
A Federated Database for Obesity Research: An IMI-SOPHIA Study

 , , , , , , ,
, , , , , , ,  , , , , , , , , , , , ,
, , , , , , , , , , , ,  and add
Show full author list
and add
Show full author list
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Harmonization and Standardization
2.2. Set-Up and Deployment of Federated Nodes
2.3. Proof-of-Concept Federated Analysis and Comparison to Meta-Analyses
3. Results
3.1. Identification of Cohorts for Federation
3.2. Data Standardization and Harmonization
3.3. Federated Database Architecture
3.4. Federated Database Access
3.5. Federated Proof-of-Concept (PoC) Analysis
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rubino, F.; Puhl, R.M.; Cummings, D.E.; Eckel, R.H.; Ryan, D.H.; Mechanick, J.I.; Nadglowski, J.; Ramos Salas, X.; Schauer, P.R.; Twenefour, D.; et al. Joint international consensus statement for ending stigma of obesity. Nat. Med. 2020, 26, 485–497. [Google Scholar] [CrossRef]
- Jepsen, C.H.; Bowman-Busato, J.; Allvin, T.; Arthurs, N.; Goossens, G.H.; Govers, E.; Jaghutriz, B.A.; Mooney, V.; Van der Schueren, B.; le Roux, C.W. Achieving consensus on the language of obesity: A modified Delphi study. EClinicalMedicine 2023, 62, 102061. [Google Scholar] [CrossRef] [PubMed]
- Papamargaritis, D.; le Roux, C.W.; Holst, J.J.; Davies, M.J. New therapies for obesity. Cardiovasc. Res. 2022, cvac176. [Google Scholar] [CrossRef] [PubMed]
- Zöller, D.; Lenz, S.; Binder, H. Distributed multivariable modeling for signature development under data protection constraints. arXiv 2018. [Google Scholar] [CrossRef]
- Wolfson, M.; Wallace, S.E.; Masca, N.; Rowe, G.; Sheehan, N.A.; Ferretti, V.; LaFlamme, P.; Tobin, M.D.; Macleod, J.; Little, J.; et al. DataSHIELD: Resolving a conflict in contemporary bioscience--performing a pooled analysis of individual-level data without sharing the data. Int. J. Epidemiol. 2010, 39, 1372–1382. [Google Scholar] [CrossRef]
- Warnat-Herresthal, S.; Schultze, H.; Shastry, K.L.; Manamohan, S.; Mukherjee, S.; Garg, V.; Sarveswara, R.; Handler, K.; Pickkers, P.; Aziz, N.A.; et al. Swarm Learning for decentralized and confidential clinical machine learning. Nature 2021, 594, 265–270. [Google Scholar] [CrossRef] [PubMed]
- Balduzzi, S.; Rucker, G.; Schwarzer, G. How to perform a meta-analysis with R: A practical tutorial. Evid. Based Ment. Health 2019, 22, 153–160. [Google Scholar] [CrossRef]
- Gaye, A.; Marcon, Y.; Isaeva, J.; LaFlamme, P.; Turner, A.; Jones, E.M.; Minion, J.; Boyd, A.W.; Newby, C.J.; Nuotio, M.L.; et al. DataSHIELD: Taking the analysis to the data, not the data to the analysis. Int. J. Epidemiol. 2014, 43, 1929–1944. [Google Scholar] [CrossRef]
- Marcon, Y.; Bishop, T.; Avraam, D.; Escriba-Montagut, X.; Ryser-Welch, P.; Wheater, S.; Burton, P.; Gonzalez, J.R. Orchestrating privacy-protected big data analyses of data from different resources with R and DataSHIELD. PLoS Comput. Biol. 2021, 17, e1008880. [Google Scholar] [CrossRef]
- Doiron, D.; Marcon, Y.; Fortier, I.; Burton, P.; Ferretti, V. Software Application Profile: Opal and Mica: Open-source software solutions for epidemiological data management, harmonization and dissemination. Int. J. Epidemiol. 2017, 46, 1372–1378. [Google Scholar] [CrossRef]
- SNOMED. Available online: https://www.snomed.org (accessed on 15 August 2023).
- LOINC. Available online: https://loinc.org (accessed on 15 August 2023).
- OMOP Common Data Model. Available online: https://ohdsi.github.io/CommonDataModel/ (accessed on 15 August 2023).
- Dragan, I.; Sparsø, T.; Kuznetsov, D.; Slieker, R.; Ibberson, M. dsSwissKnife: An R package for federated data analysis. bioRxiv 2020. [Google Scholar] [CrossRef]
- UCUM. Available online: https://ucum.org (accessed on 15 August 2023).
- RxNorm. Available online: https://www.nlm.nih.gov/research/umls/rxnorm (accessed on 15 August 2023).
- OHSDI—Observational Health Data Sciences and Informatics. Available online: https://www.ohdsi.org/ (accessed on 15 August 2023).
- OMOP CDM Version 5.4. Available online: https://ohdsi.github.io/CommonDataModel/cdm54.html (accessed on 15 August 2023).
- DataSHIELD. Available online: www.datashield.org (accessed on 15 August 2023).
- dsQueryLibrary. Available online: https://github.com/sib-swiss/dsQueryLibrary (accessed on 15 August 2023).
- dsSwissKnife R Packages. Available online: https://github.com/sib-swiss/dsSwissKnife (accessed on 15 August 2023).
- dsBaseClient R Package. Available online: https://github.com/datashield/dsBaseClient (accessed on 15 August 2023).
- metafor R Package. Available online: https://wviechtb.github.io/metafor/ (accessed on 15 August 2023).
- ggplot2 R Package. Available online: https://github.com/tidyverse/ggplot2 (accessed on 15 August 2023).
- ATHENA OHSDI Search. Available online: https://athena.ohdsi.org/ (accessed on 15 August 2023).
- Raverdy, V.; Cohen, R.V.; Caiazzo, R.; Verkindt, H.; Petry, T.B.Z.; Marciniak, C.; Legendre, B.; Bauvin, P.; Chatelain, E.; Duhamel, A.; et al. Data-driven subgroups of type 2 diabetes, metabolic response, and renal risk profile after bariatric surgery: A retrospective cohort study. Lancet Diabetes Endocrinol. 2022, 10, 167–176. [Google Scholar] [CrossRef]
- Lincoff, A.M.; Nicholls, S.J.; Riesmeyer, J.S.; Barter, P.J.; Brewer, H.B.; Fox, K.A.A.; Gibson, C.M.; Granger, C.; Menon, V.; Montalescot, G.; et al. Evacetrapib and Cardiovascular Outcomes in High-Risk Vascular Disease. N. Engl. J. Med. 2017, 376, 1933–1942. [Google Scholar] [CrossRef]
- Mathieu, C.; Zinman, B.; Hemmingsson, J.U.; Woo, V.; Colman, P.; Christiansen, E.; Linder, M.; Bode, B.; Investigators, A.O. Efficacy and Safety of Liraglutide Added to Insulin Treatment in Type 1 Diabetes: The ADJUNCT ONE Treat-To-Target Randomized Trial. Diabetes Care 2016, 39, 1702–1710. [Google Scholar] [CrossRef]
- Prinz, N.; Pomares-Millan, H.; Dannemann, A.; Giordano, G.N.; Joisten, C.; Korner, A.; Weghuber, D.; Weihrauch-Bluher, S.; Wiegand, S.; Holl, R.W.; et al. Who benefits most from outpatient lifestyle intervention? An IMI-SOPHIA study on pediatric individuals living with overweight and obesity. Obesity 2023, 31, 2375–2385. [Google Scholar] [CrossRef]
- Ducraux, P.; Waeber, G.; Marques-Vidal, P. Do Weight trajectories influence diabetes control? A prospective study in Switzerland (CoLaus study). Prev. Med. Rep. 2021, 23, 101473. [Google Scholar] [CrossRef]
- Hammersen, J.; Tittel, S.R.; Khodaverdi, S.; Reschke, F.; Flury, M.; Menzel, U.; Monkemoller, K.; Meissner, T.; Karges, B.; Holl, R.W. Metabolic control during the first two years of the COVID-19 pandemic in pediatric patients with type 1 diabetes: Results from the German DPV initiative. Acta Diabetol. 2023, 60, 757–766. [Google Scholar] [CrossRef]
- EXETER 10,000 Project (EXTEND). Available online: https://exetercrfnihr.org/about/exeter-10000/ (accessed on 15 August 2023).
- Schram, M.T.; Sep, S.J.; van der Kallen, C.J.; Dagnelie, P.C.; Koster, A.; Schaper, N.; Henry, R.M.; Stehouwer, C.D. The Maastricht Study: An extensive phenotyping study on determinants of type 2 diabetes, its complications and its comorbidities. Eur. J. Epidemiol. 2014, 29, 439–451. [Google Scholar] [CrossRef]
- The Nederlandse Obesitas Kliniek and Medtronic Join Forces in the Battle Against Morbid Obesity. Available online: https://news.medtronic.com/2016-05-25-The-Nederlandse-Obesitas-Kliniek-and-Medtronic-Join-Forces-in-the-Battle-Against-Morbid-Obesity (accessed on 15 August 2023).
- Gerstein, H.C.; Colhoun, H.M.; Dagenais, G.R.; Diaz, R.; Lakshmanan, M.; Pais, P.; Probstfield, J.; Botros, F.T.; Riddle, M.C.; Ryden, L.; et al. Dulaglutide and renal outcomes in type 2 diabetes: An exploratory analysis of the REWIND randomised, placebo-controlled trial. Lancet 2019, 394, 131–138. [Google Scholar] [CrossRef]
- Ikram, M.A.; Brusselle, G.; Ghanbari, M.; Goedegebure, A.; Ikram, M.K.; Kavousi, M.; Kieboom, B.C.T.; Klaver, C.C.W.; de Knegt, R.J.; Luik, A.I.; et al. Objectives, design and main findings until 2020 from the Rotterdam Study. Eur. J. Epidemiol. 2020, 35, 483–517. [Google Scholar] [CrossRef]
- Pi-Sunyer, X.; Astrup, A.; Fujioka, K.; Greenway, F.; Halpern, A.; Krempf, M.; Lau, D.C.; le Roux, C.W.; Violante Ortiz, R.; Jensen, C.B.; et al. A Randomized, Controlled Trial of 3.0 mg of Liraglutide in Weight Management. N. Engl. J. Med. 2015, 373, 11–22. [Google Scholar] [CrossRef]
- Tayside & Fife Diabetes—Summary and a Range of Diabetes Related Datasets. Available online: https://doi.org/10.15132/10000203 (accessed on 15 August 2023).
- OBiBa Agate. Available online: https://www.obiba.org/pages/products/agate/ (accessed on 15 August 2023).
- Sathappan, S.M.K.; Jeon, Y.S.; Dang, T.K.; Lim, S.C.; Shao, Y.M.; Tai, E.S.; Feng, M. Transformation of Electronic Health Records and Questionnaire Data to OMOP CDM: A Feasibility Study Using SG_T2DM Dataset. Appl. Clin. Inform. 2021, 12, 757–767. [Google Scholar] [CrossRef]
- Reinecke, I.; Zoch, M.; Reich, C.; Sedlmayr, M.; Bathelt, F. The Usage of OHDSI OMOP—A Scoping Review. Stud. Health Technol. Inform. 2021, 283, 95–103. [Google Scholar] [CrossRef]
- Lynch, K.E.; Deppen, S.A.; DuVall, S.L.; Viernes, B.; Cao, A.; Park, D.; Hanchrow, E.; Hewa, K.; Greaves, P.; Matheny, M.E. Incrementally Transforming Electronic Medical Records into the Observational Medical Outcomes Partnership Common Data Model: A Multidimensional Quality Assurance Approach. Appl. Clin. Inform. 2019, 10, 794–803. [Google Scholar] [CrossRef]
- Garza, M.; Del Fiol, G.; Tenenbaum, J.; Walden, A.; Zozus, M.N. Evaluating common data models for use with a longitudinal community registry. J. Biomed. Inform. 2016, 64, 333–341. [Google Scholar] [CrossRef]
- Byun, J.; Lee, D.Y.; Jeong, C.W.; Kim, Y.; Rhee, H.Y.; Moon, K.W.; Heo, J.; Hong, Y.; Kim, W.J.; Nam, S.J.; et al. Analysis of treatment pattern of anti-dementia medications in newly diagnosed Alzheimer’s dementia using OMOP CDM. Sci. Rep. 2022, 12, 4451. [Google Scholar] [CrossRef]
- Biedermann, P.; Ong, R.; Davydov, A.; Orlova, A.; Solovyev, P.; Sun, H.; Wetherill, G.; Brand, M.; Didden, E.M. Standardizing registry data to the OMOP Common Data Model: Experience from three pulmonary hypertension databases. BMC Med. Res. Methodol. 2021, 21, 238. [Google Scholar] [CrossRef]
- Belenkaya, R.; Gurley, M.; Dymshyts, D.; Araujo, S.; Williams, A.; Chen, R.; Reich, C. Standardized Observational Cancer Research Using the OMOP CDM Oncology Module. Stud. Health Technol. Inform. 2019, 264, 1831–1832. [Google Scholar] [CrossRef]
- CaRROT-Mapper. Available online: https://github.com/HDRUK/CaRROT-Mapper (accessed on 15 August 2023).
- Slieker, R.C.; Donnelly, L.A.; Fitipaldi, H.; Bouland, G.A.; Giordano, G.N.; Akerlund, M.; Gerl, M.J.; Ahlqvist, E.; Ali, A.; Dragan, I.; et al. Replication and cross-validation of type 2 diabetes subtypes based on clinical variables: An IMI-RHAPSODY study. Diabetologia 2021, 64, 1982–1989. [Google Scholar] [CrossRef]
- Slieker, R.C.; Donnelly, L.A.; Fitipaldi, H.; Bouland, G.A.; Giordano, G.N.; Akerlund, M.; Gerl, M.J.; Ahlqvist, E.; Ali, A.; Dragan, I.; et al. Distinct Molecular Signatures of Clinical Clusters in People With Type 2 Diabetes: An IMI-RHAPSODY Study. Diabetes 2021, 70, 2683–2693. [Google Scholar] [CrossRef]
- Slieker, R.C.; Donnelly, L.A.; Akalestou, E.; Lopez-Noriega, L.; Melhem, R.; Gunes, A.; Abou Azar, F.; Efanov, A.; Georgiadou, E.; Muniangi-Muhitu, H.; et al. Identification of biomarkers for glycaemic deterioration in type 2 diabetes. Nat. Commun. 2023, 14, 2533. [Google Scholar] [CrossRef]
- Penalvo, J.L.; Mertens, E.; Ademovic, E.; Akgun, S.; Baltazar, A.L.; Buonfrate, D.; Coklo, M.; Devleesschauwer, B.; Diaz Valencia, P.A.; Fernandes, J.C.; et al. Unravelling data for rapid evidence-based response to COVID-19: A summary of the unCoVer protocol. BMJ Open 2021, 11, e055630. [Google Scholar] [CrossRef]
- Pastorino, S.; Bishop, T.; Crozier, S.R.; Granstrom, C.; Kordas, K.; Kupers, L.K.; O’Brien, E.C.; Polanska, K.; Sauder, K.A.; Zafarmand, M.H.; et al. Associations between maternal physical activity in early and late pregnancy and offspring birth size: Remote federated individual level meta-analysis from eight cohort studies. BJOG Int. J. Obstet. Gynaecol. 2019, 126, 459–470. [Google Scholar] [CrossRef]
- Jannasch, F.; Dietrich, S.; Bishop, T.R.P.; Pearce, M.; Fanidi, A.; O’Donoghue, G.; O’Gorman, D.; Marques-Vidal, P.; Vollenweider, P.; Bes-Rastrollo, M.; et al. Associations between exploratory dietary patterns and incident type 2 diabetes: A federated meta-analysis of individual participant data from 25 cohort studies. Eur. J. Nutr. 2022, 61, 3649–3667. [Google Scholar] [CrossRef]
- Doiron, D.; de Hoogh, K.; Probst-Hensch, N.; Mbatchou, S.; Eeftens, M.; Cai, Y.; Schindler, C.; Fortier, I.; Hodgson, S.; Gaye, A.; et al. Residential Air Pollution and Associations with Wheeze and Shortness of Breath in Adults: A Combined Analysis of Cross-Sectional Data from Two Large European Cohorts. Environ. Health Perspect. 2017, 125, 097025. [Google Scholar] [CrossRef] [PubMed]
- EHDEN–European Health Data Evidence Network. Available online: https://www.ehden.eu/ (accessed on 15 August 2023).
- Kaissis, G.A.; Makowski, M.R.; Rückert, D.; Braren, R.F. Secure, privacy-preserving and federated machine learning in medical imaging. Nat. Mach. Intell. 2020, 2, 305–311. [Google Scholar] [CrossRef]
- Gu, X.; Sabrina, F.; Fan, Z.; Sohail, S. A Review of Privacy Enhancement Methods for Federated Learning in Healthcare Systems. Int. J. Environ. Res. Public Health 2023, 20, 6539. [Google Scholar] [CrossRef]
- Froelicher, D.; Troncoso-Pastoriza, J.R.; Raisaro, J.L.; Cuendet, M.A.; Sousa, J.S.; Cho, H.; Berger, B.; Fellay, J.; Hubaux, J.P. Truly privacy-preserving federated analytics for precision medicine with multiparty homomorphic encryption. Nat. Commun. 2021, 12, 5910. [Google Scholar] [CrossRef] [PubMed]

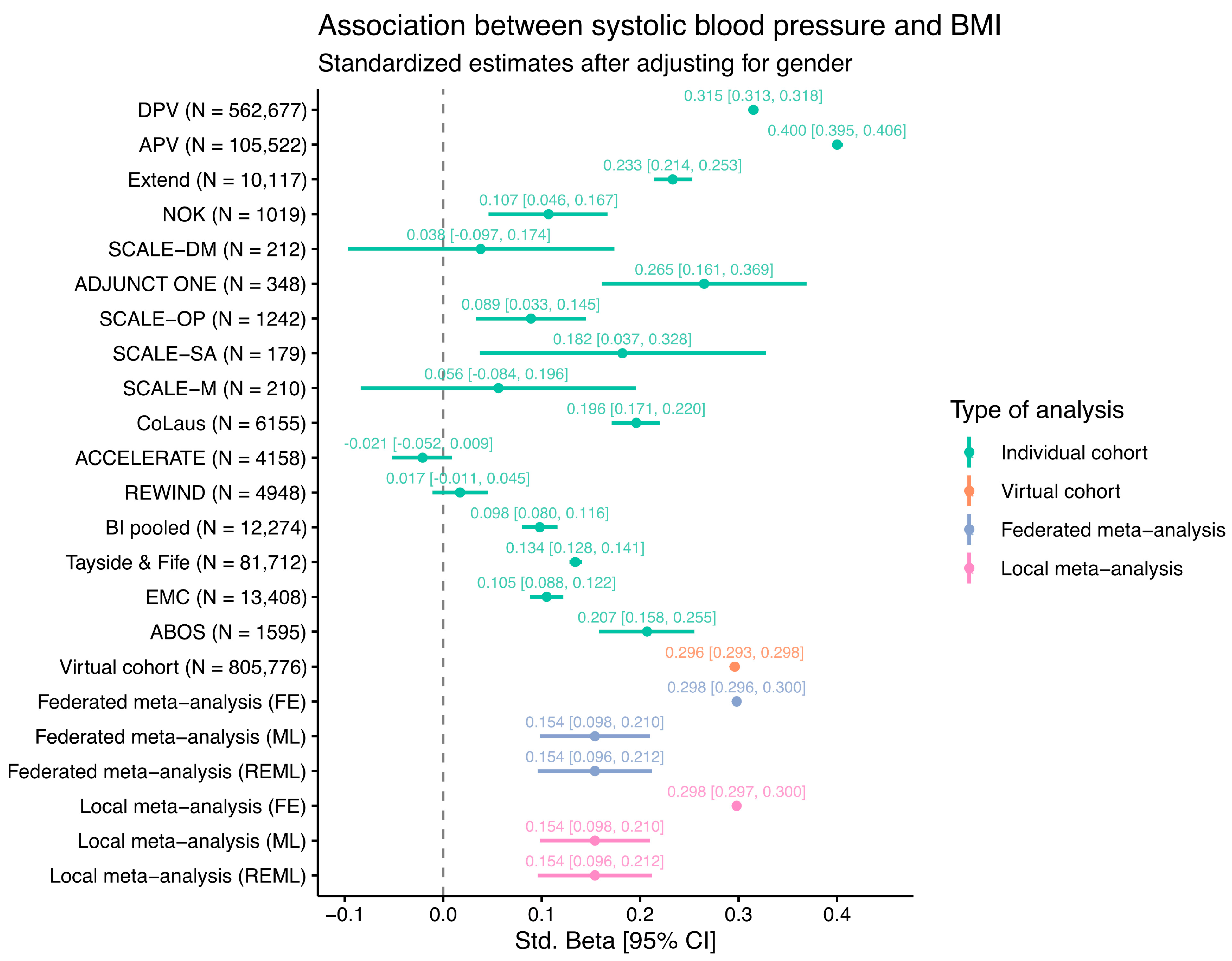

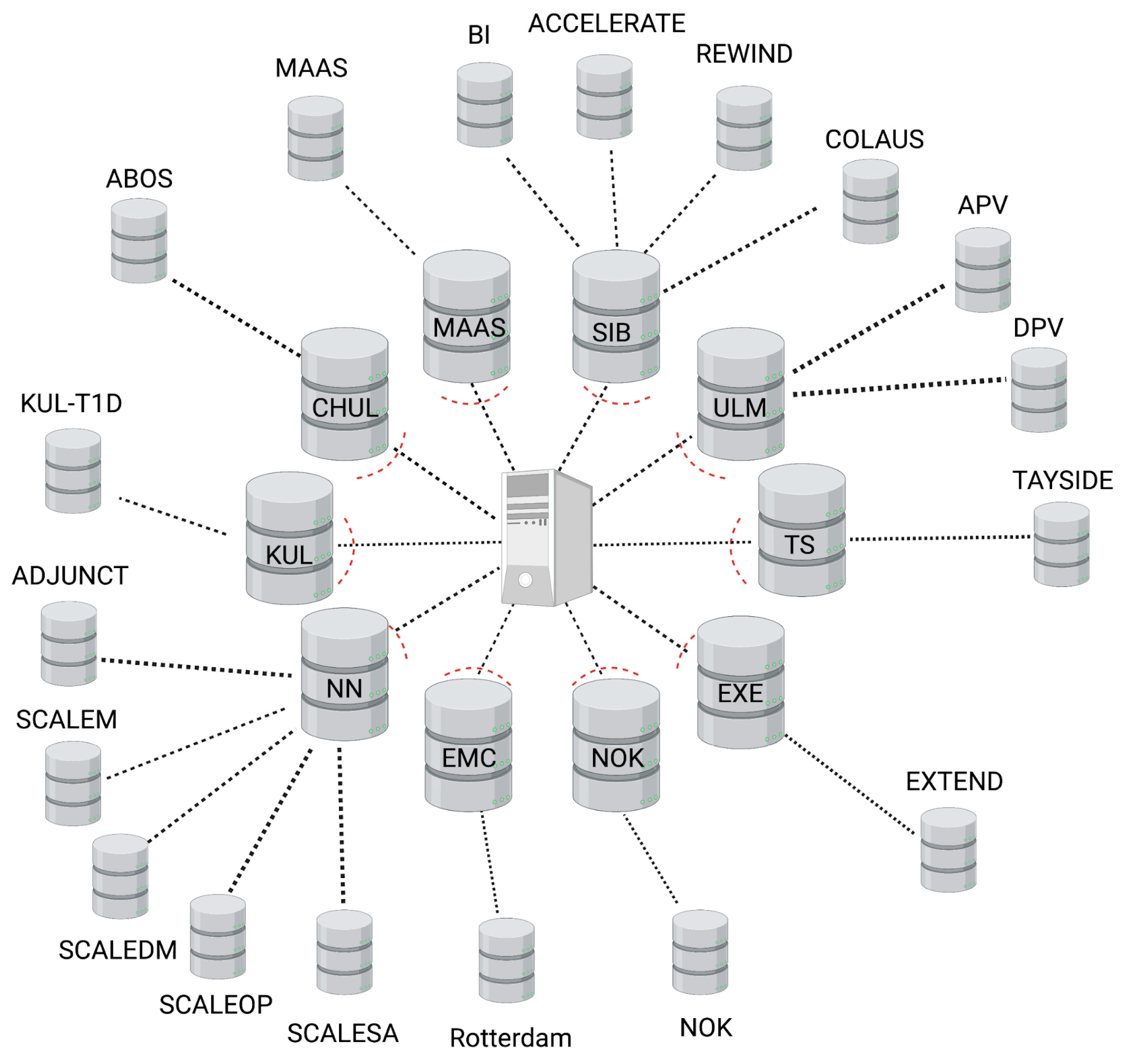{kind=link}
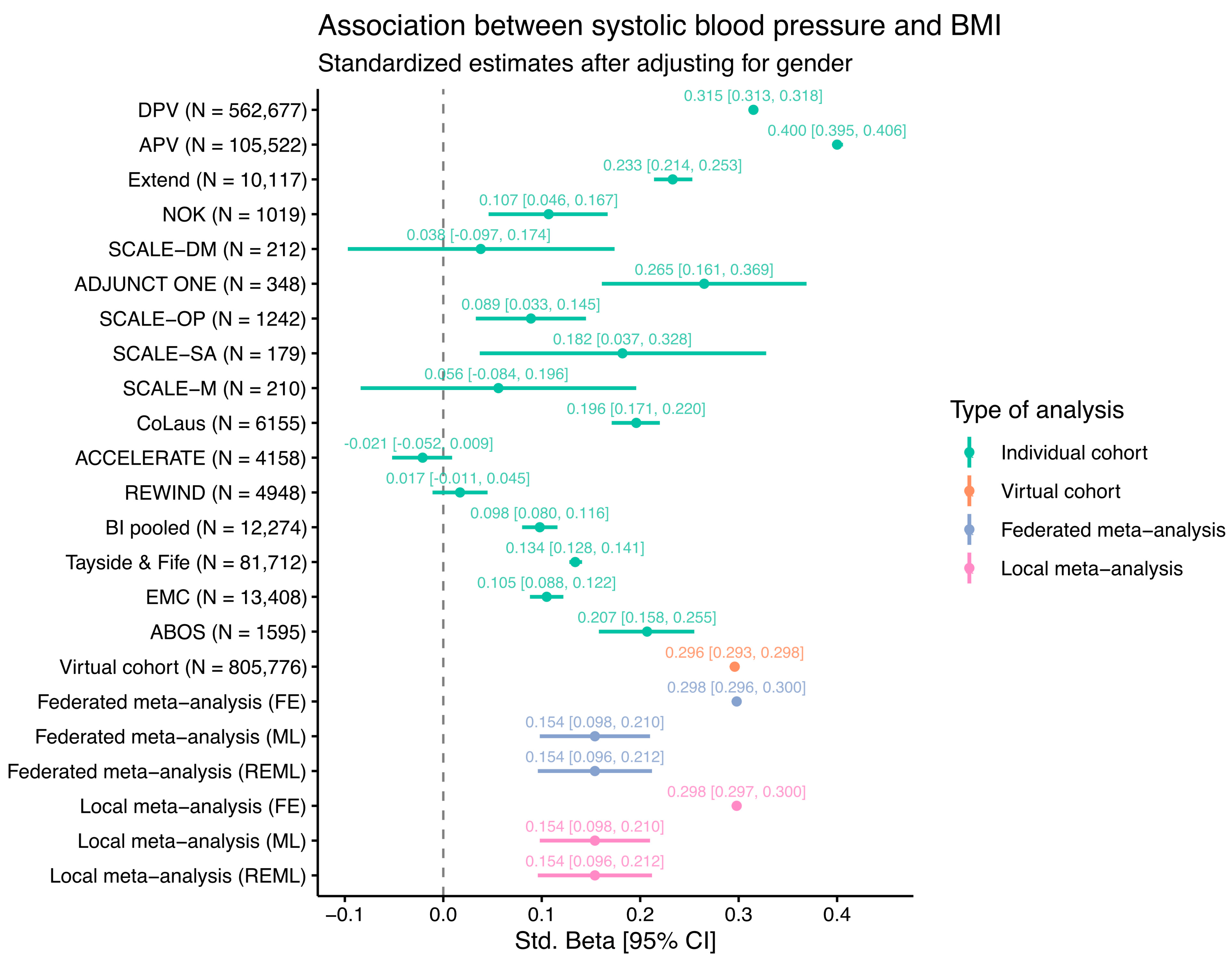{kind=link}
| Cohort | Study Design | Individuals | Data Types |
|---|---|---|---|
| ABOS [26] | OBS/Bariatric surgery | 1602 | CL,GO,MO,PO,MCO |
| ACCELERATE [27] | Placebo arm of RCT | 6047 | CL |
| ADJUNCT-ONE [28] | Placebo arm of RCT | 348 | CL |
| APV Registry [29] | OBS | 126,947 | CL |
| BI pooled trials 1 | Placebo arm of RCT | 13,125 | CL |
| CoLAUS [30] | PROS | 6733 | CL,GO,TO,MO |
| DPV Registry [31] | PROS, OBS | 638,031 | CL |
| EXTEND [32] | OBS, CROS | 10,134 | CL,GO |
| KUL-T1D | RET | 1400 | CL |
| Maastricht Study [33] 2 | PROS | 3451 | CL,GO,MO |
| NOK Discovery [34] | CROS | 564 | CL,GO |
| REWIND [35] | Placebo arm of RCT | 4949 | CL |
| Rotterdam Study [36] | PROS | 14,926 | CL,GO,TO,PO,MO,MCO |
| SCALE Diabetes [37] | Placebo arm of RCT | 212 | CL |
| SCALE Maintenance [37] | Placebo arm of RCT | 210 | CL |
| SCALE Obesity and Prediabetes [37] | Placebo arm of RCT | 1242 | CL |
| SCALE Sleep apnea [37] | Placebo arm of RCT | 179 | CL |
| Tayside/Fife T1D &T2D [38] | OBS | 87,050 | CL |
| Total | 912,299 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Delfin, C.; Dragan, I.; Kuznetsov, D.; Tajes, J.F.; Smit, F.; Coral, D.E.; Farzaneh, A.; Haugg, A.; Hungele, A.; Niknejad, A.; et al. A Federated Database for Obesity Research: An IMI-SOPHIA Study. Life 2024, 14, 262. https://doi.org/10.3390/life14020262
Delfin C, Dragan I, Kuznetsov D, Tajes JF, Smit F, Coral DE, Farzaneh A, Haugg A, Hungele A, Niknejad A, et al. A Federated Database for Obesity Research: An IMI-SOPHIA Study. Life. 2024; 14(2):262. https://doi.org/10.3390/life14020262
Chicago/Turabian StyleDelfin, Carl, Iulian Dragan, Dmitry Kuznetsov, Juan Fernandez Tajes, Femke Smit, Daniel E. Coral, Ali Farzaneh, André Haugg, Andreas Hungele, Anne Niknejad, and et al. 2024. "A Federated Database for Obesity Research: An IMI-SOPHIA Study" Life 14, no. 2: 262. https://doi.org/10.3390/life14020262
APA StyleDelfin, C., Dragan, I., Kuznetsov, D., Tajes, J. F., Smit, F., Coral, D. E., Farzaneh, A., Haugg, A., Hungele, A., Niknejad, A., Hall, C., Jacobs, D., Marek, D., Fraser, D. P., Thuillier, D., Ahmadizar, F., Mehl, F., Pattou, F., Burdet, F., ... Ibberson, M. (2024). A Federated Database for Obesity Research: An IMI-SOPHIA Study. Life, 14(2), 262. https://doi.org/10.3390/life14020262