
Improved Wafer Map Inspection Using Attention Mechanism and Cosine Normalization


Abstract
:1. Introduction
2. Related Work
2.1. Wafer Map Defect Pattern Classification
2.2. Attention Mechanism
2.3. Long-Tailed Recognition
3. Proposed Method
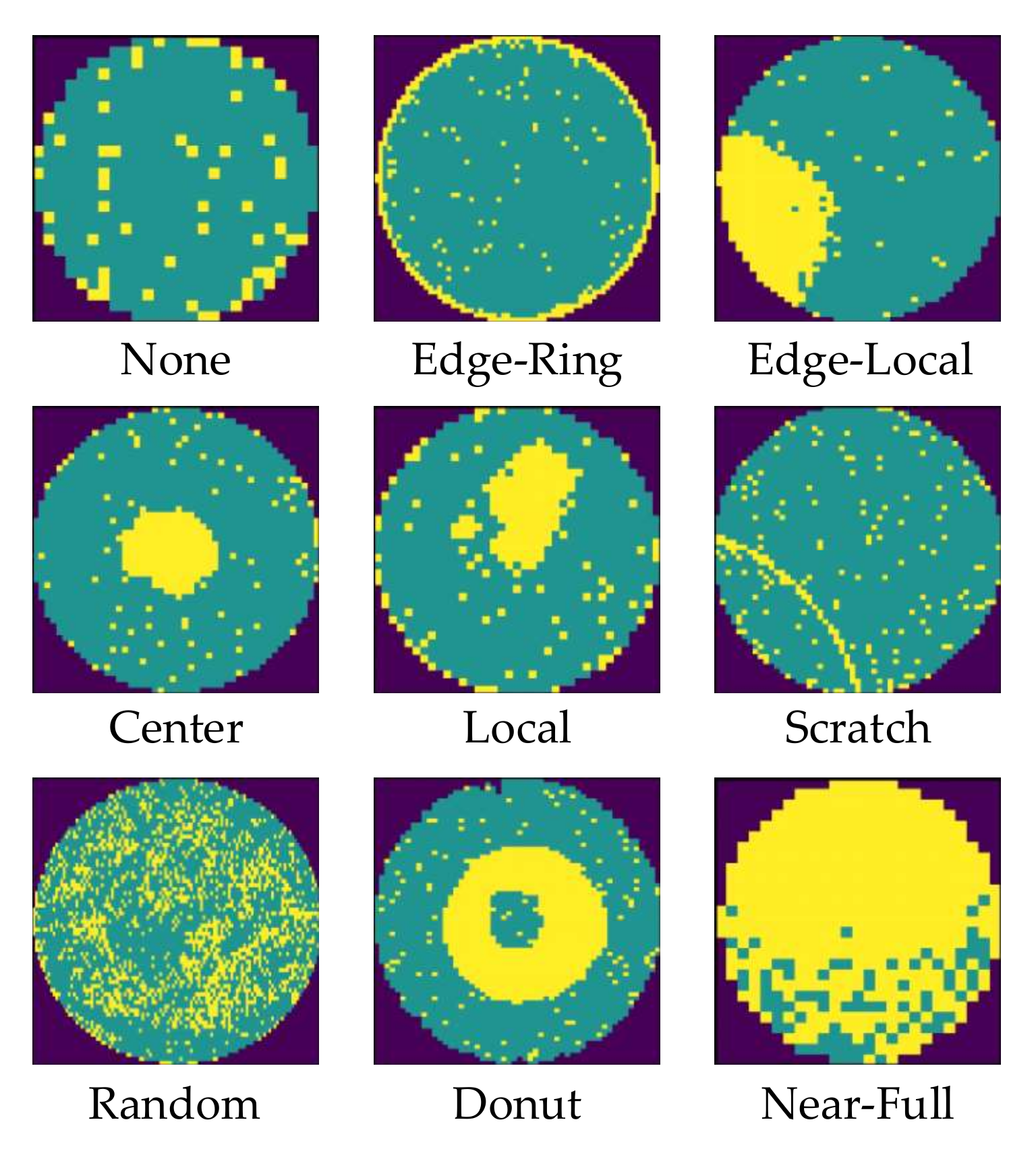
3.1. Wafer Map Processing
3.2. ResNet Backbone
3.3. Enhance Feature Representation
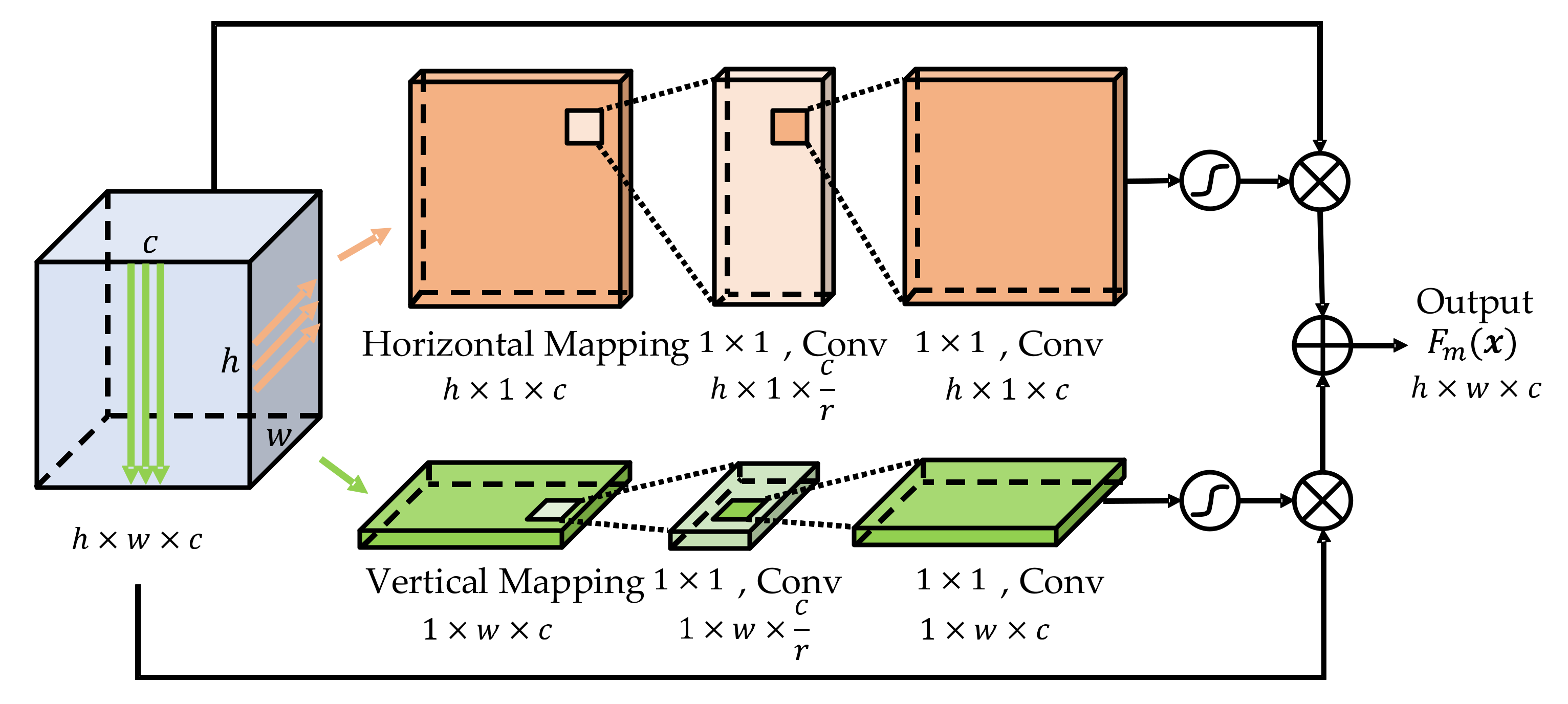
3.3.1. Revisiting The CBAM
3.3.2. Improved CBAM
3.4. Cosine Normalization
4. Experiments and Results
4.1. WM-811K Dataset
4.2. Selection of Reduction Rate
4.3. The Effect of Improved CBAM
4.4. Comparison with other Attention Mechanisms
4.5. Classifier Fine-Tuning Based on Cosine Normalization
4.6. Comparison with Common Methods for Dealing with Imbalanced Dataset
4.7. Comparison with Classical Wafer Map Inspection Algorithms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hsu, C.-Y.; Chen, W.-J.; Chien, J.-C. Similarity matching of wafer bin maps for manufacturing intelligence to empower Industry 3.5 for semiconductor manufacturing. Comput. Ind. Eng. 2020, 142, 106358. [Google Scholar] [CrossRef]
- Wu, M.-J.; Jang, J.-S.; Chen, J.-L. Wafer map failure pattern recognition and similarity ranking for large-scale data sets. IEEE Trans. Semicond. Manuf. 2015, 28, 1–12. [Google Scholar]
- Lei, L.; Sun, S.; Zhang, Y.; Liu, H.; Xu, W. PSIC-Net: Pixel-wise segmentation and image-wise classification network for surface defects. Machines 2021, 9, 221. [Google Scholar] [CrossRef]
- Maksim, K.; Kirill, B.; Eduard, Z.; Nikita, G.; Alexander, B.; Arina, L.; Vladislav, S.; Daniil, M.; Nikolay, K. Classification of wafer maps defect based on deep learning methods with small amount of data. In Proceedings of the 2019 International Conference on Engineering and Telecommunication, Dolgoprudny, Russia, 20–21 November 2019. [Google Scholar]
- Saqlain, M.; Abbas, Q.; Lee, J.Y. A deep convolutional neural network for wafer defect identification on an imbalanced dataset in semiconductor manufacturing processes. IEEE Trans. Semicond. Manuf. 2020, 33, 436–444. [Google Scholar] [CrossRef]
- Wang, R.; Chen, N. Defect pattern recognition on wafers using convolutional neural networks. Qual. Reliab. Eng. Int. 2020, 36, 1245–1257. [Google Scholar] [CrossRef]
- Reed, W.J. The Pareto, Zipf and other power laws. Econ. Lett. 2001, 74, 15–19. [Google Scholar] [CrossRef]
- Hwang, J.Y.; Kuo, W. Model-based clustering for integrated circuit yield enhancement. Eur. J. Oper. Res. 2007, 178, 143–153. [Google Scholar] [CrossRef]
- Piao, M.; Jin, C.H.; Lee, J.Y.; Byun, J.-Y. Decision tree ensemble-based wafer map failure pattern recognition based on radon transform-based features. IEEE Trans. Semicond. Manuf. 2018, 31, 250–257. [Google Scholar] [CrossRef]
- Saqlain, M.; Jargalsaikhan, B.; Lee, J.Y. A voting ensemble classifier for wafer map defect patterns identification in semiconductor manufacturing. IEEE Trans. Semicond. Manuf. 2019, 32, 171–182. [Google Scholar] [CrossRef]
- Jin, C.H.; Na, H.J.; Piao, M.; Pok, G.; Ryu, K.H. A novel DBSCAN-based defect pattern detection and classification framework for wafer bin map. IEEE Trans. Semicond. Manuf. 2019, 32, 286–292. [Google Scholar] [CrossRef]
- Chen, X.; Zhao, C.; Chen, J.; Zhang, D.; Zhu, K.; Su, Y. K-means clustering with morphological filtering for silicon wafer grain defect detection. In Proceedings of the IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference, Chongqing, China, 12–14 June 2020. [Google Scholar]
- Lee, S.; Kim, D. Distributed-based hierarchical clustering system for large-scale semiconductor wafers. In Proceedings of the 2018 IEEE International Conference on Industrial Engineering and Engineering Management, Bangkok, Thailand, 16–19 December 2018. [Google Scholar]
- Chen, H.; Pang, Y.; Hu, Q.; Liu, K. Solar cell surface defect inspection based on multispectral convolutional neural network. J. Intell. Manuf. 2020, 31, 453–468. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, V.-C.; Hoang, D.-T.; Tran, X.-T.; Van, M.; Kang, H.-J. A bearing fault diagnosis method using multi-branch deep neural network. Machines 2021, 9, 345. [Google Scholar] [CrossRef]
- Yang, P.; Wen, C.; Geng, H.; Liu, P. Intelligent fault diagnosis method for blade damage of quad-rotor UAV based on stacked pruning sparse denoising autoencoder and convolutional neural network. Machines 2021, 9, 360. [Google Scholar] [CrossRef]
- Nakazawa, T.; Kulkarni, D.V. Wafer map defect pattern classification and image retrieval using convolutional neural network. IEEE Trans. Semicond. Manuf. 2018, 31, 309–314. [Google Scholar] [CrossRef]
- Nakazawa, T.; Kulkarni, D.V. Anomaly detection and segmentation for wafer defect patterns using deep convolutional encoder-decoder neural network architectures in semiconductor manufacturing. IEEE Trans. Semicond. Manuf. 2019, 32, 250–256. [Google Scholar] [CrossRef]
- Park, S.; Jang, J.; Kim, C.O. Discriminative feature learning and cluster-based defect label reconstruction for reducing uncertainty in wafer bin map labels. J. Intell. Manuf. 2021, 32, 251–263. [Google Scholar] [CrossRef]
- Hsu, C.-Y.; Chien, J.-C. Ensemble convolutional neural networks with weighted majority for wafer bin map pattern classification. J. Intell. Manuf. 2022, 33, 831–844. [Google Scholar] [CrossRef]
- Shen, Z.; Yu, J. Wafer map defect recognition based on deep transfer learning. In Proceedings of the 2019 IEEE International Conference on Industrial Engineering and Engineering Management, Macao, China, 15–18 December 2019. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, J.; Liu, L.; Wang, P.; Zhang, J. Exploring the auxiliary learning for long-tailed visual recognition. Neurocomputing 2021, 449, 303–314. [Google Scholar] [CrossRef]
- Yin, X.; Yu, X.; Sohn, K.; Liu, X.; Chandraker, M. Feature transfer learning for deep face recognition with under-represented data. In Proceeding of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16-20 June 2019. [Google Scholar]
- Mahajan, D.; Girshick, R.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; van der Maaten, L. Exploring the limits of weakly supervised pretraining. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kang, B.; Xie, S.; Rohrbach, M.; Yan, Z.; Gordo, A.; Feng, J.; Kalantidis, Y. Decoupling representation and classifier for long-tailed recognition. In Proceedings of the International Conference on Learning Representation, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Zhou, B.; Cui, Q.; Wei, X.-S.; Chen, Z.-M. BBN: Bilateral-branch network with cumulative learning for long-tailed visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Cui, Y.; Jia, M.; Lin, T.-Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Cao, K.; Wei, C.; Gaidon, A.; Arechiga, N.; Ma, T. Learning imbalanced datasets with label-distribution-aware margin loss. In Proceedings of the 33rd Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Liu, J.; Sun, Y.; Han, C.; Dou, Z.; Li, W. Deep representation learning on long-tailed data: A learnable embedding augmentation perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liu, Z.; Miao, Z.; Zhan, X.; Wang, J.; Gong, B.; Yu, S.X. Large-scale long-tailed recognition in an open world. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yu, N.-G.; Xu, Q.; Wang, H.-L.; Lin, J. Wafer bin map inspection based on DenseNet. J. Cent. South Univ. 2020, 28, 2436–2450. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 18th IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| r | Precision | Recall | F1-Score |
|---|---|---|---|
| 1 | 0.924 | 0.932 | 0.928 |
| 8 | 0.923 | 0.937 | 0.930 |
| 16 | 0.932 | 0.940 | 0.936 |
| 32 | 0.927 | 0.938 | 0.932 |
| Attention Mechanism | None | Edge-Ring | Edge-Local | Center | Local | Scratch | Random | Donut | Near-Full | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| Coordinate [24] | 98.90 | 97.66 | 91.82 | 98.23 | 83.61 | 88.22 | 93.95 | 88.41 | 97.22 | 93.11 |
| SENet [25] | 99.10 | 98.30 | 90.28 | 98.13 | 84.29 | 86.53 | 93.28 | 89.86 | 100 | 93.31 |
| SKNet [26] | 99.12 | 97.74 | 91.28 | 98.04 | 83.72 | 85.52 | 93.02 | 88.41 | 97.22 | 92.68 |
| CBAM [27] | 98.42 | 98.32 | 92.59 | 97.39 | 83.05 | 85.19 | 93.95 | 88.41 | 100 | 93.04 |
| I-CBAM 1 | 98.55 | 97.64 | 92.98 | 97.01 | 85.38 | 89.59 | 94.88 | 92.03 | 100 | 94.22 |
| Model | None | Edge-Ring | Edge-Local | Center | Local | Scratch | Random | Donut | Near-Full | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| ResNet-18 | 98.31 | 97.23 | 89.74 | 98.60 | 81.72 | 80.47 | 88.37 | 87.68 | 94.44 | 90.73 |
| I-CBAM 1 | 98.55 | 97.64 | 92.98 | 97.01 | 85.38 | 89.59 | 94.88 | 92.03 | 100 | 94.22 |
| I-CBAM + CN 2 | 98.47 | 97.64 | 91.98 | 97.57 | 86.73 | 93.6 | 96.74 | 96.38 | 100 | 95.46 |
| Model | None | Edge-Ring | Edge-Local | Center | Local | Scratch | Random | Donut | Near-Full | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| T-based 1 | 98.78 | 97.58 | 89.51 | 97.76 | 83.28 | 84.51 | 90.7 | 92.03 | 100 | 92.68 |
| G-based 2 | 98.5 | 97.5 | 90.43 | 98.23 | 84.73 | 86.53 | 91.16 | 86.96 | 100 | 92.67 |
| CB-based 3 | 98.78 | 97.9 | 89.12 | 98.13 | 83.39 | 87.88 | 92.49 | 89.3 | 100 | 93 |
| LW-based 4 | 99.02 | 97.78 | 91.67 | 97.76 | 83.39 | 87.88 | 92.95 | 87.68 | 100 | 93.13 |
| Proposed | 98.47 | 97.64 | 91.98 | 97.57 | 86.73 | 93.6 | 96.74 | 96.38 | 100 | 95.46 |
| Model | None | Edge-Ring | Edge-Local | Center | Local | Scratch | Random | Donut | Near-Full | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| WMFPR [2] | 95.7 | 79.7 | 85.1 | 84.9 | 68.5 | 82.4 | 79.8 | 74 | 97.9 | 83.1 |
| DTE-WMFPR [9] | 100 | 86.8 | 83.5 | 95.8 | 83.5 | 86 | 95.8 | 92.3 | N/A | 90.5 |
| WMDPI [10] | 97.9 | 97.9 | 81.8 | 92.5 | 83.9 | 81.4 | 95.8 | 91.5 | 93.3 | 90.7 |
| T-DenseNet [21] | 85.5 | 66.8 | 81.5 | 64.5 | 100 | 72.6 | 65.5 | 91.2 | 99.3 | 80.8 |
| Proposed | 98.6 | 97.6 | 92 | 97.6 | 86.7 | 93.6 | 96.7 | 96.4 | 100 | 95.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Q.; Yu, N.; Essaf, F. Improved Wafer Map Inspection Using Attention Mechanism and Cosine Normalization. Machines 2022, 10, 146. https://doi.org/10.3390/machines10020146
Xu Q, Yu N, Essaf F. Improved Wafer Map Inspection Using Attention Mechanism and Cosine Normalization. Machines. 2022; 10(2):146. https://doi.org/10.3390/machines10020146
Chicago/Turabian StyleXu, Qiao, Naigong Yu, and Firdaous Essaf. 2022. "Improved Wafer Map Inspection Using Attention Mechanism and Cosine Normalization" Machines 10, no. 2: 146. https://doi.org/10.3390/machines10020146
APA StyleXu, Q., Yu, N., & Essaf, F. (2022). Improved Wafer Map Inspection Using Attention Mechanism and Cosine Normalization. Machines, 10(2), 146. https://doi.org/10.3390/machines10020146