1. Introduction
As a high-precision closed-loop control system, a hydraulic servo system can make the output (displacement, velocity or force) of a system follow the changes of the input quickly and accurately. This offers the unique advantages of fast response speed, large load stiffness and large control power and is widely used in the aerospace, heavy industry, robotics and national defense fields. However, as a high-order nonlinear system, the inherent nonlinearity, time-variability and parameter coupling of a hydraulic servo system pose challenges to the design of control methods [
1]. The determination of controller parameters and the deployment of a control strategy are the main difficulties. Thus, the question of how to control a hydraulic servo system with high precision is of great significance to its popularization and application.
The use of reinforcement learning algorithms to solve control problems such as nonlinear engineering problems has been widely studied by many researchers. For instance, Wu, M. et al. [
2] used a safe deep reinforcement learning (DRL) control method based on a safe reward shaping method and applied it to the constrained control for an electro-hydraulic servo system (EHSS). Chen, P. et al. [
3] proposed a novel control strategy of speed servo systems based on deep reinforcement learning, which can achieve proportional–integral–derivative automatic tuning and effectively overcome the effects of inertia mutation and torque disturbance. Wyrwał, D. et al. [
4] proposed a novel control strategy for a hydraulic cylinder based on deep reinforcement learning, which can automatically control the hydraulic system online so that the system can consequently maintain a consistently good control performance. Zhang, T. et al. [
5] proposed a strategy based on deep reinforcement learning for the optimization of gain parameters of a cross-coupled controller, allowing the effective convergence of the gain parameters with the optimal intervals. The optimal gain parameters obtained by the proposed strategy can significantly improve the contour control accuracy in biaxial contour tracking tasks. Zamfirache, I.A. et al. [
6] proposed a new control approach based on reinforcement learning (RL) that used policy iteration (PI) and a metaheuristic grey wolf optimizer (GWO) algorithm to train neural networks (NNs). In so doing they demonstrated good results for NN training and the solving of complex optimization problems. Shuprajhaa, T. et al. [
7] developed a generic-data-driven modified proximal policy optimization (m-PPO) for an adaptive PID controller (RL-PID) based on reinforcement learning for the control of open-loop unstable processes, which eliminated the need for process modeling and pre-requisite knowledge on process dynamics and controller tuning.
Some studies have also integrated multiple comprehensive methods to achieve optimal control. Vaerenbergh, K.V. et al. [
8] presented a practical application of a hybrid approach where reinforcement learning is the global layer to tune the controllers of every subsystem for the problem. It was shown that developing a centralized global controller for systems with many subsystems or complex interactions is usually very hard or even unfeasible. Lv, Y. et al. [
9] used an RL-based approximate dynamic programming (ADP) structure to learn the optimal tracking control input of a servo mechanism, where unknown system dynamics were approximated with a three-layer NN identifier. Radac, M.B, and Lala, T. [
10] proposed a Q-learning-like data-driven model-free (with unknown process dynamics) algorithm. They used neural networks as generic function approximators and validation on an active suspension system and it was shown to be easily amenable to artificial road profile disturbance generation for the optimal and robust control of a data-driven learning solution. Oh, T.H. et al. [
11] proposed a DDPG-based deep RL method to simultaneously design and tune several notch filters and used a real industrial servo system with multiple resonances to demonstrate the proposed method effectively. They found the optimal parameters for several notch filters and successfully suppressed multiple resonances to provide the desired performances. Chen, W. et al. [
12] proposed a novel adaptive law for the critical network in an RL framework to address the problem of nonlinear system control, which is driven by historical estimation errors but uses an auxiliary matrix instead of a historical data set, thus reducing the computational effort of the controller.
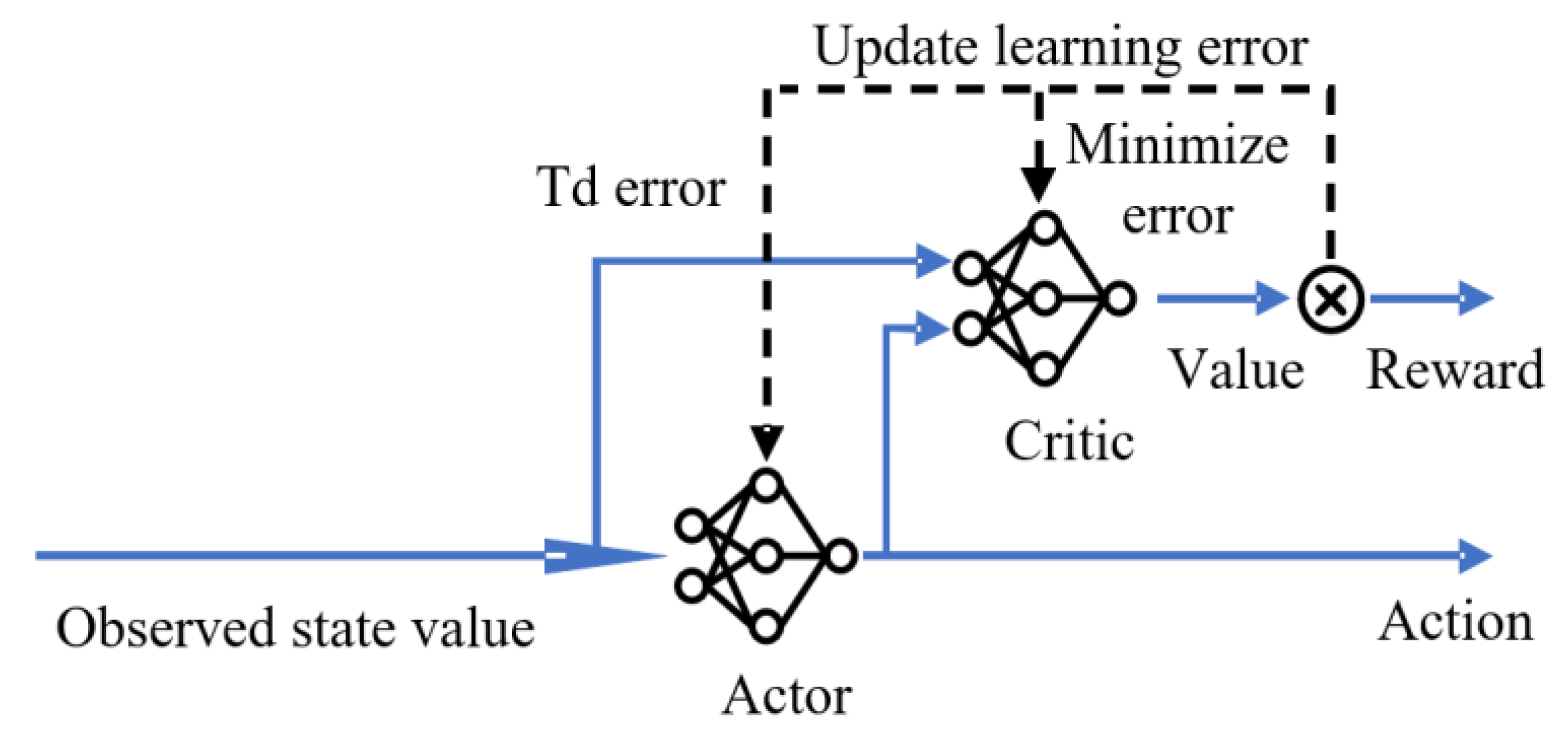
Reinforcement learning mainly learns and optimizes its own behavioral strategies through the idea and mechanism of trial and error. The behavior acts on the environment and obtains a response from the environment. The response is the evaluation index of the behavior. In the process of constantly interacting with the environment, the agent constantly changes their actions according to the rewards they get from the environment. With enough training, the agent can accumulate experience and then interact with the environment in a way that maximizes reward.
Although many studies have been undertaken in the practice of RL design and have laid a great theoretical foundation, there still exist some challenges and shortcomings. For instance, the classic reinforcement learning methods such as Q-learning do not have good generalizability and are usually only useful for specific tasks. Methods of control that have been optimized by neural network algorithms or genetic algorithms are usually effective only for specific cycle periods, lack on-line learning capabilities and have limited generalizability. Additionally, the experimental research on pure hydraulic servo systems has rarely been concerned with RL, and the verification of tests is relatively simple. As a result, most studies fail to set comparison tests or compile reinforcement learning algorithms for testing and verification.
In this study, the application of a reinforcement learning algorithm as the optimal control is presented Ref. [
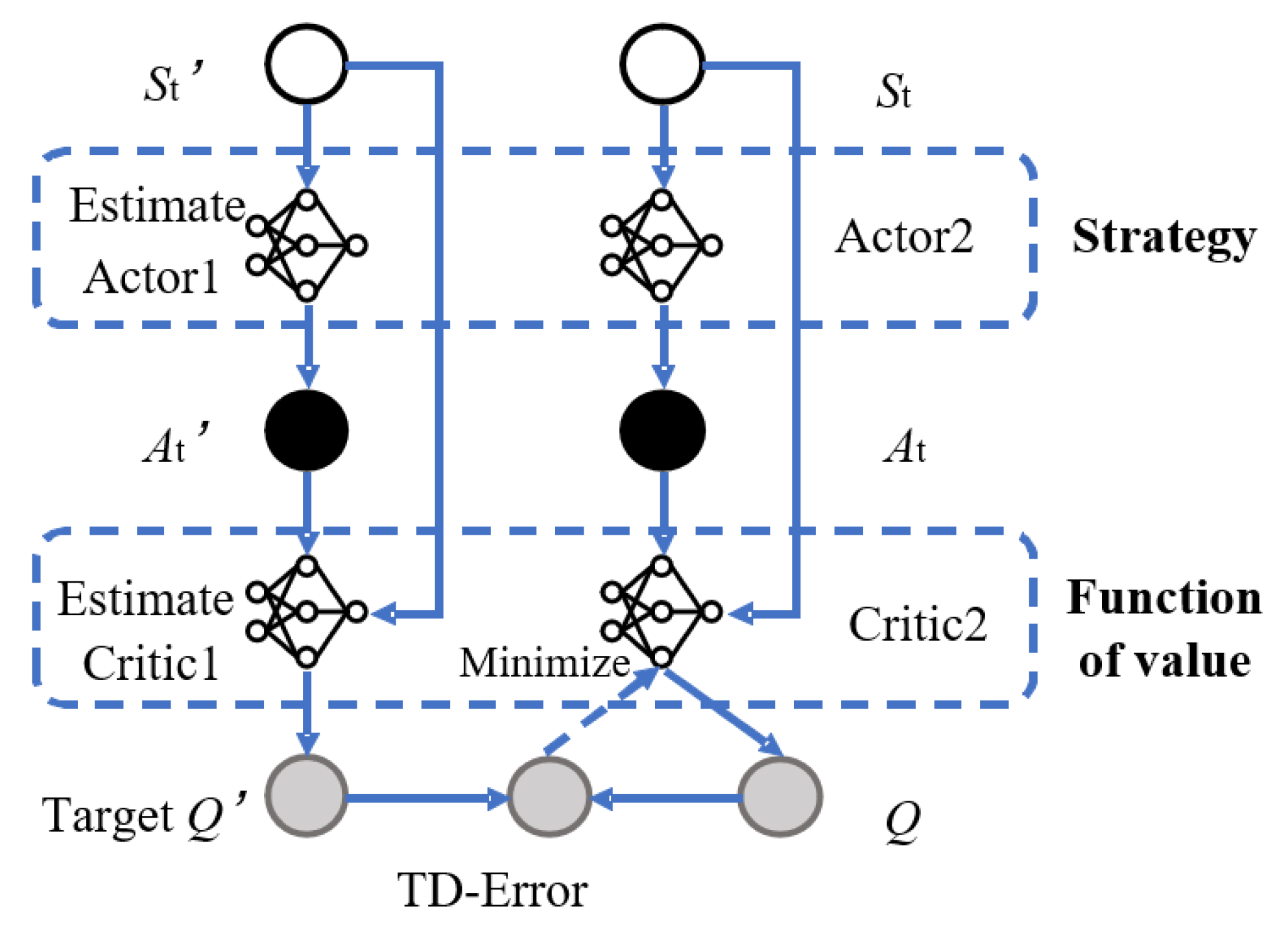
13]. This algorithm learns the optimal control strategy through direct interaction with objects. A deep neural network based on TD3 reinforcement learning training is introduced to realize this complex control [
14,
15,
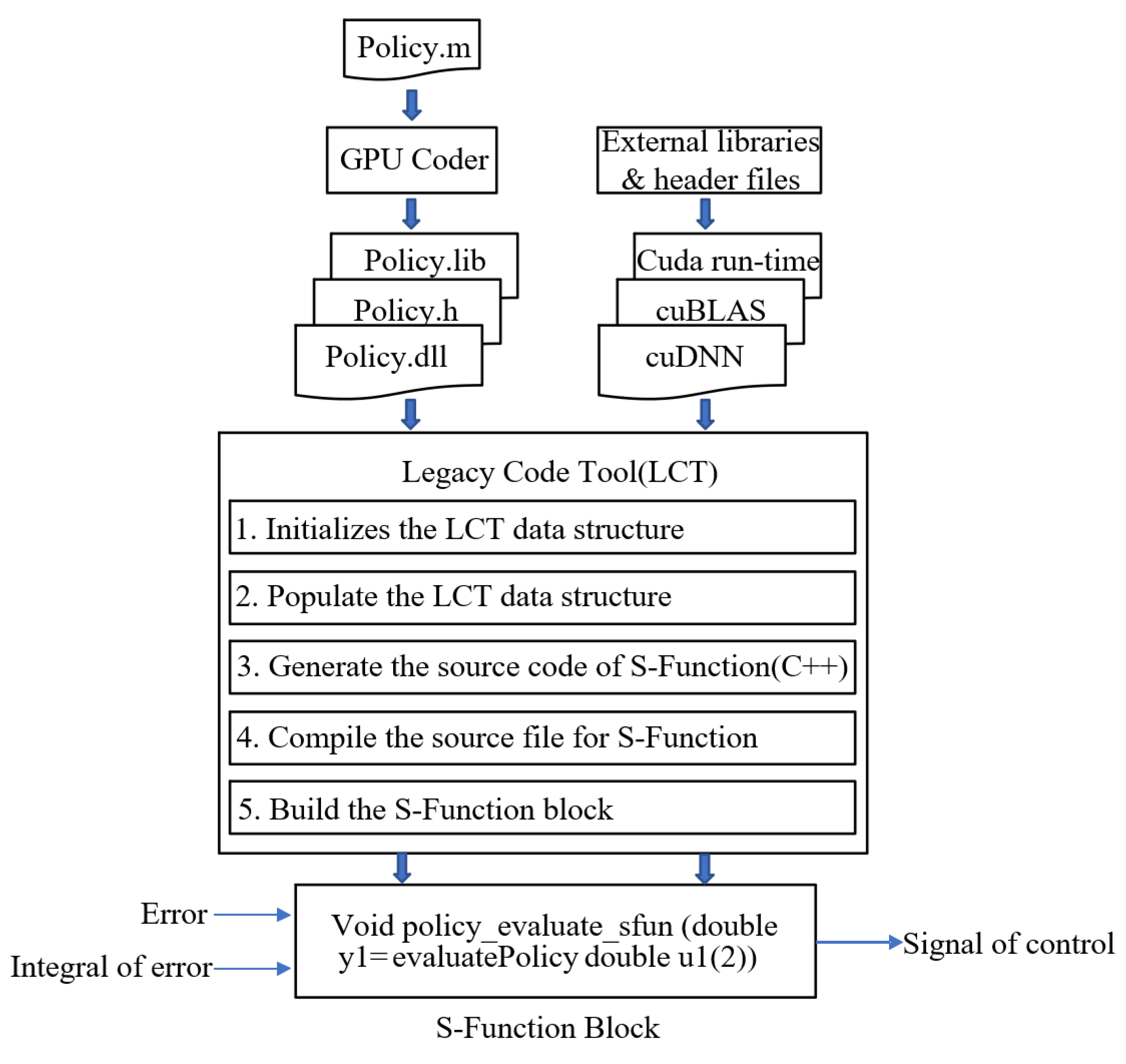
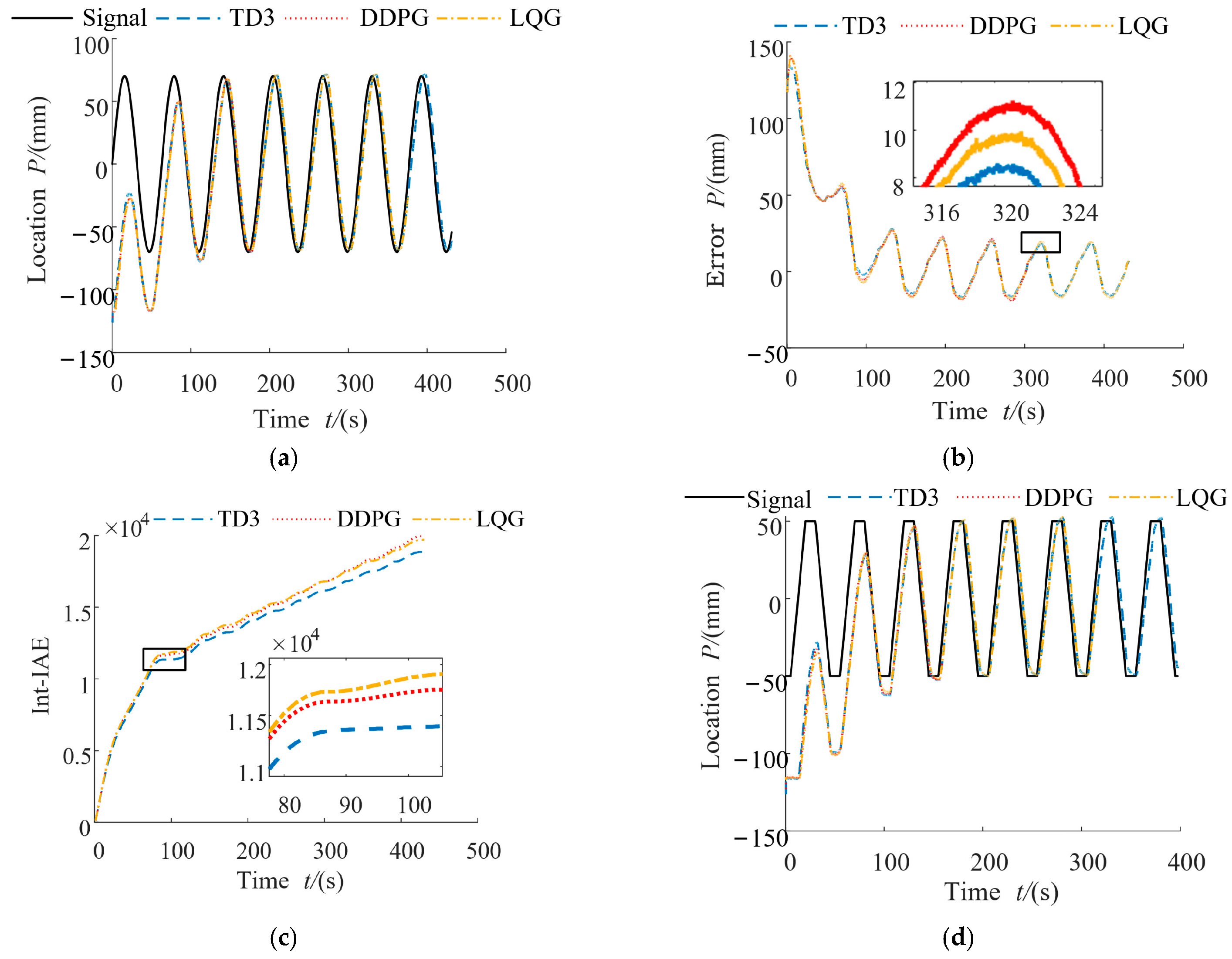
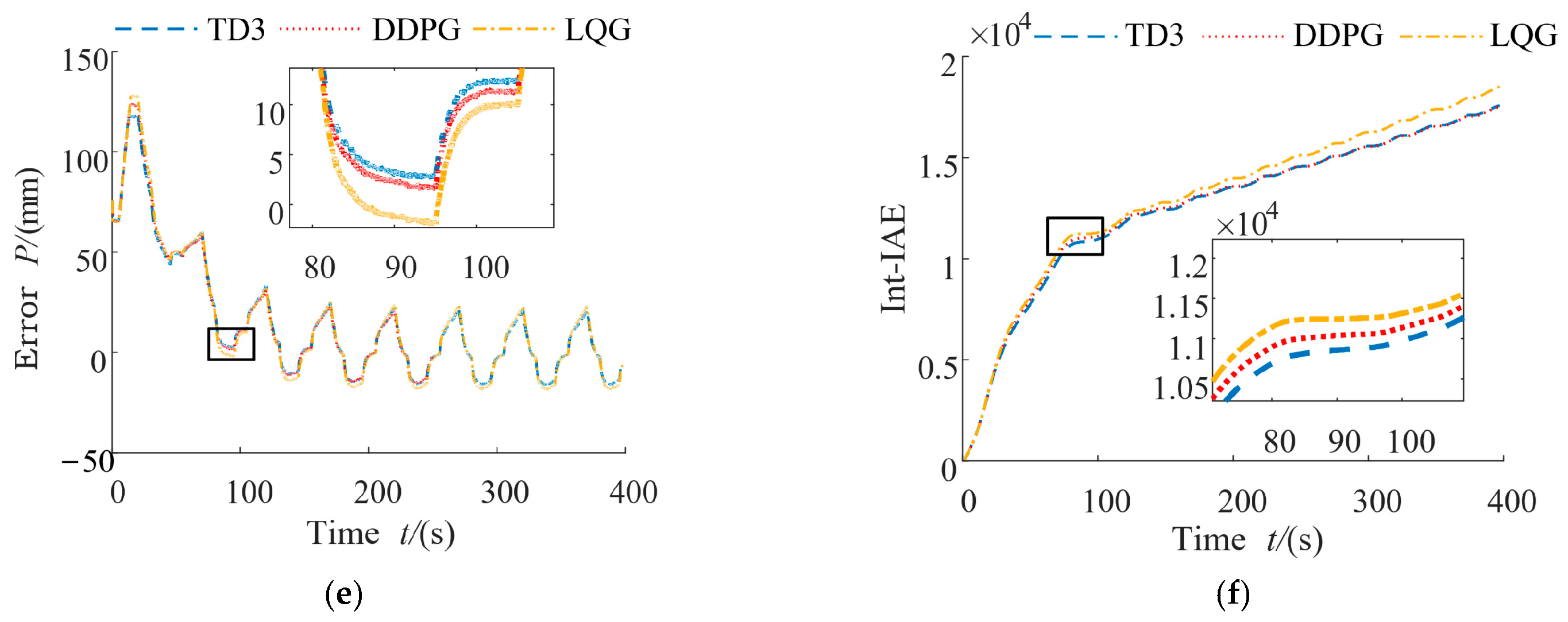
16]. Firstly, the feasibility and effectiveness of the controller are verified by simulation, and rapid prototype control is then carried out based on a Speedgoat prototype target machine. A GPU coder and LCT packaging tool are then used to deploy the reinforcement learning control program after the reinforcement learning training is completed. Finally, we verify the rationality of the control scheme and the effectiveness of the control algorithm by experiments.
2. Reinforcement Learning
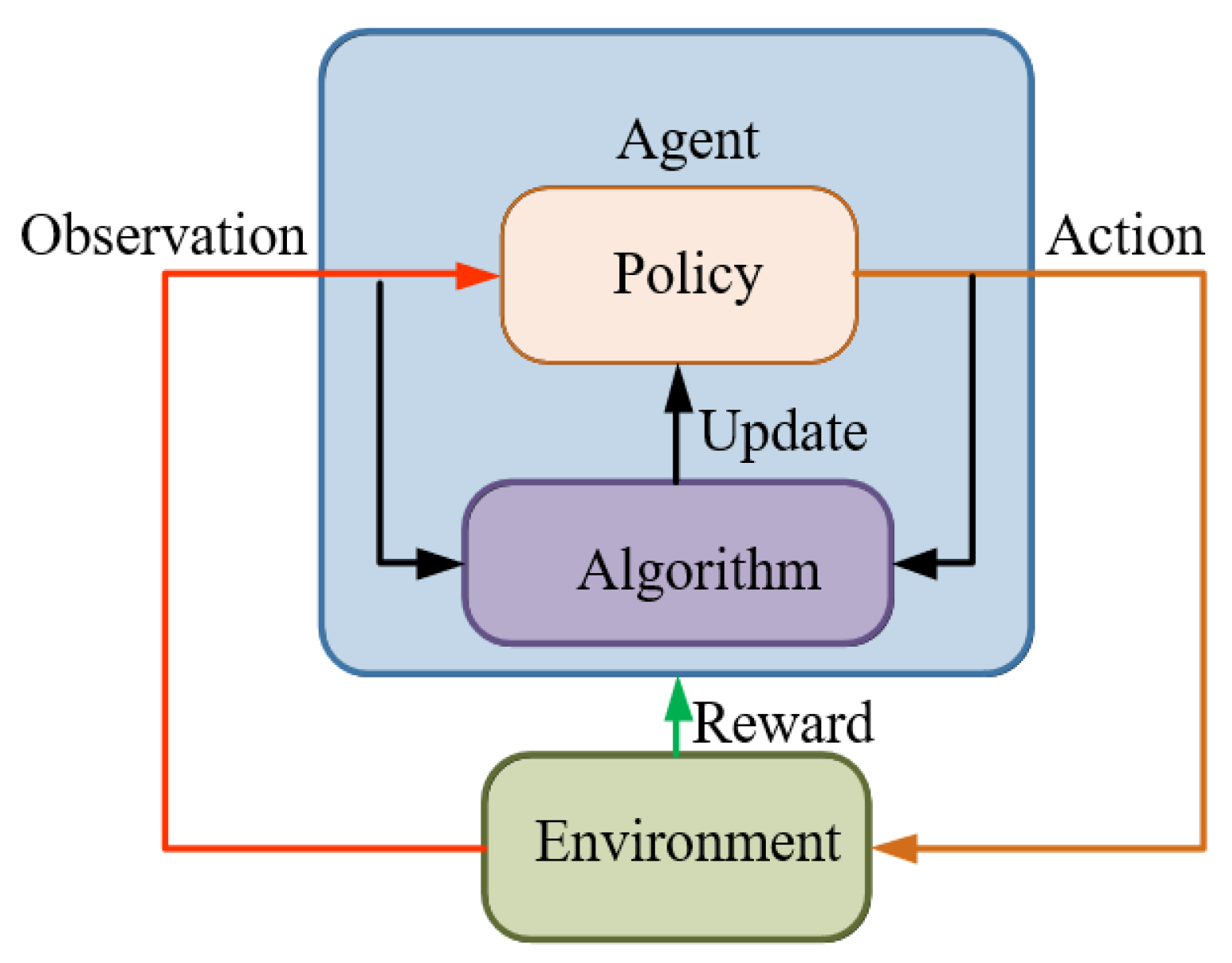
Reinforcement learning [
17] is a type of learning method in machine learning. It aims to construct and train agents to complete corresponding tasks in an unknown environment and its basic framework is shown in
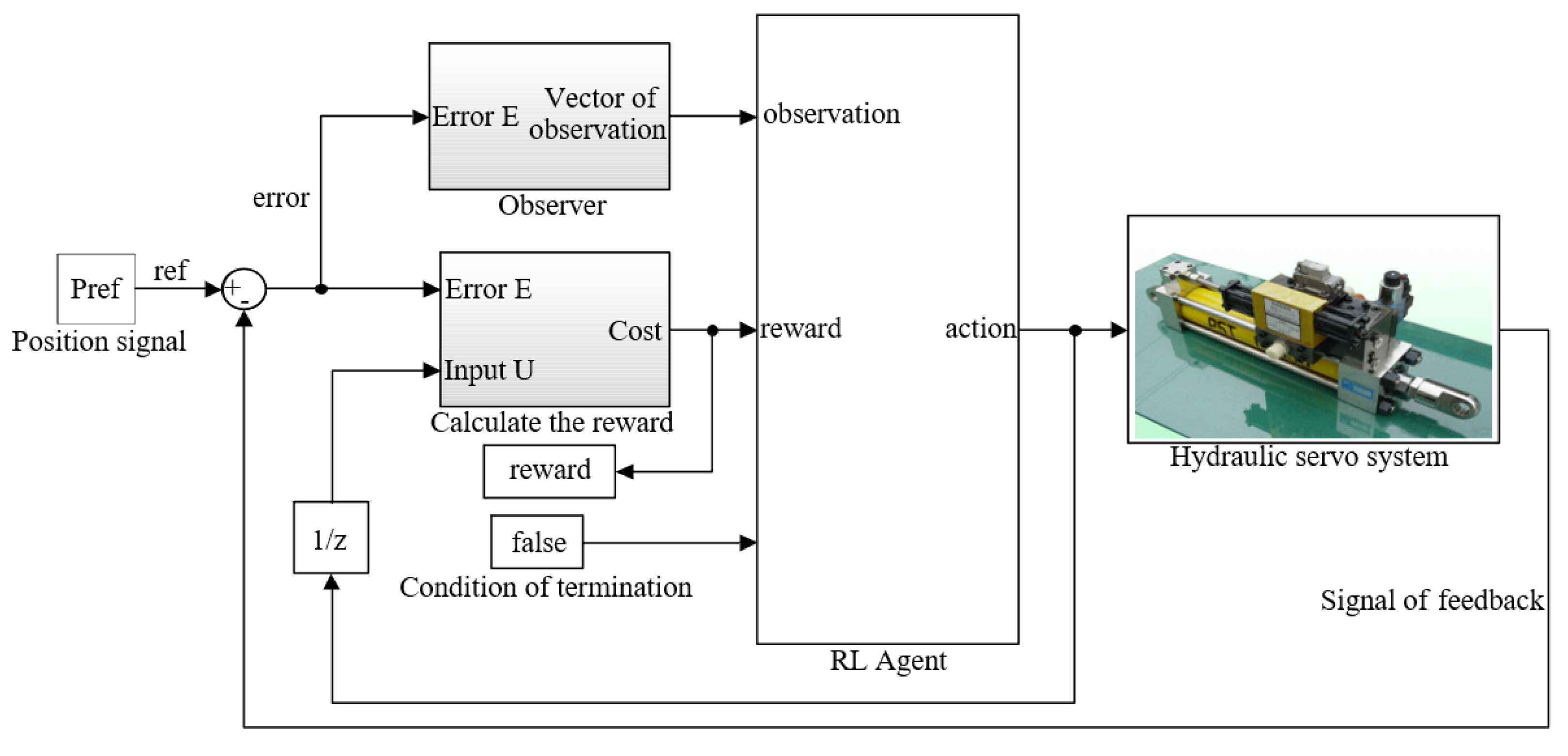
Figure 1 Since the actions in the learning process can affect the environment and the environment will then affect the subsequent actions, reinforcement learning can be regarded as, in essence, a closed-loop control, and the strategies of the agent allow it to complete the task in an optimal way through iterative updates, which is similar to the controller in the system [
18,
19].
Interactions between the agent and the environment in a period T are as follows:
- (a)
The Agent observes the system state after the previous action A;
- (b)
Under the current state of S and strategy P, agent undertakes action A by exploring the noise ϵ;
- (c)
The reward value R is obtained under the new environment state S, then the Agent updates the strategy P according to the reward value R;
- (d)
Repeat the above steps until the requirements are met.
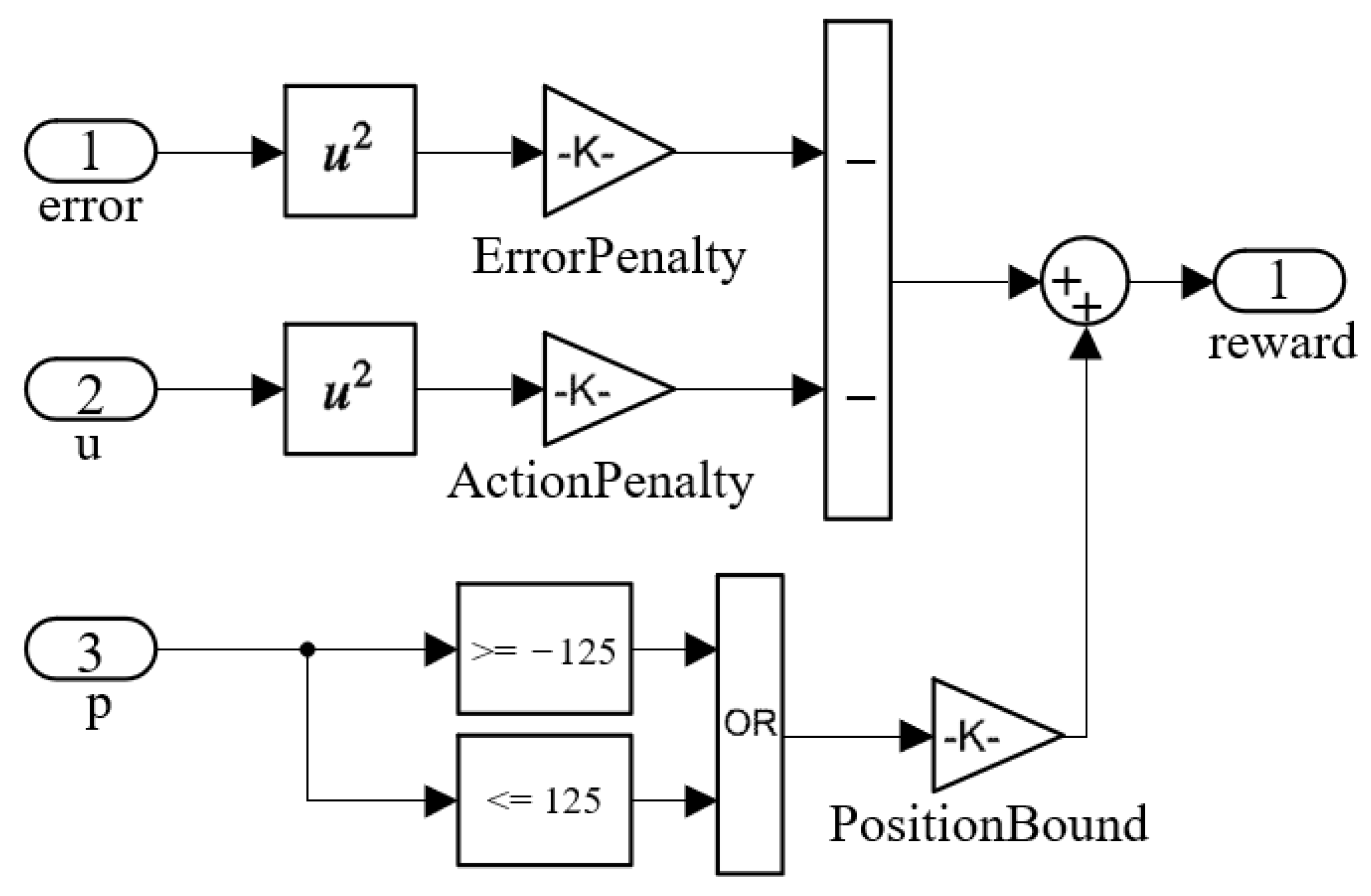
Among these illustrated above, the reward value R is to evaluate the quality of the actions made by the agent in the environment. Since the reasonable setting of a reward function determines its convergence speed and stability, it is key for the agent to learn strategy effectively.
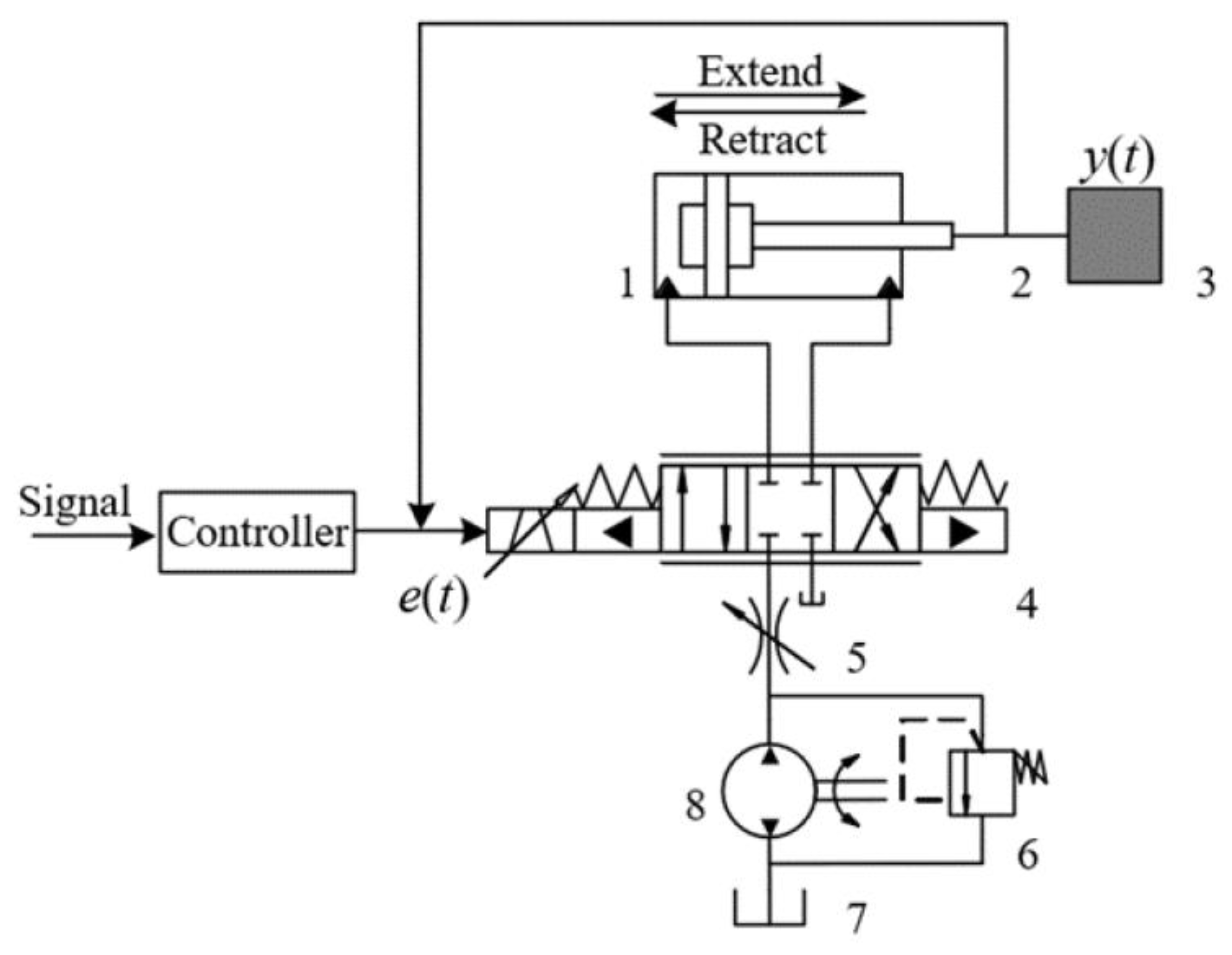
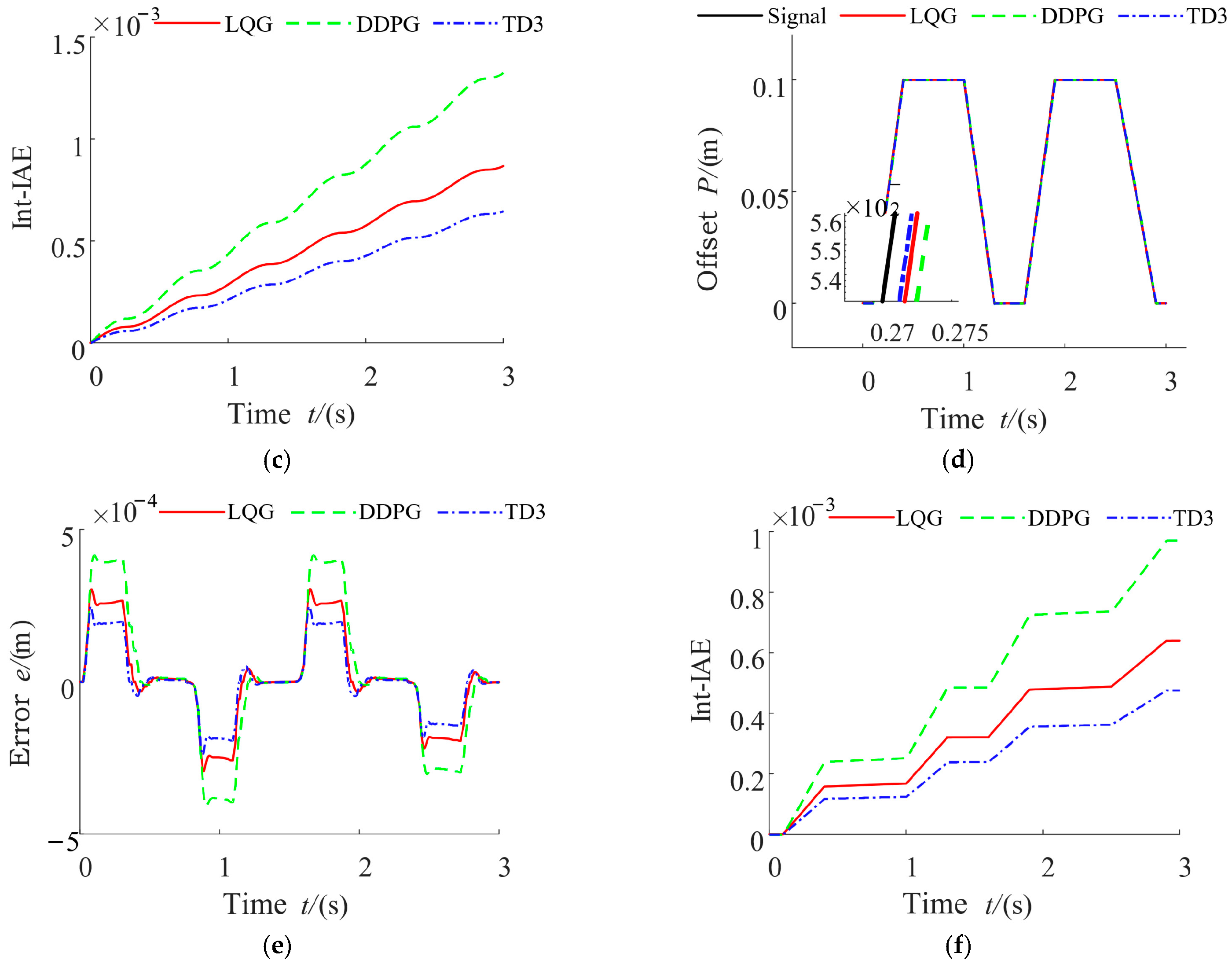
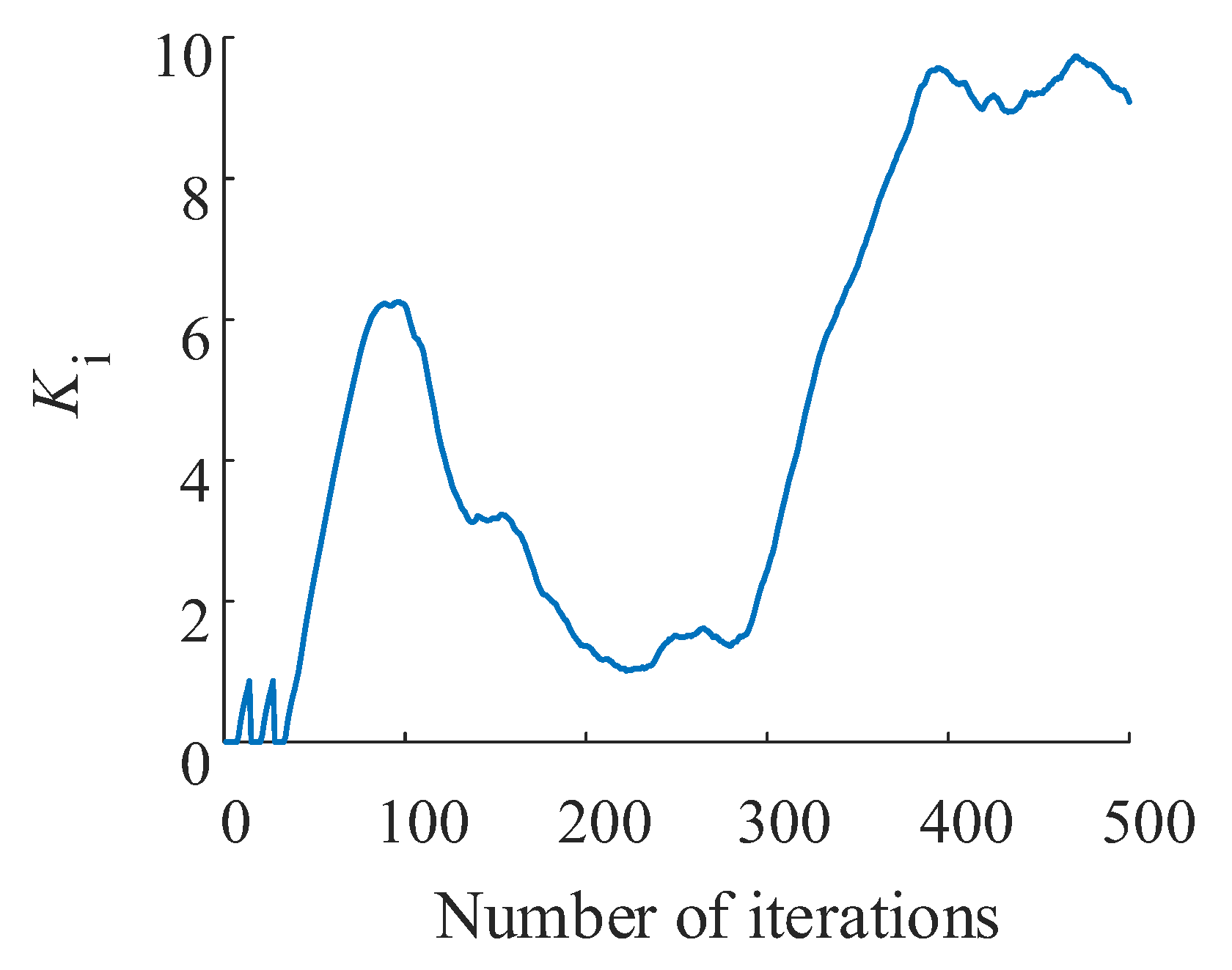
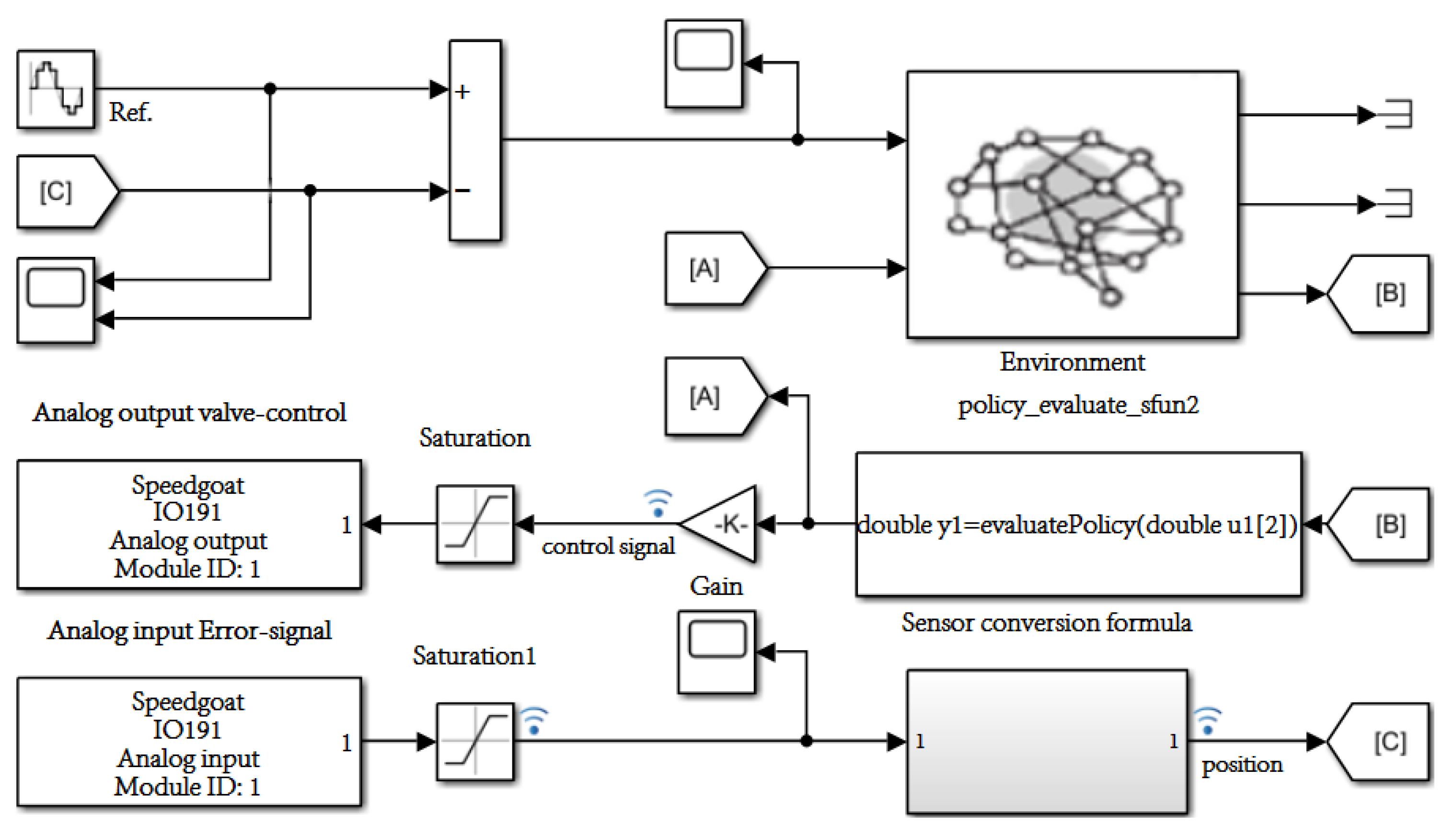
This paper takes a servo valve controlled asymmetric hydraulic cylinder system as the research object, builds a simulation environment based on a MATLAB/Simulink module, and carries out precise positional control of a hydraulic cylinder through a reinforcement learning algorithm. Additionally, the TD3 reinforcement learning algorithm was designed to interact with the environment so that ultimately the strategy of the control requirements can be satisfied. The servo valve controlled asymmetric hydraulic cylinder system is shown in
Figure 2.



 ,
, 


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}