
Impact of Image Resolution on Deep Learning Performance in Endoscopy Image Classification: An Experimental Study Using a Large Dataset of Endoscopic Images

 ,
,  ,
,  ,
, 
Abstract
:1. Introduction
2. Methods
2.1. Experimental Setup
2.2. Convolutional Neural Networks
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hassan, C.; Wallace, M.B.; Sharma, P.; Maselli, R.; Craviotto, V.; Spadaccini, M.; Repici, A. New artificial intelligence system: First validation study versus experienced endoscopists for colorectal polyp detection. Gut 2020, 69, 799–800. [Google Scholar] [CrossRef] [PubMed]
- Mossotto, E.; Ashton, J.J.; Coelho, T.; Beattie, R.M.; MacArthur, B.D.; Ennis, S. Classification of paediatric inflammatory bowel disease using machine learning. Sci. Rep. 2017, 7, 2427. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, P.; Xiao, X.; Brown, J.R.G.; Berzin, T.M.; Tu, M.; Xiong, F.; Hu, X.; Liu, P.; Song, Y.; Zhang, D.; et al. Development and validation of a deeplearning algorithm for the detection of polyps during colonoscopy. Nat. Biomed. Eng. 2018, 2, 741–748. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: Cnn architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef] [PubMed]
- Sabottke, C.F.; Spieler, B.M. The effect of image resolution on deep learning in radiography. Radiol. Artif. Intell. 2020, 2, e190015. [Google Scholar] [CrossRef] [PubMed]
- Battiti, R. Using mutual information for selecting features in supervised neural net learning. IEEE Trans. Neural Netw. 1994, 5, 537–550. [Google Scholar] [CrossRef] [Green Version]
- Borgli, H.; Thambawita, V.; Smedsrud, P.H.; Hicks, S.; Jha, D.; Eskeland, S.L.; Randel, K.R.; Pogorelov, K.; Lux, M.; Nguyen, D.T.D.; et al. HyperKvasir, a comprehensive multi-class image and video dataset for gastrointestinal endoscopy. Sci. Data 2020, 7, 283. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Vancouver, BC, Canada, 2019; pp. 8026–8037. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A largescale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Boughorbel, S.; Jarray, F.; El-Anbari, M. Optimal classifier for imbalanced data using matthews correlation coefficient metric. PLoS ONE 2017, 12, e0177678. [Google Scholar] [CrossRef] [PubMed]
- Thambawita, V.; Jha, D.; Hammer, H.L.; Johansen, H.D.; Johansen, D.; Halvorsen, P.; Riegler, M.A. An extensive study on cross-dataset bias and evaluation metrics interpretation for machine learning applied to gastrointestinal tract abnormality classification. ACM Trans. Comput. Healthc. 2020, 1, 1–29. [Google Scholar] [CrossRef]
- Pogorelov, K.; Riegler, M.; Halvorsen, P.; Schmidt, P.T.; Griwodz, C.; Johansen, D.; Eskeland, S.L.; De Lange, T. GPU-Accelerated Real-Time Gastrointestinal Diseases Detection. In Proceedings of the 2016 IEEE 29th International Symposium on Computer-Based Medical Systems (CBMS), Belfast and Dublin, Ireland, 20–24 June 2016; pp. 185–190. [Google Scholar] [CrossRef]
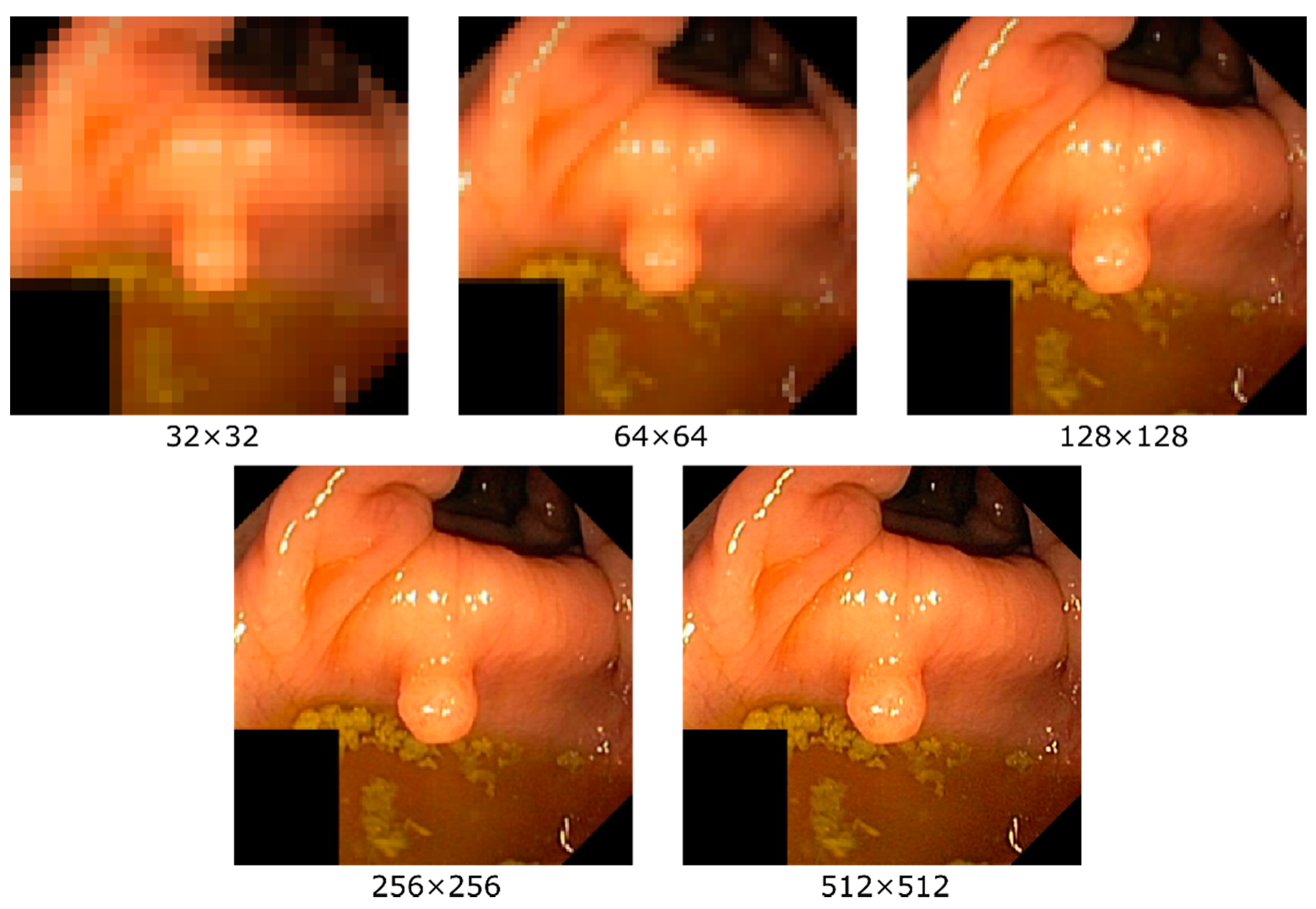


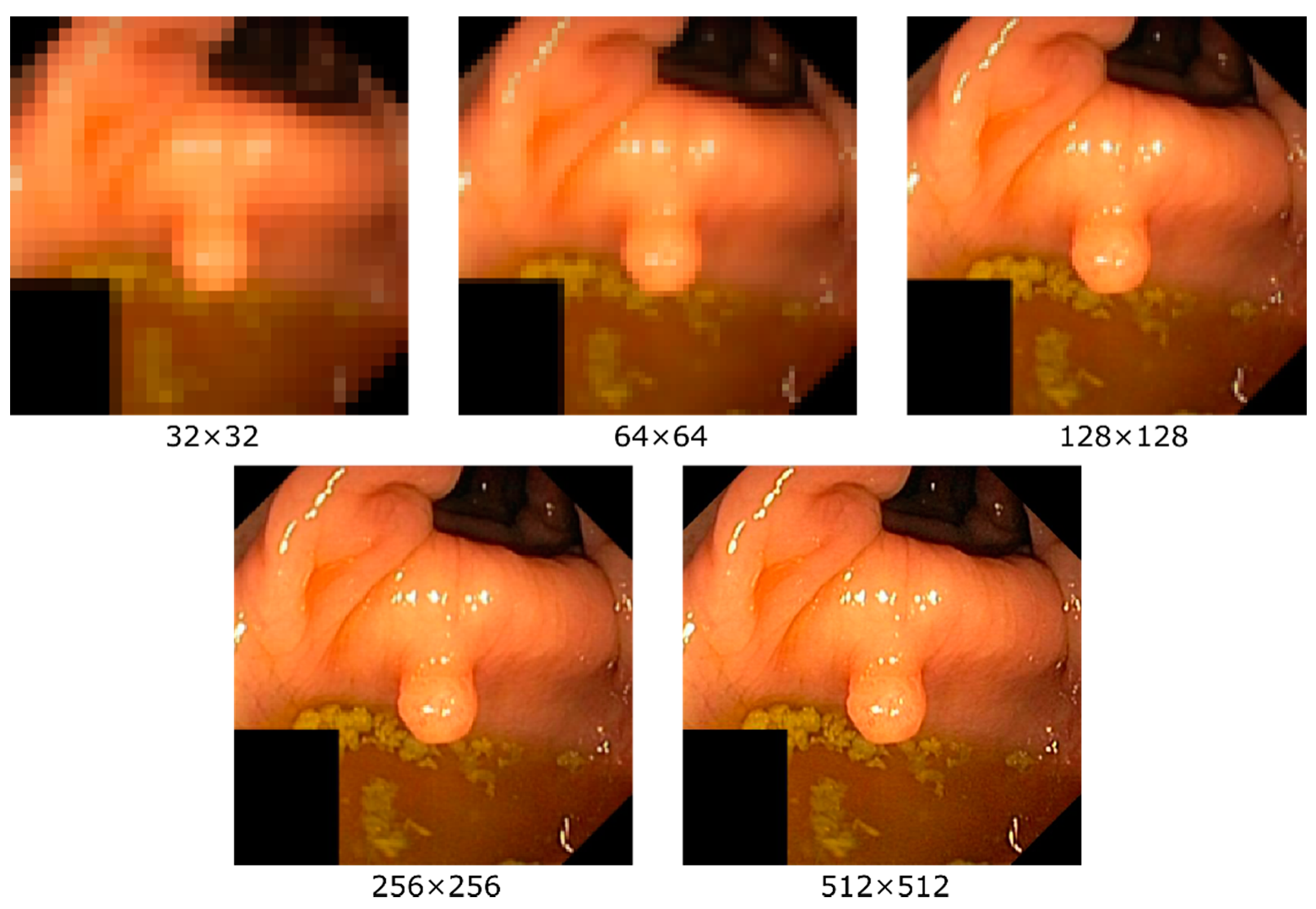{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Split 0 | Split 1 | Total |
|---|---|---|---|
| Barrett’s Esophagus | 20 | 21 | 41 |
| BBPS-0-1 | 323 | 323 | 646 |
| BBPS-2-3 | 574 | 574 | 1148 |
| Dyed-lifted-polyps | 501 | 501 | 1002 |
| Dyed-resection-margins | 494 | 495 | 989 |
| Hemorroids | 3 | 3 | 6 |
| Ileum | 4 | 5 | 9 |
| Impacted-stool | 65 | 66 | 131 |
| Normal-cecum | 504 | 505 | 1009 |
| Normal-pylorus | 499 | 500 | 999 |
| Normal-z-line | 466 | 466 | 932 |
| Esophagitis-LA grade A | 201 | 202 | 403 |
| Esophagitis-LA grade B-D | 130 | 130 | 260 |
| Colon Polyp | 514 | 514 | 1028 |
| Retroflex-rectum | 195 | 196 | 391 |
| Retroflex-stomach | 382 | 382 | 764 |
| Short-segment-Barrett’s | 26 | 27 | 53 |
| Ulcerative colitis-Mayo score 0–1 | 17 | 18 | 35 |
| Ulcerative colitis 1–2 | 5 | 6 | 11 |
| Ulcerative-colitis-Mayo 2–3 | 14 | 14 | 28 |
| Ulcerative-colitis-grade-1 | 100 | 101 | 201 |
| Ulcerative-colitis-grade-2 | 221 | 222 | 443 |
| Ulcerative-colitis-grade-3 | 66 | 67 | 133 |
| Total | 5324 | 5338 | 10662 |
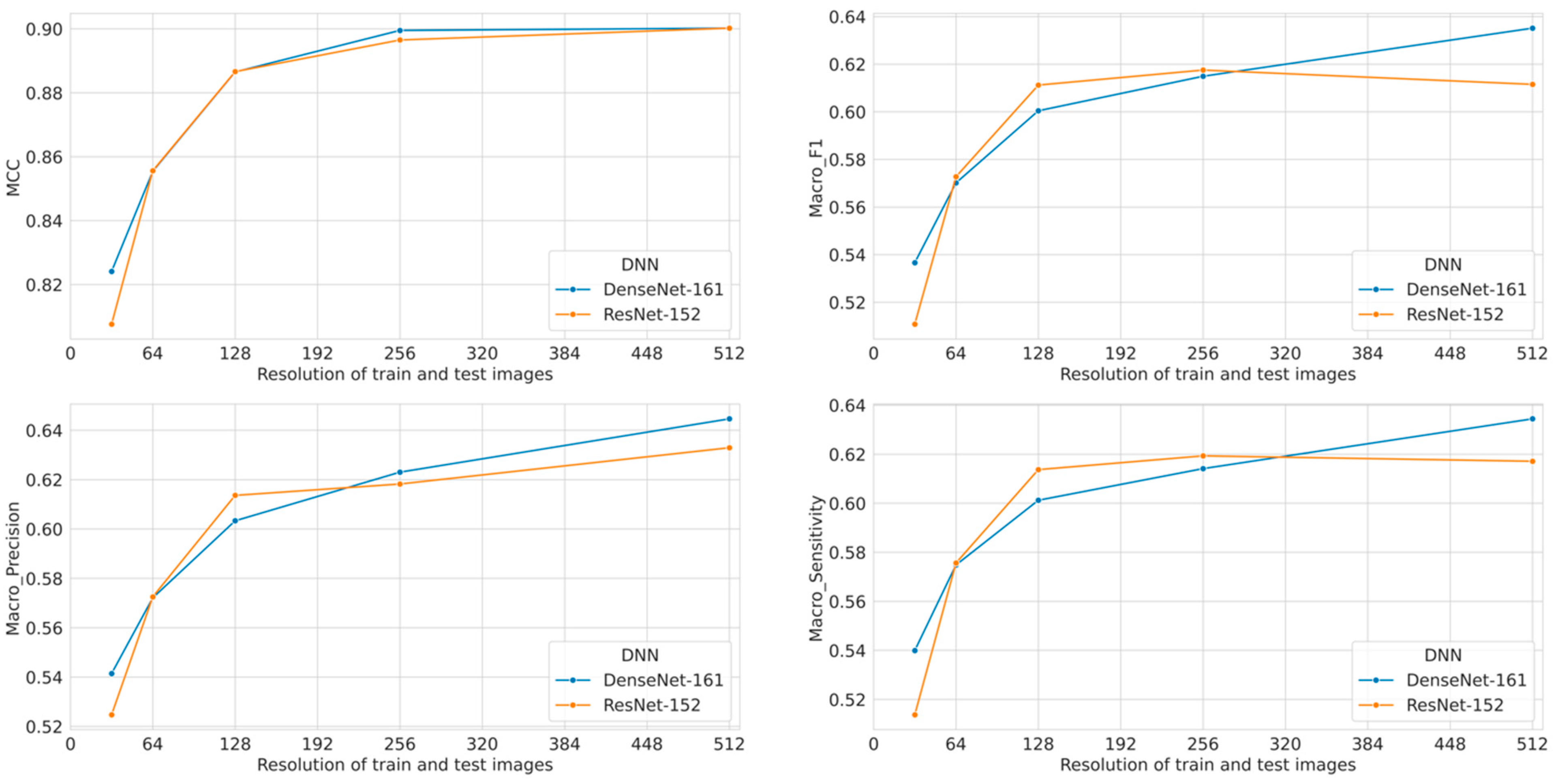
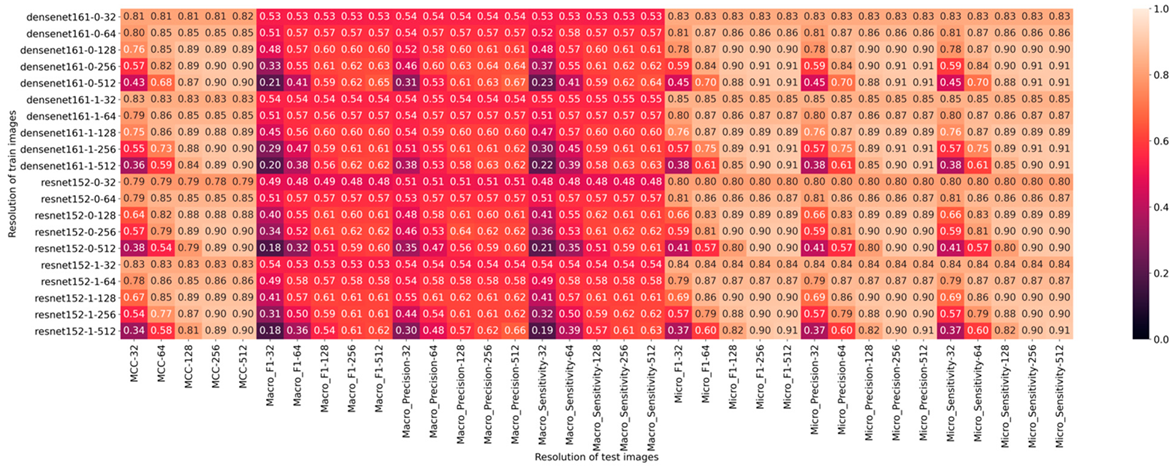
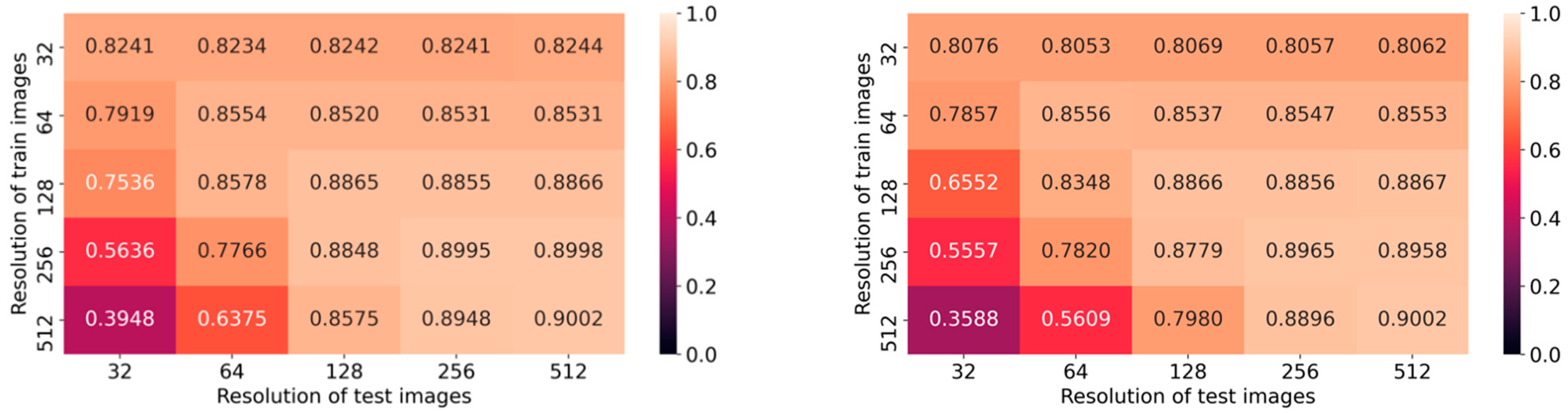
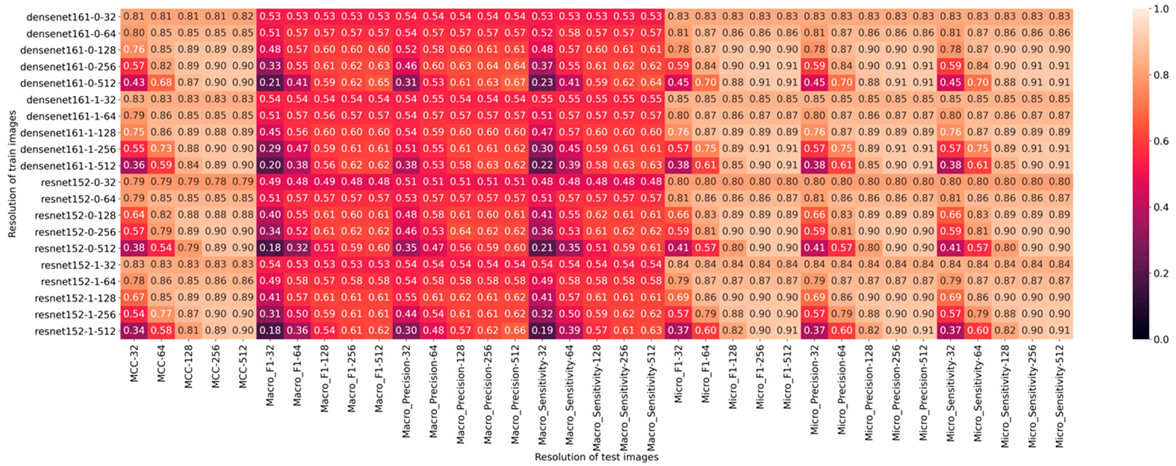
| Network | Resolution | MCC (Rk) | F1-Score | Precision | Sensitivity |
|---|---|---|---|---|---|
| DenseNet-161 | 32 × 32 | 0.8241 | 0.5366 | 0.5414 | 0.5399 |
| 64 × 64 | 0.8554 | 0.5701 | 0.5721 | 0.5748 | |
| 128 × 128 | 0.8865 | 0.6004 | 0.6033 | 0.6012 | |
| 256 × 256 | 0.8995 | 0.6149 | 0.6230 | 0.6141 | |
| 512 × 512 | 0.9002 | 0.6351 | 0.6446 | 0.6344 | |
| Resnet-152 | 32 × 32 | 0.8076 | 0.5108 | 0.5247 | 0.5137 |
| 64 × 64 | 0.8556 | 0.5727 | 0.5725 | 0.5756 | |
| 128 × 128 | 0.8866 | 0.6112 | 0.6136 | 0.6137 | |
| 256 × 256 | 0.8965 | 0.6175 | 0.6182 | 0.6193 | |
| 512 × 512 | 0.9002 | 0.6115 | 0.6329 | 0.6171 |
| Time (ms) per Image | ||
|---|---|---|
| Resolution | DenseNet-161 | Resnet-152 |
| 32 × 32 | 19.875 | 17.190 |
| 64 × 64 | 20.248 | 15.148 |
| 128 × 128 | 21.606 | 15.450 |
| 256 × 256 | 20.246 | 14.986 |
| 512 × 512 | 20.422 | 16.690 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thambawita, V.; Strümke, I.; Hicks, S.A.; Halvorsen, P.; Parasa, S.; Riegler, M.A. Impact of Image Resolution on Deep Learning Performance in Endoscopy Image Classification: An Experimental Study Using a Large Dataset of Endoscopic Images. Diagnostics 2021, 11, 2183. https://doi.org/10.3390/diagnostics11122183
Thambawita V, Strümke I, Hicks SA, Halvorsen P, Parasa S, Riegler MA. Impact of Image Resolution on Deep Learning Performance in Endoscopy Image Classification: An Experimental Study Using a Large Dataset of Endoscopic Images. Diagnostics. 2021; 11(12):2183. https://doi.org/10.3390/diagnostics11122183
Chicago/Turabian StyleThambawita, Vajira, Inga Strümke, Steven A. Hicks, Pål Halvorsen, Sravanthi Parasa, and Michael A. Riegler. 2021. "Impact of Image Resolution on Deep Learning Performance in Endoscopy Image Classification: An Experimental Study Using a Large Dataset of Endoscopic Images" Diagnostics 11, no. 12: 2183. https://doi.org/10.3390/diagnostics11122183
APA StyleThambawita, V., Strümke, I., Hicks, S. A., Halvorsen, P., Parasa, S., & Riegler, M. A. (2021). Impact of Image Resolution on Deep Learning Performance in Endoscopy Image Classification: An Experimental Study Using a Large Dataset of Endoscopic Images. Diagnostics, 11(12), 2183. https://doi.org/10.3390/diagnostics11122183