



A Hybrid Spiking Neural Network Reinforcement Learning Agent for Energy-Efficient Object Manipulation †




Abstract
1. Introduction
- The efficient development of a spiking actor for the box-reach, grasp, and box-transfer approach using a dual finger gripper in 2D space (https://www.youtube.com/watch?v=4XVODJJ6Cs8, accessed on 10 December 2022).
- The implementation of a subgoal training strategy for the RL agent via designing two distinct reward functions, one for the box-reach and one for the box-transfer subtasks, which led to smoother movements of the robotic arm.
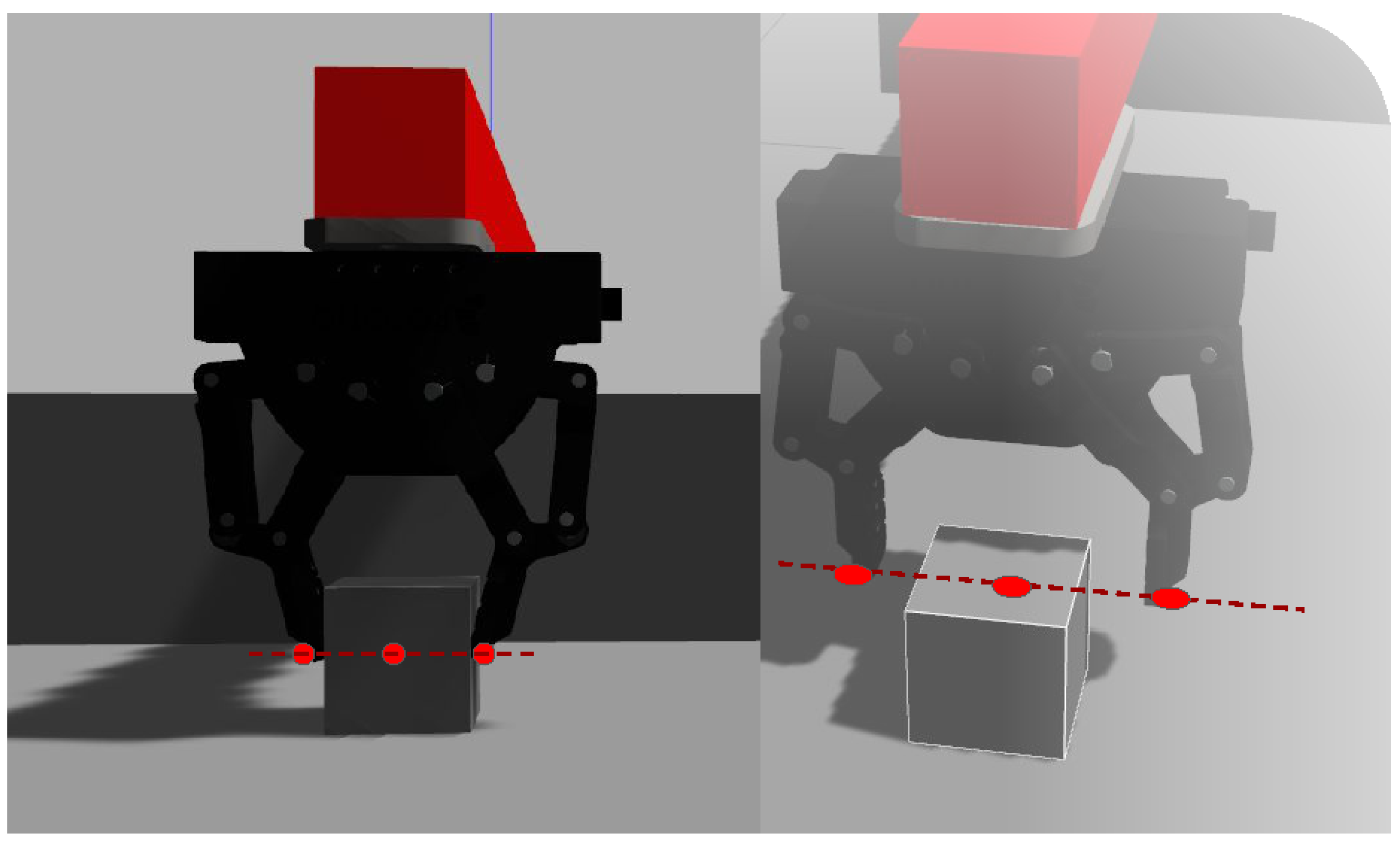
- The introduction of a more sophisticated reward function controlled through a designed collinear grasping condition for the box-reach subtask, enabling the robotic arm to attain a proper grasping position before reaching the box.
- Extensive experimental and comparative studies of the proposed subgoal hybrid-DDPG model highly demonstrating its superiority against the classical DDPG and the end-to-end approaches in terms of both performance and time efficiency.
2. Related Work
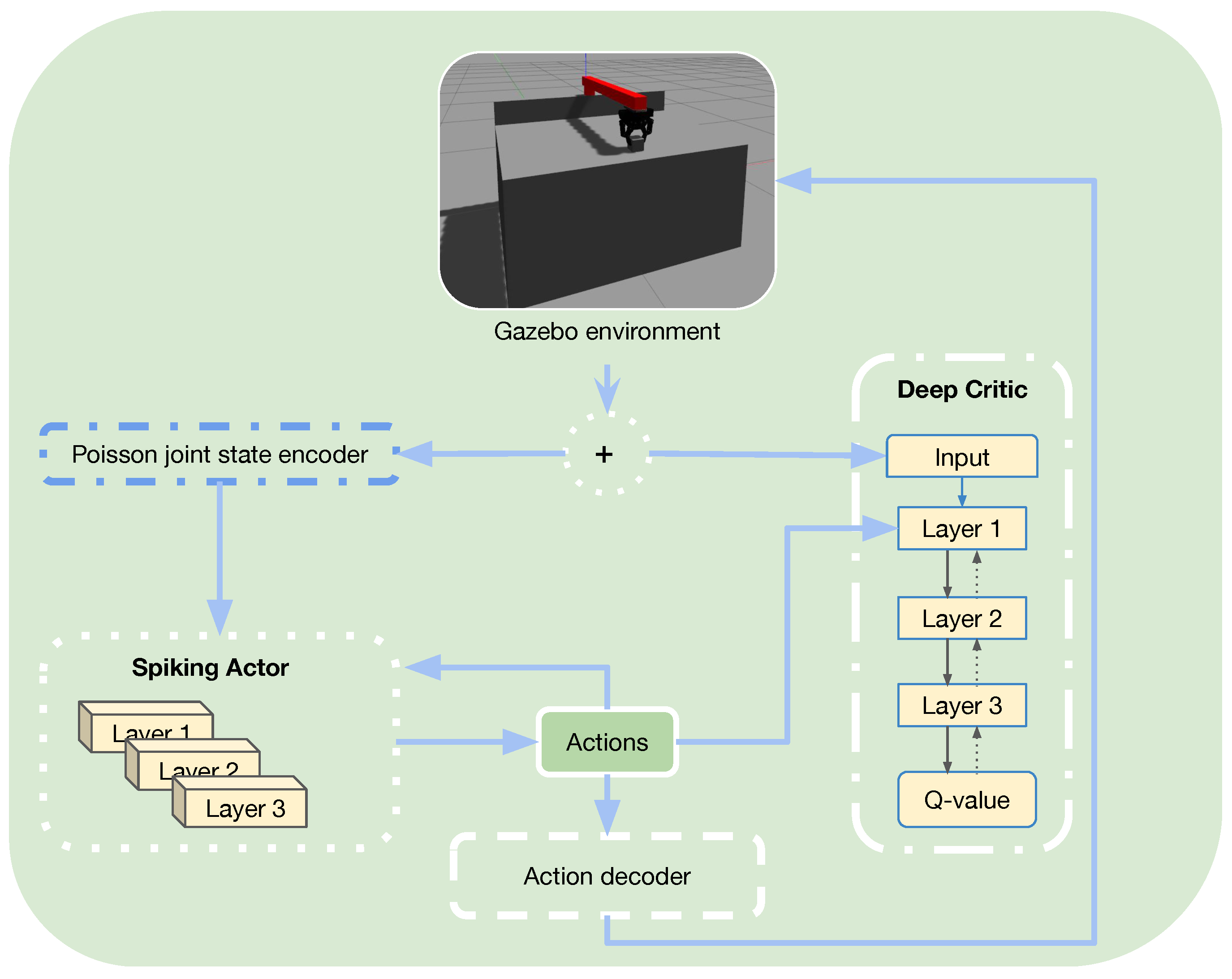
3. Materials and Methods
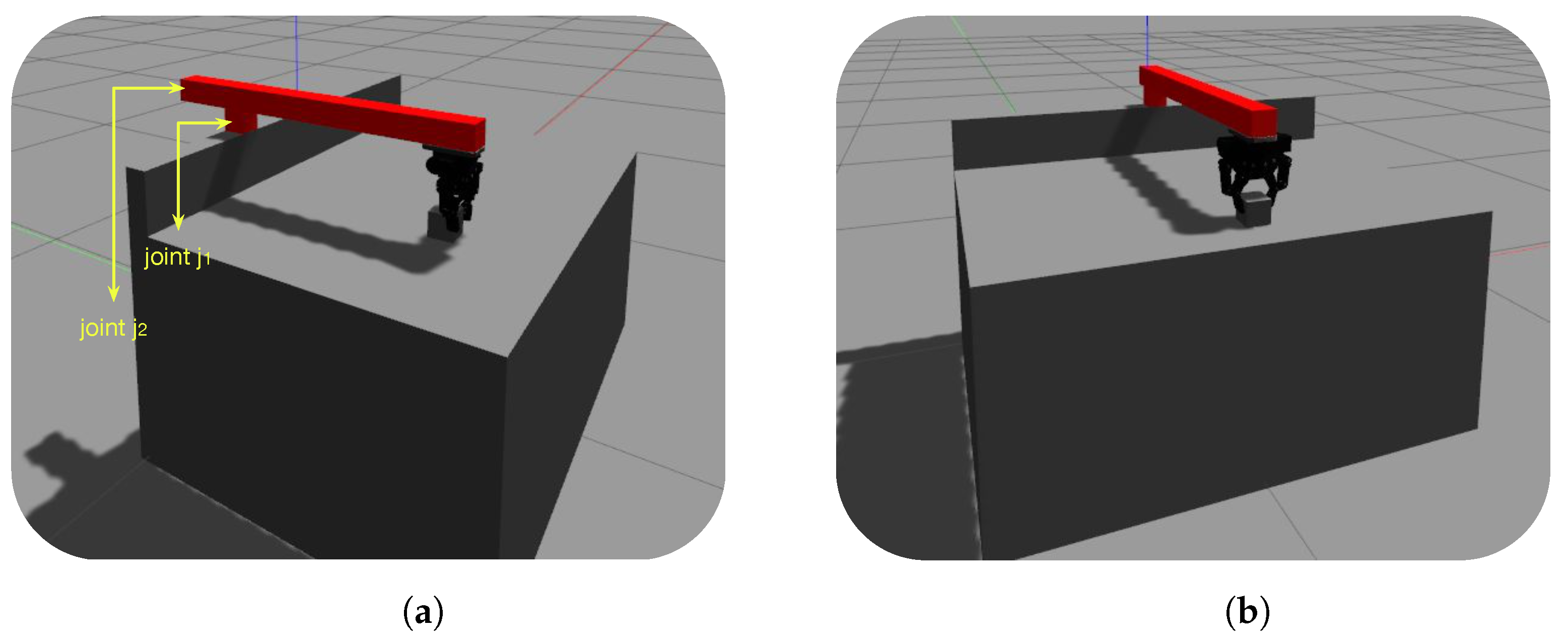
3.1. Box-Reach Learning Scheme
| Algorithm 1 Reward function for the first subgoal of target-object reach. |
Require:, the reward for goal reach. Require:, the distance threshold value for goal reach. Require:, the collision value. Require:, , the target-object’s high value indicating if the end effector would collide with the target object. Require:c, the collinear value as described in (2). Require:, , the current x, y distance, respectively, between the end effector and the target object. Require: and , the previous x, y distance, respectively, between the end effector and the target object. Require: and , distance amplifier for the x, y directions, respectively. Output:R, the reward function.
|
3.2. Box-Transfer Learning Scheme
| Algorithm 2 Reward function for the second subgoal of goal position reach. |
Require:, the reward for goal reach. Require:, the distance threshold value for goal reach. Require:, the collision value. Require:,, the target object’s z value and the value indicating if the end effector collides with the target object, respectively. Require:, the Boolean value from the contact sensor indicating that the gripper holds the target object. Require:, , the current and previous distances, respectively, between the end effector and the goal position. Require:, distance amplifier. Output:R, the reward function.
|
4. Results
4.1. Box-Reach Subtask
4.2. Box-Transfer Subtask
5. Discussion
5.1. Findings of the Box-Reach Subtask
5.2. Findings of the Box-Transfer Subtask
5.3. End-To-End Learning Scheme
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- An, S.; Zhou, F.; Yang, M.; Zhu, H.; Fu, C.; Tsintotas, K.A. Real-time monocular human depth estimation and segmentation on embedded systems. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 55–62. [Google Scholar]
- Kansizoglou, I.; Misirlis, E.; Tsintotas, K.; Gasteratos, A. Continuous Emotion Recognition for Long-Term Behavior Modeling through Recurrent Neural Networks. Technologies 2022, 10, 59. [Google Scholar] [CrossRef]
- Polydoros, A.S.; Nalpantidis, L. Survey of model-based reinforcement learning: Applications on robotics. J. Intell. Robot. Syst. 2017, 86, 153–173. [Google Scholar] [CrossRef]
- Liu, Y.; Gao, P.; Zheng, C.; Tian, L.; Tian, Y. A deep reinforcement learning strategy combining expert experience guidance for a fruit-picking manipulator. Electronics 2022, 11, 311. [Google Scholar] [CrossRef]
- Cheng, Y.; Wang, D.; Zhou, P.; Zhang, T. Model compression and acceleration for deep neural networks: The principles, progress, and challenges. IEEE Signal Process. Mag. 2018, 35, 126–136. [Google Scholar] [CrossRef]
- Mohammadpour, M.; Zeghmi, L.; Kelouwani, S.; Gaudreau, M.A.; Amamou, A.; Graba, M. An Investigation into the Energy-Efficient Motion of Autonomous Wheeled Mobile Robots. Energies 2021, 14, 3517. [Google Scholar] [CrossRef]
- Kansizoglou, I.; Bampis, L.; Gasteratos, A. Do neural network weights account for classes centers? IEEE Trans. Neural Netw. Learn. Syst. 2022, 2022, 1–10. [Google Scholar] [CrossRef]
- Swanson, L.W. Brain Architecture: Understanding the Basic Plan; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Pfeiffer, M.; Pfeil, T. Deep learning with spiking neurons: Opportunities and challenges. Front. Neurosci. 2018, 12, 774. [Google Scholar] [CrossRef]
- Balaji, A.; Das, A.; Wu, Y.; Huynh, K.; Dell’Anna, F.G.; Indiveri, G.; Krichmar, J.L.; Dutt, N.D.; Schaafsma, S.; Catthoor, F. Mapping spiking neural networks to neuromorphic hardware. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 28, 76–86. [Google Scholar] [CrossRef]
- Tang, G.; Kumar, N.; Michmizos, K.P. Reinforcement co-Learning of Deep and Spiking Neural Networks for Energy-Efficient Mapless Navigation with Neuromorphic Hardware. In Proceedings of the IEEE/RSJInternational Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 25–29 October 2020; pp. 6090–6097. [Google Scholar] [CrossRef]
- Oikonomou, K.M.; Kansizoglou, I.; Gasteratos, A. A Framework for Active Vision-Based Robot Planning using Spiking Neural Networks. In Proceedings of the 2022 30th Mediterranean Conference on Control and Automation (MED), Athens, Greece, 1–28 July 2022; pp. 867–871. [Google Scholar]
- Sevastopoulos, C.; Oikonomou, K.M.; Konstantopoulos, S. Improving Traversability Estimation through Autonomous Robot Experimentation. In Proceedings of the International Conference on Computer Vision Systems, Thessaloniki, Greece, 23–25 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 175–184. [Google Scholar]
- Dalal, M.; Pathak, D.; Salakhutdinov, R.R. Accelerating robotic reinforcement learning via parameterized action primitives. Adv. Neural Inf. Process. Syst. 2021, 34, 21847–21859. [Google Scholar]
- Kansizoglou, I.; Bampis, L.; Gasteratos, A. An active learning paradigm for online audio-visual emotion recognition. IEEE Trans. Affect. Comput. 2019, 13, 756–768. [Google Scholar] [CrossRef]
- Peters, J.; Schaal, S. Policy gradient methods for robotics. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 2219–2225. [Google Scholar]
- Pastor, P.; Kalakrishnan, M.; Chitta, S.; Theodorou, E.; Schaal, S. Skill learning and task outcome prediction for manipulation. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 3828–3834. [Google Scholar]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef]
- Nguyen, H.; La, H. Review of deep reinforcement learning for robot manipulation. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 590–595. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Kim, M.; Han, D.K.; Park, J.H.; Kim, J.S. Motion Planning of Robot Manipulators for a Smoother Path Using a Twin Delayed Deep Deterministic Policy Gradient with Hindsight Experience Replay. Appl. Sci. 2020, 10, 575. [Google Scholar] [CrossRef]
- Wen, S.; Chen, J.; Wang, S.; Zhang, H.; Hu, X. Path planning of humanoid arm based on deep deterministic policy gradient. In Proceedings of the IEEE International Conference on Robotics and Biomimetics, Kuala Lumpur, Malaysia, 12–15 December 2018; pp. 1755–1760. [Google Scholar]
- Cheng, R.; Agarwal, A.; Fragkiadaki, K. Reinforcement learning of active vision for manipulating objects under occlusions. In Proceedings of the Conference on Robot Learning, Zurich, Switzerland, 29–31 October 2018; pp. 422–431. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Kansizoglou, I.; Bampis, L.; Gasteratos, A. Deep feature space: A geometrical perspective. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6823–6838. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. In Neural Networks for Perception; Elsevier: Amsterdam, The Netherlands, 1992; pp. 65–93. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Gerstner, W.; Kistler, W.M. Spiking Neuron Models: Single Neurons, Populations, Plasticity; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Querlioz, D.; Bichler, O.; Dollfus, P.; Gamrat, C. Immunity to device variations in a spiking neural network with memristive nanodevices. IEEE Trans. Nanotechnol. 2013, 12, 288–295. [Google Scholar] [CrossRef]
- Hagras, H.; Pounds-Cornish, A.; Colley, M.; Callaghan, V.; Clarke, G. Evolving spiking neural network controllers for autonomous robots. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA ’04, New Orleans, LA, USA, 26 April–1 May 2004; Volume 5, pp. 4620–4626. [Google Scholar] [CrossRef]
- Bouganis, A.; Shanahan, M. Training a spiking neural network to control a 4-DoF robotic arm based on Spike Timing-Dependent Plasticity. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar] [CrossRef]
- Nelson, M.; Rinzel, J. The Hodgkin—Huxley Model. In The Book of Genesis; Wm. B. Eerdmans Publishing: Grand Rapids, MI, USA, 1998; pp. 29–49. [Google Scholar]
- Deng, L.; Wu, Y.; Hu, X.; Liang, L.; Ding, Y.; Li, G.; Zhao, G.; Li, P.; Xie, Y. Rethinking the performance comparison between SNNS and ANNS. Neural Netw. 2020, 121, 294–307. [Google Scholar] [CrossRef]
- Caporale, N.; Dan, Y. Spike timing-dependent plasticity: A Hebbian learning rule. Annu. Rev. Neurosci. 2008, 31, 25–46. [Google Scholar] [CrossRef]
- Ponulak, F.; Kasiński, A. Supervised learning in spiking neural networks with ReSuMe: Sequence learning, classification, and spike shifting. Neural Comput. 2010, 22, 467–510. [Google Scholar]
- Bohte, S.M.; Kok, J.N.; La Poutré, J.A. SpikeProp: Backpropagation for networks of spiking neurons. In Proceedings of the ESANN, Bruges, Belgium, 26–28 April 2000; Volume 48, pp. 419–424. [Google Scholar]
- Florian, R.V. The chronotron: A neuron that learns to fire temporally precise spike patterns. PLoS ONE 2012, 7, e40233. [Google Scholar] [CrossRef]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Shi, L. Spatio-temporal backpropagation for training high-performance spiking neural networks. Front. Neurosci. 2018, 12, 331. [Google Scholar] [CrossRef]
- Hodgkin, A.L.; Huxley, A.F. A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 1952, 117, 500. [Google Scholar]
- Jolivet, R.; Lewis, T.J.; Gerstner, W. The spike response model: A framework to predict neuronal spike trains. In Proceedings of the Artificial Neural Networks and Neural Information Processing, Istanbul, Turkey, 26–29 June 2003; pp. 846–853. [Google Scholar]
- Izhikevich, E.M. Simple model of spiking neurons. IEEE Trans. Neural Netw. 2003, 14, 1569–1572. [Google Scholar] [CrossRef]
- Burkitt, A.N. A review of the integrate-and-fire neuron model: I. Homogeneous synaptic input. Biol. Cybern. 2006, 95, 1–19. [Google Scholar]
- Youssef, I.; Mutlu, M.; Bayat, B.; Crespi, A.; Hauser, S.; Conradt, J.; Bernardino, A.; Ijspeert, A. A Neuro-Inspired Computational Model for a Visually Guided Robotic Lamprey Using Frame and Event Based Cameras. IEEE Robot. Autom. Lett. 2020, 5, 2395–2402. [Google Scholar] [CrossRef]
- Bauer, C.; Milighetti, G.; Yan, W.; Mikut, R. Human-like reflexes for robotic manipulation using leaky integrate-and-fire neurons. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 2572–2577. [Google Scholar] [CrossRef]
- Metta, G.; Sandini, G.; Konczak, J. A developmental approach to sensori-motor coordination in artificial systems. In Proceedings of the International Conference on Systems, Man, and Cybernetics, San Diego, CA, USA, 14 October 1998; Volume 4, pp. 3388–3393. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Ji, Y.; Zhang, Y.; Li, S.; Chi, P.; Jiang, C.; Qu, P.; Xie, Y.; Chen, W. NEUTRAMS: Neural network transformation and co-design under neuromorphic hardware constraints. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–13. [Google Scholar] [CrossRef]
- Davies, M. Lessons from Loihi: Progress in Neuromorphic Computing. In Proceedings of the 2021 Symposium on VLSI Circuits, Kyoto, Japan, 13–19 June 2021; pp. 1–2. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
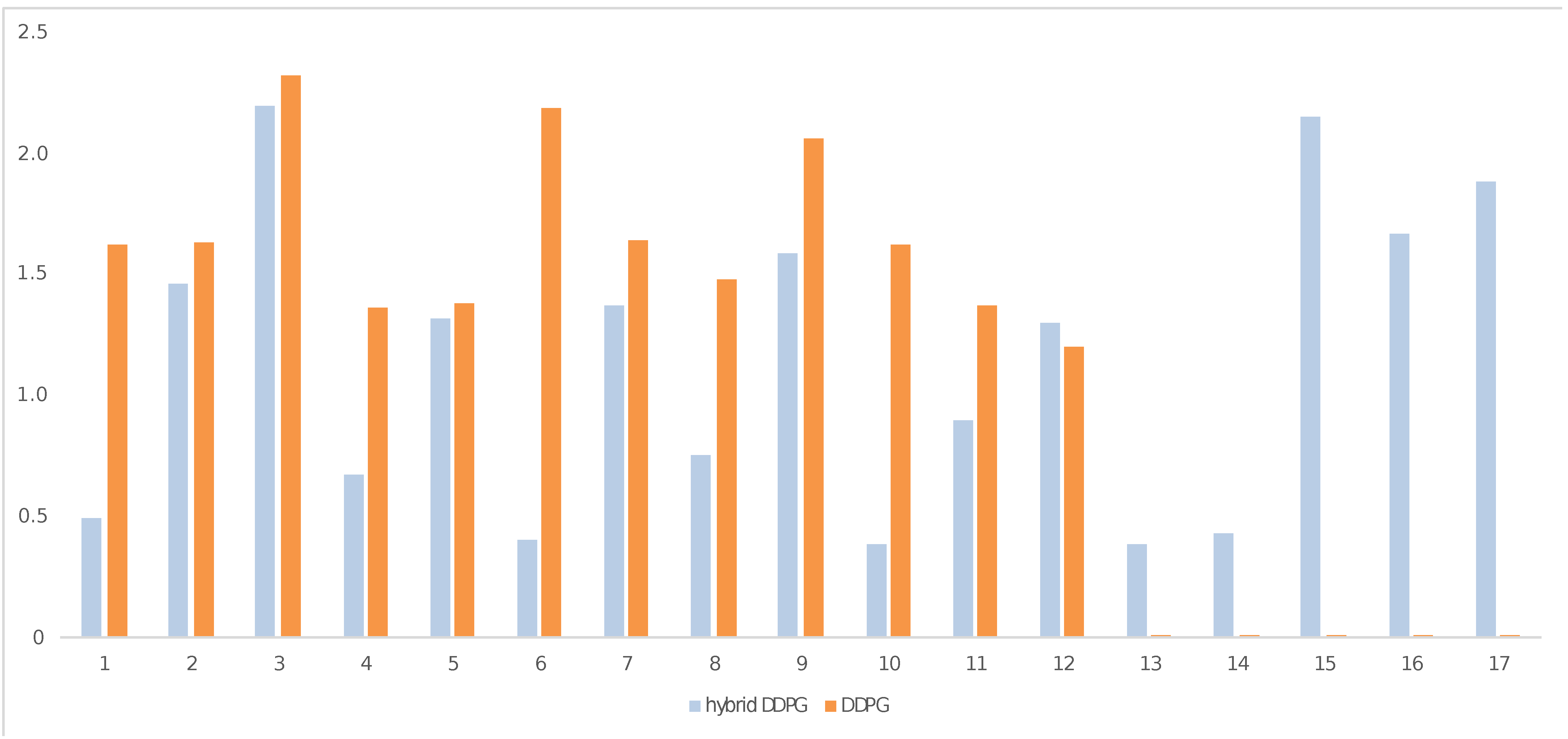{kind=link}
{kind=link}
{kind=link}
| Success Rate | Execution Time (s) | |||
|---|---|---|---|---|
| Hybrid DDPG | DDPG | Hybrid DDPG | DDPG | |
| Success Rate | Execution Time (s) | |||
|---|---|---|---|---|
| Hybrid DDPG | DDPG | Hybrid DDPG | DDPG | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oikonomou, K.M.; Kansizoglou, I.; Gasteratos, A. A Hybrid Spiking Neural Network Reinforcement Learning Agent for Energy-Efficient Object Manipulation. Machines 2023, 11, 162. https://doi.org/10.3390/machines11020162
Oikonomou KM, Kansizoglou I, Gasteratos A. A Hybrid Spiking Neural Network Reinforcement Learning Agent for Energy-Efficient Object Manipulation. Machines. 2023; 11(2):162. https://doi.org/10.3390/machines11020162
Chicago/Turabian StyleOikonomou, Katerina Maria, Ioannis Kansizoglou, and Antonios Gasteratos. 2023. "A Hybrid Spiking Neural Network Reinforcement Learning Agent for Energy-Efficient Object Manipulation" Machines 11, no. 2: 162. https://doi.org/10.3390/machines11020162
APA StyleOikonomou, K. M., Kansizoglou, I., & Gasteratos, A. (2023). A Hybrid Spiking Neural Network Reinforcement Learning Agent for Energy-Efficient Object Manipulation. Machines, 11(2), 162. https://doi.org/10.3390/machines11020162