
A Multi-Factor Driven Model for Locomotive Axle Temperature Prediction Based on Multi-Stage Feature Engineering and Deep Learning Framework


Abstract
:1. Introduction
1.1. Related Work
1.2. Novelty of the Study
- (1)
- In the study, a new locomotive axle temperature forecasting model is constructed on the locomotive status to comprehensively analyze multi-data and improve the prediction accuracy of the time series framework.
- (2)
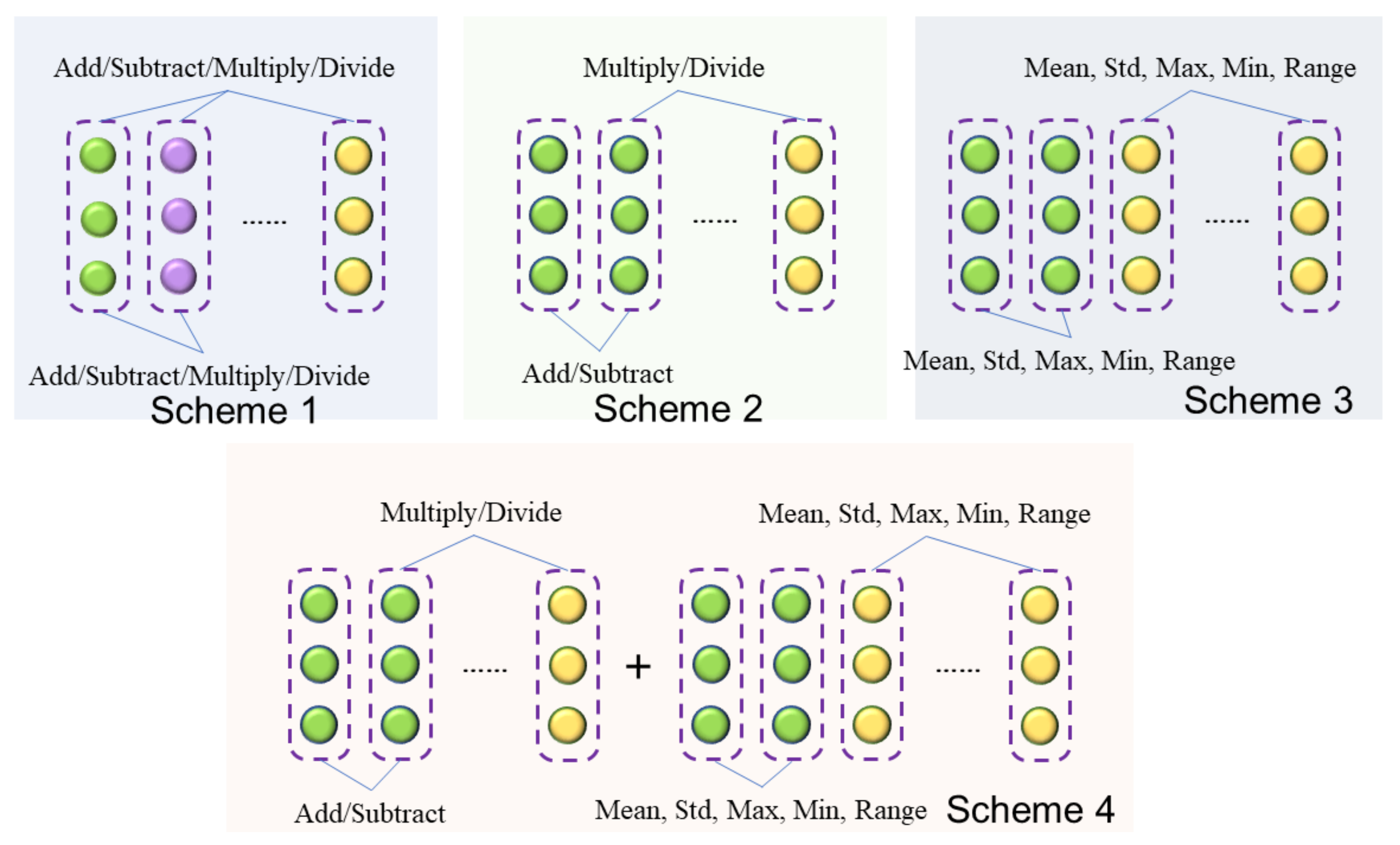
- A new two-stage feature selection method is designed in the paper. The feature crossing can search for useful features and evaluate the deep information of the datasets. The reinforcement learning algorithm is applied to select the optimal feature to ensure data quality. The hybrid two-stage feature selection structure is firstly utilized in locomotive axle temperature forecasting.
- (3)
- The stacked denoising autoencoder is used as the feature extraction approach to obtain the primary features and detailed information of the preprocessed data as the input of the bidirectional gated recurrent unit (BIGRU). For the favorable forecasting performance of deep learning, the model is firstly applied in the locomotive axle temperature prediction model as the core predictor to obtain the final result.
- (4)
- The multi-data-driven model FC-Q-SDAE-BIGRU adopted in the article is a new structure. To prove the high-precision performance of the presented axle temperature forecasting model, other alternative models were reproduced and tested with the proposed model.
2. Methodology
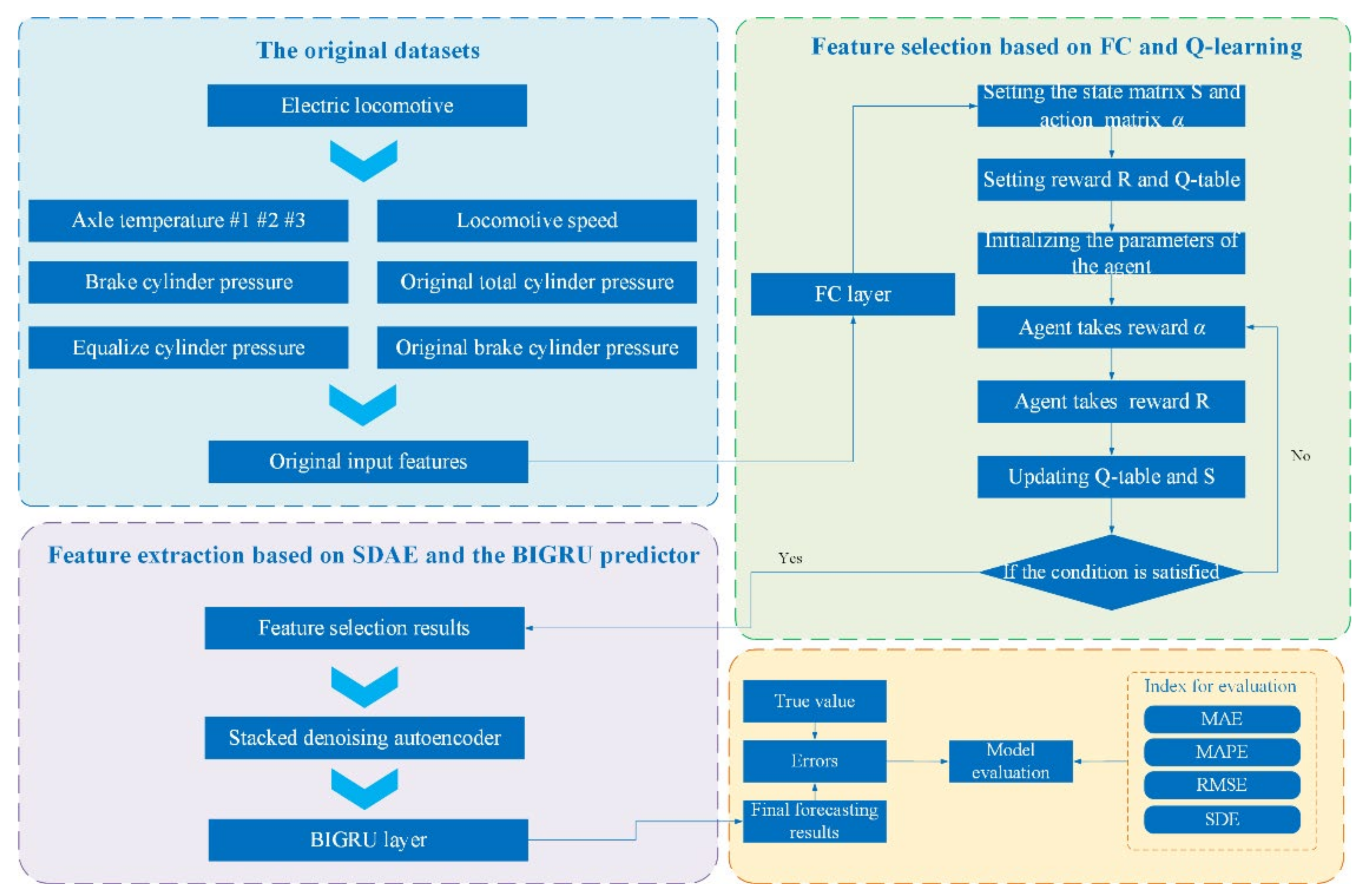
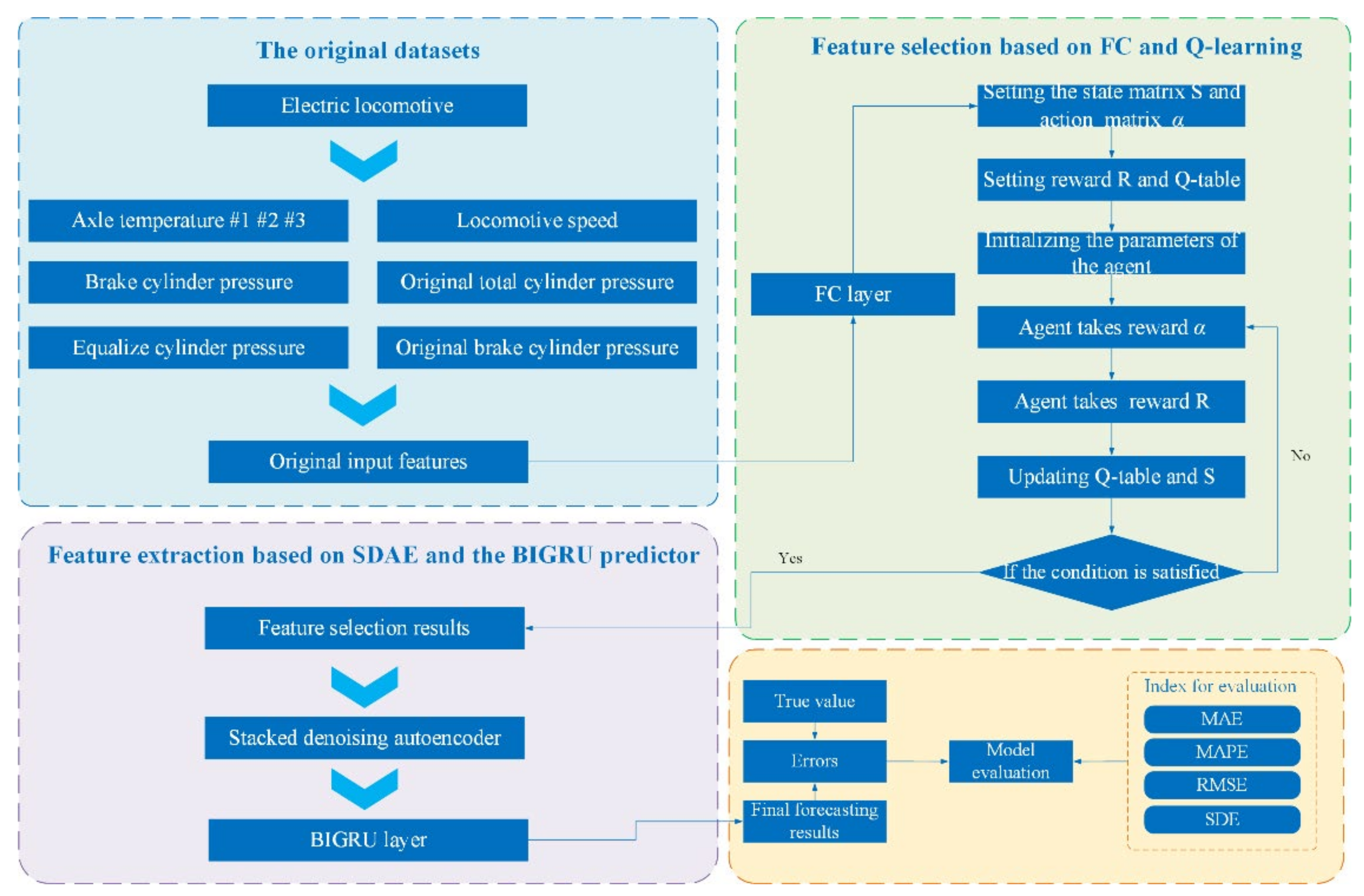
2.1. The Framework of the Proposed Model
2.2. Two-Stage Feature Selection Methods
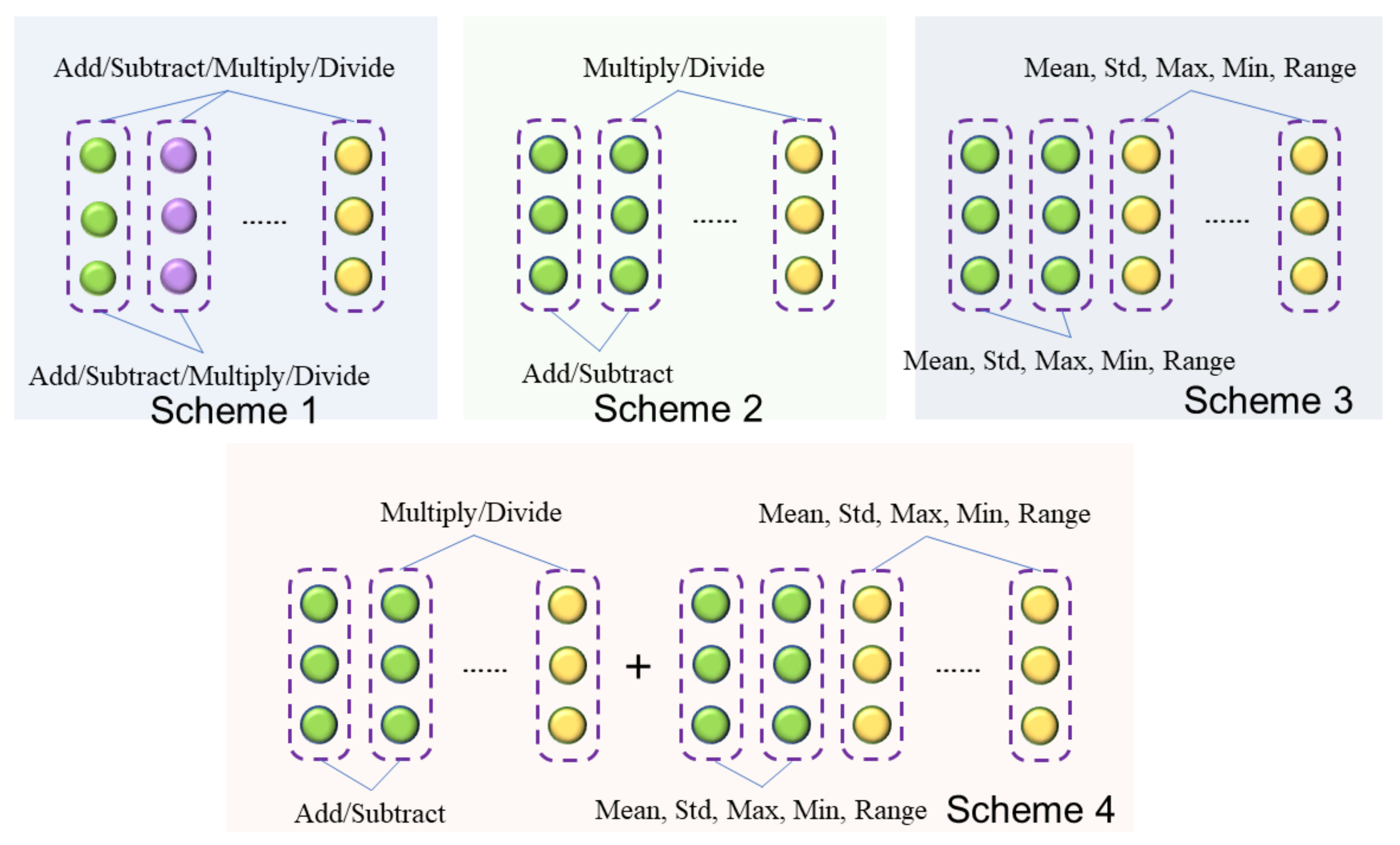
2.2.1. Stage I: Feature Crossing
2.2.2. Stage II: Feature Selection by Reinforcement Learning
| Algorithm 1 Feature Selection by Q-Learning |
| Input: Feature crossing results of four schemes Original preprocessed input features The maximum iteration: K Discount parameter: γ Learning rate: β Algorithm: 1: Initialize all parameters 2: for k = 1: K do 3: Select through the ε-greedy policy 4: Construct loss function L and reward R 5: Compute loss function L and reward R, and update the Q table: 6: end for Output: suitable features from the input |
2.3. Stacked Denoised Autoencoder
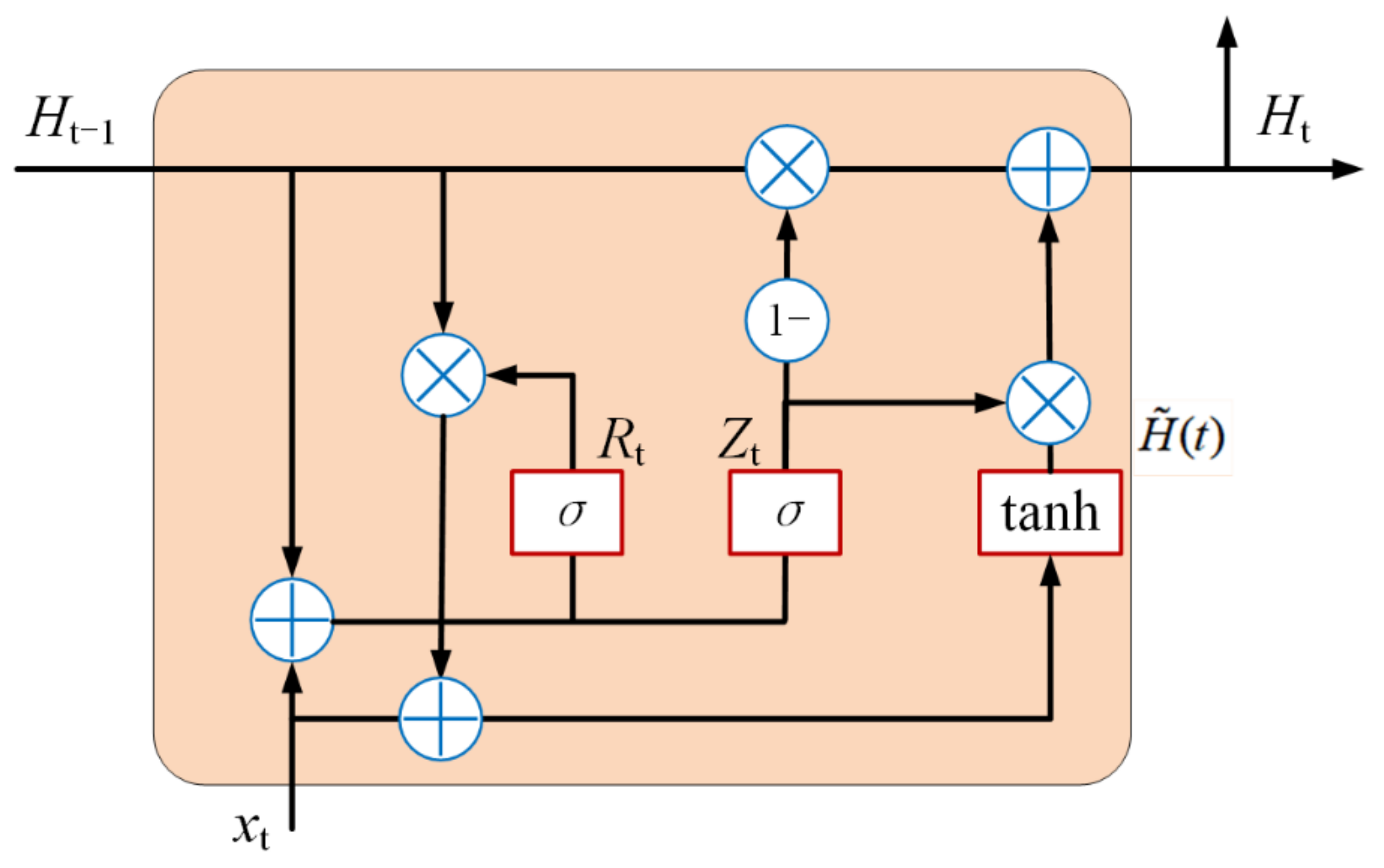
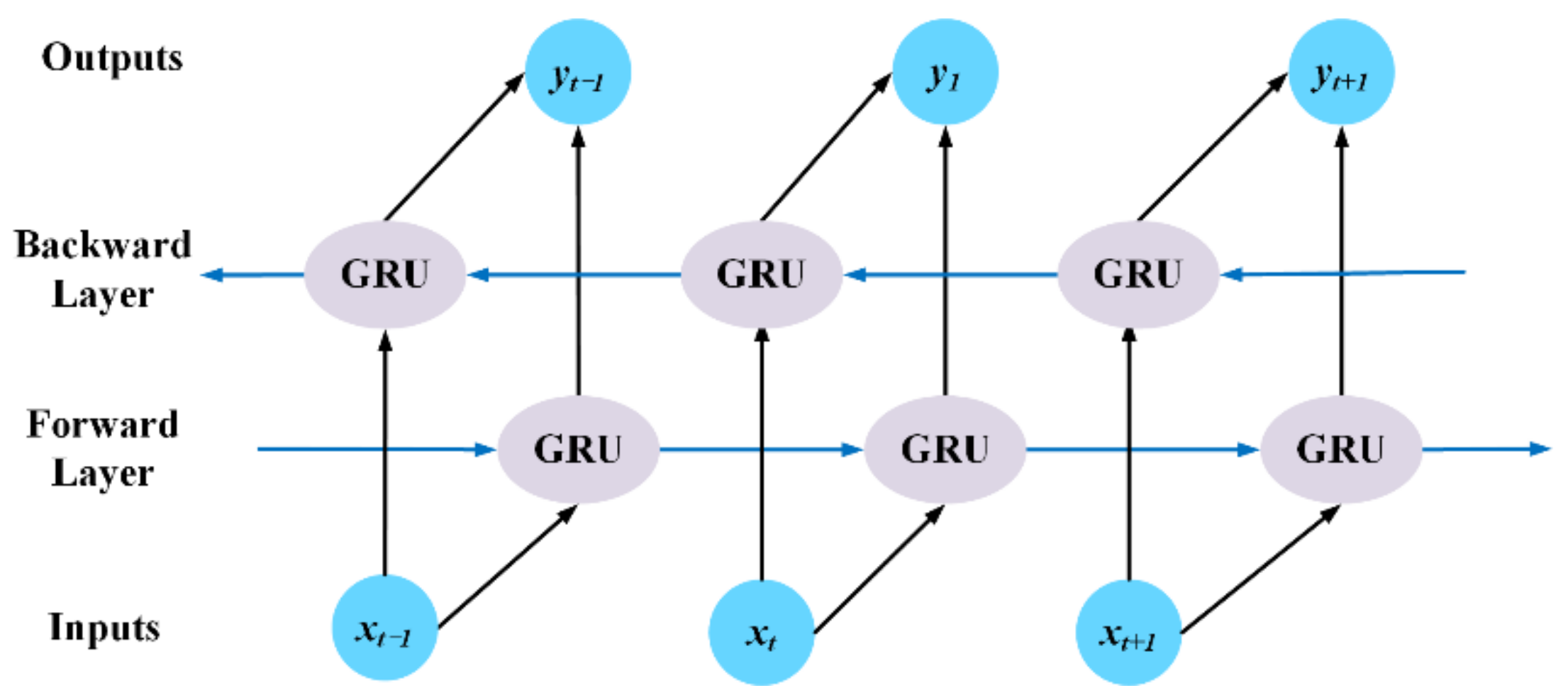
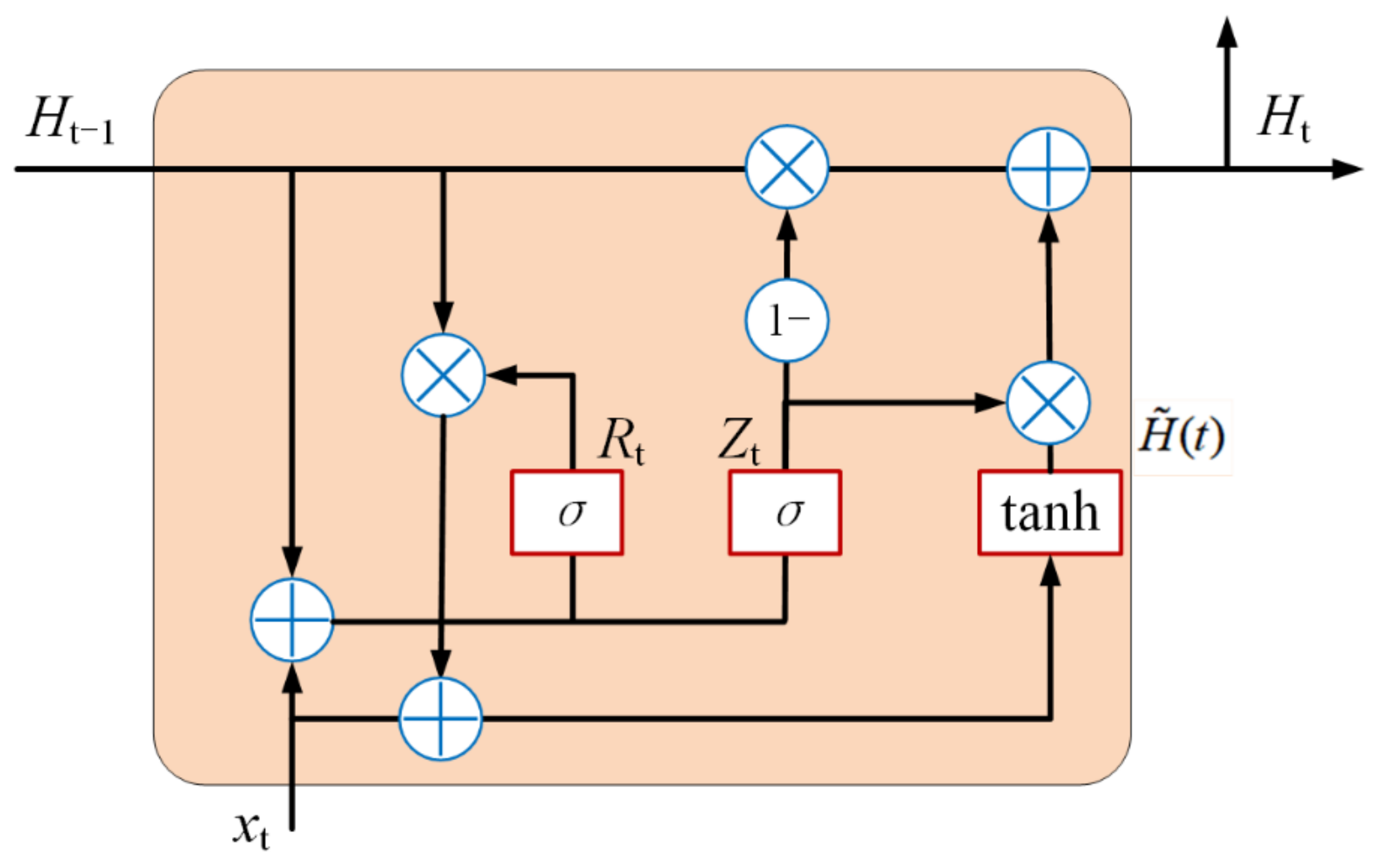
2.4. Bidirectional Gated Recurrent Unit
| Algorithm 2 The SDAE-BIGRU algorithms |
| Input: Selected features by Q-learning The weight set in the BIGRU network The number of DAE layer k is l. The maximum number of SDAE epochs: Z The maximum number of BIGRU epochs: N Algorithm: Step1: Unsupervised layer training of SDAE 1: Initialize all parameters in the SDAE 2: for z = 1: Z do 3: for k = 1: l do 4: train the first layer of DAE and use the hidden layer as the input of the second DAE. Repeat until the lth layer of DAE. 5: stack the trained n-layer DAE to obtain the SDAE with an output layer on the top 6: end for 7: end for The output will be transmitted as the optimal parameter into the BIGRU predictor Step2: Supervised layer training of BIGRU 1: Initialize all parameters in the BIGRU 2: for n = 1: N do 3: Calculate output in the single GRU 4: Compute output in the Bi-directional structure (3) Iteration ends when the stopping criterion is satisfied. 5: end for Output: The forecasting results |
3. Case Study
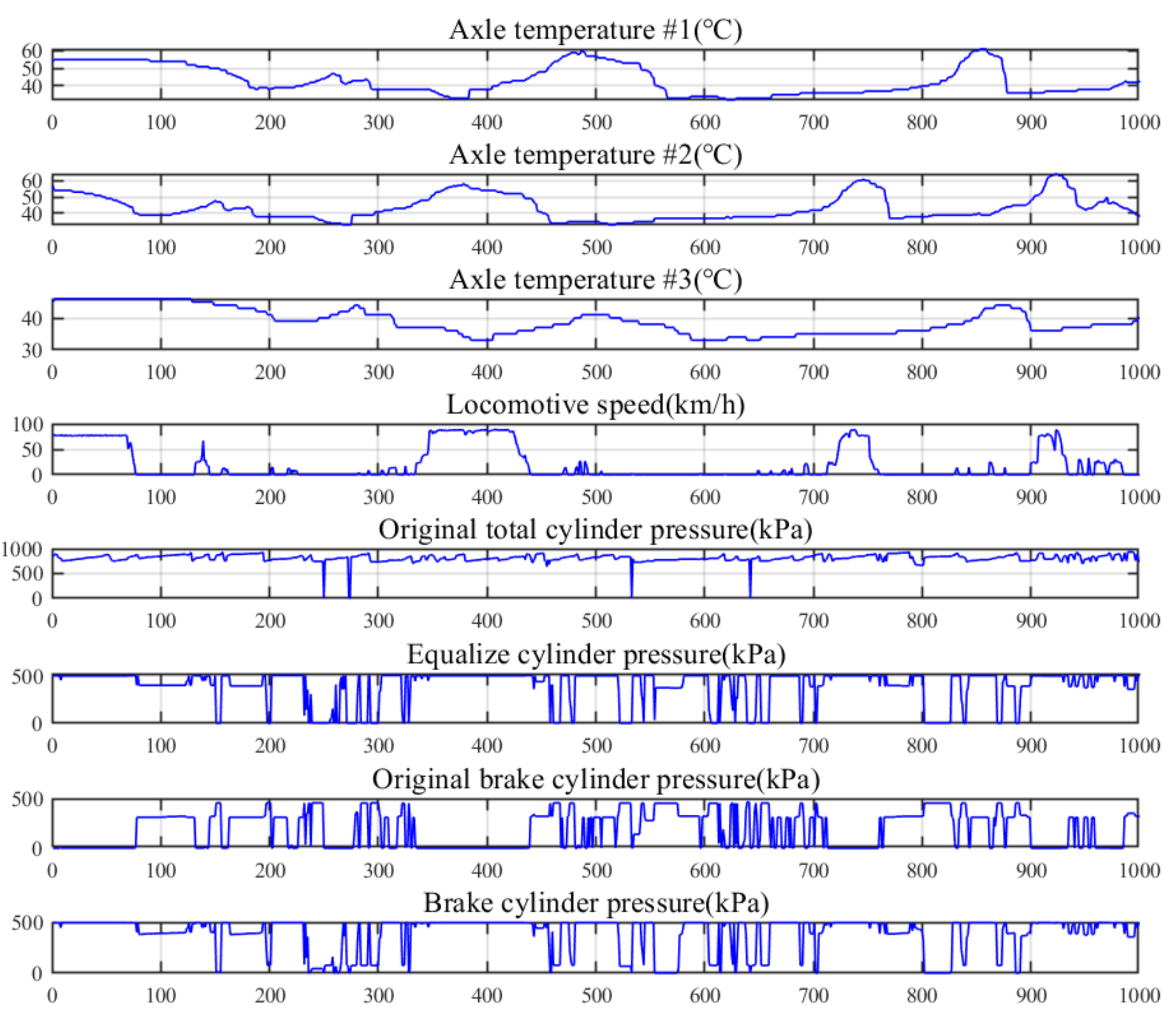
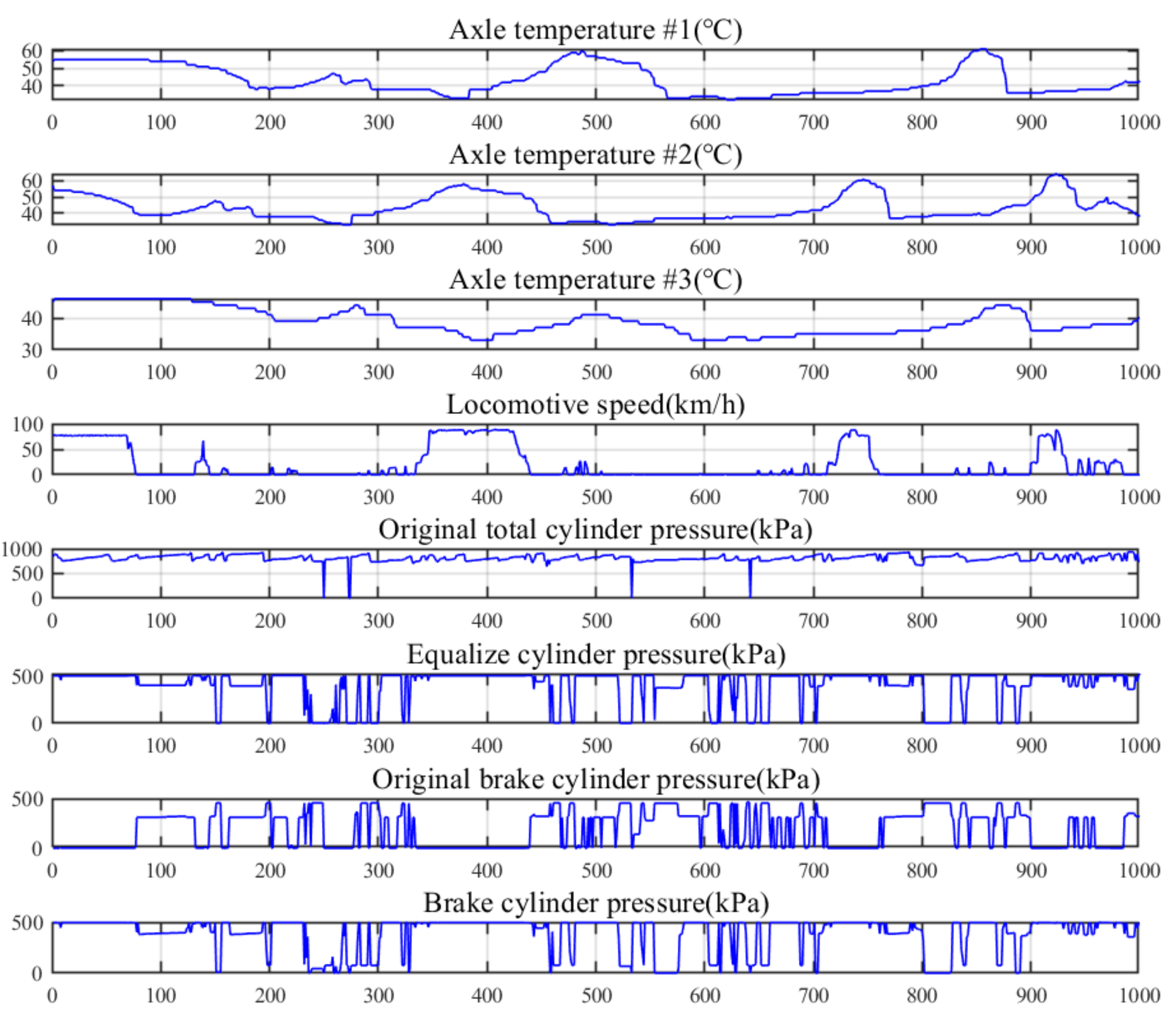
3.1. Locomotive Datasets
3.2. The Evaluation Indexes in the Study
3.3. Comparing Analysis with Alternative Algorithms
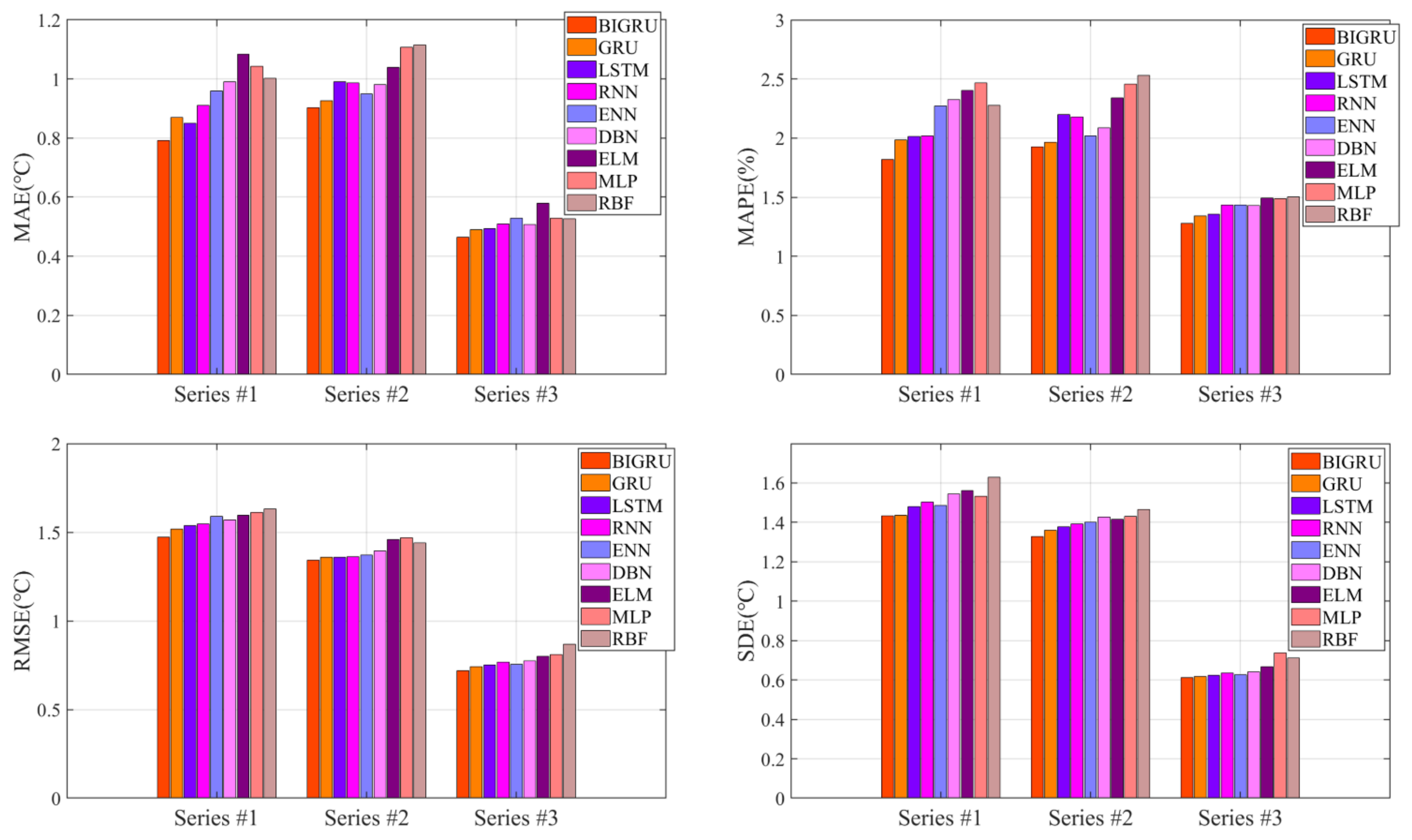
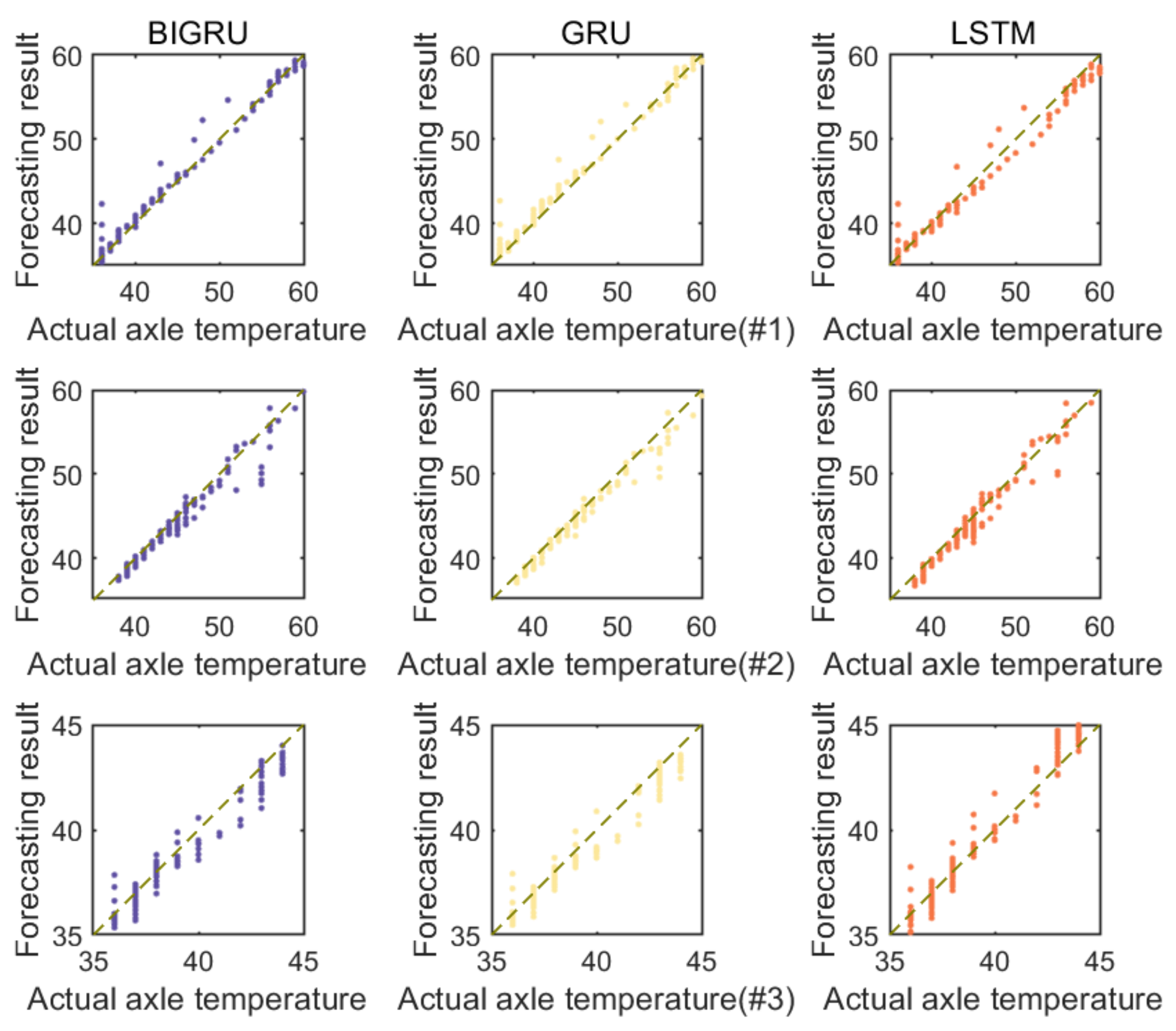
3.3.1. Comparative Experiment of Different Predictors
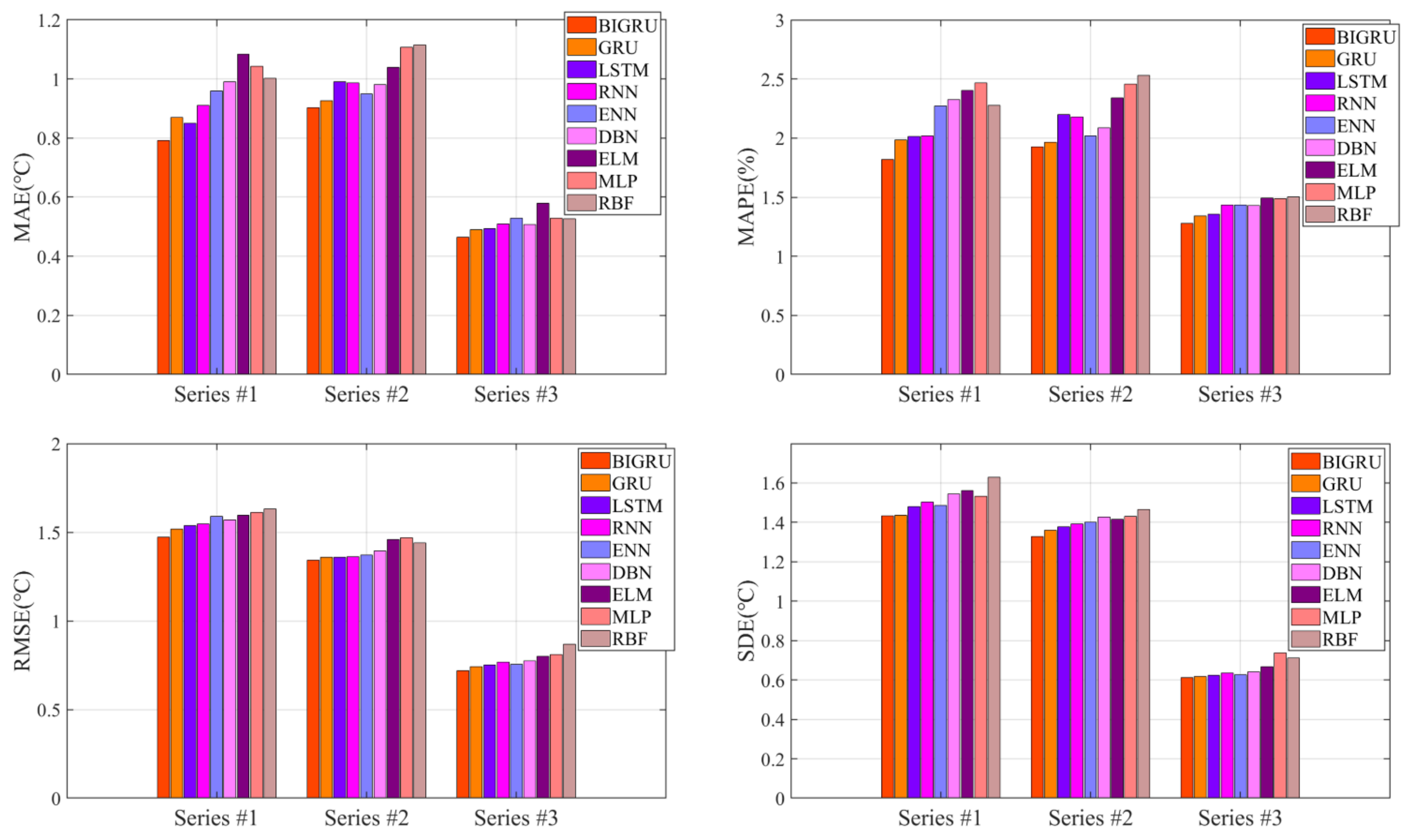
- (1)
- Compared to ELM, MLP, and RBF, other deep learning models with complex structures could obtain better axle temperature forecasting results. The forecasting accuracies of the traditional shallow neural network approaches are lower than deep learning models, which may be caused by the high fluctuation and irregular feature information of the original data. The deep learning algorithm, which could identify and analyze the series wave information by the multiple hidden layers, could effectively extract the deep information of the original data by an iterative process to obtain positive results.
- (2)
- By the deep learning networks, the accuracies of GRU and LSTM in the results outperform others. The reason may be that the gated structure can efficiently ameliorate the process and select more information, which enables GRU and LSTM to analyze the characteristics of deep data fluctuation acquisition. Meanwhile, the prediction error of the BIGRU is lower than that of others and obtains the best forecasting results in all series. The feasible cause may be that the bidirectional operation structure could optimize the analytical capability for the core information to effectively improve the training ability and raise the calculation speed. However, for different axle temperature datasets of fluctuation characteristics, it can be observed that a single predictor is difficult to adapt to various cases. As a consequence, it is essential to utilize other algorithms to increase the applicability and recognition ability of the model.

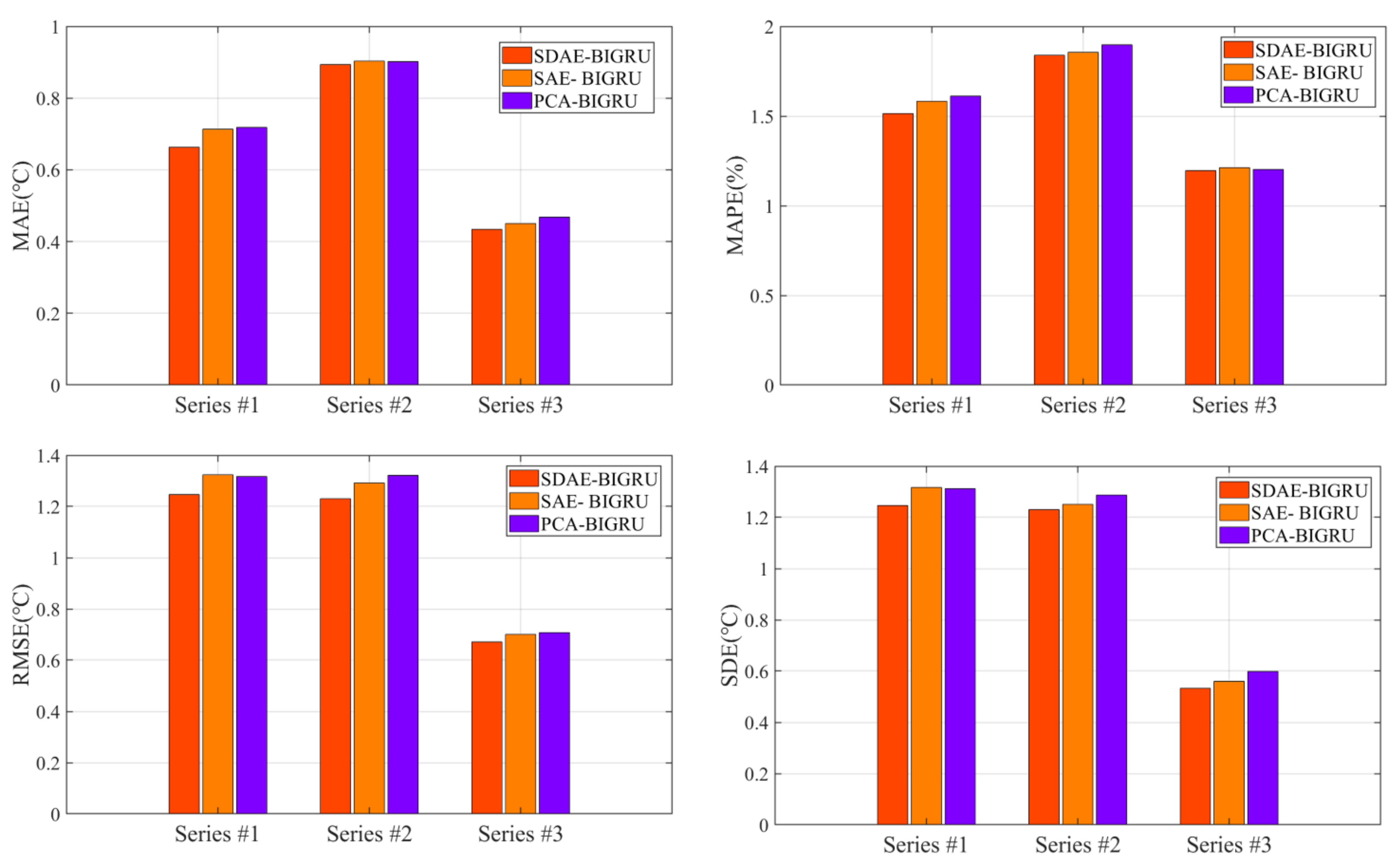
3.3.2. Comparative Experiments and Analysis of Different Feature Extraction Methods
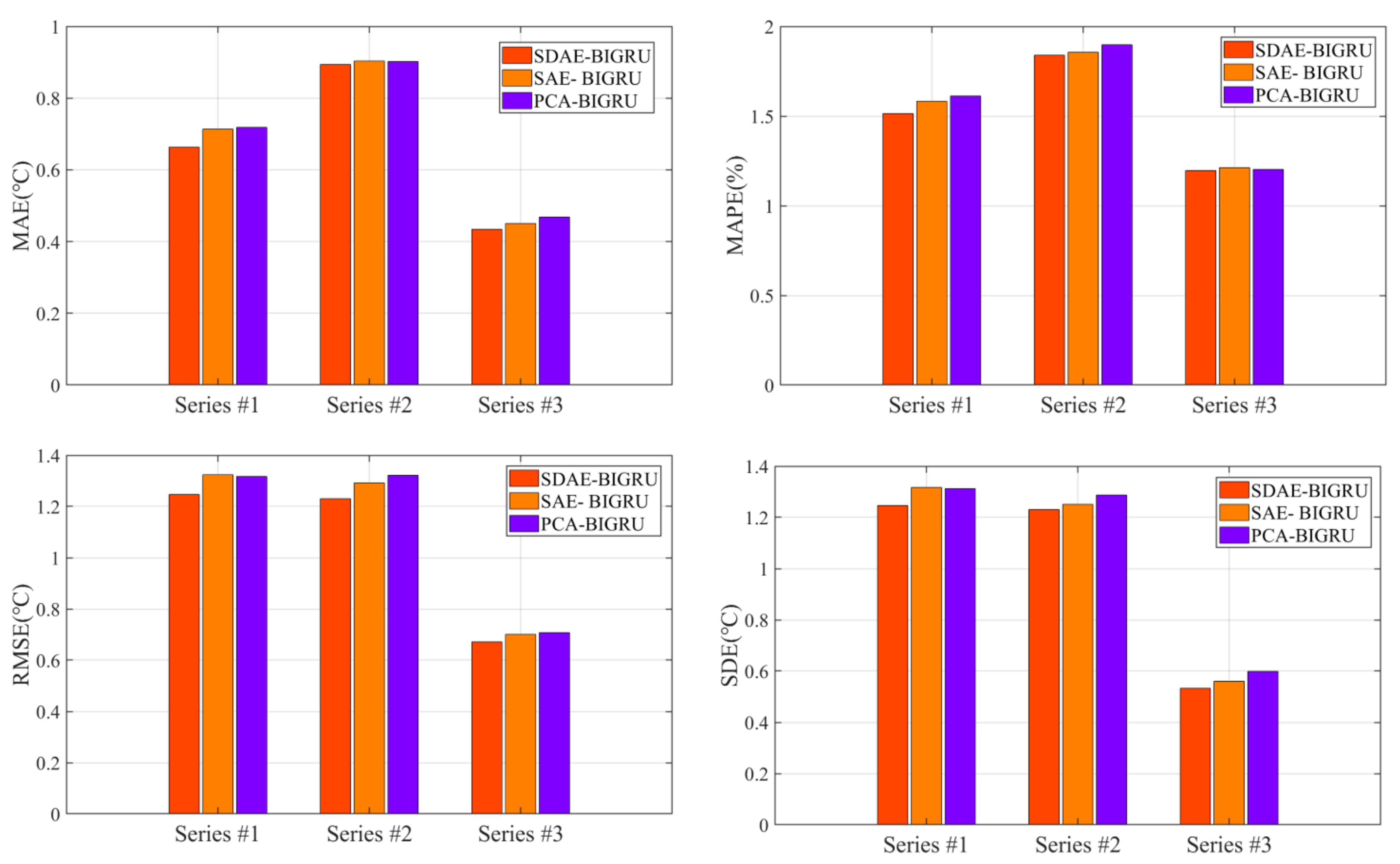
- (1)
- In contrast to single BIGRU predictors, the hybrid structure with a feature extraction algorithm can normally obtain better results with lower errors. The feature extraction algorithms effectively improve the prediction accuracy of the BIGRU, which extracts the input vector information and optimizes the fluctuation characteristics of the axle temperature datasets. The overall results showed that these feature extraction methods effectively raise the prediction accuracy in all cases. The probable reason may be that the feature extraction algorithms could deeply analyze the multi-data information and effectively reduce the modeling difficulty by raw data to promote the overall results.
- (2)
- By comparison with SAE and PCA methods, all results proved that the SDAE achieves the best results. SDAE can effectively decrease the data redundancy so that the recognition ability of the predictor can be further increased. Furthermore, the deep architecture of the SDAE is based on multi-layer DAE, which greatly increases the information extraction ability of the hybrid structure. Consequently, the feature selection approach based on SDAE is intensely effective for all datasets in axle temperature forecasting.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Indexes | Series #1 | Series #2 | Series #3 |
|---|---|---|---|---|
| SDAE-BIGRU vs. SAE- BIGRU | PMAE (%) | 7.0247 | 0.8298 | 3.1263 |
| PMAPE (%) | 4.4482 | 2.9477 | 1.4102 | |
| PRMSE (%) | 5.8370 | 4.7737 | 4.0274 | |
| PSDE (%) | 5.2867 | 1.6556 | 4.7917 | |
| SDAE-BIGRU vs. PCA- BIGRU | PMAE (%) | 7.6462 | 0.9642 | 7.3119 |
| PMAPE (%) | 6.1473 | 2.9477 | 0.4911 | |
| PRMSE (%) | 5.3941 | 6.8141 | 5.1383 | |
| PSDE (%) | 5.0270 | 4.5342 | 11.0127 | |
| SDAE-BIGRU vs. BIGRU | PMAE (%) | 16.2541 | 1.1176 | 11.1565 |
| PMAPE (%) | 16.7721 | 4.4492 | 6.3628 | |
| PRMSE (%) | 15.2911 | 8.3613 | 6.7314 | |
| PSDE (%) | 13.0474 | 7.3538 | 12.9618 |
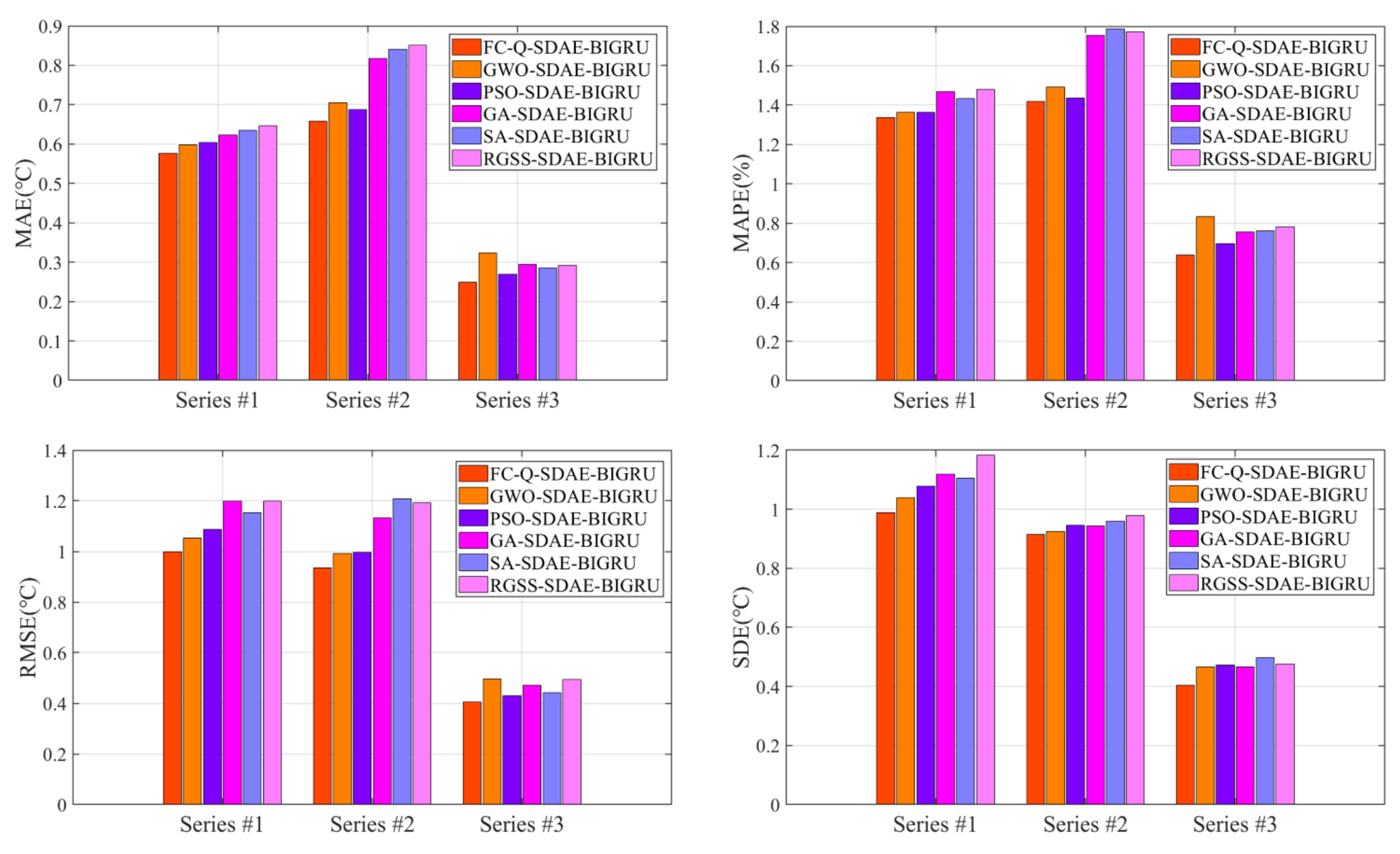
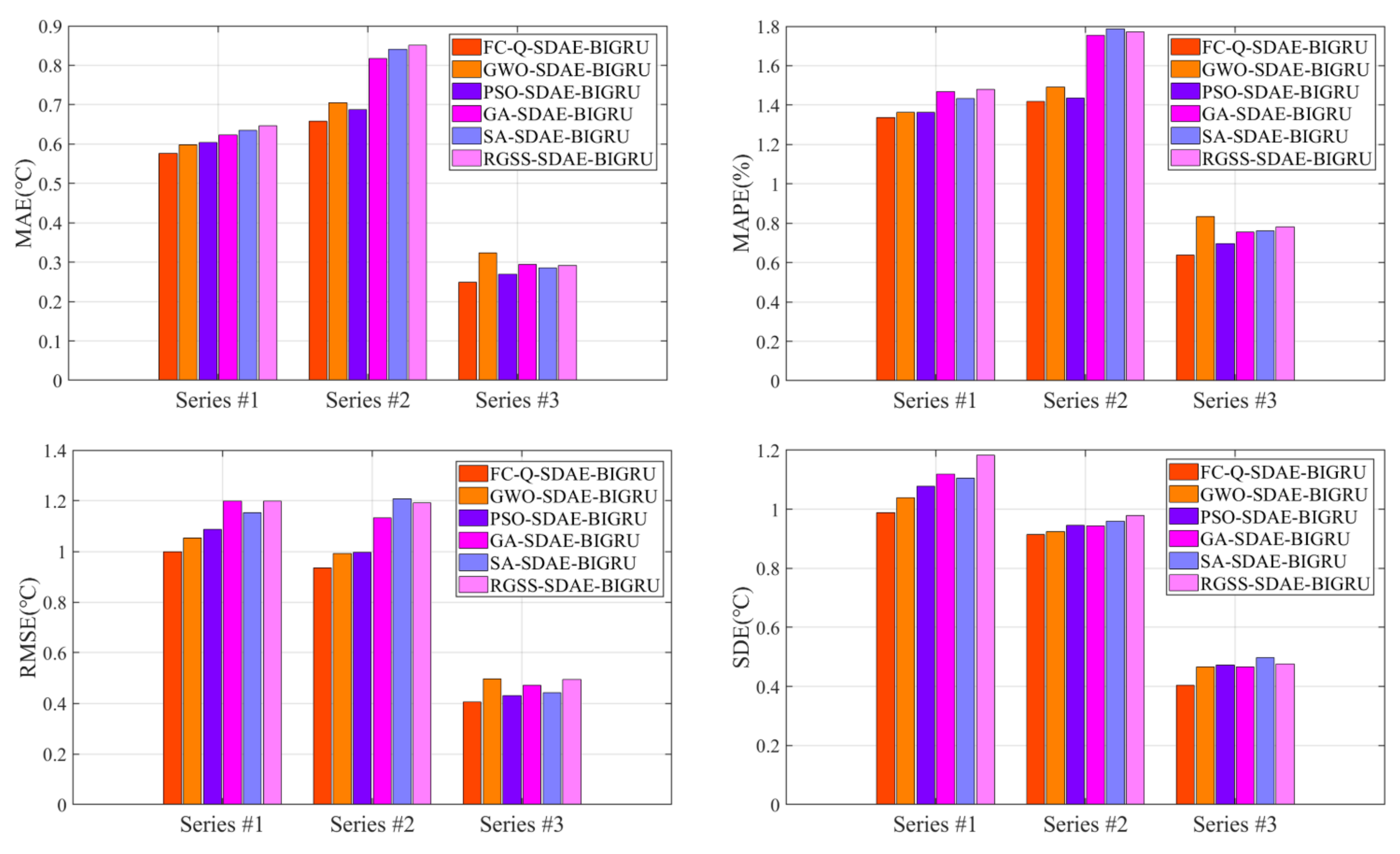
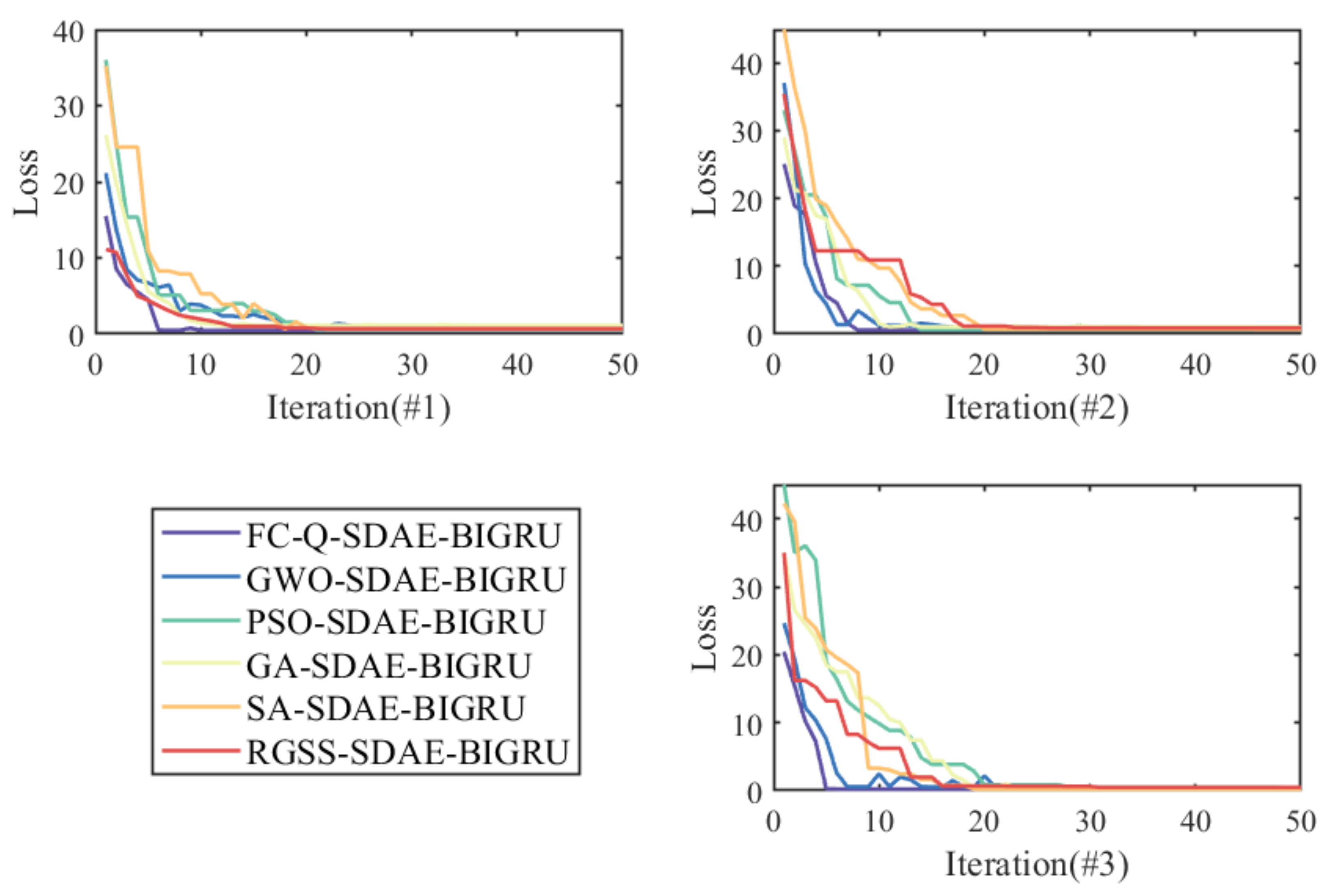
3.3.3. Comparative Experiments of Different Feature Selection Methods
- (1)
- The experimental results fully prove the ability of the feature selection algorithm to raise the prediction accuracy of SDAE-BIGRU in all cases. The possible reason is that the two-stage feature selection algorithms applied in this paper can unearth the deep correlation between axel temperature and other locomotive feature historical data, and selects the suitable features of the best quality, which could effectively avoid overfitting and obtain the best input for BIGRU.
- (2)
- By comparison with the traditional heuristic algorithms, the forecasting accuracy of the models with the reinforcement learning algorithm as feature selection is better than other methods in all datasets. Different from the population iteration process of the heuristic algorithms, the reinforcement learning algorithm improves the intelligence of the hybrid model by constantly training agents. By analyzing the relevance between input and output results, Q-learning could raise the decision-making ability and select the optimal features of axle temperature modeling.
- (3)
- The locomotive speeds and the cylinder pressures also have a great influence on the prediction results of FC-Q-SDAE-BIGRU. As the key component of the transmission system, the cylinder pressures can reflect the control status of the bogie. The speed is also a direct signal in the driven status of locomotives. In addition, the historical information on axle temperature could efficiently reflect the changing trend with the assistance of multiple auxiliary datasets. Therefore, these variables play a crucial role in establishing the prediction model. An accurate forecasting framework can conduct a precise estimation of future data changes so that the drivers and the train control centers can make accurate adjustments to stabilize the vehicles and avoid accidents.
| Methods | Indexes | Series #1 | Series #2 | Series #3 |
|---|---|---|---|---|
| FC-Q-SDAE-BIGRU vs. GWO-SDAE-BIGRU | PMAE (%) | 3.8403 | 6.5267 | 22.8677 |
| PMAPE (%) | 2.0378 | 5.0379 | 23.3769 | |
| PRMSE (%) | 5.2122 | 5.7531 | 18.5088 | |
| PSDE (%) | 4.9913 | 0.9963 | 13.2719 | |
| FC-Q-SDAE-BIGRU vs. PSO-SDAE-BIGRU | PMAE (%) | 4.7154 | 4.2024 | 7.5213 |
| PMAPE (%) | 2.0377 | 1.3020 | 8.3931 | |
| PRMSE (%) | 8.1762 | 6.1503 | 5.7634 | |
| PSDE (%) | 8.4175 | 3.2797 | 14.2463 | |
| FC-Q-SDAE-BIGRU vs. GA-SDAE-BIGRU | PMAE (%) | 7.5454 | 19.4326 | 15.2749 |
| PMAPE (%) | 8.9646 | 19.2124 | 15.3632 | |
| PRMSE (%) | 16.7306 | 17.4696 | 13.9796 | |
| PSDE (%) | 11.7552 | 3.1363 | 13.3462 | |
| FC-Q-SDAE-BIGRU vs. SA-SDAE-BIGRU | PMAE (%) | 9.1784 | 21.6088 | 12.4518 |
| PMAPE (%) | 6.8321 | 20.6416 | 16.2403 | |
| PRMSE (%) | 13.4685 | 22.4770 | 8.3616 | |
| PSDE (%) | 10.6700 | 4.7808 | 18.7424 | |
| FC-Q-SDAE-BIGRU vs. RGSS-SDAE-BIGRU | PMAE (%) | 10.8928 | 22.5579 | 14.2563 |
| PMAPE (%) | 9.6355 | 20.0147 | 18.2668 | |
| PRMSE (%) | 16.6820 | 21.5992 | 17.7818 | |
| PSDE (%) | 16.5202 | 6.6571 | 15.0032 |
| Series | Time | Locomotive Speeds | Original Total Cylinder Pressures | Equalize Cylinder Pressures | Original Brake Cylinder Pressures | Brake Cylinder Pressures | Axle Temperature |
|---|---|---|---|---|---|---|---|
| #1 | T-5 | 0 | 0 | 0 | 0 | 0 | 0 |
| T-4 | 1 | 0 | 0 | 1 | 0 | 1 | |
| T-3 | 1 | 1 | 1 | 1 | 0 | 0 | |
| T-2 | 1 | 0 | 0 | 1 | 1 | 0 | |
| T-1 | 0 | 0 | 0 | 0 | 1 | 0 | |
| #2 | T-5 | 0 | 0 | 1 | 1 | 0 | 1 |
| T-4 | 1 | 1 | 0 | 0 | 0 | 1 | |
| T-3 | 0 | 0 | 1 | 1 | 0 | 1 | |
| T-2 | 0 | 0 | 0 | 0 | 1 | 0 | |
| T-1 | 1 | 1 | 0 | 1 | 1 | 0 | |
| #3 | T-5 | 0 | 1 | 0 | 0 | 1 | 1 |
| T-4 | 1 | 1 | 1 | 0 | 1 | 0 | |
| T-3 | 1 | 0 | 0 | 1 | 1 | 1 | |
| T-2 | 1 | 1 | 0 | 1 | 1 | 0 | |
| T-1 | 0 | 1 | 1 | 1 | 1 | 1 |
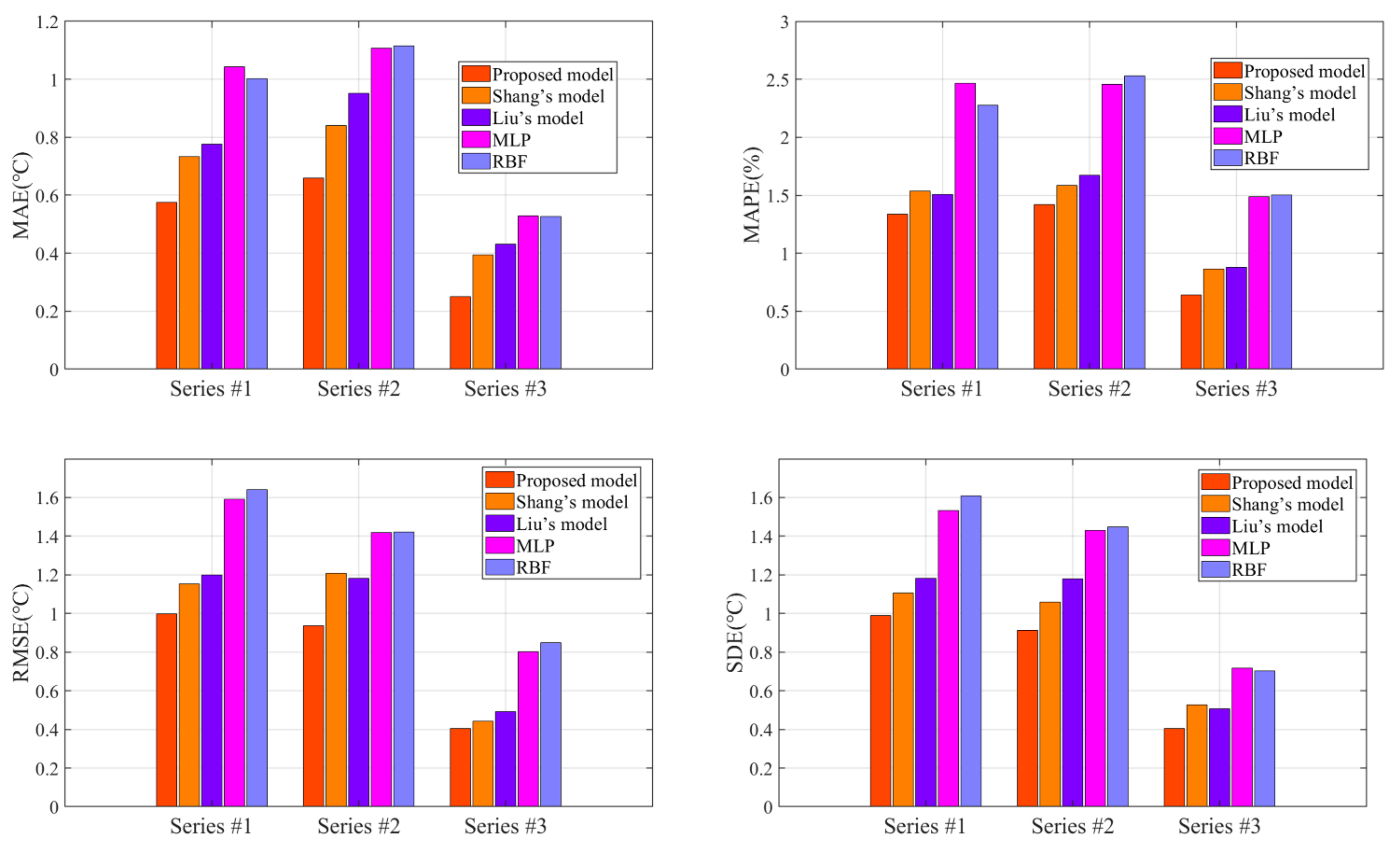
3.4. Comparative Experiments with Benchmark Models
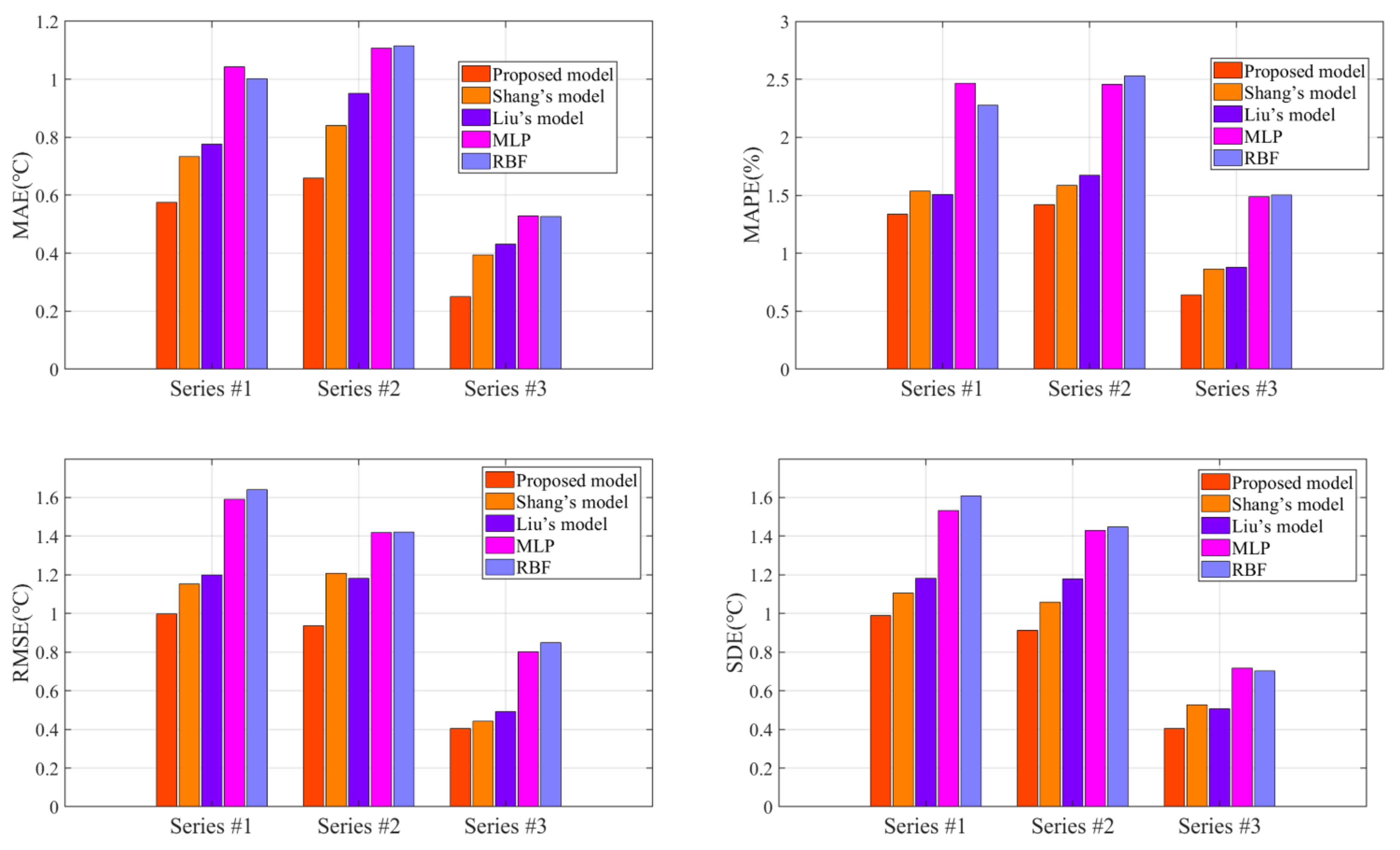
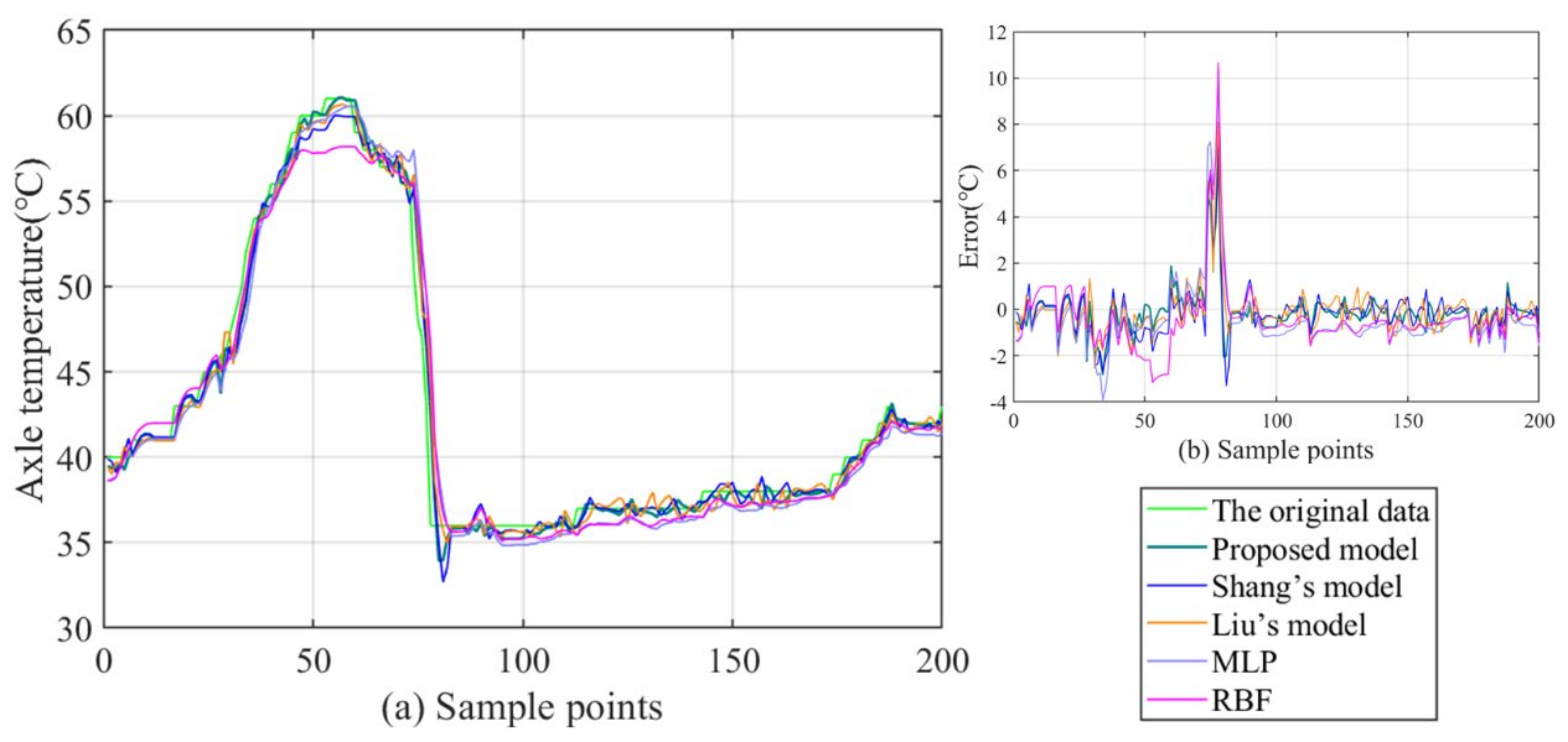
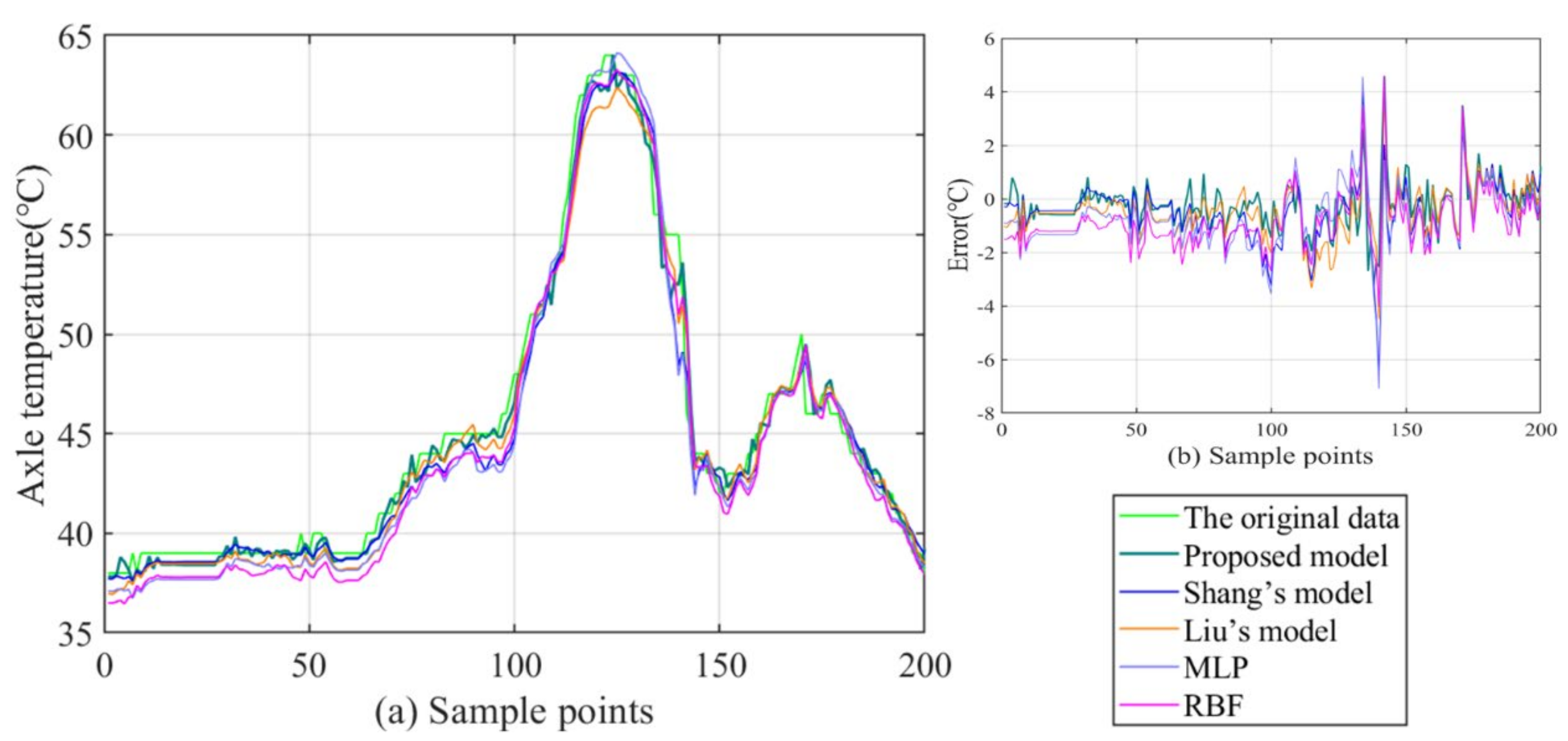
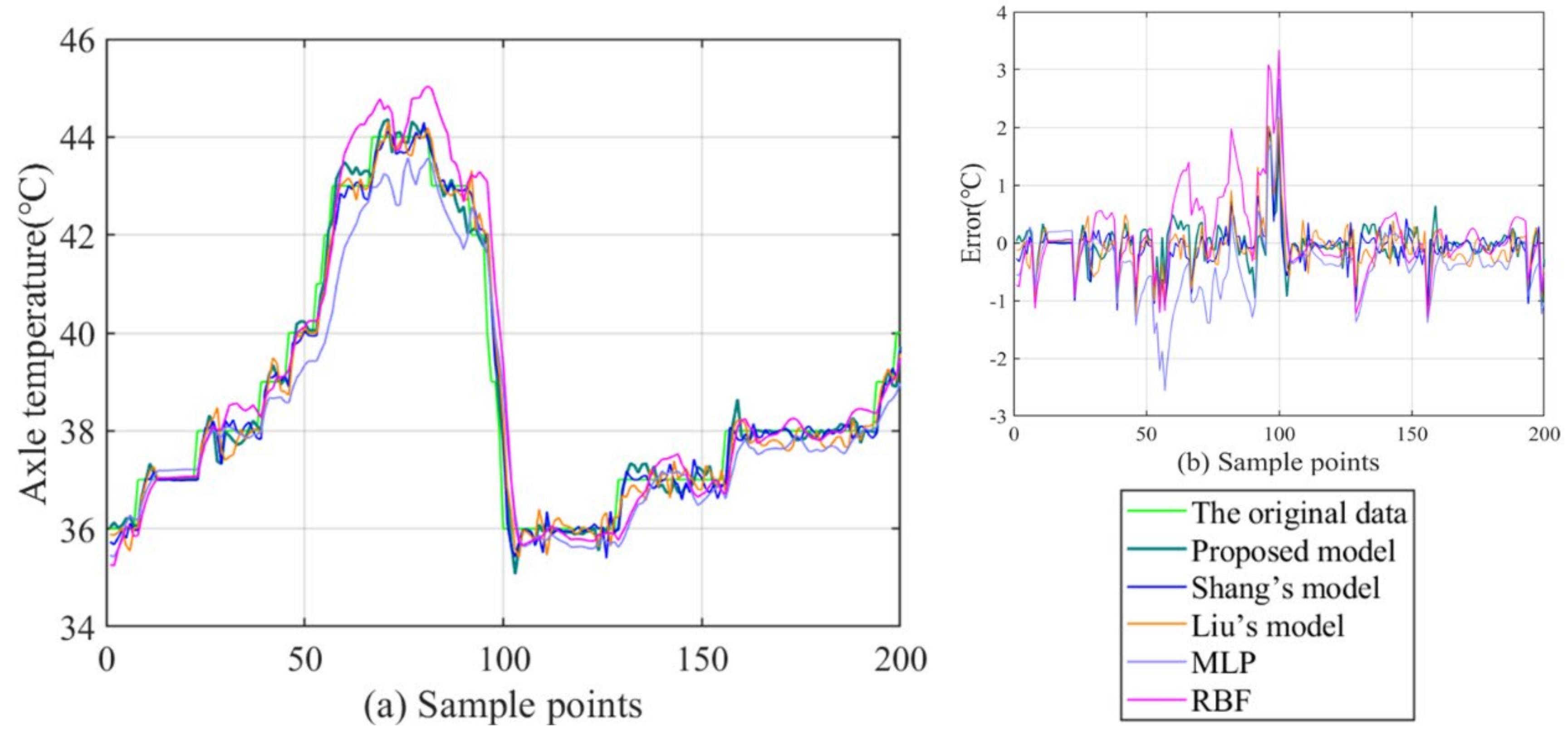
- (1)
- By comparison with the MLP and RBF, other hybrid ensemble models can achieve more satisfactory axle temperature modeling results. The single predictor can explore the simple nonlinear relation of the raw data, but it is arduous to follow the deep fluctuation information and the multi-data effect. On the contrary, the hybrid models can effectively integrate the advantages of each component and accomplish a valid modeling structure based on the multi-data.
- (2)
- In the above models, the proposed model acquires the best results with lower errors in all cases. This fully demonstrates that the FC-Q-SDAE-BIGRU framework is of favorable scientific modeling value, and combines the advantages of feature analysis and deep learning. A multi-data-driven axle temperature forecasting framework was utilized to construct more detailed mapping relationships than univariate models, and ensure that more influencing factors will be taken into account. The reinforcement learning-based two-step feature selection and SDAE-based feature extraction approaches were applied to improve the modeling input, analyze the advantageous information, and decrease the redundancy from raw data features. Finally, the application of the BIGRU model has also further improved the forecasting accuracy of classical deep learning methods.
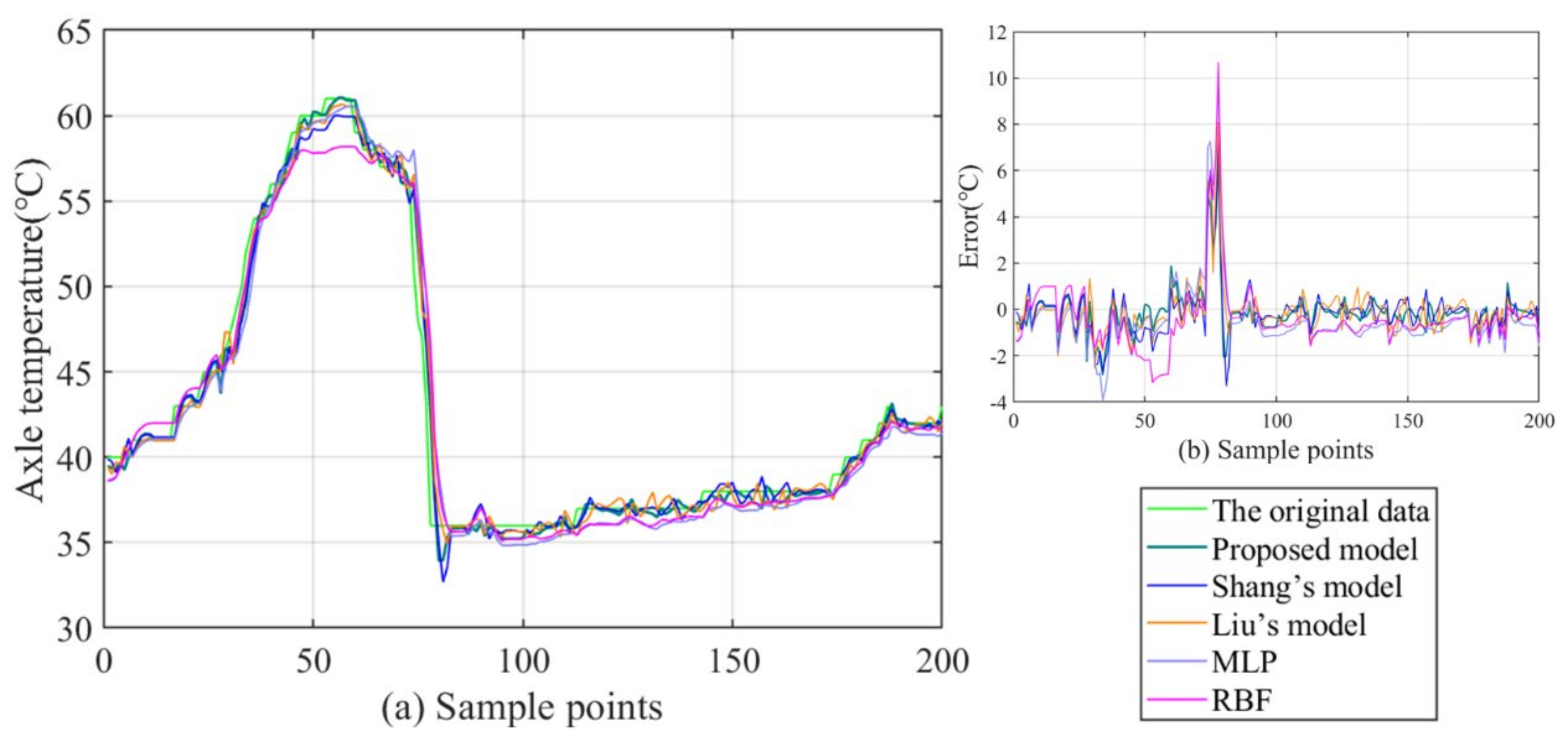
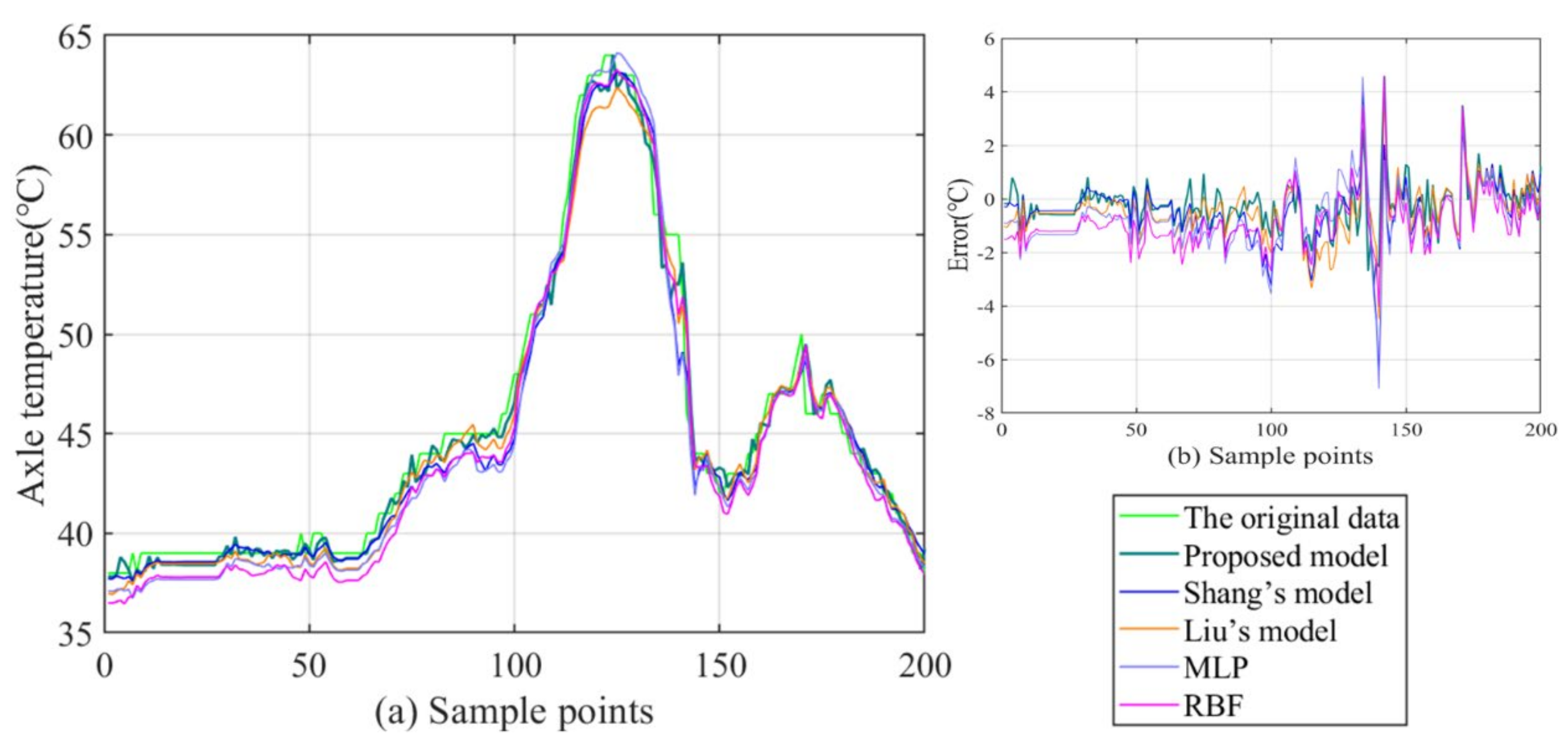

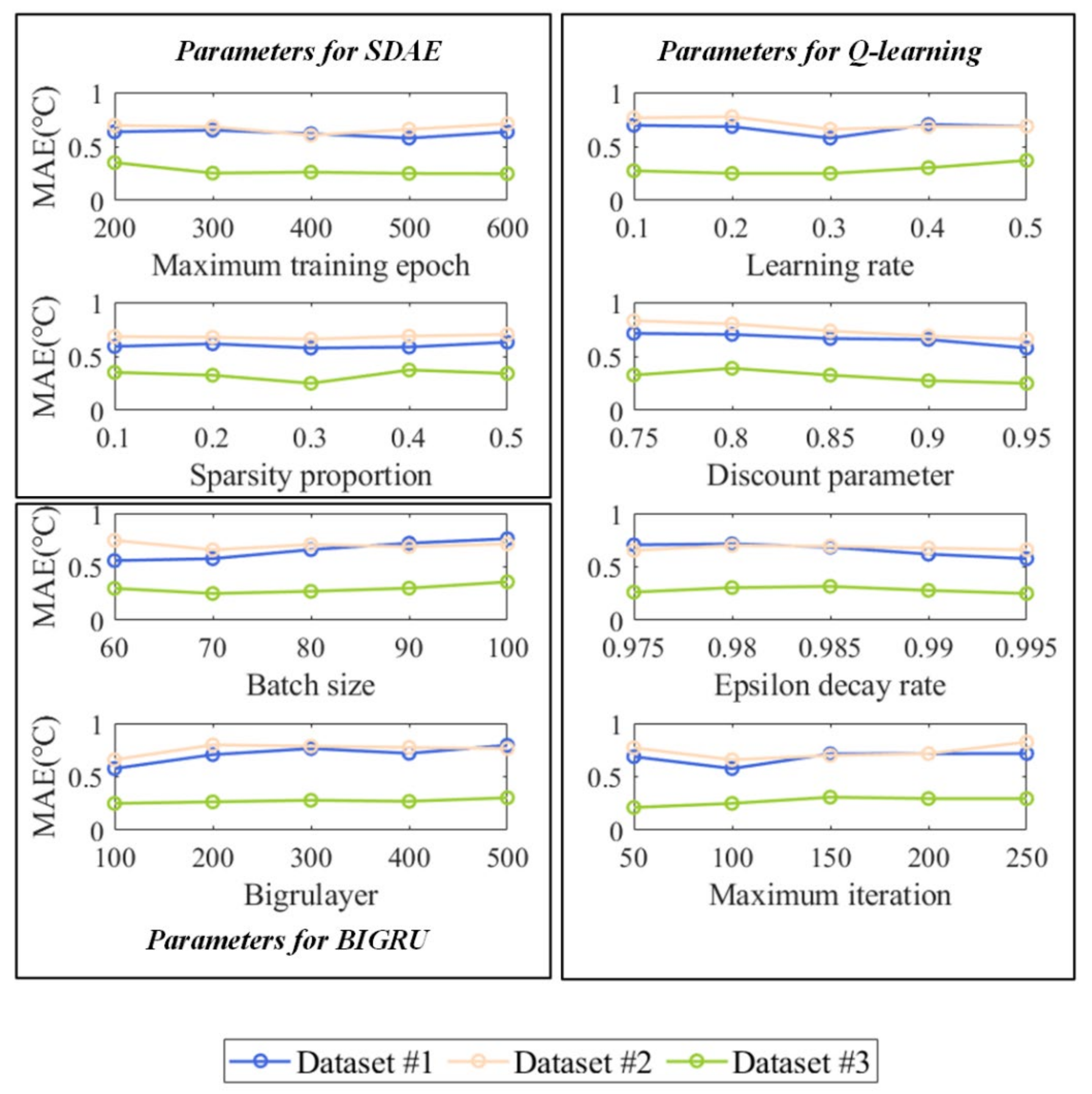
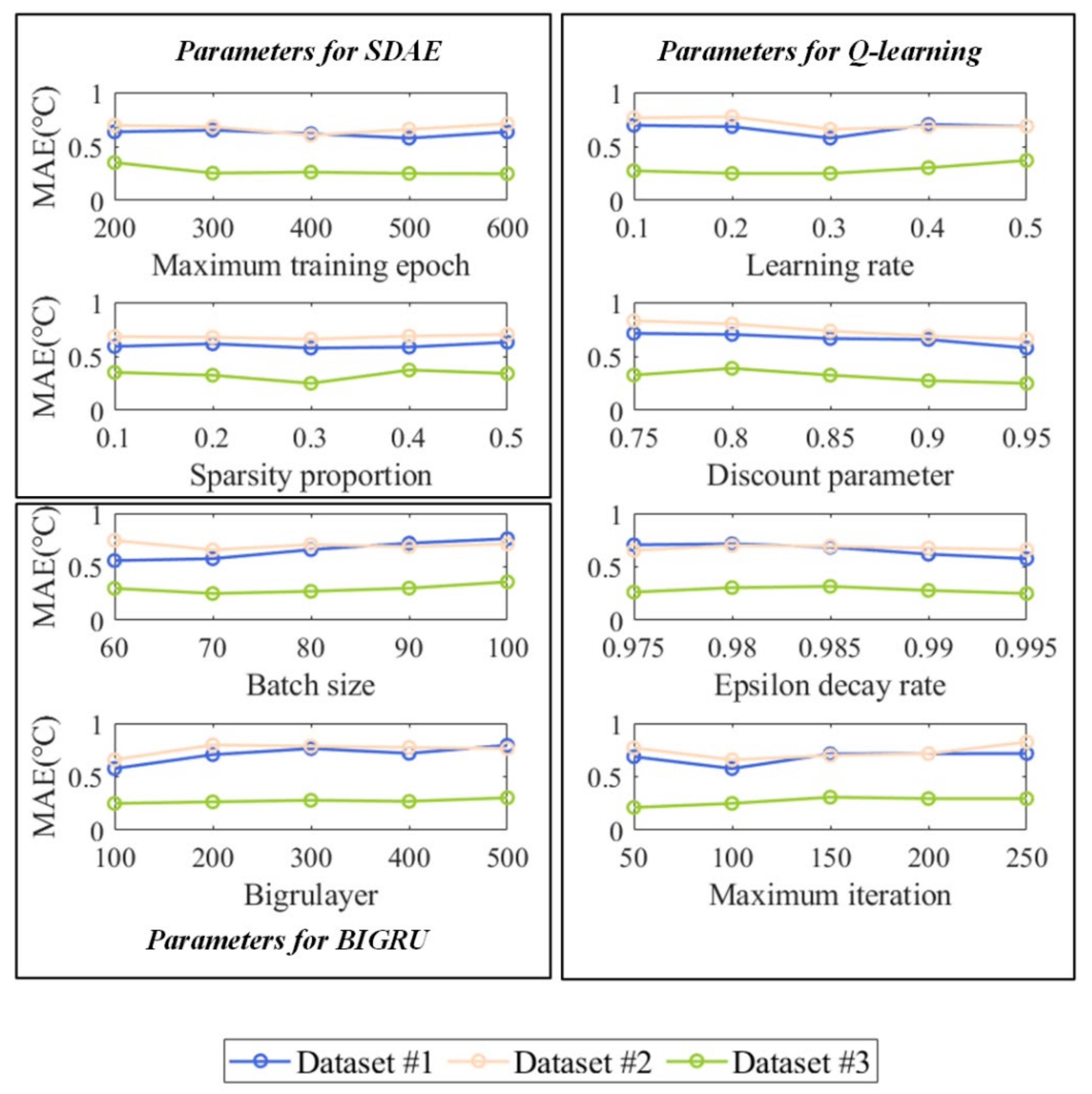
3.5. Sensitive Analysis of the Parameters and the Computational Time
4. Conclusions and Future Work
- (1)
- This paper analyzes the influence of multi-factor inputs on axle temperature forecasting modeling. The FC-Q-SDAE-BIGRU framework could deeply recognize the wave features of the raw data and analyze the influence of input features on forecasting modeling of the changing trend. The experimental results show that the auxiliary inputs are beneficial to accomplishing accurate forecasting.
- (2)
- From the comparative experiments, it could be found that the existing single predictors are not able to extract deep nonlinear characteristics to acquire satisfying results. Different from the traditional single predictor time series forecasting framework, the study designed a multi-data-driven hybrid forecasting model.
- (3)
- A new two-stage feature selection structure could be utilized to preprocess an original input. The FC method could further explore the potential features of the raw data and the reinforcement learning algorithm (Q-learning) comprehensively, considering the influence of other features from different angles on axle temperature, which helps to select the optimal features. SDAE method effectively extracts the deep cognition of the features and eliminates data redundancy, which significantly improves the modeling capability. Based on the principle of GRU and RNN, the bidirectional operation framework of GRU possess excellent time series modeling and forecasting ability that BIRGU revealed positive analytical capability and forecasting accuracy by comparison to other deep learning models and traditional neural network predictors.
- (4)
- The multi-data forecasting model combining the reinforcement learning and deep learning presented in the paper integrated the advancement of each component. In general, the proposed framework proved to be better than the benchmark models in all cases, which described excellent applicability to axle temperature forecasting.
- (1)
- Besides the axle temperature data, the influence of other factors such as power consumption, locomotive ambient temperature, and maintenance engineering plan on the abnormal trends of temperature data is also worth further studying.
- (2)
- During the life cycle, a huge amount of data will continue to accumulate with the operation of the locomotive so the forecasting model must also be constantly updated. Moreover, the intelligent big data platform could accomplish model parallel computing and analysis ability. In the future, the proposed model can be embedded into an intelligent big data platform such as Spark to further improve the comprehensive performance of the model and to establish an intelligent railway vehicle system. The systematic integration of data and models deserves further study.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Datasets | Partial FC Calculation | T-5 | T-4 | T-3 | T-2 | T-1 |
|---|---|---|---|---|---|---|
| LS-LS1-FC1 | 0 | 0 | 0 | 0 | - | |
| LS-OTCP1-FC1 | 0 | 0 | 0 | 1 | 0 | |
| #1 | LS-BCP1-FC1 | 0 | 0 | 0 | 0 | 0 |
| LS-AT1-FC1 | 0 | 0 | 0 | 0 | 0 | |
| LS-LS1-FC2 | 0 | 0 | 0 | 0 | - | |
| LS-OTCP1-FC2 | 0 | 0 | 0 | 0 | 0 | |
| LS-BCP1-FC2 | 0 | 0 | 0 | 0 | 0 | |
| LS-AT1-FC2 | 0 | 0 | 1 | 0 | 0 | |
| LS-LS1-FC3 | 0 | 0 | 0 | 0 | - | |
| OTCP-OTCP1-FC3 | 0 | 0 | 0 | 0 | - | |
| BCP-BCP1-FC3 | 1 | 0 | 0 | 0 | - | |
| AT-AT1-FC3 | 0 | 0 | 0 | 0 | - | |
| LS-LS1-FC4 | 0 | 0 | 0 | 0 | - | |
| OTCP-OTCP1-FC4 | 0 | 0 | 0 | 0 | - | |
| BCP-BCP1-FC4 | 0 | 0 | 0 | 1 | - | |
| AT-AT1-FC4 | 0 | 0 | 0 | 0 | - | |
| #2 | LS-LS2-FC1 | 0 | 0 | 0 | - | 0 |
| LS-OTCP2-FC1 | 0 | 0 | 0 | 0 | 0 | |
| LS-BCP2-FC1 | 0 | 0 | 1 | 0 | 0 | |
| LS-AT2-FC1 | 0 | 0 | 0 | 0 | 0 | |
| LS-LS2-FC2 | 0 | 0 | 0 | - | 0 | |
| LS-OTCP2-FC2 | 0 | 0 | 0 | 0 | 0 | |
| LS-BCP2-FC2 | 0 | 0 | 0 | 0 | 0 | |
| AT-AT2-FC2 | 1 | 0 | 0 | 0 | 0 | |
| LS-LS2-FC3 | 0 | 0 | 0 | - | 0 | |
| OTCP-OTCP2-FC3 | 0 | 0 | 0 | - | 0 | |
| BCP-BCP2-FC3 | 0 | 0 | 0 | - | 1 | |
| AT-AT2-FC3 | 0 | 0 | 0 | - | 0 | |
| LS-LS2-FC4 | 0 | 0 | 0 | - | 0 | |
| OTCP-OTCP2-FC4 | 0 | 0 | 0 | - | 0 | |
| BCP-BCP2-FC4 | 0 | 0 | 0 | - | 0 | |
| AT-AT2-FC4 | 0 | 0 | 1 | - | 0 | |
| #3 | LS-LS3-FC1 | 0 | 0 | - | 0 | 0 |
| LS-OTCP3-FC1 | 0 | 1 | 0 | 0 | 0 | |
| LS-BCP1-FC1 | 0 | 0 | 0 | 0 | 0 | |
| LS-AT1-FC1 | 0 | 0 | 0 | 0 | 0 | |
| LS-LS3-FC2 | 0 | 0 | - | 0 | 0 | |
| LS-OTCP3-FC2 | 0 | 0 | 0 | 0 | 0 | |
| LS-BCP3-FC2 | 0 | 0 | 0 | 0 | 0 | |
| LS-AT3-FC2 | 0 | 0 | 0 | 1 | 0 | |
| LS-LS3-FC3 | 0 | 0 | - | 0 | 0 | |
| OTCP-OTCP3-FC3 | 0 | 0 | - | 0 | 0 | |
| BCP-BCP3-FC3 | 0 | 0 | - | 0 | 0 | |
| AT-AT3-FC3 | 0 | 0 | - | 0 | 1 | |
| LS-LS3-FC4 | 0 | 0 | - | 0 | 0 | |
| OTCP-OTCP3-FC4 | 0 | 0 | - | 0 | 0 | |
| BCP-BCP3-FC4 | 1 | 0 | - | 0 | 0 | |
| AT-AT3-FC4 | 0 | 0 | - | 0 | 0 |
References
- Ghaviha, N.; Campillo, J.; Bohlin, M.; Dahlquist, E. Review of application of energy storage devices in railway transportation. Energy Procedia 2017, 105, 4561–4568. [Google Scholar] [CrossRef]
- Wu, S.C.; Liu, Y.X.; Li, C.H.; Kang, G.; Liang, S.L. On the fatigue performance and residual life of intercity railway axles with inside axle boxes. Eng. Fract. Mech. 2018, 197, 176–191. [Google Scholar] [CrossRef]
- Yan, G.; Yu, C.; Bai, Y. A New Hybrid Ensemble Deep Learning Model for Train Axle Temperature Short Term Forecasting. Machines 2021, 9, 312. [Google Scholar] [CrossRef]
- Milic, S.D.; Sreckovic, M.Z. A Stationary System of Noncontact Temperature Measurement and Hotbox Detecting. IEEE Trans. Veh. Technol. 2008, 57, 2684–2694. [Google Scholar] [CrossRef]
- Li, C.; Luo, S.; Cole, C.; Spiryagin, M. An overview: Modern techniques for railway vehicle on-board health monitoring systems. Veh. Syst. Dyn. 2017, 55, 1045–1070. [Google Scholar] [CrossRef]
- Vale, C.; Bonifácio, C.; Seabra, J.; Calçada, R.; Mazzino, N.; Elisa, M.; Terribile, S.; Anguita, D.; Fumeo, E.; Saborido, C. Novel efficient technologies in Europe for axle bearing condition monitoring—The MAXBE project. Transp. Res. Procedia 2016, 14, 635–644. [Google Scholar] [CrossRef]
- Liu, Q. High-speed Train Axle Temperature Monitoring System Based on Switched Ethernet. Procedia Comput. Sci. 2017, 107, 70–74. [Google Scholar] [CrossRef]
- Bing, C.; Shen, H.; Jie, C.; Li, L. Design of CRH axle temperature alarm based on digital potentiometer. In Proceedings of the Chinese Control Conference, Chengdu, China, 27–29 July 2016. [Google Scholar]
- Yan, G.; Yu, C.; Bai, Y. Wind Turbine Bearing Temperature Forecasting Using a New Data-Driven Ensemble Approach. Machines 2021, 9, 248. [Google Scholar] [CrossRef]
- Mi, X.; Zhao, S. Wind speed prediction based on singular spectrum analysis and neural network structural learning. Energy Convers. Manag. 2020, 216, 112956. [Google Scholar] [CrossRef]
- Wang, H.; Li, G.; Wang, G.; Peng, J.; Jiang, H.; Liu, Y. Deep learning based ensemble approach for probabilistic wind power forecasting. Appl. Energy 2017, 188, 56–70. [Google Scholar] [CrossRef]
- Shang, P.; Liu, X.; Yu, C.; Yan, G.; Xiang, Q.; Mi, X. A new ensemble deep graph reinforcement learning network for spatio-temporal traffic volume forecasting in a freeway network. Digit. Signal Processing 2022, 123, 103419. [Google Scholar] [CrossRef]
- Liu, X.; Qin, M.; He, Y.; Mi, X.; Yu, C. A new multi-data-driven spatiotemporal PM2. 5 forecasting model based on an ensemble graph reinforcement learning convolutional network. Atmos. Pollut. Res. 2021, 12, 101197. [Google Scholar] [CrossRef]
- Yan, G.; Chen, J.; Bai, Y.; Yu, C.; Yu, C. A Survey on Fault Diagnosis Approaches for Rolling Bearings of Railway Vehicles. Processes 2022, 10, 724. [Google Scholar] [CrossRef]
- Yoon, H.J.; Park, M.J.; Shin, K.B.; Na, H.S. Modeling of railway axle box system for thermal analysis. In Proceedings of the Applied Mechanics and Materials, Hong Kong, China, 17–18 August 2013; pp. 273–276. [Google Scholar]
- Ma, W.; Tan, S.; Hei, X.; Zhao, J.; Xie, G. A Prediction Method Based on Stepwise Regression Analysis for Train Axle Temperature. In Proceedings of the Computational Intelligence and Security, Wuxi, China, 16–19 December 2016; pp. 386–390. [Google Scholar]
- Xiao, X.; Liu, J.; Liu, D.; Tang, Y.; Dai, J.; Zhang, F. SSAE-MLP: Stacked sparse autoencoders-based multi-layer perceptron for main bearing temperature prediction of large-scale wind turbines. Concurr. Comput. Pract. Exp. 2021, 33, e6315. [Google Scholar] [CrossRef]
- Hao, W.; Liu, F. Axle Temperature Monitoring and Neural Network Prediction Analysis for High-Speed Train under Operation. Symmetry 2020, 12, 1662. [Google Scholar] [CrossRef]
- Abdusamad, K.B.; Gao, D.W.; Muljadi, E. A condition monitoring system for wind turbine generator temperature by applying multiple linear regression model. In Proceedings of the 2013 North American Power Symposium (NAPS), Manhattan, KS, USA, 22–24 September 2013; pp. 1–8. [Google Scholar]
- Xiao, Y.; Dai, R.; Zhang, G.; Chen, W. The use of an improved LSSVM and joint normalization on temperature prediction of gearbox output shaft in DFWT. Energies 2017, 10, 1877. [Google Scholar] [CrossRef]
- Fu, J.; Chu, J.; Guo, P.; Chen, Z. Condition monitoring of wind turbine gearbox bearing based on deep learning model. IEEE Access 2019, 7, 57078–57087. [Google Scholar] [CrossRef]
- Yang, X.; Dong, H.; Man, J.; Chen, F.; Zhen, L.; Jia, L.; Qin, Y. Research on Temperature Prediction for Axles of Rail Vehicle Based on LSTM. In Proceedings of the 4th International Conference on Electrical and Information Technologies for Rail Transportation (EITRT) 2019, Qingdao, China, 25–27 October 2019; pp. 685–696. [Google Scholar]
- Wang, S.; Chen, J.; Wang, H.; Zhang, D. Degradation evaluation of slewing bearing using HMM and improved GRU. Measurement 2019, 146, 385–395. [Google Scholar] [CrossRef]
- Li, H.; Jiang, Z.; Shi, Z.; Han, Y.; Yu, C.; Mi, X. Wind-speed prediction model based on variational mode decomposition, temporal convolutional network, and sequential triplet loss. Sustain. Energy Technol. Assess. 2022, 52, 101980. [Google Scholar] [CrossRef]
- Chen, S.; Ma, Y.; Ma, L.; Qiao, F.; Yang, H. Early warning of abnormal state of wind turbine based on principal component analysis and RBF neural network. In Proceedings of the 2021 6th Asia Conference on Power and Electrical Engineering (ACPEE), Chongqing, China, 8–11 April 2021; pp. 547–551. [Google Scholar]
- Khan, M.; Liu, T.; Ullah, F. A new hybrid approach to forecast wind power for large scale wind turbine data using deep learning with TensorFlow framework and principal component analysis. Energies 2019, 12, 2229. [Google Scholar] [CrossRef] [Green Version]
- Jaseena, K.; Kovoor, B.C. A hybrid wind speed forecasting model using stacked autoencoder and LSTM. J. Renew. Sustain. Energy 2020, 12, 023302. [Google Scholar] [CrossRef]
- Rizwan, H.; Li, C.; Liu, Y. Online dynamic security assessment of wind integrated power system using SDAE with SVM ensemble boosting learner. Int. J. Electr. Power Energy Syst. 2021, 125, 106429. [Google Scholar] [CrossRef]
- Kroon, M.; Whiteson, S. Automatic feature selection for model-based reinforcement learning in factored MDPs. In Proceedings of the 2009 International Conference on Machine Learning and Applications, Miami Beach, FL, USA, 13–15 December 2009; pp. 324–330. [Google Scholar]
- Beiranvand, F.; Mehrdad, V.; Dowlatshahi, M.B. Unsupervised feature selection for image classification: A bipartite matching-based principal component analysis approach. Knowl.-Based Syst. 2022, 250, 109085. [Google Scholar] [CrossRef]
- Gómez, M.J.; Castejón, C.; Corral, E.; García-Prada, J.C. Railway axle condition monitoring technique based on wavelet packet transform features and support vector machines. Sensors 2020, 20, 3575. [Google Scholar] [CrossRef] [PubMed]
- Paniri, M.; Dowlatshahi, M.B.; Nezamabadi-pour, H. Ant-TD: Ant colony optimization plus temporal difference reinforcement learning for multi-label feature selection. Swarm Evol. Comput. 2021, 64, 100892. [Google Scholar] [CrossRef]
- Paniri, M.; Dowlatshahi, M.B.; Nezamabadi-Pour, H. MLACO: A multi-label feature selection algorithm based on ant colony optimization. Knowl.-Based Syst. 2020, 192, 105285. [Google Scholar] [CrossRef]
- Hashemi, A.; Joodaki, M.; Joodaki, N.Z.; Dowlatshahi, M.B. Ant Colony Optimization equipped with an ensemble of heuristics through Multi-Criteria Decision Making: A case study in ensemble feature selection. Appl. Soft Comput. 2022, 124, 109046. [Google Scholar] [CrossRef]
- Hashemi, A.; Dowlatshahi, M.B.; Nezamabadi-Pour, H. MFS-MCDM: Multi-label feature selection using multi-criteria decision making. Knowl.-Based Syst. 2020, 206, 106365. [Google Scholar] [CrossRef]
- Zhang, Q.; Qian, H.; Chen, Y.; Lei, D. A short-term traffic forecasting model based on echo state network optimized by improved fruit fly optimization algorithm. Neurocomputing 2020, 416, 117–124. [Google Scholar] [CrossRef]
- Zheng, W.; Peng, X.; Lu, D.; Zhang, D.; Liu, Y.; Lin, Z.; Lin, L. Composite quantile regression extreme learning machine with feature selection for short-term wind speed forecasting: A new approach. Energy Convers. Manag. 2017, 151, 737–752. [Google Scholar] [CrossRef]
- Bayati, H.; Dowlatshahi, M.B.; Hashemi, A. MSSL: A memetic-based sparse subspace learning algorithm for multi-label classification. Int. J. Mach. Learn. Cybern. 2022, 1–18. [Google Scholar] [CrossRef]
- Hashemi, A.; Dowlatshahi, M.B.; Nezamabadi-Pour, H. MGFS: A multi-label graph-based feature selection algorithm via PageRank centrality. Expert Syst. Appl. 2020, 142, 113024. [Google Scholar] [CrossRef]
- Feng, C.; Zhang, J. Reinforcement learning based dynamic model selection for short-term load forecasting. In Proceedings of the 2019 IEEE Power&Energy Society Innovative Smart Grid Technologies Conference (ISGT), Bucharest, Romania, 29 September–2 October 2019; pp. 1–5. [Google Scholar]
- Xu, R.; Li, M.; Yang, Z.; Yang, L.; Qiao, K.; Shang, Z. Dynamic feature selection algorithm based on Q-learning mechanism. Appl. Intell. 2021, 51, 7233–7244. [Google Scholar] [CrossRef]
- Yu, R.; Ye, Y.; Liu, Q.; Wang, Z.; Yang, C.; Hu, Y.; Chen, E. Xcrossnet: Feature structure-oriented learning for click-through rate prediction. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Virtual Event, 11–14 May 2021; pp. 436–447. [Google Scholar]
- Guo, W.; Yang, Z.; Wu, S.; Chen, F. Explainable Enterprise Credit Rating via Deep Feature Crossing Network. arXiv 2021, 13843. preprint. [Google Scholar]
- Liang, J.; Hou, L.; Luan, Z.; Huang, W. Feature Selection with Conditional Mutual Information Considering Feature Interaction. Symmetry 2019, 11, 858. [Google Scholar] [CrossRef]
- Wang, Y.-H.; Li, T.-H.S.; Lin, C.-J. Backward Q-learning: The combination of Sarsa algorithm and Q-learning. Eng. Appl. Artif. Intell. 2013, 26, 2184–2193. [Google Scholar] [CrossRef]
- Taradeh, M.; Mafarja, M.; Heidari, A.A.; Faris, H.; Aljarah, I.; Mirjalili, S.; Fujita, H. An evolutionary gravitational search-based feature selection. Inf. Sci. 2019, 497, 219–239. [Google Scholar] [CrossRef]
- Luo, S. Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning. Appl. Soft Comput. 2020, 91, 106208. [Google Scholar] [CrossRef]
- Subramanian, A.; Chitlangia, S.; Baths, V. Reinforcement learning and its connections with neuroscience and psychology. Neural Netw. 2022, 145, 271–287. [Google Scholar] [CrossRef]
- Li, Q.; Yan, G.; Yu, C. A Novel Multi-Factor Three-Step Feature Selection and Deep Learning Framework for Regional GDP Prediction: Evidence from China. Sustainability 2022, 14, 4408. [Google Scholar] [CrossRef]
- Huynh, T.N.; Do, D.T.T.; Lee, J. Q-Learning-based parameter control in differential evolution for structural optimization. Appl. Soft Comput. 2021, 107, 107464. [Google Scholar] [CrossRef]
- Xiong, R.; Cao, J.; Yu, Q. Reinforcement learning-based real-time power management for hybrid energy storage system in the plug-in hybrid electric vehicle. Appl. Energy 2018, 211, 538–548. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.-A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Zhang, B.; Yu, Y.; Li, J. Network intrusion detection based on stacked sparse autoencoder and binary tree ensemble method. In Proceedings of the 2018 IEEE International Conference on Communications Workshops (ICC Workshops), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Yu, J. A selective deep stacked denoising autoencoders ensemble with negative correlation learning for gearbox fault diagnosis. Comput. Ind. 2019, 108, 62–72. [Google Scholar] [CrossRef]
- Zhang, C.; Hu, D.; Yang, T. Anomaly detection and diagnosis for wind turbines using long short-term memory-based stacked denoising autoencoders and XGBoost. Reliab. Eng. Syst. Saf. 2022, 222, 108445. [Google Scholar] [CrossRef]
- Yu, J.; Zheng, X.; Liu, J. Stacked convolutional sparse denoising auto-encoder for identification of defect patterns in semiconductor wafer map. Comput. Ind. 2019, 109, 121–133. [Google Scholar] [CrossRef]
- Niu, D.; Yu, M.; Sun, L.; Gao, T.; Wang, K. Short-term multi-energy load forecasting for integrated energy systems based on CNN-BiGRU optimized by attention mechanism. Appl. Energy 2022, 313, 118801. [Google Scholar] [CrossRef]
- Haidong, S.; Junsheng, C.; Hongkai, J.; Yu, Y.; Zhantao, W. Enhanced deep gated recurrent unit and complex wavelet packet energy moment entropy for early fault prognosis of bearing. Knowl.-Based Syst. 2020, 188, 105022. [Google Scholar] [CrossRef]
- Adelia, R.; Suyanto, S.; Wisesty, U.N. Indonesian Abstractive Text Summarization Using Bidirectional Gated Recurrent Unit. Procedia Comput. Sci. 2019, 157, 581–588. [Google Scholar] [CrossRef]
- Ren, L.; Cheng, X.; Wang, X.; Cui, J.; Zhang, L. Multi-scale Dense Gate Recurrent Unit Networks for bearing remaining useful life prediction. Future Gener. Comput. Syst. 2019, 94, 601–609. [Google Scholar] [CrossRef]
- Liu, J.; Wu, C.; Wang, J. Gated recurrent units based neural network for time heterogeneous feedback recommendation. Inf. Sci. 2018, 423, 50–65. [Google Scholar] [CrossRef]
- She, D.; Jia, M. A BiGRU method for remaining useful life prediction of machinery. Measurement 2021, 167, 108277. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, F.; Liu, S.; Wu, Y.; Wang, L. A hybrid VMD–BiGRU model for rubber futures time series forecasting. Appl. Soft Comput. 2019, 84, 105739. [Google Scholar] [CrossRef]
- Li, R.; Wang, X.; Quan, W.; Song, Y.; Lei, L. Robust and structural sparsity auto-encoder with L21-norm minimization. Neurocomputing 2021, 425, 71–81. [Google Scholar] [CrossRef]
- Shu, W.; Cai, K.; Xiong, N.N. A short-term traffic flow prediction model based on an improved gate recurrent unit neural network. IEEE Trans. Intell. Transp. Syst. 2021, 1–12. [Google Scholar] [CrossRef]


| Algorithms | Computational Time |
|---|---|
| BIGRU | 42.61 s |
| GRU | 25.45 s |
| LSTM | 28.85 s |
| ELM | 12.41 s |
| MLP | 15.93 s |
| SAE- BIGRU | 53.42 s |
| GA-SDAE-BIGRU | 107.67 s |
| GWO-SDAE-BIGRU | 99.43 s |
| PSO-SDAE-BIGRU | 93.26 s |
| FC-Q-SDAE-BIGRU | 124.08 s |
| Algorithms | Computational Time |
|---|---|
| FC-Q | 61.05 s |
| SDAE | 20.42 s |
| BIGRU | 42.61 s |
| Total | 124.08 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, G.; Bai, Y.; Yu, C.; Yu, C. A Multi-Factor Driven Model for Locomotive Axle Temperature Prediction Based on Multi-Stage Feature Engineering and Deep Learning Framework. Machines 2022, 10, 759. https://doi.org/10.3390/machines10090759
Yan G, Bai Y, Yu C, Yu C. A Multi-Factor Driven Model for Locomotive Axle Temperature Prediction Based on Multi-Stage Feature Engineering and Deep Learning Framework. Machines. 2022; 10(9):759. https://doi.org/10.3390/machines10090759
Chicago/Turabian StyleYan, Guangxi, Yu Bai, Chengqing Yu, and Chengming Yu. 2022. "A Multi-Factor Driven Model for Locomotive Axle Temperature Prediction Based on Multi-Stage Feature Engineering and Deep Learning Framework" Machines 10, no. 9: 759. https://doi.org/10.3390/machines10090759
APA StyleYan, G., Bai, Y., Yu, C., & Yu, C. (2022). A Multi-Factor Driven Model for Locomotive Axle Temperature Prediction Based on Multi-Stage Feature Engineering and Deep Learning Framework. Machines, 10(9), 759. https://doi.org/10.3390/machines10090759