
Distributed Dynamic Predictive Control for Multi-AUV Target Searching and Hunting in Unknown Environments


Abstract
:1. Introduction
2. Mathematical Modeling
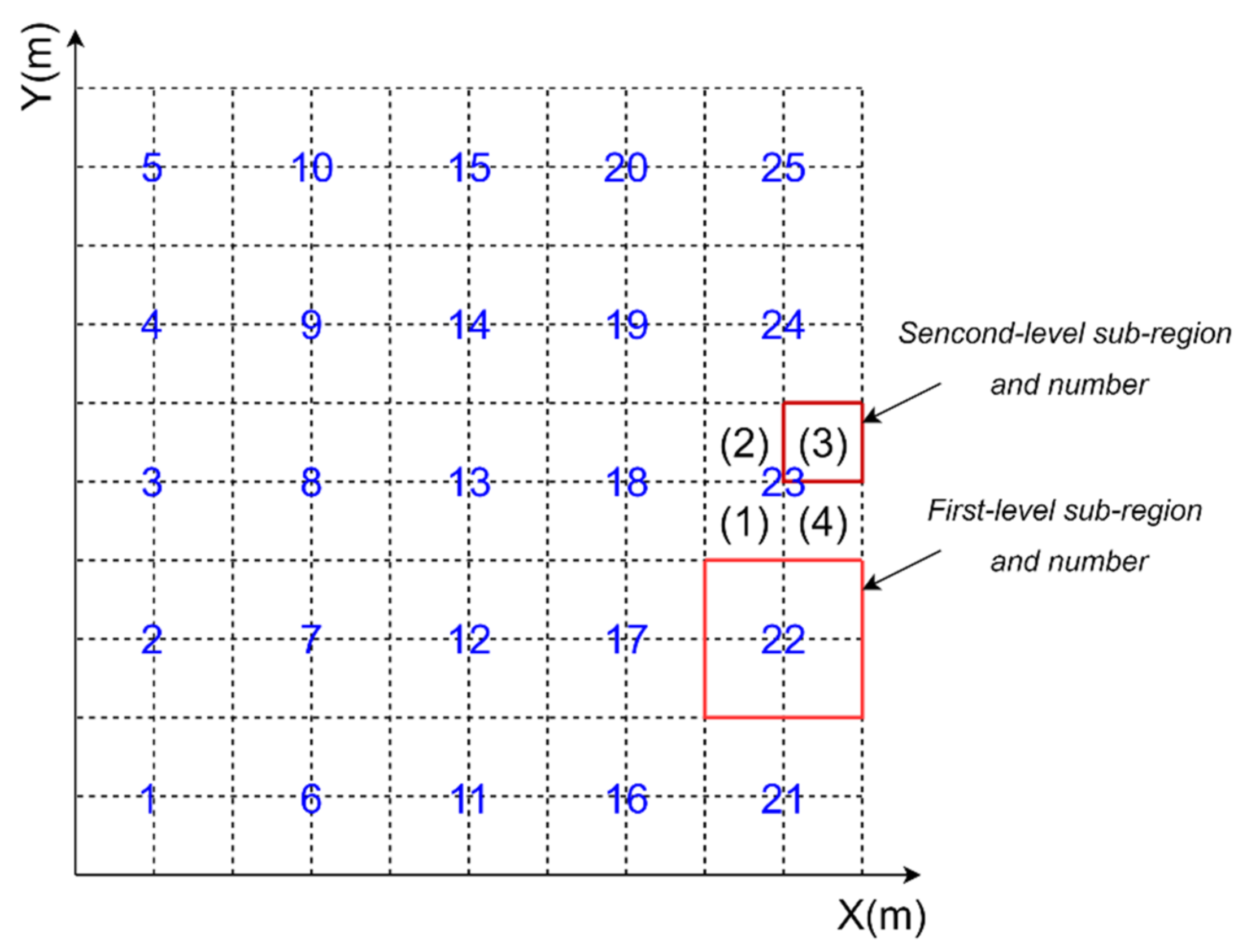
2.1. The Environment Model
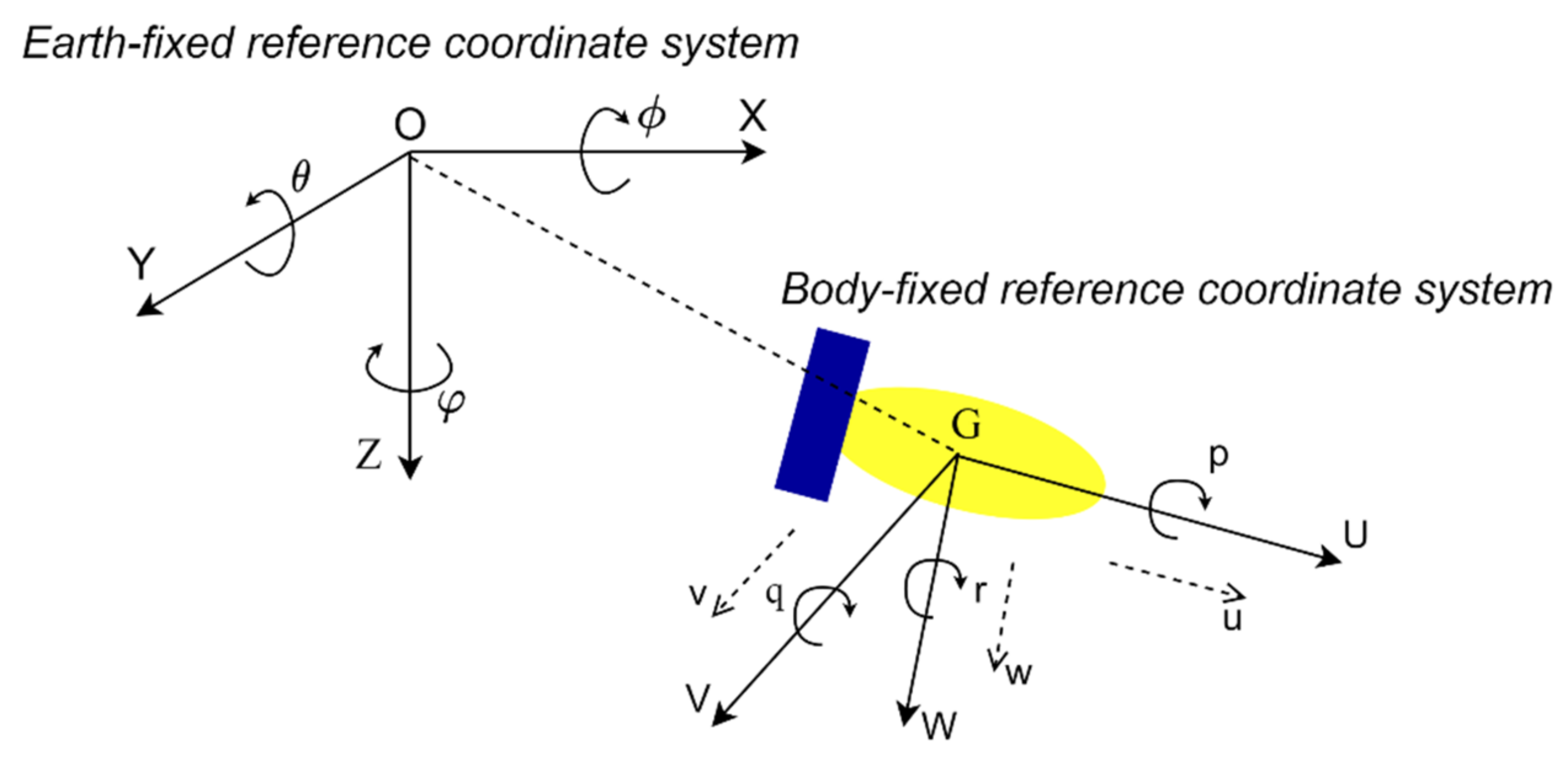
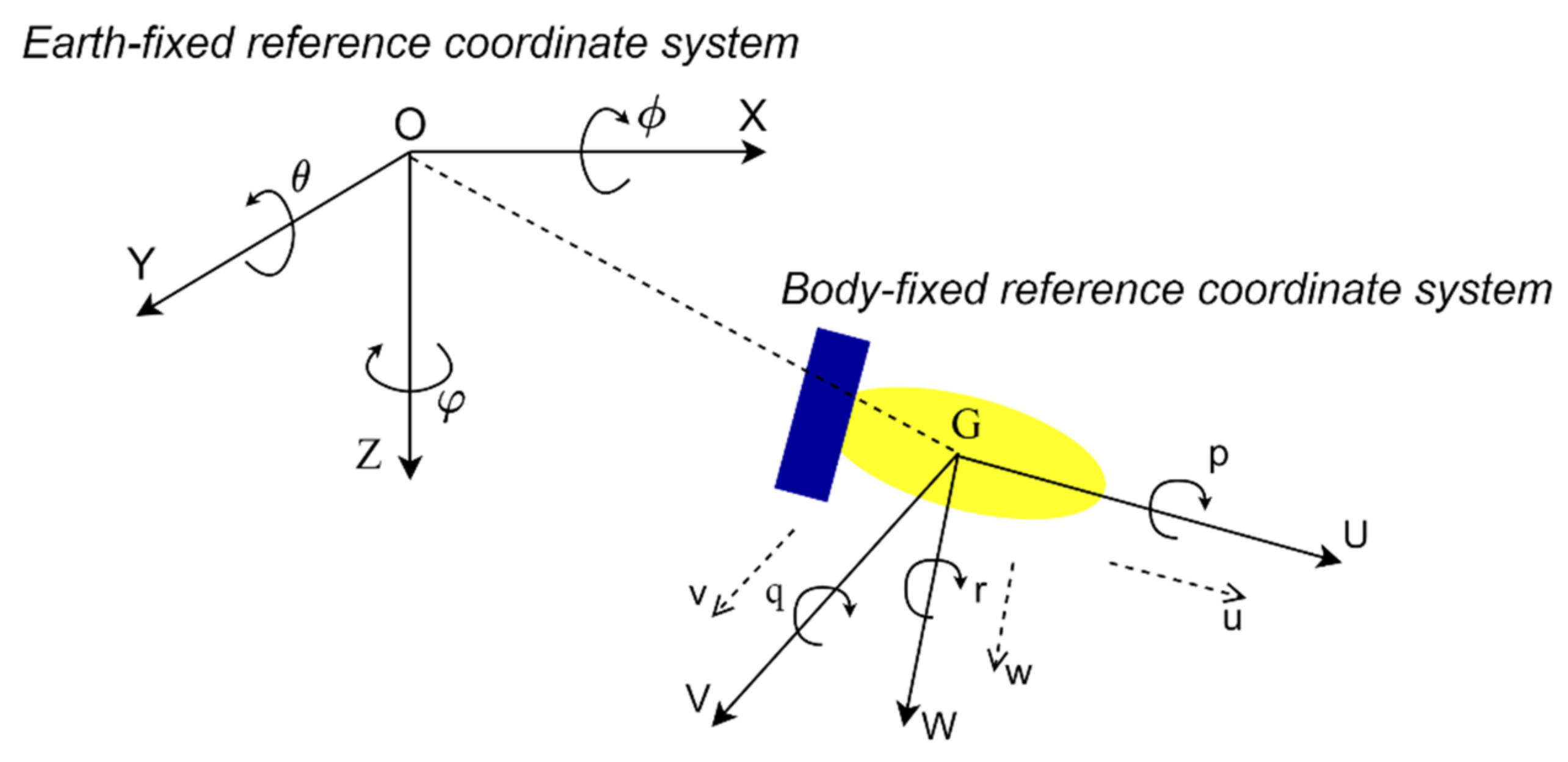
2.2. The AUV Kinematic Model
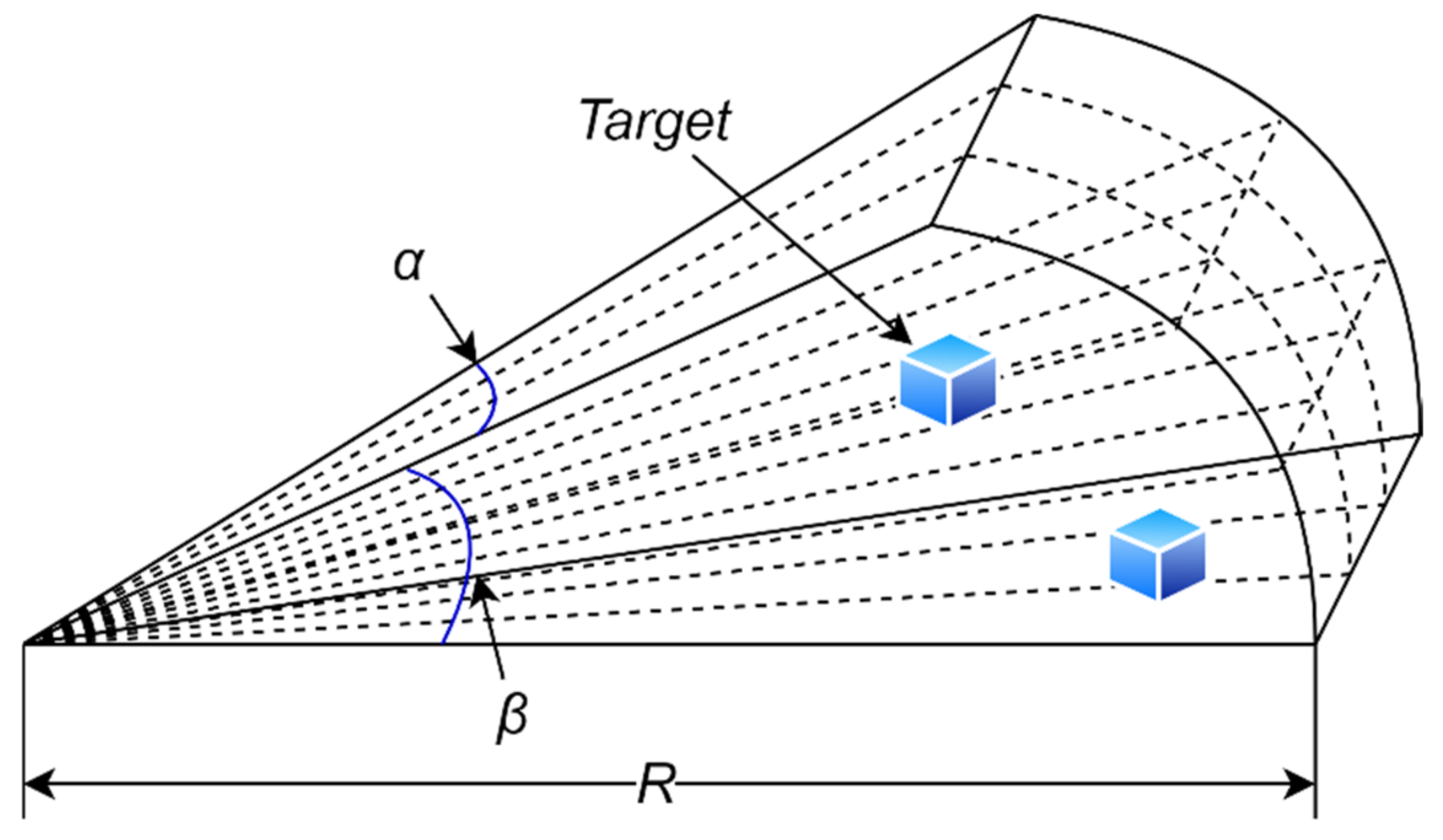
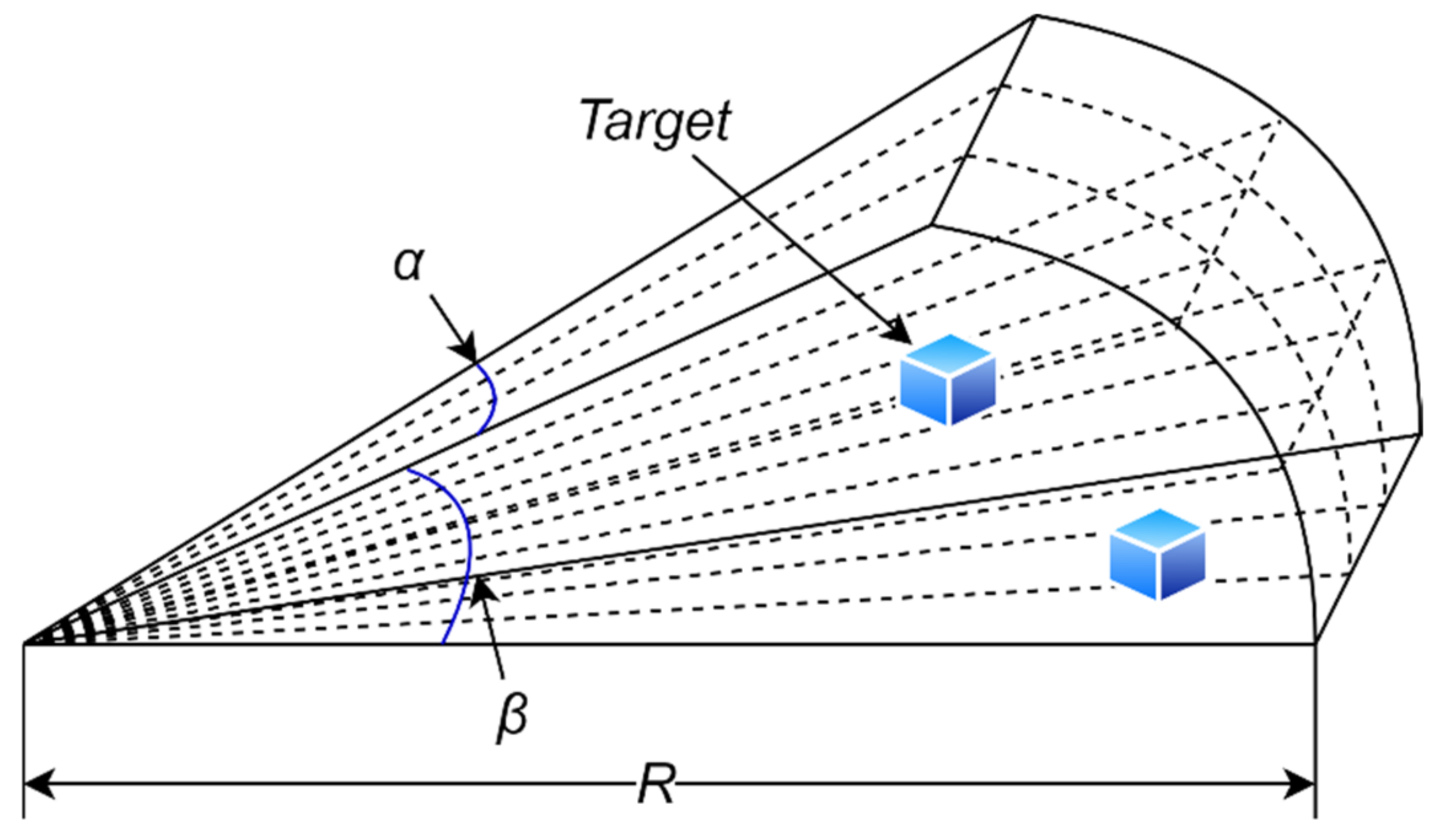
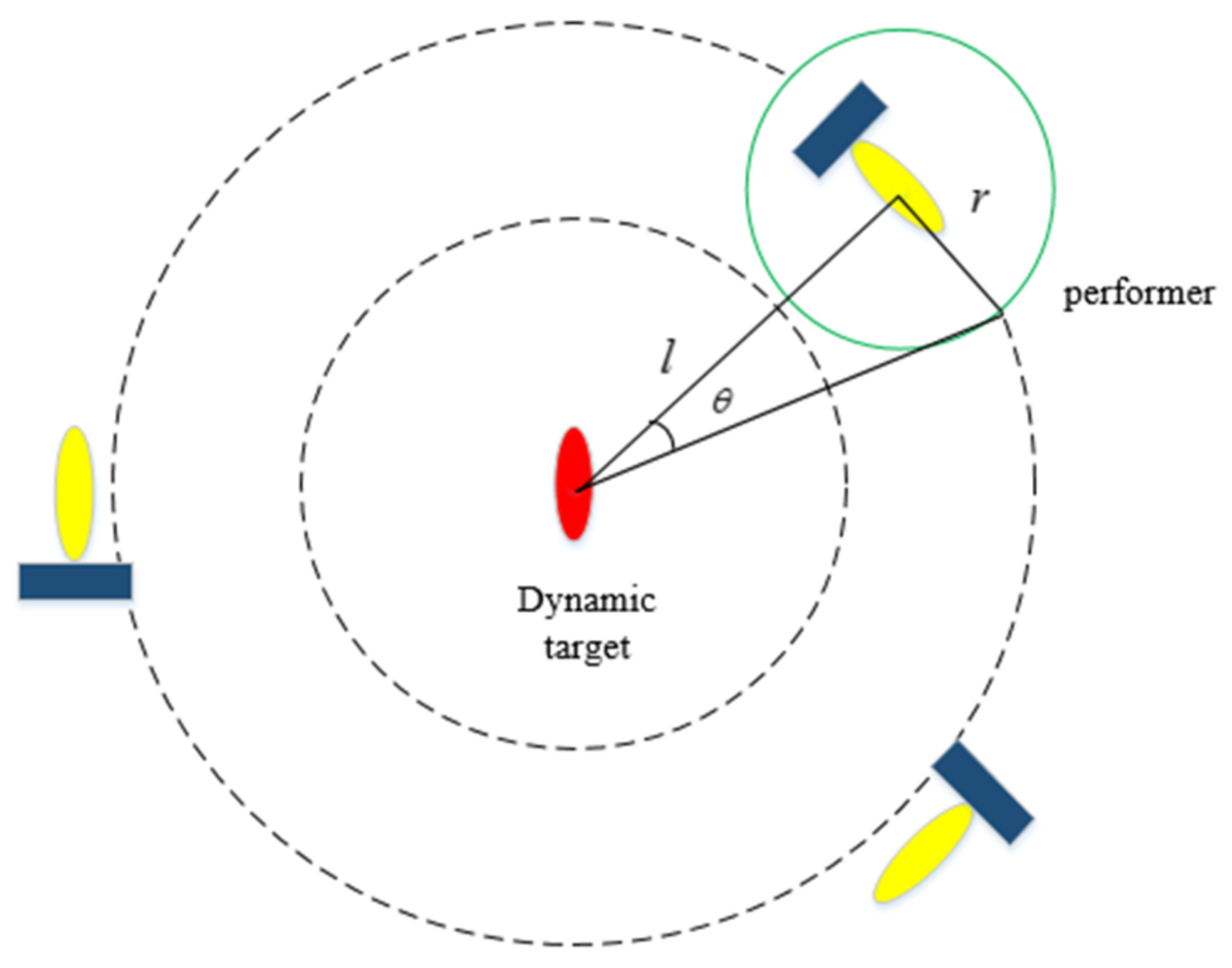
2.3. Forward-Looking Sonar Model
2.4. Target Model
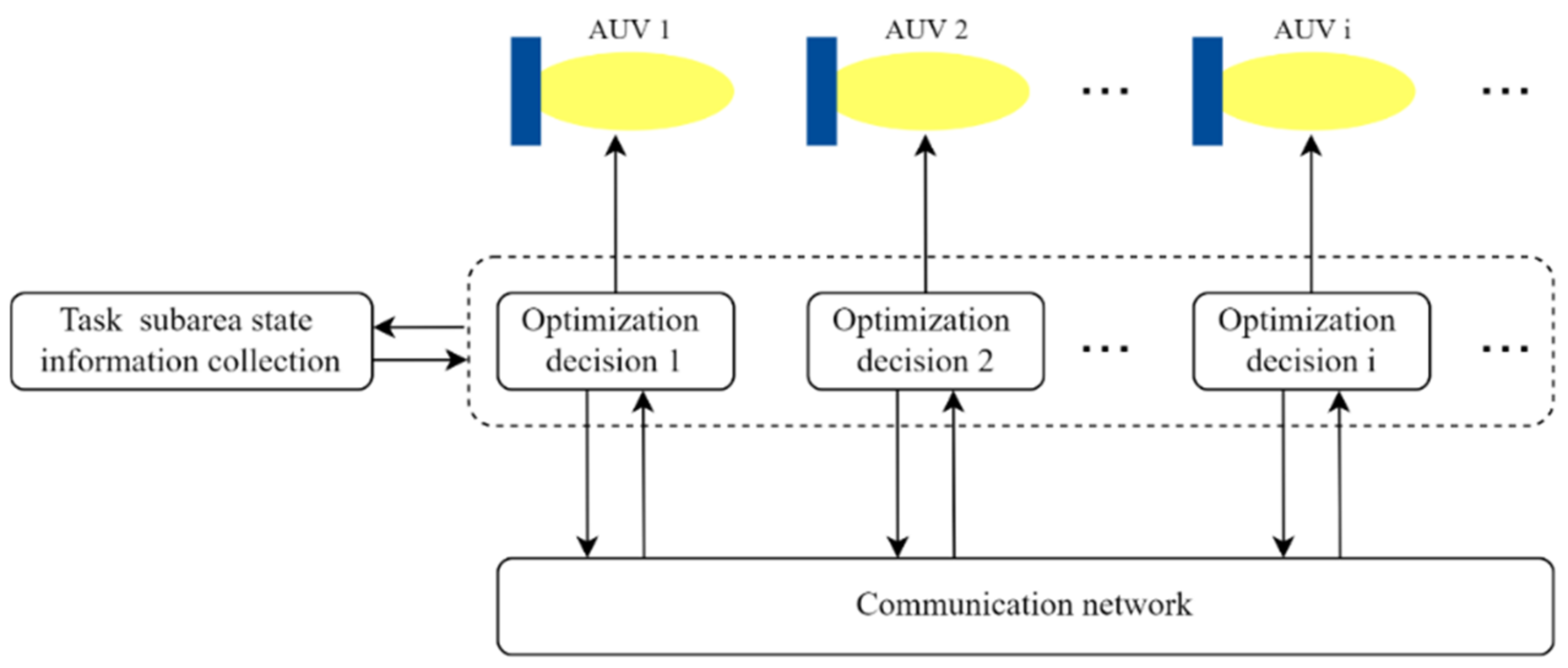
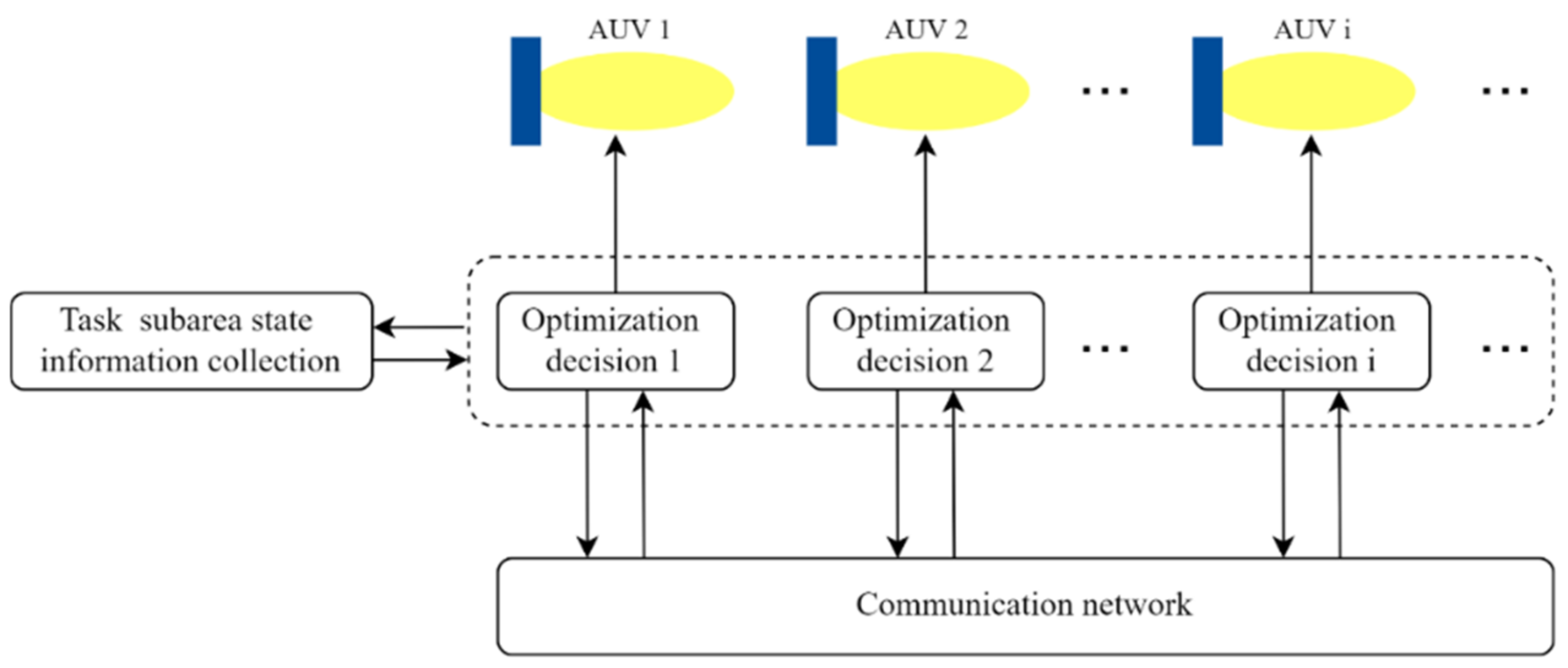
2.5. Multiple AUV Communication Content
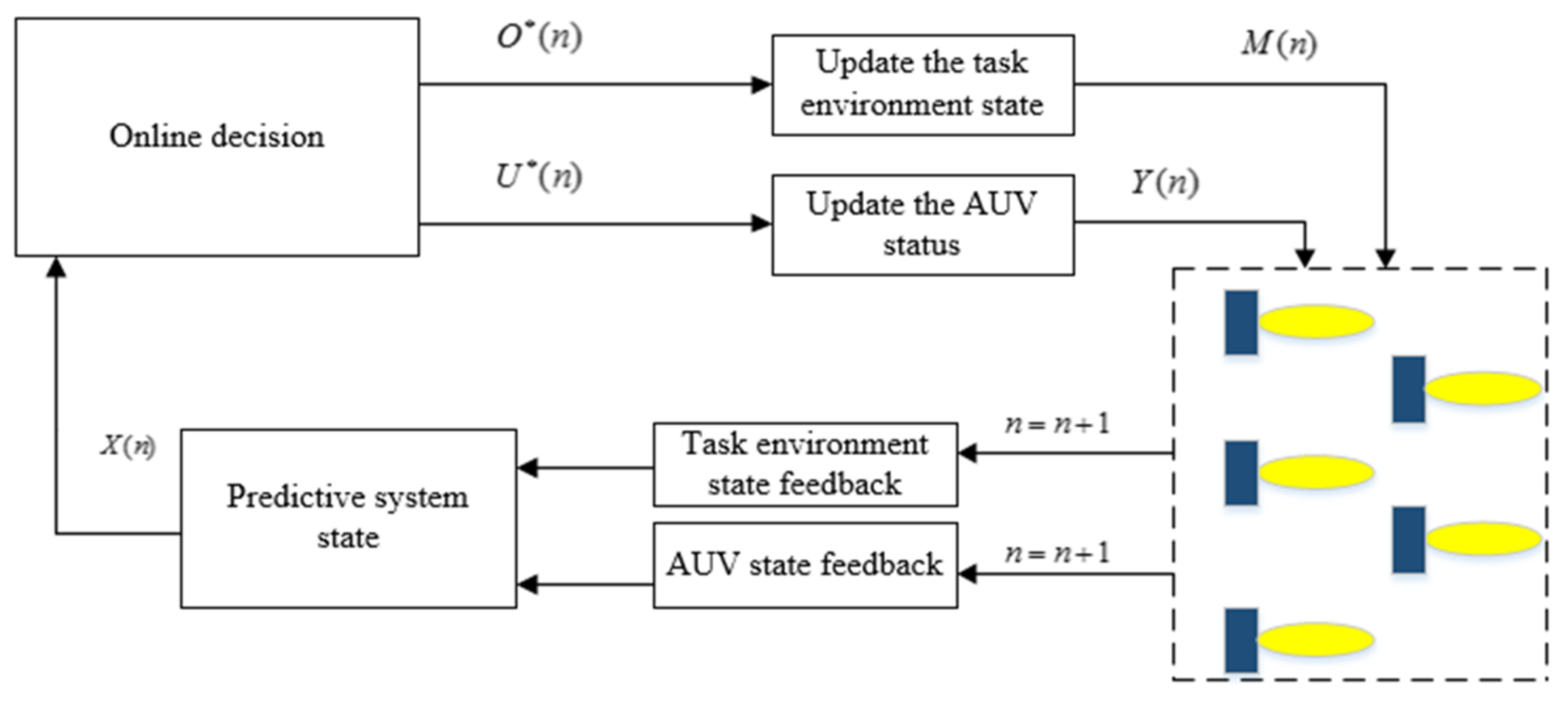
3. The Distributed Dynamic Predictive Control Algorithm
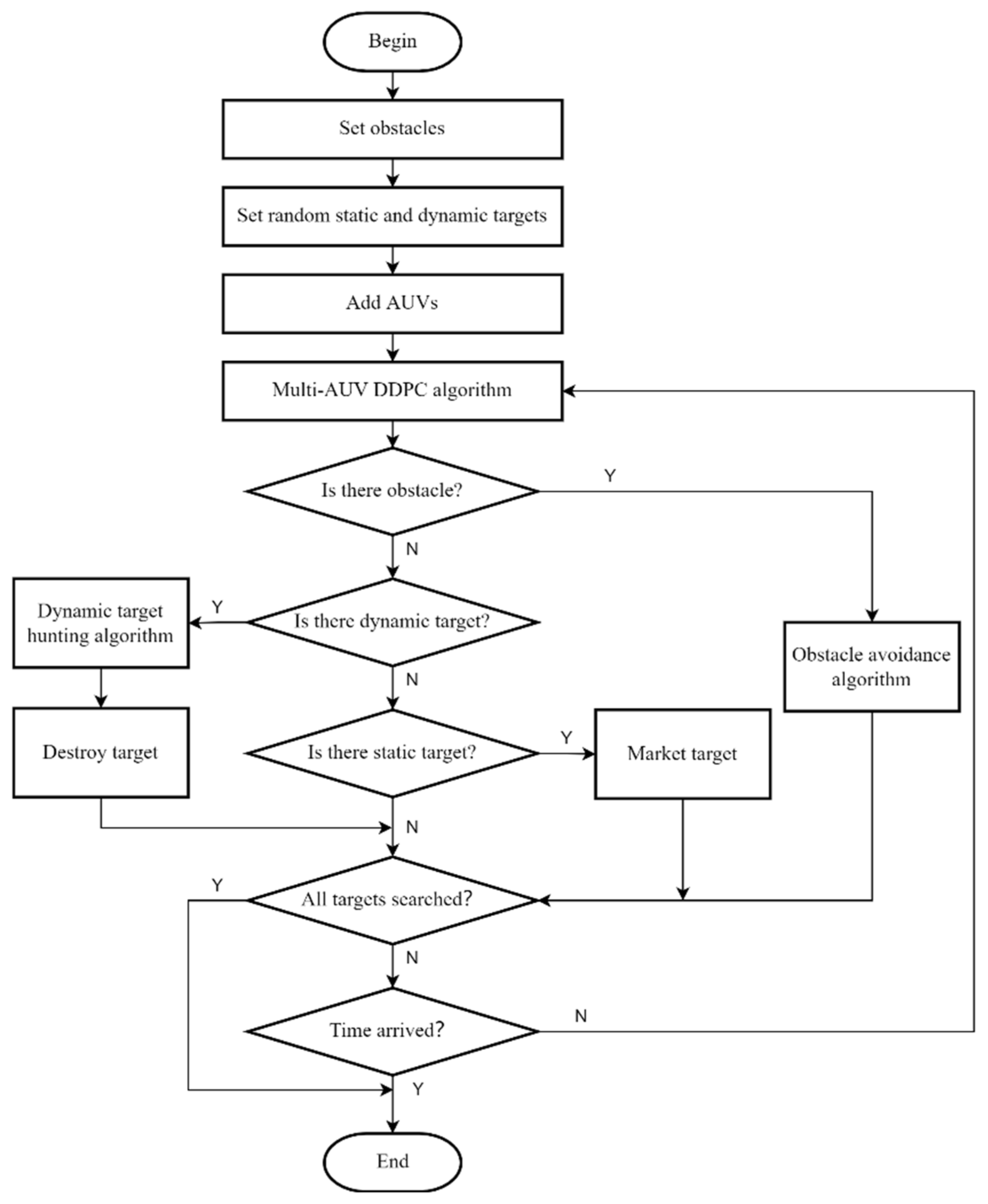
3.1. The Searching and Hunting Process
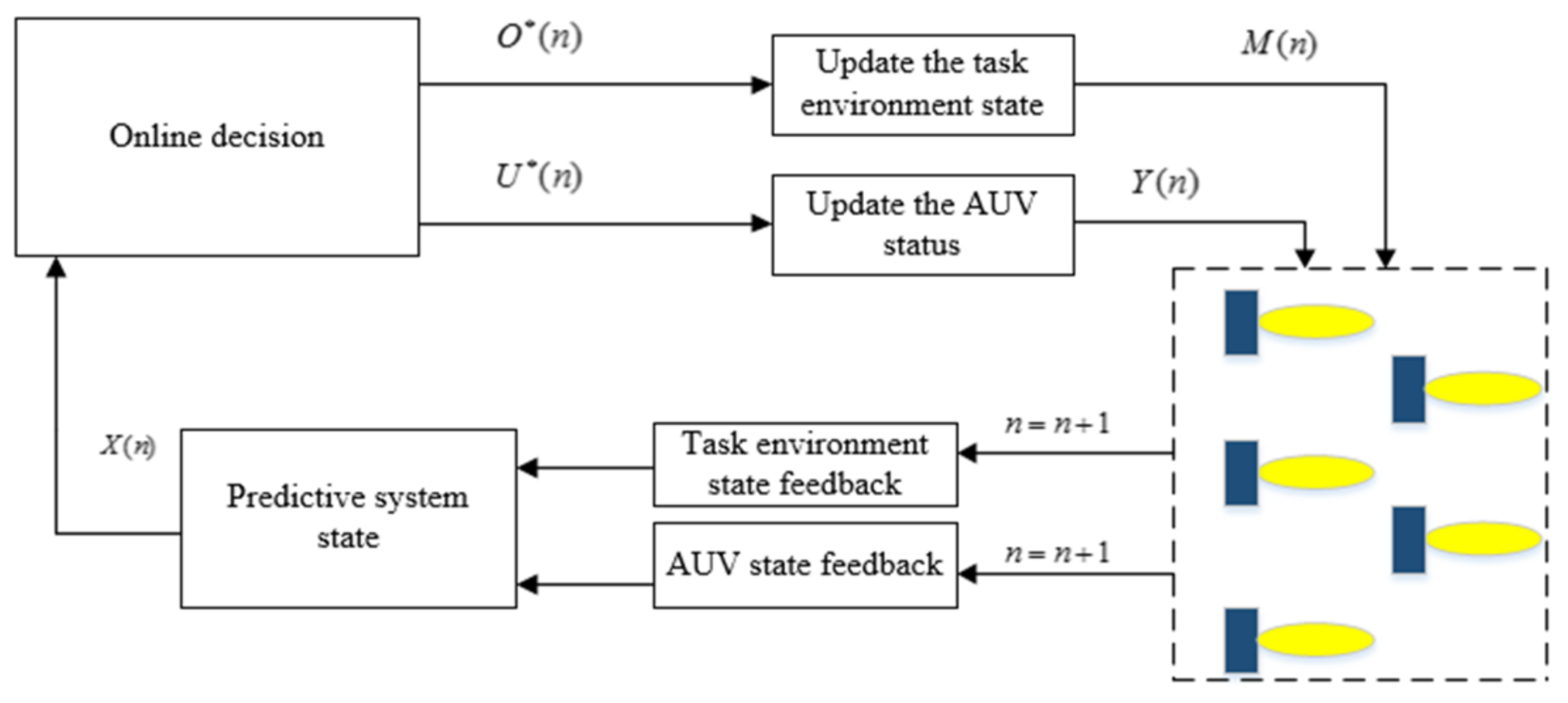
3.2. The Distributed Dynamic Predictive Control Algorithm
- (1)
- AUV and environment state feedback: The system feeds back the state information changes of the AUV of the current actuator and the task environment model and the feedback information is used as the input of the system state prediction;
- (2)
- System state prediction: The state for the N steps in the future is dynamically predicted by the feedback information, and the predicted state of the current time n is obtained. The predicted state is represented by ;
- (3)
- Online task optimization decision: The algorithm is based on distributed dynamic prediction combined with optimization methods for online decision making, confirming the actuator state input information and area state information, which are and . , and are taken as the state inputs;
- (4)
- State updates for AUV and task area: updates the state of the actuator and the state information of the entire environmental area through decision input to obtain and , respectively, and finally controls the AUV system to perform collaborative target search.
3.2.1. Task Area State
3.2.2. The AUV State
3.3. The Function of Decision-Making
- (1)
- Reduce the cost of multi-AUV cooperative target search;
- (2)
- Improve the determination degree of target information in the task area;
- (3)
- Allocate search area reasonably.
- (1)
- Regional target discovery revenue
- (2)
- Environment target search revenue
- (3)
- Execution cost
- (4)
- Sub-region predicted allocation revenue
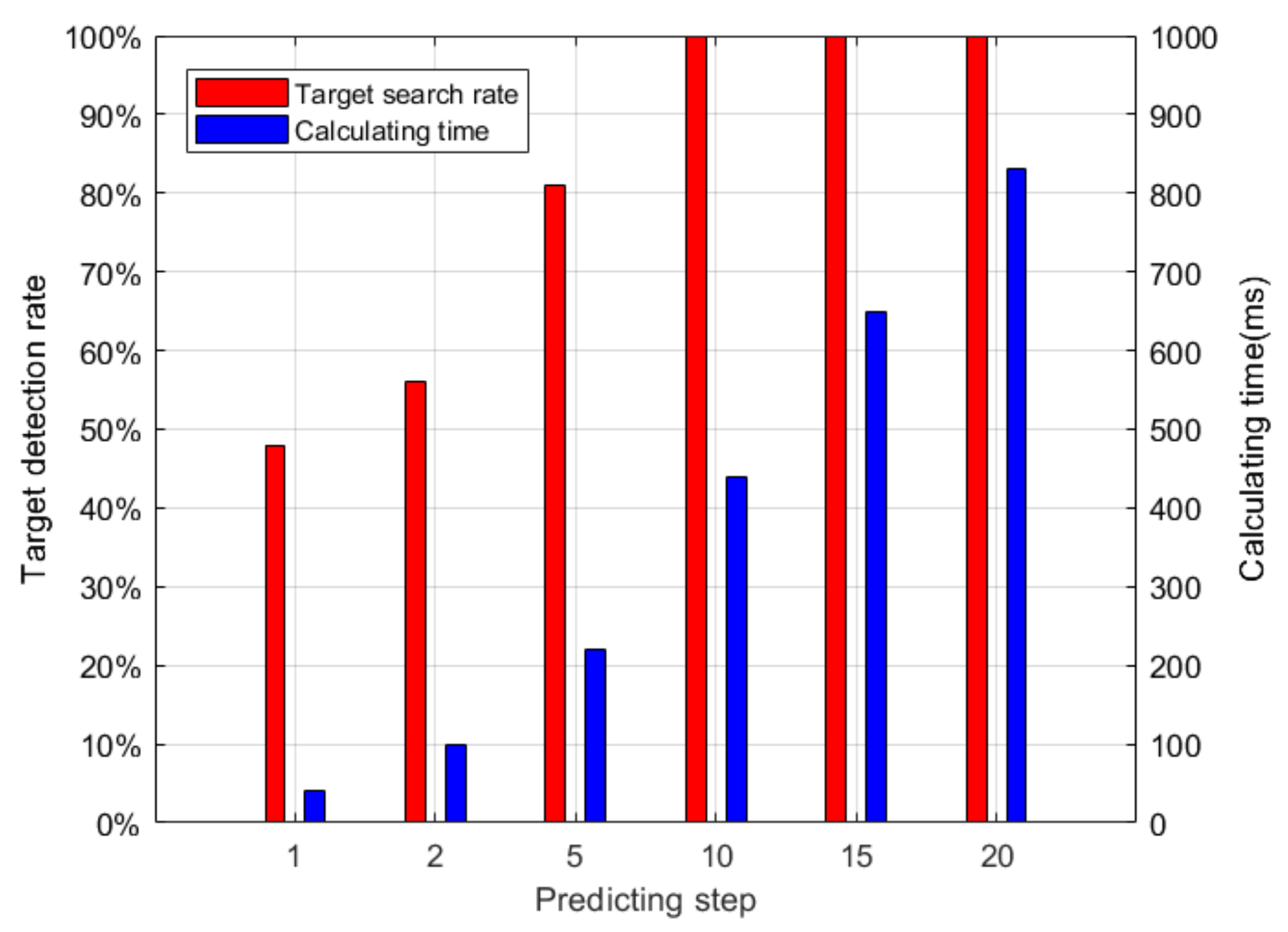
3.4. System-State Prediction and Online Optimization Decision-Making
- (1)
- System-state prediction based on rolling optimization
- (2)
- The online task-optimization decision
4. The Hunting Algorithm
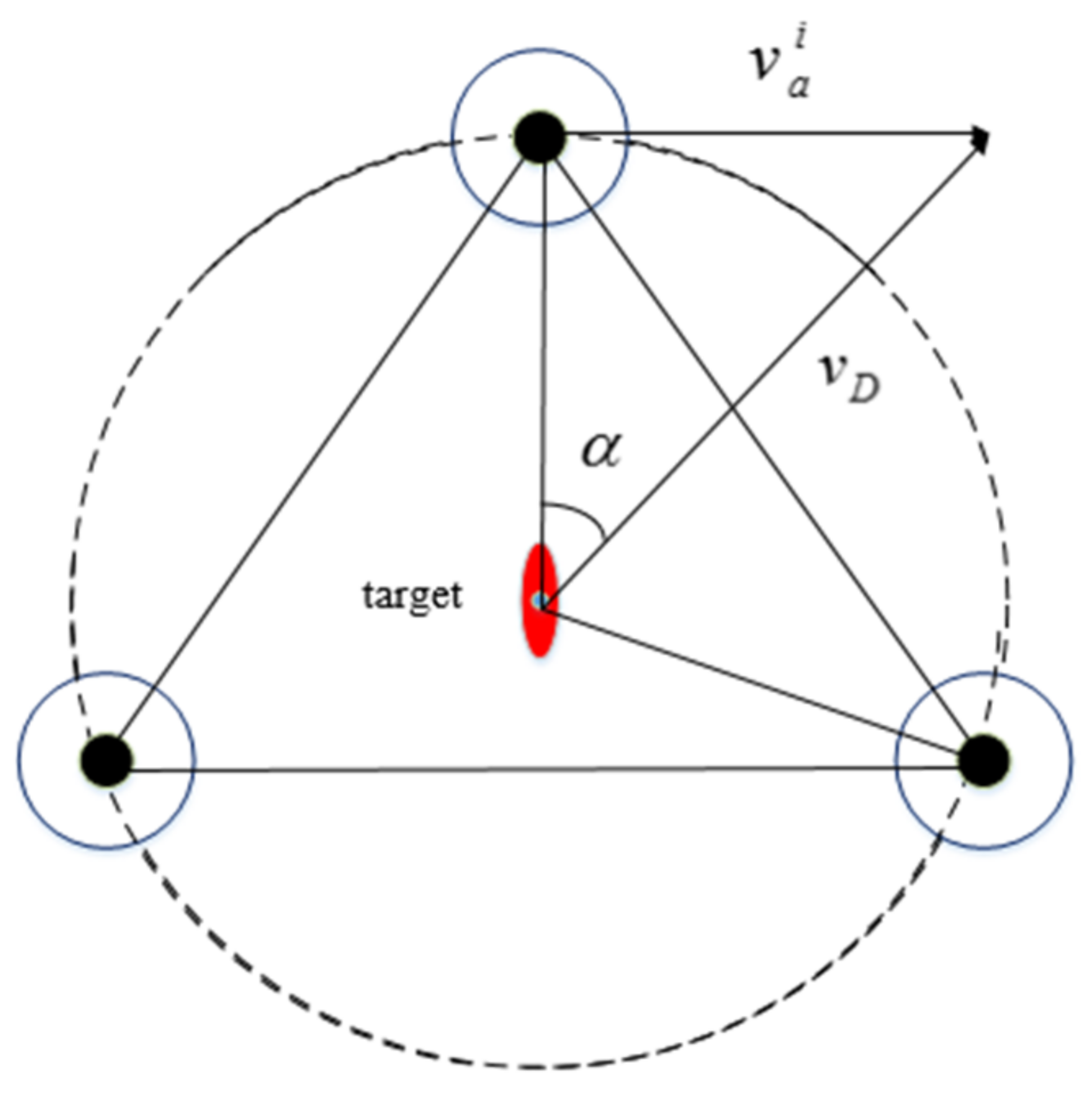
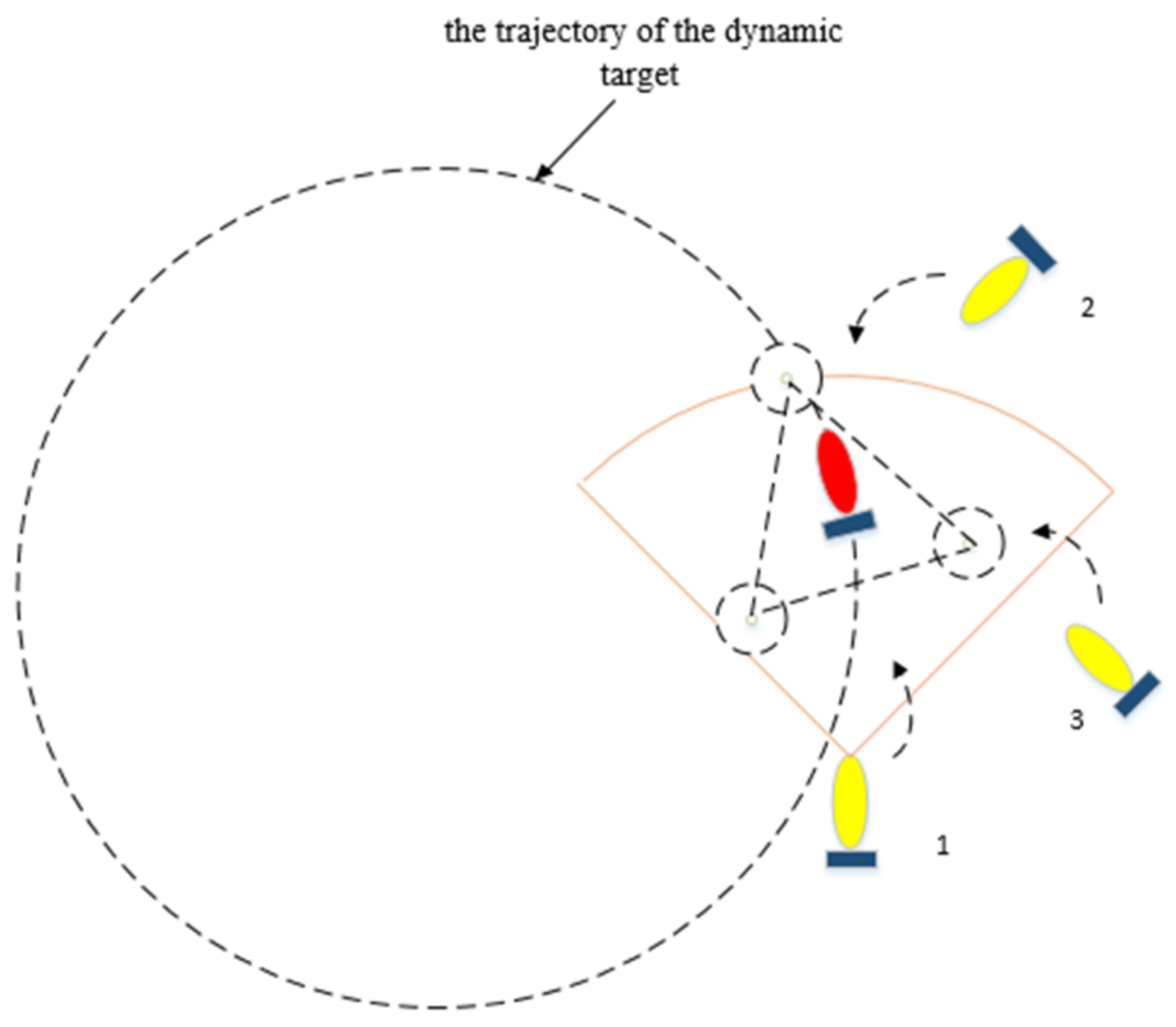
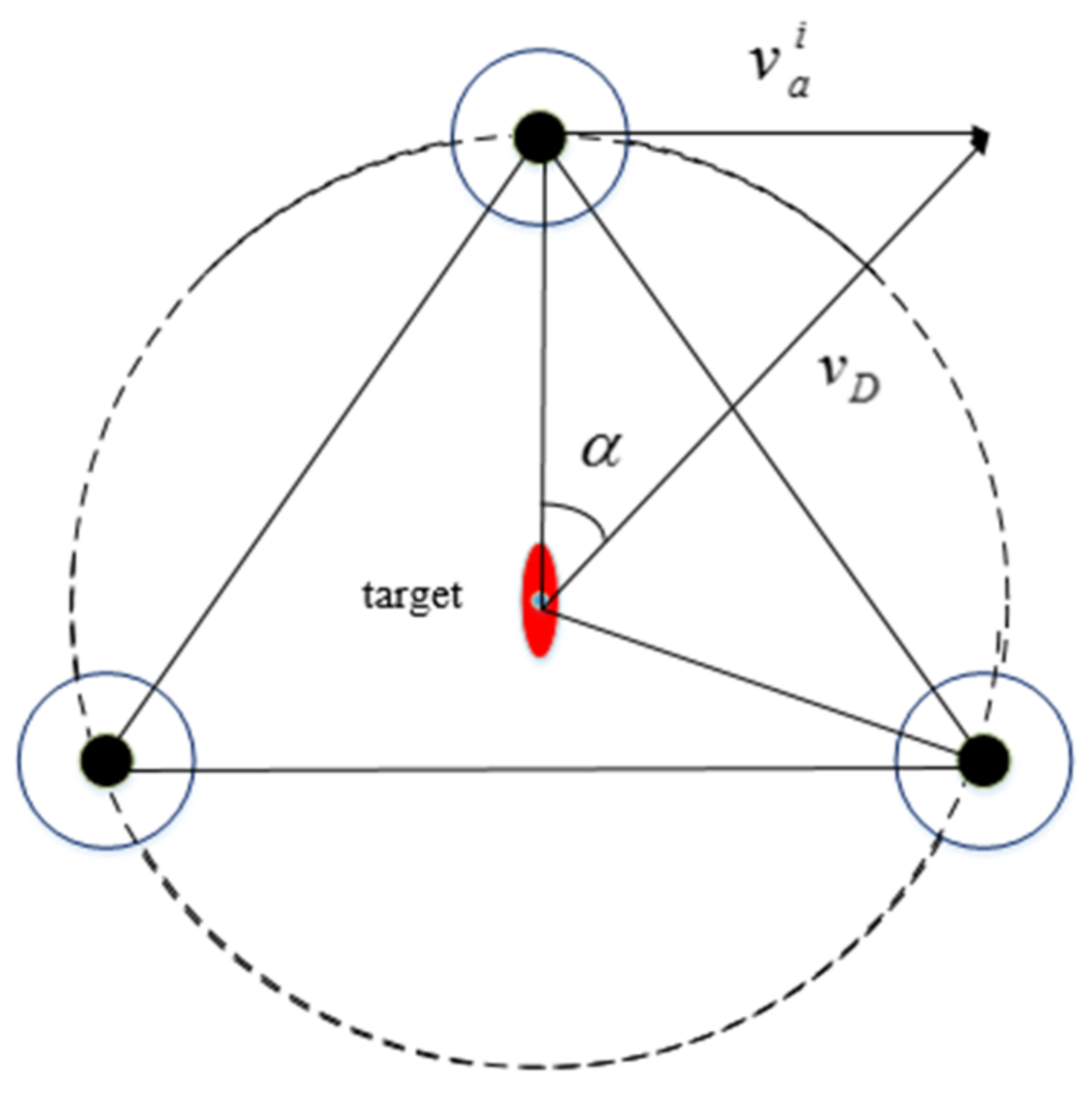
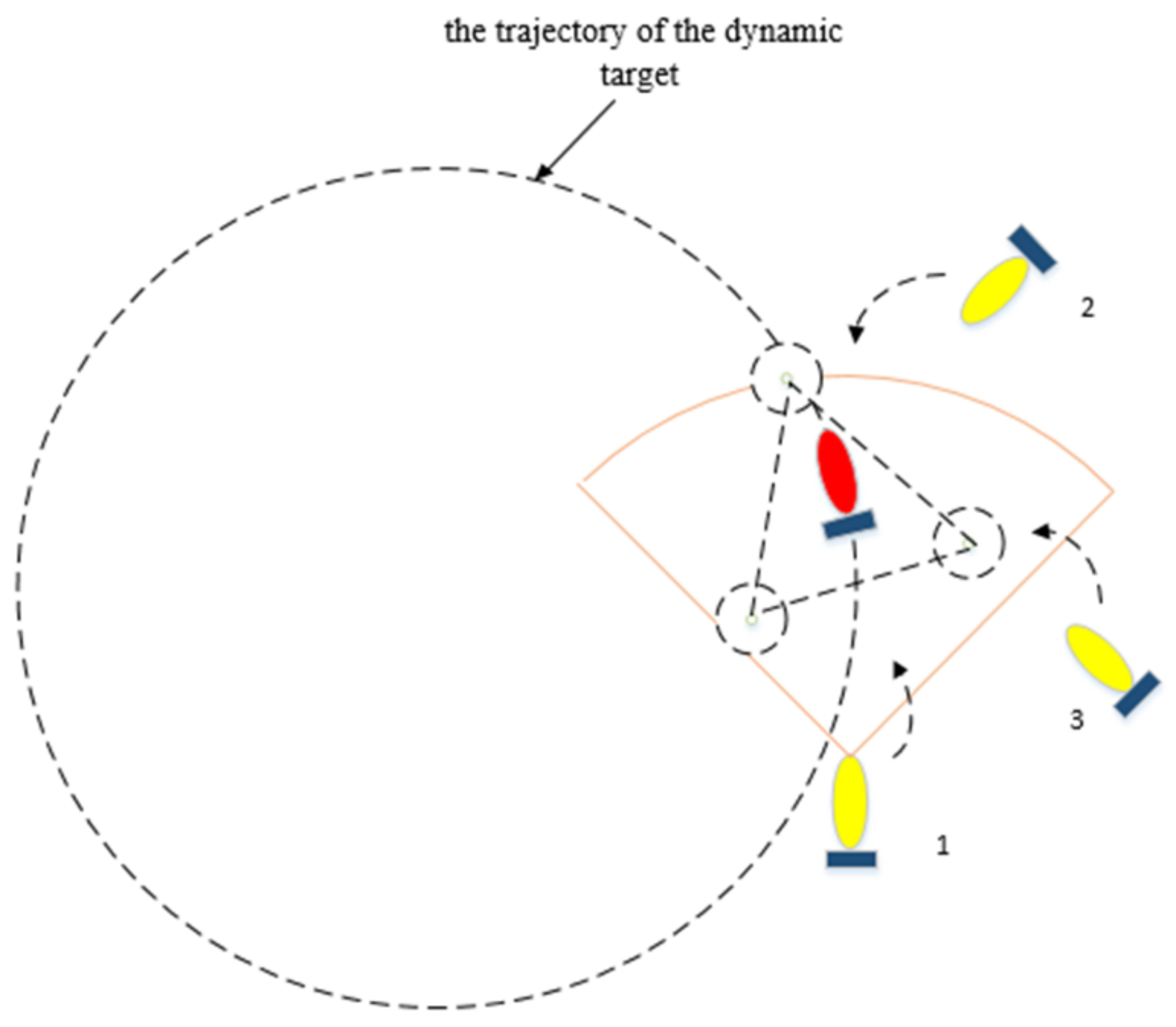
4.1. Hunting Formation
4.2. Formation of the Hunting Potential Point
4.3. The Task Assignment of the Hunting Formation
- (1)
- If an AUV fails to reach a predetermined position within the time limit after it has been identified as a hunting actuator, the contract becomes invalid and the role is changed;
- (2)
- If the required cooperative hunting executors do not all reach the corresponding potential point within the time limit, the contract is re-established;
- (3)
- After the target is destroyed, the contract becomes invalid immediately. The initiator of the hunting shall send the message of giving up to other executors in the team for role switching;
- (4)
- When the initiator gives up, a message is sent to the other executors about the success of the chase.
- (1)
- In affirming a commitment to hunt for a target, all other mission roles of the executor in effect of the contract are waived;
- (2)
- All AUVs are required to exchange information before the hunting contract becomes effective. The role switch is abandoned when the AUV that is about to sign the hunting contract has confirmed that the team does not need it.
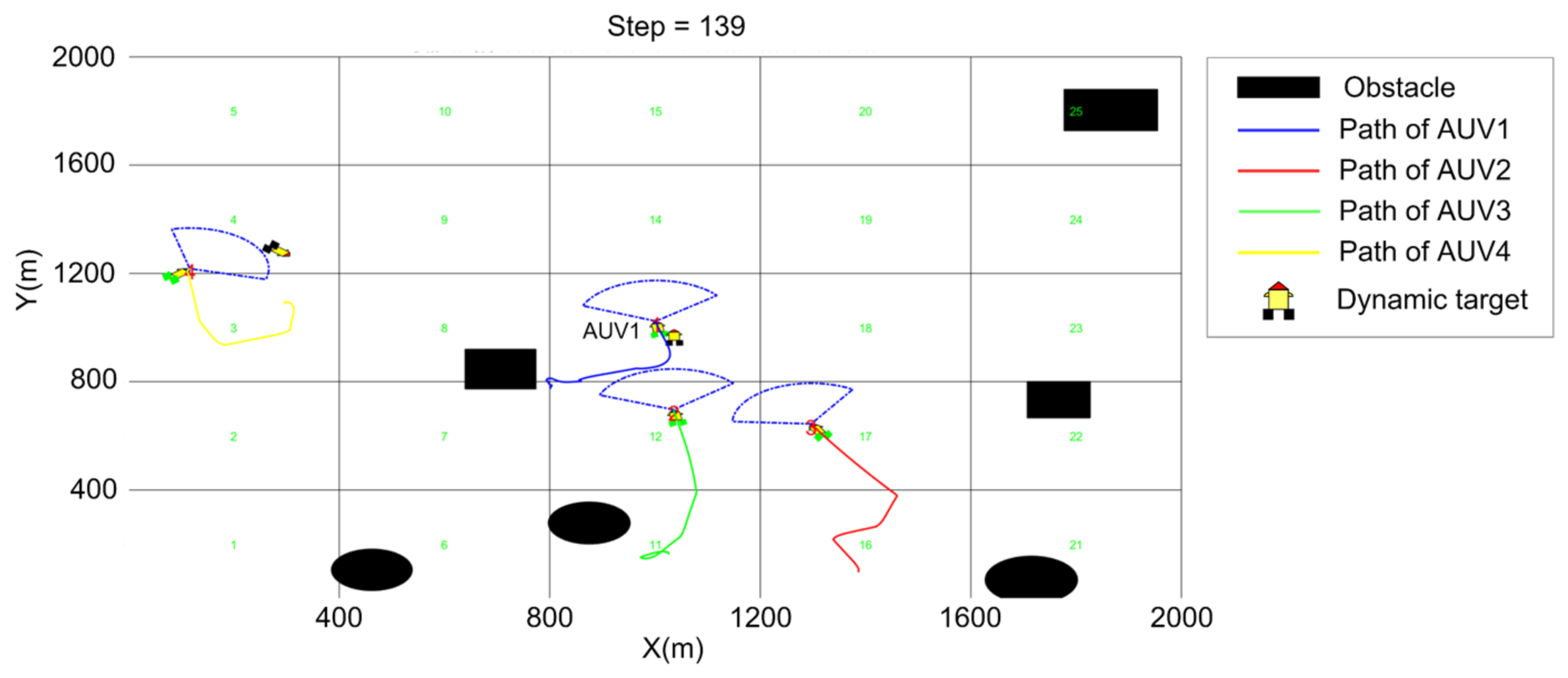
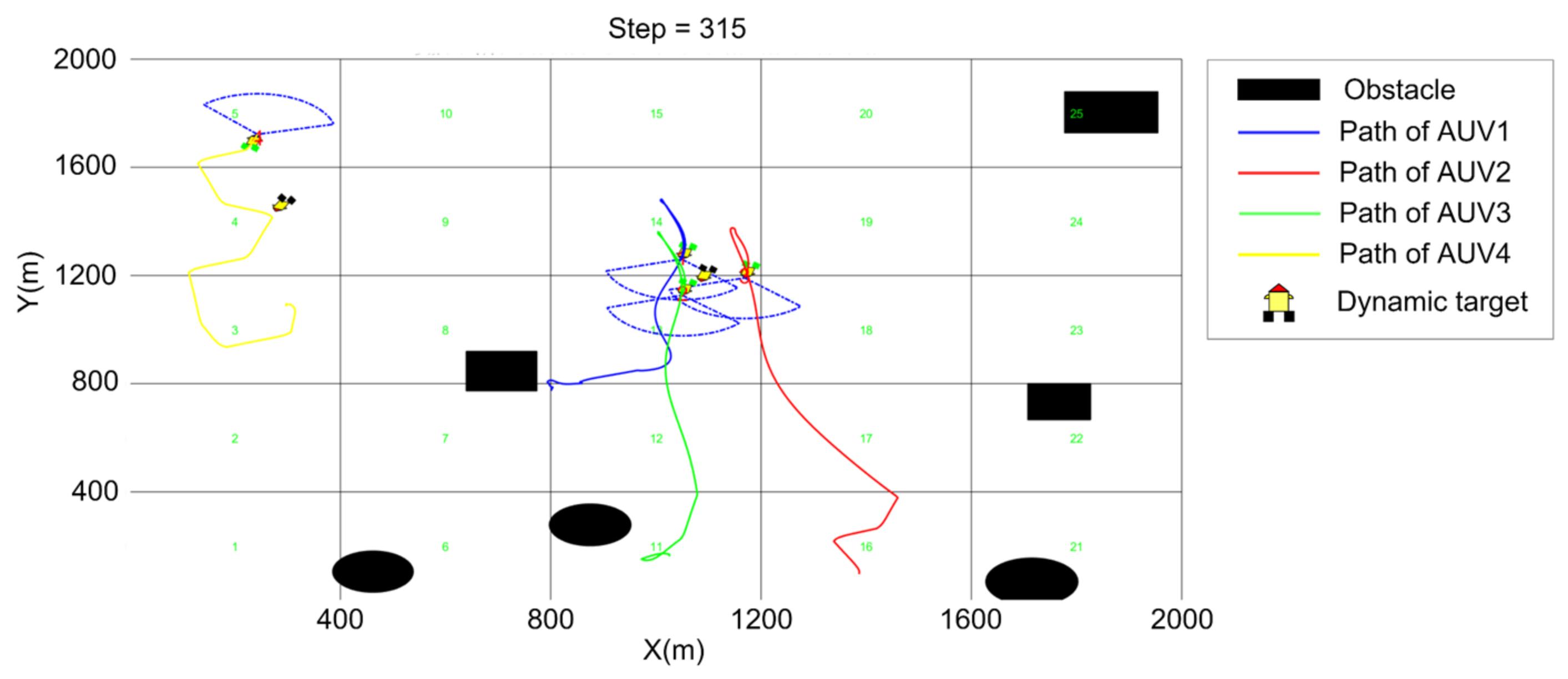
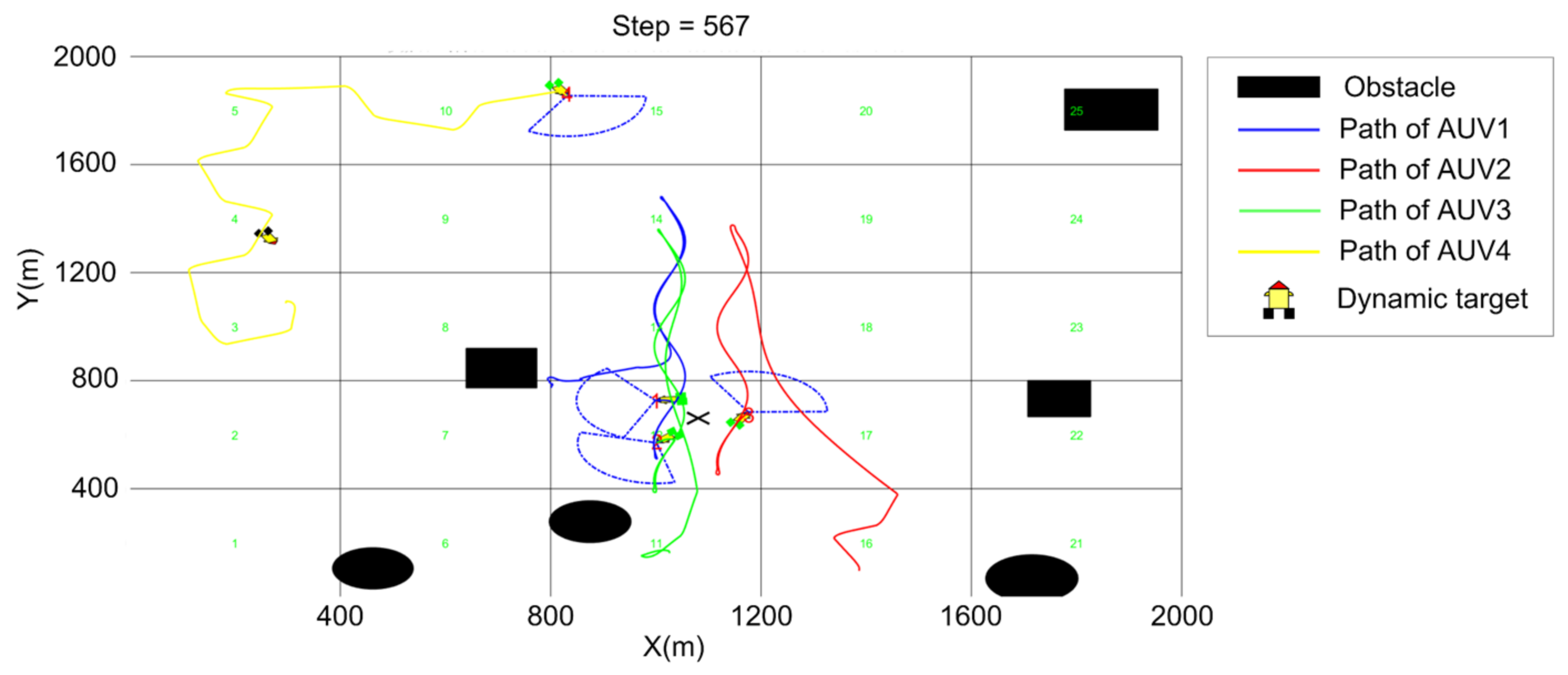
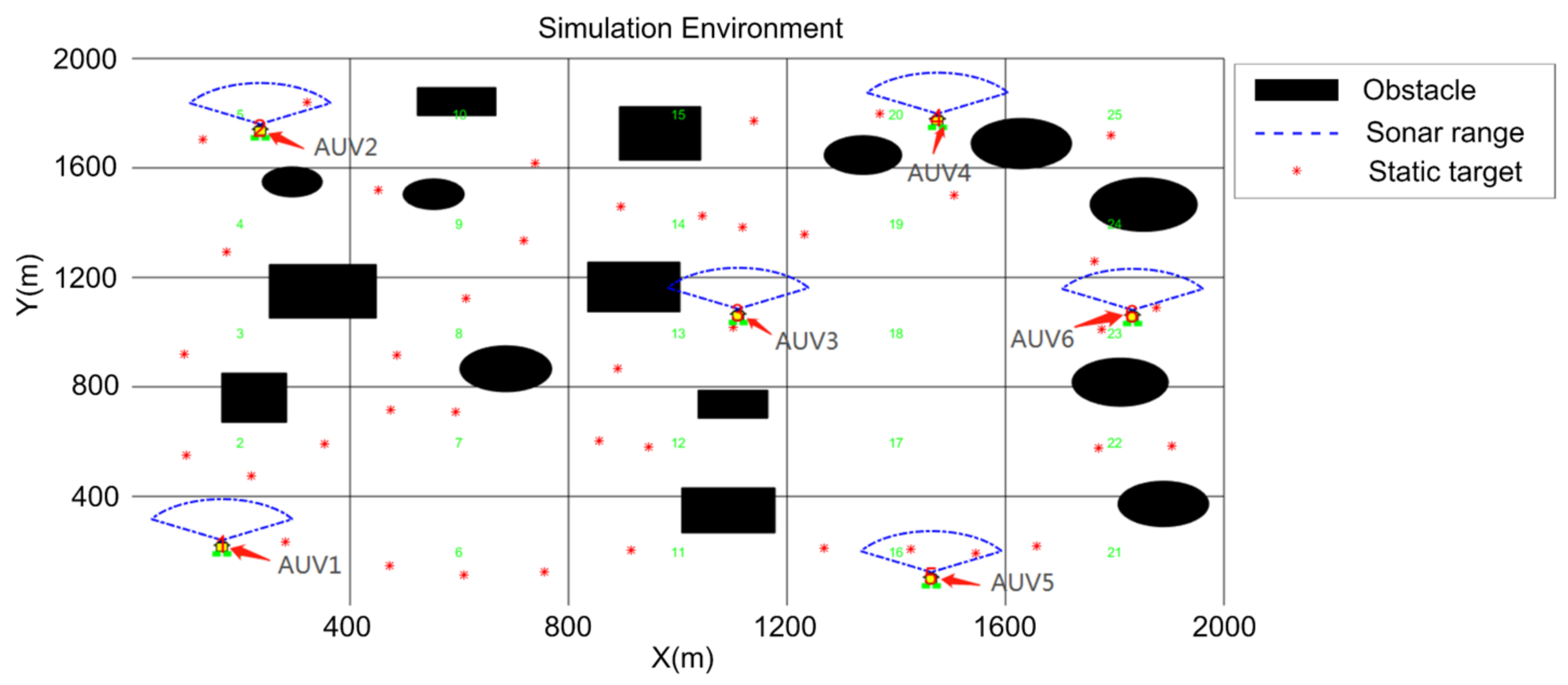
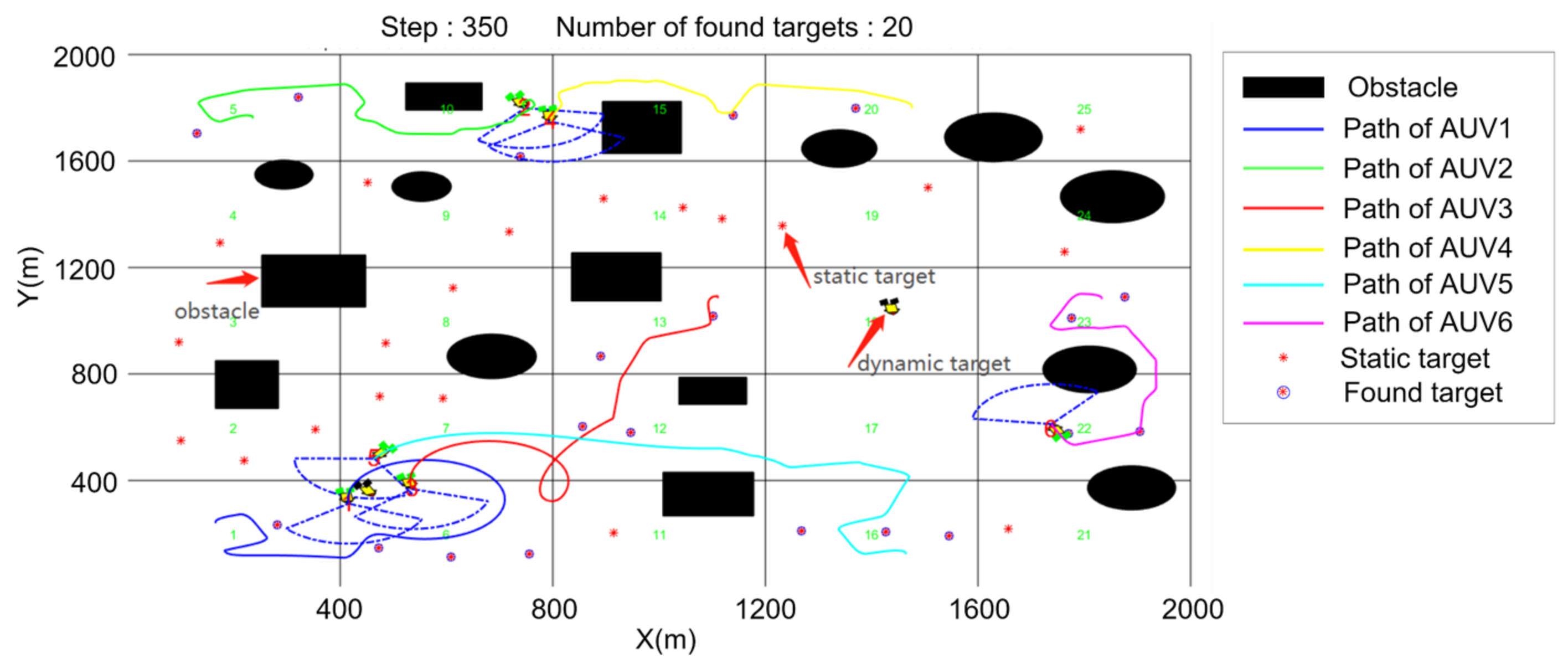
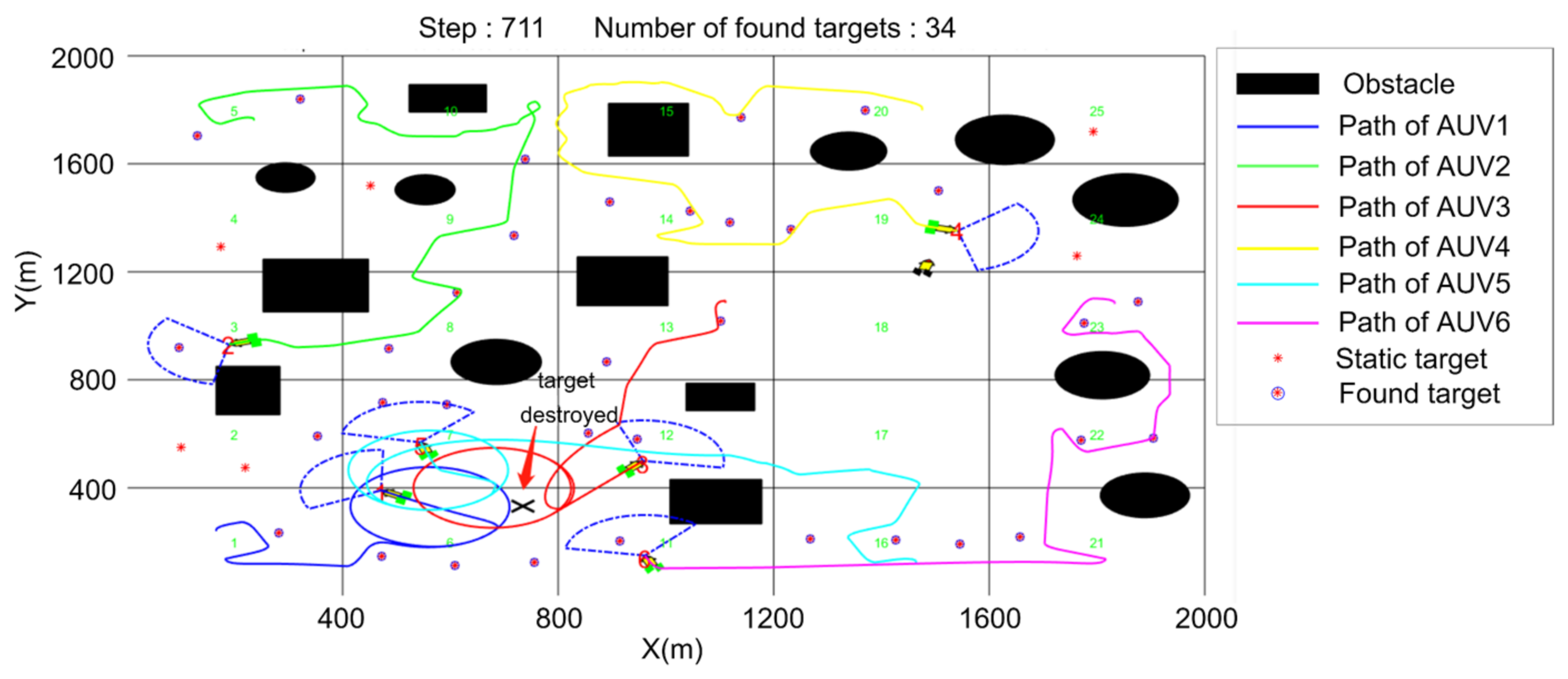
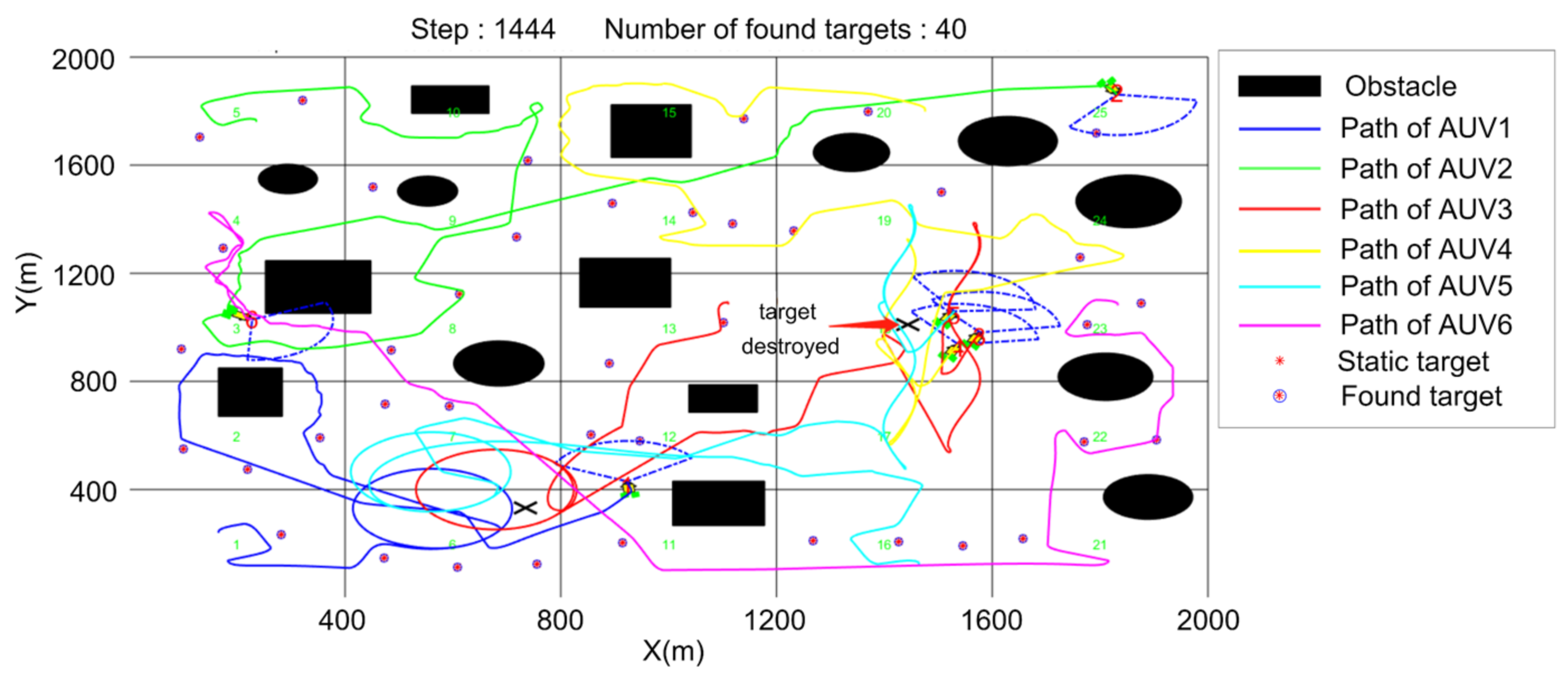
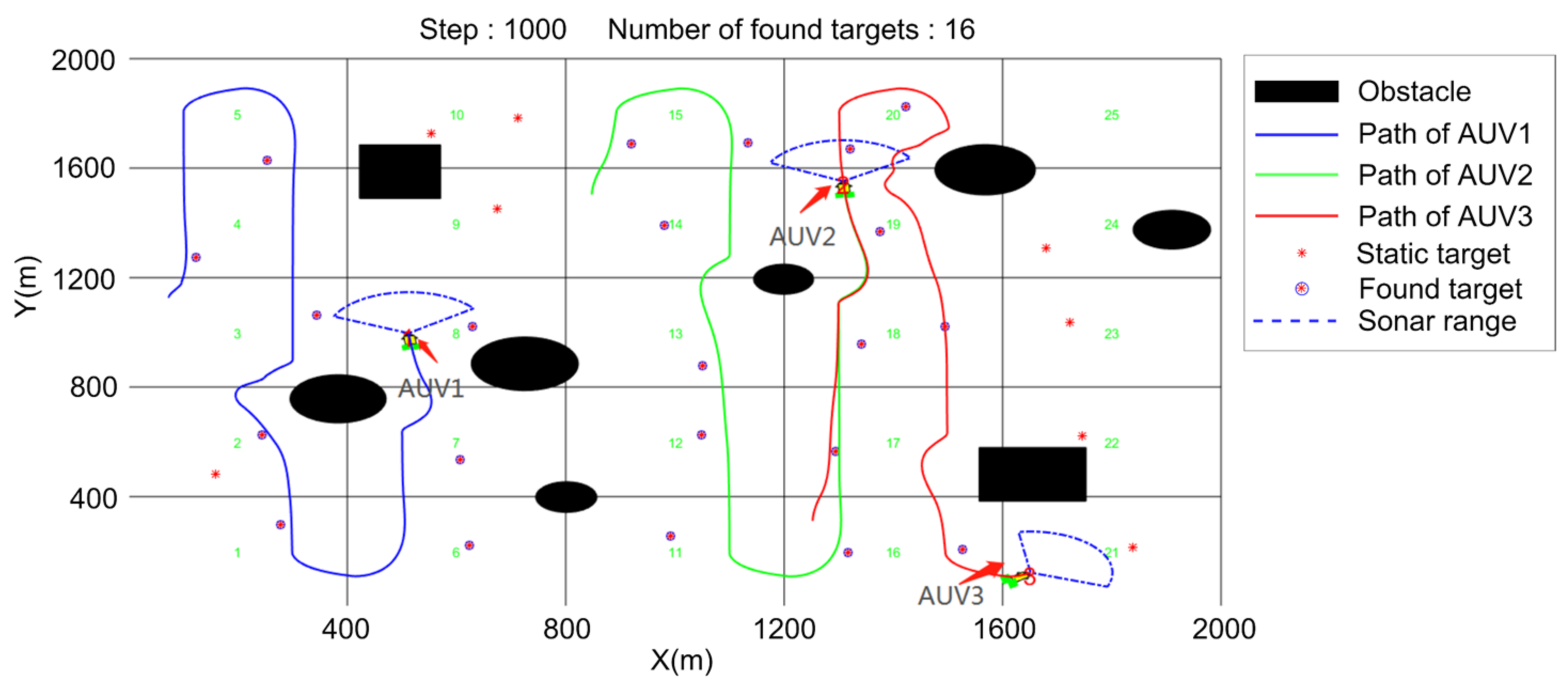
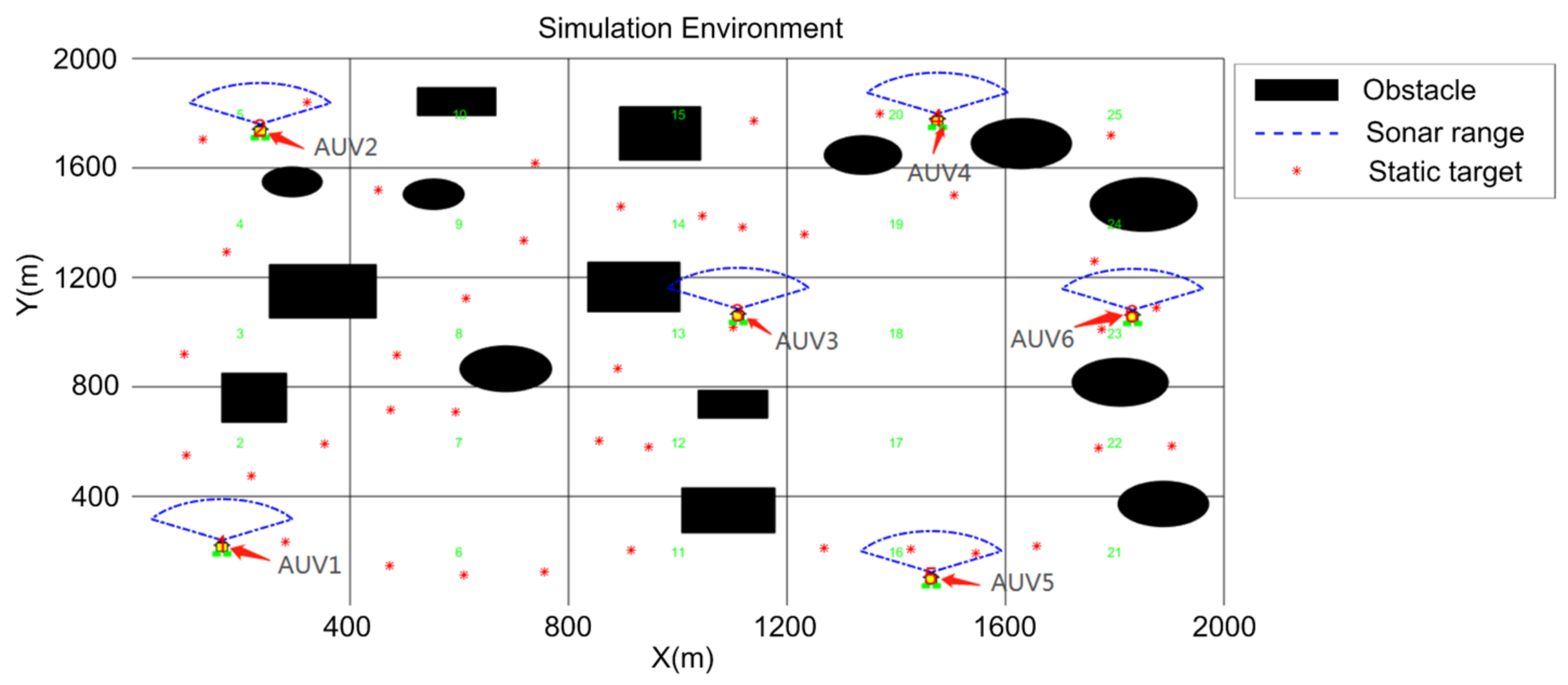
5. Simulation
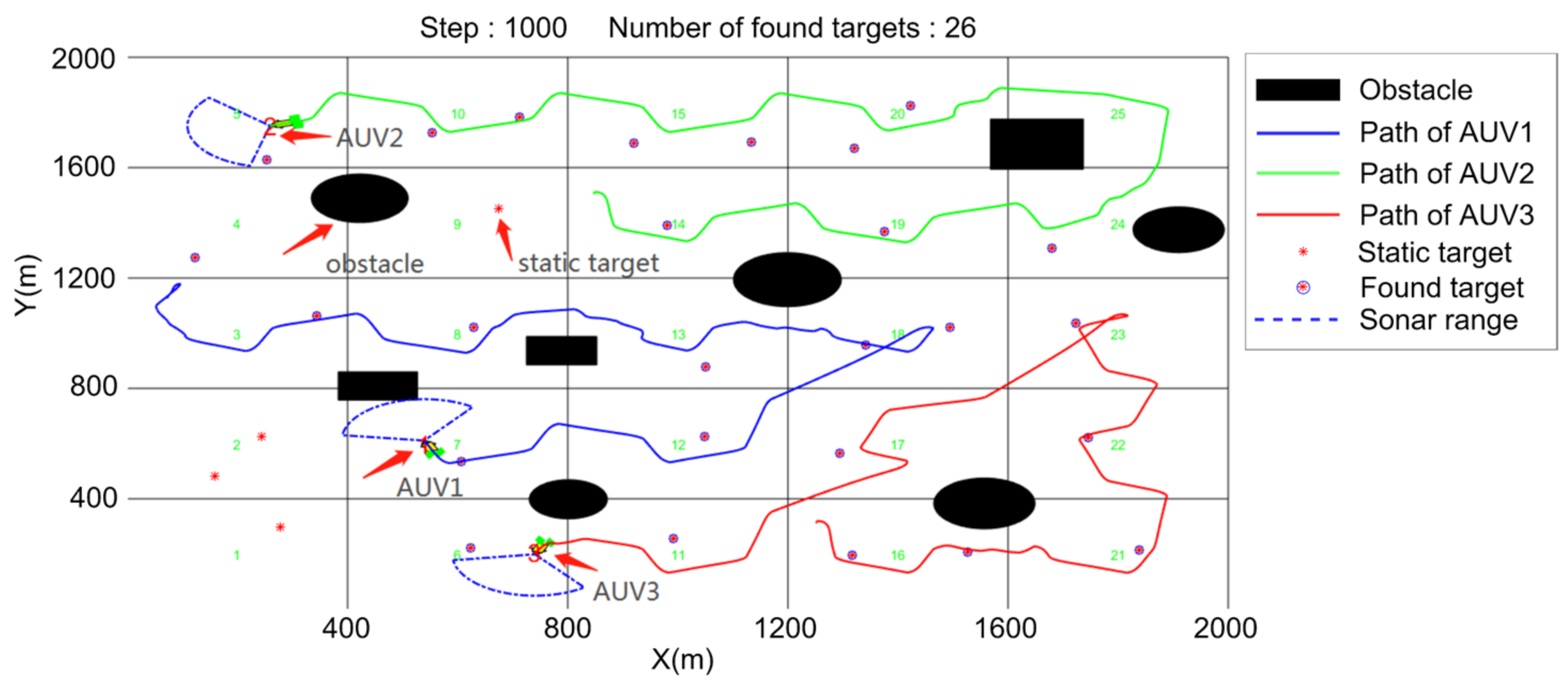
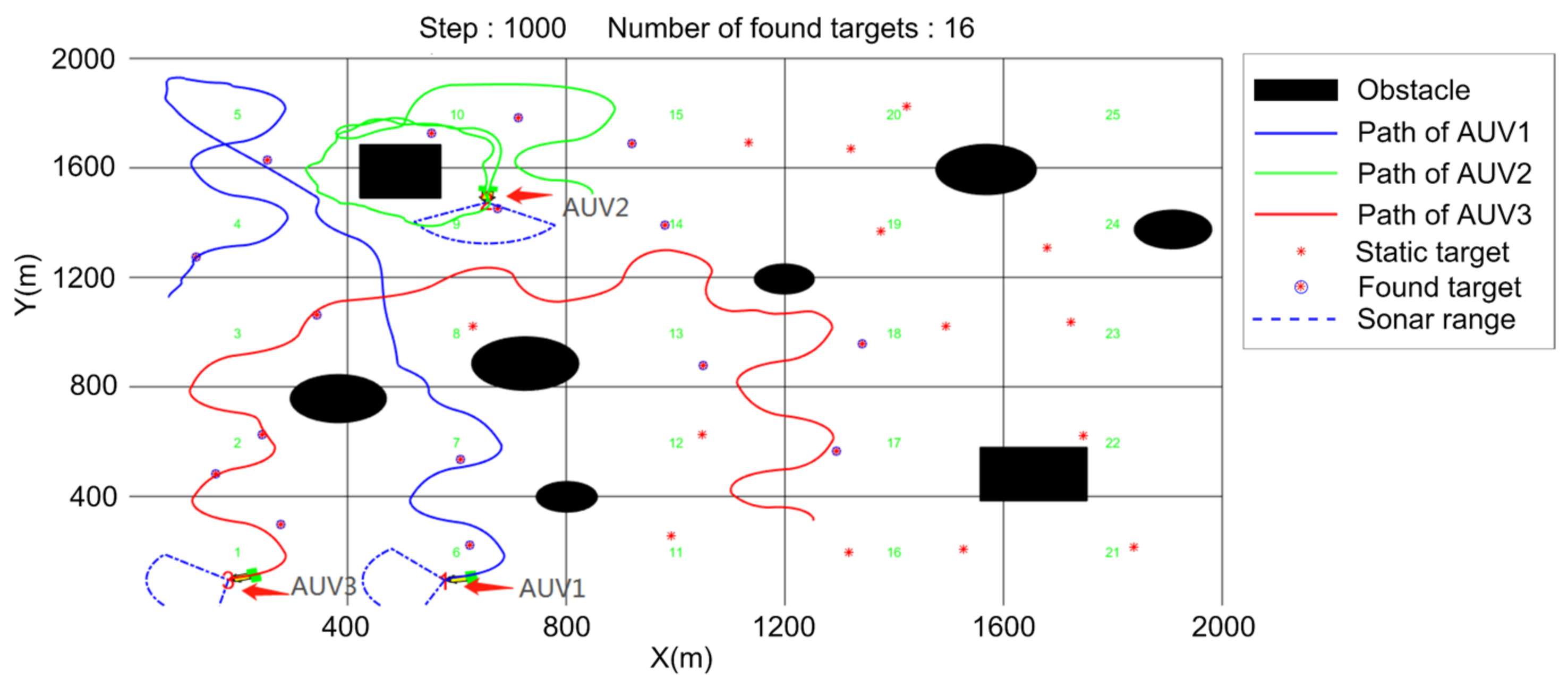
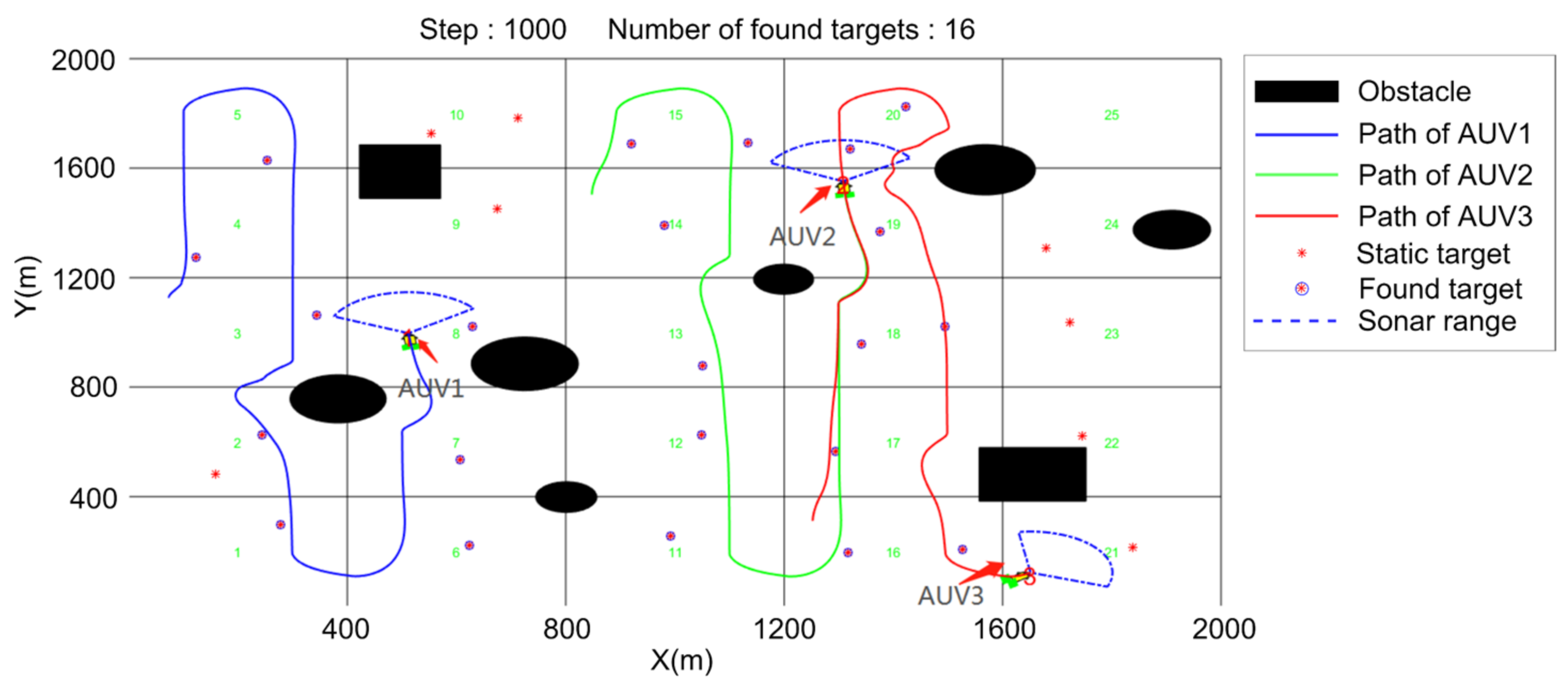
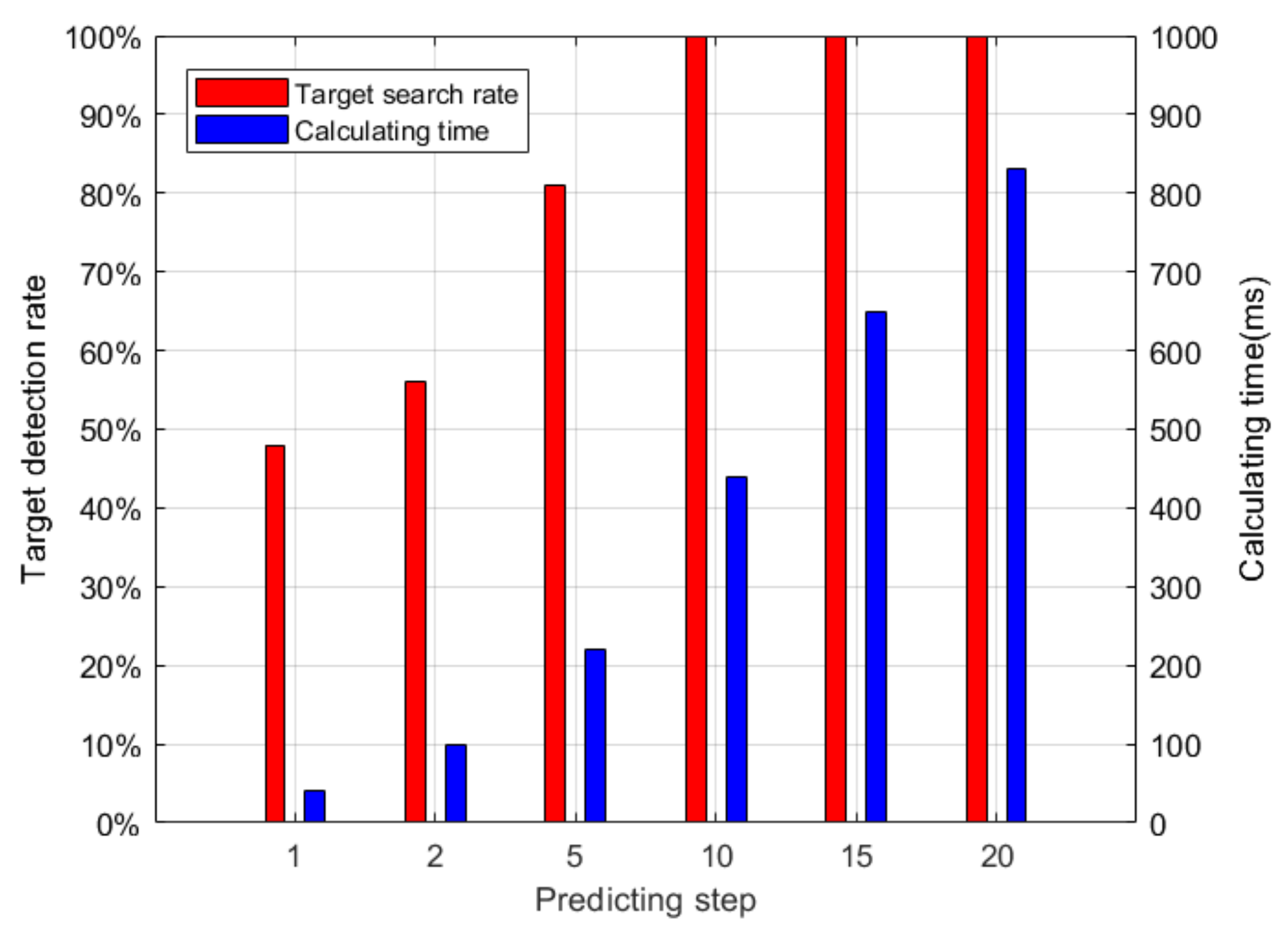
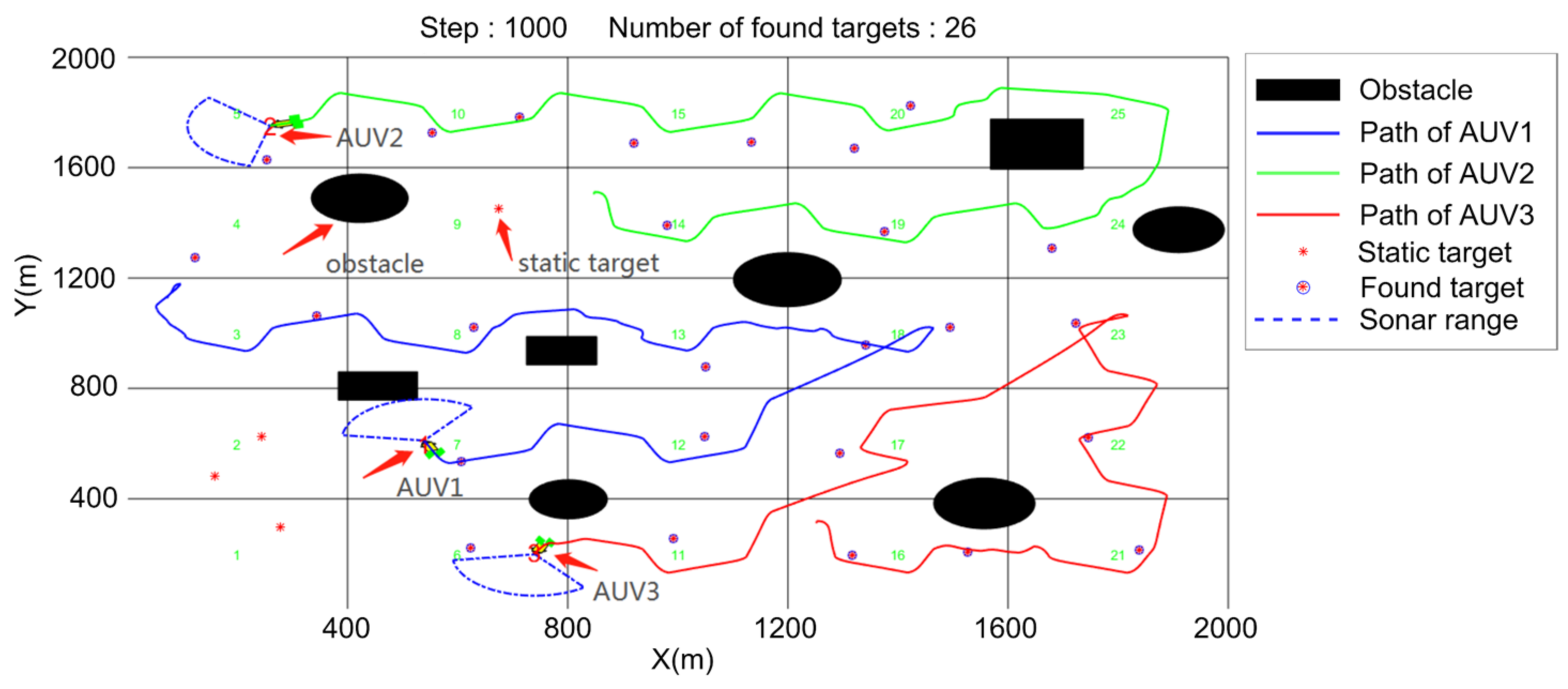
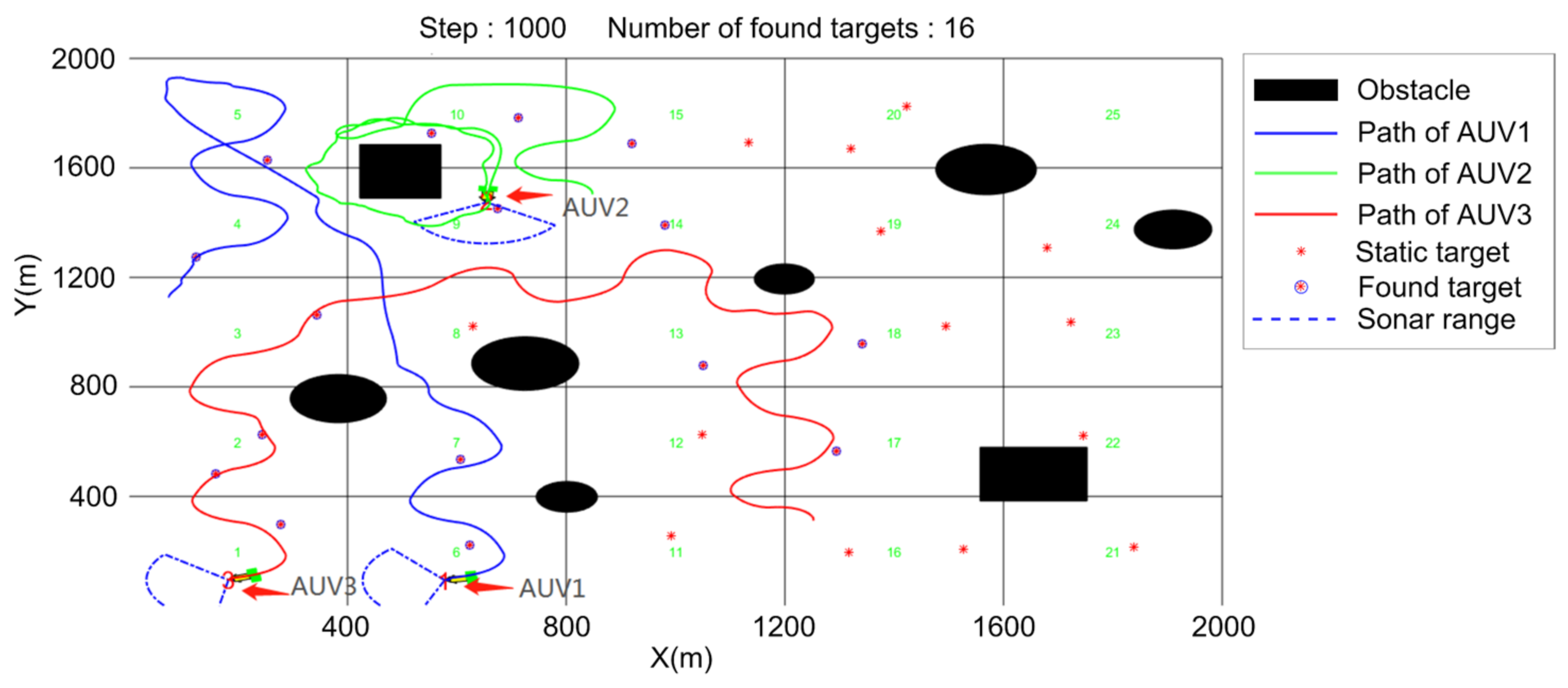
5.1. Search Algorithm Verification
- (1)
- Regional coverage;
- (2)
- Average number of found targets.
5.2. Hunting Algorithm Verification
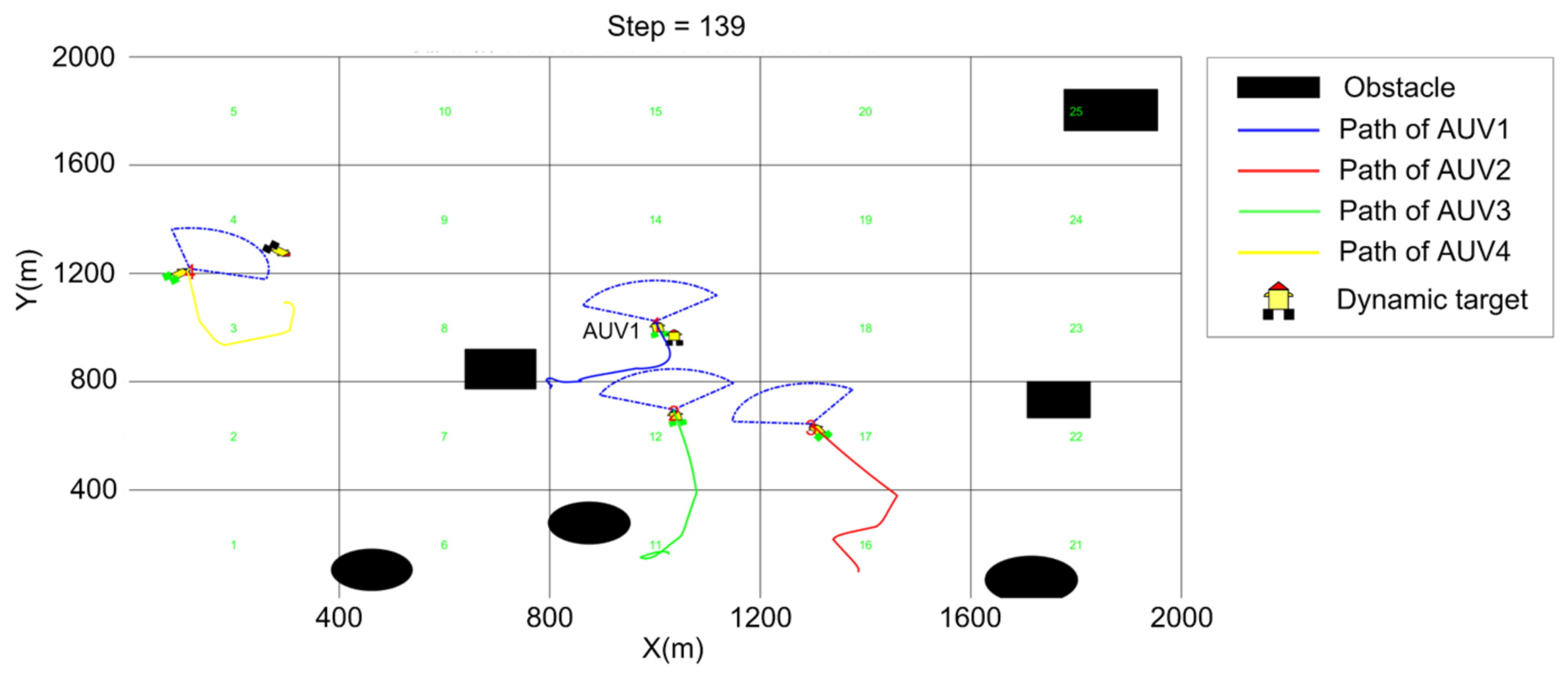
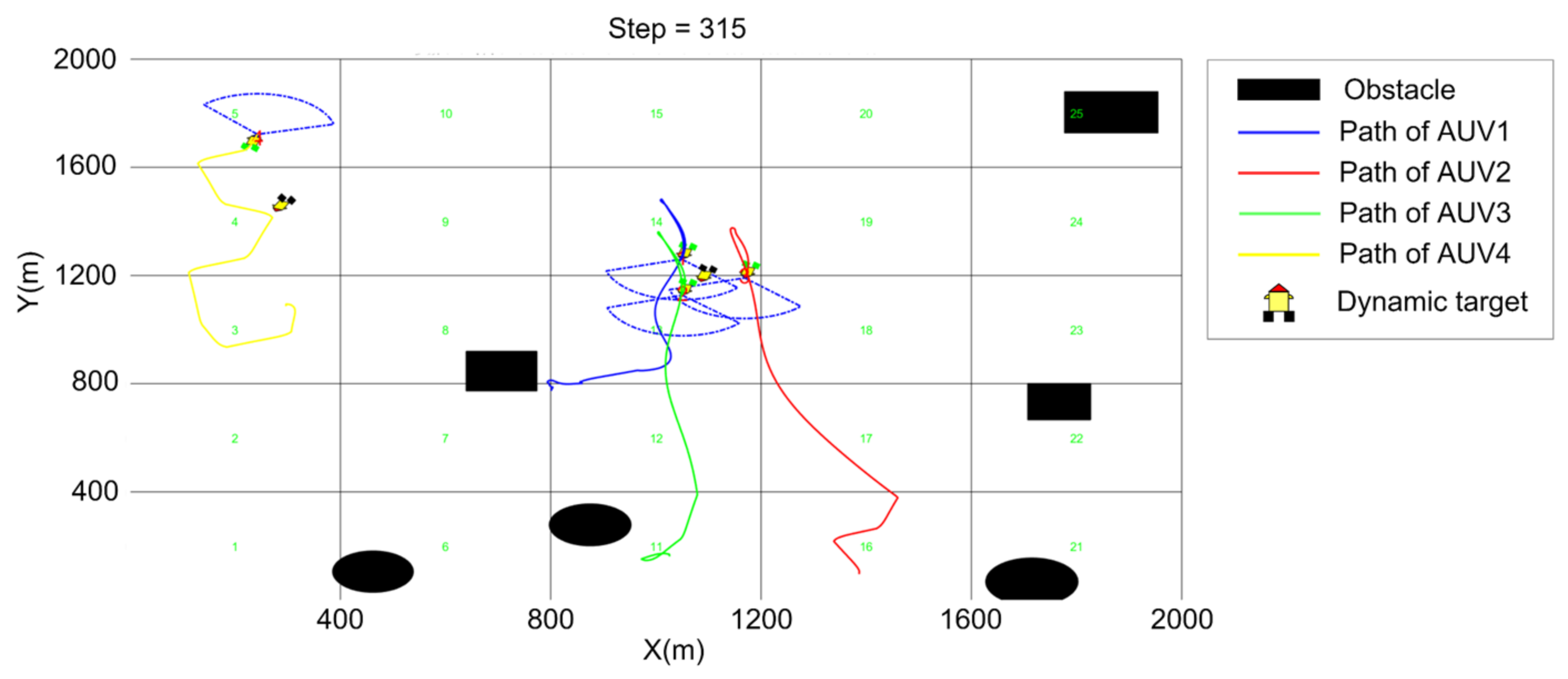
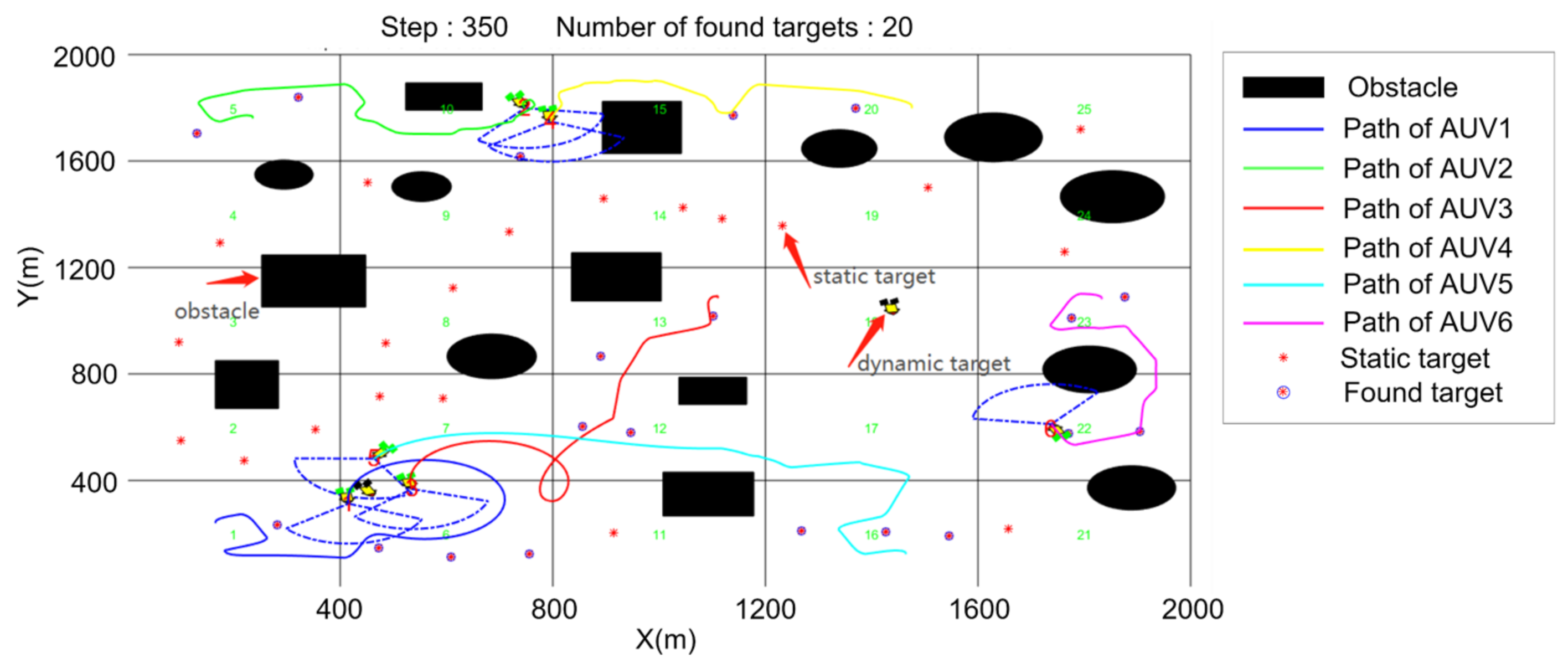
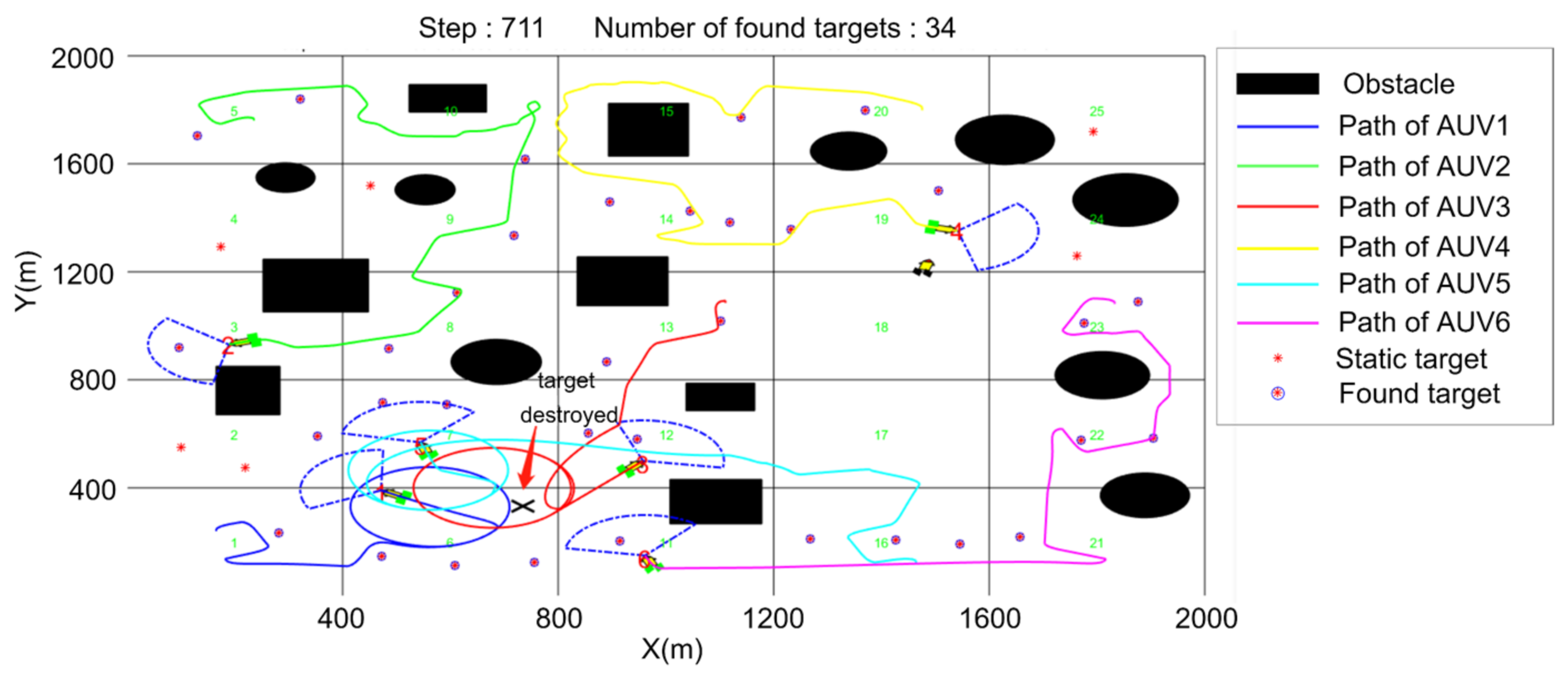
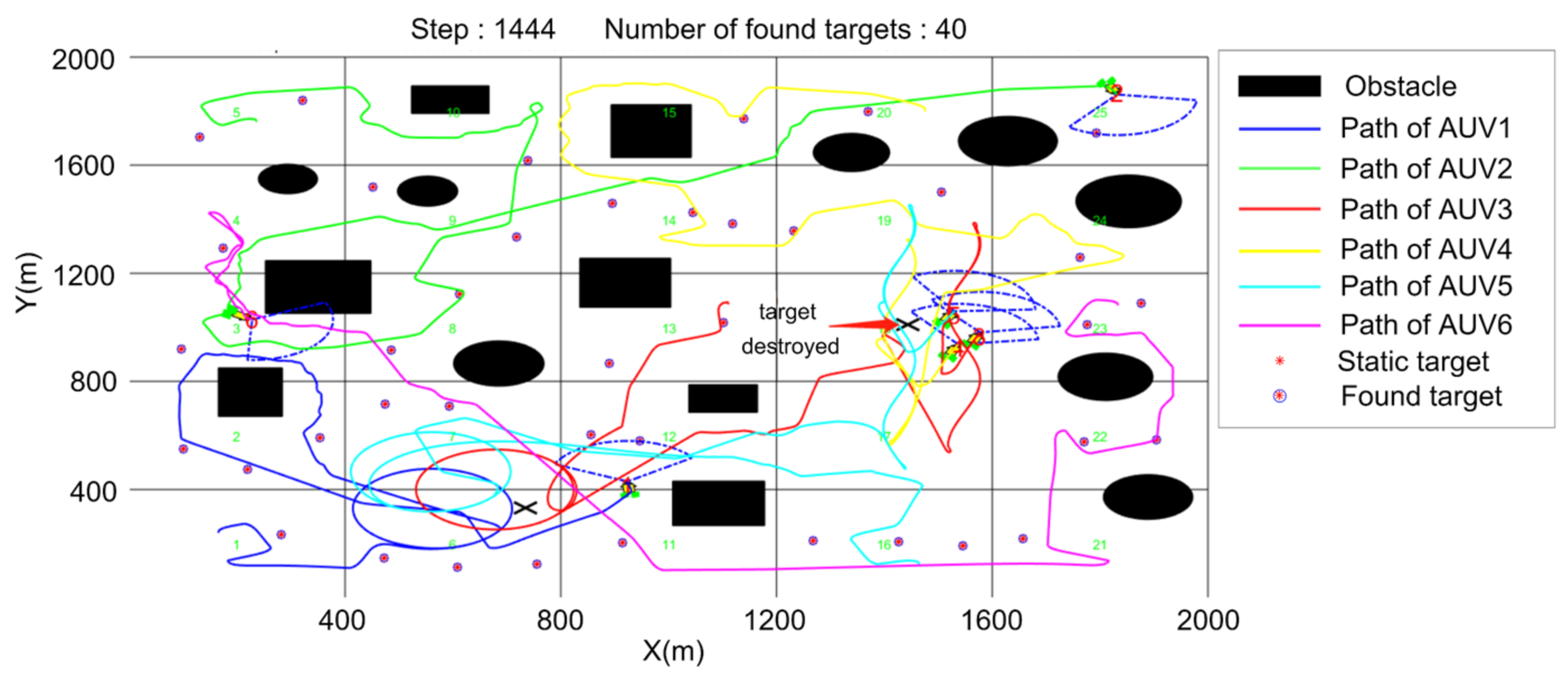
5.3. Cooperative Searching and Hunting Simulation
6. Conclusions
- (1)
- Communication delay and loss of information;
- (2)
- Complex groups of dynamic obstacles;
- (3)
- Dynamic targets with multiple motion states;
- (4)
- Application in the 3D underwater environment.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, B.; Saigol, Z.; Han, X.; Lane, D. System Identification and Controller Design of a Novel Autonomous Underwater Vehicle. Machines 2021, 9, 109. [Google Scholar] [CrossRef]
- Li, J.; Zhai, X.; Xu, J.; Li, C. Target Search Algorithm for AUV Based on Real-Time Perception Maps in Unknown Environment. Machines 2021, 9, 147. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, M.; Su, Z.; Luo, J.; Xie, S.; Peng, Y.; Pu, H.; Xie, J.; Zhou, R. Multi-AUVs Cooperative Target Search Based on Autonomous Cooperative Search Learning Algorithm. J. Mar. Sci. Eng. 2020, 8, 843. [Google Scholar] [CrossRef]
- Sun, A.L.; Cao, X. A Fuzzy-Based Bio-Inspired Neural Network Approach for Target Search by Multiple Autonomous Underwater Vehicles in Underwater Environments. Intell. Autom. Soft Comput. 2021, 27, 551–564. [Google Scholar] [CrossRef]
- Yao, P.; Qiu, L.Y. AUV path planning for coverage search of static target in ocean environment. Ocean Eng. 2021, 241, 110050. [Google Scholar] [CrossRef]
- Yue, W.; Guan, X. A Novel Searching Method Using Reinforcement Learning Scheme for Multi-UAVs in Unknown Environments. Appl. Sci. 2019, 9, 4964. [Google Scholar] [CrossRef] [Green Version]
- Luo, C.; Yang, X. A bioinspired neural network for real-time concurrent map building and complete coverage robot navigation in unknown environments. IEEE Trans. Neural Netw. 2008, 19, 1279–1298. [Google Scholar] [CrossRef]
- Cai, Y.; Yang, S. An improved PSO-based approach with dynamic parameter tuning for cooperative multi-robot target searching in complex unknown environments. Int. J. Control 2013, 86, 1720–1732. [Google Scholar] [CrossRef]
- Dadgar, M.; Jafari, S. A PSO-based multi-robot cooperation method for target searching in unknown environments. Neurocomputing 2016, 177, 62–74. [Google Scholar] [CrossRef]
- Saadaoui, H.; Bouanani, F.E. Information Sharing Based on Local PSO for UAVs Cooperative Search of Unmoved Targets. In Proceedings of the International Conference on Advanced Communication Technologies and Networking, Marrakech, Morocco, 2–4 April 2018. [Google Scholar]
- Wu, C.; Ju, B. UAV Autonomous Target Search Based on Deep Reinforcement Learning in Complex Disaster Scene. IEEE Access 2019, 7, 117227–117245. [Google Scholar] [CrossRef]
- Ivić, S.; Crnković, B.; Arbabi, H.; Loire, S.; Clary, P.; Mezić, I. Search strategy in a complex and dynamic environment: The MH370 case. Sci. Rep. 2020, 10, 19640. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Hong, B. Cooperative Multiple Mobile Targets Capturing Algorithm for Robot Troops. J. Xi’an Jiaotong Univ. 2003, 37, 573–576. [Google Scholar]
- Wang, H.; Wei, X. Research on Methods of Region Searching and Cooperative Hunting for Autonomous Underwater Vehicles. Shipbuild. China 2010, 51, 117–125. [Google Scholar]
- Meng, X.; Sun, B. Harbour protection: Moving invasion targrt interception for multi-AUV based on prediction planning interception method. Ocean Eng. 2021, 219, 108268. [Google Scholar] [CrossRef]
- Cao, X.; Xu, X.Y. Hunting Algorithm for Multi-AUV Based on Dynamic Prediction of Target Trajectory in 3D Underwater Environment. IEEE Access 2020, 8, 138529–138538. [Google Scholar] [CrossRef]
- Kapoutsis, A.; Chatzichristofis, S. DARP: Divide Areas Algorithm for Optimal Multi-Robot Coverage Path Planning. J. Intell. Robot. Syst. 2017, 86, 663–680. [Google Scholar] [CrossRef] [Green Version]
- Shojaei, K.; Arefi, M. On the neuro-adaptive feedback linearising control of underactuated autonomous underwater vehicles in three-dimensional space. IET Control Theory A 2015, 9, 1264–1273. [Google Scholar] [CrossRef]
- Zhao, S.; Lu, T. Automatic object detection for AUV navigation using imaging sonar within confined environments. In Proceedings of the IEEE Conference on Industrial Electronics & Applications, Xi’an, China, 25–27 May 2009. [Google Scholar]
- Zhou, G.; Wu, L. Constant turn model for statically fused converted measurement Kalman filters. Signal Process. 2015, 108, 400–411. [Google Scholar] [CrossRef]
- Zeigler, B.P. High autonomy systems: Concepts and models. In Proceedings of the Simulation and Planning in High Autonomy Systems, Tucson, AZ, USA, 26–27 March 1990. [Google Scholar]
- Wu, L.; Niu, Y.; Zhu, H. Modeling and characterizing of unmanned aerial vehicles autonomy. In Proceedings of the 9th World Congress on Intelligent Control and Automation, Jinan, China, 6–9 July 2010. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Information Type | Information Content |
|---|---|
| AUV state information | Coordinate |
| Velocity | |
| Course | |
| Static target information | Current time |
| Serial number of AUV | |
| Detected information | |
| Dynamic target information | Current time |
| Hunting state | |
| Serial number of AUV | |
| Sub-region state information | First-level region state at time t |
| Second-level region state at time t |
| Serial Number | Position X | Position Y |
|---|---|---|
| 1 | 460.2 | 343.5 |
| 2 | 1448.0 | 626 |
| Position X | Position Y | Position X | Position Y | Position X | Position Y | Position X | Position Y |
|---|---|---|---|---|---|---|---|
| 895.1 | 1458.5 | 471.6 | 145.2 | 1138.9 | 1771.7 | 1793.0 | 1718.9 |
| 1181.1 | 1383.0 | 755.1 | 122.6 | 1369.6 | 1798.1 | 1876.2 | 1088.7 |
| 1101.1 | 1017.0 | 913.9 | 201.9 | 1231.6 | 1356.6 | 1904.5 | 583.0 |
| 889.4 | 866.0 | 946.1 | 579.2 | 1267.5 | 209.4 | 1044.4 | 1424.5 |
| 717.3 | 1334.0 | 592.6 | 707.5 | 1426.3 | 205.6 | 738.2 | 1617.0 |
| 611.5 | 1122.6 | 450.8 | 1518.9 | 1656.9 | 216.9 | 1545.4 | 190.5 |
| 484.8 | 915.0 | 320.4 | 1839.6 | 1770.3 | 575.4 | 855.3 | 601.9 |
| 352.5 | 590.5 | 129.5 | 1703.8 | 1776.0 | 1009.4 | 473.5 | 715.1 |
| 218.3 | 473.5 | 172.9 | 1292.5 | 1762.8 | 1258.5 | 101.1 | 549.1 |
| 280.7 | 232.0 | 97.4 | 918.9 | 1505.7 | 1500 | 607.7 | 111.3 |
| Serial Number | Position X | Position Y |
|---|---|---|
| 1 | 165.4 | 239.6 |
| 2 | 235.3 | 1760.4 |
| 3 | 1110.6 | 1084.9 |
| 4 | 1475.4 | 1798.1 |
| 5 | 1464.1 | 1226.4 |
| 6 | 1832.7 | 1081.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Li, C.; Zhang, H. Distributed Dynamic Predictive Control for Multi-AUV Target Searching and Hunting in Unknown Environments. Machines 2022, 10, 366. https://doi.org/10.3390/machines10050366
Li J, Li C, Zhang H. Distributed Dynamic Predictive Control for Multi-AUV Target Searching and Hunting in Unknown Environments. Machines. 2022; 10(5):366. https://doi.org/10.3390/machines10050366
Chicago/Turabian StyleLi, Juan, Chengyue Li, and Honghan Zhang. 2022. "Distributed Dynamic Predictive Control for Multi-AUV Target Searching and Hunting in Unknown Environments" Machines 10, no. 5: 366. https://doi.org/10.3390/machines10050366
APA StyleLi, J., Li, C., & Zhang, H. (2022). Distributed Dynamic Predictive Control for Multi-AUV Target Searching and Hunting in Unknown Environments. Machines, 10(5), 366. https://doi.org/10.3390/machines10050366