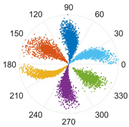
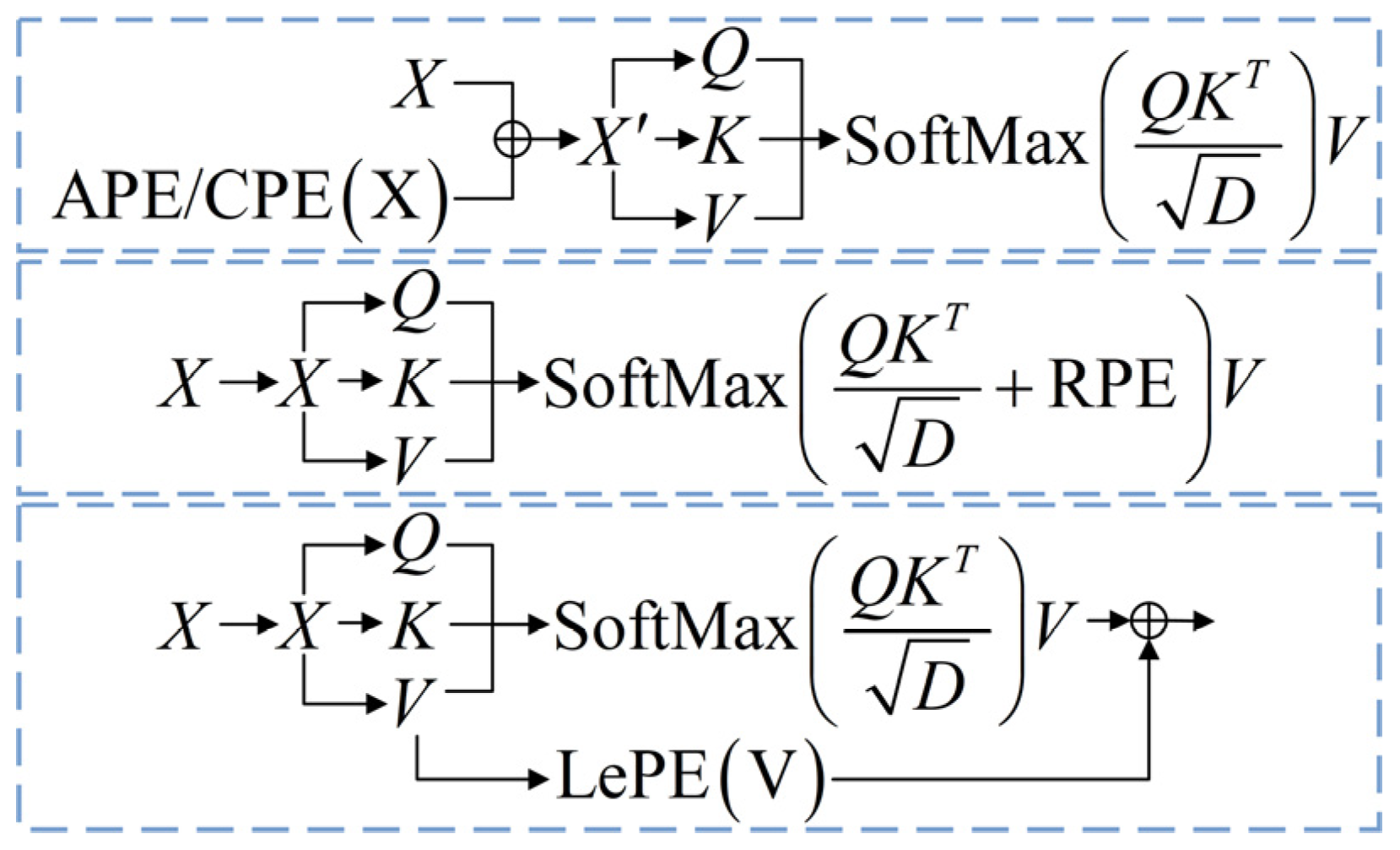
5.1. Case 1
In this case, the proposed method was validated by using the bearing dataset from the Case Western Reserve University (CWRU) [
42].
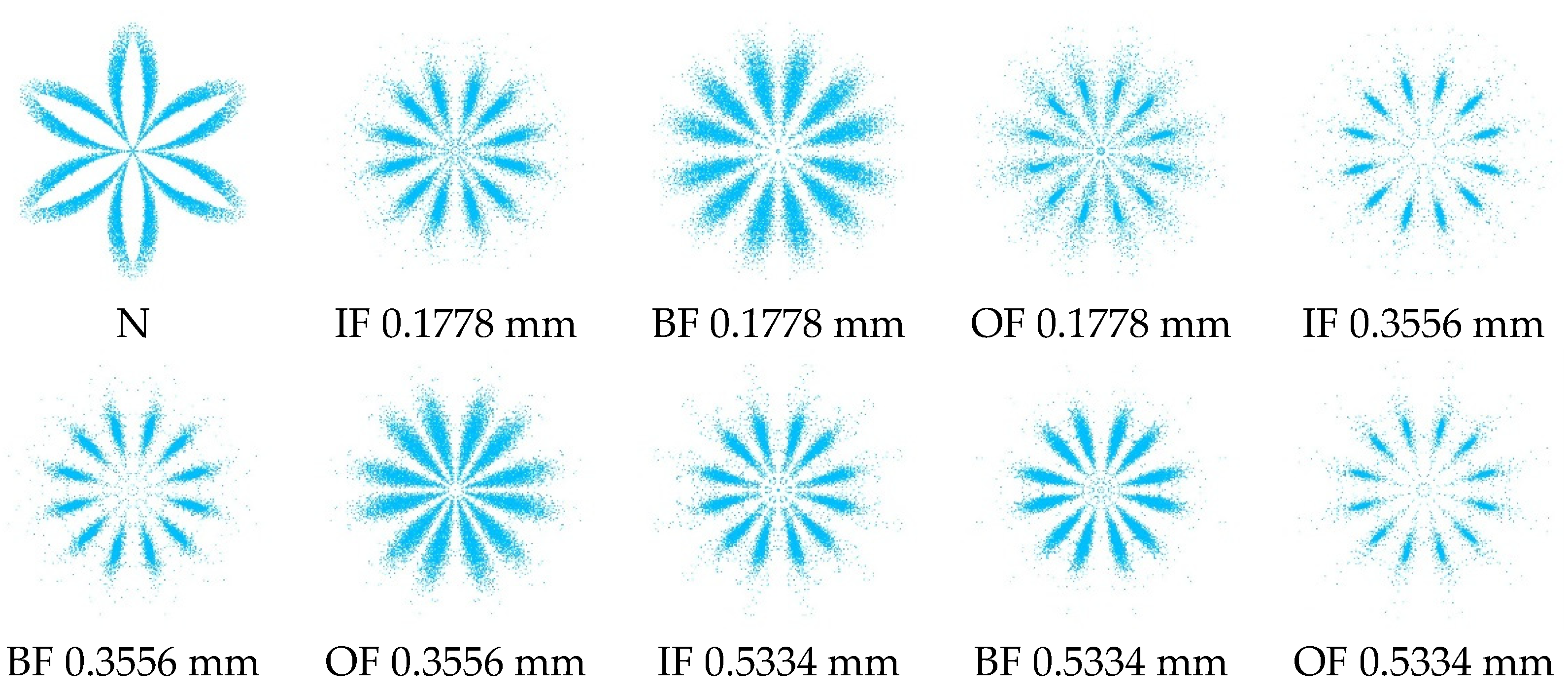
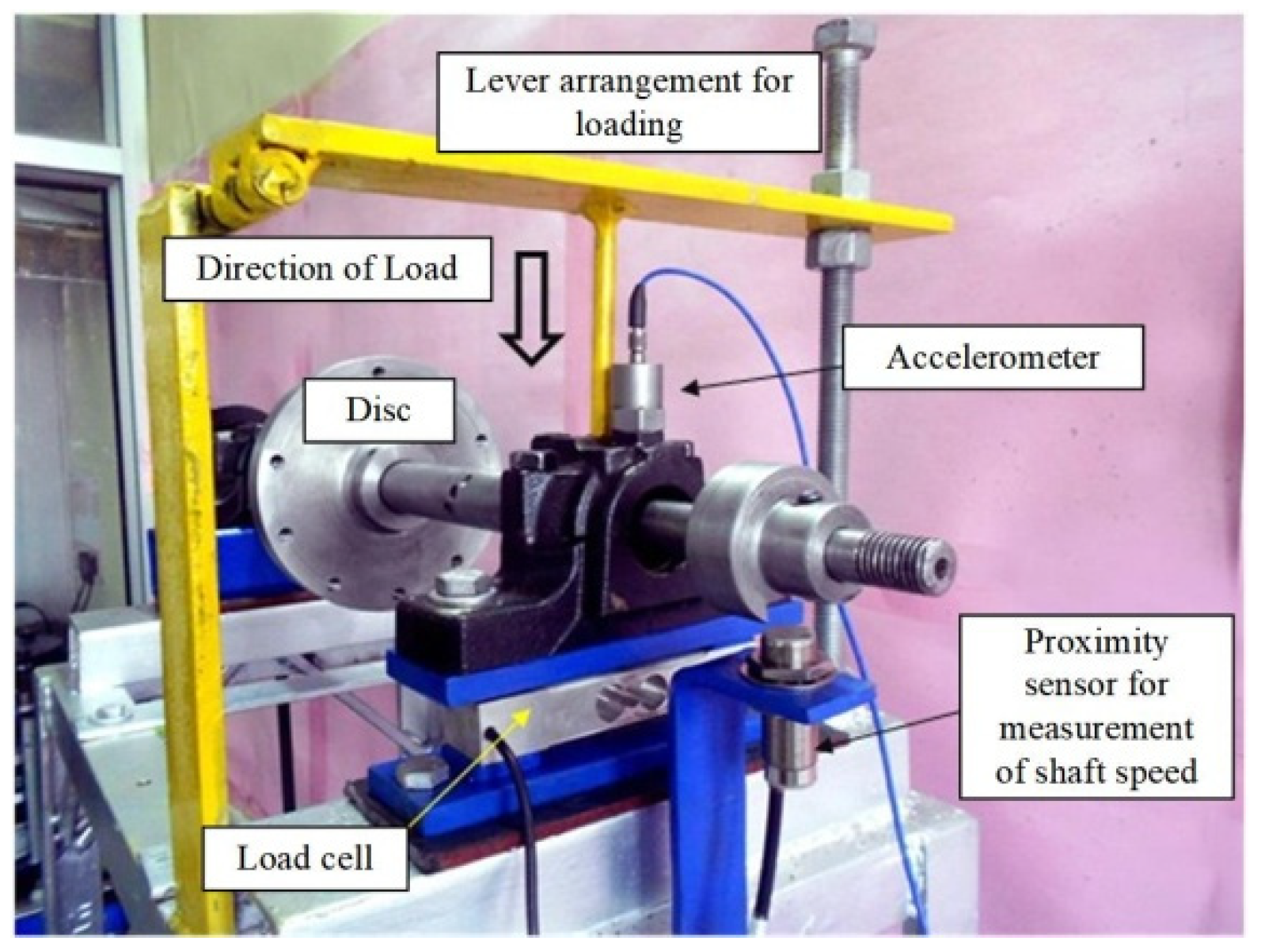
Figure 9 displays the testbed for data collection. The CWRU experiment apparatus mainly consists of an induction motor, rolling bearings, a torque transducer, and a dynamometer. The types of bearing states can be classified as normal (N), inner-race fault (IF), ball fault (BF), and outer-race fault (OF), respectively. The diameters of each fault are 0.1778 mm, 0.3556 mm, and 0.5334 mm. The experimental data were chosen from the drive end and fan end with a sampling frequency of 12 kHz. In total, ten bearing working states under the motor load of 0 hp were analyzed.
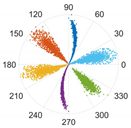
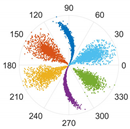
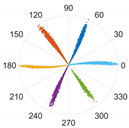
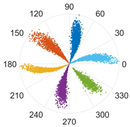
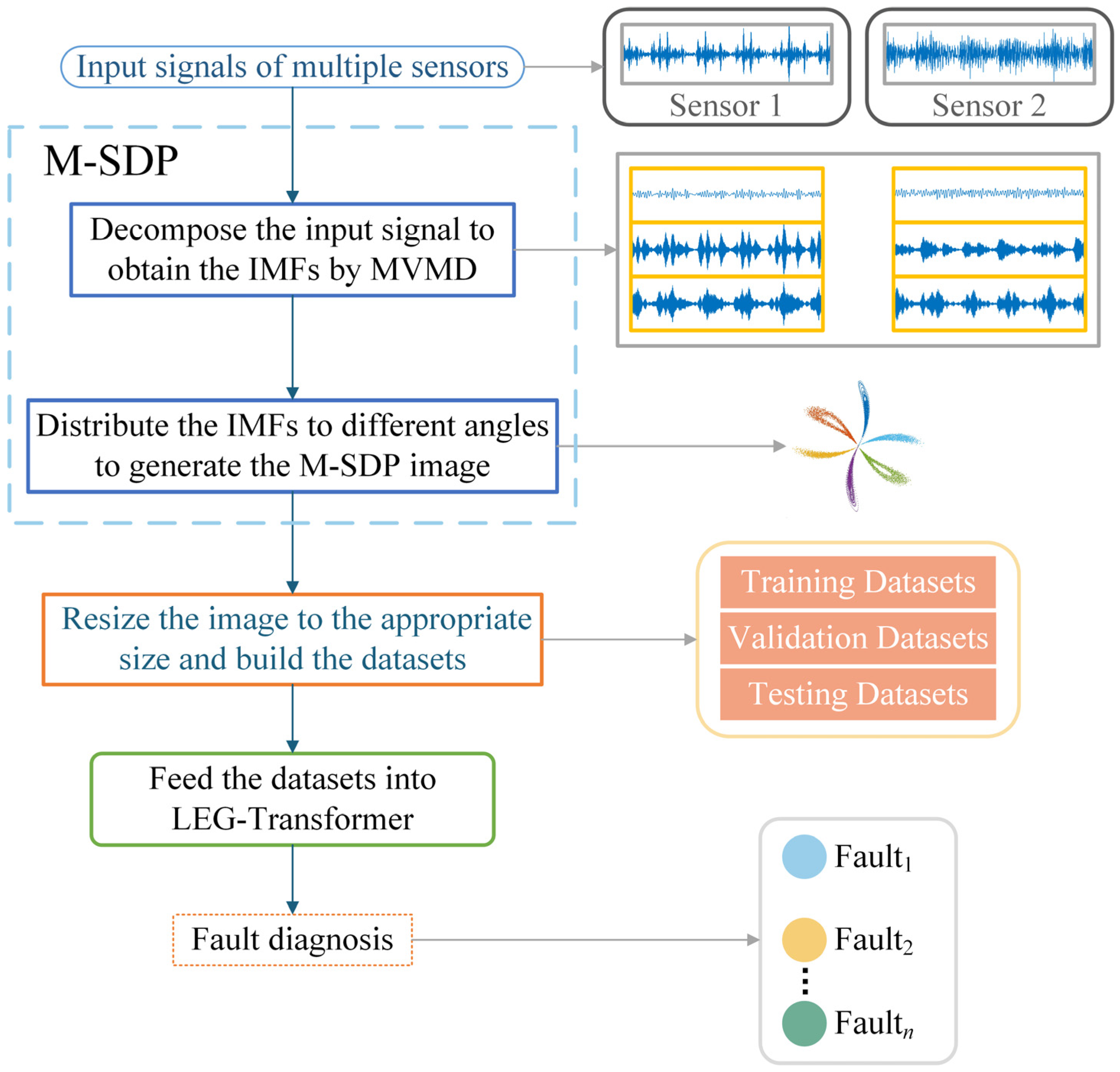
This subsection processes data from two sensors through the proposed M-SDP approach. To ensure the integrity of the individual fault features, the information collected on the drive end with the fan end was fused. Firstly, the raw fused vibration signals were divided into sub-sequence signals of equal length, containing 2048 sampling points. Secondly, a series of feature data were obtained at different scales by co-processing the information from two sensors through the MVMD method. Subsequently, the feature data of different scales were arranged at different angles to gain the M-SDP images, which realized the fusion of multisensor and multiscale information. However, the choice of internal parameters
γ,
ξ, and
L can affect the difference between each M-SDP image. Therefore, the parameters should be selected appropriately. The M-SDP datasets of outer race fault were used to analyze the parameters selection. Since we adopted 2 channel vibration signals and the number of the decomposed number was set to 3 when using MVMD, 6 IMFs needed to be mapped to the polar coordinate system, thus
γ was set at 60°. Moreover,
L was set to 1, 5, and 10, and
ξ was set to 10°, 30°, and 50°, respectively. The above parameters were combined to generate nine M-SDP images, as shown in
Table 2.
As displayed in
Table 2, the differences in shape characteristics, thickness, and curvature of each arm in the M-SDP image can be reflected by changing
ξ and
L. Specifically, the rotation angle of arms along the initial line gradually increased with the increase in parameter
ξ and the thickness of each arm increased slightly with
ξ. If the rotational curvature and the thickness of the arms were too small, it reduced the area of recognized features, and the points on the edge of each arm were scattered when they were too large. The above situation can bring obstacles to image classification. Hence, it is particularly important to select appropriate values of
ξ and
L.
In order to further select the optimal parameters, the normalized cross-correlation coefficient (NCC) method was adopted in this work. For two images
M and
N, with the same size
a ×
b, the NCC can be expressed by
where
and
denote the average value of the three channels of image
M and
N, respectively. The value of
R can be used to measure the similarity of two M-SDP images.
R ranges from 0 to 1, and the higher the value of
R is, the more similar the images of
M and
N are. The value of
L is identified by traversing the interval of [1,10] at step size 1, and the value of ξ is identified by traversing the interval of [20,50] at step size 5. Since there are ten fault types in our datasets, a 10 × 10 matrix can be obtained by calculating the correlation coefficient between every two M-SDP images. Then, the average correlation coefficient of the matrix can be calculated, which is considered the correlation coefficient of ten M-SDP fault images under the current combination of
ξ and
L. Following this, the non-correlation degree (NR) was further calculated, and the results are displayed in
Table 3. From
Table 3, the maximum values of NR correspond to
ξ = 35° and
L = 7.
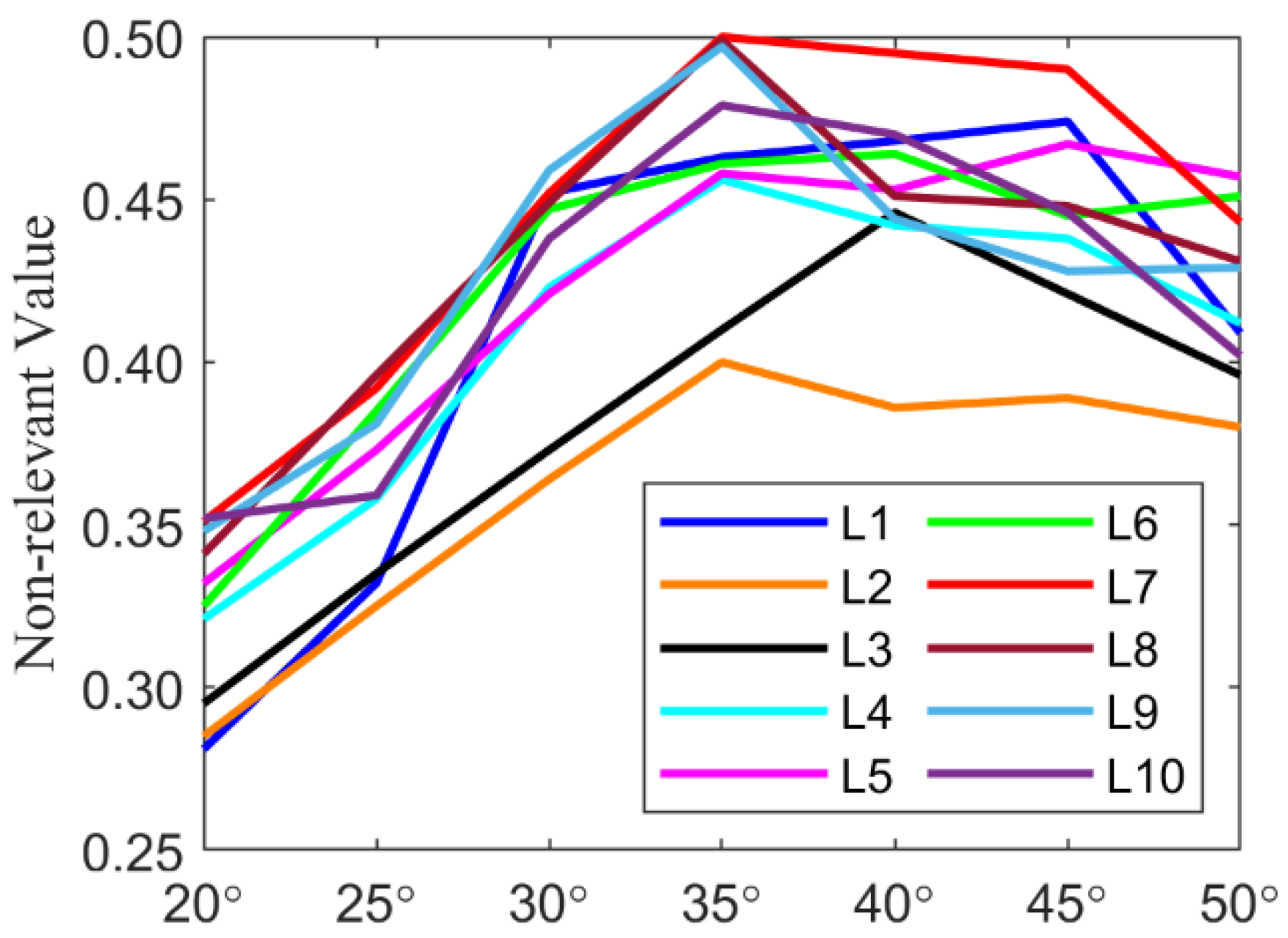
The relationship between NR and the parameters
ξ and
L can be directly reflected in
Figure 10. From
Figure 10, when the range of
ξ is from 20 to 35, the value of NR increases gradually, but it declines gradually when
ξ is between 35 and 50. When
ξ is fixed, there is usually a peak of NR at
L = 7. Thus,
ξ and
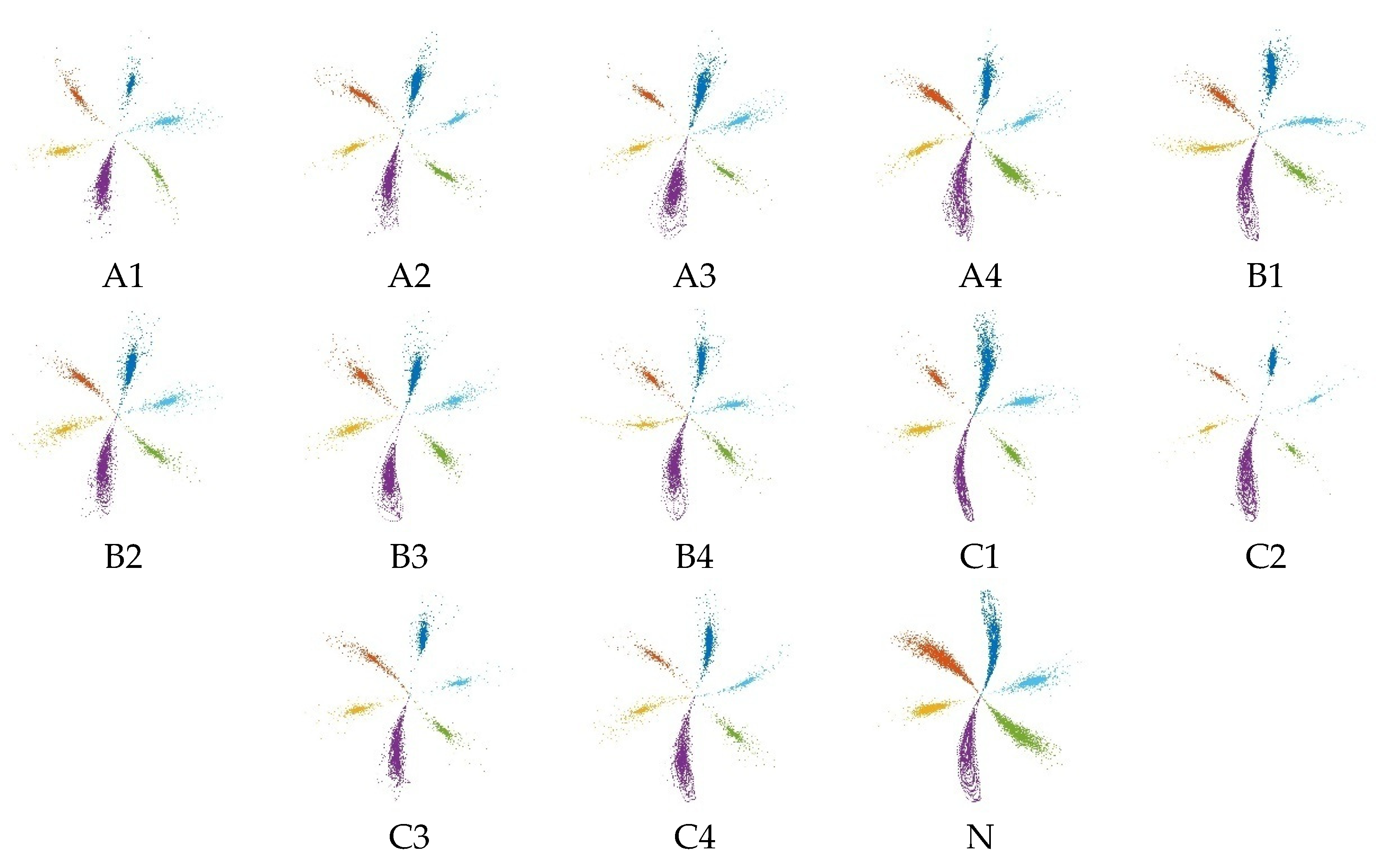
L are eventually determined by 35 and 7, respectively. According to the selected parameters, the ten types of M-SDP data obtained are shown in
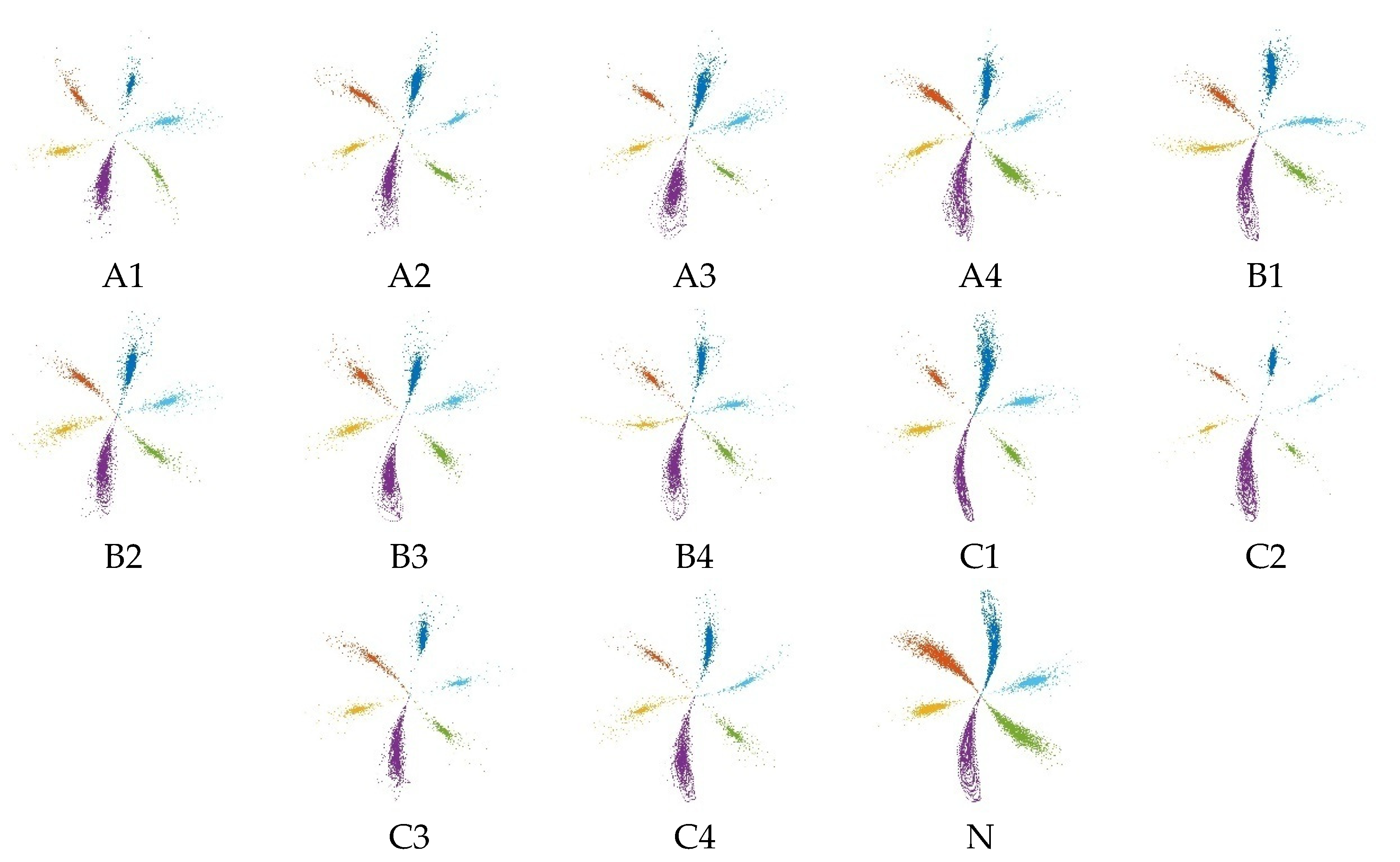
Figure 11. Meanwhile, to confirm the effectiveness of the M-SDP method, the single sensor data are processed using the original SDP method as a comparison, and ten types of SDP data are obtained as shown in
Figure 12.
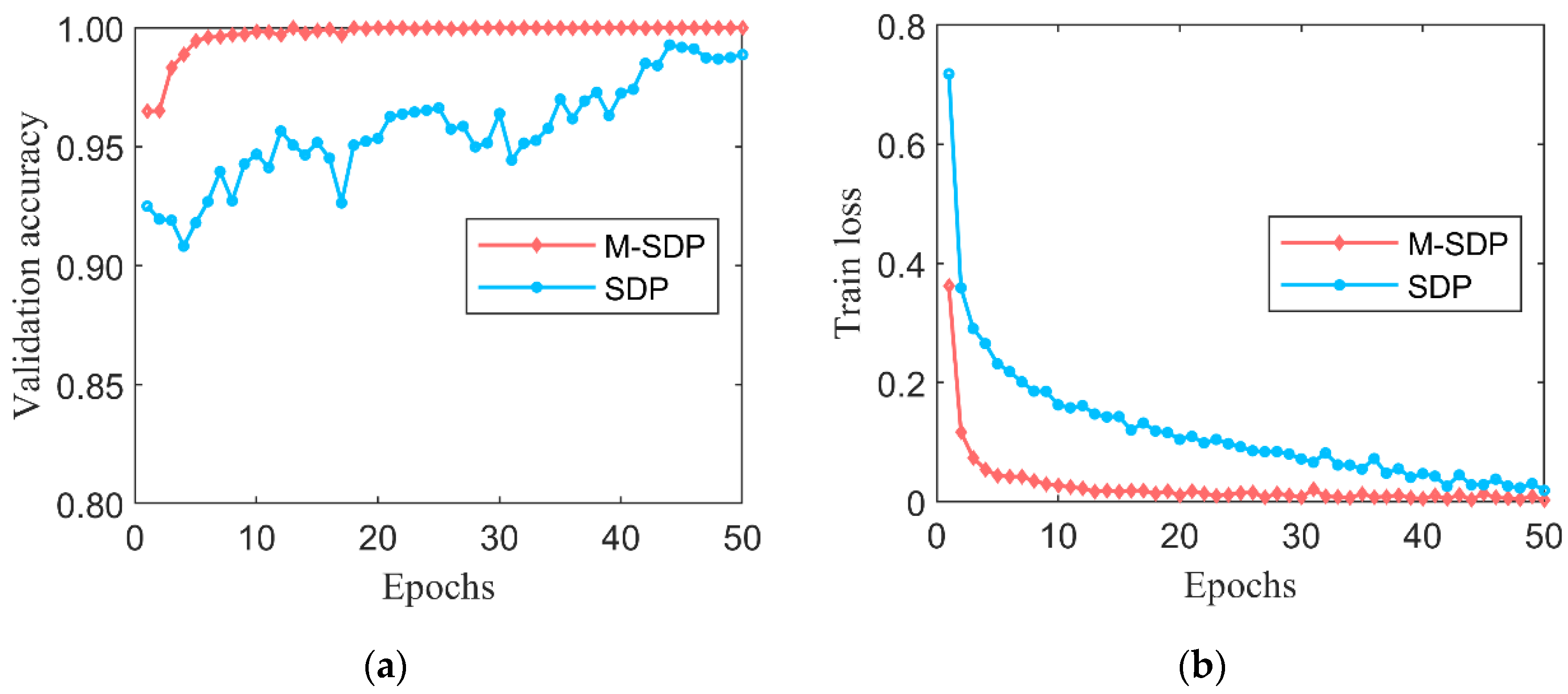
The M-SDP and SDP datasets were randomly divided to validate the diagnostic accuracy of the M-SDP method. Each bearing working condition contains 2000 samples as a training dataset, 400 samples as a validation dataset, and 100 samples as a testing dataset. The LEG Transformer designed in this paper was performed to process the prepared datasets. The initial learning rate of the model is 0.001 and the training epoch is 50. The accuracy of the obtained validation dataset is shown in
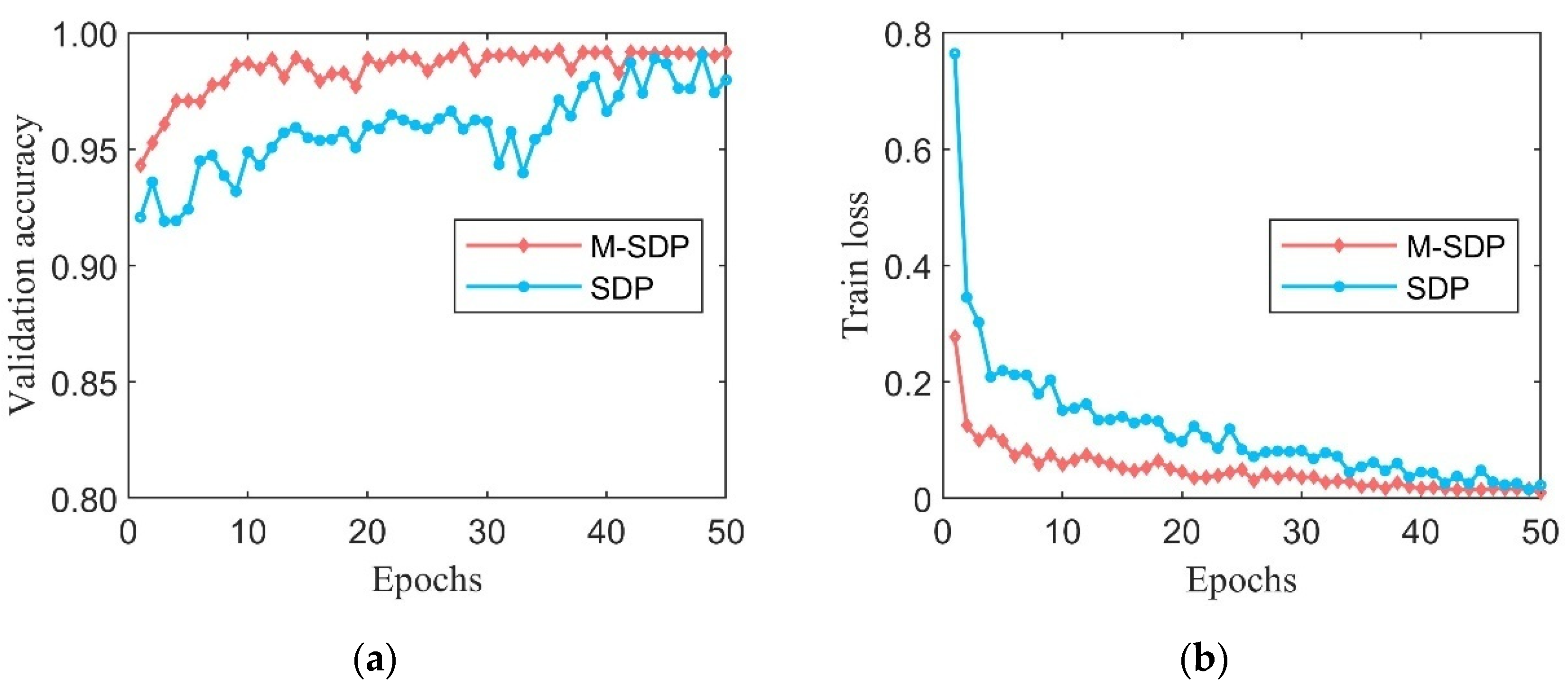
Figure 13a, and the loss curve is shown in
Figure 13b. According to the validation accuracy curves of M-SDP and SDP in
Figure 13a, the validation accuracy starts to stabilize and remains around 100% when the training epoch reaches 16. However, the accuracy of the original SDP method is still low and fluctuates wildly before the epoch training reaches 30. From
Figure 13b, it can be noticed that the loss of the M-SDP dataset also drops to very low level at epoch 10, while the original SDP has higher loss values than our proposed M-SDP method in all 50 epochs. To further ensure the reliability of the experimental results, the trained model was applied to the pre-prepared testing dataset, and the results include accuracies and standard deviation (SD) as shown in
Table 4. The M-SDP datasets have no false diagnoses during testing and show superior diagnostic stability with an average accuracy of 100%.
The above results clearly show that the M-SDP method has a compelling improvement over the original SDP, especially in accuracy and stability during training. In the industrial field, real-time fault monitoring is highly required for the efficiency and stability of diagnosis. Accidental misdiagnosis will still have a particularly negative impact on mechanical equipment. The dataset generated by the M-SDP method proposed in this paper has a fast convergence performance during training, and the diagnostic accuracy of the trained model is exceptionally high. The results demonstrate that the M-SDP method can further amplify the differences between categories while making the characteristics of each category more significant.
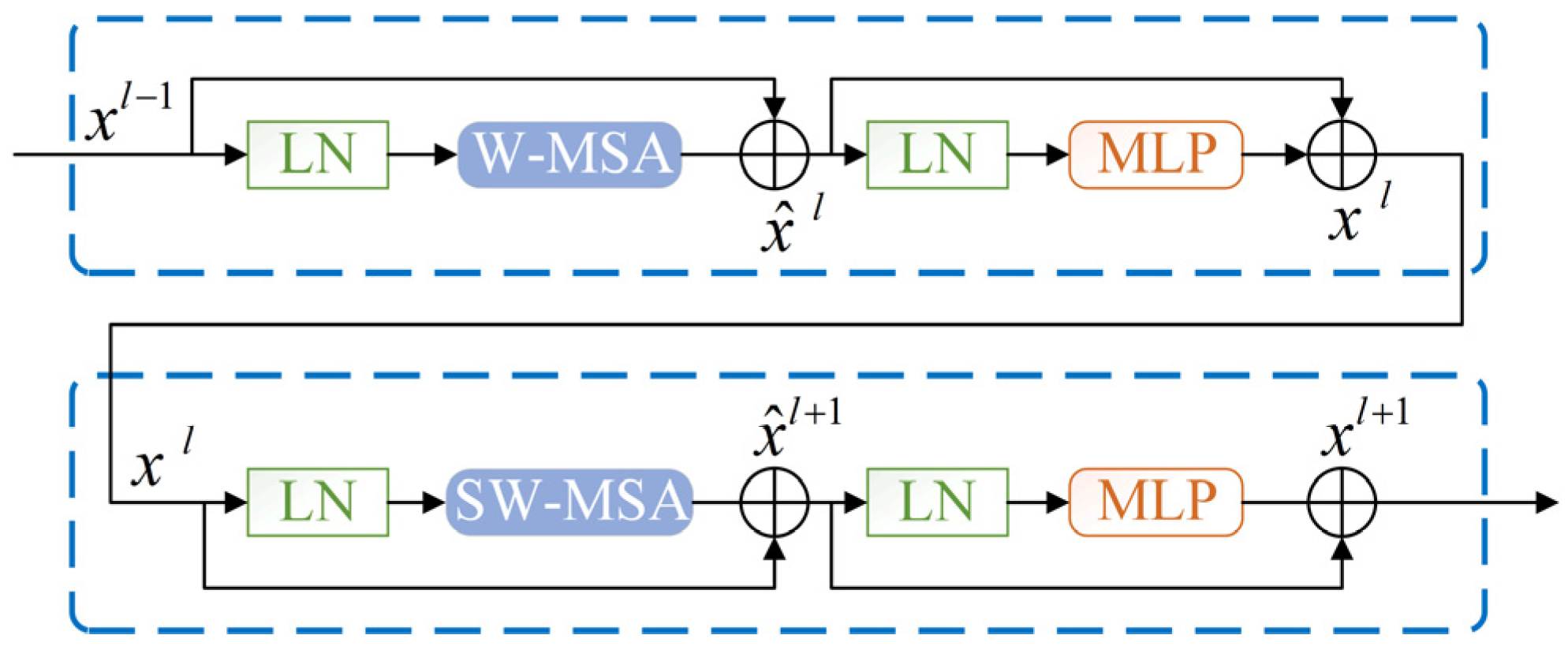
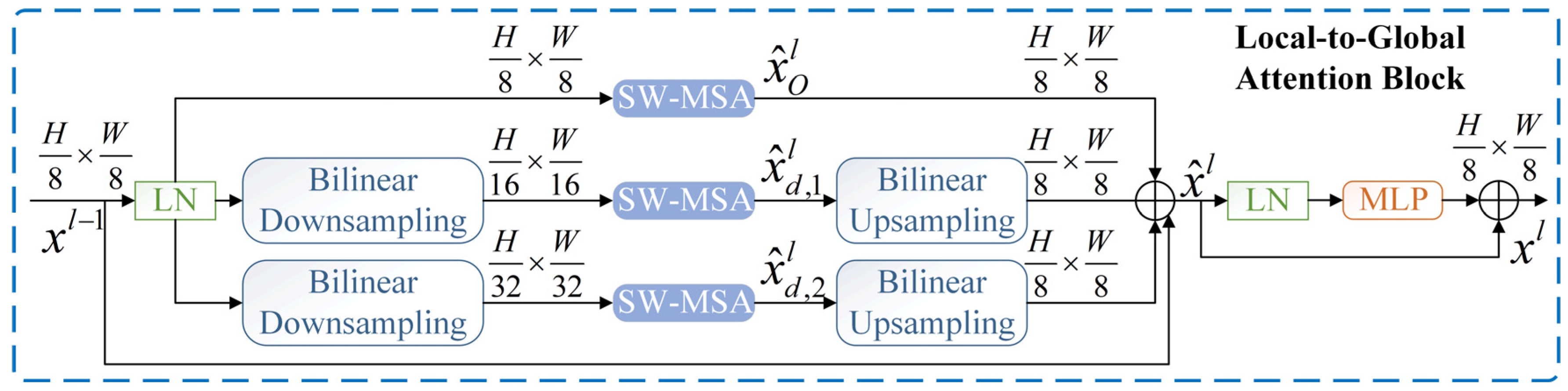
To further validate the performance of the LEG Transformer (LEGT) model exploited in this paper, it was compared with the typical Swin Transformer method for different processes. According to the analysis in the official paper of the Swin Transformer, the model trained with pre-trained weights offered by officials can achieve better recognition accuracy. For this reason, this paper introduced the pre-trained weights in model training. At the same time, more extensive comparisons were made with SE-CNN, TCNN (ResNet-50), PSO-LeNet-5, VGG-19, and Inception-V3 models. The pre-prepared M-SDP datasets were used for fault diagnosis of each deep learning model. Besides, a machine learning method named the particle-swarm-optimization-based support vector machine (PSO-SVM) was implemented to evaluate the necessity of deep learning methods [
43].
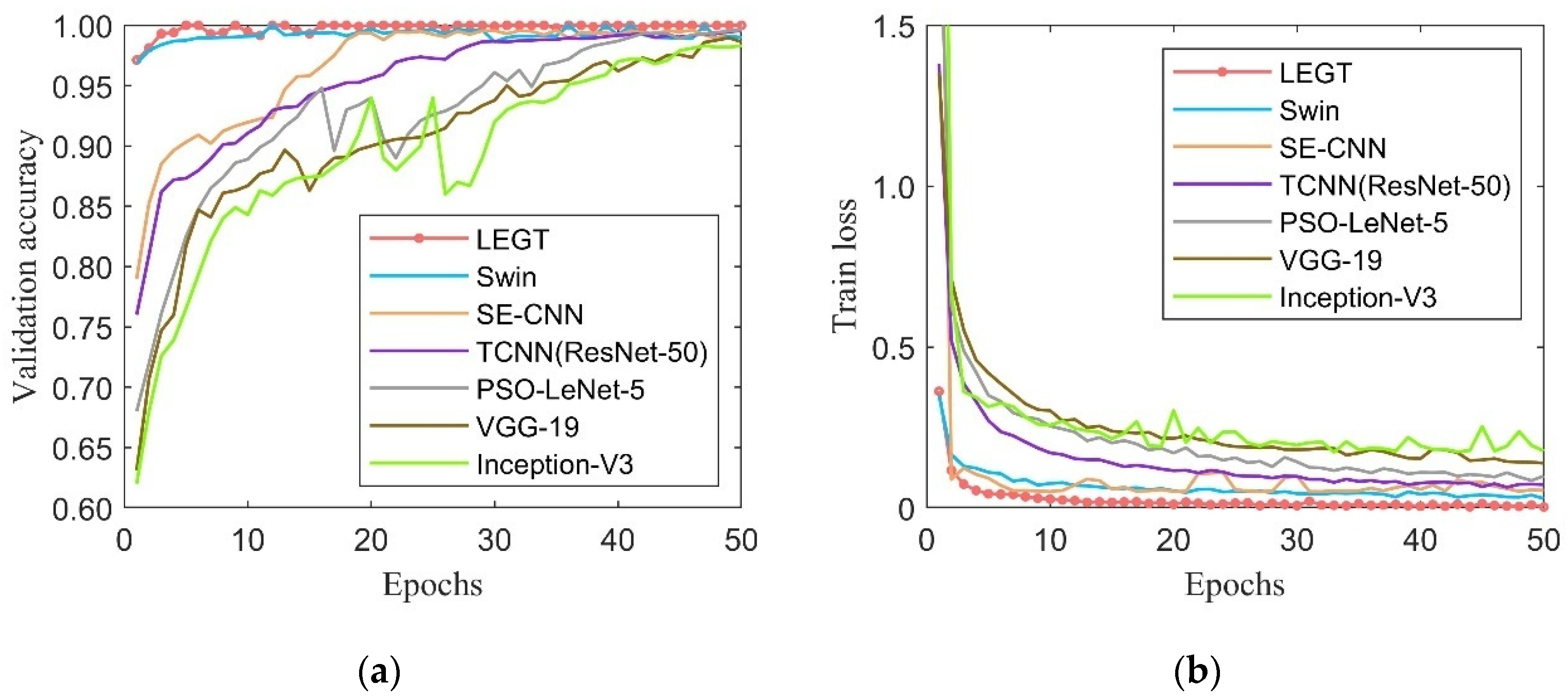
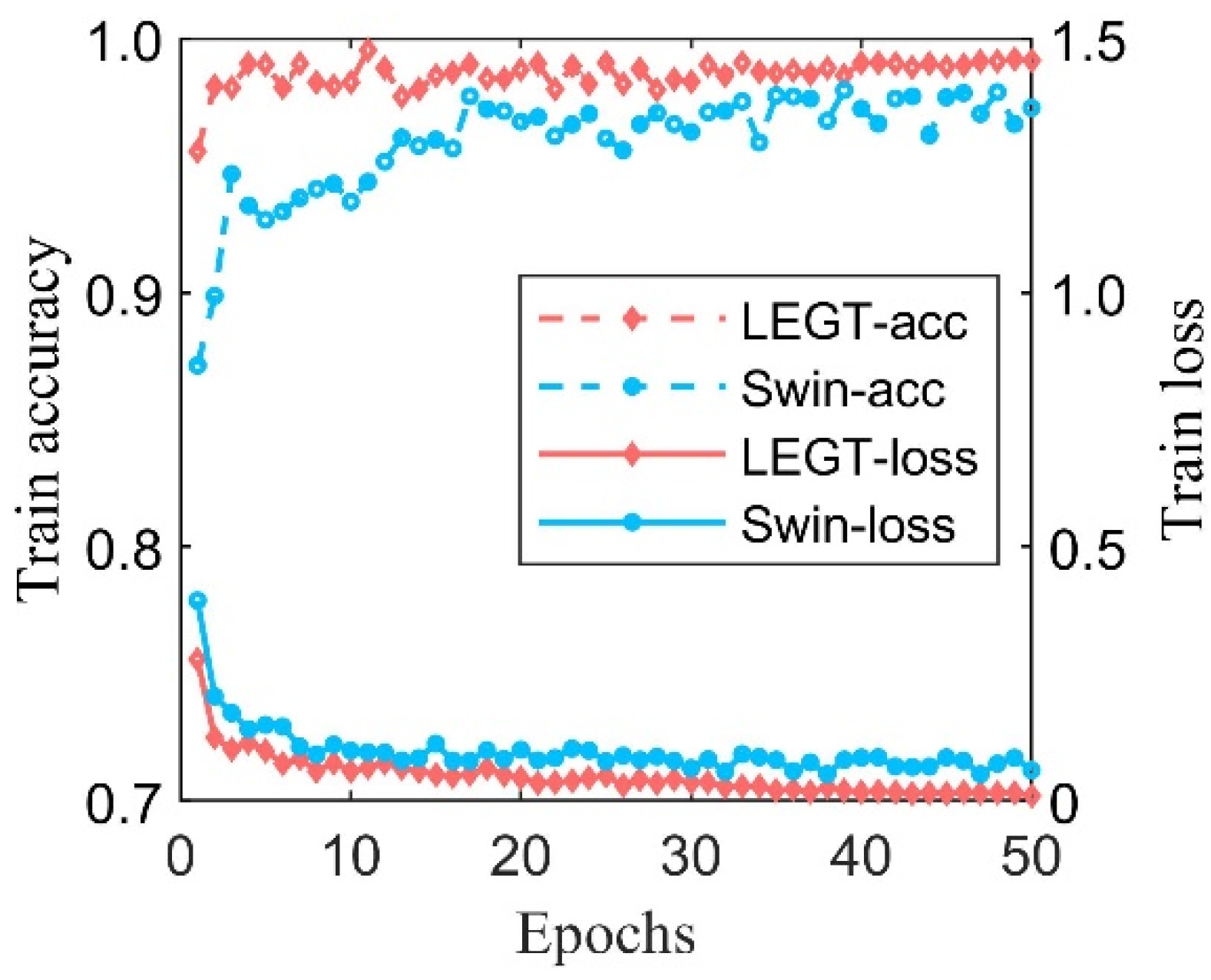
Figure 14 presents the accuracy and loss of the LEG Transformer and the typical Swin Transformer in the training process.
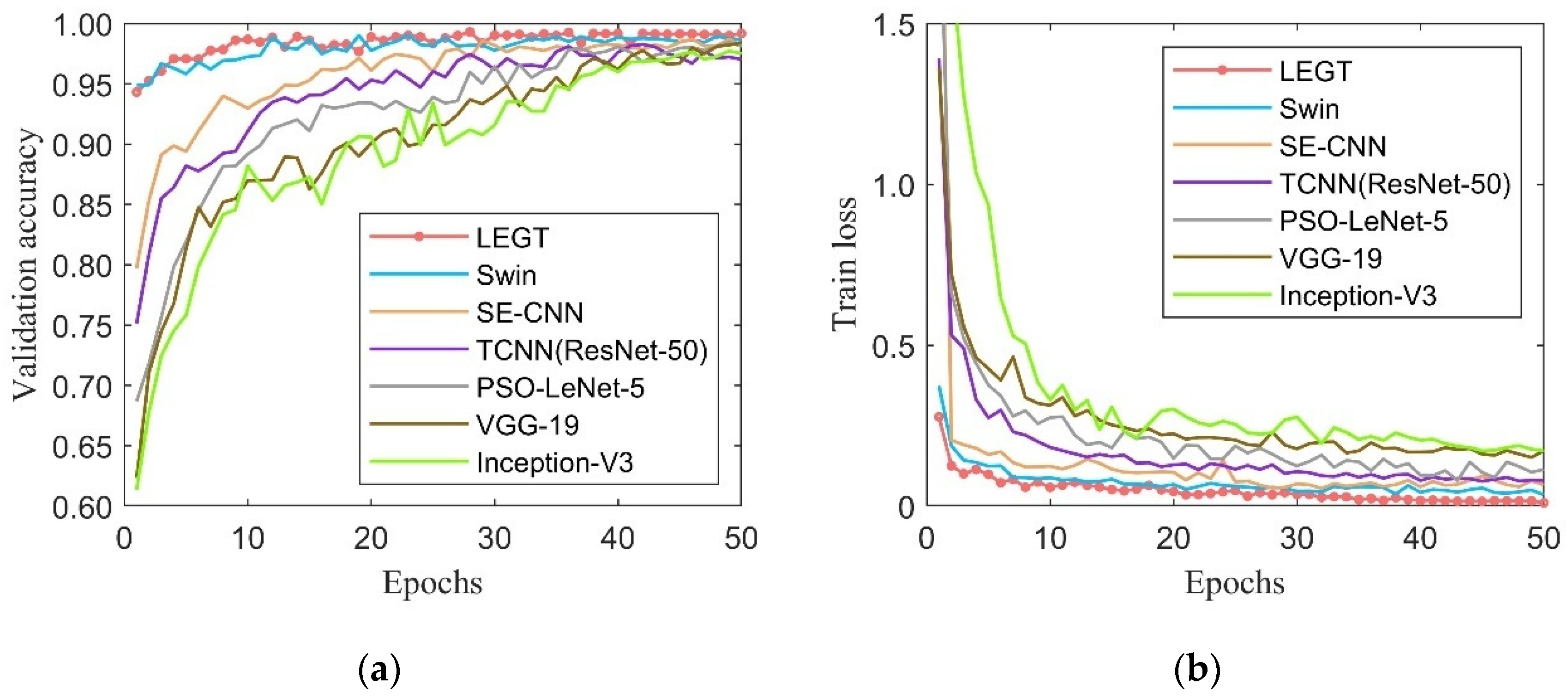
The designed LEG Transformer method achieves the desired effect at about 10 epochs during the training process. In addition, the convergence speed is significantly enhanced compared with before the improvement. The accuracy of the validation dataset and the training loss for deep learning models are shown in
Figure 15. From
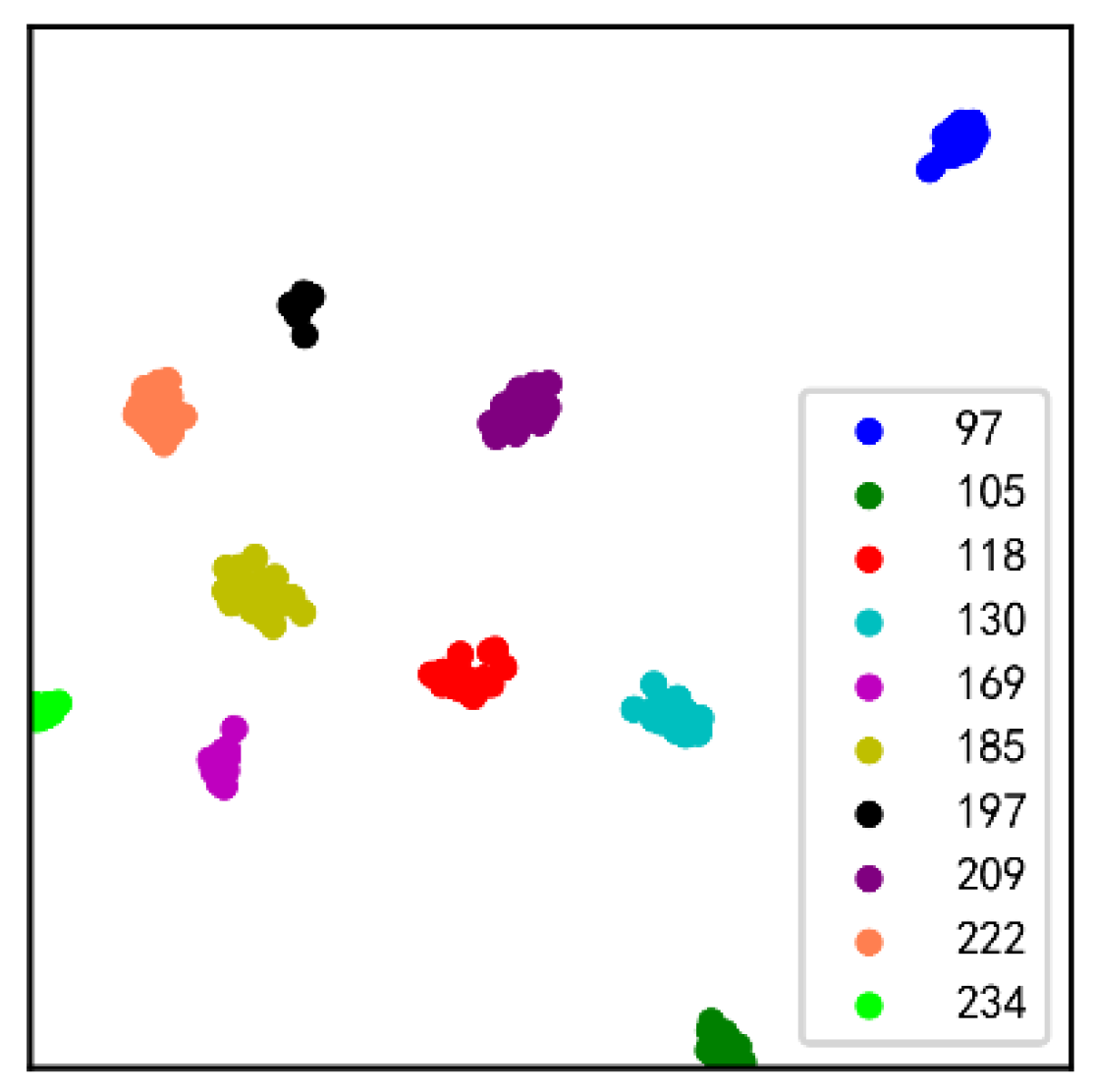
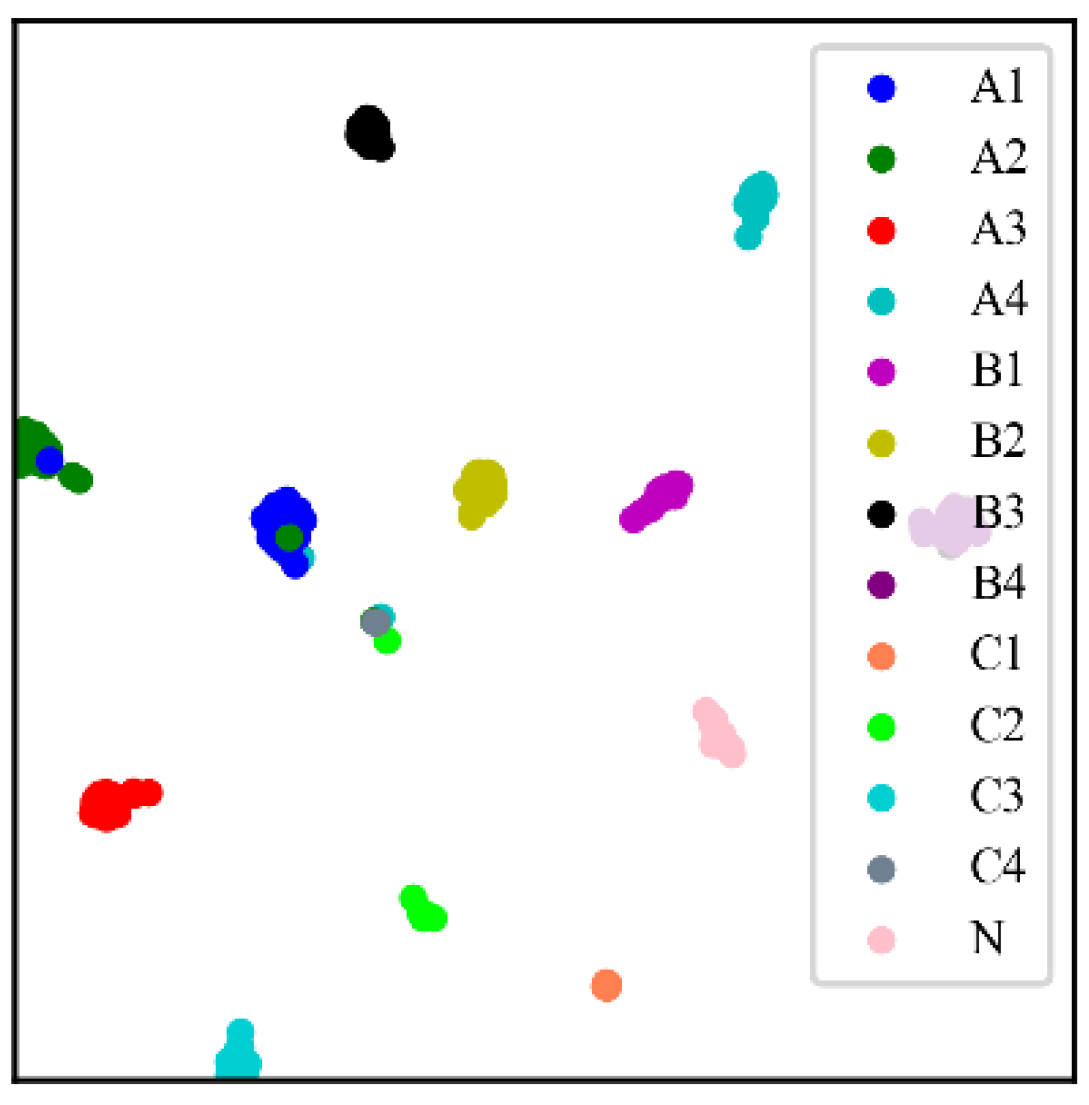
Figure 15, LEG Transformer outperforms other models in recognition accuracy over 50 epochs and has the best stability for fault diagnosis. The LEG Transformer and the Swin Transformer have higher accuracy and convergence speed than other CNN-based models, demonstrating the excellent performance of transformer-based structural models. To show the classification effect of the LEG Transformer more intuitively, the classification results are visualized using the T-distributed stochastic neighbor embedding (t-SNE) method [
44], as presented in
Figure 16. From the t-SNE figure, it can be observed that the LEG Transformer can effectively separate different features. To further verify the performance of the LEG Transformer model, each model was applied to the testing dataset.
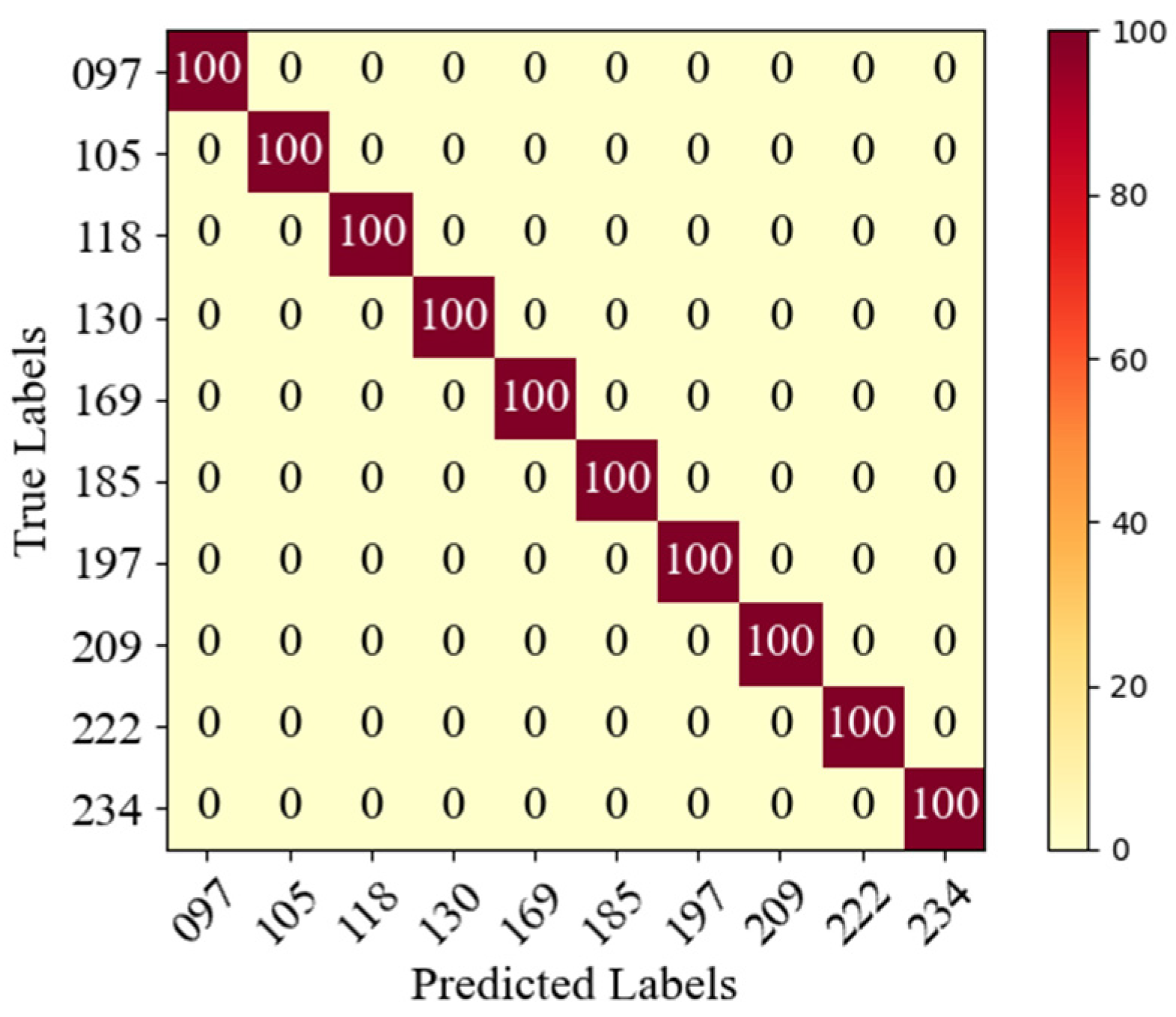
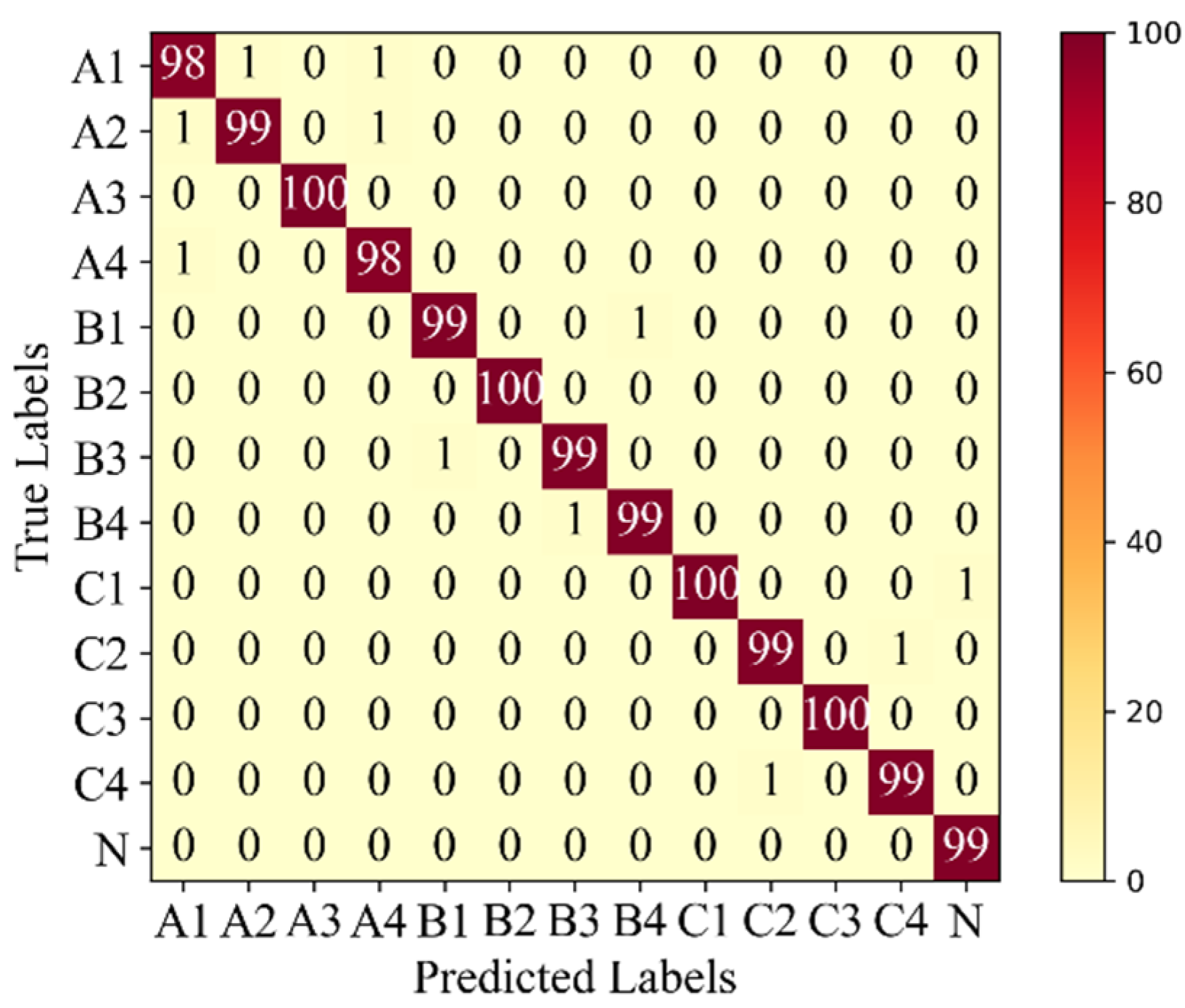
Figure 17 shows the confusion matrix of LEG Transformer in processing the testing dataset. The accuracy of each model applied to the testing dataset is shown in
Table 5.
From
Table 5, the LEG Transformer method proposed in this paper achieves up to 100% average accuracy in classifying the testing dataset. At the same time, the standard deviation of the LEG Transformer is 0. The accuracy values of the Swin Transformer, SE-CNN, TCNN(ResNet-50), PSO-LeNet-5, VGG-19, Inception-V3, and PSO-SVM are 99.97% ± 0.0002, 99.67% ± 0.0019, 99.58% ± 0.0016, 99.57% ± 0.0021, 98.68% ± 0.0072, 98.71% ± 0.0086, and 97.39 ± 0.0026, respectively.
Table 6 shows the comparative result of all models published in the literature. The results reveal that the LEG Transformer outperforms the other models. In conclusion, the proposed LEG Transformer method has superior diagnostic accuracy and stable performance.
5.2. Case 2
To further analyze the generalization capability and robustness of the proposed LEG Transformer model, this case employed it with a new dataset for testing and comparison.
Figure 18 displays the testbed for data acquisition and the roller bearing NU205E was chosen as the experimental bearing [
47]. The vibration signals were collected at a shaft speed of 2050 rpm and a load of 200 N. In this case, the vertical channel and the horizontal channel of the data acquisition device were adopted. The dataset composition that contains twelve fault types is specifically demonstrated in
Table 7.
In this case, the procedure to select internal parameters and form the M-SDP datasets is similar to Case 1. The M-SDP images for the thirteen types of bearing states are displayed in
Figure 19. The original SDP images as a comparison are presented in
Figure 20.
The M-SDP and SDP datasets are randomly split, with 2000 samples of each category as a training dataset, 400 samples as a validation dataset, and 100 samples as a testing dataset. The proposed LEG Transformer was implemented on the prepared datasets. The accuracy of the validation dataset of M-SDP and original SDP during training is displayed in
Figure 21a, and the loss curve is shown in
Figure 21b.
In the M-SDP datasets of this case,
Figure 21a,b demonstrate a significant advantage in the accuracy of the validation dataset compared with the original SDP. For different kinds of bearing states, the datasets obtained by the M-SDP method have a fast convergence speed and excellent stability of correct classification.
Table 8 demonstrates the experimental results for the testing dataset. From
Table 8, the diagnostic effect of the M-SDP datasets is better than the original SDP method in this process.
In this case, the proposed LEG Transformer (LEGT) was compared with the Swin Transformer, SE-CNN, TCNN (ResNet-50), PSO-LeNet-5, VGG-19, Inception-V3, and PSO-SVM models. The accuracy and loss curves of the LEG Transformer and the original Swin Transformer in the training process are shown in
Figure 22.
Similarly, the LEG Transformer showed significantly improved diagnostic performance over the original Swin Transformer. The accuracy of the validation datasets for deep learning models and train loss are shown in
Figure 23.
Similar to the dataset in Case 1, the LEG Transformer is still the best among all models in classification accuracy and fault diagnosis stability. The LEG Transformer visualization of the classification results for this section of the dataset is illustrated in
Figure 24. The confusion matrix of LEG Transformer is shown in
Figure 25. The classification results of the testing dataset for each model are shown in
Table 9.
The LEG Transformer has superior performance when dealing with different datasets, and these results indicate that the model has strong generalization ability and robustness.


 ,
, 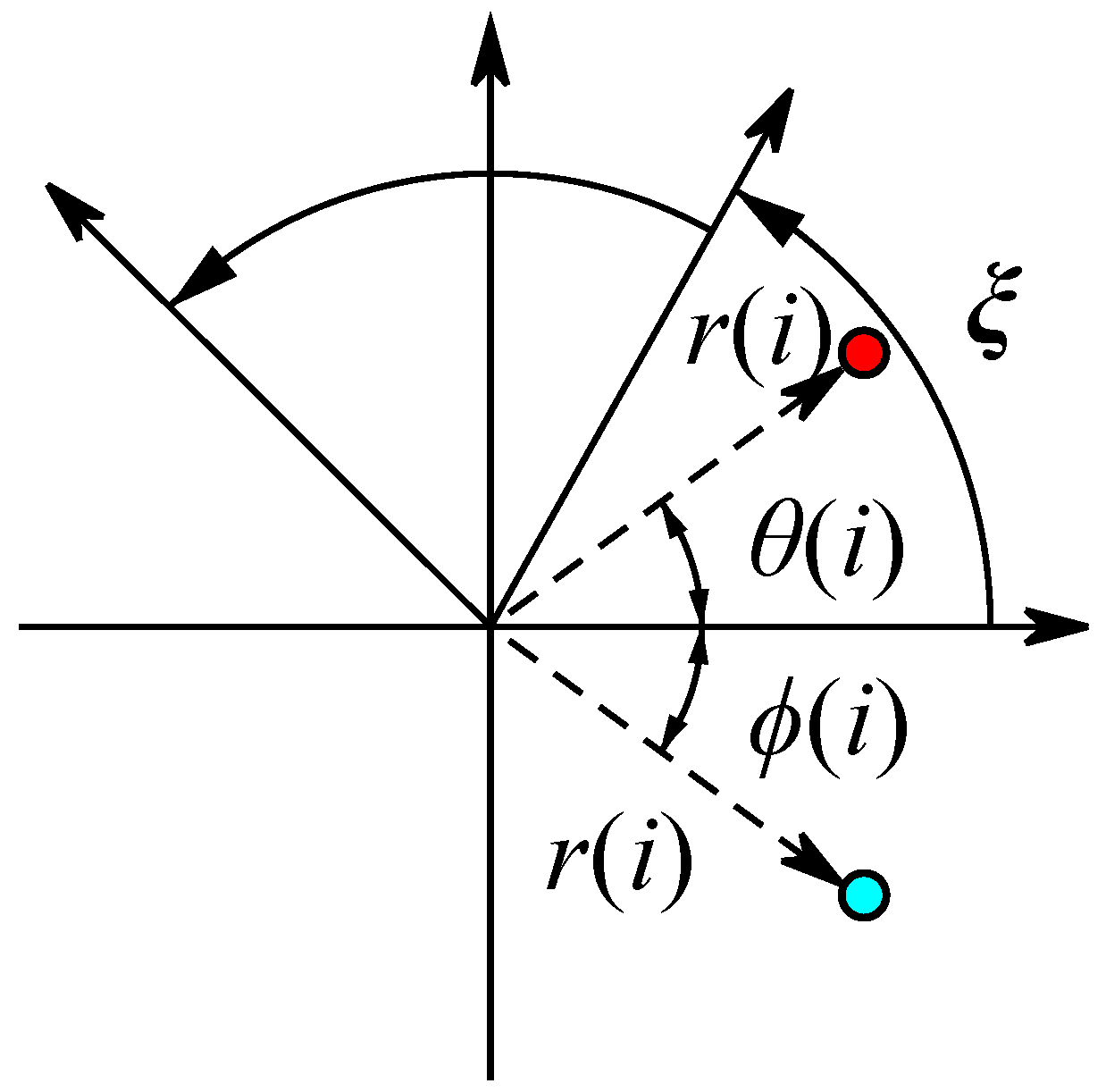








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}