
Machine Learning in CNC Machining: Best Practices
Abstract
1. Introduction
- 1.
- Focus on the data infrastructure first.
- 2.
- Start with simple models.
- 3.
- Beware of data leakage.
- 4.
- Use open-source software.
- 5.
- Leverage computation.
2. Dataset Descriptions
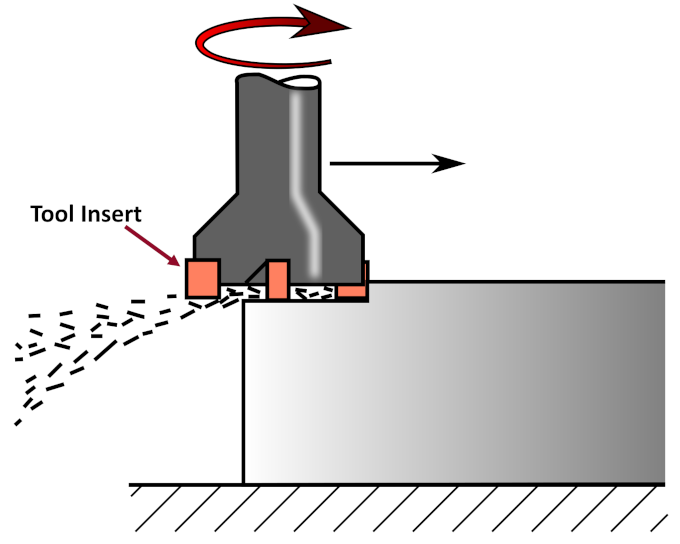
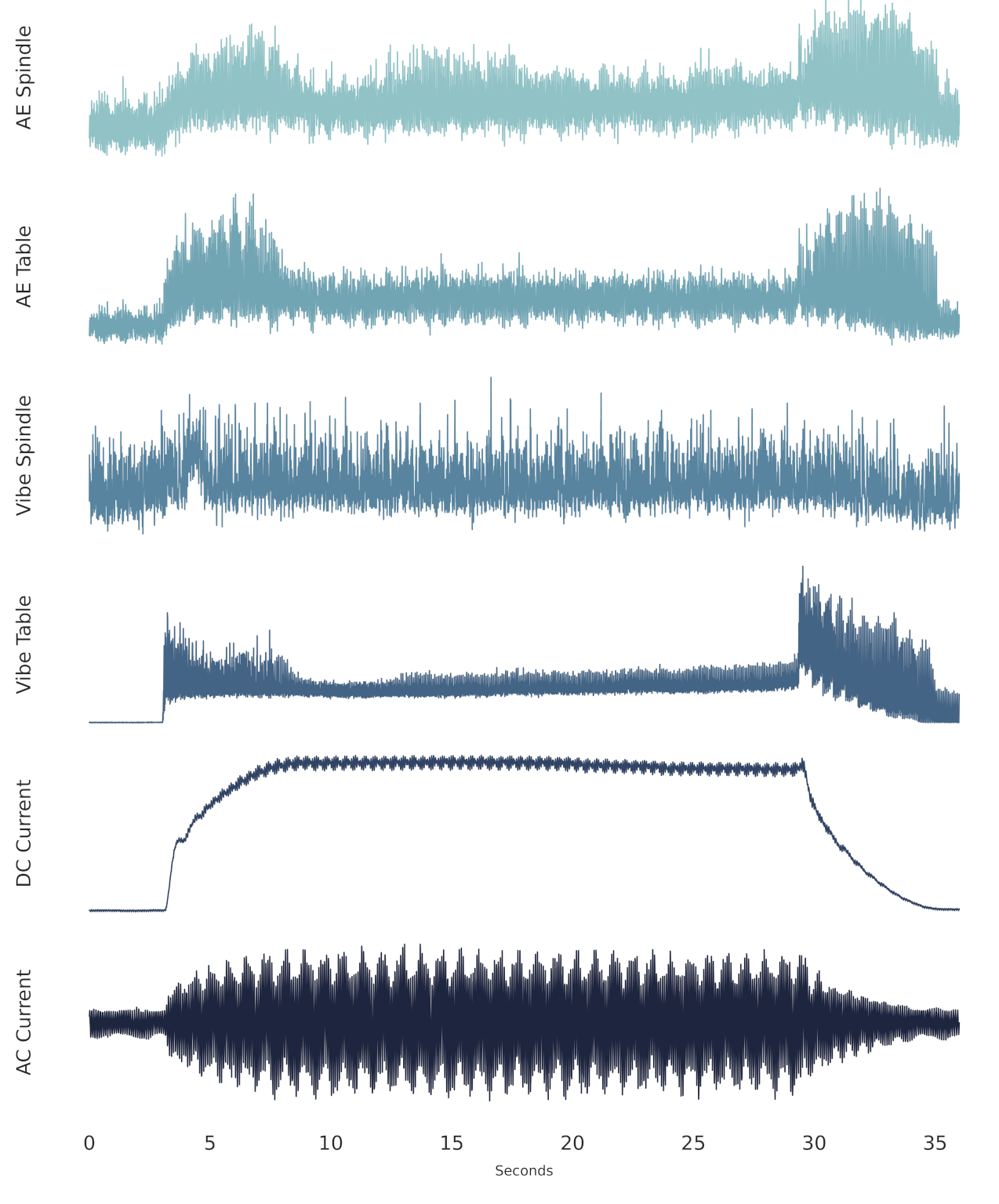
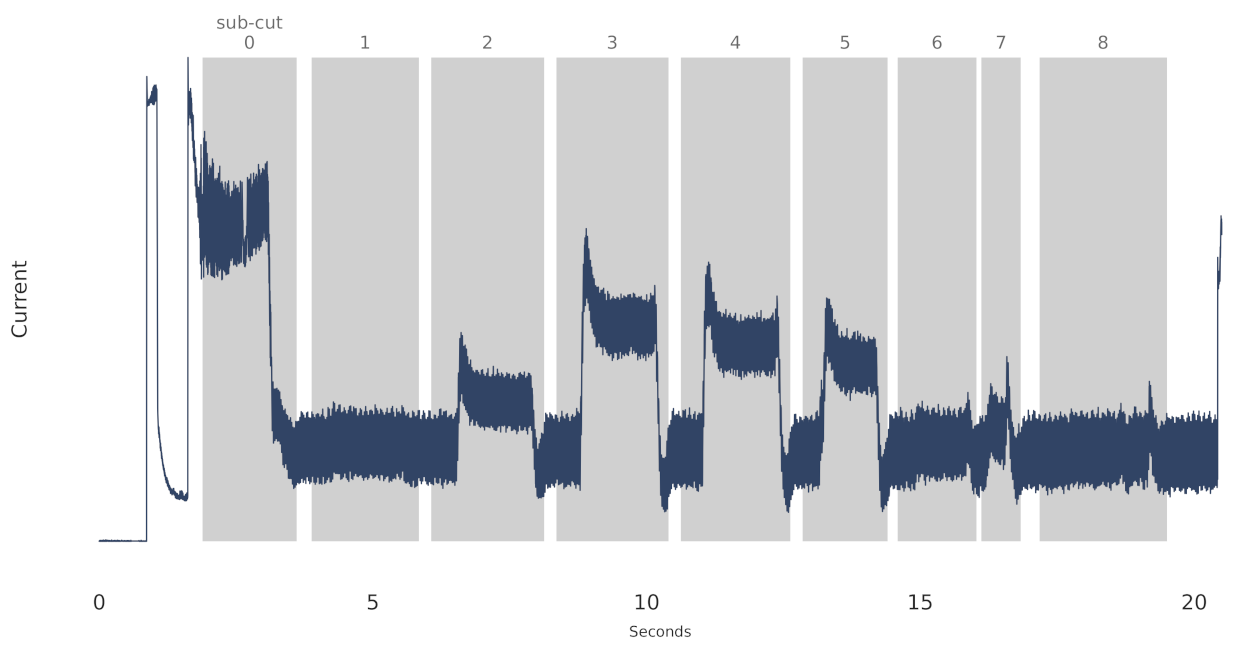
2.1. UC Berkeley Milling Dataset
2.2. CNC Industrial Dataset
3. Methods
3.1. Milling Data Preprocessing
3.2. CNC Data Preprocessing
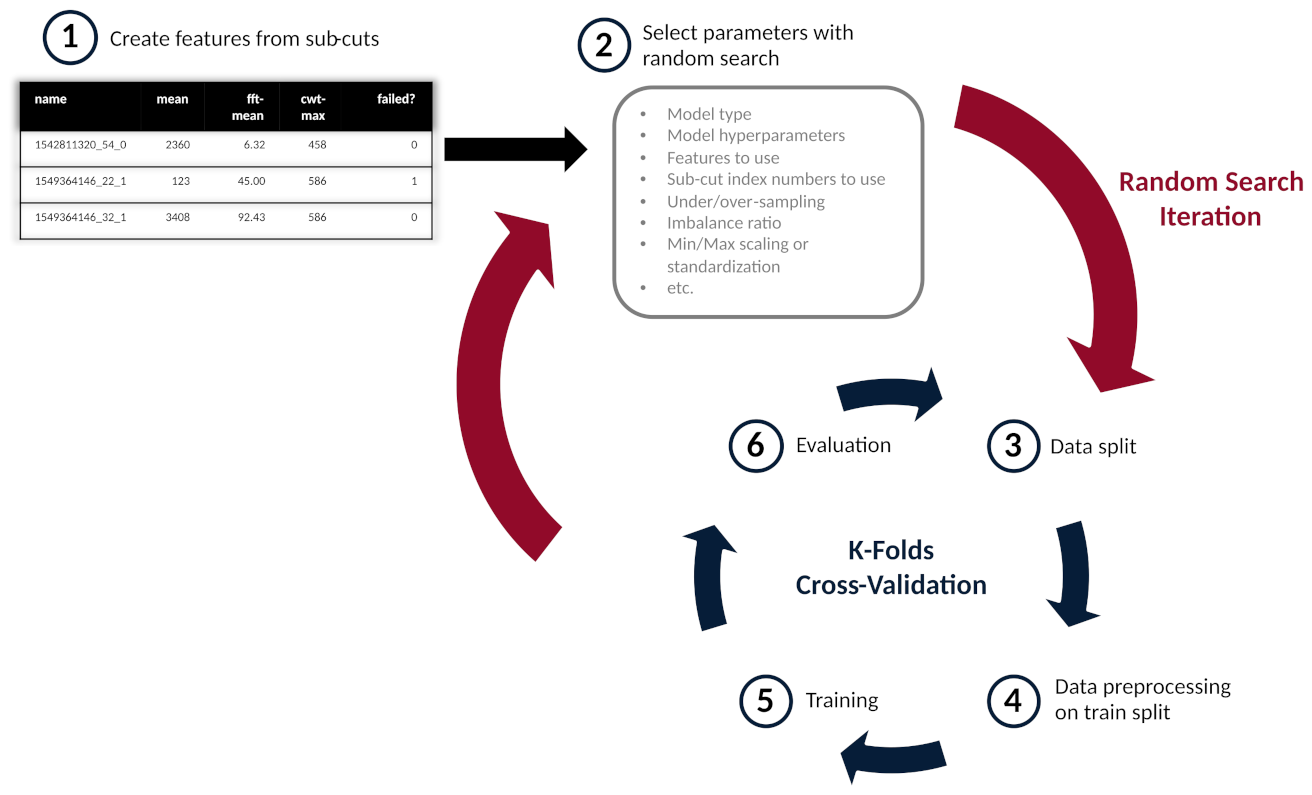
3.3. Feature Engineering
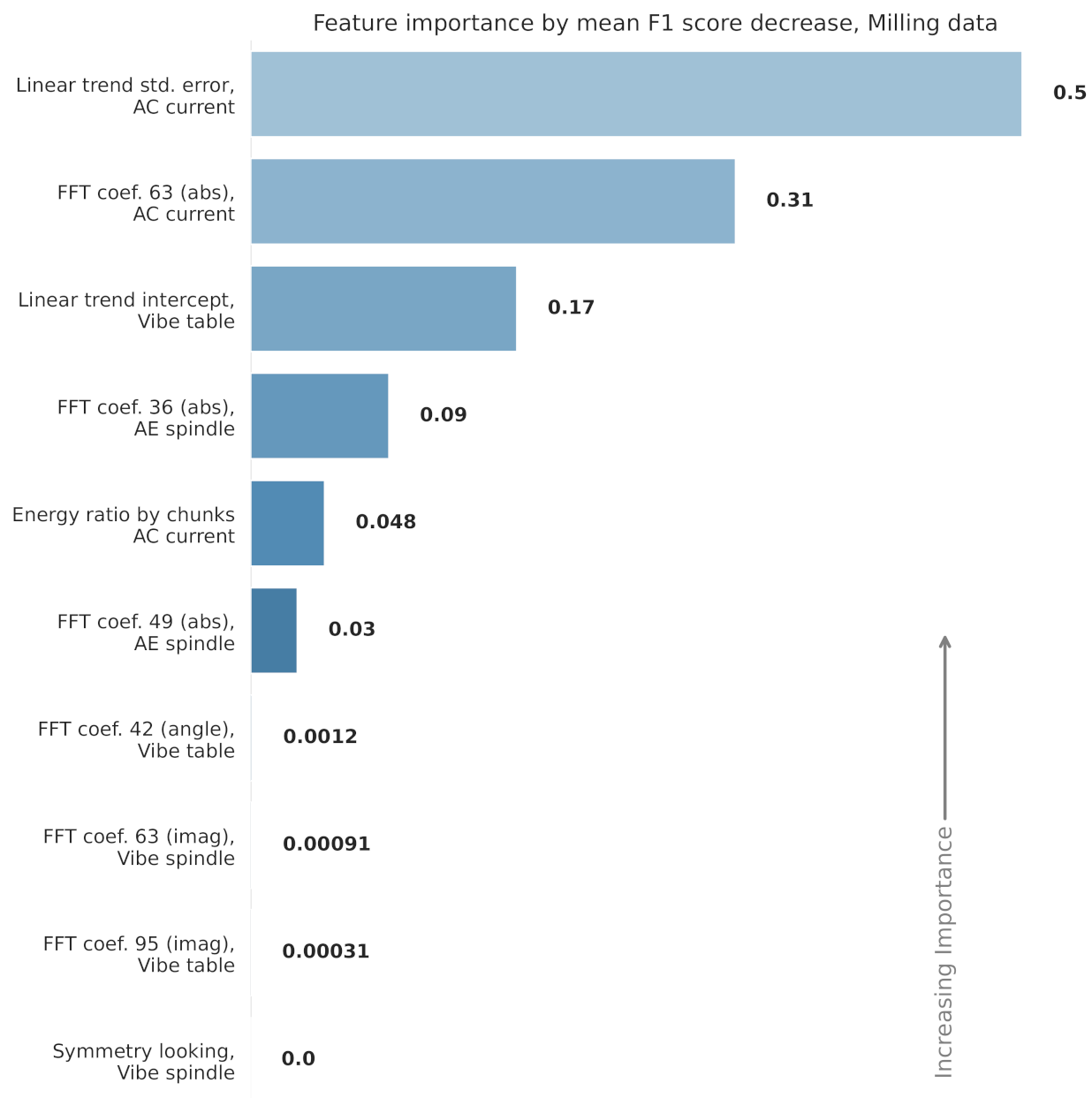
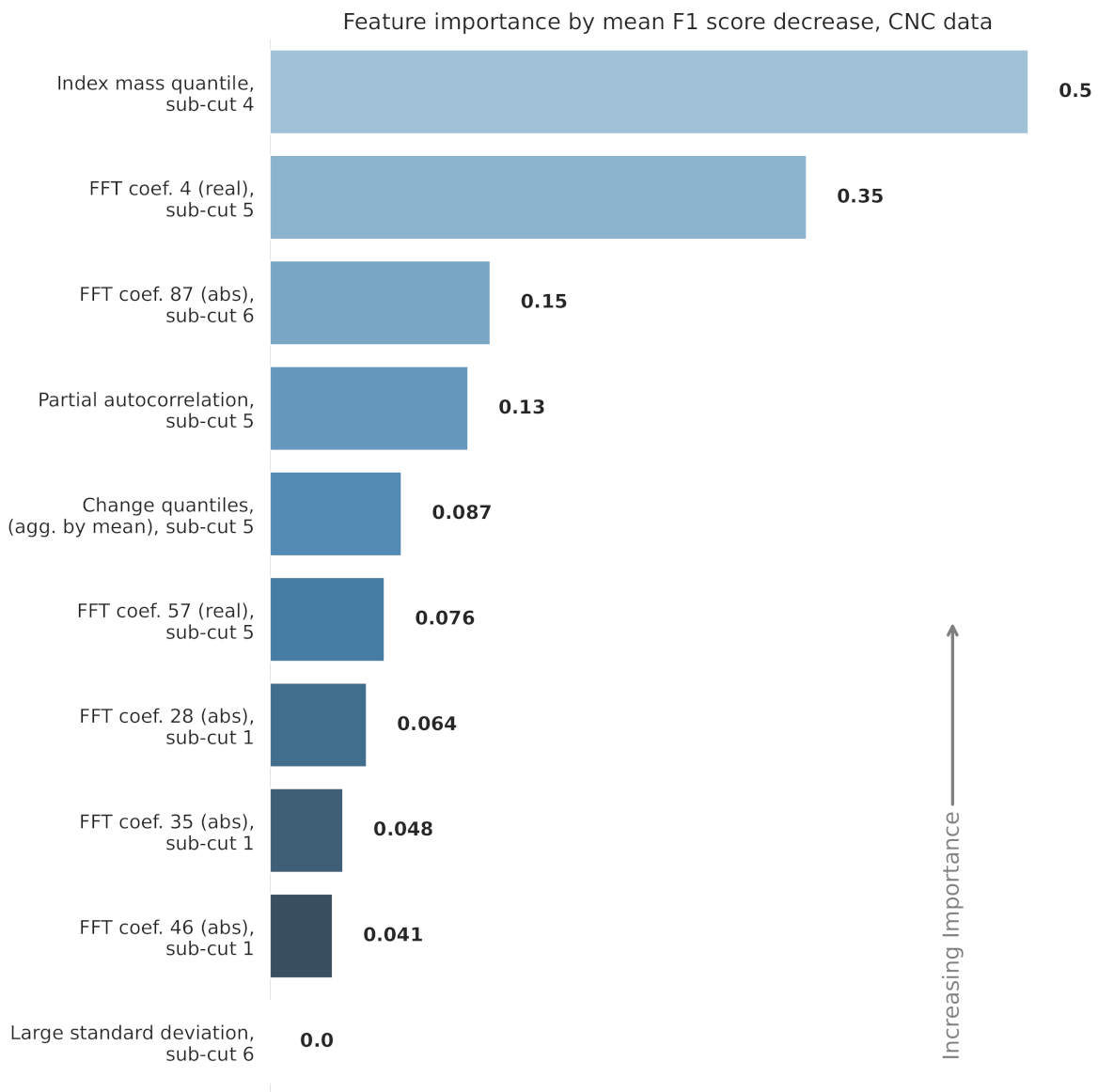
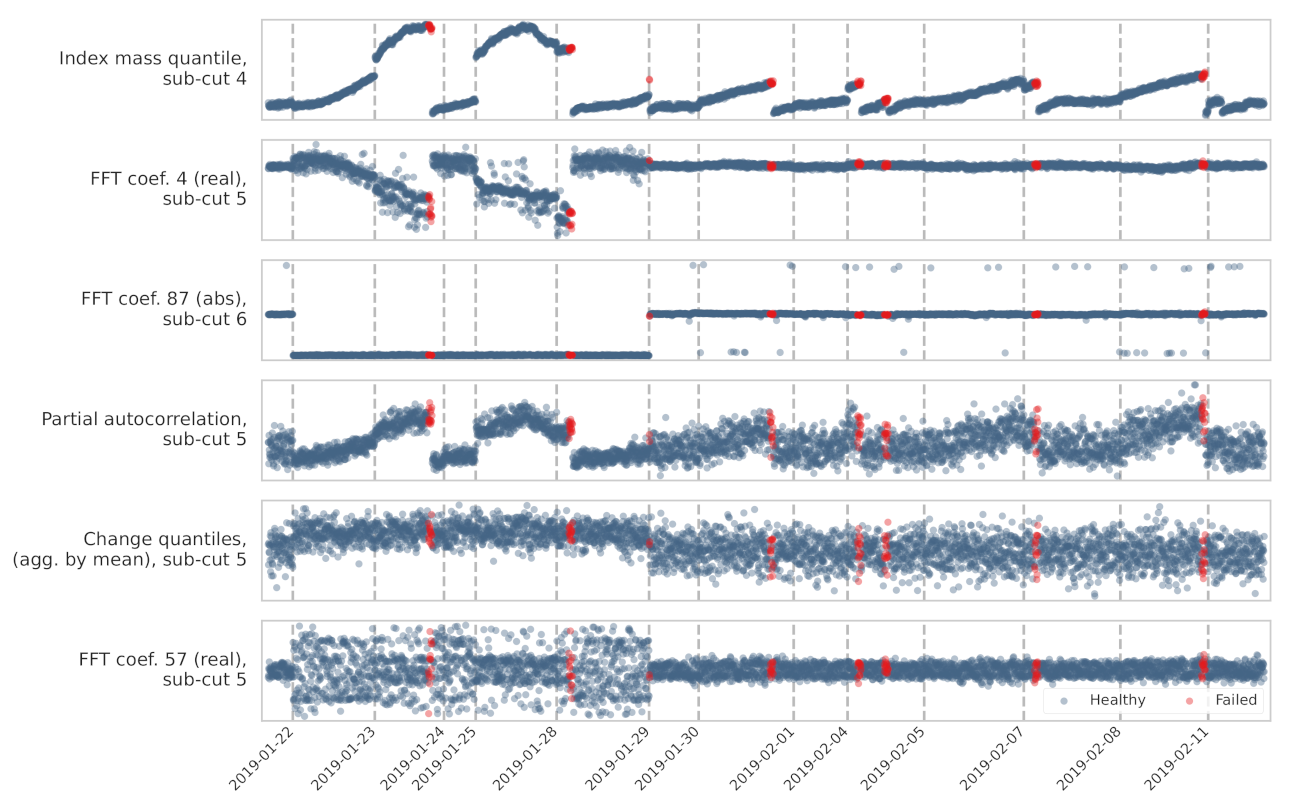
3.4. Feature Selection
3.5. Over and Under-Sampling
3.6. Machine Learning Models
4. Experiment
4.1. Random Search
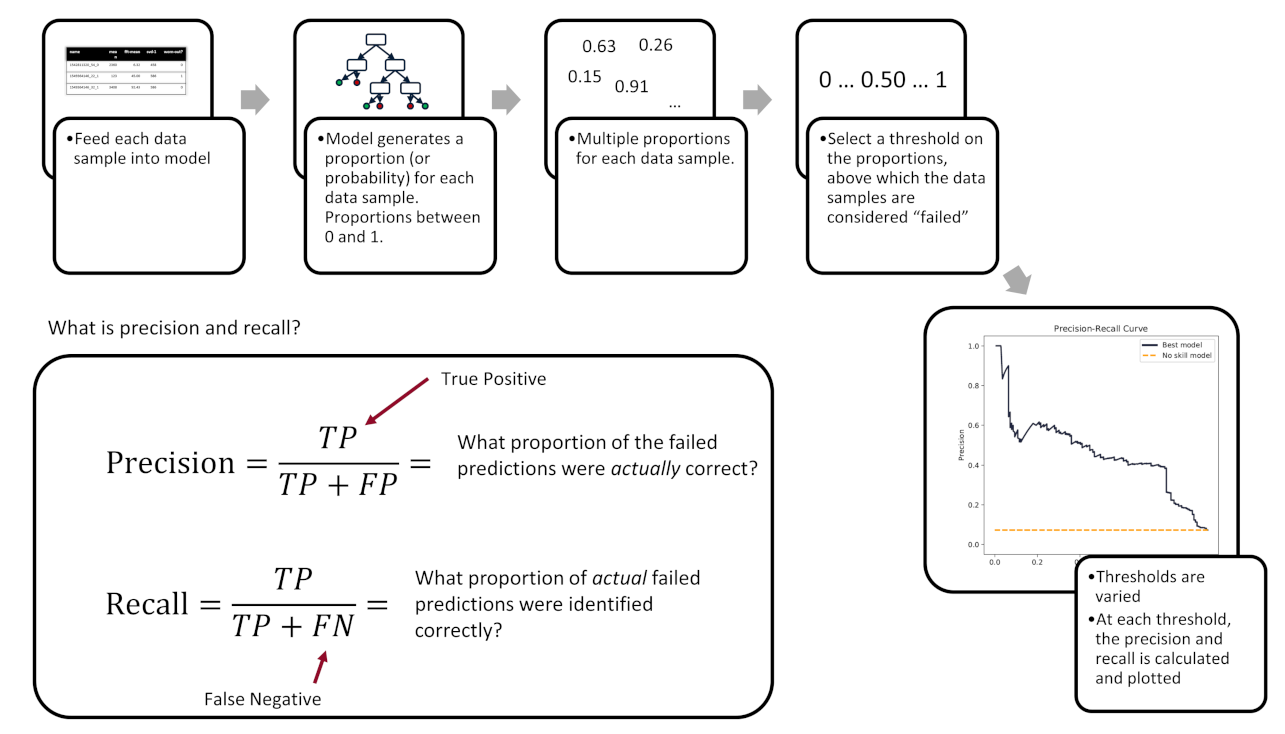
4.2. Metrics for Evaluation
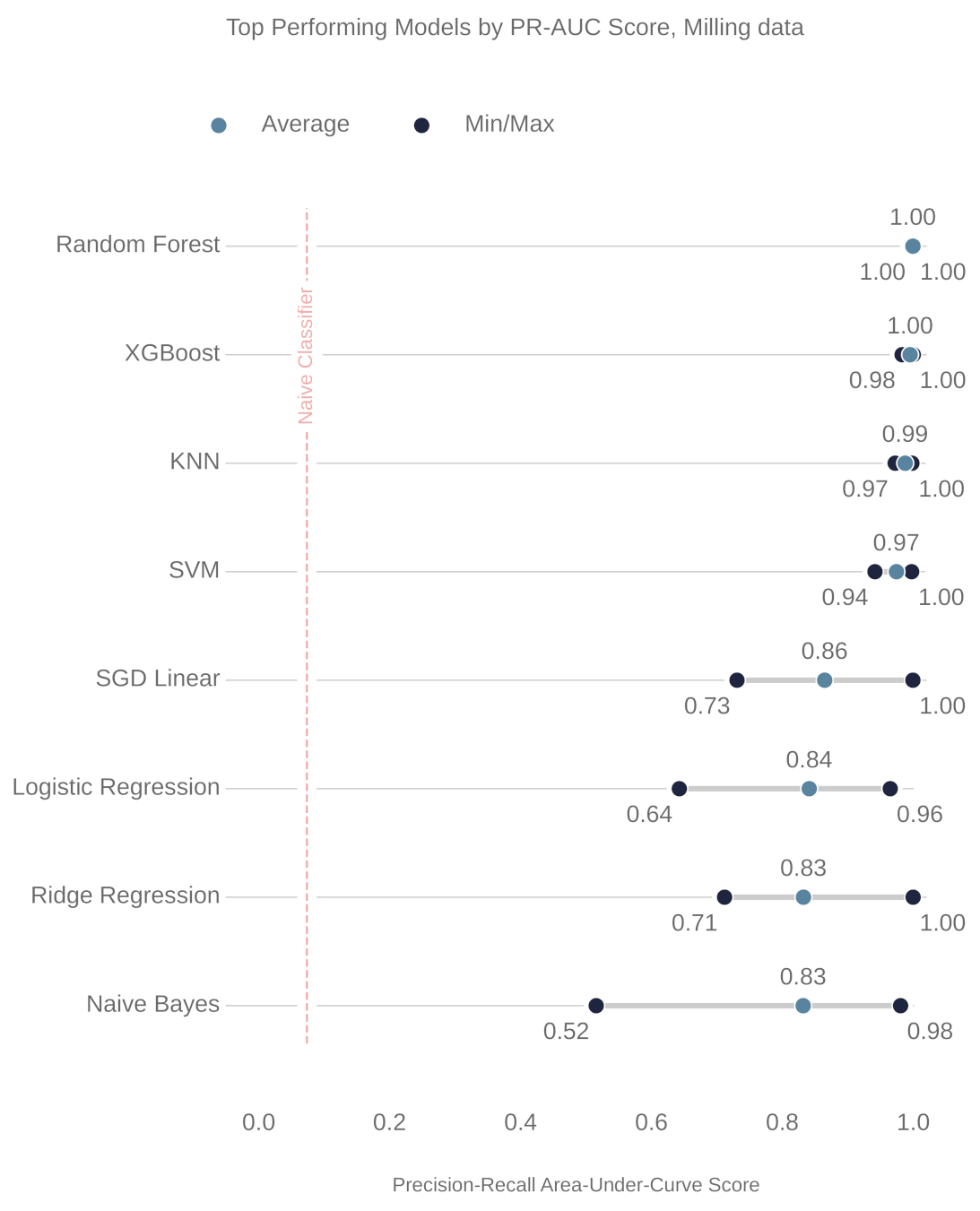
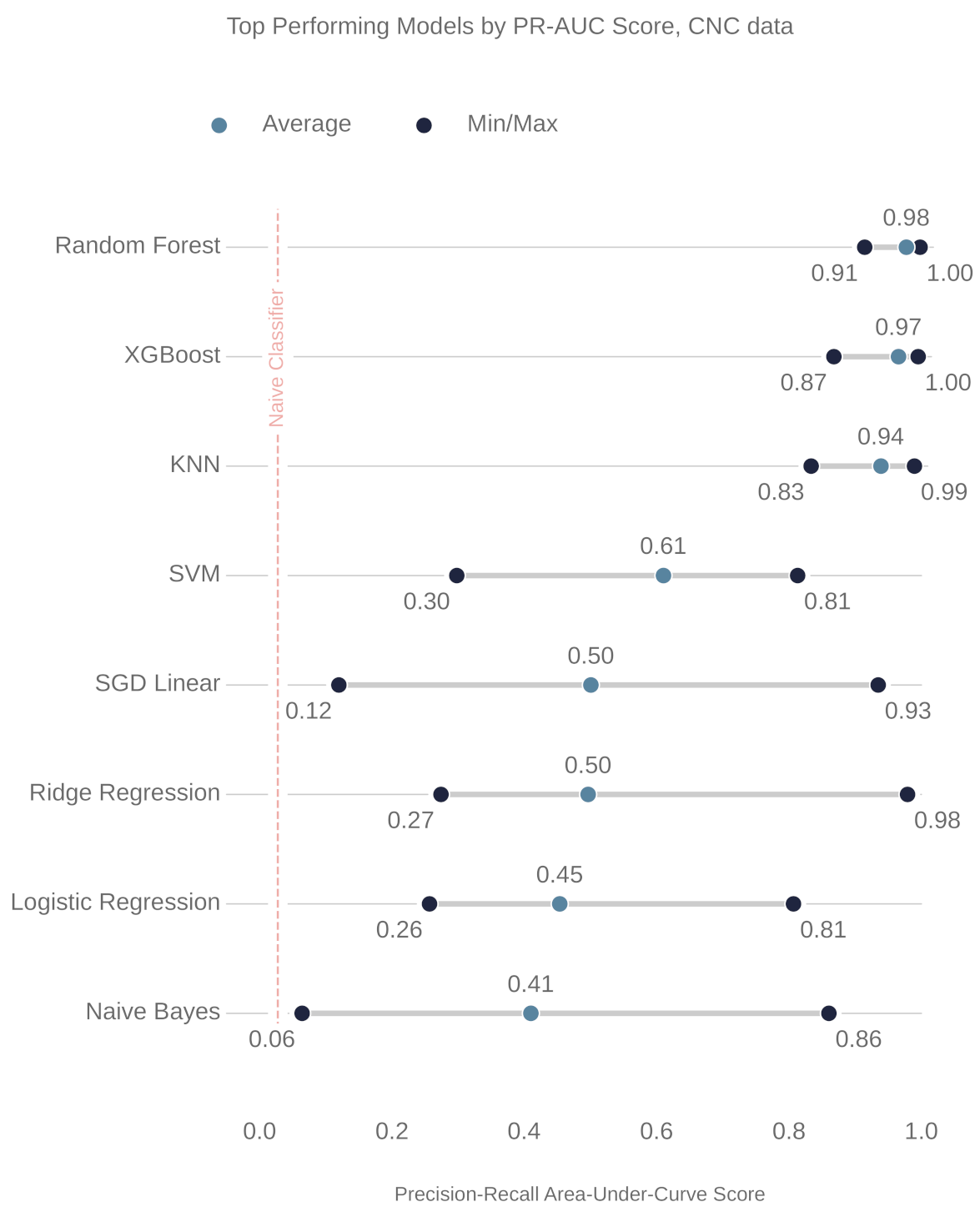
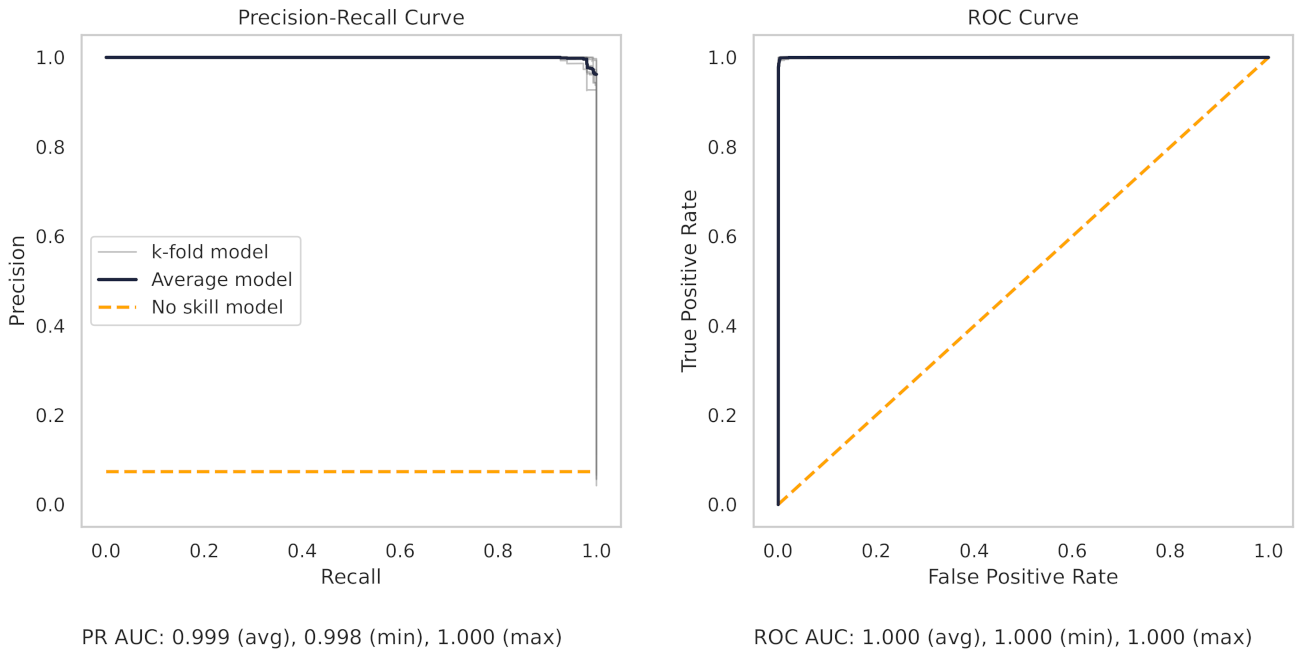
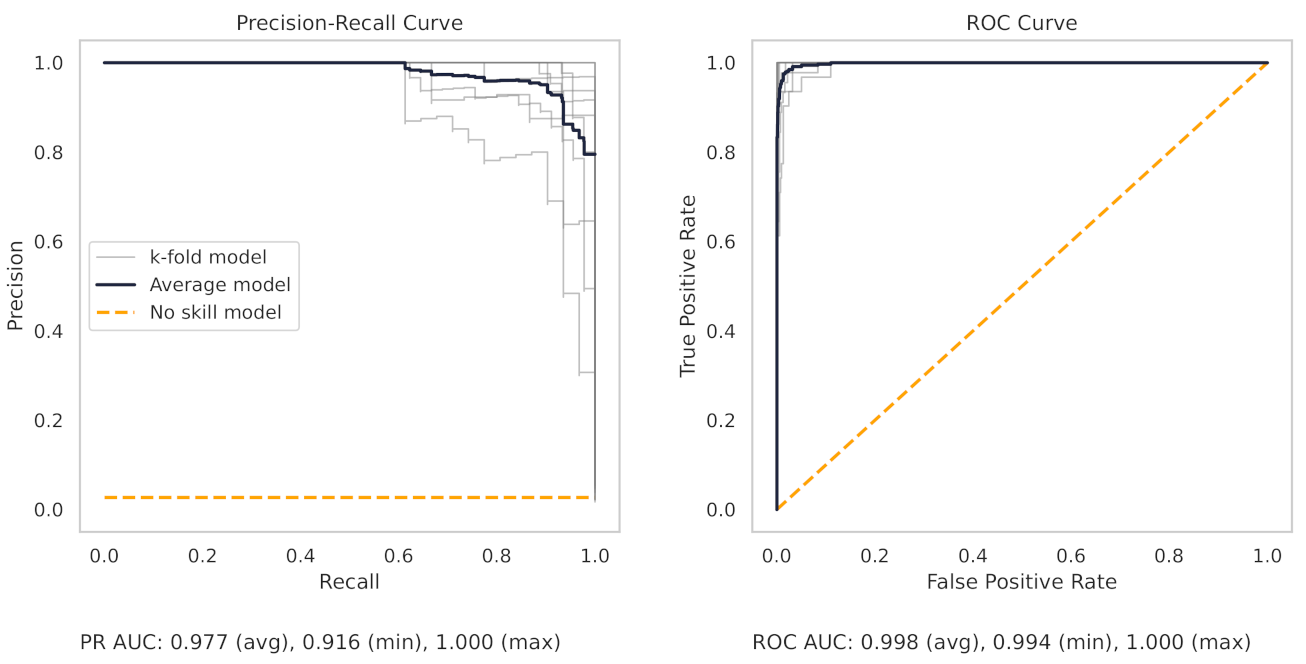
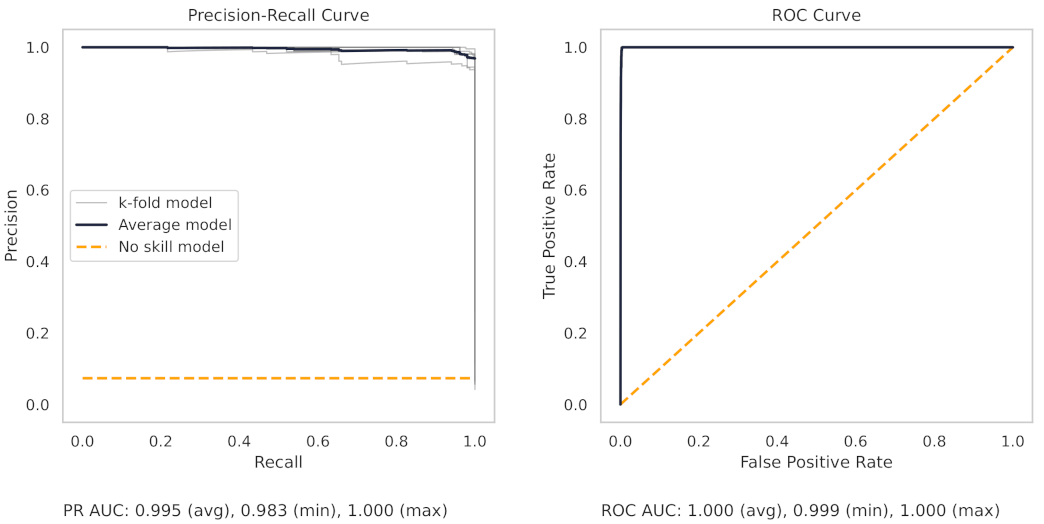
5. Results
Analysis, Shortcomings, and Recommendations
6. Discussion of Best Practices
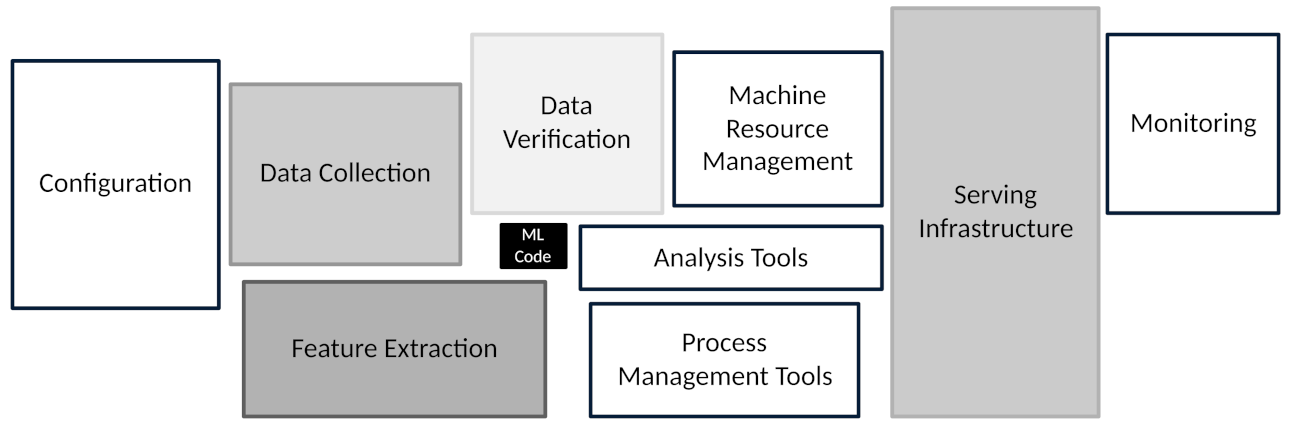
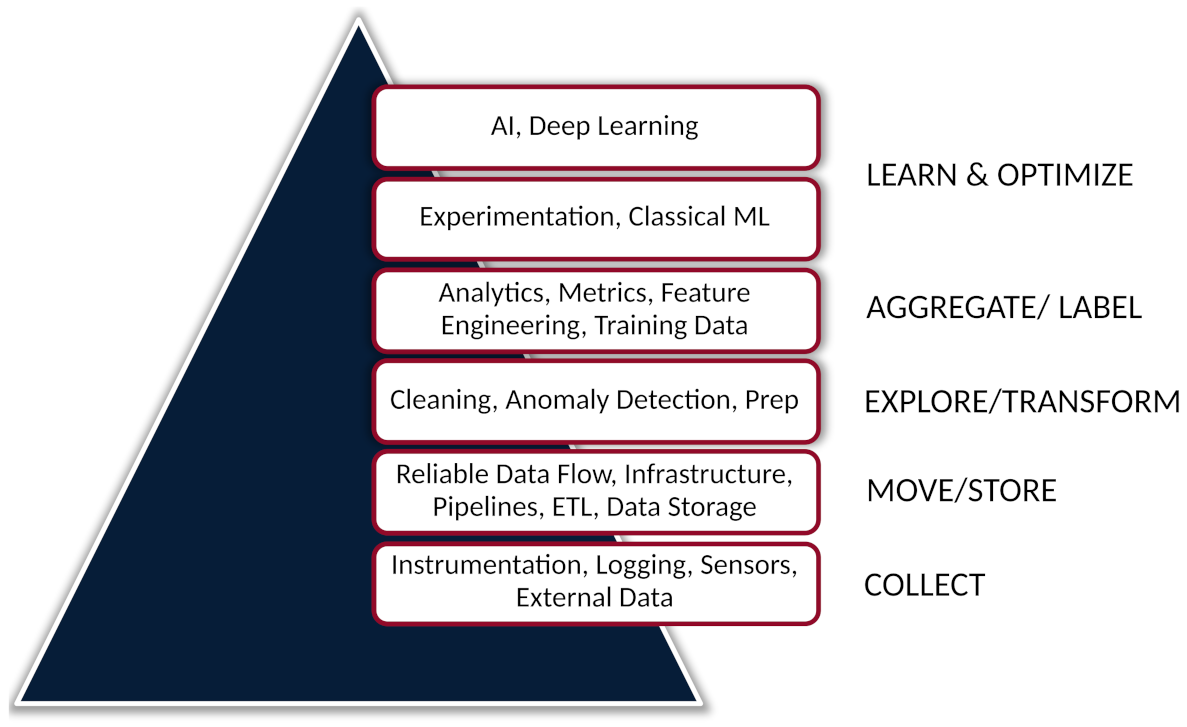
6.1. Focus on the Data Infrastructure First
6.2. Start with Simple Models
- Simple models are straightforward to implement. Modern machine learning packages, such as scikit-learn, or XGBoost, allow the implementation of classical ML models in only several lines of code.
- Simple models require less data than deep learning models.
- Simple models can produce strong results, and in many cases, outperform deep learning models.
- Simple models cost much less to train. Even a random forest model, with several terabytes of data, will only cost a few dollars to retrain on a commercial cloud provider. A large deep learning model, in contrast, may be an order of magnitude more expensive to train.
- Simple models allow for quicker iteration time. This allows users to rapidly “demonstrate [the] practical benefits” of an approach, and subsequently, avoid less-productive approaches [7].
6.3. Beware of Data Leakage
- Type 1—Preprocessing on training and test set: Preprocessing techniques, like scaling, normalization, or under-/over-sampling, must only be applied after the dataset has been split into training and testing sets. In our experiment, as noted in Section 3, these preprocessing techniques were performed after the data were split in the k-fold.
- Type 2—Feature selection on training and test set: This form of data leakage occurs when features are selected using the entire dataset at once. By performing feature selection over the entire dataset, additional information will be introduced into the testing set that should not be present. Feature selection should only occur after the train/validation/testing sets are created.
- Type 3—Temporal leakage: Temporal data leakage occurs, on time series data, when the training set includes information from a future event that is to be predicted. As an example, consider case 13 on the milling dataset. Case 13 consists of 15 cuts. Ten of these cuts are when the tool is healthy, and five of the cuts are when the tool is worn. If the cuts from the milling dataset (165 cuts in total) are randomly split into the training and testing sets, then some of the “worn” cuts from case 13 will be in both the training and testing sets. Data leakage will occur, and the results from the experiment will be too optimistic. In our actual experiments, we avoided data leakage by splitting the datasets by case, as opposed to individual cuts.
6.4. Use Open-Source Software

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Software Name | Description |
|---|---|
| scikit-learn [33] | Various classification, regression, and clustering algorithms. |
| NumPy [35] | Comprehensive mathematical software package. Supports for large multi-dimensional arrays and matrices. |
| PyTorch [55] | Popular deep learning framework. |
| TensorFlow [56] | Popular deep learning framework, originally created by Google. |
6.5. Leverage Advances in Computational Power
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Miscellaneous Tables
| Case | Depth of Cut (mm) | Feed Rate (mm/rev) | Material |
|---|---|---|---|
| 1 | 1.50 | 0.50 | cast iron |
| 2 | 0.75 | 0.50 | cast iron |
| 3 | 0.75 | 0.25 | cast iron |
| 4 | 1.50 | 0.25 | cast iron |
| 5 | 1.50 | 0.50 | steel |
| 6 | 1.50 | 0.25 | steel |
| 7 | 0.75 | 0.25 | steel |
| 8 | 0.75 | 0.50 | steel |
| 9 | 1.50 | 0.50 | cast iron |
| 10 | 1.50 | 0.25 | cast iron |
| 11 | 0.75 | 0.25 | cast iron |
| 12 | 0.75 | 0.50 | cast iron |
| 13 | 0.75 | 0.25 | steel |
| 14 | 0.75 | 0.50 | steel |
| 15 | 1.50 | 0.25 | steel |
| 16 | 1.50 | 0.50 | steel |
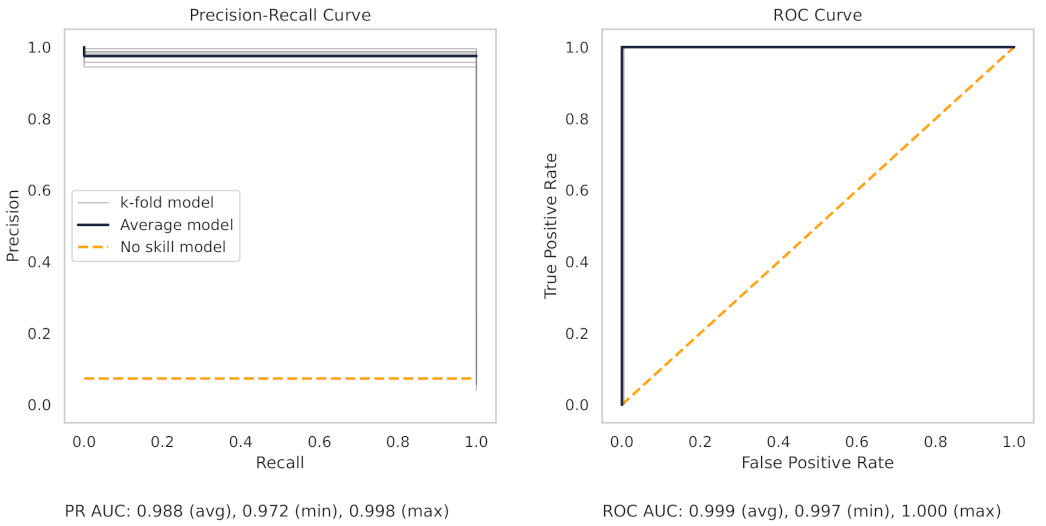
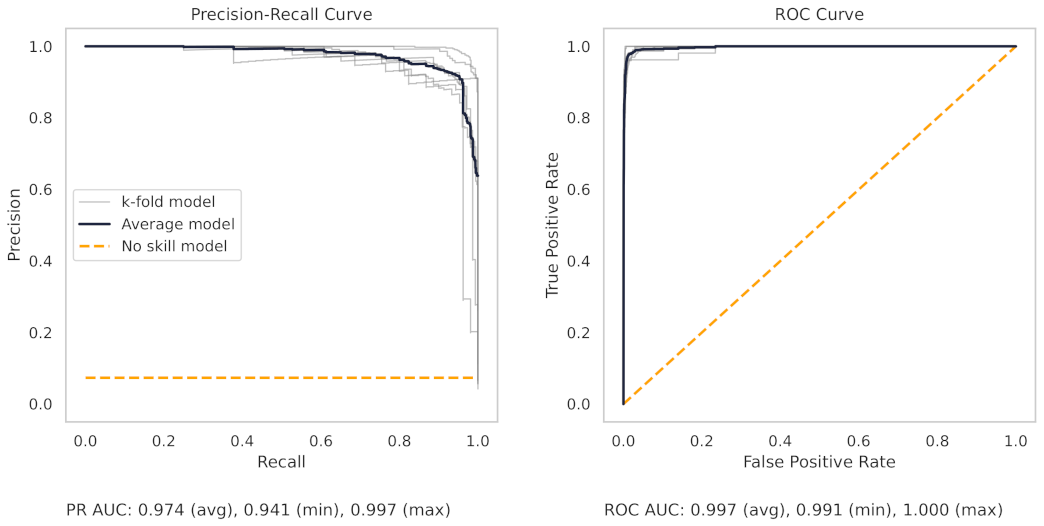
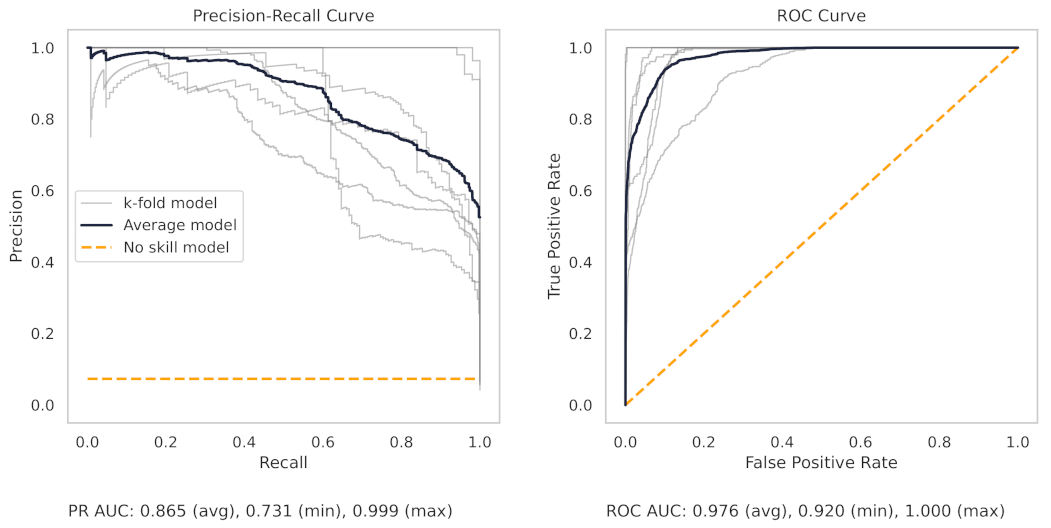
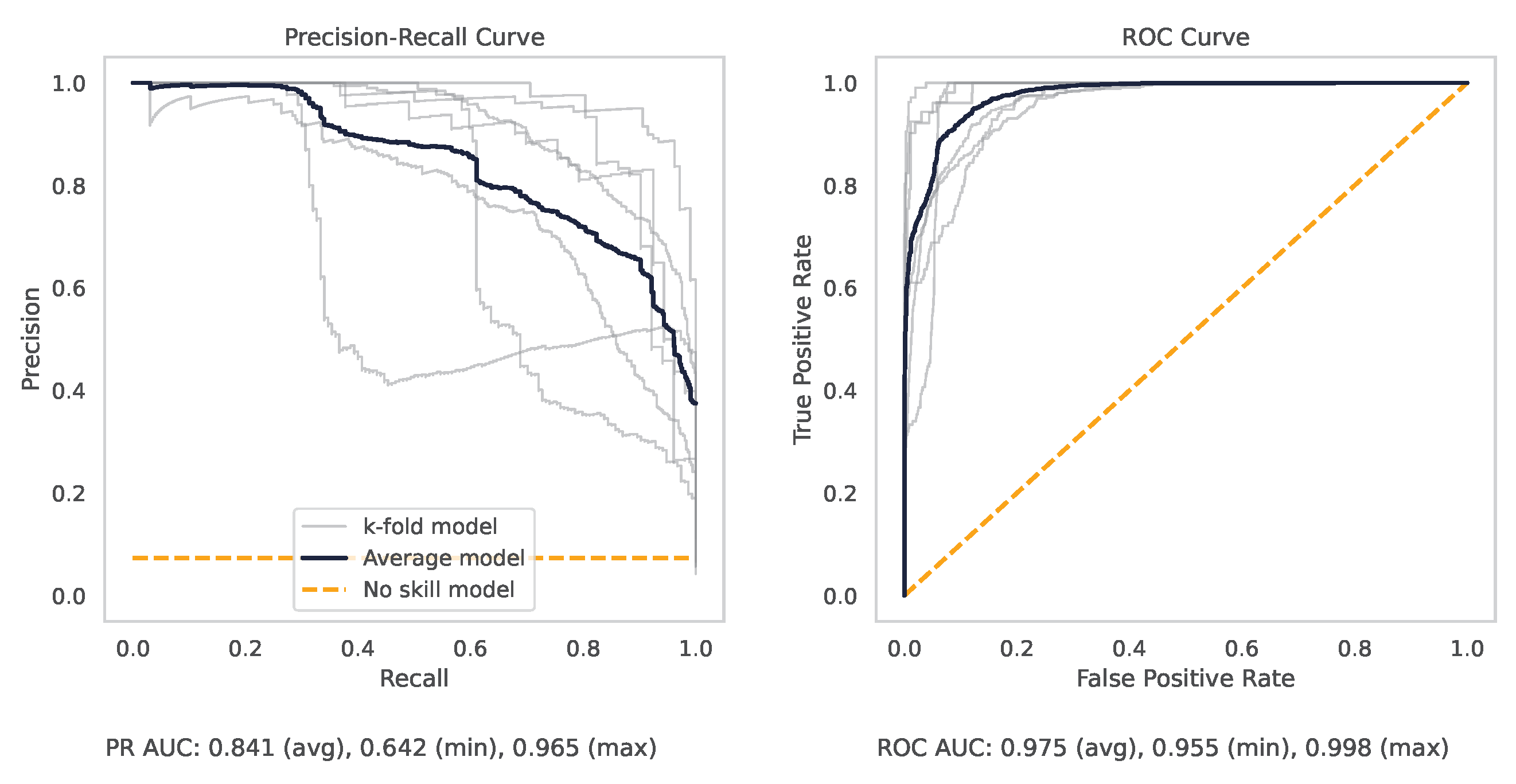
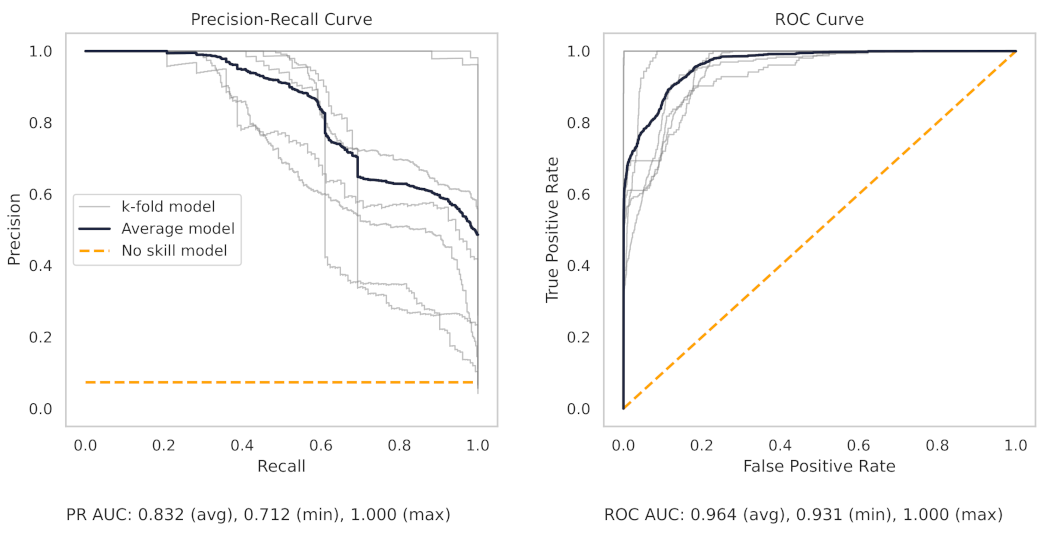
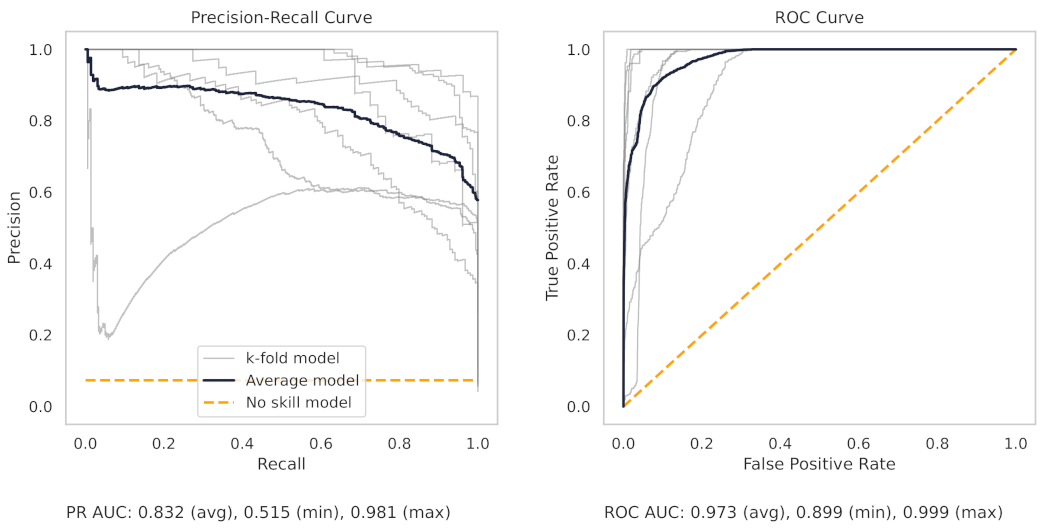
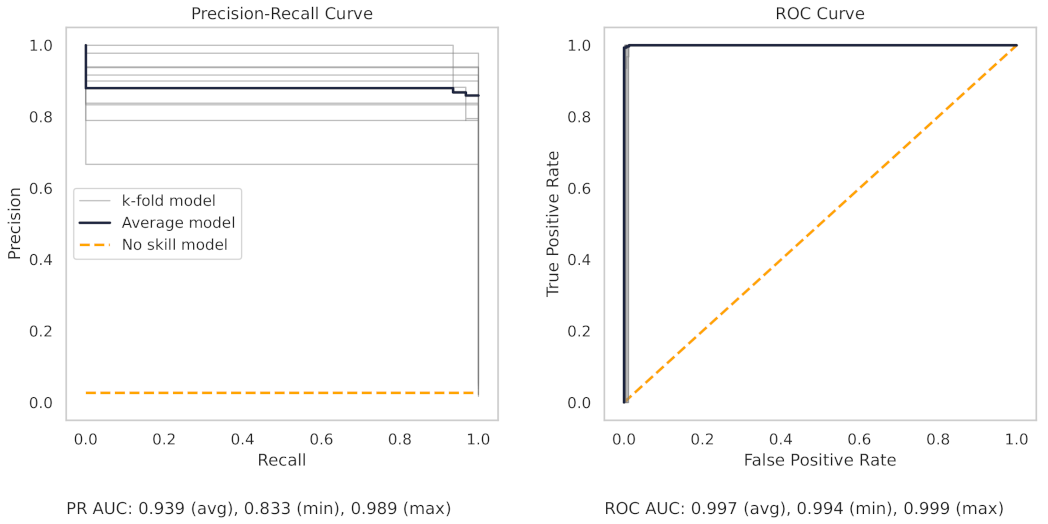
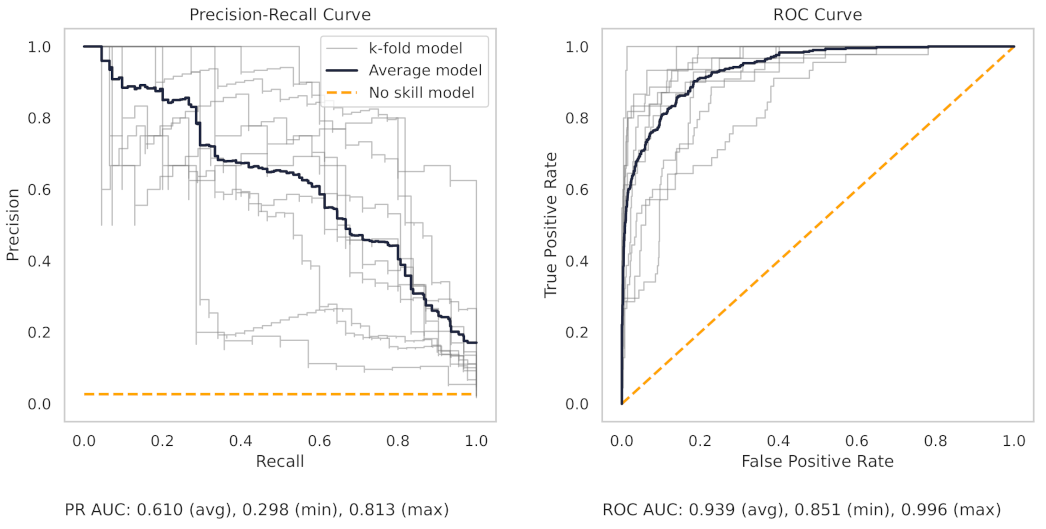
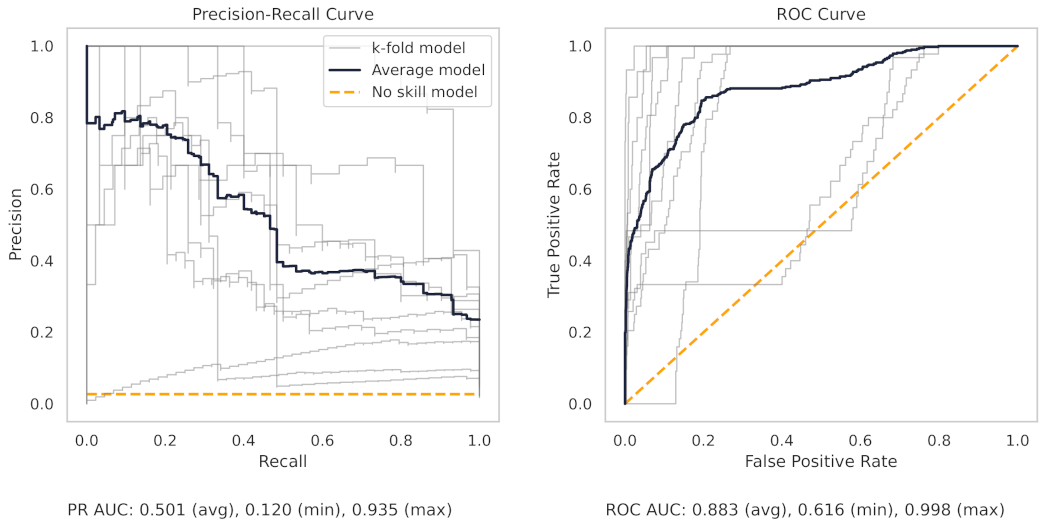
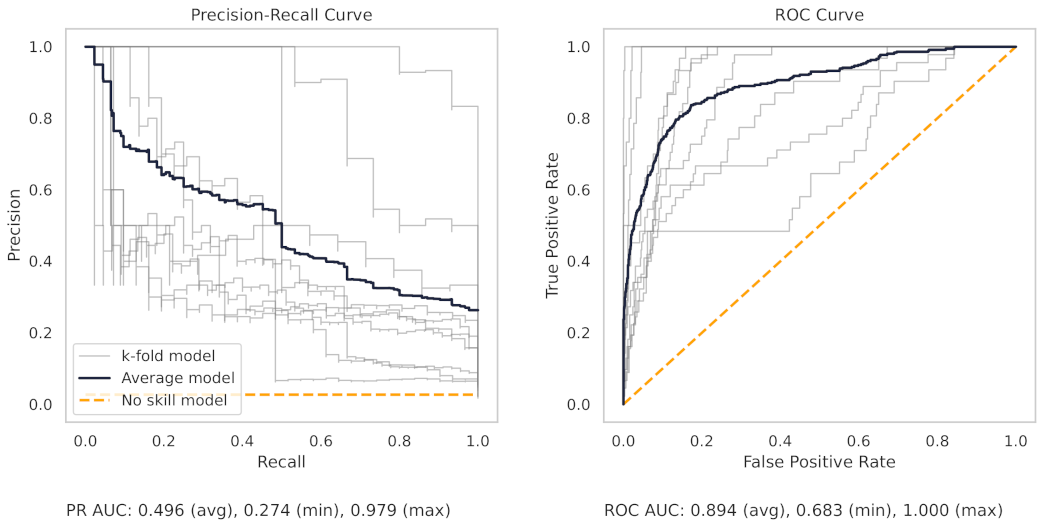
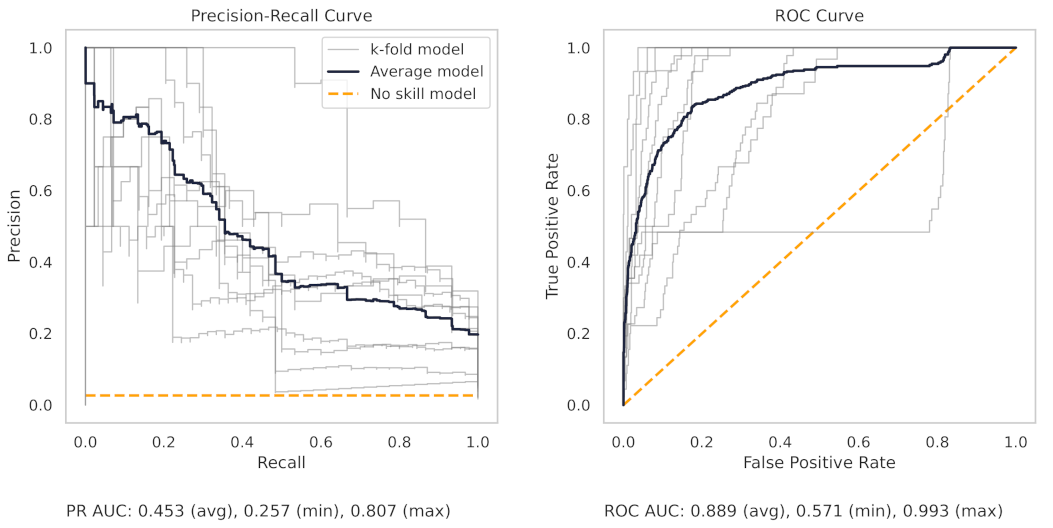
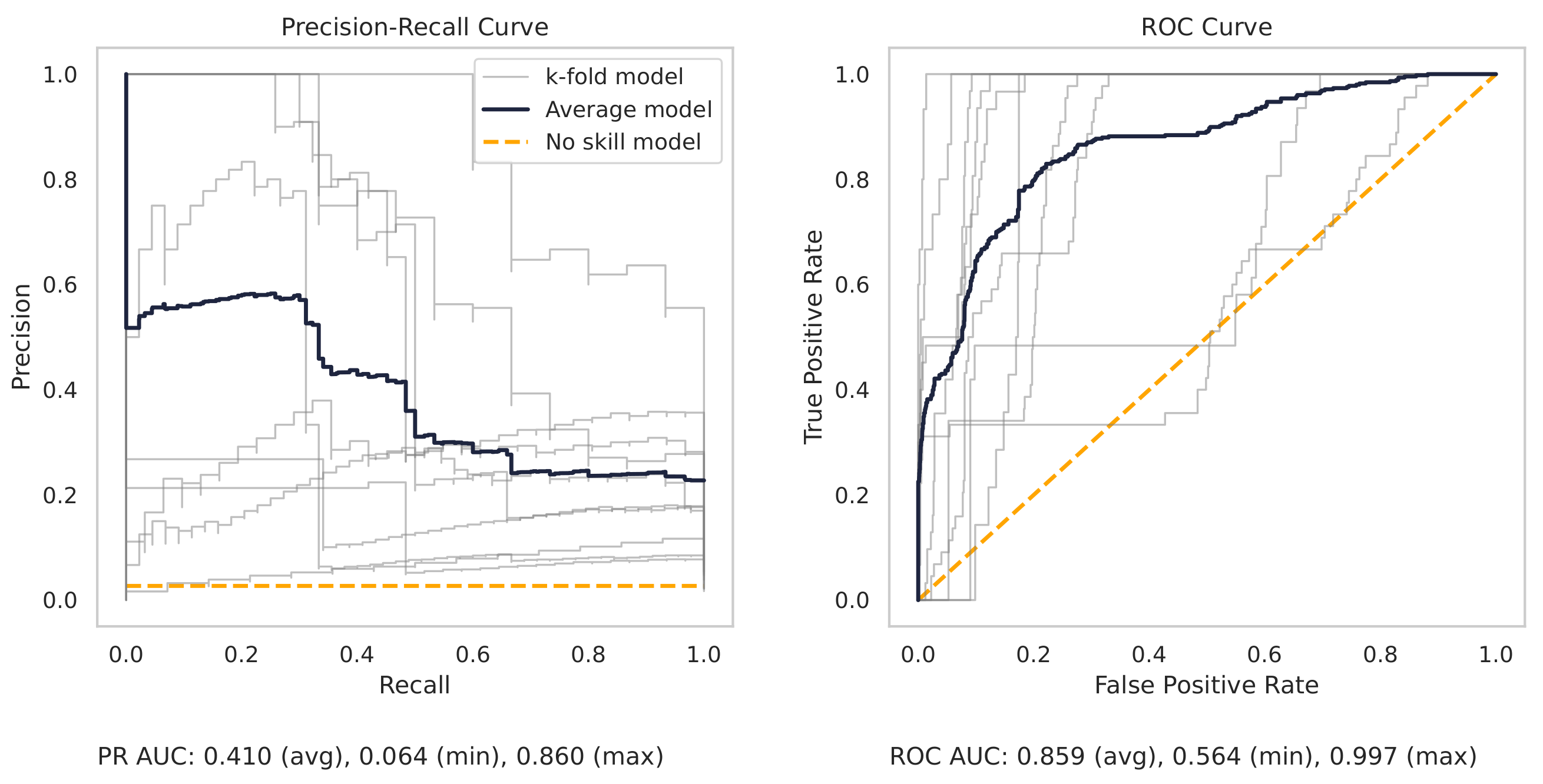
Appendix A.2. PR and ROC Curves for the Milling Dataset







Appendix A.3. PR and ROC Curves for the CNC Dataset







References
- Huyen, C. Designing Machine Learning Systems; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2022. [Google Scholar]
- Sculley, D.; Holt, G.; Golovin, D.; Davydov, E.; Phillips, T.; Ebner, D.; Chaudhary, V.; Young, M.; Crespo, J.F.; Dennison, D. Hidden technical debt in machine learning systems. In Advances in Neural Information Processing Systems. 2015. Available online: https://proceedings.neurips.cc/paper/2015/hash/86df7dcfd896fcaf2674f757a2463eba-Abstract.html (accessed on 1 July 2022).
- Zinkevich, M. Rules of Machine Learning: Best Practices for ML Engineering. 2017. Available online: https://developers.google.com/machine-learning/guides/rules-of-ml (accessed on 1 July 2022).
- Wujek, B.; Hall, P.; Günes, F. Best Practices for Machine Learning Applications; SAS Institute Inc.: Cary, NC, USA, 2016. [Google Scholar]
- Sculley, D.; Holt, G.; Golovin, D.; Davydov, E.; Phillips, T.; Ebner, D.; Chaudhary, V.; Young, M. Machine learning: The high interest credit card of technical debt. SE4ML: Software Engineering for Machine Learning (NIPS 2014 Workshop). Available online: https://research.google/pubs/pub43146/ (accessed on 1 July 2022).
- Lones, M.A. How to avoid machine learning pitfalls: A guide for academic researchers. arXiv 2021, arXiv:2108.02497. [Google Scholar]
- Shankar, S.; Garcia, R.; Hellerstein, J.M.; Parameswaran, A.G. Operationalizing Machine Learning: An Interview Study. arXiv 2022, arXiv:2209.09125. [Google Scholar]
- Zhao, Y.; Belloum, A.S.; Zhao, Z. MLOps Scaling Machine Learning Lifecycle in an Industrial Setting. Int. J. Ind. Manuf. Eng. 2022, 16, 143–153. [Google Scholar]
- Albino, G.S. Development of a Devops Infrastructure to Enhance the Deployment of Machine Learning Applications for Manufacturing. 2022. Available online: https://repositorio.ufsc.br/handle/123456789/232077 (accessed on 1 July 2022).
- Williams, D.; Tang, H. Data quality management for industry 4.0: A survey. Softw. Qual. Prof. 2020, 22, 26–35. [Google Scholar]
- Luckow, A.; Kennedy, K.; Ziolkowski, M.; Djerekarov, E.; Cook, M.; Duffy, E.; Schleiss, M.; Vorster, B.; Weill, E.; Kulshrestha, A.; et al. Artificial intelligence and deep learning applications for automotive manufacturing. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 3144–3152. [Google Scholar]
- Dilda, V.; Mori, L.; Noterdaeme, O.; Schmitz, C. Manufacturing: Analytics Unleashes Productivity and Profitability; Report; McKinsey & Company: Atlanta, GA, USA, 2017. [Google Scholar]
- Philbeck, T.; Davis, N. The fourth industrial revolution. J. Int. Aff. 2018, 72, 17–22. [Google Scholar]
- Agogino, A.; Goebel, K. Milling Data Set. NASA Ames Prognostics Data Repository; NASA Ames Research Center: Moffett Field, CA, USA, 2007. [Google Scholar]
- Bhushan, B. Modern Tribology Handbook, Two Volume Set; CRC Press: Boca Raton, FL, USA, 2000. [Google Scholar]
- Samaga, B.R.; Vittal, K. Comprehensive study of mixed eccentricity fault diagnosis in induction motors using signature analysis. Int. J. Electr. Power Energy Syst. 2012, 35, 180–185. [Google Scholar] [CrossRef]
- Akbari, A.; Danesh, M.; Khalili, K. A method based on spindle motor current harmonic distortion measurements for tool wear monitoring. J. Braz. Soc. Mech. Sci. Eng. 2017, 39, 5049–5055. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhu, H.; Hu, K.; Wu, J.; Shao, X.; Wang, Y. Multisensory data-driven health degradation monitoring of machining tools by generalized multiclass support vector machine. IEEE Access 2019, 7, 47102–47113. [Google Scholar] [CrossRef]
- von Hahn, T.; Mechefske, C.K. Computational Reproducibility Within Prognostics and Health Management. arXiv 2022, arXiv:2205.15489. [Google Scholar]
- Christ, M.; Braun, N.; Neuffer, J.; Kempa-Liehr, A.W. Time series feature extraction on basis of scalable hypothesis tests (tsfresh—A python package). Neurocomputing 2018, 307, 72–77. [Google Scholar] [CrossRef]
- He, X.; Zhao, K.; Chu, X. AutoML: A survey of the state-of-the-art. Knowl.-Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- Unterberg, M.; Voigts, H.; Weiser, I.F.; Feuerhack, A.; Trauth, D.; Bergs, T. Wear monitoring in fine blanking processes using feature based analysis of acoustic emission signals. Procedia CIRP 2021, 104, 164–169. [Google Scholar] [CrossRef]
- Sendlbeck, S.; Fimpel, A.; Siewerin, B.; Otto, M.; Stahl, K. Condition monitoring of slow-speed gear wear using a transmission error-based approach with automated feature selection. Int. J. Progn. Health Manag. 2021, 12. [Google Scholar] [CrossRef]
- Gurav, S.; Kumar, P.; Ramshankar, G.; Mohapatra, P.K.; Srinivasan, B. Machine learning approach for blockage detection and localization using pressure transients. In Proceedings of the 2020 IEEE International Conference on Computing, Power and Communication Technologies (GUCON), Greater Noida, India, 2–4 October 2020; pp. 189–193. [Google Scholar]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 1–5. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Batista, G.E.; Bazzan, A.L.; Monard, M.C. Balancing Training Data for Automated Annotation of Keywords: A Case Study. In Proceedings of the WOB, Macae, Brazil, 3–5 December 2003; pp. 10–18. [Google Scholar]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- Last, F.; Douzas, G.; Bacao, F. Oversampling for imbalanced learning based on k-means and smote. arXiv 2017, arXiv:1711.00837. [Google Scholar]
- Nguyen, H.M.; Cooper, E.W.; Kamei, K. Borderline over-sampling for imbalanced data classification. In Proceedings of the Fifth International Workshop on Computational Intelligence & Applications, Hiroshima, Japan, 10–12 November 2009; Volume 2009, pp. 24–29. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; van der Walt, S., Millman, J., Eds.; pp. 56–61. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on MACHINE Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [PubMed]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Wang, W.; Taylor, J.; Rees, R.J. Recent Advancement of Deep Learning Applications to Machine Condition Monitoring Part 1: A Critical Review. Acoust. Aust. 2021, 49, 207–219. [Google Scholar] [CrossRef]
- Cawley, G.C.; Talbot, N.L. On over-fitting in model selection and subsequent selection bias in performance evaluation. J. Mach. Learn. Res. 2010, 11, 2079–2107. [Google Scholar]
- Rogati, M. The AI hierarchy of needs. Hacker Noon, 13 June 2017. Available online: www.aipyramid.com (accessed on 9 September 2022).
- Ng, A. A Chat with Andrew on MLOps: From Model-Centric to Data-centric AI. 2021. Available online: https://www.youtube.com/watch?v=06-AZXmwHjo (accessed on 1 July 2022).
- Hand, D.J. Classifier technology and the illusion of progress. Stat. Sci. 2006, 21, 1–14. [Google Scholar] [CrossRef]
- Grinsztajn, L.; Oyallon, E.; Varoquaux, G. Why do tree-based models still outperform deep learning on tabular data? arXiv 2022, arXiv:2207.08815. [Google Scholar]
- Shwartz-Ziv, R.; Armon, A. Tabular data: Deep learning is not all you need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Kaufman, S.; Rosset, S.; Perlich, C.; Stitelman, O. Leakage in data mining: Formulation, detection, and avoidance. ACM Trans. Knowl. Discov. Data (TKDD) 2012, 6, 1–21. [Google Scholar] [CrossRef]
- Kapoor, S.; Narayanan, A. Leakage and the Reproducibility Crisis in ML-based Science. arXiv 2022, arXiv:2207.07048. [Google Scholar]
- Feller, J.; Fitzgerald, B. Understanding Open Source Software Development; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2002. [Google Scholar]
- Stack Overflow Developer Survey 2022. 2022. Available online: https://survey.stackoverflow.co/2022/ (accessed on 1 July 2022).
- Raschka, S.; Patterson, J.; Nolet, C. Machine learning in python: Main developments and technology trends in data science, machine learning, and artificial intelligence. Information 2020, 11, 193. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Sydney, Australia, 2019; pp. 8024–8035. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Sutton, R. The bitter lesson. Incomplete Ideas (blog) 2019, 13, 12. Available online: http://www.incompleteideas.net/IncIdeas/BitterLesson.html (accessed on 1 July 2022).















| Title | Author | Domain |
|---|---|---|
| Designing Machine Learning Systems: An Iterative Process for Production-Ready Applications [1] | Huyen | General ML |
| Hidden technical debt in machine learning systems [2] | Sculley et al. | General ML |
| Rules of Machine Learning: Best Practices for ML Engineering [3] | Zinkevich | General ML |
| Best practices for machine learning applications [4] | Wujek et al. | General ML |
| Machine Learning: The High-Interest Credit Card of Technical Debt [5] | Sculley et al. | General ML |
| How to avoid machine learning pitfalls: a guide for academic researchers [6] | Lones | General ML |
| Operationalizing Machine Learning: An Interview Study [7] | Shankar et al. | General ML |
| MLOps Scaling Machine Learning Lifecycle in an Industrial Setting [8] | Zhao et al. | Manufacturing & ML |
| Development of a devops infrastructure to enhance the deployment of machine learning applications for manufacturing [9] | Albino et al. | Manufacturing & ML |
| Data Quality Management for Industry 4.0: A Survey [10] | Williams and Tang | Manufacturing & ML |
| Artificial Intelligence and Deep Learning Applications for Automotive Manufacturing [11] | Luckow et al. | Manufacturing & ML |
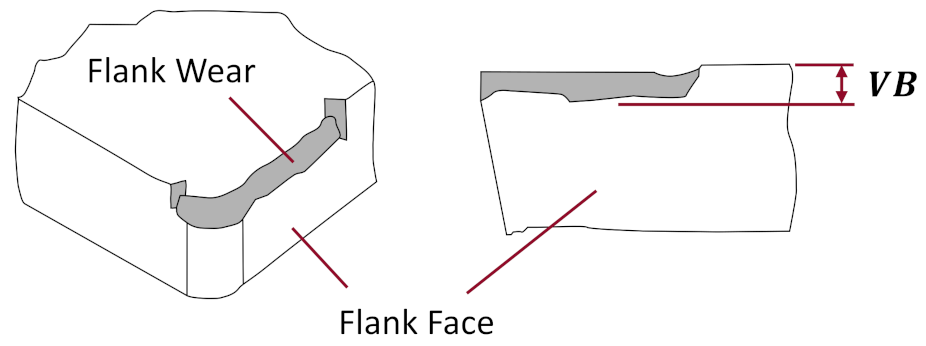
| State | Label | Flank Wear (mm) | Number of Sub-Cuts | Percentage of Sub-Cuts |
|---|---|---|---|---|
| Healthy | 0 | 0∼0.2 | 3311 | 36.63% |
| Degraded | 1 | 0.2∼0.7 | 5065 | 56.03% |
| Failed (worn) | 2 | >0.7 | 664 | 7.35% |
| State | Label | Number of Cuts | Percentage of Cuts | Number of Sub-Cuts |
|---|---|---|---|---|
| Healthy | 0 | 5352 | 97.26% | 42,504 |
| Failed (worn) | 1 | 152 | 7.35% | 1175 |
| Feature Name | Description |
|---|---|
| Basic Statistical Features | Simple statistical features. Examples: mean, root-mean-square, kurtosis |
| FFT Coefficients | Real and imaginary coefficients from the discrete fast Fourier transform (FFT) |
| Continuous Wavelet Transform | Coefficients of the continuous wavelet transform for the Ricker wavelet. |
| Method Name | Type | Description |
|---|---|---|
| Random Over-sampling | Over-sampling | Samples from minority class are randomly duplicated. |
| Random Under-sampling | Under-sampling | Samples from majority class are randomly removed. |
| SMOTE (Synthetic Minority Over-sampling Technique) [26] | Over-sampling | Synthetic samples are created from the minority class. The samples are created by interpolation between close data points. |
| ADASYN (Adaptive Synthetic sampling approach for imbalanced learning) [27] | Over-sampling | Similar to SMOTE. Number of samples generated are proportional to data distribution. |
| SMOTE-ENN [28] | Over and Under-sampling | SMOTE is performed for over-sampling. Majority class data points are then removed if n of their neighbours are from the minority class. |
| SMOTE-TOMEK [29] | Over and Under-sampling | SMOTE is performed for over-sampling. When two data points, from differing classes, are nearest to each other, these are a TOMEK-link. TOMEK link data points are removed for undersampling. |
| Borderline-SMOTE [30] | Over-sampling | Like SMOTE, but only samples near class boundary are over-sampled. |
| K-Means SMOTE [31] | Over-sampling | Clusters of minority samples are identified with K-means. SMOTE is then used for over-sampling on identified clusters. |
| SVM SMOTE [32] | Over-sampling | Class boundary is determined through SVM algorithm. New samples are generated by SMOTE along boundary. |
| Parameter | Values |
|---|---|
| No. features used | 10 |
| Scaling method | min/max scaler |
| Over-sampling method | SMOTE-TOMEK |
| Over-sampling ratio | 0.95 |
| Under-sampling method | None |
| Under-sampling ratio | N/A |
| RF bootstrap | True |
| RF classifier weight | None |
| RF criterion | entropy |
| RF max depth | 142 |
| RF min samples per leaf | 12 |
| RF min samples split | 65 |
| RF no. estimators | 199 |
| Parameter | Values |
|---|---|
| No. features used | 10 |
| Scaling method | standard scaler |
| Over-sampling method | SMOTE-TOMEK |
| Over-sampling ratio | 0.8 |
| Under-sampling method | None |
| Under-sampling ratio | N/A |
| RF bootstrap | True |
| RF classifier weight | balanced |
| RF criterion | entropy |
| RF max depth | 342 |
| RF min samples per leaf | 4 |
| RF min samples split | 5 |
| RF no. estimators | 235 |
| Parameter | Milling Dataset | CNC Dataset |
|---|---|---|
| True Positive Rate (sensitivity) | 97.3% | 90.3% |
| True Negative Rate (specificity) | 99.9% | 98.7% |
| False Negative Rate (miss rate) | 2.6% | 9.7% |
| False Positive Rate (fall out) | 0.1% | 1.3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
von Hahn, T.; Mechefske, C.K. Machine Learning in CNC Machining: Best Practices. Machines 2022, 10, 1233. https://doi.org/10.3390/machines10121233
von Hahn T, Mechefske CK. Machine Learning in CNC Machining: Best Practices. Machines. 2022; 10(12):1233. https://doi.org/10.3390/machines10121233
Chicago/Turabian Stylevon Hahn, Tim, and Chris K. Mechefske. 2022. "Machine Learning in CNC Machining: Best Practices" Machines 10, no. 12: 1233. https://doi.org/10.3390/machines10121233
APA Stylevon Hahn, T., & Mechefske, C. K. (2022). Machine Learning in CNC Machining: Best Practices. Machines, 10(12), 1233. https://doi.org/10.3390/machines10121233