Abstract
The use of herbal medicines in recent decades has increased because their side effects are considered lower than conventional medicine. Unani herbal medicines are often used in Southern Asia. These herbal medicines are usually composed of several types of medicinal plants to treat various diseases. Research on herbal medicine usually focuses on insight into the composition of plants used as ingredients. However, in the present study, we extended to the level of metabolites that exist in the medicinal plants. This study aimed to develop a predictive model of the Unani therapeutic usage based on its constituent metabolites using deep learning and data-intensive science approaches. Furthermore, the best prediction model was then utilized to extract important metabolites for each therapeutic usage of Unani. In this study, it was observed that the deep neural network approach provided a much better prediction model than other algorithms including random forest and support vector machine. Moreover, according to the best prediction model using the deep neural network, we identified 118 important metabolites for nine therapeutic usages of Unani.
1. Introduction
Herbal medicines are plant-based medicines made from different combinations of medicinal plant parts, e.g., leaves, flowers, or roots. Each part can have different medicinal uses, and many types of chemical constituents require different extraction methods. Both fresh and dried plants are used, depending on the herb (https://www.nimh.org.uk/whats-herbal-medicine, accessed on 4 June 2021). Herbal medicines have become popular drugs in the last three decades, and no less than 80% of people worldwide depend on herbal medicines. The main reasons why people tend to choose herbal medicines are because herbal medicines provide better efficacy and relatively lower side effects compared to conventional drugs [1]. The use of herbal medicines throughout the world reached USD 60 billion in 2010 and is expected to reach USD 5 trillion by 2050 [2,3]. This information shows that the use of herbal medicines is prevalent throughout the world. Some examples of herbal medicine systems around the world are Traditional Chinese Medicine (TCM) from China; Kampo from Japan; Jamu from Indonesia; and Ayurvedic, Siddha, or Unani from Southern Asia.
Unani Tibb, commonly known as Unani medicine, is practiced widely in South and Central Asia. The Arabic term “Tibb” means “medicine,” while the name “Unani” is assumed to have its roots in the Greek word “Ionan” [4]. Later on, it was also influenced by Indian and Chinese traditional systems. The Unani herbal medicines mostly utilize medicinal plants as their ingredients, and this system follows ancient concepts and principles of drug management. Research on building Unani’s scientific foundation has not been carried out much by researchers. This is needed to provide a foundation and knowledge as to why an Unani formula is useful for a particular disease. Unani medicines are made by the extraction of medicinal plants that are used as drugs against various diseases [3]. Based on [5], the Unani System of Medicine was invented in Greece and refined by Arabs into a sophisticated medical discipline using the framework of Hippocrates’ and Jalinoos’ teachings (Galen). Unani medicine has since been referred to as Greco-Arab medicine. The Hippocratic notion of the four humors are blood, phlegm, yellow bile, and black bile. According to this approach, these principles govern the health and composition of the body and pathological states. The Unani System of Medicine (USM) has been acknowledged by the World Health Organization (WHO) as an alternative system to meet the demands of the human population in terms of health care. The practice of alternative medicine is widespread.
One approach in building Unani’s scientific foundation is supervised learning by utilizing data science. Supervised learning is the machine learning task of learning a function that maps an input to an output based on examples of input–output pairs [6]. It infers a function from labeled training data consisting of a set of training examples [7]. A supervised learning algorithm utilizes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow the algorithm to determine the class labels for unseen instances correctly.
Deep learning is a supervised learning process. In this work, we want to utilize deep learning and other machine learning algorithms to find the relationship between the therapeutic usage of Unani and its constituent metabolites (compounds). The concept of deep learning also allows computers to model complicated and complex data concepts. This approach is considered effective for complex data because the principles of learning emulate the work of human neurons. In addition to supervised learning, this method can also be used for unsupervised and semi-supervised learning. This study uses a derivative of deep learning architecture: the deep neural network (DNN). The DNN is an artificial neural network with a certain level of complexity that has more than one hidden layer [8]. The DNN is considered capable of solving complex problems because this approach has a fairly complex architecture that makes it possible to study data up to the level of abstraction. According to [9], this method is beneficial in the process of visual object recognition, object detection, drug discovery, and genomics.
In this study, we utilized supervised learning to predict the interactions between the therapeutic usage of Unani formulas based on their metabolites using the deep neural network. We also compared the prediction performance of the DNN with other machine learning methods. Moreover, we determined significant metabolites based on target diseases/therapeutic usage of the Unani formula according to the best prediction model, and validated the result based on journal references and counting the structural similarity with relevant metabolites [10]. Hence, these results can be used as a reference to other research and basic knowledge of drug discovery.
2. Materials and Methods
The methods adopted in the present work are illustrated in the flowchart in Figure 1. The major steps were (1) data acquisition and preprocessing, (2) model development and comparison, and (3) the prediction of effective metabolites.
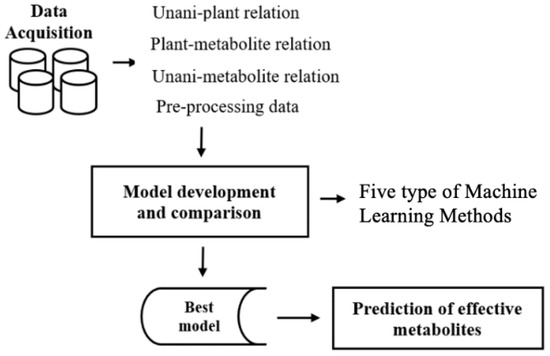
Figure 1.
Schematic diagram of the prediction of Unani efficacy and identification of metabolites for each efficacy group.
In the preliminary step, we collected the metabolite information of medicinal plants used as the composition of the Unani formulas. The Unani data we utilized in this work are the same as the data utilized in previous work [3]. Actually, these data were collected from the following book: BANGLADESH: National Formulary of Unani Medicine (ISBN 978-984-33-3253-0). The initial data for this study included Unani formulas, medicinal plants, and therapeutic usage information. The dataset consisted of 609 Unani formulas, 369 medicinal plants, and these were grouped into 18 efficacy groups (Figure 2a). The efficacy classes were as follows: (1) Blood and Lymph Diseases, (2) Cancers, (3) The Digestive System, (4) Ear, Nose, and Throat, (5) Diseases of the Eye, (6) Female-Specific Diseases, (7) Glands and Hormones, (8) The Heart and Blood Vessels, (9) Diseases of the Immune System, (10) Male-Specific Diseases, (11) Muscle and Bone, (12) Neonatal Diseases, (13) The Nervous System, (14) Nutritional and Metabolic Diseases, (15) Respiratory Diseases, (16) Skin and Connective Tissue, (17) The Urinary System, and (18) Mental and Behavioral Disorders.
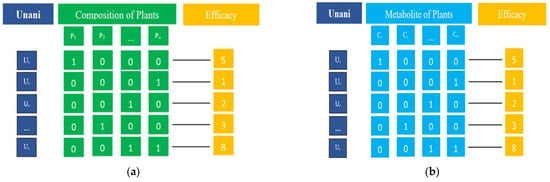
Figure 2.
Representation of the dataset including therapeutic usage for each Unani formula. (a) Unani–plant relations; (b) Unani–metabolite relations.
The initial Unani formulas consisted of plants as ingredients. Unani compounds were collected according to the corresponding plants by using the following databases: KNApSAcK Family Databases (http://www.knapsackfamily.com/KNApSAcK_Family, accessed on 25 June 2021), IJAH Analytics (http://ijah.apps.cs.ipb.ac.id, accessed on 3 July 2021), KEGG (https://www.genome.jp/kegg/, accessed on 10 July 2021), and ChEbi (https://www.ebi.ac.uk/chebi/, accessed on 11 September 2021). The distribution of metabolites collected for each medicinal plant is shown in Figure 3. The number of compounds belonging to a medicinal plant varies a lot: some plants are associated with a few metabolites, whereas some are associated with many.
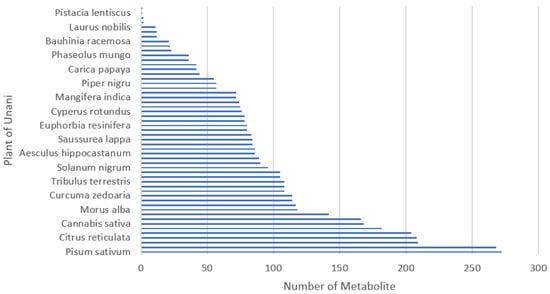
Figure 3.
The distribution of compounds for selected medicinal plants from the top of the list.
The KNApSAcK database (DB) contains information on the species–metabolite relationship (101.500), encompassing 20,741 species and 50,048 metabolites. This database also contains information on accurate mass, molecular formula, metabolite name, and mass spectra in several ionization modes [10]. IJAH Analytics is an open-access database specifically for Jamu data. This database provides the plant–metabolite relations, and we assume some metabolites might be common between Jamu and Unani because both are classified as traditional medicine. The Kyoto Encyclopedia of Genes and Genomes (KEGG) is also an open-access database containing cell, organism, and molecular information with the specific large-scale molecular datasets. The Chemical Entities of Biological Interest (ChEBI) database contains molecular entities focusing on small chemical compounds.
The minimum and maximum number of compounds associated with a formula corresponding to 18 disease classes are shown in Table 1. Finally, we represented the collected data as a two-dimensional table, in which the rows represent the Unani formulas and columns represent metabolites. Figure 2b illustrates the data representation of herbal medicine–metabolite relations. The number of metabolites associated with 369 medicinal plants is 4688. Therefore, the dimension of the matrix indicating relations between Unani formulas and metabolites is 609 × 4688.

Table 1.
The minimum and maximum metabolites of each disease’s class.
2.1. Data Preprocessing
We initially eliminated some Unani formulas with missing values and the Unani formula with multiple therapeutic usages because we only focused on determining compounds for a specific efficacy. One way to overcome the problems of imbalanced data, multiple classification, and inconsistent data is by applying filtering methods. We used a single filtering method in this research. The filtering approach creates models using an entire dataset as training data, then predicts the class of all data and eliminates misclassified data. According to this reference [11], we can use random forest and other classifier methods to remove inconsistent data and increase the performance of the model classifier. We used two types of machine learning to filter the dataset. The first dataset was created using random forest as a filter, whereas another dataset was created utilizing deep learning. Two types of filtering were applied to compare the results and to accept and utilize the better option for the final prediction.
2.2. Model Generation and Comparison
We generated a prediction model by utilizing the deep learning method. Deep learning is a form of machine learning that allows computers to learn something based on experience and understand everything in the form of concepts. Techniques and algorithms in deep learning can be used for supervised learning, unsupervised learning, and semi-supervised learning in various applications. The architecture used in this study was the deep neural network [8].
Deep learning allows a computational model consisting of several layers of processing to study data at various levels of abstraction. The representation of learning with various levels of representation obtained by compiling simple non-linear modules is a method of deep learning. To classify, a higher layer of representation is used to strengthen input and suppress irrelevant variations. The deep learning method can be used to find complex structures in high-dimensional data [9]. In this study, the method used consisted of more than one hidden layer. Figure 4 shows the input layer, hidden layer, and output layer components in deep learning.
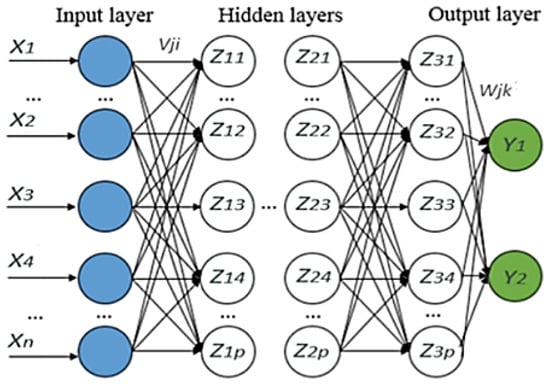
Figure 4.
The architecture of deep learning [7].
Initially, we tuned the DNN to obtain the optimal parameter values. The DNN is an advanced artificial neural network that has more than one hidden layer between the input and output layers. Each hidden layer has an activation function such as a sigmoid, rectified linear unit (ReLU), or hyperbolic tangent (tanh) function to map the input from the previous layer to the output that will be sent to the layer afterward.
The DNN can be discriminatorily trained with backpropagation using cost function derivatives to measure the difference between the target output and actual output. Backpropagation for large training data is performed on a small portion of data taken at random so that it is more efficient than considering all data together.
The DNN, with a large number of hidden layers, is challenging to optimize. The approach of using the gradient descent from a randomly generated starting point close to the actual value cannot produce a good set of weights, unless careful weight-scale initialization is completed. Therefore, the initialization of weights in DNN modeling becomes essential to improve the DNN modeling performance. We also compared the performance of the DNN with other supervised learning methods, such as random forest [12], and support vector machine [13].
2.3. Extracting Important Metabolites
According to the best prediction model, we extracted important metabolites from each class by considering the weight of variable importance in the DNN. We selected the top-15 important metabolites for each disease class and examined their weights. Among the top-15 selected metabolites, we discarded the metabolites whose weights were less than the threshold.
3. Results
3.1. Filtering Dataset
First, we removed 33 Unani formulas for fever because this symptom can be found in many disease classes. Then, we eliminated 195 Unani formulas which have more than one therapeutic usage, and also eliminated unrelated metabolites after the reduction of Unani formulas. We applied single filtering using random forest and the deep neural network, separately. The filtering process was conducted by using all datasets as training data and also as testing data, and misclassified formulas were deleted. Therefore, we obtained two datasets from two different types of filtering, namely dataset 1 as the dataset after filtering using random forest, and dataset 2 as the dataset after filtering using the deep neural network. The dimensions of the data after filtering can be seen in Table 2.
Table 2.
Summary of filtering dataset.
Next, we examined the distribution of formulas to each efficacy class after filtering. Each class in both datasets should have had enough Unani samples to generate good prediction models. Therefore, we eliminated efficacy classes 1, 2, 4, 5, 7, 9, 14, and 18 because only a few Unani formulas were available in both datasets as follows (dataset 1, dataset 2): (8, 4), (1, 0), (10, 5), (7, 1), (3, 3), (0, 0), (3, 0), and (13, 0). After this removal, the distribution of the Unani formulas in dataset 1 and dataset 2 is shown in Figure 5.
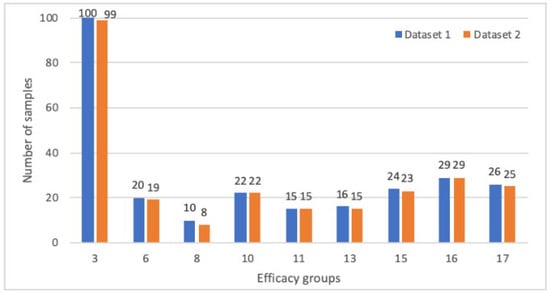
Figure 5.
Comparison of Unani data for each therapeutic’s usage after filtering.
3.2. Performance of Prediction
The datasets obtained from the previous process were used to develop a model for the prediction of therapeutic usages of Unani using machine learning approaches (Table 2). We adopted several methods, namely deep neural networks (DNN), random forest (RF), and support vector machine (SVM), etc. The deep neural network was chosen as a recommended classifier because this method is robust for imbalanced and multi-class problem data. The DNN model that was built for this study was completed according to the method proposed by [14]. This method is considered to be able to model complex data.
Tuning parameters are important factors for forming a prediction model. In terms of the deep neural network, several parameters affected the accuracy value of the DNN model, such as the activation function, the dropout value, the number of k in the validation process (k-fold cross-validation), the number of hidden layers, and the number of epochs. Each parameter was tuned by considering a range of values as follows: activation functions (“relu”, “tanh”, “sigmoid”) [15], the dropout value (0.15, 0.25, 0.40, 0.50), the value of k concerning cross-validation (4, 5, 6, 7, 8, 9, 10), the number of hidden layers (4, 6, 8, 12), and the number of epochs (30, 50, 100, 500). Then, the best DNN parameters were processed using a grid search for both datasets. The optimal parameters for both datasets were the same as follows: activation function = “relu”, dropout value = 0.40, k value = 5, number of hidden layers = 4, and number of epochs = 30. The prediction results for each fold using the DNN with the best parameters can be seen in Figure 6.
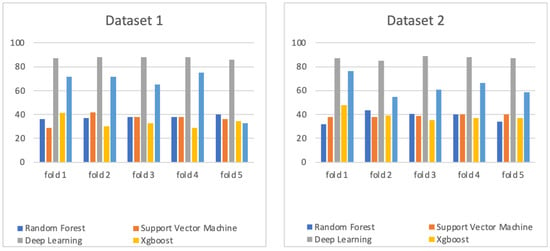
Figure 6.
Comparison of prediction accuracy of deep neural network, random forest, support vector machine, XGBoost, and K-nearest neighbors algorithms using both datasets.
In the random forest, there are several parameters that should be tuned when making the RF model, such as n_estimators as the number of trees formed by RF, max_features, max_depth, min_samples_split, min_samples_leaf, and bootstrap. For each parameter used in the tuning processes, we utilized the range of values as follows: {‘n_estimators’: (200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000); ‘max_features’: (‘auto’, ‘sqrt’); ‘max_depth’: (10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, None); ‘min_samples_split’: (2,5,10); ‘min_samples_leaf’: (1, 2, 4); and ‘bootstrap’: (True, False)}. The results obtained after a grid search for the RF model for dataset 1 and 2 were as follows: dataset 1 (n_estimators = 1000, min_samples_split = 10, min_samples_leaf = 2, max_features = ‘sqrt’, max_depth = 10), and dataset 2 (n_estimators = 400, min_samples_split = 10, min_samples_leaf = 4, max_features = ‘sqrt’, max_depth = 90, bootstrap = True). After obtaining the best parameter results, the prediction model was performed using 5-fold cross-validation. The prediction results for each fold using RF using the best parameters can be seen in Figure 6.
In the SVM, the parameters needed to be tuned to form the best SVM prediction model are the type of kernel, gamma value, and C. The SVM parameters were tuned using the search grid according to this configuration: {‘kernel’: (“rbf”, “linear”); ‘gamma’: (0.001, 0.0001, “auto”); and ‘C’: (1, 10, 100, 1000)}. The best parameters for both datasets were as follows: dataset 1 (kernel: “linear,” C: 1, and gamma: 0.001) and dataset 2 (kernel: “rbf”, C: 1 and gamma: “auto”). Then, the prediction accuracies obtained using those parameters and 5-fold cross-validation are shown in Figure 6. Similarly, we performed parameter-tuning for XGBoost and K-nearest neighbors (KNN) algorithms, and the results are shown in Figure 6.
The comparison of the classifier performances is shown in Figure 7. For the random forest, support vector machine, and XGBoost, the averages of prediction accuracy were below 40%, and for the KNN it was around 60% but still much less than the deep learning method. In this study, the DNN achieved 87.4% accuracy. The results imply that the prediction models based on RF and SVM are not able to make a good efficacy prediction using Unani’s compounds as features.
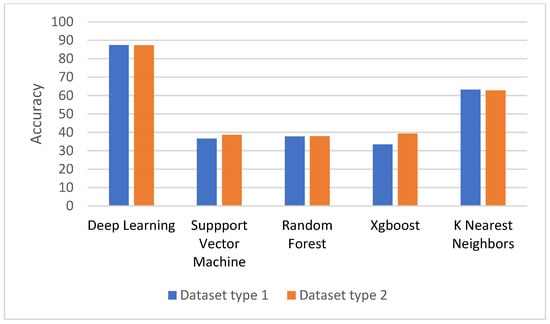
Figure 7.
Comparison of prediction accuracy between deep neural network, random forest, and support vector machine using both datasets.
One of the reasons that influenced the results was the imbalanced amount of Unani formulas belonging to different efficacy classes. It is noteworthy that the results of the prediction model based on the DNN could increase the accuracy measure by about 50% when compared to RF and SVM.
3.3. Identification of Important Metabolites
After obtaining the best prediction model, we extracted essential features, in this case metabolites, for each therapeutic usage. The potential compounds for each disease class were obtained based on variable importance from the best deep neural network model using the KerasRegressor and PermutationImportance packages. First, we selected the top-15 compounds and then discarded the compounds with the weight of variable importance lower than the threshold. In this study, we set the threshold equal to 0.01. In total, we selected 118 unique compounds for 9 efficacy groups. The statistics of the selected compounds can be seen in Table 3, and the details of the selected compounds for each disease class are available in Supplementary Table S1.
Table 3.
Statistics of the selected compound from each disease class.
3.4. Validation of Important Metabolites
We utilized three approaches to validate metabolites for each therapeutic group as follows: (1) by searching in supporting journals/articles; (2) by searching for the same metabolites in traditional medicine, in this case, Jamu and TCM; (3) by searching for metabolites with similar structures in the PubChem database (using the Simpson similarity). Equation (1) shows the formula for calculating the Simpson similarity between two compounds.
where a is the number of common features between two compounds, b is the number of features present in only one compound, and c is the number of features only present in the other compound. A list of validated metabolites/compounds for different disease classes is shown in Table 4.
Table 4.
List of validated metabolites.
Table 4 shows the list of predicted compounds for which we could find validations. Corresponding to the disease category ‘The Digestive System’, there were eight validated compounds. Out of them, 6H-dibenzo[b,d]pyran-6-one is effective against Enterophytoestrogens [16]. lyratol C is used as a drug to treat colorectal neoplasms [17]. Epithienamycin E is a substance that kills or slows the growth of microorganisms, including bacteria, viruses, fungi, and protozoans [18]. 9(S)-HOTrE enhances reverse cholesterol transport (RCT) by increasing the apoA-I transcription in human hepatocellular carcinoma (HepG2) cells [18]. Cimifoetiside A is the active ingredient in Cimicifuga spp., which is used to relieve diarrhea in TCM [20]. Gymnemic acid XII possesses a higher binding affinity to PPARγ, a promising drug target for diabetes [21]. Quercetin 7,4′-di-O-β-D-glucoside is the active ingredient in Delonix elata, which is used to relieve flatulence and purgatives in Saudi Arabia [22]. Furthermore, as therapeutic agents, phenethylamine acts as an appetite suppressant [23].
For the ‘Female-Specific’ category, we have validated five compounds. D-myo-inositol 1,2,5,6-tetracisphosphate inhibits fibroma. This process can also block chloride channels resulting in epithelial calcium activation [24]. Delphin has been reported to inhibit inflammation in some gynecological infections [25]. Butine is the active ingredient in the ingredients TCM, Albizia glaberrima, and (R)-4-hydroxy-1-methyl-L-proline from Aglaia andamanica. Additionally, Jamu takes Malvidin as a medical composition.
For the category ‘The Heart and Blood Vessels’, we found four validated compounds. Out of them, kaempferol 3-O-[α-L-rhamnopyranosyl(1→2)-β-D-galactopyranosyl]-7-O-α-L-rhamnopyranoside is a candidate agent for the treatment of cardiovascular diseases [26]. Succinic acid is an active component that is applied in Jamu. Linalyl acetate prevents hypertension-related ischemic injury and can prevent the production of ROS [28].
In the case of ‘Male-Specific Diseases’, there were seven validated compounds. According to the Simpson similarity, Obtusifoliol resembles Euphadienol, which has anti-inflammatory effects [29]. Methyl 4-hydroxy cinnamate, Δ6-protoilludene, and 3-O-Acetyloleanolic acid are active against prostate cancer [30]. Butiin demonstrates the growth inhibition of Gram-positive and Gram-negative bacteria that cause male-specific infections [32]. Gibberellin A12 is implicated in the treatment of male infertility [33]. The ∆-6-protoilludene is a precursor for the synthesis of both melleolides and armillyl orsellinates, whose cytotoxicity reflects their ability to induce apoptosis [34]. In addition, erythrodiol is an active ingredient from the herb, Rhododendron ferrugineum, which is used in TCM.
According to the category ‘Muscle and Bone’, the number of compounds validated was 4. Among them, 14-deoxo-3-O-propionyl-5,15-di-O-acetyl-7-O-benzoylmyrsinol-14beta-nicotinoate shows similarities with perfluorooctyl iodide. These metabolites are useful as organocatalysts through the activation of substrates with halogen bonds. Euphorbiaproliferin I resembles cesium and Euphorbiaproliferin G is similar to moli001259. Structural similarity is measured based on Simpson’s similarity. Furthermore, Euphorbiaproliferin D can be isolated from TCM ingredients, namely Euphorbia prolifera. Euphorbia prolifera can cure various diseases when referring to TCM.
Corresponding to the disease category ‘The Nervous System’, the validated compounds are pterostilbene, Trapain, and cyanidin 3-O-(6-O-acetyl-β-D-glucoside). The antioxidant activity of pterostilbene has been implicated in the modulation of neurological disease [35]. Trapain is a promising agent for the treatment of Alzheimer’s disease as the Cholinesterase and β-site amyloid precursor protein-cleaving enzyme 1 inhibitor [36]. Finally, cyanidin 3-O-(6-O-acetyl-β-D-glucoside) has been verified to have a neuroprotective effect [36].
In the case of ‘The Respiratory Diseases’, 6-epi-guttiferone J, 2(3H)-Furanone and 2-(3,4-dihydroxyphenyl)-ethyl-O-β-D-glucopyranoside were validated. Based on the Simpson similarity, 6-epi-guttiferone J resembles (0.902) a moderate antinociceptive agent, sesquiterpene lactone. In addition, 2(3H)-Furanone is reported to show anticancer and DNA-damaging activities in A549 lung cancer cells [38,39]. Furthermore, 2-(3,4-dihydroxyphenyl)-ethyl-O-β-D-glucopyranoside is a component of TCM herbal, Cornus mas/alba L., which is applied in the practice as an anti-inflammatory and antibacterial drug.
For the category ‘Skin and Connective Tissue’, Taxifolin 3′-glucoside, Oleanolic acid, Oleandrin, Himaphenolone, Coniferyl aldehyde, and Cedrin were the validated metabolites. Taxifolin 3′-glucoside is effective for preventing the production of inflammatory cytokines and reducing atopic dermatitis [40]. Oleanolic acid can inhibit skin tumor promotion [41]. Oleandrin is shown to induce the apoptosis of malignant cells in melanoma cell lines [42]. Himaphenolone is the active ingredient of the herb, Cedrus deodara (Roxb.) Loud, which can be used for the treatment of carbuncle sores, eczema, traumatic bleeding, burns, and scalds. Coniferyl aldehyde is similar to a drug, and Nalco L. and Cedrin resemble dihydroquercetin.
In terms of the ‘Urinary System’ category, we have validated Glyoxylic acid, Biochanin A, pyruvic acid, oxalic acid, Soyasaponin I, 2-(methyldithio)pyridine-N-oxide, Liquiritigenin, Garbanzol, and Medicagol. Glyoxylic acid and oxalic acid are involved in the formation of kidney stones [43,44]. Pyruvic acid can prevent oxalate urolithiasis in mice [45]. Soyasaponin I inhibited kidney enlargement and cyst growth in a murine model of polycystic kidney disease [46]. Then, 2-(methyldithio)pyridine-N-oxide and Garbanzol were both shown to inhibit renal neoplasm [48,49]. Lastly, Liquiritigenin, Biochanin A, and Medicagol are effective components used in Jamu [50].
4. Discussion
We tried our best to collect as many metabolites as possible for each Unani plant from various resources. Medicinal metabolites are of more importance to researchers and usually they are the first identified for various plants. Therefore, we assumed that the currently available plant–metabolite relation could produce good results up to a certain extent.
The approach adopted in the current work can be considered as a top-down approach because we started with a global set of Unani formulas in terms of plants, and then we moved down to the metabolite level and utilized state-of-the-art machine learning techniques to identify significant compounds. Hence, the approach is also a computational approach. The results we obtained are promising, showing the strength and usefulness of computational approaches in drug discovery. Our input data correspond to versatile types of diseases. In this work, we considered disease classes at an upper hierarchy, and under each class, there were diseases with some differences. Interestingly, our results also show compounds corresponding to different types of diseases under each category. This has been possible by investigating and identifying significant compounds within formulas showing bias to specific disease classes/categories using efficient algorithms. Therefore, these are the results of the systems-level investigation.
Another thing that is interesting to discuss is the other compounds (not validated) extracted from the best model of this study. The validation results show around 43% of compounds are directly or indirectly related to the therapeutic group of diseases. The remaining 69 compounds are potential candidates for further research, for example, in the fields of biochemistry, pharmacy, medicine, and so on. Last, the simple binary data to represent metabolites have performed well in this study. However, other approaches can be explored to improve the results.
5. Conclusions
A prediction of the therapeutic usage of the Unani formulas based on their constituent metabolites using the deep neural network showed the highest accuracy compared to other algorithms, e.g., the random forest and support vector machine, etc. The best prediction accuracies corresponding to DNN, KNN, Xgboost, RF, and SVM were 87.4%, 63.2%, 39.3%, 37.9%, and 38.6%, respectively. The results of this prediction indicate that the DNN performed much better compared to other algorithms. In this work, two datasets were prepared using filtering techniques, namely, dataset 1 and dataset 2. In the case of the DNN, the best accuracy was obtained from dataset 1, while RF and SVM obtained the best accuracy from dataset 2. In general, the filtering process improves prediction accuracy, but our results were mainly influenced by the type of classifier algorithms.
Based on the best classification model, we extracted important metabolites by making use of the DNN interest variable. Corresponding to the nine therapeutic uses of the Unani formula, we extracted 118 essential metabolites, 49 of which were validated using the following methods: searching in supporting health-related journals/articles, searching the same metabolites in Jamu or TCM, and searching metabolites with a similar structure and activity in the PubChem database.
For future work of this research, we need to consider increasing the number of Unani formulas; by doing this, the number of plants and metabolites will increase simultaneously. We will be finding more sources of plant–metabolite relation databases, such as open-source databases, books, and journals, so that our dataset is closer to the actual conditions and acceptable also in the industry. The authors also recommend using artificially generated data in testing to support and strengthen the prediction results of model accuracy.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/life13020439/s1, Table S1: List of important metabolites for each disease class extracted from best prediction model using variable importance of Deep Neural Network.
Author Contributions
Conceptualization, S.H.W., A.K.N., S.K. and M.A.-U.-A.; methodology, A.K.N., S.H.W., S.K., M.A.-U.-A., N.O., I.B. and M.H.; dataset preparation, S.H.W., A.K.N. and M.A.-U.-A.; machine learning implementation, S.H.W., A.K.N. and M.A.-U.-A.; validation, P.G., A.K.N. and M.A.-U.-A., writing—original draft preparation, A.K.N. and M.A.-U.-A.; writing—review and editing, S.H.W., A.K.N. and M.A.-U.-A.; supervision, M.H., N.O., S.K. and M.A.-U.-A. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Ministry of Education, Culture, Sports, Science, and Technology of Japan (20K12043) and NAIST Big Data Project and was partially supported by the National Bioscience Database Center in Japan.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are available on request from the corresponding authors.
Acknowledgments
The authors would like to thank the Ministry of Education Science and Technology Japan, which has financially supported the authors to continue the study in Japan.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ekor, M. The growing use of herbal medicines: Issues relating to adverse reactions and challenges in monitoring safety. Front. Pharmacol. 2014, 4, 177. [Google Scholar] [CrossRef]
- Wijaya, S.H.; Tanaka, Y.; Altaf-Ul-Amin, M.; Morita, A.H.; Afendi, F.M.; Batubara, I.; Kanaya, S. Utilization of KNApSAcK family databases for developing herbal medicine systems. J. Comput. Aided Chem. 2006, 17, 1–7. [Google Scholar] [CrossRef]
- Hossain, S.F.; Wijaya, S.H.; Huang, M.; Batubara, I.; Kanaya, S.; Farhad, M.A.U.A. Prediction of Plant-Disease Relations Based on Unani Formulas by Network Analysis. In Proceedings of the 2018 IEEE 18th International Conference on Bioinformatics and Bioengineering (BIBE), Taicung, Taiwain, 29–31 October 2018. [Google Scholar]
- Itrat, M. Methods of health promotion and disease prevention in Unani medicine. J. Educ. Health Promot. 2020, 9, 168. [Google Scholar] [CrossRef]
- Husain, A.; Sofi, G.D.; Tajuddin, T.; Dang, R.; Kumar, N. Unani system of medicine-introduction and challenges. Med. J. Islam. World Acad. Sci. 2010, 18, 27–30. [Google Scholar]
- Rani, M.; Nayak, R.; Vyas, O.P. An ontology-based adaptive personalized e-learning system, assisted by software agents on cloud storage. Knowl.-Based Syst. 2015, 90, 33–48. [Google Scholar] [CrossRef]
- Cortes, C.; Mohri, M.; Rostamizadeh, A. Algorithms for learning kernels based on centered alignment. J. Mach. Learn. Res. 2012, 13, 795–828. [Google Scholar]
- Kang, M.J.; Kang, J.W. Intrusion detection system using deep neural network for in-vehicle network security. PLoS ONE 2016, 11, e0155781. [Google Scholar] [CrossRef] [PubMed]
- Patel, H.; Thakkar, A.; Pandya, M.; Makwana, K. Neural network with deep learning architectures. J. Inf. Optim. Sci. 2018, 39, 31–38. [Google Scholar] [CrossRef]
- Nasution, A.K.; Wijaya, S.H.; Gao, P.; Islam, R.M.; Huang, M.; Ono, N.; Altaf-Ul-Amin, M. Prediction of Potential Natural Antibiotics Plants Based on Jamu Formula Using Random Forest Classifier. Antibiotics 2022, 11, 1199. [Google Scholar] [CrossRef] [PubMed]
- Wijaya, S.H.; Batubara, I.; Nishioka, T.; Altaf-Ul-Amin, M.; Kanaya, S. Metabolomic studies of Indonesian jamu medicines: Prediction of jamu efficacy and identification of important metabolites. Mol. Inform. 2017, 36, 1700050. [Google Scholar] [CrossRef]
- Jackins, V.; Vimal, S.; Kaliappan, M.; Lee, M.Y. AI-based smart prediction of clinical disease using random forest classifier and Naive Bayes. J. Supercomput. 2021, 77, 5198–5219. [Google Scholar] [CrossRef]
- Gunn, S.R. Support vector machines for classification and regression. ISIS Tech. Rep. 1998, 1, 5–16. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation functions: Comparison of trends in practice and research for deep learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Larrosa, M.; González-Sarrías, A.; García-Conesa, M.T.; Tomás-Barberán, F.A.; Espín, J.C. Urolithins; ellagic acid-derived metabolites produced by human colonic microflora; exhibit estrogenic and antiestrogenic activities. J. Agric. Food Chem. 2006, 54, 1611–1620. [Google Scholar] [CrossRef]
- Ren, Y.; Shen, L.; Zhang, D.W.; Dai, S.J. Two new sesquiterpenoids from Solanum lyratum with cytotoxic activities. Chem. Pharm. Bull. 2009, 57, 408–410. [Google Scholar] [CrossRef]
- Pan, R.L.; Chen, D.H.; Si, J.Y.; Zhao, X.H.; Li, Z.; Cao, L. Immunosuppressive effects of new cyclolanostane triterpene diglycosides from the aerial part of Cimicifuga foetida. Arch. Pharmacal Res. 2009, 32, 185–190. [Google Scholar] [CrossRef]
- van der Krieken, S.E.; Popeijus, H.E.; Bendik, I.; Böhlendorf, B.; Konings, M.C.; Tayyeb, J.; Plat, J. Large-Scale Screening of Natural Products Transactivating Peroxisome Proliferator-Activated Receptor α Identifies 9S-Hydroxy-10E; 12Z; 15Z-Octadecatrienoic Acid and Cymarin as Potential Compounds Capable of Increasing Apolipoprotein A-I Transcription in Human Liver Cells. Lipids 2018, 53, 1021–1030. [Google Scholar] [PubMed]
- Sanders, B.; Lankenau, S.E.; Bloom, J.J.; Hathazi, D. “Research chemicals”: Tryptamine and phenethylamine use among high-risk youth. Subst. Use Misuse 2008, 43, 389–402. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Tiwari, P.; Sharma, P.; Khan, F.; Singh Sangwan, N.; Nath Mishra, B.; Singh Sangwan, R. Structure activity relationship studies of gymnemic acid analogues for antidiabetic activity targeting PPARγ. Curr. Comput.-Aided Drug Des. 2015, 11, 57–71. [Google Scholar] [CrossRef]
- Al-Taweel, A.M.; Abdel-Kader, M.S.; Fawzy, G.A.; Perveen, S.; Maher, H.M.; Al-Zoman, N.Z.; AI-Showiman, H. Isolation of flavonoids from Delonix data and determination of its rutin content using capillary electrophoresis. Pak. J. Pharm. Sci. 2015, 28, 1897–1903. [Google Scholar]
- Pawar, R.S.; Grundel, E. Overview of regulation of dietary supplements in the USA and issues of adulteration with phenethylamines (PEAs). Drug Test. Anal. 2017, 9, 500–517. [Google Scholar] [CrossRef] [PubMed]
- Mattingly, R.R.; Stephens, L.R.; Irvine, R.F.; Garrison, J.C. Effects of transformation with the v-src oncogene on inositol phosphate metabolism in rat-1 fibroblasts. D-myo-inositol 1; 4; 5; 6-tetrakisphosphate is increased in v-src-transformed rat-1 fibroblasts and can be synthesized from D-myo-inositol 1; 3; 4-trisphosphate in cytosolic extracts. J. Biol. Chem. 1991, 266, 15144–15153. [Google Scholar]
- Abdin, M.; Hamed, Y.S.; Akhtar, H.M.S.; Chen, D.; Chen, G.; Wan, P.; Zeng, X. Antioxidant and anti-inflammatory activities of target anthocyanins di-glucosides isolated from Syzygium cumini pulp by high speed counter-current chromatography. J. Food Biochem. 2020, 44, 1050–1062. [Google Scholar] [CrossRef]
- Oh, S.M.; Kim, Y.P.; Chung, K.H. Biphasic effects of kaempferol on the estrogenicity in human breast cancer cells. Arch. Pharmacal Res. 2006, 29, 354–362. [Google Scholar] [CrossRef]
- Xiao, J.; Sun, G.B.; Sun, B.; Wu, Y.; He, L.; Wang, X.; Sun, X.B. Kaempferol protects against doxorubicin-induced cardiotoxicity in vivo and in vitro. Toxicology 2012, 292, 53–62. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, Y.S.; Kwon, S.; Lee, H.S.; Seol, G.H. Linalyl acetate prevents hypertension-related ischemic injury. PLoS ONE 2018, 13, e0198082. [Google Scholar] [CrossRef]
- Wang, S.; Guan, X.; Zhong, X.; Yang, Z.; Huang, W.; Jia, B.; Cui, T. Simultaneous determination of cucurbitacin IIa and cucurbitacin IIb of Hemsleya amabilis by HPLC–MS/MS and their pharmacokinetic study in normal and indomethacin-induced rats. Biomed. Chromatogr. 2016, 30, 1632–1640. [Google Scholar] [CrossRef] [PubMed]
- Acquaviva, R.; Di Giacomo, C.; Sorrenti, V.; Galvano, F.; Santangelo, R.; Cardile, V.; Vanella, L. Antiproliferative effect of oleuropein in prostate cell lines. Int. J. Oncol. 2012, 41, 31–38. [Google Scholar]
- Acharya, N.; Acharya, S.; Shah, U.; Shah, R.; Hingorani, L. A comprehensive analysis on Symplocos racemosa Roxb.: Traditional uses; botany; phytochemistry and pharmacological activities. J. Ethnopharmacol. 2016, 181, 236–251. [Google Scholar] [CrossRef]
- Kulikova, V.; Morozova, E.; Rodionov, A.; Koval, V.; Anufrieva, N.; Revtovich, S.; Demidkina, T. Non-stereoselective decomposition of (±)-S-alk (en) yl-l-cysteine sulfoxides to antibacterial thiosulfinates catalyzed by C115H mutant methionine γ-lyase from Citrobacter freundii. Biochimie 2018, 151, 42–44. [Google Scholar] [CrossRef]
- Sakata, T.; Oda, S.; Tsunaga, Y.; Shomura, H.; Kawagishi-Kobayashi, M.; Aya, K.; Higashitani, A. Reduction of gibberellin by low temperature disrupts pollen development in rice. Plant Physiol. 2014, 164, 2011–2019. [Google Scholar] [CrossRef] [PubMed]
- Engels, B.; Heinig, U.; McElroy, C.; Meusinger, R.; Grothe, T.; Stadler, M.; Jennewein, S. Isolation of a gene cluster from Armillaria gallica for the synthesis of armillyl orsellinate–type sesquiterpenoids. Appl. Microbiol. Biotechnol. 2020, 105, 211–224. [Google Scholar] [CrossRef] [PubMed]
- McCormack, D.; McFadden, D. A review of pterostilbene antioxidant activity and disease modification. Oxidative Med. Cell. Longev. 2013, 2013, 575482. [Google Scholar] [CrossRef] [PubMed]
- Bhakta, H.K.; Park, C.H.; Yokozawa, T.; Tanaka, T.; Jung, H.A.; Choi, J.S. Potential anti-cholinesterase and β-site amyloid precursor protein cleaving enzyme 1 inhibitory activities of cornuside and gallotannins from Cornus officinalis fruits. Arch. Pharmacal Res. 2017, 40, 836–853. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wu, J.; Liu, F.; Tong, L.; Chen, Z.; Chen, J.; Huang, C. Neuroprotective effects of anthocyanins and its major component cyanidin-3-O-glucoside (C3G) in the central nervous system: An outlined review. Eur. J. Pharmacol. 2019, 858, 172500. [Google Scholar] [CrossRef] [PubMed]
- Calderón-Montano, J.M.; Burgos-Morón, E.; Orta, M.L.; Pastor, N.; Austin, C.A.; Mateos, S.; López-Lázaro, M. Alpha; beta-unsaturated lactones 2-furanone and 2-pyrone induce cellular DNA damage; formation of topoisomerase I-and II-DNA complexes and cancer cell death. Toxicol. Lett. 2013, 222, 64–71. [Google Scholar] [CrossRef]
- Xin, X.Q.; Chen, Y.; Zhang, H.; Li, Y.; Yang, M.H.; Kong, L.Y. Cytotoxic seco-cytochalasins from an endophytic Aspergillus sp. harbored in Pinellia ternata tubers. Fitoterapia 2019, 132, 53–59. [Google Scholar] [CrossRef] [PubMed]
- Ahn, J.Y.; Choi, S.E.; Jeong, M.S.; Park, K.H.; Moon, N.J.; Joo, S.S.; Seo, S.J. Effect of taxifolin glycoside on atopic dermatitis-like skin lesions in NC/Nga mice. Phytother. Res. 2010, 24, 1071–1077. [Google Scholar] [CrossRef]
- Cho, J.; Tremmel, L.; Rho, O.; Camelio, A.M.; Siegel, D.; Slaga, T.J.; DiGiovanni, J. Evaluation of pentacyclic triterpenes found in Perilla frutescens for inhibition of skin tumor promotion by 12-O-tetradecanoylphorbol-13-acetate. Oncotarget 2015, 6, 39292. [Google Scholar] [CrossRef]
- Lin, Y.; Dubinsky, W.P.; Ho, D.H.; Felix, E.; Newman, R.A. Determinants of human and mouse melanoma cell sensitivities to oleandrin. J. Exp. Ther. Oncol. 2008, 7, 195–205. [Google Scholar]
- Umekawa, T.; Yamate, T.; Amasaki, N.; Kohri, K.; Kurita, T. Osteopontin mRNA in the kidney on an experimental rat model of renal stone formation without renal failure. Urol. Int. 1995, 55, 6–10. [Google Scholar] [CrossRef] [PubMed]
- Kohri, K.E.A.; Nomura, S.; Kitamura, Y.; Nagata, T.; Yoshioka, K.; Iguchi, M.; Sinohara, H. Structure and expression of the mRNA encoding urinary stone protein (osteopontin). J. Biol. Chem. 1993, 268, 15180–15184. [Google Scholar] [CrossRef] [PubMed]
- Robitaille, L.; Mamer, O.A.; Miller, W.H., Jr.; Levine, M.; Assouline, S.; Melnychuk, D.; Hoffer, L.J. Oxalic acid excretion after intravenous ascorbic acid administration. Metabolism 2009, 58, 263–269. [Google Scholar] [CrossRef] [PubMed]
- Kropp, H.; Sundelof, J.G.; Hajdu, R.; Kahan, F.M. Metabolism of thienamycin and related carbapenem antibiotics by the renal dipeptidase; dehydropeptidase-I. Antimicrob. Agents Chemother. 1983, 22, 62–70. [Google Scholar] [CrossRef]
- Philbrick, D.J.; Bureau, D.P.; Collins, F.W.; Holub, B.J. Evidence that soyasaponin Bb retards disease progression in a murine model of polycystic kidney disease. Kidney Int. 2003, 63, 1230–1239. [Google Scholar] [CrossRef] [PubMed]
- O’Donnell, G.; Poeschl, R.; Zimhony, O.; Gunaratnam, M.; Moreira, J.B.; Neidle, S.; Gibbons, S. Bioactive pyridine-N-oxide disulfides from Allium stipitatum. J. Nat. Prod. 2009, 72, 360–365. [Google Scholar] [CrossRef]
- Stahlhut, S.G.; Siedler, S.; Malla, S.; Harrison, S.J.; Maury, J.; Neves, A.R.; Forster, J. Assembly of a novel biosynthetic pathway for production of the plant flavonoid fisetin in Escherichia coli. Metab. Eng. 2015, 31, 84–93. [Google Scholar] [CrossRef] [PubMed]
- IJAH Analytics. Available online: http://ijah.apps.cs.ipb.ac.id/#/home (accessed on 13 December 2022).







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).