

Recognition of Wheat Leaf Diseases Using Lightweight Convolutional Neural Networks against Complex Backgrounds
Abstract
:1. Introduction
- (1)
- In order to closely simulate the authentic wheat environment, a dataset of two wheat leaf diseases (wheat powdery mildew and wheat stripe rust) and healthy leaves with intricate natural backgrounds was constructed.
- (2)
- Five lightweight neural network models were fine-tuned using pre-trained weights from the ImageNet dataset. The influence of various initial learning rates on model performance during the training process was discussed.
- (3)
- The effects of six different training strategies on the five models was evaluated.
- (4)
- The optimal initial learning rate and training strategy were selected to retrain the MnasNet model, and the model’s performance advantages were confirmed by visually verifying the model results.
2. Materials and Methods
2.1. Image Acquisition
2.2. Image Preprocessing
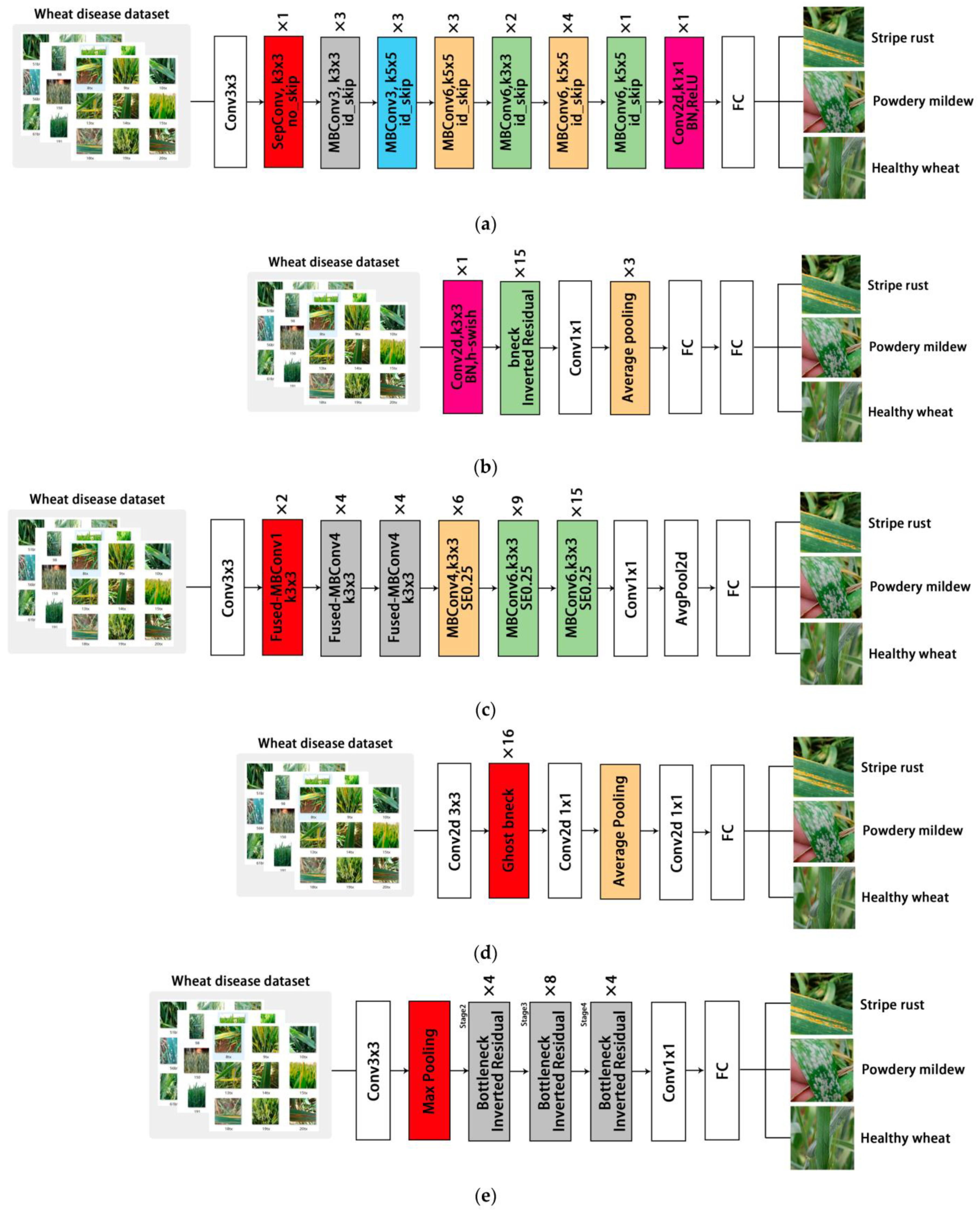
2.3. Lightweight Convolutional Neural Networks
2.3.1. MobileNetV3-Large
2.3.2. ShuffleNetV2
2.3.3. GhostNet
2.3.4. MnasNet
2.3.5. EfficientNetV2
2.4. Model Fine-Tuning
2.5. Model Optimization
2.5.1. Learning Rate
2.5.2. Optimizer
2.5.3. Warm-Up Training and Cosine Annealing
2.6. Evaluation Indicators
2.7. Experimental Environment
3. Results
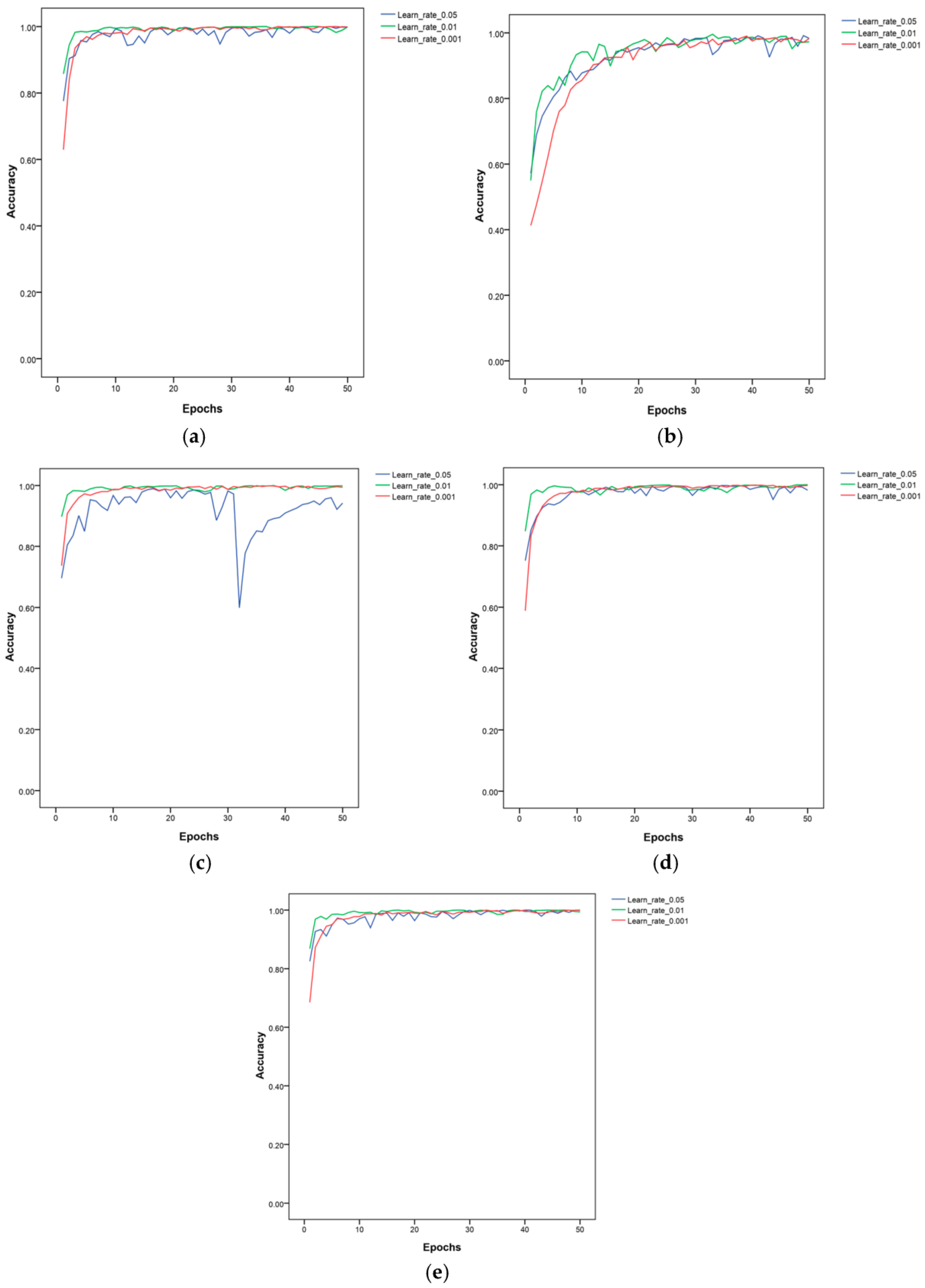
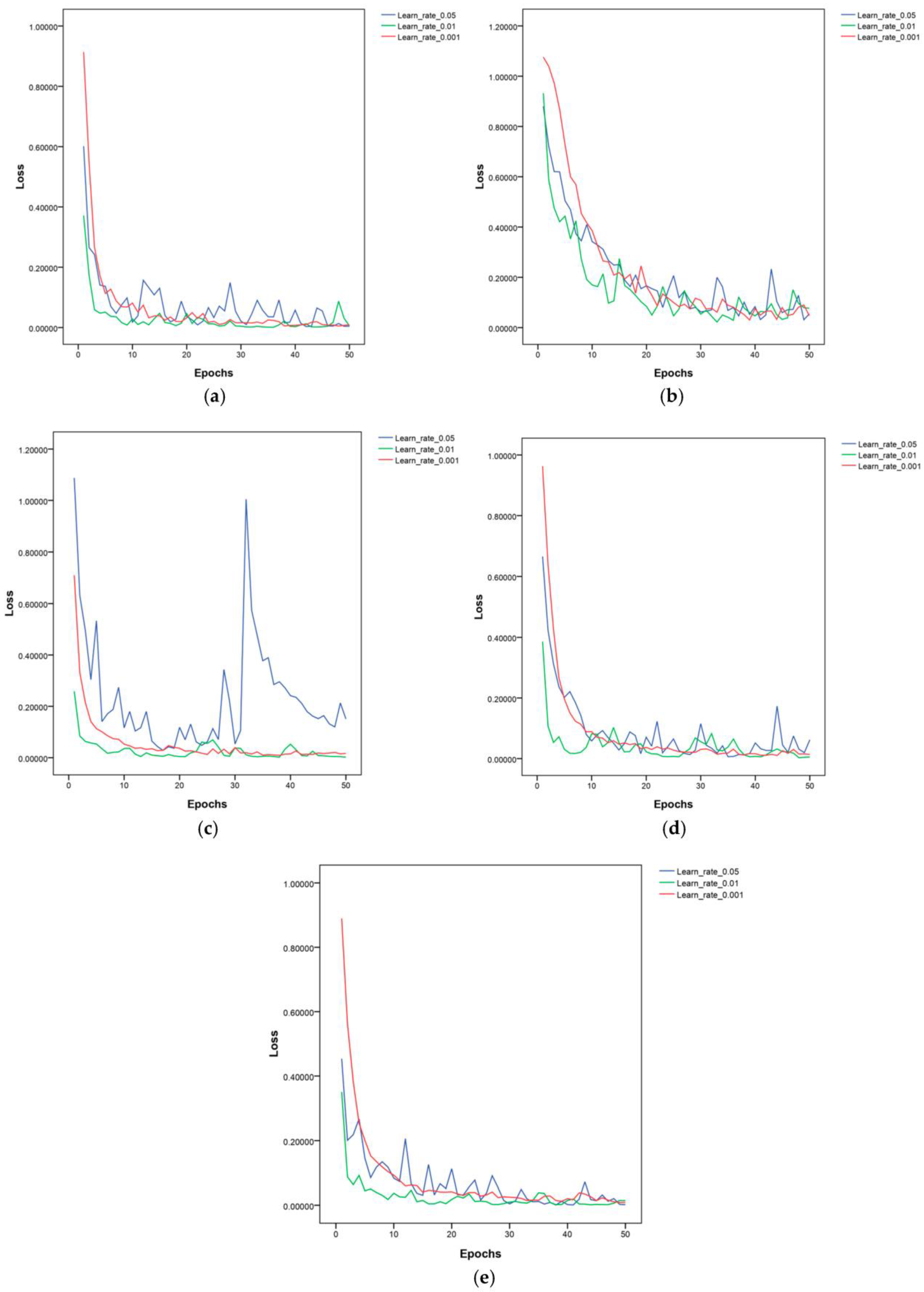
3.1. The Learning Rate’s Effect on the Performance of Lightweight Models
3.2. Impact of Using Different Training Strategies on the Lightweight Models
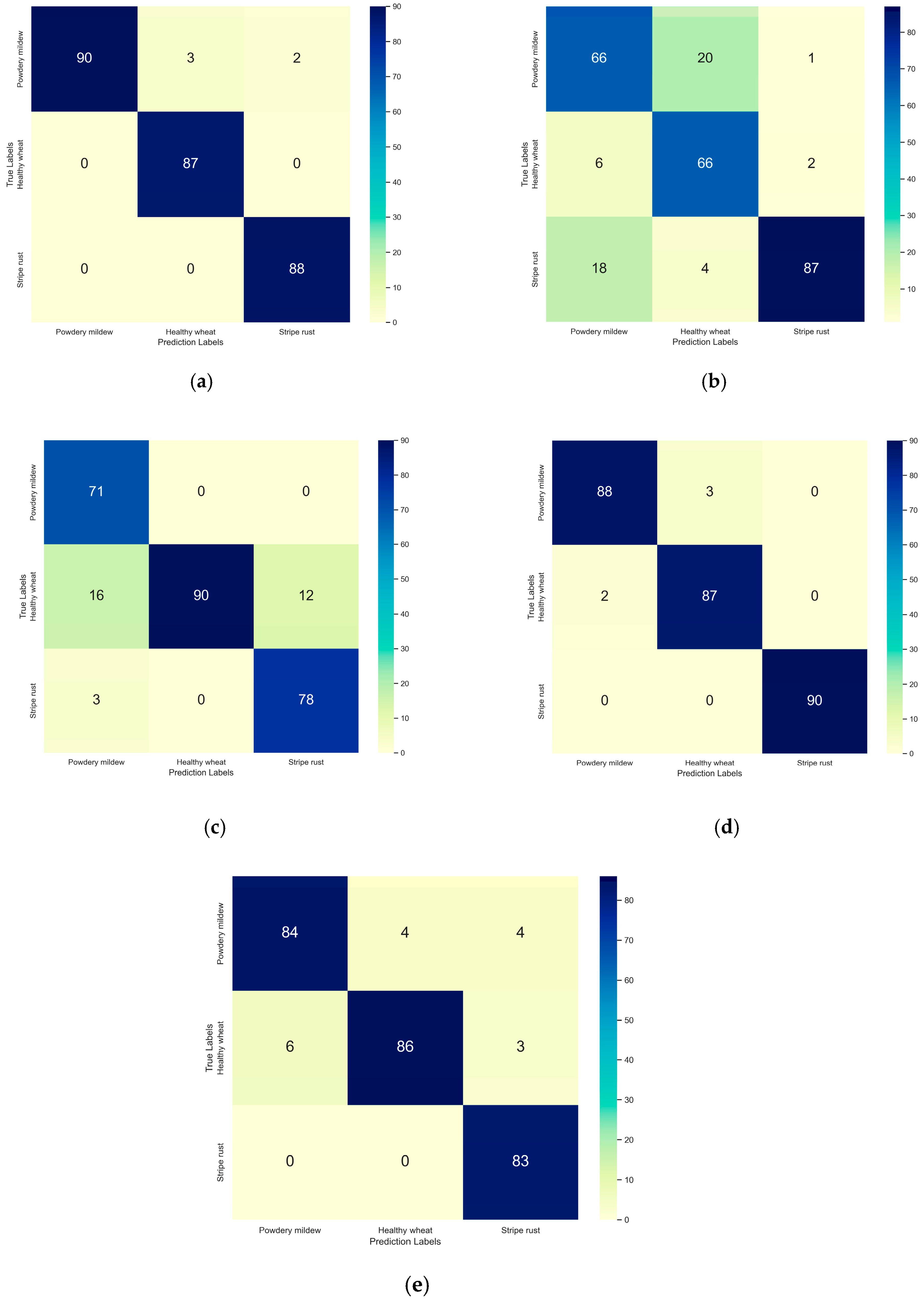
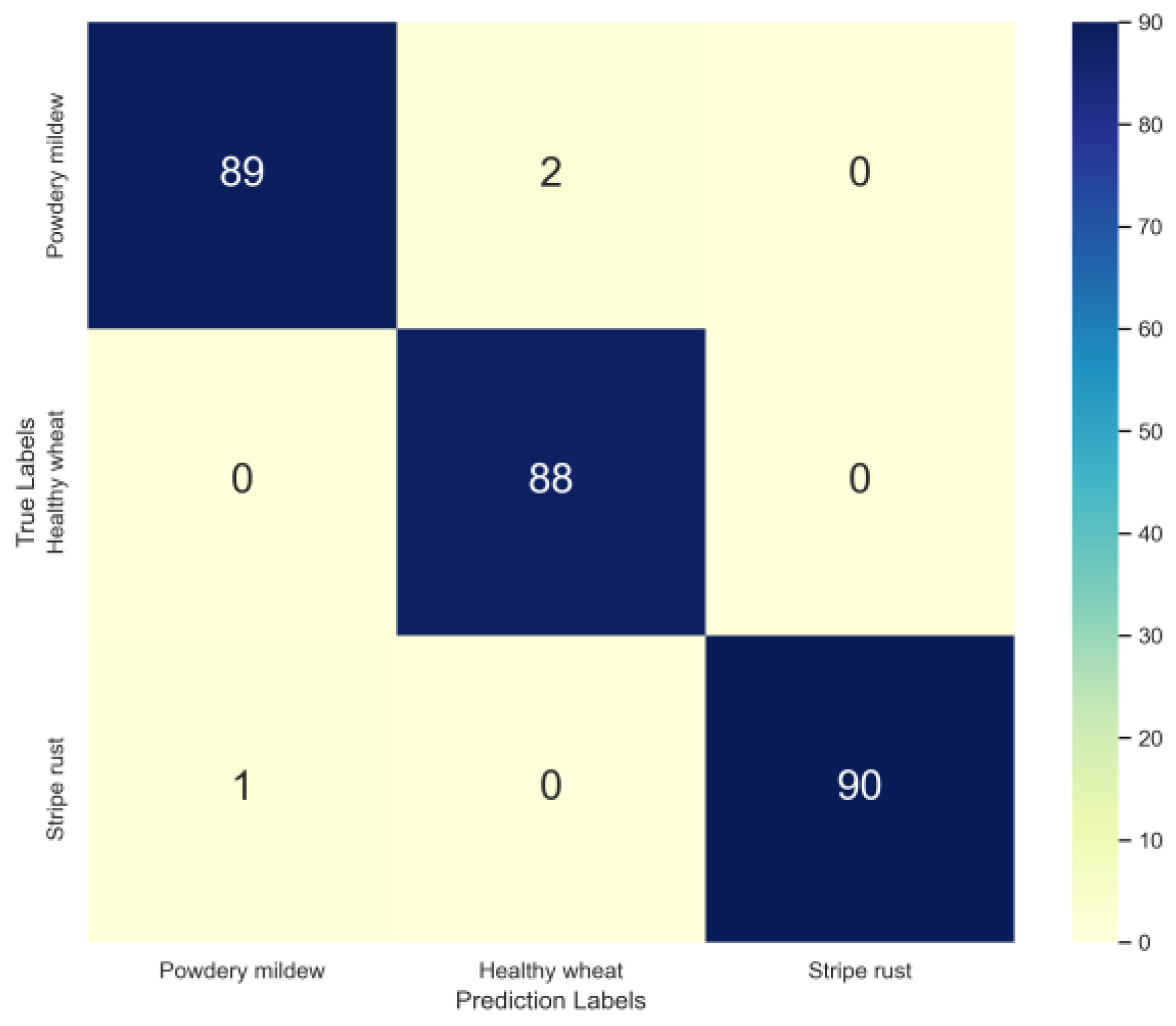
3.3. Model Testing
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Curtis, B.C.; Rajaram, S.; Gómez Macpherson, H. Bread Wheat: Improvement and Production; FAO Plant Production and Protection Series No. 30; FAO: Rome, Italy, 2002. [Google Scholar]
- Ruan, C.; Dong, Y.; Huang, W.; Huang, L.; Ye, H.; Ma, H.; Guo, A.; Sun, R. Integrating Remote Sensing and Meteorological Data to Predict Wheat Stripe Rust. Remote Sens. 2022, 14, 1221. [Google Scholar] [CrossRef]
- Kang, Y.; Zhou, M.; Merry, A.; Barry, K. Mechanisms of powdery mildew resistance of wheat—A review of molecular breeding. Plant Pathol. 2020, 69, 601–617. [Google Scholar] [CrossRef]
- Dweba, C.C.; Figlan, S.; Shimelis, H.A.; Motaung, T.E.; Sydenham, S. Fusarium head blight of wheat: Pathogenesis and control strategies. Crop Prot. 2017, 91, 114–122. [Google Scholar] [CrossRef]
- Lins, E.A.; Rodriguez, J.P.M.; Scoloski, S.I.; Pivato, J.; Lima, M.B.; Fernandes, J.M.C.; da Silva Pereira, P.R.V.; Lau, D.; Rieder, R. A method for counting and classifying aphids using computer vision. Comput. Electron. Agric. 2020, 169, 105200. [Google Scholar] [CrossRef]
- Jongman, M.; Carmichael, P.C.; Bill, M. Technological Advances in Phytopathogen Detection and Metagenome Profiling Techniques. Curr. Microbiol. 2020, 77, 675–681. [Google Scholar] [CrossRef]
- Shahi, T.B.; Xu, C.-Y.; Neupane, A.; Guo, W. Recent Advances in Crop Disease Detection Using UAV and Deep Learning Techniques. Remote Sens. 2023, 15, 2450. [Google Scholar] [CrossRef]
- Shahi, T.B.; Sitaula, C.; Neupane, A.; Guo, W. Fruit classification using attention-based MobileNetV2 for industrial applications. PLoS ONE 2022, 17, e0264586. [Google Scholar] [CrossRef]
- Thomas, G.; Balocco, S.; Mann, D.; Simundsson, A.; Khorasani, N. Intelligent Agricultural Machinery Using Deep Learning. IEEE Instrum. Meas. Mag. 2021, 24, 93–100. [Google Scholar] [CrossRef]
- Attri, I.; Awasthi, L.K.; Sharma, T.P.; Rathee, P. A review of deep learning techniques used in agriculture. Ecol. Inform. 2023, 77, 102217. [Google Scholar] [CrossRef]
- Dong, M.; Mu, S.; Shi, A.; Mu, W.; Sun, W. Novel method for identifying wheat leaf disease images based on differential amplification convolutional neural network. Int. J. Agric. Biol. Eng. 2020, 13, 205–210. [Google Scholar] [CrossRef]
- Genaev, M.A.; Skolotneva, E.S.; Gultyaeva, E.I.; Orlova, E.A. Image-Based Wheat Fungi Diseases Identification by Deep Learning. Plants 2021, 10, 1500. [Google Scholar] [CrossRef]
- Pan, Q.; Gao, M.; Wu, P.; Yan, J.; Li, S. A Deep-Learning-Based Approach for Wheat Yellow Rust Disease Recognition from Unmanned Aerial Vehicle Images. Sensors 2021, 21, 6540. [Google Scholar] [CrossRef] [PubMed]
- Goyal, L.; Sharma, C.M.; Singh, A.; Singh, P.K. Leaf and spike wheat disease detection & classification using an improved deep convolutional architecture. Inform. Med. Unlocked 2021, 25, 100642. [Google Scholar]
- Jiang, J.; Liu, H.; Zhao, C.; He, C.; Ma, J.; Cheng, T.; Zhu, Y.; Cao, W.; Yao, X. Evaluation of Diverse Convolutional Neural Networks and Training Strategies for Wheat Leaf Disease Identification with Field-Acquired Photographs. Remote Sens. 2022, 14, 3446. [Google Scholar] [CrossRef]
- Pan, Q.; Gao, M.; Wu, P.; Yan, J.; AbdelRahman, M.A.E. Image Classification of Wheat Rust Based on Ensemble Learning. Sensors 2022, 22, 6047. [Google Scholar] [CrossRef]
- Nigam, S.; Jain, R.; Marwaha, S.; Arora, A.; Haque, M.A.; Dheeraj, A.; Singh, V.K. Deep transfer learning model for disease identification in wheat crop. Ecol. Inform. 2023, 75, 102068. [Google Scholar] [CrossRef]
- Yoshua, B. Practical recommendations for gradient-based training of deep architectures. arXiv 2012, arXiv:1206.5533. [Google Scholar]
- Dong, X.; Tan, T.; Potter, M.; Tsai, Y.-C.; Kumar, G.; Saripalli, V.R.; Trafalis, T. To raise or not to raise: The autonomous learning rate question. Ann. Math. Artif. Intell. 2023. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; pp. 13029–13038. [Google Scholar]
- Wang, C.-Y.; Mark Liao, H.-Y.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. Cspnet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2020, arXiv:1907.11692. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. In Proceedings of the 5th International Conference on Learning Representations, ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- She, D.; Jia, M. Wear indicator construction of rolling bearings based on multi-channel deep convolutional neural network with exponentially decaying learning rate. Measurement 2019, 135, 368–375. [Google Scholar] [CrossRef]
- Goyal, P.; Dollár, P.; Girshick, R.B.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, large minibatch SGD: Training imagenet in 1 h. CoRR 2017, arXiv:1706.02677. [Google Scholar]
- Coleman, C.A.; Narayanan, D.; Kang, D.; Zhao, T.; Zhang, J.; Nardi, L.; Bailis, P.; Olukotun, K.; Re, C.; Zaharia, M. DAWNBench: An Endto-End Deep Learning Benchmark and Competition. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wang, Y.; Zheng, C.; Dong, W.; Gao, H. An efficient identification model of corn diseases based onimproved convolutional neural network. J. Anhui Sci. Technol. Univ. 2023, 38, 2444–2460. [Google Scholar]
- Fan, K.; Gu, S.; Wang, X.; Zhao, M.; Wang, G.; Li, Z. LF-MRI-based detection and classification of ginkgo embryos. Trans. CSAE 2022, 38, 293–301. [Google Scholar]
- Fan, X.; Xu, Y.; Zhou, J.; Li, Z.; Peng, X.; Wang, X. Detection system for grape leaf diseases based on transfer learning and updated CNN. Trans. CSAE 2021, 37, 151–159. [Google Scholar]
- Liu, Y.; Zhang, J. Research advances in deep neural networks learning rate strategies. Control. Decis. 2023, 38, 2444–2460. [Google Scholar]
- Iiduka, H. Appropriate Learning Rates of Adaptive Learning Rate Optimization Algorithms for Training Deep Neural Networks. IEEE Trans. Cybern. 2022, 52, 13250–13261. [Google Scholar] [CrossRef]
- Benkendorf, D.J.; Hawkins, C.P. Effects of sample size and network depth on a deep learning approach to species distribution modeling. Ecol. Inform. 2020, 60, 101137. [Google Scholar] [CrossRef]
- Nguyen, Q.H.; Ly, H.-B.; Ho, L.S.; Al-Ansari, N.; Le, H.V.; Tran, V.Q.; Prakash, I.; Pham, B.T. Influence of Data Splitting on Performance of Machine Learning Models in Prediction of Shear Strength of Soil. Math. Probl. Eng. 2021, 2021, 4832864. [Google Scholar] [CrossRef]
- Howard, A.G.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 15–20 June 2019; pp. 1314–1324. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. arXiv 2018, arXiv:abs/1807.11164. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA; Seattle, WA, USA, 13–19 June 2019; pp. 1577–1586. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 15–20 June 2019; pp. 2815–2823. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:abs/2104.00298. [Google Scholar]
- Fagbohungbe, O.; Qian, L. Impact of Learning Rate on Noise Resistant Property of Deep Learning Models. arXiv 2022, arXiv:abs/2205.07856. [Google Scholar]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2015; pp. 464–472. [Google Scholar]
- Li, X.-L. Preconditioned Stochastic Gradient Descent. IEEE Trans. Neural Netw. Learn. Syst. 2015, 29, 1454–1466. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. CoRR 2014, arXiv:abs/1412.6980. [Google Scholar]
- Shen, L.; Chen, C.; Zou, F.; Jie, Z.; Sun, J.; Liu, W. A Unified Analysis of AdaGrad with Weighted Aggregation and Momentum Acceleration. IEEE Trans. Neural Netw. Learn. Syst. 2018. [Google Scholar] [CrossRef]
- Zou, F.; Shen, L.; Jie, Z.; Zhang, W.; Liu, W. A Sufficient Condition for Convergences of Adam and RMSProp. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA; Seattle, WA, USA, 13–19 June 2019; pp. 11119–11127. [Google Scholar]
- Zhuang, J.; Tang, T.M.; Ding, Y.; Tatikonda, S.C.; Dvornek, N.C.; Papademetris, X.; Duncan, J.S. AdaBelief Optimizer: Adapting Stepsizes by the Belief in Observed Gradients. arXiv 2020, arXiv:abs/2010.07468. [Google Scholar]
- Abramson, D.; Krishnamoorthy, M.; Dang, H. Simulated Annealing Cooling Schedules for the School Timetabling Problem. Asia-Pac. J. Oper. Res. 1998, 16, 1–22. [Google Scholar]
- Shafiq, M.; Gu, Z. Deep Residual Learning for Image Recognition: A Survey. Appl. Sci. 2022, 12, 8972. [Google Scholar] [CrossRef]
- An, Q.; Wu, S.; Shi, R.; Wang, H.; Yu, J.; Li, Z. Intelligent Detection of Hazardous Goods Vehicles and Determination of Risk Grade Based on Deep Learning. Sensors 2022, 22, 7123. [Google Scholar] [CrossRef]
- Shahrabadi, S.; Gonzalez, D.; Sousa, N.; Adão, T.; Peres, E.; Magalhães, L. Benchmarking Deep Learning models and hyperparameters for Bridge Defects Classification. Procedia Comput. Sci. 2023, 219, 345–353. [Google Scholar] [CrossRef]
- Vasudevan, S. Mutual Information Based Learning Rate Decay for Stochastic Gradient Descent Training of Deep Neural Networks. Entropy 2020, 22, 560. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Dou, Y.; Sun, T.; Qiao, P.; Wen, D. An automatic learning rate decay strategy for stochastic gradient descent optimization methods in neural networks. Int. J. Intell. Syst. 2022, 37, 7334–7355. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Training Set | Validation Set | Test Set |
|---|---|---|---|
| Stripe rust | 630 | 180 | 90 |
| Powdery mildew | 630 | 180 | 90 |
| Healthy wheat | 630 | 180 | 90 |
| Total samples | 1890 | 540 | 270 |
| Models | Layer | Original Parameters (M) | Fine-Tuned Parameters (M) |
|---|---|---|---|
| MobileNetV3-large | 191 | 20.91 | 16.04 |
| ShuffleNetV2_x2.0 | 167 | 28.21 | 20.41 |
| GhostNetV1 | 282 | 19.77 | 14.89 |
| EfficientNetV2-s | 550 | 81.86 | 76.98 |
| MnasNet1_3 | 157 | 23.96 | 19.09 |
| Models | Learning Rate | Train Accuracy (%) | Average Train Accuracy (%) | Test Accuracy (%) | Average Test Accuracy (%) | Test Time (s) |
|---|---|---|---|---|---|---|
| MobileNetV3-large | 0.05 | 99.94 | 99.39 | 92.96 | 87.52 | 14.75 |
| 98.94 | 91.85 | |||||
| 99.31 | 77.77 | |||||
| 0.01 | 100.00 | 100.00 | 93.70 | 85.31 | 15.01 | |
| 100.00 | 89.25 | |||||
| 100.00 | 73.00 | |||||
| 0.001 | 99.94 | 99.92 | 87.77 | 87.89 | 15.52 | |
| 99.89 | 88.51 | |||||
| 99.94 | 87.40 | |||||
| ShuffleNetV2_x2.0 | 0.05 | 99.94 | 99.92 | 77.77 | 77.88 | 15.68 |
| 100 | 85.15 | |||||
| 99.84 | 70.74 | |||||
| 0.01 | 100.00 | 99.96 | 93.70 | 91.48 | 15.92 | |
| 99.89 | 93.33 | |||||
| 100.00 | 87.04 | |||||
| 0.001 | 100.00 | 100.00 | 84.07 | 80.98 | 15.33 | |
| 100.00 | 72.96 | |||||
| 100.00 | 85.92 | |||||
| GhostNetV1 | 0.05 | 99.15 | 98.89 | 71.85 | 74.19 | 15.43 |
| 99.15 | 81.11 | |||||
| 98.37 | 69.62 | |||||
| 0.01 | 99.57 | 99.53 | 67.03 | 66.91 | 15.26 | |
| 99.73 | 73.33 | |||||
| 99.31 | 60.37 | |||||
| 0.001 | 98.84 | 98.89 | 65.92 | 62.96 | 15.93 | |
| 98.84 | 60.74 | |||||
| 99.00 | 62.22 | |||||
| EfficientNetV2-s | 0.05 | 100.00 | 100.00 | 95.18 | 94.19 | 21.01 |
| 100.00 | 94.07 | |||||
| 100.00 | 93.33 | |||||
| 0.01 | 100.00 | 100.00 | 92.59 | 94.93 | 21.68 | |
| 100.00 | 95.18 | |||||
| 100.00 | 97.03 | |||||
| 0.001 | 100.00 | 99.94 | 97.77 | 97.52 | 21.36 | |
| 99.89 | 98.14 | |||||
| 99.94 | 96.66 | |||||
| MnasNet1_3 | 0.05 | 99.84 | 99.78 | 55.18 | 62.34 | 15.39 |
| 99.78 | 63.33 | |||||
| 99.73 | 68.51 | |||||
| 0.01 | 99.89 | 99.87 | 87.03 | 78.26 | 15.54 | |
| 100 | 83.70 | |||||
| 100 | 64.07 | |||||
| 0.001 | 99.89 | 99.85 | 97.77 | 97.64 | 15.01 | |
| 99.84 | 98.14 | |||||
| 99.84 | 97.03 |
| Model | Training Strategy | Test Accuracy | Average Test Accuracy |
|---|---|---|---|
| MobileNetV3 | SGD | 87.77 | 87.89 |
| 88.51 | |||
| 87.40 | |||
| SGD + StepLR | 86.30 | 89.13 | |
| 85.93 | |||
| 91.85 | |||
| Warm-up + cosine annealing + SGD | 86.30 | 86.79 | |
| 85.93 | |||
| 88.15 | |||
| Adam | 88.52 | 85.06 | |
| 80.00 | |||
| 86.67 | |||
| Adam + StepLR | 85.19 | 87.53 | |
| 90.74 | |||
| 86.67 | |||
| Warm-up + cosine annealing + Adam | 85.93 | 87.53 | |
| 87.41 | |||
| 89.26 | |||
| MnasNet | SGD | 87.77 | 97.64 |
| 88.51 | |||
| 87.40 | |||
| SGD + StepLR | 98.15 | 98.65 | |
| 98.89 | |||
| 98.89 | |||
| Warm-up + cosine annealing + SGD | 87.78 | 94.19 | |
| 98.15 | |||
| 96.67 | |||
| Adam | 60.00 | 67.03 | |
| 61.11 | |||
| 80.00 | |||
| Adam + StepLR | 96.30 | 95.67 | |
| 95.19 | |||
| 95.56 | |||
| Warm-up + cosine annealing + Adam | 79.26 | 85.80 | |
| 86.30 | |||
| 91.85 | |||
| EfficientNetV2 | SGD | 97.77 | 97.52 |
| 98.14 | |||
| 96.66 | |||
| SGD + StepLR | 95.93 | 97.04 | |
| 97.41 | |||
| 97.78 | |||
| Warm-up + cosine annealing + SGD | 91.11 | 94.20 | |
| 96.67 | |||
| 94.81 | |||
| Adam | 90.37 | 85.06 | |
| 85.56 | |||
| 79.26 | |||
| Adam + StepLR | 91.11 | 84.69 | |
| 83.33 | |||
| 79.63 | |||
| Warm-up + cosine annealing + Adam | 81.11 | 84.07 | |
| 87.78 | |||
| 83.33 | |||
| GhostNet | SGD | 71.85 | 74.19 |
| 81.11 | |||
| 69.62 | |||
| SGD + StepLR | 61.48 | 70.99 | |
| 73.33 | |||
| 78.15 | |||
| Warm-up + cosine annealing + SGD | 71.48 | 62.84 | |
| 61.11 | |||
| 55.93 | |||
| Adam | 56.67 | 48.89 | |
| 32.59 | |||
| 57.41 | |||
| Adam + StepLR | 33.70 | 31.98 | |
| 27.41 | |||
| 34.81 | |||
| Warm-up + cosine annealing + Adam | 49.26 | 44.07 | |
| 33.33 | |||
| 49.63 | |||
| ShuffleNetV2 | SGD | 93.70 | 91.48 |
| 93.33 | |||
| 87.40 | |||
| SGD + StepLR | 81.11 | 79.51 | |
| 72.96 | |||
| 84.44 | |||
| Warm-up + cosine annealing + SGD | 92.96 | 88.52 | |
| 86.67 | |||
| 85.93 | |||
| Adam | 78.15 | 69.88 | |
| 61.11 | |||
| 70.37 | |||
| Adam + StepLR | 84.07 | 77.04 | |
| 78.89 | |||
| 68.15 | |||
| Warm-up + cosine annealing + Adam | 65.93 | 64.69 | |
| 58.52 | |||
| 69.63 |
| Diseases of Wheat | Accuracy (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| Powdery mildew | 98.89 | 97.80 | 98.89 | 98.34 |
| Healthy wheat | 99.28 | 100.00 | 97.78 | 98.88 |
| Stripe rust | 99.63 | 98.90 | 100.00 | 99.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, X.; Zeng, M.; Chen, J.; Maimaiti, M.; Liu, Q. Recognition of Wheat Leaf Diseases Using Lightweight Convolutional Neural Networks against Complex Backgrounds. Life 2023, 13, 2125. https://doi.org/10.3390/life13112125
Wen X, Zeng M, Chen J, Maimaiti M, Liu Q. Recognition of Wheat Leaf Diseases Using Lightweight Convolutional Neural Networks against Complex Backgrounds. Life. 2023; 13(11):2125. https://doi.org/10.3390/life13112125
Chicago/Turabian StyleWen, Xiaojie, Minghao Zeng, Jing Chen, Muzaipaer Maimaiti, and Qi Liu. 2023. "Recognition of Wheat Leaf Diseases Using Lightweight Convolutional Neural Networks against Complex Backgrounds" Life 13, no. 11: 2125. https://doi.org/10.3390/life13112125
APA StyleWen, X., Zeng, M., Chen, J., Maimaiti, M., & Liu, Q. (2023). Recognition of Wheat Leaf Diseases Using Lightweight Convolutional Neural Networks against Complex Backgrounds. Life, 13(11), 2125. https://doi.org/10.3390/life13112125