1. Introduction
As technology advances rapidly, motors have become indispensable in industrial production, serving as the backbone of modern industrial systems [
1,
2,
3]. However, motors often operate in harsh environments and complex conditions, which can lead to issues such as fatigue damage, overheating, and insulation material degradation. These problems can cause equipment failure or even shutdowns, posing significant threats to the safe and stable operation of enterprises [
4,
5,
6]. Therefore, implementing condition monitoring and precise fault diagnosis for motor bearings has emerged as a critical challenge in the industrial sector [
7,
8].
Traditional motor fault diagnosis techniques primarily rely on collecting signals, such as the current and vibration during motor operation, combined with advanced signal processing algorithms to detect faults [
9]. To avoid the need for additional sensors and the installation space required by conventional vibration-signal-based methods, this study utilized current signals for feature extraction and fault diagnosis. Common current signal analysis methods include fast Fourier transform (FFT) [
10], wavelet transform (WT) [
11], empirical mode decomposition (EMD) [
12], and variational mode decomposition (VMD) [
13]. For instance, Merabet [
14] employed the FFT for stator current spectral analysis, defining residual indicators to visualize changes in electrical and mechanical quantities, thereby enabling the real-time health monitoring and diagnosis of motor systems. Lu [
15] proposed a gearbox fault diagnosis method based on motor current signature analysis, using variational mode decomposition and genetic algorithms to remove irrelevant information and wavelet transforms to extract fault features while suppressing noise, achieving effective gearbox fault diagnosis. Wu [
16] introduced a bearing fault diagnosis method for induction motors, processing stator current signals with wavelet denoising and quasi-synchronous sampling to extract harmonic features, and mapping these features to fault labels using Random Vector Functional Link networks for an accurate distinction between healthy and faulty bearings. Jin [
17], based on the dynamics and equivalent circuit model of a V-shaped ultrasonic motor (VSUM), investigated the relationship between real-time output characteristics and input signals by considering the nonlinear effects of preload variations, and established a current prediction model to simplify fault diagnosis. However, manually extracted fault features are often insufficient, with subtle fault characteristics easily overlooked or masked by noise.
With the development of artificial intelligence, intelligent fault diagnosis methods have gained significant attention, primarily categorized into machine learning [
18] and deep learning approaches [
19]. Machine learning-based methods rely on traditional signal-processing techniques for feature extraction, followed by classification using algorithms such as Support Vector Machines (SVMs), Random Forests, Principal Component Analysis (PCA), and Enhanced Principal Component Analysis (EPCA). For example, Santer [
20] utilized current and vibration signals, proposing feature extraction methods based on envelope analysis and a wavelet packet transform, combined with a SVM for bearing fault detection in motors. Zhang [
21] introduced a Harmonic Drive (HD) fault diagnosis method, eliminating speed effects through Equal Angular Displacement Signal Segmentation (EADSS) and optimizing weight matrices with an improved NAP method and cosine distance. Subsequently, PCA was used for feature extraction, followed by fault diagnosis with a Backpropagation Neural Network (BPNN). Liao [
22] proposed a motor current signature analysis (MCSA) method based on Enhanced Principal Component Analysis (EPCA), employing power frequency filtering to reduce interference, enhance harmonic features, and extract fault characteristics for effective diagnosis. Nevertheless, machine learning-based methods are cumbersome and lack strong interdependencies between steps, limiting further improvements in diagnostic efficiency [
23].
In contrast, deep learning methods can automatically learn features from raw data, significantly reducing the reliance on manual feature extraction and offering new opportunities for fault diagnosis technology. In recent years, CNNs have been increasingly applied to motor fault detection [
24,
25,
26]. Some researchers have proposed models combining 1D CNN and Recurrent Neural Networks (RNNs) for induction motor fault detection, incorporating multi-head mechanisms to enhance the feature attention, simplifying the diagnostic process, and improving the accuracy [
27]. Morales-Perez, Carlos [
28] developed an ITSC fault diagnosis method based on current signal imaging and CNNs, highlighting fault spectrum features and converting them into images for CNN input, achieving high-precision fault identification with a test accuracy of 98.62%. Liu [
29] introduced a fault diagnosis model combining CNN and Bidirectional Long Short-Term Memory (BiLSTM) networks. By extracting frequency-domain features from three-phase currents using CEEMD and leveraging CNN-BiLSTM, they addressed open-circuit fault detection and classification in permanent magnet synchronous motor inverters. Du [
30] proposed a hybrid CNN model with multi-scale convolutional kernels for feature extraction and dynamic weighted layers for feature fusion. Experiments demonstrated its superiority over existing CNN models in bearing and gearbox fault diagnosis for motors.
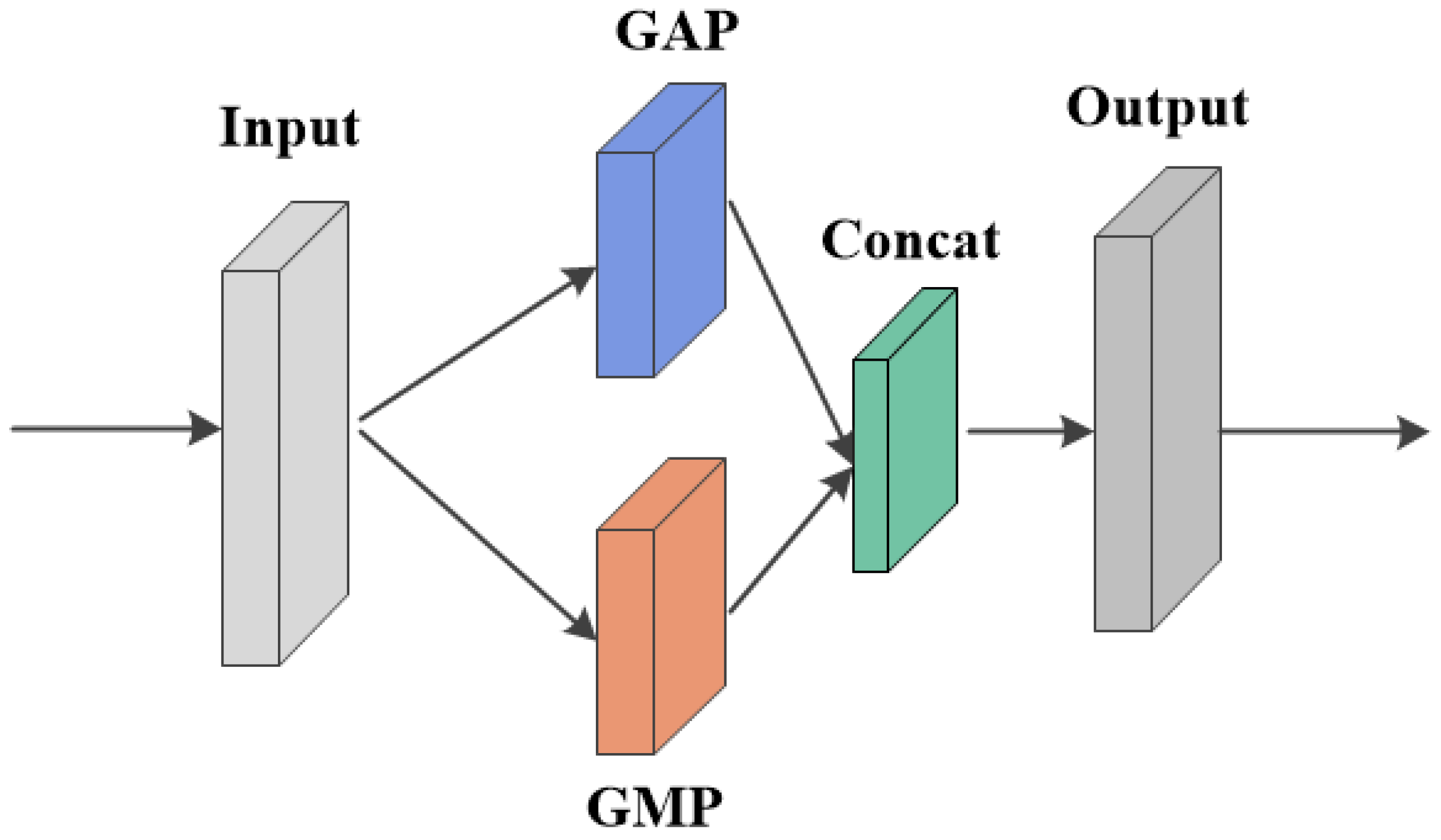
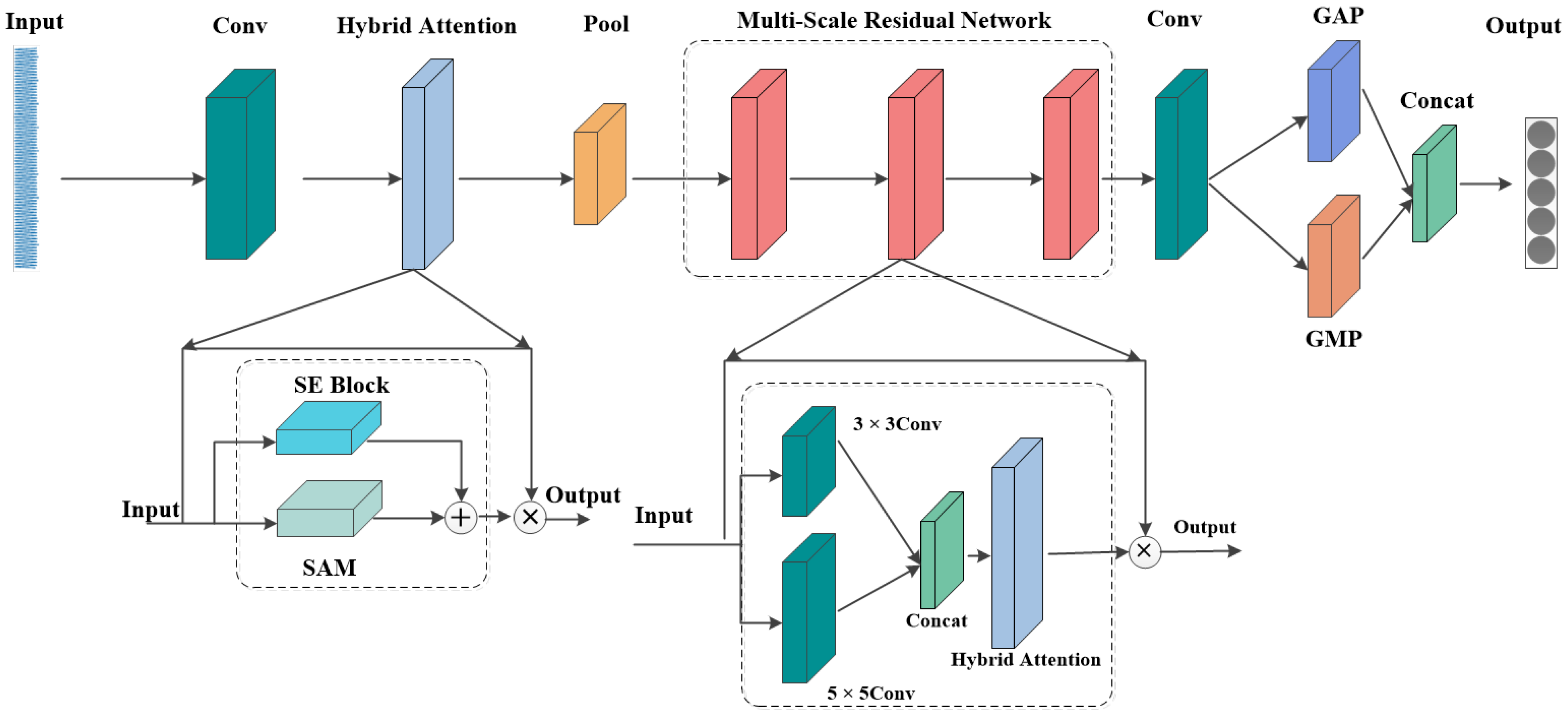
In summary, while CNNs are increasingly being utilized for motor bearing fault diagnosis, they frequently encounter challenges, such as limited feature extraction in complex conditions, insufficient diagnostic accuracy, and inadequate generalization capabilities. To address these limitations, this paper innovatively proposes a multi-scale residual CNN model specifically designed for motor bearing fault detection. The model integrates a hybrid attention mechanism that combines a squeeze and excitation (SE) block and spatial attention mechanism (SAM), thereby significantly enhancing the feature representation. By synergistically combining the hybrid attention mechanism with multi-scale residual modules, the model effectively captures and amplifies both local and global features. Additionally, the integration of dual global pooling further refines the feature extraction process. Empirical validation using publicly available datasets demonstrates that these enhancements enable the model to achieve a high diagnostic accuracy and robust generalization.
The rest of this article is organized as follows:
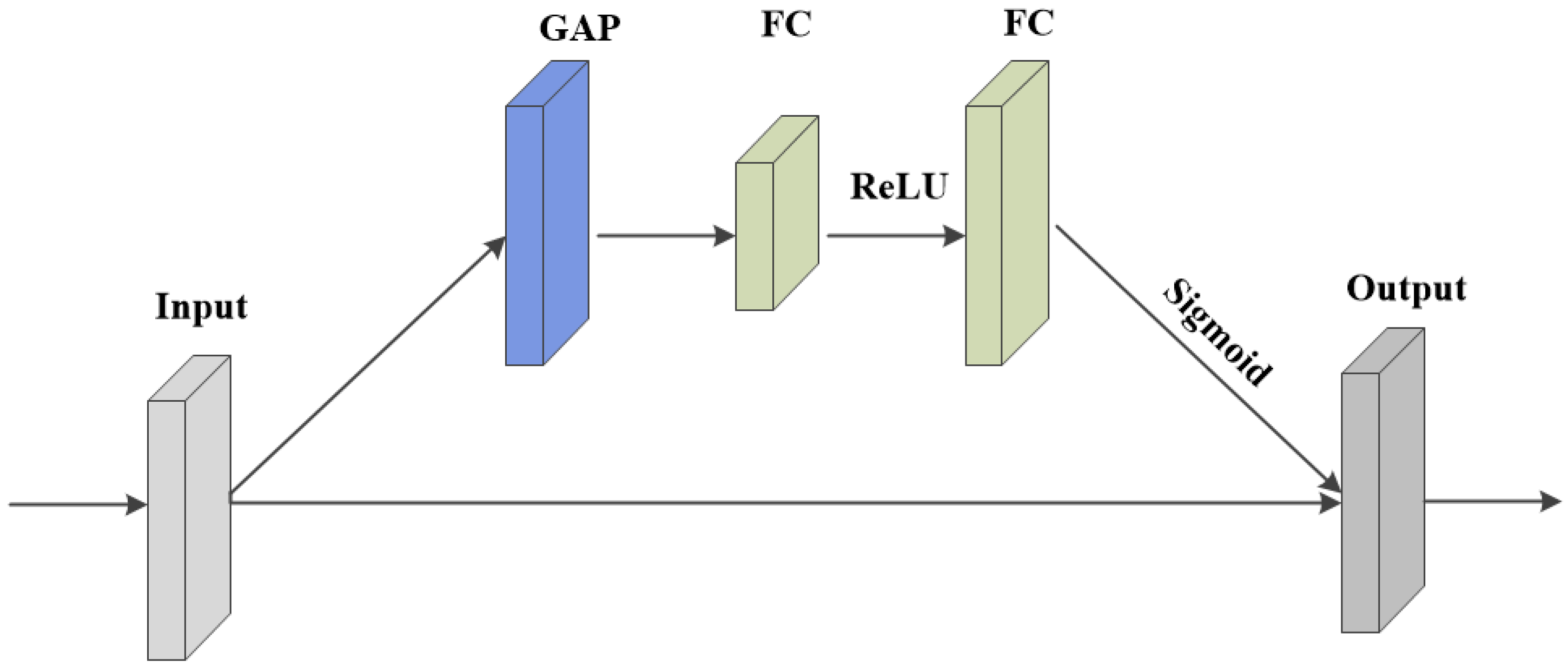
Section 2 presents an overview of CNN and SE modules.
Section 3 elaborates on the proposed hybrid attention mechanism, multi-scale residual network, and dual global pooling module.
Section 4 introduces the experimental datasets, data preprocessing, and an analysis of how model parameters influenced the performance.
Section 5 assesses the model’s performance through comparative and ablation experiments. Finally,
Section 6 concludes this paper.
5. Experiments and Analysis
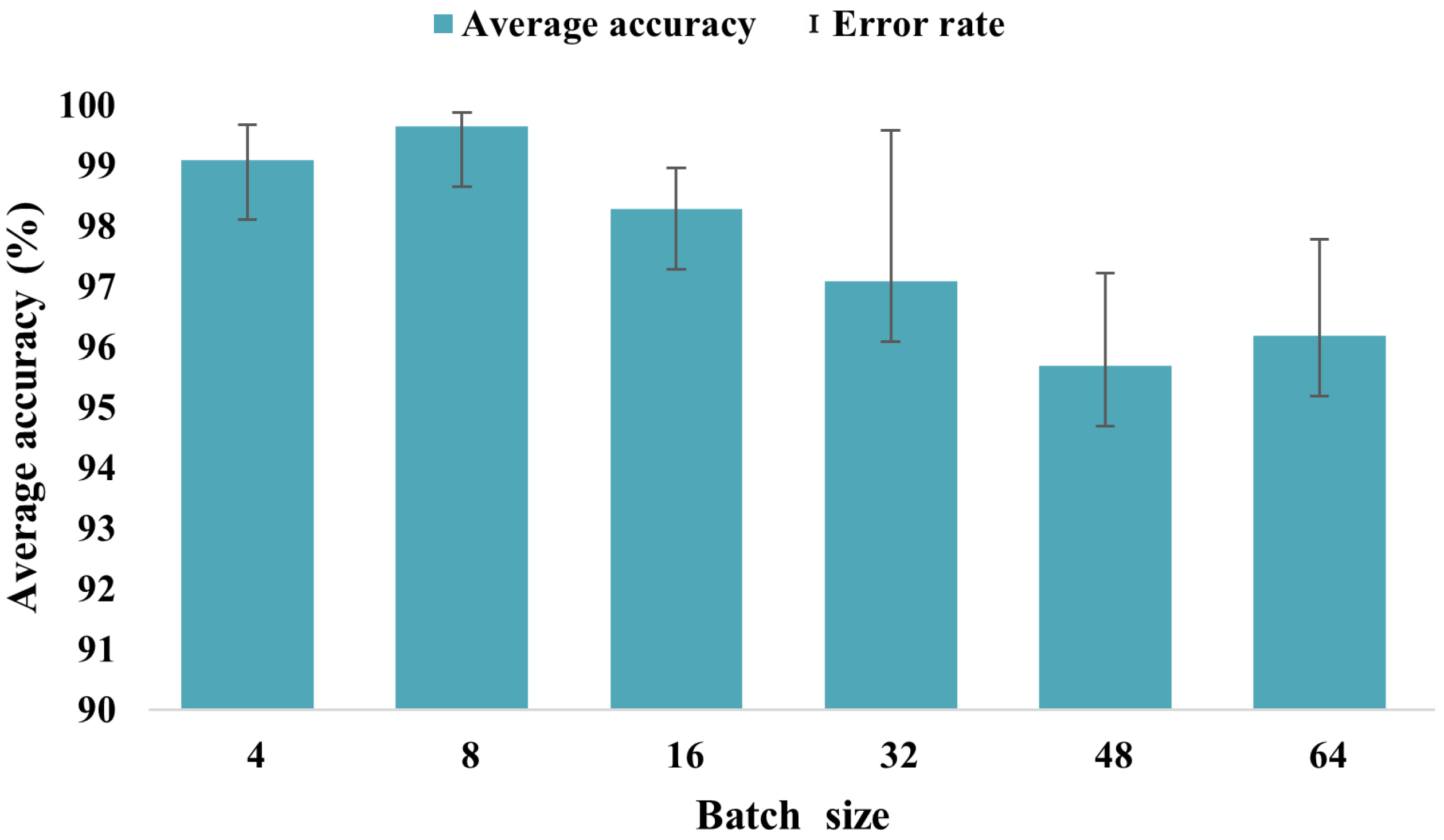
5.1. Model Parameter Settings
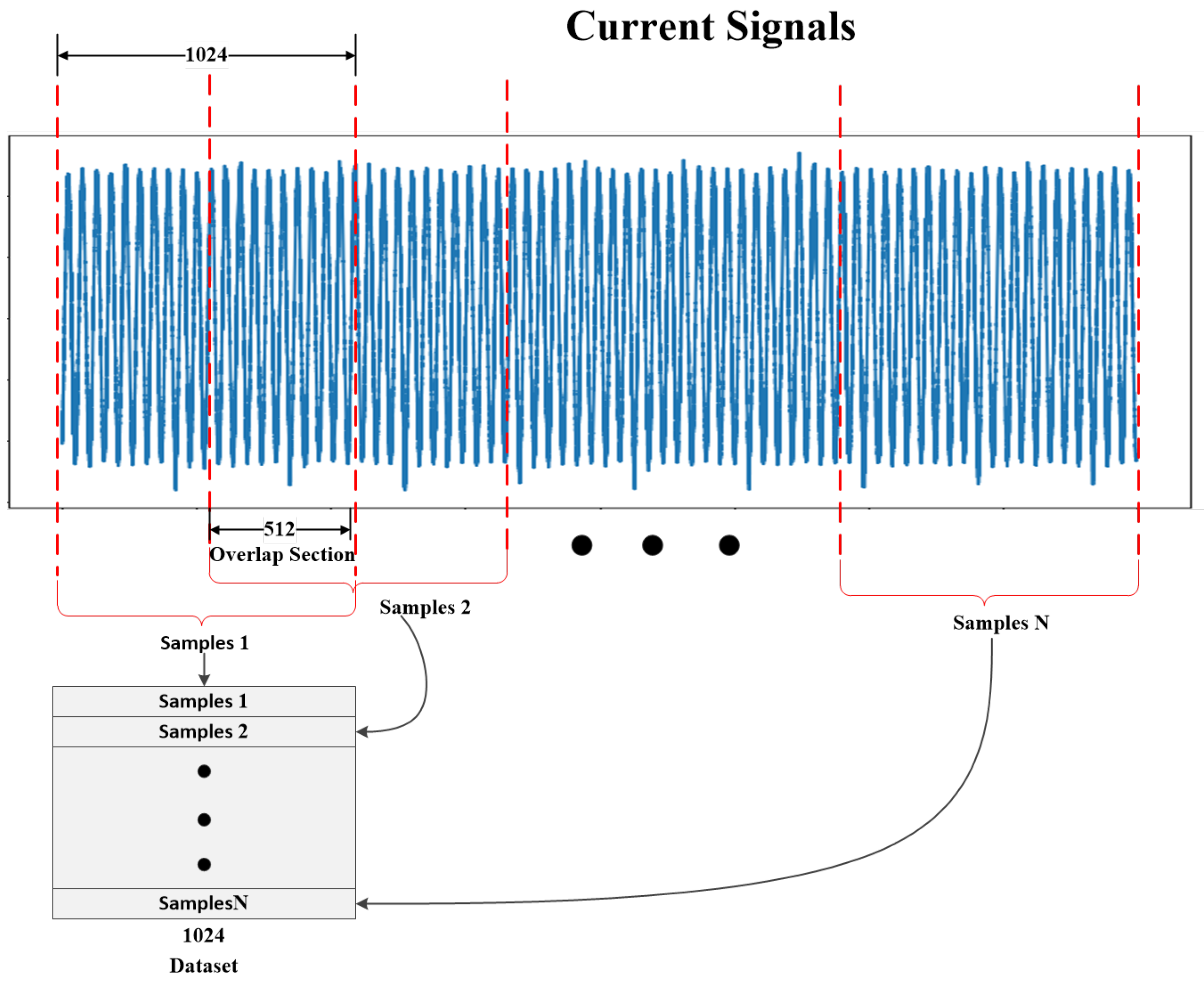
The model was trained using the Adam optimizer to update the weights, with a learning rate decay mechanism for dynamic adjustment. The batch size was set to 8, and the maximum number of iterations was 300. The dataset was split into training, validation, and testing sets in a 6:2:2 ratio. Detailed model parameters are provided in
Table 4. The experiments were conducted within the environment of TensorFlow 2.4.0 and Python 3.8, with the model initially trained on a PC equipped with an Intel i7-12700H processor (Intel, Santa Clara, CA, USA) operating at 4.7 GHz and featuring 16 GB of RAM.
5.2. Model Training
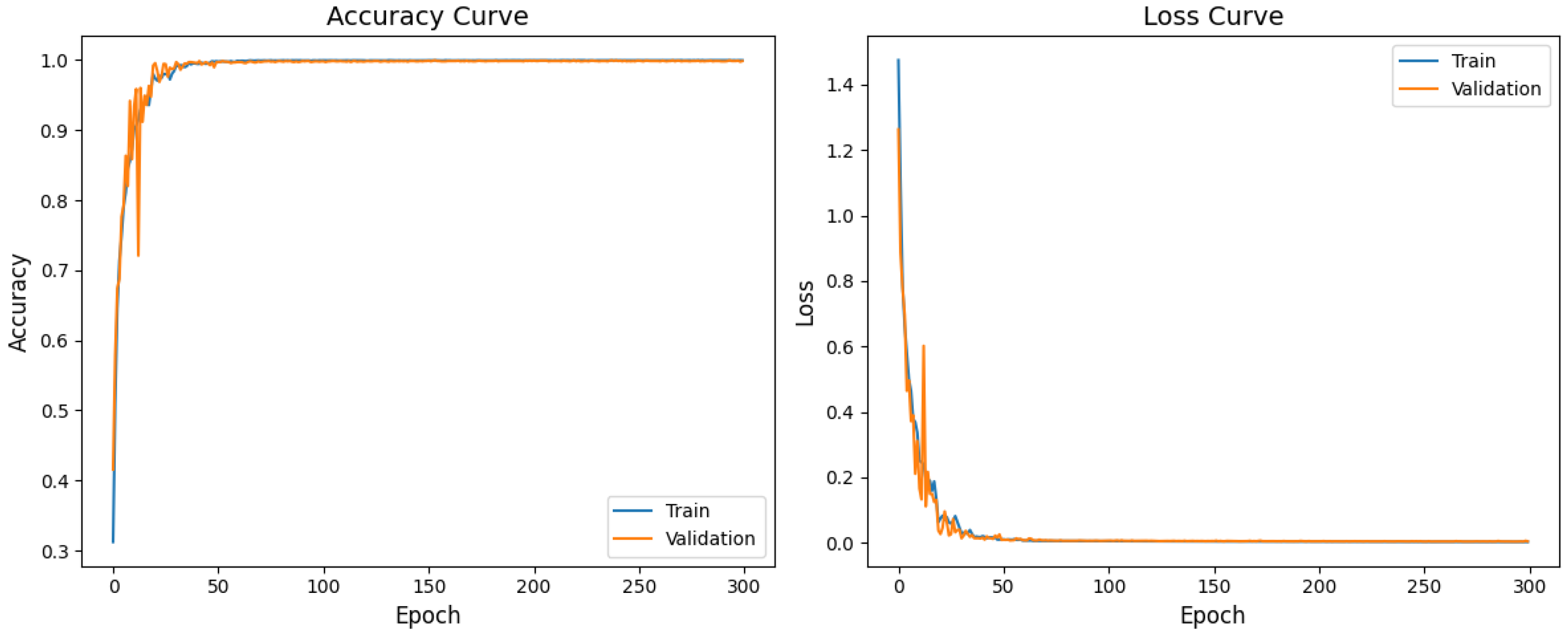
The model was trained 10 times, with 300 iterations each, where it achieved an average accuracy of 99.7%. As shown in
Figure 16, the accuracy and loss rate curves indicate that the accuracy began to converge after 50 iterations and stabilized after 100. The loss gradually approached zero as the iterations increased, which reflected the model’s progressive learning of data features.
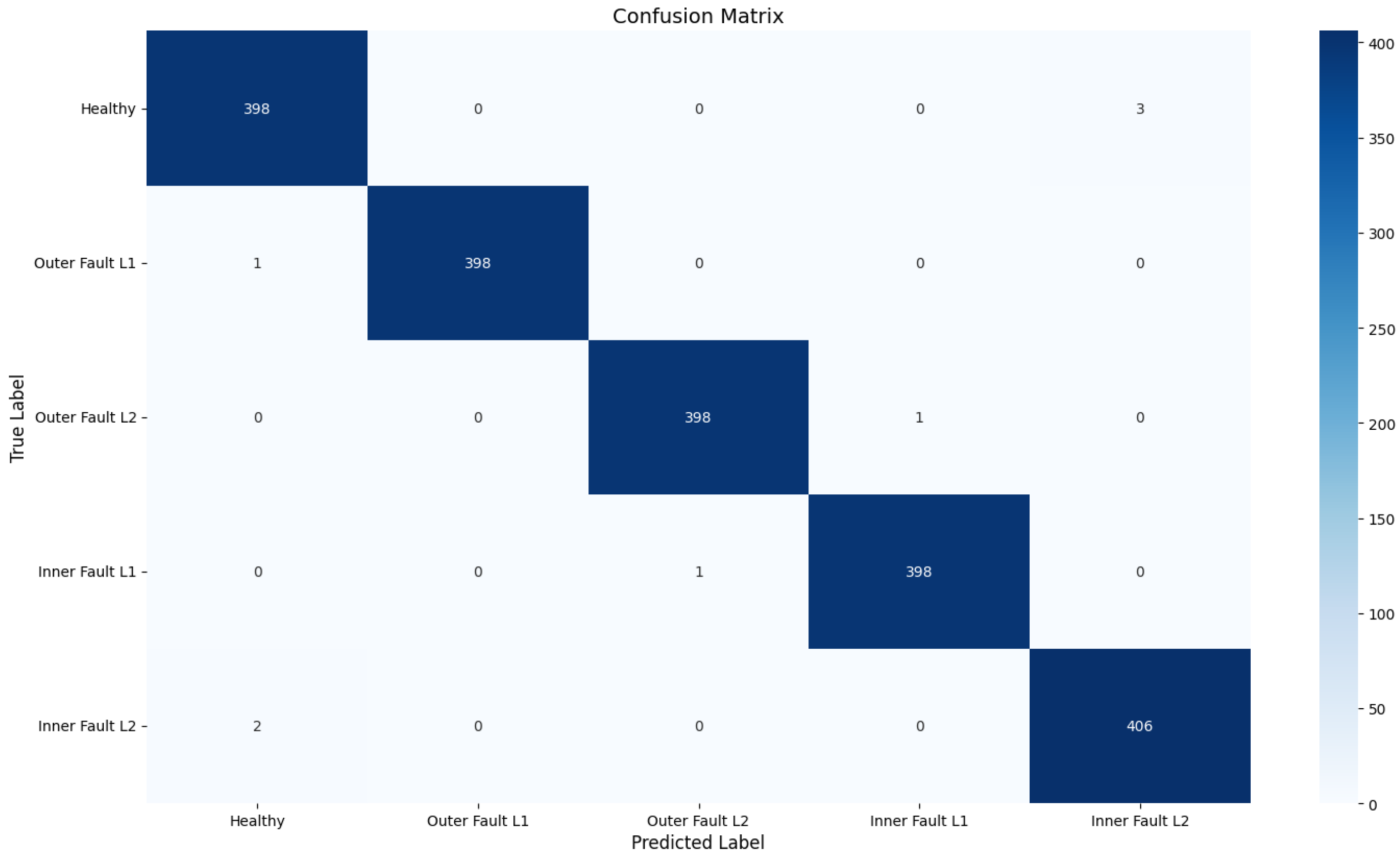
To verify the model’s cross-condition generalization in motor bearing fault detection, tests were conducted on four bearing faults. The confusion matrix in
Figure 17 shows the model’s performance. The model underwent consecutive detections as follows: 401 for healthy bearings, 399 for outer fault L1, and 399 for outer fault L2, with misclassifications occurring 3, 1, and 1 times, respectively. Additionally, it performed 399 consecutive detections for both inner fault L1 and inner fault L2, misjudging them 1 and 2 times, respectively. These experimental results demonstrate that the model maintained a high level of detection accuracy, even in cross-condition motor bearing fault detection scenarios.
5.3. Comparison of Single-Phase and Dual-Phase Currents on Model Performance
The University of Paderborn bearing fault dataset comprises two current signals (U,V), namely, Current Signal 1 and Current Signal 2. To assess how these signals affected the model performance, this study compared the model’s performance when trained solely on each signal individually versus when trained on both signals concurrently. The findings of this comparison are summarized in
Table 5.
(1) Dual-phase vs. single-phase currents: The dual-phase current signals achieved an accuracy of 99.7%, recall of 99.85%, and F1 score of 99.78%, which all surpassed the single-phase currents. This indicates that the dual-phase currents provided richer feature information, which enhanced the model accuracy and robustness.
(2) Accuracy advantage: the higher accuracy of the dual-phase currents reduced the misclassification risks, which ensured more reliable fault detection.
(3) Recall advantage: The superior recall of the dual-phase currents ensured more comprehensive fault case identification, which minimized the risk of missed detections.
(4) F1 score improvement: The improved F1 score reflected a better balance between the precision and recall, which met the dual needs of accurate fault identification and comprehensive case coverage.
In summary, the dual-phase current signals offered significant advantages in motor fault detection by providing more accurate and robust performance. Thus, this study used dual-phase current signals as inputs for the motor fault detection model to better distinguish the various fault patterns.
5.4. Performance Comparison of Classic Fault Diagnosis Models
5.4.1. The University of Paderborn’s Bearing Dataset
This study employed a multi-dimensional evaluation method to compare the overall performances of four fault diagnosis models based on the University of Paderborn’s bearing dataset, with the experimental results presented in
Table 6.
As shown in
Table 6, the AMCNN, LeNet5, AlexNet, and Transformer models achieved respective accuracies of 98.45%, 89.88%, 97.56%, and 98.77%. By contrast, the deep convolutional neural network model proposed in this study attained a superior accuracy of 99.7%, alongside higher recall and F1 scores. Although LeNet5 boasted a faster inference time than the model presented herein, the latter significantly outperformed the former across key evaluation metrics, including the accuracy, recall, and F1 score. In summary, the model introduced in this paper demonstrated exceptional accuracy and robustness in motor bearing fault detection tasks, highlighting its superior ability to effectively identify and classify motor bearing faults.
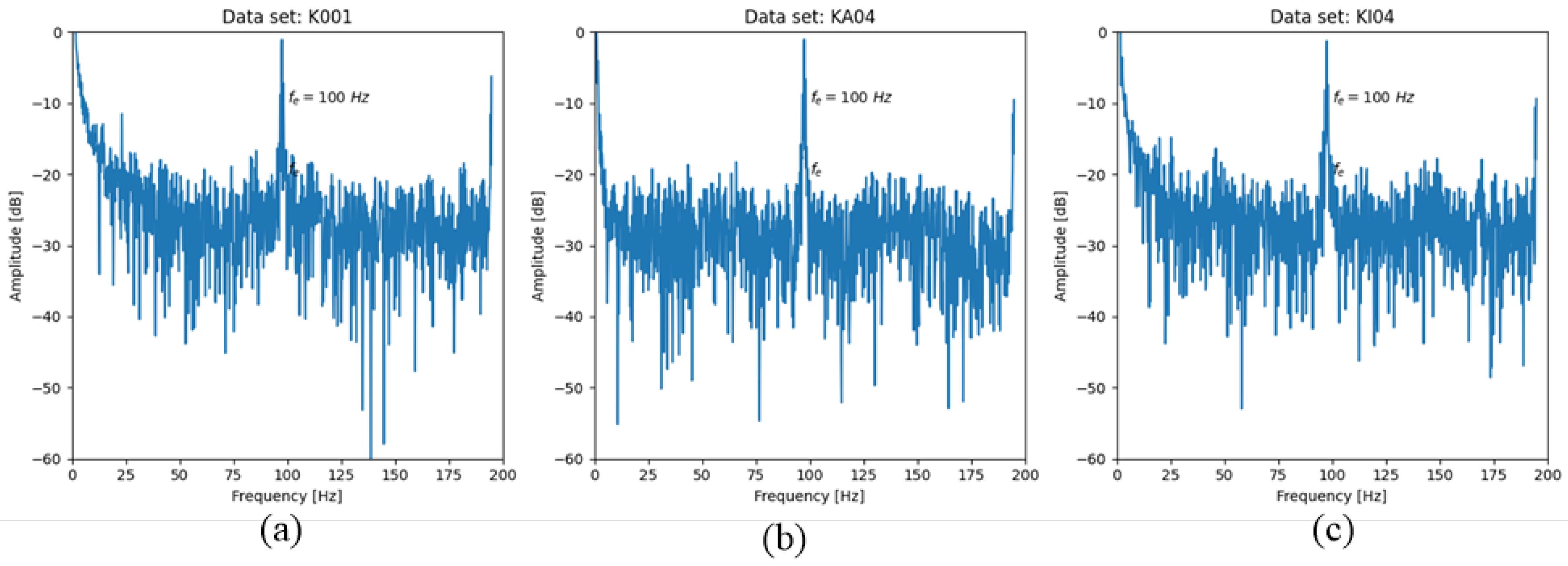
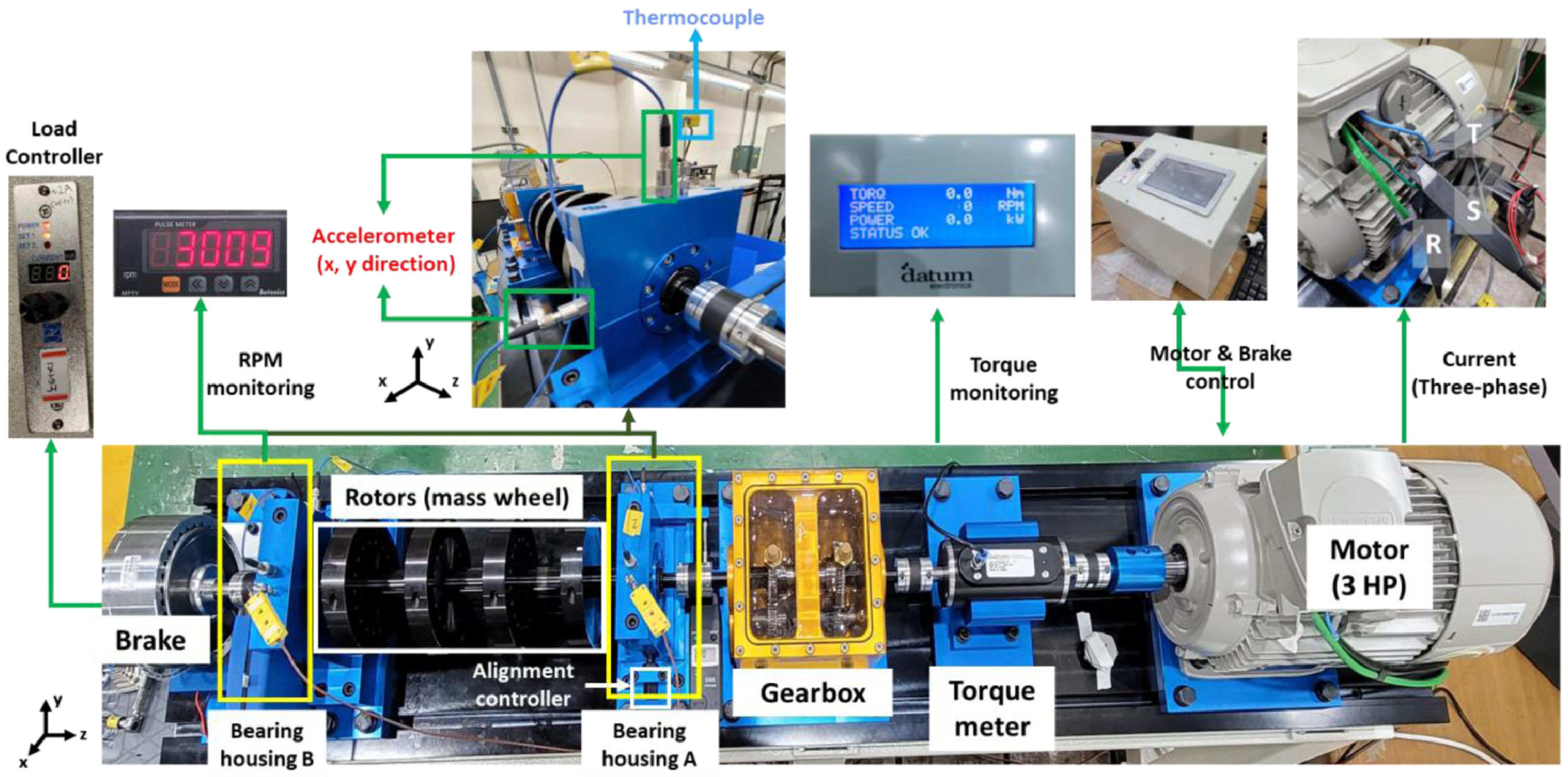
5.4.2. Vibration and Motor Current Dataset of Rolling Element Bearings
To evaluate the model’s generalization and universality, this study employed the vibration and motor current dataset of rolling element bearings [
34], encompassing current data from four states: healthy, outer ring fault, inner ring fault, and ball fault. The comparative experimental results are presented in
Table 7.
The experimental results presented in this table demonstrate the superior performance of the model proposed in this paper compared with other established models. The model achieved remarkable accuracy, recall, and F1 scores of 99.68%, 99.79%, and 99.73%, respectively, which outperformed the AMCNN, LeNet5, AlexNet, and Transformer models. While LeNet5 showed the fastest inference time, this paper’s model also maintained a relatively low inference time of 0.21 s, thus balancing the efficiency and effectiveness. These results highlight the model’s potential for real-time and high-precision bearing fault detection applications.
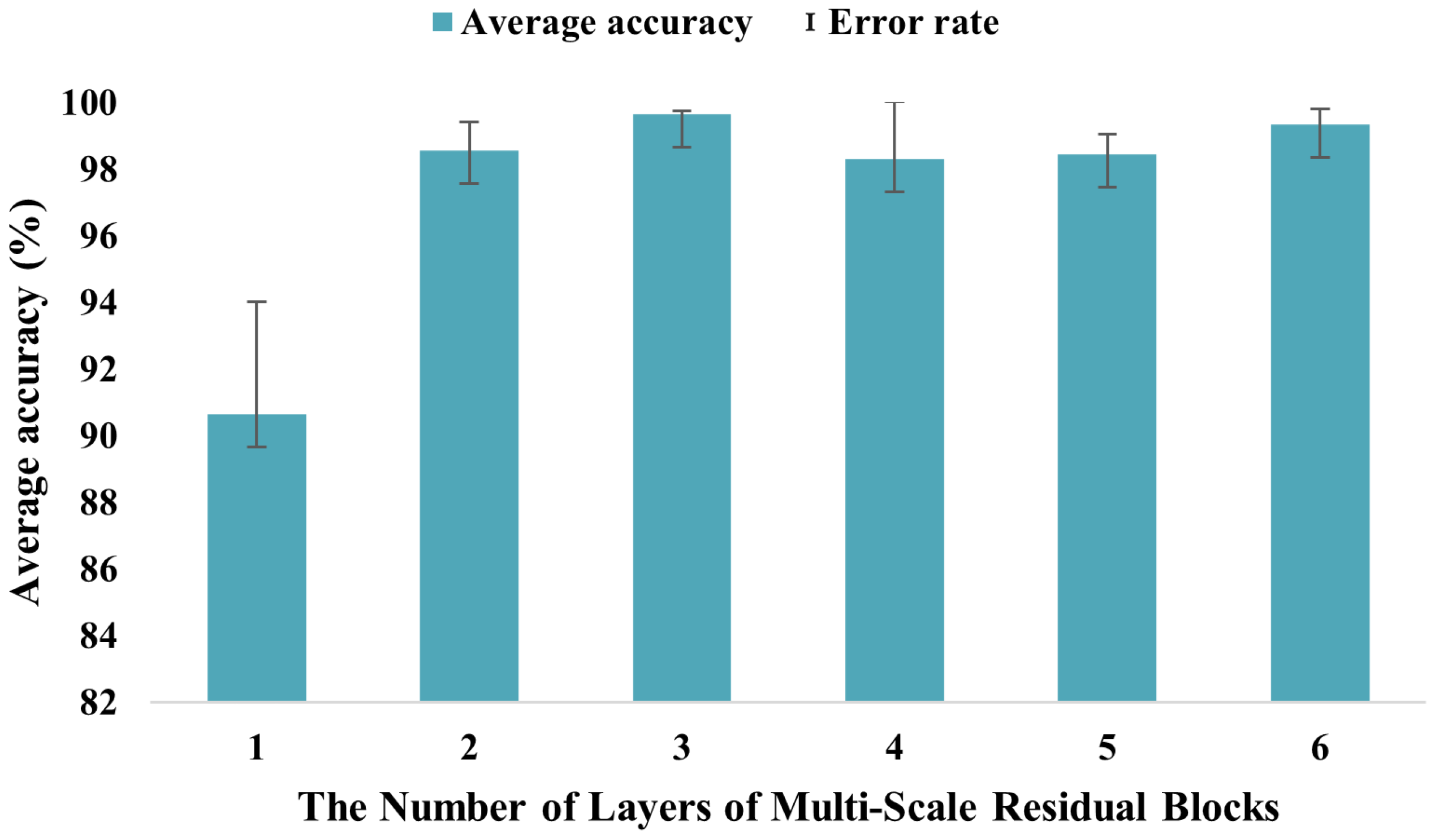
5.5. Ablation Experiment
To evaluate the model performance, an ablation study was conducted using the bearing dataset of the University of Paderborn in Germany to evaluate the effects of multi-scale residual modules, hybrid attention mechanisms, and dual global pooling, with the results shown in
Table 8.
a. Multiscale residual modules and hybrid attention mechanism: Models using only global average or max pooling had accuracies of 98.47% and 97.85%, while omitting the dual global pooling reduced the accuracy to 95.61%. This highlights the dual global pooling’s importance in feature integration.
b. Multi-scale residual blocks and dual global pooling: Excluding the hybrid attention mechanism lowered the accuracy and recall to 97.48% and 97.33%, with an F1 score of 97.4%. This shows the hybrid attention mechanism enhanced the performance by integrating channel and spatial information.
c. Hybrid attention mechanism and dual global pooling: Omitting the multi-scale residual modules resulted in the lowest performance (97.48% accuracy, 97.33% recall, 97.4% F1 score). This indicates the multi-scale residual modules significantly boosted the performance by extracting features across scales and dimensions.
d. Full combination of all three techniques: when all three were used together, the model achieved the optimal performance, with a 99.7% accuracy, 99.85% recall, and 99.78% F1 score, showing that their synergy enhanced the model’s overall performance in motor fault detection.
In summary, the ablation studies demonstrated that multi-scale residual modules, hybrid attention mechanisms, and dual global pooling are all key to improving the model’s accuracy and reliability in motor fault detection. Their effective combination significantly boosted the performance.
6. Conclusions
A deep convolutional neural network model for motor fault detection is proposed in this paper. The model employs a spatial hybrid attention mechanism post-convolutional layer to extract channel and spatial information from the feature map. Subsequently, a three-layer multi-scale residual module acquires local and global features from the current signal following max pooling. Then, double global pooling is utilized to extract richer and more comprehensive feature information, thereby enhancing the model’s performance. Finally, the softmax function is used to output the classification results. The Adam optimizer and sparse categorical cross-entropy loss are employed to compile the model, with early stopping and learning rate decay applied to enhance the training effectiveness. While the experimental results indicate that the model could effectively detect bearing faults within the tested data range, it is important to note that the model’s effectiveness was assessed using motor bearing fault data collected by Padburn University under laboratory conditions, as well as rolling bearing vibration and motor current fault diagnosis datasets under variable-speed conditions. Compared with the single-phase current signals, this model demonstrated higher accuracy, recall, and F1 scores that outperformed the AMCNN, LeNet5, AlexNet, and Transformer models within the tested data range. However, the model has not yet been applied to engine fault detection, particularly under harsh industrial conditions. Future research will focus on validating the model’s performance in more complex and diverse industrial environments and across different types of motor faults.


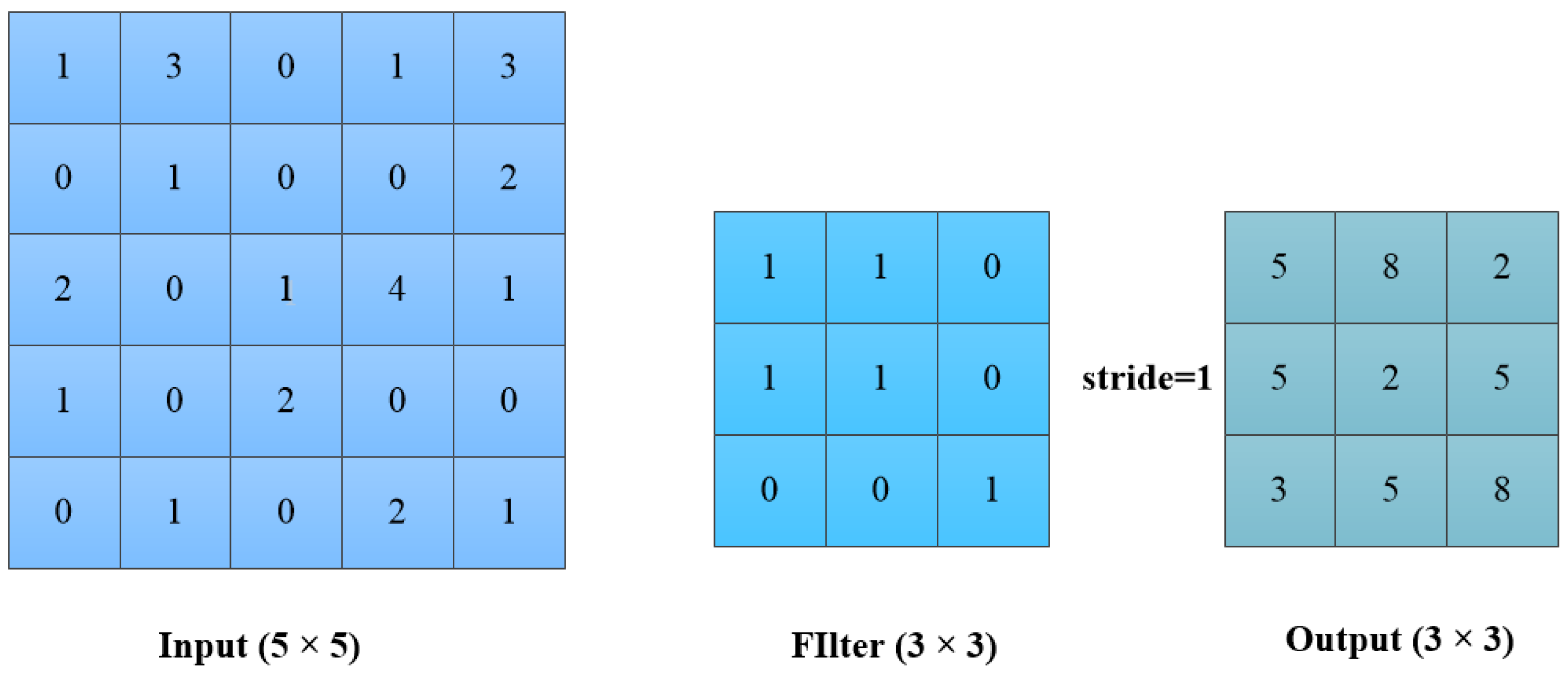
 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}