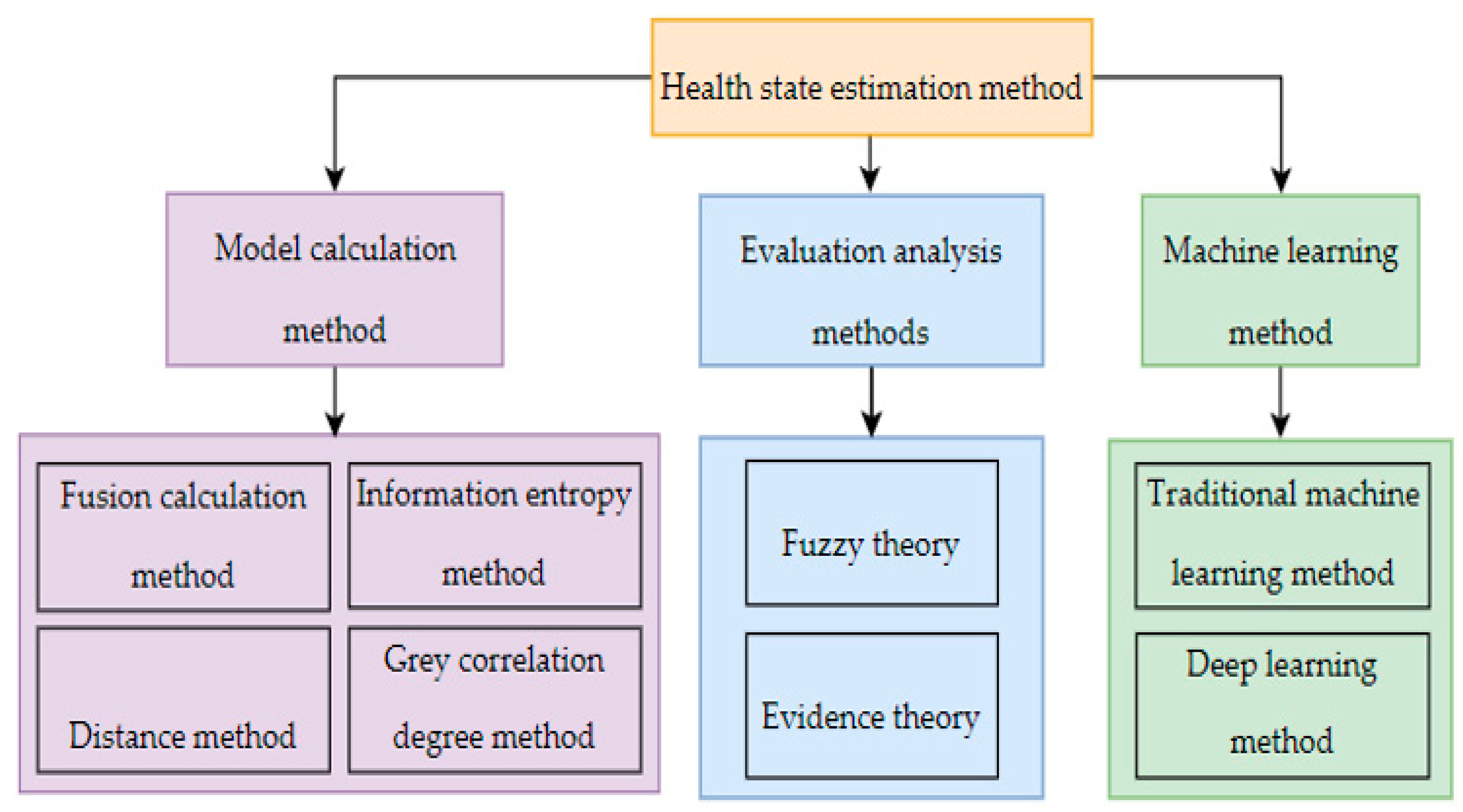
2.2.2. Data-Driven Method
Machine learning makes a computer simulate human learning behavior and continuously trains the model by obtaining new information to improve the generalization ability of the model [
54]. Due to the powerful data processing ability of machine learning, this method is widely used in data mining, speech recognition, computer vision, fault diagnosis and life prediction. According to the depth of learning, machine learning methods can be divided into traditional machine learning and deep learning methods, as shown in
Figure 3. Traditional machine learning algorithms largely rely on expert prior knowledge and signal processing technology, which is difficult to automatically process and for analysis of massive monitoring data. Deep learning is developed from the traditional machine learning algorithm. With its powerful feature extraction ability, it provides a solution for training massive data and opens up a new direction for the field of machine learning [
55].
- (1)
Traditional machine learning methods
The methods based on traditional machine learning mainly include the methods based on neural network and support vector machine (SVM). The characteristics of each method are given in
Table 5.
- a
Neural network
As a mathematical processing method to simulate the structure and function of biological nervous systems, a neural network has the ability of automatic learning and summary. It mainly includes an input layer, hidden layer and output layer, which are often used to solve problems such as classification and regression [
56]. After years of research and exploration, it has shown strong advantages in the field of remaining life prediction. The remaining life prediction method based on a neural network aims to take the original measurement data or the features extracted based on the original measurement data as the input of the neural network, continuously adjust the structure and parameters of the network through a certain training algorithm, and use the optimized network to predict the residual life of the equipment online. The prediction process does not need any prior information and is completely based on the prediction results obtained from the monitoring data [
57]. At present, the methods based on a neural network mainly include the methods based on a multi-layer perceptrons (MLP) neural network, the methods based on a radial basis function (RBF) neural network and the methods based on extreme learning machines (ELMS).
Multilayer perceptron neural network (MLP) is a kind of feedforward neural network with a hidden layer, and the neuron model of the hidden layer and output layer is consistent. MLP is mostly trained by back propagation (BP) algorithm. In addition to using BP algorithm to train MLP, other methods are also used for training, such as in [
58]. Bezazi et al. [
59] used MLP artificial neural network to model the composite structure monitoring data, and trained the network through maximum likelihood estimation and Bayesian reasoning. The results showed that the network has good generalization ability. On this basis, Pierce et al. [
60] further analyzed the robustness of the network based on interval uncertainty technology. This kind of research provides another idea for MLP-based neural network training.
Because MLP has the ability to approximate any form of nonlinear function by adding hidden layers or hidden elements, it has attracted extensive attention in the field of remaining life prediction.
Radial basis function neural network (RBF) neural network is a neural network structure proposed in the 1980s. It has a three-layer feedforward network with a single hidden layer, and can approach any continuous nonlinear function with any accuracy [
61,
62]. The biggest difference between RBF neural network and MLP neural network in structure is that the independent variable of excitation function is the product of distance and deviation between input vector and weight vector, rather than the weighted sum between input vector and weight vector. Liu et al. [
63] pointed out that the key to an RBF neural network model is to correctly select the appropriate RBF center. The number and location of RBF centers in the hidden layer directly affect the approximation ability of the network. Li et al. [
64] constructed a life prediction model of accelerated life test by using the method of grey RBF neural network. The test showed that the prediction result is obviously better than BP neural network. When Li et al. [
65] used RBF neural network for relay life prediction, the input information of RBF neural network was not the original relay overtravel time with non-stationary characteristics, but the random term obtained through wavelet transform. The output information of RBF neural network realized the relay life prediction again through wavelet packet reconstruction. Chen et al. [
66] proposed a multivariate grey RBF hybrid model for remaining life prediction of industrial equipment, which integrates the advantages of grey model and RBF neural network, effectively ensures the prediction accuracy and has practical engineering application value.
The remaining life prediction method based on RBF neural network only contains one hidden layer, and the fitting accuracy is high. It can overcome the problems of falling into local optimization and slow convergence of the learning process, and can realize the dynamic determination of the network structure and the data center of the hidden layer unit.
Limit learning machine (elms), as a new learning algorithm for a single hidden layer feedforward neural network, was proposed by Huang [
67]. The basic idea of the elms training process is to randomly select the input weight and hidden layer deviation value, manually select the number of hidden layer neurons according to the engineering practice experience, and determine the output weight by the least square method, so as to realize the rapid determination of network structure and parameters.
Li et al. [
68] studied the problem of remaining life prediction of fan mechanical transmission components based on elms, and introduced in detail the principle, parameter selection and optimization process of the elms algorithm, so as to predict the trend and value of relevant performance parameters and realize the evaluation of performance parameters and the prediction of residual life. Liu et al. [
69] extracted the features that can better reflect the bearing degradation process through the joint approximate diagonalization method of the two-layer feature matrix, and input the extracted features into the elms model to accurately predict the remaining life of the bearing. On this basis, Liu et al. [
70] improved the feature extraction method, also used the elms method to train the extracted features, and applied this method to the study of the remaining life of bearings. Du et al. [
71] proposed a multi classification probability elms model based on sigmoid a posteriori probability mapping and Lagrange pairwise coupling method, which solved the problem of remaining life prediction of UAV transmitters. Yang et al. [
72] proposed a remaining life prediction method based on elms, compared the relationship and difference between elms and BP artificial neural network, and found that the internal parameters of elms do not need iterative calculation. The test showed that the model based on elms is slightly inferior to the model based on BP artificial neural network in prediction accuracy and stability, but can significantly reduce the training time.
The remaining life prediction method based on elms has the following advantages: It can make a rapid remaining life prediction and effectively reduce the model training time. The activation function can use discontinuous functions. The problem of sensitive selection of learning parameters and easily falling into local extremum in gradient descent learning algorithm is avoided.
Although the method based on elms has many advantages, it also has some shortcomings. Since the deviation between the input weight and the hidden layer is generated randomly, the network training effect of elms cannot be guaranteed, which may be good and bad from time to time. At the same time, the number of hidden layer nodes needs to be selected according to experience and experimental methods, which makes it difficult to ensure the optimal model. In addition, because the output weight is calculated by the least square method, the method based on elms will face the problem of expanding the influence of outliers and noise.
- b
Method based on support vector machine
Support vector machine (SVM) was developed based on VC dimension theory and the structural risk minimization principle. It was first proposed by Cortes and Vapnik in 1995. It is mainly used to solve the classification and regression problems of ML and is suitable for analyzing small samples and multidimensional data [
73,
74].
The main idea of the research on the remaining life prediction method based on SVM is to train the support vector machine model with the condition monitoring data obtained in the actual project, determine the model parameters (insensitivity coefficient, penalty factor, kernel function parameters, etc.), predict the future state of the system based on the trained SVM model, and obtain the residual life of the equipment by comparing with the preset failure threshold.
Due to the multidimensional, nonlinear and uncertain characteristics of condition monitoring data in practical engineering, it is usually difficult to ensure the accuracy of SVM model parameters by simply using a SVM method to train condition monitoring data. SVM model parameters directly affect the remaining life results of equipment. Therefore, scholars began to pay attention to how to combine SVM with other methods to predict the remaining life of equipment.
In order to eliminate the interference information in the data, Miao et al. [
75] combined wavelet analysis with SVM to predict the remaining life of a gyroscope. Nieto et al. [
76] proposed an algorithm based on Hybrid Particle Swarm Optimization and SVM for spacecraft engine remaining life prediction, solved the optimization problem of super parameters in the training process of support vector machine, and further improved the accuracy of prediction. Aiming at the problem that SVM cannot effectively deal with non-static sequences with monotonic trends, Maior et al. [
77] proposed a method combining empirical mode decomposition and SVM for degradation data analysis and remaining life prediction, and applied the proposed method to the analysis of a motor. The results showed that this method can improve the prediction performance compared with simple SVM.
The remaining life prediction method based on SVM is more suitable for analyzing small samples and multidimensional data. However, there are also many defects. For example, with the increase in the sample set, the linearity will increase, resulting in the increase of overfitting and calculation time. It is difficult to obtain the prediction of probability formula, that is, it is impossible to evaluate the uncertainty of remaining life prediction; the Kernel function must satisfy the Mercer condition.
Table 5.
Classification and characteristics of traditional machine learning remaining life prediction methods.
Table 5.
Classification and characteristics of traditional machine learning remaining life prediction methods.
| Traditional Machine Learning Remaining Life Prediction Method | Advantages | Disadvantages |
|---|
| Neural network | MLP | Has the ability to approximate any form of nonlinear function by adding hidden layers or hidden elements [60]. | The effect is good without obvious disadvantages [60]. |
| RBF | The network contains only one hidden layer, and the fitting accuracy is high; It can overcome falling into local optimization and realize the dynamic determination of the network structure and the data center of the hidden layer unit [61,62]. | The effect is good without obvious disadvantages [66]. |
| ELM | Short training time; The activation function can use discontinuous functions; It avoids the problems of sensitive selection of learning parameters and easily falling into local extremum [67]. | Since the deviation between the input weight and the hidden layer is generated randomly, the network training effect of elms cannot be guaranteed, which may be good and bad from time to time. The number of hidden layer nodes needs to be selected according to experience and experimental methods, which makes it difficult to ensure the optimal model [72]. |
| SVM | The remaining life prediction method based on SVM is more suitable for analyzing small samples and multidimensional data [75]. | With the increase of the sample set, the linearity will increase, resulting in the increase of overfitting and calculation time. It is difficult to obtain the prediction of probability formula, that is, it is impossible to evaluate the uncertainty of remaining life prediction; the Kernel function must satisfy the Mercer condition [77]. |
- (2)
Deep learning
The research on equipment remaining life prediction methods based on deep learning mainly include: methods based on deep neural network (DNN), methods based on deep belief network (DBN), methods based on convolutional neural network (CNN) and methods based on recurrent neural network (RNN). The characteristics of each method are given in
Table 6.
Deep neural network (DNN) is usually a multilayer neural network formed by stacking multilayer feature representation models. The common feature representation models include AE and denoising automatic encoder (DAE). The main idea of the method based on DNN is to extract the high-level features of the original data through multiple AE or DAE stacking networks, and then realize the prediction of the remaining life based on regression fitting method or feedforward neural network. Zhou et al. [
78] proposed an early diagnosis method of micro, slowly varying faults based on DNN. The high-dimensional fault features extracted by deep learning are transformed into one-dimensional fault features through the PCA method, and then the life prediction model is constructed by using the nonlinear fitting method. Yan et al. [
79] studied a remaining life prediction method combining deep DAE and regression analysis for the big data analysis of industrial systems. Two deep DAEs were used to process the far end signal and near end signal, respectively to obtain the overall trend and current change process. The outputs of the two deep DAEs were fused to predict the residual life of the equipment through linear regression.
The DNN prediction method has the following characteristics: Useful features can be extracted through multiple dimensionality reduction of input data, which can facilitate model training. Because the DAE has the function of noise reduction and filtering, the network formed by the stacking of multiple DAEs can process the monitoring data containing noise, which fully reflects the strong robustness and universality of this method.
As a typical deep learning method, DBN is mainly a deep network composed of multiple restricted Boltzman machines (RBM) stacked and a classification layer or regression layer. It can not only realize the feature representation and extraction of observation data from low-level to high-level, but also discover the distributed features of input data [
80]. Deutsch et al. [
81] successfully applied DBN to predict the remaining life of bearings, but the prediction accuracy of the proposed method was much lower than that of the particle filter method. Deutsch et al. [
82] also proposed a remaining life prediction method for rotating equipment integrating DBN and a feedforward neural network (FNN), which is based on the improvement and expansion of the DBN method and can effectively combine the feature extraction ability of DBN with the prediction performance of FNN.
In order to obtain the probability distribution of remaining life, DBN and particle filter have been effectively combined to further improve the prediction accuracy [
83]. On this basis, Zhao et al. [
84] effectively combined the advantages of DBN and RVM to study a new method for predicting the remaining life of Li batteries. Because DBN has strong feature extraction ability, it effectively solves the uncertainty problem caused by artificial feature extraction and selection, and realizes the goal of intelligent feature extraction. At the same time, the time-domain signal under this method does not need to meet the requirements of periodicity, so it has a broad application space in the field of remaining life prediction.
However, DBN still has several limitations: The short-term prediction performance is good, while the long-term prediction performance is poor. It cannot reflect the uncertainty of the prediction results. Generally, it needs to be combined with other methods to reflect the uncertainty of the prediction results.
As a kind of classical feedforward neural network, CNN was first proposed by Lecun and was used to solve the problem of image processing. It is mainly composed of several convolution layers and pooling layers. The purpose is to extract the topology features hidden in the monitoring data step by step by constructing multiple filters, and the extracted features will become more and more abstract with the deepening of the network level [
85]. For CNN, the convolution layer uses the original input data to convolute multiple local filters, and the subsequent pooling layer can extract the most important features with a fixed length. The commonly used pooling function is the maximum pooling function [
86].
The research on remaining life prediction based on CNN began in 2016. Babu et al. [
87] applied deep CNN to the field of remaining life prediction, used two convolution layers and two pooling layers to extract the characteristics of the original signal, and combined with MLP to predict the remaining life. Li et al. [
88] proposed a multivariable equipment residual life estimation method based on deep CNN. In order to better extract features, the time window method is used to obtain samples. At the same time, because some effective information will be filtered out by the pooling operation, the pooling layer is ignored in the process of building the network. Ren et al. [
89] studied the problem of bearing remaining life prediction based on CNN, combined a series of extracted features, namely the spectrum main energy vector, into a feature map, and extracted a one-dimensional vector that is helpful for predicting the remaining life through the structure of CNN. The one-dimensional vector is input into the deep neural network to predict the residual life. The bearing test showed that the proposed method is better than the traditional ML method.
The research on remaining life prediction based on CNN has the following characteristics: It is suitable for engineering equipment that can monitor massive data. It can realize automatic feature extraction and recognition without manual participation and intervention. The weight-sharing feature makes the number of parameters of CNN model less and the optimization process more convenient. However, the remaining life prediction based on CNN is still in the preliminary exploration stage, the research results have not been systematic, and the uncertainty of remaining life cannot be given quantitatively. Therefore, the methods based on CNN still require in-depth research.
RNN is a kind of feedforward neural network including a feedforward connection and an internal feedback connection, and is mainly used to process the monitoring vector sequence with interdependent characteristics. Due to its special network structure, it can retain the state information at the last moment on the hidden layer, so it has strong advantages in the field of complex dynamic system modeling [
90].
The basic idea of remaining life prediction methods based on RNN is to take the monitoring data input in the project as the input of the RNN network, and train the model parameters through back propagation through time (BPTT), so as to realize the remaining life prediction of equipment. It should be noted that the internal feedback connection of an RNN depicts the pre- and post-dependence of monitoring data. Liu et al. [
91] used an adaptive RNN to predict the remaining life of Li batteries, and online optimized the weight of the network structure through a cyclic Levenberg–Marquardt method. The remaining life prediction method based on RNN can integrate the original learning samples with the new learning mode to realize the retraining of samples. It can not only improve the accuracy of remaining life prediction, but also has the characteristics of fast convergence and high stability. However, the traditional RNN usually has the problem of “memory decay”, because there is no structure to control memory flow in the traditional circulation layer. When dealing with long-term dependent degradation data, the traditional RNN methods will face the problem of gradient disappearance or explosion, and the prediction accuracy will be seriously affected. On the other hand, RNN cannot effectively analyze and process multidimensional data, and usually needs to be combined with other methods for these purposes.
Scholars have also proposed other improved deep learning methods to predict the RUL, which show better performance than the current popular models. For instance, Zhang et al. [
91] proposed a dual-task network structure based on bidirectional gated recurrent unit (BiGRU) and multigate mixture-of-experts (MMoE), which simultaneously evaluates the health state and predict the RUL of industrial equipment.
Table 6.
Classification and characteristics of deep learning remaining life prediction methods.
Table 6.
Classification and characteristics of deep learning remaining life prediction methods.
| Deep Learning Method | Advantages | Disadvantages |
|---|
| DNN | Model training is convenient; It can process the monitoring data containing noise, which shows that the method has strong robustness and universality [78]. | The effect is good without obvious disadvantages [79]. |
| DBN | DBN has strong feature extraction ability [80]. | The short-term prediction performance is good, while the long-term prediction performance is poor; It cannot reflect the uncertainty of the prediction results [84]. |
| CNN | It is applicable to engineering equipment that can monitor massive data; It can realize automatic feature extraction and recognition without manual participation and intervention; The weight-sharing feature makes the number of parameters of a CNN model less and the optimization process more convenient [85]. | It is still in the preliminary exploration stage, and the research results have not been systematized;
The uncertainty of remaining life cannot be given quantitatively [89]. |
| RNN | It can integrate the original learning samples with the new learning mode to realize the retraining of samples, improve the prediction accuracy, and has the characteristics of fast convergence and high stability [90]. | Traditional RNN usually has the problem of “memory decline”. When dealing with long-term dependent degraded data, it will face the problem of gradient disappearance or explosion, and the prediction accuracy will be affected; RNN cannot effectively analyze and process multidimensional data [92]. |
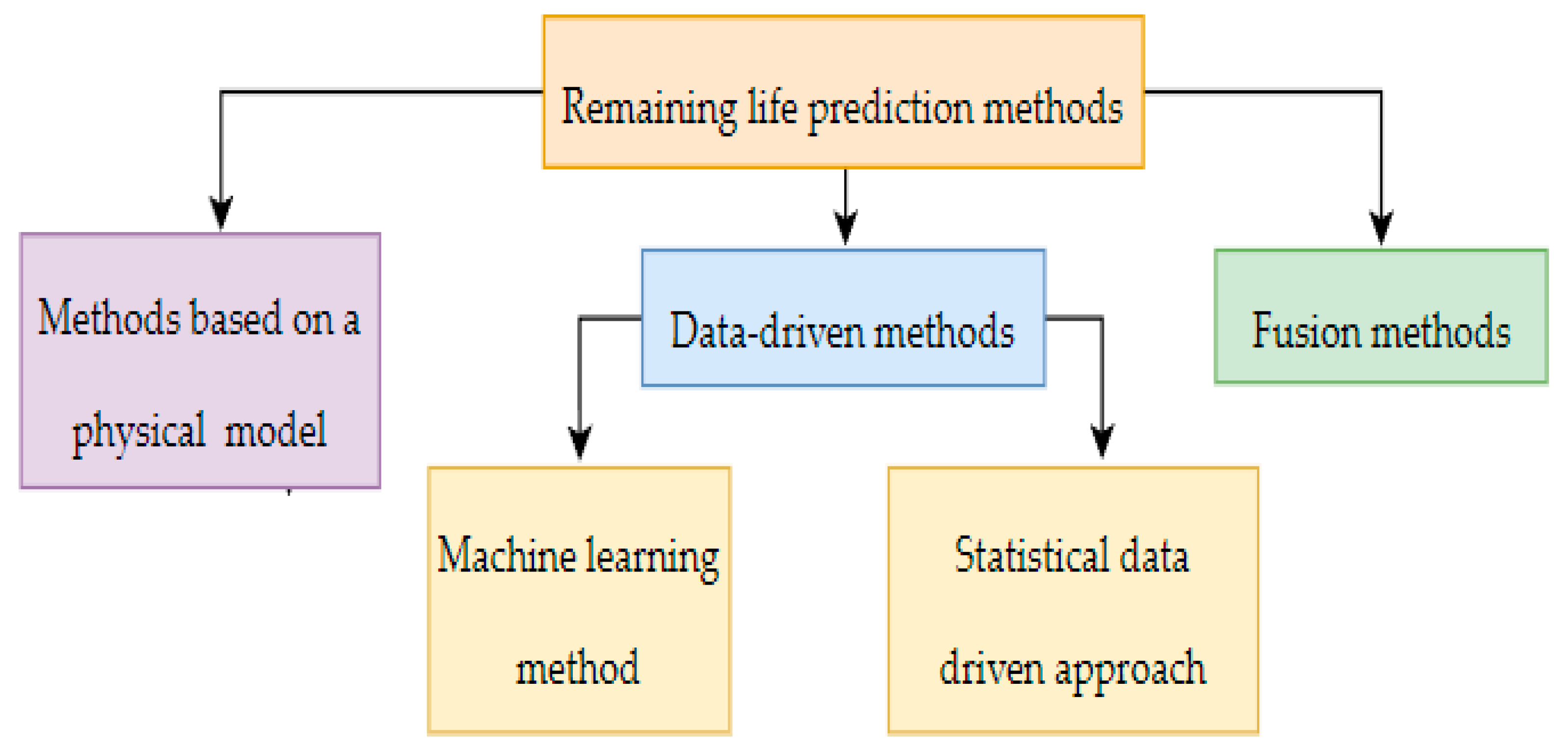
- 2.
Statistical data-driven approach
The statistical data-driven method is based on the theory of probability statistics, using the historical data degradation trajectory of similar systems or products, establishing the relationship between the data system and the degradation model, and estimating the parameters of the degradation model, so as to obtain the analytical probability distribution of the remaining life of the object or system and realize the prediction of the remaining life [
93].
Statistical data-driven methods assume that the degradation model is known in advance, and directly use the condition monitoring data or environmental data to estimate the model parameters offline or online. However, the degradation model in practical engineering is unknown, and the degradation models of different types of equipment are different. The improper selection of a degradation model will seriously affect the prediction accuracy of remaining life. Typical methods include Wiener process, gamma process, inverse Gaussian process, Markov model and so on (see
Table 7).
The method based on the Wiener process is mainly applicable to the non-monotonic case of equipment performance degradation process. This method mainly uses the following mathematical model to describe the degradation process:
where
x0 is the initial performance degradation value;
λ(
s) is the drift parameter;
σ is the diffusion coefficient;
B(
t) is the standard Brownian motion.
After obtaining the equipment performance degradation process model, the remaining life distribution of the equipment can be calculated by using the relevant theory of the Wiener process on the basis of giving its failure value. In order to realize the accurate real-time prediction of the remaining life of the equipment, usually, the real-time monitoring information of the equipment can be used to dynamically update the remaining life prediction results. Gebraeel et al. [
94] first established the degradation model of equipment based on the Wiener process with linear drift (or linearization), and assumed that the drift coefficient obeyed the normal distribution. According to the degradation data observed in real time, the online update of the random drift coefficient was realized by using the method of Bayesian reasoning. The Gebraeel method has had a great impact in the field of equipment life prediction and health management. However, the remaining life prediction results obtained by the Gebraeel method are only applicable to linear degradation equipment or equipment whose performance degradation data can be directly linearized. Moreover, the Brownian motion term in the degradation model used in this method is only treated as the observation error, so that the remaining life distribution obtained is not the exact solution in the sense of first arrival time.
The gamma process is often used to model the degradation trajectory of monotonic data, such as metal wear and crack growth. Abdel et al. [
95] first proposed it in 1975 and used the gamma process to model continuous monotonic degradation data. Bagdonavicius considered the influence of dynamic environments in the degradation model and proposed a remaining life prediction method based on the gamma process considering dynamic environments [
96]. Lawless et al. [
97] considered the problem that the parameters in the gamma process are random variables. In practical application, the duty cycle of the system may not be periodic, which would lead to aperiodic degradation measurements. Both of these factors affect the accuracy of health assessment and RUL prediction. In order to meet these challenges, Zhao et al. [
98] propose a Gamma state-space model of power equipment, which considers the temporal uncertainty, measurement uncertainty, and device-to-device heterogeneity. This method introduces a new idea for health assessment and RUL prediction.
The basic idea of the inverse Gaussian process is to assume that the degradation is strictly monotonic, and the increment of degradation obeys an inverse Gaussian distribution. The degradation process is described by the change in increment. The inverse Gaussian process was first proposed by Wasan et al. [
99] in 1968, but it was not applied to the degradation modeling of equipment by Wang et al. [
100] until 2010. The inverse Gaussian process is used to describe the monotonic degradation process due to the connection between the inverse Gaussian distribution and the linear drift Wiener process. Compared with the gamma process, the inverse Gaussian process is easier to deduce and implement mathematically, and more flexible and applicable.
The Markov chain method is often used in the degradation modeling of processes with continuous time discrete state characteristics. This method is based on two assumptions: one is that the future degradation state is only determined by the current degradation state, that is, it is memoryless. Second, the system monitoring data can reflect its working state. The remaining life prediction method based on Markov chain defines the first arrival time by the time when the degradation process first reaches the failure state, and calculates the remaining life according to the first arrival time. Kharoufeh et al. [
101] carried out a series of studies on this method and proposed a degradation model based on Markov chain considering environmental impact. Lee et al. [
102] incorporated a Markov property in the degradation process into remaining life prediction based on a regression model.
Table 7.
Classification and characteristics of statistical data-driven remaining life prediction methods.
Table 7.
Classification and characteristics of statistical data-driven remaining life prediction methods.
| Statistical Data-Driven Remaining Life Prediction Method | Characteristics |
|---|
| Wiener process | It is applicable to the non-monotonic situation of equipment performance degradation process [94]. |
| Gamma process | Degradation trajectory modeling commonly used for monotone data [98]. |
| Inverse Gaussian | Assuming that the degradation is strictly monotonic, and the increment of degradation obeys an inverse Gaussian distribution, the degradation process is described by the change in increment [100]. |
| Markov | Degradation modeling for processes with continuous time discrete state characteristics [102]. |




{kind=link}
{kind=link}
{kind=link}