
An Investigation of Real-Time Robotic Polishing Motion Planning Using a Dynamical System


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
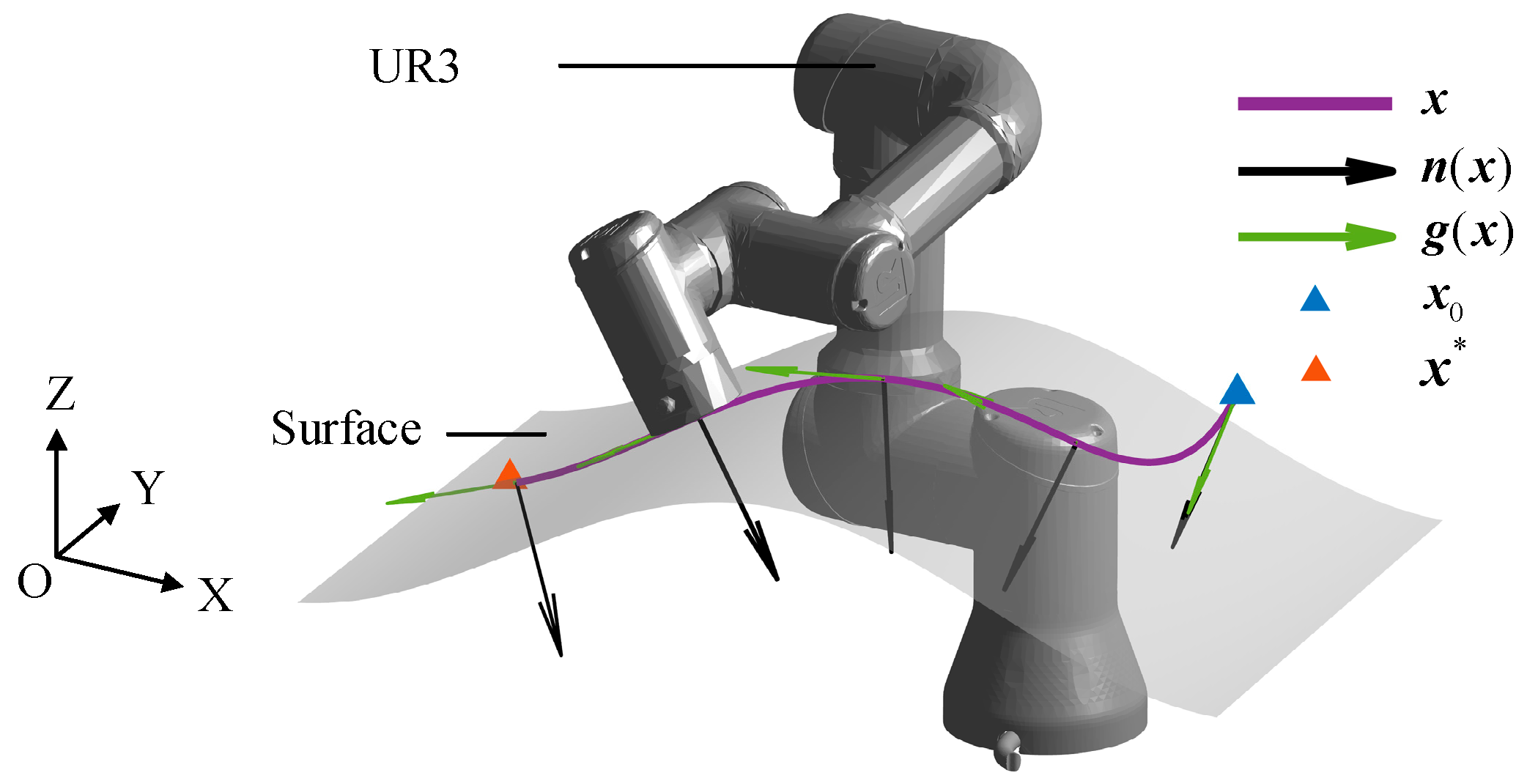
2. Contact Motion-Planning Strategy Based on Dynamic Systems
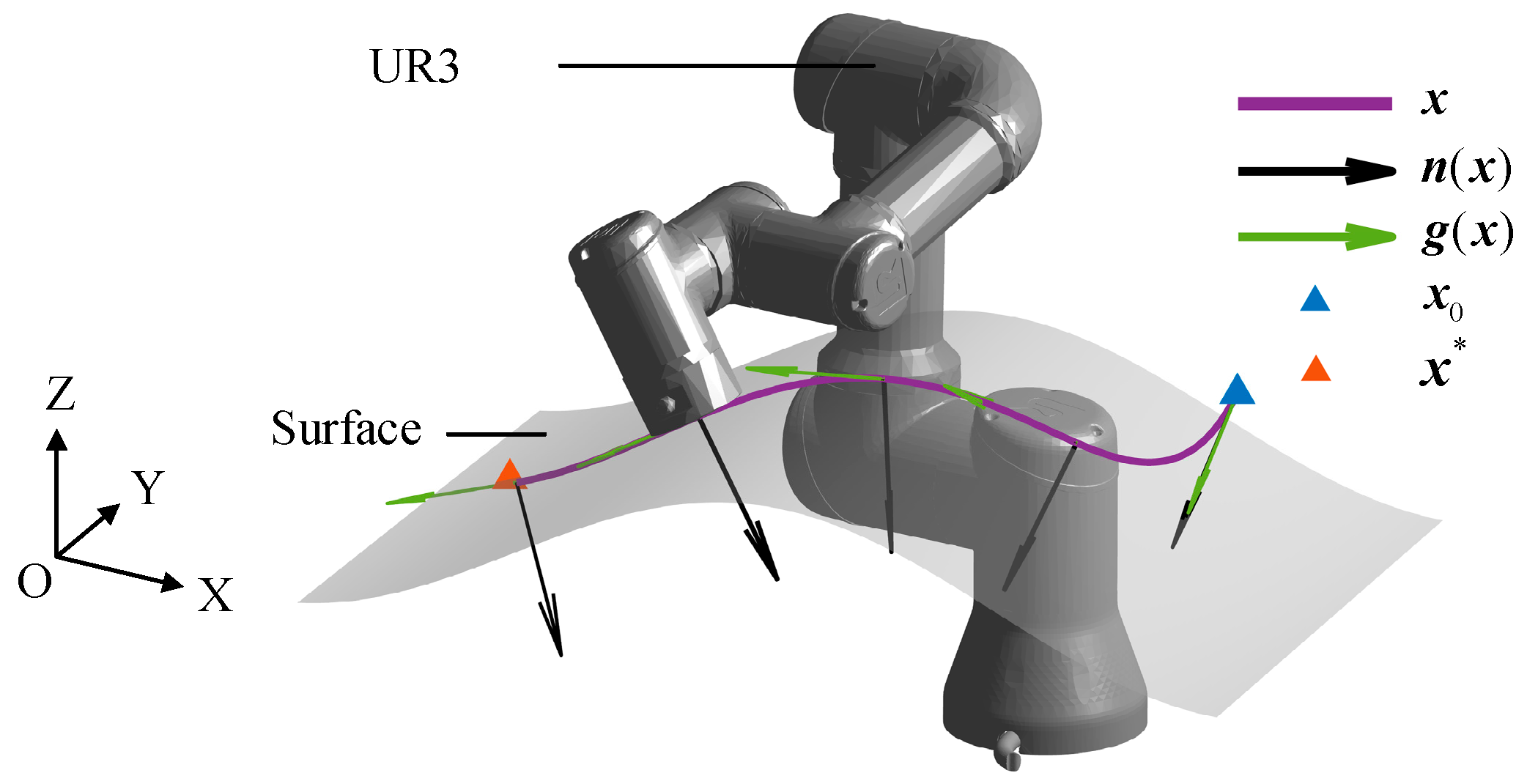
2.1. Locally Modulated Dynamic Systems
2.2. Learning about Locally Modulated Dynamic Systems
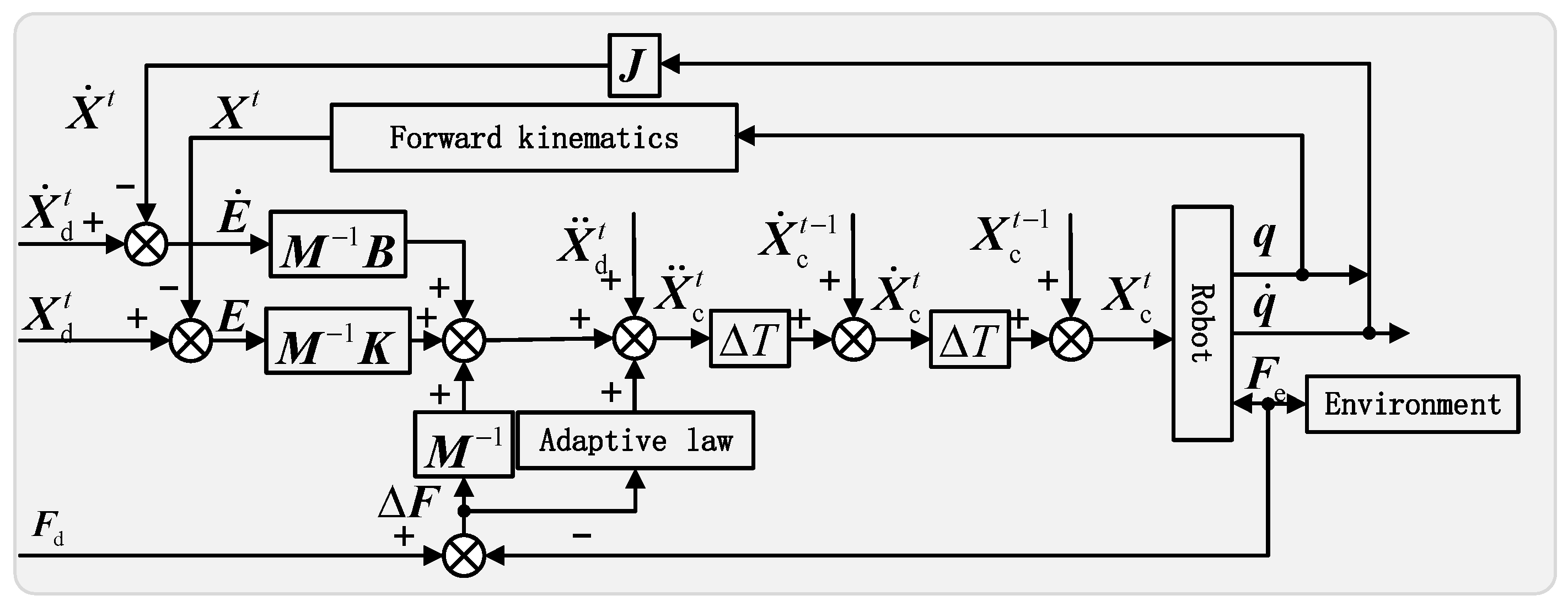
3. Integrated Adaptive Admittance Control Strategy for Robots
3.1. Integral Adaptive Admittance Control
3.2. Stability and Convergence Analysis
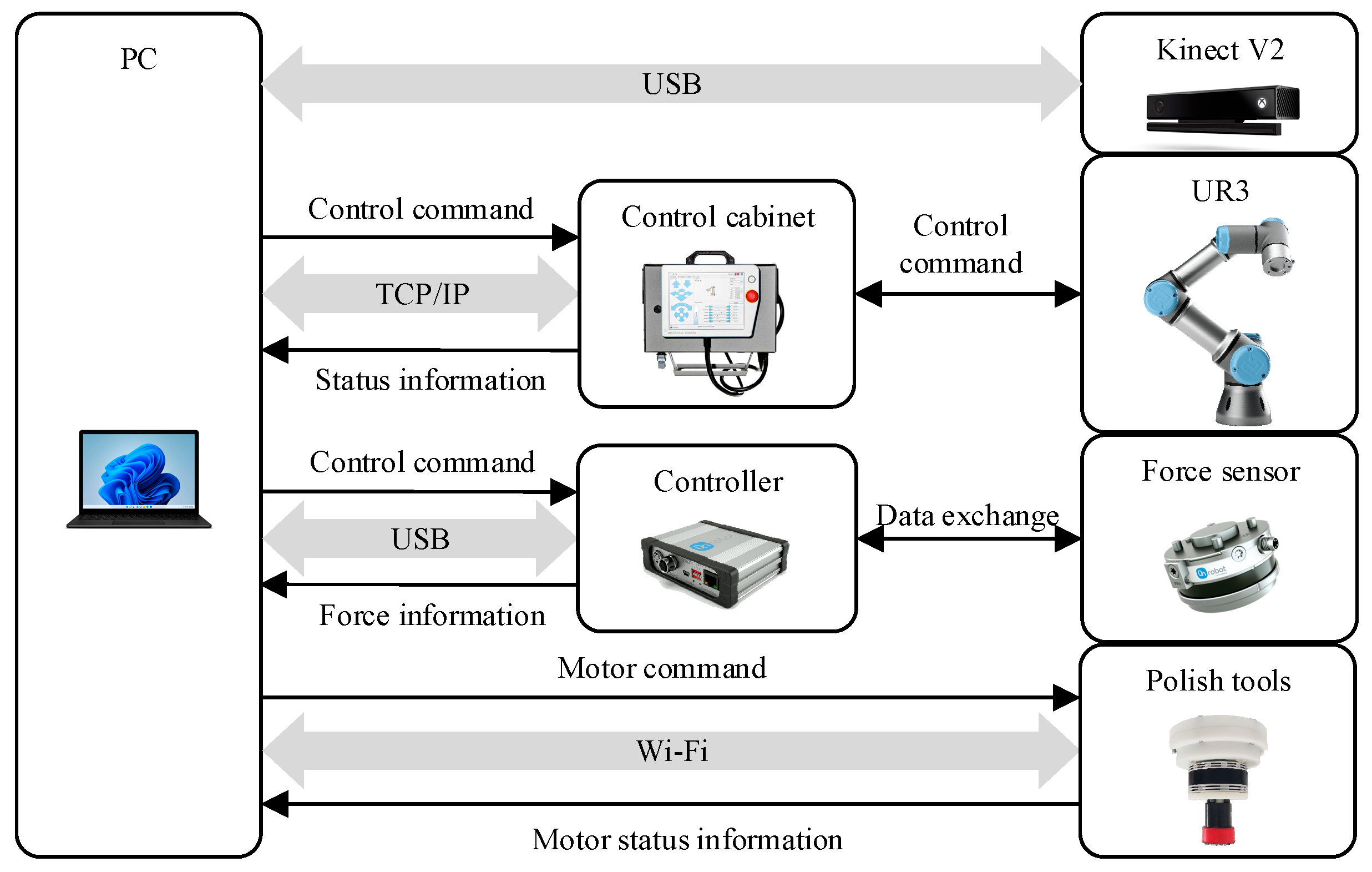
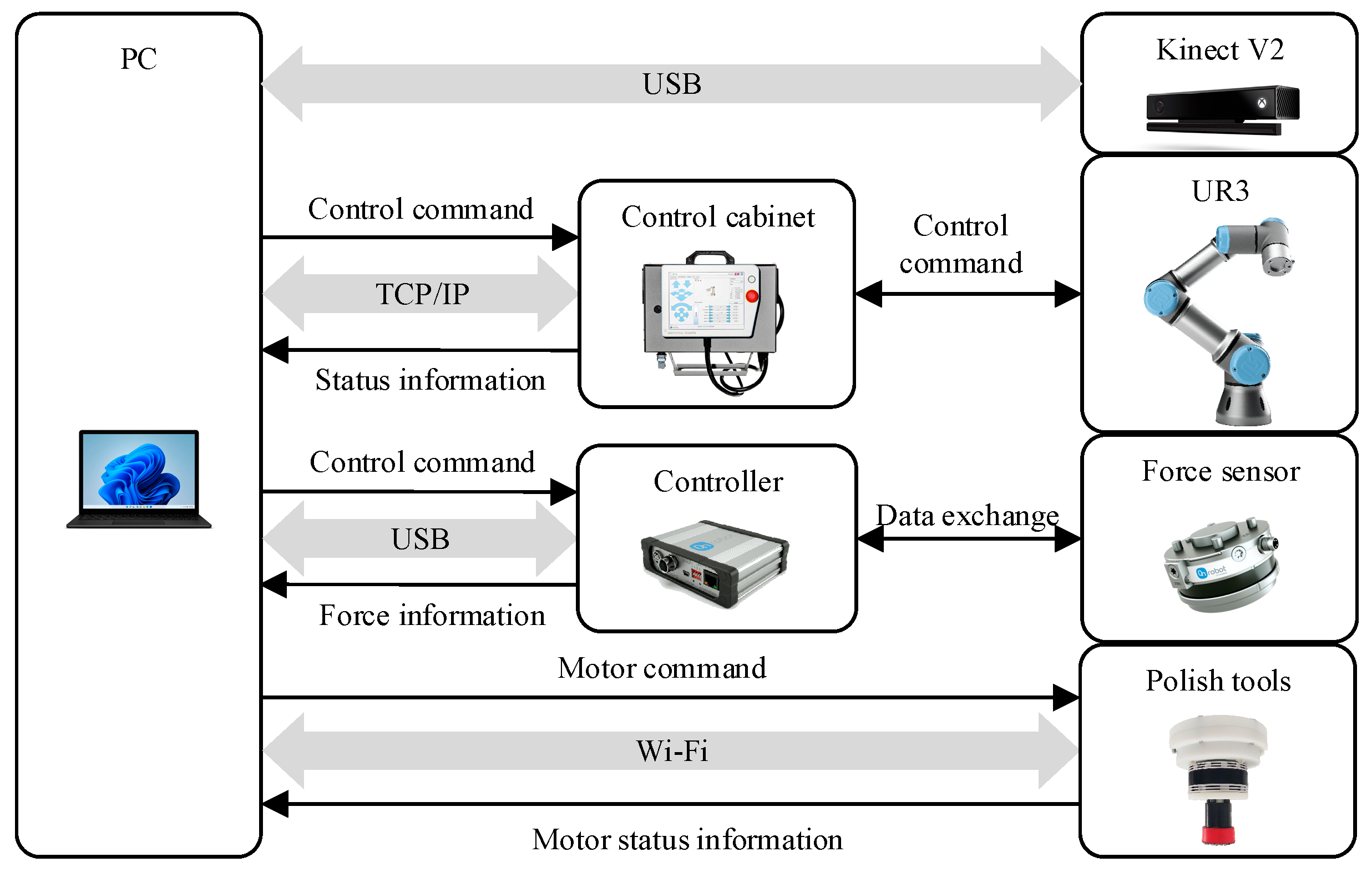
4. Real-Time Motion-Planning Experiment
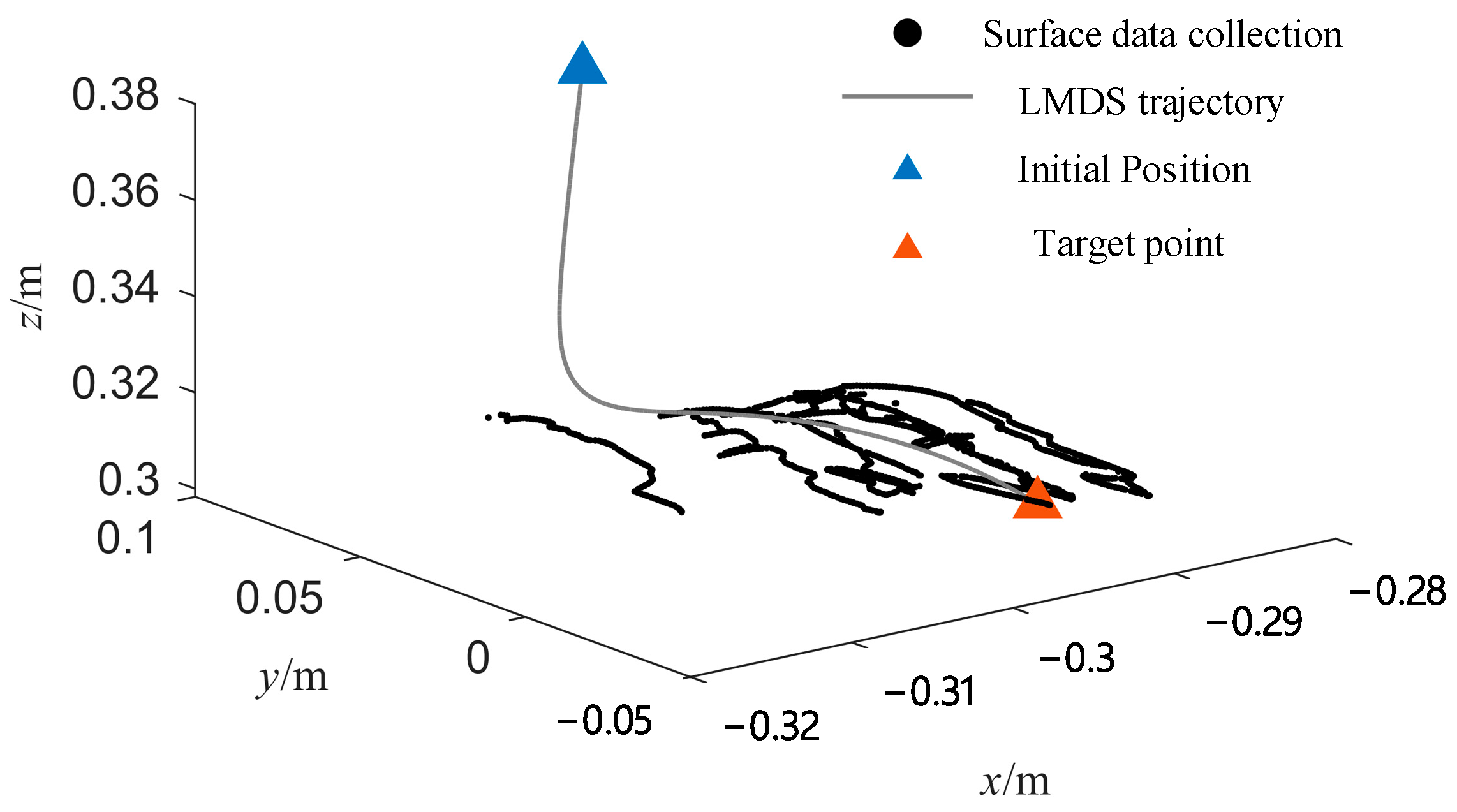
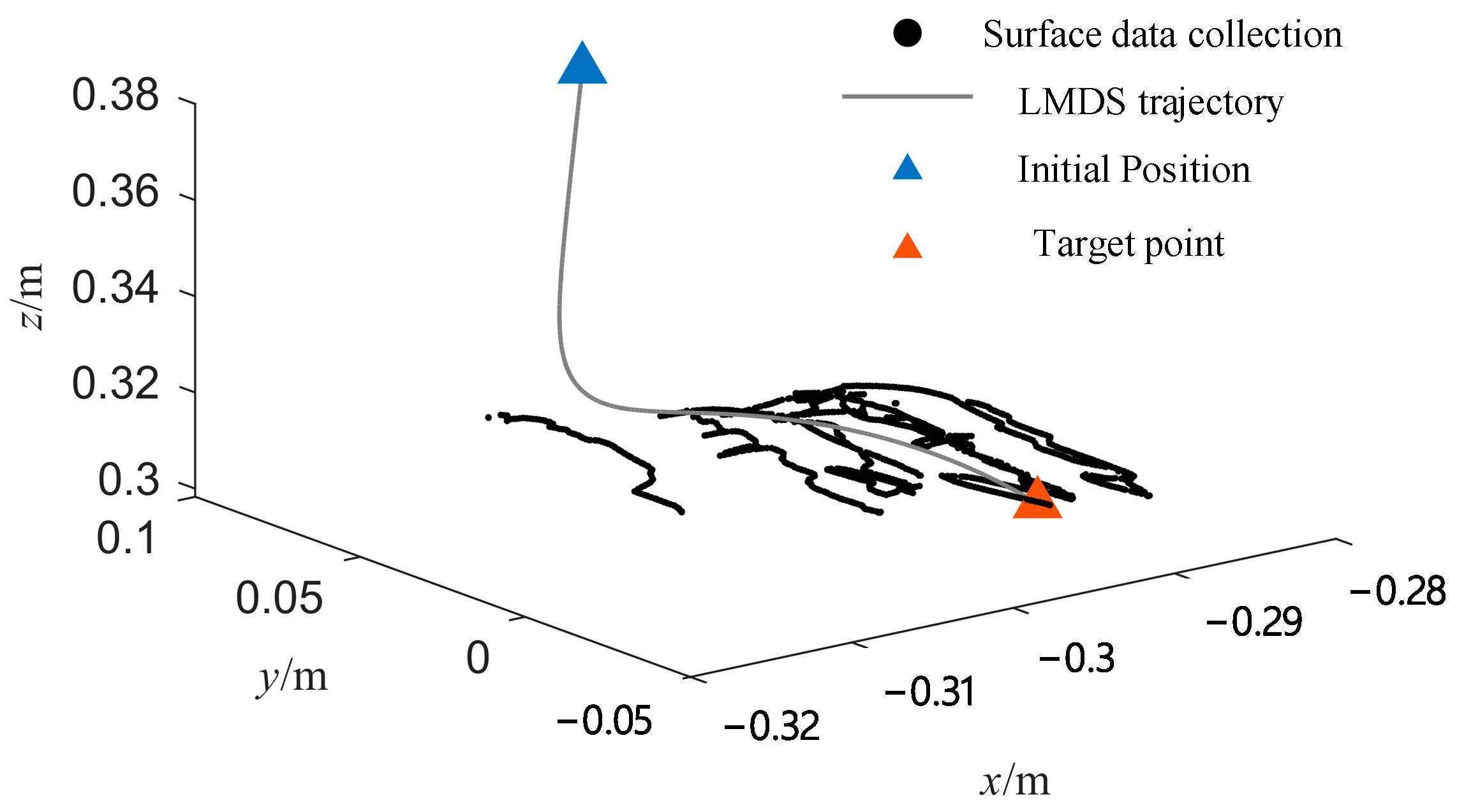
4.1. Real-Time Motion-Planning Simulation
| Algorithm 1 Calculate LMDS | |
| Input: , | |
| 1: Distance | |
| 2: Normal vector | |
| 3: Target vector | . |
| 4: Projection vector | . |
| 5: Potation vector | . |
| 6: Rotation vector | . |
| 7: Rotation angle | . |
| 8: Rotation matrix | . |
| Output: | |
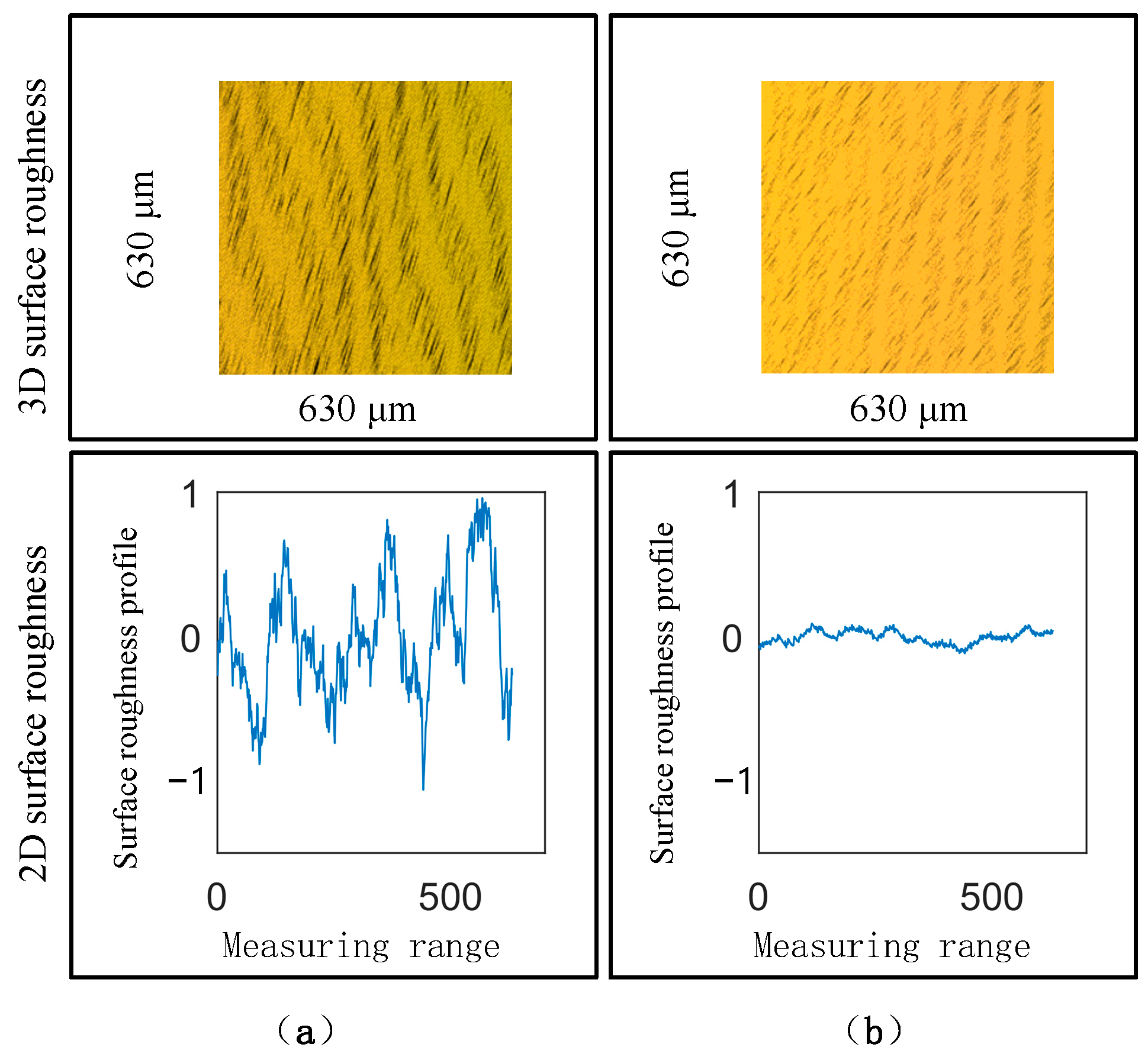
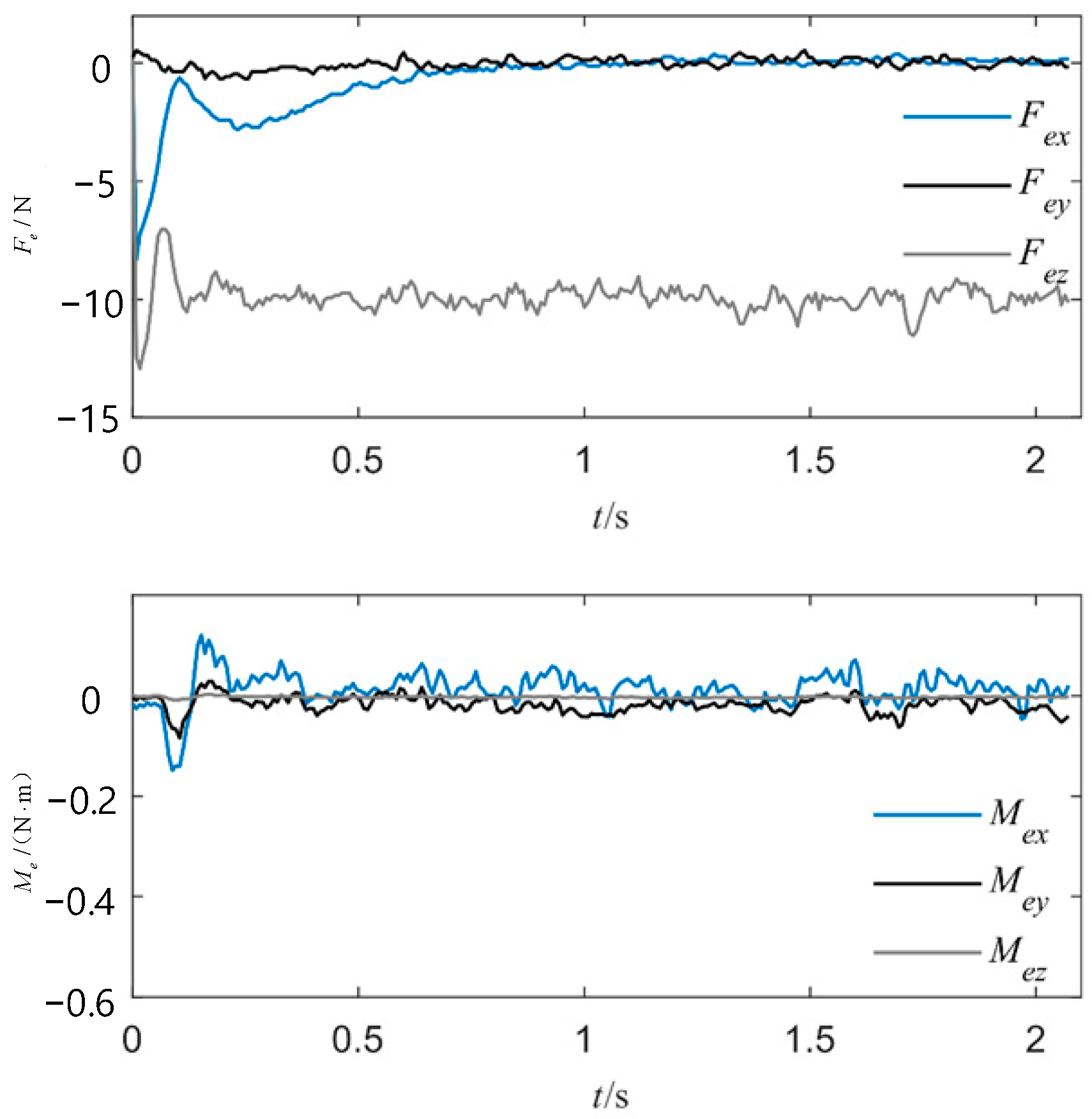
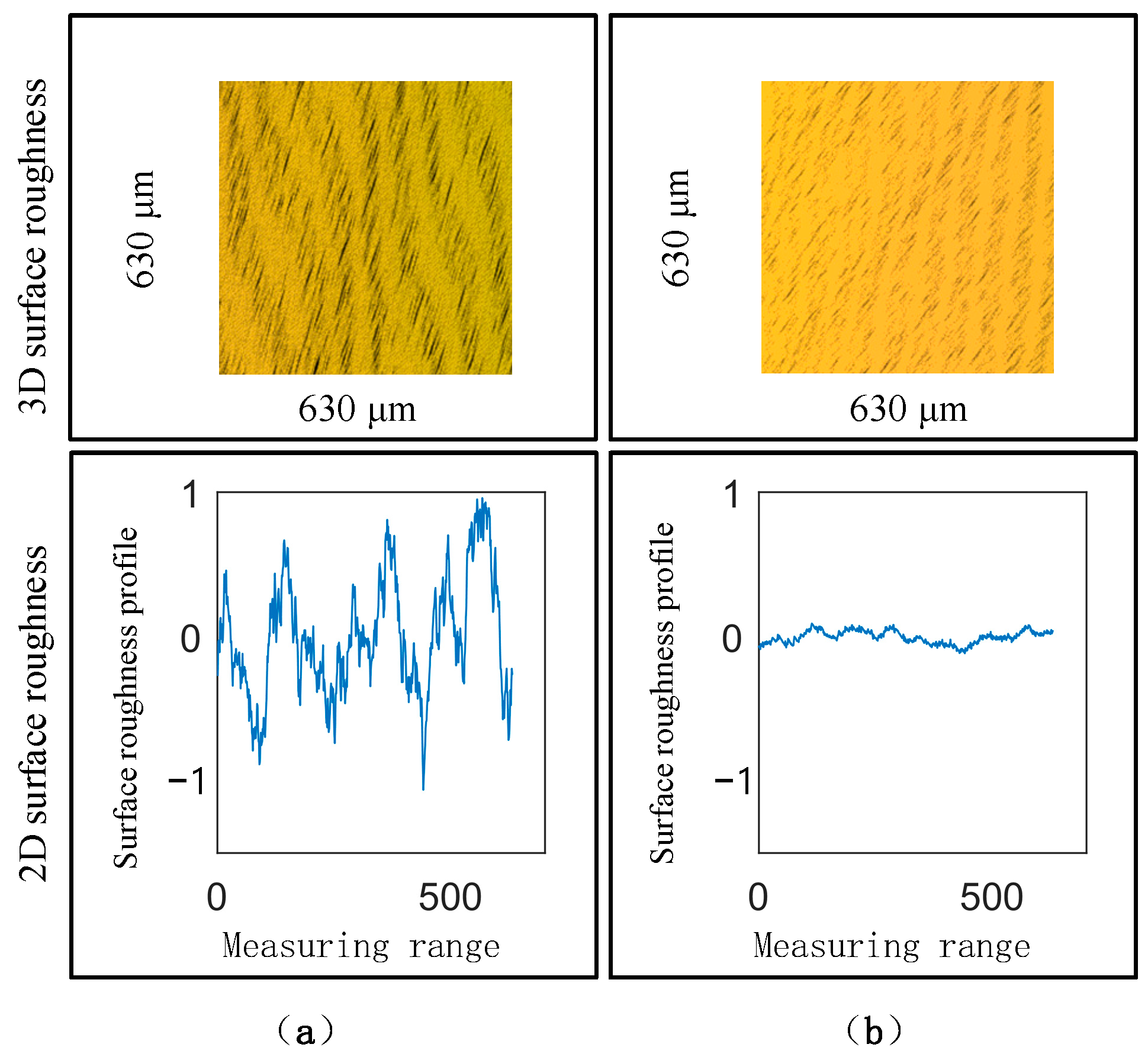
4.2. Local Polishing Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, Q.; Ding, B. Design of Backstepping Sliding Mode Control for a Polishing Robot Pneumatic System Based on the Extended State Observer. Machines 2023, 11, 904. [Google Scholar] [CrossRef]
- Dai, S.; Li, S.; Ji, W.; Wang, R.; Liu, S. Adaptive Friction Compensation Control of Robotic Pneumatic End-Effector Based on LuGre Model. Ind. Robot Int. J. Robot. Res. Appl. 2023, 50, 848–860. [Google Scholar] [CrossRef]
- Zeng, X.; Zhu, G.; Gao, Z.; Ji, R.; Ansari, J.; Lu, C. Surface polishing by industrial robots: A review. Int. J. Adv. Manuf. Technol. 2023, 125, 3981–4012. [Google Scholar] [CrossRef]
- Manuel, A.; Kappey, J.; Meurer, T. Real-time freeform surface and path tracking for force controlled robotic tooling applications. Robot. Comput. Integr. Manuf. 2020, 65, 101955. [Google Scholar]
- Ding, Y.; Min, X. Force/position Hybrid Control Method for Surface Parts Polishing Robot. J. Syst. Simul. 2020, 32, 817–825. [Google Scholar]
- Dai, J.; Chen, C.-Y.; Zhu, R.; Yang, G.; Wang, C.; Bai, S. Suppress vibration on robotic polishing with impedance matching. Actuators 2021, 10, 59. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, J.; Jin, Y. An improved rational Bezier model for pneumatic constant force control device of robotic polishing with hysteretic nonlinearity. Int. J. Adv. Manuf. Technol. 2022, 123, 665–674. [Google Scholar] [CrossRef]
- Wahballa, H.; Duan, J.; Wang, W.; Dai, Z. Experimental study of robotic polishing process for complex violin surface. Machines 2023, 11, 147. [Google Scholar] [CrossRef]
- Sharkawy, A.N.; Koustoumpardis, P.N. Human–robot interaction: A review and analysis on variable admittance control, safety, and perspectives. Machines 2022, 10, 591. [Google Scholar] [CrossRef]
- Kang, G.; Oh, H.S.; Seo, J.K.; Kim, U.; Choi, H.R. Variable admittance control of robot manipulators based on human intention. IEEE/ASME Trans. Mechatron. 2019, 24, 1023–1032. [Google Scholar] [CrossRef]
- Nemec, B.; Yasuda, K.; Mullennix, N.; Likar, N.; Ude, A. Learning by demonstration and adaptation of finishing operations using virtual mechanism approach. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 7219–7225. [Google Scholar]
- Mirrazavi, S.; Khoramshahi, M.; Billard, A. A dynamical system approach for catching softly a flying object: Theory and experiment. IEEE Trans. Robot. 2016, 32, 462–471. [Google Scholar]
- Salehian, S.S.M.; Billard, A. A dynamical system based approach for controlling robotic manipulators during non-contact/contact transitions. IEEE Robot. Autom. Lett. 2018, 3, 2738–2745. [Google Scholar] [CrossRef]
- Kronander, K.; Billard, A. Passive interaction control with dynamical systems. IEEE Robot. Autom. Lett. 2016, 1, 106–113. [Google Scholar] [CrossRef]
- Ding, L.; Liu, K.; Zhu, G.; Wang, Y.; Li, Y. Adaptive Robust Control via a Nonlinear Disturbance Observer for Cable-Driven Aerial Manipulators. Int. J. Control. Autom. Syst. 2023, 21, 604–615. [Google Scholar] [CrossRef]
- Khalil, H.K.; Grizzle, J.W. Nonlinear Systems; Prentice Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Kronander, K.; Khansari, M.; Billard, A. Incremental motion learning with locally modulated dynamical systems. Robot. Auton. Syst. 2015, 70, 52–62. [Google Scholar] [CrossRef]
- Vapnik, V.N. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Carr, J.C.; Beatson, R.K.; Cherrie, J.B.; Mitchell, T.J.; Fright, W.R.; McCallum, B.C.; Evans, T.R. Reconstruction and representation of 3D objects with radial basis functions. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, New York, NY, USA, 12–17 August 2001; pp. 67–76. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wang, X.; Yang, Z.; Zou, Y. An Investigation of Real-Time Robotic Polishing Motion Planning Using a Dynamical System. Machines 2024, 12, 278. https://doi.org/10.3390/machines12040278
Wang X, Wang X, Yang Z, Zou Y. An Investigation of Real-Time Robotic Polishing Motion Planning Using a Dynamical System. Machines. 2024; 12(4):278. https://doi.org/10.3390/machines12040278
Chicago/Turabian StyleWang, Xinqing, Xin Wang, Zhenyu Yang, and Yupeng Zou. 2024. "An Investigation of Real-Time Robotic Polishing Motion Planning Using a Dynamical System" Machines 12, no. 4: 278. https://doi.org/10.3390/machines12040278
APA StyleWang, X., Wang, X., Yang, Z., & Zou, Y. (2024). An Investigation of Real-Time Robotic Polishing Motion Planning Using a Dynamical System. Machines, 12(4), 278. https://doi.org/10.3390/machines12040278