
Rendering Natural Bokeh Effects Based on Depth Estimation to Improve the Aesthetic Ability of Machine Vision

Abstract
:1. Introduction
- (1)
- It is difficult to obtain image-depth data, but the model does not perform well when the training data are limited. Therefore, we use the idea of style transfer to synthesize images and increase the number of datasets.
- (2)
- In order to better combine the relationship between image parts, we propose an image-depth-estimation model based on Transformer.
- (3)
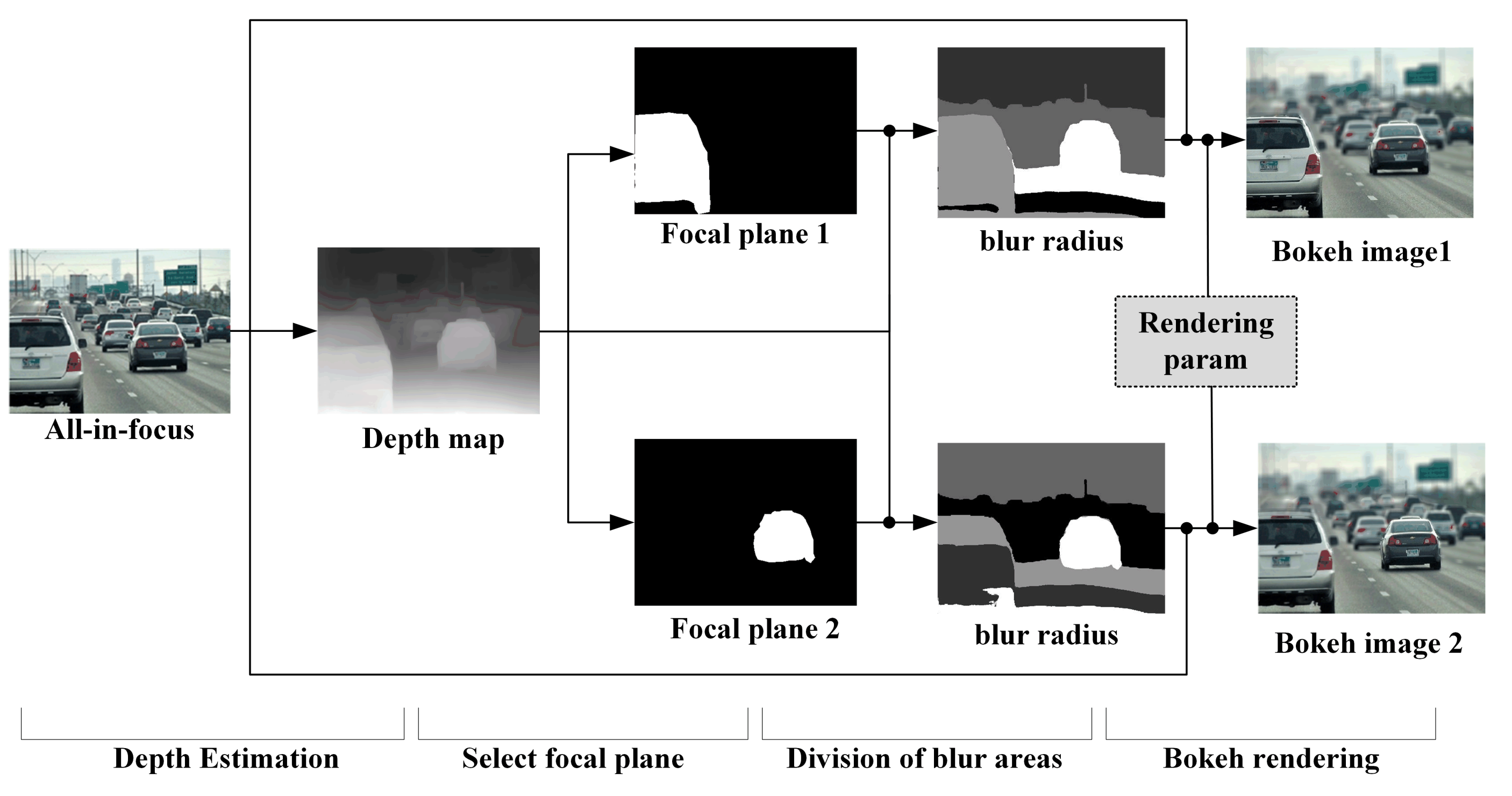
- In order to meet the characteristics of the bokeh image—the further the object is from the focal plane, the more blurred it is—we propose the image-background subregion-blurring method. Different blur radii can be obtained by choosing different focal planes, which makes the bokeh-rendering effect more diverse and does not oversegment the objects, producing bokeh images with different effects.
2. Related Work
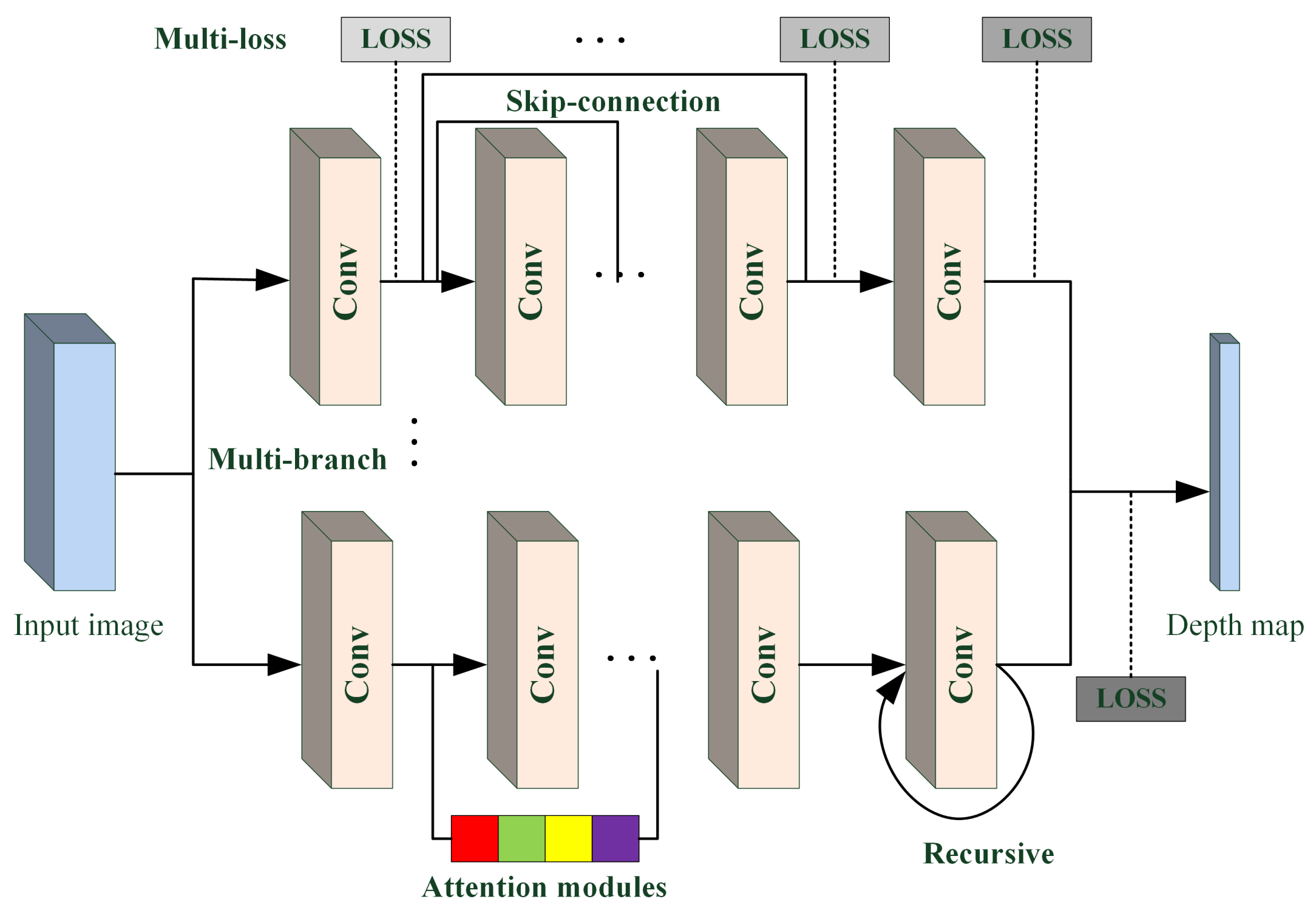
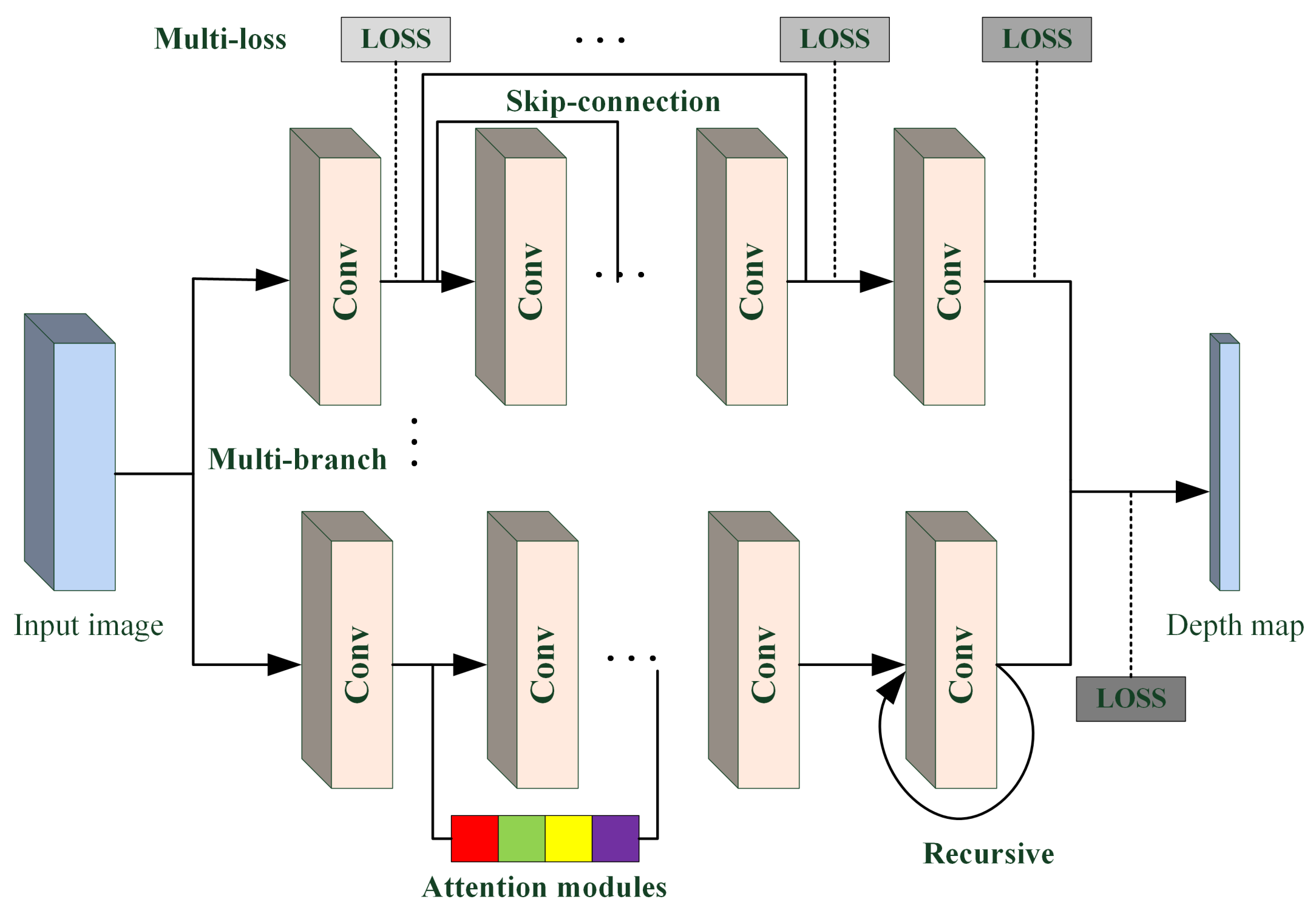
2.1. Image-Depth Estimation Based on Deep Learning
2.2. Bokeh-Effect Rendering
3. Method
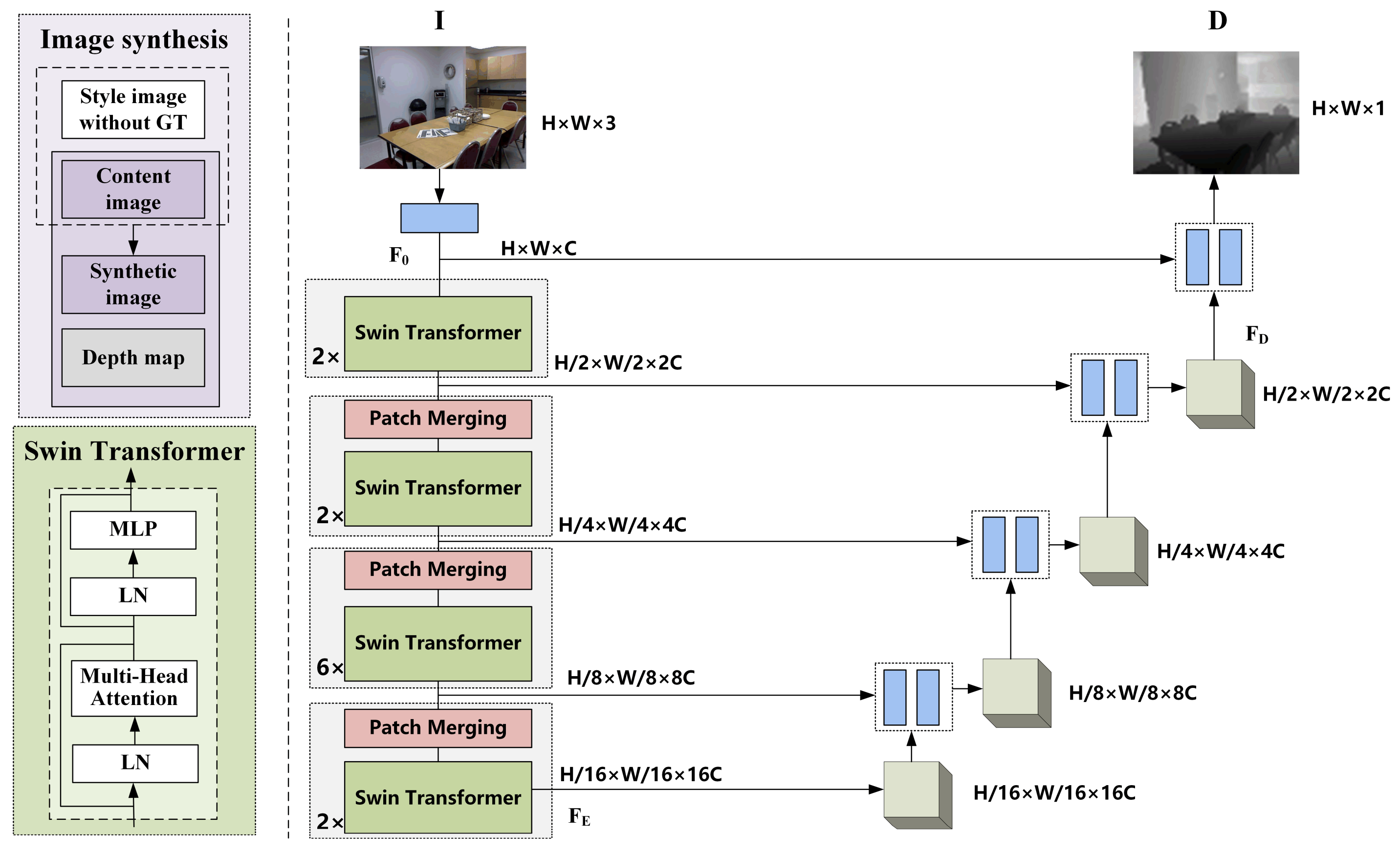
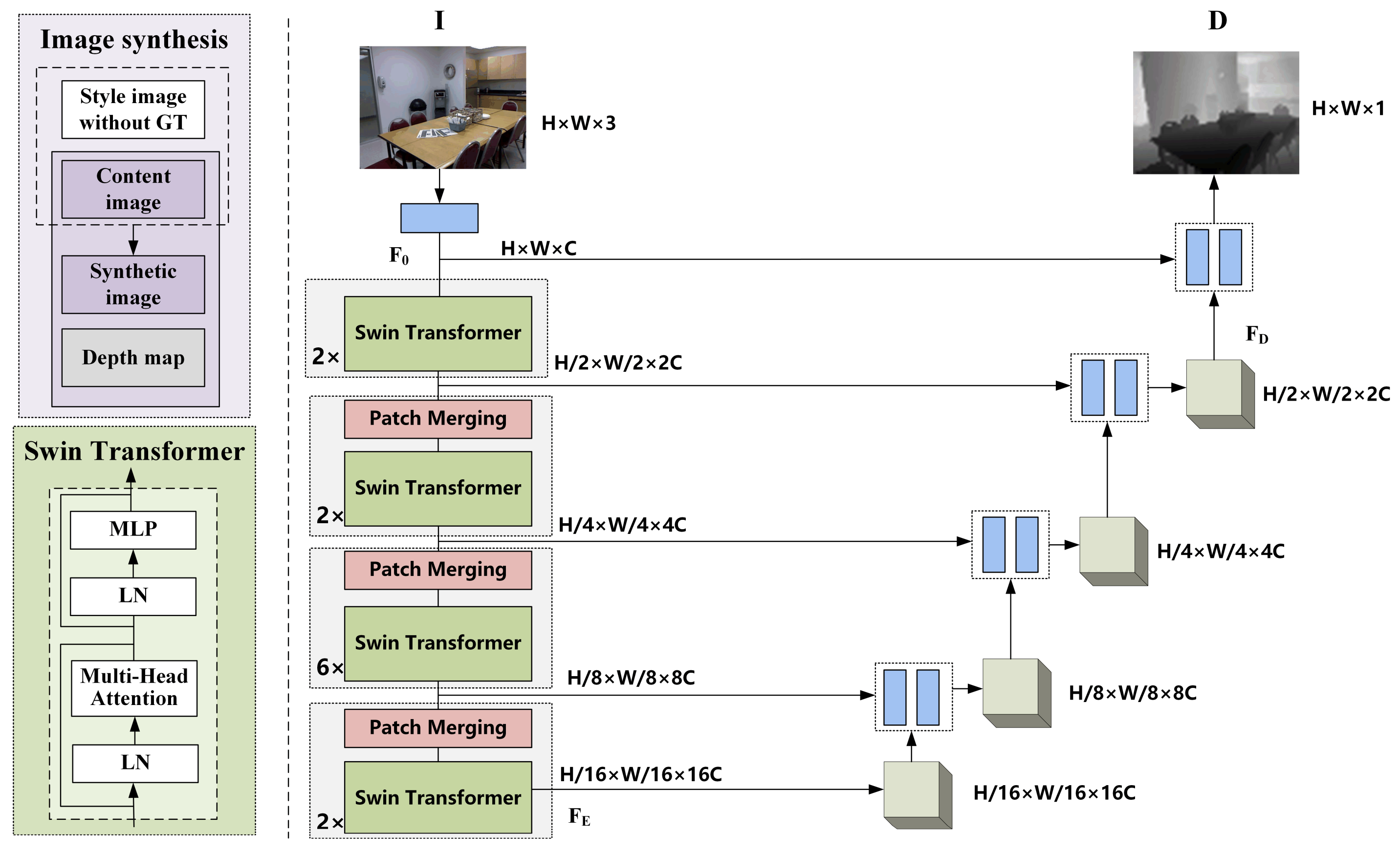
3.1. Image-Depth Estimation
3.1.1. Overall Pipeline
3.1.2. Image Synthesis
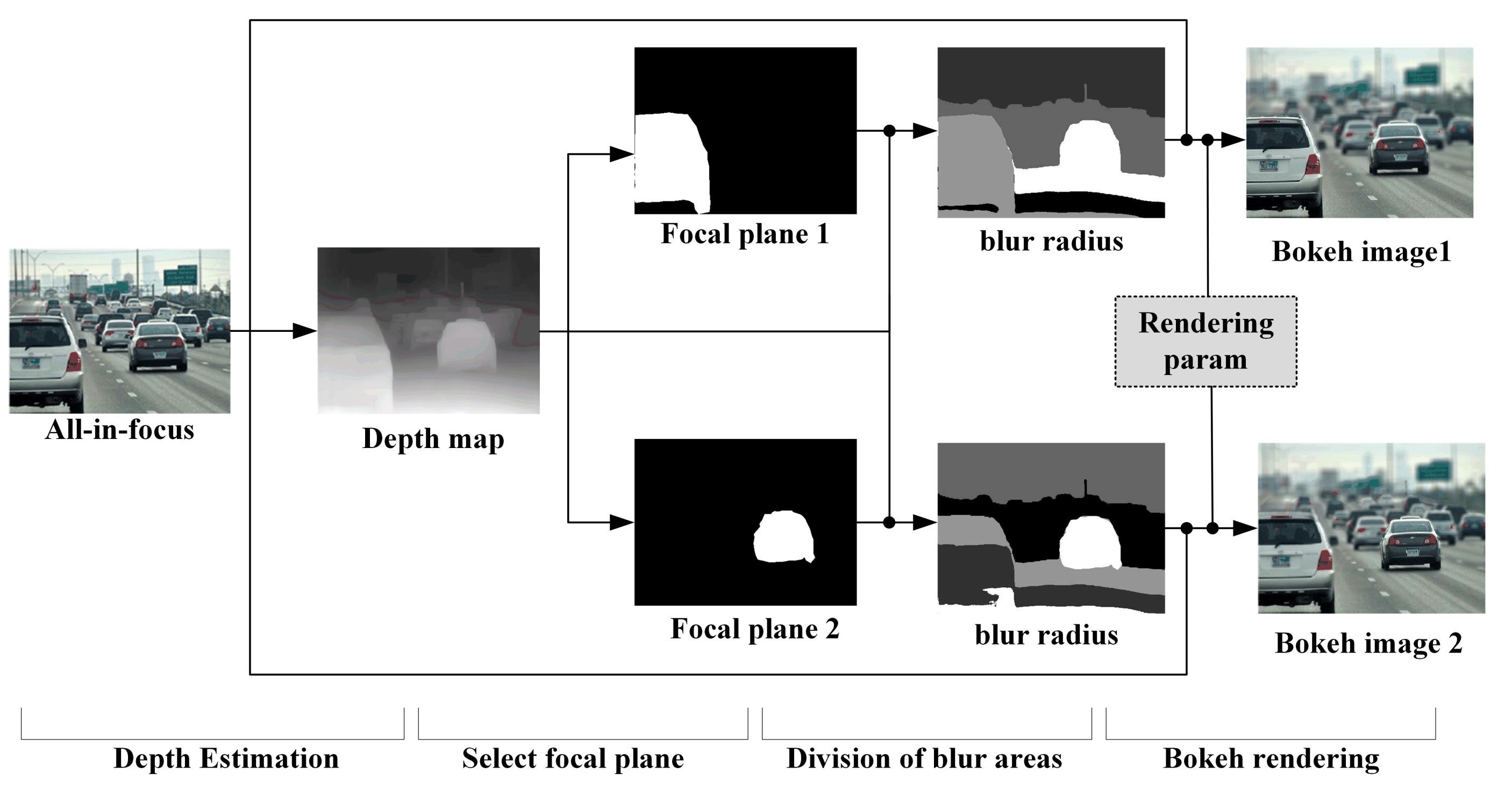
3.2. Bokeh-Effect Rendering
3.2.1. Uniform Bokeh Effects
3.2.2. Natural Bokeh Effect
4. Experiments
4.1. Evaluation of Depth-Estimation Model
4.1.1. Depth-Estimation Dataset and Evaluation Metrics
4.1.2. Performance Evaluation
4.2. Image-Depth-Estimation Visualization
4.3. Visualization of Bokeh Effect
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- León Araujo, H.; Gulfo Agudelo, J.; Crawford Vidal, R.; Ardila Uribe, J.; Remolina, J.F.; Serpa-Imbett, C.; López, A.M.; Patiño Guevara, D. Autonomous Mobile Robot Implemented in LEGO EV3 Integrated with Raspberry Pi to Use Android-Based Vision Control Algorithms for Human-Machine Interaction. Machines 2022, 10, 193. [Google Scholar] [CrossRef]
- Vrochidou, E.; Oustadakis, D.; Kefalas, A.; Papakostas, G.A. Computer Vision in Self-Steering Tractors. Machines 2022, 10, 129. [Google Scholar] [CrossRef]
- Lei, L.; Sun, S.; Zhang, Y.; Liu, H.; Xu, W. PSIC-Net: Pixel-Wise Segmentation and Image-Wise Classification Network for Surface Defects. Machines 2021, 9, 221. [Google Scholar] [CrossRef]
- Wang, F.; Chen, J.; Zhong, H.; Ai, Y.; Zhang, W. No-Reference Image Quality Assessment Based on Image Multi-Scale Contour Prediction. Appl. Sci. 2022, 12, 2833. [Google Scholar] [CrossRef]
- Shen, X.; Hertzmann, A.; Jia, J.; Paris, S.; Price, B.; Shechtman, E.; Sachs, I. Automatic Portrait Segmentation for Image Stylization. In Proceedings of the 37th Annual Conference of the European Association for Computer Graphics, Lisbon, Portugal, 9–13 May 2016; Eurographics Association: Goslar, Germany, 2016; pp. 93–102. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth Map Prediction from a Single Image Using a Multi-Scale Deep Network. arXiv 2014, arXiv:1406.2283. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Li, J.; Klein, R.; Yao, A. A Two-Streamed Network for Estimating Fine-Scaled Depth Maps from Single RGB Images; IEEE Computer Society: Washington, DC, USA, 2017; pp. 3392–3400. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2004, arXiv:1409.1556. [Google Scholar]
- Kim, Y.; Jung, H.; Min, D.; Sohn, K. Deep Monocular Depth Estimation via Integration of Global and Local Predictions. IEEE Trans. Image Processing 2018, 27, 4131–4144. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Xu, C.; Yang, J.; Gao, J.; Cui, Z. Progressive Hard-Mining Network for Monocular Depth Estimation. IEEE Trans. Image Processing 2018, 27, 3691–3702. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Zhao, H.; Hu, Z.; Peng, J. Attention-Based Context Aggregation Network for Monocular Depth Estimation. Int. J. Mach. Learn. Cyber. 2021, 12, 1583–1596. [Google Scholar] [CrossRef]
- Islam, N.U.; Park, J. Depth Estimation from a Single RGB Image Using Fine-Tuned Generative Adversarial Network. IEEE Access 2021, 9, 32781–32794. [Google Scholar] [CrossRef]
- Lei, Z.; Wang, Y.; Li, Z.; Yang, J. Attention Based Multilayer Feature Fusion Convolutional Neural Network for Unsupervised Monocular Depth Estimation. Neurocomputing 2021, 423, 343–352. [Google Scholar] [CrossRef]
- Garg, R.; Bg, V.K.; Carneiro, G.; Reid, I. Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue. In Proceedings of the Computer Vision-ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 740–756. [Google Scholar]
- Ye, X.; Ji, X.; Sun, B.; Chen, S.; Wang, Z.; Li, H. DRM-SLAM: Towards Dense Reconstruction of Monocular SLAM with Scene Depth Fusion. Neurocomputing 2020, 396, 76–91. [Google Scholar] [CrossRef]
- Zhu, A.Z.; Yuan, L.; Chaney, K.; Daniilidis, K. Unsupervised Event-Based Learning of Optical Flow, Depth, and Egomotion. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 989–997. [Google Scholar]
- Zhao, S.; Fu, H.; Gong, M.; Tao, D. Geometry-Aware Symmetric Domain Adaptation for Monocular Depth Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9780–9790. [Google Scholar]
- Zheng, C.; Cham, T.-J.; Cai, J. T2Net: Synthetic-to-Realistic Translation for Solving Single-Image Depth Estimation Tasks. In Proceedings of the Computer Vision-ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 798–814. [Google Scholar]
- Pnvr, K.; Zhou, H.; Jacobs, D. SharinGAN: Combining Synthetic and Real Data for Unsupervised Geometry Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13971–13980. [Google Scholar]
- Qi, X.; Liao, R.; Liu, Z.; Urtasun, R.; Jia, J. GeoNet: Geometric Neural Network for Joint Depth and Surface Normal Estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 283–291. [Google Scholar]
- Yan, H.; Zhang, S.; Zhang, Y.; Zhang, L. Monocular Depth Estimation with Guidance of Surface Normal Map. Neurocomputing 2018, 280, 86–100. [Google Scholar] [CrossRef]
- Huang, K.; Qu, X.; Chen, S.; Chen, Z.; Zhao, F. Superb Monocular Depth Estimation Based on Transfer Learning and Surface Normal Guidance. Sensors 2020, 20, 4856. [Google Scholar] [CrossRef] [PubMed]
- Purohit, K.; Suin, M.; Kandula, P.; Ambasamudram, R. Depth-Guided Dense Dynamic Filtering Network for Bokeh Effect Rendering. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 3417–3426. [Google Scholar]
- Dutta, S.; Das, S.D.; Shah, N.A.; Tiwari, A.K. Stacked Deep Multi-Scale Hierarchical Network for Fast Bokeh Effect Rendering from a Single Image. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 2398–2407. [Google Scholar]
- Ignatov, A.; Patel, J.; Timofte, R. Rendering Natural Camera Bokeh Effect with Deep Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1676–1686. [Google Scholar]
- Choi, M.-S.; Kim, J.-H.; Choi, J.-H.; Lee, J.-S. Efficient Bokeh Effect Rendering Using Generative Adversarial Network. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, Korea, 1–3 November 2020; pp. 1–5. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1510–1519. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7576, pp. 746–760. [Google Scholar]
- Saxena, A.; Chung, S.H.; Ng, A.Y. Learning Depth from Single Monocular Images. In Proceedings of the 18th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 5–8 December 2005; MIT Press: Cambridge, MA, USA, 2005; pp. 1161–1168. [Google Scholar]
- Godard, C.; Aodha, O.M.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6602–6611. [Google Scholar]
- Xu, D.; Ricci, E.; Ouyang, W.; Wang, X.; Sebe, N. Monocular Depth Estimation Using Multi-Scale Continuous CRFs as Sequential Deep Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1426–1440. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pilzer, A.; Lathuilière, S.; Sebe, N.; Ricci, E. Refine and Distill: Exploiting Cycle-Inconsistency and Knowledge Distillation for Unsupervised Monocular Depth Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9760–9769. [Google Scholar]
- Bhattacharyya, S.; Shen, J.; Welch, S.; Chen, C. Efficient Unsupervised Monocular Depth Estimation Using Attention Guided Generative Adversarial Network. J. Real-Time Image Proc. 2021, 18, 1357–1368. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Error | Accuracy | |||||
|---|---|---|---|---|---|---|---|
| abs.rel | sq.rel | RMSE | logRMSE | <1.25 | <1.252 | <1.253 | |
| Eigen | 0.203 | 1.548 | 6.307 | 0.282 | 0.702 | 0.890 | 0.959 |
| Godard | 0.148 | 1.344 | 5.927 | 0.247 | 0.803 | 0.922 | 0.964 |
| PHN | 0.136 | - | 4.082 | 0.164 | 0.864 | 0.966 | 0.989 |
| T2Net | 0.168 | 1.119 | 4.674 | 0.243 | 0.772 | 0.912 | 0.996 |
| Xu | 0.132 | 0.911 | - | 0.162 | 0.804 | 0.945 | 0.981 |
| Pilzer | 0.142 | 1.123 | 5.785 | 0.239 | 0.795 | 0.924 | 0.968 |
| GASDA | 0.149 | 1.003 | 4.995 | 0.227 | 0.824 | 0.941 | 0.973 |
| SharinGAN | 0.109 | 0.673 | 3.770 | 0.190 | 0.864 | 0.954 | 0.981 |
| AgFU-Net | 0.1190 | 0.9219 | 5.033 | 0.211 | 0.851 | 0.947 | 0.977 |
| EESP | 0.1196 | 0.889 | 4.329 | 0.192 | 0.865 | 0.943 | 0.989 |
| Ours | 0.119 | 0.899 | 4.349 | 0.189 | 0.966 | 0.944 | 0.988 |
| Models | Error | Accuracy | |||||
|---|---|---|---|---|---|---|---|
| abs.rel | sq.rel | RMSE | logRMSE | <1.25 | <1.252 | <1.253 | |
| Eigen | 0.215 | 0.212 | 0.907 | 0.285 | 0.611 | 0.887 | 0.971 |
| PHN | 0.169 | - | 0.573 | - | 0.785 | 0.943 | 0.981 |
| T2Net | 0.257 | 0.281 | 0.915 | 0.305 | 0.540 | 0.832 | 0.946 |
| Xu | 0.163 | - | 0.655 | - | 0.706 | 0.925 | 0.981 |
| Ours | 0.165 | 0.188 | 0.605 | 0.179 | 0.788 | 0.934 | 0.980 |
| Models | Training Set | Error | ||
|---|---|---|---|---|
| abs.rel | sq.rel | RMSE | ||
| PHN | T | 0.179 | - | 4.32 |
| Xu | T | 0.174 | - | 4.27 |
| Godard | F | 0.398 | 4.723 | 7.801 |
| T2Net | F | 0.508 | 6.589 | 8.935 |
| GASDA | F | 0.403 | 6.709 | 10.424 |
| SharinGAN | F | 0.377 | 4.900 | 8.388 |
| Ours | F | 0.389 | 4.922 | 8.389 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Zhang, Y.; Ai, Y.; Zhang, W. Rendering Natural Bokeh Effects Based on Depth Estimation to Improve the Aesthetic Ability of Machine Vision. Machines 2022, 10, 286. https://doi.org/10.3390/machines10050286
Wang F, Zhang Y, Ai Y, Zhang W. Rendering Natural Bokeh Effects Based on Depth Estimation to Improve the Aesthetic Ability of Machine Vision. Machines. 2022; 10(5):286. https://doi.org/10.3390/machines10050286
Chicago/Turabian StyleWang, Fan, Yingjie Zhang, Yibo Ai, and Weidong Zhang. 2022. "Rendering Natural Bokeh Effects Based on Depth Estimation to Improve the Aesthetic Ability of Machine Vision" Machines 10, no. 5: 286. https://doi.org/10.3390/machines10050286
APA StyleWang, F., Zhang, Y., Ai, Y., & Zhang, W. (2022). Rendering Natural Bokeh Effects Based on Depth Estimation to Improve the Aesthetic Ability of Machine Vision. Machines, 10(5), 286. https://doi.org/10.3390/machines10050286