
Longitudinal Cluster Analysis of Hemodialysis Patients with COVID-19 in the Pre-Vaccination Era

 ,
,  , , , , , and
, , , , , and
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Patients
2.2. Data Collection
2.3. Cytokine Determinations
2.4. Immunofluorescence Analyses
2.5. General Statistical Methods
2.6. Statistical Methods for Clustering Analysis
3. Results
3.1. Longitudinal Clustering of the Derivation Cohort
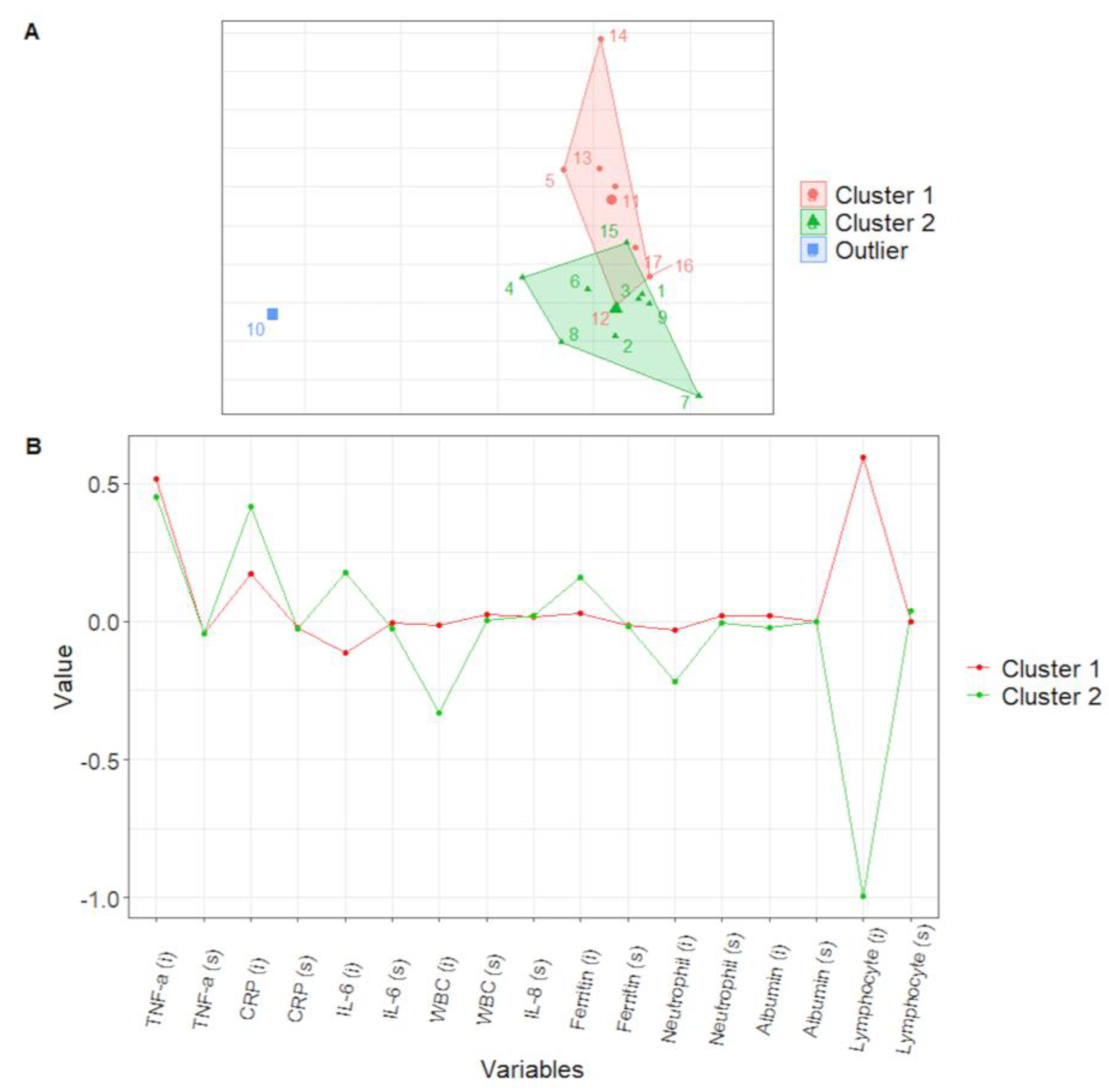
3.2. Validation Cohort
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wiersinga, W.J.; Rhodes, A.; Cheng, A.C.; Peacock, S.J.; Prescott, H.C. Pathophysiology, Transmission, Diagnosis, and Treatment of Coronavirus Disease 2019 (COVID-19): A Review. JAMA 2020, 324, 782–793. [Google Scholar] [CrossRef] [PubMed]
- Lusczek, E.R.; Ingraham, N.E.; Karam, B.S.; Proper, J.; Siegel, L.; Helgeson, E.S.; Lotfi-Emran, S.; Zolfaghari, E.J.; Jones, E.; Usher, M.G.; et al. Characterizing COVID-19 clinical phenotypes and associated comorbidities and complication profiles. PLoS ONE 2021, 16, e024895. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.M.; Weiner, D.E.; Aweh, G.; Miskulin, D.C.; Manley, H.J.; Stewart, C.; Ladik, V.; Hosford, J.; Lacson, E.C.; Johnson, D.S.; et al. COVID-19 Among US Dialysis Patients: Risk Factors and Outcomes from a National Dialysis Provider. Am. J. Kidney Dis. 2021, 77, 748–756.e1. [Google Scholar] [CrossRef] [PubMed]
- Lano, G.; Braconnier, A.; Bataille, S.; Cavaille, G.; Moussi-Frances, J.; Gondouin, B.; Bindi, P.; Nakhla, M.; Mansour, J.; Halin, P.; et al. Risk factors for severity of COVID-19 in chronic dialysis patients from a multicentre French cohort. Clin. Kidney J. 2020, 13, 878–888. [Google Scholar] [CrossRef]
- Sinharay, S. International Encyclopedia of Education, 3rd ed.; Elsevier Science: Amsterdam, The Netherlands, 2010. [Google Scholar]
- Mahnke, Y.D.; Brodie, T.M.; Sallusto, F.; Roederer, M.; Lugli, E. The who’s who of T-cell differentiation: Human memory T-cell subsets. Eur. J. Immunol. 2013, 43, 2797–2809. [Google Scholar] [CrossRef]
- Fenoglio, D.; Dentone, C.; Parodi, A.; Di Biagio, A.; Bozzano, F.; Vena, A.; Fabbi, M.; Ferrera, F.; Altosole, T.; Bruzzone, B.; et al. Characterization of T lymphocytes in severe COVID-19 patients. J. Med. Virol. 2021, 93, 5608–5613. [Google Scholar] [CrossRef]
- Rey, D.; Neuhäuser, M. Wilcoxon-Signed-Rank Test. In International Encyclopedia of Statistical Science; Lovric, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Fox, J. Applied Regression Analysis and Generalized Linear Models, 2nd ed.; Sage Publications: Thousand Oaks, CA, USA, 2008. [Google Scholar]
- Galecki, A.; Burzykowski, T. Linear Mixed-Effects Models Using R; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Jin, X.; Han, J. K-Means Clustering. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2011. [Google Scholar]
- Noor, F.M.; Islam, M.M. Prevalence and Associated Risk Factors of Mortality Among COVID-19 Patients: A Meta-Analysis. J. Community Health 2020, 45, 1270–1282. [Google Scholar] [CrossRef]
- Li, J.; Li, M.; Zheng, S.; Li, M.; Zhang, M.; Sun, M.; Li, X.; Deng, A.; Cai, Y.; Zhang, H. Plasma albumin levels predict risk for nonsurvivors in critically ill patients with COVID-19. Biomark. Med. 2020, 14, 827–837. [Google Scholar] [CrossRef]
- Thijssen, S.; Wystrychowski, G.; Usvyat, L.; Kotanko, P.; Levin, N.W. Determinants of serum albumin concentration analyzed in a large cohort of patients on maintenance hemodialysis. J. Ren. Nutr. 2007, 17, 70–74. [Google Scholar] [CrossRef]
- San-Cristobal, R.; Martín-Hernández, R.; Ramos-Lopez, O.; Martinez-Urbistondo, D.; Micó, V.; Colmenarejo, G.; Villares Fernandez, P.; Daimiel, L.; Martínez, J.A. Longwise Cluster Analysis for the Prediction of COVID-19 Severity within 72 h of Admission: COVID-DATA-SAVE-LIFES Cohort. J. Clin. Med. 2022, 11, 3327. [Google Scholar] [CrossRef] [PubMed]
- Han, L.; Shen, P.; Yan, J.; Huang, Y.; Ba, X.; Lin, W.; Wang, H.; Huang, Y.; Qin, K.; Wang, Y.; et al. Exploring the Clinical Characteristics of COVID-19 Clusters Identified Using Factor Analysis of Mixed Data-Based Cluster Analysis. Front. Med. 2021, 8, 644724. [Google Scholar] [CrossRef]
- Bergamaschi, L.; Mescia, F.; Turner, L.; Hanson, A.L.; Kotagiri, P.; Dunmore, B.J.; Ruffieux, H.; De Sa, A.; Huhn, O.; Morgan, M.D.; et al. Longitudinal analysis reveals that delayed bystander CD8+ T cell activation and early immune pathology distinguish severe COVID-19 from mild disease. Immunity 2021, 54, 1257–1275.e8. [Google Scholar] [CrossRef] [PubMed]
- Kenny, G.; McCann, K.; O’Brien, C.; Savinelli, S.; Tinago, W.; Yousif, O.; Lambert, J.S.; O’Broin, C.; Feeney, E.R.; De Barra, E.; et al. Identification of Distinct Long COVID Clinical Phenotypes Through Cluster Analysis of Self-Reported Symptoms. Open Forum Infect. Dis. 2022, 9, ofac060. [Google Scholar] [CrossRef] [PubMed]
- Nicholson, C.; Beattie, L.; Beattie, M.; Razzaghi, T.; Chen, S. A machine learning and clustering-based approach for county-level COVID-19 analysis. PLoS ONE 2022, 17, e0267558. [Google Scholar] [CrossRef] [PubMed]
- Pérez-Ortega, J.; Almanza-Ortega, N.N.; Torres-Poveda, K.; Martínez-González, G.; Zavala-Díaz, J.C.; Pazos-Rangel, R. Application of Data Science for Cluster Analysis of COVID-19 Mortality According to Sociodemographic Factors at Municipal Level in Mexico. Mathematics 2022, 10, 2167. [Google Scholar] [CrossRef]
- Sadeghi, B.; Cheung, R.C.Y.; Hanbury, M. Using hierarchical clustering analysis to evaluate COVID-19 pandemic preparedness and performance in 180 countries in 2020. BMJ Open 2021, 11, e049844. [Google Scholar] [CrossRef]
- Betjes, M.G.; Meijers, R.W.; Litjens, N.H. Loss of renal function causes premature aging of the immune system. Blood Purif. 2013, 36, 173–178. [Google Scholar] [CrossRef]
- Sepe, V.; Gregorini, M.; Rampino, T.; Esposito, P.; Coppo, R.; Galli, F.; Libetta, C. Vitamin e-loaded membrane dialyzers reduce hemodialysis inflammaging. BMC Nephrol. 2019, 20, 412. [Google Scholar] [CrossRef]
- El Karoui, K.; De Vriese, A.S. COVID-19 in dialysis: Clinical impact, immune response, prevention, and treatment. Kidney Int. 2022, 101, 883–894. [Google Scholar] [CrossRef]
- Goffin, E.; Candellier, A.; Vart, P.; Noordzij, M.; Arnol, M.; Covic, A.; Lentini, P.; Malik, S.; Reichert, L.J.; Sever, M.S.; et al. COVID-19-related mortality in kidney transplant and haemodialysis patients, a comparative, prospective registry-based study. Nephrol. Dial. Transplant. 2021, 36, 2094–2105. [Google Scholar] [CrossRef]
- Esposito, P.; Picciotto, D.; Cappadona, F.; Russo, E.; Falqui, V.; Conti, N.E.; Parodi, A.; Mallia, L.; Cavagnaro, S.; Battaglia, Y.; et al. The Evolving Scenario of COVID-19 in Hemodialysis Patients. Int. J. Environ. Res. Public Health 2022, 19, 10836. [Google Scholar] [CrossRef] [PubMed]
- Loftus, T.J.; Shickel, B.; Balch, J.A.; Tighe, P.J.; Abbott, K.L.; Fazzone, B.; Anderson, E.M.; Rozowsky, J.; Ozrazgat-Baslanti, T.; Ren, Y.; et al. Phenotype clustering in health care: A narrative review for clinicians. Front. Artif. Intell. 2022, 5, 842306. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
| Cluster 1 | Cluster 2 | p | |
|---|---|---|---|
| N | 7 | 8 * | |
| Age, years | 68.1 ± 15.6 | 64.4 ± 10.7 | 0.7 |
| Sex, M/F | 1/6 | 7/1 | 0.01 |
| Dialysis vintage, months | 32.6 ± 19.6 | 72.8 ± 56.3 | 0.1 |
| WBC, ×109/L | 5.4 ± 1.3 | 4.4 ± 1.5 | 0.33 |
| Lymphocytes, ×109/L | 1.1 ± 0.5 | 0.4 ± 0.2 | 0.012 |
| Neutrophils, ×109/L | 3.8 ± 1.4 | 3.5 ± 1.5 | 1 |
| Lymphocytes, (% WBC) | 21.0 ± 7.5 | 11.8 ± 4.9 | 0.03 |
| Neutrophils, (% WBC) | 66.6 ± 13.8 | 78.6 ± 6.2 | 0.06 |
| CD8 + TSCM/CD8+ | 0.6 ± 0.4 | 2.3 ± 1.7 | 0.038 |
| Albumin, g/L | 34.6 ± 3.5 | 33.1 ± 4.2 | 0.6 |
| LDH, U/L | 201.2 ± 42.3 | 323.0 ± 88.8 | 0.012 |
| Procalcitonin, ng/ml | 0.9 ± 0.5 | 3.3 ± 3.6 | 0.02 |
| CRP, mg/L | 22.2 ± 16.3 | 72.6 ± 44.1 | 0.017 |
| All Patients | Cluster 1 | Cluster 2 | p Cluster 1 vs. 2 | |
|---|---|---|---|---|
| N | 30 | 16 | 14 | |
| Age, years | 73.3 ± 16.3 | 75.7 ± 15.5 | 70.4 ± 17.3 | 0.4 |
| Sex, M/F (M%) | 16/14 (53) | 6/10 (37) | 10/4 (71) | 0.08 |
| Dialysis vintage, months | 36 (14–71) | 43 (28–75) | 27 (7–64) | 0.1 |
| WBC, ×109/L | 6.5 ± 4.9 | 5.4 ±5.1 | 7.7± 4.6 | 0.02 |
| Lymphocytes, ×109/L | 0.7 ± 0.3 | 0.9± 0.3 | 0.6 ± 0.3 | 0.03 |
| Neutrophils, ×109/L | 5.0 ± 4.3 | 3.6 ± 3.9 | 6.6± 4.4 | 0.01 |
| Lymphocytes, (% WBC) | 15.4 ± 9.5 | 21.2 ± 9.5 | 9.1 ± 4.3 | <0.0001 |
| Neutrophils, (% WBC) | 70.1 ± 19.7 | 59.3 ± 20.8 | 82.5 ± 6.9 | <0.0001 |
| LDH, U/L | 234.0 ± 72.1 | 207.9 ± 49.1 | 260.1 ± 83.4 | 0.09 |
| Albumin, g/L | 33.0 ±4 2 | 33.9 ± 2 | 32.8 ± 2.2 | 0.3 |
| Procalcitonin, ng/ml | 1.4 (0.6–4.6) | 0.8 (0.4–1.6) | 3.6 (1.2–9.5) | 0.07 |
| CRP, mg/L | 14.7 (4.0–39.0) | 8.0 (2.8–20.1) | 32.6 (12.1–50.1) | 0.01 |
| Clinical severity score > 0, n (%) | 27 (90) | 13 (80) | 14 (100) | 0.04 |
| Clinical severity score, n - 0 - 1 - 2 | 3 20 7 | 3 12 1 | 0 8 6 | 0.018 |
| Outcomes | ||||
| Hospitalization, n (%) | 12 (40) | 3 (18) | 9 (64) | 0.02 |
| Death, n (%) | 6 (20) | 1 (6.2) | 5 (35) | 0.07 |
| High-flow oxygen therapy, n (%) | 4 (13) | 0 | 4 (28) | 0.02 |
| Duration of SARS-CoV-2 infection, days | 21 (13–28) | 22 (14.5–35) | 20 (11–31) | 0.38 |
| NPV | PPV | |
|---|---|---|
| Clinical severity score > 0 | 0.19 (3/16) | 1 (14/14) |
| Hospitalization | 0.81 (13/16) | 0.64 (9/14) |
| Death | 0.94 (15/16) | 0.36 (5/14) |
| High-flow oxygen therapy | 1 (16/16) | 0.29 (4/14) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Esposito, P.; Garbarino, S.; Fenoglio, D.; Cama, I.; Cipriani, L.; Campi, C.; Parodi, A.; Vigo, T.; Franciotta, D.; Altosole, T.; et al. Longitudinal Cluster Analysis of Hemodialysis Patients with COVID-19 in the Pre-Vaccination Era. Life 2022, 12, 1702. https://doi.org/10.3390/life12111702
Esposito P, Garbarino S, Fenoglio D, Cama I, Cipriani L, Campi C, Parodi A, Vigo T, Franciotta D, Altosole T, et al. Longitudinal Cluster Analysis of Hemodialysis Patients with COVID-19 in the Pre-Vaccination Era. Life. 2022; 12(11):1702. https://doi.org/10.3390/life12111702
Chicago/Turabian StyleEsposito, Pasquale, Sara Garbarino, Daniela Fenoglio, Isabella Cama, Leda Cipriani, Cristina Campi, Alessia Parodi, Tiziana Vigo, Diego Franciotta, Tiziana Altosole, and et al. 2022. "Longitudinal Cluster Analysis of Hemodialysis Patients with COVID-19 in the Pre-Vaccination Era" Life 12, no. 11: 1702. https://doi.org/10.3390/life12111702
APA StyleEsposito, P., Garbarino, S., Fenoglio, D., Cama, I., Cipriani, L., Campi, C., Parodi, A., Vigo, T., Franciotta, D., Altosole, T., Grosjean, F., Viazzi, F., Filaci, G., & Piana, M. (2022). Longitudinal Cluster Analysis of Hemodialysis Patients with COVID-19 in the Pre-Vaccination Era. Life, 12(11), 1702. https://doi.org/10.3390/life12111702