
Curriculum Design and Sim2Real Transfer for Reinforcement Learning in Robotic Dual-Arm Assembly †

 ,
,
Abstract
1. Introduction
- We establish a simulation and training environment for dual-arm robotic assembly using robosuite, coupled with the MuJoCo physics engine.
- We integrate the simulation with SB3 RL methods, employing the OpenAI Gym standard [8].
- We design a training methodology based on a reverse curriculum, enhancing both convergence rates and sample efficiency.
- We investigate how variations in curriculum parameters influence the process characteristics observed in simulations.
- We transfer the trained policy to a real-world setup, comparing its performance to simulation and traditional control strategies.
2. Related Work
2.1. Reinforcement Learning
2.2. Robust Sim2Real Transfer
2.3. Simulation Environment
2.4. Control of Robotic Assembly
2.5. Curriculum Learning
3. Problem Formulation
4. Methodology
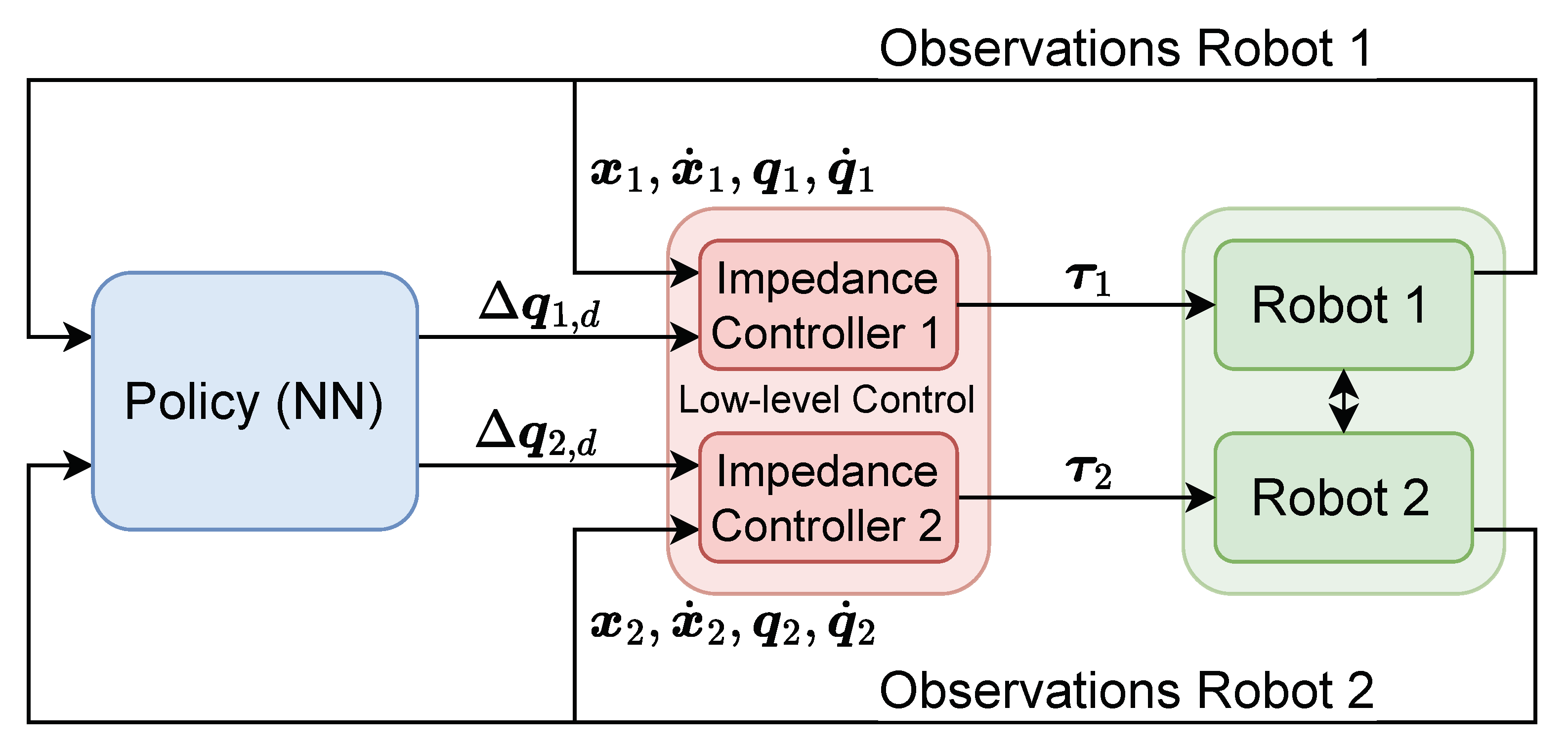
4.1. Low-Level Control
4.2. Reinforcement Learning
- Positions and quaternions of the peg and the hole;
- A difference vector and angle between the peg and the hole;
- Parallel distance c and perpendicular projected distance d between the peg and the hole;
- The state of each robot, which encompasses the sine and cosine of the joint angles , joint velocities , as well as positions and quaternions of the end-effectors (EE).
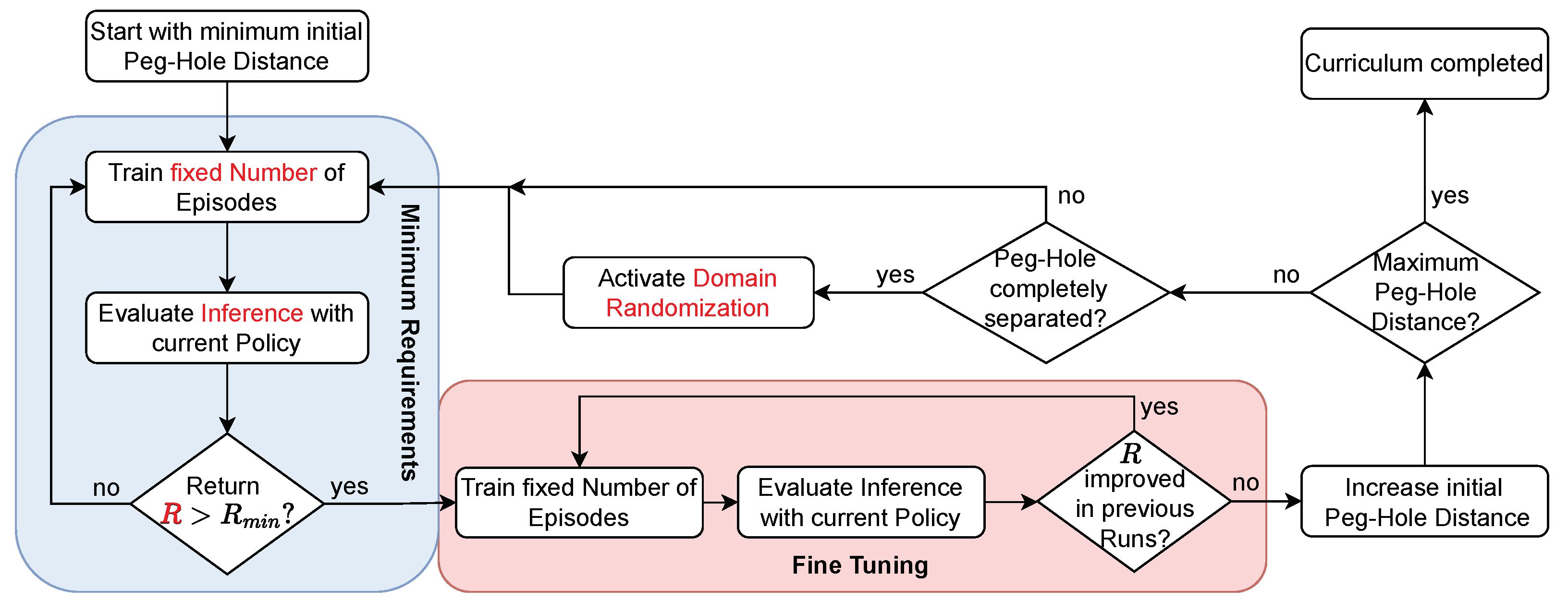
4.3. Reverse Curriculum Generation
- Minimum Requirements: After a predetermined number of training episodes, an inference test determines whether the policy achieves a return R that surpasses a set threshold . If successful, the curriculum progresses to the fine-tuning phase. Else, this phase is repeated.
- Fine Tuning: Subsequent to additional training over a fixed number of episodes, another inference is evaluated. If there is a relative improvement R across a specified number of inferences, the fine-tuning phase is extended. If improvement stalls, the difficulty of the initial state is increased, advancing the curriculum to the next iteration, which starts again at the Minimum Requirements phase.
4.4. Domain Randomization
4.5. Deployment on Real-World Hardware
- Training the Policy: The first step involves training the policy within the introduced simulated environment. After finishing the training, the policy is exported as a PyTorch file. This format is chosen for its flexibility and compatibility with various deployment environments.
- Low-Level Control System: The low-level joint space impedance controllers are implemented in C++ to interface with the libfranka library on each robot. This ensures real-time control of the robot’s joint motors with a frequency of 1 kHz.
- Connecting both Robots: Both robots are connected to a central computer that runs the Robot Operating System 2 (ROS 2) [32]. ROS 2 facilitates communication between the robot’s specific low-level controllers and the central policy, enabling coordinated actions and reliable low latency data exchange. The motion planning framework MoveIt 2 [33] is used in tandem with ros2_control and RViz to provide an interface for managing and visualizing the robot state as well as an option for classical trajectory planning and execution with interchangeable low-level controllers on the robot hardware. The policy is embedded within ROS 2, providing setpoints for the low-level controllers. This integration allows the high-level policy to guide the robot’s actions based on sensory inputs while still meeting real-time constraints. To further streamline the process of integrating a policy into the real-world control system, we developed several ROS 2-based tools. This control utils package provides a simplified python interface for trajectory planning and interfacing MoveIt 2 by wrapping its API utilizing pymoveit2.
- Data Recording: To evaluate the performance of the policy, we set up a recording and logging mechanisms to capture the joint efforts, joint velocities, and EE forces of every robot arm as well as the total time needed for every episode.
5. Results
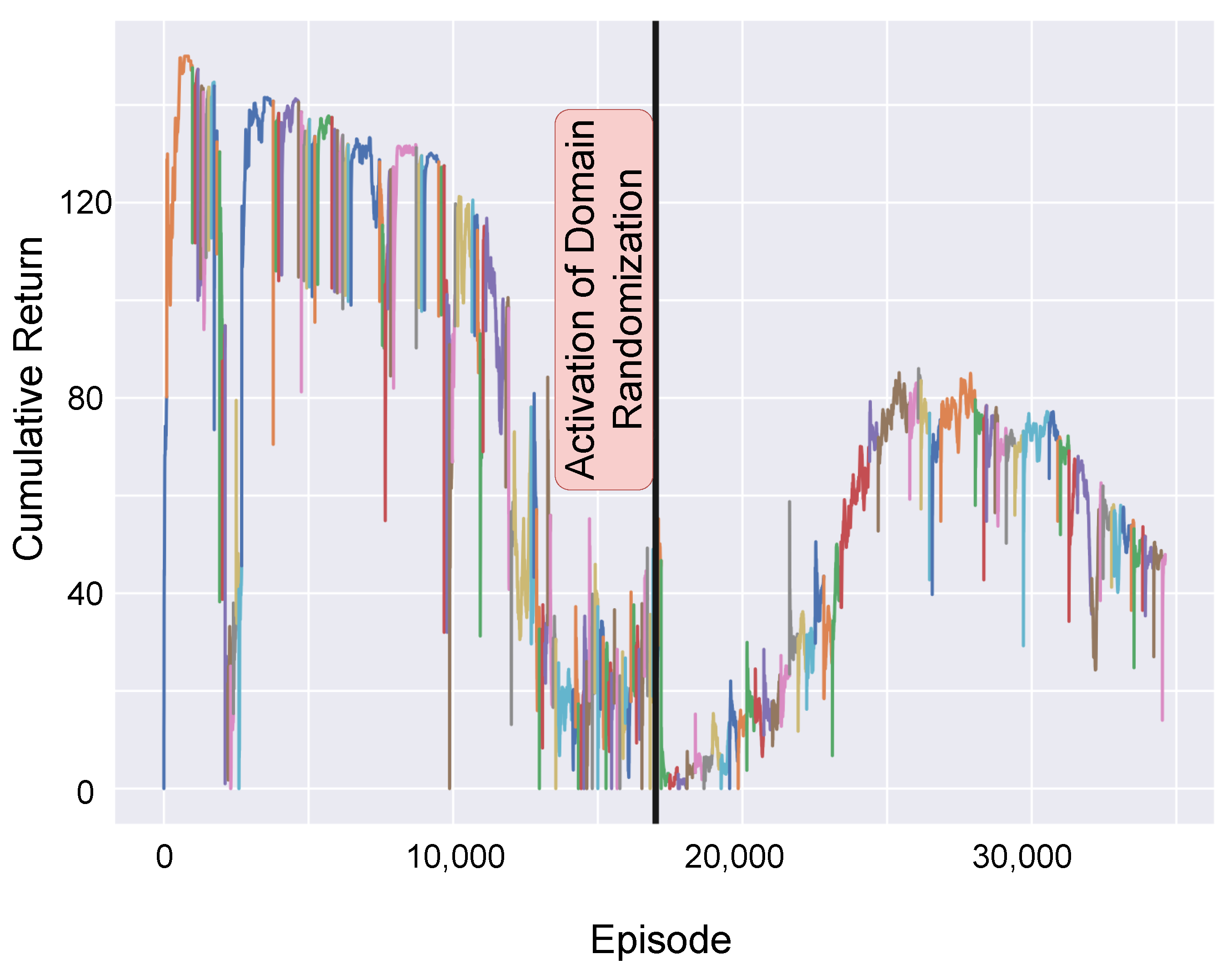
5.1. Training in Simulation
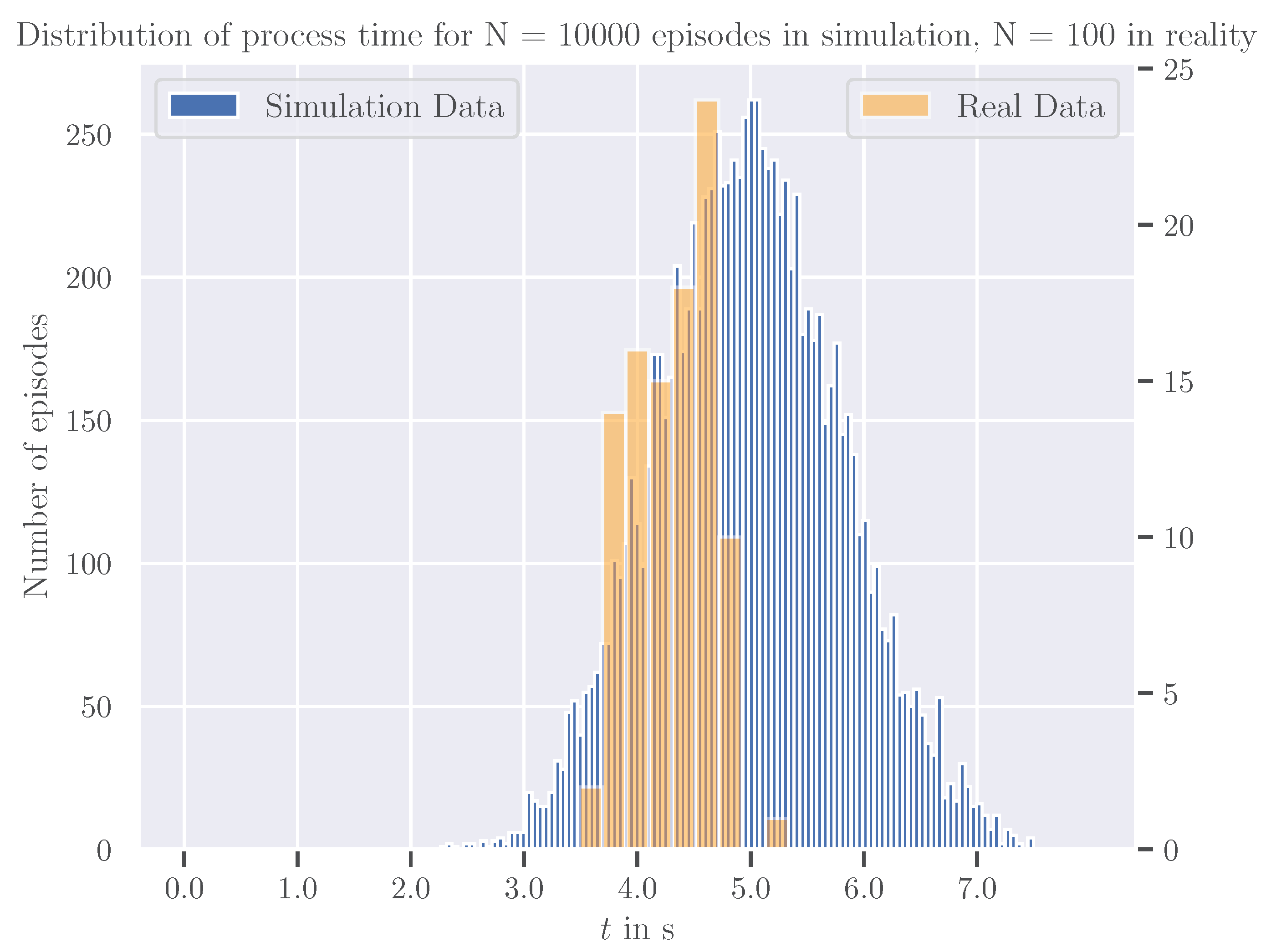
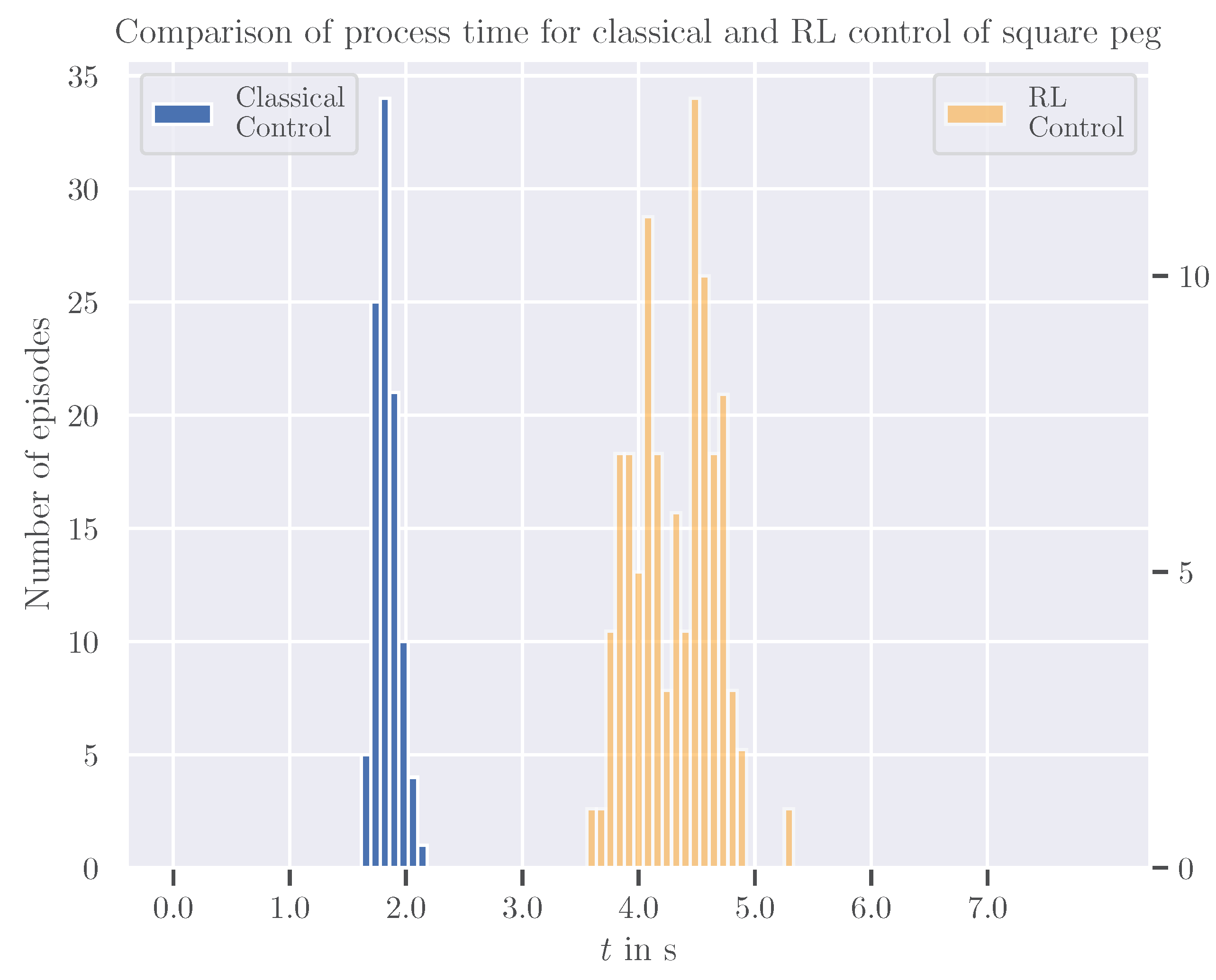
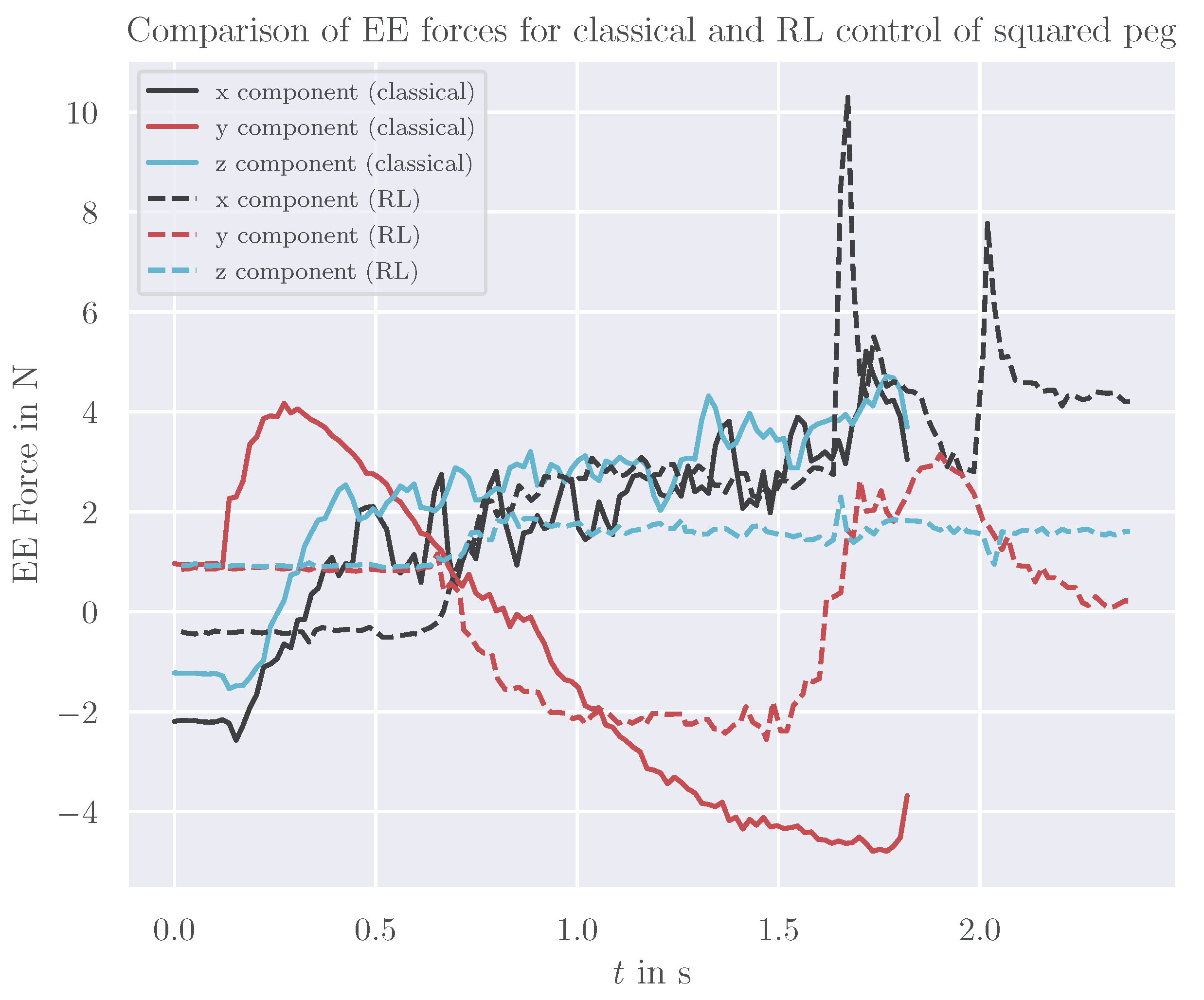
5.2. Transfer to Reality and Evaluation
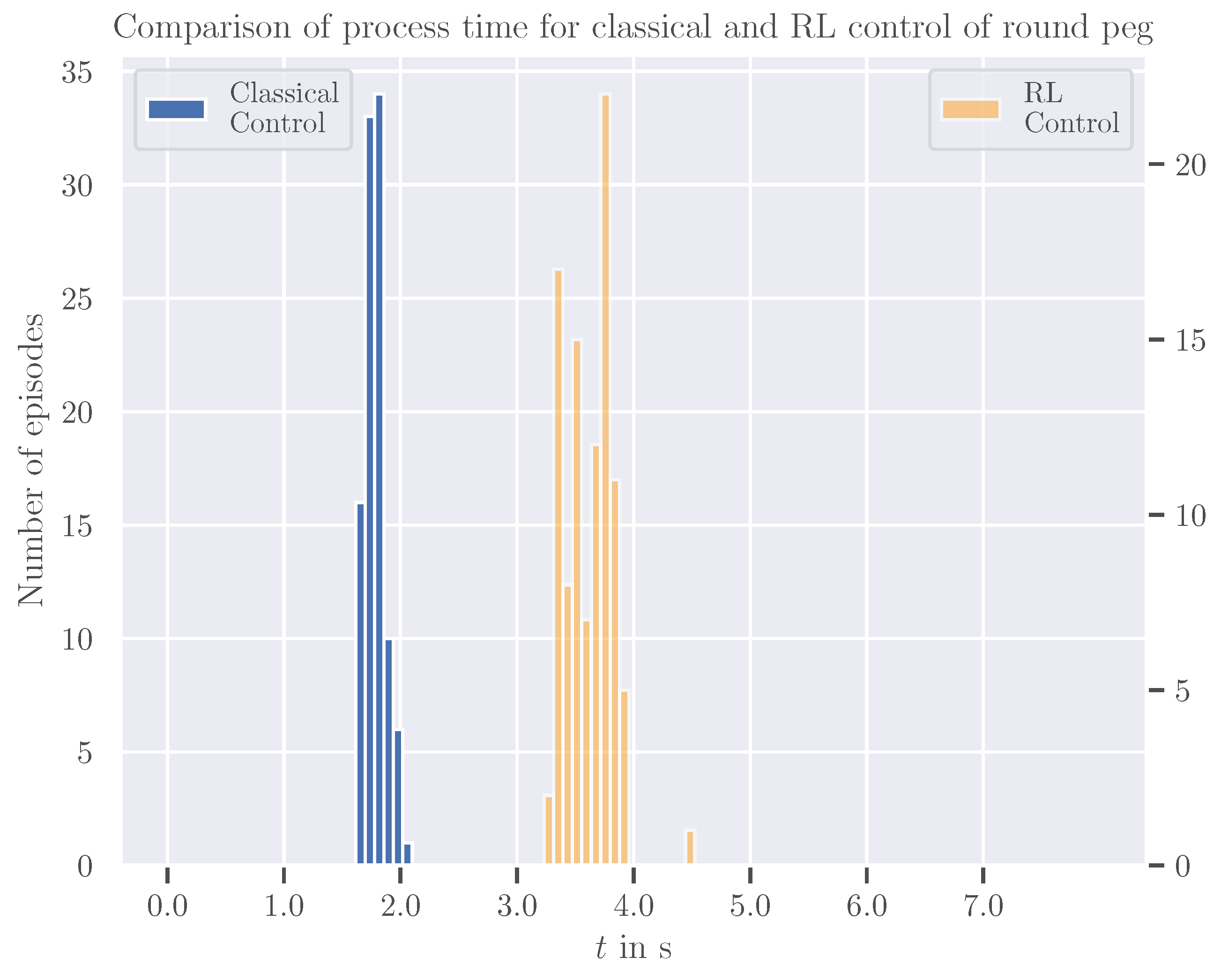
5.3. Adapted Peg Shape
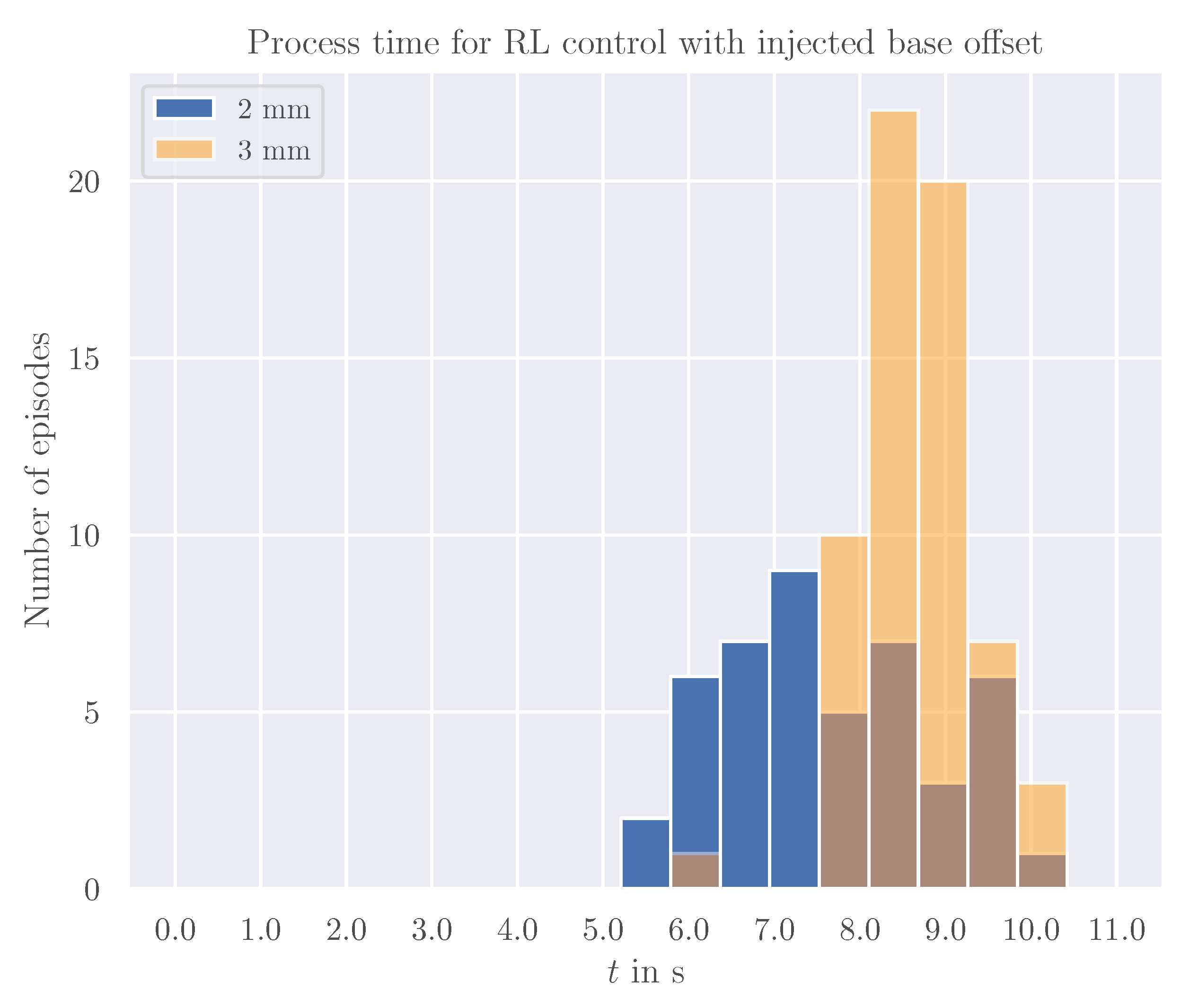
5.4. Injected Calibration Offset
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| EE | end-effector |
| DR | domain randomization |
| HER | Hindsight Experience Replay |
| MDPI | Multidisciplinary Digital Publishing Institute |
| NN | neural network |
| PLAI | policy-level action integration |
| RL | reinforcement learning |
| Sim2Real | simulation-to-reality |
| SAC | Soft Actor-Critic |
| SB3 | Stable Baselines3 |
References
- Wrede, K.; Donath, O.; Wohlfahrt, T.; Feldmann, U. Curriculum-Organized Reinforcement Learning for Robotic Dual-arm Assembly. In Proceedings of the Automation, Robotics & Communications for Industry 4.0/5.0, Innsbruck, Austria, 7–9 February 2024; pp. 8–14. [Google Scholar] [CrossRef]
- Jiang, J.; Huang, Z.; Bi, Z.; Ma, X.; Yu, G. State-of-the-Art Control Strategies for Robotic PiH Assembly. Robot. Comput.-Integr. Manuf. 2020, 65, 101894. [Google Scholar] [CrossRef]
- Yuan, F.; Shen, X.; Wu, J.; Wang, L. Design of Mobile Phone Automatic Assembly System Based on Machine Vision. J. Phys. Conf. Ser. 2022, 2284, 012012. [Google Scholar] [CrossRef]
- Zhu, Y.; Wong, J.; Mandlekar, A.; Martín-Martín, R.; Joshi, A.; Nasiriany, S.; Zhu, Y. Robosuite: A Modular Simulation Framework and Benchmark for Robot Learning. arXiv 2022, arXiv:2009.12293. [Google Scholar] [CrossRef]
- Todorov, E.; Erez, T.; Tassa, Y. MuJoCo: A Physics Engine for Model-Based Control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 5026–5033. [Google Scholar] [CrossRef]
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-Baselines3: Reliable Reinforcement Learning Implementations. J. Mach. Learn. Res. 2021, 22, 1–8. [Google Scholar]
- Salvato, E.; Fenu, G.; Medvet, E.; Pellegrino, F.A. Crossing the Reality Gap: A Survey on Sim-to-Real Transferability of Robot Controllers in Reinforcement Learning. IEEE Access 2021, 9, 153171–153187. [Google Scholar] [CrossRef]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A. Reinforcement Learning: An Introduction, nachdruck ed.; Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Zhao, W.; Queralta, J.P.; Westerlund, T. Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics: A Survey. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, ACT, Australia, 1–4 December 2020; pp. 737–744. [Google Scholar] [CrossRef]
- Scheiderer, C.; Dorndorf, N.; Meisen, T. Effects of Domain Randomization on Simulation-to-Reality Transfer of Reinforcement Learning Policies for Industrial Robots. In Advances in Artificial Intelligence and Applied Cognitive Computing; Transactions on Computational Science and Computational Intelligence; Arabnia, H.R., Ferens, K., Kozerenko, E.B., Olivas Varela, J.A., Tinetti, F.G., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 157–169. [Google Scholar] [CrossRef]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar] [CrossRef]
- Tang, B.; Lin, M.A.; Akinola, I.A.; Handa, A.; Sukhatme, G.S.; Ramos, F.; Fox, D.; Narang, Y.S. IndustReal: Transferring Contact-Rich Assembly Tasks from Simulation to Reality. In Proceedings of the Robotics: Science and Systems XIX, Daegu, Republic of Korea, 10–14 July 2023; Volume 19. [Google Scholar]
- Coumans, E.; Bai, Y. PyBullet, a Python Module for Physics Simulation for Games, Robotics and Machine Learning. 2016. Available online: http://pybullet.org (accessed on 19 September 2024).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Alles, M.; Aljalbout, E. Learning to Centralize Dual-Arm Assembly. Front. Robot. AI 2022, 9, 830007. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Ji, Z.; Wu, J.; Lai, Y.K. An Open-Source Multi-goal Reinforcement Learning Environment for Robotic Manipulation with Pybullet. In Towards Autonomous Robotic Systems; Fox, C., Gao, J., Ghalamzan Esfahani, A., Saaj, M., Hanheide, M., Parsons, S., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 14–24. [Google Scholar] [CrossRef]
- Panerati, J.; Zheng, H.; Zhou, S.; Xu, J.; Prorok, A.; Schoellig, A.P. Learning to Fly—A Gym Environment with PyBullet Physics for Reinforcement Learning of Multi-agent Quadcopter Control. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 7512–7519. [Google Scholar] [CrossRef]
- Mittal, M.; Yu, C.; Yu, Q.; Liu, J.; Rudin, N.; Hoeller, D.; Yuan, J.L.; Singh, R.; Guo, Y.; Mazhar, H.; et al. Orbit: A Unified Simulation Framework for Interactive Robot Learning Environments. IEEE Robot. Autom. Lett. 2023, 8, 3740–3747. [Google Scholar] [CrossRef]
- Serrano-Muñoz, A.; Arana-Arexolaleiba, N.; Chrysostomou, D.; Boegh, S. Skrl: Modular and Flexible Library for Reinforcement Learning. J. Mach. Learn. Res. 2022, 24, 1–9. [Google Scholar]
- Nasiriany, S.; Liu, H.; Zhu, Y. Augmenting Reinforcement Learning with Behavior Primitives for Diverse Manipulation Tasks. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 7477–7484. [Google Scholar] [CrossRef]
- Wilcox, A.; Balakrishna, A.; Dedieu, J.; Benslimane, W.; Brown, D.; Goldberg, K. Monte Carlo Augmented Actor-Critic for Sparse Reward Deep Reinforcement Learning from Suboptimal Demonstrations. Adv. Neural Inf. Process. Syst. 2022, 35, 2254–2267. [Google Scholar]
- Xu, M.; Veloso, M.; Song, S. ASPiRe: Adaptive Skill Priors for Reinforcement Learning. Adv. Neural Inf. Process. Syst. 2022, 35, 38600–38613. [Google Scholar]
- Park, H.; Bae, J.H.; Park, J.H.; Baeg, M.H.; Park, J. Intuitive Peg-in-Hole Assembly Strategy with a Compliant Manipulator. In Proceedings of the IEEE ISR 2013, Seoul, Republic of Korea, 24–26 October 2013; pp. 1–5. [Google Scholar] [CrossRef]
- Broenink, J.F.; Tiernego, M.L.J. Peg-in-Hole Assembly Using Impedance Control with a 6 DOF Robot. In Proceedings of the 8th European Simulation Symposium, Genoa, Italy, 24–26 October 1996; pp. 504–508. [Google Scholar]
- Nottensteiner, K.; Stulp, F.; Albu-Schäffer, A. Robust, Locally Guided Peg-in-Hole Using Impedance-Controlled Robots. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 5771–5777. [Google Scholar] [CrossRef]
- Park, H.; Kim, P.K.; Bae, J.H.; Park, J.H.; Baeg, M.H.; Park, J. Dual Arm Peg-in-Hole Assembly with a Programmed Compliant System. In Proceedings of the 2014 11th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Kuala Lumpur, Malaysia, 12–15 November 2014; pp. 431–433. [Google Scholar] [CrossRef]
- Florensa, C.; Held, D.; Wulfmeier, M.; Zhang, M.; Abbeel, P. Reverse Curriculum Generation for Reinforcement Learning. In Proceedings of the 1st Annual Conference on Robot Learning, PMLR, Mountain View, CA, USA, 13–15 November 2017; pp. 482–495. [Google Scholar]
- Aljalbout, E.; Frank, F.; Karl, M. On the Role of the Action Space in Robot Manipulation Learning and Sim-to-Real Transfer. IEEE Robot. Autom. Lett. 2024, 9, 5895–5902. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the 35th International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Pieter Abbeel, O.; Zaremba, W. Hindsight Experience Replay. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Macenski, S.; Foote, T.; Gerkey, B.; Lalancette, C.; Woodall, W. Robot Operating System 2: Design, Architecture, and Uses in the Wild. Sci. Robot. 2022, 7, eabm6074. [Google Scholar] [CrossRef] [PubMed]
- Coleman, D.T.; Sucan, I.A.; Chitta, S.; Correll, N. Reducing the Barrier to Entry of Complex Robotic Software: A MoveIt! Case Study. arXiv 2014, arXiv:1404.3785. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Optimizer | Adam |
| Learning Rate | |
| Discount Factor | 0.99 |
| Entropy Coefficient | Auto (init 1.0) |
| Batch Size | 256 |
| Buffer Size | |
| Replay Buffer Size | 6 |
| Architecture Actor | 1 × 256 neurons as hidden layer |
| Architecture Critic | 2 × 256 neurons as hidden layers |
| Activation Function | ReLU with bias |
| Parameter | Value |
|---|---|
| Planning Time | 1 s |
| Planner | RRTConnect |
| Max. Velocity | 20% of max. values |
| Max. Acceleration | 20% of max. values |
| Cartesian planning | True |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wrede, K.; Zarnack, S.; Lange, R.; Donath, O.; Wohlfahrt, T.; Feldmann, U. Curriculum Design and Sim2Real Transfer for Reinforcement Learning in Robotic Dual-Arm Assembly. Machines 2024, 12, 682. https://doi.org/10.3390/machines12100682
Wrede K, Zarnack S, Lange R, Donath O, Wohlfahrt T, Feldmann U. Curriculum Design and Sim2Real Transfer for Reinforcement Learning in Robotic Dual-Arm Assembly. Machines. 2024; 12(10):682. https://doi.org/10.3390/machines12100682
Chicago/Turabian StyleWrede, Konstantin, Sebastian Zarnack, Robert Lange, Oliver Donath, Tommy Wohlfahrt, and Ute Feldmann. 2024. "Curriculum Design and Sim2Real Transfer for Reinforcement Learning in Robotic Dual-Arm Assembly" Machines 12, no. 10: 682. https://doi.org/10.3390/machines12100682
APA StyleWrede, K., Zarnack, S., Lange, R., Donath, O., Wohlfahrt, T., & Feldmann, U. (2024). Curriculum Design and Sim2Real Transfer for Reinforcement Learning in Robotic Dual-Arm Assembly. Machines, 12(10), 682. https://doi.org/10.3390/machines12100682