
Fuzzy Flocking Control for Multi-Agents Trapped in Dynamic Equilibrium Under Multiple Obstacles


Abstract
1. Introduction
- (1)
- A dynamic equilibrium judgment rule is proposed to determine whether the agent is trapped in dynamic equilibrium. If the agent is trapped in dynamic equilibrium, the fuzzy expected velocity is calculated by the established membership functions and fuzzy rules. In contrast, if the agent is not trapped, the projected expected velocity is obtained by the obstacle projection method.
- (2)
- The sensing radius region of the agent is divided into four subregions and a nonnegative subsection function is designed to adjust the attractive/repulsive potentials in these subregions.
- (3)
- A fuzzy flocking control (FFC) algorithm is developed for multi-agents trapped in dynamic equilibrium under multiple obstacles. In the algorithm, the interaction term between agents is reconstructed using the fuzzy expected velocity, projected expected velocity, and nonnegative subsection function.
2. Preliminaries
2.1. Agent-Based Representation
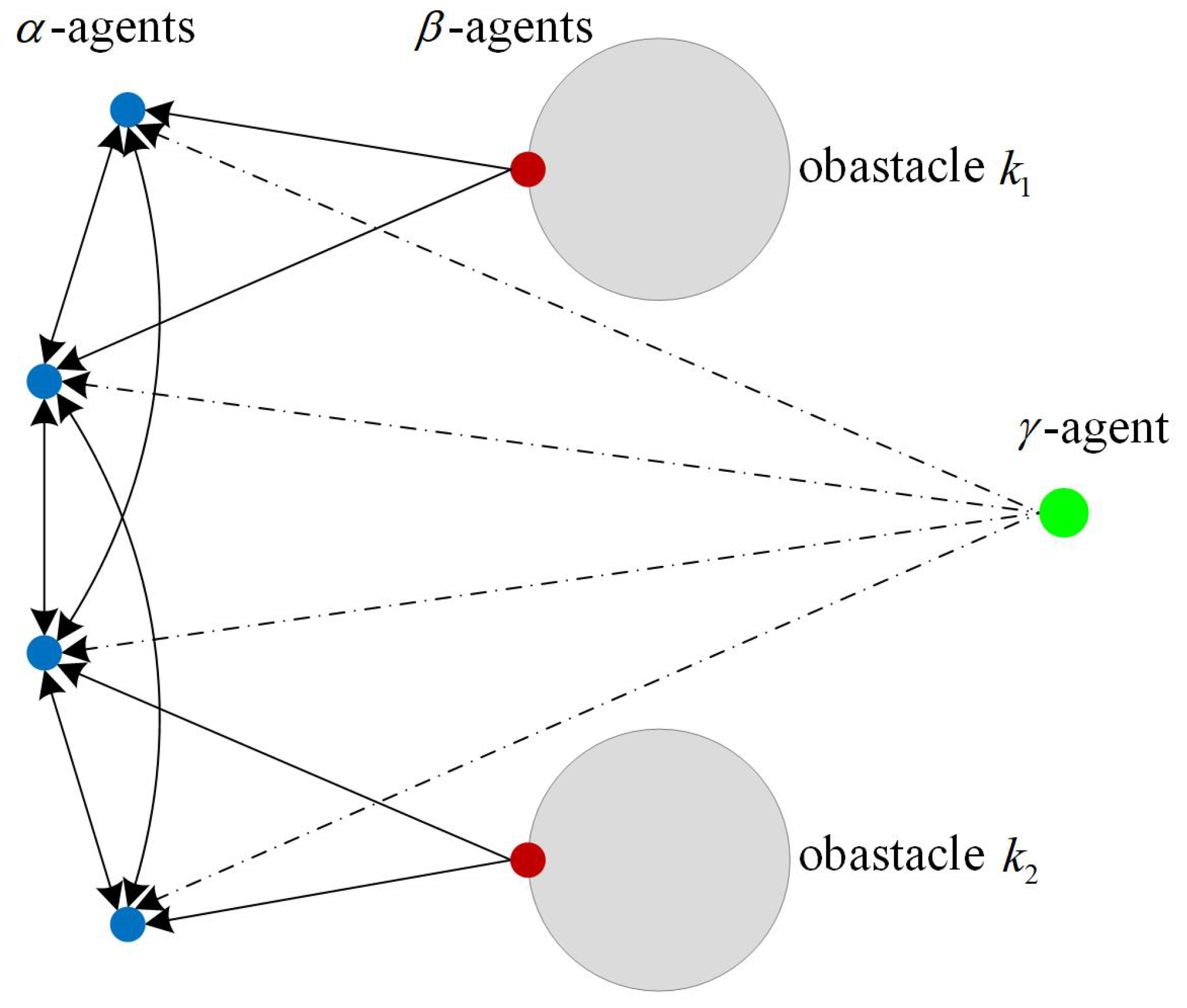
2.2. Proximity Net of -Agents and -Agents
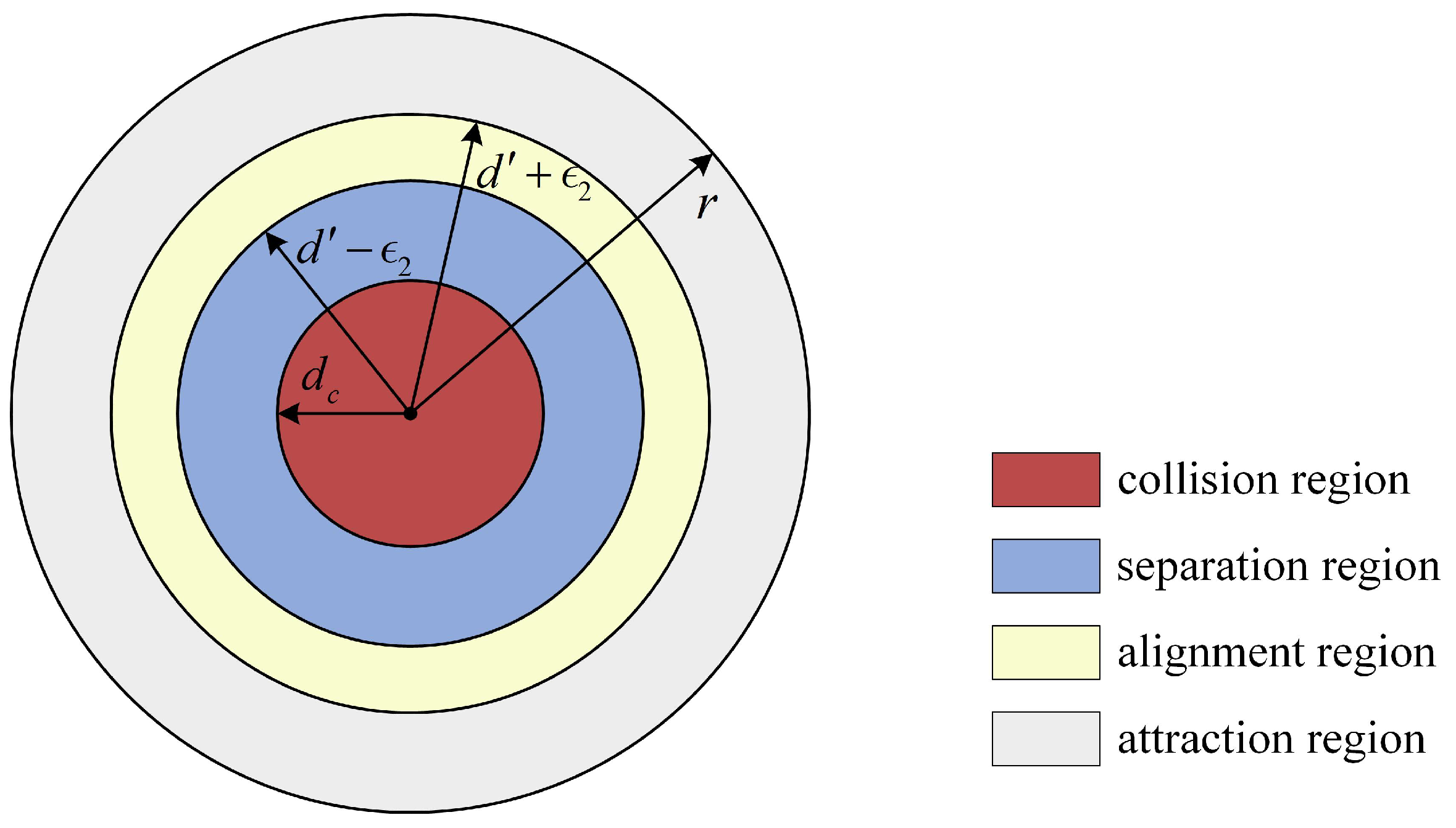
2.3. Collective Potential Functions
2.4. A Previous Algorithm for Evaluating
2.4.1. Evaluate
2.4.2. Evaluate
2.4.3. Evaluate
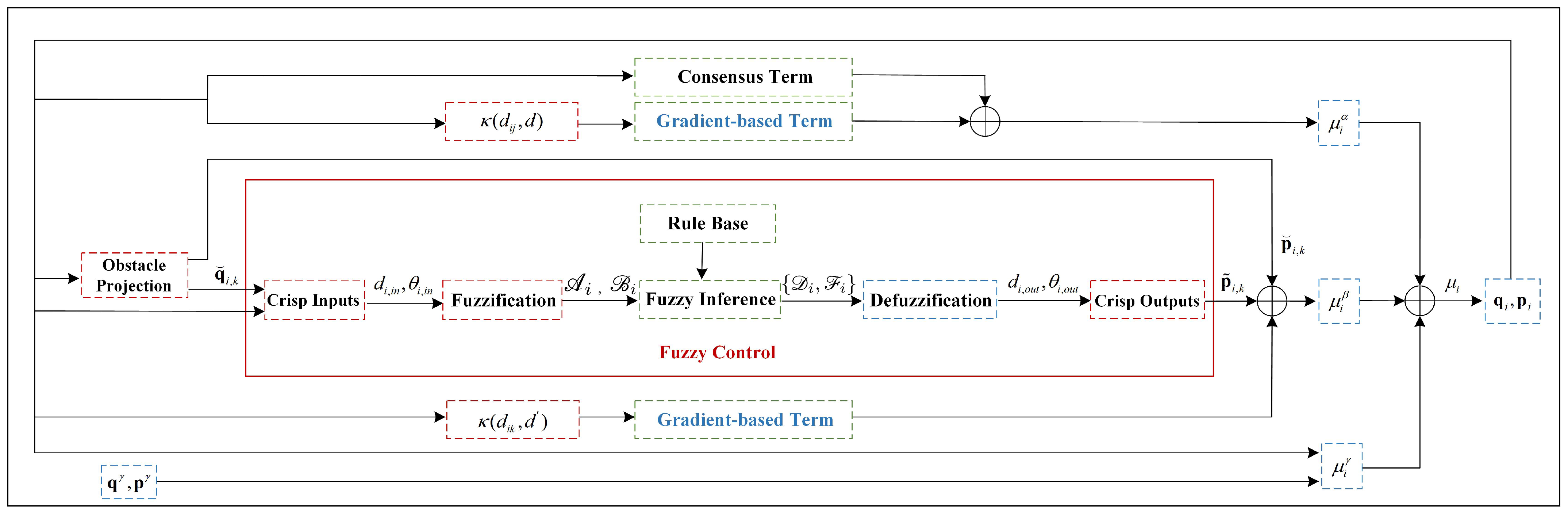
3. Proposed Algorithm
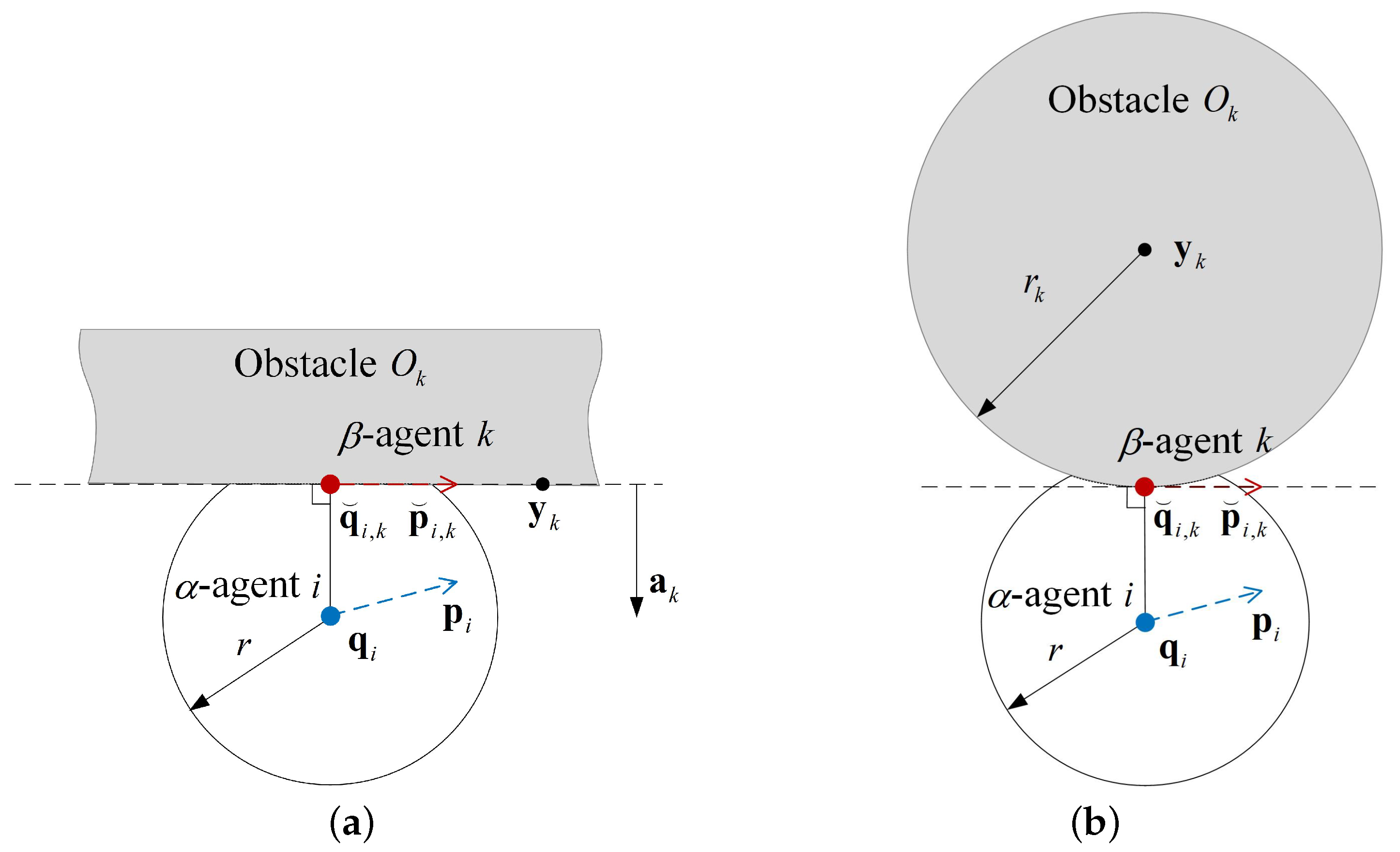
3.1. Evaluate
3.1.1. Fuzzy Expected Velocity Calculated by Fuzzy Control
3.1.2. Nonnegative Subsection Function
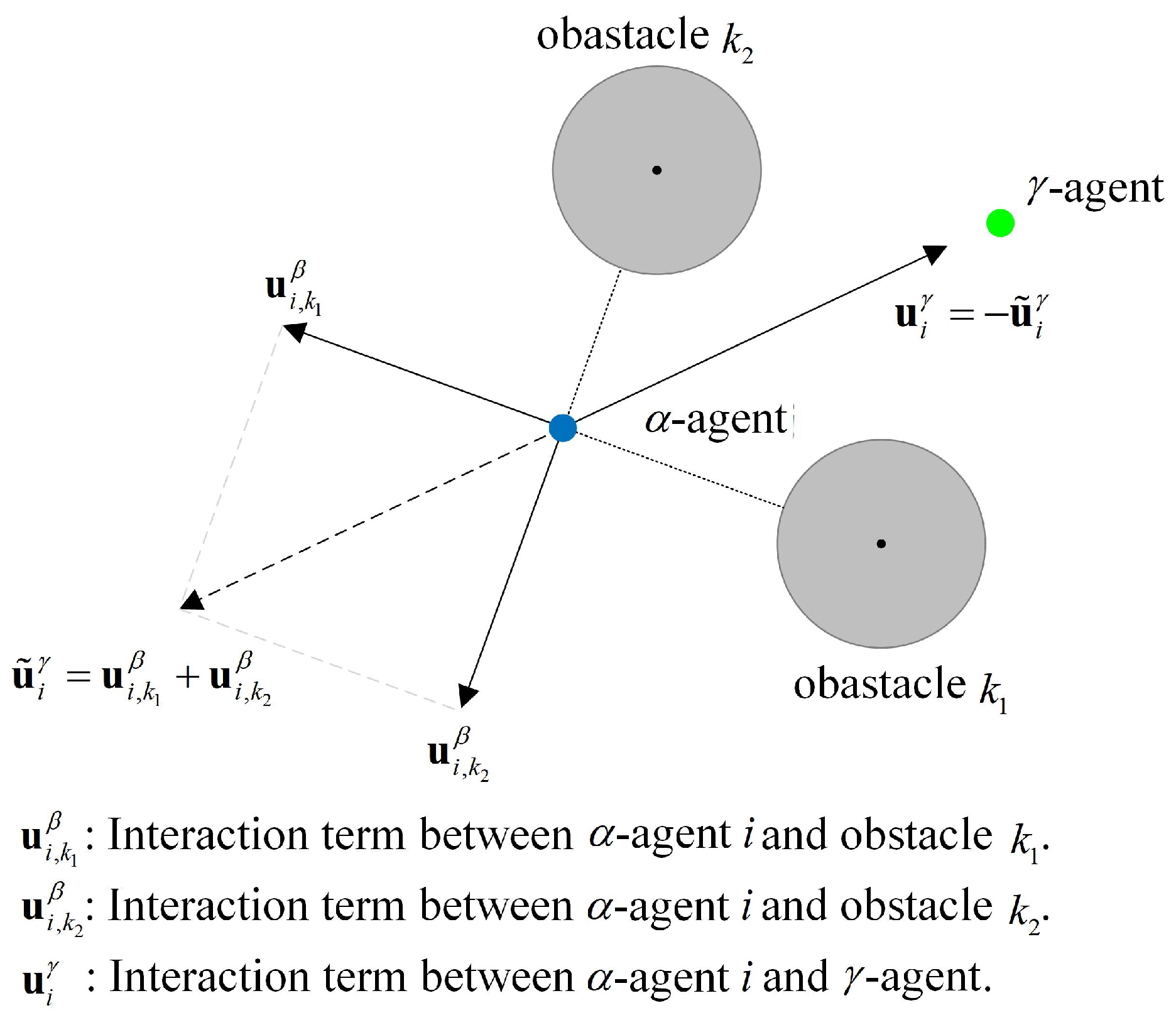
3.2. Evaluate
3.3. Evaluate
| Algorithm 1 FFC algorithm |
|
4. Properties Analysis of FFC Algorithm
5. Experimental Results and Discussion
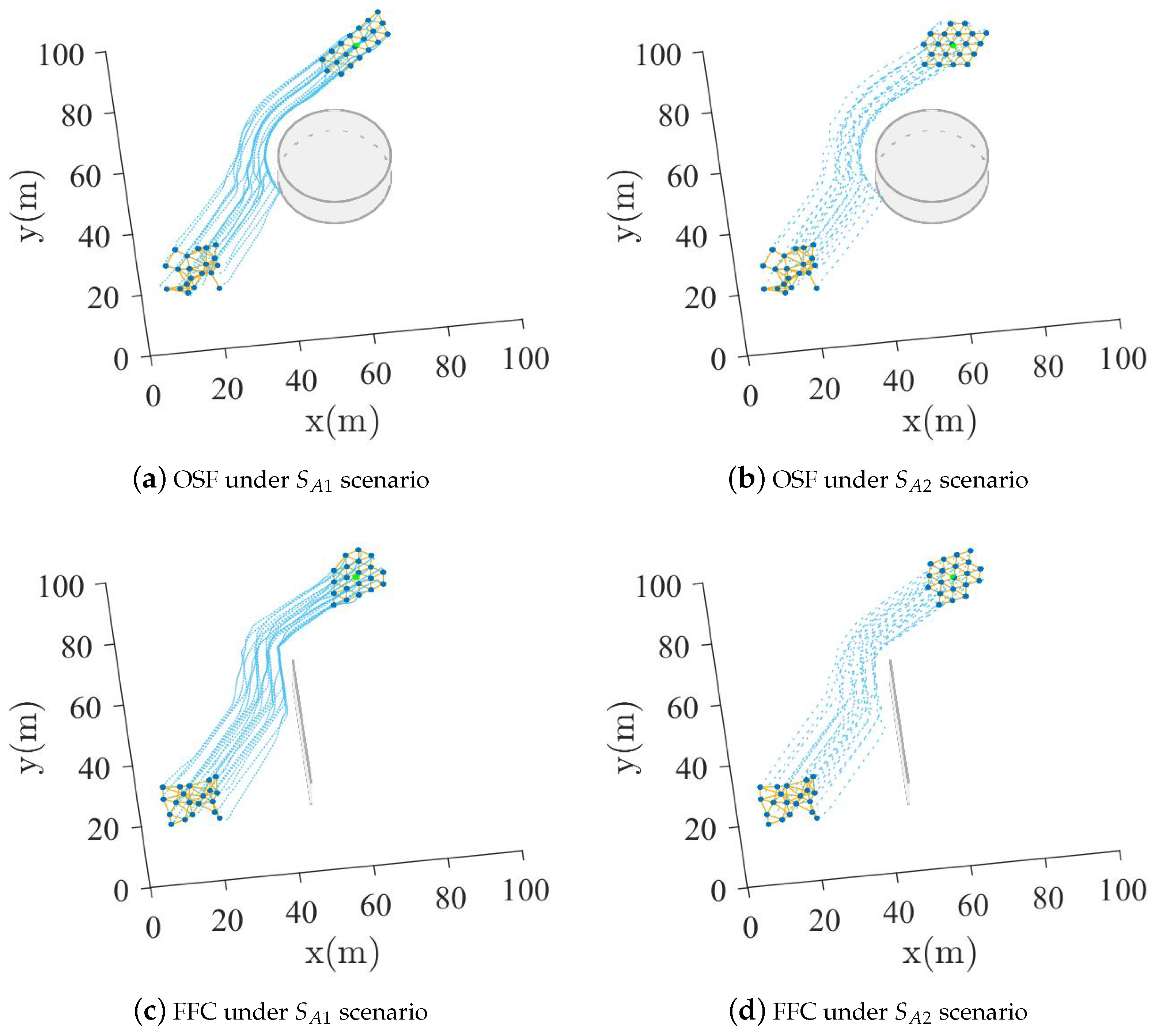
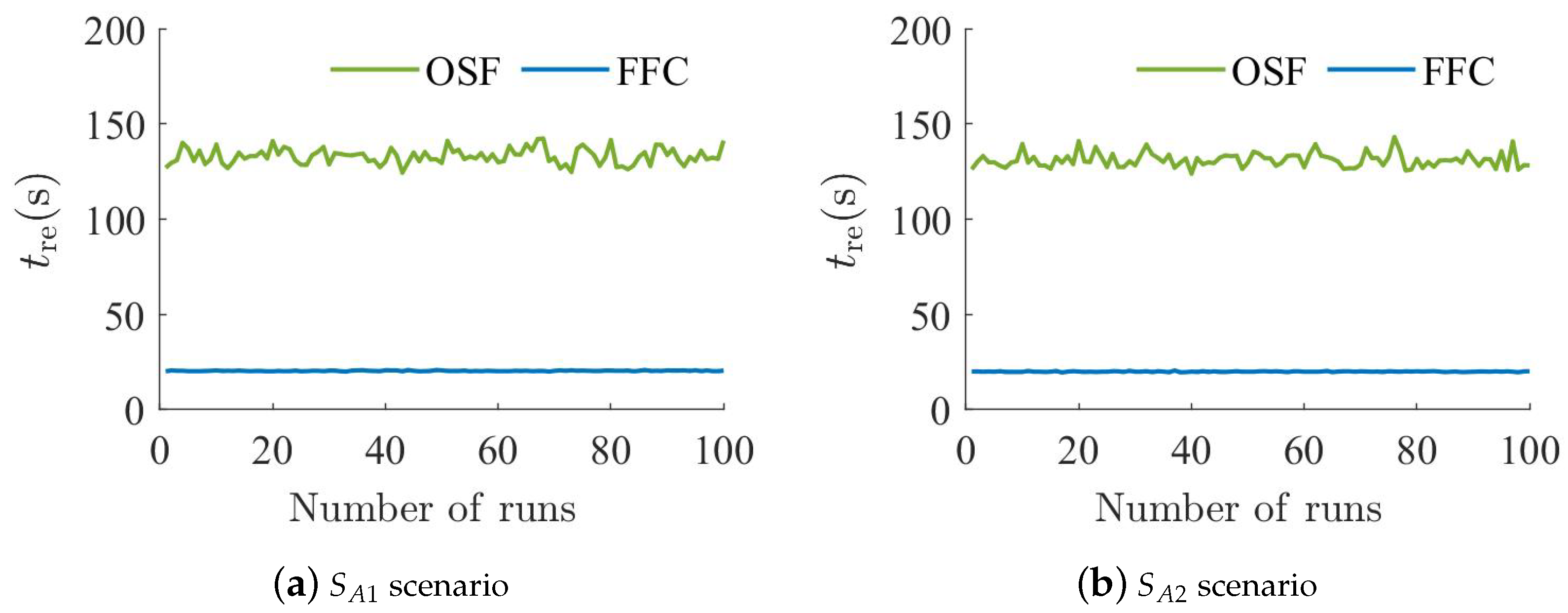
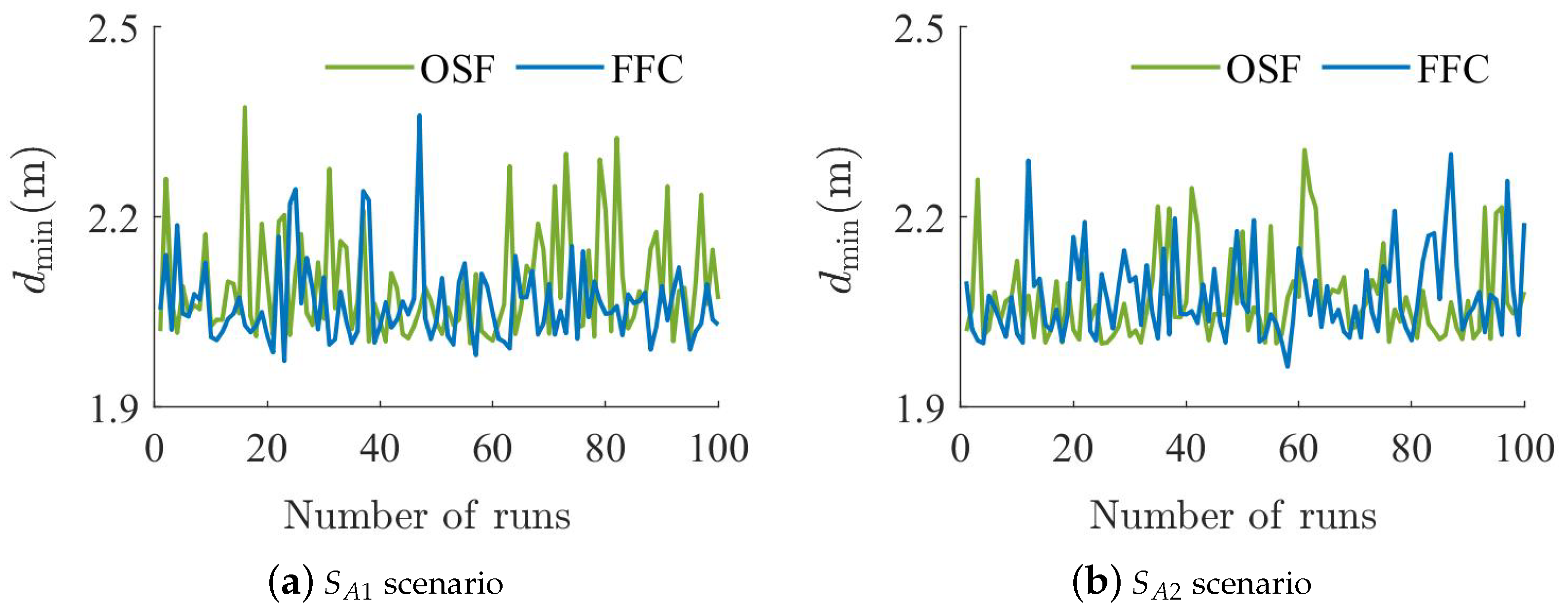
5.1. Spherical or Wall Obstacle Scenario Experiment
- :
- There is a spherical obstacle of radius 15 at coordinates .
- :
- There is a wall obstacle of length 30 at coordinates .
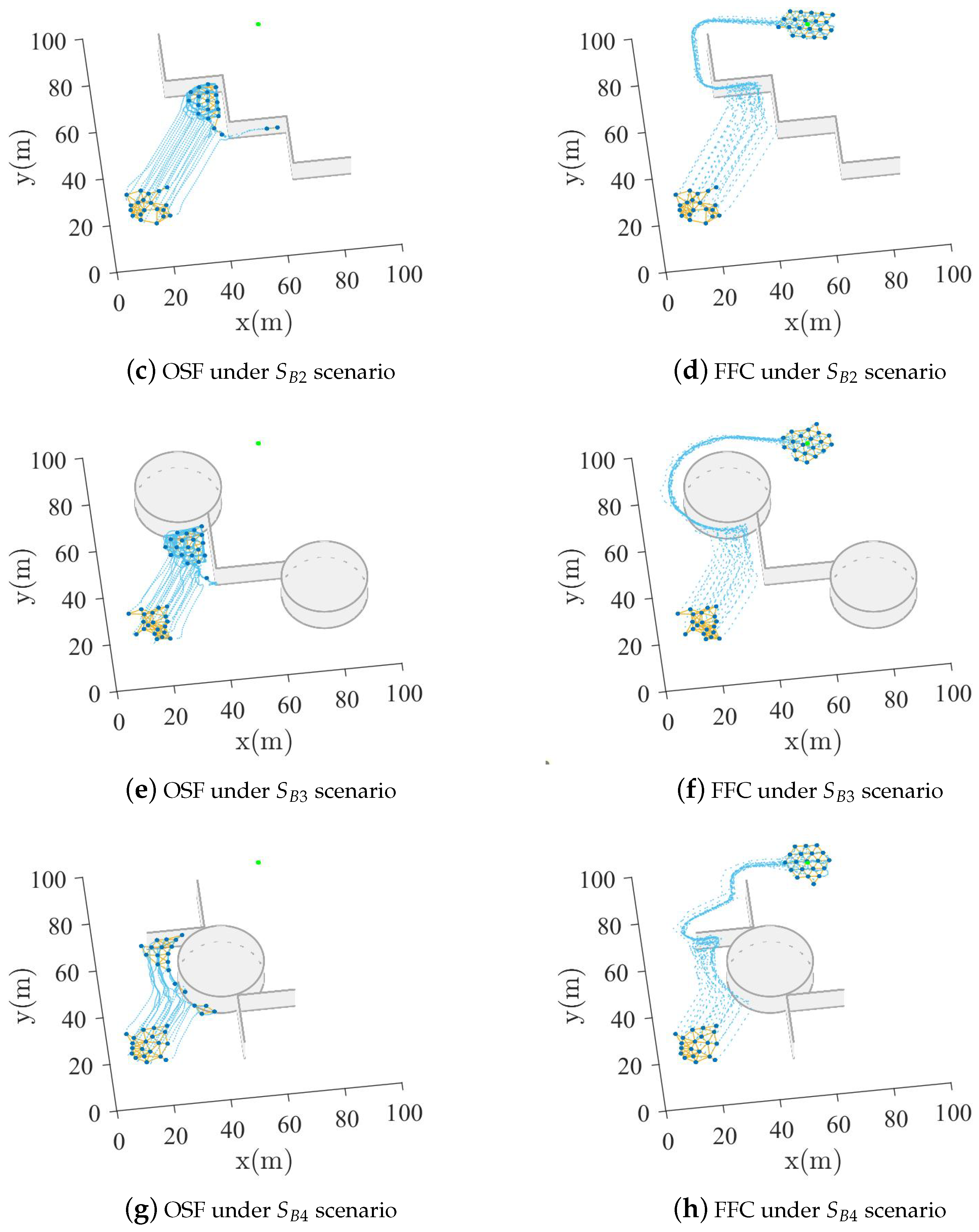
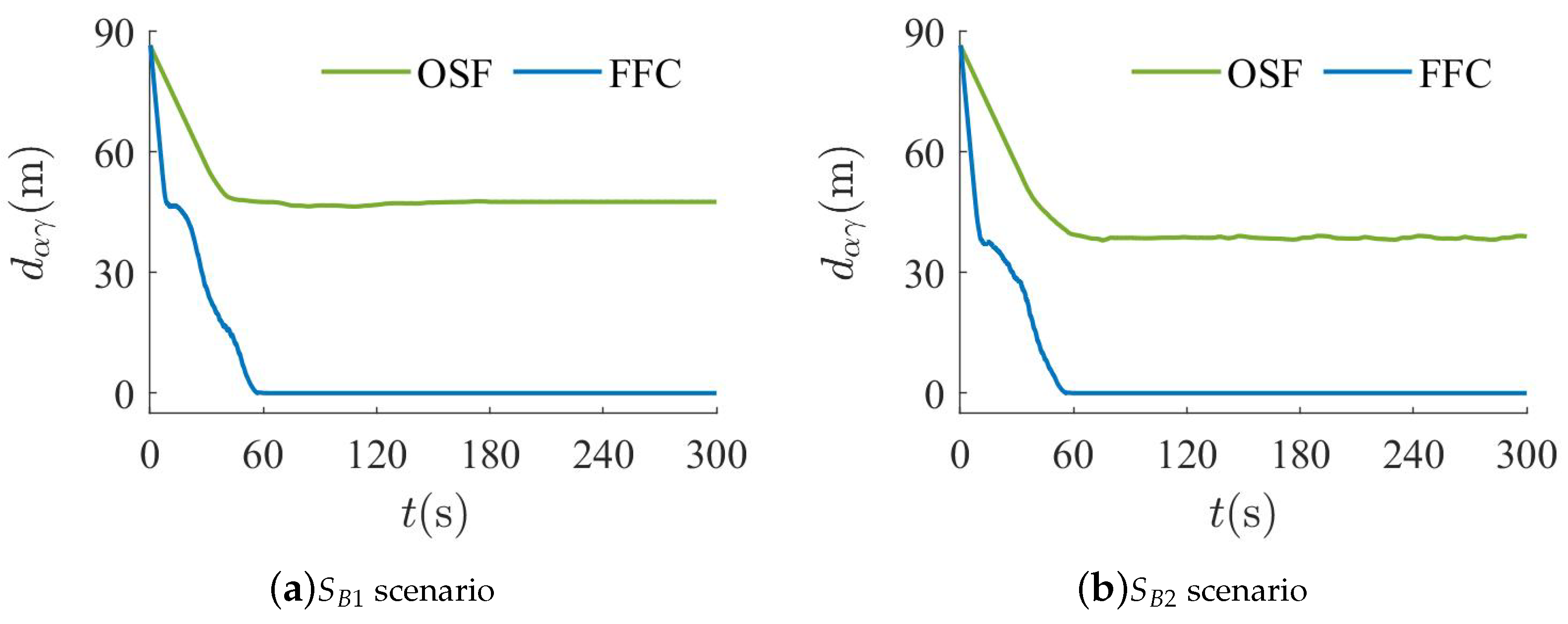
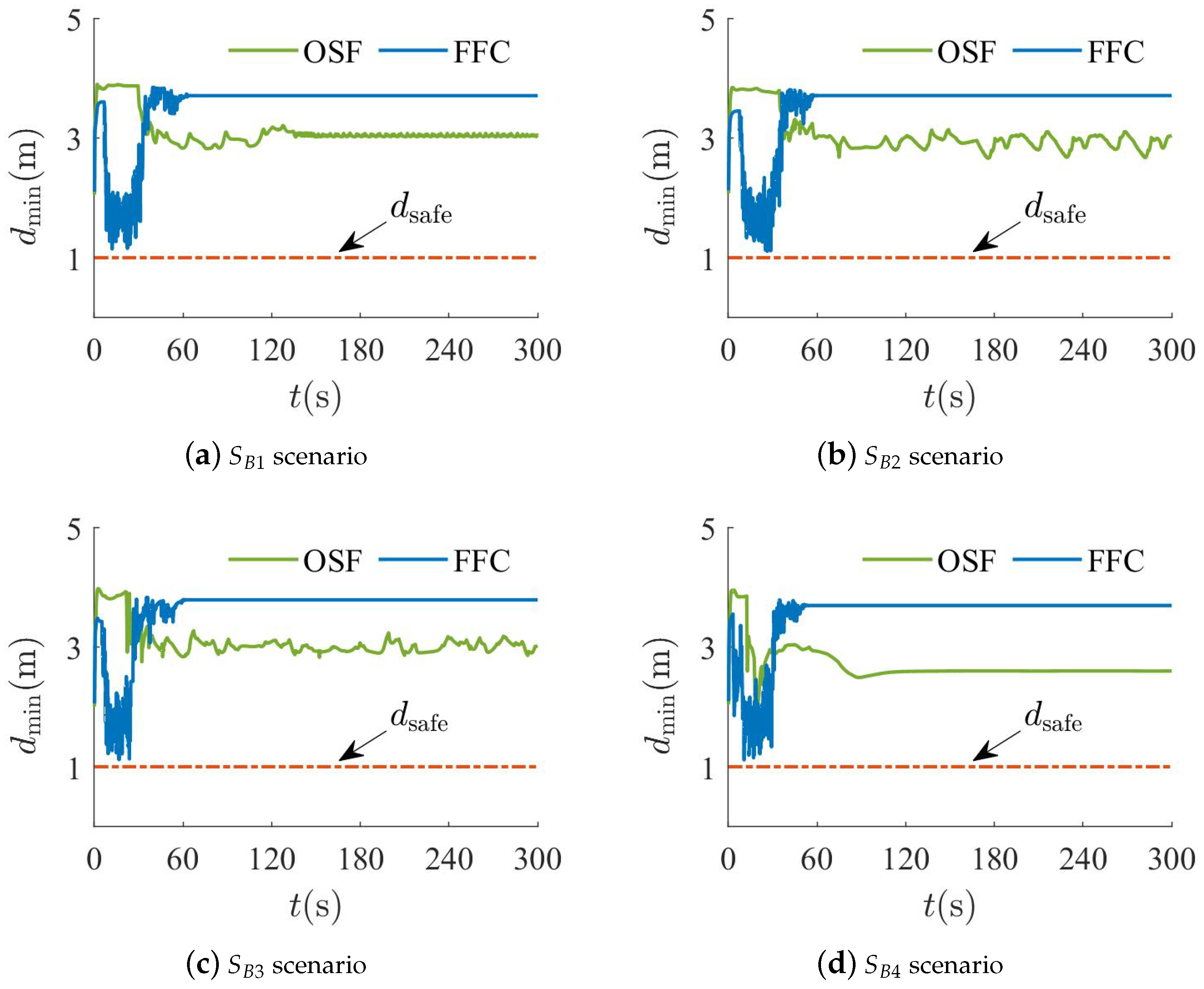
5.2. Spherical and Wall Obstacle Combination Scenario Experiment
- :
- There are three spherical obstacles of radius 15 at coordinates , , and .
- :
- There are six wall obstacles of length 20 at coordinates , , , , , and .
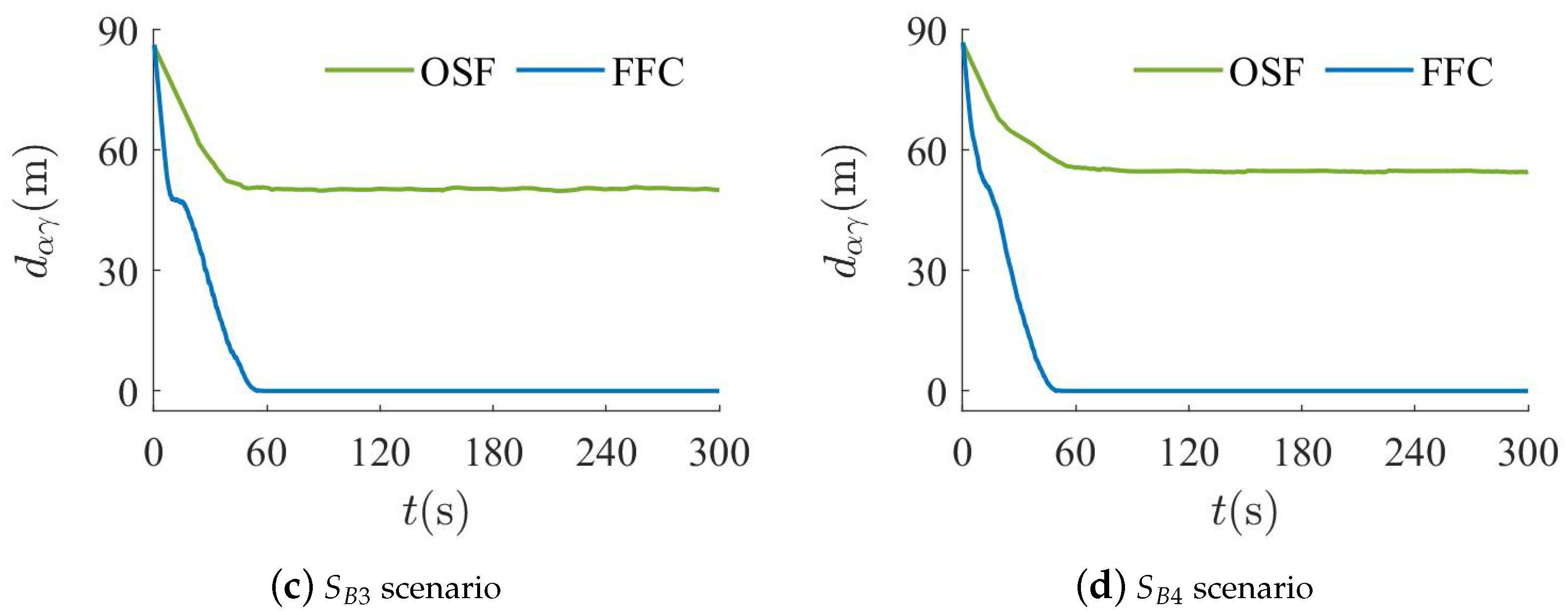
- :
- There are two spherical obstacles of radius 15 at coordinates and . Moreover, there are two wall obstacles of length 24 at coordinates and .
- :
- There is a spherical obstacle of radius 15 at coordinates . In addition, there are four wall obstacles of length 20 at coordinates , , , and .
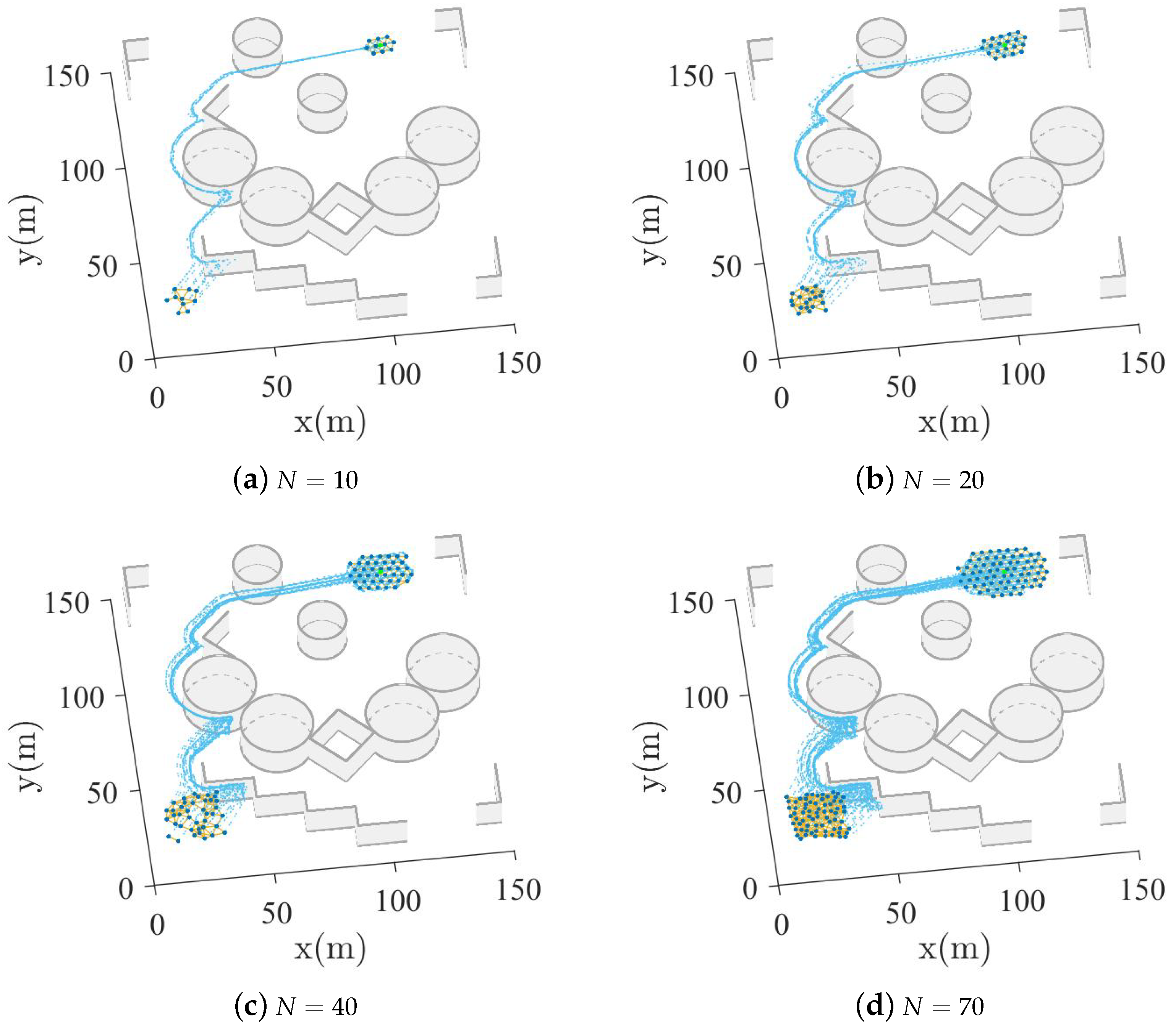
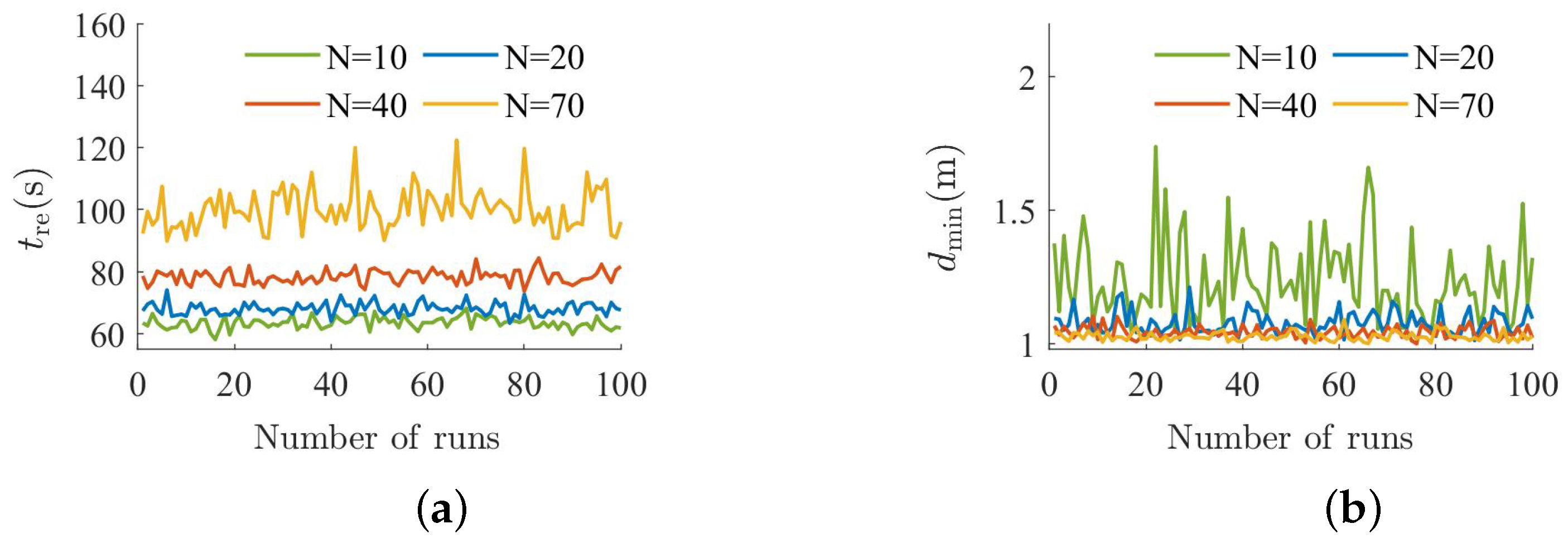
5.3. Complex Obstacle Scenario Experiment
- :
- There are four spherical obstacles of radius 15 at coordinates , , , and , and two spherical obstacles of radius 10 at coordinates and . Additionally, there are seven wall obstacles of length 10 at coordinates , , , , , , and , seven wall obstacles of length 20 at coordinates , , , , , , and , two wall obstacles of length at coordinates and , and four wall obstacles of length at coordinates , , , and .
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yan, C.; Wang, C.; Xiang, X.; Low, K.H.; Wang, X.; Xu, X.; Shen, L. Collision-Avoiding Flocking with Multiple Fixed-Wing UAVs in Obstacle-Cluttered Environments: A Task-Specific Curriculum-Based MADRL Approach. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 10894–10908. [Google Scholar] [CrossRef]
- Tran, V.P.; Garratt, M.A.; Kasmarik, K.; Anavatti, S.G.; Leong, A.S.; Zamani, M. Multi-gas source localization and mapping by flocking robots. Inf. Fusion 2023, 91, 665–680. [Google Scholar] [CrossRef]
- Shi, L.; Cheng, Y.; Shao, J.; Sheng, H.; Liu, Q. Cucker-Smale flocking over cooperation-competition networks. Automatica 2022, 135, 109988. [Google Scholar] [CrossRef]
- Li, J.; Zhang, W.; Su, H.; Yang, Y. Flocking of partially-informed multi-agent systems avoiding obstacles with arbitrary shape. Auton. Agents Multi-Agent Syst. 2015, 29, 943–972. [Google Scholar] [CrossRef]
- Lyu, Y.; Hu, J.; Chen, B.M.; Zhao, C.; Pan, Q. Multivehicle Flocking with Collision Avoidance via Distributed Model Predictive Control. IEEE Trans. Cybern. 2021, 51, 2651–2662. [Google Scholar] [CrossRef] [PubMed]
- Pignotti, C.; Vallejo, I.R. Flocking estimates for the Cucker–Smale model with time lag and hierarchical leadership. J. Math. Anal. Appl. 2018, 464, 1313–1332. [Google Scholar] [CrossRef]
- Jiang, W.; Liu, K.; Charalambous, T. Multi-agent consensus with heterogeneous time-varying input and communication delays in digraphs. Automatica 2021, 135, 109950. [Google Scholar] [CrossRef]
- Zou, Y.; An, Q.; Miao, S.; Chen, S.; Wang, X.; Su, H. Flocking of uncertain nonlinear multi-agent systems via distributed adaptive event-triggered control. Neurocomputing 2021, 465, 503–513. [Google Scholar] [CrossRef]
- Yu, Z.; Jiang, H.; Hu, C. Second-order consensus for multiagent systems via intermittent sampled data control. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 1986–2002. [Google Scholar] [CrossRef]
- Olfati-Saber, R. Flocking for multi-agent dynamic systems: Algorithms and theory. IEEE Trans. Autom. Control 2006, 51, 401–420. [Google Scholar] [CrossRef]
- Sakai, D.; Fukushima, H.; Matsuno, F. Flocking for Multirobots Without Distinguishing Robots and Obstacles. IEEE Trans. Control Syst. Technol. 2017, 25, 1019–1027. [Google Scholar] [CrossRef]
- Jia, Y.; Wang, L. Leader–Follower Flocking of Multiple Robotic Fish. IEEE/ASME Trans. Mechatron. 2015, 20, 1372–1383. [Google Scholar] [CrossRef]
- Wu, J.; Yu, Y.; Ma, J.; Wu, J.; Han, G.; Shi, J.; Gao, L. Autonomous Cooperative Flocking for Heterogeneous Unmanned Aerial Vehicle Group. IEEE Trans. Veh. Technol. 2021, 70, 12477–12490. [Google Scholar] [CrossRef]
- Su, H.; Wang, X.; Lin, Z. Flocking of Multi-Agents with a Virtual Leader. IEEE Trans. Autom. Control 2009, 54, 293–307. [Google Scholar] [CrossRef]
- Zhou, Z.; Ouyang, C.; Hu, L.; Xie, Y.; Chen, Y.; Gan, Z. A framework for dynamical distributed flocking control in dense environments. Expert Syst. Appl. 2024, 241, 122694. [Google Scholar] [CrossRef]
- Yan, T.; Xu, X.; Li, Z.; Li, E. Flocking of multi-agent systems with unknown nonlinear dynamics and heterogeneous virtual leader. Int. J. Control Autom. Syst. 2021, 19, 2931–2939. [Google Scholar] [CrossRef]
- Sun, Z.; Xu, B. A flocking algorithm of multi-agent systems to optimize the configuration. In Proceedings of the 2021 China Automation Congress (CAC), Beijing, China, 22–24 October 2021; pp. 7680–7684. [Google Scholar] [CrossRef]
- Zhao, W.; Chu, H.; Zhang, M.; Sun, T.; Guo, L. Flocking Control of Fixed-Wing UAVs with Cooperative Obstacle Avoidance Capability. IEEE Access 2019, 7, 17798–17808. [Google Scholar] [CrossRef]
- Qiu, Z.; Zhao, X.; Li, S.; Xie, Y.; Chen, C.; Gui, W. Finite-time formation of multiple agents based on multiple virtual leaders. Int. J. Syst. Sci. 2018, 49, 3448–3458. [Google Scholar] [CrossRef]
- Duhé, J.F.; Victor, S.; Melchior, P. Contributions on artificial potential field method for effective obstacle avoidance. Fract. Calc. Appl. Anal. 2021, 24, 421–446. [Google Scholar] [CrossRef]
- Azzabi, A.; Nouri, K. An advanced potential field method proposed for mobile robot path planning. Trans. Inst. Meas. Control 2019, 41, 3132–3144. [Google Scholar] [CrossRef]
- Semnani, S.H.; Liu, H.; Everett, M.; De Ruiter, A.; How, J.P. Multi-agent motion planning for dense and dynamic environments via deep reinforcement learning. IEEE Rob. Autom. Lett. 2020, 5, 3221–3226. [Google Scholar] [CrossRef]
- Beaver, L.E.; Malikopoulos, A.A. An overview on optimal flocking. Annu. Rev. Control 2021, 51, 88–99. [Google Scholar] [CrossRef]
- Szczepanski, R.; Bereit, A.; Tarczewski, T. Efficient local path planning algorithm using artificial potential field supported by augmented reality. Energies 2021, 14, 6642. [Google Scholar] [CrossRef]
- Song, J.; Hao, C.; Su, J. Path planning for unmanned surface vehicle based on predictive artificial potential field. Int. J. Adv. Rob. Syst. 2020, 17, 1729881420918461. [Google Scholar] [CrossRef]
- Bayat, F.; Najafinia, S.; Aliyari, M. Mobile robots path planning: Electrostatic potential field approach. Expert Syst. Appl. 2018, 100, 68–78. [Google Scholar] [CrossRef]
- He, Z.; Chu, X.; Liu, C.; Wu, W. A novel model predictive artificial potential field based ship motion planning method considering COLREGs for complex encounter scenarios. ISA Trans. 2023, 134, 58–73. [Google Scholar] [CrossRef]
- Szczepanski, R. Safe artificial potential field-novel local path planning algorithm maintaining safe distance from obstacles. IEEE Rob. Autom. Lett. 2023, 8, 4823–4830. [Google Scholar] [CrossRef]
- Mao, X.; Zhang, H.; Wang, Y. Flocking of quad-rotor UAVs with fuzzy control. ISA Trans. 2018, 74, 185–193. [Google Scholar] [CrossRef] [PubMed]
- Ntakolia, C.; Moustakidis, S.; Siouras, A. Autonomous path planning with obstacle avoidance for smart assistive systems. Expert Syst. Appl. 2023, 213, 119049. [Google Scholar] [CrossRef]
- Yu, H.; Zhang, T.; Jian, J. Flocking with obstacle avoidance based on fuzzy logic. In Proceedings of the IEEE ICCA 2010, Xiamen, China, 9–11 June 2010; pp. 1876–1881. [Google Scholar] [CrossRef]
- Sharma, A.K.; Singh, D.; Singh, V.; Verma, N.K. Aerodynamic Modeling of ATTAS Aircraft Using Mamdani Fuzzy Inference Network. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 3566–3576. [Google Scholar] [CrossRef]
- Song, W.; Yang, Y.; Fu, M.; Qiu, F.; Wang, M. Real-Time Obstacles Detection and Status Classification for Collision Warning in a Vehicle Active Safety System. IEEE Trans. Intell. Transp. Syst. 2018, 19, 758–773. [Google Scholar] [CrossRef]
- Wu, J.; Ji, Y.; Sun, X.; Liang, W. Obstacle Boundary Point and Expected Velocity-Based Flocking of Multiagents with Obstacle Avoidance. Int. J. Intell. Syst. 2023, 2023, 1493299. [Google Scholar] [CrossRef]
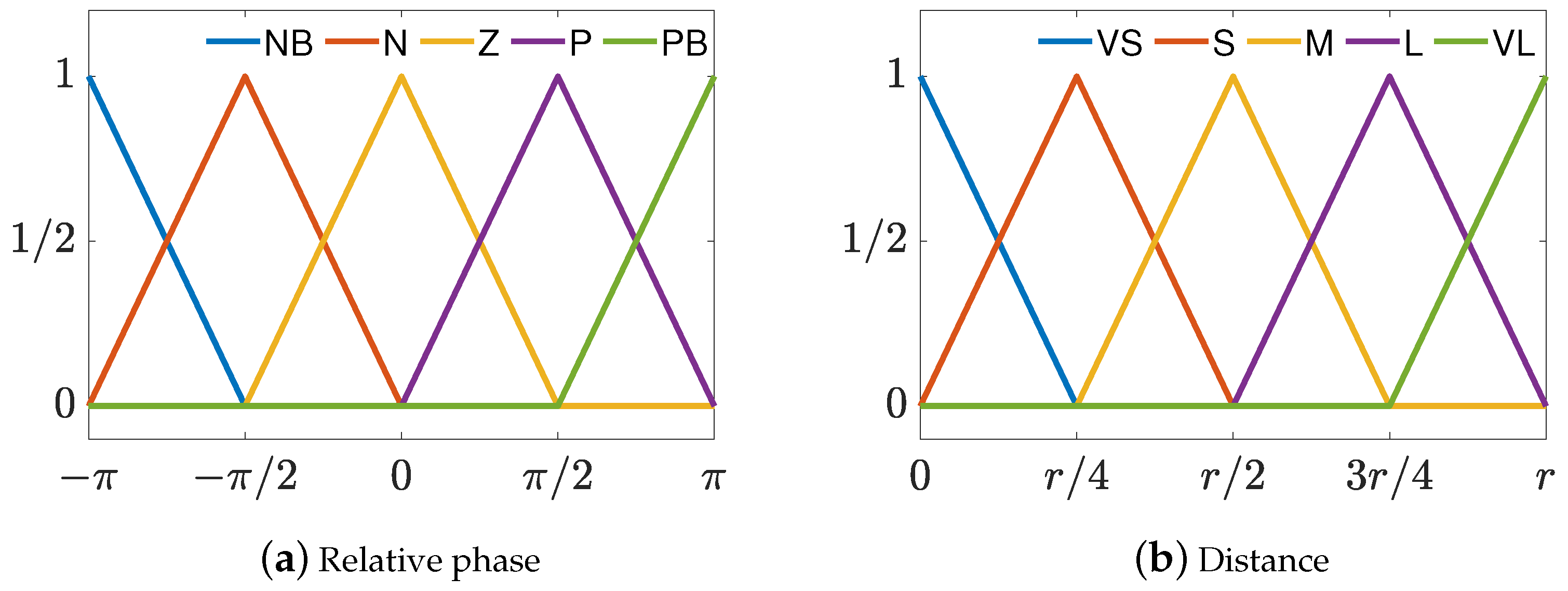


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VS | S | M | L | VL | |||
|---|---|---|---|---|---|---|---|
| \ | |||||||
| NB | P\S | P\S | P\L | P\VL | P\VL | ||
| N | PB\S | PB\S | PB\M | PB\VL | PB\VL | ||
| Z | P\S | P \S | P\M | P\VL | P\VL | ||
| P | NB\S | NB\S | NB\M | NB\VL | NB\VL | ||
| PB | N\S | N\S | N\L | N\VL | N\VL | ||
| Experiments | Parameters |
|---|---|
| A, B, and C | , |
| , , , , , | |
| , , , , | |
| 10,000, , , , | |
| , , , . |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, W.; Sun, X.; Ji, Y.; Liu, X.; Wu, J.; He, Z. Fuzzy Flocking Control for Multi-Agents Trapped in Dynamic Equilibrium Under Multiple Obstacles. Machines 2025, 13, 119. https://doi.org/10.3390/machines13020119
Liang W, Sun X, Ji Y, Liu X, Wu J, He Z. Fuzzy Flocking Control for Multi-Agents Trapped in Dynamic Equilibrium Under Multiple Obstacles. Machines. 2025; 13(2):119. https://doi.org/10.3390/machines13020119
Chicago/Turabian StyleLiang, Weibin, Xiyan Sun, Yuanfa Ji, Xinyi Liu, Jianhui Wu, and Zhongxi He. 2025. "Fuzzy Flocking Control for Multi-Agents Trapped in Dynamic Equilibrium Under Multiple Obstacles" Machines 13, no. 2: 119. https://doi.org/10.3390/machines13020119
APA StyleLiang, W., Sun, X., Ji, Y., Liu, X., Wu, J., & He, Z. (2025). Fuzzy Flocking Control for Multi-Agents Trapped in Dynamic Equilibrium Under Multiple Obstacles. Machines, 13(2), 119. https://doi.org/10.3390/machines13020119