1. Introduction
The tower height and rotor diameter of high-power wind turbines are often tens or even hundreds of meters. To ensure good mechanical performance and vibration reduction effects, vibration-damping components need to be installed in key parts of the wind turbine [
1]. The elastic support of the gearbox is a crucial component of the wind turbine’s elastic support system, and its structural–mechanical properties directly affect the vibration reduction performance and service life of the wind turbine’s damping system. Therefore, structural–mechanical performance metrics have always been a key focus during the design of the gearbox’s elastic support in wind turbines.
With the development of computer science and the improvement of hardware capabilities, simulation experiments have become a widely recognized method for replacing physical experiments and acquiring real-world data [
2]. Many researchers have used simulation experiments to study the relationship between design parameters and performance metrics. For instance, Kai Yang et al. conducted finite element analysis of the bone grinding process with SolidWorks 2018 and Abaqus 2023 to investigate the effects of various parameters on grinding forces, and they validated their findings through physical experiments [
3]. Chao Zheng et al. conducted a three-dimensional multi-body contact nonlinear finite element analysis based on the Mooney–Rivlin constitutive model. They systematically investigated the effects of key parameters, including thickness, height, and rubber hardness, on the sealing performance of hydrogenated nitrile rubber, providing valuable insights for the design of future sealing components [
4]. Analytical frameworks derived from simulation experiments are capable of accurately capturing the correlation among design variables and performance metrics. However, traditional models often have limitations when dealing with complex data and revealing underlying nonlinear relationships. Therefore, there is an urgent need to explore more advanced modeling approaches.
Recently, the application of machine learning techniques in engineering has gradually increased, and neural networks have been widely applied in engineering design. Compared to traditional modeling methods, neural networks demonstrate more significant advantages in handling complex data and uncovering nonlinear relationships [
5]. Xiaoyu Huang et al. used an improved sparrow algorithm to optimize machine learning models for predicting the relative dynamic elastic modulus of rubber concrete in order to investigate its durability. They also verified the rationality of the developed model through a sensitivity analysis using CAM [
6]. D. Pan et al. proposed a modeling method that trains neural networks with experimental data. The characteristic parameters of dampers were used as the input to the neural network model, with the damping force as the output. Numerical simulation examples were provided, demonstrating that the method can effectively predict damper performance [
7]. Liangcheng Dai et al. combined physical parameter models with neural network models and proposed an accurate hybrid neural network model for hydraulic dampers to simulate their dynamic performance under various working conditions. The model’s accuracy was verified by comparing its results with experimental results [
8]. These research findings indicate that machine learning has broad potential for improving the accuracy of engineering design and performance prediction.
However, engineering design often involves numerous design parameters and performance metrics. In these scenarios, employing conventional neural network frameworks—Such asBP [
9], RBF [
10], and GRNN [
11]—to study the link between design variables and performance measures frequently results in unsatisfactory outcomes. The unsuitability of traditional neural networks for multi-task scenarios primarily stems from their lack of effective inter-task sharing mechanisms and discrimination capabilities. These networks are typically optimized for a single task, failing to fully account for task differences and shared information, which leads to task conflicts or insufficient feature modeling [
12]. While methods such as model fusion and ensemble learning can handle multiple tasks, these approaches mainly combine the results of independent tasks and fail to effectively consider the interactions between tasks [
13]. Moreover, neural network training depends heavily on datasets, but most data on rubber vibration-damping components currently come from experiments, which are costly and result in a limited sample size. Research on the relationship between design parameters and performance metrics for rubber vibration-damping components based on a multi-task learning framework is still relatively scarce.
In order to mitigate the challenges stemming from restricted datasets, Yuexing Han et al. proposed an improved HP-VAE-GAN method for generating material images to achieve data augmentation, and they validated the method’s effectiveness through texture experiments on similar material images [
14]. Christopher Bowles et al. utilized generative adversarial networks (GANs) to generate synthetic samples with a realistic appearance in order to enhance training data, demonstrating the feasibility of introducing GAN-generated synthetic data into training datasets for two brain segmentation tasks [
15]. However, GANs and VAEs are currently primarily used for image generation and prediction, with their application in other types of tasks still limited. To reduce experimental costs, many researchers have generated datasets based on simulation experiments. Mahziyar Darvishi et al. conducted a finite element analysis (FEA) to study materials with different honeycomb structures and used corresponding analytical equations to validate the results, thus creating the datasets needed for machine learning algorithms to select the optimal honeycomb structure [
16]. Defu Zhu et al. established sandstone sample data based on a finite element analysis and used a machine learning model optimized via particle swarm optimization to predict the shear strength parameters of sandstone [
17]. Datasets generated from simulation experiments can significantly reduce costs and experimental time; however, issues such as the error between simulation experiments and real experiments, as well as the choice of sampling method for the dataset, still impact their quality. These issues need to be further addressed.
Compared to traditional neural networks, multi-task learning (MTL) networks enhance model performance by sharing learning structures across multiple related tasks [
18], as demonstrated in models such as MMOE [
19], PLE [
20], and CSN [
21]. In practical applications, Fei Luo et al. improved the accuracy and robustness of cross-regional wind energy and fossil fuel power generation forecasts based on an enhanced MMOE model, and they validated the model’s advantages through benchmark experiments [
22]. Jiaobo Zhang et al. designed a cross-stitch attention network (CACSNet) based on shared attention mechanisms, demonstrating excellent performance in gas porosity prediction. Additionally, detailed ablation experiments and parameter analysis further validated the effectiveness of the structure [
23]. As separate models do not need to be built or optimized for each task, MTL models require fewer parameters. More importantly, when a single model is trained to perform multiple tasks simultaneously, it should be able to work synergistically, thereby revealing common latent structures. This allows the model to achieve better single-task performance, even when the dataset for each task is limited [
24]. Although MTL has achieved impressive results regarding its generalization to multiple tasks, existing MTL research still primarily relies on manually designed features or parameter sharing at the problem level [
25]. To avoid gradient conflicts between tasks, which is a common issue in MTL, researchers have increasingly recognized the importance of finding appropriate weighting strategies for MTL. This ensures that the overall experience loss is minimized without sacrificing the learning performance of individual tasks [
26]. Therefore, optimizing the loss function in multi-task learning is crucial.
To address the issues in datasets and multi-task learning neural networks, in this study, we propose an optimized Latin hypercube sampling method based on a digital twin model of a gearbox elastic support combined with simulation experiments to generate the dataset required for the neural network. This approach balances the relationship between experimental cost and dataset quality. The effectiveness of the simulation experiment is validated through physical experiments. Given the complexity and nonlinear characteristics of structured data for gearbox elastic support, we introduce an improved PLE-LSTM neural network. Based on the PLE model framework and leveraging the nonlinear modeling capabilities of the LSTM module, the prediction accuracy of the entire neural network is enhanced. To resolve issues such as gradient conflicts and imbalance between tasks in multi-task learning, the GradNorm optimization algorithm is incorporated to dynamically weight the loss functions of each task, thereby coordinating the learning process between tasks and improving the overall performance of the model. The main contributions of this study are as follows:
Based on a digital twin model of gearbox elastic support, an optimized Latin hypercube sampling method is proposed, combined with simulation experiments to generate the dataset required for the neural network, significantly saving experimental costs and time.
An improved PLE-LSTM neural network based on the PLE model framework is proposed, effectively capturing and extracting the complexity and nonlinear characteristics of the structured data of the gearbox elastic support.
The GradNorm optimization algorithm is incorporated to dynamically weight the loss functions of each task, optimizing the learning process between tasks and thereby improving the model’s overall effectiveness.
The effectiveness of the proposed method is validated through ablation experiments on different datasets. The experimental results show that, with the same sample size, the proposed method outperforms traditional methods, achieving better results.
2. Method
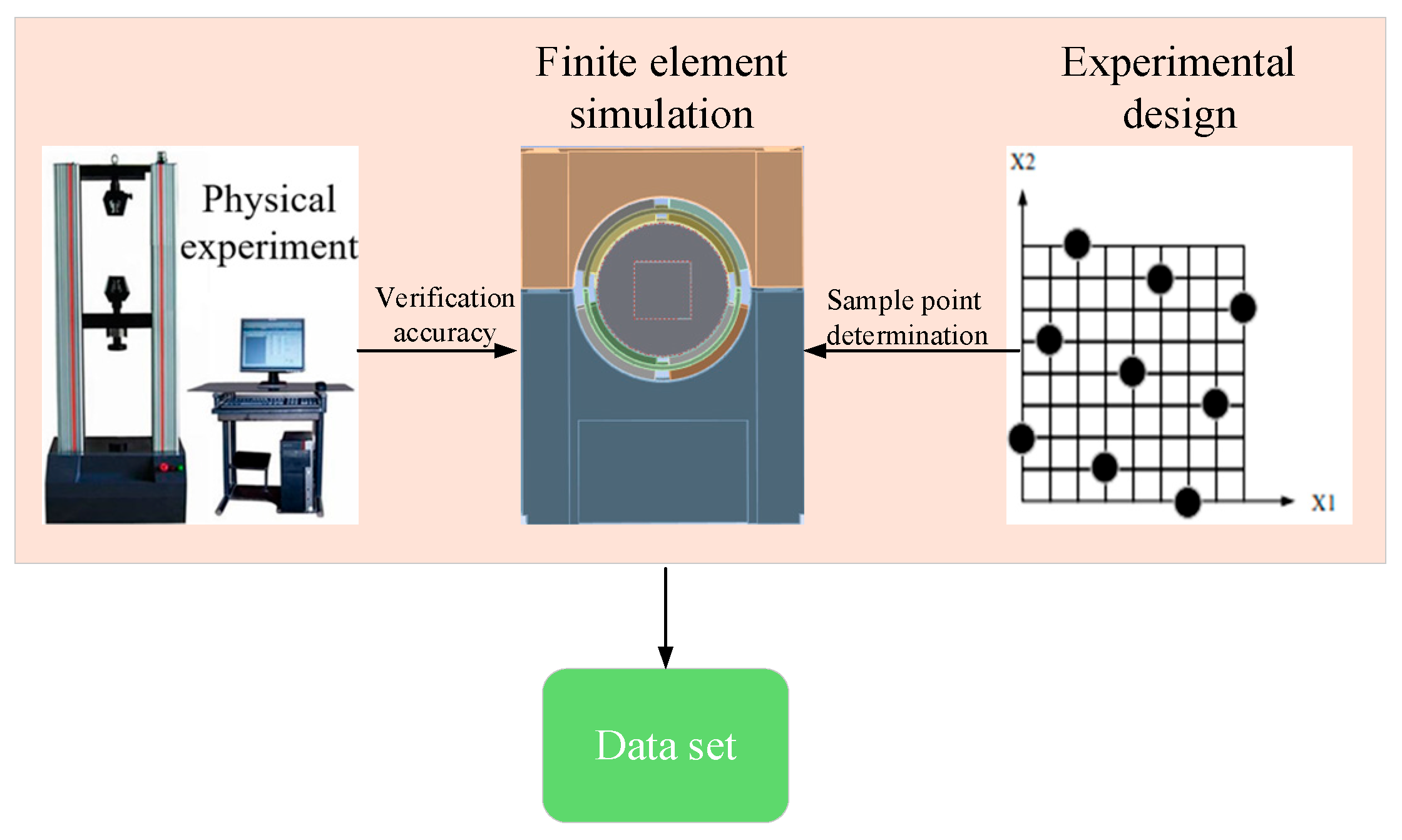
In this section, we first introduce the data generation method based on optimal Latin hypercube sampling combined with finite element simulation experiments. Then, we introduce the refined PLE-LSTM network design derived from the PLE multi-task framework. Lastly, we detail the strategy for enhancing loss functions for multiple tasks through GradNorm. The overall framework is shown in
Figure 1.
2.1. Dataset Generation
In the industrial field, dataset generation through physical experiments is often costly, time-consuming, and difficult to scale or repeat, with outcomes heavily dependent on specific conditions and equipment. These limitations hinder the exploration of extreme scenarios and reduce the generalizability of the data. Although simulation experiments offer a more cost-effective and flexible alternative, inherent discrepancies between real-world results can compromise dataset integrity and affect the training efficiency of network models. To address these challenges, in this study, we propose a cost-efficient dataset generation method that integrates simulation experiments with optimal Latin hypercube sampling, effectively balancing performance, generalizability, and reliability. The overall process of this method is illustrated in
Figure 2.
2.2. Optimal Latin Hypercube Sampling
Latin hypercube sampling (LHS) is a widely used statistical method in numerical simulation and experimental design, with the aim of achieving efficient sampling in high-dimensional parameter spaces. This method was first introduced by M.D. McKay, R.J. Beckman, and W.J. Conover. The basic idea is that it assumes a known functional relationship between input variables
and the output response:
Assuming that the experimental region is a unit cube
, the total mean of variable
over
is:
If
experimental points
, are selected in
, the mean of
at these
experimental points is given by:
Here,
= {
} represents a design consisting of
points. The Latin hypercube design selects
using a sampling method such that the corresponding estimate
is unbiased, i.e.,
From the above inference, it can be concluded that the Latin hypercube design uses an equal-probability stratified sampling method, which has excellent spatial filling capabilities within the entire range of input parameter distributions and their domains. The parameter samples generated by this method are highly representative. Compared to other design methods, the Latin hypercube design can achieve the desired research objectives with fewer samples.
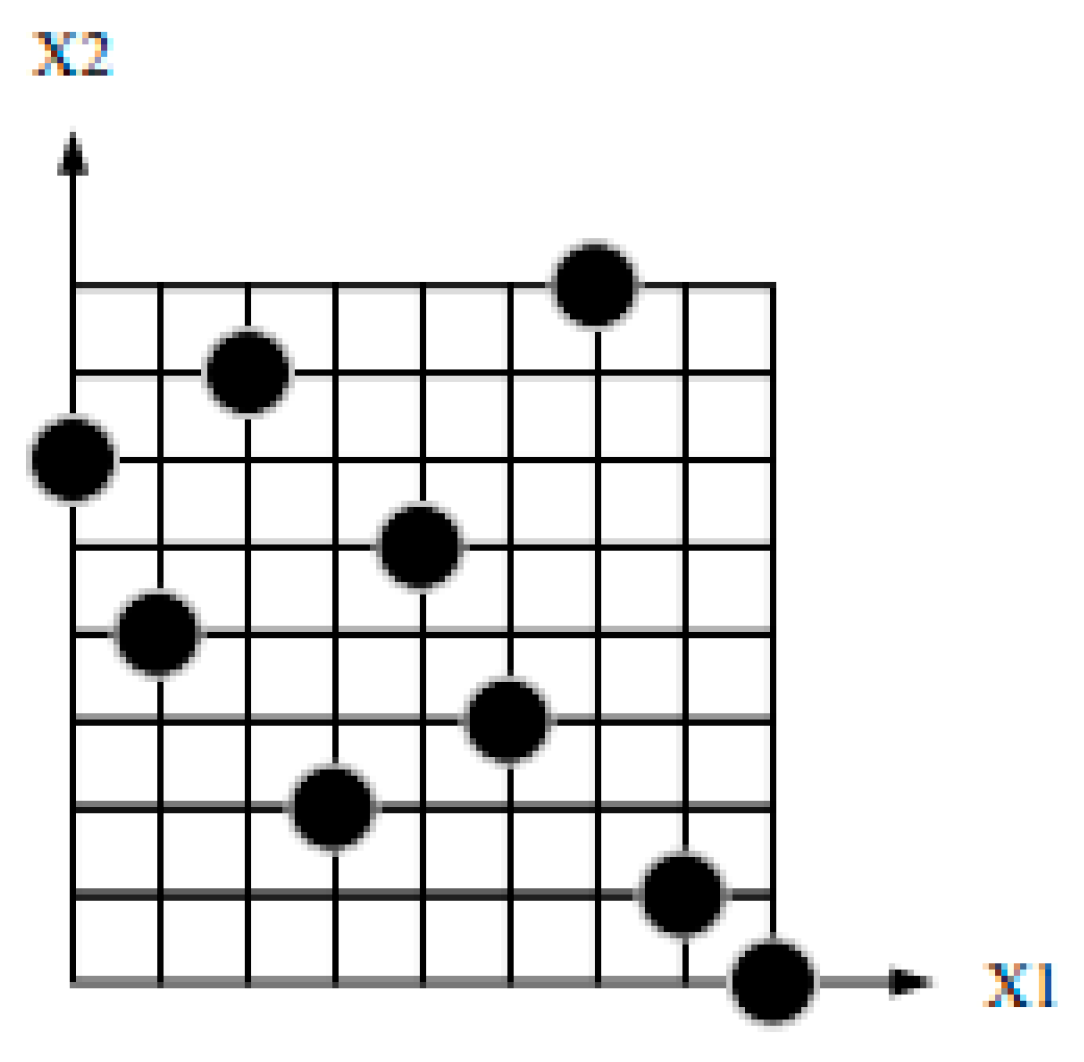
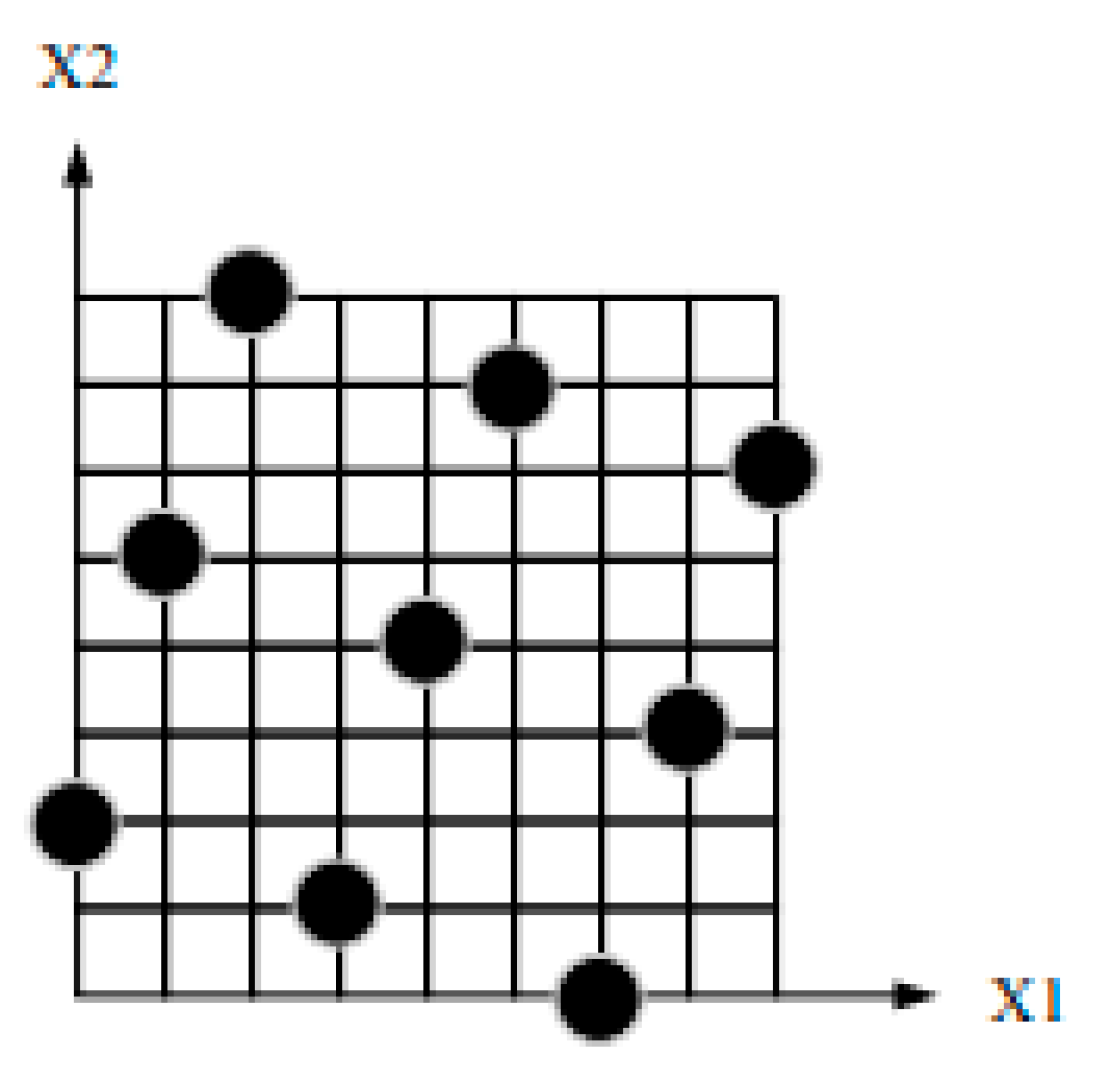
Optimal Latin hypercube design is an improvement of the Latin hypercube design, further enhancing the uniformity of sampling and improving the data fitting accuracy. It demonstrates better spatial filling capabilities and balance. For example, in the case of a two-factor, nine-level analysis sample, the two methods differ in the number of sample points collected and their distribution, as shown in
Figure 3 and
Figure 4.
As shown in the comparison chart, Latin hypercube sampling (LHS) ensures uniform sampling across individual dimensions but relies on basic stratified sampling, which may lead to sample clustering or gaps in high-dimensional spaces. In contrast, optimal Latin hypercube sampling (OLHS) mitigates these issues by providing a more uniformly distributed sample set. With its optimized coverage, OLHS better spans the parameter space and reduces redundancy. As a result, for the same sample size, OLHS offers improved spatial coverage and representativeness, enhancing dataset quality and boosting model training efficiency and prediction accuracy.
2.3. Multi-Task Learning Network Framework
Multi-task learning (MTL) network models are a type of machine learning framework designed to enhance the model’s generalization ability and performance by simultaneously learning multiple related tasks. The core idea is to leverage the relationships between different tasks, promoting the joint learning of features through shared representations, thereby improving the predictive ability of each individual task.
Traditional multi-task learning faces two main issues: one is the “balancing” problem (also known as the “teeter-totter” problem), and the other is negative transfer.
- (1)
The “teeter-totter” problem: In multi-task learning, when the correlation between tasks is complex, improving the performance of one task may be accompanied by a decline in the performance of others. In other words, multiple tasks cannot be improved simultaneously, and the performance may be worse than when modeled separately.
- (2)
Negative transfer: The performance of multi-task learning is worse than training each task separately, as joint training leads to a decline in task performance. This phenomenon is more pronounced when the tasks have weak or even conflicting correlations.
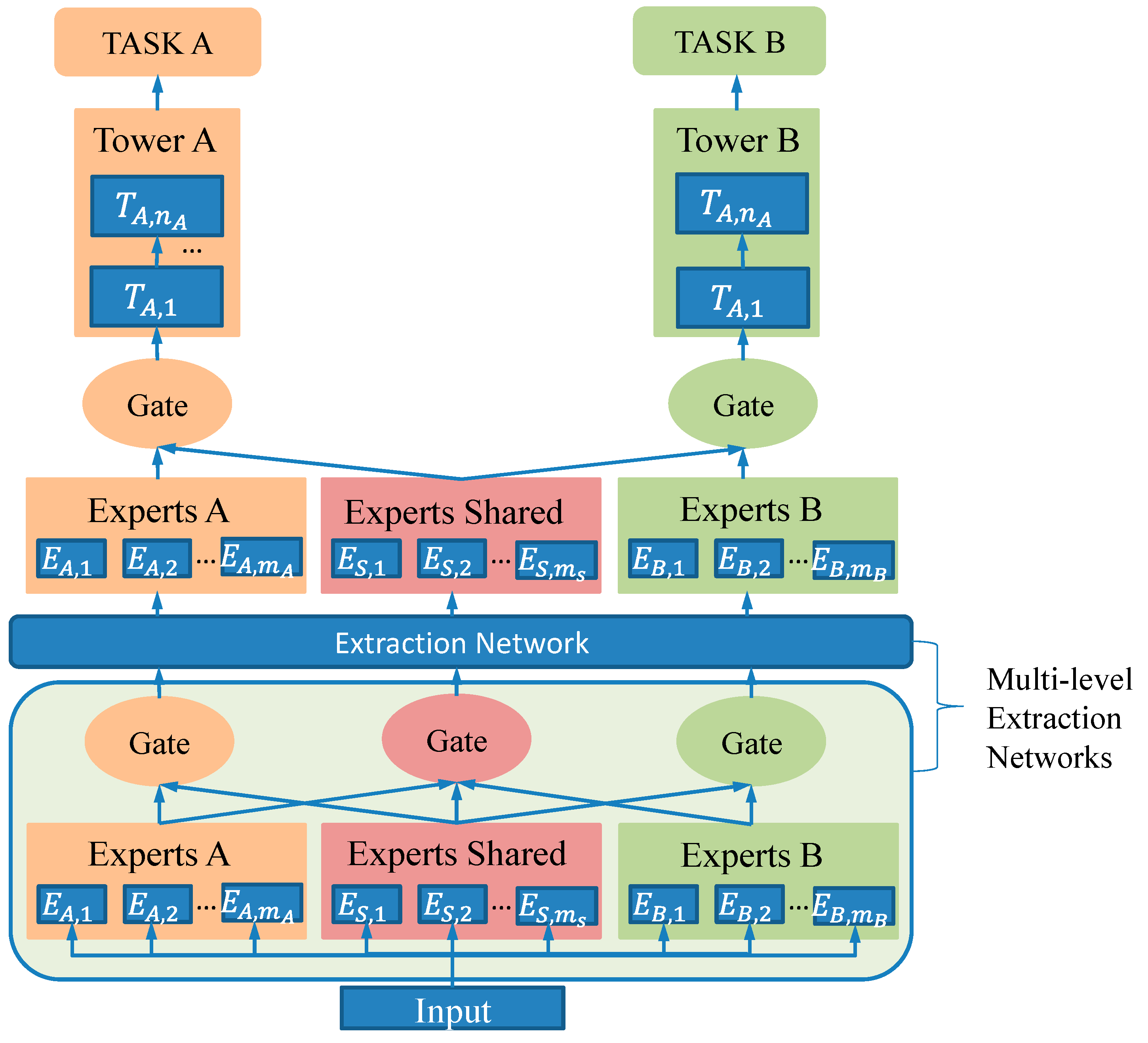
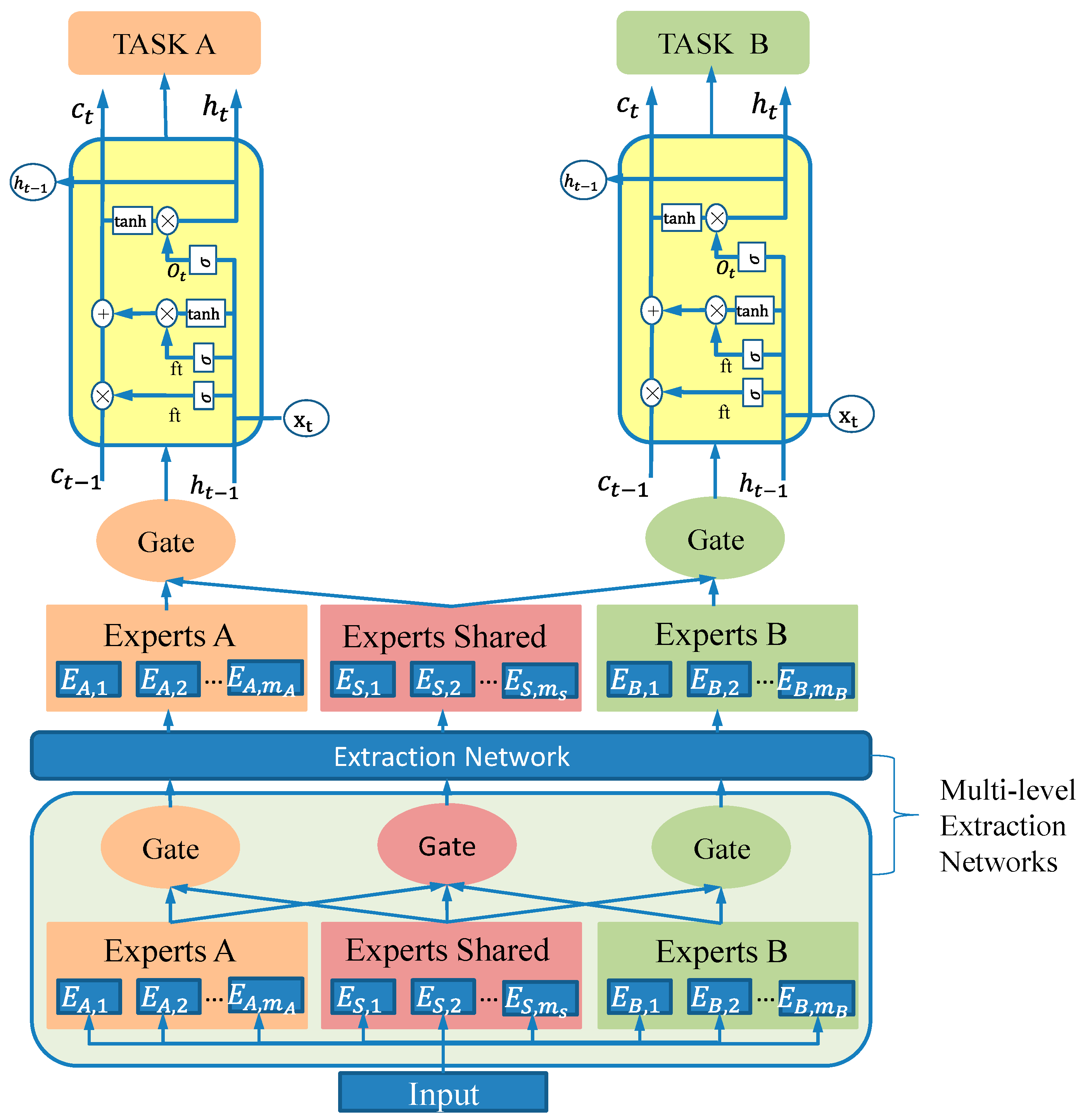
To address the issue of negative transfer, the cross-stitch network learns static linear combinations to fuse task representations but fails to capture sample-dependent dynamic changes. The MMoE model combines gating and expert networks to handle task correlations but overlooks the differences and interaction information among experts. In contrast, the PLE model reduces harmful parameter interference by sharing experts and task-specific experts, and it uses multi-layer experts and gating networks to extract deep features in the lower layers while separating task-specific parameters in the higher layers. This effectively captures complex task correlations and improves model performance.
In the PLE framework, the CGC module serves as the core, incorporating specialized expert modules in the lower layers and task-specific tower networks in the upper layers. Each expert module consists of multiple sub-networks—referred to as experts—whose number is controlled by a hyperparameter. The tower networks are also multi-layered, with their depth and width being configurable. Shared experts are responsible for learning common patterns across tasks, while task-specific experts focus on features unique to each task. Each tower integrates knowledge from both the shared and task-specific experts. Consequently, the shared experts are trained using data from all tasks, whereas the task-specific experts are updated exclusively with data from their respective tasks. The structure of the CGC network is illustrated in
Figure 5.
As illustrated above, within the CGC framework, common experts and task-oriented specialists are selectively integrated using a gating mechanism. The structure of the gating network is based on a single-layer feedforward network with SoftMax as the activation function. The input to the gating network is the selector, which computes the weighted sum of the selected vectors, i.e., the output of the experts. More precisely, the output of the gating network for task
k is represented as:
Here,
is the input representation, and
is the weighting function, which calculates the weight vector for the task through a linear transformation followed by a SoftMax layer.
In this equation,
,
are the numbers of shared experts and task-specific experts for task
k, respectively, and d is the dimensionality of the input representation
, which is the selected matrix composed of all selected vectors, including both the shared experts and task-specific experts for task
k:
Finally, the prediction for task
k is given by:
Here, represents the tower network for task k.
CGC removes the connections between task-specific towers and experts with other tasks, reducing interference. At the same time, by combining the advantages of the dynamic fusion of input representations through the gating network, CGC better handles the balance between tasks and sample dependencies.
PLE (progressive layered extraction) constructs a feature extraction network through multiple layers of CGC (completely shared gate-controlled) connections to progressively extract higher-order shared information. This network not only designs gating networks for task-specific experts but also introduces gating networks for shared experts to integrate the knowledge of all experts in each layer. In this configuration, the task parameters in PLE are not completely isolated in the initial stages as they are in CGC; instead, they become progressively differentiated through deeper network layers. Moreover, the gating mechanisms in the upper feature extraction layers depend on the integrated outputs from lower-layer gating systems rather than on the direct processing of the raw input, thereby offering more targeted guidance for the abstract representations generated by the higher-level experts. The structure of the PLE network is illustrated in
Figure 6.
In PLE, the weight function, selection matrix, and gating network calculations are the same as in CGC. Specifically, in the j-th extraction network of PLE, the gating network for task
k is represented as:
In the equation, is the weighting function for the task, and serve as the outputs. j represents the matrix selected by task in the j-th extraction network.
After computing all the gating networks and experts, the final prediction for task
k in PLE is given by:
PLE (progressive layered extraction) adopts a progressive separation routing mechanism, which comprehensively absorbs information from lower-level experts, gradually extracts higher-level shared knowledge, and progressively separates task-specific parameters. During the process of knowledge extraction and transformation, PLE uses higher-level shared experts to jointly extract, aggregate, and route lower-level representations. This not only captures shared knowledge but also progressively allocates it to the tower layers of specific tasks. This mechanism enables more efficient and flexible joint representation learning and knowledge sharing, significantly enhancing the adaptability and performance of multi-task learning.
2.4. LSTM Neural Network
Long short-term memory (LSTM) is a special type of recurrent neural network (RNN) designed to address the vanishing gradient problem faced by traditional RNNs when processing long sequences. It effectively retains and processes long-term dependencies through a unique gating mechanism. The core of LSTM consists of a unit that includes a forget gate, an input gate, and an output gate. Each gate is a special structure that controls the flow of information. Its internal structure is shown below
Figure 7.
The computational formula of the LSTM neural network model is as follows:
Here, denotes the nonlinear Sigmoid function; represents the input gate; represents the forget gate; is the updated cell state; is the output gate; is the input information; is the output information obtained; represents the respective weights; and represents the corresponding bias terms.
LSTM, with its flexible gating mechanism, multi-level nonlinear feature transformations, and efficient capture of temporal dynamic patterns, is able to precisely model complex nonlinear dependencies in long sequences while adapting to the diversity and complexity of the data. Due to these advantages, LSTM excels in many nonlinear data modeling tasks.
2.5. PLE-LSTM Neural Network
In contrast to the PLE network model framework, PLE-LSTM substitutes the tower layer, which is responsible for fitting the output of each task, with an LSTM neural network. The framework of the PLE-LSTM model is illustrated in
Figure 8.
Given that the hyperelastic rubber materials used in gearbox elastic supports exhibit strong nonlinearity and large deformations, replacing the PLE model’s tower layer with an LSTM network can greatly enhance its ability to model such behavior. LSTM’s gating mechanism and nonlinear activation functions allow it to capture complex task-specific nonlinear dependencies. Additionally, its dynamic weighting of short- and long-term information improves robustness to noise and data variability. By leveraging LSTM’s state accumulation, the tower layer can better extract and integrate features from shared and task-specific experts, leading to more representative high-level features and improved multi-task prediction performance.
2.6. Multi-Task Loss Function Based on GradNorm
In multi-task learning, due to significant differences in importance, scale, and other factors between tasks, directly combining losses by linearly weighting the loss functions may cause the loss of certain tasks to dominate, thereby suppressing the learning of other tasks and negatively impacting the overall model performance.
GradNorm is a method that calculates task sample weights based on gradient loss, decreasing the sample weight of tasks with a fast learning speed and increasing the sample weight of tasks with a slow learning speed. This helps to balance the learning speeds of different tasks, thereby improving the sufficiency of task learning. GradNorm dynamically adjusts sample weights based on the learning speed of each task, thus introducing a temporal dimension to the sample weights. The faster the loss decreases, the faster the task converges during the learning process. The basic principle of GradNorm is as follows.
First, the variables
are introduced, and the gradient of the loss is measured:
Here: is the gradient normalization value of task i, and it is the product of the weight of task i and loss of task i, with respect to the L2 norm of parameter W. The larger the value of , the larger the loss magnitude of that task.
is the global gradient normalization value (i.e., the expected value of the gradient normalization values of all tasks).
Next, variable
is defined to measure the learning speed of task
i,
where
,
represent the loss of task
i at steps 0 and
t, respectively.
represents the expected backward training speed of each task,
is the relative backward training speed of task
i. The larger the value of
, the slower task
i trains compared to the other tasks.
Finally, the objective function of GradNorm is represented as follows:
As shown in the equation above, when the loss of a task is too large or too small, increases. This leads to an increase in . The process of optimizing encourages the model to select the appropriate subtask , ensuring that the magnitudes and speeds of the subtasks are approximately balanced. This helps to maintain the synchronization of gradient updates across subtasks. Finally, is used to update the subtask weights .
3. Experiment
In this study, we verified the reliability of the simulation results through an elastic support stiffness test of the gearbox, and we combined optimal Latin hypercube sampling with the simulation experiment to construct a data set for training the neural network model.
3.1. Physical Test
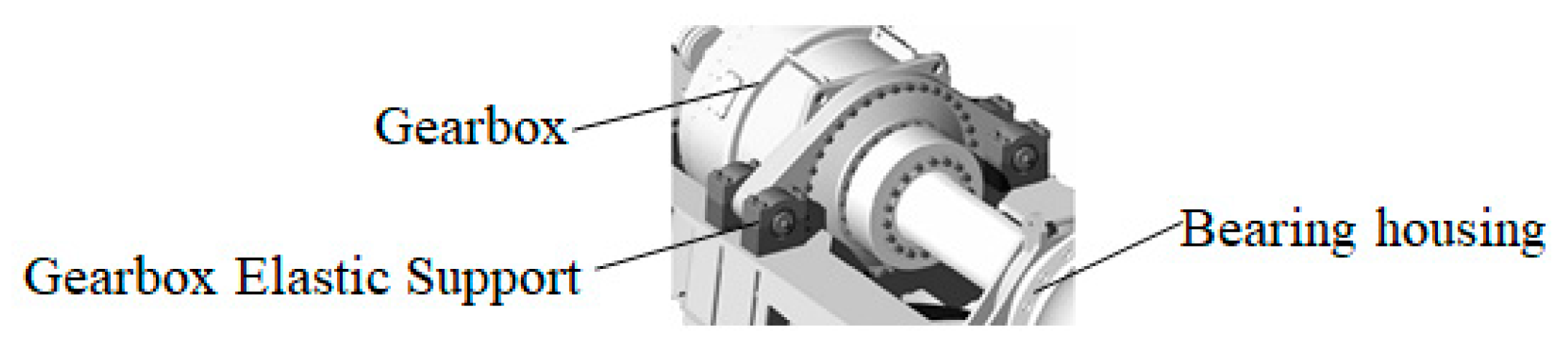
A gearbox elastic support is mainly used in three-point support wind turbine systems and is typically installed in pairs within the support seats on both sides of the gearbox. It primarily bears the weight of the gearbox as well as various loads transmitted from the rotor. Featuring excellent vibration damping performance, it can effectively resist both radial and axial loads while providing a certain degree of displacement compensation. An installation schematic of the gearbox elastic support is shown in
Figure 9.
This study investigates the elastic support of a gearbox in a high-power wind turbine from a specific company, with physical tests performed to evaluate its bidirectional stiffness. The vertical and lateral forces acting on the gearbox elastic support are determined by actual operating conditions, both being 1650 kN.
A servo-hydraulic universal testing machine is employed to measure the directional deformation of the gearbox elastic support under varying load values, allowing for the calculation of the bidirectional static stiffness of the entire structure. The experimental setups for evaluating the vertical and lateral stiffness of the gearbox elastic support are shown in
Figure 10 and
Figure 11, respectively.
The static stiffness of the gearbox elastic support is calculated using the secant method, as follows:
In this equation, is the measured load value, and is the measured directional displacement of the torque arm (transverse or vertical) under the load value.
is the directional displacement of the torque arm in the vertical direction under pre-compression, and the directional displacement of the torque arm in the lateral direction under pre-compression is 0.
To test the elastic support bidirectional stiffness of the gearbox and simulate the actual operating conditions, a vertical displacement of 10 mm is first applied to the elastic gearbox support, ensuring that the upper and lower supports of the elastic support are in close contact. Then, a load of 1650 kN is applied to the torsion arm of the gearbox elastic support in both the lateral and vertical directions. The vertical and lateral displacements of the torsion arm of the gearbox elastic support are measured to evaluate the stiffness.
3.1.1. Establishment of a 3D Model
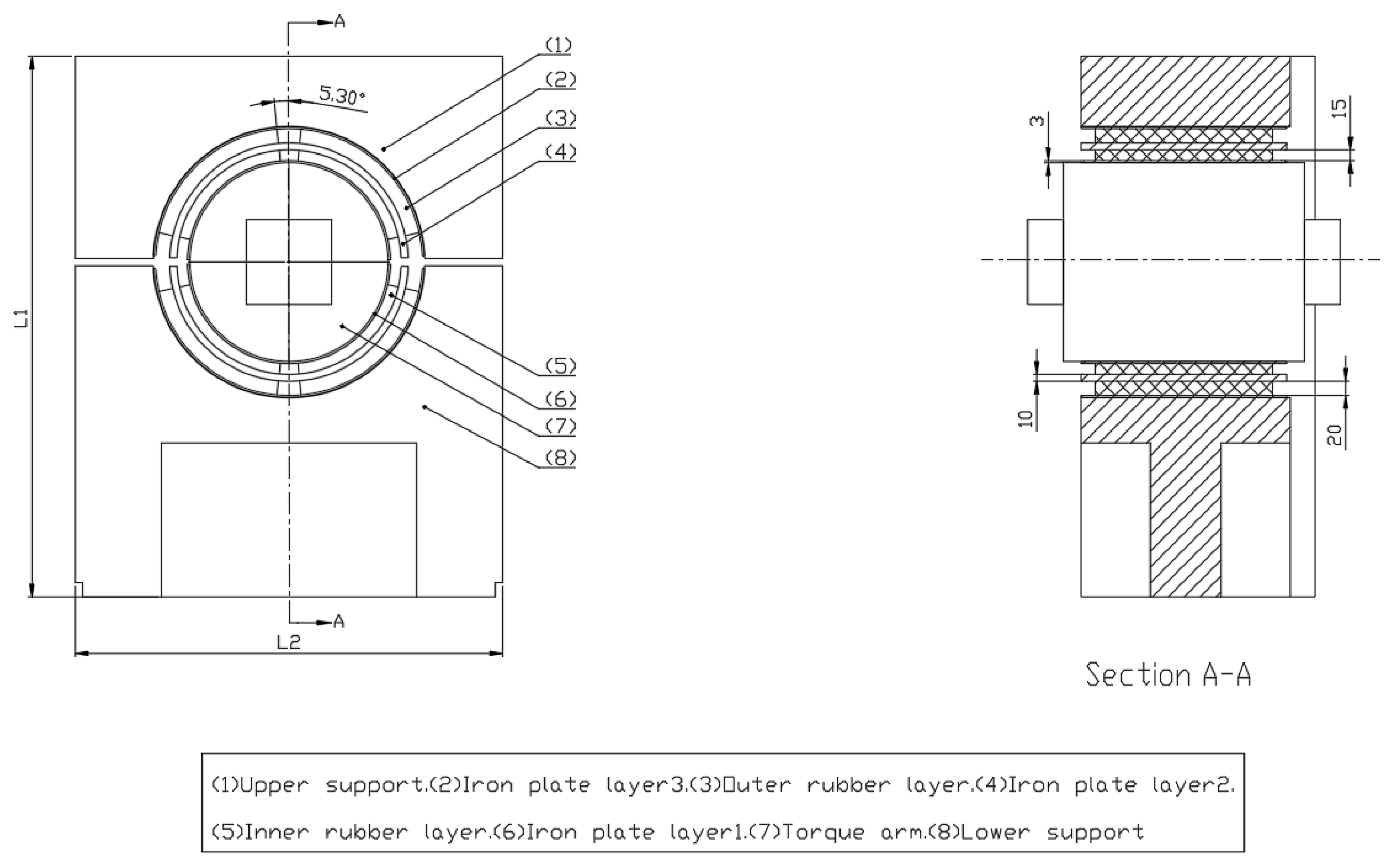
To perform simulation calculations, parametric modeling of the gearbox elastic support is required. A schematic diagram of the gearbox elastic support is shown below (see
Figure 12). The metal–rubber composite structure consists of three layers of metal sheets, two layers of rubber, and upper and lower support seats. A metal sheet layer (Layer 1) is placed between the torque arm and the inner rubber layer, while a metal sheet layer (Layer 3) is positioned between the upper and lower support seats and the outer rubber layer. A metal sheet layer (Layer 2) is inserted between the inner and outer rubber layers. The metal layers are bonded to the rubber layers through vulcanization. The thicknesses of Layers 1 and 3 are the same.
Five parameters, namely the thickness of the inner iron sheet D1, the thickness of the inner rubber layer D2, the thickness of iron sheet layer 2 D3, the thickness of the outer rubber layer D4, and the rubber angle
are selected as design parameters. According to industrial design requirements, the value ranges of these five design variables are as shown in
Table 1.
3.1.2. Rubber Material Parameters
The elastic support of the gearbox adopts a metal–rubber composite structure, in which the metal components are made of QT345 material. Its specific parameters are shown in the
Table 2 below. The rubber part uses natural rubber with a Shore hardness of 77. The elastic supports of gearboxes usually have higher requirements for service life during use. Compared with modified rubber, natural rubber has a higher strength and excellent fatigue resistance. Therefore, in the wind power generation industry, natural rubber is the most widely used elastic material.
The yield stress is = 345 Mpa, the allowable stress is [] = /n, and n is the security coefficient. The safety factor is set to 1.5 (the safety factor for QT345 is between 1.5 and 2.0), and allowable stress [] = 230 MPa.
Natural rubber plays a critical role in the stiffness and vibration-damping performance of the gearbox elastic support structure. However, due to its highly nonlinear behavior and large deformation characteristics, the constitutive modeling of rubber is inherently complex, posing significant challenges for the design and engineering application of rubber components [
27]. Numerous studies have been conducted to address the selection of appropriate constitutive models for rubber materials [
28]. Currently, researchers commonly adopt phenomenological models that treat rubber as a continuous medium, describing its mechanical behavior by constructing a strain energy density function. The general form of the strain energy density function for rubber is expressed as:
The above equation is expanded using a Taylor series.
In the equation, is the deviatoric (shear) strain energy potential;
is the volumetric (dilatational) strain energy potential;
is the degree of the polynomial;
,
are the shear and compressibility parameters of the material, respectively, and are obtained from rubber material experiments. Generally, it is common to deal with rubber materials for most works as incompressible and set
to zero. So, a lot of focus on hyperelastic models is awarded to the deviatoric strain potential [
29].
are the first and second strain invariants.
is the volume ratio after deformation to before deformation. For incompressible materials
= 1 [
30].
For Equation (19), if
N = 1 and the polynomial model includes only first-order terms, then the strain energy function reduces to the Mooney–Rivlin constitutive model expression:
For Equation (19), if
N = 1 with
i = 1 and
j = 0, then the strain energy function reduces to the Neo-Hookean constitutive model expression:
For Equation (19), if
N = 3 and
i ≠ 0,
j = 0, then the strain energy function reduces to the Yeoh constitutive model expression:
The Mooney–Rivlin model features a relatively simple strain energy function and can accurately capture the mechanical behavior of rubber materials under small to moderate deformations. However, it falls short in describing material hardening during large deformations. Similar to the Mooney–Rivlin model, the Neo-Hookean model is also suitable for small to moderate deformation scenarios but exhibits limited adaptability under large deformation conditions. In contrast, the Yeoh model offers higher accuracy in characterizing the mechanical properties of rubber materials, particularly as it provides a more precise and stable representation of the stress–strain relationship under large deformations. Given that the gearbox elastic support undergoes significant strain under normal operating conditions, in this study, the Yeoh model is adopted as the constitutive model for the rubber material, and it is applied in the subsequent numerical simulation analyses.
To ensure the accuracy of the model parameters, in this study, a natural rubber compression sample with a Shore hardness of 77 is used as an example, with the true stress–strain data of the sample obtained through uniaxial compression tests. Data fitting for the constitutive model is carried out using ANSYS 2022 simulation software. These parameters not only accurately reflect the mechanical properties of the rubber material under large strain conditions but also provide a solid foundation for subsequent simulation calculations, which helps improve the predictive accuracy of the model and enhances its reliability in practical engineering applications. The rubber specimen, experimental equipment, and rubber model parameters are detailed below, as shown in
Figure 13 and
Table 3.
3.1.3. Finite Element Analysis of Gearbox Elastic Support
Using the statics module in ANSYS Workbench, a force analysis of the gearbox elastic support under-rated working conditions is carried out. In order to simulate the actual working conditions, first, a vertical displacement of 10 mm is applied to the upper support of the gearbox elastic support to ensure that the upper support makes contact with the lower support. The upper and lower supports are set as frictional contact, and the friction coefficient is set to 0.2. Second, the mesh is divided. The sweeping method is adopted for the rubber element of the gearbox elastic support with a mesh size of 14 mm. A tetrahedral mesh is used for both the iron sheet and the upper and lower support pedestals. The mesh size of the upper and lower support pedestals is 35 mm, and that of the iron sheet is 15 mm. Finally, the bottom of the support seat under the elastic support of the gearbox is set as a fixed constraint, and a 1650 kN load is applied to the upper and side surfaces of the torsion arm of the elastic support for simulation. The simulation results are shown below.
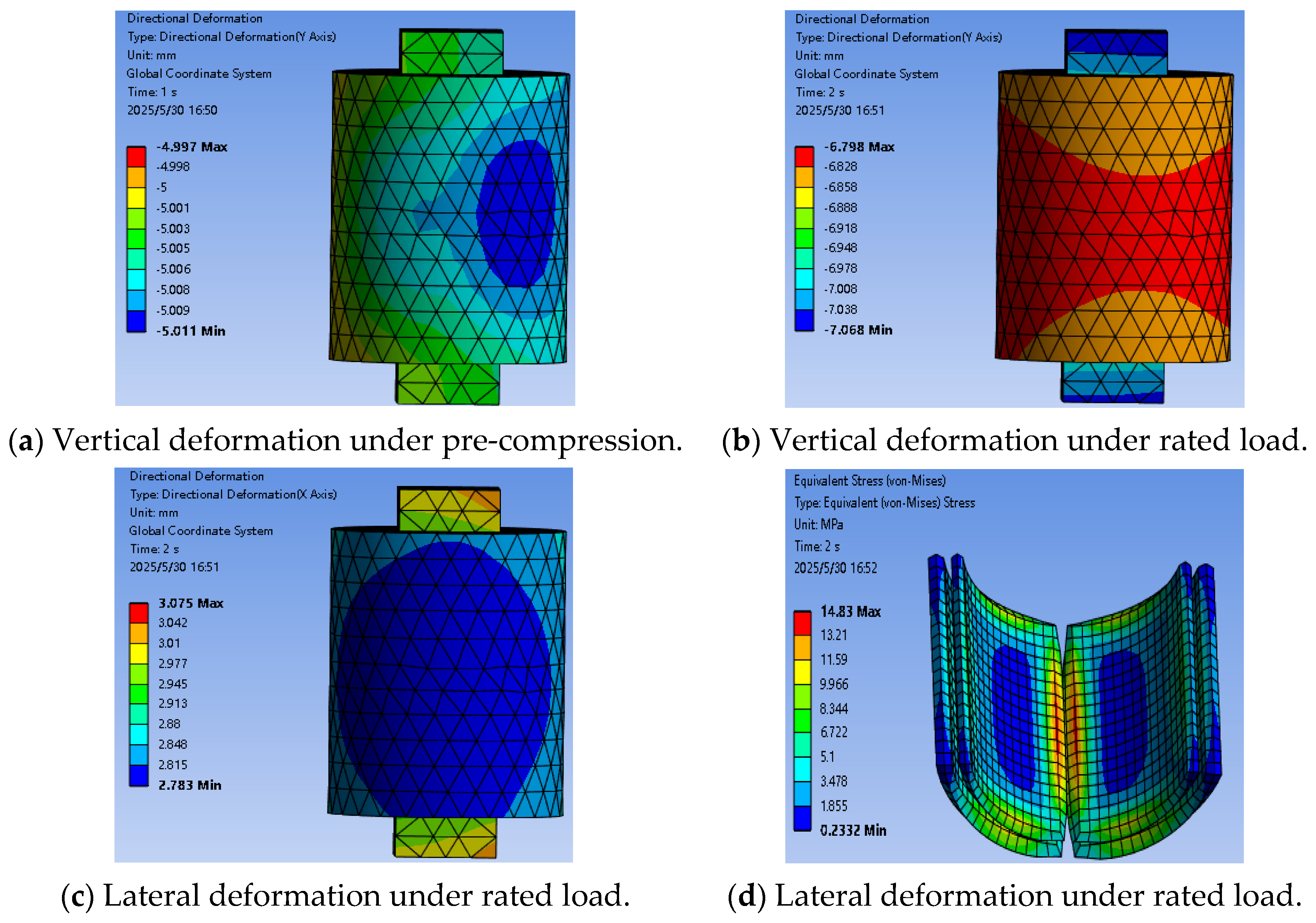
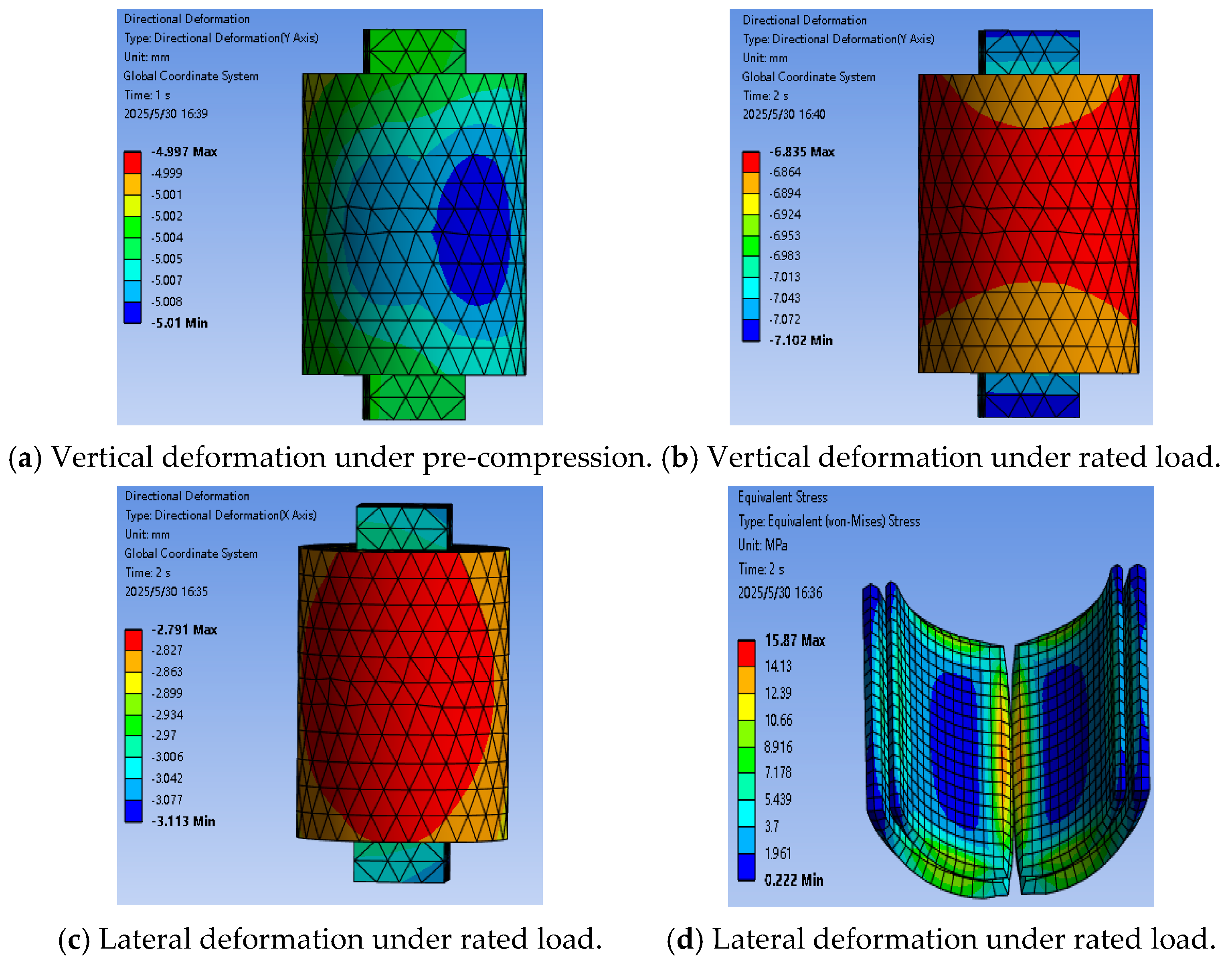
Figure 14 presents the finite element simulation results of the gearbox elastic support under different working conditions, allowing for an evaluation of its stiffness performance and the equivalent stress distribution of the rubber components.
Figure 14a illustrates the vertical deformation of the torque arm under pre-compression conditions,
Figure 14b and
Figure 14c show the deformation of the torque arm in the vertical and horizontal directions, respectively, under a rated load of 1650 kN, and
Figure 14d presents the equivalent stress contour of the rubber component under the same load. In the simulation, the average vertical deformation of the torque arm of the elastic support under a rated load is used as the displacement to evaluate the vertical stiffness of the elastic support, while the average horizontal deformation of the torque arm under a rated load is used to evaluate the horizontal stiffness. According to the stiffness calculation formula, the vertical static stiffness obtained from the simulation is 816.83 kN/mm, with an error of 8.5% compared to the physical experimental results; the horizontal static stiffness is 546.35 kN/mm, with an error of 8.7%. The discrepancies between the finite element analysis outcomes and the empirical experimental data are below 10%, effectively confirming the simulation’s reliability.
3.1.4. Experimental Design
An experimental design is employed using the optimal Latin hypercube sampling method combined with a finite element analysis. Input variables are sampled within the specified parameter range, resulting in a total of 500 samples. These 500 samples are then used as design points for a simulation analysis with ANSYS Workbench 2022 to generate a dataset. The hardness of the rubber material in data set 1 is 77, and that of the rubber material in dataset 2 is 75. The two datasets with different rubber hardness values are presented in
Table 4 and
Table 5, respectively.
3.2. Data Preprocessing
In this section, two datasets generated using the optimal Latin hypercube sampling method and ANSYS Workbench simulation are processed to meet the needs of multi-task learning model training. The data consist of five design variables as inputs and four performance metrics as outputs, which are used for both model training and evaluation.
Before training the neural network, the data need to be normalized. The purpose of data normalization is to adjust features with different scales or units to the same range in order to improve the efficiency and stability of model training. This helps to prevent certain features from disproportionately affecting the model due to their large or small value ranges, thus accelerating the convergence of the algorithm and enhancing the model’s performance. Normalization is especially important when dealing with features that have different units or value ranges, as it helps to ensure a more balanced contribution from all features to the model. The formula used for data normalization is as follows:
In the equation:
represents the normalized values;
represents raw data;
is the maximum value of the data;
is the minimum value of the data.
To evaluate the model performance in this study, the mean squared error (MSE) and the coefficient of determination (R
2) are employed to assess the predictive results of the network model. The formulas for the MSE and R
2 are as follows.
Here: is the predicted value, is the true value, is the average of the true values, is the sample size.
3.3. Model Comparison Experiment Based on Multi-Task Learning
The multi-task learning model is implemented based on the programming software Pycharm 2023. The model’s input consists of five structural design parameters of the gearbox’s elastic support, while the output includes four structural performance parameters of the elastic support. Specifically, Task 1 is the vertical stiffness of the elastic support, Task 2 is the maximum equivalent stress of the elastic support, Task 3 is the lateral stiffness of the elastic support, and Task 4 is the mass of the elastic support.
The multi-task learning PLE and PLE-LSTM frameworks are both composed of two layers of CGC neural networks. The lower CGC network consists of five expert networks and five gating networks, while the upper CGC neural network is made up of five expert networks, four gating networks, and four tower networks. The upper expert networks receive inputs from the lower gating networks and pass the outputs to the upper gating networks. After processing the received data, the gating networks forward the results to the tower networks, which ultimately process the data and generate predictive outputs. In the multi-task learning PLE framework, both the expert and tower networks are fully connected neural networks, with 64 and 32 neurons in the hidden layers, respectively. For the PLE-LSTM learning framework, the tower networks are replaced by LSTM networks. All other settings remain consistent with those of the PLE framework.
For comparison, MLP and MMOE are introduced as control groups in this experiment. The MLP has a simple structure and is a typical hard parameter-sharing model in multi-task learning. In this experiment, the MLP structure is configured with three hidden layers containing 13, 27, and 13 neurons. The activation function used is ReLU. The MMOE framework consists of five expert networks, four tower networks, and four gating units. The expert networks are fully connected neural networks with two hidden layers containing 64 and 32 neurons
The MLP, PLE, MMOE, and PLE-LSTM network frameworks are used to train the data. The mean square error (MSE) is used as a loss function for each task. After training, the determination coefficients (R
2) obtained for the four models on the verification set are shown in
Table 6.
The prediction accuracy pairs of the four tasks under different models are shown in
Figure 15.
As shown in the above, PLE-LSTM, which is an improvement of the PLE framework, outperforms the other models in Tasks 1, 3, and 4. However, for the nonlinear features of Task 2, the prediction accuracy remains relatively low. Compared to the linear weighted approach used to optimize the loss function in the PLE-LSTM framework, in this study, dynamic loss weight allocation based on the GradNorm method is implemented, integrating the total loss function. Then, ablation experiments are carried out with other loss function optimization methods on the data set of mechanical properties of elastic support structures. After training, the predictive ability of the network model trained on the verification dataset using various methods is examined, as shown in
Table 7.
Under the same PLE-LSTM network architecture and parameter configuration conditions, the loss function optimization strategy proposed in this study is clearly superior to the other methods. As shown in
Figure 16, the optimized loss function exhibits a faster convergence rate during training, with the loss value decreasing rapidly, allowing the model to learn more efficiently. Additionally, optimizing the loss function results in a significant reduction in the overall loss value, greatly improving model performance, as reflected by smaller errors. Furthermore, the loss curve of the optimized function is smoother, with less fluctuation, indicating improved stability during the training process. In contrast, the unoptimized loss function curve shows substantial fluctuations. Finally, the optimized loss function enhances the model’s generalization ability, effectively preventing overfitting or underfitting. This ensures that the model continues to perform well when handling new data.
3.4. Method Validation
As shown in previous comparisons conducted by a particular company, the discrepancies between the physical and simulation experimental results are relatively small, indicating that simulations can effectively reflect the actual performance. In this study, the neural network prediction results are also compared with the simulation results to verify the feasibility of the proposed method. The comparison between the neural network predictions and the simulation results is shown in
Table 8.
As shown in
Table 8 and
Figure 17, the prediction errors between the neural network and simulation results for all four tasks are within 8%, fully demonstrating the reliability and effectiveness of the proposed method in performance prediction.
4. Conclusions
This study employs the multi-task learning (PLE) neural network framework, coupled with a dynamic weighting loss function optimization technique, to conduct multi-objective predictions of the mechanical performance indicators for the gearbox elastic support structure of wind turbine systems.
First, this study combines simulation experiments with the optimal Latin hypercube sampling method to generate the dataset required for the neural network. The reliability of the simulation results is validated through a stiffness experiment. The dataset generated using this method effectively avoids the high costs associated with physical experiments, providing reliable data support for the subsequent training of the network model.
Next, it is found that the improved PLE LSTM model based on the multi-task learning PLE network framework can better deal with the nonlinear characteristics of the rubber material in gearbox elastic support. The GradNorm loss function optimization method can dynamically adjust the weight of each task, thus effectively avoiding overfitting problems and unbalanced multi-task loss reduction.
Finally, through ablation experiments on various datasets, it is verified that the PLE-LSTM network architecture introduced in this research surpasses alternative multi-task learning frameworks in modeling the performance metrics of the gearbox elastic support structure. Moreover, the loss optimization strategy utilized herein exhibits exceptional effectiveness in tackling issues of early convergence and uneven loss reduction compared to other optimization approaches.
In conclusion, the method proposed in this study provides a reliable and economical alternative to traditional physical tests of the gearbox elastic support structure. By utilizing simulation experiments and optimized neural network models, our method accurately predicts multi-objective performance at a lower experimental cost. This method provides practical value for the efficient development and optimization of damping elements in wind power systems.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}