
A New Hybrid Ensemble Deep Learning Model for Train Axle Temperature Short Term Forecasting


Abstract
:1. Introduction
1.1. Related Work
1.2. Novelty of the Study
- (a)
- The time series prediction helps with the real-time monitoring onboard and the fault diagnosis of axle temperature to ensure the train safety and efficient operation. To deal with the evolving information of axle temperature series, a time series hybrid prediction model is proposed to support short-term axle temperature forecasting for early warning. Different to the multiple regression models and physical methods in the previous study, the proposed innovative model can handle the axle temperature data and reduce the calculation complexity without a decrease in the prediction accuracy.
- (b)
- The decomposition algorithm could efficiently process non-stationary data from a time series. The CEEMD is applied for the first time in the original non-stationary axle temperature datasets to reduce the random fluctuations and to preprocess and decompose the raw data into multiple sub-series for digging into the primary component hidden in the raw datasets. Compared to the EMD and EEMD, problems of the mode mixing and the contamination in the signal reconstruction have been solved in CEEMD so that the information of the datasets can be better extracted to enhance the predictive ability of the predictor.
- (c)
- In the predictive process, the long short-term memory network is utilized to learn the characteristics of the decomposed IMFs. The improved version BILSTM can further learn long-term dependency of sequences by the deep learning structure of the evaluation of past and future information without keeping redundant characteristics [34]. It is also the first application in axle temperature prediction.
- (d)
- Different to other statistical computation or neural network methods, the proposed model is an ensemble predicting method focusing on the new hybrid metaheuristic optimization algorithm PSOGSA, which takes advantage of the exploitation function from PSO and the exploration function from GSA. The hybrid algorithm used each subsequence prediction result matrix from CEEMD-BILSTM and the weight matrix to find the optimal solution in the objective function and combine the calculation results for output.
- (e)
- The proposed hybrid CEEMD-BILSTM-PSOGSA is a novel structure. Recently, many applied forecasting models of the axle temperature have been single predictors. Therefore, the combining performance of hybrid models and the ability of the single models are worth studying. To test the robustness and accuracy and to evaluate the total performance, the experiments were conducted as the benchmark test.
2. Methodology
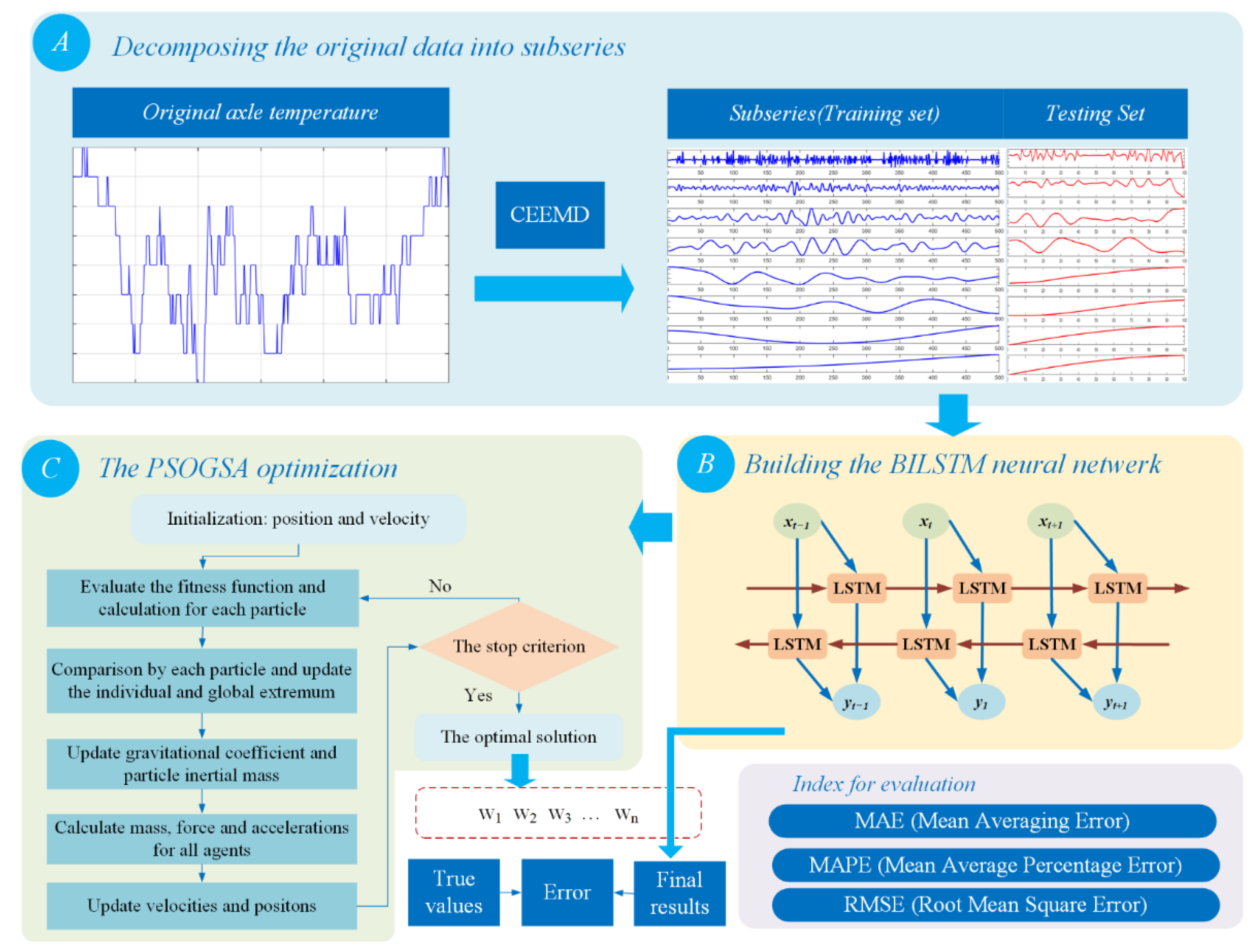
2.1. The Overall Structure of the Axle Temperature Forecasting Model
2.2. Complementary Ensemble Empirical Mode Decomposition Method
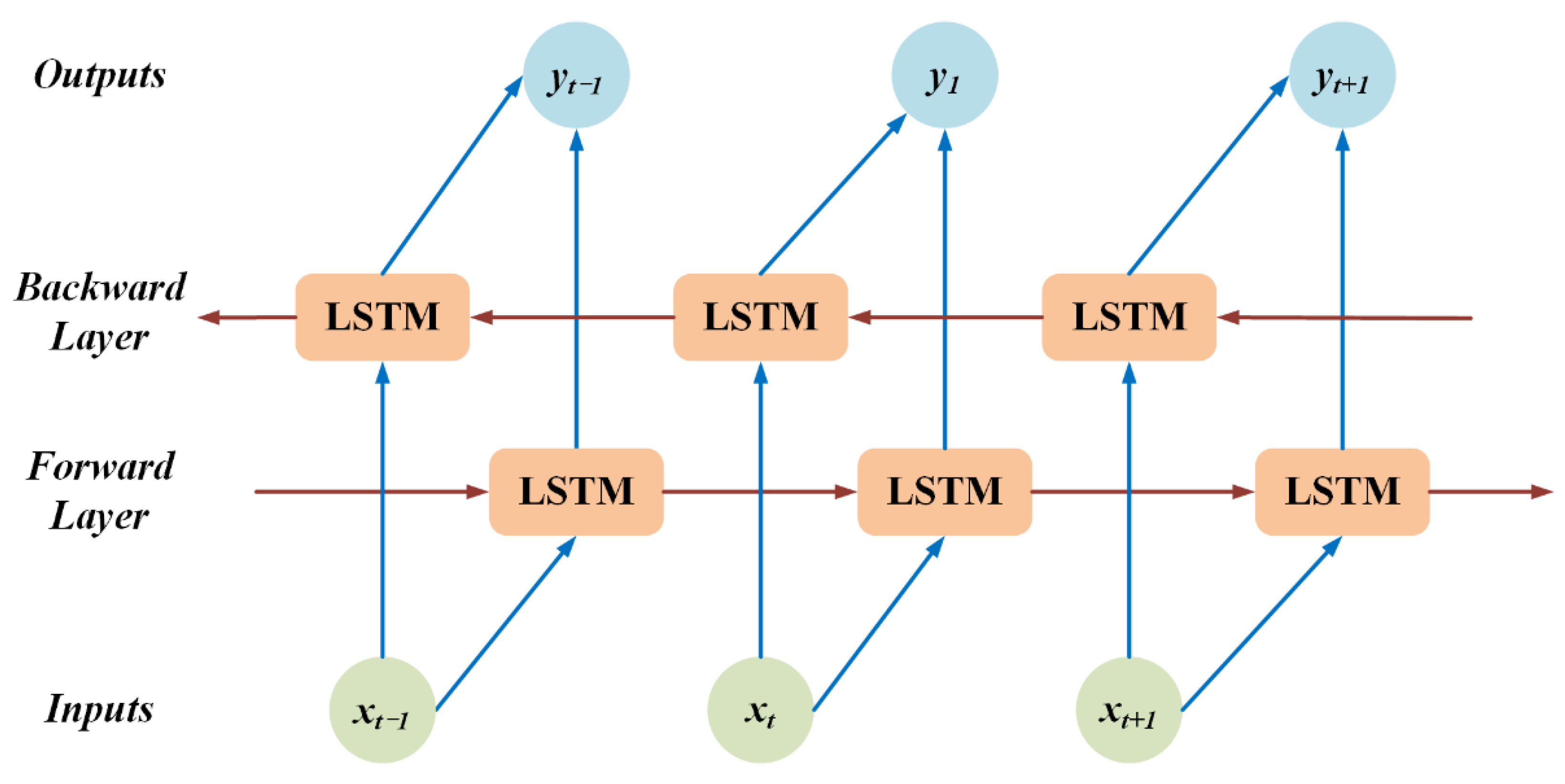
2.3. Bi-Directional Long Short-Term Memory Method
- ▪
- it, ft, and ot are respectively vectors for the input gate, forget gate, and output gate.
- ▪
- rt and are the cell status and the values vectors.
- ▪
- xt is the input data and ht is the output variable.
- ▪
- wcx, wix, wfx, wox, wch, wih, wfh, woh represent the relative weight matrices.
- ▪
- bi, br, bf, bo are the relative bias vectors and σ is a sigmoid activation function.
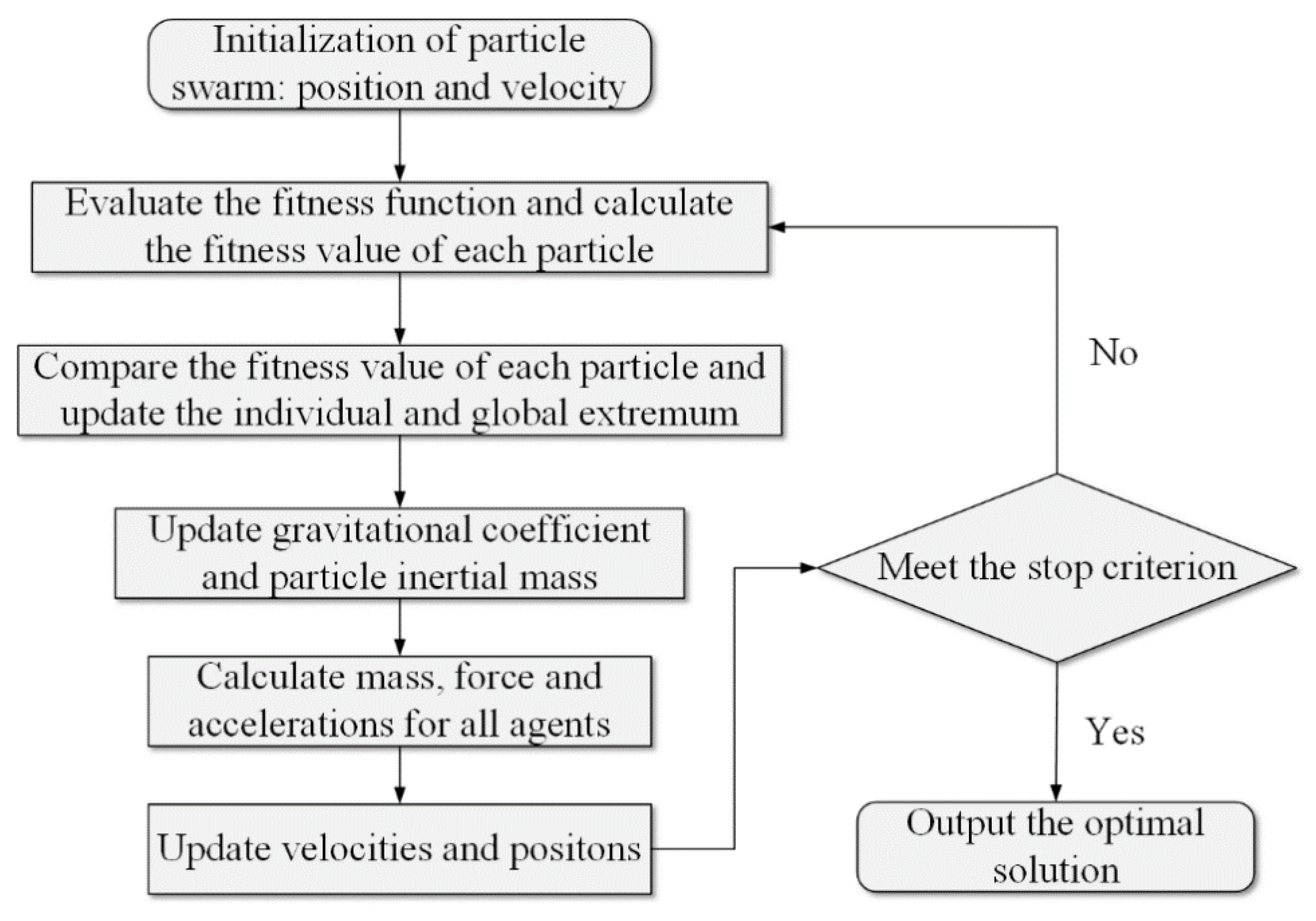
2.4. Ensemble Learning Method Based on PSOGSA Optimization
3. Case Study
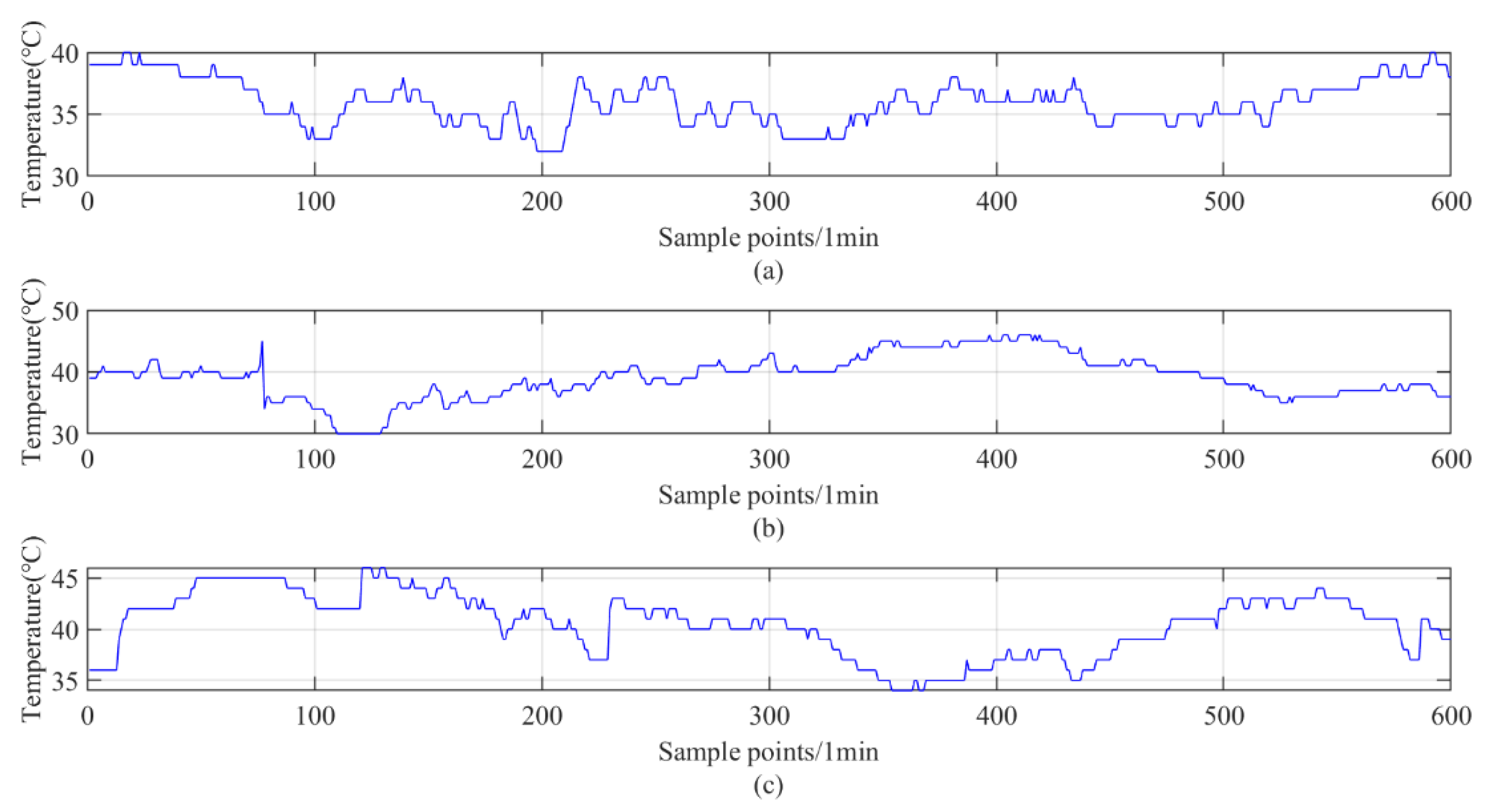
3.1. The Applied Datasets
3.2. The Evaluation Indexes in the Study
3.3. Comparing Experiments and Results
3.3.1. Experimental Results of Part 1
3.3.2. Experimental Results of Part 2
3.3.3. Experimental Results of Part 3
3.4. Comparison and Discussion with Alternative Algorithms
3.4.1. Analysis of Applied Single Predictors
- (a)
- The prediction accuracies of the neural network model and deep learning models are much higher than that of ARIMA and ARMA in all the datasets. For the statistical regression methods, the high fluctuation, nonstationary and nonlinear features of axle temperature series may increase the difficulty of the prediction process and lead to low prediction accuracy. The corresponding experiment results of three datasets reflected the insufficient ability of ARIMA and ARMA methods to solve nonlinear modeling. Besides, the prediction accuracy of the MLP is lower than other deep learning models in the series. It demonstrates that the performance of the shallow neural network is not good as the deep neural network in the research. The multiple hidden layers in the deep neural networks may complete the analysis of the deep wave information of original datasets and improve training and optimization capabilities to analyze the fluctuation and nonlinear features of the temperature data. Taking advantage of the deep learning methods, they can conduct a full analysis by the continuous iteration training process to keep stable and robust in the calculation of the temperature datasets.
- (b)
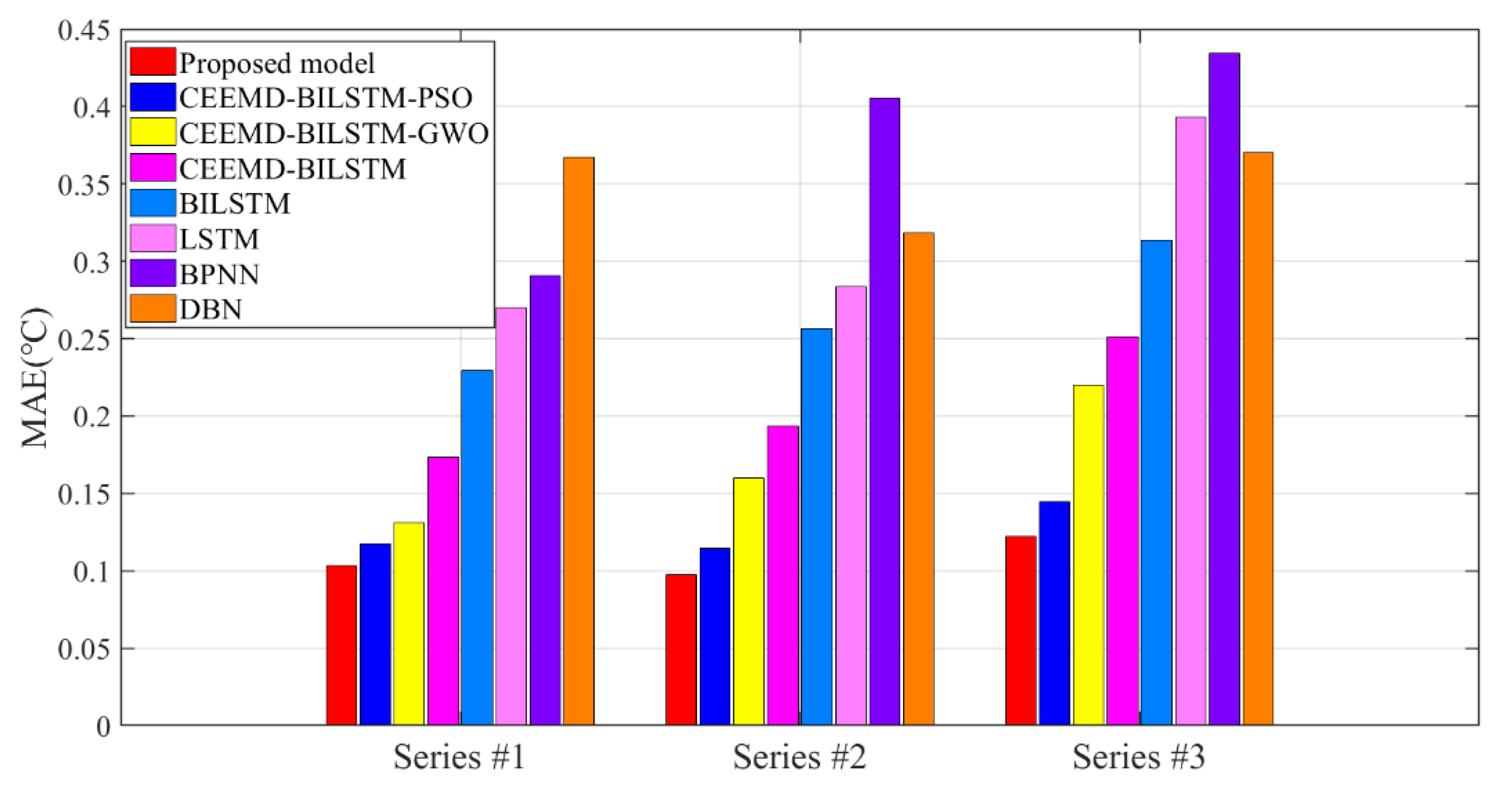
- Comparing the results of the LSTM and other benchmarks DBN, ENN, BPNN, MLP, ARIMA, and ARMA, the prediction error of the is lower than that of others and BILSTM obtains the best prediction results in all series. In Figure 6, Figure 7 and Figure 8, the evaluation values of BILSTM are lower than the neural networks and deep networks. The difference in the figures can be found that the MAPE of BILSTM is 0.6086% and the MAPE of BPNN is 1.1015%. The possible reason may be that the bidirectional operation structure could analyze the contextual information to increase the calculation speed and recognition abilities for different data series so that the type of neural network training can acquire optimal results in axle temperature time-series forecasting. However, it can be observed that a single predictor is not enough to efficiently handle different axle temperature series. Because of the hidden layer structures from different deep networks, the recognition abilities of the deep networks for various types of time series are also varied, so that it is essential to utilize other algorithms to increase the applicability and robustness of the model.
3.4.2. Analysis of Applied Decomposition Methods
- (a)
- The results from the EMD-BILSTM, EEMD-BILSTM and CEEMD-BILSTM models have shown better accuracy than the single BILSTM model. Therefore, the BILSTM with the decomposition algorithms has the ability to achieve better feature extraction of the axle temperature series and to produce more accurate forecasting results than the single BILSTM. Although the decomposition methods may raise the complexity and the time costs to a certain extent, considering the overall improvement effect, the application of real-time decomposition is feasible and is worthy of recognition in forecasting.
- (b)
- From the tables, it can be found that the forecasting errors of the EMD-BILSTM are higher than the EEMD-BILSTM and CEEMD-BILSTM in all series, which is a gradual decrease process. This application proves that the ability of the EMD method on decomposing the original signal and selecting the related partial characteristic of the original signal is lower than other models. The possible reason is that the mode mixing problem affects the processing and extraction capabilities of the EMD method for non-stationary and nonlinear data. Likewise, the signal reconstruction problem can also reduce the accuracy of the EEMD by the data decomposition, which leads to the production of white noise.
- (c)
- The comparable data in the tables have proved that the CEEMD is more efficient than the EMD and EEMD to raise the prediction accuracy. The CEEMD algorithm can raise sharply more than 32% of the accuracy for a single BILSTM in the forecasting results in all datasets, which can be also reflected in Figure 6, Figure 7 and Figure 8. Due to the function of improvement in eliminating the residual noise and the mode mixing, the CEEMD takes advantage of EEMD and represents a superior research potential to deepen the information extraction for temperature data.
3.4.3. Analysis of Different Optimization Methods
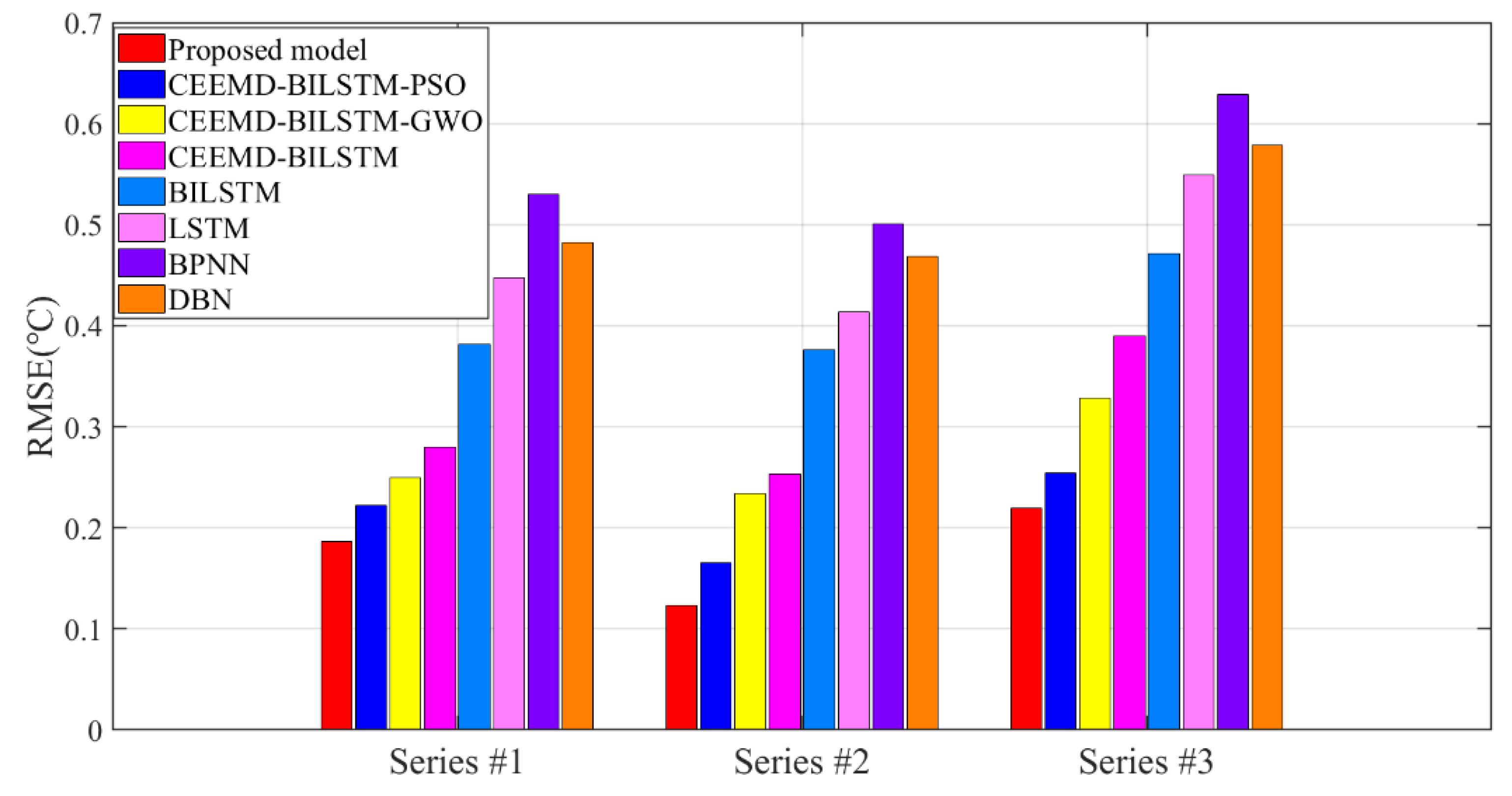
- (a)
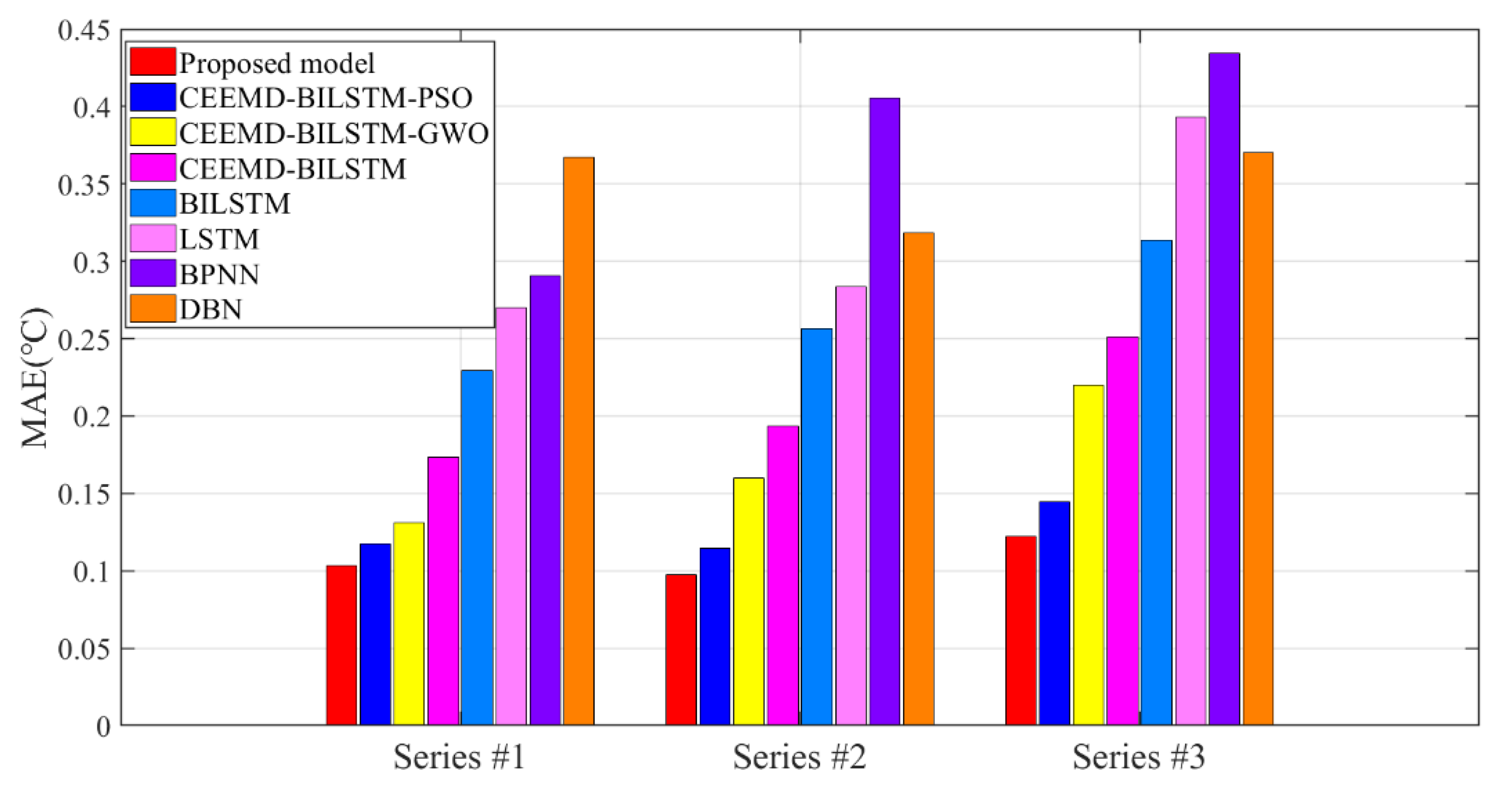
- The forecasting models show satisfying accuracy and robustness for the research of temperature changes. In Figure 6, Figure 7 and Figure 8, the forecasting accuracy of the proposed CEEMD-BILSTM-PSOGSA is higher than the CEEMD-BILSTM and BILSTM model. The ensemble optimization in hybrid models could efficiently forecast the temporal trend of temperature and improve the predictive performance to more than 67%. The possible reason may be that the PSOGSA algorithm could conduct an efficient weight optimization process by the axle temperature features, which is also the first time in the data-driven approaches of the axle temperature data. The evaluation values of the CEEMD-BILSTM-PSOGSA framework is the lowest among all the models in all the datasets.
- (b)
- The hybrid model also outperforms the classical single predictors and regression methods, which is affected by the optimization in the prediction process from many aspects. In Figure 6, Figure 7 and Figure 8, all the hybrid models have better forecasting accuracies than the single predictors in all datasets. In addition to the deep networks’ ability to process nonstationary data, the proposed hybrid models are highly adaptable, so the decomposition methods and optimization algorithms effectively analyze and simulate the trend of nonstationary and nonlinear data, which contributed to better accuracy than the single models and the effective application of hybrid models indicates a possible research direction of time-series prediction for the early warning.
- (c)
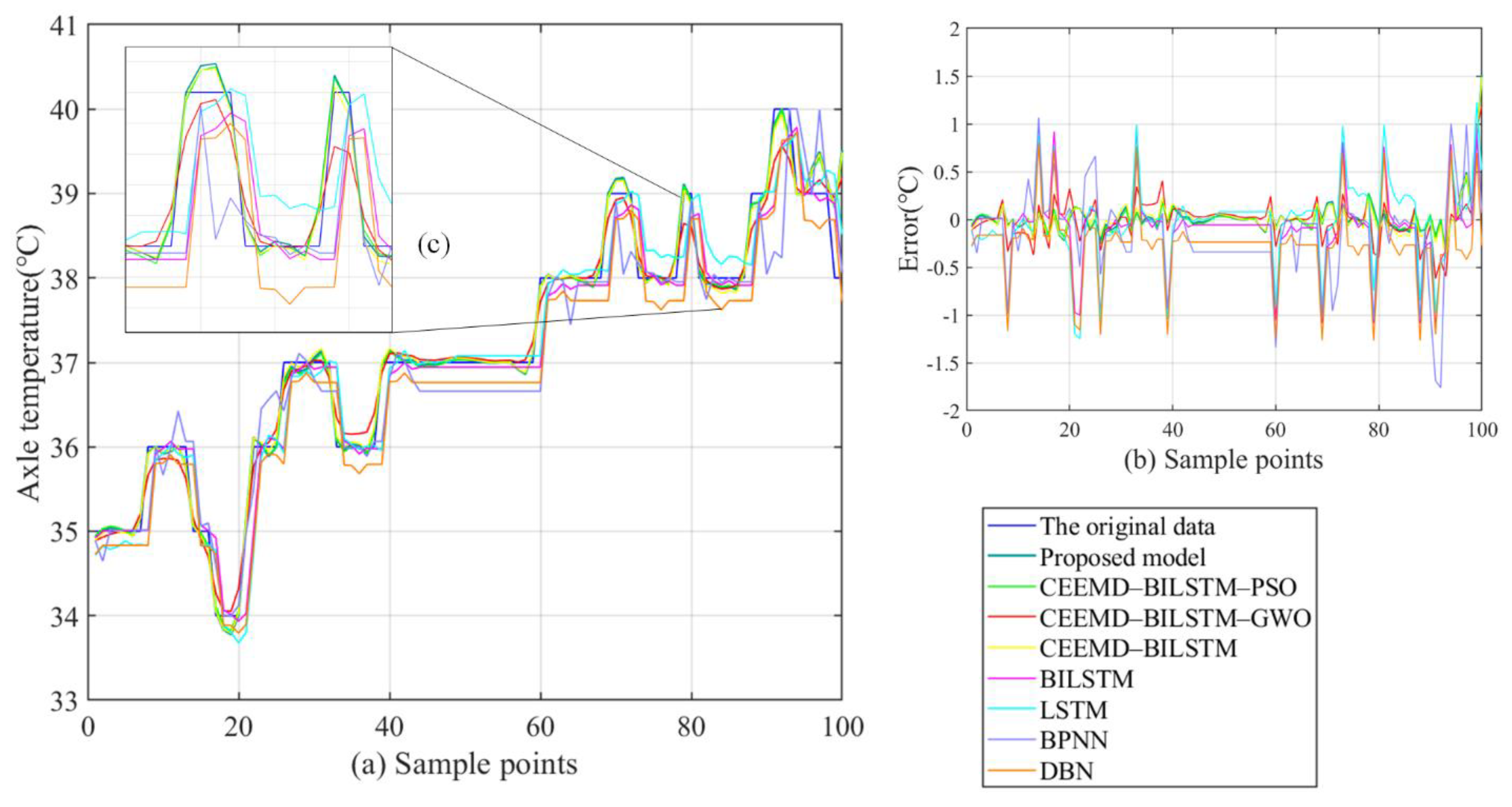
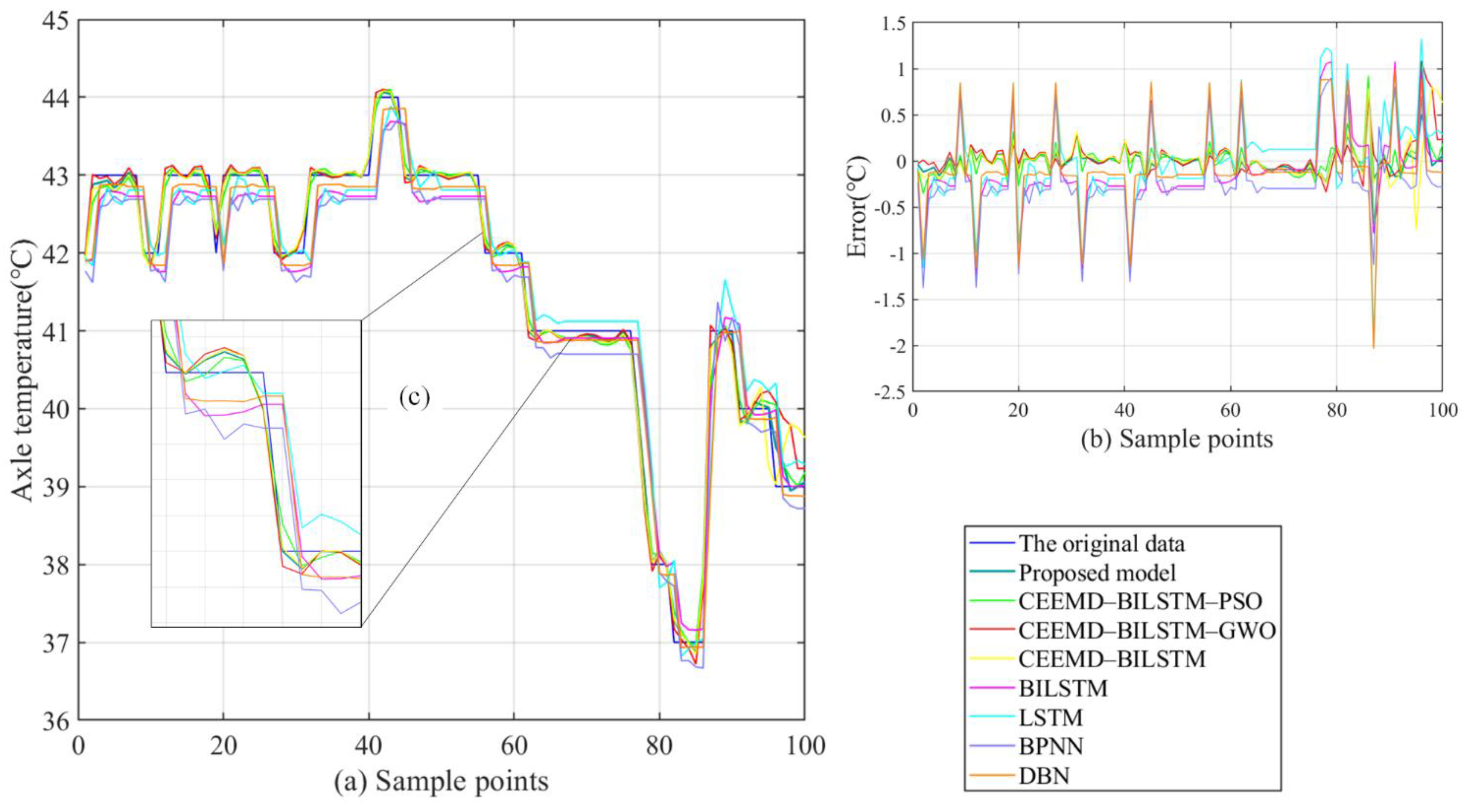
- The proposed CEEMD-BILSTM-PSOGSA model obtains the best forecasting results of all data series with the evaluation indexes. The MAE can reach less than 0.1 °C and the MAPE can achieve almost 0.2%. Compared with other hybrid models, the proposed model still outperforms them from 11.9% to 47.7% in the indexes. Figure 10, Figure 11 and Figure 12 show the final forecasting results and the deviation from the original data of all the models. The predicted values of the proposed model are closer to the original data than others. Figure 9 represents the changes in the loss during the iterations of PSOGSA, PSO, and GWO. In comparison, the PSOGSA has a faster convergence speed and a lower final loss than PSO and GWO in all the datasets, which credits the excellent exploration and the research localization abilities from the combination of the PSO and GSA algorithms. Thus, the CEEMD-BILSTM-PSOGSA model integrates the superiorities of the single algorithms and has excellent application foregrounds in axle temperature forecasting.
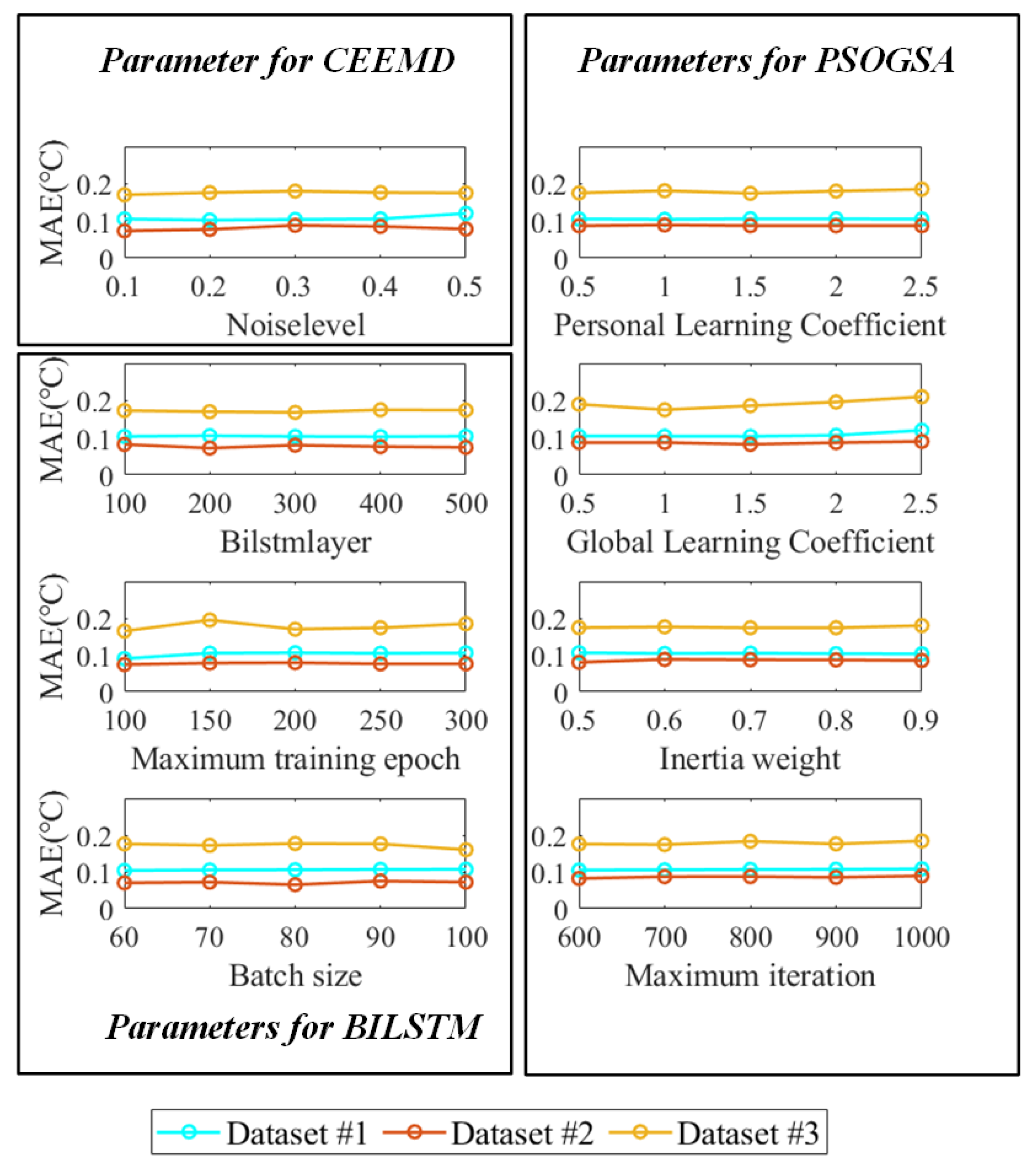
3.5. Sensitive Analysis of the Parameters and the Validation of the Model
4. Conclusions and Future Work
- (a)
- The predictive performance of the deep networks with bidirectional operation structure is better than regression methods and shallow neural networks. The deep structure can contribute to the analysis of the fluctuation and nonlinear features of the axle temperature datasets. Therefore, the prediction by the deep networks has an effective application in the research of axle temperature forecasting.
- (b)
- The proposed model proved the fact that the decomposition algorithms can efficiently raise the accuracy of the BILSTM. In the EMD series, the CEEMD showed excellent adaptive decomposition ability in the process of the axle temperature data and had a positive effect to improve the predictive ability rather than the EEMD and the EMD in all data series.
- (c)
- The ensemble process based on the PSOGSA optimization algorithm is significantly better for the integration of deep network sub-series and for an improvement of the prediction accuracy. Besides, the optimization levels of the proposed algorithm also outperform the PSO and GWO algorithms.
- (d)
- Compared with the classical predictors and other involved hybrid models, the proposed effective model combined all advantages of the components and presented a good prediction ability and adaptability in axle temperature forecasting, which offered a new approach for the prediction and early warning for the effective axle temperature research.
- (a)
- The proposed model used a univariate axle temperature framework by time series, which may be affected by the historical data. Moreover, the accuracy and reliability of the model will be in recession according to the locomotive running period. To guarantee the regular function of the model, it is necessary to update model parameters and to take the correlation by multivariate of the operating environment into consideration.
- (b)
- This paper aims to the short-term forecasting research of locomotive axle temperature. For the massive data generated by the locomotive during long-term operation in the future, an effective data processing platform can conduct a more comprehensive analysis of the locomotive. Within the application of the big data platform technology, the proposed hybrid model can be embedded into the distributed computing system for further application in the big data platform.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| ARIMA | Autoregressive Integrated Moving Average |
| BPNN | Back Propagation Neural Network |
| BILSTM | Bi-directional Long Short-Term Memory |
| CEEMD | Complementary Empirical Mode Decomposition |
| DBN | Deep Belief Network |
| GA | Generic Optimization |
| EMD | Empirical Mode Decomposition |
| EEMD | Ensemble Empirical Mode Decomposition |
| ENN | Elman Neural Network |
| GSA | Gravitational Search Algorithm |
| GWO | Grey Wolf Optimization |
| IMF | Intrinsic Mode Function |
| LSTM | Long Short-Term Memory |
| MLP | Multi-Layer Perceptron |
| MAE | Mean Averaging Error |
| MAPE | Mean Average Percentage Error |
| MGWO | Modified Grey Wolf Optimization |
| MSE | Mean Squared Error |
| PSO | Particle Swarm Optimization |
| PSOGSA | Particle Swarm Optimization and Gravitational Search Algorithm |
| RMSE | Root Mean Square Error |
Nomenclature
| wi(t) | The ith plus white noise |
| The ith positive signals | |
| The ith negative signals | |
| dj(t) | The jth IMF item obtained by the CEEMD method |
| rN(t) | The remainder of the raw signals |
| it | The vectors for the input gate |
| ft | The vectors for the forget gate |
| ot | The vectors for the output gate |
| rt | The cell status |
| The values vectors | |
| xt | The input data |
| ht | The output variable. |
| wcx, wix wfx, wox, wch, wih wfh, woh | The relative weight matrices |
| bi, br, bf, bo | The relative bias vectors |
| σ | Sigmoid activation function |
| ct | New call status |
| vi, Vi | The velocity |
| xi(t), Xi(t) | The current location of ith particle |
| t | The iteration |
| d1, d2 | The acceleration coefficients |
| pbest | The local best location of ith particle |
| gbest | The global optimal result |
| rand | Uniform random variable between the interval [0, 1] |
| aci(t) | The acceleration of the ith agent |
| A(t) | The raw data |
| The predictive result |
References
- Li, C.; Luo, S.; Cole, C.; Spiryagin, M. An overview: Modern techniques for railway vehicle on-board health monitoring systems. Veh. Syst. Dyn. 2017, 55, 1045–1070. [Google Scholar] [CrossRef]
- Wu, S.C.; Liu, Y.X.; Li, C.H.; Kang, G.; Liang, S.L. On the fatigue performance and residual life of intercity railway axles with inside axle boxes. Eng. Fract. Mech. 2018, 197, 176–191. [Google Scholar] [CrossRef]
- Ma, W.; Tan, S.; Hei, X.; Zhao, J.; Xie, G. A Prediction Method Based on Stepwise Regression Analysis for Train Axle Temperature. In Proceedings of the 12th International Conference on Computational Intelligence and Security, Wuxi, China, 16–19 December 2016; pp. 386–390. [Google Scholar]
- Milic, S.D.; Sreckovic, M.Z. A Stationary System of Noncontact Temperature Measurement and Hotbox Detecting. IEEE Trans. Veh. Technol. 2008, 57, 2684–2694. [Google Scholar] [CrossRef]
- Singh, P.; Huang, Y.P.; Wu, S.-I. An Intuitionistic Fuzzy Set Approach for Multi-attribute Information Classification and Decision-Making. Int. J. Fuzzy Syst. 2020, 22, 1506–1520. [Google Scholar] [CrossRef]
- Bing, C.; Shen, H.; Jie, C.; Li, L. Design of CRH axle temperature alarm based on digital potentiometer. In Proceedings of the Chinese Control Conference, Chengdu, China, 27–29 July 2016. [Google Scholar]
- Vale, C.; Bonifácio, C.; Seabra, J.; Calçada, R.; Mazzino, N.; Elisa, M.; Terribile, S.; Anguita, D.; Fumeo, E.; Saborido, C. Novel efficient technologies in Europe for axle bearing condition monitoring—The MAXBE project. Transp. Res. Procedia 2016, 14, 635–644. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q. High-speed Train Axle Temperature Monitoring System Based on Switched Ethernet. Procedia Comput. Sci. 2017, 107, 70–74. [Google Scholar] [CrossRef]
- Yuan, H.; Wu, N.; Chen, X.; Wang, Y. Fault Diagnosis of Rolling Bearing Based on Shift Invariant Sparse Feature and Optimized Support Vector Machine. Machines 2021, 9, 98. [Google Scholar] [CrossRef]
- Pham, M.-T.; Kim, J.-M.; Kim, C.-H. 2D CNN-Based Multi-Output Diagnosis for Compound Bearing Faults under Variable Rotational Speeds. Machines 2021, 9, 199. [Google Scholar] [CrossRef]
- Yang, X.; Dong, H.; Man, J.; Chen, F.; Zhen, L.; Jia, L.; Qin, Y. Research on Temperature Prediction for Axles of Rail Vehicle Based on LSTM. In Proceedings of the 4th International Conference on Electrical and Information Technologies for Rail Transportation (EITRT), Singapore, 25–27 October 2019; pp. 685–696. [Google Scholar]
- Luo, C.; Yang, D.; Huang, J.; Deng, Y.D.; Long, L.; Li, Y.; Li, X.; Dai, Y.; Yang, H. LSTM-Based Temperature Prediction for Hot-Axles of Locomotives. ITM Web Conf. 2017, 12, 01013. [Google Scholar] [CrossRef] [Green Version]
- Yan, G.; Yu, C.; Bai, Y. Wind Turbine Bearing Temperature Forecasting Using a New Data-Driven Ensemble Approach. Machines 2021, 9, 248. [Google Scholar] [CrossRef]
- Mi, X.; Zhao, S. Wind speed prediction based on singular spectrum analysis and neural network structural learning. Energy Convers. Manag. 2020, 216, 112956. [Google Scholar] [CrossRef]
- Gou, H.; Ning, Y. Forecasting Model of Photovoltaic Power Based on KPCA-MCS-DCNN. Comput. Model. Eng. Sci. 2021, 128, 803–822. [Google Scholar] [CrossRef]
- Wang, H.; Li, G.; Wang, G.; Peng, J.; Jiang, H.; Liu, Y. Deep learning based ensemble approach for probabilistic wind power forecasting. Appl. Energy 2017, 188, 56–70. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Q. Short-Term Traffic Flow Prediction Based on LSTM-XGBoost Combination Model. Comput. Model. Eng. Sci. 2020, 125, 95–109. [Google Scholar] [CrossRef]
- Dong, S.; Yu, C.; Yan, G.; Zhu, J.; Hu, H. A Novel Ensemble Reinforcement Learning Gated Recursive Network for Traffic Speed Forecasting. In Proceedings of the 2021 Workshop on Algorithm and Big Data, Fuzhou, China, 12–14 March 2021; pp. 55–60. [Google Scholar]
- Liu, X.; Qin, M.; He, Y.; Mi, X.; Yu, C. A new multi-data-driven spatiotemporal PM2.5 forecasting model based on an ensemble graph reinforcement learning convolutional network. Atmos. Pollut. Res. 2021, 12, 101197. [Google Scholar] [CrossRef]
- Mashaly, A.F.; Alazba, A.A. MLP and MLR models for instantaneous thermal efficiency prediction of solar still under hyper-arid environment. Comput. Electron. Agric. 2016, 122, 146–155. [Google Scholar] [CrossRef]
- Lee, H.; Han, S.-Y.; Park, K.; Lee, H.; Kwon, T. Real-Time Hybrid Deep Learning-Based Train Running Safety Prediction Framework of Railway Vehicle. Machines 2021, 9, 130. [Google Scholar] [CrossRef]
- Hong, S.; Zhou, Z.; Zio, E.; Wang, W. An adaptive method for health trend prediction of rotating bearings. Digit. Signal Process. 2014, 35, 117–123. [Google Scholar] [CrossRef]
- Wang, H.; Liu, L.; Dong, S.; Qian, Z.; Wei, H. A novel work zone short-term vehicle-type specific traffic speed prediction model through the hybrid EMD–ARIMA framework. Transp. B Transp. Dyn. 2016, 4, 159–186. [Google Scholar] [CrossRef]
- Bai, Y.; Zeng, B.; Li, C.; Zhang, J. An ensemble long short-term memory neural network for hourly PM2.5 concentration forecasting. Chemosphere 2019, 222, 286–294. [Google Scholar] [CrossRef]
- Chang, Y.; Fang, H.; Zhang, Y. A new hybrid method for the prediction of the remaining useful life of a lithium-ion battery. Appl. Energy 2017, 206, 1564–1578. [Google Scholar] [CrossRef]
- Hao, W.; Liu, F. Axle Temperature Monitoring and Neural Network Prediction Analysis for High-Speed Train under Operation. Symmetry 2020, 12, 1662. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, H.; Zhao, G.; Lian, J. Constructing a PM2.5 concentration prediction model by combining auto-encoder with Bi-LSTM neural networks. Environ. Model. Softw. 2020, 124, 104600. [Google Scholar] [CrossRef]
- Kouchami-Sardoo, I.; Shirani, H.; Esfandiarpour-Boroujeni, I.; Besalatpour, A.A.; Hajabbasi, M.A. Prediction of soil wind erodibility using a hybrid Genetic algorithm—Artificial neural network method. CATENA 2020, 187, 104315. [Google Scholar] [CrossRef]
- Xing, Y.; Yue, J.; Chen, C.; Xiang, Y.; Shi, M. A Deep Belief Network Combined with Modified Grey Wolf Optimization Algorithm for PM2.5 Concentration Prediction. Appl. Sci. 2019, 9, 3765. [Google Scholar] [CrossRef] [Green Version]
- Singh, P. A novel hybrid time series forecasting model based on neutrosophic-PSO approach. Int. J. Mach. Learn. Cybern. 2020, 11, 1643–1658. [Google Scholar] [CrossRef]
- Zhang, Y.; Cui, N.; Feng, Y.; Gong, D.; Hu, X. Comparison of BP, PSO-BP and statistical models for predicting daily global solar radiation in arid Northwest China. Comput. Electron. Agric. 2019, 164, 104905. [Google Scholar] [CrossRef]
- Zhu, S.; Yang, L.; Wang, W.; Liu, X.; Lu, M.; Shen, X. Optimal-combined model for air quality index forecasting: 5 cities in North China. Environ. Pollut. 2018, 243, 842–850. [Google Scholar] [CrossRef]
- Tan, S.; Ma, W.; Hei, X.; Xie, G.; Chen, X.; Zhang, J. High Speed Train Axle Temperature Prediction Based on Support Vector Regression. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; pp. 2223–2227. [Google Scholar]
- Yildirim, Ö. A novel wavelet sequence based on deep bidirectional LSTM network model for ECG signal classification. Comput. Biol. Med. 2018, 96, 189–202. [Google Scholar] [CrossRef]
- Yeh, J.R.; Shieh, J.S.; Huang, N.E. Complementary Ensemble Empirical Mode Decomposition: A Novel Noise Enhanced Data Analysis Method. Adv. Adapt. Data Anal. 2010, 2, 135–156. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble Empirical Mode Decomposition: A Noise-Assisted Data Analysis Method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Xue, X.; Zhou, J.; Xu, Y.; Zhu, W.; Li, C. An adaptively fast ensemble empirical mode decomposition method and its applications to rolling element bearing fault diagnosis. Mech. Syst. Signal Process. 2015, 62–63, 444–459. [Google Scholar] [CrossRef]
- Zhu, S.; Lian, X.; Wei, L.; Che, J.; Shen, X.; Yang, L.; Qiu, X.; Liu, X.; Gao, W.; Ren, X.; et al. PM2.5 forecasting using SVR with PSOGSA algorithm based on CEEMD, GRNN and GCA considering meteorological factors. Atmos. Environ. 2018, 183, 20–32. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Wu, Y.; Yuan, M.; Dong, S.; Lin, L.; Liu, Y. Remaining useful life estimation of engineered systems using vanilla LSTM neural networks. Neurocomputing 2018, 275, 167–179. [Google Scholar] [CrossRef]
- Hou, M.; Pi, D.; Li, B. Similarity-based deep learning approach for remaining useful life prediction. Measurement 2020, 159, 107788. [Google Scholar] [CrossRef]
- Yildirim, O.; Baloglu, U.B.; Tan, R.-S.; Ciaccio, E.J.; Acharya, U.R. A new approach for arrhythmia classification using deep coded features and LSTM networks. Comput. Methods Programs Biomed. 2019, 176, 121–133. [Google Scholar] [CrossRef]
- Cheng, H.; Ding, X.; Zhou, W.; Ding, R. A hybrid electricity price forecasting model with Bayesian optimization for German energy exchange. Int. J. Electr. Power Energy Syst. 2019, 110, 653–666. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Huang, M.-L.; Chou, Y.-C. Combining a gravitational search algorithm, particle swarm optimization, and fuzzy rules to improve the classification performance of a feed-forward neural network. Comput. Methods Programs Biomed. 2019, 180, 105016. [Google Scholar] [CrossRef] [PubMed]
- Duman, S.; Yorukeren, N.; Altas, I.H. A novel modified hybrid PSOGSA based on fuzzy logic for non-convex economic dispatch problem with valve-point effect. Int. J. Electr. Power Energy Syst. 2015, 64, 121–135. [Google Scholar] [CrossRef]
- Rashedi, E.; Nezamabadi-pour, H.; Saryazdi, S. GSA: A Gravitational Search Algorithm. Inf. Sci. 2009, 179, 2232–2248. [Google Scholar] [CrossRef]
- Mirjalili, S.; Hashim, S.Z.M. A new hybrid PSOGSA algorithm for function optimization. In Proceedings of the 2010 International Conference on Computer and Information Application, Tianjin, China, 3–5 December 2010; pp. 374–377. [Google Scholar]
- Bounar, N.; Labdai, S.; Boulkroune, A. PSO–GSA based fuzzy sliding mode controller for DFIG-based wind turbine. ISA Trans. 2019, 85, 177–188. [Google Scholar] [CrossRef]
- Qu, Z.; Zhang, K.; Mao, W.; Wang, J.; Liu, C.; Zhang, W. Research and application of ensemble forecasting based on a novel multi-objective optimization algorithm for wind-speed forecasting. Energy Convers. Manag. 2017, 154, 440–454. [Google Scholar] [CrossRef]
- Kong, W.; Wang, B. Combining Trend-Based Loss with Neural Network for Air Quality Forecasting in Internet of Things. Comput. Model. Eng. Sci. 2020, 125, 849–863. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Published Year | Predictors |
|---|---|---|
| [11] | 2019 | LSTM |
| [12] | 2017 | LSTM |
| [26] | 2020 | BPNN |
| [33] | 2019 | SVM |
| Dataset | Maximum (°C) | Minimum (°C) | Average (°C) |
|---|---|---|---|
| 1 | 40 | 32 | 35.9317 |
| 2 | 46 | 30 | 39.0567 |
| 3 | 46 | 34 | 40.4950 |
| Series | Forecasting Models | MAE (°C) | MAPE (%) | RMSE (°C) |
|---|---|---|---|---|
| #1 | BILSTM | 0.2297 | 0.6159 | 0.3814 |
| LSTM | 0.2702 | 0.7522 | 0.4475 | |
| DBN | 0.3673 | 0.8565 | 0.4516 | |
| ENN | 0.2814 | 0.7531 | 0.4832 | |
| BPNN | 0.2805 | 0.9234 | 0.5297 | |
| MLP | 0.5456 | 1.6037 | 0.7350 | |
| ARIMA | 0.5835 | 1.7129 | 0.8644 | |
| ARMA | 0.6326 | 1.9583 | 1.1152 | |
| #2 | BILSTM | 0.2568 | 0.6086 | 0.3764 |
| LSTM | 0.2838 | 0.6987 | 0.4167 | |
| DBN | 0.3185 | 0.7586 | 0.4684 | |
| ENN | 0.3911 | 0.7922 | 0.4396 | |
| BPNN | 0.4055 | 1.1015 | 0.5007 | |
| MLP | 0.7026 | 1.8110 | 0.8988 | |
| ARIMA | 0.7941 | 1.9375 | 0.9259 | |
| ARMA | 0.9102 | 2.1479 | 1.2074 | |
| #3 | BILSTM | 0.3135 | 0.6830 | 0.4710 |
| LSTM | 0.3929 | 0.7851 | 0.5490 | |
| DBN | 0.3703 | 0.7582 | 0.5784 | |
| ENN | 0.3563 | 0.7225 | 0.5739 | |
| BPNN | 0.4342 | 1.0436 | 0.6290 | |
| MLP | 0.7340 | 1.6931 | 1.0061 | |
| ARIMA | 0.9351 | 1.7859 | 1.2134 | |
| ARMA | 1.1046 | 1.8705 | 1.3743 |
| Series | Forecasting Models | MAE (°C) | MAPE (%) | RMSE (°C) |
|---|---|---|---|---|
| #1 | BILSTM | 0.2297 | 0.6159 | 0.3814 |
| EMD-BILSTM | 0.2180 | 0.5987 | 0.3466 | |
| EEMD-BILSTM | 0.2115 | 0.5673 | 0.3092 | |
| CEEMD-BILSTM | 0.1735 | 0.4545 | 0.2797 | |
| #2 | BILSTM | 0.2568 | 0.6086 | 0.3764 |
| EMD-BILSTM | 0.2329 | 0.5272 | 0.3039 | |
| EEMD-BILSTM | 0.2164 | 0.4802 | 0.2736 | |
| CEEMD-BILSTM | 0.1937 | 0.4628 | 0.2529 | |
| #3 | BILSTM | 0.3135 | 0.6830 | 0.4710 |
| EMD-BILSTM | 0.2901 | 0.6321 | 0.4361 | |
| EEMD-BILSTM | 0.2831 | 0.5954 | 0.4055 | |
| CEEMD-BILSTM | 0.2511 | 0.5692 | 0.3895 |
| Methods | Indexes | Series #1 | Series #2 | Series #3 |
|---|---|---|---|---|
| EMD-BILSTM vs. BILSTM | PMAE (%) | 5.0936 | 9.3069 | 7.4641 |
| PMAPE (%) | 2.7927 | 13.3750 | 7.4524 | |
| PRMSE (%) | 9.1243 | 19.2614 | 7.4098 | |
| EEMD-BILSTM vs. BILSTM | PMAE (%) | 7.9234 | 15.7321 | 9.9697 |
| PMAPE (%) | 7.8909 | 21.0976 | 12.8258 | |
| PRMSE (%) | 18.9303 | 27.3114 | 13.9066 | |
| CEEMD-BILSTM vs. BILSTM | PMAE (%) | 24.4467 | 24.5717 | 19.9043 |
| PMAPE (%) | 26.2056 | 23.9566 | 16.6618 | |
| PRMSE (%) | 26.6650 | 32.8108 | 17.3036 |
| Methods | Indexes | Series #1 | Series #2 | Series #3 |
|---|---|---|---|---|
| CEEMD-BILSTM-PSOGSA vs. CEEMD-BILSTM | PMAE (%) | 40.8360 | 49.6644 | 51.4138 |
| PMAPE (%) | 39.7360 | 54.3431 | 38.3345 | |
| PRMSE (%) | 33.5001 | 51.2456 | 43.7741 | |
| CEEMD-BILSTM-PSOGSA vs. BILSTM | PMAE (%) | 55.0283 | 62.0327 | 61.0845 |
| PMAPE (%) | 55.5285 | 65.2810 | 48.6091 | |
| PRMSE (%) | 51.2323 | 67.2423 | 53.5032 |
| Methods | Indexes | Series #1 | Series #2 | Series #3 |
|---|---|---|---|---|
| CEEMD-BILSTM-PSOGSA vs. CEEMD-BILSTM-PSO | PMAE (%) | 11.9352 | 14.9956 | 15.5709 |
| PMAPE (%) | 15.1487 | 18.2276 | 17.4118 | |
| PRMSE (%) | 16.2162 | 25.4534 | 13.7795 | |
| CEEMD-BILSTM-PSOGSA vs. CEEMD-BILSTM-GWO | PMAE (%) | 21.2652 | 38.9480 | 44.5958 |
| PMAPE (%) | 20.9067 | 47.7756 | 33.2953 | |
| PRMSE (%) | 25.5702 | 47.3077 | 33.3738 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, G.; Yu, C.; Bai, Y. A New Hybrid Ensemble Deep Learning Model for Train Axle Temperature Short Term Forecasting. Machines 2021, 9, 312. https://doi.org/10.3390/machines9120312
Yan G, Yu C, Bai Y. A New Hybrid Ensemble Deep Learning Model for Train Axle Temperature Short Term Forecasting. Machines. 2021; 9(12):312. https://doi.org/10.3390/machines9120312
Chicago/Turabian StyleYan, Guangxi, Chengqing Yu, and Yu Bai. 2021. "A New Hybrid Ensemble Deep Learning Model for Train Axle Temperature Short Term Forecasting" Machines 9, no. 12: 312. https://doi.org/10.3390/machines9120312
APA StyleYan, G., Yu, C., & Bai, Y. (2021). A New Hybrid Ensemble Deep Learning Model for Train Axle Temperature Short Term Forecasting. Machines, 9(12), 312. https://doi.org/10.3390/machines9120312