
Automated Screening of Precancerous Cervical Cells Through Contrastive Self-Supervised Learning

 , , , , , ,
, , , , , ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Cohort
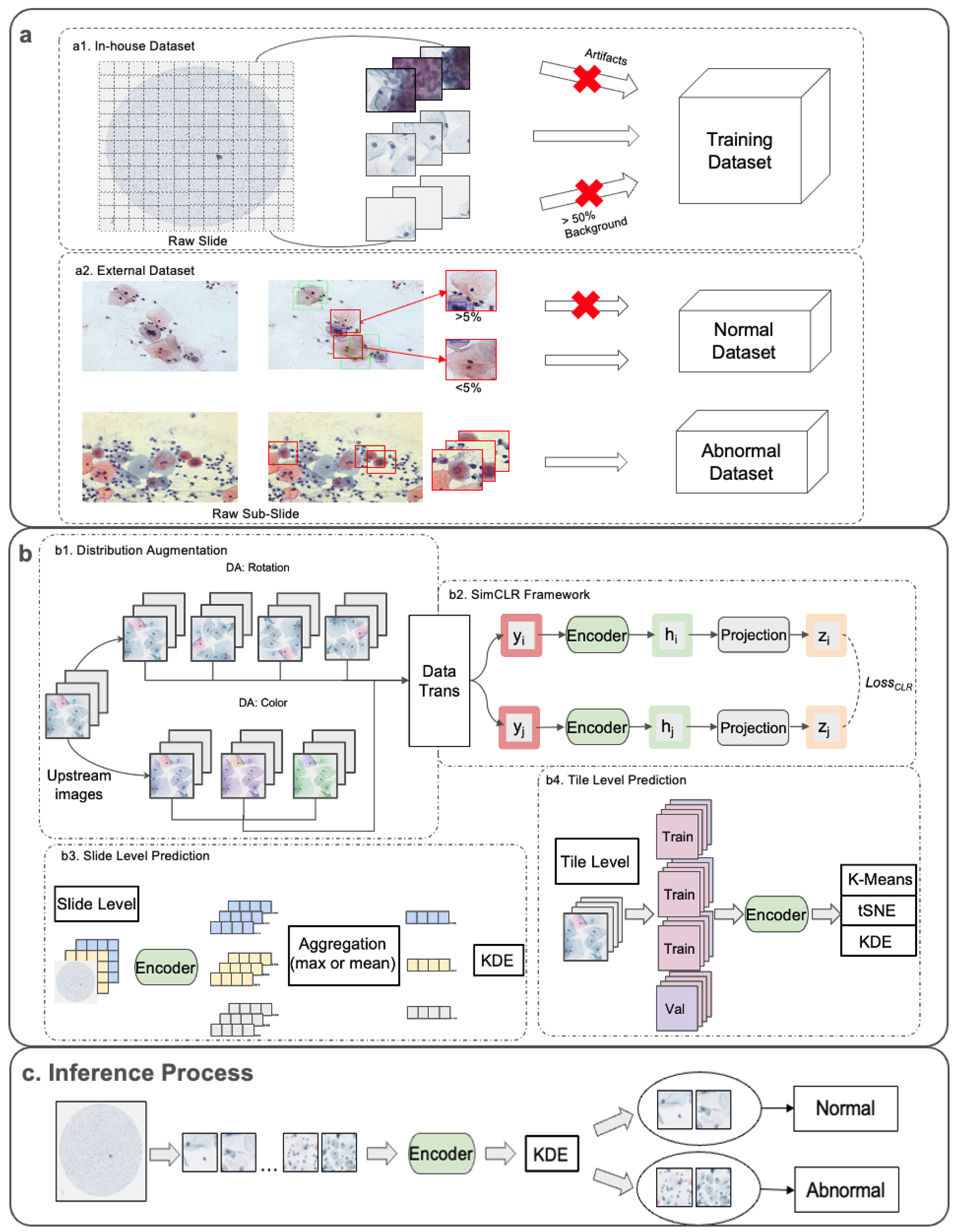
2.2. Overall Framework
2.2.1. Dataset Preprocessing
2.2.2. Upstream Pretraining Tasks
2.2.3. Downstream Analysis Approaches
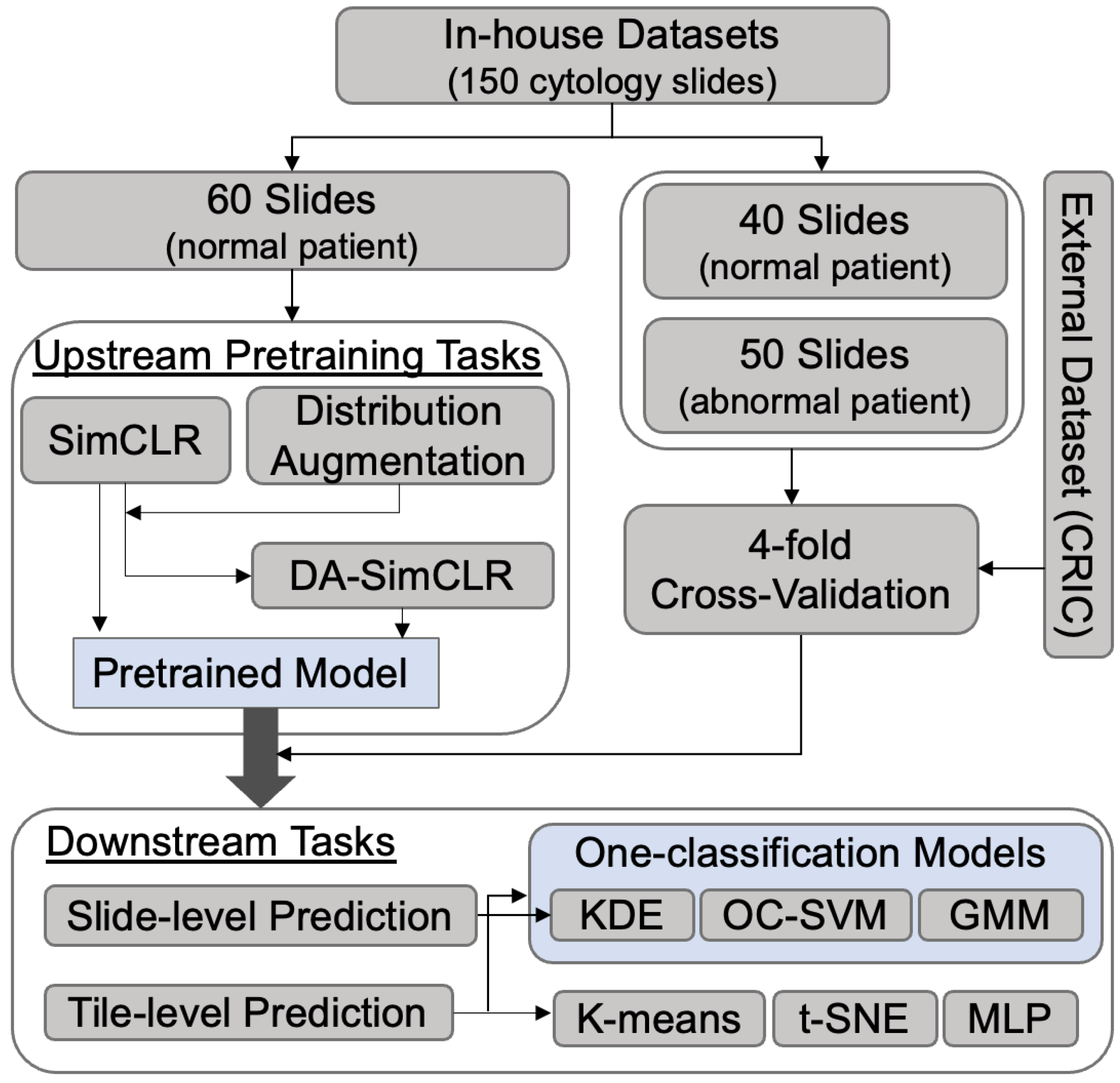
2.3. Experiments
2.3.1. Dataset Preparation
2.3.2. Upstream Pretraining Tasks
2.3.3. Downstream Tasks
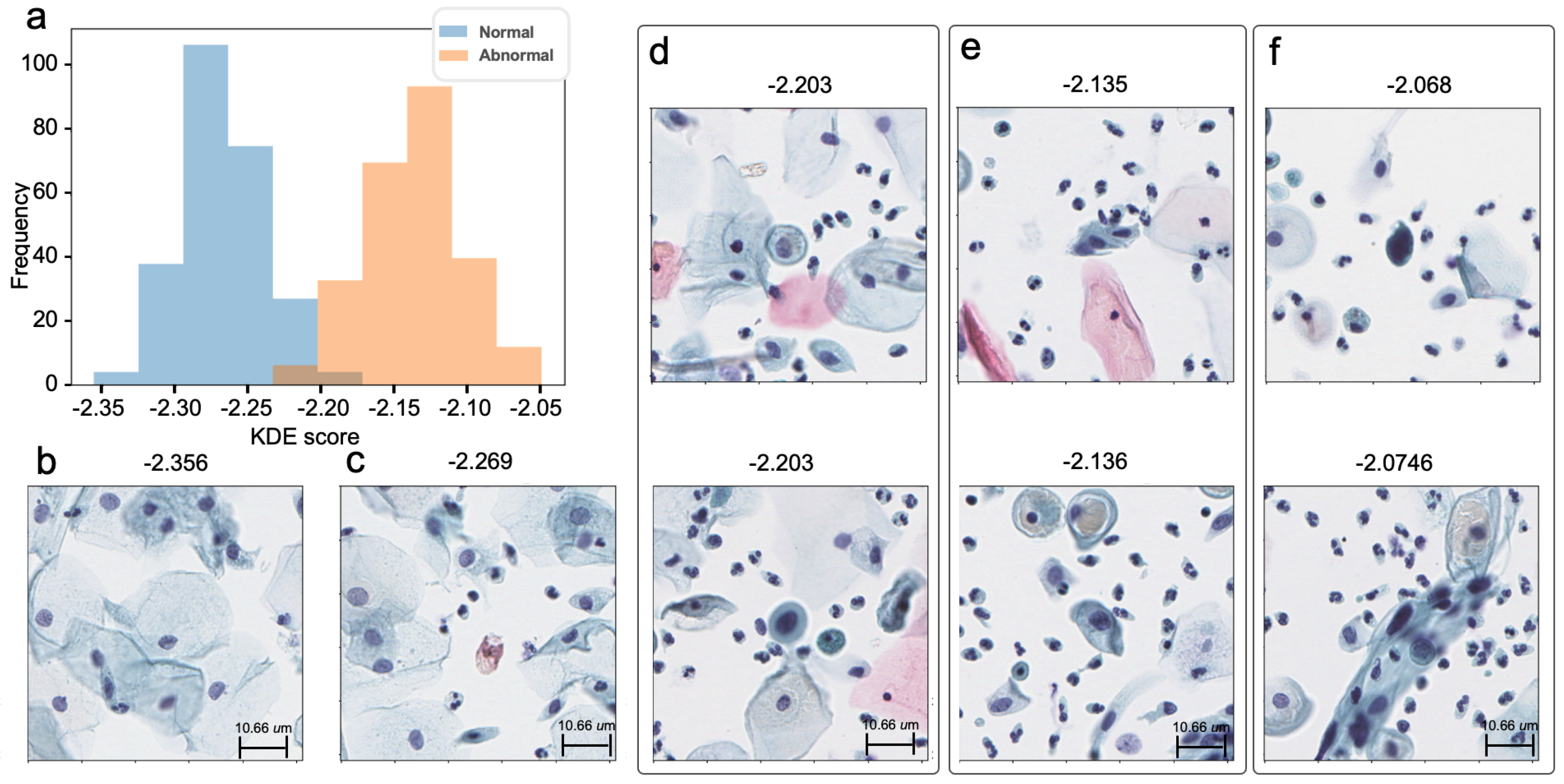
3. Results
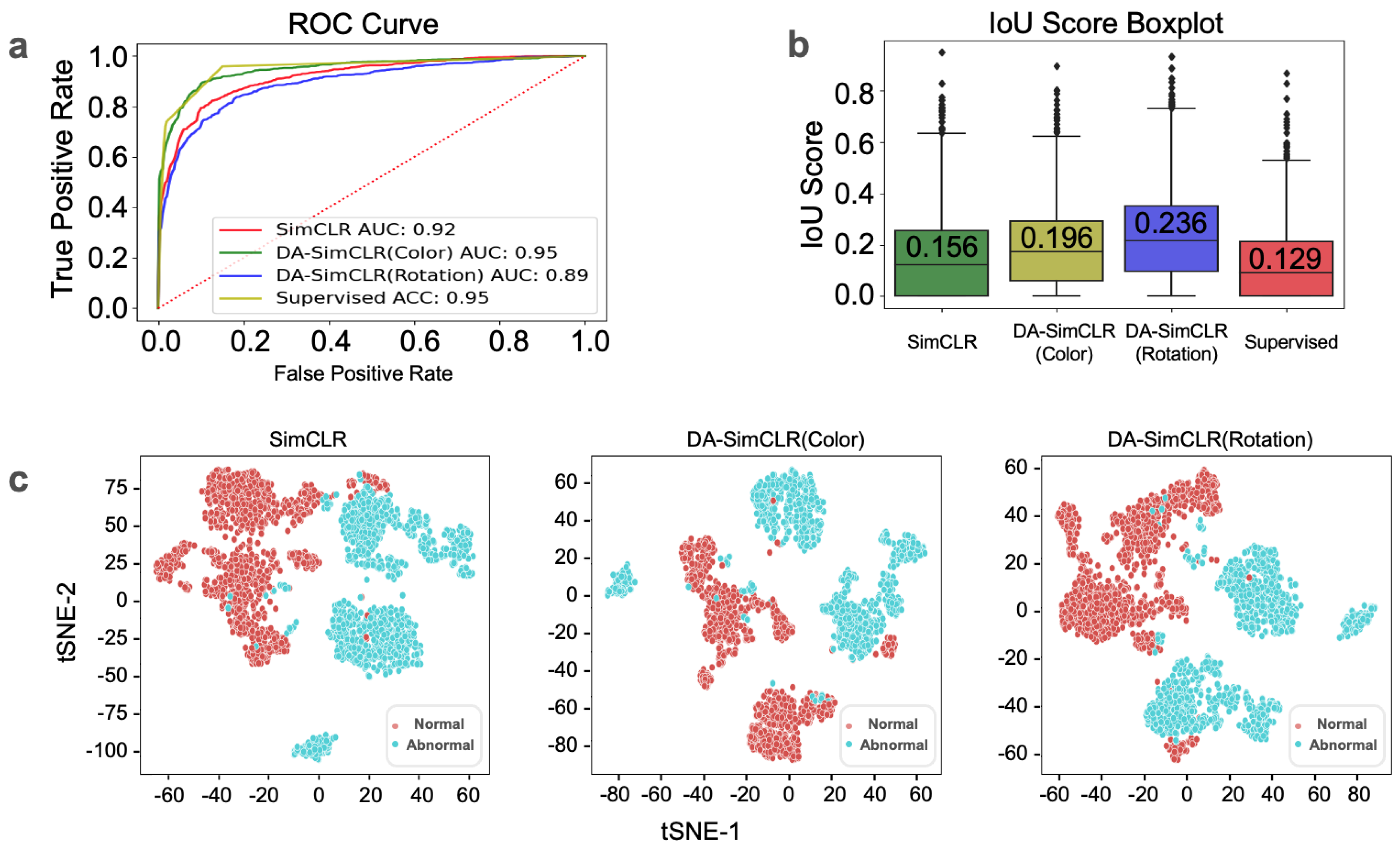
3.1. In-House Tile-Level Prediction
3.2. In-House Slide-Level Prediction
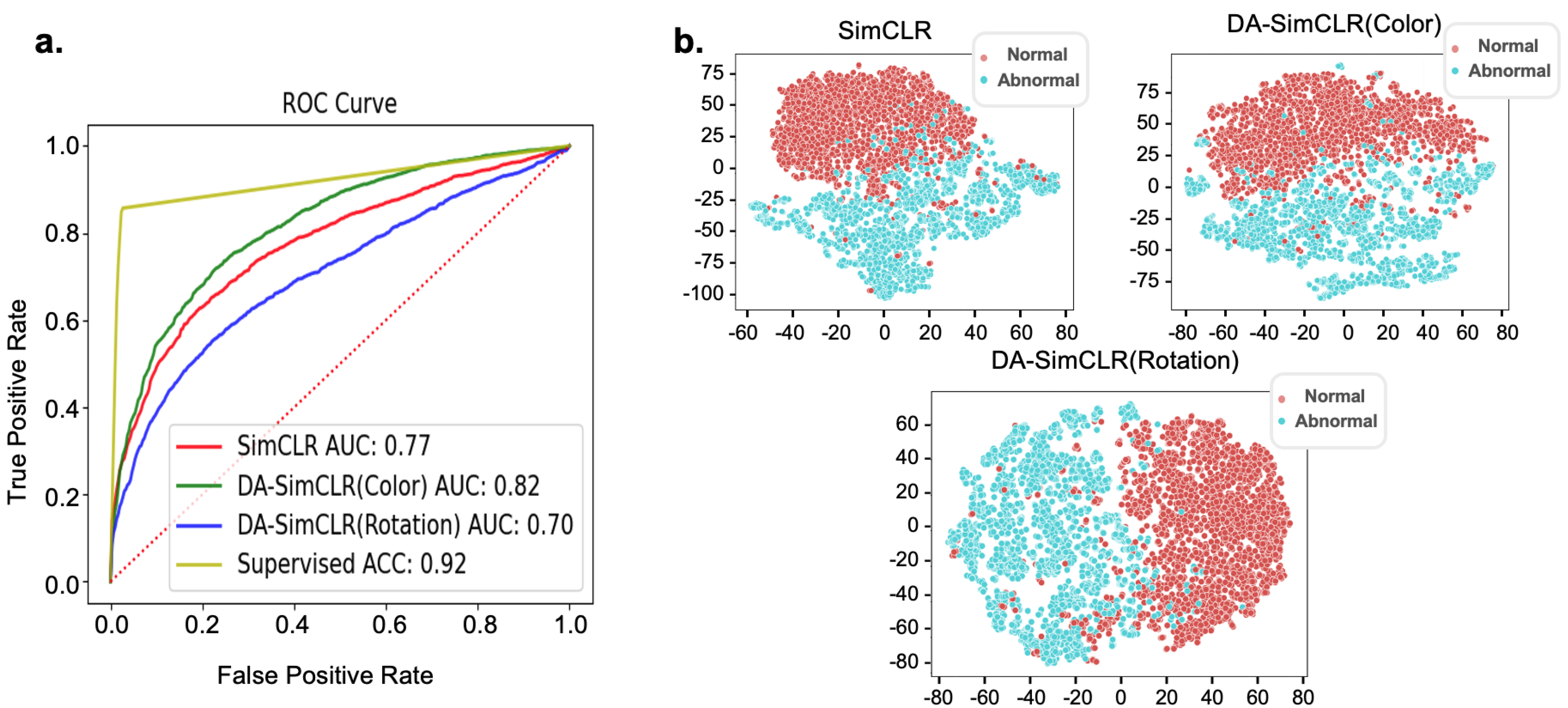
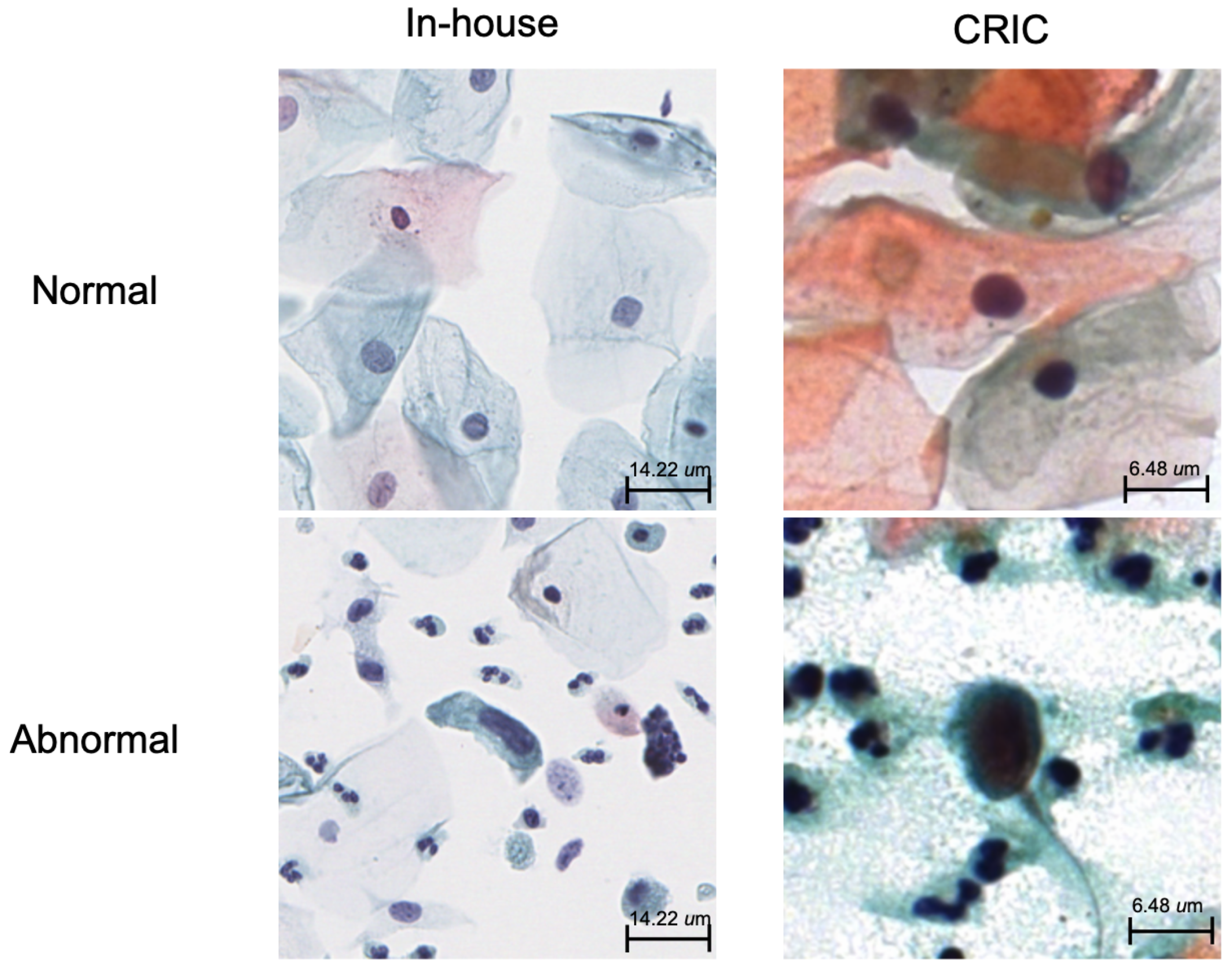
3.3. External Validation with CRIC Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| International Agency for Research on Cancer | IARC |
| Artificial intelligence | AI |
| Deep learning | DL |
| Regions of interest | ROI |
| One-class classification | OCC |
| Distribution-augmented | DA |
| Negative for Intraepithelial Lesion | NILM |
| The Bethesda System | TBS |
| Simple framework for contrastive learning visual representations | SimCLR |
| Kernel density estimation | KDE |
| One-class support vector machine | OC-SVM |
| Gaussian mixture model | GMM |
| t-distributed stochastic neighbor embedding | t-SNE |
| Liquid-based cytology | LBC |
| High-grade squamous intraepithelial lesion | HSIL |
| Atypical squamous cells–cannot exclude HSIL | ASC-H |
| Center for Recognition and Inspection of Cells | CRIC |
| Multilayer perceptron | MLP |
| Intersection over union | IOU |
| Area under the curve | AUC |
| Receiver operating characteristic | ROC |
References
- IARC. Biennial Report 2020–2021; International Agency for Research on Cancer: Lyon, France. Available online: https://publications.iarc.fr/607 (accessed on 1 November 2024).
- Deshou, H.; Changhua, W.; Qinyan, L.; Wei, L.; Wen, F. Clinical utility of Liqui-PREP™ cytology system for primary cervical cancer screening in a large urban hospital setting in China. J. Cytol. 2009, 26, 20–25. [Google Scholar] [CrossRef] [PubMed]
- Swid, M.A.; Monaco, S.E. Should screening for cervical cancer go to primary human papillomavirus testing and eliminate cytology? Mod. Pathol. 2022, 35, 858–864. [Google Scholar] [CrossRef] [PubMed]
- Monsonego, J.; Autillo-Touati, A.; Bergeron, C.; Dachez, R.; Liaras, J.; Saurel, J.; Zerat, L.; Chatelain, P. Liquid-based cytology for primary cervical cancer screening: A multi-centre study. Br. J. Cancer 2001, 84, 360–366. [Google Scholar] [CrossRef] [PubMed]
- Klinkhamer, P.J.; Meerding, W.J.; Rosier, P.F.; Hanselaar, A.G. Liquid-based cytology: A review of the literature with methods of evidence-based medicine. Cancer Cytopathol. Interdiscip. Int. J. Am. Cancer Soc. 2008, 99, 263–271. [Google Scholar] [CrossRef]
- Oh, J.K.; Shin, H.R.; Sohn, J.H.; Khang, S.K. Diagnostic accuracy of conventional Pap test, liquid-based cytology and human papillomavirus DNA testing in cervical cancer screening in Korea: A meta-analysis. Epidemiol. Health 2008, 30, 178–187. [Google Scholar] [CrossRef]
- Bao, H.; Sun, X.; Zhang, Y.; Pang, B.; Li, H.; Zhou, L.; Wu, F.; Cao, D.; Wang, J.; Turic, B.; et al. The artificial intelligence-assisted cytology diagnostic system in large-scale cervical cancer screening: A population-based cohort study of 0.7 million women. Cancer Med. 2020, 9, 6896–6906. [Google Scholar] [CrossRef]
- Hou, X.; Shen, G.; Li, Y.; Wang, T.; Ma, X. Artificial Intelligence in Cervical Cancer Screening and Diagnosis. Front. Oncol. 2022, 12, 851367. [Google Scholar] [CrossRef]
- Lew, M.; Wilbur, D.C.; Pantanowitz, L. Computational Cytology: Lessons Learned from Pap Test Computer-Assisted Screening. Acta Cytol. 2021, 65, 286–300. [Google Scholar] [CrossRef]
- Tang, H.P.; Cai, D.; Kong, Y.Q.; Ye, H.; Ma, Z.X.; Lv, H.S.; Tuo, L.R.; Pan, Q.J.; Liu, Z.H.; Han, X. Cervical cytology screening facilitated by an artificial intelligence microscope: A preliminary study. Cancer Cytopathol. 2021, 129, 693–700. [Google Scholar] [CrossRef]
- Wentzensen, N.; Lahrmann, B.; Clarke, M.A.; Kinney, W.; Tokugawa, D.; Poitras, N.; Locke, A.; Bartels, L.; Krauthoff, A.; Walker, J.; et al. Accuracy and Efficiency of Deep-Learning-Based Automation of Dual Stain Cytology in Cervical Cancer Screening. J. Natl. Cancer Inst. 2021, 113, 72–79. [Google Scholar] [CrossRef]
- Rahaman, M.M.; Li, C.; Yao, Y.; Kulwa, F.; Wu, X.; Li, X.; Wang, Q. DeepCervix: A deep learning-based framework for the classification of cervical cells using hybrid deep feature fusion techniques. Comput. Biol. Med. 2021, 136, 104649. [Google Scholar] [CrossRef] [PubMed]
- Pramanik, R.; Biswas, M.; Sen, S.; Souza Júnior, L.A.; Papa, J.P.; Sarkar, R. A fuzzy distance-based ensemble of deep models for cervical cancer detection. Comput. Methods Programs Biomed. 2022, 219, 106776. [Google Scholar] [CrossRef] [PubMed]
- Araújo, F.H.D.; Silva, R.R.V.; Ushizima, D.M.; Rezende, M.T.; Carneiro, C.M.; Campos Bianchi, A.G.; Medeiros, F.N.S. Deep learning for cell image segmentation and ranking. Comput. Med. Imaging Graph. Off. J. Comput. Med. Imaging Soc. 2019, 72, 13–21. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. Int. Conf. Mach. Learn. 2020, 119, 1597–1607. Available online: https://proceedings.mlr.press/v119/chen20j.html (accessed on 1 November 2024).
- Caron, M.; Bojanowski, P.; Joulin, A.; Douze, M. Deep clustering for unsupervised learning of visual features. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 132–149. [Google Scholar] [CrossRef]
- Sohn, K.; Li, C.L.; Yoon, J.; Jin, M.; Pfister, T. Learning and evaluating representations for deep one-class classification. arXiv 2020, arXiv:2011.02578. [Google Scholar]
- Hojjati, H.; Ho, T.K.K.; Armanfard, N. Self-supervised anomaly detection: A survey and outlook. arXiv 2022, arXiv:2205.05173. [Google Scholar]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep One-Class Classification. Int. Conf. Mach. Learn. 2018, 80, 4393–4402. Available online: https://proceedings.mlr.press/v80/ruff18a.html (accessed on 1 November 2024).
- Wang, T.; Isola, P. Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere. Proc. Mach. Learn. Res. 2020, 119, 9929–9939. Available online: https://proceedings.mlr.press/v119/wang20k.html (accessed on 1 November 2024).
- Pangarkar, M.A. The Bethesda System for reporting cervical cytology. CytoJournal 2022, 19, 28. [Google Scholar] [CrossRef]
- Hsu, W.; Markey, M.K.; Wang, M.D. Biomedical imaging informatics in the era of precision medicine: Progress, challenges, and opportunities. J. Am. Med. Inform. Assoc. 2013, 20, 1010–1013. [Google Scholar] [CrossRef]
- Chen, Y.C. A tutorial on kernel density estimation and recent advances. Biostat. Epidemiol. 2017, 1, 161–187. [Google Scholar] [CrossRef]
- Schölkopf, B.; Williamson, R.C.; Smola, A.; Shawe-Taylor, J.; Platt, J. Support vector method for novelty detection. Adv. Neural Inf. Process. Syst. 2000, 582–588. [Google Scholar]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G. Visualizaing Data using t-SNE. JMLR 2008, 9, 2579–2605. Available online: http://jmlr.org/papers/v9/vandermaaten08a.html (accessed on 1 November 2024).
- The Bethesda System for Reporting Cervical Cytology: Definitions, Criteria, and Explanatory Notes; Nayar, R., Wilbur, D.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Alrajjal, A.; Pansare, V.; Choudhury, M.S.R.; Khan, M.Y.A.; Shidham, V.B. Squamous intraepithelial lesions (SIL: LSIL, HSIL, ASCUS, ASC-H, LSIL-H) of Uterine Cervix and Bethesda System. CytoJournal 2021, 18, 16. [Google Scholar] [CrossRef]
- Rezende, M.T.; Silva, R.; Bernardo, F.O.; Tobias, A.H.G.; Oliveira, P.H.C.; Machado, T.M.; Costa, C.S.; Medeiros, F.N.S.; Ushizima, D.M.; Carneriro, C.M.; et al. Cric searchable image database as a public platform for conventional pap smear cytology data. Sci. Data 2021, 8, 151. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Winkens, J.; Bunel, R.; Roy, A.G.; Stanforth, R.; Natarajan, V.; Ledsam, J.R.; MacWilliams, P.; Kohli, P.; Karthikesalingam, A.; Kohl, S.; et al. Contrastive training for improved out-of-distribution detection. arXiv 2020, arXiv:2007.05566. [Google Scholar]
- Ando, Y.; Cho, J.; Park, N.J.Y.; Ko, S.; Han, H. Toward Interpretable Cell Image Representation and Abnormality Scoring for Cervical Cancer Screening Using Pap Smears. Bioengineering 2024, 11, 567. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| In-House Dataset | ||||
|---|---|---|---|---|
| 100 normal slides | 50 abnormal slides | 150 total slides | ||
| (184,842 tiles) | (249,600 tiles) | (434,442 tiles) | ||
| Upstream Pretraining Tasks | 60 slides | N/A | 60 normal slides | |
| (96,646 normal tiles) | (96,646 normal tiles) | |||
| Downstream | Slide Level | 40 normal slides | 50 abnormal slides | 90 slides |
| Tile Level | 1356 tiles | 1356 tiles | 2712 tiles | |
| (from 26 normal slides) | (from 26 abnormal slides) | |||
| External dataset (CRIC) | ||||
| Downstream | Tile Level | 2628 tiles | 2628 tiles | 5256 tiles |
| Downstream Analysis | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Upstream Pretrain Model |
K-Means Clustering Classifier |
One-Class Classification Models | Supervised Classifier | ||||||
| Precision | Recall | F1 Score | KDE | OC-SVM | GMM | GMM | Recall | F1 Score | |
| SimCLR | 0.92 | 0.95 | 0.93 | 0.92 | 0.94 | 0.97 | 0.96 | 0.95 | 0.95 |
| ± (0.079) | ± (0.072) | ± (0.041) | ± (0.10) | ± (0.07) | ± (0.02) | ± (0.059) | ± (0.053) | ± (0.032) | |
| DA-SimCLR | 0.94 | 0.95 | 0.95 | 0.95 | 0.85 | 0.94 | |||
| (Color) | ± (0.068) | ± (0.019) | ± (0.034) | ± (0.05) | ± (0.05) | ± (0.05) | |||
| DA-SimCLR | 0.94 | 0.95 | 0.94 | 0.89 | 0.92 | 0.92 | |||
| (Rotation) | ± (0.074) | ± (0.045) | ± (0.032) | ± (0.14) | ± (0.09) | ± (0.10) | |||
| Downstream Analysis | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Upstream Pretrain Model | K-Means Clustering Classifier | One-Class Classification Models | Supervised Classifier | ||||||
| Precision | Recall | F1 Score | KDE | OC-SVM | GMM | Precision | Recall | F1 Score | |
| SimCLR | 0.83 | 0.91 | 0.87 | 0.60 | 0.77 | 0.40 | 0.98 | 0.86 | 0.91 |
| ± (0.01) | ± (0.05) | ± (0.03) | ± (0.07) | ± (0.04) | ± (0.09) | ± (0.0082) | ± (0.077) | ± (0.047) | |
| DA-SimCLR | 0.85 | 0.74 | 0.78 | 0.74 | 0.82 | 0.61 | |||
| (Color) | ± (0.02) | ± (0.10) | ± (0.06) | ± (0.03) | ± (0.01) | ± (0.03) | |||
| DA-SimCLR | 0.83 | 0.94 | 0.88 | 0.51 | 0.70 | 0.40 | |||
| (Rotation) | ± (0.01) | ± (0.03) | ± (0.01) | ± (0.04) | ± (0.03) | ± (0.07) | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chun, J.; Yu, A.; Ko, S.; Chong, G.; Park, J.; Han, H.; Park, N.J.; Cho, J. Automated Screening of Precancerous Cervical Cells Through Contrastive Self-Supervised Learning. Life 2024, 14, 1565. https://doi.org/10.3390/life14121565
Chun J, Yu A, Ko S, Chong G, Park J, Han H, Park NJ, Cho J. Automated Screening of Precancerous Cervical Cells Through Contrastive Self-Supervised Learning. Life. 2024; 14(12):1565. https://doi.org/10.3390/life14121565
Chicago/Turabian StyleChun, Jaewoo, Ando Yu, Seokhwan Ko, Gunoh Chong, Jiyoung Park, Hyungsoo Han, Nora Jeeyoung Park, and Junghwan Cho. 2024. "Automated Screening of Precancerous Cervical Cells Through Contrastive Self-Supervised Learning" Life 14, no. 12: 1565. https://doi.org/10.3390/life14121565
APA StyleChun, J., Yu, A., Ko, S., Chong, G., Park, J., Han, H., Park, N. J., & Cho, J. (2024). Automated Screening of Precancerous Cervical Cells Through Contrastive Self-Supervised Learning. Life, 14(12), 1565. https://doi.org/10.3390/life14121565