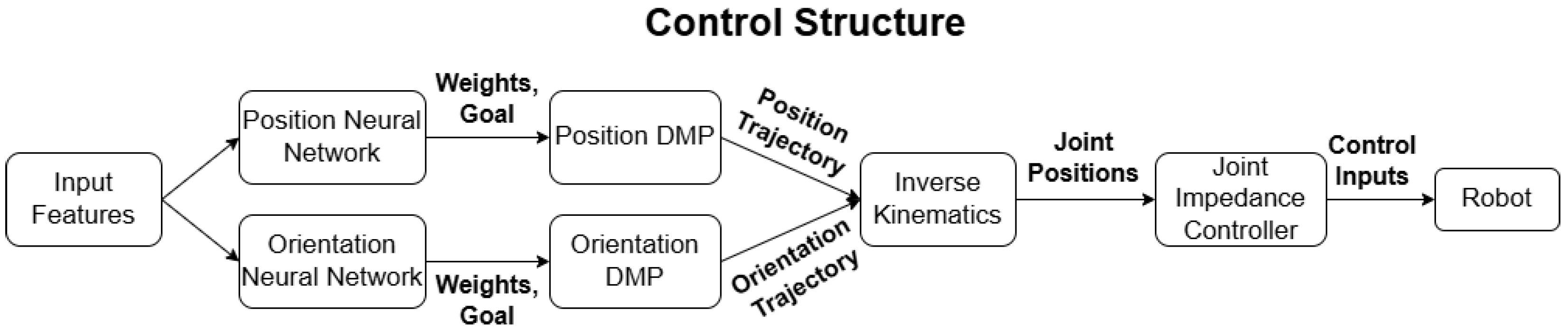
1. Introduction
Robotic manipulators have the potential for many benefits in our society. They have been applied in many settings to increase productivity by automating repetitive tasks, improving efficiency, increasing safety, and enhancing reliability [
1,
2]. Recently, there has been increased research into using robotic manipulators in complex environments with high degrees of uncertainty and requiring a high level of expertise, such as in medical applications [
3,
4,
5] and maintenance settings [
6,
7]. These new applications of robotics increase the need for programming interfaces that can be quickly customized and programmed to complete different tasks to suit the needs of the expery without relying on programming and robotics expertise.
Learning from demonstration, also known as behavioral cloning or imitation learning, is a supervised machine learning technique designed to be a more intuitive and flexible method of robot programming [
8] that can also be used to transfer skills from users who are not experts in programming or robotics. Instead of designing specific control architectures, learning from demonstration frameworks allows users who are experts in the desired tasks to interact directly with robots to transfer skills. Demonstrations performed by one or more experts are collected by the system and are used to generate a model of how the task should be completed. This model can then be used to complete the same task and potentially generalize to variations in the task or environment. The ability to learn from demonstration frameworks to be utilized by non-programmers allows them to be an important step toward the flexible programming of robotic manipulators.
Dynamic motion primitives (DMPs) are a learning-from-demonstration method and represent trajectories using second-order dynamic systems [
9]. They have several characteristics that make them attractive for learning from demonstrations in robotics, including stability guarantees, learning from a single demonstration, and the capability for generalization. They are a flexible framework that can be formulated in different task spaces, such as joint space or Cartesian space, making them suitable for various purposes. They can also learn from a single demonstration, which can reduce the time and resources required to collect training data.
DMPs can be combined with neural networks to extend the functionality of DMPs by forming what is known as neural DMPs [
10]. This allows for further generalization of DMPs through training from multiple demonstrations. However, this can come at the cost of requiring more investment into the demonstration collection process, which can be time-consuming and expensive, as experts are required for very specialized tasks. Additionally, leveraging the function approximation capabilities of neural networks, neural DMPs can increase the complexity and duration of tasks that can be modeled. This presents the option of learning from a full demonstration instead of dividing it into sub-tasks, eliminating the need for experts to process and divide the demonstrations once they have been collected.
1.1. Motivation
A common approach used when programming robots for tasks, including for learning from demonstration, is to break down tasks into sub-tasks. Segmenting tasks in this manner has several advantages, such as reducing the complexity where modeling is required and some flexibility to combine motions in different orders, and it can be very effective in controlled and well-structured environments such as manufacturing [
8]. However, decomposing tasks can introduce challenges in current DMP-based controllers, such as requiring a carefully designed framework to combine the sub-tasks, which may need to be modified for changes in the task and require a larger time investment into collecting and processing demonstrations. As such, the systems are still reliant on individuals with robotics and programming expertise, particularly when the system may need to be retrained quickly and often for specific tasks such as in medical and maintenance applications. This limits their usefulness and customization to the user’s specific needs. As such, this paper aims to compare the use of DMPs when using demonstrations of complete tasks to DMPs using demonstrations of individual sub-tasks, with the goal of reducing the necessary technical expertise and resource investment required for programming from demonstration.
Decreasing the reliance on expert programmers and roboticists when teaching new skills is one step toward reducing the barrier to entry for robotic systems for widespread use. Leveraging neural DMPs is one avenue of learning sequences of tasks from complete demonstrations to create a programming interface for robot manipulators. This will allow experts to provide demonstrations in applications such as leg positioning during rehabilitation, or machinery repairing sequences, which can then be transferred to a robot manipulator without modifying the underlying framework. However, while this can result in a faster transfer of skills, it may come with trade-offs when compared to a segmented approach. Comparisons between learning from full and segmented approaches have not been thoroughly addressed in current research.
Collecting a sufficient number of high-quality demonstrations is another challenge to be overcome to increase the prevalence of learning from demonstration for robotics. The lack of available demonstrations is more prevalent in tasks that occur infrequently or that may occur in dangerous locations, such as deep sea welding or maintenance tasks in outer space. The number of training samples varies between different learning methods, meaning methods that are effective with few samples can reduce the time and effort required during data collection. Synthetically generated data have also been used to train models for certain tasks [
11], although this is limited by the ability to simulate the completion of the objective and can often negate the modeling benefits obtained from learning by demonstration. Data augmentation can also be used to circumvent this challenge by increasing both the number and variety of samples in the datasets [
12].
1.2. Contributions
In this paper, we demonstrate the ability of neural DMPs to learn a skill with few human demonstrations and compare it to a model that has learned from demonstrations split into sub-tasks, as traditionally performed in DMPs. The trade-offs in accuracy, along with other important factors such as the amount of input required from human experts and the potential task flexibility capabilities between the two models, are then analyzed. To assess these trade-offs quantitatively and qualitatively, we utilize neural DMPs with a simple yet nontrivial task—pouring water into a glass. We perform the learning both from a full demonstration and by segmenting the demonstration into sub-tasks; then, we compare them in terms of the required human input, accuracy, and potential for flexibility. The main contributions are as follows:
We demonstrate that neural DMPs can be used to learn a task made up of multiple sub-tasks from full demonstrations (unsegmented).
We compare the accuracy of neural DMP models trained using full demonstrations to those trained using simpler sub-tasks and examine key trade-offs between the models trained using full demonstrations to those trained using simpler sub-tasks.
We demonstrate the ability of neural DMP models to learn from a dataset that requires minimal human demonstrations to generalize for a pouring task.
The remainder of this paper is structured as follows.
Section 2 explores the related works and knowledge gaps. Next,
Section 3 describes the theoretical foundation and training methods for DMPs.
Section 4 outlines the process used to collect demonstrations to form the dataset, and
Section 5 presents the results after training the models and implementing them on the robot.
Section 6 discusses the results, and
Section 7 summarizes the conclusions and presents potential future directions.
2. Related Works
Dynamic motion primitives (DMPs) are a versatile method of learning from demonstration that represents trajectories using second-order dynamical systems [
13]. They are composed of a set of basis functions, learned weights, and attractor dynamics, allowing a model to be trained from a single demonstration. DMPs have been formulated for both joint space and Cartesian space and have been augmented to incorporate environmental feedback and external stimuli [
14]. They are a proven method of effective learning from demonstrations, but they can have certain drawbacks, such as only learning from a single demonstration, which can limit the ability to generalize.
While traditional DMPs are formulated for joint or Cartesian position control, formulations for both quaternion [
15] and rotation-matrix-based orientations [
16], as well as combined positions and orientation for Cartesian spaces [
17,
18], have been developed. Joint-space DMPs tend to be popular when recording robot joint states during demonstrations, such as for kinesthetic teaching or teleoperation-based interfaces [
19]. While joint-space DMPs can be used with passive observations, this often requires overcoming the correspondence problem or mapping human joints to robot joint space (retargeting), which can be challenging due to different kinesthetic makeups and redundancies [
20]. As such, position, orientation, and Cartesian space DMPs are popular when humans perform the demonstrations independently of the robot. Additionally, DMPs can represent point-to-point motions or periodic motions or even have goals with a non-zero velocity [
14]. While each method is rooted in similar theoretical formulations, selecting the correct DMP for a particular task representation is crucial. In this paper, demonstrations were collected using passive observation; therefore, Cartesian DMPs were selected to control the position and orientation of the end effector in completing the task. Point-to-point DMPs were selected as the demonstrations, and segmented demonstrations had zero starting and ending velocities and accelerations.
While modifications to adapt to uncertain environments serve to improve the robustness of DMPs, applying them to more complex tasks requires additional strategies. Integrating via-points into the DMP formulation allows further control when specific and known points in a trajectory are critical for task execution. These can be incorporated based on knowledge of the desired trajectory [
21] and have also been implemented at run time for dynamic obstacle avoidance or changing environmental factors [
22]. However, it should be noted that even with via points, the amount to which a motion primitive can be adapted to meet the constrained point in the trajectory is limited [
21]. Further control over tasks with multiple distinct steps can be obtained by training and executing multiple consecutive DMPs, which is a common strategy [
17,
23]. While the segmentation can be performed autonomously, typically using zero velocity crossing [
24], this can require human oversight, which can become more difficult to obtain when highly trained experts are required. When combined with a higher-level planner that selects from a library of primitives [
25,
26], this can provide further task generalization and adaptability. However, the system is still limited to the primitives that it has and requires the processing of environmental data to select the correct primitive.
Adding more control to DMPs through via points and DMP chaining introduces additional control for tasks but requires more effort to implement and train. Sidiropoulos and Doulgeri [
22] utilize via points in real time, but this requires monitoring the environment for obstacles or changes in the environment that are known to impact the current task. Similarly, static via points require known points critical to the trajectory, which need to be selected in some manner [
21]. While DMP chaining can be performed through velocity zero-crossing [
24], it may still require human oversight to correct segmentation or when specific augmentations are required. These techniques reintroduce task knowledge handcrafted human inputs, albeit to a lesser extent, which are preferably to be avoided when using learning from demonstration.
A key feature of DMPs is that they learn from a single demonstration, which provides both advantages and disadvantages. Data-driven models that do not require large amounts of data are useful in machine learning to reduce the time and effort required to collect datasets. In robotics, particularly for techniques that collect demonstrations from the robot, the ability to learn from small datasets is even more advantageous as it can reduce the physical wear on the system. However, it is often desirable to learn using multiple demonstrations to integrate characteristics of different experts and generalize over tasks. As such, different methods have been explored to allow DMPs to learn from multiple demonstrations.
A variety of techniques have been used to train DMPs from multiple demonstrations. Early methods have explored adding an additional term to the DMP known as the style parameter [
27]. Other approaches focus on training multiple DMPs and finding locally optimal solutions through quadratic optimization [
28,
29]; however, these methods tend not to scale efficiently, as training and storing DMPs for each demonstration is required. A combination of Gaussian mixture models (GMMs) and Gaussian mixture regression (GMR) [
30] has also been used to train DMPs for multiple demonstrations, including demonstrations of correct and incorrect behaviors [
31]. Using DMPs along with a learned cost function in model predictive control (MPC) has also been used [
32] and has been shown to scale more efficiently with the number of demonstrations. Linear regression has also been used to learn unique weights throughout a task space based on multiple demonstrations [
33].
Currently, neural networks are a popular method being used to generalize over multiple demonstrations [
10]. Often referred to as neural DMPs, this technique uses a neural network to approximate the weights of a DMP using environmental factors as inputs and using trajectory representation characteristics of the DMPs. End-to-end policies, which take images of the environments, have been developed to avoid hand-crafted features [
11]. Neural DMPs for orientation are less common but have been investigated [
18], and the weights are learned by comparing the forcing functions. Different types of neural networks, including traditional networks and recurrent neural networks (RNNs) [
34], as well as convolutional neural networks (CNNs) [
35], have been used.
Different loss functions have been used while learning the weights for DMPs from neural networks. When this is performed, it must be differentiable with respect to the desired outputs, generally the weights and desired goal position, to ensure that back-propagation can occur in the network. The forcing functions from the learned model and the demonstrations have been used to generate the loss function and neural network weight updates for both position and orientation representations [
18]. Another method computes the loss function for training a position of neural DMP by comparing the output trajectory to the demonstration, as opposed to comparing the weights, which do not have a physical meaning [
36], and is found to increase the performance of the networks. Auto-encoders have also been used to learn latent space representations of tasks for motion generation [
37], so they are also able to compare reconstructed trajectories to demonstrations. For this system, the loss function for the position was determined by comparing the demonstration trajectory and the modeled trajectory as in [
36], while the orientation loss function compared the learned and modeled forcing function as in [
18].
While the use of DMPs has been common in robotics, limited research has explored the use of neural DMPs to learn longer sequences of tasks from a single demonstration. This paper aims to fill this gap by first developing a neural DMP model trained from a single demonstration and then comparing it to one trained from segmented demonstrations. The comparison is performed in terms of task precision, the additional time required to process demonstrations, and the potential for flexibility within the framework.
4. Demonstration Collection
Demonstrations were collected using the Xsens Awinda motion capture suit and software (
https://www.movella.com/products/xsens (accessed on 30 September 2024)), which uses Inertial Measurement Unit (IMU) data to estimate human poses [
41] at 60 frames per second. The sensors are worn by the demonstrator, which is shown in
Figure 2. The Cartesian position and orientations were extracted by the Xsens Awinda software relative to a coordinate frame set during the calibration of the sensors. A rotational transformation was required to convert and align the axes of the hand from the Xsens IMUs from data collection to the robot end effector. This was implemented using rotations from the Scipy version 1.13.0 Python Library [
42] through Euler angle rotations.
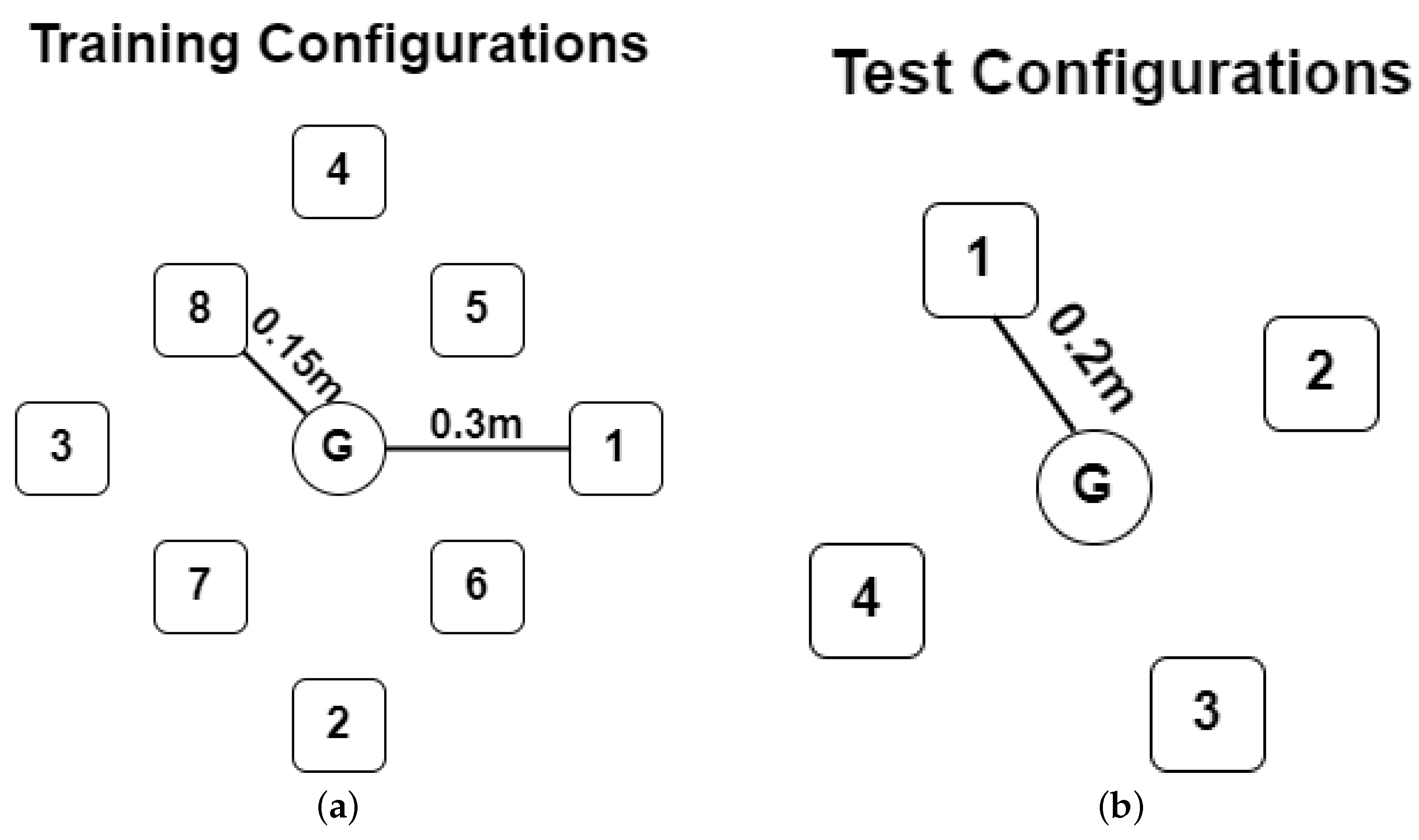
Demonstrations for the training set were collected from four demonstrators, each of which performed a pouring action in eight different configurations, shown in
Figure 3a, for three different amounts of water. For each demonstrator, this took approximately half an hour, including the setup, calibration, and explanation of the demonstrations, resulting in a total demonstration collection time of 2 h.
Figure 4 depicts an actual demonstration data collection session. The water levels were measured using weights, which had the following values: 799 g, 522 g, and 273 g. One participant collected demonstrations from an additional four configurations shown in
Figure 3b and an additional two water levels of 397.5 g and 660.5 g to be used as a testing set. All our experiments received ethical approval from the University of Waterloo Human Research Ethics Board at the University of Waterloo, Ontario, Canada. Before the experiment, participants received proper information and gave informed consent to participate in the study.
One demonstration consisted of the demonstrator starting with their hands at their sides, reaching for the pouring container, pouring into the goal container until they judged it to be full (as only the 273 g level could be entirely poured into the goal container) or the pouring container was empty, returning the pouring container to its original location, and returning their hand to their side. The demonstrators were also told to grip the container in a specific region that was suitable for a robot gripper to grasp. While it was not a specific exclusion criterion, each of the demonstrators was right-handed and used their dominant hand to pour. The position of the pouring container was varied around the goal container, as seen in
Figure 3a,b, where the goal position is shown as a circle, while the pouring container positions are shown as rectangles.
The trajectories were resampled using cubic splines to ensure consistent numbers of data points. The orientation trajectories of the demonstrator’s pouring hand were used to learn a forcing function with LWR to create the labels for the orientation model, while the position trajectory of the demonstrator was used directly as the label for the position model. The implementation of a full vision system was beyond the scope of this project, as the same system would be added to frameworks using the full and segmented demonstrations and would not meaningfully impact the comparison. Additionally, the input features for the models consisted of elements that could feasibly be extracted from image feature extractors. As such, features manually extracted from the demonstrations and environment configuration were used. They included the starting position and orientation of the demonstrator’s hand, the Cartesian position of the pouring container, and the goal container, and the water level normalized to between 0 (empty) and 1 (largest water level). The inputs also included the position difference between the pouring container and the goal container, as well as between the starting hand position and the pouring container in each Cartesian axis.
The collected demonstrations were segmented into three sub-tasks to train one set of DMPs for the pouring task. The first segment included reaching for the container with water and required the end effector to navigate the environment, avoiding the goal container. The second segment began when the manipulator grasped the container and consisted of transporting the container to the goal container, pouring the water, and returning the container to its original location. This segment required the associated DMP to capture the pouring motion, including factors such as the angle at which the pouring container is tilted and the location of the end effector to successfully pour into the receiving container, while also navigating the environment to avoid collisions with the goal container. The final segment started after the pouring container had been released and required the manipulator to return to its initial position without colliding with any containers.
The segmentation points for this task were selected to best align with the input features and to best suit the DMP formulation. Each section was aligned with the available inputs to the system, with each segment beginning and ending at one of the locations specified in the input vector. The first segment, reaching for the pouring container, began at the initial position and ended at the specified position of the pouring container. The third segment, returning from the pouring container to the initial position, used the same two positions but in opposite order. The second segment started and ended at the initial position of the pouring container. Breaking the task into segments with defined starting and ending points based on information from the environment helped ensure the neural DMP had the necessary inputs required to learn the desired trajectories. These points also represented points of low velocity in the demonstrations, which helped with the segmentation process and was compatible with the standard formulation of DMPs.
The data were segmented through a combination of automated analysis and manual point selection. After applying a low-pass filter to the demonstration, the Cartesian velocity of the demonstrator’s pouring hand was used as an input for the data segmentation. The velocity components were combined to find the magnitude of the velocity and were input into the SciPy peak detection algorithm [
42], which identified key points in the velocity profiles. The key points were used to define segmentation candidates, which were presented to the human supervisor. The human supervisor then used their experience and task knowledge to approve the suggested segmentation points or select new and appropriate segmentation points. Every demonstration of the same segment was normalized to be completed in a fixed time.
4.1. Dataset Formulation and Augmentation
The training datasets for the position and orientation models are described in this section. The position dataset was formulated as follows:
where
is a vector of input features with
K features,
values are the Cartesian position trajectories, and
M is the number of training pairs. The input vector remains the same as the position dataset; however, the output consists of two components, as shown in Equation (
14).
where
are terms for each of the three dimensions used for the quaternion DMP formulation calculated using LWR.
is the final orientation in the form of a quaternion and was added to the dataset so the neural DMP could learn the goal orientation as well as the weights and used during the simulation of the DMP.
To reduce the over-fitting caused by the exposure of the model to repeated identical input values, a small random deviation was added to each of the environment parameters that made up the inputs. This included the position of the goal container and pouring container, along with the initial position and orientation of the demonstrator’s pouring hand. The deviation was sampled from a normal distribution and served to ensure the model could generalize to different starting and environment parameters.
4.2. Training and Validation Sets for Cross Fold Validation
With the augmented datasets collected, the training and validation datasets for the training process described in
Section 3.6 were created. For this task, the training dataset was split into four folds, with each fold removing two configurations for the validation set and the remaining six configurations were used for training. The configurations removed for each fold were selected to be far from each other to ensure the model’s training samples were still distributed across the workspace. This resulted in the following pairing of configurations to remove for each fold, with the configuration number denoted with a capital letter “C” followed by the location of the starting container given by
Figure 3a.
Fold 1: C1 and C8 used for validation;
Fold 3: C2 and C5 used for validation;
Fold 3: C3 and C6 used for validation;
Fold 4: C4 and C7 used for validation.
The datasets were created from the augmented dataset, and the number of samples in the training and validation sets for each fold can be seen in
Table 1. For the remainder of the paper, “C” followed by a number indicates a training/validation configuration, and “V” followed by a number indicates a testing configuration, with the number corresponding to the configurations in
Figure 3a and
Figure 3b, respectively. “L” followed by a number indicates the water level described earlier in this section, with levels 1–3 indicating the levels in the training set from least to most and levels 4–5 indicating the levels in the test data set from least to most.
6. Discussion
When comparing the models generated from the full demonstrations to those that utilized the segmented demonstrations, several factors are considered. These include the accuracy of the models on cases seen and not seen during training, the amount of expert human input that was required, and the potential for task flexibility within the framework. These factors, and how they relate to the desired application, should also be taken into account when selecting whether to use full or segmented demonstrations. The desired accuracy, availability of demonstrations, expected timeline, and task complexity should be balanced with the trade-offs of the different methods to select a suitable strategy. For example, segmented demonstrations may be appropriate for a maintenance task such as replacing a component in machinery, which is composed of distinct sub-tasks. Learning from full demonstrations on the other hand may be more well suited to manipulating human joints during rehabilitation, where there are fewer distinct sub-tasks, and would require large amounts of time from physicians to annotate demonstrations. However, this paper is not meant to be a guide for selecting a method, as the variability of applications and factors is large. Instead, this paper aims to present some of the trade-offs between the two methods, which the reader can use in the context of their application.
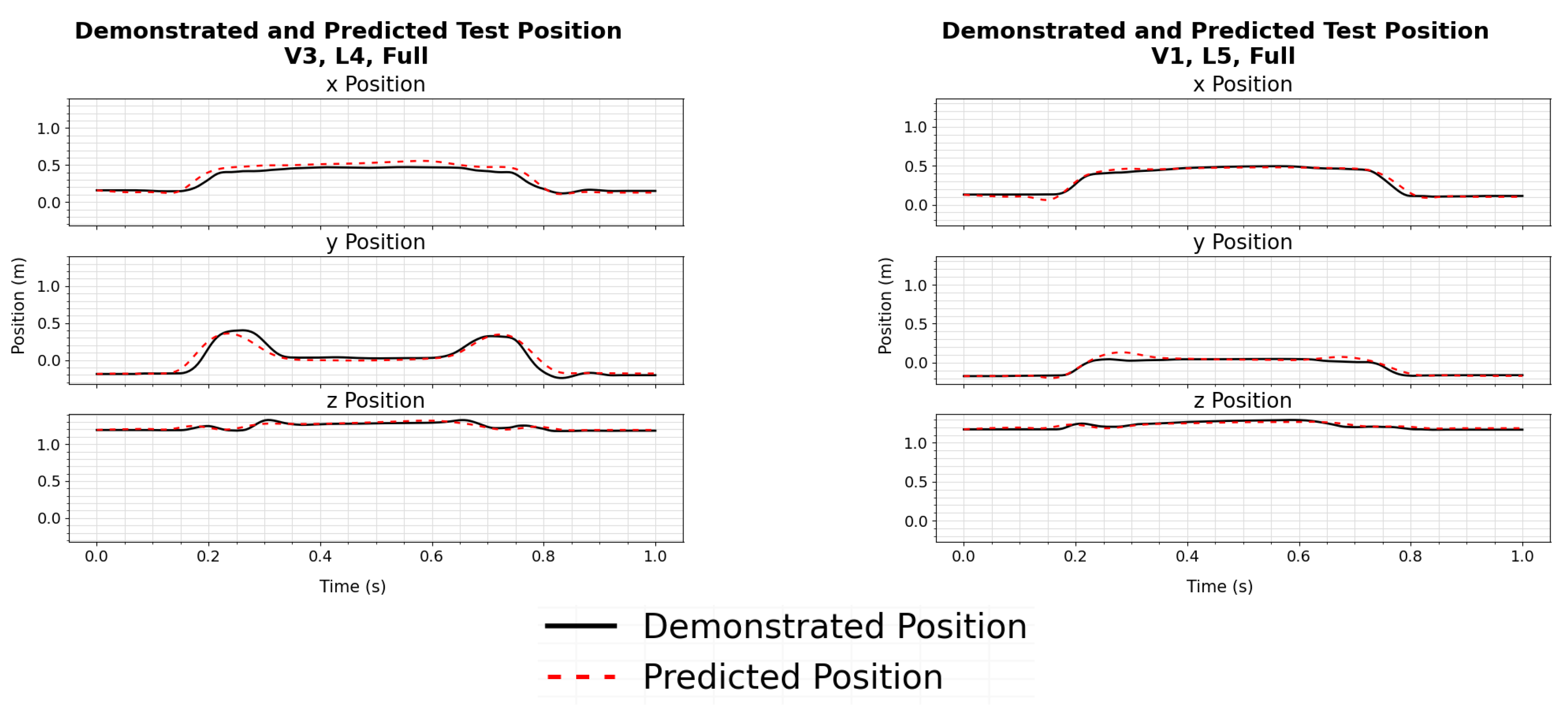
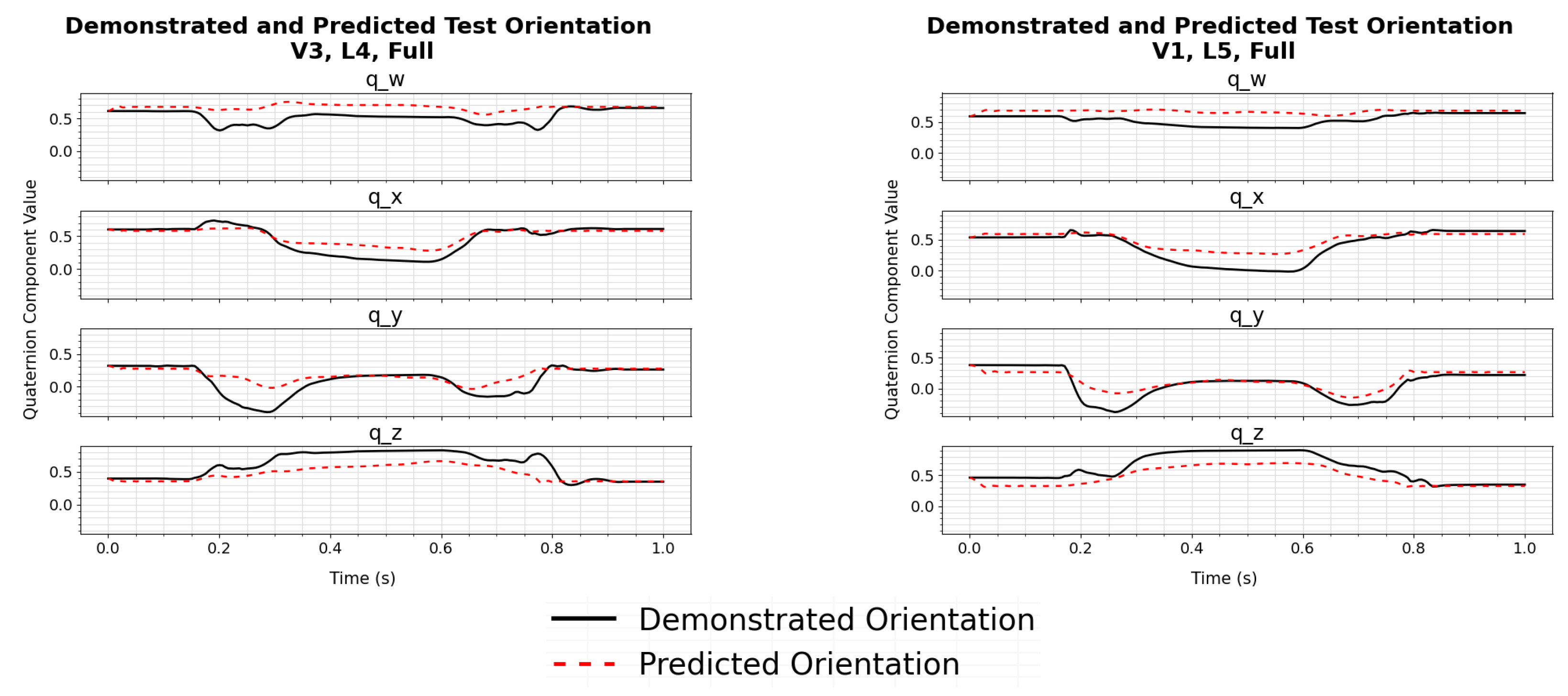
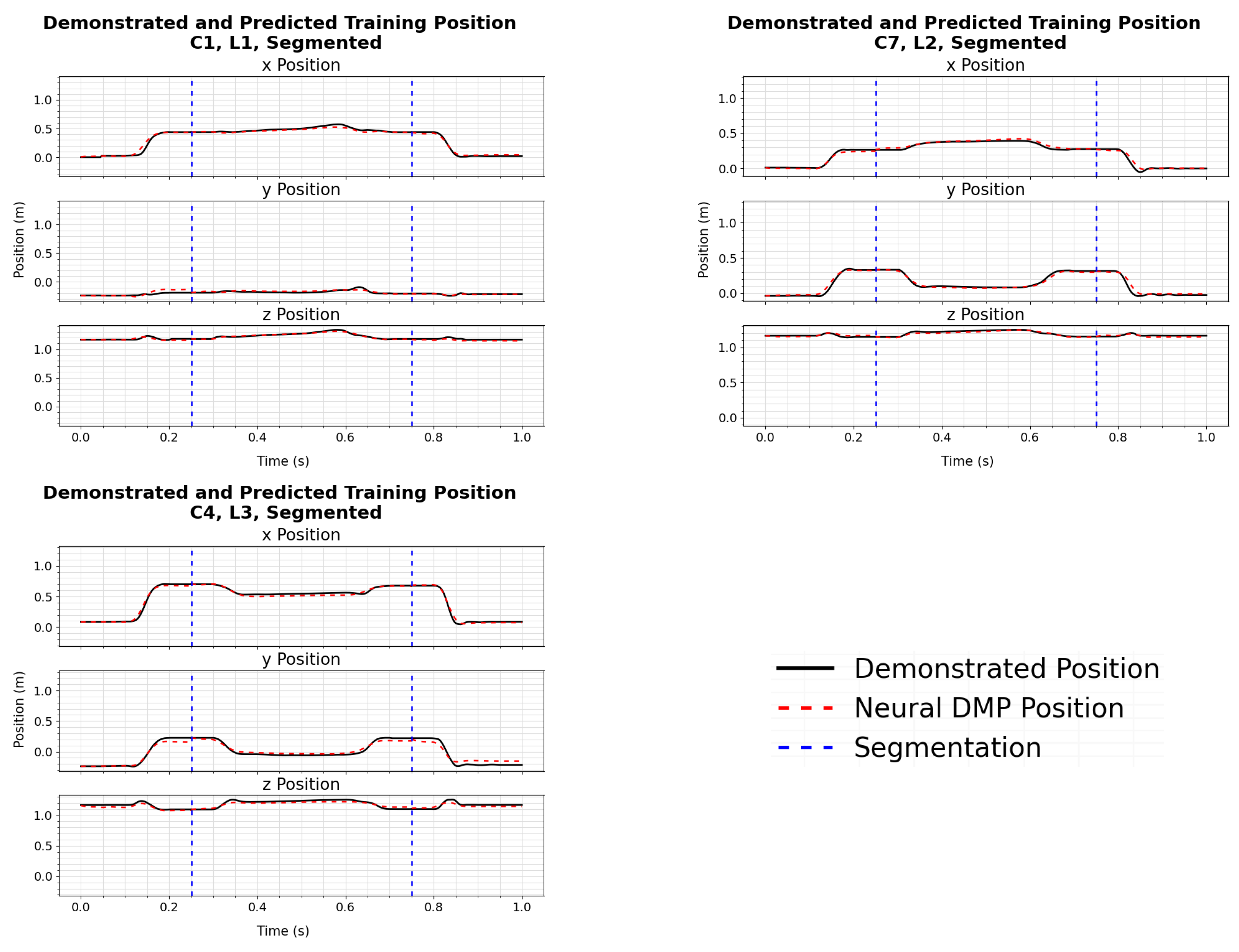
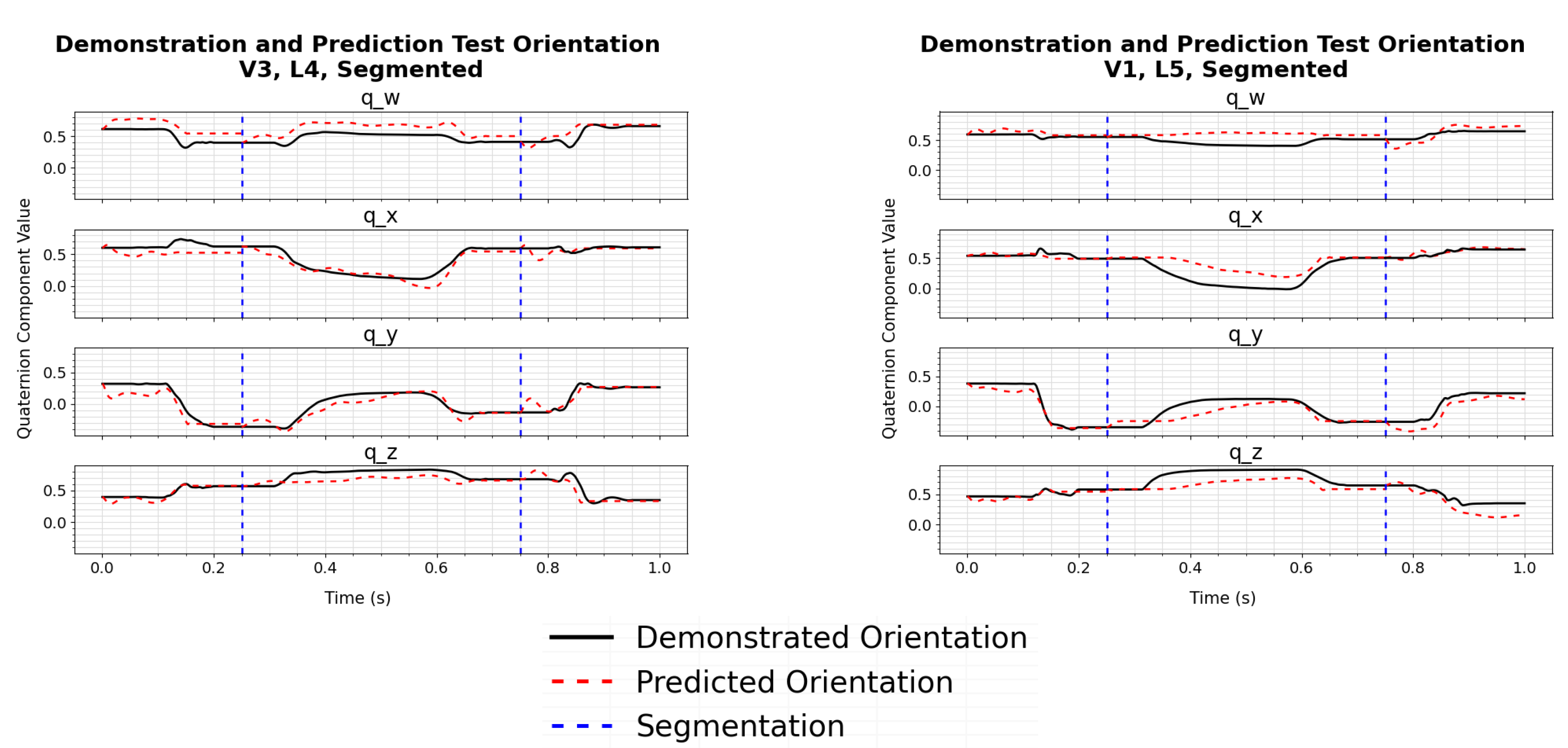
The results show that the models trained from the segmented demonstrations are more accurate in determining the correct trajectories for configurations seen during training, and new configurations. This can be seen over the full set of trajectories by comparing the losses in
Table 2 and
Table 3. This can also be seen by comparing individual sample trajectories generated from models trained using full demonstrations in
Figure 5,
Figure 6,
Figure 7 and
Figure 8 to the corresponding sample trajectories from models trained using segmented trajectories in
Figure 9,
Figure 10,
Figure 11 and
Figure 12. In particular, the trajectories from the models trained using full demonstrations show increased error in later sections of the trajectories, which is similar to the position and orientation trajectories presented in [
14,
17]. While both the full and segmented trajectories were successfully implemented on the physical robotic system, the difference in accuracy could have a larger impact for more precise tasks.
The models that learned from segmented demonstrations required additional time and effort from the expert. The main source of added time was the segmentation and annotation of the demonstrations, as discussed in
Section 4, and required an additional 2 weeks to design the semi-automated segmentation and to supervise the segmentation. While this was feasible for the relatively simple task presented in this paper, it would require additional time for more complex tasks. This could be further extended in cases where more demonstrations are required, or where the experimentation of the segmentation points need to be experimented with to successfully learn a task.
The segmented models could achieve a higher task flexibility than the full models, largely due to their potential to be combined into new sequences or used for new tasks. For example, the reaching segment used in the pouring task could be reused for other tasks that require this motion, such as sorting tasks or assembly tasks. A relatively simple high-level planner was used in this paper, but this could be extended further to incorporate additional functionality, such as confirming each sub-task is complete before moving to the next [
25]. In comparison, the models trained on full demonstrations would require new demonstrations and full re-training to be applied to different applications and would require structural changes to implement higher-level frameworks.
7. Conclusions
This paper presents a framework that uses neural DMPs for skill transfer between humans and a robot manipulator. The neural DMPs were trained to complete a pouring task using full demonstrations and demonstrations segmented into individual sub-tasks. The neural DMPs required a small number of demonstrations, requiring only 24 human examples, to learn and generalize for a pouring task and were able to generalize to new configurations of the task not seen during training. The neural DMP formulation and robot control strategy were discussed, followed by a description and analysis of the demonstration, collection, training, and testing processes, as well as an implementation of a Franka Emika Panda 7-DoF manipulator. This allowed for a comparison of the accuracy of each method while also allowing for some analysis of the input requirements from a human expert and the task flexibility of each method.
Several trade-offs between the models trained on full demonstrations and the models trained on segmented demonstrations were discussed. It was found that the model trained using the segmented demonstrations had a higher accuracy on the training and testing datasets, indicating that shorter motion primitives could increase the accuracy. Additionally, the models trained on segmented demonstrations are anticipated to have higher task flexibility, requiring fewer changes to the framework and minimal retraining to be applied to new tasks. However, the segmentation and annotation of the demonstrations required for this method significantly increased the amount of time required by the expert as they are required to both perform and annotate the demonstrations.
While this paper provides an in-depth comparison between neural DMP models that learn from a full demonstration to models that learn from sub-tasks, future work could expand on this comparison. This could include analyzing the differences in performance for tasks with different lengths and complexities or finding the ideal locations of how to subdivide different tasks. Further work could also be performed to assess the suitability of sub-tasks to transfer to new skills.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}