; McSharry, P.; Ramig, L. Accurate Telemonitoring of Parkinson’s Disease Progression by Noninvasive Speech Tests. IEEE Trans. Biomed. Eng. 2010, 57, 884–893. [Google Scholar] [CrossRef] [Green Version]
- Sakar, C.; Serbes, G.; Tunc, H.; Nizam, H.; Sakar, B.; Tutuncu, M.; Aydin, T.; Isenkul, M.; Apaydin, H. A comparative analysis of speech signal processing algorithms for Parkinson’s disease classification and the use of the tunable Q-factor wavelet transform. Appl. Soft Comput. J. 2018, 74, 255–263. [Google Scholar] [CrossRef]
- Tsanas, A.; Little, M.A.; McSharry, P.E.; Spielman, J.; Ramig, L.O. Novel Speech Signal Processing Algorithms for High-Accuracy Classification of Parkinson’s Disease. IEEE Trans. Bio-Med Eng. 2012, 59, 1264–1271. [Google Scholar] [CrossRef] [Green Version]
- Tuncer, T.; Dogan, S.; Acharya, U.R. Automated detection of Parkinson’s disease using minimum average maximum tree and singular value decomposition method with vowels. Biocybern. Biomed. Eng. 2019, 40, 211–220. [Google Scholar] [CrossRef]
- Cigdem, O.; Demirel, H. Performance analysis of different classification algorithms using different feature selection methods on Parkinson’s disease detection. J. Neurosci. Methods 2018, 309, 81–90. [Google Scholar] [CrossRef] [PubMed]
- Kursun, O.; Gumus, E.; Sertbas, A.; Favorov, O.V. Selection of vocal features for Parkinson’s Disease diagnosis. Int. J. Data Min. Bioinform. 2012, 6, 144–161. [Google Scholar] [CrossRef] [PubMed]
- Zuo, W.L.; Wang, Z.Y.; Liu, T.; Chen, H.L. Effective detection of Parkinson’s disease using an adaptive fuzzy k-nearest neighbor approach. Biomed. Signal Process. Control 2013, 8, 364–373. [Google Scholar] [CrossRef]
- Hariharan, M.; Polat, K.; Sindhu, R. A new hybrid intelligent system for accurate detection of Parkinson’s disease. Comput. Methods Programs Biomed. 2014, 113, 904–913. [Google Scholar] [CrossRef] [PubMed]
- Rovini, E.; Maremmani, C.; Moschetti, A.; Esposito, D.; Cavallo, F. Comparative Motor Pre-clinical Assessment in Parkinson’s Disease Using Supervised Machine Learning Approaches. Anim. Biomed. Eng. 2018, 46, 2057–2068. [Google Scholar] [CrossRef] [PubMed]
- Sakar, C.O.; Kursun, O. Telediagnosis of Parkinson’s disease using measurements of dysphonia. J. Med Syst. 2010, 34, 591–599. [Google Scholar] [CrossRef]
- Peker, M.; Baha Şen Delen, D. Computer-Aided Diagnosis of Parkinson’s Disease Using Complex-Valued Neural Networks and mRMR Feature Selection Algorithm. J. Healthc. Eng. 2015, 6, 281–302. [Google Scholar] [CrossRef] [Green Version]
- Benba, A.; Jilbab, A.; Hammouch, A. Hybridization of best acoustic cues for detecting persons with Parkinson’s disease. In Proceedings of the 2014 Second World Conference on Complex Systems (WCCS14), Agadir, Morocco, 10–12 November 2014. [Google Scholar]
- Shirvan, R.A.; Tahami, E. Voice analysis for detecting Parkinson’s disease using genetic algorithm and KNN classification method. In Proceedings of the 2011 18th Iranian Conference of Biomedical Engineering (ICBME), Tehran, Iran, 14–16 December 2011. [Google Scholar]
- Nasreen, S. A survey of feature Selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014. [Google Scholar]
- Liu, Y.; Li, Y.; Tan, X.; Wang, P.; Zhang, Y. Local discriminant preservation projection embedded ensemble learning based dimensionality reduction of speech data of Parkinson’s disease. Biomed. Signal Process. Control 2021, 63, 102165. [Google Scholar] [CrossRef]
- El Moudden, I.; Ouzir, M.; Elbernoussi, S. Feature selection and extraction for class prediction in dysphonia measures analysis: A case study on Parkinson’s disease speech rehabilitation. Technol. Health Care 2017, 25, 693–708. [Google Scholar] [CrossRef] [PubMed]
- Moudden, I.E.; Ouzir, M.; Elbernoussi, S. Automatic Speech Analysis in Patients with Parkinson’s Disease using Feature Dimension Reduction. In Proceedings of the 3rd International Conference on Mechatronics and Robotics Engineering (ICMRE 2017), Paris, France, 8–12 February 2017. [Google Scholar]
- Yang, S.; Zheng, F.; Luo, X.; Cai, S.; Wu, Y.; Liu, K.; Wu, M.; Chen, J.; Krishnan, S. Effective Dysphonia Detection Using Feature Dimension Reduction and Kernel Density Estimation for Patients with Parkinson’s Disease. PLoS ONE 2014, 9, e88825. [Google Scholar]
- Ali, L.; Zhu, C.; Zhang, Z.; Liu, Y. Automated Detection of Parkinson’s Disease Based on Multiple Types of Sustained Phonations using Linear Discriminant Analysis and Genetically Optimized Neural Network. IEEE J. Transl. Eng. Health Med. 2019, 7, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.L.; Huang, C.C.; Yu, X.G.; Xu, X.; Sun, X.; Wang, G.; Wang, S.J. An efficient diagnosis system for detection of Parkinson’s disease using fuzzy k-nearest neighbor approach. Expert Syst. Appl. 2013, 40, 263–271. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [Green Version]
- Tenenbaum, J.B.; Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef] [PubMed]
- Adeli, E.; Wu, G.; Saghafi, B.; An, L.; Shi, F.; Shen, D. Kernel-based Joint Feature Selection and Max-Margin Classification for Early Diagnosis of Parkinson’s Disease. Sci. Rep. 2017, 7, 41069. [Google Scholar] [CrossRef]
- Avci, D.; Dogantekin, A. An Expert Diagnosis System for Parkinson Disease Based on Genetic Algorithm-Wavelet Kernel-Extreme Learning Machine. Parkinson’s Dis. 2016, 2016, 5264743. [Google Scholar] [CrossRef] [Green Version]
- Grover, S.; Bhartia, S.; Yadav, A.; Seeja, K.R. Predicting Severity of Parkinson’s Disease Using Deep Learning. Procedia Comput. Sci. 2018, 132, 1788–1794. [Google Scholar] [CrossRef]
- Vásquez-Correa, J.C.; Arias-Vergara, T.; Orozco-Arroyave, J.R.; Eskofier, B.; Klucken, J.; Nöth, E. Multimodal Assessment of Parkinson’s Disease: A Deep Learning Approach. IEEE J. Biomed. Health Inform. 2019, 23, 1618–1630. [Google Scholar] [CrossRef]
- He, X. Locality Preserving Projections; University of Chicago: Chicago, IL, USA, 2005. [Google Scholar]
- Yu, G.; Peng, H.; Wei, J.; Ma, Q. Enhanced locality preserving projections using robust path-based similarity. Neurocomputing 2011, 74, 598–605. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, X.; Huang, G.B.; Liu, T.; Tan, X. Taste recognition in E-Tong using Local Discriminant Preservation Projection. IEEE Trans. Cybern. 2018, 49, 947–960. [Google Scholar] [CrossRef]
- Chen, Y.; Xu, X.H.; Lai, J.H. Optimal locality preserving projection for face recognition. Neurocomputing 2011, 74, 3941–3945. [Google Scholar] [CrossRef]
- Fu, Y.W.; Chen, H.L.; Chen, S.J.; Li, L.J.; Hunang, S.S.; Cai, Z.N. Hybrid Extreme Learning Machine Approach for Early Diagnosis of Parkinson’s Disease. In Proceedings of the International Conference in Swarm Intelligence, Hefei, China, 17–20 October 2014; Springer: Cham, Switzerland, 2014; pp. 342–349. [Google Scholar]
- Coates, A.; Ng, A.Y. Learning feature representations with K-means. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; pp. 561–580. [Google Scholar] [CrossRef]
- Grigorios, F.T.; Aristidis, C.L. The global kernel k-means algorithm for clustering in feature space. IEEE Trans. Neural Netw. 2009, 20, 1181–1194. [Google Scholar] [CrossRef]
- He, L.; Zhang, H. Kernel K-means sampling for nyström approximation. IEEE Trans. Image Process. 2018, 27, 2108–2120. [Google Scholar] [CrossRef] [PubMed]
- Tsanas, A.; Little, M.A.; Fox, C.; Ramig, L.O. Ramig: Objective automatic assessment of rehabilitative speech treatment in Parkinson’s disease. IEEE Trans. Neural Syst. Rehabil. Eng. 2013, 22, 181–190. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sakar, B.E.; Isenkul, M.E.; Sakar, C.O.; Sertbas, A.; Gurgen, F.; Delil, S.; Apaydin, H.; Kursun, O. Collection and Analysis of a Parkinson Speech Dataset with Multiple Types of Sound Recordings. IEEE J. Biomed. Health Inform. 2013, 17, 828–834. [Google Scholar] [CrossRef]
- Little, M.; McSharry, P.; Hunter, E.; Spielman, J.; Ramig, L. Suitability of Dysphonia Measurements for Telemonitoring of Parkinson’s Disease. IEEE Trans. Bio-Med. Eng. 2009, 56, 1015–1022. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deng, X.; Liu, Q.; Deng, Y.; Mahadevan, S. An improved method to construct basic probability assignment based on the confusion matrix for classification problem. Inf. Sci. 2016, 340–341, 250–261. [Google Scholar] [CrossRef]
- Galaz, Z.; Mekyska, J.; Mzourek, Z.; Smekal, Z.; Rektorova, I.; Eliasova, I.; Kostalova, M.; Mrackova, M.; Berankova, D. Prosodic analysis of neutral, stress-modified and rhymed speech in patients with Parkinson’s disease. Comput. Methods Programs Biomed. 2016, 127, 301–317. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Attributes | |||||
|---|---|---|---|---|---|---|
| Patients | Healthy People | Instances | Features | Classes | Reference | |
| LSVT | 14 | 0 | 126 | 309 | 2 | [36] |
| PSDMTSR | 20 | 20 | 1040 | 26 | 2 | [37] |
| Parkinson | 24 | 8 | 195 | 23 | 2 | [38] |
| SelfData | 10 | 21 | 403 | 26 | 2 | -- |
| Parameter | Meaning | Parameter Setting |
|---|---|---|
| Layers of deep instance space | 2 | |
| Numbers of independent instance space | 3 | |
| Penalty factor for | 10−4,10−3,…,104 | |
| Penalty factor for | 10−4,10−3,…,104 | |
| Kernel parameter for affinity matrix | 10−4,10−3,…,104 | |
| Number of nearest neighbor instances in | 5 | |
| Dimension after FR | 5,10,15,… | |
| Instance output rate of each hierarchical | 0.8 |
| Prediction Labels | |||
|---|---|---|---|
| Positive (P) | Negative (N) | ||
| Real label | Positive (P) | ||
| Negative (N) | |||
| Methods | Only-FS | Only-FE (B) | Only-FE (H) | D-Spair (B) | D-Spair (H) | BD-SFREM (B) | BD-SFREM (H) | ||
|---|---|---|---|---|---|---|---|---|---|
| Datasets/ EM/Classifier | |||||||||
| LSVT | ACC | SVM (linear) | 78.57 | 78.57 | 78.57 | 83.33 | 83.33 | 85.71 | 92.86 |
| SVM (RBF) | 76.19 | 73.81 | 71.43 | 83.33 | 85.71 | 83.33 | 90.48 | ||
| pre | SVM (linear) | 95.24 | 82.76 | 91.30 | 88.89 | 88.89 | 96.00 | 100.00 | |
| SVM (RBF) | 95.00 | 90.48 | 78.57 | 92.00 | 92.31 | 96.00 | 96.15 | ||
| Rec | SVM (linear) | 71.43 | 85.71 | 75.00 | 85.71 | 85.71 | 85.71 | 89.29 | |
| SVM (RBF) | 67.86 | 67.86 | 78.57 | 82.14 | 85.71 | 85.71 | 89.29 | ||
| G-mean | SVM (linear) | 81.44 | 74.23 | 80.18 | 82.07 | 82.07 | 89.21 | 94.49 | |
| SVM (RBF) | 79.38 | 76.26 | 67.01 | 83.91 | 85.71 | 89.21 | 91.05 | ||
| F-score | SVM (linear) | 81.63 | 84.21 | 82.35 | 87.27 | 87.27 | 90.57 | 94.34 | |
| SVM (RBF) | 79.17 | 77.55 | 78.57 | 86.79 | 88.89 | 90.57 | 92.59 | ||
| PSDMTSR | Acc | SVM (linear) | 45.19 | 54.81 | 52.56 | 55.77 | 56.41 | 58.07 | 58.33 |
| SVM(RBF) | 46.79 | 55.77 | 55.77 | 55.77 | 56.73 | 57.37 | 58.97 | ||
| Pre | SVM (linear) | 42.11 | 57.89 | 54.88 | 60.98 | 60.42 | 65.43 | 61.61 | |
| SVM (RBF) | 46.21 | 59.18 | 59.78 | 5918 | 61.29 | 60.18 | 60.45 | ||
| Rec | SVM (linear) | 45.19 | 35.26 | 28.85 | 32.05 | 37.18 | 33.97 | 44.23 | |
| SVM (RBF) | 47.44 | 37.18 | 35.26 | 37.18 | 36.54 | 43.59 | 51.92 | ||
| G-mean | SVM (linear) | 40.74 | 51.20 | 46.19 | 50.47 | 53.03 | 52.80 | 56.60 | |
| SVM (RBF) | 46.16 | 52.58 | 51.86 | 52.58 | 53.02 | 55.69 | 58.55 | ||
| F-Score | SVM (linear) | 31.87 | 43.82 | 37.82 | 42.02 | 46.03 | 44.73 | 51.49 | |
| SVM (RBF) | 42.36 | 45.67 | 44.35 | 45.67 | 45.78 | 50.56 | 55.86 | ||
| Parkinson | Acc | SVM (linear) | 59.68 | 66.13 | 66.13 | 67.74 | 79.03 | 96.77 | 95.16 |
| SVM (RBF) | 61.29 | 59.68 | 61.29 | 67.74 | 62.90 | 83.87 | 79.03 | ||
| Pre | SVM (linear) | 90.32 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| SVM (RBF) | 84.21 | 90.32 | 84.21 | 82.61 | 80.00 | 97.62 | 93.02 | ||
| Rec | SVM (linear) | 56.00 | 58.00 | 58.00 | 60.00 | 74.00 | 96.00 | 94.00 | |
| SVM (RBF) | 64.00 | 56.00 | 64.00 | 76.00 | 72.00 | 82.00 | 80.00 | ||
| G-mean | SVM (linear) | 64.81 | 76.16 | 76.16 | 77.46 | 86.02 | 97.98 | 96.95 | |
| SVM (RBF) | 56.57 | 64.81 | 56.57 | 50.33 | 42.43 | 86.70 | 77.46 | ||
| F-score | SVM (linear) | 69.14 | 73.42 | 73.42 | 75.00 | 85.06 | 97.96 | 96.91 | |
| SVM (RBF) | 72.73 | 69.14 | 72.73 | 79.17 | 75.79 | 89.13 | 86.02 | ||
| Self Data | Acc | SVM (linear) | 47.55 | 44.76 | 45.45 | 58.04 | 55.24 | 58.74 | 58.74 |
| SVM (RBF) | 45.45 | 43.36 | 45.45 | 46.85 | 46.15 | 49.65 | 58.04 | ||
| Pre | SVM (linear) | 35.06 | 33.33 | 34.15 | 38.89 | 36.36 | 40.54 | 40.00 | |
| SVM (RBF) | 33.75 | 32.53 | 34.52 | 35.00 | 34.57 | 34.38 | 33.33 | ||
| Rec | SVM (linear) | 51.92 | 51.92 | 53.85 | 26.92 | 30.77 | 28.85 | 26.29 | |
| SVM (RBF) | 51.92 | 51.92 | 55.77 | 53.85 | 53.85 | 42.31 | 15.38 | ||
| G-mean | SVM (linear) | 48.37 | 45.95 | 46.79 | 45.18 | 46.15 | 46.77 | 45.50 | |
| SVM (RBF) | 46.56 | 44.69 | 46.97 | 48.04 | 50.39 | 47.73 | 35.60 | ||
| F-score | SVM (linear) | 41.86 | 40.60 | 41.79 | 31.82 | 33.33 | 33.71 | 32.18 | |
| SVM (RBF) | 40.91 | 40.00 | 42.65 | 42.42 | 42.11 | 37.93 | 24.05 | ||
| Methods | Only-FS | Only-FE (B) | D-Spair (B) | BD-SFREM (B) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Datasets/ EM/Classifier | (O) | (H) | (O) | (H) | (O) | (H) | (O) | (H) | ||
| LSVT | ACC | SVM (linear) | 78.57 | 80.95 | 78.57 | 85.71 | 83.33 | 85.71 | 85.71 | 85.71 |
| SVM (RBF) | 76.19 | 83.33 | 73.81 | 83.33 | 83.33 | 85.71 | 83.33 | 92.86 | ||
| pre | SVM (linear) | 95.24 | 95.45 | 82.76 | 95.83 | 88.89 | 95.83 | 96.00 | 100.00 | |
| SVM (RBF) | 95.00 | 92.00 | 90.48 | 88.89 | 92.00 | 92.31 | 96.00 | 96.30 | ||
| Rec | SVM (linear) | 71.43 | 75.00 | 85.71 | 82.14 | 85.71 | 82.14 | 85.71 | 85.71 | |
| SVM (RBF) | 67.86 | 82.14 | 67.86 | 85.71 | 82.14 | 85.71 | 85.71 | 92.86 | ||
| G-mean | SVM (linear) | 81.44 | 83.45 | 74.23 | 87.34 | 82.07 | 87.34 | 88.10 | 85.71 | |
| SVM (RBF) | 79.38 | 83.91 | 76.26 | 82.07 | 83.91 | 85.71 | 88.10 | 92.86 | ||
| F-score | SVM (linear) | 81.63 | 84.00 | 84.21 | 88.46 | 87.27 | 88.46 | 89.21 | 88.89 | |
| SVM (RBF) | 79.17 | 86.79 | 77.55 | 87.27 | 86.79 | 88.89 | 89.21 | 94.55 | ||
| PSDMTSR | Acc | SVM (linear) | 45.19 | 48.08 | 54.81 | 58.01 | 55.77 | 57.69 | 58.01 | 57.05 |
| SVM(RBF) | 47.44 | 52.88 | 55.77 | 57.37 | 55.77 | 57.37 | 57.37 | 60.26 | ||
| Pre | SVM (linear) | 42.11 | 47.86 | 57.89 | 62.89 | 60.98 | 65.79 | 65.43 | 60.19 | |
| SVM(RBF) | 64.22 | 56.92 | 59.18 | 60.36 | 59.18 | 60.36 | 60.18 | 61.11 | ||
| Rec | SVM (linear) | 25.64 | 42.95 | 35.26 | 39.10 | 32.05 | 32.05 | 33.97 | 41.67 | |
| SVM(RBF) | 44.87 | 23.72 | 37.18 | 42.95 | 37.18 | 42.95 | 43.59 | 56.41 | ||
| G-mean | SVM (linear) | 40.74 | 47.80 | 51.20 | 54.84 | 50.47 | 51.68 | 52.80 | 54.94 | |
| SVM(RBF) | 58.01 | 44.11 | 52.58 | 55.53 | 52.58 | 55.53 | 55.69 | 60.13 | ||
| F-Score | SVM (linear) | 31.87 | 45.27 | 43.82 | 48.22 | 42.02 | 43.10 | 44.73 | 49.24 | |
| SVM(RBF) | 52.83 | 33.48 | 45.67 | 50.19 | 45.67 | 50.19 | 50.56 | 58.67 | ||
| Parkinson | Acc | SVM (linear) | 59.68 | 72.58 | 66.13 | 74.19 | 67.74 | 82.26 | 96.77 | 85.48 |
| SVM (RBF) | 61.29 | 67.74 | 59.68 | 70.97 | 67.74 | 67.74 | 83.87 | 85.48 | ||
| Pre | SVM (linear) | 90.32 | 86.67 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| SVM (RBF) | 84.21 | 85.71 | 90.32 | 79.63 | 82.61 | 82.61 | 97.62 | 100.00 | ||
| Rec | SVM (linear) | 56.00 | 78.00 | 58.00 | 68.00 | 60.00 | 78.00 | 96.00 | 82.00 | |
| SVM (RBF) | 64.00 | 72.00 | 56.00 | 86.00 | 76.00 | 76.00 | 82.00 | 82.00 | ||
| G-mean | SVM (linear) | 64.81 | 62.45 | 76.16 | 82.46 | 77.46 | 88.32 | 97.98 | 90.55 | |
| SVM (RBF) | 56.57 | 60.00 | 64.81 | 26.77 | 50.33 | 50.33 | 86.70 | 90.55 | ||
| F-score | SVM (linear) | 69.14 | 82.11 | 73.42 | 80.95 | 75.00 | 87.64 | 97.96 | 90.11 | |
| SVM (RBF) | 72.73 | 78.26 | 69.14 | 82.69 | 79.17 | 79.17 | 89.13 | 90.11 | ||
| Self Data | Acc | SVM (linear) | 47.55 | 48.25 | 44.76 | 45.45 | 58.04 | 47.55 | 58.74 | 62.94 |
| SVM(RBF) | 45.45 | 46.15 | 43.36 | 45.45 | 46.85 | 50.35 | 49.65 | 49.65 | ||
| Pre | SVM (linear) | 35.06 | 35.53 | 33.33 | 33.75 | 38.89 | 35.05 | 40.54 | 47.06 | |
| SVM (RBF) | 33.75 | 33.77 | 32.53 | 34.15 | 35.00 | 35.82 | 34.38 | 32.14 | ||
| Rec | SVM (linear) | 51.92 | 51.92 | 51.92 | 51.92 | 26.92 | 51.92 | 28.85 | 15.38 | |
| SVM (RBF) | 51.92 | 50.00 | 51.92 | 53.85 | 53.85 | 46.15 | 42.31 | 34.62 | ||
| G-mean | SVM (linear) | 48.37 | 48.95 | 45.95 | 46.56 | 45.18 | 48.36 | 46.77 | 37.23 | |
| SVM (RBF) | 46.56 | 46.88 | 44.69 | 46.79 | 48.04 | 49.34 | 47.73 | 44.90 | ||
| F-score | SVM (linear) | 41.86 | 42.19 | 40.60 | 40.91 | 31.82 | 41.86 | 33.71 | 23.19 | |
| SVM (RBF) | 40.91 | 40.31 | 40.00 | 41.79 | 42.42 | 40.34 | 37.93 | 33.33 | ||
| Hierarchical Space | Original Space | Deep Space 1 | Deep Space 2 | ||
|---|---|---|---|---|---|
| Datasets/EM | |||||
| LSVT | ACC | 83.33 | 92.86 | 85.71 | 92.86 |
| pre | 92.00 | 96.30 | 95.83 | 96.30 | |
| Rec | 82.14 | 92.86 | 82.14 | 92.86 | |
| G-mean | 83.91 | 92.86 | 87.34 | 92.86 | |
| F-score | 86.79 | 94.55 | 88.46 | 94.55 | |
| PSDMTSR | ACC | 57.37 | 54.49 | 60.26 | 60.26 |
| pre | 60.18 | 56.36 | 61.11 | 61.11 | |
| Rec | 43.59 | 39.74 | 56.41 | 56.41 | |
| G-mean | 55.69 | 52.45 | 60.13 | 60.13 | |
| F-score | 50.56 | 46.62 | 58.67 | 58.67 | |
| Parkinson | ACC | 83.87 | 82.26 | 85.48 | 93.55 |
| pre | 97.62 | 67.90 | 1.00 | 97.62 | |
| Rec | 82.00 | 92.00 | 82.00 | 94.00 | |
| G-mean | 86.70 | 61.91 | 90.55 | 92.83 | |
| F-score | 89.13 | 89.32 | 90.11 | 95.92 | |
| SelfData | ACC | 49.65 | 49.65 | 56.64 | 56.64 |
| pre | 34.38 | 32.14 | 40.74 | 40.74 | |
| Rec | 42.31 | 34.62 | 42.31 | 42.31 | |
| G-mean | 47.73 | 44.90 | 52.37 | 52.37 | |
| F-score | 37.93 | 33.33 | 41.51 | 41.51 |
| Methods | mRMR | Pvalue | SVMRFE | PCA | LDA | DBN | SE | HBD-SFREM | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Datasets/EM/Classifier | (B) | (H) | |||||||||
| LSVT | ACC | SVM (linear) | 76.19 | 83.33 | 73.81 | 83.33 | 78.57 | 78.57 | 71.43 | 88.10 | 92.86 |
| SVM (RBF) | 83.33 | 80.95 | 83.33 | 69.05 | 80.95 | 92.86 | 90.48 | ||||
| pre | SVM (linear) | 100.00 | 100.00 | 94.74 | 95.65 | 91.30 | 95.24 | 94.44 | 100.00 | 100.00 | |
| SVM (RBF) | 100.00 | 91.67 | 83.87 | 100.00 | 95.45 | 96.30 | 96.15 | ||||
| Rec | SVM (linear) | 64.29 | 75.00 | 64.29 | 78.57 | 75.00 | 71.43 | 60.71 | 89.29 | 89.29 | |
| SVM (RBF) | 75.00 | 78.57 | 92.86 | 53.57 | 75.00 | 92.86 | 89.29 | ||||
| G-mean | SVM (linear) | 80.18 | 86.60 | 77.26 | 85.42 | 80.18 | 81.44 | 75.08 | 94.48 | 94.49 | |
| SVM (RBF) | 86.60 | 82.07 | 77.26 | 73.19 | 83.45 | 92.86 | 91.05 | ||||
| F-score | SVM (linear) | 78.26 | 85.71 | 76.60 | 86.27 | 82.35 | 81.63 | 73.91 | 94.34 | 94.34 | |
| SVM (RBF) | 85.71 | 84.62 | 88.14 | 69.77 | 84.00 | 94.55 | 92.59 | ||||
| PSDMTSR | Acc | SVM (linear) | 48.08 | 46.47 | 52.56 | 57.05 | 48.40 | 47.60 | 60.26 | 61.22 | 66.35 |
| SVM(RBF) | 56.41 | 56.41 | 55.77 | 56.73 | 53.85 | 60.26 | 61.22 | ||||
| Pre | SVM (linear) | 47.86 | 45.99 | 56.25 | 63.10 | 47.13 | 46.27 | 64.29 | 69.23 | 72.57 | |
| SVM(RBF) | 62.82 | 59.09 | 57.38 | 58.27 | 54.76 | 61.11 | 64.00 | ||||
| Rec | SVM (linear) | 42.95 | .40.38 | 23.08 | 33.97 | 26.28 | 29.81 | 64.15 | 40.38 | 52.56 | |
| SVM(RBF) | 31.41 | 41.67 | 44.87 | 47.44 | 44.23 | 56.41 | 51.28 | ||||
| G-mean | SVM (linear) | 47.80 | 46.07 | 43.51 | 52.18 | 43.05 | 44.15 | 58.58 | 57.56 | 64.90 | |
| SVM(RBF) | 50.57 | 54.45 | 54.69 | 55.96 | 52.98 | 60.13 | 60.41 | ||||
| F-Score | SVM (linear) | 45.27 | 43.00 | 32.73 | 44.17 | 33.74 | 36.26 | 53.73 | 51.01 | 60.97 | |
| SVM(RBF) | 41.88 | 48.87 | 50.36 | 52.30 | 48.94 | 58.67 | 56.94 | ||||
| Parkinson | Acc | SVM (linear) | 72.58 | 82.26 | 80.65 | 64.52 | 69.35 | 64.52 | 67.74 | 96.77 | 95.16 |
| SVM (RBF) | 72.58 | 79.03 | 72.58 | 61.29 | 75.81 | 93.55 | 98.39 | ||||
| Pre | SVM (linear) | 100.00 | 100.00 | 80.65 | 100.00 | 96.97 | 100.00 | 87.50 | 100.00 | 100.00 | |
| SVM (RBF) | 100.00 | 93.02 | 78.95 | 76.00 | 100.00 | 97.92 | 100.00 | ||||
| Rec | SVM (linear) | 74.00 | 78.00 | 100.00 | 56.00 | 64.00 | 56.00 | 70.00 | 96.00 | 94.00 | |
| SVM (RBF) | 66.00 | 80.00 | 90.00 | 76.00 | 70.00 | 94.00 | 98.00 | ||||
| G-mean | SVM (linear) | 86.02 | 88.32 | 00.00 | 74.83 | 76.59 | 74.83 | 63.90 | 97.98 | 96.95 | |
| SVM (RBF) | 81.24 | 77.46 | 00.00 | 00.00 | 83.67 | 92.83 | 98.99 | ||||
| F-score | SVM (linear) | 85.06 | 87.64 | 89.29 | 71.79 | 77.11 | 71.79 | 77.78 | 97.96 | 96.91 | |
| SVM (RBF) | 79.52 | 86.02 | 84.11 | 76.00 | 82.35 | 95.92 | 98.99 | ||||
| Self Data | Acc | SVM (linear) | 48.25 | 44.76 | 60.14 | 48.25 | 45.45 | 41.26 | 61.54 | 64.34 | 61.54 |
| SVM(RBF) | 47.55 | 45.45 | 51.75 | 45.45 | 45.45 | 56.64 | 66.43 | ||||
| Pre | SVM (linear) | 35.90 | 34.12 | 36.84 | 35.90 | 35.87 | 34.00 | 42.86 | 53.85 | 42.86 | |
| SVM (RBF) | 35.80 | 34.52 | 33.33 | 34.88 | 35.87 | 40.74 | 70.00 | ||||
| Rec | SVM (linear) | 53.85 | 55.77 | 13.46 | 53.85 | 63.46 | 65.38 | 17.31 | 13.46 | 17.31 | |
| SVM (RBF) | 55.77 | 55.77 | 32.69 | 57.69 | 63.46 | 42.31 | 13.46 | ||||
| G-mean | SVM (linear) | 48.25 | 44.76 | 60.14 | 48.25 | 45.45 | 42.38 | 38.76 | 35.46 | 38.76 | |
| SVM (RBF) | 49.25 | 46.31 | 34.18 | 49.25 | 47.24 | 52.37 | 36.08 | ||||
| F-score | SVM (linear) | 45.32 | 44.69 | 41.83 | 45.04 | 46.43 | 44.74 | 24.66 | 21.54 | 24.66 | |
| SVM (RBF) | 43.08 | 42.34 | 19.72 | 43.08 | 45.83 | 41.51 | 22.58 | ||||
| Datasets | LSVT | PSDMTSR | Parkinson | SelfData | |
|---|---|---|---|---|---|
| Methods | |||||
| HBD-SFREM (B) | SVM (linear) | 92.86 | 61.22 | 96.77 | 64.34 |
| SVM (RBF) | 92.86 | 60.26 | 93.55 | 56.64 | |
| HBD-SFREM (H) | SVM (linear) | 92.86 | 66.35 | 95.16 | 61.54 |
| SVM (RBF) | 90.48 | 61.22 | 98.39 | 66.43 | |
| Relief [4] | SVM (linear) | 78.57 | 45.19 | 59.68 | 47.55 |
| SVM (RBF) | 76.19 | 47.44 | 61.29 | 45.45 | |
| mRMR [3] | SVM (linear) | 76.19 | 48.08 | 72.58 | 48.25 |
| SVM (RBF) | 83.33 | 56.41 | 72.58 | 47.55 | |
| LDA-NN-GA [20] | 81.42 | 61.38 | 80.83 | 63.00 | |
| ReliefF-FC-SVM (RBF) [6] | 82.54 | 61.38 | 81.67 | 62.67 | |
| SFFS-RF [40] | 81.64 | 60.63 | 80.83 | 60.00 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, M.; Ma, J.; Wang, P.; Huang, Z.; Li, Y.; Liu, H.; Hameed, Z. Hierarchical Boosting Dual-Stage Feature Reduction Ensemble Model for Parkinson’s Disease Speech Data. Diagnostics 2021, 11, 2312. https://doi.org/10.3390/diagnostics11122312
Yang M, Ma J, Wang P, Huang Z, Li Y, Liu H, Hameed Z. Hierarchical Boosting Dual-Stage Feature Reduction Ensemble Model for Parkinson’s Disease Speech Data. Diagnostics. 2021; 11(12):2312. https://doi.org/10.3390/diagnostics11122312
Chicago/Turabian StyleYang, Mingyao, Jie Ma, Pin Wang, Zhiyong Huang, Yongming Li, He Liu, and Zeeshan Hameed. 2021. "Hierarchical Boosting Dual-Stage Feature Reduction Ensemble Model for Parkinson’s Disease Speech Data" Diagnostics 11, no. 12: 2312. https://doi.org/10.3390/diagnostics11122312
APA StyleYang, M., Ma, J., Wang, P., Huang, Z., Li, Y., Liu, H., & Hameed, Z. (2021). Hierarchical Boosting Dual-Stage Feature Reduction Ensemble Model for Parkinson’s Disease Speech Data. Diagnostics, 11(12), 2312. https://doi.org/10.3390/diagnostics11122312