
Lightweight Detection of Train Underframe Bolts Based on SFCA-YOLOv8s


Abstract
1. Introduction
2. YOLOv8s Model
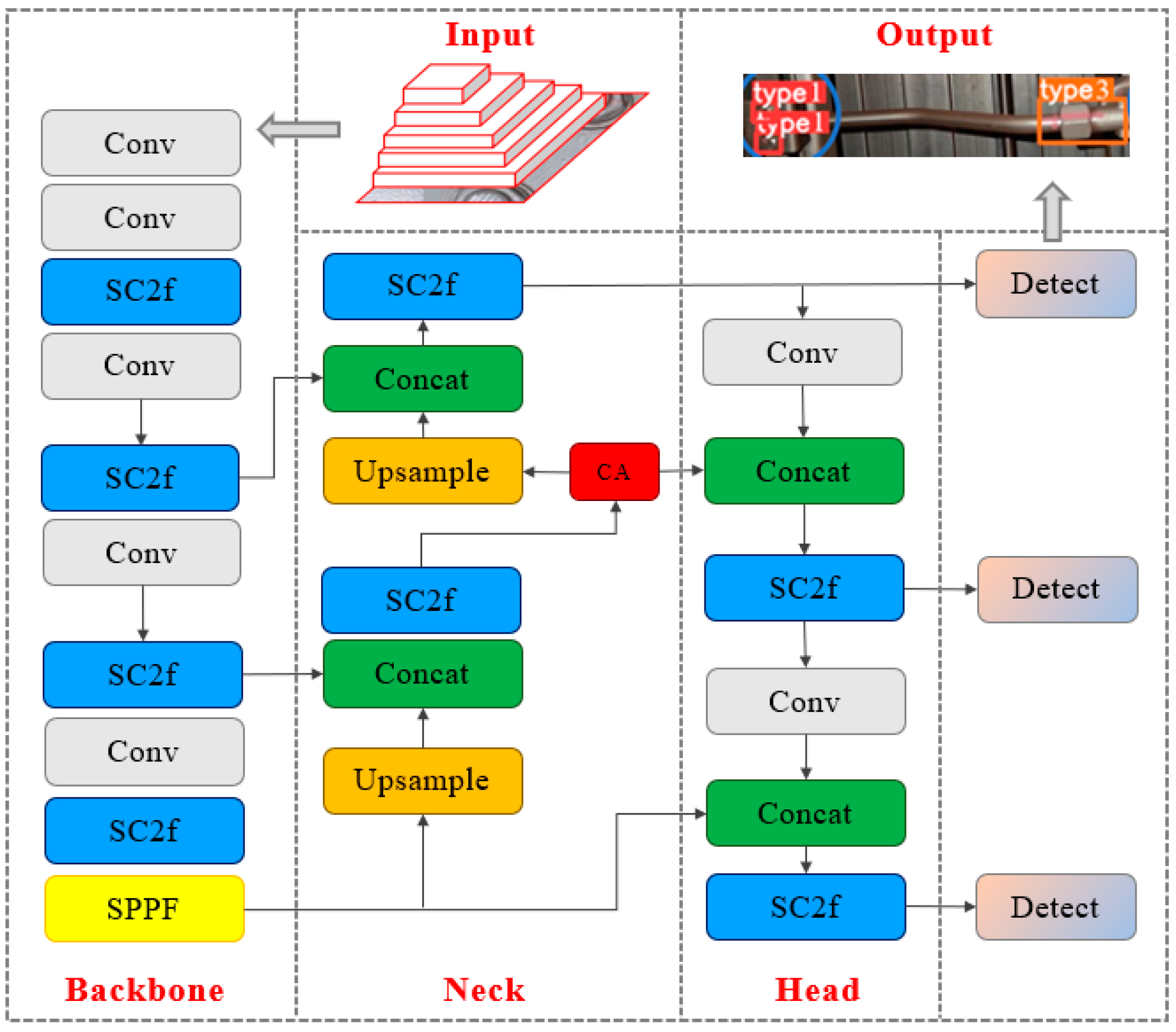
3. Improved SFCA-YOLOv8s Model
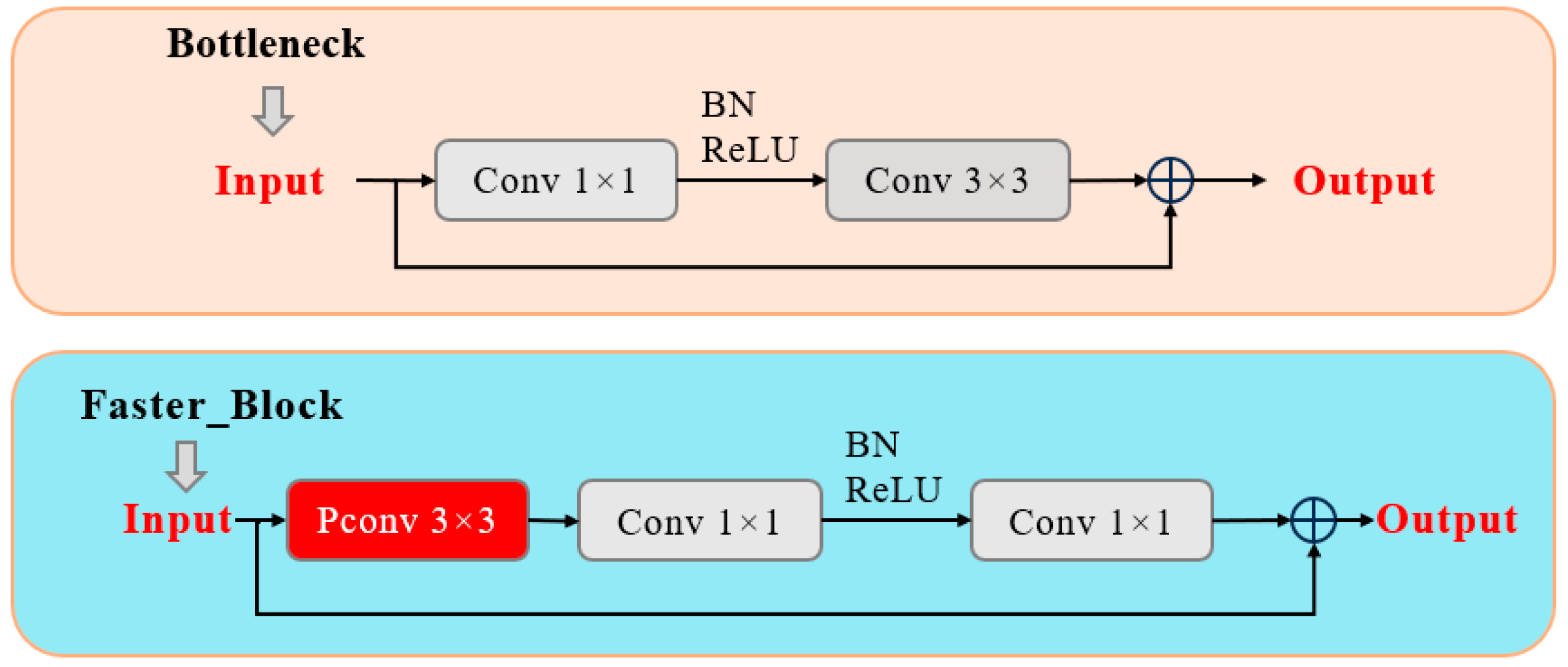
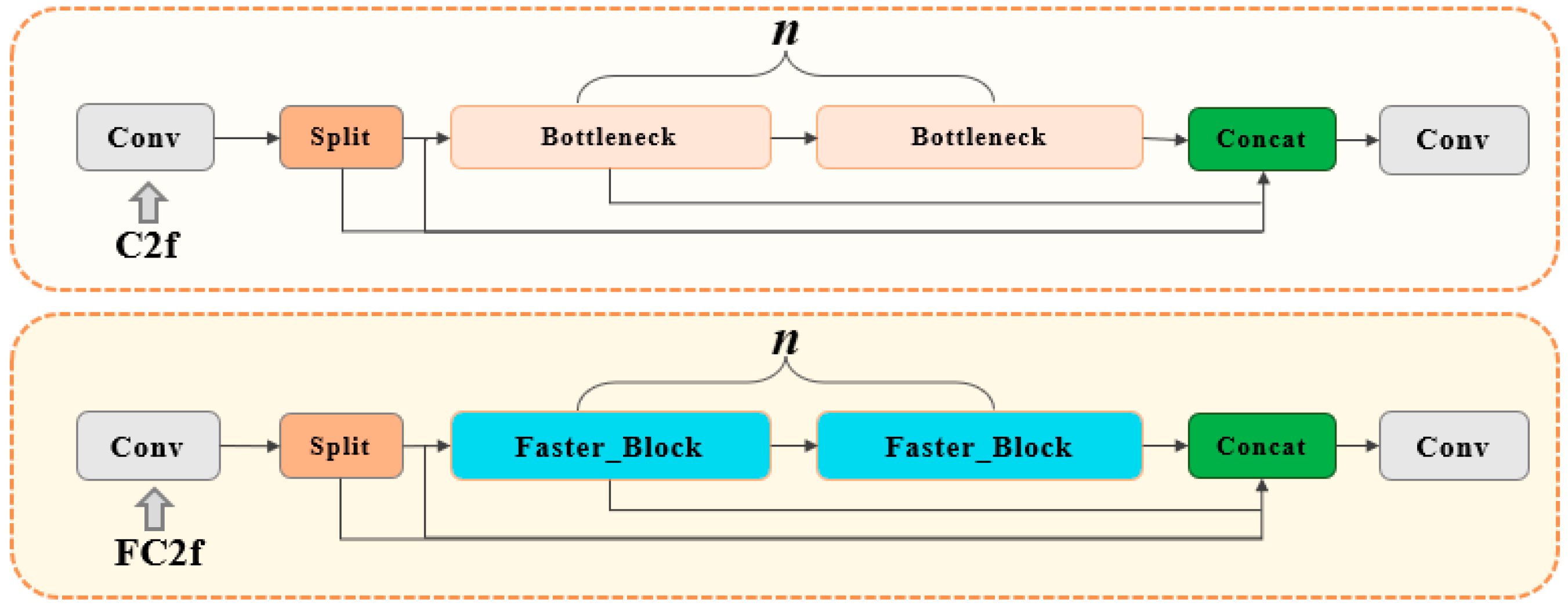
- The Bottleneck in the C2f structure was replaced with a Faster_Block to design the FC2f module, which improves computational speed by reducing memory access;
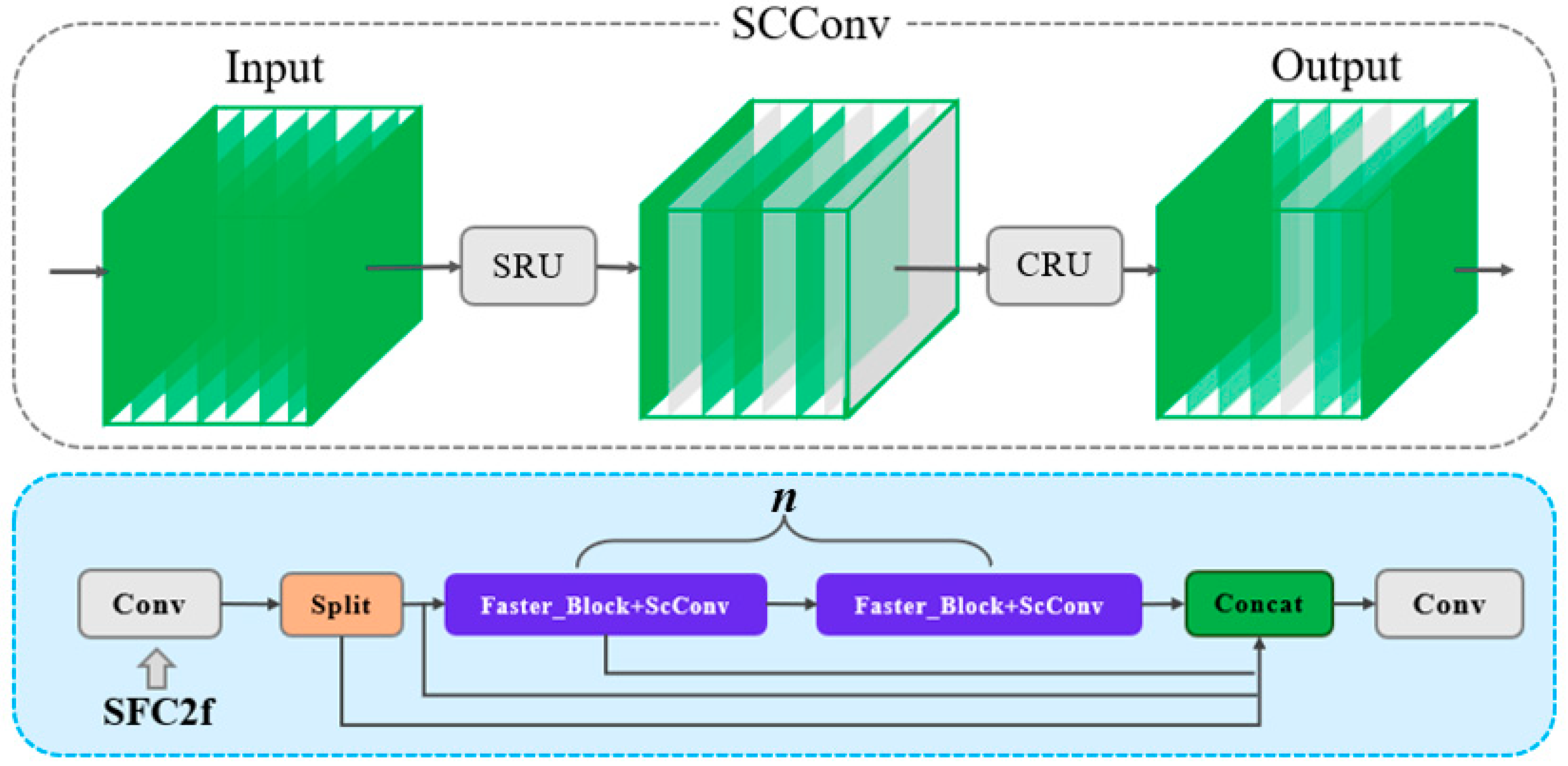
- The FC2f module was combined with ScConv (Spatial and Channel Reconstruction Convolution) lightweight convolution to design the final SFC2f module, replacing all C2f modules in YOLOv8s, and improving network detection accuracy by suppressing redundant information in spatial and channel dimensions;
- The CA attention mechanism module was added to the original network, and the target regression loss function was replaced with the more bolt-specific MPDIoU loss function to improve the accuracy of target detection;
- Finally, the LAMP score pruning method was used to prune the improved model, thereby increasing the network’s detection speed.
3.1. SFC2f Module
- The separation process uses Group Normalization (GN) to evaluate the information content in different feature maps. GN scales the input features based on the mean and standard deviation , followed by control through threshold gating. This process can be mathematically represented as:where γ and β are learnable parameters, optimized during the training process. These parameters are typically initialized randomly and adjusted through backpropagation. Specifically, the optimization process involves minimizing the loss function using a gradient-based optimizer, such as SGD (stochastic gradient descent) or Adam. As the network iteratively processes the training data, γ and β are updated at each step based on the gradients of the loss with respect to these parameters, allowing them to learn the best values for capturing the relationships between input features and the target output, and ϵ is a small constant used for numerical stability. The information evaluation of the feature map is shown in Equations (4) and (5):
- After the separation operation, the feature maps are divided into with greater information and with less redundant information. The reconstruction process combines these features to reduce spatial redundancy and enhance relevant features. The reconstruction process is mathematically represented as:
- The spatially refined features generated by the SRU are split into two parts, with channel numbers and , where is the split ratio (0 ≤ ≤1). Both parts are compressed using a 1 × 1 convolution kernel, resulting in and .This process can be mathematically described as:
- The compressed features and are subjected to Global Weighted Consolidation (GWC) and Partial Weighted Consolidation (PWC), respectively. The output results are then combined to form the transformed features and . Mathematically, the transformation process is expressed as:where and are the learnable matrices of GWC and PWC, respectively.
3.2. Coordinate Attention Mechanism
3.3. MPDIoU Loss Function Improvement
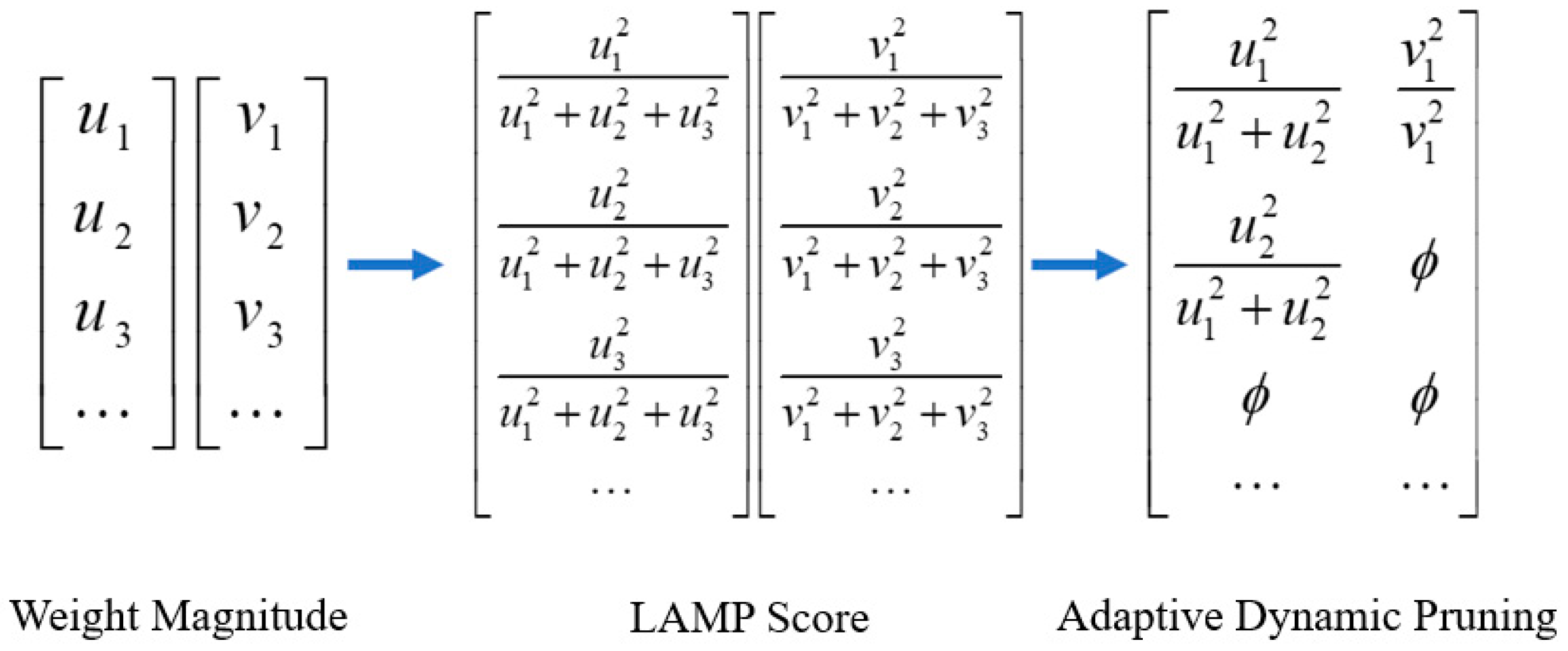
3.4. LAMP Score-Based Pruning Algorithm
4. Testing Platform and Dataset Construction
4.1. Testing Platform
4.2. Bolt Dataset Construction
5. Experimental Results and Analysis
5.1. Experimental Environment and Basic Configuration
5.2. Evaluation Metrics
5.3. Detailed Experimental Analysis
5.3.1. SFC2f Module Experiment
5.3.2. Lightweighting Effect Analysis
5.3.3. Pruning Effect Analysis
5.3.4. Ablation Experiments
5.3.5. Comparative Experiment Analysis
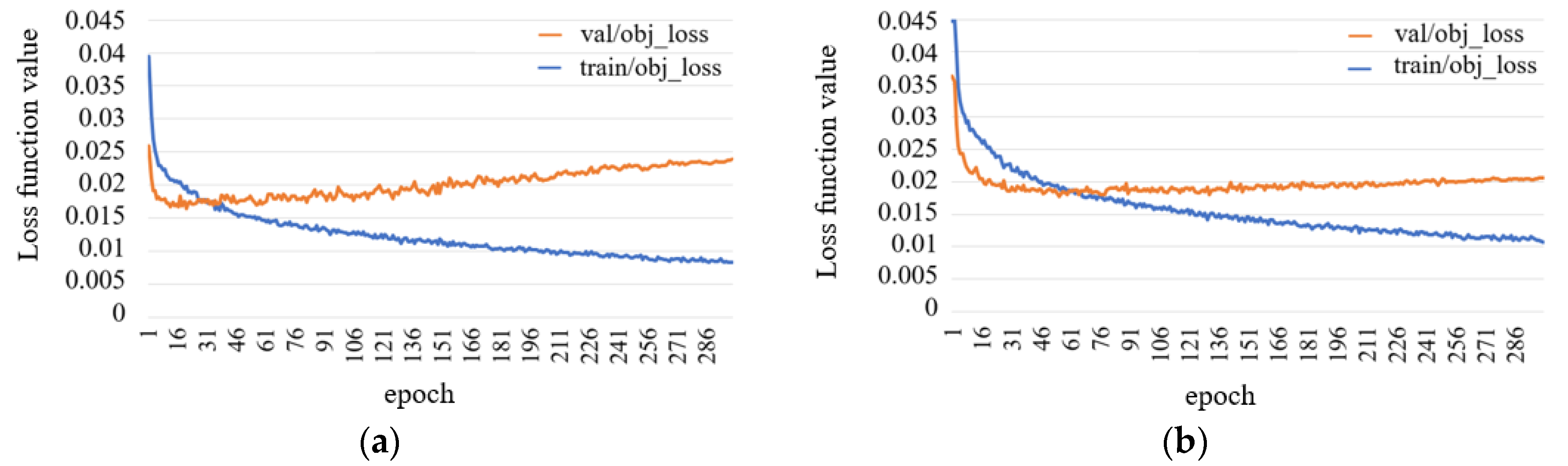
5.3.6. Visualization Comparative Analysis
6. Conclusions
- The original C2f module of YOLOv8s was improved and replaced with the newly designed SFC2f module, reducing the model’s complexity by 1.6 GFLOPs, while the mAP increased by 1.6%. Additionally, the CA attention mechanism and MPDIoU loss function were introduced, resulting in an improvement in accuracy by 2.8%, recall by 3.7%, and mAP by 3.4%, compared to the original network. This improved the accuracy of bolt localization in complex backgrounds.
- SE and CBAM attention modules were added to the YOLOv8s network for comparison. The results showed that the network with the CA attention module performed better in bolt recognition without significantly increasing the number of parameters and computational complexity. The addition of the CA module also mitigated the impact of increased network layers and parameters on training accuracy.
- LAMP score-based pruning algorithm was introduced. Through experiments, a Speed-up of 2 was selected for pruning, resulting in a 36 FPS increase in detection speed and a reduction of parameters by 3.8M compared to the original network. The final network achieved a 2.8% improvement in mAP. Compared to the original model, the SFCA-YOLOv8s model achieved higher precision, a faster detection speed, lower computational cost, and better balancing detection accuracy, speed, and lightweighting.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, L.; Gou, J. Research on detection method of railway encroachment obstacles based on YOLOv4. J. Railw. Sci. Eng. 2022, 19, 528–536. [Google Scholar] [CrossRef]
- Junzhi, Z.; Jianxi, Y.; Hao, L. Bridge apparent disease recognition based on improved YOLOv3 algorithm in complex background. J. Railw. Sci. Eng. 2021, 18, 3257–3266. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, B.; Wang, H. Application of deep learning object detection algorithm in freight train coupler recognition. J. Railw. Sci. Eng. 2020, 17, 2479–2484. [Google Scholar] [CrossRef]
- Yang, P.; Wang, H.; Zhang, Y. A deep learning-based method for detecting bolt loosening of subway car body. J. Rail Transit Equip. Technol. 2021, 288, 38–41. [Google Scholar] [CrossRef]
- Wang, C.; Wang, N.; Ho, S.C.; Chen, X.; Song, G. Design of a new vision-based method for the bolts looseness detection in flange connections. J. IEEE Trans. Ind. Electron. 2020, 67, 1366–1375. [Google Scholar] [CrossRef]
- Sun, J.; Xie, Y.; Cheng, X. A fast bolt-loosening detection method of running train’s key components based on binocular vision. J. IEEE Access 2019, 7, 32227–32239. [Google Scholar] [CrossRef]
- Chang, C.; Yen, C.; Chang, H.; Chen, Y.; Hsu, M.; Wang, W.; Yang, D. An Integrated YOLOv5 and Hierarchical Human-Weight-First Path Planning Approach for Efficient UAV Searching Systems. Machines 2024, 12, 65. [Google Scholar] [CrossRef]
- Yang, R.; Hu, Y.; Yao, Y. Fruit target detection based on BCo-YOLOv5 model. Mob. Inf. Syst. 2022, 20, 1–8. [Google Scholar] [CrossRef]
- Han, G.; Wang, R.; Yuan, Q.; Li, S.; Zhao, L.; He, M.; Yang, S.; Qin, L. Detection of Bird Nests on Transmission Towers in Aerial Images Based on Improved YOLOv5s. Machines 2023, 11, 257. [Google Scholar] [CrossRef]
- Cao, J.; Bao, W.; Shang, H. GCL-YOLO: A ghost conv-based lightweight YOLO network for UAV small object detection. Remote Sens. 2023, 15, 4932. [Google Scholar] [CrossRef]
- Sun, T.; Liu, G.; Tang, Z. Pedestrian detection in lightweight subway station based on MCA-YOLOv5s. Comput. Syst. Appl. 2023, 32, 120–130. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Wang, J.; Yuan, J.; Zhu, Y. Surface defect detection algorithm for drum rollers based on improved YOLOv8s. J. Zhejiang Univ. (Eng. Ed.) 2024, 58, 370–380+387. [Google Scholar]
- Wang, C.; Liu, H. YOLOv8-VSC: Lightweight algorithm for strip surface defect detection. J. Front. Comput. Sci. Technol. 2024, 18, 151. [Google Scholar]
- Yang, Y.; Kuang, X.; Tang, B. YOLOv5 mask wear detection algorithm based on attention mechanism. Digit. Technol. Appl. 2023, 41, 113–115. [Google Scholar] [CrossRef]
- Li, J.; Wen, Y.; He, L. SCConv: Spatial and channel reconstruction convolution for feature redundancy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6153–6162. [Google Scholar]
- Gu, G.; Jia, Y.; Wen, B. Fault identification algorithm of catenary string and current carrier ring based on YOLOv5s. J. Railw. Sci. Eng. 2023, 20, 1066–1076. [Google Scholar] [CrossRef]
- Wu, S.; Liu, L.; Zhang, H. Research on defect pattern detection algorithm of railway fasteners based on transfer learning. J. Railw. Sci. Eng. 2022, 19, 3612–3624. [Google Scholar] [CrossRef]
- Zhang, J.; Feng, Y.; Wang, S. Image detection algorithm of core bolt based on WLD-LPQ feature. J. Railw. Sci. Eng. 2018, 15, 2349–2358. [Google Scholar] [CrossRef]
- Ai, Q.; Zhang, J.; Wu, F. AF-ICNet unstructured scene semantic segmentation method based on small target category attention mechanism and feature fusion. Acta Photonica Sin. 2023, 52, 189–202. [Google Scholar]
- Zhang, Y.; Ren, W. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Ma, S.; Xu, Y. MPDIoU: A loss for efficient and accurate bounding box regression. arXiv 2023. arXiv:2307.07662. [Google Scholar]
- Shen, C.; Ma, C.; Gao, W. Multiple attention mechanism enhanced YOLOX for remote sensing object detection. Sensors 2023, 23, 1261. [Google Scholar] [CrossRef] [PubMed]
- Yao, Z.; Yang, H.; Hu, J. Track surface defect detection method based on machine vision and convolutional neural network. J. China Railw. Soc. 2021, 43, 101–107. [Google Scholar]
- Liu, Y.; Liu, Y.; Zhang, Y. Video anomaly detection method integrating SCConv and attention mechanism. Control. Eng. 2024, 1–9. [Google Scholar] [CrossRef]
- Wu, K.; Xu, Z.; Shan, H. Rapid detection method of glass insulator self-explosion defect based on FasterNet and YOLOv5. High Volt. Technol. 2024, 50, 1865–1876. [Google Scholar] [CrossRef]
- Zou, Y.; Gao, Y.; Zhao, N. Research on crack detection of concrete dam based on improved Yolov5s. Autom. Instrum. 2023, 289, 1–5+15. [Google Scholar]
- Huo, Y.; Zhang, J.; Chen, T. Dynamic gesture recognition method based on improved YOLOv5+Mobile Net. Software 2023, 44, 47–52. [Google Scholar]
- Liu, L.; Zhang, S.; Bai, Y. Lightweight military aircraft detection algorithm based on improved YOLOv8. Comput. Eng. Appl. 2024, 1–15. Available online: http://kns.cnki.net/kcms/detail/11.2127.TP.20240624.1509.008.html (accessed on 10 August 2024).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Split Ratio/ | % | Params/M | FLOPs/G | FPS/ms |
|---|---|---|---|---|
| baseline | 90.5 | 11.2 | 15.8 | 220.7 |
| 0.1 | 90.9 | 10.4 | 14.2 | 221.6 |
| 0.2 | 91.2 | 10.4 | 14.2 | 222.1 |
| 0.3 | 91.4 | 10.4 | 14.2 | 223.3 |
| 0.4 | 91.7 | 10.4 | 14.2 | 225 |
| 0.5 | 91.3 | 10.4 | 14.2 | 223.4 |
| 0.6 | 91.2 | 10.4 | 14.2 | 223.1 |
| 0.7 | 90.9 | 10.4 | 14.2 | 222.7 |
| 0.8 | 90.6 | 10.4 | 14.2 | 221.9 |
| 0.9 | 90.8 | 10.4 | 14.2 | 221.5 |
| Model | FLOPs/G | (%) | (%) | % | FPS/ms |
|---|---|---|---|---|---|
| CSPNet baseline | 15.8 | 92.0 | 84.5 | 90.5 | 220.7 |
| GhostNet | 8.3 | 88.6 | 85.1 | 89.4 | 221.4 |
| FasterNet | 11.4 | 91.0 | 83.7 | 90.6 | 216.8 |
| MobileNetV3 | 11.0 | 91.9 | 84.7 | 91.3 | 220.9 |
| SFC2f-Net | 14.2 | 92.1 | 86.3 | 91.7 | 225 |
| Model | Layers | Param/M | FLOPs/G | (%) | (%) | % |
|---|---|---|---|---|---|---|
| SFC2f-Net | 108 | 13.7 | 14.2 | 92.1 | 86.3 | 91.7 |
| +CBAM | 119 | 14.2 | 14.3 | 92.7 | 85.3 | 92.7 |
| +SE | 114 | 13.1 | 14.3 | 92.3 | 84.4 | 91.2 |
| +CA | 118 | 11.5 | 14.3 | 94.8 | 89.2 | 93.9 |
| Speed-Up | FLOPs (G) | Params/M | (%) | |
|---|---|---|---|---|
| 1 baseline | 225 | 14.2 | 11.5 | 93.9 |
| 1.5 | 225.9 | 9.5 | 9.8 | 93.5 |
| 2 | 261 | 7.3 | 7.7 | 93.3 |
| 2.5 | 275.3 | 6.7 | 6.5 | 88.4 |
| 3 | 291.8 | 5.2 | 5.9 | 84.2 |
| Methods | SFC2f | CA | MPDIoU | LAMP | FLOPs (G) | % | |
|---|---|---|---|---|---|---|---|
| YOLOv8s | — | — | — | — | 15.8 | 220.7 | 90.5 |
| SFC2f | √ | — | — | — | 14.2 | 225 | 91.7 |
| MPDIoU | √ | √ | — | — | 14.2 | 225.5 | 93.6 |
| CA | √ | √ | √ | — | 14.2 | 224.2 | 93.9 |
| LAMP | √ | √ | √ | √ | 7.3 | 261 | 93.3 |
| Model | (%) | (%) | % | Params/M | FPS/ms |
|---|---|---|---|---|---|
| Mask R-CNN | 81.5 | 74.7 | 77.6 | 44.2 | 71.2 |
| RetinaNet | 82.2 | 76.4 | 78.9 | 36.3 | 85.5 |
| YOLOv4 | 80.1 | 77.5 | 79.2 | 52.6 | 90.4 |
| YOLOv5s | 90.5 | 83.5 | 88.9 | 7.1 | 215.7 |
| YOLOX-s | 93.2 | 85.2 | 92.5 | 9.0 | 86.9 |
| YOLOv7 | 92.7 | 84.9 | 92.4 | 37.2 | 95.6 |
| SFCA-YOLOv8s | 93.5 | 87.8 | 93.3 | 7.7 | 261 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Li, J.; Zhang, C.; Dong, H. Lightweight Detection of Train Underframe Bolts Based on SFCA-YOLOv8s. Machines 2024, 12, 714. https://doi.org/10.3390/machines12100714
Li Z, Li J, Zhang C, Dong H. Lightweight Detection of Train Underframe Bolts Based on SFCA-YOLOv8s. Machines. 2024; 12(10):714. https://doi.org/10.3390/machines12100714
Chicago/Turabian StyleLi, Zixiao, Jinjin Li, Chuanlong Zhang, and Huajun Dong. 2024. "Lightweight Detection of Train Underframe Bolts Based on SFCA-YOLOv8s" Machines 12, no. 10: 714. https://doi.org/10.3390/machines12100714
APA StyleLi, Z., Li, J., Zhang, C., & Dong, H. (2024). Lightweight Detection of Train Underframe Bolts Based on SFCA-YOLOv8s. Machines, 12(10), 714. https://doi.org/10.3390/machines12100714