1. Introduction
Fault diagnosis is crucial in ensuring the reliability and safety of complex systems in various domains [
1]. It involves identifying and addressing malfunctions that affect system performance, safety, and longevity. Fault diagnosis is important in many domains, such as aerospace, automotive, industrial manufacturing, healthcare, and marine systems. In particular, in marine systems, the harsh and unpredictable operational environment makes timely and precise fault diagnosis essential for maintaining vessel safety, optimizing performance, and reducing downtime.
Fault diagnosis methods can be classified into model-based and data-driven approaches [
2]. Each approach has unique methodologies, advantages, and challenges, making them suitable for different scenarios depending on the availability of data and the nature of the system being analyzed. Model-based diagnosis employs analytical models derived from the physical processes of a system. It generates residuals by comparing measured and estimated variables, providing insights into the system’s dynamic behavior and enhancing the understanding of its physical operations. However, this approach faces challenges related to uncertainties caused by modeling errors and measurement inaccuracies. Despite these challenges, model-based diagnosis is suitable for scenarios with limited data availability. Data-driven diagnosis uses data monitoring for fault detection and classification. This approach employs techniques such as neural networks, Bayesian networks, and Principal Component Analysis, making it particularly effective for real-time processing due to its lower computational demands. However, it necessitates data processing and the extraction of relevant features from the data. Data-driven diagnosis is highly effective when a sufficient amount of data for both normal and faulty conditions is available. The approach introduced in this study can be classified as a data-driven anomaly detection method since it identifies abnormalities based solely on the analysis of signal data.
In fault diagnosis, it is essential to distinguish between faults and signal abnormalities. A fault is a defect or malfunction in a system component that results in improper operation or failure to meet performance criteria, typically associated with specific components or subsystems [
3]. In contrast, signal abnormalities represent deviations from normal behavior, which may indicate faults, environmental changes, aging, or transient disturbances. While abnormalities reflect deviations from expected system performance, they do not always correspond to specific faults. When a pattern of abnormalities is observed consistently, particularly when related to key components or subsystems, it often suggests the presence of underlying faults.
Researchers have extensively utilized correlation and clustering techniques for fault diagnosis across various domains, including nuclear power plants, battery systems, and industrial processes. These methods often combine correlation analysis with clustering algorithms such as DBSCAN, K-means, and hierarchical clustering to enhance detection accuracy and feature relevance. However, most existing approaches are application-specific and lack generalizability, detailed anomaly characterization, and intuitive visualization capabilities, which limits their broader utility.
A novel anomaly detection algorithm is introduced, based on applying a clustering algorithm to the correlation matrix calculated from a set of signals during a specific, small time interval and repeating this process over the period of study. The algorithm is called Clustered Correlation Health Scan and is abbreviated as CCH-Scan. It is applied to a set of signals that must be correlated under normal conditions. CCH-Scan scans the signal over time and detects which signals show abnormal behavior and during which time intervals. An abnormal signal at a specific time period is a signal that behaves differently or is less correlated with the majority of the remaining signals.
The case study concerns fault diagnosis in the cylinders of a 12-cylinder dual-fuel marine engine, specifically the analysis of abnormalities in the ECDT signal using the CCH-Scan algorithm. The details of this signal will be explained later in the paper. Over a period of five months, 12 signals of the exhaust valve closing dead time (ECDT) were analyzed. ECDT is an important signal related to the closing of the exhaust valve in a marine dual-fuel engine, which will be described in
Section 3. Abnormalities in such a signal usually require immediate intervention by engineers to perform an exhaust valve overhaul. The ECDT signal will be described in more detail later. The focus is to identify the cylinders with abnormal ECDT signals, the duration of ECDT signal abnormalities, and the degree of these abnormalities. The parameters of the algorithm will be examined, and their impact will be assessed using a quality score. A metric to evaluate the degree of abnormality in the signals will also be introduced. This approach effectively identifies abnormal signals, pinpoints the timing of abnormalities, and assesses the extent of these abnormalities. The findings are consistent with ground-truth data from a technical maintenance report, indicating strong potential for application in other contexts.
In summary, the primary contribution of this paper is the introduction of a novel Clustered Correlation Health Scan anomaly detection algorithm, applied to diagnosing cylinder faults in a marine dual-fuel engine. Specifically, this research addresses the issue of abnormal ECDT faults, which have not been extensively studied in the existing literature. Experimental validation was conducted to demonstrate the efficacy and reliability of the proposed algorithm.
The remainder of this paper is organized as follows:
Section 2 presents related work in the literature.
Section 3 introduces the exhaust system in a marine dual-fuel engine.
Section 4 provides a detailed description of the CCH-Scan algorithm. In
Section 5, faults identified in a technical report are discussed.
Section 6 presents data cleaning, characteristics, and visualization.
Section 7 discusses the results of applying the algorithm. Finally,
Section 8 concludes the paper.
2. Related Work
Researchers have used correlation in different ways in their fault diagnosis methods across a wide variety of applications. Peng et al. proposed an intelligent fault diagnosis method for nuclear power plants (NPPs), based on correlation analysis (CA) for filtering irrelevant features and a Deep Belief Network (DBN) for fault detection through unsupervised pre-training and supervised fine-tuning, detecting multiple fault types using a dataset from a simulation model [
4]. Liu et al. proposed a novel fault diagnosis algorithm, Correlation Coefficient-DBSCAN (CCDBSCAN), for power transformers based on Dissolved Gas Analysis (DGA) [
5]. This method enhances traditional DBSCAN clustering by introducing a correlation coefficient to capture and amplify the similarity between transformer faults, thereby improving clustering accuracy. Cheng et al. introduced a spatio-temporal multi-correlation fusion (STMF) technique that integrates vibration signals from multiple sensors by exploring spatial correlations and applying adaptive weights. This method significantly enhances rotor bearing and gear failure diagnosis in rotor systems. By utilizing correlation analysis to fuse data from different sensors, the authors achieved notable improvements in diagnostic performance compared to other fusion methods [
6]. He et al. introduced a Multiblock Temporal Convolutional Network (MBTCN) for fault diagnosis in multivariate processes, with a methodology that involves dividing variables into sub-blocks based on process mechanisms and utilizing a one-dimensional Temporal Convolutional Network to extract temporally correlated features within each sub-block [
7]. Wang et al. proposed an advanced fault diagnosis method for lithium-ion battery systems using a multivariate statistical analysis-based cross-voltage correlation approach [
8]. Their methodology combines Independent Component Analysis (ICA) and Principal Component Analysis (PCA) to process high-dimensional, non-Gaussian correlation coefficient (CC) signals efficiently.
Clustering algorithms such as DBSCAN, K-means, agglomerative, and mean shift clustering are widely adopted in various contexts and applications in fault detection and diagnosis systems. Li et al. proposed a method for diagnosing thermal runaway in EV lithium-ion batteries using DBSCAN clustering on voltage data [
9]. Li et al. introduced a fault diagnosis method for rolling bearings that integrates symmetrized dot pattern (SDP) analysis with an improved density-based spatial clustering algorithm (ASDP-DBSCAN) [
10]. SDP visualizes vibration signals for better pattern recognition, while optimized parameters and enhanced DBSCAN clustering improve accuracy and noise reduction. Wang et al. proposed FKM-ICS, an enhanced K-means clustering method for unbalanced vehicle fault diagnosis in railways [
11]. It improves traditional K-means by using a novel cluster-center approximation and refined feature weights, leading to more accurate and efficient diagnostics. Yu et al. introduced a fault detection system using agglomerative hierarchical clustering combined with a stacked denoising autoencoder (SDAE) [
12]. Fong et al. introduced a new fault diagnosis method using non-stationary vibration signals. They combined mean shift clustering with short-time Fourier transform to de-noise and extract time-varying harmonics without prior system knowledge [
13].
Researchers have developed many anomaly detection methods that incorporate both correlation and clustering. These methods have been widely used in fault detection. Fields of application include mechanical systems, wireless sensor networks, and industrial processes.
Chen et al. proposed a method introducing K-medoids clustering to a three-direction correlation dimension to monitor the health state of wheel bearings [
14]. The correlation dimension is a measure of the dimensionality of the space occupied by a set of random points. The algorithm begins by extracting 3D correlation dimensions from vibration signals in the x, y, and z directions, capturing the nonlinear dynamics of the bearings. These dimensions are then clustered using the K-medoids algorithm to group data into three states: normal, outer-ring fault, and cage fault. To address overlapping clusters, a two-step clustering refinement is applied, where subsets of data are clustered multiple times, and the resulting centers are re-clustered to create distinct, non-overlapping 3D spheres. These spheres represent the bearing states and are used for fault diagnosis by checking whether new vibration data falls within a specific sphere.
Yoo introduced a fault detection algorithm that utilizes sensor correlations to both reduce complexity and retain the physical interpretability of the data [
15]. The process begins by normalizing sensor measurements collected during normal operations and calculating a correlation matrix across all sensor pairs. Only pairs with strong linear relationships are selected, and the corresponding two-dimensional data subsets are used to build clustering models—typically using Gaussian mixtures—to characterize normal operating behavior. When new data is received, it is normalized similarly and evaluated by computing the Mahalanobis distance from the established clusters. These distances are aggregated into a fault index that, if exceeding a set threshold, signals an anomaly.
Liu et al. introduced a Metric-Correlation-Based Fault Detection (MCFD) approach, a novel method to identify potential faults in wireless sensor networks that may evade detection by traditional spatiotemporal correlation techniques [
16]. MCFD leverages internal system metric correlations within individual nodes. For each sensor, pairwise correlations between system metrics are quantified using Spearman’s rank correlation coefficient and aggregated into periodic correlation value views. These views are then analyzed using an improved density-based clustering algorithm, which identifies outliers by adapting to varying local densities.
Wang et al. introduced an automated fault detection method for cloud systems by analyzing workload-metric correlations [
17]. The method first applies online incremental clustering to dynamically identify user access patterns, adapting to fluctuating workloads. Using canonical correlation analysis, it models relationships between workload vectors and multilayer system metrics. Anomalies are flagged via EWMA control charts that detect abrupt deviations in correlation coefficients.
3. Marine Dual-Fuel Engine
The marine dual-fuel engine operates on both liquefied natural gas (LNG) and diesel fuel. The engine is crucial for maritime propulsion, being the primary energy source for marine vessels. However, its significant contribution to greenhouse gas emissions requires improvements to reduce its environmental impact [
18]. A dual-fuel engine is more efficient, flexible, and environmentally safer than traditional diesel engines. The use of LNG reduces the emission of air pollutant gases such as carbon dioxide (CO
2) and sulfur oxides (SOx) [
19]. Robust performance is essential for a ship’s reliable operation and maneuverability, ensuring safe navigation and operational efficiency [
20].
The dual-fuel engine comprises the five main subsystems of a diesel engine (fuel injection, air intake, exhaust, cooling, lubricating systems) [
21], in addition to the gas supply system. The fuel and gas injection systems control fuel and gas delivery to the engine’s cylinders; the cooling system prevents overheating through water and air cooling; the lubrication system reduces friction and cleans engine parts [
22]; and the air intake and exhaust systems manage combustion air supply and emissions. Given its complexity and the harsh operational environment at sea, effective fault diagnosis is vital.
The data used in this paper were collected from a two-stroke dual-fuel engine. Two-stroke engines complete a cycle in one crankshaft revolution, making them more efficient than four-stroke engines [
23].
An exhaust system in a vessel’s engine is critical in managing emissions and ensuring compliance with environmental regulations. An exhaust manifold collects exhaust gases from the engine’s cylinders using an exhaust valve and directs them toward the turbocharger. The exhaust valve controls the flow of exhaust gases, making it the main component of the exhaust system. The valve’s opening and closing operations are controlled by a spring, air, and oil system, based on the crankshaft’s position, indicating the engine’s cycle stages. Therefore, the exhaust valve’s operation is linked to the crankshaft angle.
Faults in the exhaust system are considered critical due to their effect on performance and efficiency. One common fault is exhaust valve leakage, which leads to increased exhaust temperatures and reduced power output. Hu et al. explored the use of acoustic emission signals as one of the methods to address this problem [
24]. Another significant concern is air leakage in the exhaust valve, which can compromise engine efficiency. Witkowski et al. identified this type of fault using PCA clustering analysis combined with neural networks [
25]. Additionally, insufficient airflow in the air system can occur, impacting engine performance. Tu et al. addressed this issue by utilizing Kernel Principal Component Analysis (KPCA) for feature extraction [
26]. Faults in turbines and air filters, such as clogging, are also critical for engine operation.
Basurko et al. employed artificial neural networks for diagnosing these faults [
27]. Furthermore, exhaust pipe blockage can severely impede gas flow, affecting overall engine efficiency. Zhong et al. implemented techniques like semi-supervised PCA for timely detection, though other options also exist [
28]. Finally, exhaust gas leakage, resulting from various system failures, presents another challenge for diesel engines. Wang et al. diagnosed this fault using hybrid techniques that combine manifold learning and anomaly detection [
29]. This review shows the complexity of diagnosing faults in the exhaust system and the variety of approaches available. Despite extensive research on fault diagnosis in exhaust systems, the specific fault addressed in this study has not been previously explored in the literature.
During the opening of the exhaust valve, when the crankshaft reaches a certain angle, a signal from the Engine Control System (ECS) triggers the “exhaust valve open” command. This allows servo oil to flow through a rail valve, activating the Exhaust Valve Actuator. The actuator enables oil to enter the system, pushing a piston upwards to open the exhaust valve. During the valve closing process, at a different angle, the Engine Control System sends a “close” signal to the rail valve. A spring lowers the Exhaust Valve Actuator, releasing oil from beneath the piston. The oil then returns to the system, closing the exhaust valve as it drains back through the return pipe. This opening and closing mechanism of the exhaust valve is shown in
Figure 1. The exhaust valve closing dead time (ECDT) refers to the time between the closing command and the initial movement of the spindle. The valve’s closing dead time is typically longer than its opening dead time, as shown in
Figure 2.
4. CCH-Scan Algorithm
4.1. Principle
The proposed algorithm, CCH-Scan, analyzes a group of signals that normally exhibit correlation. CCH-Scan identifies deviations in the behavior of these signals, indicating the time intervals during which abnormalities occur. An abnormal signal is defined as one that shows less correlation (i.e., different behavior) compared to the majority of the other signals. The form of data used in the algorithm is described in
Section 4.2.
The algorithm consists of an inner algorithm operating within an outer algorithm.
Figure 3 provides a high-level overview of the CCH-Scan framework, illustrating its key stages, which will be elaborated further in this section. The inner algorithm uses the correlation between the signals to perform clustering within a small sliding window time interval, denoted as
. The inner algorithm is summarized in Algorithm 1 and explained in detail in
Section 4.3.
In the outer algorithm, the inner algorithm operates on a sliding window time interval
with a duration of
T, which slides with a time shift
over the entire study period represented by the time interval
. The outer algorithm is summarized in Algorithm 2 and explained in detail in
Section 4.4.
The outer algorithm is divided into two main steps: the application of the inner algorithm and the aggregation of results.
In the application step of the outer algorithm, it is assumed that , where p is an index referring to the sliding window time interval .
In the aggregation step, the total study period
is divided into smaller intervals
. For each interval
, the results obtained from all intervals
are aggregated under the condition that
. The way in which the total period of study is divided is elaborated in
Figure 4.
| Algorithm 1 Inner Algorithm |
- 1:
Input: Signals , Algorithm C - 2:
Calculate correlation matrix: - 3:
for each i,j in 1 to N do - 4:
- 5:
end for - 6:
Calculate discretized correlation matrix: - 7:
for each in 1 to N do - 8:
if then - 9:
- 10:
else - 11:
- 12:
end if - 13:
end for - 14:
Cluster the discretized correlation matrix: - 15:
- 16:
Determine the cluster with most signals: - 17:
- 18:
for each i do - 19:
Compute Abnormality Indicator: - 20:
if then - 21:
- 22:
add to - 23:
else - 24:
- 25:
add to - 26:
end if - 27:
Compute Abnormality Metric:
- 28:
- 29:
end for - 30:
Calculate Overall Silhouette Score : - 31:
for each in 1 to N do - 32:
- 33:
end for - 34:
for each u in 1 to N do - 35:
- 36:
- 37:
- 38:
end for - 39:
- 40:
Output:, ,
|
| Algorithm 2 CCH-Scan Algorithm |
- 1:
Input: , Algorithm C, x, s, T - 2:
- 3:
while
do - 4:
s.t. - 5:
- 6:
INNER(,C) - 7:
SAVE () - 8:
- 9:
- 10:
end while - 11:
- 12:
while
do - 13:
- 14:
while do - 15:
if and then - 16:
- 17:
- 18:
for each i in 1 to N do - 19:
- 20:
- 21:
end for - 22:
- 23:
SAVE - 24:
for each i in 1 to N do - 25:
if then - 26:
- 27:
else - 28:
- 29:
end if - 30:
end for - 31:
end if - 32:
- 33:
end while - 34:
for each i in 1 to N do - 35:
- 36:
- 37:
if then - 38:
- 39:
else - 40:
- 41:
end if - 42:
- 43:
end for - 44:
if then - 45:
- 46:
else - 47:
- 48:
end if - 49:
- 50:
for each i in 1 to N do - 51:
- 52:
end for - 53:
- 54:
- 55:
end while - 56:
Output: , , ,
|
4.2. Data Definition
The data used by the algorithm is a group of signals. This data is represented in the form of a matrix
as shown in (
1).
The rows of matrix represent the signals, and the columns represent the time instances. The number of signals to be analyzed is N. Each signal has an index k, where .
has
R values, where each value is denoted as
and corresponds to a time instance
.
can be represented as in (
2).
The integer i is an index that refers to the order of the elements with respect to time. For simplicity, the reference of time starts at . It is given that .
4.3. Inner Algorithm
The inner algorithm applied on the interval is divided into six steps, where computations are performed.
Computing the correlation matrix.
The signal
is a portion of the signal
and is represented as shown in (
3). It is given that
. The correlation matrix
shown in (
4) has elements
. Each of the elements
is the Pearson Correlation between the two signals
and
with
as shown in (
5). The rows of the correlation matrix represent the signals, and the columns represent how much these signals correlate to the other signals. All the diagonal elements of the correlation matrix are equal to 1.
Computing the discretized correlation matrix.
The discretized correlation matrix
shown in (
6) has elements
shown in (
7). The number
is a threshold representing the value above which, when the absolute value of the correlation exceeds, the correlation is considered sufficiently correlated. The choice of
x will be discussed later. The value
of the matrix
represents whether the correlation between the sub-signal
and
is considered sufficiently correlated or not. The aim is to group the signals based on the correlation with each of the other signals. The rows
of the matrix
represent a signal
, and the columns of the matrix represent the evaluation of the correlation with the other signals.
Applying a clustering algorithm.
The integer
i can be seen as an index to the elements to be classified and
j as an index to the features describing these elements. The signals to be classified are represented by the elements in the set
as shown in (
8). An element
, which corresponds to a signal, is a horizontal vector as shown in (
9).
A clustering algorithm
C such as DBSCAN, Meanshift, K-means, or any other algorithm is applied to the discretized correlation matrix
. The result of the clustering is a cluster
for each
. No specific clustering algorithm must be used, but some algorithms may show better results than others.
Table 1 provides an overview of some widely used clustering algorithms and some of their parameters.
Table 1.
Popular clustering algorithms.
Table 1.
Popular clustering algorithms.
| Algorithm | Parameters | Concept |
|---|
| DBSCAN clustering [30]. | -
: Maximum distance for neighbors.
- : Minimum neighbors for a core point | Groups points that are closely packed and labels points in low-density areas as outliers. |
| K-Means clustering [31]. | - k: Number of clusters. | Partitions data into k clusters by minimizing squared distances between points and their nearest centroid. |
| agglomerative clustering [32]. | - : desired number of clusters.
- Distance metrics.
- Linkage criteria. | A bottom-up approach where each point starts as its own cluster and merges based on distance between clusters. |
| Mean shift clustering [33]. | - W: Bandwidth. | Locates dense regions in the data by shifting centroids to the mean of points within a defined radius. |
- 4.
Computing the Abnormality Indicator.
In the scenario of normal behavior and perfect conditions, the system is expected to operate where all the signals must be correlated. So, the largest number of signals should be in correlation with each other. If a few signals operate with less correlation with the majority, they are considered to perform abnormally. Based on this, it is assumed that the cluster with the largest number of signals is the normal cluster, and any other signal outside this cluster is abnormal. The abnormality indicator
indicates if a signal
is considered abnormal by the inner algorithm during the sliding window time interval
. The computation of
is shown in (
10), where
is the cluster that has the largest number of points.
Using the abnormality indicator
, two clusters can be defined, the normal cluster
and the abnormal cluster
, as shown in (
11) and (
12) respectively. The classified signals are either in the normal or the abnormal cluster, as shown in (
13).
- 5.
Computing the Degree of Abnormality Metric.
The degree of abnormality metric
measures the extent of difference between a signal and normal signals. It is equal to the Manhattan distance between the
i-th signal, represented by
shown in (14), and the center of the normal cluster, represented by
shown in (
15). The center of the normal cluster
is calculated as shown in (
16), where
is the number of normal signals. The formula to compute the degree of abnormality metric
is shown in (
17).
- 6.
Calculating the overall Silhouette Score.
The overall Silhouette Score
measures the quality of clustering, with values close to 1 indicating well-separated clusters and values near −1 indicating potential misclassification of points [
34]. In order to calculate the overall Silhouette Score
, the Silhouette Score
for each signal of index
u is calculated first based on the value of the abnormality indicator
. The cluster
represents the cluster to which
belongs, and
represents the opposite cluster. The computation of
, shown in (
21), is based on the computations shown in (
18)–(
20). Then, the average silhouette coefficient
across all signals is calculated as shown in (
22).
4.4. Outer Algorithm
The outer algorithm is applied to the total period of study represented by the interval . The outer algorithm is summarized in Algorithm 2, and it is composed of two steps. Step 1 is dedicated to applying the inner algorithms using a sliding window. Step 2 is dedicated to aggregating the results.
Applying the inner algorithm.
A window with an interval
is used. This window has a size
T and slides with each iteration
p by a duration of
s until reaching the end of the interval
, as elaborated in
Figure 4. It is assumed that
. For each iteration
p, the algorithm is applied, and the result obtained is the abnormality indicators
, the Silhouette Score
, and the degree of abnormality metrics
.
Aggregating the results.
The interval is divided into sub-intervals . In each iteration q, the following are computed:
4.5. Abnormalities Detection
An abnormality
obtained by the algorithm can be defined as:
The characteristics of the abnormality are obtained as follows:
w is the abnormality number, an integer used to identify the abnormality.
is the start time of the abnormality. It is the time when the abnormality indicator changes from 0 to 1.
is the end time of the abnormality. It is the time when the abnormality indicator changes from 1 to 0.
is the signal number i, which the abnormality corresponds to.
is the abnormality’s degree of abnormality.
is the algorithm’s quality score to obtain this abnormality.
is the algorithm’s voting score to obtain this abnormality.
The two scores
and
are used to measure the significance of obtaining the abnormality by the algorithm and can be used to filter some of the abnormalities.
shows the quality of the clustering that allowed obtaining this abnormality, while
measures the degree of consistency of the algorithm’s result within the calculations from multiple time intervals.
4.6. Algorithm Evaluation
The following two parameters are used to evaluate the algorithm:
The total duration with abnormalities:
5. Faults and Abnormal ECDT Signals
The results from the algorithm are to be compared with abnormalities associated with faults recorded in a technical report summarized in
Table 2. This ground truth data does not specify all the faults that occurred and the exact period of time the faults occurred; however, it shows some reported faults and the date they were reported. During the study period, four faults were reported, each characterized by having an abnormal ECDT in certain cylinders.
For Fault 1, the report indicates that the ECDT of cylinders 1, 2, 5, and 11 were abnormal on 20 September 2021. The report stated that a service engineer must urgently overhaul exhaust valves 1, 2, and 5, and that if this was not feasible, the three new exhaust valves must be changed. Moreover, there were two instances of gas trips or slowdowns during a voyage that occurred due to a timing failure in exhaust valve 11. This failure resulted in the valve not opening or closing at the correct times, leading to disruptions in the engine’s performance and potentially compromising safety. The report also states that to prevent further issues and ensure optimal operation, exhaust valve 11 must be overhauled to restore its functionality and maintain the vessel’s performance.
For Fault 2, the closing dead time of exhaust valve 8 was abnormal on 3 November 2021, indicating a potential malfunction that could affect the engine’s performance and efficiency. The report indicates that to address this issue and ensure that valve 8 operates correctly, it must be overhauled by the manufacturer known for its expertise in servicing and maintaining its engine systems. This overhaul must be carried out to restore proper functionality and help prevent further operational problems.
For Fault 3, the report also states that the closing dead time of exhaust valve 4 was abnormal on 4 November 2021, and that valve 4 must also be overhauled by the manufacturing company.
For Fault 4, the report indicates that a dead closing time alarm occurred on 16 January 2022 and that the top part of a certain exhaust valve has been overhauled.
6. Data Preparation
The data being analyzed is real data collected from a 2-stroke marine dual-fuel engine for a ship owned by a well-known shipping company. The data from the ship were collected during propulsion and for a duration of 5 months. The names of the shipping company, ship, and engine are not disclosed in this paper to maintain confidentiality. Additionally, the dates presented have been shifted from the actual dates to preserve data integrity. The data extracted are for a dual-fuel exhaust valve closing dead time (ECDT) for 12 cylinders, and the period of study is from 1 September 2021 to 31 January 2022. The ECDT is represented as a function of time with a non-uniform sampling rate of about 10 s. The data contains about 1.2 million instances for each of the 12 cylinders.
Despite its usefulness, the dataset suffers from several limitations related to temporal resolution, data granularity, and missing key parameters, all of which constrain the depth of analysis and modeling. Specifically, there is one value of the ECDT for each cycle of the engine. Assuming that the rotational speed of the motor is 60 rpm, this corresponds to one ECDT value every second. However, the recording of these values is saved only every 10 s. As a result, most of the ECDT values are not present in the dataset, leading to a significant loss of temporal resolution. Moreover, there are no measurements, such as crank angle or stroke, at the cycle level. Instead, the available data consists of only one ECDT value every 10 cycles. Finally, the average value of ECDT is about 140 ms, which is relatively small compared to the duration of a single cycle, highlighting the fine-scale variability that is not captured by the coarse sampling.
The first step in preparing the data is eliminating outliers. The outliers are a few isolated, extremely high values that are impossible to attain. These outliers were removed by eliminating points with ECDT values higher than a threshold (of 500 ms) and replacing them with an interpolated value. The choice of the threshold was made after visualization of the data and realizing that it was capable of eliminating all the outliers.
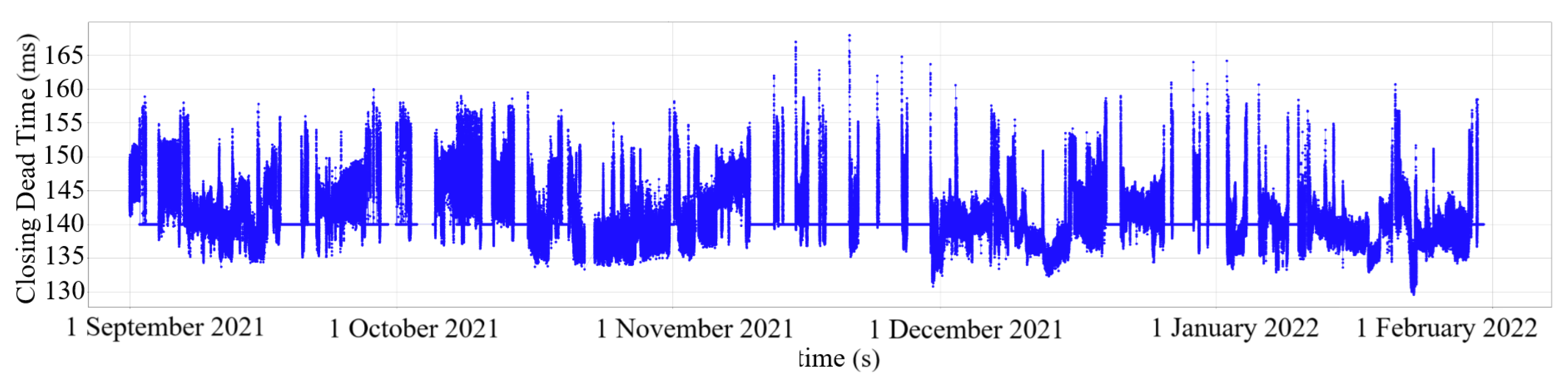
Figure 5 shows the ECDT for cylinder 1 after removing the outliers.
The second step is to identify and select continuous periods of usable data while filtering out intervals with prolonged data absence.
Figure 5 shows the presence of some long periods with a constant ECDT equal to 140 ms, indicating the absence of data. To solve this, some periods for study were selected from the 5 months to apply the algorithm.
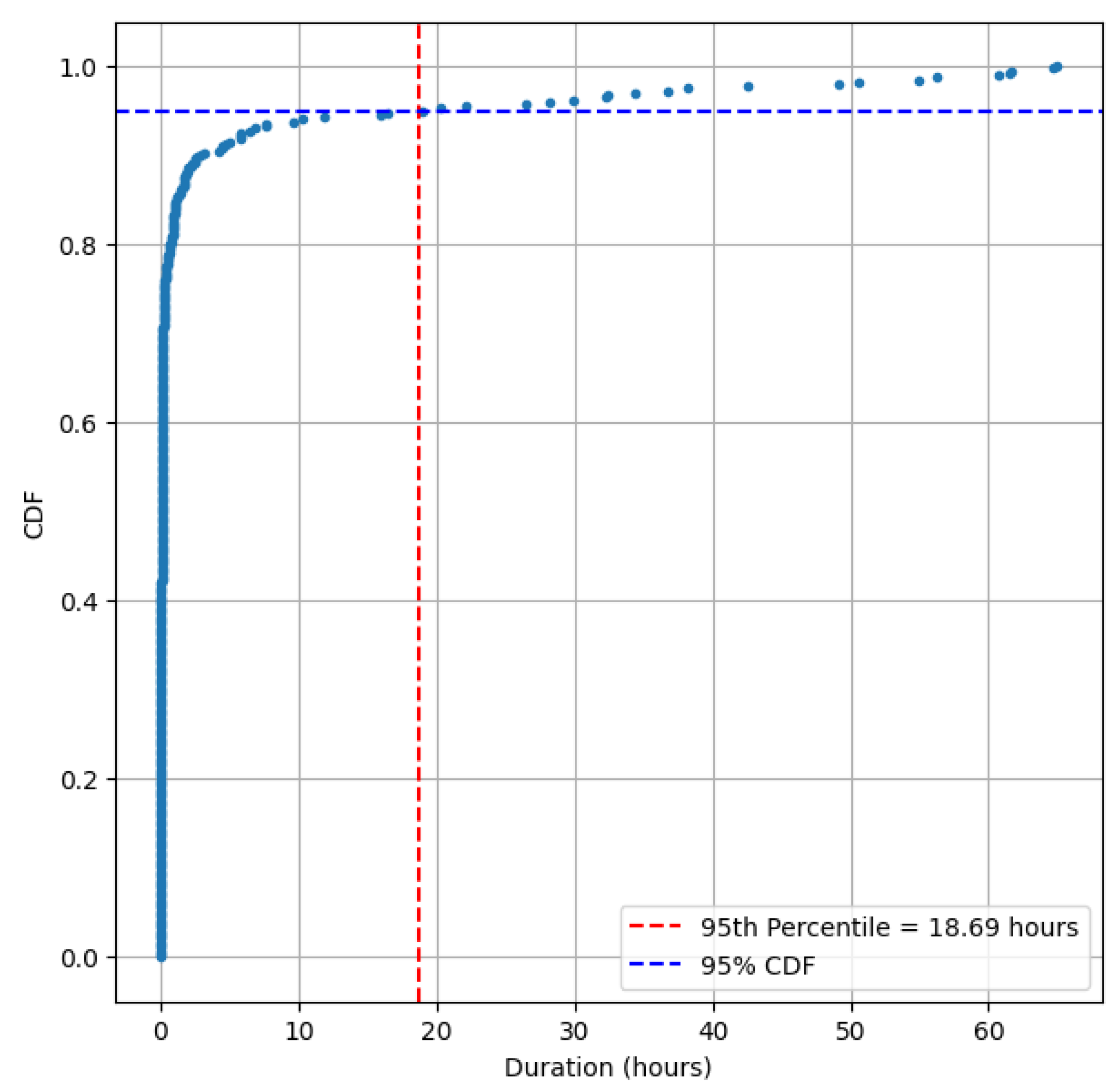
Figure 6 shows the CDF of the duration with the absence of data. Therefore, the top
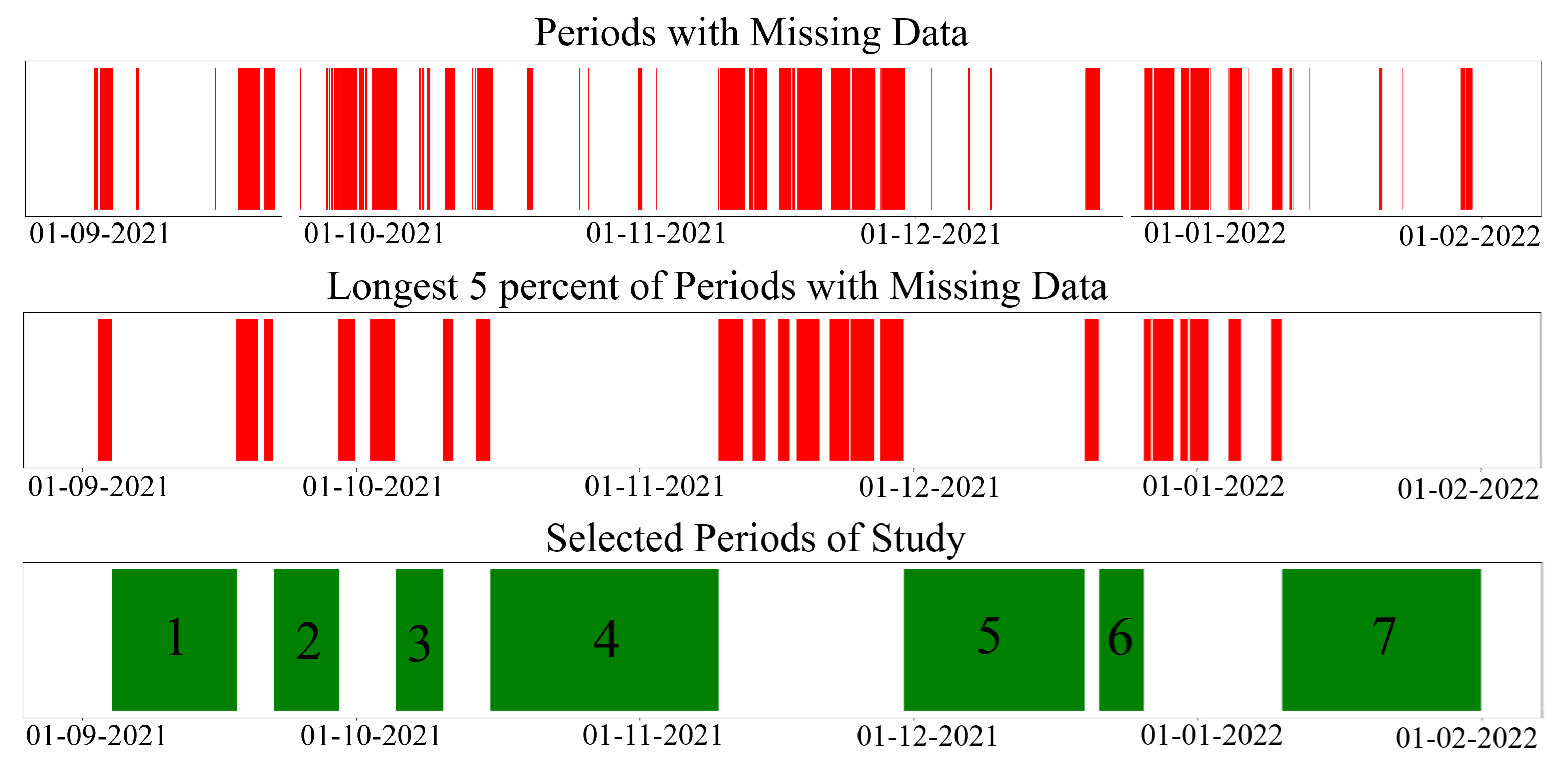
of the periods with the absence of data were eliminated. Then, out of the remaining data periods, the periods longer than 4 days were selected for study and are shown in
Table 3. The format used in the table is for time “YYYY-MM-DD hh:mm:ss” and for duration “DD days hh:mm:ss,” where
Y,
M,
D,
h,
m, and
s represent year, month, day, hour, minute, and second, respectively.
Figure 7 shows the periods with missing data and the selected periods for study. Finally, the number of selected periods for study is 7, and it contains 800 K instances for each cylinder with a total duration of 97 days 13:25:21. Overall, the cylinders’ ECDT has a minimum of 122.3 s, a maximum of 191.3 s, an average of 137.65 s, and a standard deviation of 5.09 s.
The aim is to use this data to detect the cylinders with an abnormal ECDT and in which periods. The results from the algorithm are to be compared with abnormalities associated with faults recorded in a technical report shown in
Table 2.
7. Results
7.1. Clustering Algorithm
Different clustering algorithms could be adopted in the clustering step of the inner algorithm of CCH-scan. The aim of this section is to analyze the effect of the choice of clustering algorithm and its parameters on the results obtained by CCH-scan. Four clustering algorithms were adopted with different parameters. In each case, the clustering quality
Q and the duration of abnormalities
D were computed in each scenario as shown in
Table 4. The adopted clustering algorithms are DBSCAN, K-means, agglomerative, and mean shift clustering. For the DBSCAN algorithm, two parameters were studied: maximum distance
and minimum number of points
. For K-means, the parameter studied is the number of clusters
k. For agglomerative clustering, the studied parameter is the desired number of clusters
. For mean shift clustering, the studied parameter is the bandwidth
W. The total number of scenarios is 22.
Looking at the results in
Table 4, several observations can be made:
When K-means was used, the clustering quality decreases with the increase in the number of clusters K.
When using agglomerative clustering, the clustering quality decreases with the increase in the number of clusters N.
Better clustering quality can be seen when using DBSCAN and mean shift compared to K-means and agglomerative clustering.
In DBSCAN, results showed only a slight advantage of using over using .
In DBSCAN, the change in the maximum distance for neighbors has a great influence on the result. The increase in increases the quality of clustering and decreases the duration of abnormalities.
In mean shift clustering, the increase in W increases the quality of clustering and decreases the duration of abnormalities.
The results of the mean shift algorithm had a slight advantage over DBSCAN.
Therefore, in general, changing the parameters of a clustering algorithm could increase the quality of clustering, but the drawback is that this will make the algorithm more selective in detecting abnormalities. As seen in
Table 4, the increase in bandwidth in the mean shift algorithm results in limiting the duration of abnormalities.
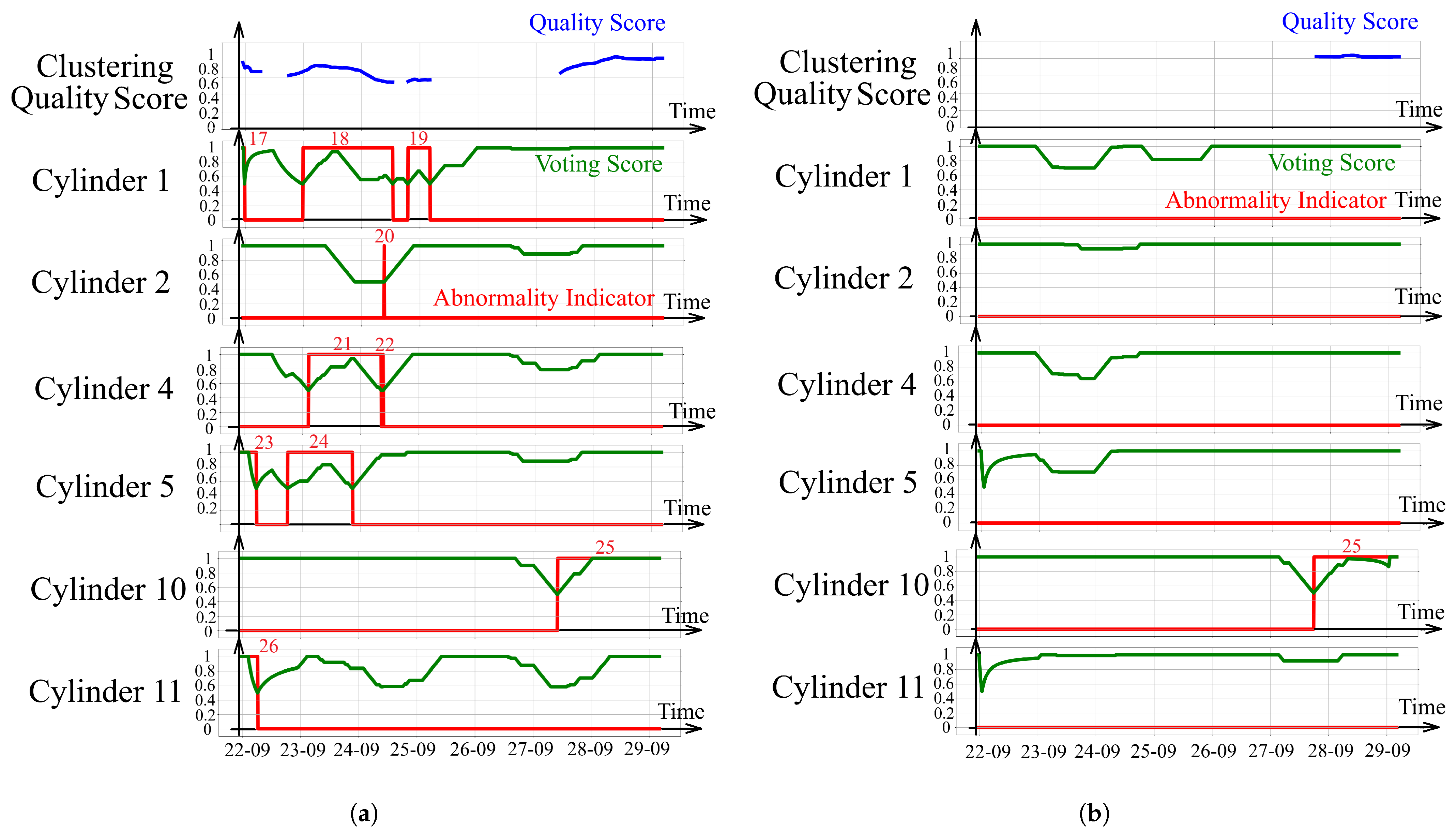
Figure 8 provides insight into the algorithm’s behavior on a period of study, highlighting the voting score and demonstrating the impact of clustering parameter variations on the results.
Figure 8a shows the abnormality indicator, quality score, and voting score as a function of time obtained by applying CCH-Scan with mean shift with
on the period of study 2. As noticed, 10 abnormalities were obtained, having abnormality numbers from 12 to 26.
Figure 8b also shows the result of applying CCH-Scan on the second period of study, but this time using the value
for the mean shift algorithm. In
Figure 8b, only one abnormality with the number 25 was obtained. Comparing the results in
Figure 8a,b, it is seen that increasing the bandwidth
W did not allow the detection of some abnormalities. The abnormalities that were not detected to have lower voting scores and quality scores compared to the abnormality that remained.
There is no perfect choice of the parameters, but certain choices are more reasonable than others. The parameters could be tuned to obtain the most logical outcome. In practice, the choice of the parameters of the algorithms requires experience in the system and statistical analysis, such as knowing how much the estimated duration of abnormalities is. In this study, these statistics are not available.
When looking at the voting score in
Figure 8a, it is seen that abnormalities 19, 20, and 22 have a low voting score of around 0.5. This means that the calculations by the inner algorithm did not indicate abnormality for about half of the time. On the other hand, when looking at the voting score for abnormalities 23, 25, and 26, it can be seen that the voting score remained equal to 1 for a period of time. This means that all the calculations by the inner algorithm indicate an abnormality. The information by the algorithm concerning abnormalities 23, 25, and 26 can be trusted more than that concerning abnormalities 19, 20, and 22.
7.2. Discretization Constant
The discretization constant
x varies between 0 and 1. It is a threshold that represents the value for which, when the absolute value of the correlation exceeds, the correlation is considered to be sufficient. In this section, the effect of the choice of
x on the result of CCH-Scan is discussed. The algorithm was applied with different values of
x while using
min,
h, and mean shift clustering with
.
Table 5 shows the clustering quality and the total duration
D of abnormality for different values of the discretization constant
x. The results show that as
x increases, the clustering quality increases, and the duration of abnormalities decreases. The value
is the most intuitive choice; however, different values of
x could be chosen. Having statistical information concerning the estimated duration of abnormalities, with expertise in the system, allows for a suitable choice of
x.
7.3. Changing s and T
The aim is to study how CCH-Scan is affected by the change in the shift
s and duration
T of the sliding window. The algorithm was applied with different values of
s and
T while using
and mean shift clustering with
.
Table 6 shows the abnormality duration and clustering quality when changing
s and
T.
The results in
Table 6 show that as
s gets larger, a slight decrease is observed in the clustering quality and a slight increase in the duration of abnormalities. However, for larger values of
T, these variations become insignificant. When
s is small enough with respect to
T, no more improvement in quality is obtained. Smaller values of
s relative to
T allow obtaining more results from the inner algorithm, thus yielding more precise results. The increase in
T shows a decrease in the quality of abnormalities and an increase in the durations of abnormalities. However, when the duration of
T is small enough, these changes become insignificant.
7.4. Analysis of Abnormalities
CCH-Scan was applied with
and
while using
and mean shift clustering with
. The number of abnormalities obtained is 79. An abnormality
is characterized by its duration
, the degree of abnormality
, the quality score of abnormality
, and the voting score of abnormality
. Based on these characteristics, abnormalities could be queried or filtered, and several statistics could be computed. For example, abnormalities with very short durations may be removed from the analysis.
Table 7 shows some statistics related to the obtained abnormalities.
These statistics can serve as a reference to help characterize and compare a specific abnormality to the general characteristics of the obtained abnormalities. For example, the average duration for an abnormality is 16.36 h, with an average degree of abnormality equal to 0.548.
To obtain the most abnormal signals, it is possible to focus on the degree of abnormality
. For example,
Table 8 shows the abnormalities with the top 10 percent degree of abnormality
. Looking at this table, it can be seen that the top 3 abnormalities (
, 8, and 11) happened at the same time on 2021-09-17 between 19:50:19 and 22:40:19.
Sometimes, the algorithm detects abnormalities but with low confidence in the results. For example,
Table 9 shows the abnormalities with the minimum 10 percent quality score
and voting scores
. These abnormalities could be neglected when analyzing the results.
Statistics can also be performed at the cylinder level. This helps in indicating where necessary maintenance action should be prioritized.
Table 10 shows the number of abnormalities, total abnormality duration, and degree of abnormality corresponding to each cylinder. Looking at the results, it can be seen that cylinders 3 and 9 did not have any abnormalities during the period of study. Cylinders 6, 7, 8, 10, and 12 showed a low level of abnormality. However, cylinders 1, 2, 4, 5, and 11 exhibited a serious degree of abnormality, indicating that necessary actions need to be taken. These results show high consistency with the reported findings in
Table 2.
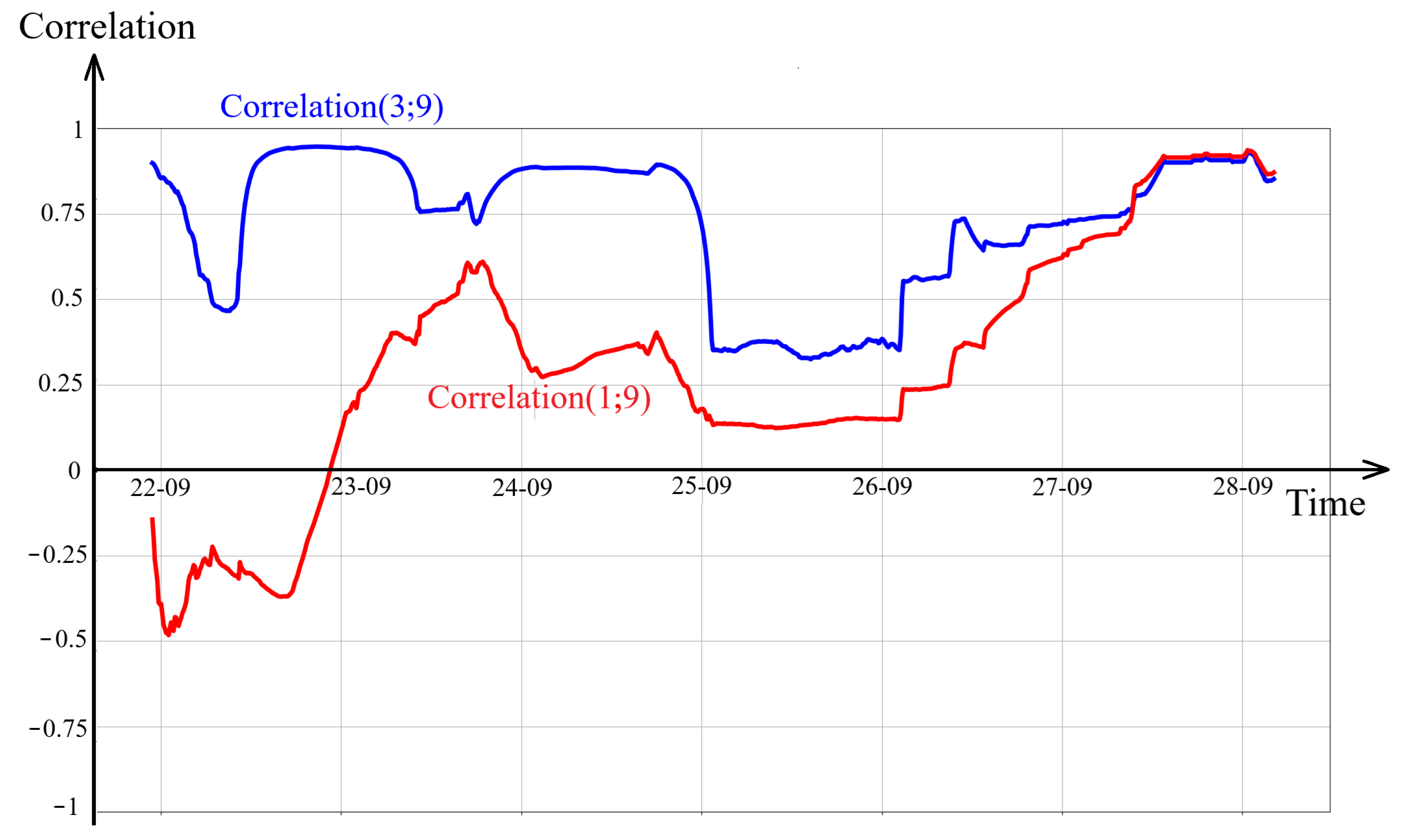
Figure 9 shows the correlation as a function of time for the second study period between the ECDT of cylinders 3 and 9 (in blue) and between cylinders 1 and 9 (in red). It is seen that the correlation between the ECDT of cylinders 3 and 9 is high during the second period of the study, as defined in
Table 3. This is consistent with the fact that these two cylinders did not show any abnormalities. The correlation between cylinder 1, which showed a high degree of abnormality, and cylinder 9, which did not show any abnormality, is low for the majority of period 2.
As mentioned before, a fault is a defect or malfunction within a system component that causes improper operation or failure to meet performance standards, often linked to specific components or subsystems. The technical report documented 4 faults, as shown in
Table 2. Each of these faults was linked to abnormalities in the ECDT of some cylinders. However, abnormalities represent deviations from normal behavior but do not always indicate faults. Observing a pattern of abnormalities may indicate the presence of underlying faults.
The obtained abnormalities could be plotted as a function of time to observe which groups of abnormalities occurred around the same period and compare the results to the reports.
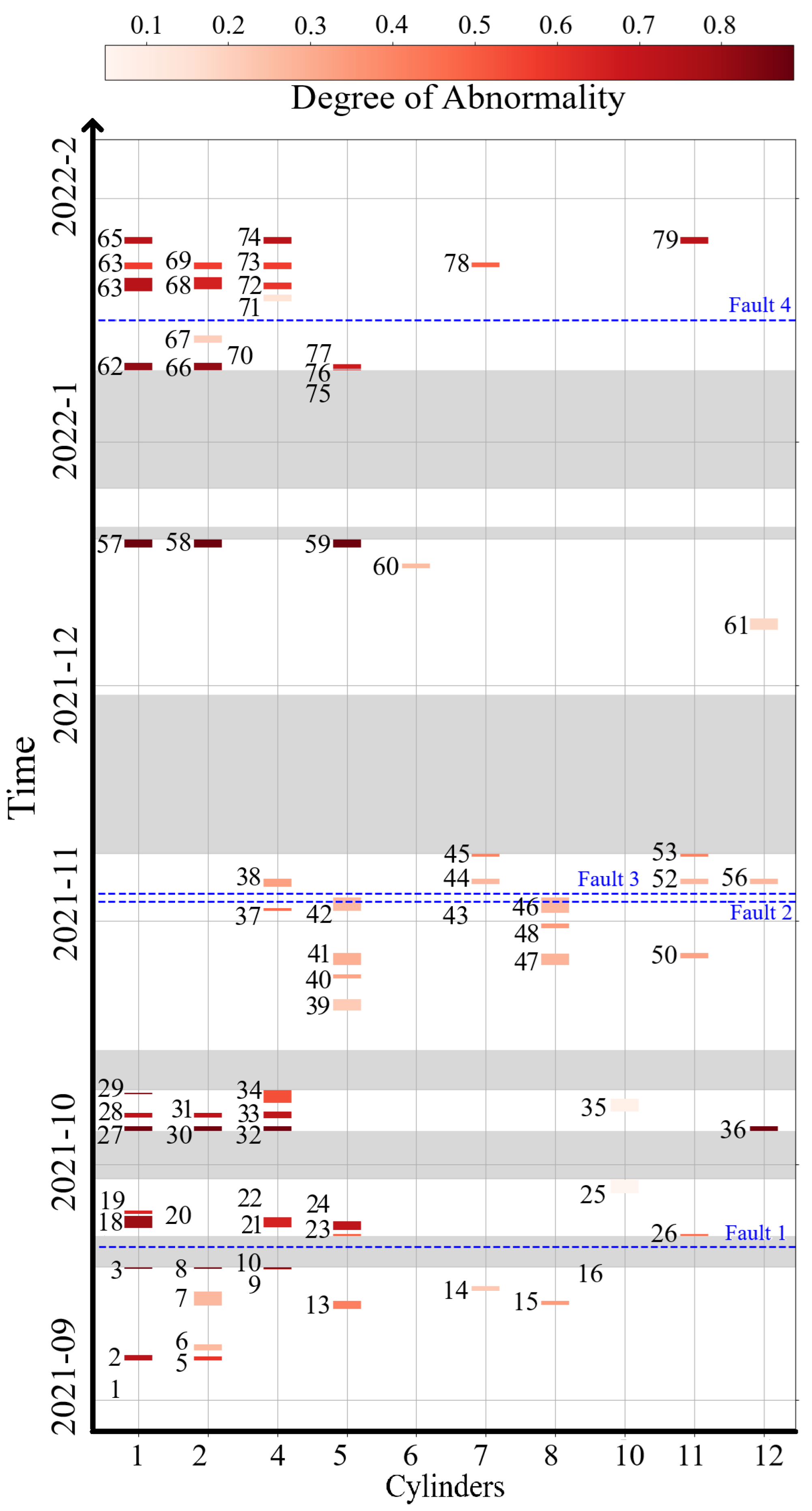
Figure 10 shows a timeline of the abnormalities obtained by CCH-Scan and the corresponding degree of abnormality.
Looking at the results, it can be seen that the abnormalities obtained by CCH-Scan are grouped into three main clusters based on the time of occurrence. These groups can be mapped to the four faults reported in
Table 2. For example, the obtained abnormalities with
can be related to “Fault 1”, abnormalities with
can be associated with “Fault 2” and “Fault 3”, and abnormalities with
(except for abnormalities 60 and 61) can be linked to “Fault 4”.
It is also noticeable that during the first 18-day period, no significant abnormalities were detected, which aligns with the reports on faults.
“Fault 1” in the report indicates faults in cylinders 1, 2, 5, and 11, and this is consistent with the plot. However, the plot also shows several other serious abnormalities that were not reported, such as in cylinder 4. “Fault 2” and “Fault 3” from the report indicate faults in cylinders 4 and 8, which were detected by the algorithm, but the algorithm also identified issues in other cylinders that were not reported.
Although the ground truth from the technical reports is not complete and fully reliable, there is a high degree of alignment with the results obtained by the algorithm.
8. Conclusions
This paper introduces CCH-Scan, a novel anomaly detection algorithm designed to analyze correlated signals in normal operating conditions. The algorithm applies a clustering technique to correlation matrices derived from signal sets within specific short time intervals, repeating this process over the study period. The methodology and algorithm details are thoroughly explained.
CCH-Scan was applied to exhaust valve closing dead time (ECDT) signals to detect abnormalities in a 12-cylinder marine dual-fuel engine. The significance of this critical signal in the exhaust system of a marine dual-fuel engine is highlighted. The algorithm includes several parameters—such as the clustering algorithm, discretization constant, shift (s), and duration (T)—which influence the results, particularly the duration and quality of detected abnormalities. The effect of varying these parameters was explored within the case study.
While there is no one-size-fits-all set of parameters, the optimal choice depends on the specific application and expert knowledge of the system. Abnormalities were identified, analyzed, and plotted over time, revealing the time of occurrence and degree of abnormality. These results were compared with a technical maintenance report, showing a high degree of consistency. The detected abnormalities were grouped into three categories, each corresponding to a distinct fault.
Despite the modest reliability of ground truth data typical in industrial projects, CCH-Scan demonstrated promising potential for diverse applications. While the algorithm showed strong performance, its numerous parameters may present challenges in tuning. Future work will focus on comparing CCH-Scan with other methods in varied environments to enhance its understanding and broaden its applicability.
Future research will address several open challenges and opportunities for advancing CCH-Scan. Key directions include improving parameter sensitivity analysis and developing parameter tuning strategies. Further validation across different types of machinery and operational contexts is important. Additionally, efforts will be made to evaluate the algorithm’s performance under noisy conditions and with missing or incomplete data. Quantitative benchmarking of CCH-Scan against established anomaly detection techniques will be pursued once more accurate ground truth data becomes available. Finally, investigations into real-time applicability will be crucial to extending the algorithm’s utility in industrial environments.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}