
A Novel Combination Neural Network Based on ConvLSTM-Transformer for Bearing Remaining Useful Life Prediction



Abstract
1. Introduction
- (1)
- The ConvLSTM network is not a simple serial combination of CNN and LSTM. It can achieve a deep integration of CNN and LSTM by the embedded convolutional operation in the state transitions of LSTM and hence can capture spatiotemporal correlation features from the long-time degradation signal of mechanical equipment.
- (2)
- The ConvLSTM can directly extract the feature information reflecting the equipment degradation from the raw data without any complex signal processing techniques and prior knowledge. The transformation of high-dimensional raw data to low-dimensional features is realized through the stacking of the deep ConvLSTM network. It effectively reduces the data dimension of the raw data and ensures the efficient operation of the Transformer.
- (3)
- The Transformer network is constructed to perform RUL prediction analysis on the extracted spatiotemporal features and deeply explores the mapping law between deep-level nonlinear feature information and equipment service performance degradation. It further improves the accuracy of RUL prediction results and successfully expands the application of the Transformer in mechanical equipment RUL prediction.
2. Preliminaries
2.1. Convolutional Neural Network
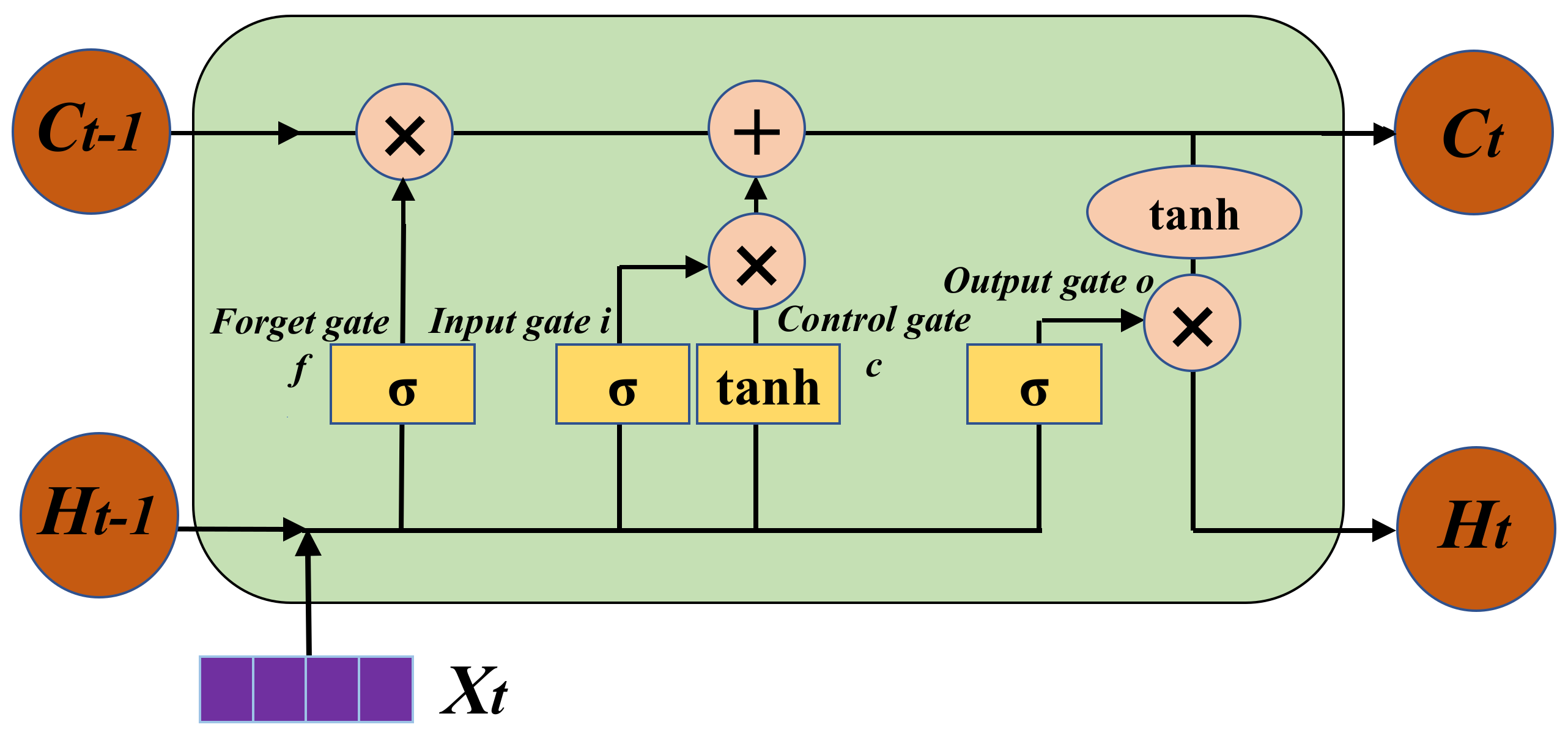
2.2. Long Short-Term Memory Network
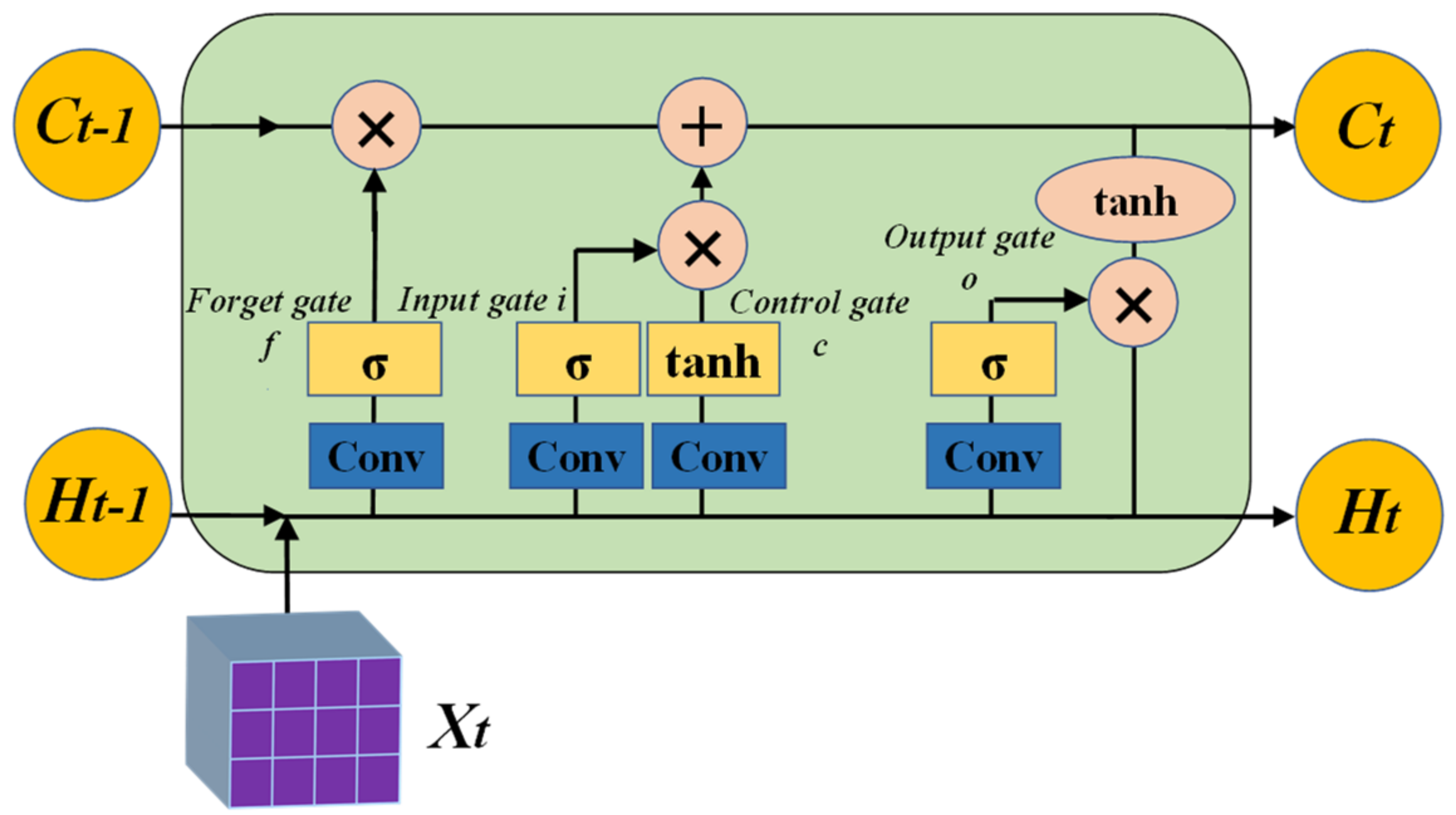
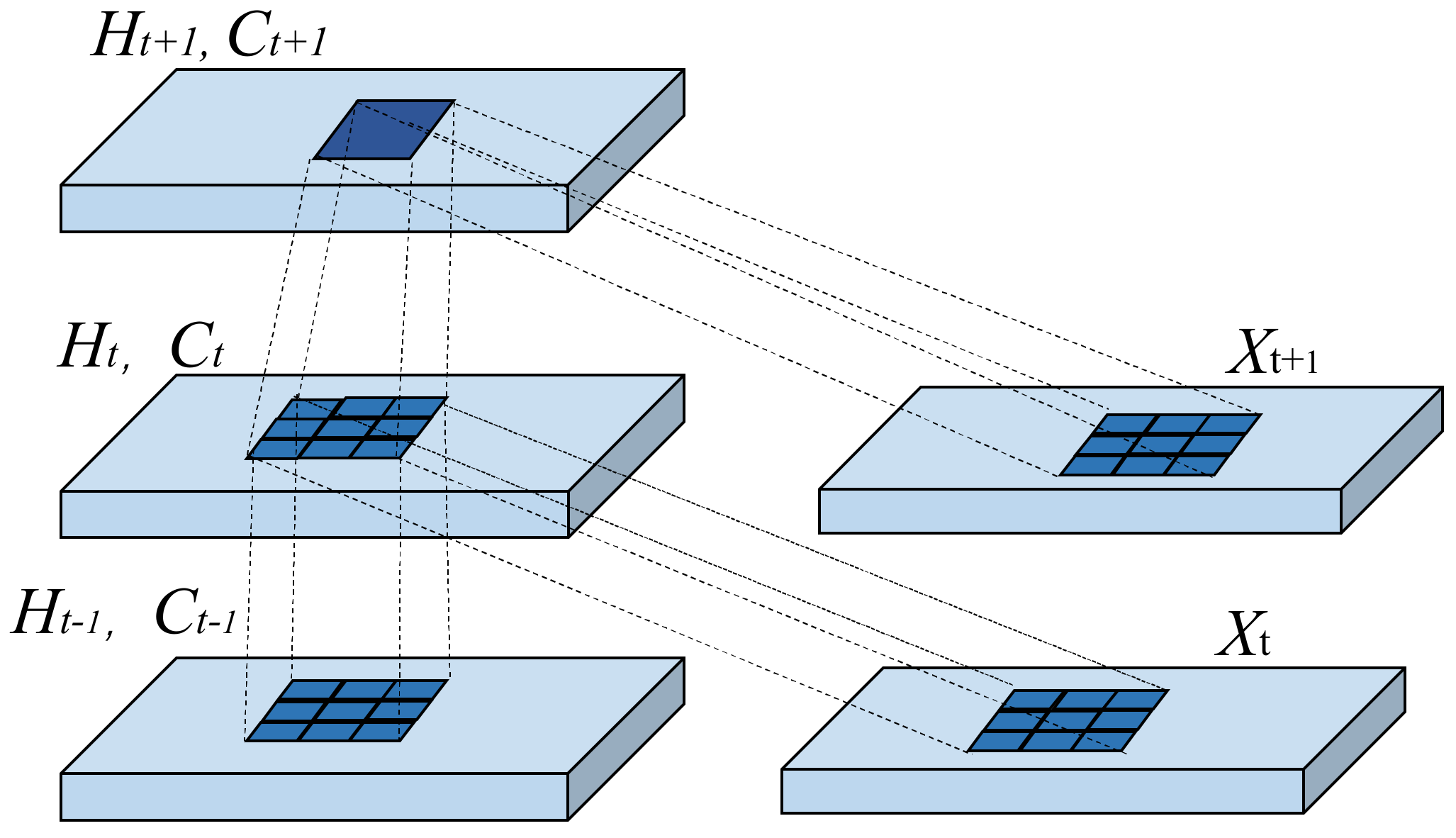
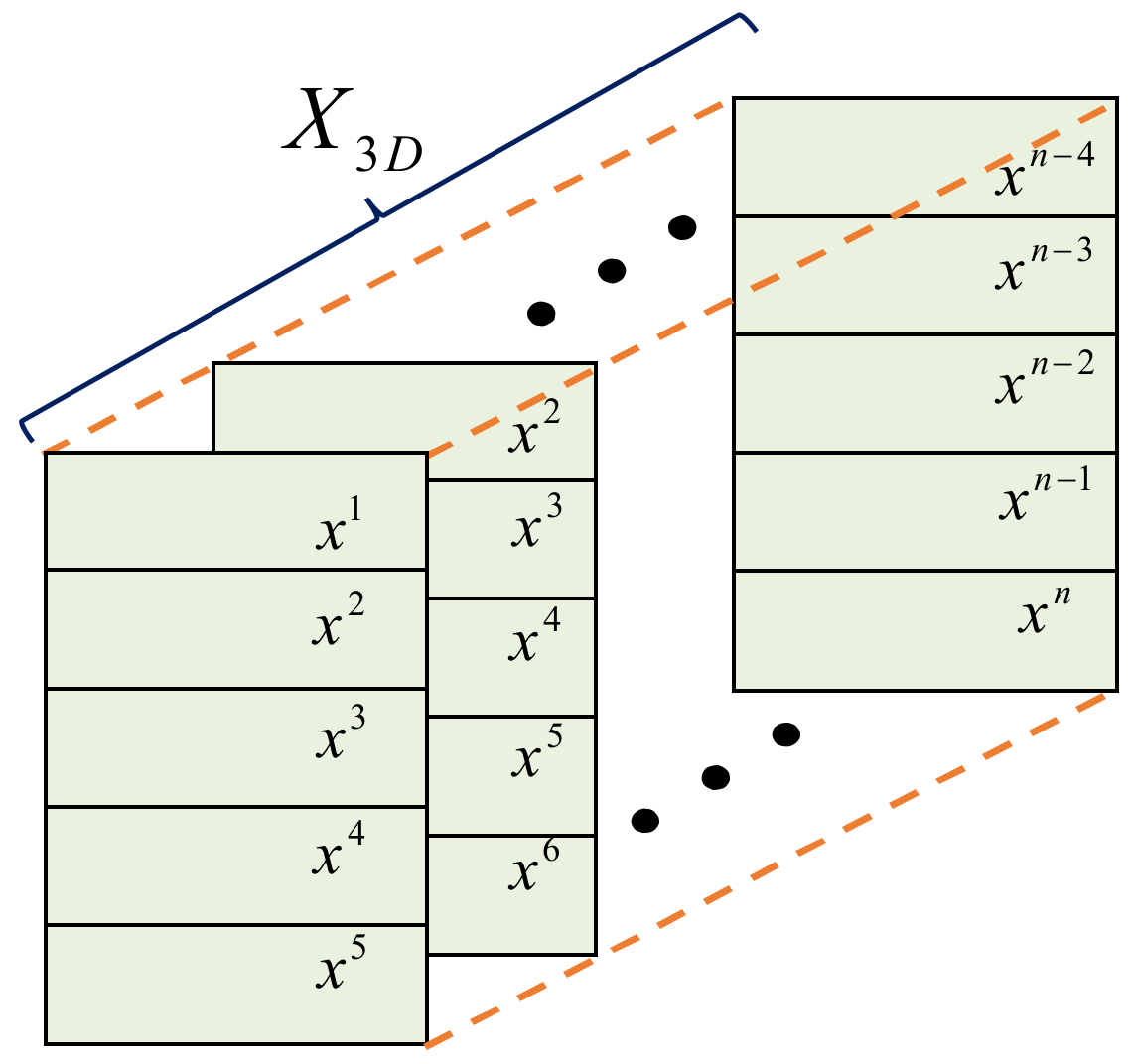
2.3. ConvLSTM Network
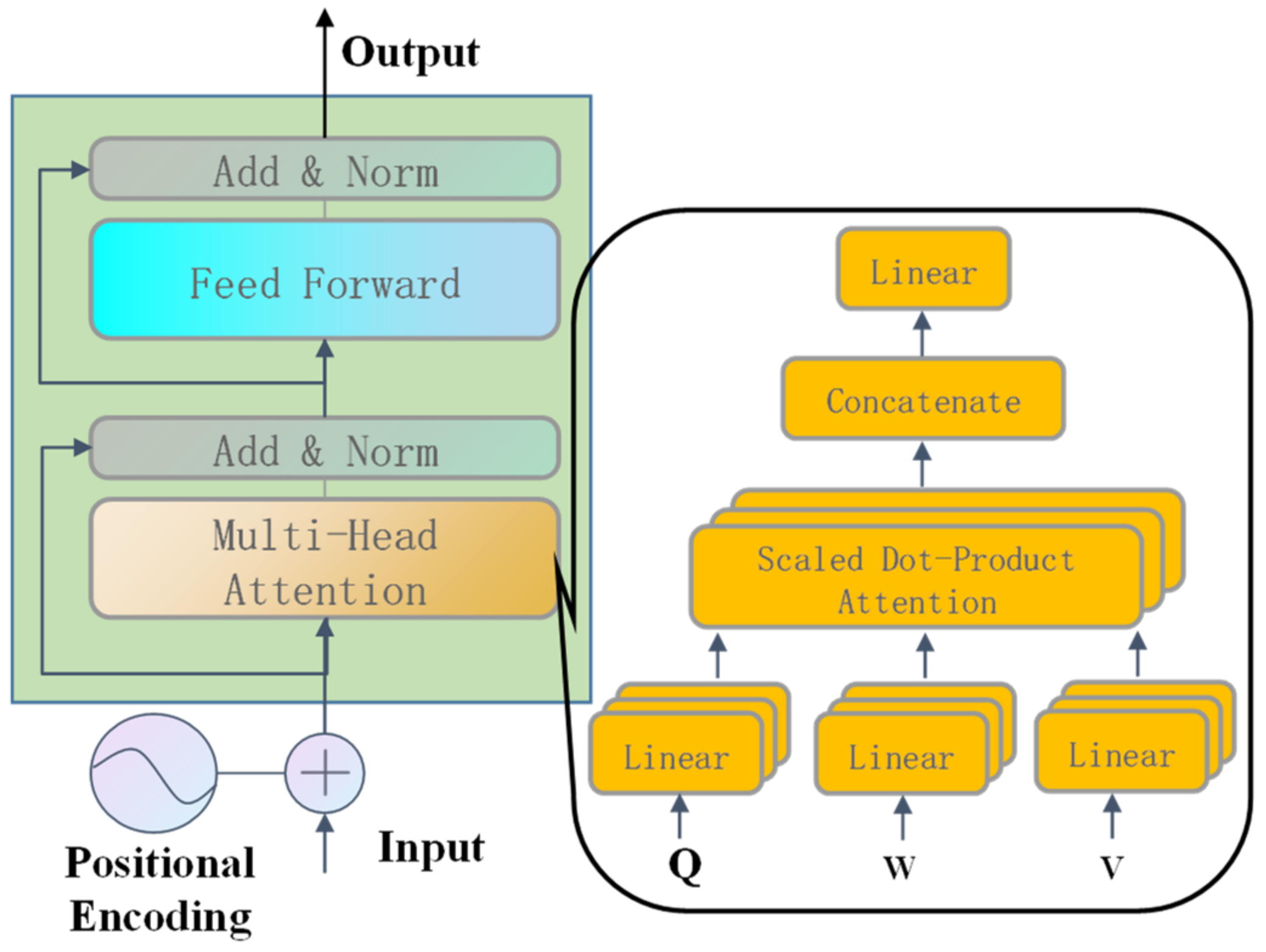
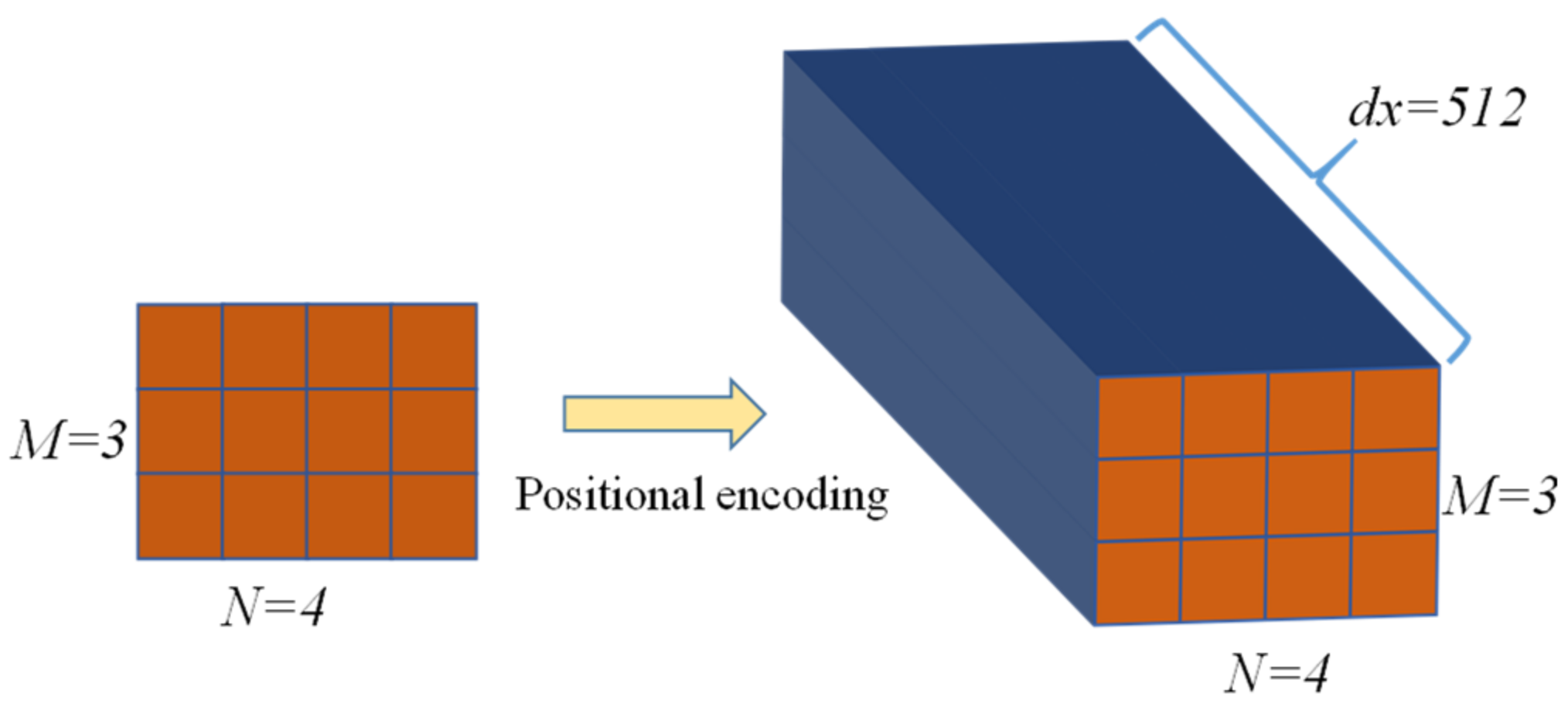
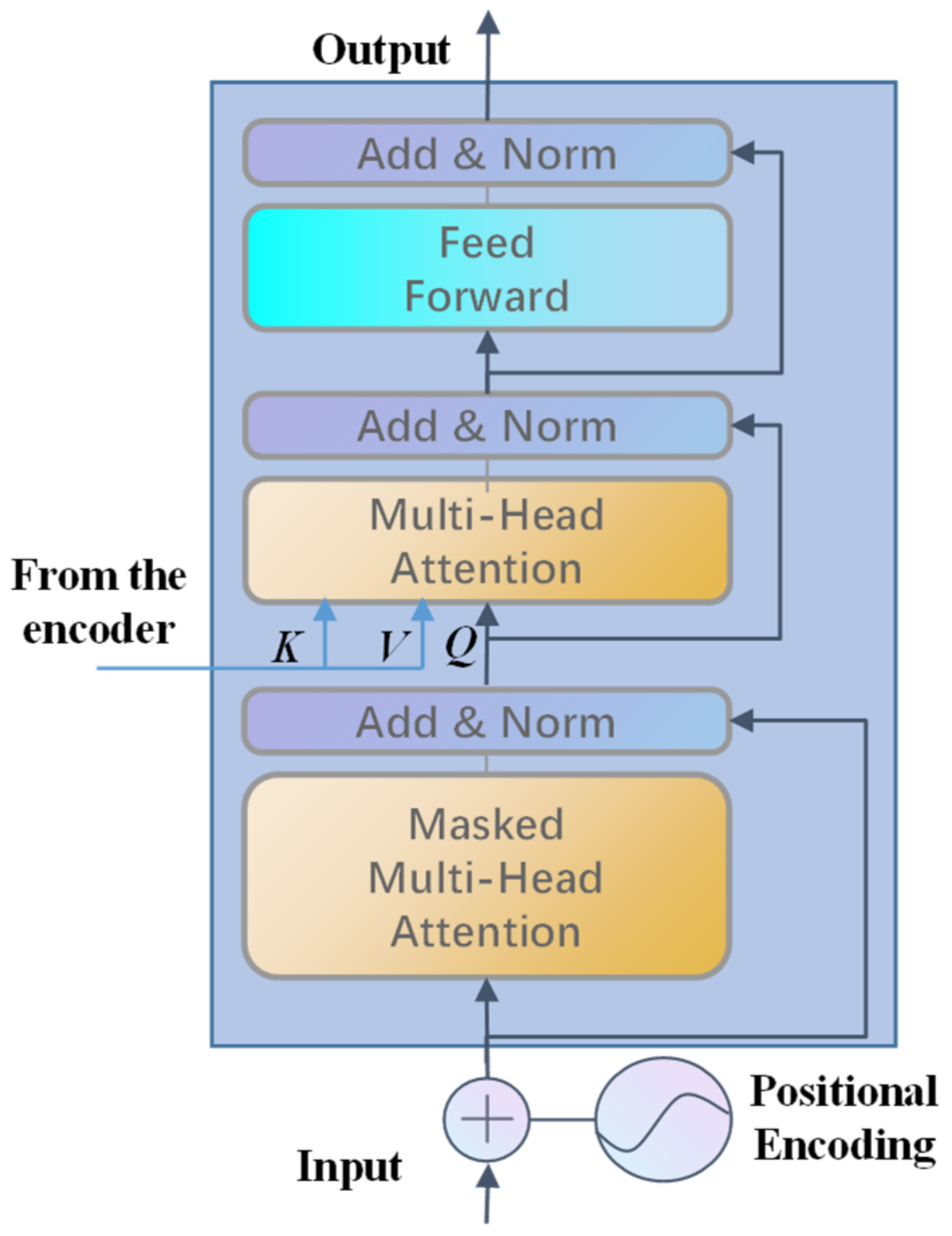
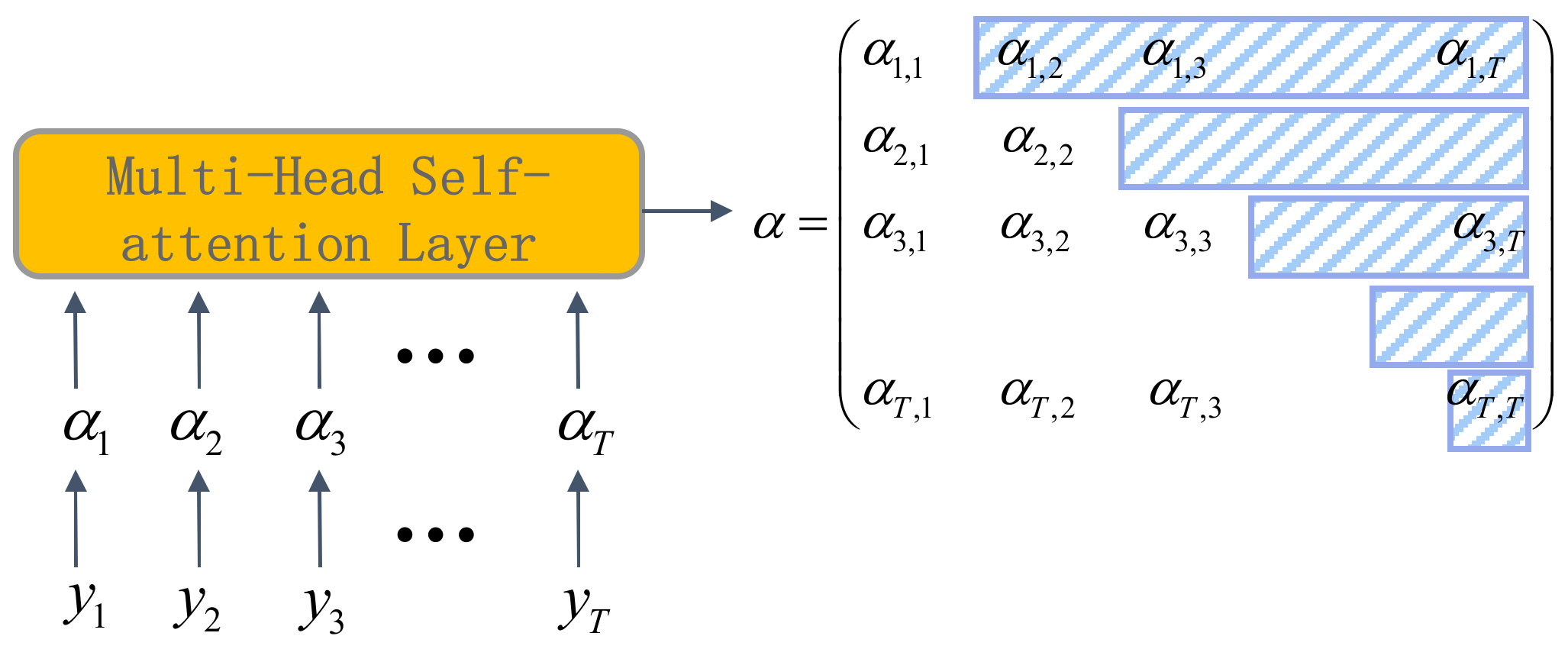
3. Transformer Neural Network
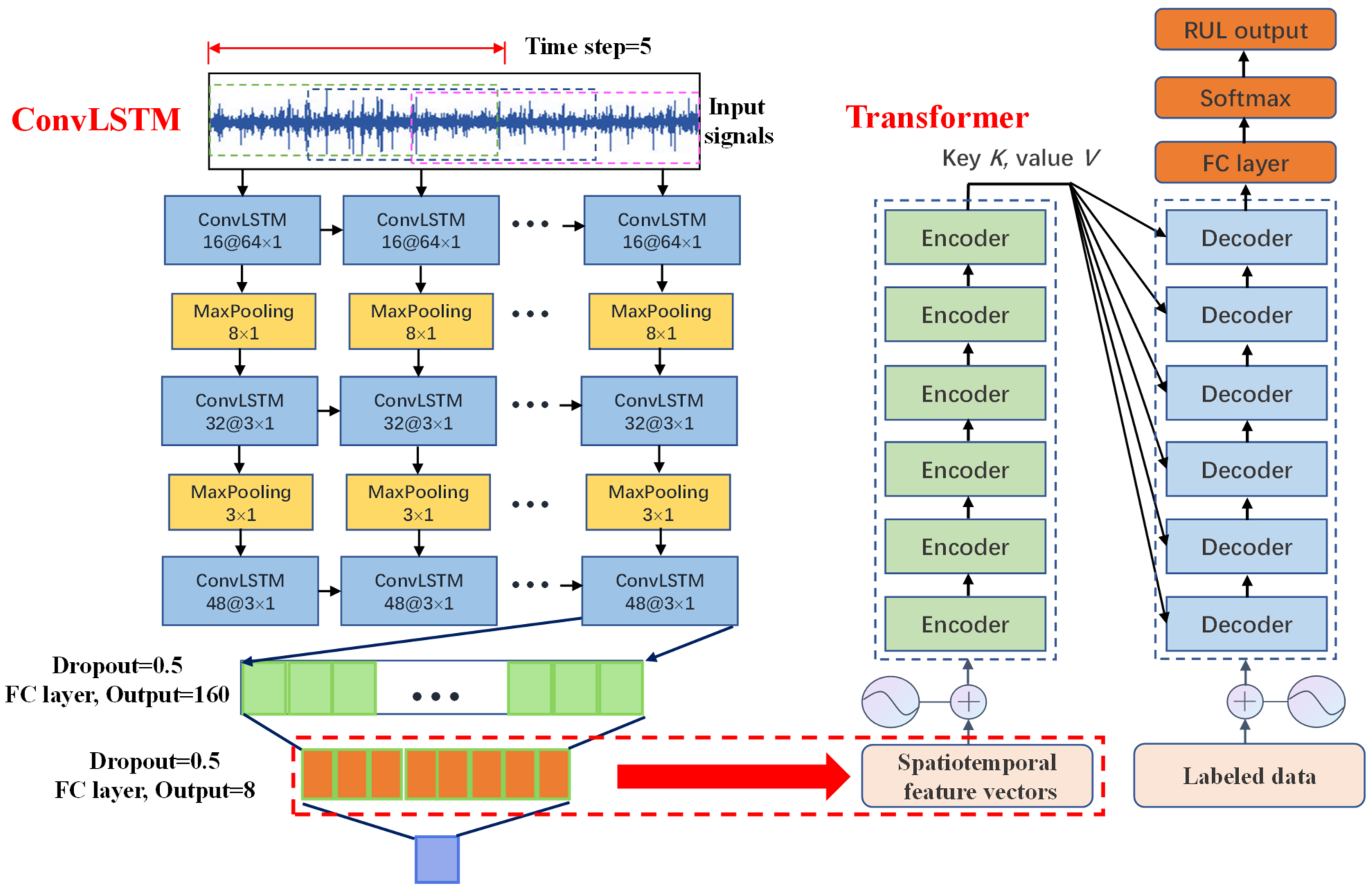
4. Convlstm-Transformer Model
5. Experimental Verification
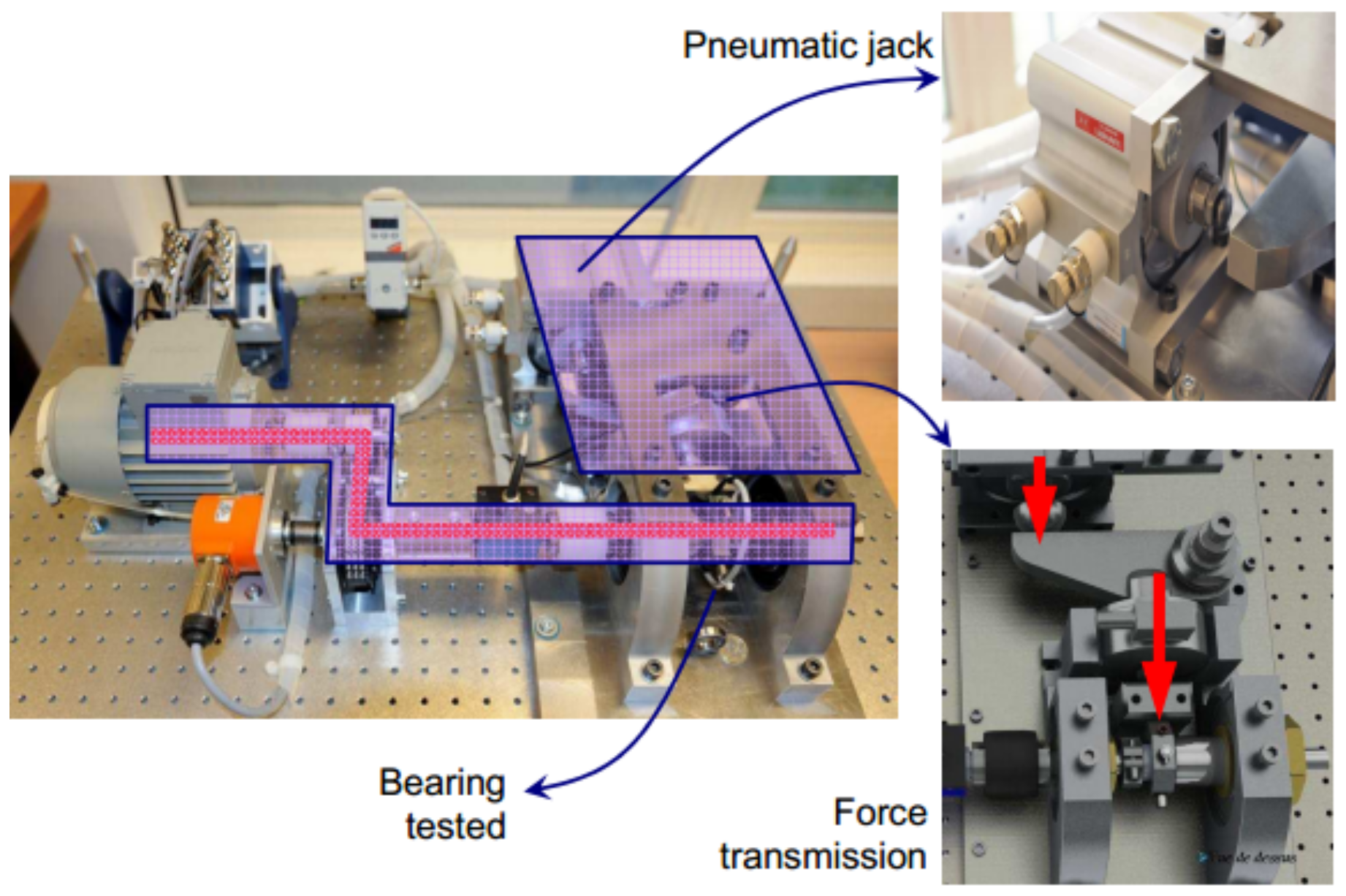
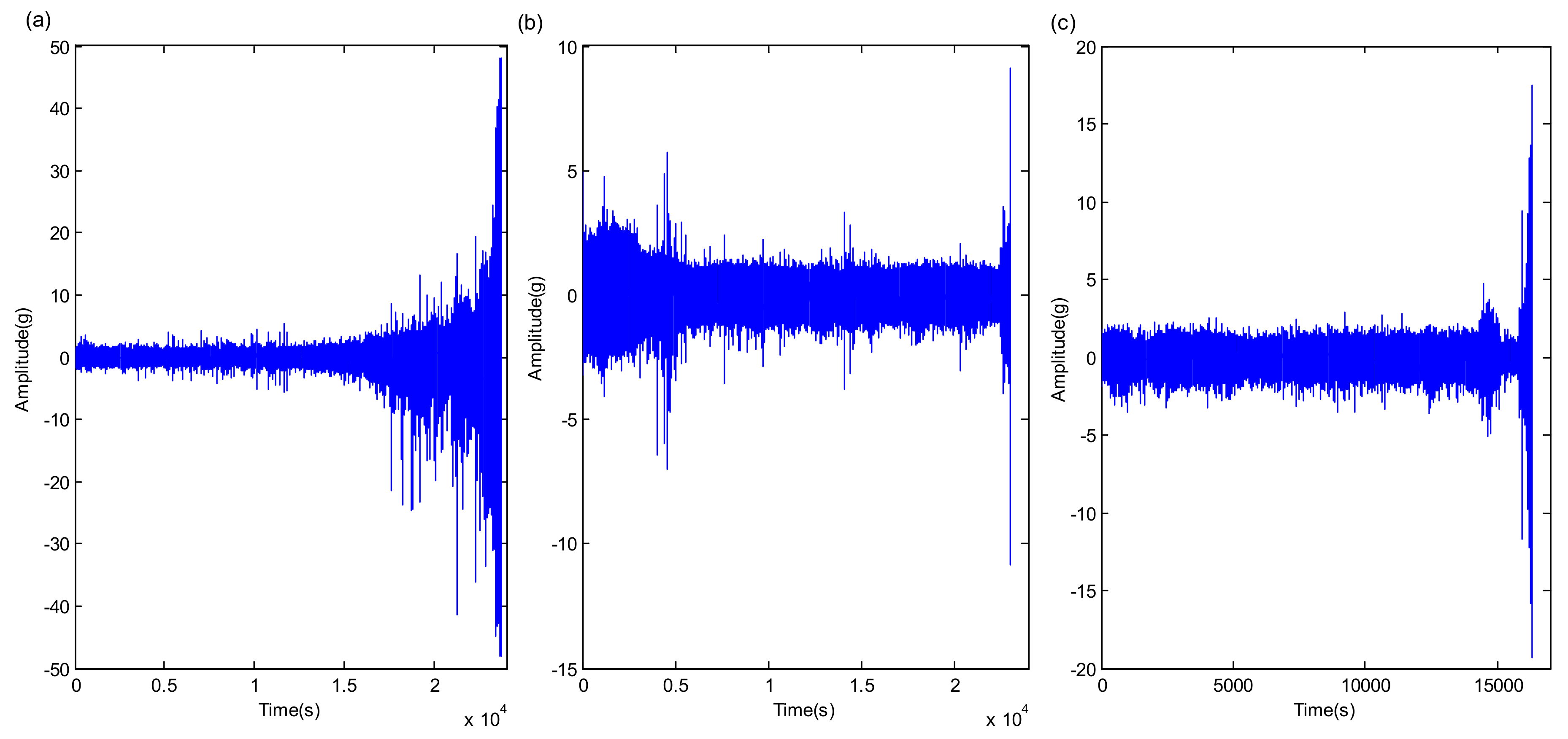
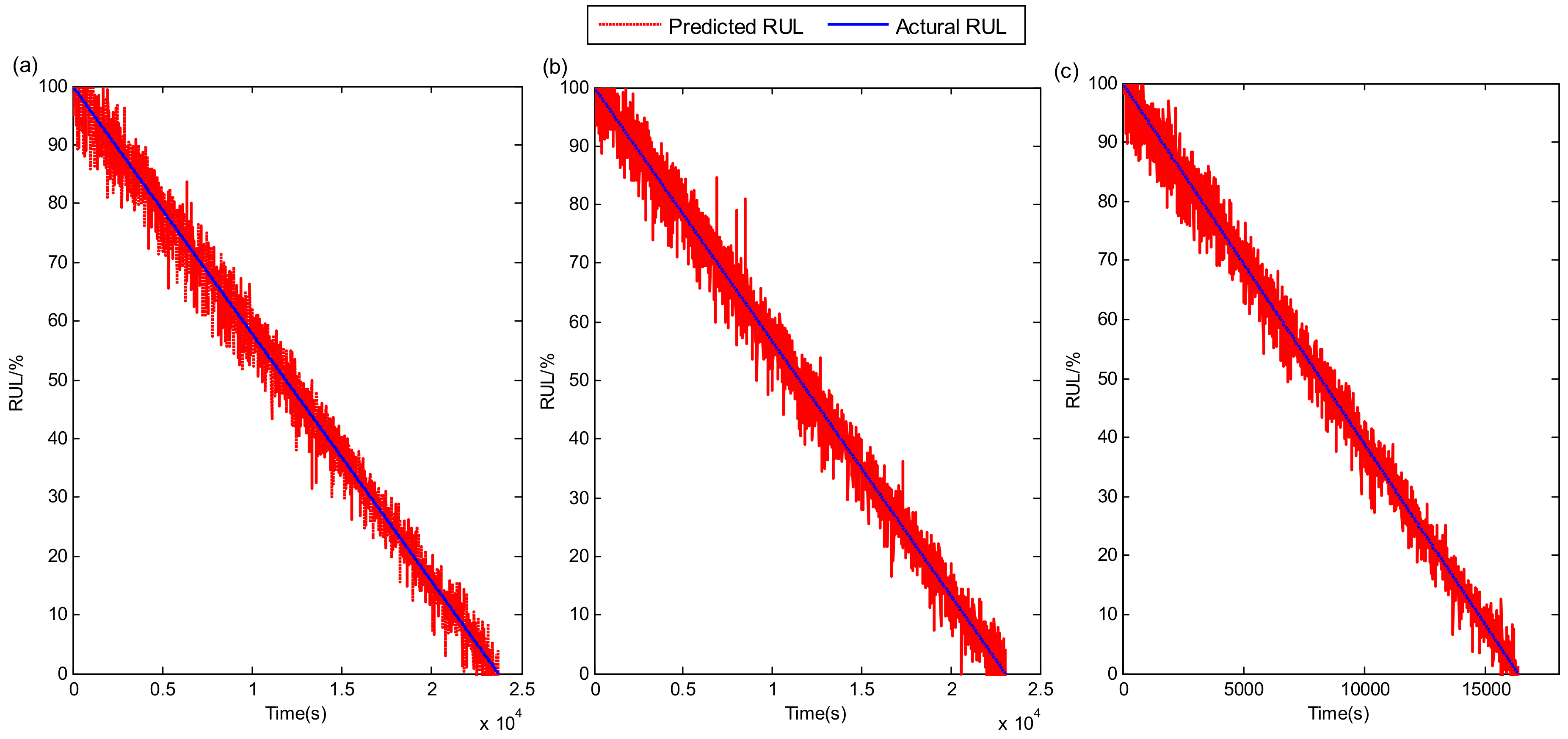
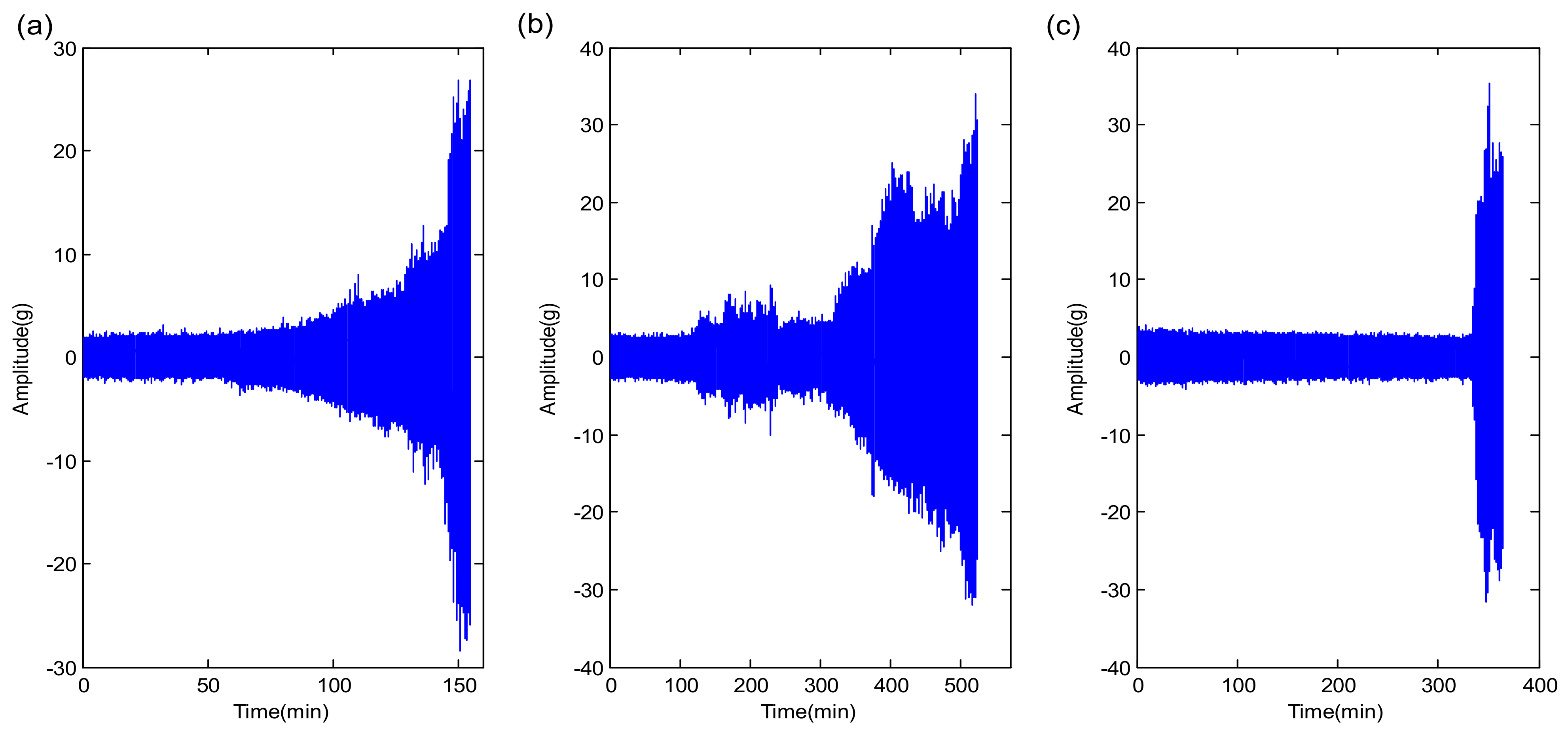
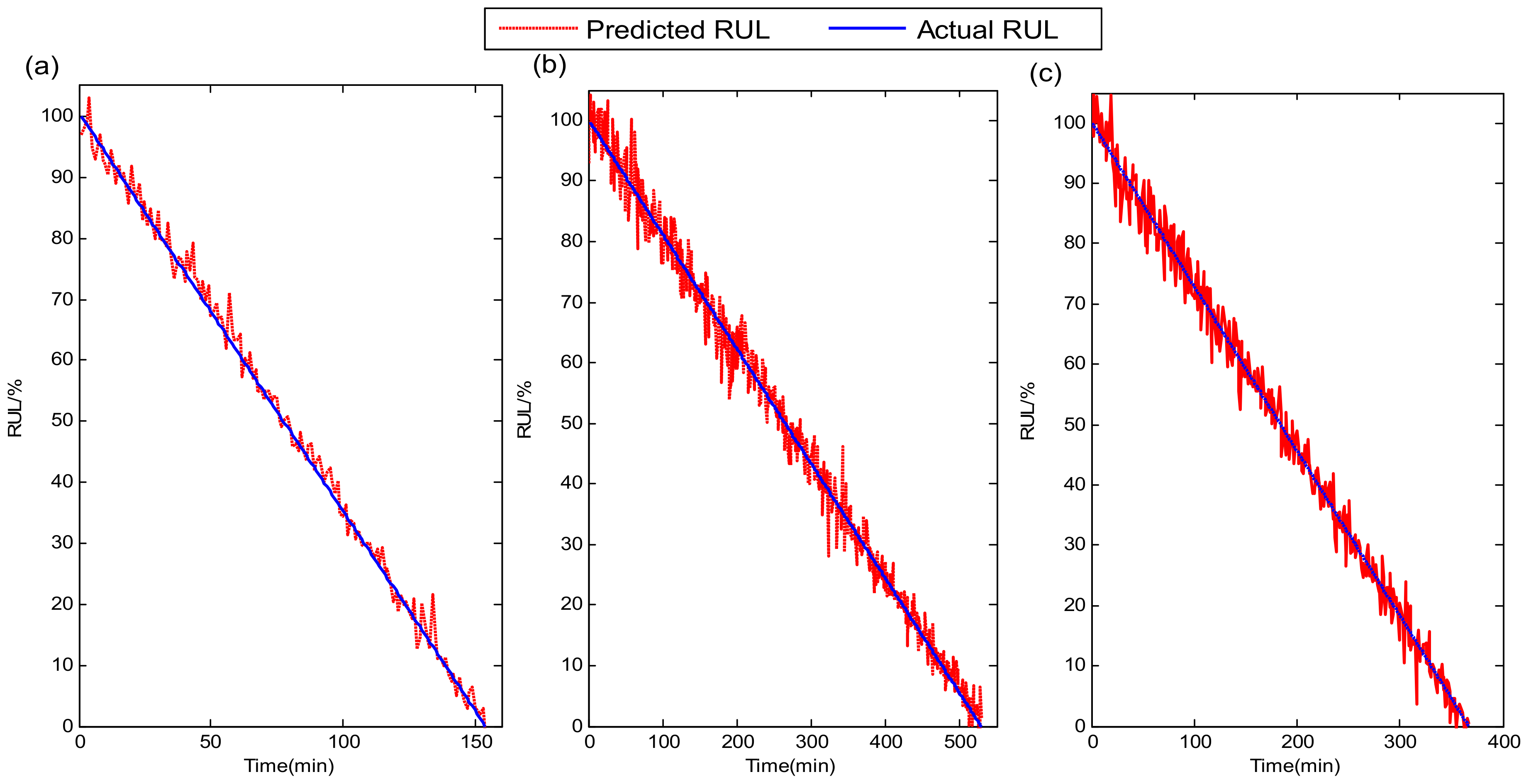
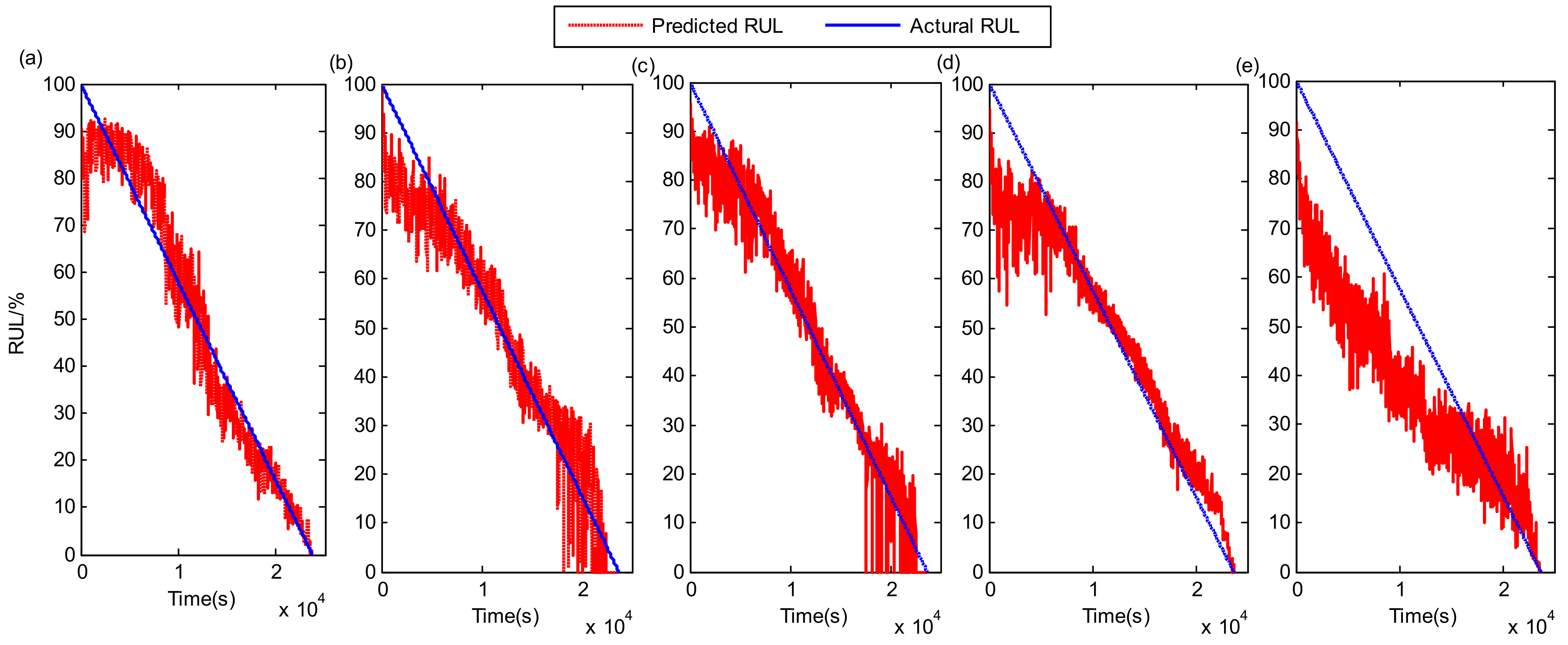
5.1. PHM 2012 Bearing RUL Prediction
5.2. XJTU-SY Bearing RUL Prediction
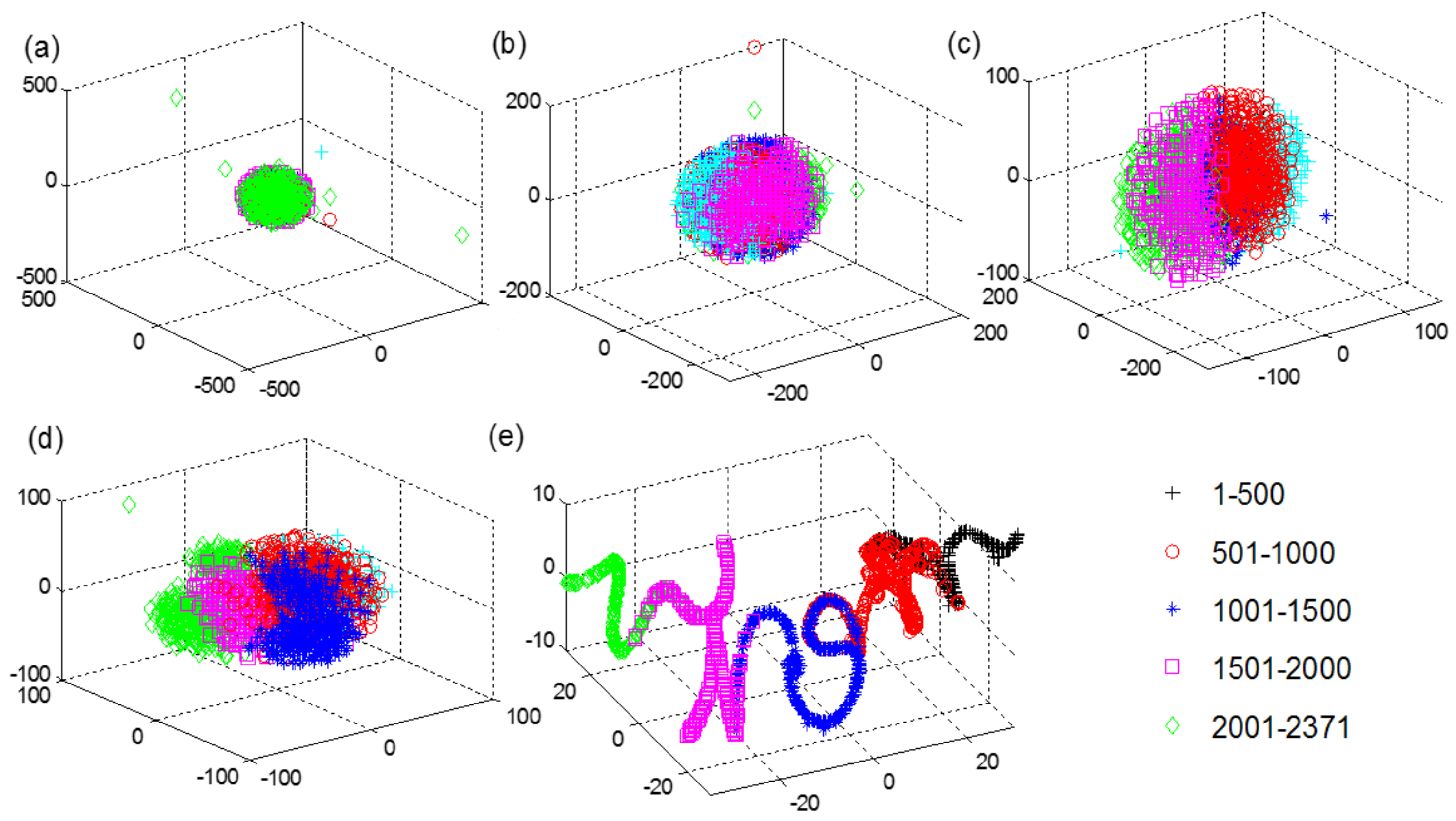
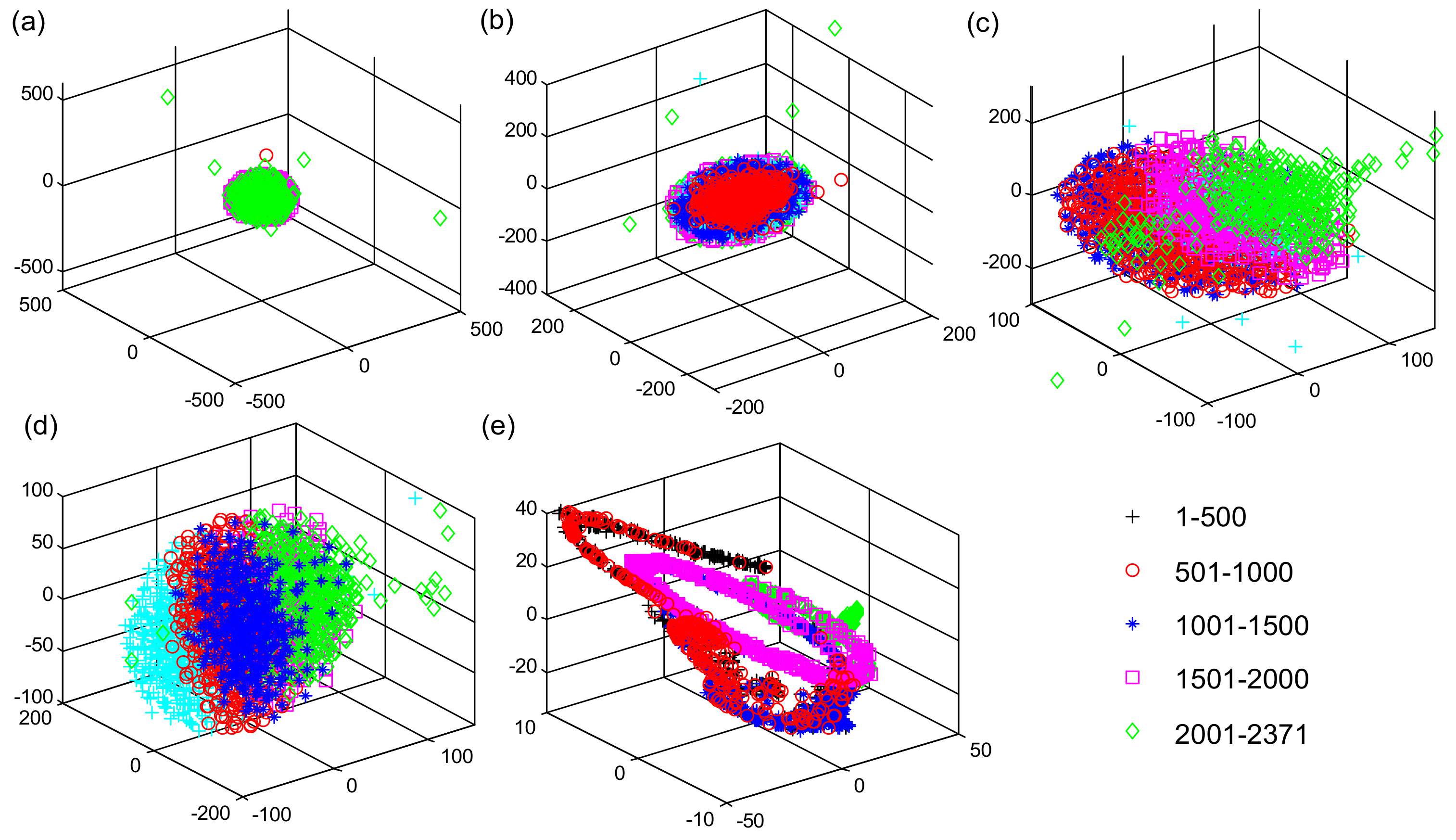
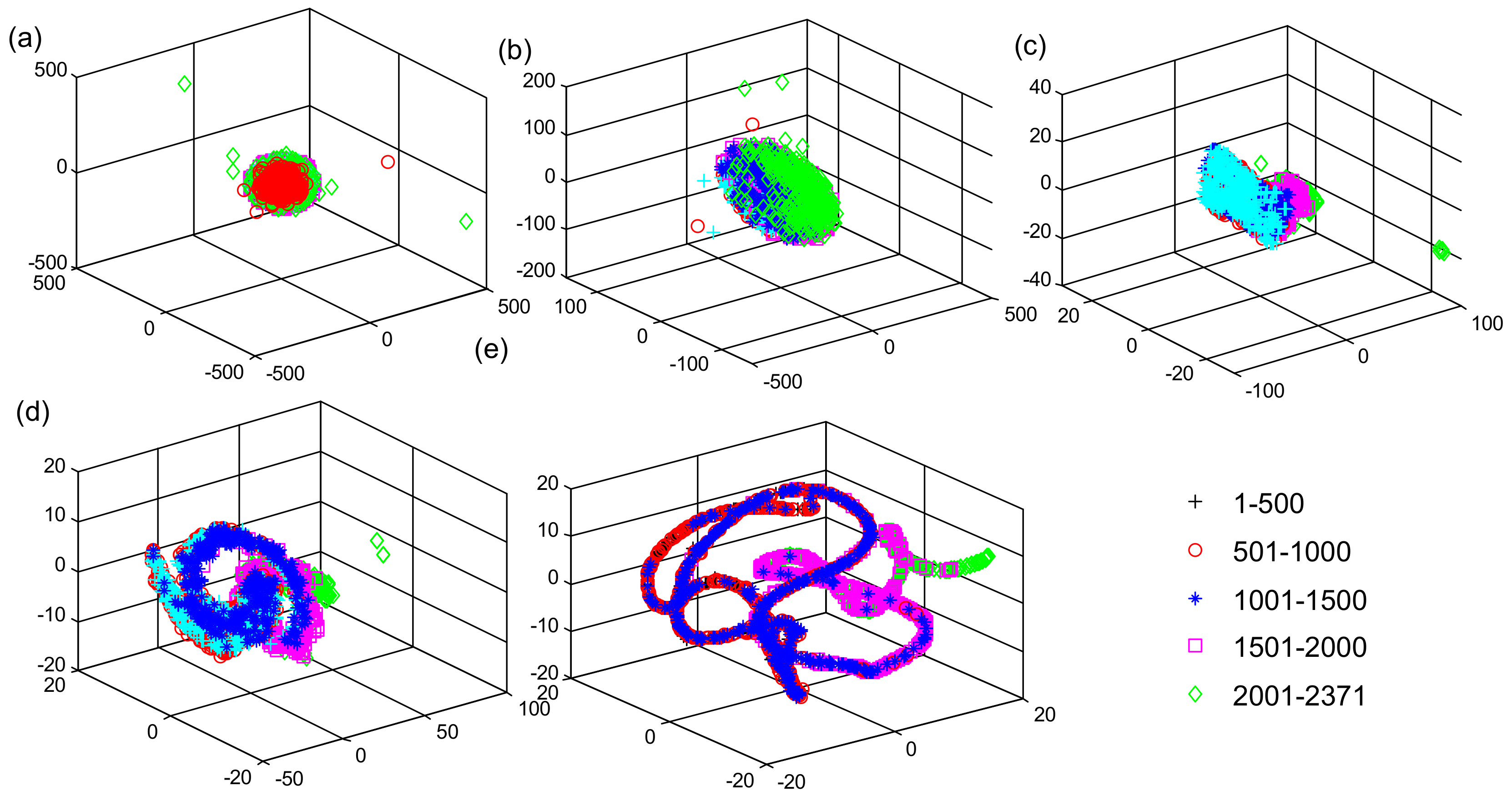
5.3. Spatiotemporal Feature Visualization Analysis
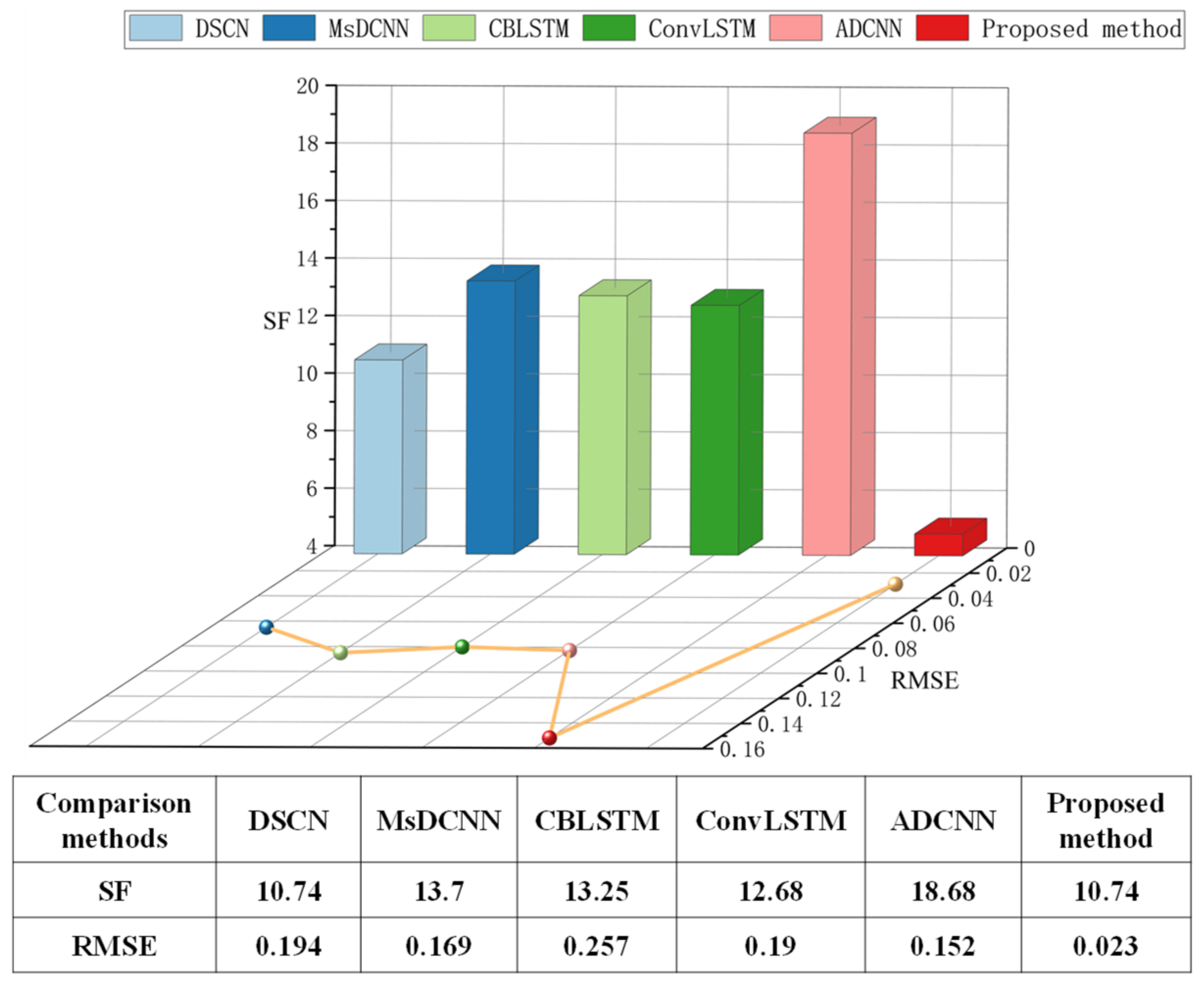
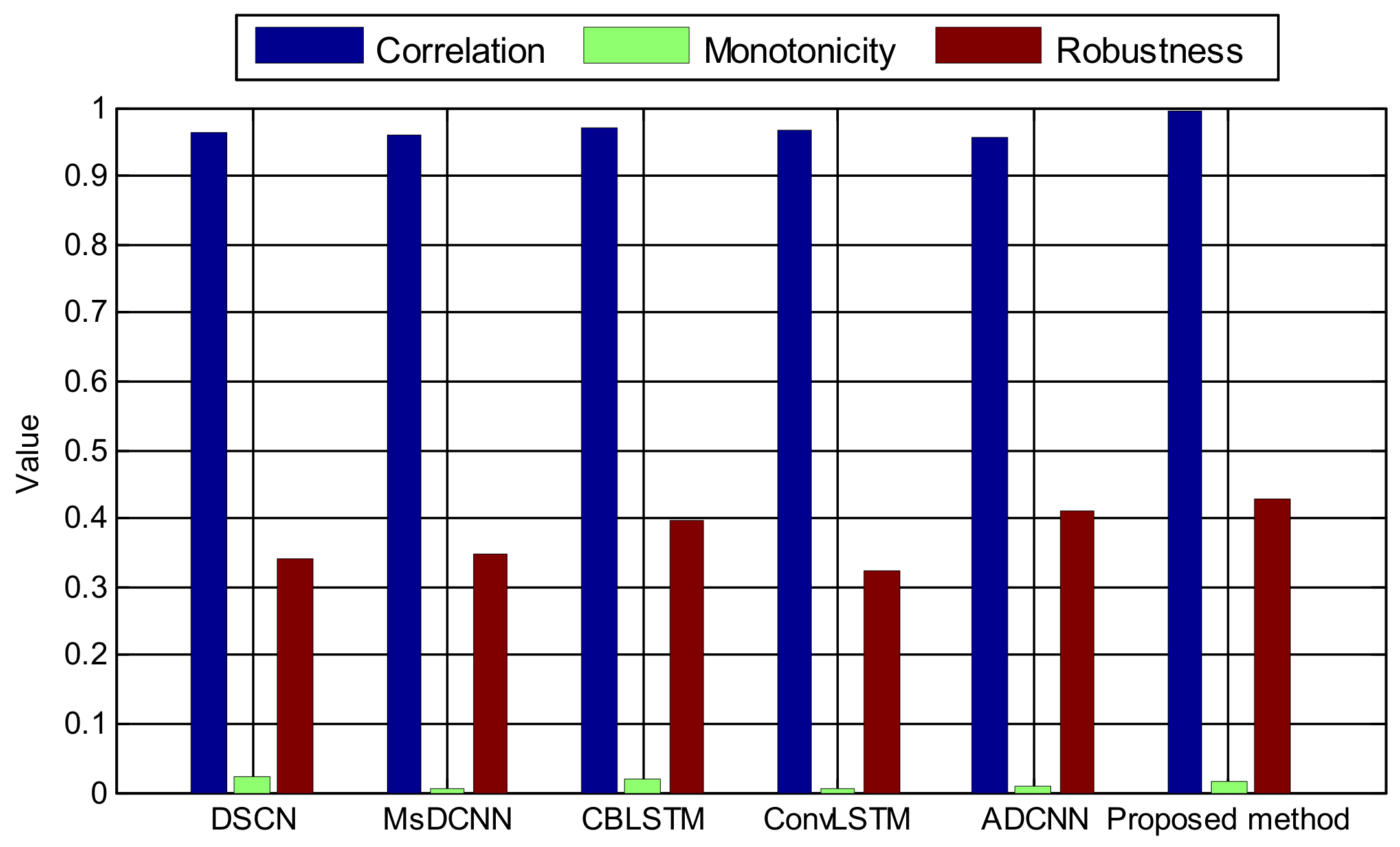
5.4. Comparison with the State-of-the-Art methods
5.5. Generalization Capability Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lei, Y.; Li, N.; Gontarz, S.; Lin, J.; Radkowski, S.; Dybala, J. A Model-Based Method for Remaining Useful Life Prediction of Machinery. IEEE Trans. Reliab. 2016, 65, 1314–1326. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Guo, L.; Li, N.; Yan, T.; Lin, J. Machinery health prognostics: A systematic review from data acquisition to RUL prediction. Mech. Syst. Signal Process. 2018, 104, 799–834. [Google Scholar] [CrossRef]
- Peng, W.; Ye, Z.-S.; Chen, N. Joint online RUL prediction for multi-deteriorating systems. IEEE Trans. Ind. Informat. 2019, 15, 2870–2878. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Benkedjouh, T.; Medjaher, K.; Zerhouni, N.; Rechak, S. Remaining useful life estimation based on nonlinear feature reduction and support vector regression. Eng. Appl. Artif. Intell. 2013, 26, 1751–1760. [Google Scholar] [CrossRef]
- Gebraeel, N.; Lawley, M.; Liu, R.; Parmeshwaran, V. Residual life predictions from vibration-based degradation signals: A neural network approach. IEEE Trans. Ind. Electron. 2004, 51, 694–700. [Google Scholar] [CrossRef]
- Moosavian, A.; Ahmadi, H.; Tabatabaeefar, A.; Sakhaei, B. An appropriate procedure for detection of journal-bearing fault using power spectral density, k-nearest neighbor and support vector machine. Int. J. Smart Sens. Intell. Syst. 2017, 5, 685–700. [Google Scholar] [CrossRef]
- Dong, M.; He, D. A segmental hidden semi-Markov model (HSMM)-based diagnosticsand prognostics framework and methodology. Mech. Syst. Signal Process. 2007, 21, 2248–2266. [Google Scholar] [CrossRef]
- Chen, H.; Wang, J.; Tang, B.; Xiao, K.; Li, J. An integrated approach to planetary gearbox fault diagnosis using deep belief networks. Meas. Sci. Technol. 2016, 28, 025010. [Google Scholar] [CrossRef]
- Lei, Y.; Jia, F.; Lin, J.; Xing, S.; Ding, S.X. An Intelligent Fault Diagnosis Method Using Unsupervised Feature Learning Towards Mechanical Big Data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- Ren, L.; Sun, Y.; Wang, H.; Zhang, L. Prediction of Bearing Remaining Useful Life with Deep Convolution Neural Network. IEEE Access 2018, 6, 13041–13049. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, N.; Peng, W. Estimation of Bearing Remaining Useful Life Based on Multiscale Convolutional Neural Network. IEEE Trans. Ind. Electron. 2018, 66, 3208–3216. [Google Scholar] [CrossRef]
- Deng, F.; Bi, Y.; Liu, Y.; Yang, S. Deep-Learning-Based Remaining Useful Life Prediction Based on a Multi-Scale Dilated Convolution Network. Mathematics 2021, 9, 3035. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Li, N.; Yan, T. Deep separable convolutional network for remaining useful life prediction of machinery. Mech. Syst. Signal Process. 2019, 134, 106330. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, D.Z.; Yan, R.Q.; Mao, K.Z.; Shen, F.; Wang, J.J. Machine Health Monitoring Using Local Feature-Based Gated Recurrent Unit Networks. IEEE Trans. Ind. Electron. 2017, 65, 1539–1548. [Google Scholar] [CrossRef]
- Liu, J.; Li, Q.; Chen, W.; Yan, Y.; Qiu, Y.; Cao, T. Remaining useful life prediction of PEMFC based on long short-term memory recurrent neural networks. Int. J. Hydrog. Energy 2019, 44, 5470–5480. [Google Scholar] [CrossRef]
- Li, X.; Zhang, L.; Wang, Z.; Dong, P. Remaining useful life prediction for lithium-ion batteries based on a hybrid model combining the long short-term memory and Elman neural networks. J. Energy Storage 2019, 21, 510–518. [Google Scholar] [CrossRef]
- Shen, Z.; Fan, X.; Zhang, L.; Yu, H. Wind speed prediction of unmanned sailboat based on CNN and LSTM hybrid neural network. Ocean Eng. 2022, 254, 111352. [Google Scholar] [CrossRef]
- Agga, A.; Abbou, A.; Labbadi, M.; El Houm, Y.; Ali, I.H.O. CNN-LSTM: An efficient hybrid deep learning architecture for predicting short-term photovoltaic power production. Electr. Power Syst. Res. 2022, 208, 107908. [Google Scholar] [CrossRef]
- Chu, C.-H.; Lee, C.-J.; Yeh, H.-Y. Developing Deep Survival Model for Remaining Useful Life Estimation Based on Convolutional and Long Short-Term Memory Neural Networks. Wirel. Commun. Mob. Comput. 2020, 2020, 8814658. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Plizzari, C.; Cannici, M.; Matteucci, M. Spatial temporal transformer network for skeleton-based action recognition. In Proceedings of the International Conference on Pattern Recognition, Virtual Event, 10–15 January 2021; Springer: Cham, Switzerland, 2021; pp. 694–701. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Xu, M.; Dai, W.; Liu, C.; Gao, X.; Lin, W.; Qi, G.J.; Xiong, H. Spatial-temporal transformer networks for traffic flow forecasting. arXiv 2020, arXiv:2001.02908. [Google Scholar]
- Yu, C.; Ma, X.; Ren, J.; Zhao, H.; Yi, S. Spatio-temporal graph transformer networks for pedestrian trajectory prediction. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 507–523. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Kameoka, H.; Huang, W.-C.; Tanaka, K.; Kaneko, T.; Hojo, N.; Toda, T. Many-to-Many Voice Transformer Network. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 29, 656–670. [Google Scholar] [CrossRef]
- Ahmed, K.; Keskar, N.S.; Socher, R. Weighted transformer network for machine translation. arXiv 2017, arXiv:1711.02132. [Google Scholar]
- Moishin, M.; Deo, R.C.; Prasad, R.; Raj, N.; Abdulla, S. Designing Deep-Based Learning Flood Forecast Model with ConvLSTM Hybrid Algorithm. IEEE Access 2021, 9, 50982–50993. [Google Scholar] [CrossRef]
- Li, N.; Liu, S.; Liu, Y.; Zhao, S.; Liu, M. Neural speech synthesis with transformer network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33. [Google Scholar]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Chebel-Morello, B.; Zerhouni, N.; Varnier, C. PRONOSTIA: An experimental platform for bearings accelerated degradation tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management; PHM’12, No. CPF12PHM-CDR2012. IEEE: Piscataway, NY, USA, 2012; pp. 1–8. [Google Scholar]
- Wang, B.; Lei, Y.; Li, N.; Li, N. A hybrid prognostics approach for estimating remaining useful life of rolling element bearings. IEEE Trans. Reliab. 2018, 69, 401–412. [Google Scholar] [CrossRef]
- Van der Maaten LJ, P.; Hinton, G.E. Visualizing high-dimensional data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Li, H.; Zhao, W.; Zhang, Y.; Zio, E. Remaining useful life prediction using multi-scale deep convolutional neural network. Appl. Soft Comput. 2020, 89, 106113. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Wang, J.; Mao, K. Learning to monitor machine health with convolutional bi-directional LSTM networks. Sensors 2017, 17, 273. [Google Scholar] [CrossRef]
- Plakias, S.; Boutalis, Y.S. Fault detection and identification of rolling element bearings with Attentive Dense CNN. Neurocomputing 2020, 405, 208–217. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, L.; Xu, J. Degradation Feature Selection for Remaining Useful Life Prediction of Rolling Element Bearings. Qual. Reliab. Eng. Int. 2016, 32, 547–554. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rotating Speed/Load | Operating Conditions | ||
|---|---|---|---|
| 1800 rpm/ 4000 N | 1650 rpm/4200 N | 1500 rpm/5000N | |
| Dataset | Bearing1 (1_1–1_7) | Bearing2 (2_1–2_7) | Bearing3 (3_1–3_3) |
| Training set | rest of Bearing1 | rest of Bearing2 and Bearing3 | |
| Testing Set | Bearing1_3 | Bearing2_5 | Bearing3_2 |
| Rotating Speed/Load | Operating Conditions | ||
|---|---|---|---|
| 2100 rpm/ 12 kN | 2250 rpm/ 11 kN | 2400 rpm/ 10 kN | |
| Dataset | Bearing1 (1_1–1_5) | Bearing2 (2_1–2_5) | Bearing3 (3_1–3_5) |
| Training Set | rest of Bearing1 | rest of Bearing2 and Bearing3 | |
| Testing Set | Bearing1_3 | Bearing2_3 | Bearing3_3 |
| Computation Time (s) | PHM 2012 Dataset | XJTU-SY Dataset | ||
|---|---|---|---|---|
| Bearing1_3 | Bearing2_5 | Bearing1_3 | Bearing2_3 | |
| ConvLSTM | 3760.15 | 2270.82 | 250.12 | 1209.1 |
| Transformer | 445.13 | 251.75 | 22.31 | 105.14 |
| Sum up | 4205.28 | 2522.57 | 272.43 | 1314.24 |
| Training Data Samples Number | 6 | 5 | 4 | 3 |
|---|---|---|---|---|
| SF | 4.76 | 4.80 | 4.89 | 5.20 |
| RMSE | 0.029 | 0.029 | 0.035 | 0.041 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, F.; Chen, Z.; Liu, Y.; Yang, S.; Hao, R.; Lyu, L. A Novel Combination Neural Network Based on ConvLSTM-Transformer for Bearing Remaining Useful Life Prediction. Machines 2022, 10, 1226. https://doi.org/10.3390/machines10121226
Deng F, Chen Z, Liu Y, Yang S, Hao R, Lyu L. A Novel Combination Neural Network Based on ConvLSTM-Transformer for Bearing Remaining Useful Life Prediction. Machines. 2022; 10(12):1226. https://doi.org/10.3390/machines10121226
Chicago/Turabian StyleDeng, Feiyue, Zhe Chen, Yongqiang Liu, Shaopu Yang, Rujiang Hao, and Litong Lyu. 2022. "A Novel Combination Neural Network Based on ConvLSTM-Transformer for Bearing Remaining Useful Life Prediction" Machines 10, no. 12: 1226. https://doi.org/10.3390/machines10121226
APA StyleDeng, F., Chen, Z., Liu, Y., Yang, S., Hao, R., & Lyu, L. (2022). A Novel Combination Neural Network Based on ConvLSTM-Transformer for Bearing Remaining Useful Life Prediction. Machines, 10(12), 1226. https://doi.org/10.3390/machines10121226