1.1. Background
Railway signal equipment is an important part of the infrastructure used to ensure the safe operation of trains. In the daily operation of trains, railway signal equipment generates operation fault maintenance data. These data are mainly recorded text collected by onsite maintenance personnel according to their own language habits and experience/knowledge, including the fault symptoms, fault diagnosis process, and fault classification results of all signal devices. The number of fault data are determined by the number of device faults, and the data content is recorded according to the fault diagnosis process and can be written in perfect detail without specific rules. These railway signal fault text data undergo a series of checks by signal experts from the initial processing records to the final archiving, and they contain rich knowledge from fault handling experts [
1,
2]. However, due to the unstructured characteristics of their storage, they are not conducive to computer analysis or processing, resulting in accumulation and wasted resources; thus, they are not properly utilized. At present, the task of fault classification for signal equipment is still completed by equipment maintenance personnel, and the classification results may be inaccurate and arbitrary. Driven by the current development direction of railway big data and intelligent operations and maintenance, research on fault diagnosis models based on text data can mine the pattern relationships between fault records and corresponding fault equipment categories, achieve automatic classification and processing of fault data, and provide efficient theoretical reference for maintenance personnel to quickly locate and address faults according to fault phenomena when equipment fails [
3,
4,
5].
In recent years, the continuous advancement in deep learning technology has led to its increasingly profound application in the field of natural language processing. Scholars have been endeavoring to employ word vector technology and deep learning techniques to further enhance the precision of intelligent analysis for railway signal fault text. In the field of natural language processing, recurrent neural networks (RNNs) and convolutional neural networks (CNNs) are commonly employed deep learning methods. RNNs and CNNs leverage their respective strengths to extract sequential information and local features from text data; however, they also possess certain limitations. Specifically, CNNs tend to lose textual sequence information during the learning process, while RNNs lack the ability to capture local context effectively. With the successful application of attention mechanisms in deep learning, it has been realized that neural networks can efficiently and accurately extract key task-related information from a vast amount of text data while marginalizing non-key information. This effectively enhances the performance of neural networks [
6,
7,
8] and has emerged as a prominent research area within the field of deep learning. The diverse range of railway signal equipment, complex fault mechanisms, varying amounts of maintenance text data for different equipment types, imbalanced class distributions, and short data lengths pose significant challenges to fault diagnosis algorithms during the learning process.
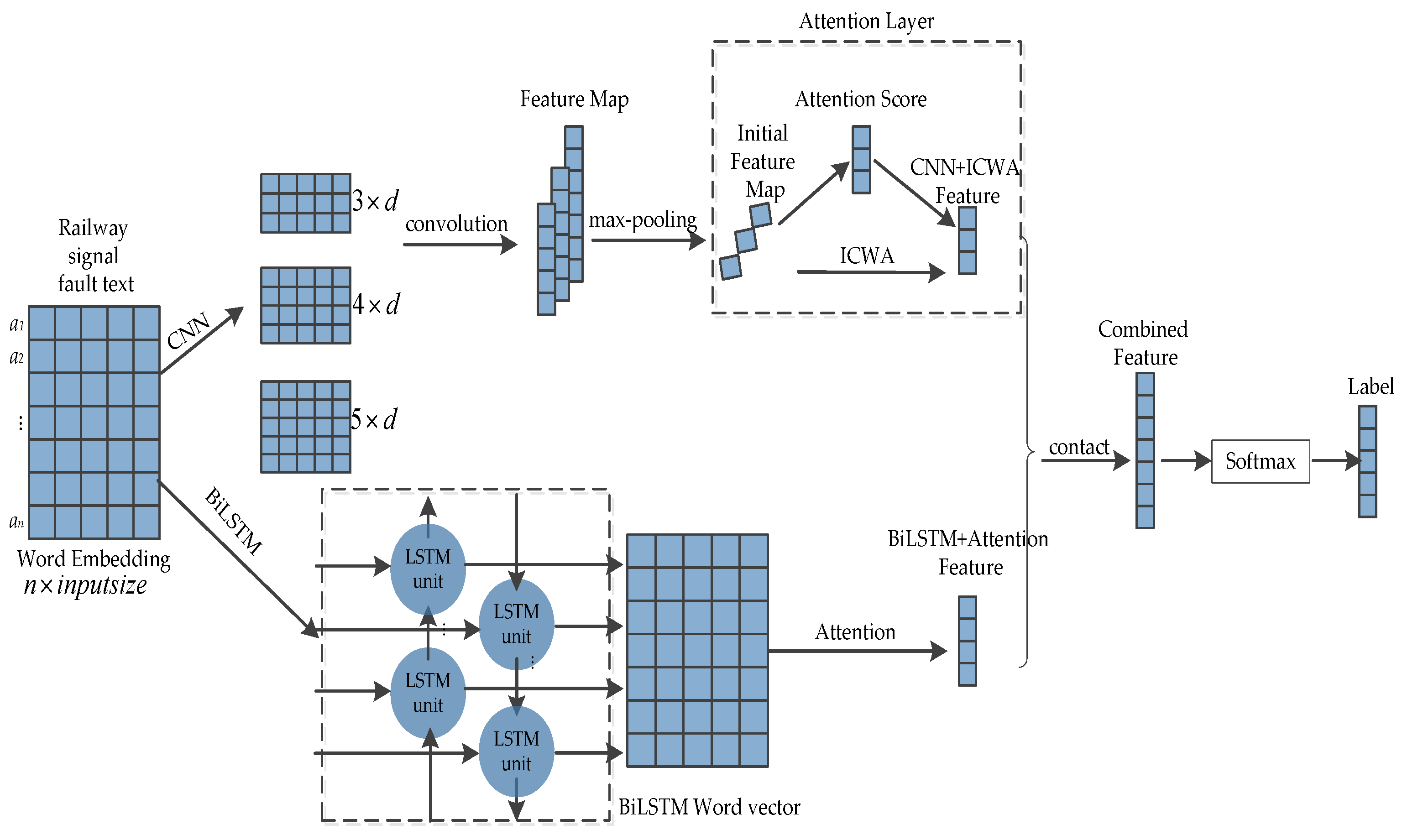
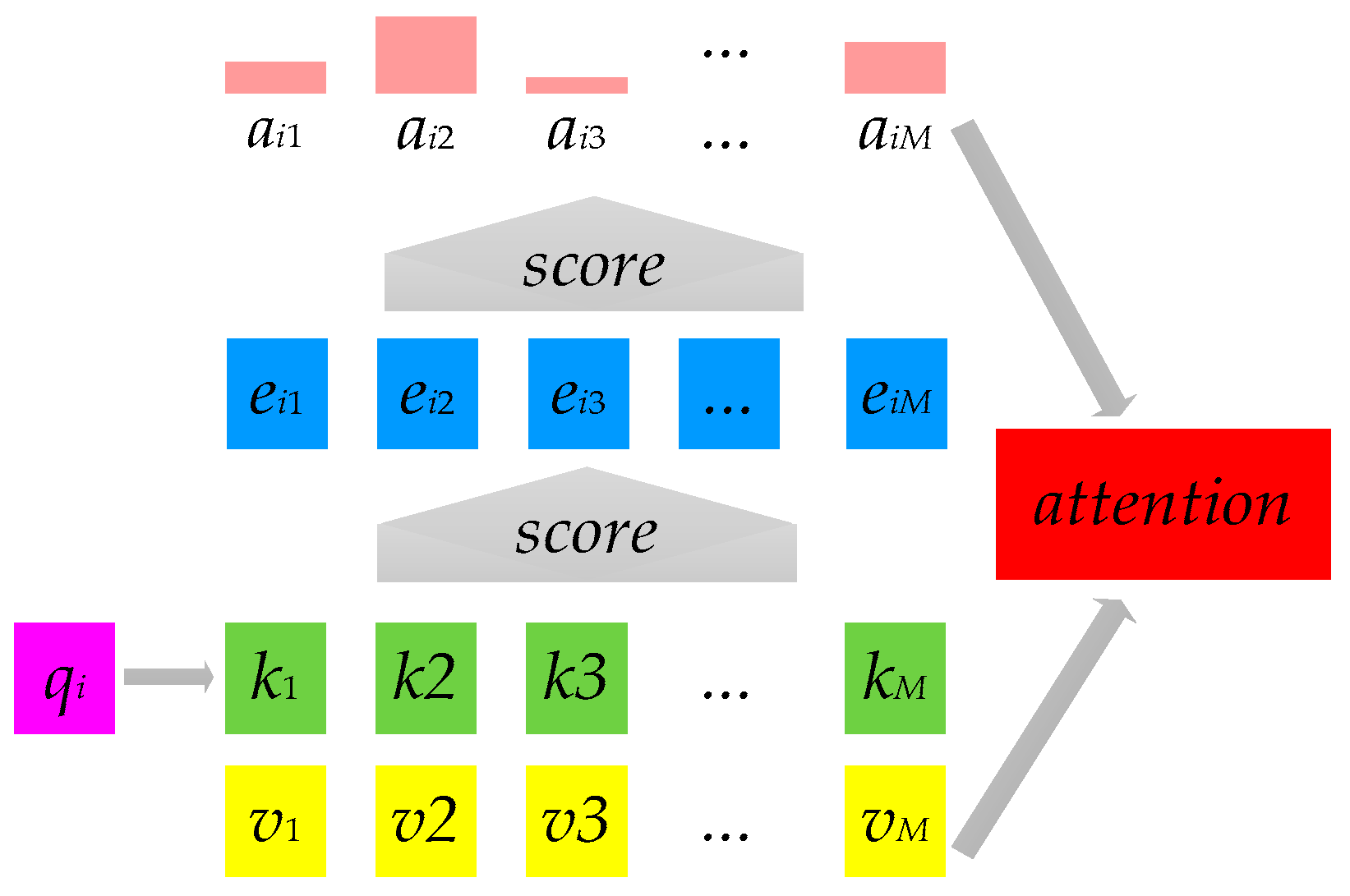
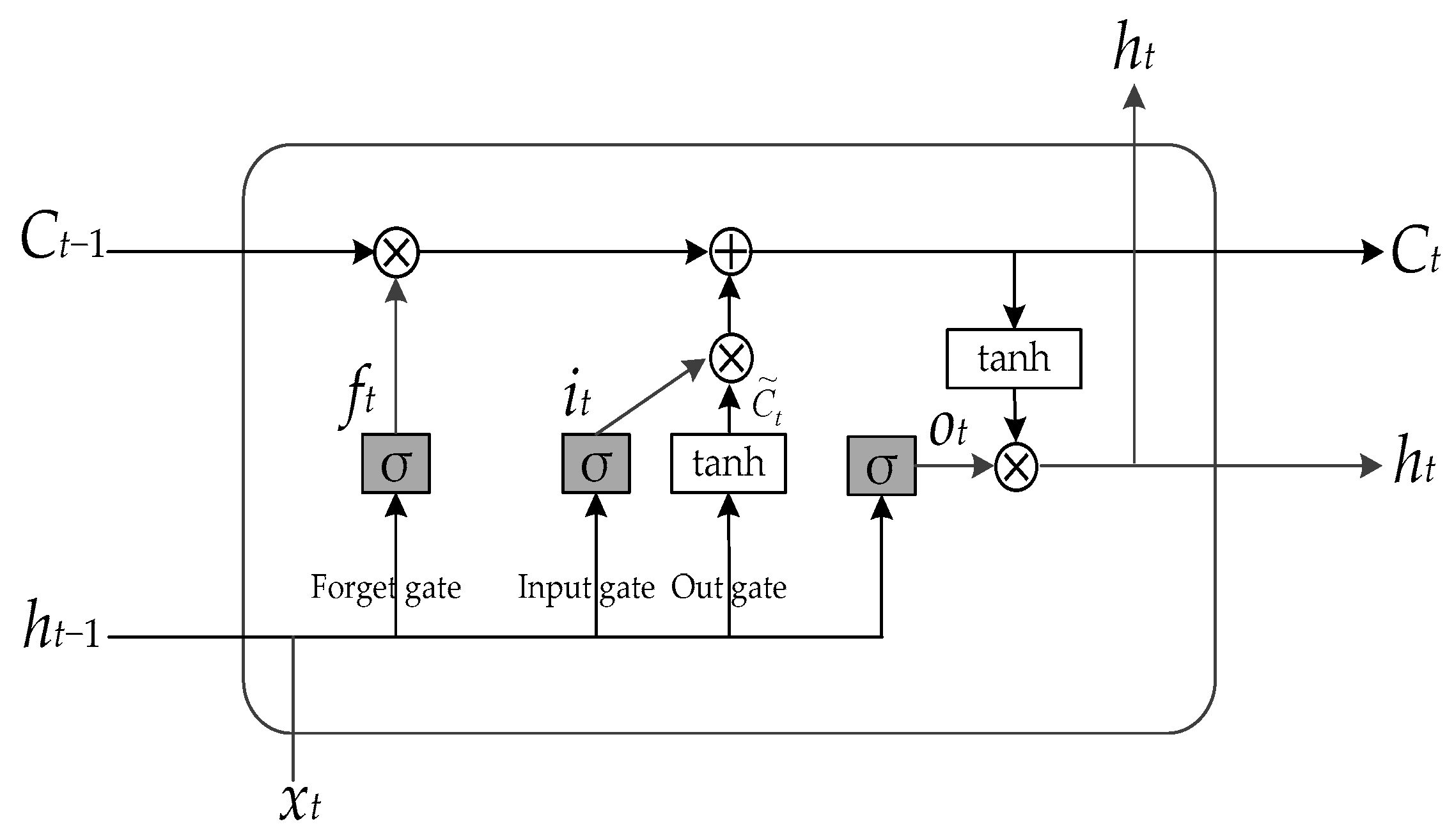
Based on the aforementioned issues, this paper proposes a fault diagnosis method (DEIAM) for railway signal equipment utilizing data augmentation and an enhanced attention mechanism. Specifically, it employs easy data augmentation (EDA) and back-translation techniques to augment the training dataset size and address sample imbalance. Additionally, it leverages Word2Vec for word vectorization and utilizes a CNN to capture local text features across different convolutional kernel sizes. Furthermore, an improved channel-wise attention (ICWA) mechanism is employed to focus on text features that contribute significantly to the classification results, resulting in the generation of CNN+ICWA text feature vectors. Moreover, BiLSTM is utilized to learn contextual information from the text features, followed by an attention mechanism for weighting important features within the text. These weighted learning results are then incorporated into the BiLSTM-generated text feature vector, leading to the generation of internal semantic BiLSTM+attention feature vectors. Finally, fusion of these two types of feature vectors enhances their overall quality and improves the model’s accuracy for fault diagnosis.
1.2. Literature Review
The fault diagnosis model, driven primarily by text data, classifies fault text through the extraction of its data features and subsequently accomplishes fault diagnosis via text classification [
9]. The accuracy of fault diagnosis is directly influenced by factors such as dataset characteristics, feature extraction algorithms, and classification algorithms.
The railway signal fault data are the maintenance data generated by equipment during its actual operation. Due to variations in the frequency of faults among different equipment, there exists an imbalance in the volume of fault data across various categories. The methods for addressing dataset imbalance primarily encompass techniques to enhance the original samples, such as EDA [
10] and back-translation; approaches to augment text representation data, including oversampling or undersampling [
11,
12]; and algorithmic strategies, such as ensemble learning and cost-sensitive functions [
13,
14]. Li [
9] employed the ADASYN (adaptive synthetic sampling) method to address the imbalance in fault data from high-speed rail signal equipment by synthesizing samples from underrepresented categories in the training dataset, aiming to enhance the data distribution ratio and ultimately improve the overall performance of fault diagnosis models. Yang [
15] utilized the SVM-SMOTE algorithm to randomly generate additional samples for the small and medium-sized categories within the text vector representing railway signal equipment faults, thereby addressing the problem of imbalanced sample data.
The feature extraction algorithms commonly employed in the literature include the bag-of-words model, TF-IDF, probabilistic topic models, and feature representation based on deep learning [
16,
17,
18]. Shang [
19] utilized a labeled-LDA probabilistic topic model to extract the fault text data characteristics of vehicle equipment within the train control system. Wei [
20] incorporated prior knowledge in the railways field to calibrate label information, employed a cost-sensitive support vector machine to address class imbalances in fault data, and subsequently applied the latent Dirichlet allocation method with local and global double-layer topic labels for feature extraction in fault text classification. Song [
3] utilized the Word2Vec model for processing fault terms and generating word vectors, which were then used to extract the fault text features of train control vehicles through a CNN. Finally, Zhou [
21] applied CNNs for extracting vehicle fault text data features and adopted a classifier that combines a random forest algorithm with cost-sensitive learning techniques for diagnosing faults in vehicle equipment.
Classification models can be categorized into two forms: single and integrated. Single classification models based on deep learning include Bayesian, KNN, and RNN models. In the realm of continuous optimization for natural language classification models, researchers have been assimilating the merits of individual models and endeavoring to effectively amalgamate them into an integrated framework, thereby attaining enhanced classification outcomes. Similarly, in the field of railway signal equipment fault diagnosis, researchers have also conducted relevant research and exploration. Wei [
5] employed word frequency weighting to enhance the word vectors generated by the BERT model for extracting text feature vectors. Subsequently, a combination of BiLSTM and an improved attention mechanism was utilized to classify the fault text of train control vehicle equipment and enable fault diagnosis. Shang [
22] introduced long short-term memory (LSTM) and a BP neural network into a vehicle equipment fault diagnosis model, where LSTM learned the temporal characteristic information from the vehicle equipment fault text data while a Bayesian regularization (BR) algorithm optimized the generalization ability of the BP neural network model for completing the learning process with fault data samples and achieving unknown sample-based fault type diagnosis. Drawing upon bidirectional long short-term memory’s (BiLSTM) advantages in extracting temporal features from fault text, Lin [
23] constructed a railway switch fault diagnosis model by combining BiLSTM with a model based on correlation (MLCBA), thereby enabling intelligent diagnosis of switch faults.
Drawing on the expertise of scholars and experts in text classification and considering the data characteristics specific to railway signal equipment fault text, this paper incorporates data augmentation and attention mechanisms into the fault diagnosis method for railway signal equipment. Firstly, an enhanced channel attention mechanism was employed to focus on local features captured by CNNs that contributed significantly to the classification results. Secondly, an attention mechanism was utilized to emphasize the contextual sequence features of text learned by BiLSTM. The combination of these two approaches enables comprehensive feature learning for fault text and further improves the fault diagnosis performance for railway signal equipment.
The rest of this paper is structured as follows.
Section 2 briefly reviews the fundamental methods and theories relevant to this research.
Section 3 presents the theoretical background and research framework of the DEIAM model proposed in this paper.
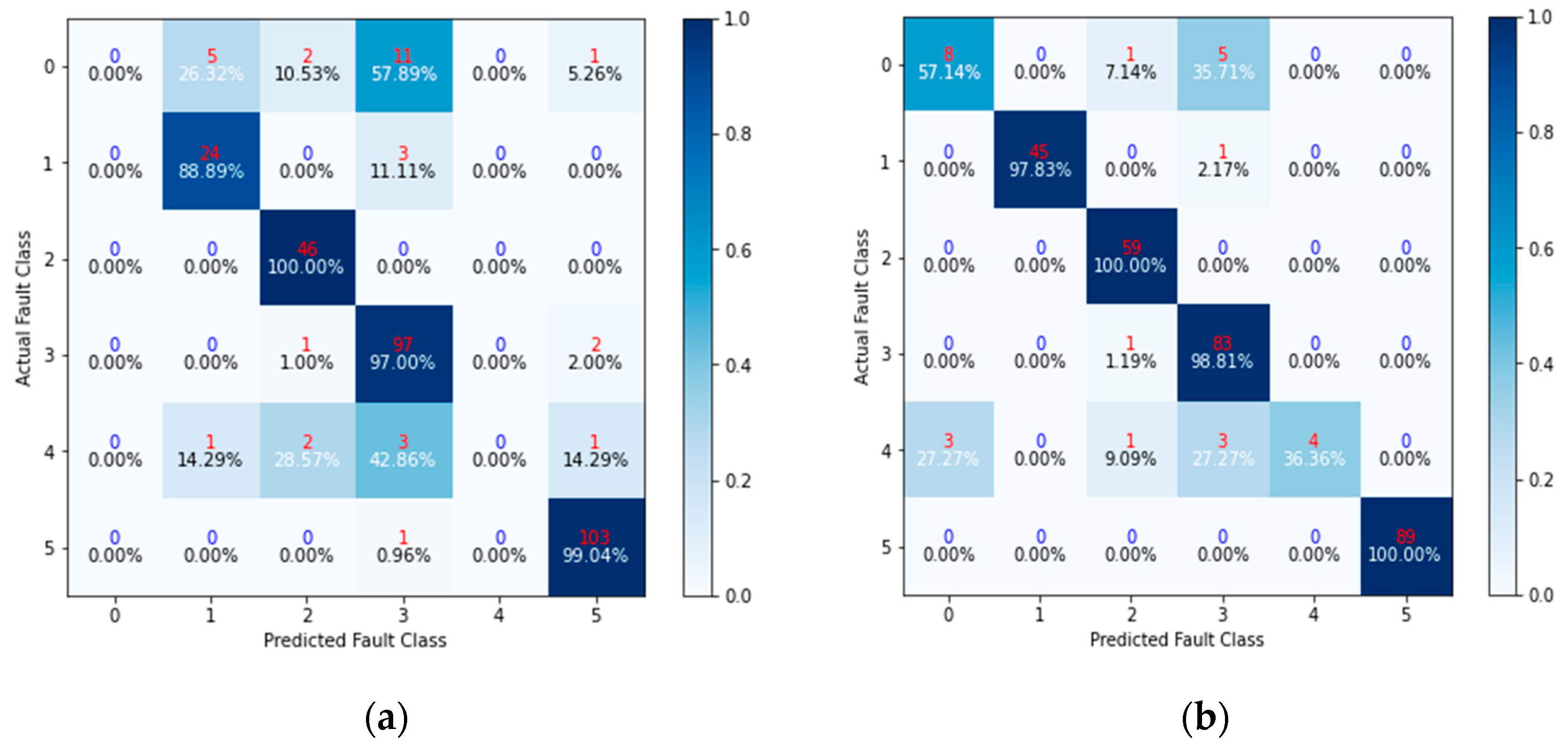
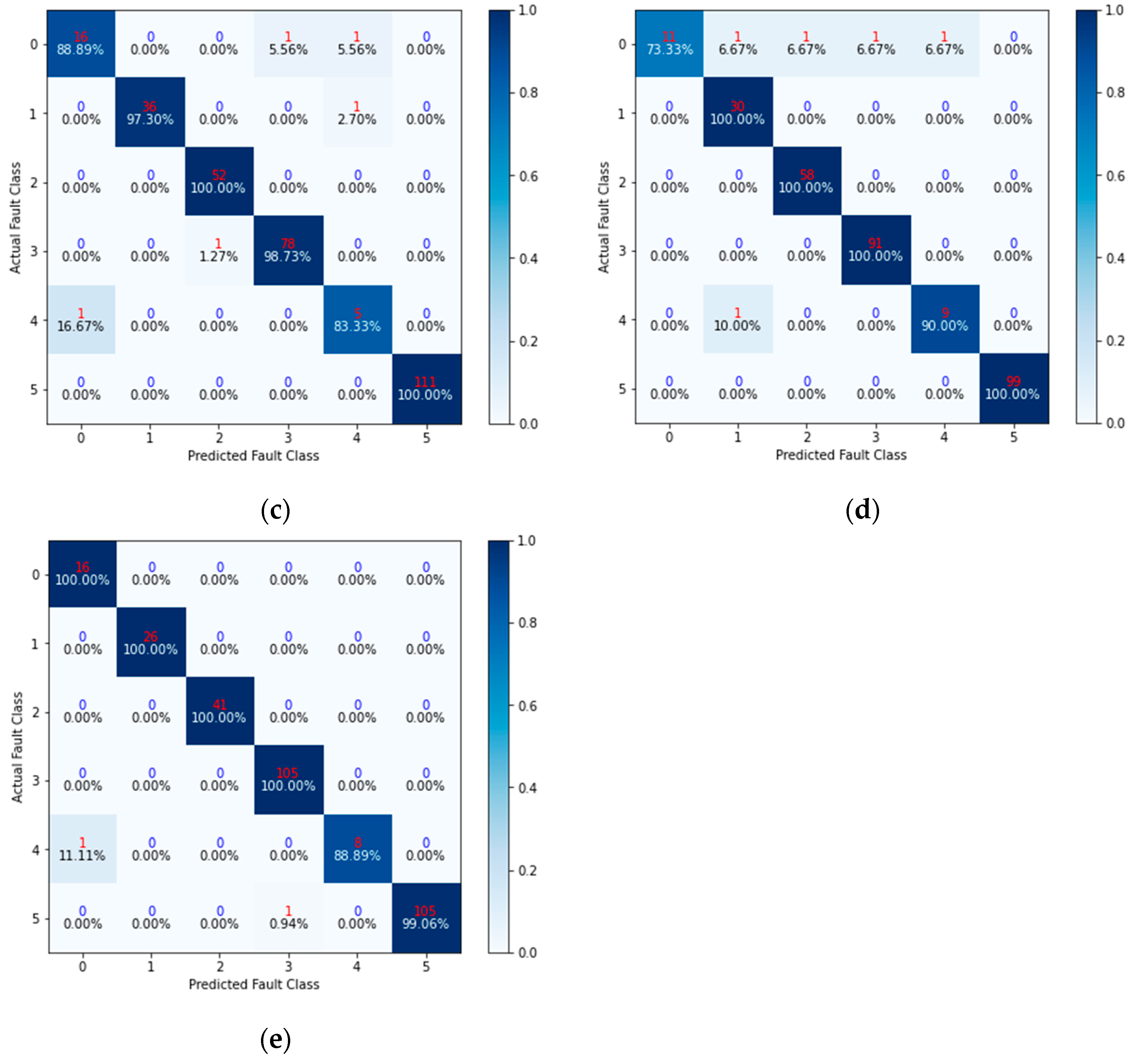
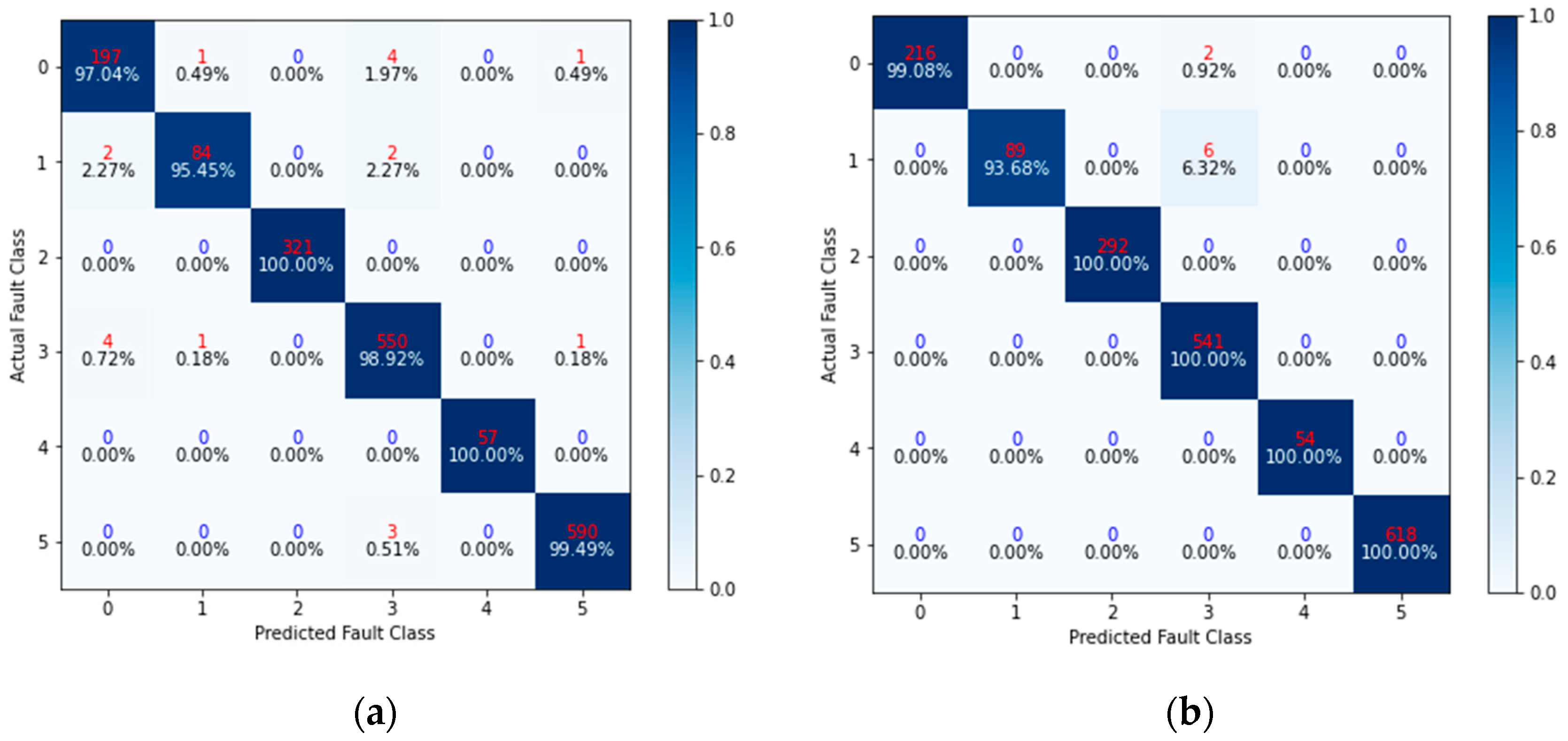
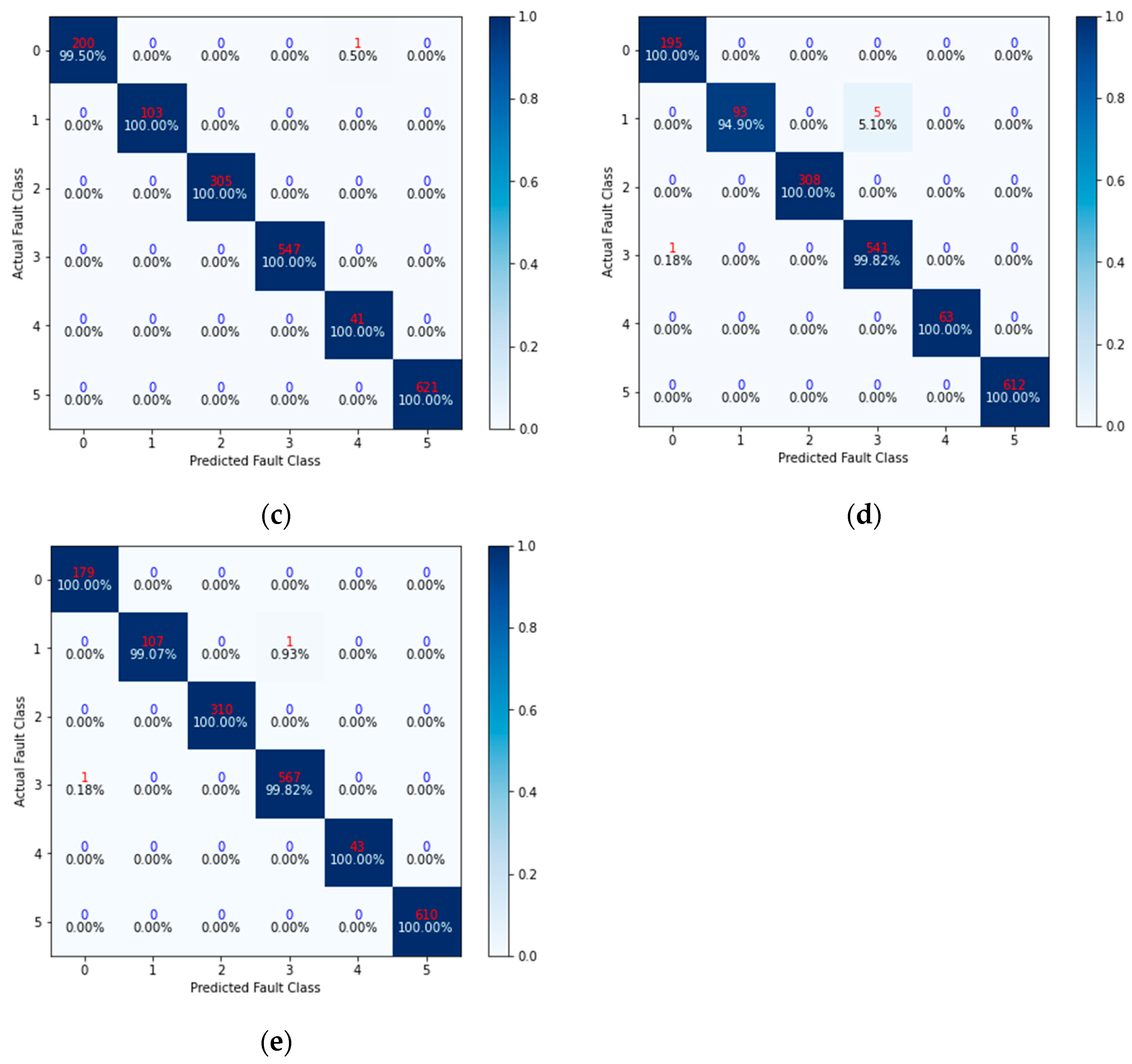
Section 4 details the comparison experiment and discusses the results.
Section 5 concludes the paper and explores future work.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}