
Machine Learning-Based Three-Month Outcome Prediction in Acute Ischemic Stroke: A Single Cerebrovascular-Specialty Hospital Study in South Korea

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
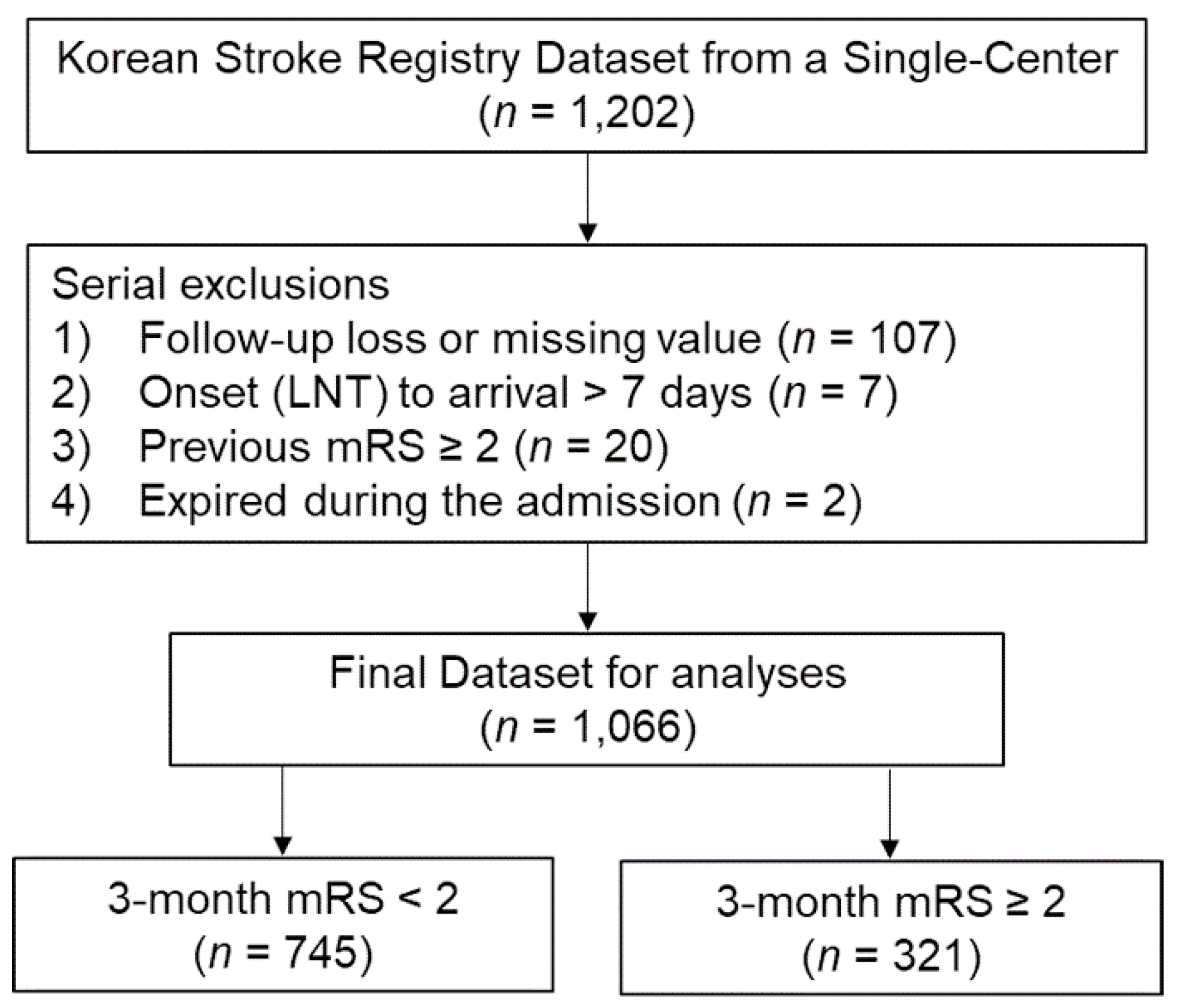
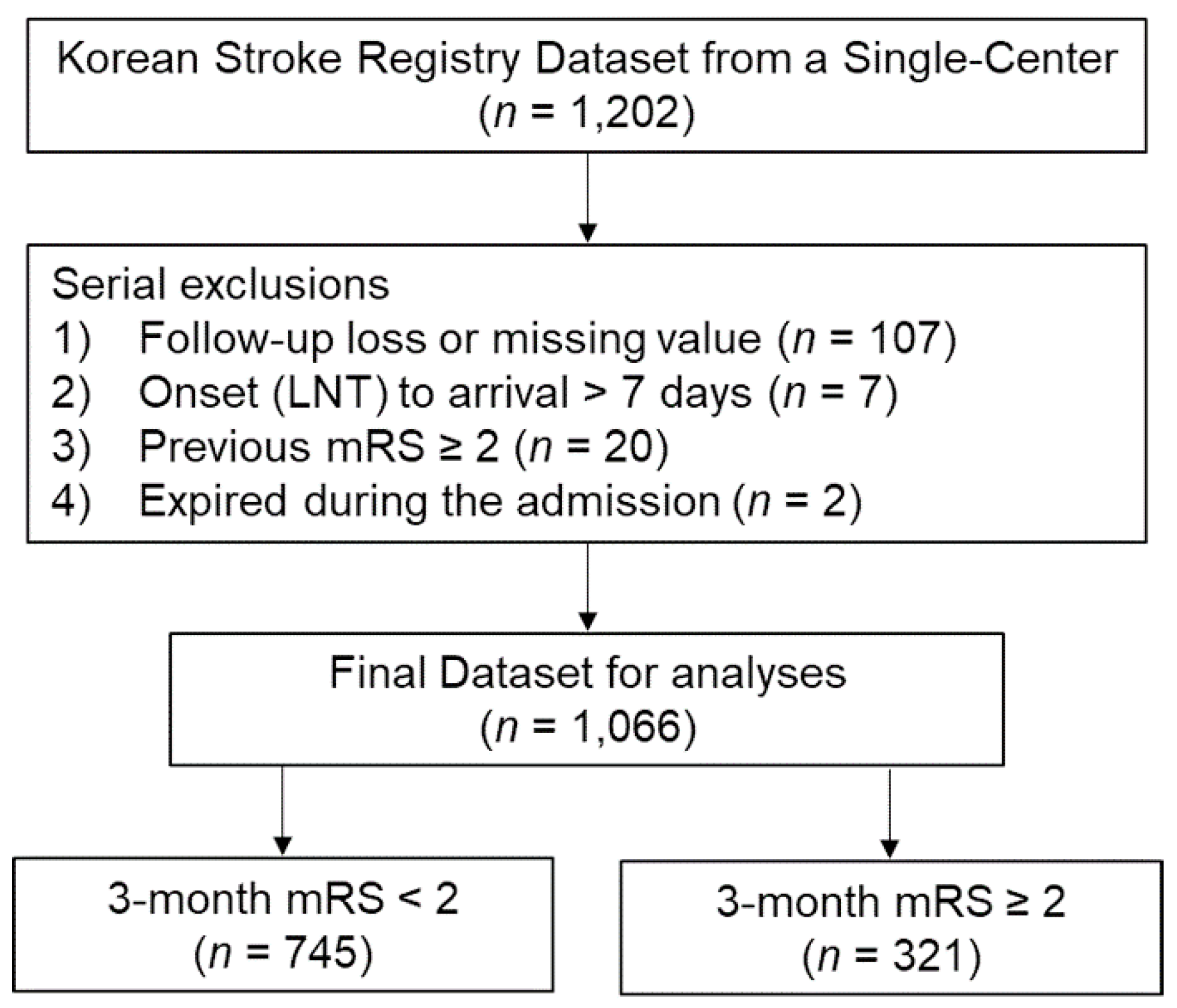
2.1. Data Source and Patients
2.2. Variables
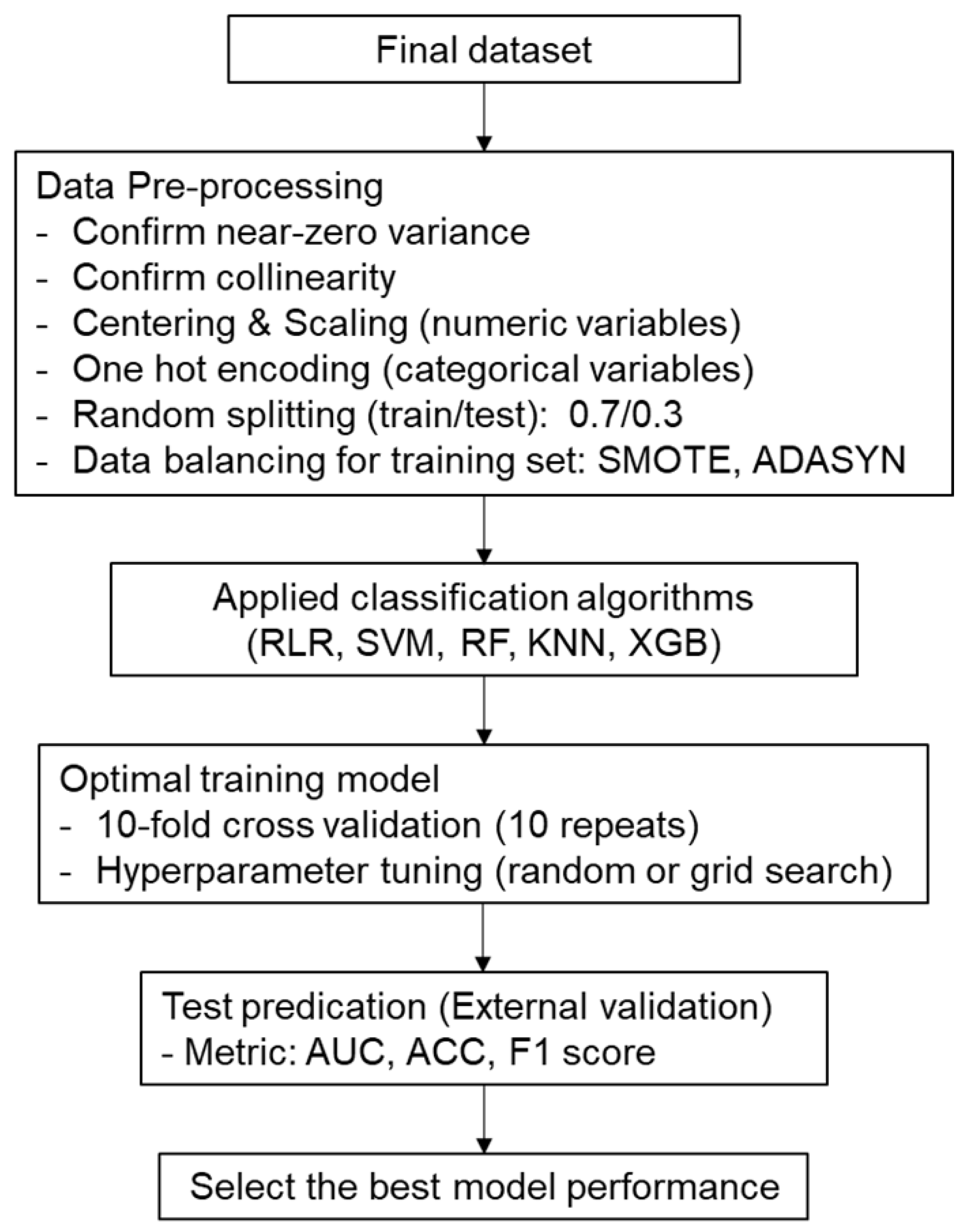
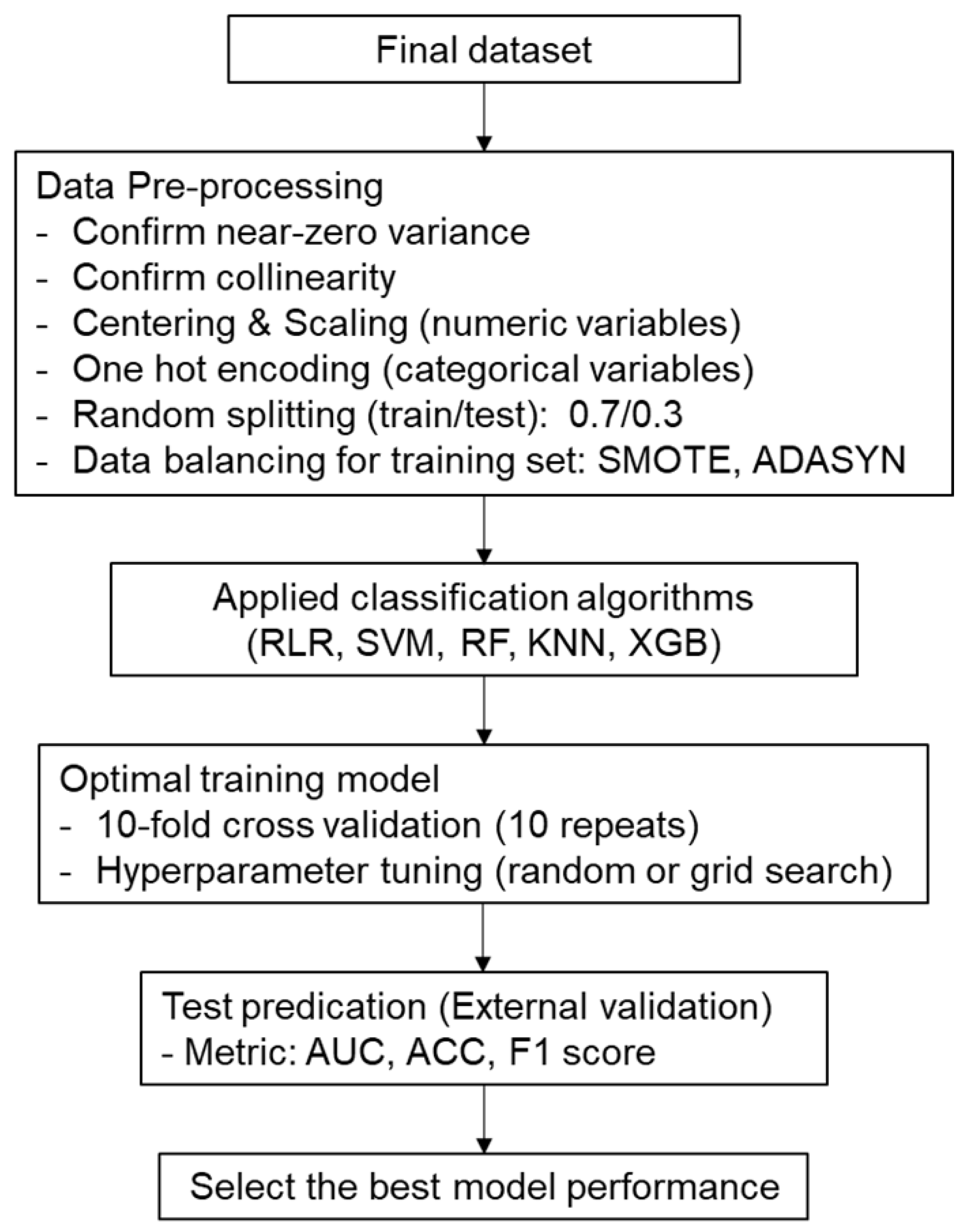
2.3. Data Analysis and Machine Learning Processes
3. Results
3.1. Baseline Characteristics
3.2. Data Pre-Processing
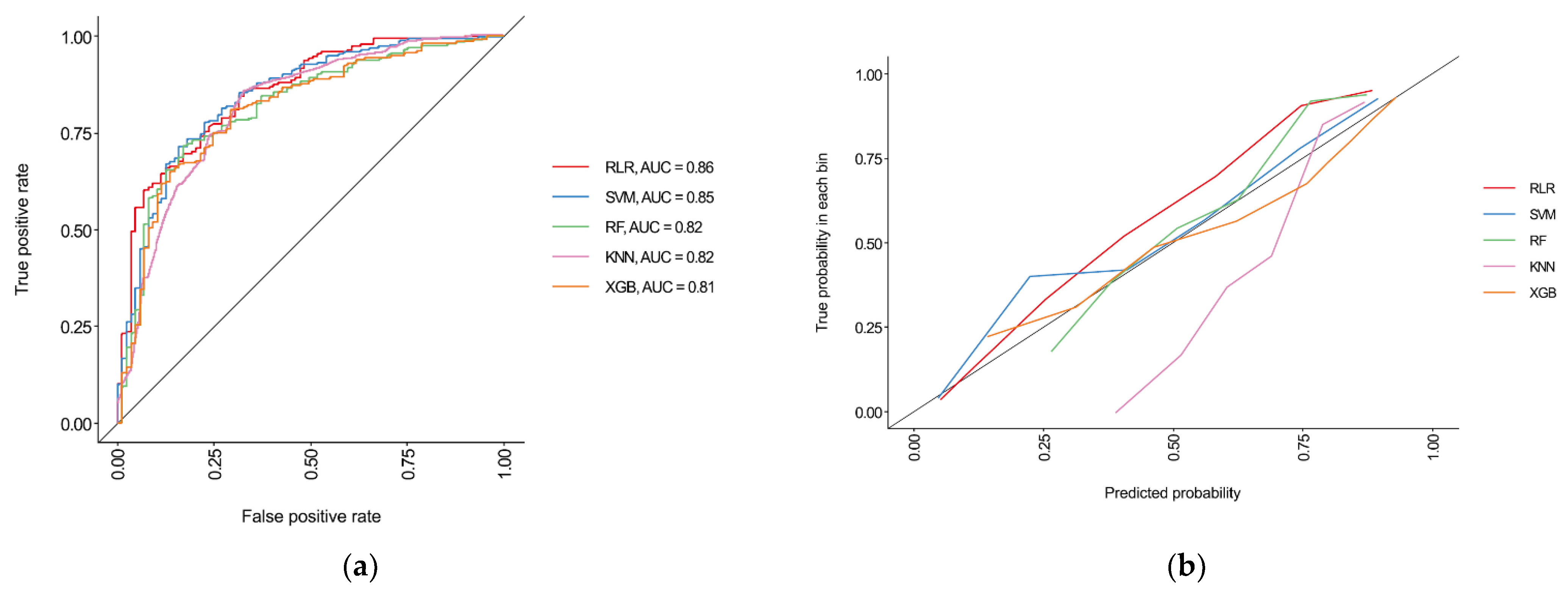
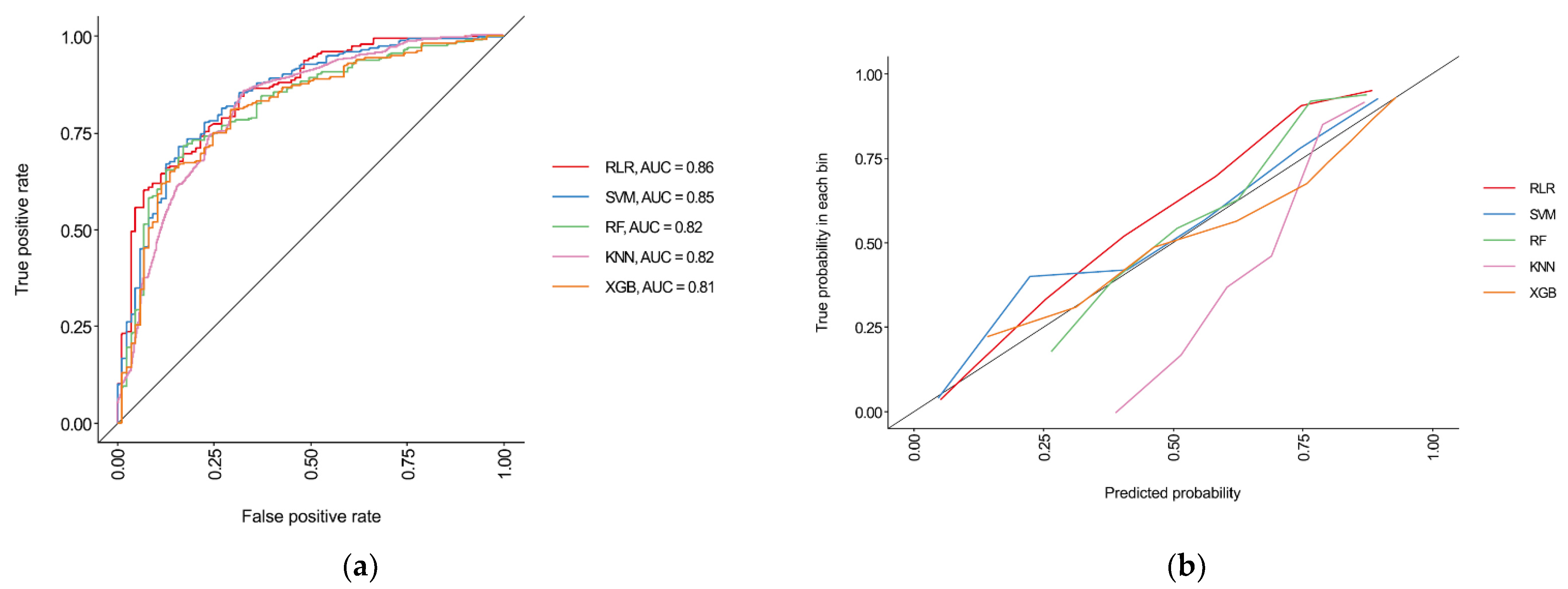
3.3. Performances of Machine Learning Algorithms
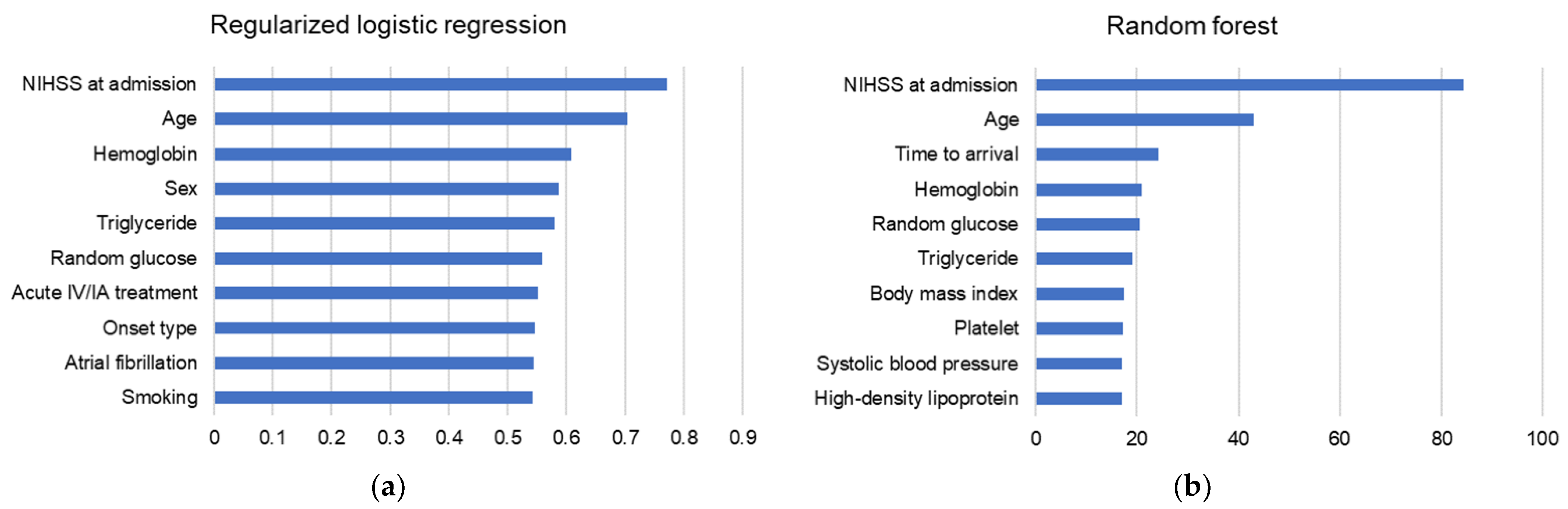
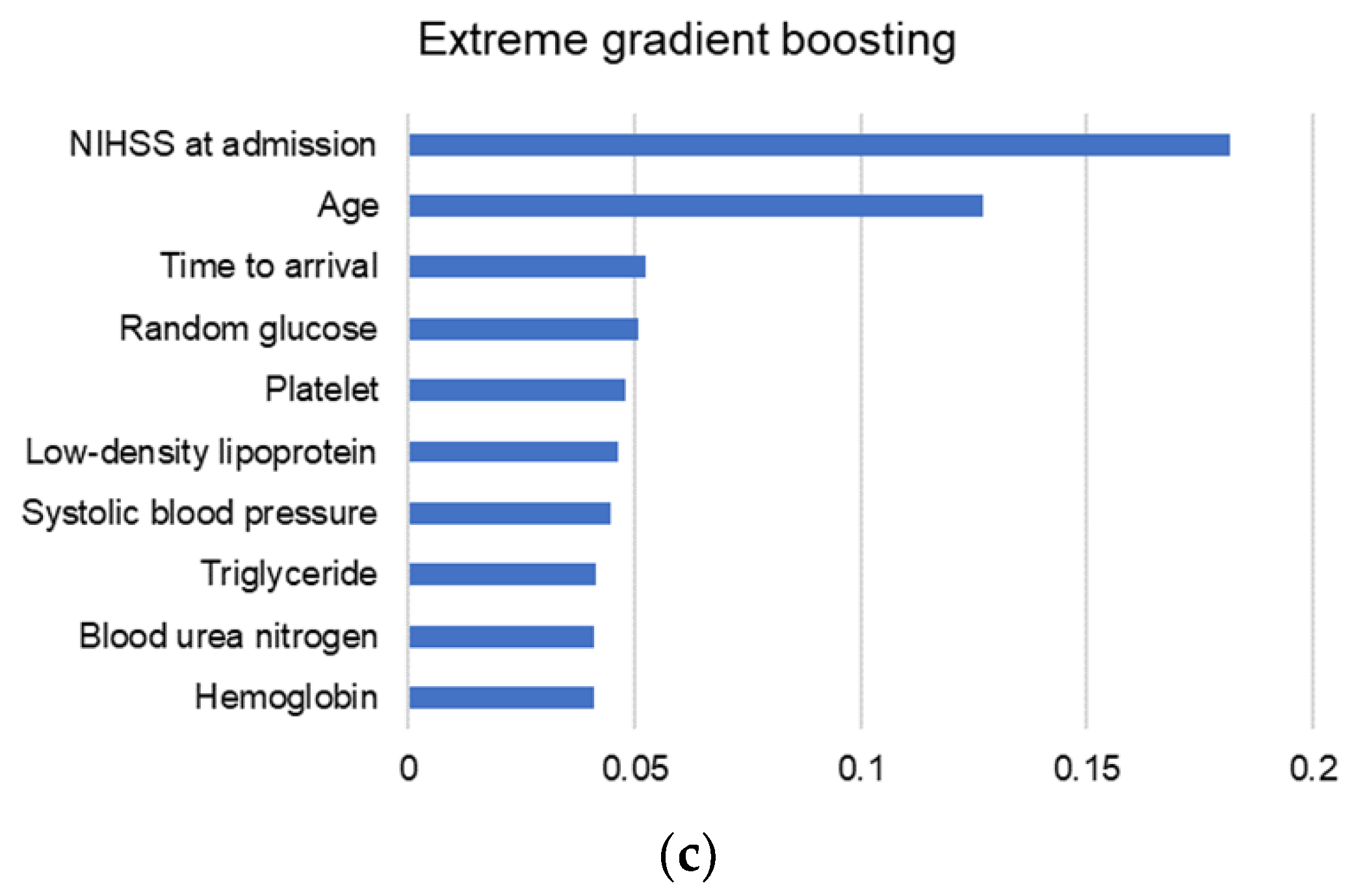
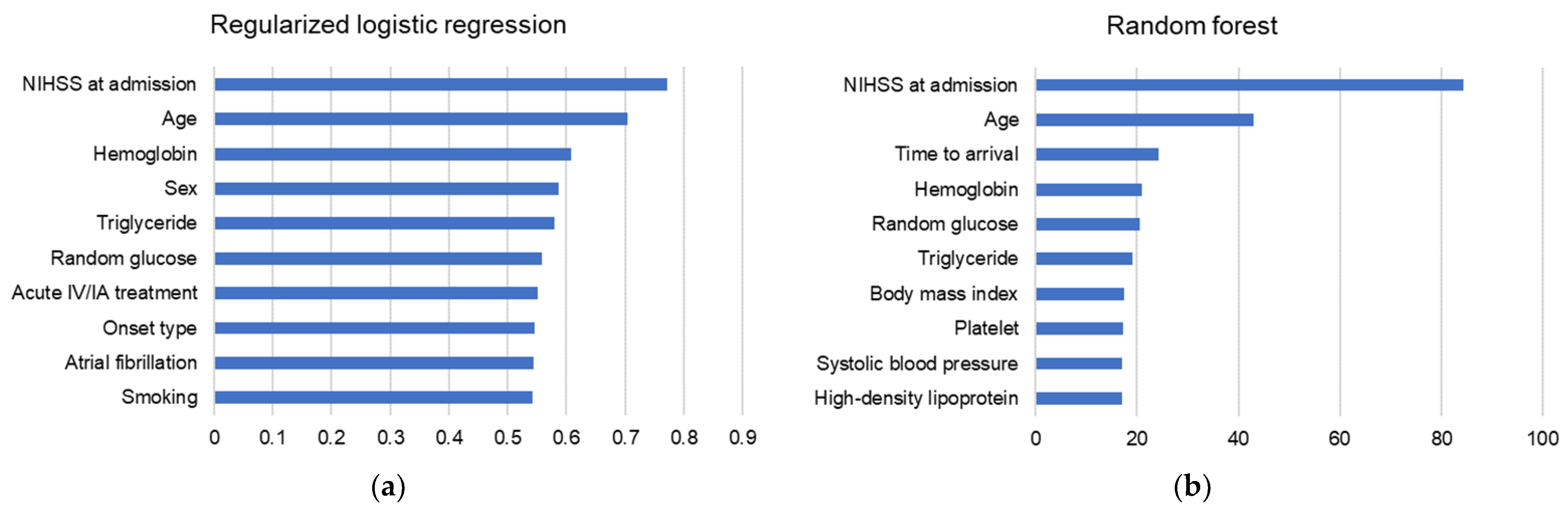
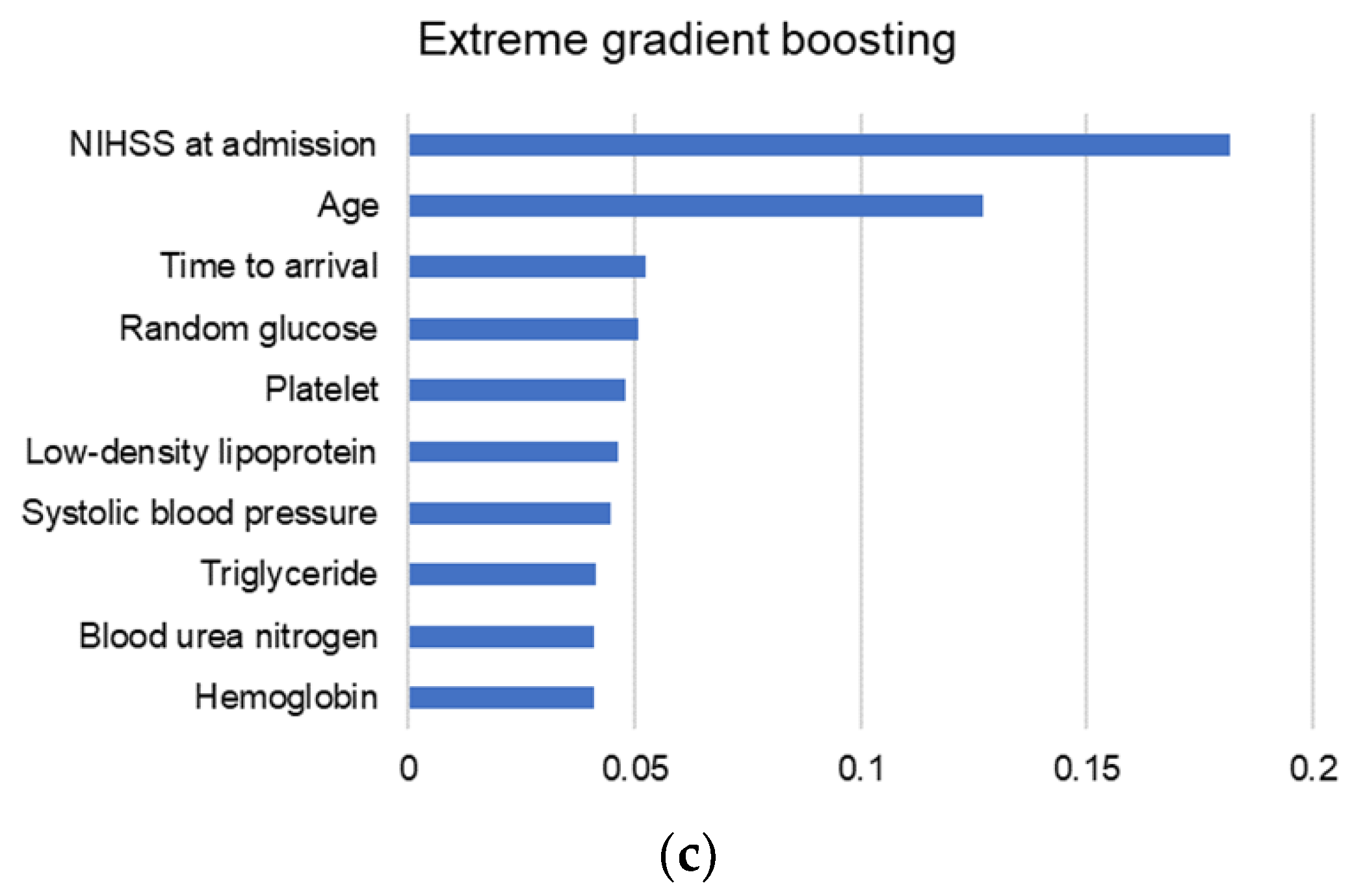
3.4. Variable Importance
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Donkor, E.S. Stroke in the 21st Century: A Snapshot of the Burden, Epidemiology, and Quality of Life. Stroke Res. Treat. 2018, 2018, 3238165. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, Y.; Shi, Y.Z.; Zhang, N.; Wang, S.; Ungvari, G.S.; Ng, C.H.; Wang, Y.L.; Zhao, X.Q.; Wang, Y.J.; Wang, C.X.; et al. The Disability Rate of 5-Year Post-Stroke and Its Correlation Factors: A National Survey in China. PLoS ONE 2016, 11, e0165341. [Google Scholar] [CrossRef] [Green Version]
- Kavga, A.; Kalemikerakis, I.; Faros, A.; Milaka, M.; Tsekoura, D.; Skoulatou, M.; Tsatsou, I.; Govina, O. The Effects of Patients’ and Caregivers’ Characteristics on the Burden of Families Caring for Stroke Survivors. Int. J. Environ. Res. Public Health 2021, 18, 7298. [Google Scholar] [CrossRef]
- Paolucci, S.; Iosa, M.; Coiro, P.; Venturiero, V.; Savo, A.; De Angelis, D.; Morone, G. Post-stroke Depression Increases Disability More Than 15% in Ischemic Stroke Survivors: A Case-Control Study. Front. Neurol. 2019, 10, 926. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hung, M.C.; Hsieh, C.L.; Hwang, J.S.; Jeng, J.S.; Wang, J.D. Estimation of the long-term care needs of stroke patients by integrating functional disability and survival. PLoS ONE 2013, 8, e75605. [Google Scholar] [CrossRef] [Green Version]
- Matsumoto, K.; Nohara, Y.; Soejima, H.; Yonehara, T.; Nakashima, N.; Kamouchi, M. Stroke Prognostic Scores and Data-Driven Prediction of Clinical Outcomes After Acute Ischemic Stroke. Stroke 2020, 51, 1477–1483. [Google Scholar] [CrossRef]
- Ntaios, G.; Faouzi, M.; Ferrari, J.; Lang, W.; Vemmos, K.; Michel, P. An integer-based score to predict functional outcome in acute ischemic stroke: The ASTRAL score. Neurology 2012, 78, 1916–1922. [Google Scholar] [CrossRef] [PubMed]
- Saposnik, G.; Kapral, M.K.; Liu, Y.; Hall, R.; O’Donnell, M.; Raptis, S.; Tu, J.V.; Mamdani, M.; Austin, P.C.; Investigators of the Registry of the Canadian Stroke Network; et al. IScore: A risk score to predict death early after hospitalization for an acute ischemic stroke. Circulation 2011, 123, 739–749. [Google Scholar] [CrossRef]
- Drozdowska, B.A.; Singh, S.; Quinn, T.J. Thinking About the Future: A Review of Prognostic Scales Used in Acute Stroke. Front. Neurol. 2019, 10, 274. [Google Scholar] [CrossRef]
- Wang, W.Y.; Sang, W.W.; Jin, D.; Yan, S.M.; Hong, Y.; Zhang, H.; Yang, X. The Prognostic Value of the iScore, the PLAN Score, and the ASTRAL Score in Acute Ischemic Stroke. J. Stroke Cerebrovasc. Dis. 2017, 26, 1233–1238. [Google Scholar] [CrossRef]
- Heo, J.; Yoon, J.G.; Park, H.; Kim, Y.D.; Nam, H.S.; Heo, J.H. Machine Learning-Based Model for Prediction of Outcomes in Acute Stroke. Stroke 2019, 50, 1263–1265. [Google Scholar] [CrossRef]
- Liu, G.; Ntaios, G.; Zheng, H.; Wang, Y.; Michel, P.; Wang, D.Z.; Fang, J.; Papavasileiou, V.; Liu, L.; Dong, K.; et al. External validation of the ASTRAL score to predict 3- and 12-month functional outcome in the China National Stroke Registry. Stroke 2013, 44, 1443–1445. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liew, B.X.W.; Peolsson, A.; Rugamer, D.; Wibault, J.; Lofgren, H.; Dedering, A.; Zsigmond, P.; Falla, D. Clinical predictive modelling of post-surgical recovery in individuals with cervical radiculopathy: A machine learning approach. Sci. Rep. 2020, 10, 16782. [Google Scholar] [CrossRef]
- Krittanawong, C.; Virk, H.U.H.; Bangalore, S.; Wang, Z.; Johnson, K.W.; Pinotti, R.; Zhang, H.; Kaplin, S.; Narasimhan, B.; Kitai, T.; et al. Machine learning prediction in cardiovascular diseases: A meta-analysis. Sci. Rep. 2020, 10, 16057. [Google Scholar] [CrossRef]
- Scrutinio, D.; Ricciardi, C.; Donisi, L.; Losavio, E.; Battista, P.; Guida, P.; Cesarelli, M.; Pagano, G.; D’Addio, G. Machine learning to predict mortality after rehabilitation among patients with severe stroke. Sci. Rep. 2020, 10, 20127. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Yang, X.; Huang, H.; Peng, C.; Ge, Y.; Wu, H.; Wang, J.; Xiong, G.; Yi, Y. Extreme Gradient Boosting Model Has a Better Performance in Predicting the Risk of 90-Day Readmissions in Patients with Ischaemic Stroke. J. Stroke Cerebrovasc. Dis. 2019, 28, 104441. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.O.R.; Jeong, Y.S.; Kim, J.H.; Lee, J.W.; Park, D.; Kim, H.S. Machine Learning-Based Cardiovascular Disease Prediction Model: A Cohort Study on the Korean National Health Insurance Service Health Screening Database. Diagnostics 2021, 11, 943. [Google Scholar] [CrossRef]
- Liebeskind, D.S.; Scalzo, F. Editorial: Machine Learning and Decision Support in Stroke. Front. Neurol. 2020, 11, 486. [Google Scholar] [CrossRef]
- Korean Stroke Society. Korean Stroke Registry Guideline. Available online: http://www.strokedb.or.kr/bbs/index.asp?bbs_code=open_material (accessed on 3 August 2021).
- Quinn, T.J.; Dawson, J.; Walters, M. John Rankin; his life, legacy and the 50th anniversary of the Rankin Stroke Scale. Scott. Med. J. 2008, 53, 44–47. [Google Scholar] [CrossRef]
- Alaka, S.A.; Menon, B.K.; Brobbey, A.; Williamson, T.; Goyal, M.; Demchuk, A.M.; Hill, M.D.; Sajobi, T.T. Functional Outcome Prediction in Ischemic Stroke: A Comparison of Machine Learning Algorithms and Regression Models. Front. Neurol. 2020, 11, 889. [Google Scholar] [CrossRef]
- Jang, S.K.; Chang, J.Y.; Lee, J.S.; Lee, E.J.; Kim, Y.H.; Han, J.H.; Chang, D.I.; Cho, H.J.; Cha, J.K.; Yu, K.H.; et al. Reliability and Clinical Utility of Machine Learning to Predict Stroke Prognosis: Comparison with Logistic Regression. J. Stroke 2020, 22, 403–406. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, D.W.; Miao, R.; Deng, Z.Y.; Lu, Y.Y.; Liang, Y.; Huang, L. Sparse Logistic Regression With L 1/2 Penalty for Emotion Recognition in Electroencephalography Classification. Front. Neuroinform. 2020, 14, 29. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Liu, H.; Yang, P.; Xie, W. Supporting Regularized Logistic Regression Privately and Efficiently. PLoS ONE 2016, 11, e0156479. [Google Scholar] [CrossRef] [PubMed]
- Stiglic, G.; Povalej Brzan, P.; Fijacko, N.; Wang, F.; Delibasic, B.; Kalousis, A.; Obradovic, Z. Comprehensible Predictive Modeling Using Regularized Logistic Regression and Comorbidity Based Features. PLoS ONE 2015, 10, e0144439. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reid, S.; Tibshirani, R. Regularization Paths for Conditional Logistic Regression: The clogitL1 Package. J. Stat. Softw. 2014, 58, 12. [Google Scholar] [CrossRef]
- Blagus, R.; Lusa, L. SMOTE for high-dimensional class-imbalanced data. BMC Bioinform. 2013, 14. [Google Scholar] [CrossRef] [Green Version]
- Haibo, H.; Yang, B.; Garcia, E.A.; Shutao, L. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- Rosset, S. Model selection via the AUC. In Proceedings of the Twenty-First International Conference on Machine Learning-ICML, Banff Alberta, Canada, 4 July 2004. [Google Scholar]
- Luque, A.; Carrasco, A.; Martín, A.; de las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Arboix, A.; Garcia-Eroles, L.; Comes, E.; Oliveres, M.; Balcells, M.; Pacheco, G.; Targa, C. Predicting spontaneous early neurological recovery after acute ischemic stroke. Eur. J. Neurol. 2003, 10, 429–435. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | mRS < 2 (n = 745) | mRS ≥ 2 (n = 321) | p Value |
|---|---|---|---|
| Age, years old | 65.8 ± 11.3 | 74.4 ± 11.4 | <0.001 |
| Male, n (%) | 251 (33.7) | 156 (48.6) | <0.001 |
| Body mass index, kg/m2 | 24.2 ± 3.1 | 23.8 ± 3.5 | 0.060 |
| Abdominal circumference, cm | 85.2 ± 9.2 | 84.6 ± 10.2 | 0.310 |
| NIHSS at admission | 2.3 ± 3.2 | 6.3 ± 5.9 | <0.001 |
| Clear onset, n (%) | 605 (81.2) | 245 (76.3) | 0.082 |
| Onset (or LNT) to arrival, day | 1.4 ± 1.6 | 1.2 ± 1.5 | 0.120 |
| Stroke subtype, n (%) | 0.066 | ||
| Small vessel occlusion | 289 (38.8) | 106 (33.0) | |
| Large artery atherosclerosis | 280 (37.6) | 143 (44.5) | |
| Cardiogenic embolism | 79 (10.6) | 40 (12.5) | |
| Others | 97 (13.0) | 32 (10.0) | |
| Circulation, n (%) | 0.097 | ||
| Anterior | 521 (69.9) | 244 (76.0) | |
| Posterior | 223 (29.9) | 76 (23.7) | |
| Multiple | 1 (0.1) | 1 (0.3) | |
| Side, n (%) | 0.264 | ||
| Right | 350 (47.0) | 153 (47.7) | |
| Left | 341 (45.8) | 136 (42.4) | |
| Bilateral | 54 (7.2) | 32 (10.0) | |
| Acute treatment, n (%) | <0.001 | ||
| None | 673 (90.3%) | 254 (79.1%) | |
| Intravenous only | 13 (1.7%) | 10 (3.1%) | |
| Intraarterial only | 38 (5.1%) | 42 (13.1%) | |
| Intravenous and intraarterial | 21 (2.8%) | 15 (4.7%) | |
| Systolic blood pressure, mmHg | 156.6 ± 27.0 | 159.0 ± 26.1 | 0.179 |
| Diastolic blood pressure, mmHg | 87.6 ± 15.4 | 87.1 ± 16.3 | 0.609 |
| Hemoglobin, g/dl | 14.1 ± 1.7 | 13.4 ± 1.9 | <0.001 |
| Platelet, 103/µL | 238.3 ± 66.1 | 231.5 ± 68.6 | 0.125 |
| Total cholesterol, mg/dl | 191.8 ± 46.5 | 188.6 ± 48.4 | 0.305 |
| Triglyceride, mg/dl | 166.4 ± 131.4 | 141.2 ± 127.2 | 0.004 |
| High density lipoprotein, mg/dl | 49.3 ± 12.2 | 48.1 ± 11.6 | 0.135 |
| Low density lipoprotein, mg/dl | 109.4 ± 40.6 | 113.0 ± 42.6 | 0.189 |
| Random glucose, mg/dl | 140.8 ± 57.1 | 149.7 ± 62.6 | 0.028 |
| HbA1c, % | 6.2 ± 1.2 | 6.4 ± 1.4 | 0.077 |
| Blood urea nitrogen, mg/dl | 16.4 ± 5.4 | 17.7 ± 7.6 | 0.007 |
| Creatinine, mg/dl | 0.9 ± 0.3 | 0.9 ± 0.4 | 0.389 |
| Variables | mRS < 2 (n = 745) | mRS ≥ 2 (n = 321) | p Value |
|---|---|---|---|
| Previous stroke, n (%) | 0.785 | ||
| None | 640 (85.9) | 270 (84.1) | |
| Hemorrhagic | 17 (2.3) | 9 (2.8) | |
| Ischemic | 85 (11.4) | 40 (12.5) | |
| Mixed | 2 (0.3) | 2 (0.6) | |
| Unknown | 1 (0.1) | 0 (0.0) | |
| Previous TIA, n (%) | 14 (1.9) | 4 (1.2) | 0.633 |
| Previous PAD, n (%) | 4 (0.5) | 3 (0.9) | 0.746 |
| Previous CAD, n (%) | 72 (9.7) | 38 (11.8) | 0.337 |
| Previous cancer, n (%) | 9 (1.2) | 5 (1.6) | 0.868 |
| Previous hypertension, n (%) | 0.224 | ||
| None | 293 (39.3) | 109 (34.0) | |
| Known | 395 (53.0) | 188 (58.6) | |
| Diagnosed at admission | 57 (7.7) | 24 (7.5) | |
| Previous diabetes, n (%) | 0.087 | ||
| None | 556 (74.6) | 223 (69.5) | |
| Known | 159 (21.3) | 88 (27.4) | |
| Diagnosed at admission | 30 (4.0) | 10 (3.1) | |
| Previous dyslipidemia, n (%) | 0.650 | ||
| None | 278 (37.3) | 122 (38.0) | |
| Known | 222 (29.8) | 87 (27.1) | |
| Diagnosed at admission | 245 (32.9) | 112 (34.9) | |
| Smoking, n (%) | 0.002 | ||
| None | 499 (67.0) | 252 (78.5) | |
| Current | 242 (32.5) | 69 (21.5) | |
| Quit ≥ 5 years | 2 (0.3) | 0 (0.0) | |
| Quit < 5 years | 2 (0.3) | 0 (0.0) | |
| Previous AF, n (%) | 0.009 | ||
| None | 658 (88.3) | 261 (81.3) | |
| Known | 41 (5.5) | 30 (9.3) | |
| Diagnosed at admission | 46 (6.2) | 30 (9.3) | |
| Previous antiplatelet, n (%) | 191 (25.6) | 81 (25.2) | 0.950 |
| Previous anticoagulation, n (%) | 19 (2.6) | 14 (4.4) | 0.170 |
| PSCE-high risk, n (%) | 20 (2.7) | 8 (2.5) | >0.999 |
| PSCE-medium risk, n (%) | 34 (4.6) | 17 (5.3) | 0.721 |
| Metric | RLR | SVM | RF | KNN | XGB |
|---|---|---|---|---|---|
| AUC (95% CI) | 0.86 (0.82–0.90) | 0.85 (0.81–0.89) | 0.82 (0.77–0.87) | 0.82 (0.77–0.87) | 0.81 (0.76–0.86) |
| F1 | 0.84 | 0.86 | 0.85 | 0.84 | 0.85 |
| Accuracy (95% CI) | 0.78 (0.73–0.83) | 0.80 (0.75–0.85) | 0.77 (0.72–0.82) | 0.73 (0.67–0.78) | 0.77 (0.72–0.82) |
| Sensitivity (95% CI) | 0.83 (0.77–0.87) | 0.90 (0.86–0.94) | 0.89 (0.83–0.92) | 0.99 (0.97–1.00) | 0.89 (0.84–0.93) |
| Specificity (95% CI) | 0.69 (0.58–0.77) | 0.56 (0.46–0.66) | 0.53 (0.43–0.63) | 0.10 (0.05–0.18) | 0.50 (0.39–0.60) |
| Precision (95% CI) | 0.86 (0.81–0.90) | 0.83 (0.77–0.87) | 0.81 (0.76–0.86) | 0.72 (0.67–0.77) | 0.80 (0.75–0.85) |
| NPV (95% CI) | 0.63 (0.53–0.72) | 0.71 (0.60–0.81) | 0.66 (0.55–0.76) | 0.90 (0.60–0.98) | 0.66 (0.54–0.76) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, D.; Jeong, E.; Kim, H.; Pyun, H.W.; Kim, H.; Choi, Y.-J.; Kim, Y.; Jin, S.; Hong, D.; Lee, D.W.; et al. Machine Learning-Based Three-Month Outcome Prediction in Acute Ischemic Stroke: A Single Cerebrovascular-Specialty Hospital Study in South Korea. Diagnostics 2021, 11, 1909. https://doi.org/10.3390/diagnostics11101909
Park D, Jeong E, Kim H, Pyun HW, Kim H, Choi Y-J, Kim Y, Jin S, Hong D, Lee DW, et al. Machine Learning-Based Three-Month Outcome Prediction in Acute Ischemic Stroke: A Single Cerebrovascular-Specialty Hospital Study in South Korea. Diagnostics. 2021; 11(10):1909. https://doi.org/10.3390/diagnostics11101909
Chicago/Turabian StylePark, Dougho, Eunhwan Jeong, Haejong Kim, Hae Wook Pyun, Haemin Kim, Yeon-Ju Choi, Youngsoo Kim, Suntak Jin, Daeyoung Hong, Dong Woo Lee, and et al. 2021. "Machine Learning-Based Three-Month Outcome Prediction in Acute Ischemic Stroke: A Single Cerebrovascular-Specialty Hospital Study in South Korea" Diagnostics 11, no. 10: 1909. https://doi.org/10.3390/diagnostics11101909
APA StylePark, D., Jeong, E., Kim, H., Pyun, H. W., Kim, H., Choi, Y.-J., Kim, Y., Jin, S., Hong, D., Lee, D. W., Lee, S. Y., & Kim, M.-C. (2021). Machine Learning-Based Three-Month Outcome Prediction in Acute Ischemic Stroke: A Single Cerebrovascular-Specialty Hospital Study in South Korea. Diagnostics, 11(10), 1909. https://doi.org/10.3390/diagnostics11101909