
Recent Advances in Multi-Agent Reinforcement Learning for Intelligent Automation and Control of Water Environment Systems



Abstract
1. Introduction
- Intelligent pump station scheduling: Modeling multiple pump stations as cooperative agents, MADRL integrates predictive management with adaptive control to achieve optimal trade-offs between energy consumption and water supply efficiency.
- Urban flood control: Under extreme rainfall conditions, drainage nodes must collaboratively optimize retention and discharge strategies. MADRL enables the learning of disaster response policies in simulated environments.
- Joint scheduling of multiple water sources and watershed management: In large-scale basins with coupled water sources, MADRL supports multi-objective water resource allocation and coordination.
- Emergency pollution control: In response to sudden water quality events, multiple sensing and control nodes collaborate to optimize the timing and spatial extent of emergency interventions.
2. Theoretical Fundamental and Modeling Mechanisms of Multi-Agent DRL
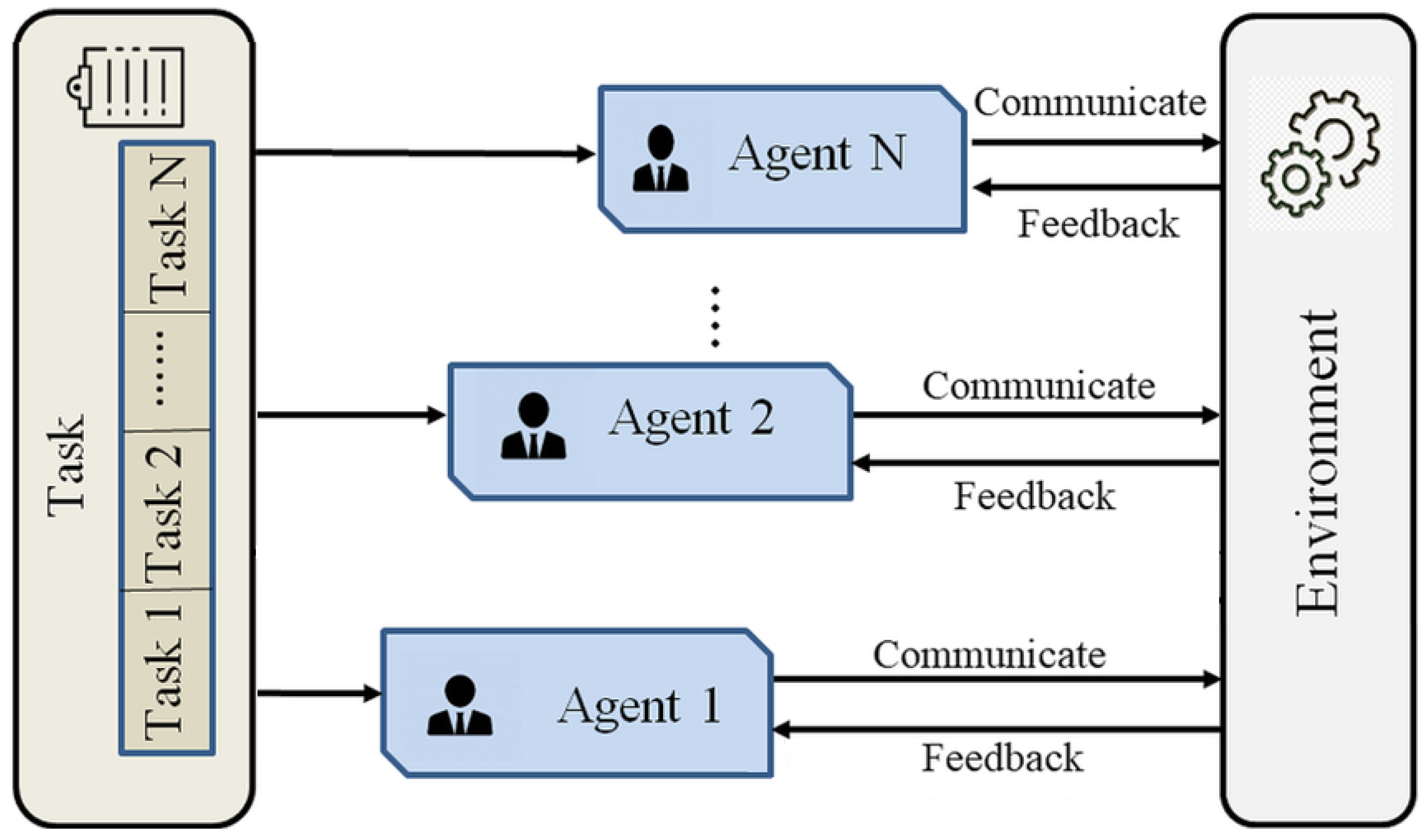
2.1. Problem Formulation and Modeling Framework
- denotes the system state space (e.g., water quality parameters, flow conditions, meteorological inputs);
- represents the set of available control actions (e.g., switching pumps on/off, adjusting chemical dosages, regulating flow rates);
- is the state transition probability function;
- is the agent’s decision-making policy;
- is the discount factor used to balance immediate and future rewards.
2.2. Identification of Key State Variables in Water Environment System Regulation
- (1)
- Pollutant concentration.
- (2)
- Flow velocity, discharge, and water level.
- (3)
- Operational status of control facilities.
2.3. Action Space Design and Classification in Intelligent Control
- (1)
- Fixed action sequences.
- When the agent executes action , the system maintains the current control state without adjustment (e.g., keeping the current pump speed, gate open, or aeration intensity);
- When executing action , the system switches to the next predefined control mode or scheduling scheme (e.g., sequentially activating different water treatment units or rotating pump operations according to a fixed schedule).
- (2)
- Variable action sets.
- At each decision step t, the agent selects an action based on a learned policy , which defines a probability distribution over all candidate actions.
- This approach provides greater flexibility in control and is more adaptable to non-stationary water quality disturbances or multi-objective regulatory tasks.
- Action constraints : to limit the feasible action set;
- Penalty functions : to discourage unsafe or costly actions;
- Safety filtering mechanisms: to override or restrict high-risk action execution.
2.4. Reward Mechanism Design in Intelligent Regulation of Water Environment Systems
- (1)
- Duration or cumulative degree of pollutant concentration violations.
- (2)
- Energy consumption or operational cost of control actions.
- (3)
- Water quality recovery time or target achievement time.
- (4)
- Water level and volume balance indicators.
- (5)
- Multi-objective integration via weighted aggregation.
3. Training Paradigms in Multi-Agent DRL
3.1. Independent Learning Paradigm
3.2. Centralized Learning Paradigm
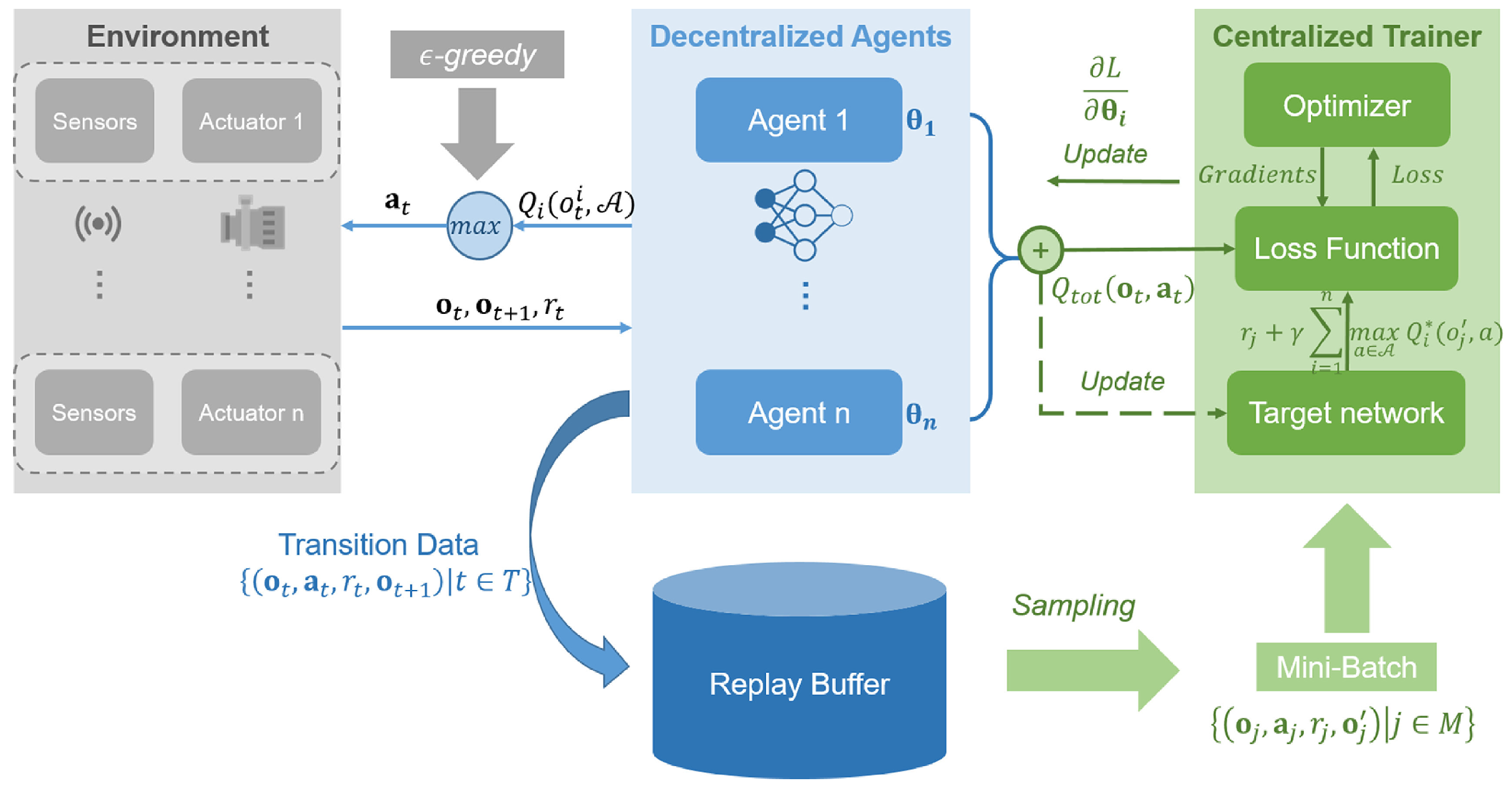
3.3. Centralized Training with Decentralized Execution in Water Environment Systems
3.3.1. Value Decomposition Approaches for Distributed Control
- Multi-point water quality control involves maintaining indicators such as dissolved oxygen (DO), ammonium nitrogen (), or total phosphorus (TP) within target thresholds across multiple monitoring sections;
- Zonal aeration strategy optimization uses independently operating aeration units to locally regulate oxygenation while contributing to system-wide water quality balance [27].
3.3.2. Applications of Centralized Value Function Methods in Multi-Agent Regulation
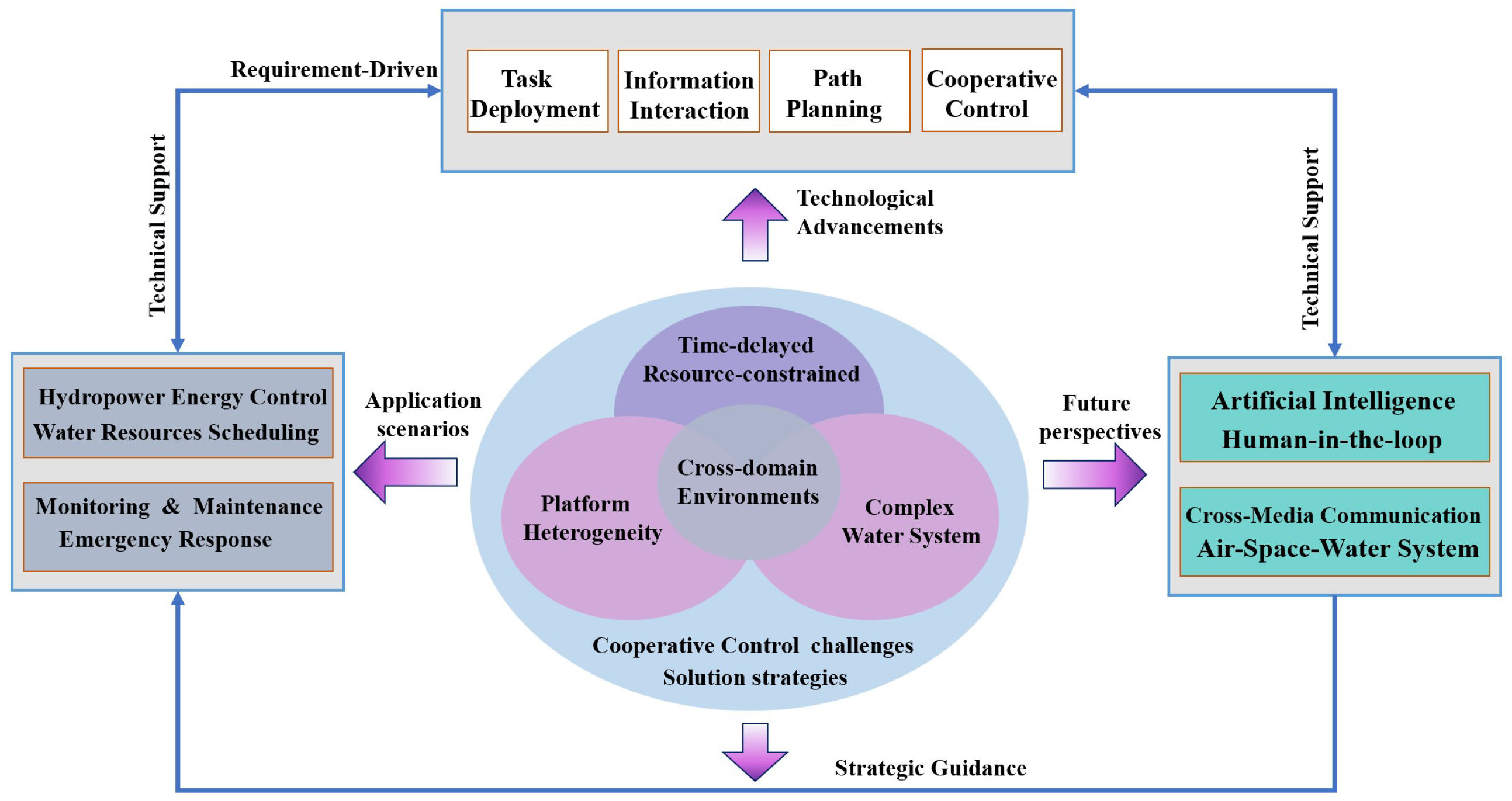
4. Cross-Domain Collaborative Control and Decision Architectures in Water Environment Systems
- Task deployment and optimization;
- Information perception and transmission mechanisms;
- Path planning and agent scheduling;
- Multi-agent cooperative control strategies.
4.1. Strategies of Task Deployment in Collaborative Control
- (1)
- Centralized task deployment strategies.
- Multi-section pollutant source tracking;
- Eutrophication emergency remediation;
- Unified water quality standard enforcement across river basins.
- (2)
- Distributed task deployment strategies.
4.2. Communication Mechanisms for Multi-Agent Collaboration in Intelligent Water Environment Systems
4.2.1. Intelligent Communication Mechanisms for Collaborative Regulation in Water Environment Systems
4.2.2. Graph Topologies for Air–Water–Land Multi-Agent Collaboration in Water Environment Systems
4.2.3. Communication-Aware Collaboration and Adaptive Swarm Control Strategies
4.2.4. Cross-Regional Integrated Sensing and Control System Architectures
4.3. Path Planning and Adaptive Control for Water Infrastructure Systems in Complex Environments
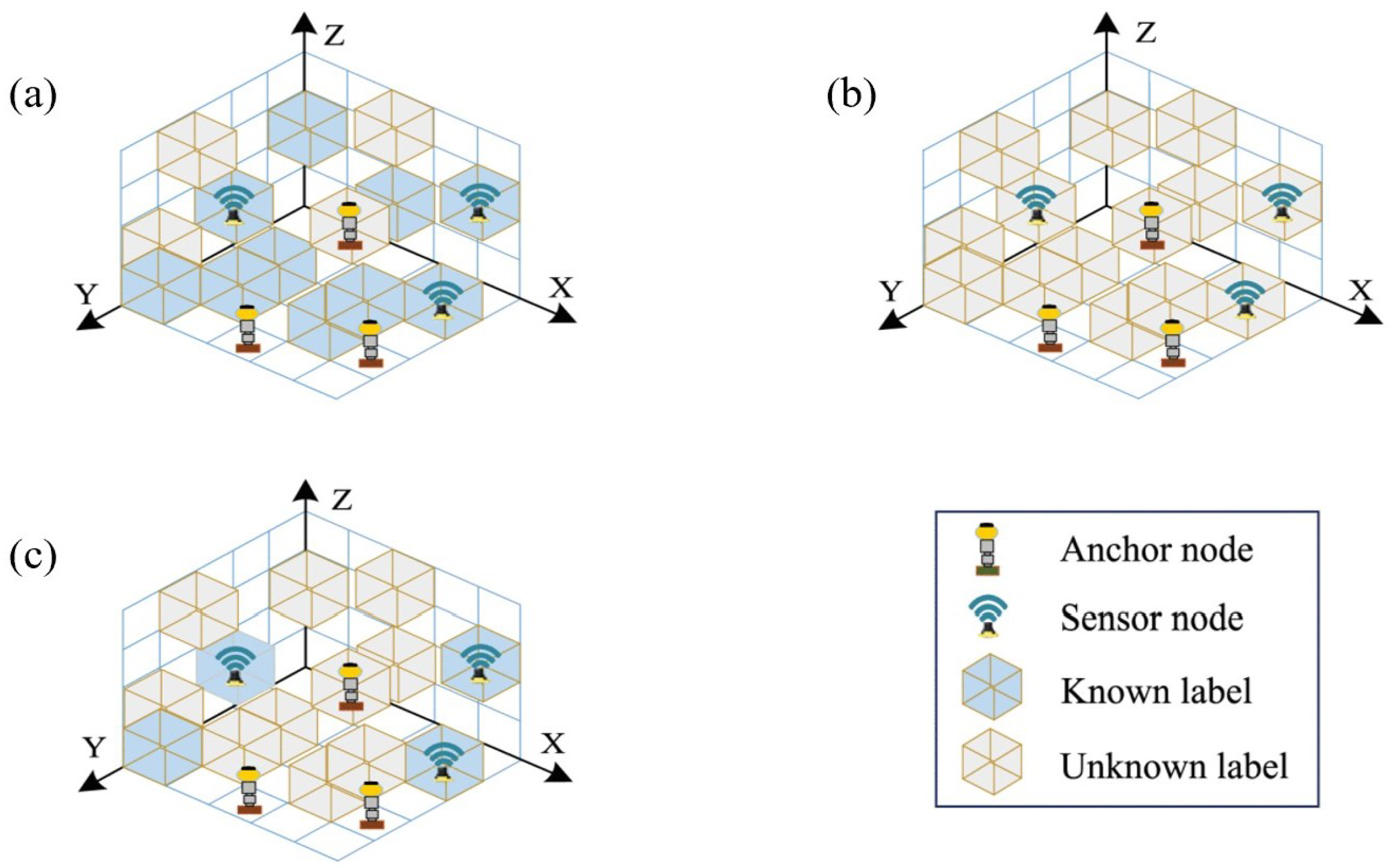
4.3.1. Multi-Platform Collaborative Mapping for Water Environment Infrastructure Systems
4.3.2. Target Situation Awareness in Intelligent Water Environment Systems
4.3.3. Dynamic Monitoring and Target Tracking Mechanisms
4.4. Towards Application-Oriented Deployment of Cross-Domain Control Architectures
5. Application Practices of Multi-Agent Reinforcement Learning in Water Environment Systems
5.1. Urban Drainage and Emergency Pollution Control
5.1.1. Intelligent Regulation Requirements and Reinforcement Learning
5.1.2. Robustness Assessment and Fault Tolerance Under Communication Failures
5.2. Multi-Agent Intelligent Control for Urban Water Distribution Systems
5.2.1. Intelligent Control Requirements in Water Supply Systems
5.2.2. Multi-Agent Modeling and Task Decomposition for Water Supply Networks
5.2.3. Applications of Deep Reinforcement Learning in Water Supply Control
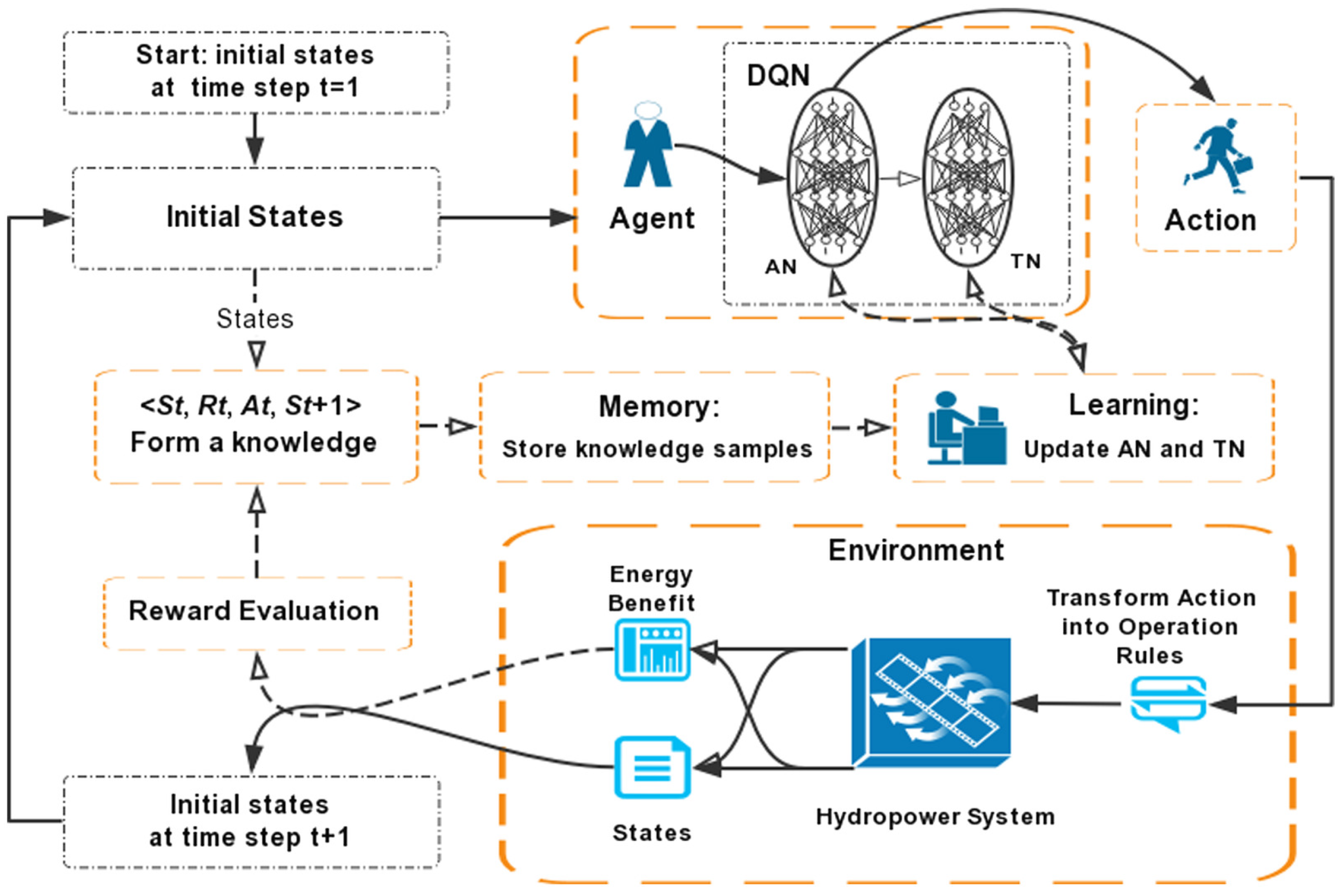
5.3. Multi-Agent Regulation in Hydropower Energy Systems
5.3.1. Hydropower Scheduling Problems and DRL-Based Hydropower System Control
5.3.2. Cutting-Edge Applications of Multi-Agent DRL in Hydropower Systems
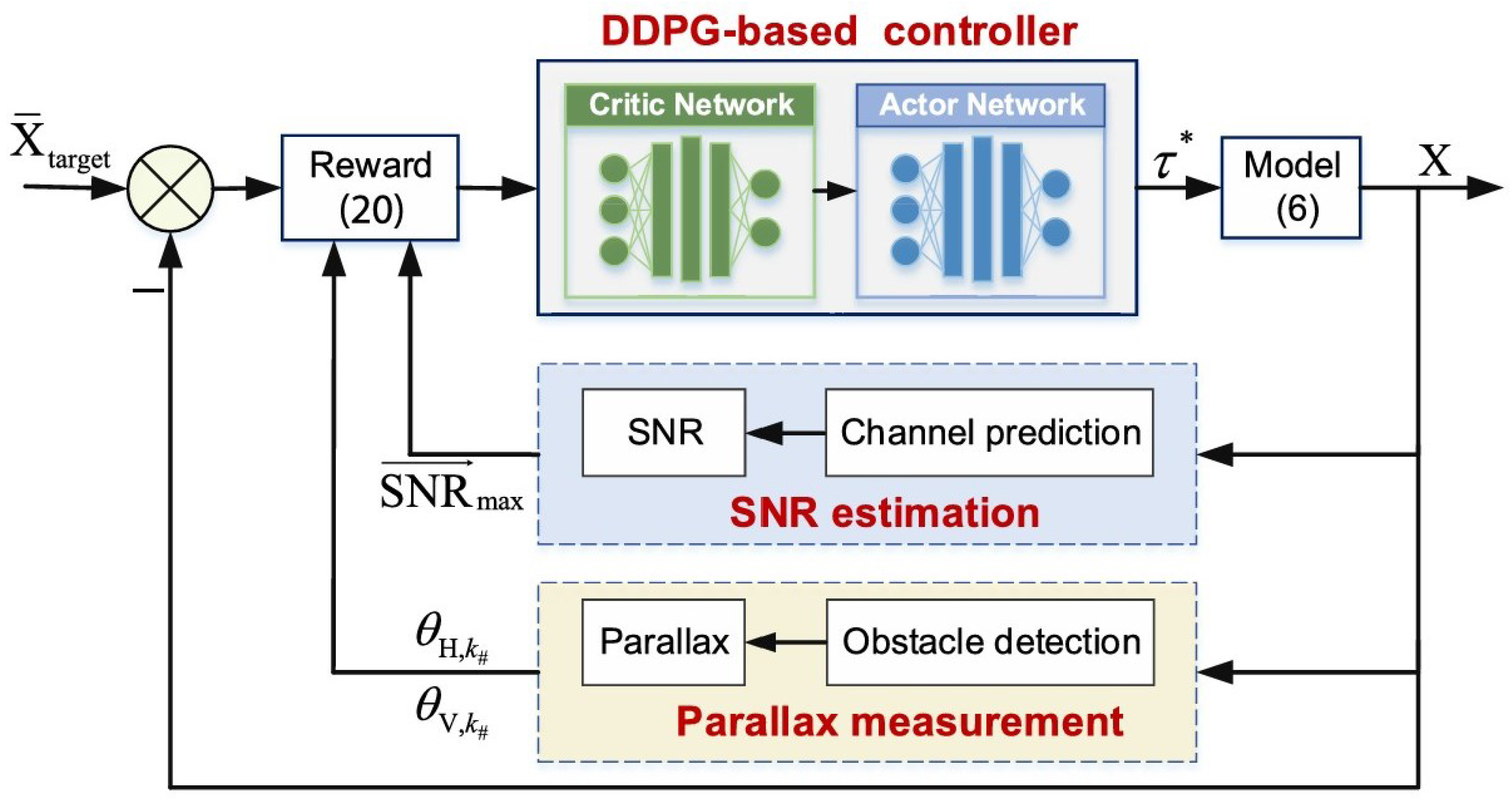
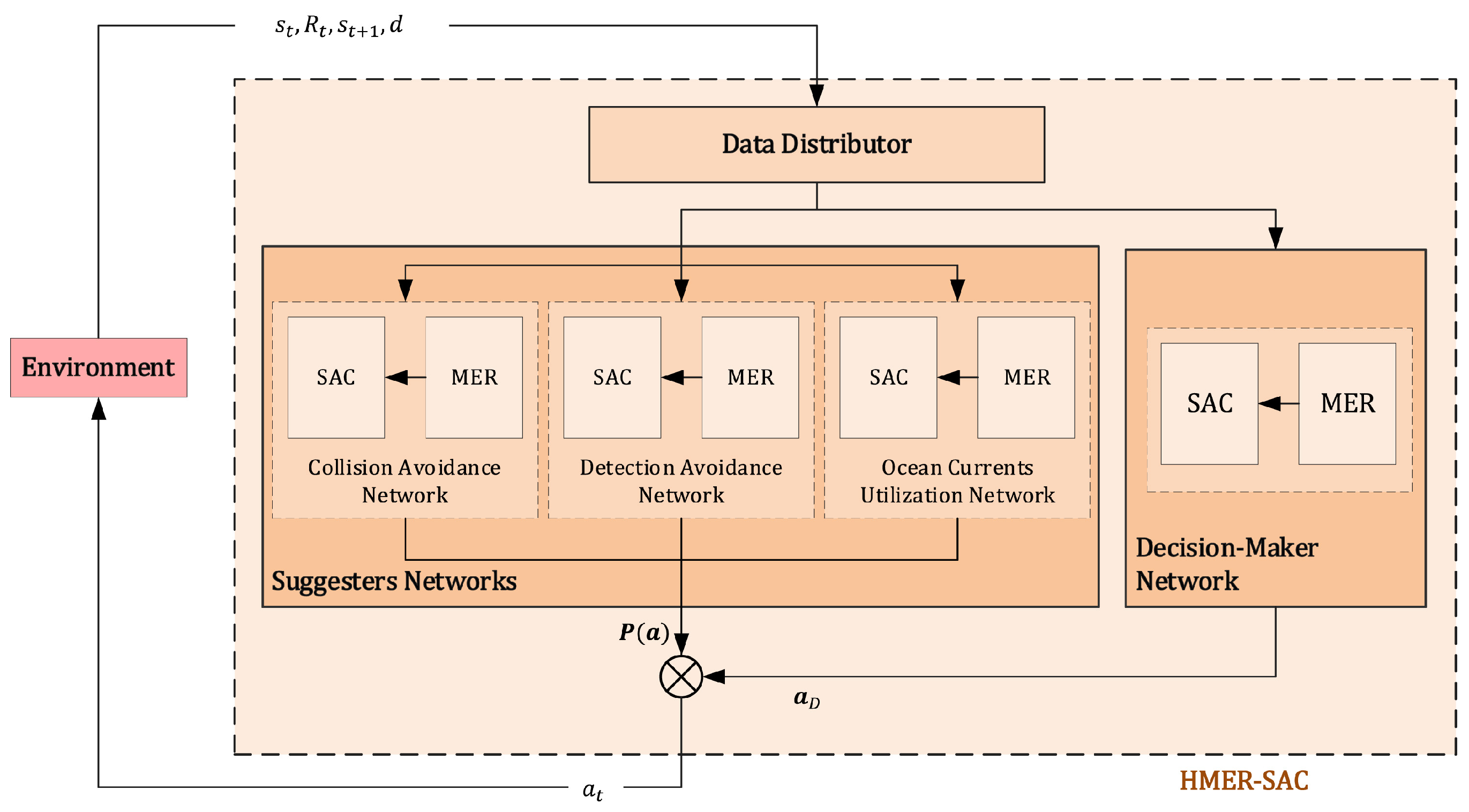
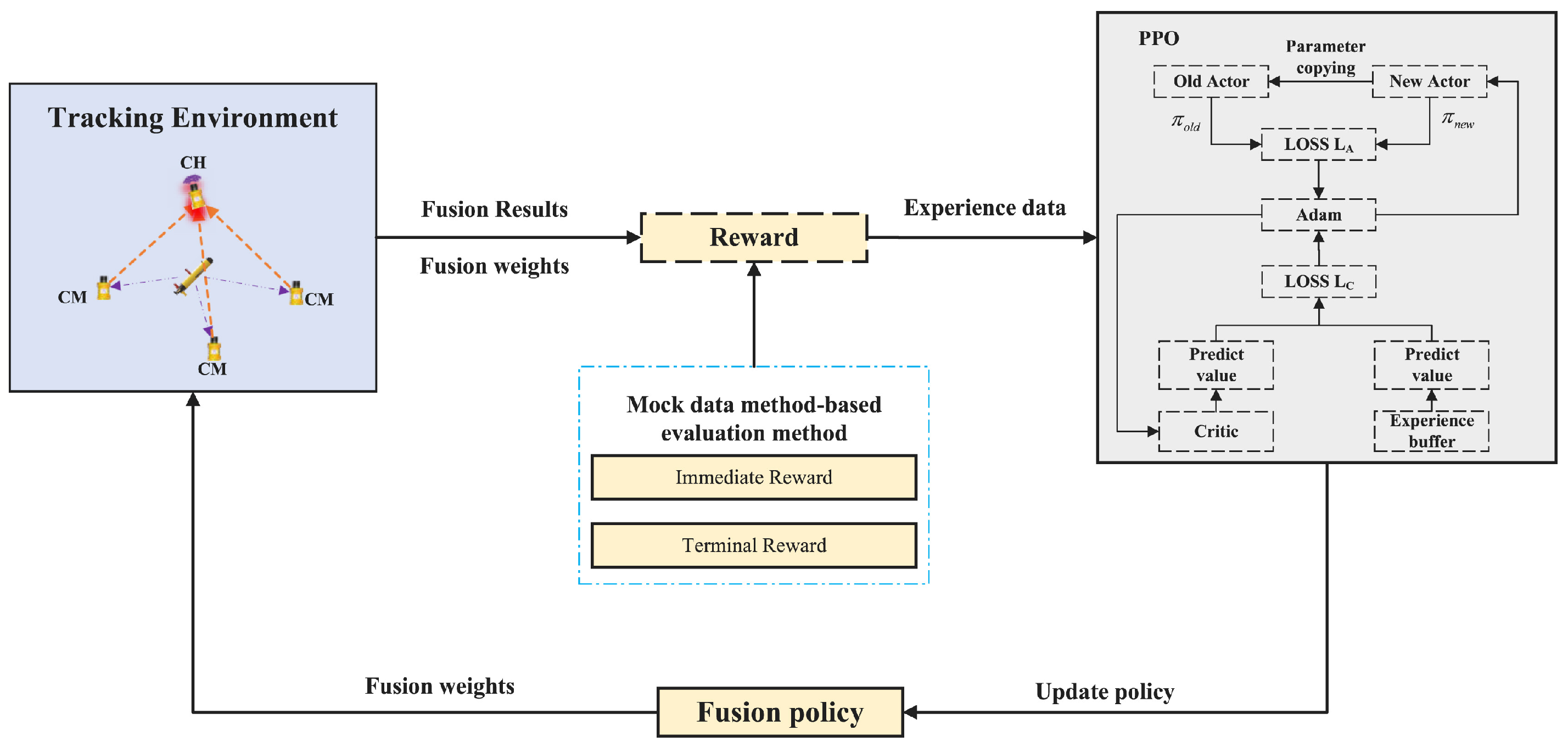
5.4. Intelligent Task and Path Control in Multi-Platform Autonomous Monitoring Systems
5.4.1. Multi-Agent Task Allocation and Coordination Mechanisms
5.4.2. Autonomous Path Planning and Dynamic Obstacle Avoidance Strategies
5.4.3. Multi-Source Data Fusion and Real-Time Control in Water Body Monitoring Tasks
6. Cross-Domain Generalization and Digital Twin Integration in Multi-Agent Systems
6.1. Policy Transfer and Robustness in Heterogeneous Scenarios
6.2. Integration Potential of Digital Twins in Intelligent Water System Control
6.3. Edge Computing and Control Latency Optimization
7. Research Challenges and Future Directions
7.1. Challenges and Technical Limitations
7.2. Future Research Directions
7.2.1. Building a Data Ecosystem and AI Integration for Intelligent Water Systems
7.2.2. Perception-Driven Communication Mechanisms
- Developing task-sensitive communication triggers tailored to non-stationary environments;
- Designing multi-scale communication structures and hierarchical architectures to accommodate system heterogeneity;
- Incorporating graph-based attention and multi-modal fusion for efficient heterogeneous information integration;
- Exploring co-optimization frameworks that jointly address communication and control strategies.
7.2.3. Self-Organizing Multi-Agent Collaboration
7.2.4. Collaborative Control Architecture for Complex Water Systems
- Task decomposition and role assignment: The global control objective is decomposed into multiple sub-goals, each corresponding to a control layer or agent role. For instance, in water resource management, the upper layer may handle high-level scheduling tasks such as water allocation and inter-regional distribution, while the lower layer focuses on local actuation tasks like pump control and feedback-based flow adjustments.
- Hierarchical policy learning: The high-level controller (meta-controller) learns to assign sub-tasks or intermediate goals to lower-level controllers, while the low-level controllers optimize their actions based on local observations to fulfill the high-level directives. This structure can be implemented using the options framework or hierarchical reinforcement learning (HRL), which improves policy interpretability and enhances transferability across tasks.
- State abstraction and coordination mechanisms: Each layer can define its own state–action space abstraction to reduce learning complexity. Communication between layers or across subsystems can be facilitated through intermediate variables, shared representations, or attention-based mechanisms, enabling inter-layer coordination and policy alignment.
- Multi-agent cooperation within hierarchical structures: Each sub-task can be further handled by one or more agents operating under a hierarchical framework. Mechanisms such as centralized training with decentralized execution (CTDE), heterogeneous reward design, and graph neural networks (GNNs) are employed to promote agent collaboration and information sharing. For example, in wastewater treatment, individual agents can control flow regulation, chemical dosing, and energy optimization, while in watershed-scale management, agents can coordinate water storage operations, pollutant dispersion control, and ecological flow management.
7.2.5. Modeling Large-Scale Heterogeneous Multi-Agent Systems
- Modeling heterogeneous tasks and role-based structures: Develop agent modeling frameworks that accommodate varying structures, roles, capabilities, and objectives, including clear task decomposition and role assignments;
- Multi-objective game theory and cooperative strategy learning: Employ game-theoretic models and multi-objective optimization techniques to support robust strategy formation under both cooperative and adversarial conditions;
- Cross-scale coordination and communication protocol design: Design efficient and scalable communication protocols to resolve asynchrony and coordination issues arising from distributed, multi-scale decision-making processes;
- Generalization and scalability: Construct RL training architectures that offer high generalizability and scalability, thereby improving performance, adaptability, and robustness in complex, uncertain real-world environments.
7.2.6. Adaptability and Robustness of Intelligent Models Under Extreme Conditions
- Extreme scenario modeling and synthetic environment construction: Develop high-fidelity simulation environments that emulate events such as flooding, pollution surges, and water shortages to support adversarial training and generalization of agent behavior;
- Safety-constrained reinforcement learning: Introduce risk-sensitivity metrics, dynamic safety threshold functions, and multi-objective constraint modeling to improve system boundary awareness and ensure secure policy execution;
- Uncertainty modeling and robust optimization: Apply Bayesian reinforcement learning and distributed decision-making frameworks to explicitly represent environmental and prediction uncertainties, thereby improving model robustness under disruptive conditions;
- Integration of fault tolerance and emergency response: Incorporate fault diagnosis, contingency planning, and multi-source coordination mechanisms to combine RL-based control with traditional emergency management systems for enhanced responsiveness during critical events.
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chen, F.; Sewlia, M.; Dimarogonas, D.V. Cooperative control of heterogeneous multi-agent systems under spatiotemporal constraints. Annu. Rev. Control 2024, 57, 100946. [Google Scholar] [CrossRef]
- Li, W.; Shi, F.; Li, W.; Yang, S.; Wang, Z.; Li, J. Review on Cooperative Control of Multi-Agent Systems. Int. J. Appl. Math. Control Eng. 2024, 7, 10–17. [Google Scholar]
- Jain, G.; Kumar, A.; Bhat, S.A. Recent developments of game theory and reinforcement learning approaches: A systematic review. IEEE Access 2024, 12, 9999–10011. [Google Scholar] [CrossRef]
- Zhu, R.; Liu, L.; Li, P.; Chen, N.; Feng, L.; Yang, Q. DC-MAC: A delay-aware and collision-free MAC protocol based on game theory for underwater wireless sensor networks. IEEE Sens. J. 2024, 24, 6930–6941. [Google Scholar] [CrossRef]
- He, X.; Hu, Z.; Yang, H.; Lv, C. Personalized robotic control via constrained multi-objective reinforcement learning. Neurocomputing 2024, 565, 126986. [Google Scholar] [CrossRef]
- Cheng, J.; Cheng, M.; Liu, Y.; Wu, J.; Li, W.; Frangopol, D.M. Knowledge transfer for adaptive maintenance policy optimization in engineering fleets based on meta-reinforcement learning. Reliab. Eng. Syst. Saf. 2024, 247, 110127. [Google Scholar] [CrossRef]
- Jiang, Q.; Li, J.; Sun, Y.; Huang, J.; Zou, R.; Ma, W.; Guo, H.; Wang, Z.; Liu, Y. Deep-reinforcement-learning-based water diversion strategy. Environ. Sci. Ecotechnol. 2024, 17, 100298. [Google Scholar] [CrossRef]
- Zuccotto, M.; Castellini, A.; Torre, D.L.; Mola, L.; Farinelli, A. Reinforcement learning applications in environmental sustainability: A review. Artif. Intell. Rev. 2024, 57, 88. [Google Scholar] [CrossRef]
- Jiao, P.; Ye, X.; Zhang, C.; Li, W.; Wang, H. Vision-based real-time marine and offshore structural health monitoring system using underwater robots. Comput.-Aided Civ. Infrastruct. Eng. 2024, 39, 281–299. [Google Scholar] [CrossRef]
- Kartal, S.K.; Cantekin, R.F. Autonomous Underwater Pipe Damage Detection Positioning and Pipe Line Tracking Experiment with Unmanned Underwater Vehicle. J. Mar. Sci. Eng. 2024, 12, 2002. [Google Scholar] [CrossRef]
- Ravier, R.; Garagić, D.; Galoppo, T.; Rhodes, B.J.; Zulch, P. Multiagent Reinforcement Learning and Game-Theoretic Optimization for Autonomous Sensor Control. In Proceedings of the 2024 IEEE Aerospace Conference, Big Sky, MT, USA, 2–9 March 2024; pp. 1–12. [Google Scholar] [CrossRef]
- Shi, H.; Li, J.; Mao, J.; Hwang, K.S. Lateral Transfer Learning for Multiagent Reinforcement Learning. IEEE Trans. Cybern. 2023, 53, 1699–1711. [Google Scholar] [CrossRef]
- Han, S.; Dastani, M.; Wang, S. Sparse communication in multi-agent deep reinforcement learning. Neurocomputing 2025, 625, 129344. [Google Scholar] [CrossRef]
- Luo, J.; Zhang, W.; Jiongming, S.; Yuan, W.; Chen, J. Research Progress of Multi-Agent Game Theoretic Learning. J. Syst. Eng. Electron. 2022. [Google Scholar] [CrossRef]
- Rutherford, A.; Ellis, B.; Gallici, M.; Cook, J.; Lupu, A.; Ingvarsson Juto, G.; Willi, T.; Hammond, R.; Khan, A.; Schroeder de Witt, C.; et al. Jaxmarl: Multi-agent rl environments and algorithms in jax. Adv. Neural Inf. Process. Syst. 2024, 37, 50925–50951. [Google Scholar]
- Nagoev, Z.; Bzhikhatlov, K.; Pshenokova, I.; Unagasov, A. Algorithms and Software for Simulation of Intelligent Systems of Autonomous Robots Based on Multi-Agent Neurocognitive Architectures; Springer: Berlin/Heidelberg, Germany, 2024; pp. 381–391. [Google Scholar]
- Wu, P.; Guan, Y. Multi-agent deep reinforcement learning for computation offloading in cooperative edge network. J. Intell. Inf. Syst. 2025, 63, 567–591. [Google Scholar] [CrossRef]
- Milani, S.; Topin, N.; Veloso, M.; Fang, F. Explainable reinforcement learning: A survey and comparative review. ACM Comput. Surv. 2024, 56, 1–36. [Google Scholar] [CrossRef]
- Ernst, D.; Louette, A. Introduction to Reinforcement Learning; Feuerriegel, S., Hartmann, J., Janiesch, C., Zschech, P., Eds.; Springer: Singapore, 2024; pp. 111–126. [Google Scholar]
- Tam, P.; Ros, S.; Song, I.; Kang, S.; Kim, S. A survey of intelligent end-to-end networking solutions: Integrating graph neural networks and deep reinforcement learning approaches. Electronics 2024, 13, 994. [Google Scholar] [CrossRef]
- Boyajian, W.L.; Clausen, J.; Trenkwalder, L.M.; Dunjko, V.; Briegel, H.J. On the convergence of projective-simulation–based reinforcement learning in Markov decision processes. Quantum Mach. Intell. 2020, 2, 13. [Google Scholar] [CrossRef] [PubMed]
- Albrecht, S.V.; Christianos, F.; Schäfer, L. Multi-Agent Reinforcement Learning: Foundations and Modern Approaches; MIT Press: Cambridge, MA, USA, 2024. [Google Scholar]
- Li, Y.; Tsang, Y.P.; Wu, C.H.; Lee, C.K.M. A multi-agent digital twin–enabled decision support system for sustainable and resilient supplier management. Comput. Ind. Eng. 2024, 187, 109838. [Google Scholar] [CrossRef]
- Tong, Y.; Fei, S. Research on Multi object Occlusion Tracking and Trajectory Prediction Method Based on Deep Reinforcement Learning. In Proceedings of the 2024 6th International Conference on Robotics, Intelligent Control and Artificial Intelligence (RICAI), Nanjing, China, 6–8 December 2024; pp. 656–659. [Google Scholar]
- Palmer, G.; Tuyls, K.; Bloembergen, D.; Savani, R. Lenient multi-agent deep reinforcement learning. arXiv 2017, arXiv:1707.04402. [Google Scholar]
- Zheng, Y.; Meng, Z.; Hao, J.; Zhang, Z. Weighted double deep multiagent reinforcement learning in stochastic cooperative environments. In Pacific Rim International Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2018; pp. 421–429. [Google Scholar]
- Micieli, M.; Botter, G.; Mendicino, G.; Senatore, A. UAV thermal images for water presence detection in a Mediterranean headwater catchment. Remote Sens. 2021, 14, 108. [Google Scholar] [CrossRef]
- Zhang, C.; Wu, Z.; Li, Z.; Xu, H.; Xue, Z.; Qian, R. Multi-agent Reinforcement Learning-Based UAV Swarm Confrontation: Integrating QMIX Algorithm with Artificial Potential Field Method. In Proceedings of the 2024 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Kuching, Malaysia, 6–10 October 2024; pp. 161–166. [Google Scholar]
- Romero, A.; Song, Y.; Scaramuzza, D. Actor-critic model predictive control. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 14777–14784. [Google Scholar]
- Zhang, J.; Han, S.; Xiong, X.; Zhu, S.; Lü, S. Explorer-actor-critic: Better actors for deep reinforcement learning. Inf. Sci. 2024, 662, 120255. [Google Scholar] [CrossRef]
- Zhao, E.; Zhou, N.; Liu, C.; Su, H.; Liu, Y.; Cong, J. Time-aware MADDPG with LSTM for multi-agent obstacle avoidance: A comparative study. Complex Intell. Syst. 2024, 10, 4141–4155. [Google Scholar] [CrossRef]
- Kuba, J.G.; Chen, R.; Wen, M.; Wen, Y.; Sun, F.; Wang, J.; Yang, Y. Trust region policy optimisation in multi-agent reinforcement learning. arXiv 2021, arXiv:2109.11251. [Google Scholar]
- Harris, A.; Liu, S. Maidrl: Semi-centralized multi-agent reinforcement learning using agent influence. In Proceedings of the 2021 IEEE Conference on Games (CoG), Copenhagen, Denmark, 17–20 August 2021; pp. 01–08. [Google Scholar]
- Ke, C.; Chen, H. Cooperative path planning for air–sea heterogeneous unmanned vehicles using search-and-tracking mission. Ocean Eng. 2022, 262, 112020. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, X.; Mao, Y.; Shuai, C.; Jiao, L.; Wu, Y. Analysis of resource allocation and PM2.5 pollution control efficiency: Evidence from 112 Chinese cities. Ecol. Indic. 2021, 127, 107705. [Google Scholar] [CrossRef]
- Zhang, H.; Zhao, H.; Liu, R.; Kaushik, A.; Gao, X.; Xu, S. Collaborative task offloading optimization for satellite mobile edge computing using multi-agent deep reinforcement learning. IEEE Trans. Veh. Technol. 2024, 73, 15483–15498. [Google Scholar] [CrossRef]
- Jouini, O.; Sethom, K.; Namoun, A.; Aljohani, N.; Alanazi, M.H.; Alanazi, M.N. A survey of machine learning in edge computing: Techniques, frameworks, applications, issues, and research directions. Technologies 2024, 12, 81. [Google Scholar] [CrossRef]
- Han, S.; Zhang, T.; Li, X.; Yu, J.; Zhang, T.; Liu, Z. The Unified Task Assignment for Underwater Data Collection with Multi-AUV System: A Reinforced Self-Organizing Mapping Approach. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 1833–1846. [Google Scholar] [CrossRef]
- Davis, A.; Wills, P.S.; Garvey, J.E.; Fairman, W.; Karim, M.A.; Ouyang, B. Developing and field testing path planning for robotic aquaculture water quality monitoring. Appl. Sci. 2023, 13, 2805. [Google Scholar] [CrossRef]
- Ullah, R.; Abbas, A.W.; Ullah, M.; Khan, R.U.; Khan, I.U.; Aslam, N.; Aljameel, S.S. EEWMP: An IoT-Based Energy-Efficient Water Management Platform for Smart Irrigation. Sci. Program. 2021, 2021, 5536884. [Google Scholar] [CrossRef]
- Lenczner, G.; Chan-Hon-Tong, A.; Le Saux, B.; Luminari, N.; Le Besnerais, G. DIAL: Deep interactive and active learning for semantic segmentation in remote sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3376–3389. [Google Scholar] [CrossRef]
- Moubayed, A.; Sharif, M.; Luccini, M.; Primak, S.; Shami, A. Water leak detection survey: Challenges & research opportunities using data fusion & federated learning. IEEE Access 2021, 9, 40595–40611. [Google Scholar]
- Xue, D.; Yuan, L.; Zhang, Z.; Yu, Y. Efficient Multi-Agent Communication via Shapley Message Value. In IJCAI; Cambridge University Press: Cambridge, UK, 2022; pp. 578–584. [Google Scholar] [CrossRef]
- Abadal, S.; Jain, A.; Guirado, R.; López-Alonso, J.; Alarcón, E. Computing graph neural networks: A survey from algorithms to accelerators. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Balasubramanian, E.; Elangovan, E.; Tamilarasan, P.; Kanagachidambaresan, G.; Chutia, D. Optimal energy efficient path planning of UAV using hybrid MACO-MEA* algorithm: Theoretical and experimental approach. J. Ambient Intell. Humaniz. Comput. 2023, 14, 13847–13867. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Gupta, J.K.; Morales, P.; Allen, R.; Kochenderfer, M.J. Deep implicit coordination graphs for multi-agent reinforcement learning. arXiv 2020, arXiv:2006.11438. [Google Scholar]
- Ou, M.; Xu, S.; Luo, B.; Zhou, H.; Zhang, M.; Xu, P.; Zhu, H. 3D Ocean Temperature Prediction via Graph Neural Network with Optimized Attention Mechanisms. IEEE Geosci. Remote. Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Cao, W.; Yan, J.; Yang, X.; Luo, X.; Guan, X. Communication-Aware Formation Control of AUVs with Model Uncertainty and Fading Channel via Integral Reinforcement Learning. IEEE/CAA J. Autom. Sin. 2023, 10, 159–176. [Google Scholar] [CrossRef]
- Yan, M.; Wang, Z. Water Quality Prediction Method Based on Reinforcement Learning Graph Neural Network. IEEE Access 2024, 12, 184421–184430. [Google Scholar] [CrossRef]
- Fan, X.; Zhang, X.; Yu, X. A graph convolution network-deep reinforcement learning model for resilient water distribution network repair decisions. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 1547–1565. [Google Scholar] [CrossRef]
- Zhu, M.; Wen, Y.Q. Design and Analysis of Collaborative Unmanned Surface-Aerial Vehicle Cruise Systems. J. Adv. Transp. 2019, 2019, 1323105. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Z.; Srivastava, G.; Alghamdi, T.A.; Khan, F.; Kumari, S.; Xiong, H. Industrial blockchain threshold signatures in federated learning for unified space-air-ground-sea model training. J. Ind. Inf. Integr. 2024, 39, 100593. [Google Scholar] [CrossRef]
- Du, Y.; Fu, H.; Wang, S.; Sun, Z. A Real-Time Collaborative Mapping Framework using UGVs and UAVs. In Proceedings of the 2024 IEEE International Conference on Unmanned Systems (ICUS), Nanjing, China, 18–20 October 2024; pp. 584–590. [Google Scholar]
- Samadzadegan, F.; Toosi, A.; Dadrass Javan, F. A critical review on multi-sensor and multi-platform remote sensing data fusion approaches: Current status and prospects. Int. J. Remote Sens. 2025, 46, 1327–1402. [Google Scholar] [CrossRef]
- Matsuki, H.; Scona, R.; Czarnowski, J.; Davison, A.J. CodeMapping: Real-Time Dense Mapping for Sparse SLAM using Compact Scene Representations. arXiv 2021, arXiv:2107.08994. [Google Scholar] [CrossRef]
- Ghasemieh, A.; Kashef, R. Towards explainable artificial intelligence in deep vision-based odometry. Comput. Electr. Eng. 2024, 115, 109127. [Google Scholar] [CrossRef]
- Zhong, X.; Pan, Y.; Behley, J.; Stachniss, C. Shine-mapping: Large-scale 3d mapping using sparse hierarchical implicit neural representations. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 8371–8377. [Google Scholar]
- Billings, G.; Camilli, R.; Johnson-Roberson, M. Hybrid visual SLAM for underwater vehicle manipulator systems. IEEE Robot. Autom. Lett. 2022, 7, 6798–6805. [Google Scholar] [CrossRef]
- Brecko, A.; Kajati, E.; Koziorek, J.; Zolotova, I. Federated Learning for Edge Computing: A Survey. Appl. Sci. 2022, 12, 9124. [Google Scholar] [CrossRef]
- Chen, D.; Deng, T.; Jia, J.; Feng, S.; Yuan, D. Mobility-aware decentralized federated learning with joint optimization of local iteration and leader selection for vehicular networks. Comput. Netw. 2025, 263, 111232. [Google Scholar] [CrossRef]
- Lindsay, J.; Ross, J.; Seto, M.L.; Gregson, E.; Moore, A.; Patel, J.; Bauer, R. Collaboration of Heterogeneous Marine Robots Toward Multidomain Sensing and Situational Awareness on Partially Submerged Targets. IEEE J. Ocean. Eng. 2022, 47, 880–894. [Google Scholar] [CrossRef]
- Braca, P.; Willett, P.; LePage, K.; Marano, S.; Matta, V. Bayesian Tracking in Underwater Wireless Sensor Networks with Port-Starboard Ambiguity. IEEE Trans. Signal Process. 2014, 62, 1864–1878. [Google Scholar] [CrossRef]
- Chen, J.; Wu, H.T.; Lu, L.; Luo, X.; Hu, J. Single underwater image haze removal with a learning-based approach to blurriness estimation. J. Vis. Commun. Image Represent. 2022, 89, 103656. [Google Scholar] [CrossRef]
- Wang, L.; Xu, L.; Tian, W.; Zhang, Y.; Feng, H.; Chen, Z. Underwater image super-resolution and enhancement via progressive frequency-interleaved network. J. Vis. Commun. Image Represent. 2022, 86, 103545. [Google Scholar] [CrossRef]
- Guo, Y.; Li, Y.; Tan, H.; Zhang, Z.; Ye, J.; Ren, C. Research on Target Tracking Simulation System Framework for Multi-Static Sonar Buoys. J. Phys. Conf. Ser. 2023, 2486, 012097. [Google Scholar] [CrossRef]
- Xuan, W.; Jian-She, G.; Bo-Jie, H.; Zong-Shan, W.; Hong-Wei, D.; Jie, W. A lightweight modified YOLOX network using coordinate attention mechanism for PCB surface defect detection. IEEE Sens. J. 2022, 22, 20910–20920. [Google Scholar] [CrossRef]
- Yan, J.; Yi, M.; Yang, X.; Luo, X.; Guan, X. Broad-Learning-Based Localization for Underwater Sensor Networks with Stratification Compensation. IEEE Internet Things J. 2023, 10, 13123–13137. [Google Scholar] [CrossRef]
- Han, L.; Tang, G.; Cheng, M.; Huang, H.; Xie, D. Adaptive Nonsingular Fast Terminal Sliding Mode Tracking Control for an Underwater Vehicle-Manipulator System with Extended State Observer. J. Mar. Sci. Eng. 2021, 9, 501. [Google Scholar] [CrossRef]
- Motoi, N.; Hirayama, D.; Yoshimura, F.; Sabra, A.; Fung, W.k. Sliding Mode Control with Disturbance Estimation for Underwater Robot. In Proceedings of the 2022 IEEE 17th International Conference on Advanced Motion Control (AMC), Padova, Italy, 18–20 February 2022; pp. 317–322. [Google Scholar] [CrossRef]
- Chen, B.; Hu, J.; Zhao, Y.; Ghosh, B.K. Finite-time observer based tracking control of uncertain heterogeneous underwater vehicles using adaptive sliding mode approach. Neurocomputing 2022, 481, 322–332. [Google Scholar] [CrossRef]
- Soriano, T.; Pham, H.A.; Gies, V. Experimental investigation of relative localization estimation in a coordinated formation control of low-cost underwater drones. Sensors 2023, 23, 3028. [Google Scholar] [CrossRef]
- Zeng, J.; Wan, L.; Li, Y.; Zhang, Z.; Xu, Y.; Li, G. Robust composite neural dynamic surface control for the path following of unmanned marine surface vessels with unknown disturbances. Int. J. Adv. Robot. Syst. 2018, 15, 1729881418786646. [Google Scholar] [CrossRef]
- Luo, G.; Shen, Y. A study on path optimization of construction machinery by fusing ant colony optimization and artificial potential field. Adv. Control Appl. Eng. Ind. Syst. 2024, 6, e125. [Google Scholar] [CrossRef]
- Tang, J.; Pan, Q.; Chen, Z.; Liu, G.; Yang, G.; Zhu, F.; Lao, S. An improved artificial electric field algorithm for robot path planning. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 2292–2304. [Google Scholar] [CrossRef]
- Yan, J.; Zhang, L.; Yang, X.; Chen, C.; Guan, X. Communication-Aware Motion Planning of AUV in Obstacle-Dense Environment: A Binocular Vision-Based Deep Learning Method. IEEE Trans. Intell. Transp. Syst. 2023, 24, 14927–14943. [Google Scholar] [CrossRef]
- Hu, B.B.; Zhang, H.T.; Liu, B.; Ding, J.; Xu, Y.; Luo, C.; Cao, H. Coordinated Navigation Control of Cross-Domain Unmanned Systems via Guiding Vector Fields. IEEE Trans. Control Syst. Technol. 2024, 32, 550–563. [Google Scholar] [CrossRef]
- Sharif, S.; Zeadally, S.; Ejaz, W. Space-aerial-ground-sea integrated networks: Resource optimization and challenges in 6G. J. Netw. Comput. Appl. 2023, 215, 103647. [Google Scholar] [CrossRef]
- Garofalo, G.; Giordano, A.; Piro, P.; Spezzano, G.; Vinci, A. A distributed real-time approach for mitigating CSO and flooding in urban drainage systems. J. Netw. Comput. Appl. 2017, 78, 30–42. [Google Scholar] [CrossRef]
- Tian, W.; Fu, G.; Xin, K.; Zhang, Z.; Liao, Z. Improving the interpretability of deep reinforcement learning in urban drainage system operation. Water Res. 2024, 249, 120912. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, Z.; Wang, Y.; Zeng, S.; Dong, X. Evaluation of uncertain signals’ impact on deep reinforcement learning-based real-time control strategy of urban drainage systems. J. Environ. Manag. 2022, 324, 116448. [Google Scholar] [CrossRef]
- Heo, S.; Nam, K.; Kim, S.; Yoo, C. XRL-FlexSBR: Multi-agent reinforcement learning-driven flexible SBR control with explainable performance guarantee under diverse influent conditions. J. Water Process Eng. 2024, 66, 105991. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, Y.; Dong, X. Dimensions of superiority: How deep reinforcement learning excels in urban drainage system real-time control. Water Res. X 2025, 28, 100313. [Google Scholar] [CrossRef]
- Mendoza, E.; Andramuño, J.; Núñez, J.; Córdova, L. Intelligent multi-agent architecture for a supervisor of a water treatment plant. J. Phys. Conf. Ser. 2021, 2090, 012124. [Google Scholar] [CrossRef]
- Jiménez, A.F.; Cárdenas, P.F.; Jiménez, F. Intelligent IoT-multiagent precision irrigation approach for improving water use efficiency in irrigation systems at farm and district scales. Comput. Electron. Agric. 2022, 192, 106635. [Google Scholar] [CrossRef]
- Zaman, M.; Tantawy, A.; Abdelwahed, S. Optimizing Smart City Water Distribution Systems Using Deep Reinforcement Learning. In Proceedings of the 2023 IEEE 20th International Conference on Smart Communities: Improving Quality of Life using AI, Robotics and IoT (HONET), Boca Raton, FL, USA, 4–6 December 2023; pp. 228–233. [Google Scholar]
- Candelieri, A.; Perego, R.; Archetti, F. Bayesian optimization of pump operations in water distribution systems. J. Glob. Optim. 2018, 71, 213–235. [Google Scholar] [CrossRef]
- Xu, J.; Wang, H.; Rao, J.; Wang, J. Zone scheduling optimization of pumps in water distribution networks with deep reinforcement learning and knowledge-assisted learning. Soft Comput. 2021, 25, 14757–14767. [Google Scholar] [CrossRef]
- Donâncio, H.; Vercouter, L.; Roclawski, H. The Pump Scheduling Problem: A Real-World Scenario for Reinforcement Learning. arXiv 2022, arXiv:2210.11111. [Google Scholar]
- Hung, F.; Yang, Y.E. Assessing adaptive irrigation impacts on water scarcity in nonstationary environments—A multi-agent reinforcement learning approach. Water Resour. Res. 2021, 57, e2020WR029262. [Google Scholar] [CrossRef]
- Wang, D.; Li, A.; Yuan, Y.; Zhang, T.; Yu, L.; Tan, C. Energy-saving scheduling for multiple water intake pumping stations in water treatment plants based on personalized federated deep reinforcement learning. Environ. Sci. Water Res. Technol. 2025, 11, 1260–1270. [Google Scholar] [CrossRef]
- Quan, Y.; Xi, L. Smart generation system: A decentralized multi-agent control architecture based on improved consensus algorithm for generation command dispatch of sustainable energy systems. Appl. Energy 2024, 365, 123209. [Google Scholar] [CrossRef]
- Hu, S.; Gao, J.; Zhong, D.; Wu, R.; Liu, L. Real-Time Scheduling of Pumps in Water Distribution Systems Based on Exploration-Enhanced Deep Reinforcement Learning. Systems 2023, 11, 56. [Google Scholar] [CrossRef]
- Luo, W.; Wang, C.; Zhang, Y.; Zhao, J.; Huang, Z.; Wang, J.; Zhang, C. A deep reinforcement learning approach for joint scheduling of cascade reservoir system. J. Hydrol. 2025, 651, 132515. [Google Scholar] [CrossRef]
- Jiang, W.; Liu, Y.; Fang, G.; Ding, Z. Research on short-term optimal scheduling of hydro-wind-solar multi-energy power system based on deep reinforcement learning. J. Clean. Prod. 2022, 385, 135704. [Google Scholar] [CrossRef]
- Wu, R.; Wang, R.; Hao, J.; Wu, Q.; Wang, P. Multiobjective multihydropower reservoir operation optimization with transformer-based deep reinforcement learning. J. Hydrol. 2024, 632, 130904. [Google Scholar] [CrossRef]
- Mitjana, F.; Denault, M.; Demeester, K. Managing chance-constrained hydropower with reinforcement learning and backoffs. Adv. Water Resour. 2022, 169, 104308. [Google Scholar] [CrossRef]
- Riemer-Sørensen, S.; Rosenlund, G.H. Deep Reinforcement Learning for Long Term Hydropower Production Scheduling. In Proceedings of the 2020 International Conference on Smart Energy Systems and Technologies (SEST), Istanbul, Turkey, 7–9 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Hu, S.; Gao, J.; Zhong, D. Multi-agent reinforcement learning framework for real-time scheduling of pump and valve in water distribution networks. Water Supply 2023, 23, 2833–2846. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Q.; Yu, J.; Sun, Q.; Hu, H.; Liu, X. A multi-agent deep-reinforcement-learning-based strategy for safe distributed energy resource scheduling in energy hubs. Electronics 2023, 12, 4763. [Google Scholar] [CrossRef]
- Wu, X.; Gao, Z.; Yuan, S.; Hu, Q.; Dang, Z. A dynamic task allocation algorithm for heterogeneous UUV swarms. Sensors 2022, 22, 2122. [Google Scholar] [CrossRef]
- Nguyen, T.; La, H.M.; Le, T.D.; Jafari, M. Formation Control and Obstacle Avoidance of Multiple Rectangular Agents with Limited Communication Ranges. IEEE Trans. Control Netw. Syst. 2017, 4, 680–691. [Google Scholar] [CrossRef]
- Lin, C.; Han, G.; Zhang, T.; Shah, S.B.H.; Peng, Y. Smart Underwater Pollution Detection Based on Graph-Based Multi-Agent Reinforcement Learning Towards AUV-Based Network ITS. IEEE Trans. Intell. Transp. Syst. 2023, 24, 7494–7505. [Google Scholar] [CrossRef]
- Zhang, C.; Cheng, P.; Du, B.; Dong, B.; Zhang, W. AUV path tracking with real-time obstacle avoidance via reinforcement learning under adaptive constraints. Ocean Eng. 2022, 256, 111453. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, H.; Fan, X.; Lyu, W. Research progress of path planning methods for autonomous underwater vehicle. Math. Probl. Eng. 2021, 2021, 8847863. [Google Scholar] [CrossRef]
- Chu, Z.; Wang, F.; Lei, T.; Luo, C. Path planning based on deep reinforcement learning for autonomous underwater vehicles under ocean current disturbance. IEEE Trans. Intell. Veh. 2022, 8, 108–120. [Google Scholar] [CrossRef]
- Tao, M.; Li, Q.; Yu, J. Multi-Objective Dynamic Path Planning with Multi-Agent Deep Reinforcement Learning. J. Mar. Sci. Eng. 2024, 13, 20. [Google Scholar] [CrossRef]
- Khatri, P.; Gupta, K.K.; Gupta, R.K. Raspberry Pi-based smart sensing platform for drinking-water quality monitoring system: A Python framework approach. Drink. Water Eng. Sci. 2019, 12, 31–37. [Google Scholar] [CrossRef]
- Fonseca, J.; Bhat, S.; Lock, M.; Stenius, I.; Johansson, K.H. Adaptive sampling of algal blooms using autonomous underwater vehicle and satellite imagery: Experimental validation in the baltic sea. arXiv 2023, arXiv:2305.00774. [Google Scholar]
- Mancy, H.; Ghannam, N.E.; Abozeid, A.; Taloba, A.I. Decentralized multi-agent federated and reinforcement learning for smart water management and disaster response. Alex. Eng. J. 2025, 126, 8–29. [Google Scholar] [CrossRef]
- Ren, J.; Zhu, Q.; Wang, C. Edge Computing for Water Quality Monitoring Systems. Mob. Inf. Syst. 2022, 2022, 5056606. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. Int. Conf. Mach. Learn. 2017, 70, 1126–1135. [Google Scholar]
- Yang, J.; Liu, J.; Qiu, G.; Liu, J.; Jawad, S.; Zhang, S. A spatio-temporality-enabled parallel multi-agent-based real-time dynamic dispatch for hydro-PV-PHS integrated power system. Energy 2023, 278, 127915. [Google Scholar] [CrossRef]
- Li, Y.; Wu, B.; Feng, Y.; Fan, Y.; Jiang, Y.; Li, Z.; Xia, S.T. Semi-supervised robust training with generalized perturbed neighborhood. Pattern Recognit. 2022, 124, 108472. [Google Scholar] [CrossRef]
- Yang, Z.; Jin, H.; Tang, Y.; Fan, G. Risk-Aware Constrained Reinforcement Learning with Non-Stationary Policies. In Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, Auckland, New Zealand, 6–10 May 2024; pp. 2029–2037. [Google Scholar]
- Heo, S.; Oh, T.; Woo, T.; Kim, S.; Choi, Y.; Park, M.; Kim, J.; Yoo, C. Real-scale demonstration of digital twins-based aeration control policy optimization in partial nitritation/Anammox process: Policy iterative dynamic programming approach. Desalination 2025, 593, 118235. [Google Scholar] [CrossRef]
- Cavalieri, S.; Gambadoro, S. Digital twin of a water supply system using the asset administration shell. Sensors 2024, 24, 1360. [Google Scholar] [CrossRef]
- Yang, J.; Xi, M.; Wen, J.; Li, Y.; Song, H.H. A digital twins enabled underwater intelligent internet vehicle path planning system via reinforcement learning and edge computing. Digit. Commun. Networks 2024, 10, 282–291. [Google Scholar] [CrossRef]
- Zhang, Z.; Tian, W.; Liao, Z. Towards coordinated and robust real-time control: A decentralized approach for combined sewer overflow and urban flooding reduction based on multi-agent reinforcement learning. Water Res. 2023, 229, 119498. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Zhang, X.; Guo, J.; Li, F. Cloud–edge collaborative inference with network pruning. Electronics 2023, 12, 3598. [Google Scholar] [CrossRef]
- Qian, P.; Liu, G. Application of High-Frequency Intelligent Sensing Network in Monitoring and Early Warning of Water Quality Dynamic Change. Int. J. Comput. Intell. Syst. 2024, 17, 195. [Google Scholar] [CrossRef]
- Ding, Y.; Sun, Q.; Lin, Y.; Ping, Q.; Peng, N.; Wang, L.; Li, Y. Application of artificial intelligence in (waste)water disinfection: Emphasizing the regulation of disinfection by-products formation and residues prediction. Water Res. 2024, 253, 121267. [Google Scholar] [CrossRef]
- Jiang, J.; Lu, Z. Learning attentional communication for multi-agent cooperation. In Advances in Neural Information Processing Systems 31 (NeurIPS 2018); MIT Press: Cambridge, MA, USA, 2018; pp. 7265–7275. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State Variable S | Action Variable A | Reward Function R | Control Objective |
|---|---|---|---|
| Water quality status | Chemical dosing rate | Penalty for threshold exceedance of pollutants | Control nutrient levels to prevent eutrophication |
| Time correlation parameters | Associated control operations | Penalty based on recovery time | Evaluate the system’s recovery efficiency after pollution events |
| Water level/flow indicators | Gate or valve scheduling control | Penalty for deviation from target water level | Maintain water levels within the target range |
| Operational status of devices | Regulatory actions of the agent | Penalty for energy consumption and operational cost | Optimize resource utilization to enhance economic efficiency |
| Learning Paradigm | Core Concept | Evaluation | Representative Algorithms |
|---|---|---|---|
| Independent learning | This approach ignores interactions among agents and | Offers high scalability but is prone to non-stationarity | DRUQN, DLCQN, DDRQN |
| learns individual policies independently. | due to the lack of inter-agent coordination. | WDDQN | |
| Centralized learning | Treats all agents as a unified entity, enabling joint policy optimization. | Immune to environmental non-stationarity but prone to curse of dimensionality. | — |
| Value function decomposition | Decomposes global value function to optimize the | Solves credit assignment, struggles in non-stationary | QMIX, WQMIX, |
| the overall objective. | or complex environments. | QPLEX, Qatten | |
| Centralized value function | Trains a value network with global information | Reduces problems of high dimensionality and non- | MADDPG, MATRPO, |
| to guide independent policy learning. | stationarity problem. | MAPPO, MATD3 |
| Technical Category | Algorithm Type | Technical Characteristics | Model Limitations |
|---|---|---|---|
| Task deployment | Heuristic algorithm and game-theoretic strategy | Construct goal allocation | Ignore intrinsic correlation between complex tasks |
| Self-organizing mapping algorithm | Adaptive capability of edge intelligence | Lack of coordination in task execution | |
| Information exchange | Local topology control by autonomous learning | Flexible topology configuration | Difficult to ensure network connectivity |
| Graph-theoretic or Q-learning-based | Capability-aware routing | Difficult to balance transmission rate | |
| Path planning | Robust optimization or state estimation | Multi-sensor fusion | Data heterogeneity across cross-domain platforms |
| Federated learning or centralized learning | Edge computing algorithms | High computational cost and parameter space | |
| Cooperative control | Centralized or distributed architecture | Architecture-based coordination | Communication overhead and latency |
| Federated learning algorithm | Centralized/unified cross-domain training | Data heterogeneity and high control cost |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, L.; Pei, Y. Recent Advances in Multi-Agent Reinforcement Learning for Intelligent Automation and Control of Water Environment Systems. Machines 2025, 13, 503. https://doi.org/10.3390/machines13060503
Jia L, Pei Y. Recent Advances in Multi-Agent Reinforcement Learning for Intelligent Automation and Control of Water Environment Systems. Machines. 2025; 13(6):503. https://doi.org/10.3390/machines13060503
Chicago/Turabian StyleJia, Lei, and Yan Pei. 2025. "Recent Advances in Multi-Agent Reinforcement Learning for Intelligent Automation and Control of Water Environment Systems" Machines 13, no. 6: 503. https://doi.org/10.3390/machines13060503
APA StyleJia, L., & Pei, Y. (2025). Recent Advances in Multi-Agent Reinforcement Learning for Intelligent Automation and Control of Water Environment Systems. Machines, 13(6), 503. https://doi.org/10.3390/machines13060503