
Gearbox Fault Diagnosis Based on Refined Time-Shift Multiscale Reverse Dispersion Entropy and Optimised Support Vector Machine


Abstract
1. Introduction
- This paper proposes a novel RTSMRDE method for the multiscale feature extraction of gearbox faults.
- Utilizing data dimensionality reduction methods to extract sensitive features from the initial high-dimensional feature matrix, resulting in more accurate fault recognition.
- Constructing an intelligent diagnosis model for gearbox based on RTSMRDE, t-SNE, and SSA-SVM.
- Validating the effectiveness through simulation signals, gearbox datasets, and experimental data. The experimental results indicate that the fault diagnosis model performs significantly better than six other methods in terms of overall performance.
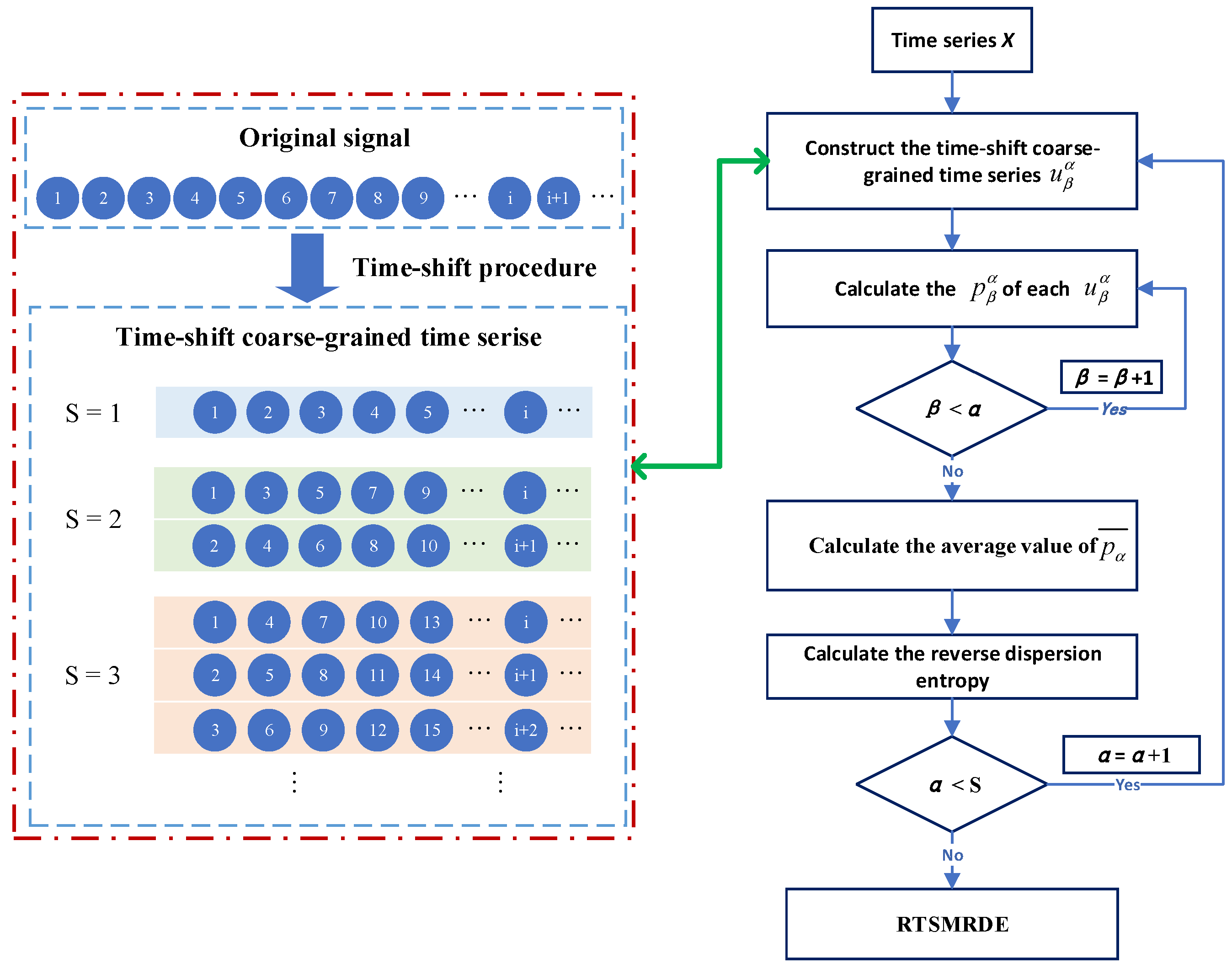
2. Refined Time-Shift Multiscale Reverse Dispersion Entropy
2.1. Reverse Dispersion Entropy
2.2. Multiscale Reverse Dispersion Entropy
2.3. Refined Time-Shift Multiscale Reverse Dispersion Entropy
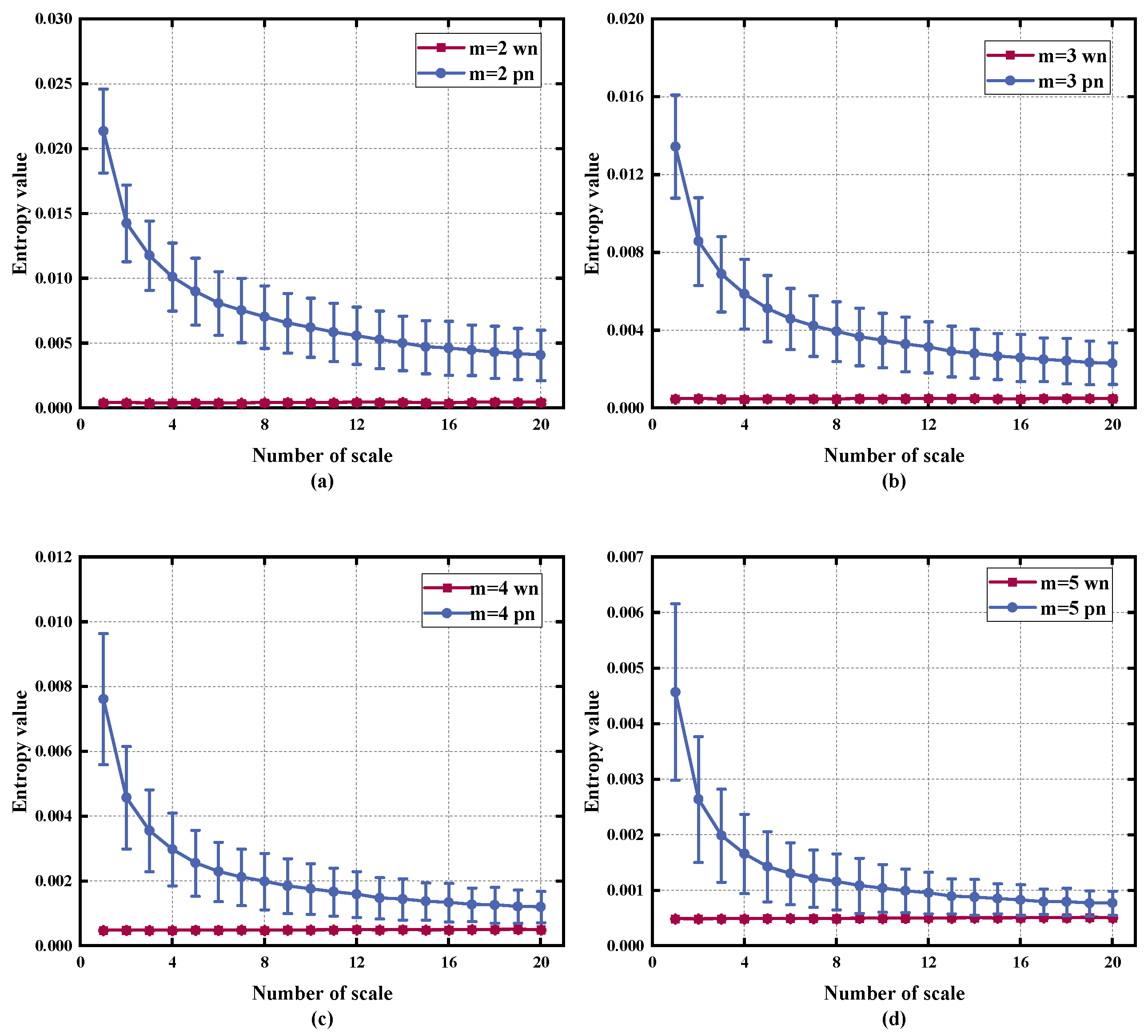
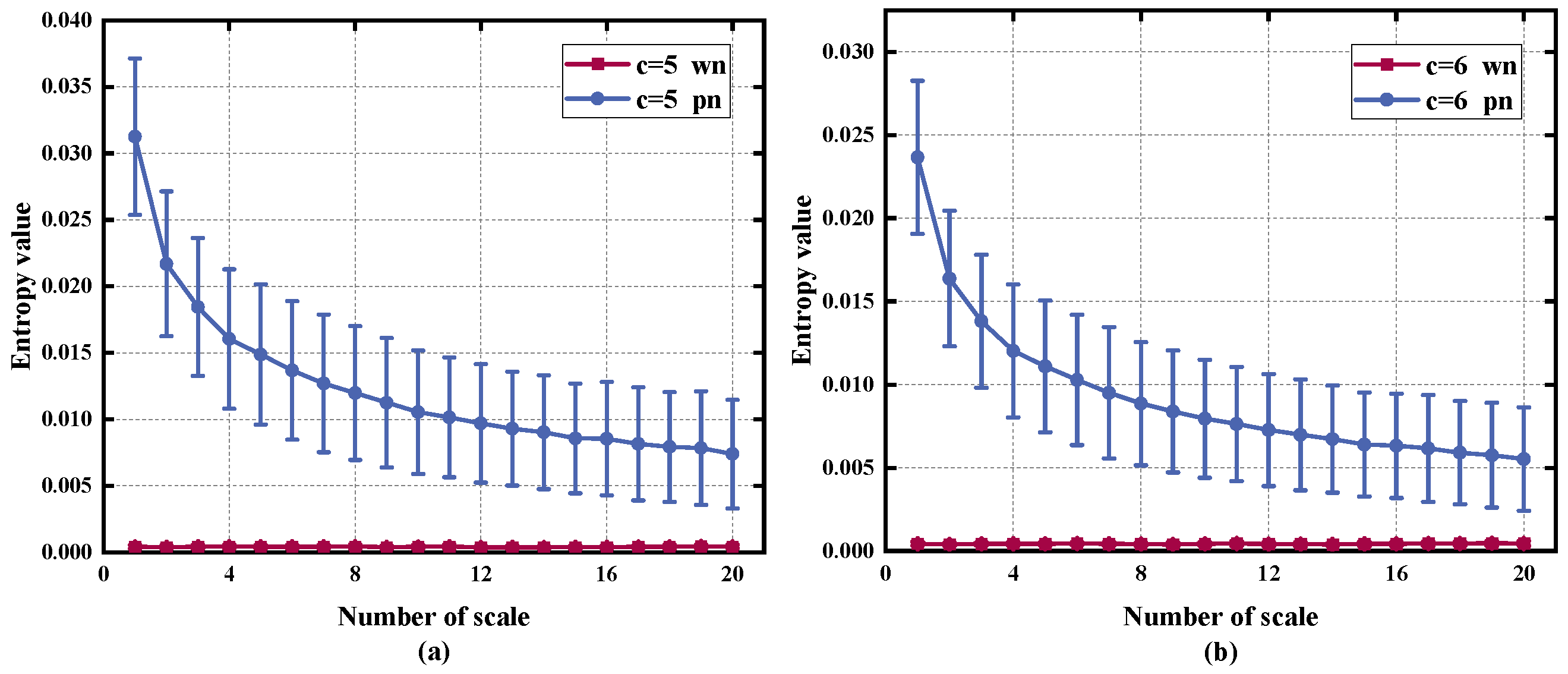
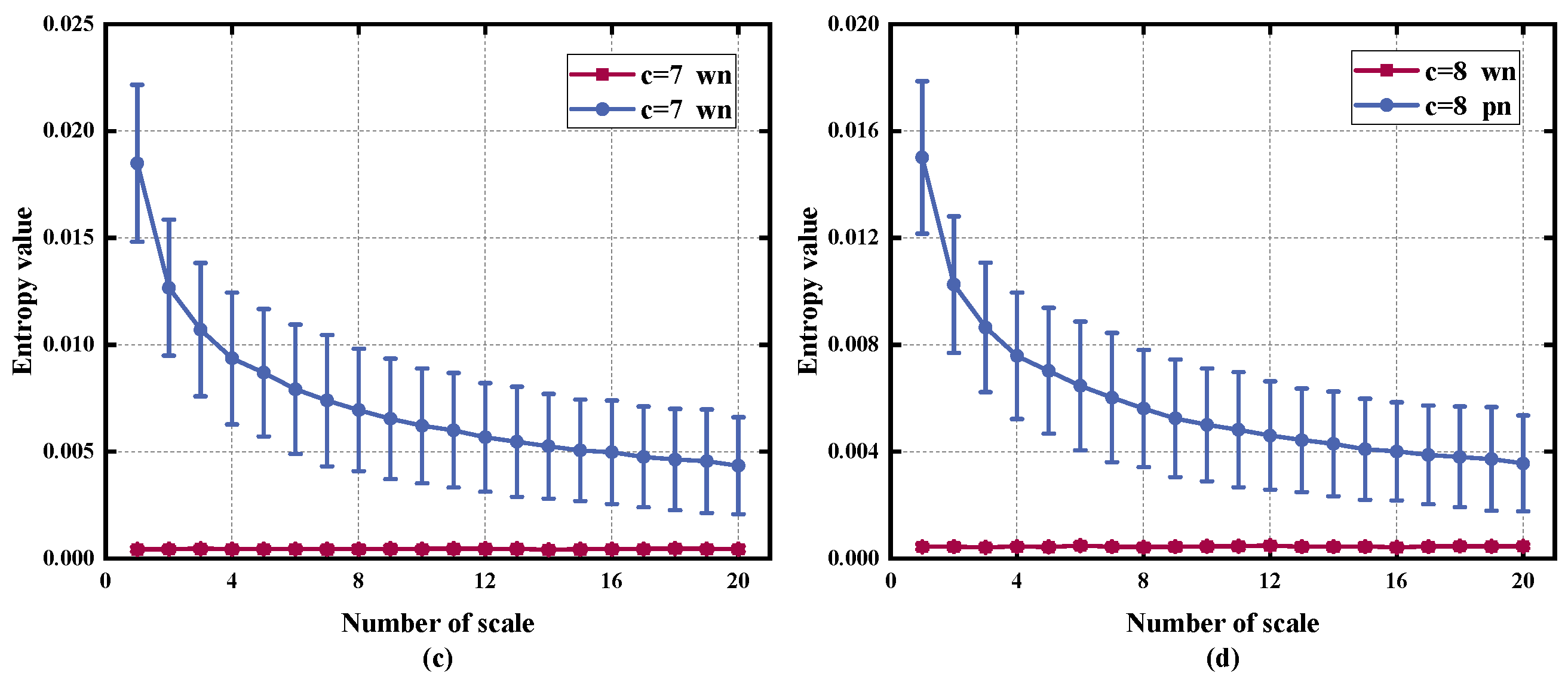
2.4. Parameters Selection
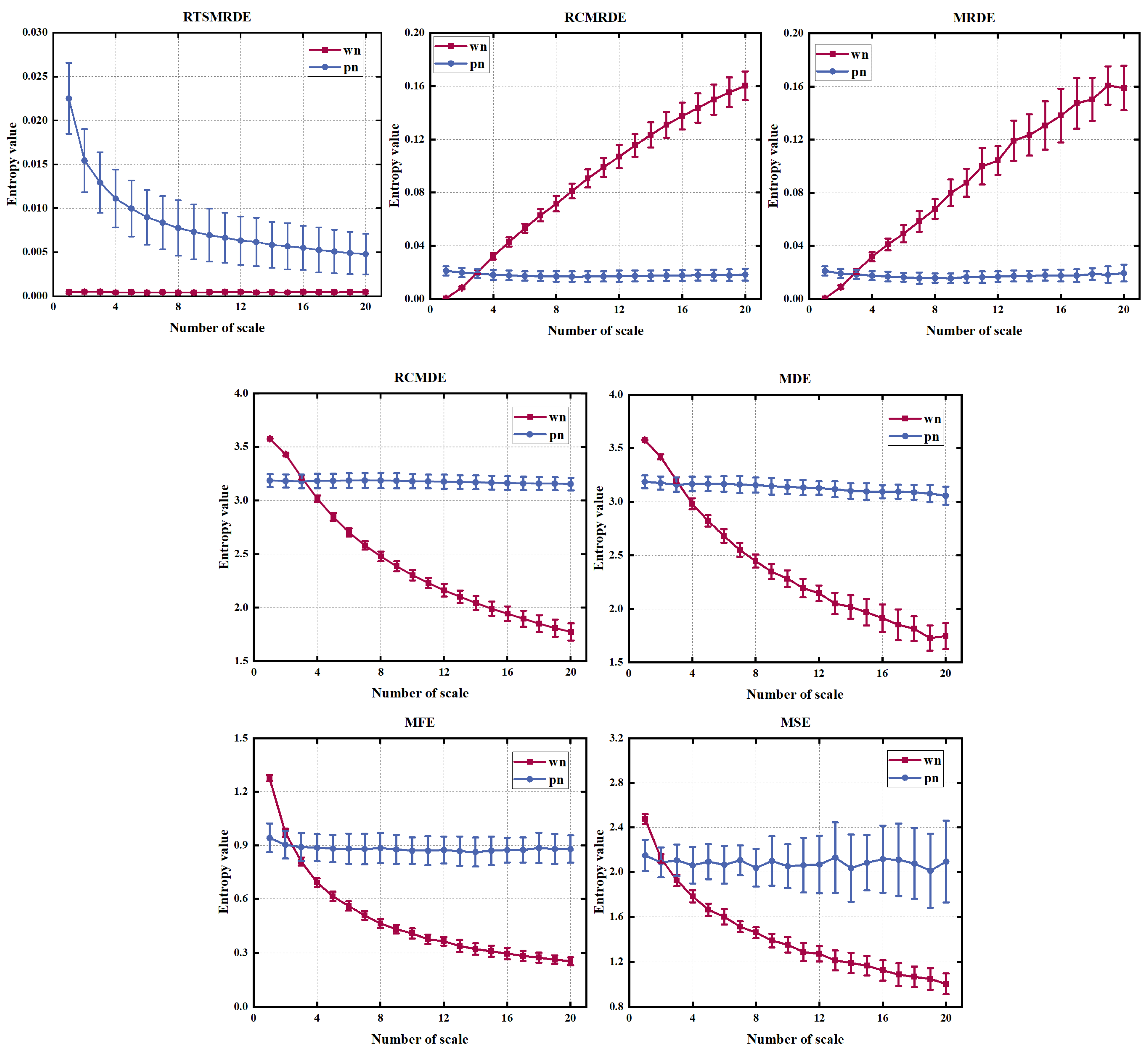
2.5. Comparison of RTSMRDE and Other Entropy Methods Using White Noise and Pink Noise
3. The Proposed Intelligent Gearbox Fault Diagnosis Method
3.1. Data Reduction Method
3.2. Support Vector Machine
3.3. Sparrow Search Algorithm
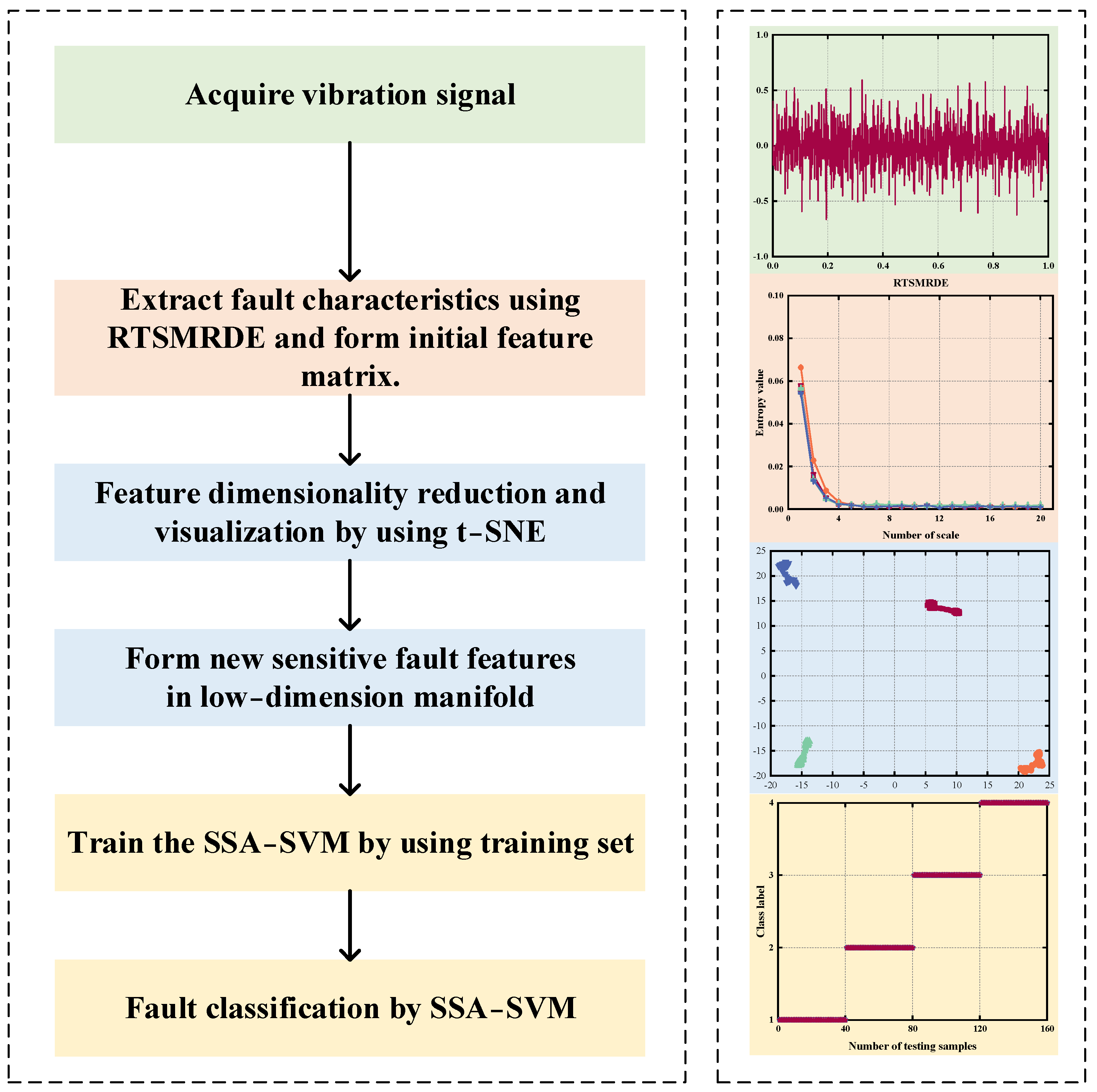
3.4. The Proposed Fault Diagnosis Scheme
4. Experimental Verification
4.1. Case 1: Data from Southeast University Gearbox Dataset
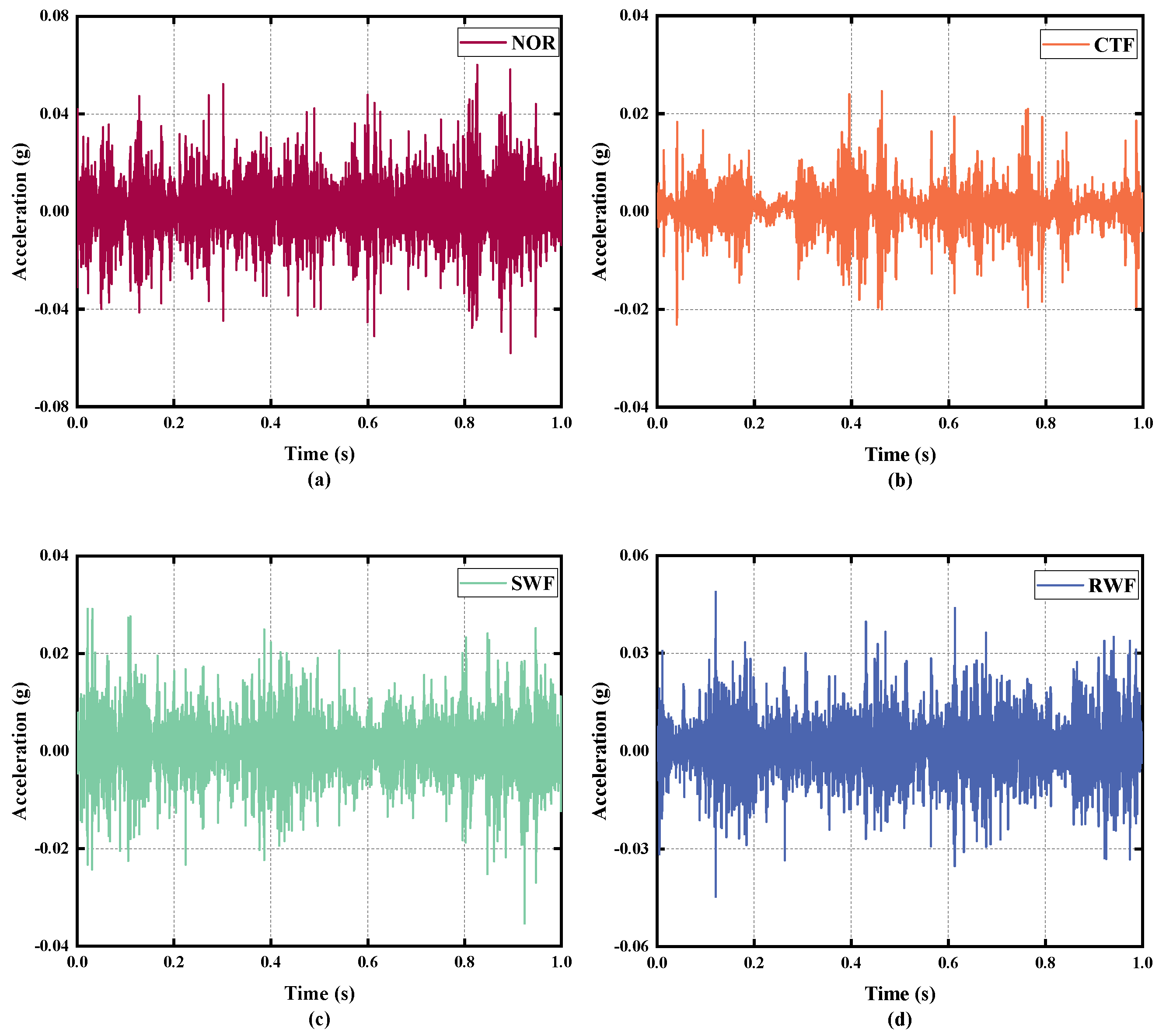
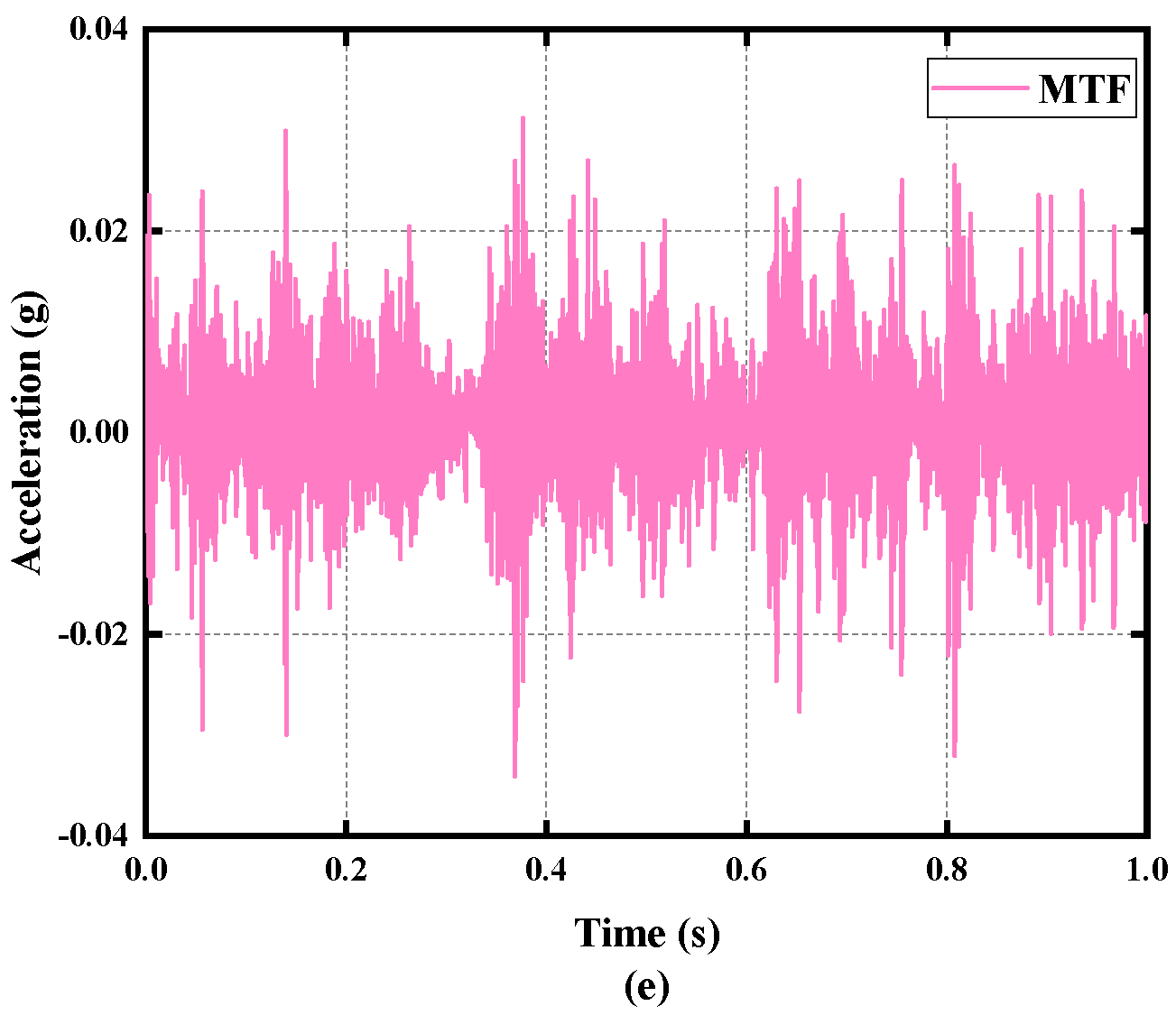
4.1.1. Description and Division of Data
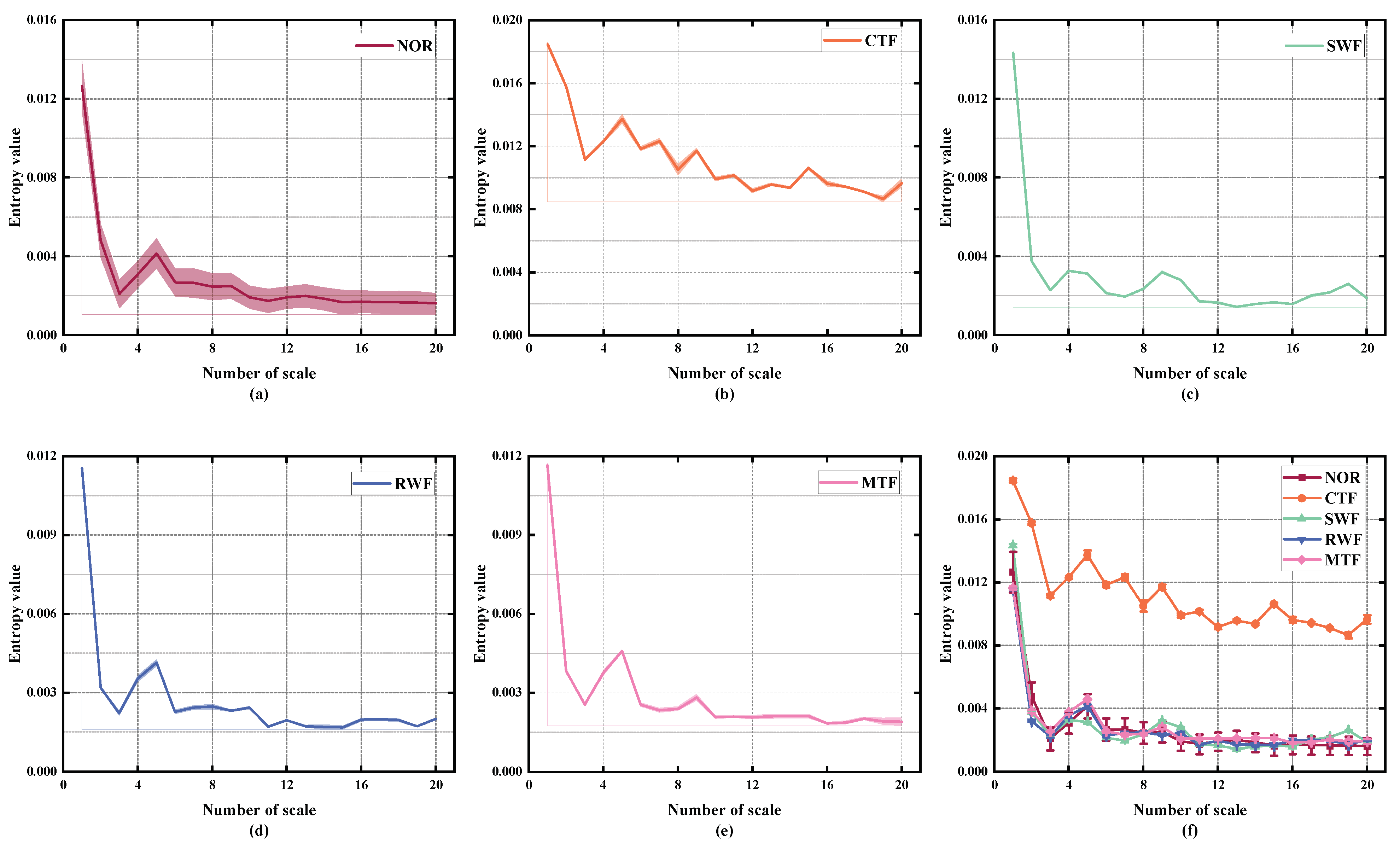
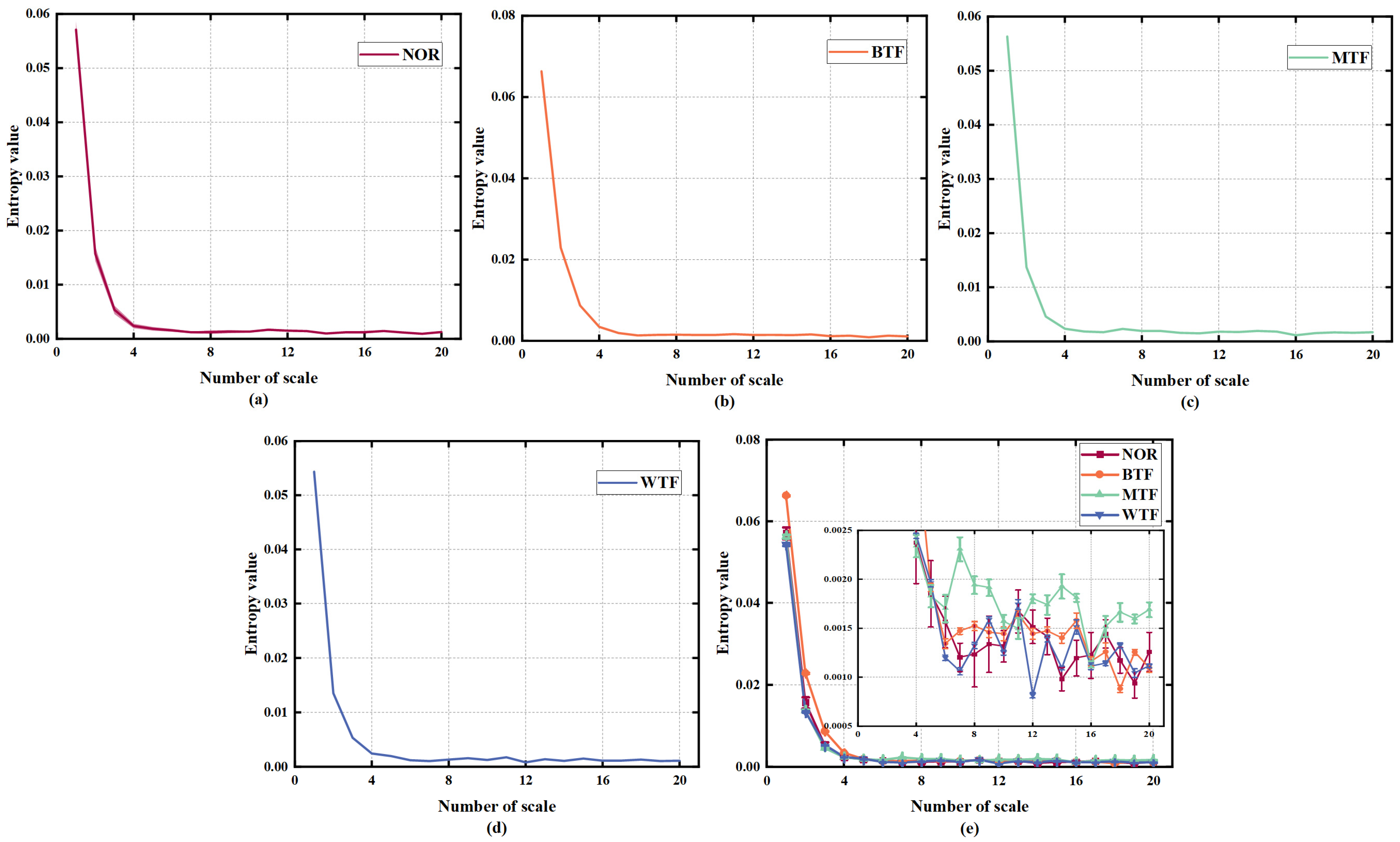
4.1.2. Feature Extraction for D1
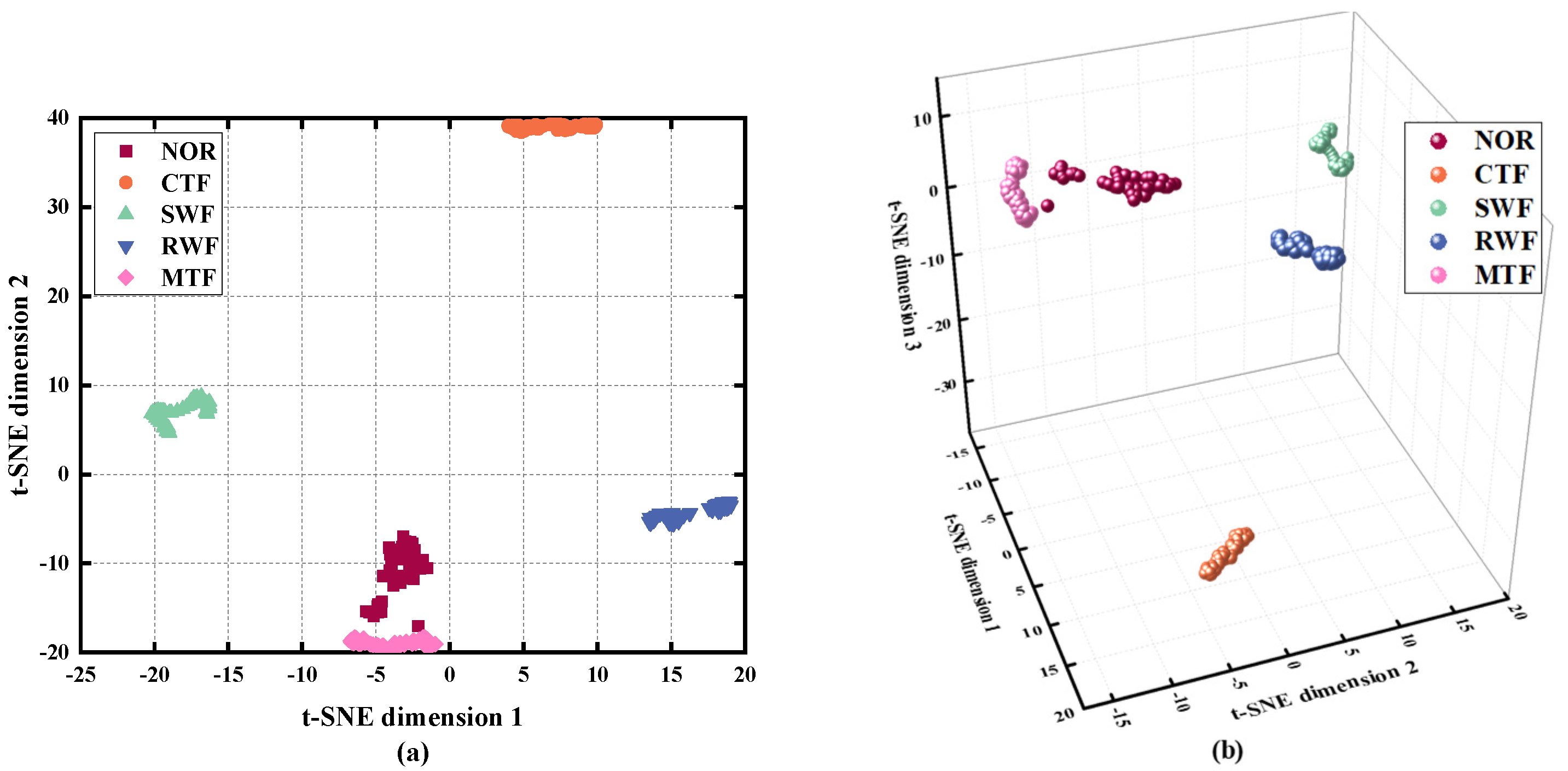
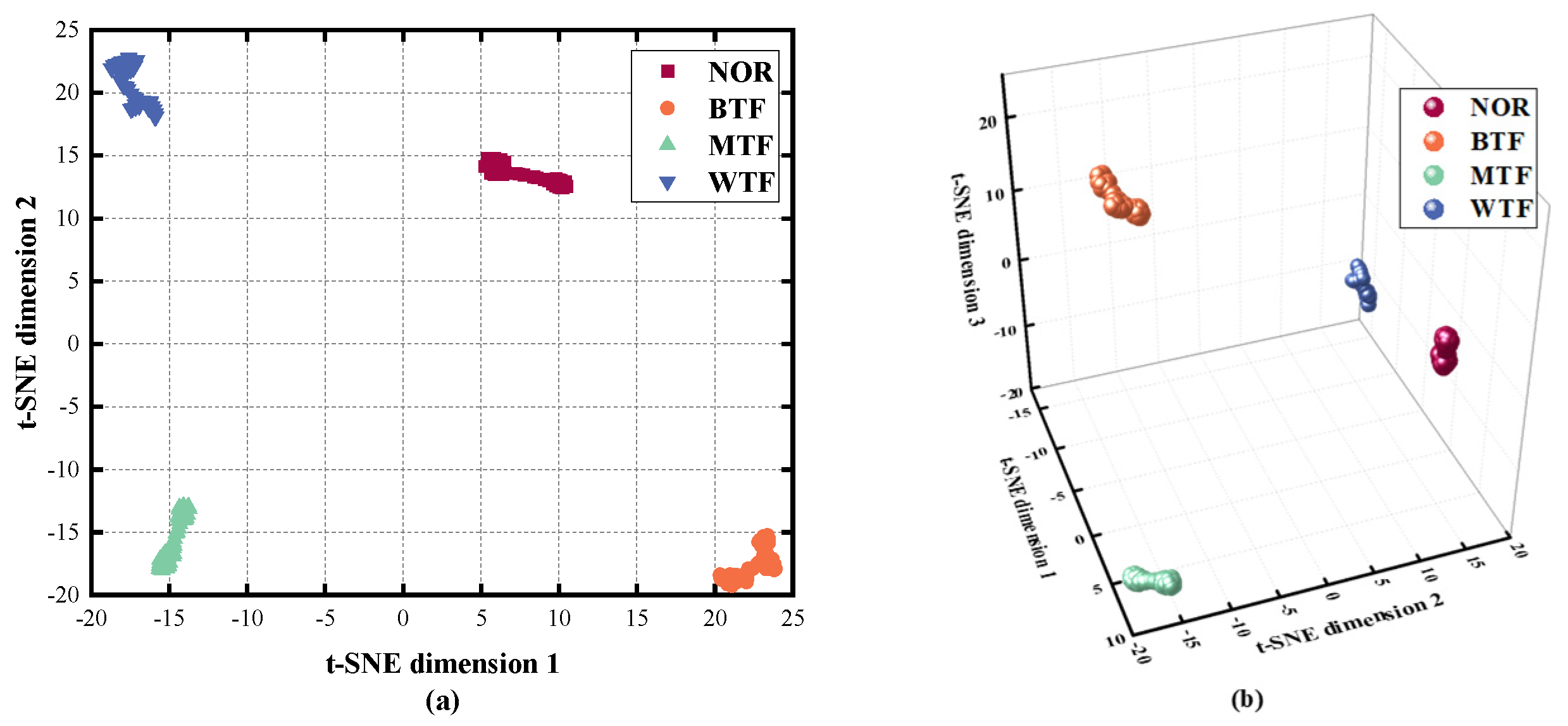
4.1.3. Data Reduction and Visualization
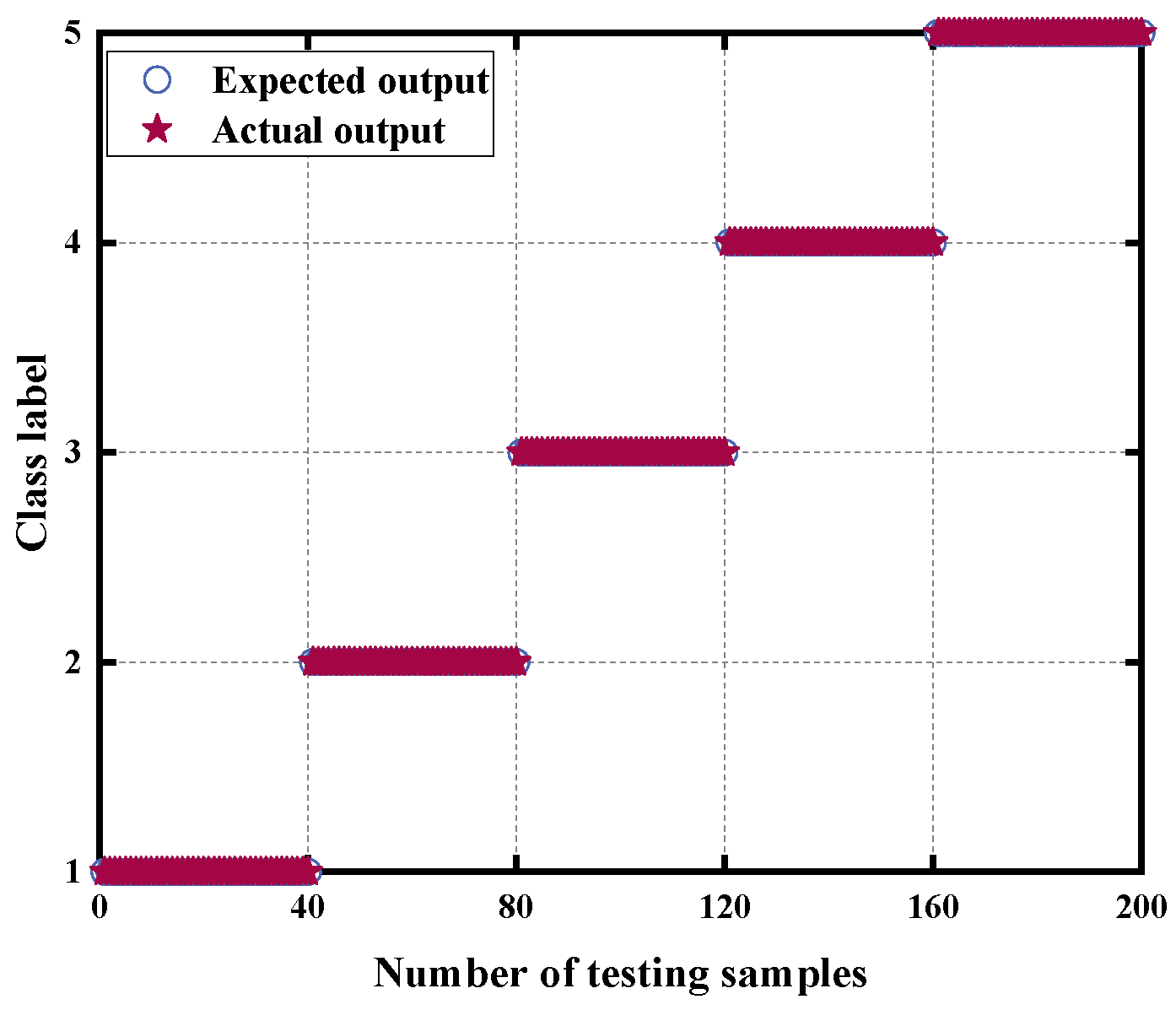
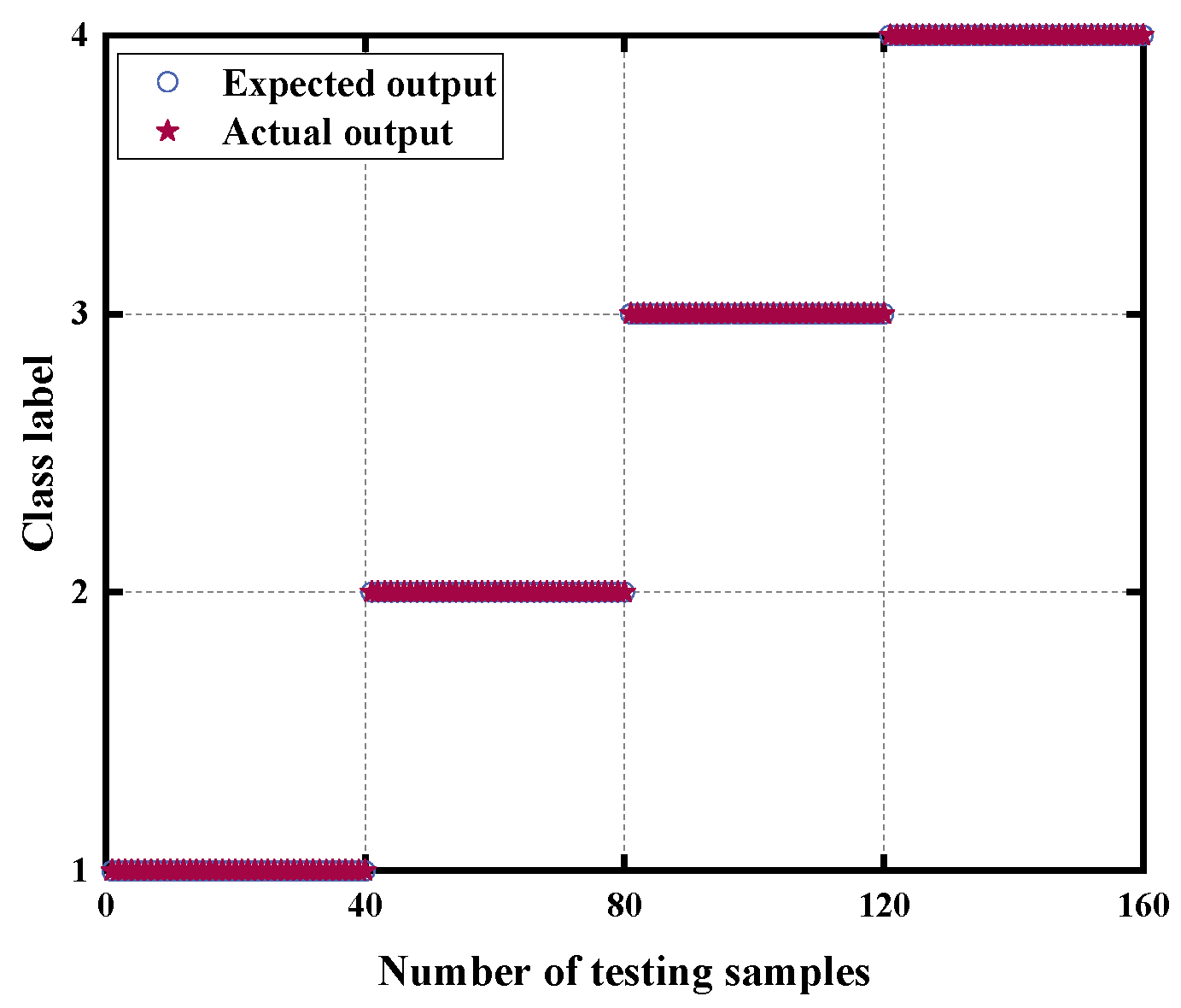
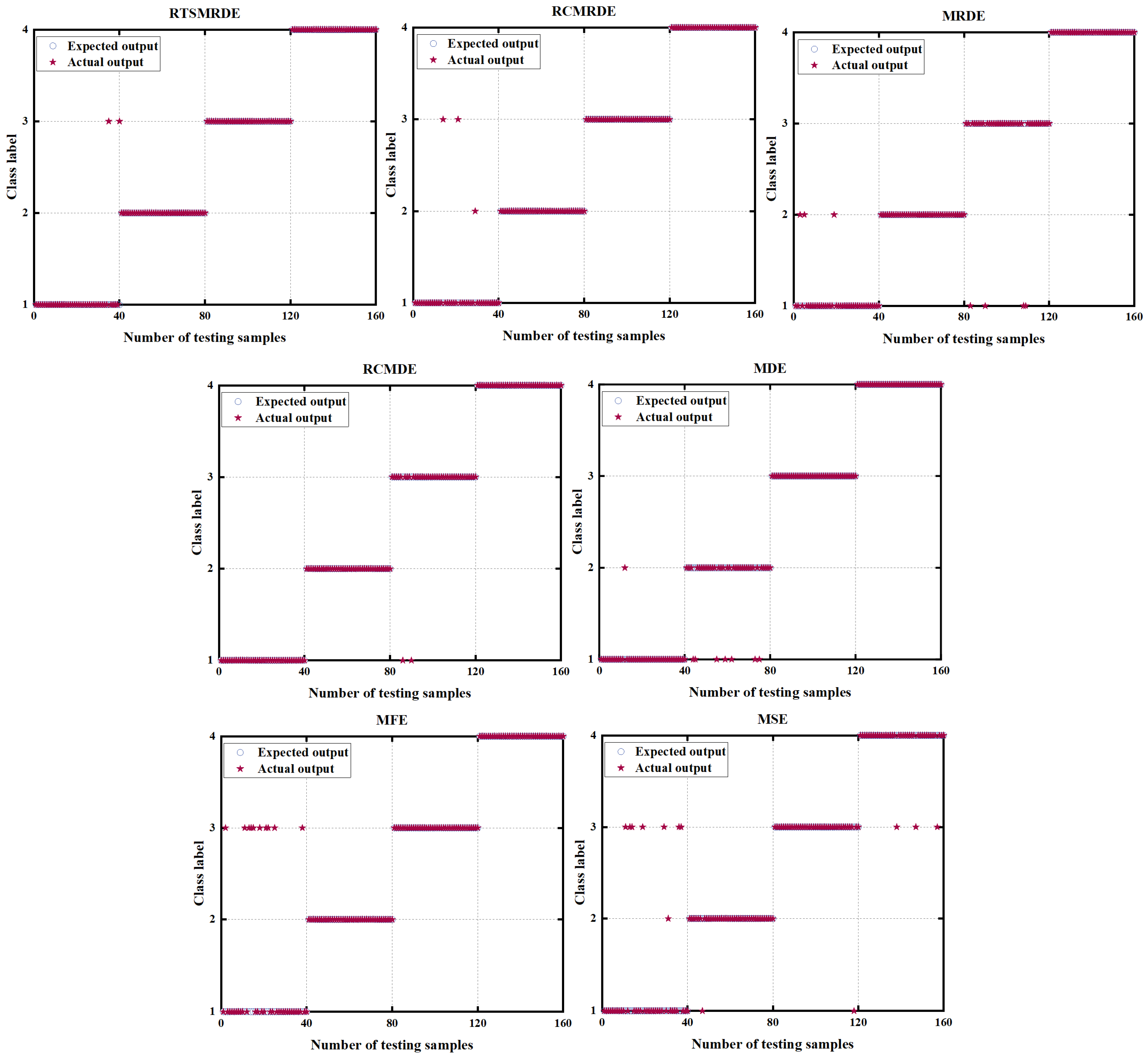
4.1.4. Analysis of Diagnosis Results
4.2. Case 2: Data from MFS
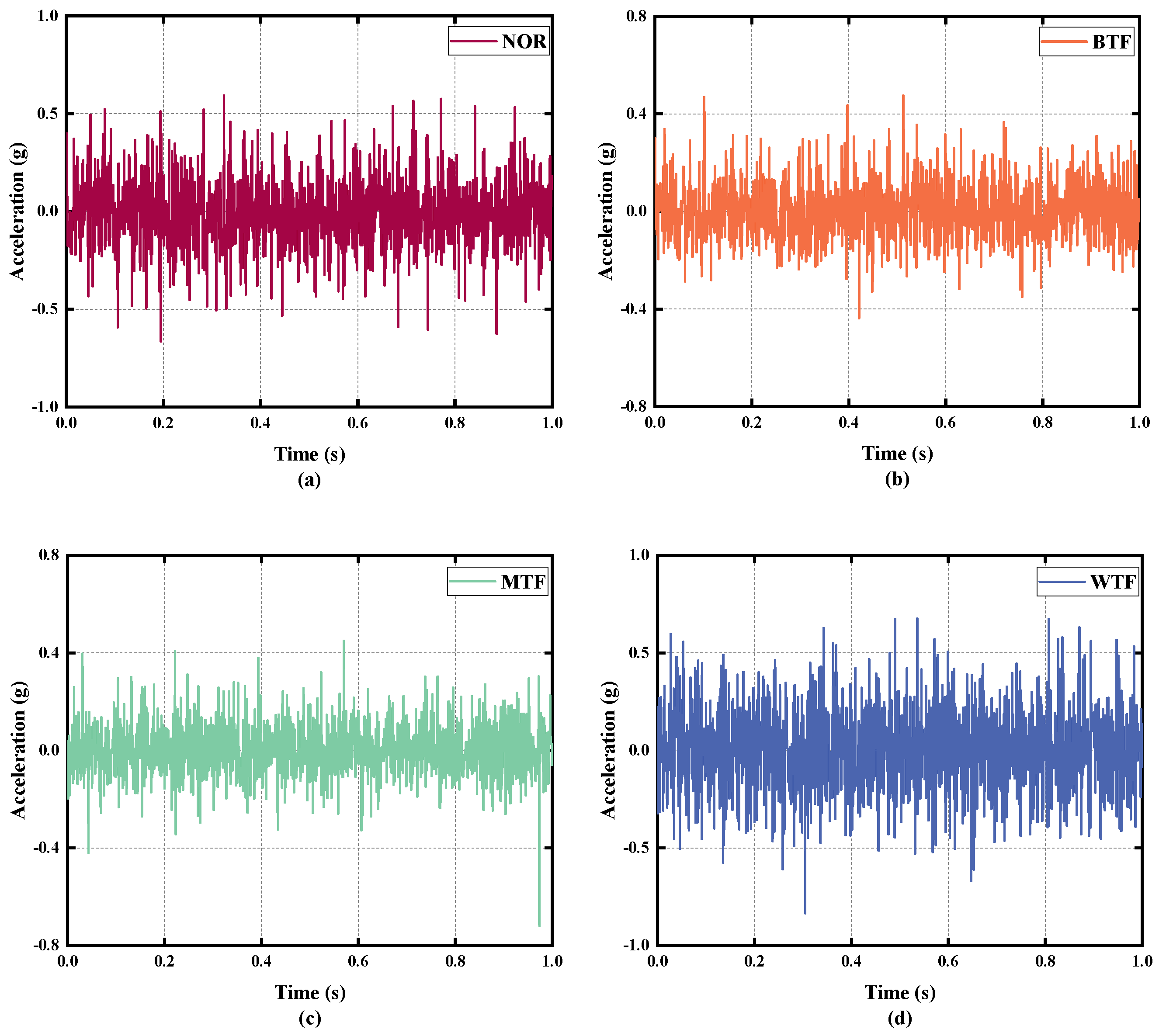
4.2.1. Description and Division of Data
4.2.2. Feature Extraction for D2
4.2.3. Data Reduction and Visualization
4.2.4. Analysis of Diagnosis Results
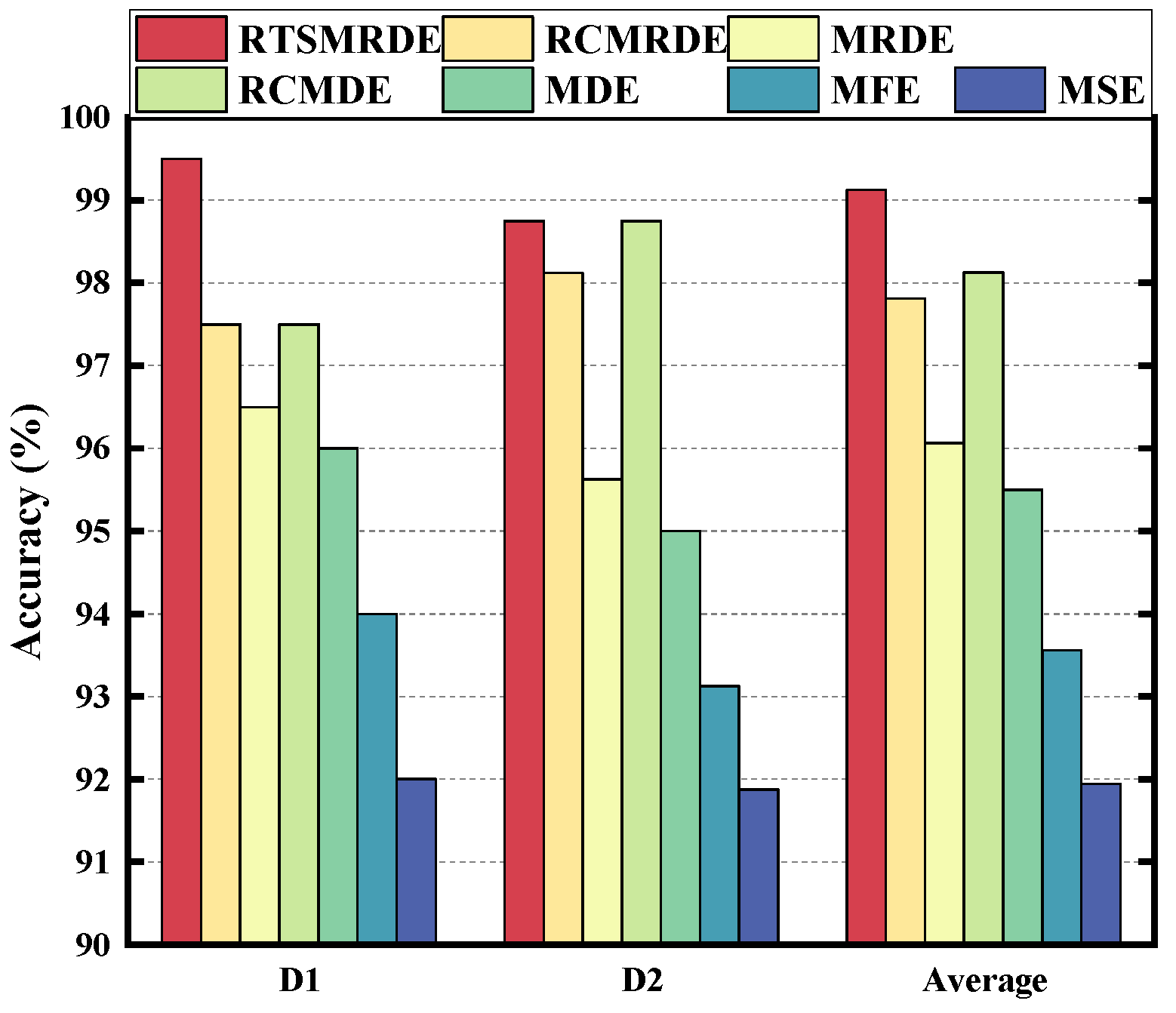
4.3. Contrast Analysis
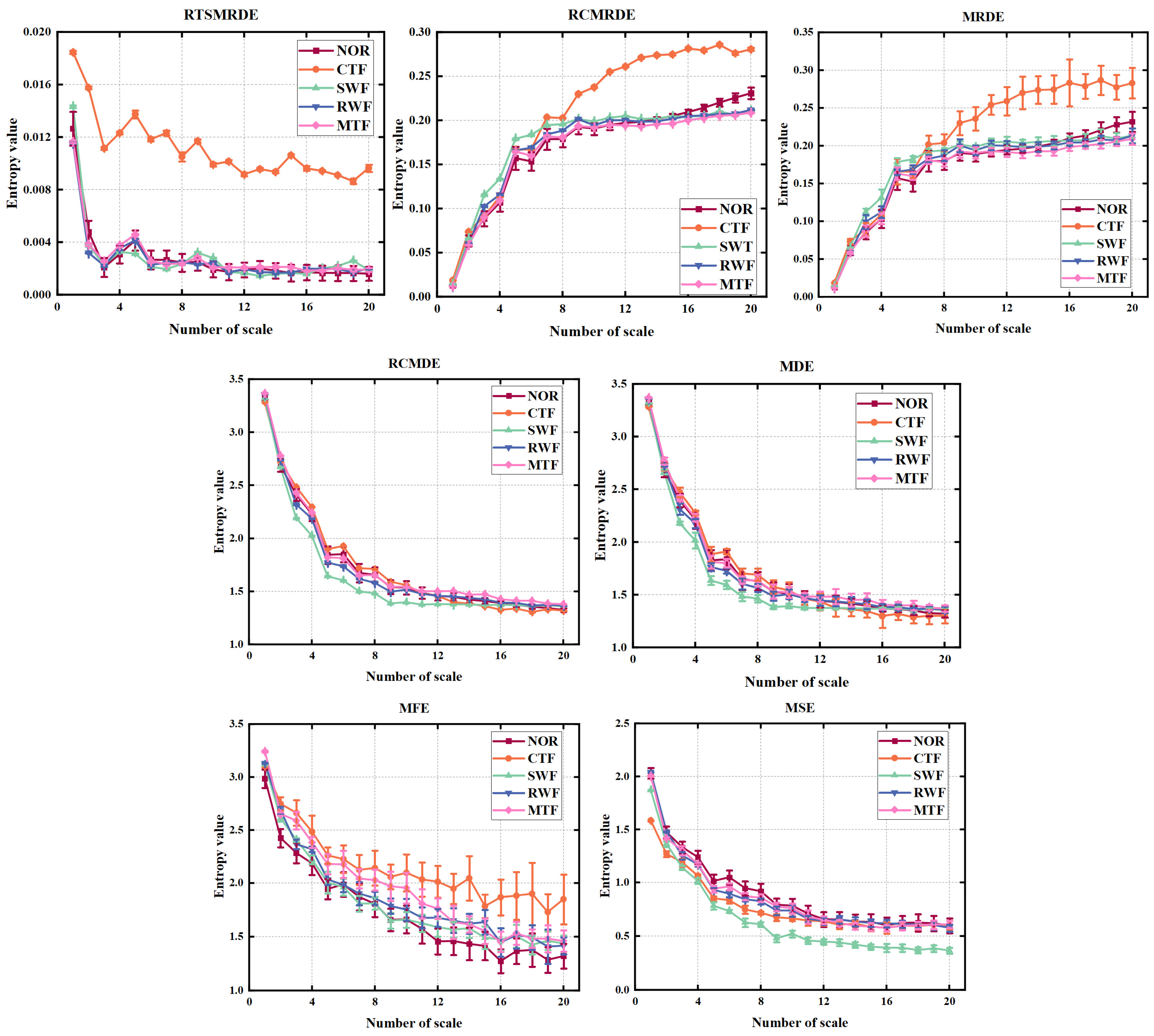
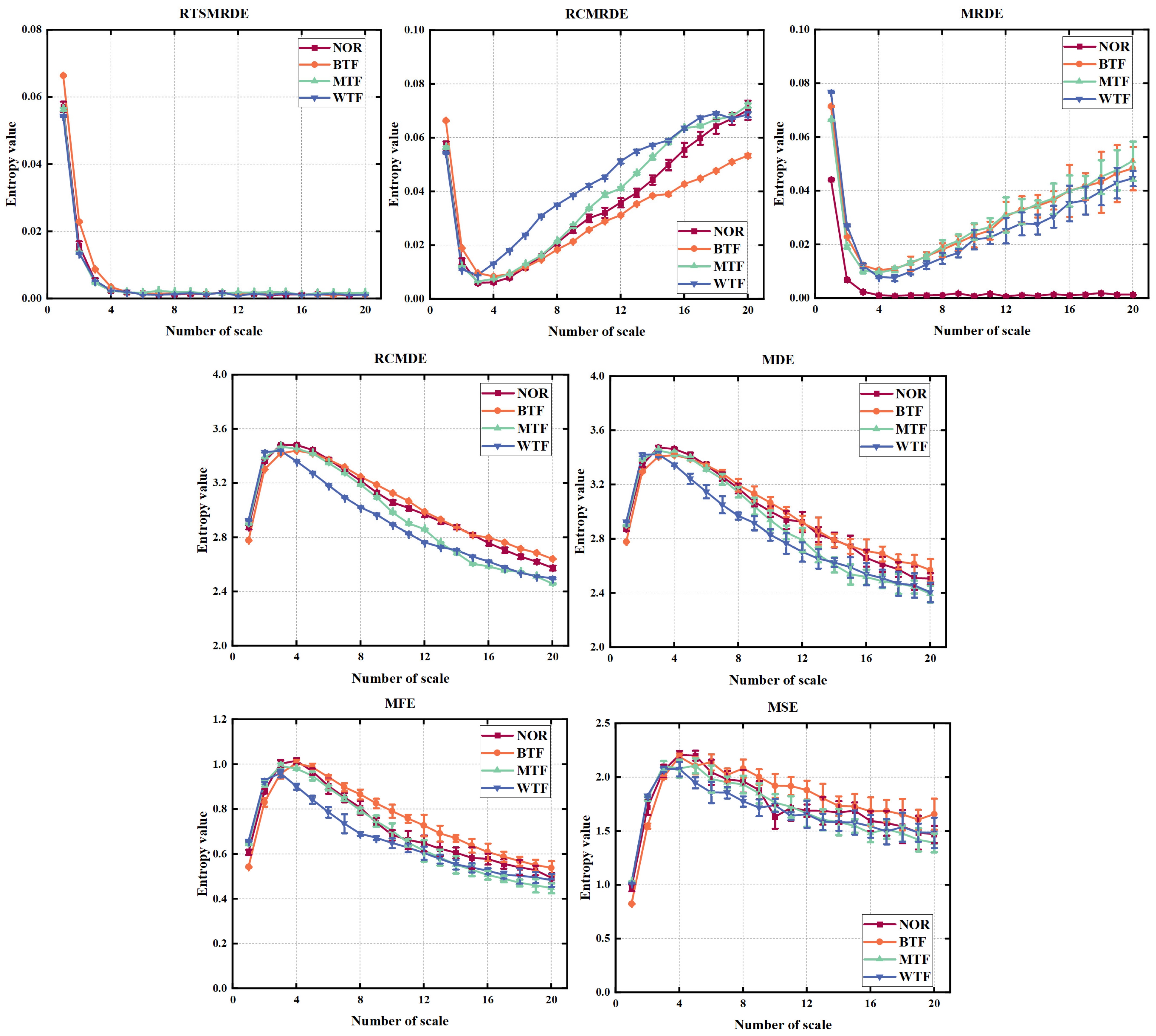
4.3.1. Comparison of RTSMRDE with Other Different Entropy Algorithms
4.3.2. Comparison between Using and Not Using Data Reduction Methods
5. Conclusions
- The RTSMRDE is based on MRDE, combined with the ideas of time shifting coarse-graining operations. It overcomes the shortcomings of traditional multiscale reverse dispersion entropy and can effectively and comprehensively extract the fault characteristics of gearboxes.
- The t-SNE can effectively remove redundant features in high-dimensional fault feature sets, thus obtaining a sensitive and easily classifiable low-dimensional feature set.
- Constructing a novel diagnosis model for gearbox faults based on RTSMRDE, t-SNE, and SSA-SVM.
- The proposed method was validated with noise signals and experimental datasets and demonstrated a more prominent overall performance in terms of feature extraction capability and computational speed.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MSE | Multiscale Sample Entropy |
| MFE | Multiscale Fuzzy Entropy |
| MPE | Multiscale Permutation Entropy |
| DE | Dispersion Entropy |
| MDE | Multiscale Dispersion Entropy |
| RCMDE | Refined Composite Multiscale Dispersion Entropy |
| RDE | Reverse Dispersion Entropy |
| MRDE | Multiscale Reverse Dispersion Entropy |
| RCMRDE | Refined Composite Multiscale Reverse Dispersion Entropy |
| RTSMRDE | Refined Time-Shifted Multiscale Reverse Dispersion Entropy |
| t-SNE | t-distributed Stochastic Neighbour Embedding |
| SSA-SVM | Sparrow Search Algorithm-Support Vector Machine |
| PN | pink noise |
| WN | white noise |
References
- Cheng, Y.; Zhu, H.; Wu, J.; Shao, X. Machine Health Monitoring Using Adaptive Kernel Spectral Clustering and Deep Long Short-Term Memory Recurrent Neural Networks. IEEE Trans. Ind. Inform. 2018, 15, 987–997. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Xu, X.; Qiao, Z.; Lei, Y. Repetitive transient extraction for machinery fault diagnosis using multiscale fractional order entropy infogram. Mech. Syst. Signal Process. 2018, 103, 312–326. [Google Scholar] [CrossRef]
- Zheng, J.D.; Pan, H.Y. Use of generalized refined composite multiscale fractional dispersion entropy to diagnose the faults of rolling bearing. Nonlinear Dyn. 2020, 101, 1417–1440. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Ma, H.; Luo, Z.; Li, X. Federated learning for machinery fault diagnosis with dynamic validation and self-supervision. Knowl.-Based Syst. 2021, 213, 106679. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, Z.; Lu, C. Self-adaptive bearing fault diagnosis based on permutation entropy and manifold-based dynamic time warping. Mech. Syst. Signal Process. 2019, 114, 658–673. [Google Scholar] [CrossRef]
- Vakharia, V.; Gupta, V.; Kankar, P. A multiscale permutation entropy based approach to select wavelet for fault diagnosis of ball bearings. J. Vib. Control 2014, 21, 3123–3131. [Google Scholar] [CrossRef]
- Jia, Y.; Xu, M.; Wang, R. Symbolic Important Point Perceptually and Hidden Markov Model Based Hydraulic Pump Fault Diagnosis Method. Sensors 2018, 18, 4460. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Liu, Z.; Liang, X.; Si, S. The Entropy Algorithm and Its Variants in the Fault Diagnosis of Rotating Machinery: A Review. IEEE Access 2018, 6, 66723–66741. [Google Scholar] [CrossRef]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef]
- Khoshnami, A.; Sadeghkhani, I. Sample entropy-based fault detection for photovoltaic arrays. IET Renew. Power Gener. 2018, 12, 1966–1976. [Google Scholar] [CrossRef]
- Zheng, J.; Pan, H.; Cheng, J. Rolling bearing fault detection and diagnosis based on composite multiscale fuzzy entropy and ensemble support vector machines. Mech. Syst. Signal Process. 2017, 85, 746–759. [Google Scholar] [CrossRef]
- Dong, Z.; Zheng, J.; Huang, S.; Pan, H.; Liu, Q. Time-Shift Multi-scale Weighted Permutation Entropy and GWO-SVM Based Fault Diagnosis Approach for Rolling Bearing. Entropy 2019, 21, 621. [Google Scholar] [CrossRef]
- Costa, M.; Goldberger, A.L.; Peng, C.-K. Multiscale Entropy Analysis of Complex Physiologic Time Series. Phys. Rev. Lett. 2002, 89, 068102. [Google Scholar] [CrossRef]
- Wang, Z.; Yao, L.; Cai, Y. Rolling bearing fault diagnosis using generalized refined composite multiscale sample entropy and optimized support vector machine. Measurement 2020, 156, 107574. [Google Scholar] [CrossRef]
- Dangdang, Z.; Han, B.; Liu, G.; Li, Y.; Yu, H. Cross-Domain Intelligent Fault Diagnosis Method of Rotating Machinery Using Multi-Scale Transfer Fuzzy Entropy. IEEE Access 2021, 9, 95481–95492. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, Y.; Dai, Q. Gear compound fault detection method based on improved multiscale permutation entropy and local mean decomposition. J. Vibroeng. 2021, 23, 1171–1183. [Google Scholar] [CrossRef]
- Rostaghi, M.; Azami, H. Dispersion Entropy: A Measure for Time-Series Analysis. IEEE Signal Process. Lett. 2016, 23, 610–614. [Google Scholar] [CrossRef]
- Azami, H.; Escudero, J. Amplitude- and Fluctuation-Based Dispersion Entropy. Entropy 2018, 20, 210. [Google Scholar] [CrossRef]
- Li, Y.; Gao, X.; Wang, L. Reverse Dispersion Entropy: A New Complexity Measure for Sensor Signal. Sensors 2019, 19, 5203. [Google Scholar] [CrossRef]
- Xing, J.; Xu, J. An Improved Incipient Fault Diagnosis Method of Bearing Damage Based on Hierarchical Multi-Scale Reverse Dispersion Entropy. Entropy 2022, 24, 770. [Google Scholar] [CrossRef] [PubMed]
- Zheng, J.; Pan, H.; Liu, Q.; Ding, K. Refined time-shift multiscale normalised dispersion entropy and its application to fault diagnosis of rolling bearing. Phys. A Stat. Mech. Its Appl. 2019, 545, 123641. [Google Scholar] [CrossRef]
- Azami, H.; Rostaghi, M.; Abásolo, D.; Escudero, J. Refined Composite Multiscale Dispersion Entropy and its Application to Biomedical Signals. IEEE Trans. Biomed. Eng. 2017, 64, 2872–2879. [Google Scholar] [CrossRef]
- Grbovic, M.; Li, W.; Xu, P.; Usadi, A.K.; Song, L.; Vucetic, S. Decentralized fault detection and diagnosis via sparse PCA based decomposition and Maximum Entropy decision fusion. J. Process Control 2012, 22, 738–750. [Google Scholar] [CrossRef]
- Li, D.; Hu, G.; Spanos, C.J. A data-driven strategy for detection and diagnosis of building chiller faults using linear discriminant analysis. Energy Build. 2016, 128, 519–529. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Li, X.; Liang, T. Rolling bearing fault detection using continuous deep belief network with locally linear embedding. Comput. Ind. 2018, 96, 27–39. [Google Scholar] [CrossRef]
- Tu, D.; Zheng, J.; Jiang, Z.; Pan, H. Multiscale Distribution Entropy and t-Distributed Stochastic Neighbor Embedding-Based Fault Diagnosis of Rolling Bearings. Entropy 2018, 20, 360. [Google Scholar] [CrossRef]
- Yin, A.; Lu, J.; Dai, Z.; Li, J.; Ouyang, Q. Isomap and Deep Belief Network-Based Machine Health Combined Assessment Model. Stroj. Vestn.-J. Mech. Eng. 2016, 62, 740–750. [Google Scholar] [CrossRef]
- Zheng, J.; Jiang, Z.; Pan, H. Sigmoid-based refined composite multiscale fuzzy entropy and t-SNE based fault diagnosis approach for rolling bearing. Measurement 2018, 129, 332–342. [Google Scholar] [CrossRef]
- Li, D.; Gu, M.; Liu, S.; Sun, X.; Gong, L.; Qian, K. Continual learning classification method with the weighted k-nearest neighbor rule for time-varying data space based on the artificial immune system. Knowl.-Based Syst. 2022, 240, 108145. [Google Scholar] [CrossRef]
- Wei, Y.; Yang, Y.; Xu, M.; Huang, W. Intelligent fault diagnosis of planetary gearbox based on refined composite hierarchical fuzzy entropy and random forest. ISA Trans. 2020, 109, 340–351. [Google Scholar] [CrossRef]
- Saliha, S.; Nabil, E.A. A Novel Hybrid Method Based on Fireworks Algorithm and Artificial Neural Network for Photovoltaic System Fault Diagnosis. Int. J. Renew. Energy Res. 2022, 12, 239–247. [Google Scholar]
- Zhang, J.; Zhang, Q.; Qin, X.; Sun, Y. A two-stage fault diagnosis methodology for rotating machinery combining optimized support vector data description and optimized support vector machine. Measurement 2022, 200, 111651. [Google Scholar] [CrossRef]
- Chen, H.; Li, S. Multi-Sensor Fusion by CWT-PARAFAC-IPSO-SVM for Intelligent Mechanical Fault Diagnosis. Sensors 2022, 22, 3647. [Google Scholar] [CrossRef] [PubMed]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Li, W.; Shen, X.; Li, Y. A Comparative Study of Multiscale Sample Entropy and Hierarchical Entropy and Its Application in Feature Extraction for Ship-Radiated Noise. Entropy 2019, 21, 793. [Google Scholar] [CrossRef]
- Luo, S.; Yang, W.; Luo, Y. A Novel Fault Detection Scheme Using Improved Inherent Multiscale Fuzzy Entropy With Partly Ensemble Local Characteristic-Scale Decomposition. IEEE Access 2019, 8, 6650–6661. [Google Scholar] [CrossRef]
- Zhang, Y.; Tong, S.; Cong, F.; Xu, J. Research of Feature Extraction Method Based on Sparse Reconstruction and Multiscale Dispersion Entropy. Appl. Sci. 2018, 8, 888. [Google Scholar] [CrossRef]
- Luo, S.; Yang, W.; Luo, Y. Fault Diagnosis of a Rolling Bearing Based on Adaptive Sparest Narrow-Band Decomposition and RefinedComposite Multiscale Dispersion Entropy. Entropy 2020, 22, 375. [Google Scholar] [CrossRef]
- Li, Y.; Jiao, S.; Geng, B.; Zhou, Y. Research on feature extraction of ship-radiated noise based on multi-scale reverse dispersion entropy. Appl. Acoust. 2020, 173, 107737. [Google Scholar] [CrossRef]
- Liu, A.; Yang, Z.; Li, H.; Wang, C.; Liu, X. Intelligent Diagnosis of Rolling Element Bearing Based on Refined Composite Multiscale Reverse Dispersion Entropy and Random Forest. Sensors 2022, 22, 2046. [Google Scholar] [CrossRef] [PubMed]
- Shao, S.; McAleer, S.; Yan, R.; Baldi, P. Highly Accurate Machine Fault Diagnosis Using Deep Transfer Learning. IEEE Trans. Ind. Inform. 2018, 15, 2446–2455. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | m = 2 | m = 3 | m = 4 | m = 5 |
|---|---|---|---|---|
| Seconds | 1.121 s | 3.403 s | 14.575 s | 80.805 s |
| Type | c = 5 | c = 6 | c = 7 | c = 8 |
|---|---|---|---|---|
| Seconds | 1.025 s | 1.092 s | 1.290 s | 1.549 s |
| Entropy Methods | Parameters |
|---|---|
| MSE [36] | m = 2, n = 2, d = 1, s = 20, r = 0.15 SD |
| MFE [37] | m = 3, d = 1, s = 20, r = 0.15 SD |
| MDE [38] | m = 3, c = 6, d = 1, s = 20 |
| RCMDE [39] | m = 2, c = 9, d = 1, s = 20 |
| MRDE [40] | m = 3, c = 5, d = 1, s = 20 |
| RCMRDE [41] | m = 2, c = 5, d = 1, s = 20 |
| RTSMRDE (proposed) | m = 2, c = 6, d = 1, s = 20 |
| Type | RTSMRDE | RCMRDE | MRDE | RCMDE | MDE | MFE | MSE |
|---|---|---|---|---|---|---|---|
| Seconds | 1.081 s | 4.576 s | 0.550 s | 4.380 s | 0.549 s | 4.315 s | 3.305 s |
| Fault Types | Motor Speed (r/min) | Number of Training Samples | Number of Testing Samples | Class Label |
|---|---|---|---|---|
| Normal | 1200 | 10 | 40 | NOR |
| Chipped tooth | 1200 | 10 | 40 | CTF |
| Surface wear | 1200 | 10 | 40 | SWF |
| Root wear | 1200 | 10 | 40 | RWF |
| Missing tooth | 1200 | 10 | 40 | MTF |
| Fault Types | Motor Speed (r/min) | Number of Training Samples | Number of Testing Samples | Class Label |
|---|---|---|---|---|
| Normal | 1750 | 10 | 40 | NOR |
| Broken tooth | 1750 | 10 | 40 | BTF |
| Missing tooth | 1750 | 10 | 40 | MTF |
| Wear tooth | 1750 | 10 | 40 | WTF |
| Data | RTSMRDE | RCMRDE | MRDE | RCMDE | MDE | MFE | MSE |
|---|---|---|---|---|---|---|---|
| D1 | 4.62 s | 17.56 s | 2.40 s | 17.65 s | 2.36 s | 19.26 s | 14.08 s |
| D2 | 3.76 s | 14.23 s | 1.81 s | 14.36 s | 1.83 s | 15.77 s | 12.22 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Jiang, H. Gearbox Fault Diagnosis Based on Refined Time-Shift Multiscale Reverse Dispersion Entropy and Optimised Support Vector Machine. Machines 2023, 11, 646. https://doi.org/10.3390/machines11060646
Wang X, Jiang H. Gearbox Fault Diagnosis Based on Refined Time-Shift Multiscale Reverse Dispersion Entropy and Optimised Support Vector Machine. Machines. 2023; 11(6):646. https://doi.org/10.3390/machines11060646
Chicago/Turabian StyleWang, Xiang, and Han Jiang. 2023. "Gearbox Fault Diagnosis Based on Refined Time-Shift Multiscale Reverse Dispersion Entropy and Optimised Support Vector Machine" Machines 11, no. 6: 646. https://doi.org/10.3390/machines11060646
APA StyleWang, X., & Jiang, H. (2023). Gearbox Fault Diagnosis Based on Refined Time-Shift Multiscale Reverse Dispersion Entropy and Optimised Support Vector Machine. Machines, 11(6), 646. https://doi.org/10.3390/machines11060646