
TCEDN: A Lightweight Time-Context Enhanced Depression Detection Network

 ,
,  ,
,
Abstract
1. Introduction
- We define an Attention-Weighted Aggregation Module (AWAM) to aggregate frame-level features of video representation, which reduces the model’s input while enhancing model performance, effectively lowering the computational complexity of the model.
- We propose a facial feature weighting module with self-learning weights, which integrates video raw features and facial movement features in a self-learning weight manner, effectively improving the accuracy of depression detection.
- We adopt a 3D-CNN optimized based on ConvLSTM to model the task of depression recognition, effectively reducing the potential loss of spatial feature information in the model concatenation process by avoiding feature flattening.
- We conduct end-to-end experiments on the corresponding datasets, showing that the TCEDN model performs comparably or even better than state-of-the-art methods. Furthermore, our approach demonstrates lower computational complexity while avoiding pre-training costs.
2. Related Work
2.1. Hand-Crafted Methods
2.2. Deep Learning Methods
2.3. Time-Difference Operation
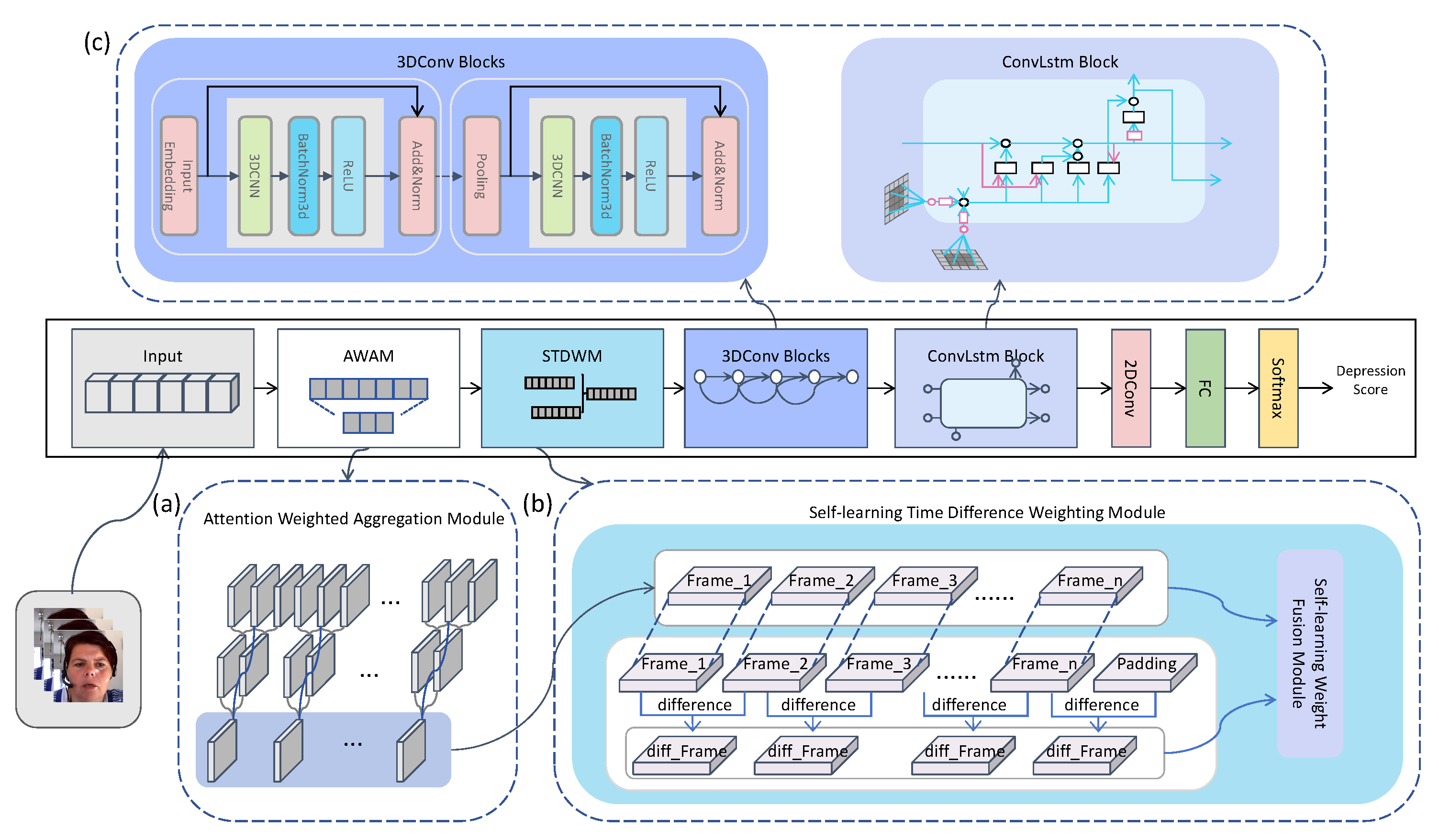
3. Proposed Method
3.1. Attention-Weighted Aggregation Module
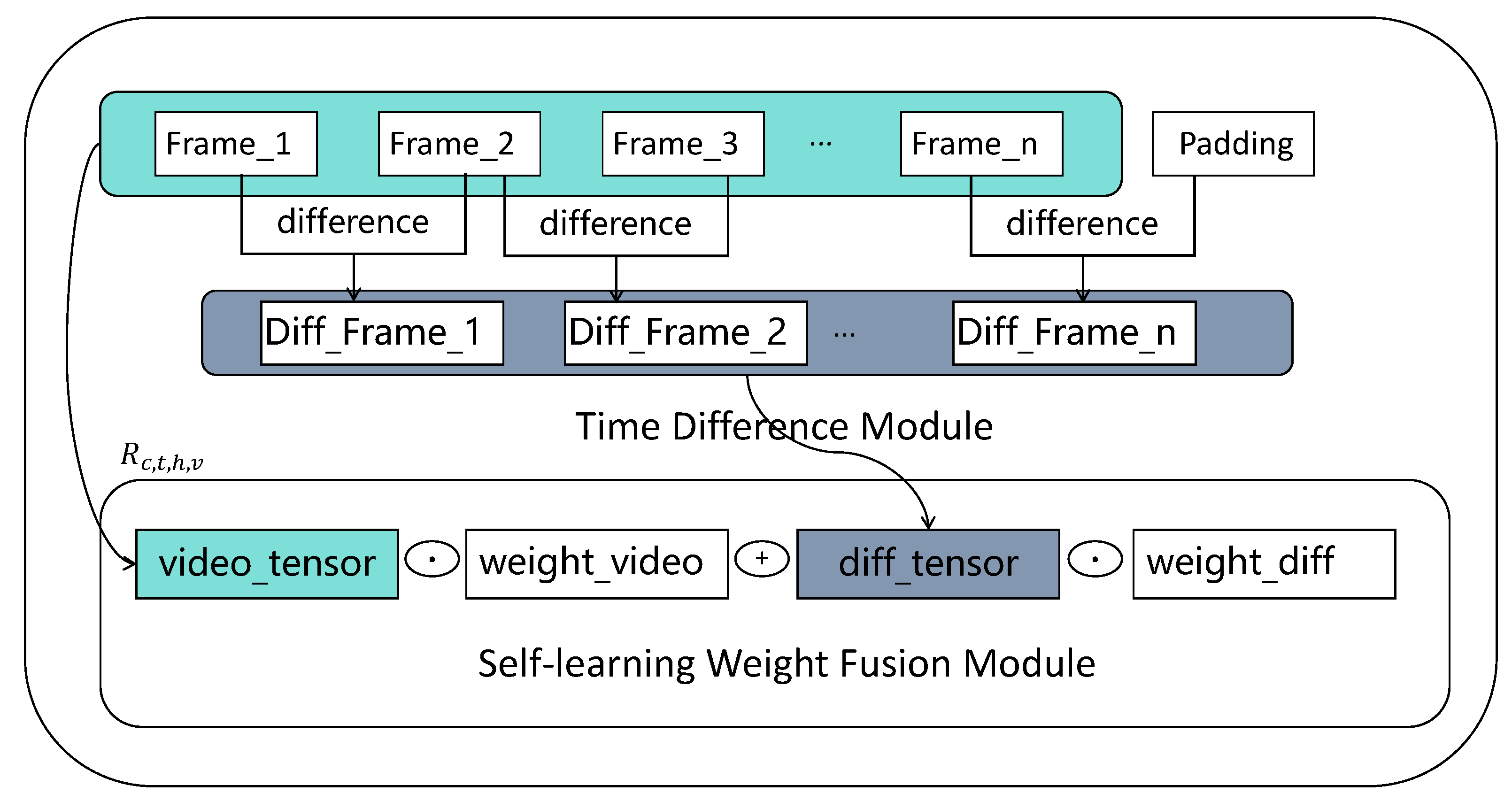
3.2. Self-Learning Time-Difference Weighting Module
3.2.1. Time-Difference Module
3.2.2. Self-Learning Weight Fusion Module
3.3. Depression Video Recognition Network
3.3.1. 3D-CNN Block
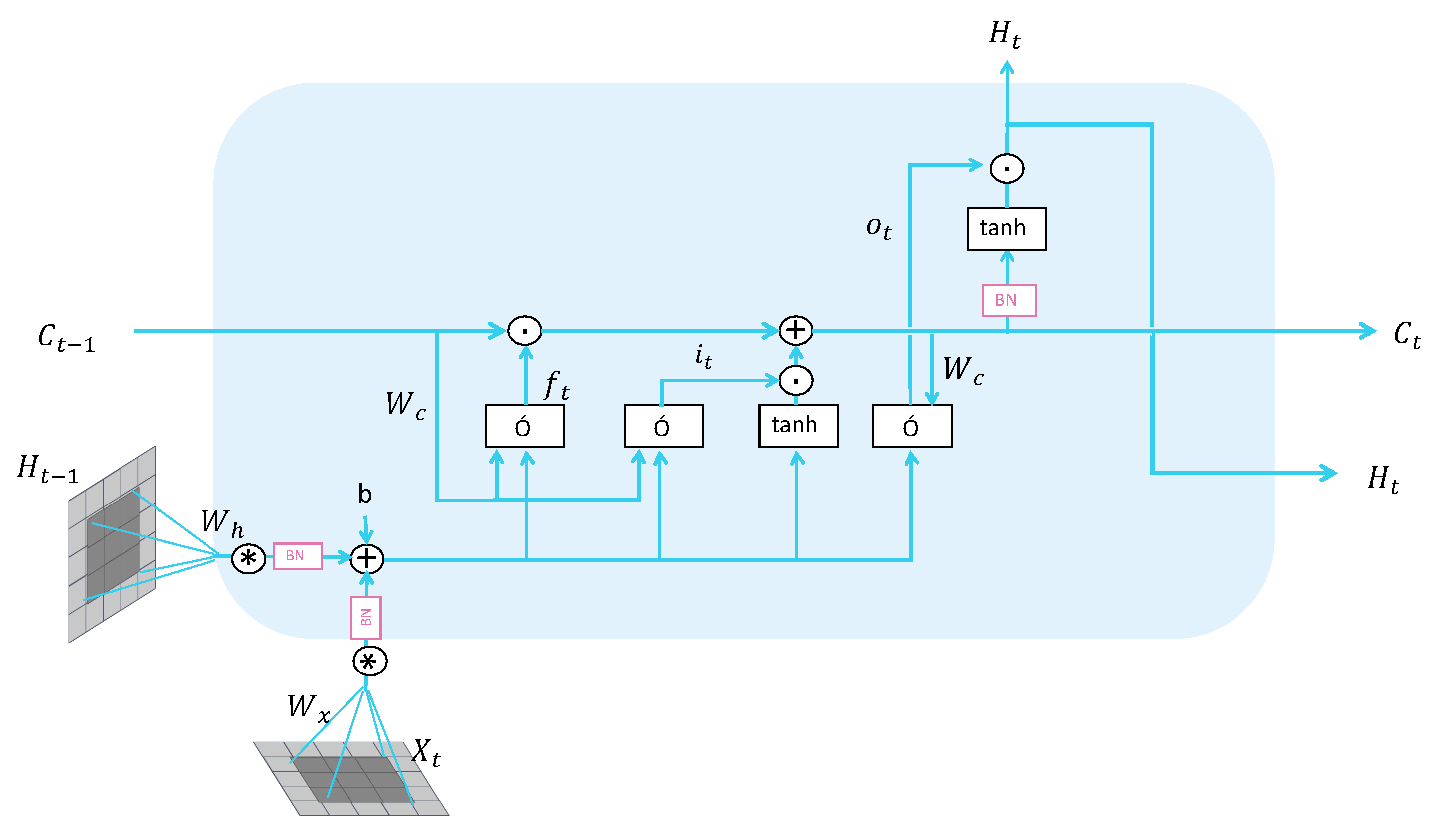
3.3.2. ConvLSTM Module
4. Experimental Dataset and Settings
4.1. Datasets and Pre-Processing
- Experimental Setup: TCEDN’s performance is being assessed through depression detection experiments using video data from the AVEC2013 and AVEC2014 public datasets. BDI-II depression scores are being used as labels for these experiments.
- AVEC2013 Dataset: the AVEC2013 dataset consists of 150 videos divided into training, validation (development), and test sets, each containing 50 videos with corresponding depression score labels.
- AVEC2014 Dataset: AVEC2014 involves two tasks during video recording: “Freeform” and “NorthWind”. Each task includes training, validation, and test sets, with each set comprising 50 videos with depression scores.
- BDI-II: The AVEC2013 and AVEC2014 datasets use BDI-II scores as labels for video predictions. The severity of depression can be categorized into four levels: minimal (0–13), mild (14–19), moderate (20–28), and severe (29–63).
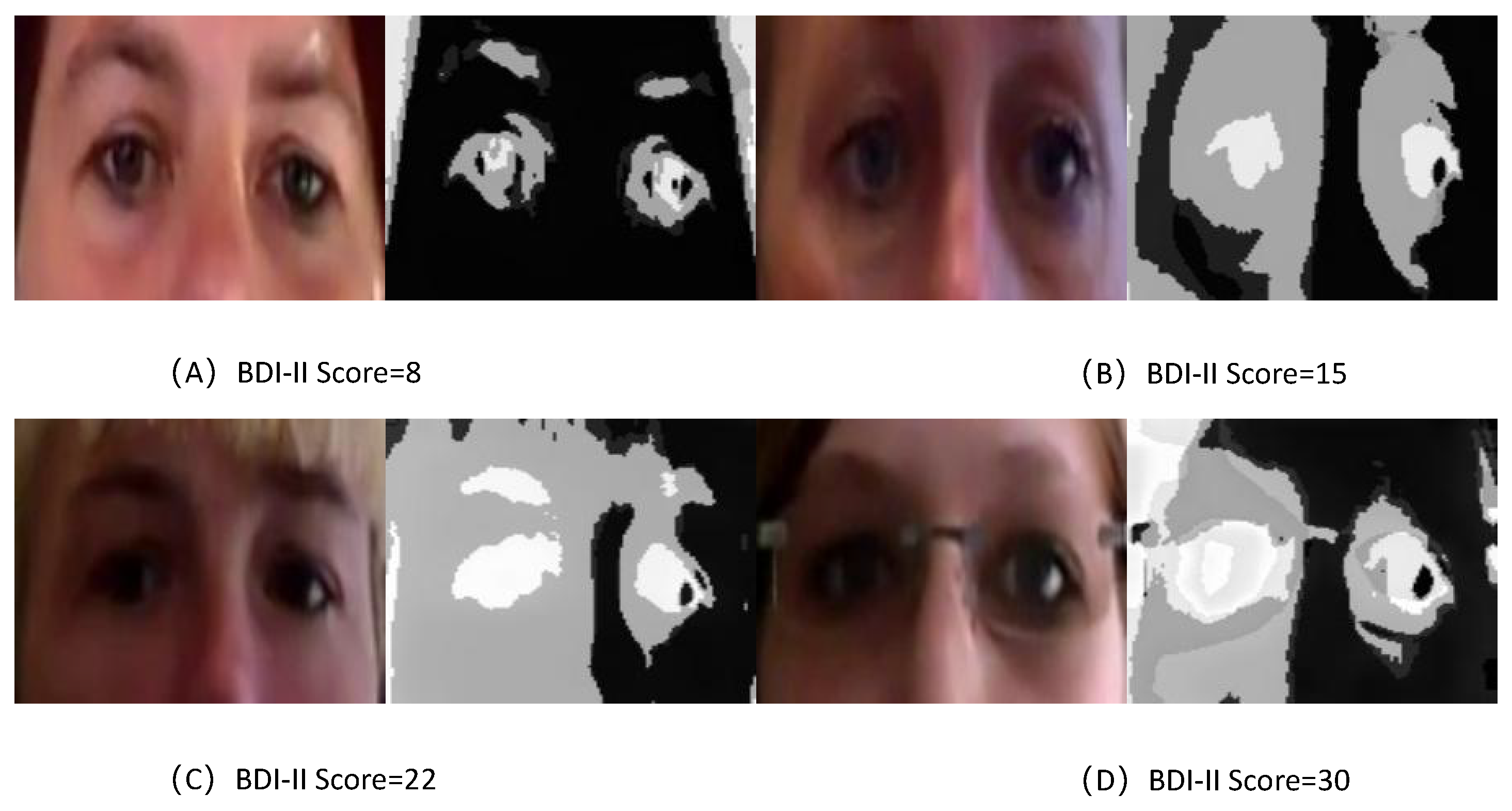
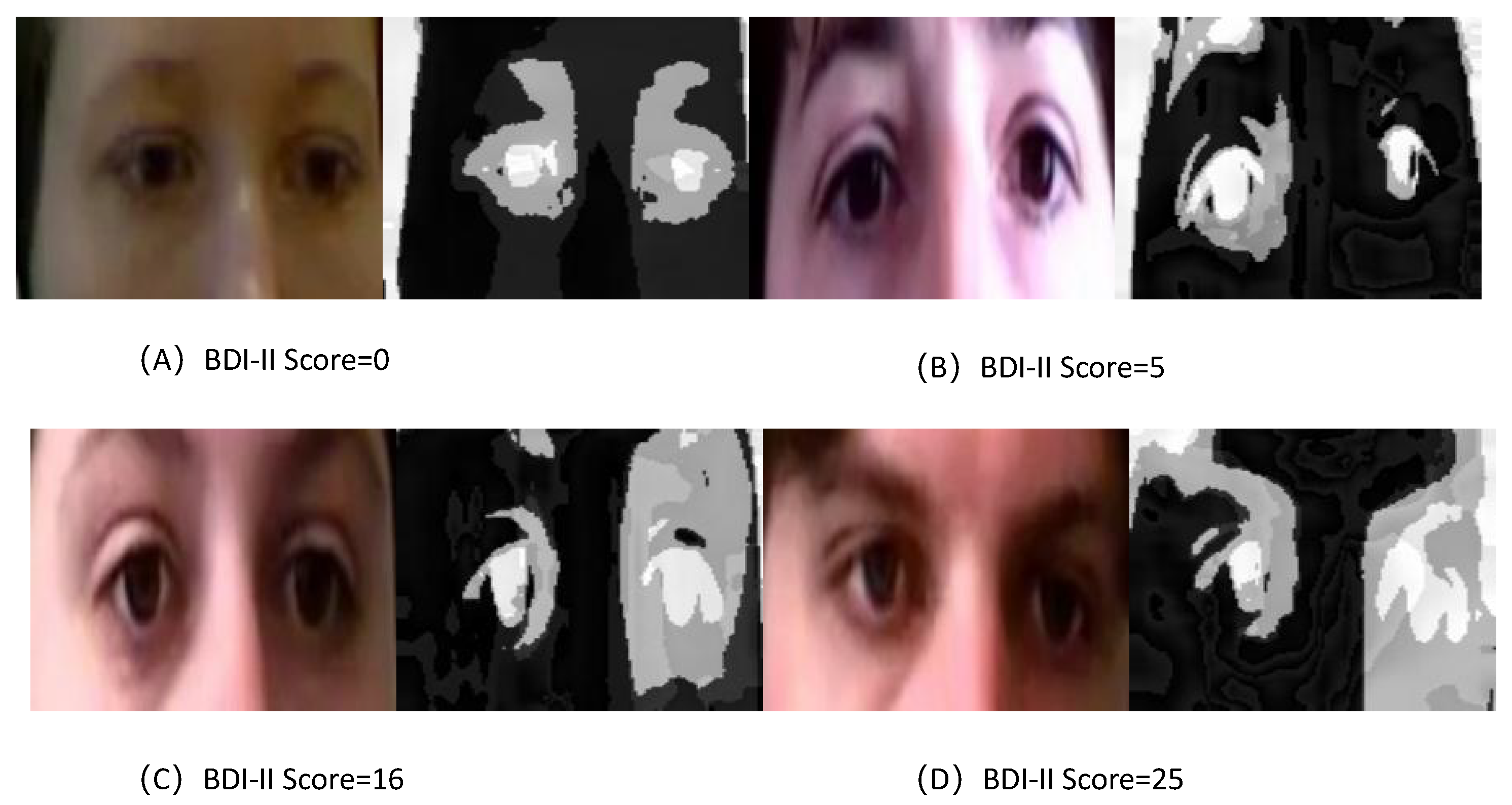
- Data Processing: Uniformly sample 48 or 66 frames for each given video. For each frame, we employed the Multi-Task Cascaded Convolutional Networks (MTCNN) [45] for face detection and alignment, followed by cropping the portion containing the eyes (sized at 270 × 80) to form the video data of the eye region. Subsequently, each video sample of the eye region was used as input for the TCEDN model.
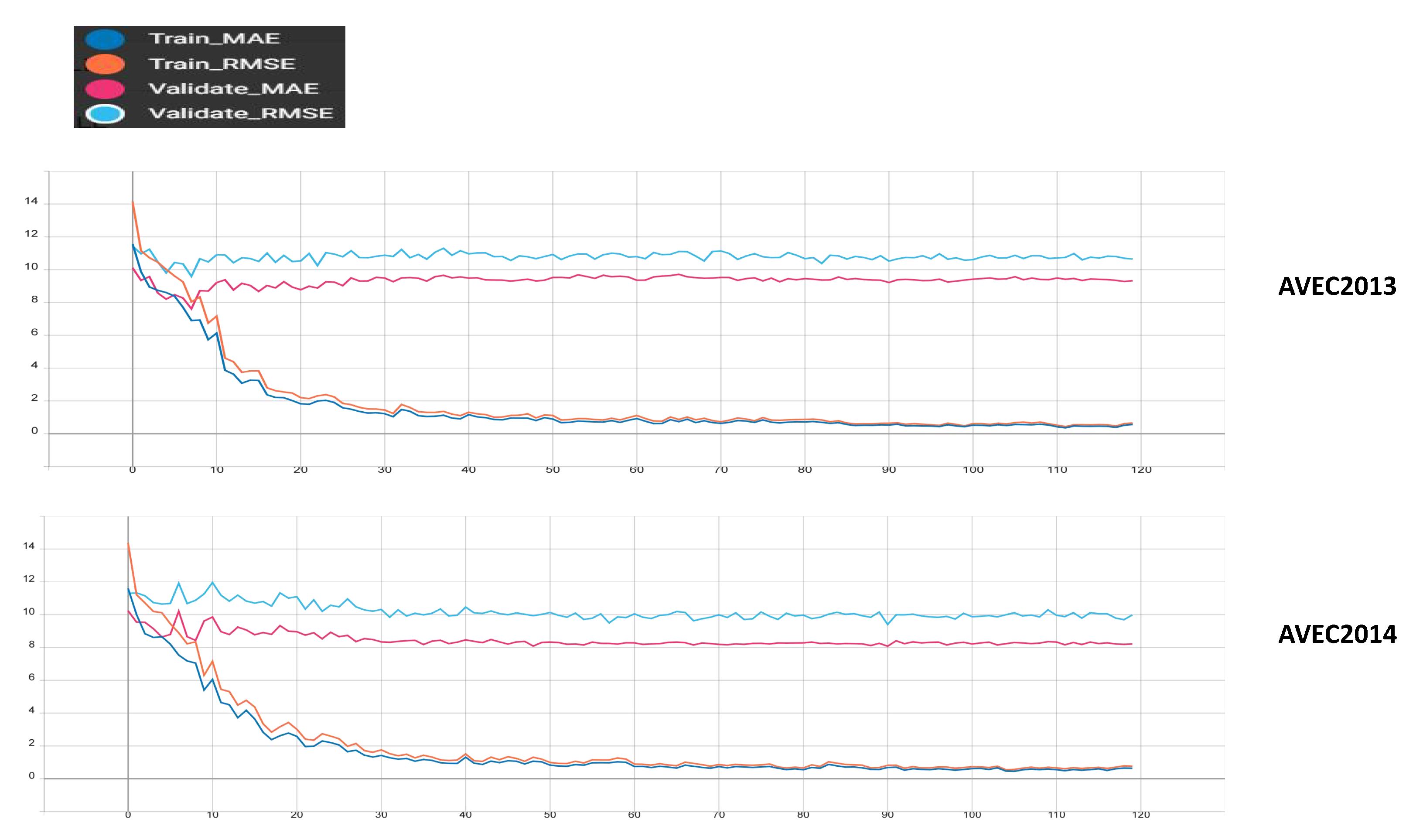
4.2. Implement Details and Evaluation Metrics
5. Results and Analysis
5.1. Influence of Different Time Steps on TCEDN
5.2. Evaluation of Different Modules in TCEDN
5.3. Slicing Effects in Different Regions
5.4. Comparison with State-of-the-Art
5.4.1. Performance Comparison of Methods Based on the AVEC2013 Dataset
5.4.2. Performance Comparison of Methods Based on the AVEC2014 Dataset
5.4.3. Comparison of Computational Complexity of Different Methods
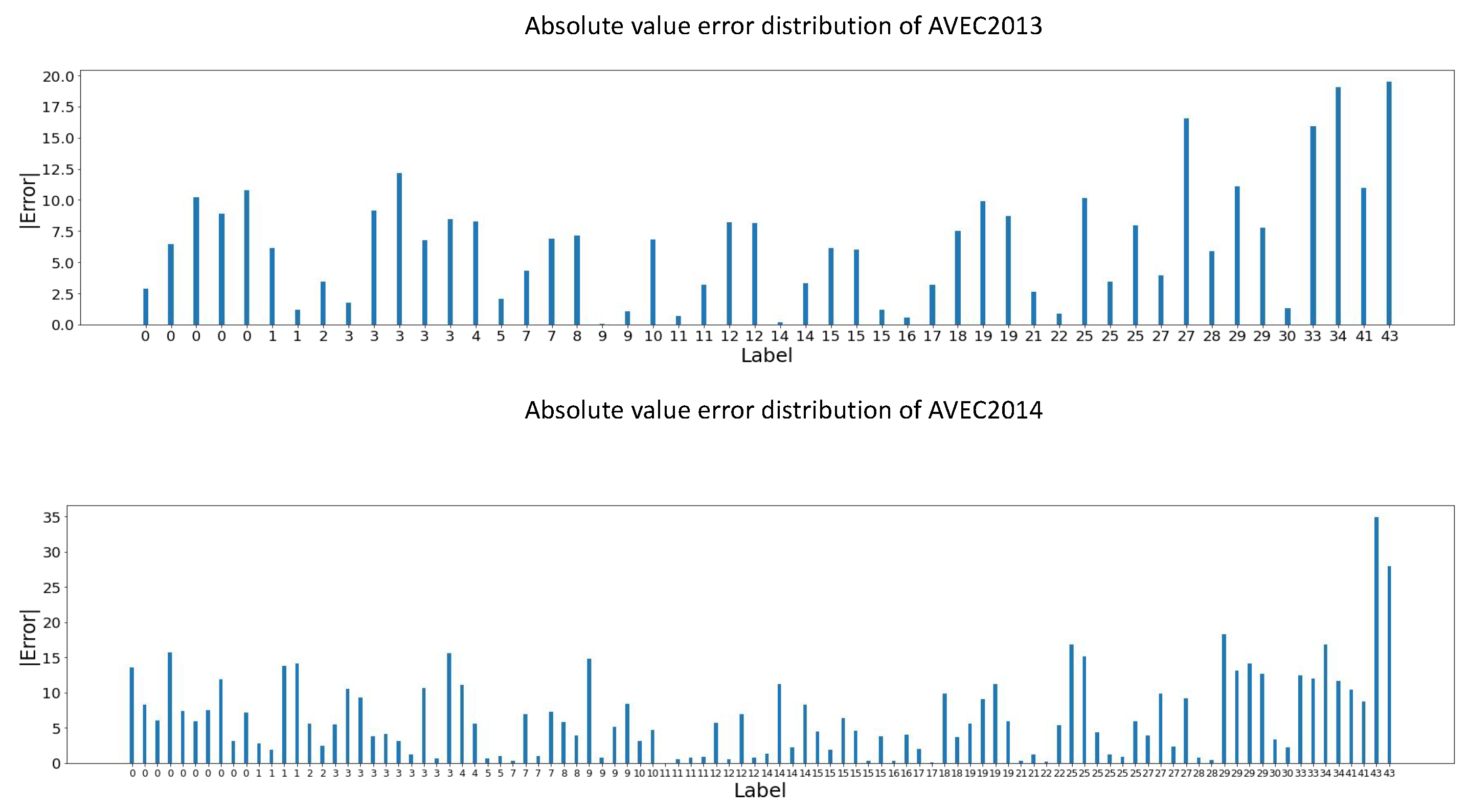
5.5. Error Analysis of TCEDN
5.6. Robustness Analysis of TCEDN
5.7. Feature Visualization of TCEDN
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| TCEDN | Time-Context Enhanced Depression Detection Network |
| 3D-CNN | 3-Dimensional Convolutional Neural Network |
| ConvLSTM | Convolutional Long Short-Term Memory Network |
| AVEC2013 | Audio/Visual Emotion Challenge 2013 |
| AVEC2014 | Audio/Visual Emotion Challenge 2014 |
| MDD | Major Depressive Disorder |
| HAMD | Hamilton Depression Rating Scale |
| BDI-II | Beck Depression Inventory-II |
| PHQ-9 | Patient Health Questionnaire-9 |
| CNNs | Convolutional Neural Networks |
| LSTM | Long Short-Term Memory |
| AWAM | Attention-Weighted Aggregation Module |
| RNN | Recurrent Neural Network |
| 2D-CNN | 2-Dimensional Convolutional Neural Network |
| LPQ | Local Phase Quantization |
| SVR | Support Vector Regression |
| MHH | Motion History Histogram |
| LGBP-TOP | Local Gabor Binary Patterns from Three Orthogonal Planes |
| LBP-TOP | Local Binary Patterns from Three Orthogonal Planes |
| LPQ-TOP | Local Phase Quantization from Three Orthogonal Planes |
| FDHH | Feature Dynamic History Histogram |
| DLGA-CNN | Deep Local Global Attention CNN |
| DAERNet | Dual Attention and Element Recalibration Network |
| STDWM | Self-Learning Time-Difference Weighting Module |
| SWFM | Self-Learning Weight Fusion Module |
| MTCNN | Multi-Task Cascaded Convolutional Network |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Square Error |
| PLS | Partial Least Square |
| MHI | Motion History Image |
| MFA | Marginal Fisher Analysis |
| DTL | Deep Transformation Learning |
| DepressNet | Deep Regression Networks |
| MSN | Multi-scale Spatiotemporal Network |
| MAD | Maximization and Differentiation Network |
| LQGDNet | Local Quaternion and Global Deep Network |
| MTDAN | Multi-scale Temporal difference Attention Networks |
| OpticalDR | Optical Imaging Model for Privacy-Protective Depression Recognition |
| rPPG | remote photoplethysmography signals |
| Grad-CAM | Gradient-Weighted Class Activation Mapping |
References
- Soloff, P.H.; Lis, J.A.; Kelly, T.; Cornelius, J.; Ulrich, R. Self-mutilation and suicidal behavior in borderline personality disorder. J. Personal. Disord. 1994, 8, 257–267. [Google Scholar] [CrossRef]
- Bordalo, F.; Carvalho, I.P. The role of alexithymia as a risk factor for self-harm among adolescents in depression–A systematic review. J. Affect. Disord. 2022, 297, 130–144. [Google Scholar] [CrossRef] [PubMed]
- Zuckerman, H.; Pan, Z.; Park, C.; Brietzke, E.; Musial, N.; Shariq, A.S.; Iacobucci, M.; Yim, S.J.; Lui, L.M.; Rong, C.; et al. Recognition and treatment of cognitive dysfunction in major depressive disorder. Front. Psychiatry 2018, 9, 655. [Google Scholar] [CrossRef] [PubMed]
- Kroenke, K.; Strine, T.W.; Spitzer, R.L.; Williams, J.B.; Berry, J.T.; Mokdad, A.H. The PHQ-8 as a measure of current depression in the general population. J. Affect. Disord. 2009, 114, 163–173. [Google Scholar] [CrossRef]
- Tully, P.J.; Winefield, H.R.; Baker, R.A.; Turnbull, D.A.; De Jonge, P. Confirmatory factor analysis of the Beck Depression Inventory-II and the association with cardiac morbidity and mortality after coronary revascularization. J. Health Psychol. 2011, 16, 584–595. [Google Scholar] [CrossRef]
- Zimmerman, M.; Martinez, J.H.; Young, D.; Chelminski, I.; Dalrymple, K. Severity classification on the Hamilton depression rating scale. J. Affect. Disord. 2013, 150, 384–388. [Google Scholar] [CrossRef]
- Richter, T.; Fishbain, B.; Fruchter, E.; Richter-Levin, G.; Okon-Singer, H. Machine learning-based diagnosis support system for differentiating between clinical anxiety and depression disorders. J. Psychiatr. Res. 2021, 141, 199–205. [Google Scholar] [CrossRef]
- Pampouchidou, A.; Simos, P.G.; Marias, K.; Meriaudeau, F.; Yang, F.; Pediaditis, M.; Tsiknakis, M. Automatic assessment of depression based on visual cues: A systematic review. IEEE Trans. Affect. Comput. 2017, 10, 445–470. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, J.; Hao, B.; Hu, P.; Wang, X.; Mei, J.; Li, S. Automatic depression detection via facial expressions using multiple instance learning. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1933–1936. [Google Scholar]
- Al Jazaery, M.; Guo, G. Video-based depression level analysis by encoding deep spatiotemporal features. IEEE Trans. Affect. Comput. 2018, 12, 262–268. [Google Scholar] [CrossRef]
- de Melo, W.C.; Granger, E.; Lopez, M.B. MDN: A deep maximization-differentiation network for spatio-temporal depression detection. IEEE Trans. Affect. Comput. 2021, 14, 578–590. [Google Scholar] [CrossRef]
- Song, S.; Jaiswal, S.; Shen, L.; Valstar, M. Spectral representation of behaviour primitives for depression analysis. IEEE Trans. Affect. Comput. 2020, 13, 829–844. [Google Scholar] [CrossRef]
- Guo, W.; Yang, H.; Liu, Z.; Xu, Y.; Hu, B. Deep neural networks for depression recognition based on 2d and 3d facial expressions under emotional stimulus tasks. Front. Neurosci. 2021, 15, 609760. [Google Scholar] [CrossRef] [PubMed]
- Scherer, S.; Stratou, G.; Morency, L.P. Audiovisual behavior descriptors for depression assessment. In Proceedings of the 15th ACM on International Conference on Multimodal Interaction, Sydney, Australia, 9–13 December 2013; pp. 135–140. [Google Scholar]
- Girard, J.M.; Cohn, J.F.; Mahoor, M.H.; Mavadati, S.; Rosenwald, D.P. Social risk and depression: Evidence from manual and automatic facial expression analysis. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Zhao, X.; Tian, Q. Spontaneous speech emotion recognition using multiscale deep convolutional LSTM. IEEE Trans. Affect. Comput. 2019, 13, 680–688. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zhu, X.; Wang, Y.; Dai, J.; Yuan, L.; Wei, Y. Flow-guided feature aggregation for video object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 408–417. [Google Scholar]
- Wang, S.; Zhou, Y.; Yan, J.; Deng, Z. Fully motion-aware network for video object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 542–557. [Google Scholar]
- Zhang, S.; Zhang, X.; Zhao, X.; Fang, J.; Niu, M.; Zhao, Z.; Yu, J.; Tian, Q. MTDAN: A lightweight multi-scale temporal difference attention networks for automated video depression detection. IEEE Trans. Affect. Comput. 2023, 15, 1078–1089. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Valstar, M.; Schuller, B.; Smith, K.; Eyben, F.; Jiang, B.; Bilakhia, S.; Schnieder, S.; Cowie, R.; Pantic, M. Avec 2013: The continuous audio/visual emotion and depression recognition challenge. In Proceedings of the 3rd ACM International Workshop on Audio/Visual Emotion Challenge, Barcelona, Spain, 21 October 2013; pp. 3–10. [Google Scholar]
- Valstar, M.; Schuller, B.; Smith, K.; Almaev, T.; Eyben, F.; Krajewski, J.; Cowie, R.; Pantic, M. Avec 2014: 3d dimensional affect and depression recognition challenge. In Proceedings of the 4th International Workshop on Audio/Visual Emotion Challenge, Orlando, FL, USA, 3–7 November 2014; pp. 3–10. [Google Scholar]
- Joshi, J.; Goecke, R.; Parker, G.; Breakspear, M. Can body expressions contribute to automatic depression analysis? In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–7. [Google Scholar]
- Wen, L.; Li, X.; Guo, G.; Zhu, Y. Automated depression diagnosis based on facial dynamic analysis and sparse coding. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1432–1441. [Google Scholar] [CrossRef]
- Dhall, A.; Goecke, R. A temporally piece-wise fisher vector approach for depression analysis. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015; pp. 255–259. [Google Scholar]
- Meng, H.; Huang, D.; Wang, H.; Yang, H.; Ai-Shuraifi, M.; Wang, Y. Depression recognition based on dynamic facial and vocal expression features using partial least square regression. In Proceedings of the 3rd ACM International Workshop on Audio/Visual Emotion Challenge, Barcelona, Spain, 21 October 2013; pp. 21–30. [Google Scholar]
- Zhu, Y.; Shang, Y.; Shao, Z.; Guo, G. Automated depression diagnosis based on deep networks to encode facial appearance and dynamics. IEEE Trans. Affect. Comput. 2017, 9, 578–584. [Google Scholar] [CrossRef]
- Jan, A.; Meng, H.; Gaus, Y.F.B.A.; Zhang, F. Artificial intelligent system for automatic depression level analysis through visual and vocal expressions. IEEE Trans. Cogn. Dev. Syst. 2017, 10, 668–680. [Google Scholar] [CrossRef]
- de Melo, W.C.; Granger, E.; Hadid, A. Combining global and local convolutional 3d networks for detecting depression from facial expressions. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–8. [Google Scholar]
- He, L.; Chan, J.C.W.; Wang, Z. Automatic depression recognition using CNN with attention mechanism from videos. Neurocomputing 2021, 422, 165–175. [Google Scholar] [CrossRef]
- Zheng, W.; Yan, L.; Gou, C.; Wang, F.Y. Graph attention model embedded with multi-modal knowledge for depression detection. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Zhang, S.; Yang, Y.; Chen, C.; Liu, R.; Tao, X.; Guo, W.; Xu, Y.; Zhao, X. Multimodal emotion recognition based on audio and text by using hybrid attention networks. Biomed. Signal Process. Control 2023, 85, 105052. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, D.; Sahli, H. Transformer encoder with multi-modal multi-head attention for continuous affect recognition. IEEE Trans. Multimed. 2020, 23, 4171–4183. [Google Scholar] [CrossRef]
- Zhao, Y.; Liang, Z.; Du, J.; Zhang, L.; Liu, C.; Zhao, L. Multi-head attention-based long short-term memory for depression detection from speech. Front. Neurorobot. 2021, 15, 684037. [Google Scholar] [CrossRef] [PubMed]
- Niu, M.; Zhao, Z.; Tao, J.; Li, Y.; Schuller, B.W. Dual attention and element recalibration networks for automatic depression level prediction. IEEE Trans. Affect. Comput. 2022, 14, 1954–1965. [Google Scholar] [CrossRef]
- Xu, Y.; Gao, L.; Tian, K.; Zhou, S.; Sun, H. Non-local convlstm for video compression artifact reduction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7043–7052. [Google Scholar]
- Zhao, Y.; Xiong, Y.; Lin, D. Recognize actions by disentangling components of dynamics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6566–6575. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 20–36. [Google Scholar]
- Li, Y.; Ji, B.; Shi, X.; Zhang, J.; Kang, B.; Wang, L. Tea: Temporal excitation and aggregation for action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 909–918. [Google Scholar]
- Wang, L.; Tong, Z.; Ji, B.; Wu, G. Tdn: Temporal difference networks for efficient action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 21–25 June 2021; pp. 1895–1904. [Google Scholar]
- Liu, Z.; Luo, D.; Wang, Y.; Wang, L.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Lu, T. Teinet: Towards an efficient architecture for video recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11669–11676. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Pérez Espinosa, H.; Escalante, H.J.; Villaseñor-Pineda, L.; Montes-y Gómez, M.; Pinto-Avedaño, D.; Reyez-Meza, V. Fusing affective dimensions and audio-visual features from segmented video for depression recognition: INAOE-BUAP’s participation at AVEC’14 challenge. In Proceedings of the 4th International Workshop on Audio/Visual Emotion Challenge, Orlando, FL, USA, 3–7 November 2014; pp. 49–55. [Google Scholar]
- Kaya, H.; Salah, A.A. Eyes whisper depression: A CCA based multimodal approach. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 961–964. [Google Scholar]
- Casado, C.Á.; Cañellas, M.L.; López, M.B. Depression recognition using remote photoplethysmography from facial videos. IEEE Trans. Affect. Comput. 2023, 14, 3305–3316. [Google Scholar] [CrossRef]
- Zhou, X.; Jin, K.; Shang, Y.; Guo, G. Visually interpretable representation learning for depression recognition from facial images. IEEE Trans. Affect. Comput. 2018, 11, 542–552. [Google Scholar] [CrossRef]
- Shang, Y.; Pan, Y.; Jiang, X.; Shao, Z.; Guo, G.; Liu, T.; Ding, H. LQGDNet: A local quaternion and global deep network for facial depression recognition. IEEE Trans. Affect. Comput. 2021, 14, 2557–2563. [Google Scholar] [CrossRef]
- De Melo, W.C.; Granger, E.; Hadid, A. A deep multiscale spatiotemporal network for assessing depression from facial dynamics. IEEE Trans. Affect. Comput. 2020, 13, 1581–1592. [Google Scholar] [CrossRef]
- Pan, Y.; Jiang, J.; Jiang, K.; Wu, Z.; Yu, K.; Liu, X. OpticalDR: A Deep Optical Imaging Model for Privacy-Protective Depression Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 1303–1312. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. Vggface2: A dataset for recognising faces across pose and age. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar]
- Kang, Y.; Jiang, X.; Yin, Y.; Shang, Y.; Zhou, X. Deep transformation learning for depression diagnosis from facial images. In Proceedings of the Biometric Recognition: 12th Chinese Conference, CCBR 2017, Shenzhen, China, 28–29 October 2017; pp. 13–22. [Google Scholar]
- De Melo, W.C.; Granger, E.; Hadid, A. Depression detection based on deep distribution learning. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4544–4548. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Difference Steps | AVEC2013 | AVEC2014 | ||
|---|---|---|---|---|
| RMSE↓ | MAE↓ | RMSE↓ | MAE↓ | |
| step_1 | 8.03 | 6.61 | 7.91 | 6.48 |
| step_2 | 9.00 | 6.99 | 8.10 | 6.68 |
| step_3 | 8.97 | 7.36 | 8.24 | 6.74 |
| step_4 | 9.04 | 7.21 | 8.04 | 6.58 |
| fusion | 8.33 | 6.77 | 7.99 | 6.55 |
| Dataset | Methods | RMSE ↓ | MAE ↓ |
|---|---|---|---|
| AVEC2013 | 3D-CNN | 9.39 | 7.68 |
| 3D-CNN + Lstm(baseline) | 9.28 | 7.37 | |
| 3D-CNN + ConvLstm | 8.78 | 7.32 | |
| STDWM + 3D-CNN+ConvLstm | 8.03 | 6.61 | |
| AWAM + 3D-CNN+ConvLstm | 8.67 | 6.69 | |
| SpliceConv + 3D-CNN + ConvLstm | 8.51 | 6.98 | |
| AWAM + STDWM + 3D-CNN + ConvLstm(ours) | 7.83 | 6.48 | |
| AVEC2014 | 3D-CNN | 8.90 | 7.43 |
| 3D-CNN + Lstm(baseline) | 9.20 | 7.22 | |
| 3D-CNN + ConvLstm | 8.24 | 6.68 | |
| STDWM + 3D-CNN + ConvLstm | 7.91 | 6.48 | |
| AWAM + 3D-CNN + ConvLstm | 8.02 | 6.50 | |
| SpliceConv + 3D-CNN + ConvLstm | 9.00 | 7.12 | |
| AWAM + STDWM + 3D-CNN + ConvLstm(ours) | 7.82 | 6.30 |
| Methods | AVEC2013 | AVEC2014 | ||
|---|---|---|---|---|
| RMSE↓ | MAE↓ | RMSE↓ | MAE↓ | |
| eyes slice | 7.83 | 6.48 | 7.82 | 6.30 |
| face slice | 8.78 | 7.32 | 9.57 | 7.12 |
| fusion | 8.93 | 6.91 | 8.82 | 7.11 |
| Methods | Year | Method Category |
|---|---|---|
| Baseline [24] | 2013 | HM |
| MHH + PLS [29] | 2013 | HM |
| MHI + SVR [46] | 2014 | HM |
| LPQ + 1-NN [47] | 2014 | HM |
| LPQ-TOP + MFA [27] | 2015 | HM |
| rPPG + LGBP-TOP [48] | 2023 | HM |
| Two-stream CNNs [30] | 2017 | DLM |
| Two-stream 3DCNN [32] | 2019 | DLM |
| DepressNet [49] | 2020 | DLM |
| ResNet-50 [11] | 2021 | DLM |
| Two-stream RNN + 3DCNN [10] | 2021 | DLM |
| DLGA-CNN [33] | 2021 | DLM |
| MDN-50 [11] | 2021 | DLM |
| DAERNet [38] | 2021 | DLM |
| LQGDNet [50] | 2021 | DLM |
| MSN [51] | 2022 | DLM |
| Behavior primitives [12] | 2022 | DLM |
| MTDAN [22] | 2023 | DLM |
| OpticalDR [52] | 2024 | DLM |
| Methods | Year | RMSE ↓ | MAE ↓ | Param. ↓ | FLOPS ↓ |
|---|---|---|---|---|---|
| Baseline [24] | 2013 | 13.61 | 10.88 | – | – |
| MHH + PLS [29] | 2013 | 11.19 | 9.14 | – | – |
| LPQ + 1-NN [47] | 2014 | 9.72 | 7.86 | – | – |
| LPQ-TOP + MFA [27] | 2015 | 10.27 | 8.22 | – | – |
| Two-stream CNNs [30] | 2017 | 9.82 | 7.58 | – | – |
| Two-stream 3DCNN [32] | 2019 | 8.26 | 6.40 | – | – |
| DepressNet [49] | 2020 | 8.19 | 6.30 | – | – |
| ResNet-50 [11] | 2021 | 8.81 | 6.92 | 63 | 12.22 |
| DLGA-CNN [33] | 2021 | 8.39 | 6.59 | – | – |
| Two-stream RNN + 3DCNN [10] | 2021 | 8.28 | 7.37 | 33.64 | 8.51 |
| MDN-50 [11] | 2021 | 8.13 | 6.39 | 21 | 7.40 |
| DAERNet [38] | 2021 | 8.13 | 6.28 | – | – |
| LQGDNet [50] | 2021 | 8.20 | 6.38 | – | – |
| MSN [51] | 2022 | 7.90 | 5.98 | 77.70 | 164.90 |
| Behavior primitives [12] | 2022 | 8.10 | 6.16 | – | – |
| rPPG + LGBP-TOP [48] | 2023 | 8.01 | 6.43 | – | – |
| MTDAN [22] | 2023 | 8.08 | 6.14 | 0.90 | 1.97 |
| OpticalDR [52] | 2024 | 8.48 | 7.53 | 67.28 | 4.36 |
| Ours | 2024 | 7.83 | 6.48 | 5.08 | 2.85 |
| Methods | Year | RMSE ↓ | MAE ↓ | Param. ↓ | FLOPS ↓ |
|---|---|---|---|---|---|
| Baseline [25] | 2014 | 10.86 | 8.86 | – | – |
| LPQ + 1-NN [47] | 2014 | 10.27 | 8.20 | – | – |
| MHHPLS [29] | 2014 | 10.50 | 8.44 | – | – |
| MHI + SVR [46] | 2014 | 9.84 | 8.46 | – | – |
| Two-stream CNNs [30] | 2017 | 9.55 | 7.47 | – | – |
| CNN + DTL [54] | 2017 | 9.43 | 7.74 | – | – |
| VGG-Face + FDHH [31] | 2017 | 8.04 | 6.68 | – | – |
| Two-stream 3DCNN [32] | 2019 | 8.31 | 6.59 | 33.64 | 8.51 |
| DepressNet [49] | 2020 | 8.55 | 6.39 | – | – |
| Two-stream RNN + 3DCNN [10] | 2021 | 9.22 | 7.20 | – | – |
| ResNet-50 [11] | 2021 | 8.40 | 6.79 | 63 | 12.22 |
| DLGA-CNN [33] | 2021 | 8.30 | 6.51 | – | – |
| MDN-50 [11] | 2021 | 8.16 | 6.45 | 21 | 7.4 |
| Behavior primitives [12] | 2022 | 8.30 | 6.78 | – | – |
| DAERNet [38] | 2022 | 8.07 | 6.14 | – | – |
| MSN [51] | 2022 | 7.61 | 5.82 | 77.70 | 164.90 |
| MTDAN [22] | 2023 | 7.93 | 6.35 | 0.90 | 1.97 |
| rPPG + LGBP-TOP [48] | 2023 | 8.49 | 6.57 | – | – |
| OpticalDR [52] | 2024 | 8.82 | 7.89 | 67.28 | 4.36 |
| Ours | 2024 | 7.82 | 6.30 | 5.08 | 2.85 |
| Methods | AVEC2013 | AVEC2014 | Param.↓ | FLOPS↓ | ||
|---|---|---|---|---|---|---|
| RMSE↓ | MAE↓ | RMSE↓ | MAE↓ | |||
| ResNet-50 [11] | 8.81 | 6.92 | 8.40 | 6.79 | 63 | 12.22 |
| TS-RNN + 3DCNN [10] | 8.28 | 7.37 | 9.22 | 7.20 | 33.64 | 8.51 |
| MDN-50 [11] | 8.13 | 6.39 | 8.16 | 6.45 | 21 | 7.40 |
| MSN [51] | 7.90 | 5.98 | 7.61 | 5.82 | 77.70 | 164.90 |
| MTDAN [22] | 8.08 | 6.14 | 7.93 | 6.35 | 0.90 | 1.97 |
| OpticalDR [52] | 8.48 | 7.53 | 8.82 | 7.89 | 67.28 | 4.36 |
| Ours | 7.83 | 6.48 | 7.82 | 6.30 | 5.08 | 2.85 |
| Dataset | Robustness Testing Methods | RMSE ↓ | MAE ↓ |
|---|---|---|---|
| AVEC2013 | Image Rotation by 30 Degrees | 8.63 | 6.96 |
| Image Rotation by 60 Degrees | 8.95 | 7.03 | |
| Image Rotation by 90 Degrees | 8.67 | 6.98 | |
| Image with Gaussian Noise | 9.35 | 7.28 | |
| Image with Random Noise | 8.49 | 7.03 | |
| Image with Random Occlusion | 8.11 | 6.86 | |
| AVEC2014 | Image Rotation by 30 Degrees | 8.72 | 6.96 |
| Image Rotation by 60 Degrees | 8.90 | 7.08 | |
| Image Rotation by 90 Degrees | 8.74 | 7.01 | |
| Image with Gaussian Noise | 9.12 | 7.33 | |
| Image with Random Noise | 8.26 | 6.75 | |
| Image with Random Occlusion | 8.12 | 6.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, K.; Miao, S.; Jin, X.; Mu, Y.; Zheng, H.; Tian, Y.; Wang, P.; Yu, Q.; Hu, D. TCEDN: A Lightweight Time-Context Enhanced Depression Detection Network. Life 2024, 14, 1313. https://doi.org/10.3390/life14101313
Yan K, Miao S, Jin X, Mu Y, Zheng H, Tian Y, Wang P, Yu Q, Hu D. TCEDN: A Lightweight Time-Context Enhanced Depression Detection Network. Life. 2024; 14(10):1313. https://doi.org/10.3390/life14101313
Chicago/Turabian StyleYan, Keshan, Shengfa Miao, Xin Jin, Yongkang Mu, Hongfeng Zheng, Yuling Tian, Puming Wang, Qian Yu, and Da Hu. 2024. "TCEDN: A Lightweight Time-Context Enhanced Depression Detection Network" Life 14, no. 10: 1313. https://doi.org/10.3390/life14101313
APA StyleYan, K., Miao, S., Jin, X., Mu, Y., Zheng, H., Tian, Y., Wang, P., Yu, Q., & Hu, D. (2024). TCEDN: A Lightweight Time-Context Enhanced Depression Detection Network. Life, 14(10), 1313. https://doi.org/10.3390/life14101313