1. Introduction
Quality inspection is an essential and critical part of industrial production. According to reports, the global quality inspection industry has maintained a rapid growth of more than 10%, and the global inspection and testing market is expected to reach EUR 252.68 billion in 2022, showing great potential for development. Surface defect detection refers to the use of vision-related technology to locate and classify defects that exist on the surface of a workpiece. It has always been an important part of industrial quality inspection. In industrial production, defects sometimes occur in industrial parts, which are caused by dithering of production equipment, abrupt changes in production environment, etc. In addition, some industrial parts such as flanges, bearings, gears and rails are in contact with the working scenario of stress for a long time, causing many types of defects on the contact surface. Flanges are mainly used in the industrial field, and they are a common and important part of industrial manufacturing. Surface quality has a critical effect on the use of flanges. When the flange surface appears unpolished, sand holes, scratches or flange hole bruising defects will affect the sealing performance of the flange in the connection or even lead to the inability of its use. Timely inspection of products for surface defects can prevent products with quality problems from entering the market, as well as avoid the occurrence of greater costs. At the same time, a batch of products for defect detection and statistics on the type and number of defects can provide some guidance for subsequent production.
Before industrial intelligence was promoted, surface defect inspection was mainly performed manually. It comes at a high cost. Due to individual differences, the subjectivity of manual inspections and the long working hours make manual inspections prone to errors. The use of machines for surface defect inspection allows uniform evaluation criteria to be set. Such use is also far more efficient than manual inspection, and the cost of machines is far lower than manual labor. Therefore, transforming defect inspection tasks from manual to automated inspection is urgently needed.
Researchers have solved the above problems by classical machine vision methods. Machine vision detection methods acquire images of the target by high-precision industrial cameras and obtain the required information through the calculation of some image processing algorithms. For example, Zhao et al. (2017) [
1] proposed an improved frame difference method for template matching to detect print defects. Liu et al. (2018) [
2] used support vector machines for defect detection of solar cell wafers. Yuan et al. (2016) [
3] used the Otsu (weighted target variance)-based method for rail defect detection. These methods satisfy the needs of defect detection tasks. However, these methods do not extract features efficiently. As a consequence, they are not effective in detecting defects in complex environments [
4]. Using a deep learning approach for surface defect detection can alleviate these problems [
5].
With the improvement in computing power of devices, researchers can use huge amounts of data to train deep learning models, allowing deep learning to reach its full potential in computer vision. A growing number of studies have shown that convolutional neural networks (CNNs) and their extensions show very powerful performance in defect detection and can solve most of the problems that cannot be solved by classical machine vision methods. Tabernik et al. (2020) [
6] proposed a segmentation-based deep learning architecture which achieves steel defect detection by first outputting pixel-level defect regions from a segmentation network and then a classification network for binary image classification. Liu et al. (2021) [
7] improved the data enhancement method and lightened YOLOv5 for detecting surface defects on metal bases. Wang et al. (2021) [
8] used an improved RetinaNet for surface defect detection of vehicle navigation guides and achieved a high accuracy rate. Chen et al. (2022) [
9] embedded Gabor kernels in Faster R-CNN to overcome the problem of texture interference in fabric defect detection achieved good results. Wen et al. (2021) [
10] used an encoder encoder-decoder mask extraction network to generate an insulator mask image which eliminated the complex background. Then, they used the improved RCNN to detect the insulator defects. These studies have shown good performance in their engineering scenarios and have greatly advanced the application of deep learning techniques in surface defect detection. However, some unresolved issues remain in the field of surface defect detection. For example, the feature extraction performance is generally improved by increasing the depth of the CNNs, posing the risk of gradient disappearance. Convolution-based CNNs are considered locally sensitive and have a lack global dependency. The receptive field can be improved by increasing the convolutional kernel, but the computational cost increases with the increase of convolutional kernels, and further improvement is difficult to obtain [
11].
In the domain of deep learning, the self-attention-based transformer (Vaswani et al., 2017) [
12] is a mainstream architecture; self-attention modules can correlate long-term dependencies in data, driving the popularity of transformers. Recently, many researchers have found that the transformer has also shown good performance in computer vision. Dosovitskiy et al. (2020) [
13] demonstrated that the vision transformer performs better than CNNs after pre-training with a sufficient amount of data. Liu et al. (2021) [
14] proposed the shifted window transformer architecture, which reduces the computational complexity of the transformer and makes it easier to deploy in detection and segmentation tasks. At present, researchers have used transformers for surface defect-related vision tasks. Li et al. (2022) [
15] combined CNNs with transformers to achieve good results on a steel surface defect classification task. Although transformers can correlate global data, their computational complexity is quadratic in image size, precluding their use in high-resolution images. The features extracted using transformers do not have hierarchical distinctions and cannot effectively fuse features, introducing difficulties in achieving the desired results for tasks with large variations in target scale [
14]. Most of the loss functions defined by past defect detection models are only used to discriminate sample similarity, and no differentiated treatment exists for easy and hard to classify samples, resulting in models that do not converge well [
16].
Based on the above problems, a novel defect detection method is proposed in this paper. We use the Swin transformer architecture for feature extraction of surface defects and attempt to design a one-stage surface defect detection algorithm with superior performance to meet the real-time requirements of industrial defect detection while ensuring accuracy. We used the Swin transformer tiny as the backbone feature extraction network, fine-tuned its structure and improved its ability to extract multi-scale features. It exhibits powerful feature extraction and can output hierarchical features for detecting defect targets at different scales. Meanwhile, the computational cost of the Swin transformer is similar to that of CNNs [
14]. A weighted bi-directional feature pyramid network (BiFPN) is used as the feature fusion module of the network. We use it to fuse the four scale features output in the Swin transformer with a very high efficiency. We fuse features at different scales in this way in a weighted manner so that local features at different scales can be fused together more effectively, thus greatly enhancing the robustness of image features [
17]. The head of the network is based on the anchor frame for detection, with a total of five scales of detection output, which is designed for surface defects with large-scale variations. They share a detection head, potentially reducing the parameters and alleviating the problem of uneven learnable samples on different scales. We choose focal loss as the loss function, potentially improving the model’s focus on hard-to-discriminate samples. This allows the model to focus more on those defects that are difficult to detect, which is helpful for the surface defect detection task [
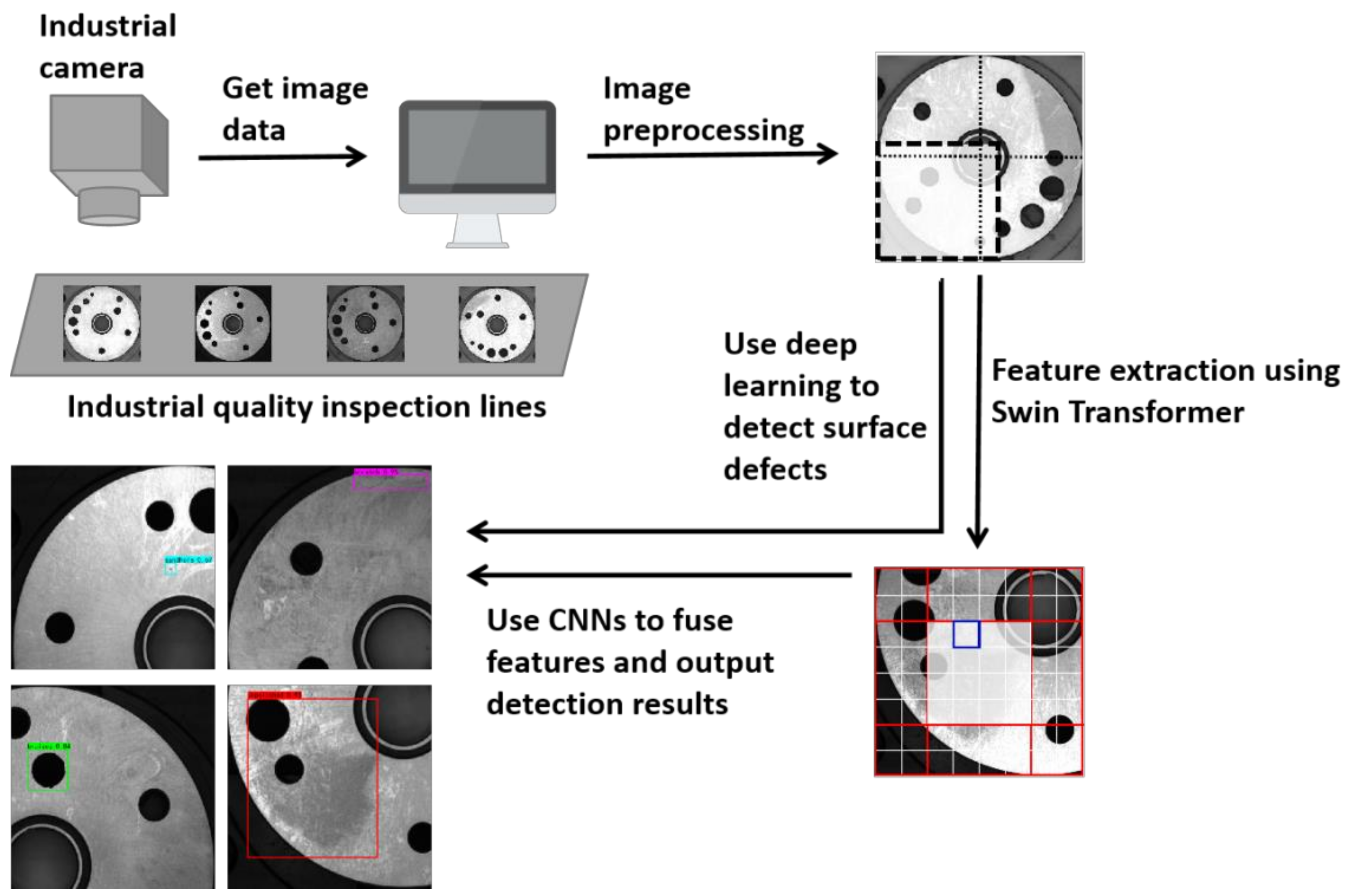
18]. The proposed model outperforms mainstream target detection algorithms on our private dataset of flange surface defects task and outperforms most existing models on public datasets of steel surface defects. The diagram of the process for detecting defects in flanges using our method is shown in
Figure 1.
2. Method
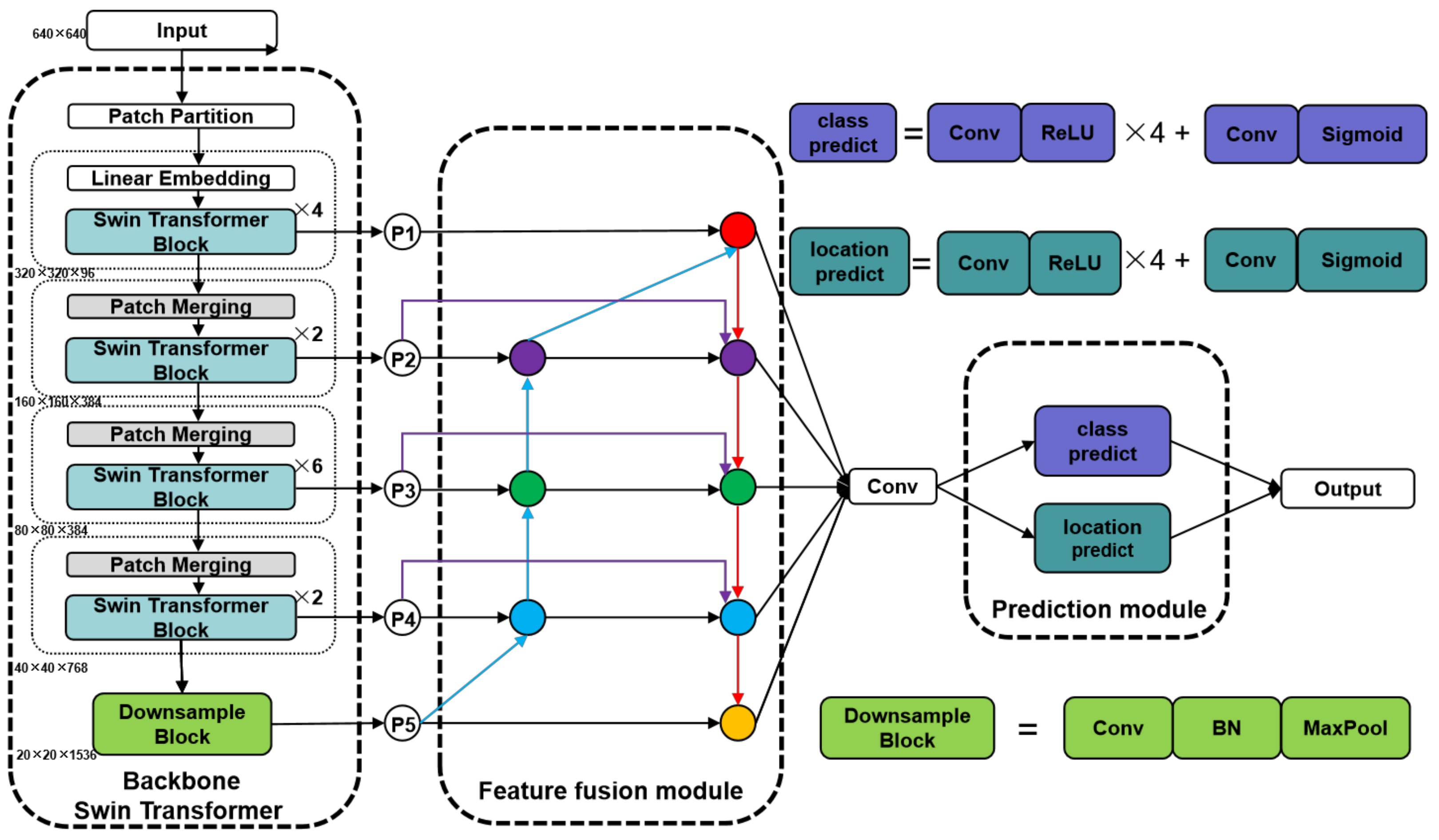
The overall architecture of the proposed method is shown in the
Figure 2, containing the backbone, feature fusion module and prediction module. The images are input into the patch partition in a Swin transformer to be split into non-overlapping patches. The feature of each patch is set to the concatenation of the original pixel RGB values. The size of each patch is 4 × 4, resulting in a feature dimension of each patch of 48 (4 × 4 × 3). The original features are adjusted to 96 after passing through the linear embedding layer. Then, the Swin transformer blocks are used for self-attentive computation and the first scale features are output. The patch merging layers are responsible for reducing the number of tokens, which can produce feature representations at different scales. A patch merging layer and several Swin transformer blocks are used as a combination to perform feature extraction. Three such combinations are present, and they can produce three layers of features at different scales. The deepest feature of the Swin transformer goes through a downsample block and outputs the fifth scale feature. The features of these five scales are input into the neck of the network for weighted feature fusion, after which the outputs of the five scales are fed into the detection head of the network for category and location prediction to obtain the final detection results.
2.1. Backbone
As shown in
Figure 2, after an image of size H × W × 3 is input into the backbone, it is first processed by patch partition to transform the image into 4 × 4 × 3 patches. The dimensions are converted from 48 to 96 by linear embedding. Unlike the original Swin transformer tiny, we input the data into four Swin transformer blocks for the first self-attentive computation. Many fine-grained features are present in the shallow layer with higher resolution, and we expect the network to learn these features in the shallow layer, benefiting the detection of surface defects on small targets. The obtained output P1 is input into the neck and input into patch merging for scale transformation. The transformed features are input to the Swin transformer block for self-attentive calculation. Patch merging with several Swin transformer blocks is configured as a combination of three groups, where the number of Swin transformer blocks are 2, 6 and 2. These blocks output P2, P3 and P4, respectively, to the neck of the network. P4 is downsampled by a simple structure consisting of convolution, batch normalization and Maxpool to obtain the output P5, helping enhance the perceptual field of the original Swin transformer.
2.1.1. Patch Merging
Given that the self-attentive computation does not change the size and dimension of the features, and we want to get hierarchical features in the Swin transformer as in CNNs, we need to add a patch merging layer. The schematic diagram of patch merging is shown in
Figure 3, where the first operation is to sample the incoming data at one point intervals and patch the sampled results in a dimension so that the dimension of the feature is expanded by four times and the size is reduced to one half of the original size. The second operation converts a feature of dimension 4C to 2C using a convolutional operation with a kernel size of 1 × 1. The patch merging operation consisting of the first operation and the second operation can achieve a hierarchy of features, which is important for target detection.
2.1.2. Swin Transformer Block
The flow chart of a Swin transformer block is shown in
Figure 4, where
is the input and
is the output.
LN stands for layer normalization, MLP stands for multilayer perceptron, W-MSA stands for windows multi-head self-attention and SW-MSA stands for shifted windows multi-head self-attention. These modules are used alternately in the Swin transformer block, and the mathematical expression can be expressed as
W-MSA is more efficient than global multi-head self-attention, and it enables dense prediction of high-resolution images. Given that its self-attention computation is performed within a local window, assuming here that N × N patches are within each window and the size of each patch is H × W, the computational complexity of global multi-head self-attention is
The computational complexity of shifted windows multi-head self-attention is
where C is the channel of the feature. The computational complexity is quadratic to HW when using MSA for self-attentive computation, while it is linear to HW when using W-MSA, making W-MSA capable of affordable computation for large HW.
Given that the windows separated by W-MSA are fixed, no information exchange occurs between different windows, which will bring adverse effects to the modelling ability of the model. Therefore, SW-MSA is introduced, which enables information communication between different windows by a simple window shift. As shown in
Figure 3, W-MSA and SW-MSA are used alternately in the Swin transformer block so that the model can perform self-attentive calculations and perform best on large-scale images. The schematic diagrams of MSA, W-MSA and SW-MSA are shown in
Figure 5.
Each non-overlap window W of W-MSA can be expressed as
The shared projection matrix on all windows is
,
,
. Q, K and V denote query, key and value, respectively,
indicating relative position bias. d is the dimension of query/key. They are used to calculate the self-attentive mechanism in one window, which can be formulated as
2.2. Feature Fusion Module
After the input data passes through several layers of patch merging and Swin transformer block, the feature extraction module will extract richer semantic information and obtain more channels, but the size of the data will also be reduced and some fine-grained information will disappear, resulting in the inability to extract these features. By fusing the features of different layers, the shallow features can be made to acquire the deep semantic information and the deep network to acquire the shallow fine-grained information to improve the detection capability of the model [
19]. We use BiFPN as the feature fusion part, which is structured as shown in the neck part in
Figure 2. The blue arrows represent the paths from the deep features to the shallow layers, which are responsible for transmitting semantic information. The red arrows represent the transfer of texture information from shallow to deep layers. The purple arrow transfers the raw features extracted by the backbone to the final output, which allows the model to fuse more features with minimal computational cost.
A total of five different scales of features are output from the backbone, where and are the features extracted by the Swin transformer block. is obtained from downsampling on the basis of . Adding consumes only a small amount of computational resources, but it can improve the detection performance of the model for large-scale targets. For the one-way path input nodes , their contribution to feature fusion is small, thereby simplifying its fusion process. Let the nodes with bi-directional paths (bottom-up and top-down) be a feature network layer (e.g., ,). For the feature network layer, a variety of weighted feature fusion processes is taken.
For example, its feature fusion process is shown in Equation (6), where represent the weights, represent the features and is a constant to ensure a stable value.
The
features from the backbone input are weighted,
is upsampled to have the same size as
and then weighted, and the two are summed and convolved to obtain
. We weight
, weight
and weight
after downsampling it to the same size as
, and compute
by convolution after summing the total of the three.
performs multiple feature fusions and these are not simply summed, but a weighted summation is performed to enhance the effect of important features on the fusion results. The features are weighted using fast normalised fusion, which is calculated in Equations (7) and (8). Using the Relu activation function ensures that each
and
= 0.0001 ensures stable values. BiFPN integrates fast normalized fusion with bi-directional cross-scale connectivity to efficiently fuse features from different scales.
2.3. Prediction Module
The prediction module is shared by five scale outputs, which is based on the anchor box for detection. The five scales of features output by the feature fusion side will first adjust the dimensionality to 256 uniformly and then will be sent to the class predict block and location predict block to predict the fused features. From
Figure 2, which shows their structure, Weight × Height × Number of classes × Anchor is output from the class predict block. Weight × Height × 4 × Anchor is output from the location predict block, where 4 indicates the prediction of the target’s location. Among them, three sizes of anchor box {
} are used, configured with three aspect ratios {1:2,1:1,2:1}. Each size of the feature output is assigned nine anchor boxes. We share the head module for the prediction of the results because it can reduce the number of parameters and can effectively alleviate the overfitting and improve the accuracy of the detection.
2.4. Loss Function
The two-stage target detection algorithm first calculates the region proposal and then performs target detection in the area where the target may exist. Given that the one-stage target detection algorithm does not have the process of region proposal, this will lead to a situation in which the foreground and background are extremely unbalanced. In addition, a large number of small target defects are found in the surface defects of industrial parts, which are prone to many negative samples during detection. When the number of negative samples is high to a certain extent, it will weaken the effect of those important samples on training. Therefore, we choose focal loss [
20] as the loss function to overcome this problem.
The standard cross-entropy (CE) loss can be expressed as
ground-truth class is represented by
is the probability value of the model predicting y = 1.
is defined as the following equation
Then, the CE loss can be expressed as
Generally, adding weighting factors is a solution to the class imbalance problem. We treat balance CE loss as the baseline of focal loss, which can be expressed as
-balance CE loss weights the importance of positive and negative samples. The focal loss adds a moderator to the CE loss, which differentiates the difficulty of the sample classification so that the model focuses on the difficult samples. Focal loss can be expressed as
manner where
is the modulation factor,
is the focusing parameter that adjusts the rate at which easily classified samples are down-weighted. In our experiments,
is set to 2, which is the same as in [
20].
3. Experiment
3.1. Dataset
The original flange surface defect data was collected by Daheng MER-500 industrial camera, and 200 pictures with a resolution of 2592 × 1944 were collected under three different lighting conditions. If the large size of the original map is directly downsampled and then fed into the model, it will lead to the disappearance of small target features, which is unfavorable for the feature extraction of the model and will directly lead to the missing detection of small target defects. Therefore, before labelling the data, some pre-processing of the original data is needed.
As shown in
Figure 6a, we first crop the redundant background in the image to keep the grey area and then crop a pair of images into four copies according to the overlap rate of 15%, and the size of each image is 1040 × 1040. On this basis, downsampling is performed to adjust the size to 640 × 640 for input to the model.
There are two reasons for processing the data as described above: (1) If the 2592 × 1944 pixel image is directly adjusted to a 640 × 640 pixel image, it will lead to the disappearance of fine-grained features, which is negative for the model to fit the flange surface defects. (2) Cropping the image according to a 15% overlap rate will ensure the integrity of the medium-sized defect bruises and enable the model to learn its features better. If the pictures are not cropped according to the certain overlap rate, it will lead to the learning targets being separated, which is disadvantageous for the model to fit the data [
21].
After pre-processing the original image data, we annotated the processed images according to the criteria of the VOC dataset, and the annotation of four different defects is shown in
Figure 6b.
We use a mixture of rotation, translation, flip and contrast to augment the data, expanding the amount of data to 10 times the original size. Notably, we have used some advanced data enhancement methods such as mosaic, cutmix and cutout for our experiments and found that these methods are not suitable for surface defect data enhancement. Given that many small targets are already present in the original data, further stitching operations will make extracting the features of the small targets difficult for the model. By contrast, using these methods generates a certain amount of redundant gradient information, which is detrimental to the training of the model. After suitable data enhancement, 80% of the data is used for model training, 10% for validation and 10% for testing.
3.2. Evaluation
We mainly use mAP, frames per second (FPS), parameters, and FLOPs as the main evaluation metrics of the model [
22]. mAP is the metric used to evaluate multi-category detection, which is the mean value of AP (average precision). AP is the area under the precision-recall curve for a particular class. Precision refers to the proportion of correctly predicted ‘TRUE’ samples out of all predicted ‘TRUE’ samples, and it is calculated as
Recall refers to the proportion of correctly predicted ‘TRUE’ samples out of all predicted ‘TRUE’ samples, and it is calculated as
AP is the average value of AP under different IoU (IoU from 0.50 to 0.95 where the step is 0.05), and the IoU is calculated as in (16), where X represents the detection area and Y represents the real area of the target. The larger the IoU, the more accurate the detection result.
The equation for mAP is calculated as
The closer the mAP is to 1, the better the detection of the model.
FPS represents how many images the model can process per second, and it is the most intuitive indicator of the detection speed. The higher the FPS, the faster the detection speed of the model.
The FPS is calculated as
where t represents the time in units of seconds to detect an image.
Floating point operations (FLOPs) represents the computational volume of the model. Parameters represent the complexity of the model. Smaller values of these two indicators indicate a more streamlined model.
3.3. Training Strategy and Experimental Environment
Before training the surface defect data, we load the weights of the backbone feature network after pre-training on the image Net1k [
23] dataset, allowing the network to converge faster and preventing overfitting [
24]. The pre-training strategy is as follows: optimizer is SGD, learning rate is 0.02, momentum is 0.9, weight decay is 0.0001 and epoch is set to 300 [
25].
For the flange surface defect data, our training strategy is as follows: optimizer is SGD [
26] (learning rate is 0.002, momentum is 0.9 and weight decay is 0.0001). Batch size is set to 24 and epoch is set to 100.
Our experimental environment is as follows: Ubuntu 20.04.4, Intel Xeon Silver 4210 CPU, NVIDIA A10*2 GPU, 64 GB RAM, Python version 3.7, Torch version 1.9.0 and CUDA version 11.1.
3.4. Comparison Method
We choose the most advanced one-stage detection algorithms YOLOX [
27] and RetinaNet and the most classical two-stage detection algorithm, Faster-RCNN [
28], as the methods for comparison experiments. We use CSPdarknet-L as the backbone of YOLOX and resnet50 [
29] as the backbone of RetinaNet and Faster-RCNN, which have similar FLOPs and parameters as the Swin transformer tiny.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}