Abstract
In recent years, the use of reinforcement learning and imitation learning to complete robot control tasks have become more popular. Demonstration and learning by experts have always been the goal of researchers. However, the lack of action data has been a significant limitation to learning by human demonstration. We propose an architecture based on a new 3D keypoint tracking model and generative adversarial imitation learning to learn from expert demonstrations. We used 3D keypoint tracking to make up for the lack of action data in simple images and then used image-to-image conversion to convert human hand demonstrations into robot images, which enabled subsequent generative adversarial imitation learning to learn smoothly. The estimation time of the 3D keypoint tracking model and the calculation time of the subsequent optimization algorithm was 30 ms. The coordinate errors of the model projected to the real 3D key point under correct detection were all within 1.8 cm. The tracking of key points did not require any sensors on the body; the operator did not need vision-related knowledge to correct the accuracy of the camera. By merely setting up a generic depth camera to track the mapping changes of key points after behavior clone training, the robot could learn human tasks by watching, including picking and placing an object and pouring water. We used pybullet to build an experimental environment to confirm our concept of the simplest behavioral cloning imitation to attest the success of the learning. The effectiveness of the proposed method was accomplished by a satisfactory performance requiring a sample efficiency of 20 sets for pick and place and 30 sets for pouring water.
1. Introduction
With the development of science and technology, robots are increasingly being used in human society, replacing some industries that require a large labor force and creating efficient productivity. Notwithstanding that, the roles of most robots are still focused on industrial applications. Due to the aging trend of the world’s population, the application of robots for long-term care at home has gradually received attention [1,2]. In recent years, the use of reinforcement learning (RL) and imitation learning (IL) to complete robot control tasks has become more popular. Deep IL is used to train deep neural networks on demonstration data [3], and since hard-coded robot control rules are not required, robots used in daily life have good application potential. The difficulty of using household robots lies in the variability of tasks and environments, while general robots require professional personnel and knowledge to be manipulated. Allowing humans to demonstrate specific actions and robot learning opens up the possibility of household robots [2]. A semantic-like framework with diverse settings towards fewer online interactions and human demonstrations, as well as more sample efficiency, is addressed in a so-called in-the-wild human-imitating robot learning approach [4]. Similar to the so-called cycle generative adversarial networks (CycleGAN) imitation learning module [5], this study aimed to observe human demonstrations only by setting up simple equipment such as depth cameras without using additional manipulators, wearing inertial measurement units (IMUs), and other equipment to complete tasks, forming more intuitive teachings.
In recent years, studies on the use of imitation learning to complete manipulator tasks have achieved quite good results [6,7,8,9], but these studies have established that explicit actions given by human experts can be obtained, which usually requires that the additional form of the demonstrator and the learner are usually the same, [7] through virtual augmented reality and manipulators for demonstration [8], through known controller models to collect demonstration data [9], and through a designed 6D manipulator used to manipulate the arm for insertion tasks. Although good results have been achieved in the virtual augmented reality method used in household robots [10], modeling must first be embedded in the virtual and the current environments.
In certain situations wherein complete action information cannot be obtained, learning based on observation alone becomes a big problem [11]. The agent is allowed to use the experience to self-supervise the training model (the inverse kinematics model) and then apply it to specific tasks to amend the lack of action data. However, in the case of learning from human demonstrations, besides the lack of action information, the difference in the form of the human hand and the manipulator in the observation data also makes direct imitation impossible. The current research on solving human hand demonstration learning is divided into several directions. The human hand demonstration image is converted into a robot image through image conversion, which is transferrable [12,13,14,15]. After image conversion is used, model-based method learning [13] converts the transformed robot image to mark the keypoints of the arm to form a keypoint trajectory and then use the distance difference with the keypoint during learning as a reward function for training [14]. The control is divided into low-level and high-level controllers. In addition to converting images, high-level controllers also generate predictive images, which are then handed over to low-level controllers to generate actions. In addition to image generation, some researchers also use the characteristics of domain adaption to make the features extracted by the robot the same as the human hand and then bring the features into the inverse kinematics model to generate actions, most of which are trained by model-free reinforcement learning methods [15].
Some RL-related image processing works have established the architecture of reinforced transformer networks for an array of medical tasks such as coronary CT angiography vessel-level image quality assessment [16]. Image processing works that involve IL have advanced in sparse search issues, including urban driving with conditional imitation learning [17] and multi-task imitation learning for enabling a vision-based robotic manipulation system [18], to name a few.
With image conversion to solve the problem of the human hand image, inspired by an earlier study [12], we are aware of the limitation to be two-dimensional information on the converted image from capturing the keypoints [13]. Leveraging the method from [13] and a sensor-free three-dimensional solution [19], our converted image was critically used as a demonstration trajectory by directly collecting the keypoints of the human hand and the three-dimensional changes to compensate for the lack of action data. Through comparison, the observation value was not affected by the slight deviation of the image after the conversion.
The proposed framework involves learning from experts based on 3D keypoint tracking and imitation learning and attempts to deliver four contributions:
- A.
- Using keypoint tracking to make up for the lack of motion data in simple images, followed by image conversion to convert the human hand demonstration into a robot image, enabling the subsequent imitation learning to be received and learned smoothly, which only relies on a basic depth camera;
- B.
- With no overlapping of items, each category only needs to collect 40 images and be augmented with data to obtain the 3D pose and type of the item (hand, finger, and object) [7,9,10]. When it is a single-label task, the estimation time of the model plus the calculation time of the subsequent optimization algorithm takes 30 ms. The coordinate errors of the model projected to the real 3D key point under correct detection are all within 1.8 cm.
- C.
- Maintaining the same movement range of the key points of the same robot and human under the condition of the same grasping posture;
- D.
- Using image transformation to solve the problem of different observations by human hand and manipulator;
- E.
- Using imitation learning to achieve robotic learning of human demonstration tasks.
This paper, in Section 2, first highlights the hardware and software support of the proposed framework. In Section 3, a four-faceted systematic approach for keypoint extraction and imitation learning is presented. Section 4 then demonstrates an experimental environment as an example with effectiveness assessments. Section 5 addresses limitations for future research.
2. Background
To learn from human demonstrations, our method relies on several key steps: heat map regression to keypoints, human image conversion, and imitation learning. In this section, we review the first two steps of the technology we borrowed.
2.1. Heat Map Regression Keypoint Extraction
Heat map regression is widely used in semantic landmark positioning [17]. Leveraging the method [17] and Gaussian functions [2,3,4] for handling keypoints of human faces, hands, and bodies, as well as household items, the keypoints on a 2D picture are marked, and the 2D Gaussian function is used to convert the keypoints to generate a Gaussian function heat map. The formula of the two-dimensional Gaussian function is defined as Equation (1):
An amplitude mean is set to 255. If it is set to 1, it is too small when calculating the loss function, which affects the training result x0 and y0, the center coordinates of the generation; and are Gaussian parameters, which affect the size of the generated point.
2.2. Cycle Generative Adversarial Networks
The goal of image-to-image conversion is to use a set of aligned image-pair training to learn the mapping between the input image and the output image. Traditional image conversion requires pairing the images in advance. For many tasks, the paired training data is not available. In one report on CycleGAN [20], a method of learning was proposed to transform an image from the source domain X to the target domain Y without pairing examples. The goal of CycleGAN is to learn the two-domain mapping G: X→Y and F: Y→X and introduce the discriminators D_X and D_Y to train using adversarial loss to make the image distribution from the source domain indistinguishable from the target domain image distribution. The constraints of this mapping are seriously insufficient; therefore, CycleGAN couples it with the inverse mapping F: Y→X and introduces cycle-consistency loss to promote F(G(X)) ≈ X (and vice versa).
Therefore, the objective function of CycleGAN is shown in Equation (2), where λ is a hyperparameter:
where is the adversarial loss:
is the cycle consistency loss:
2.3. Behavior Clone
Behavior cloning [19,21] is the most intuitive and simple method in imitation learning. As literally defined, it is an agent whose behavior after observation needs to be trained to be as close as possible to the demonstrator and expert. Since the behaviors of our expected experts usually have the largest or better functional value, the meaning of behavior cloning is to find a decision function that minimizes the action probability distribution of the expert strategy. The Kullbac–Leibler (KL)-divergence performance is as follows:
This makes behavioral cloning a simple supervised learning problem. We proposed to use maximum log-likelihood to minimize KL-divergence so that the neural network can have the best regression results. Therefore, if the value of the loss function is small, the agent can better imitate the expert’s strategy, which can be similar to the maximum reward strategy when making decisions.
2.4. Soft Q-Function (Q) Imitation Learning (SQIL)
SQIL [22] proposes an alternative to adversarial imitation learning to learn reward functions from demonstrations. The key idea of SQIL is to encourage agents to return to the demo state when they encounter a new state that has not been observed, thereby motivating them to match the demonstration data for a long period. Therefore, SQIL sets the reward of the demonstration data as a constant reward of r = 1 and sets a constant reward of r = 0 for the data interacting with the environment. This makes the problem a reinforcement learning problem with sparse rewards. SQIL can be implemented by making minor modifications to any standard Q-learning or off-policy actor–critic algorithm.
3. System Design
In the problem setting, we expected that the task that the robot learned could be specified by a set of human demonstrations, and each demonstration movie is an image observation trajectory depicting the human performing the task. The demonstrations are not accessed via remote operation or teaching box learning, which usually requires specific hardware and expertise. Besides, the rewards are not assumed to be provided through the environment settings. Therefore, our goal is to achieve robot learning with minimal professional knowledge and equipment. The task description demonstrated by humans is a step towards this goal.
This section details keypoint detection, CycleGAN training, and other design choices in robot learning that reflect this goal.
3.1. Keypoint Detection
For the tracking of keypoints, we referred to the very popular heat map regression method to train the model. The model mainly comprises EfficientNet as a branch of the convolutional neural networks (ConvNets) family [23], as shown in Figure 1. Its backbone function, similar to the one in EfficientNet, extracts the features of the image and uses them to encode the image and uses EfficientNet-B2 [23] to simplify the architecture. The process uses multiple depthwise separable convolutions to productively reduce the model parameters. The mobile inverted bottleneck convolutional 2D (MBConv2d) model architecture is mainly the inverted residual block, and Squeeze-and-Excitation Net is the 2D mobile architecture MobileNetV2 [24,25]. These two are the basis for the MBConv2d model to build EfficientNet. The residual network [26], which is reduced after the increase in the number of channels, leads to better feature information. First, the length is changed to the shape of the original number of channels and the size is 1, and multiplication is performed using the original data. The important channel is given a larger weight, which is the attention concentration mechanism, as detailed earlier [26]. Similar to the previous report [25], the feature output layer in the EfficientNet model is connected to the upsampling layer in the head and concatenated using the concatenate method.
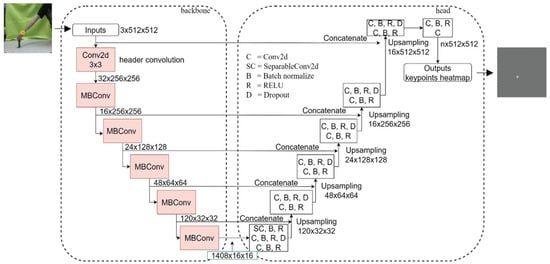
Figure 1.
The keypoint prediction model.
The head part uses a neural network model [23,24] as the output prediction of the key point heat map, except for the general convolution layer (abbreviation C = Conv2d) and the deconvolution layer (abbreviation D) in the original architecture. This study uses batch normalization (see abbreviation B = Batch normalize) to randomly turn off neurons (see abbreviation D = Dropout) to avoid overfitting and uses depthwise separable convolution to replace the convolutional layer at the bottom of the u-shaped network, as shown in Figure 1, to avoid excessive parameters. A comparison of the amount of video memory occupied by the depthwise separable convolution and the number of model parameters clearly reveals that the use of depthwise separable convolution can effectively reduce the size of the memory occupied by the general neural network model parameters. As shown in Figure 1, the left is the backbone, which comprises the MBConv block of EfficientNet. After encoding, it is decoded by the right head, and finally, the heat map of the key points is output.
The model generates the input image through the 2D Gaussian function to generate a Gaussian heat map, and then the generated Gaussian heat map is used for the mean square error. In addition, the thermal image generated by the model is obtained through the soft-argmax and is two-dimensional in nature. The coordinates of the keypoints are calculated with the actual coordinates of the keypoints marked. In the data collection of the demonstration action, the image and depth information are stored separately. In addition to the subsequent image conversion, the image is also used to predict the position of the keypoint through the trained prediction model, and the predicted keypoint position is the position in the image; thus, it is necessary to map the 2-dimensional keypoint information back to the real marking information. Equation (6) is used to convert the stored depth information to obtain the value in the Z direction, where the subscript c represents the camera as the position information of the fiducial coordinates. The matrix in the middle is the internal parameters of the camera, and u and v are the keypoint coordinates of the 2D image annotation.
3.2. Translation for Human Expert Image
CycleGAN needs images of two source domains (hand and manipulator). Herein, a random strategy was used to collect the images of the hand and manipulator, since CycleGAN does not need to pair the images of the hand and manipulator with the same posture, as it need not deliberately be the same in number.
3.3. Imitation Learning
Part of the human demonstration trajectory was collected in the aforementioned experiment. The position information was obtained through the tracking of the keypoints. The subscript t was the sequence of the number of frames captured by the demonstration video. To supplement the lack of movement in the manual demonstration and learning, we used the position change of the keypoints as the movement information : ; in this way, a sequence of motion trajectories was generated, and the observation value to be used as a demonstration trajectory was a robot converted by a human hand through CycleGAN Image sequence . After pairing the action sequence with the image sequence, the demonstration sequence was ; this sequence was trained by subsequent imitation.
3.4. System Structure
Since this research aimed to allow people without knowledge of robot manipulation to teach robots through their own demonstrations, and these people cannot recollect robot images or images of keypoints for each task; hence, we hypothesized an architecture. When a person demonstrates an action, the depth camera saves the depth and image information, uploads it to the local or the cloud, and selects different modules according to different tasks through different task modules that have been pre-trained by developers and manufacturers. These modules include different CycleGAN models and keypoint tracking models. The module converts the image of the demonstration action into a robot image and the image and depth information into actionable information. After the conversion, the demonstration data is integrated and transmitted to the robot for the execution of imitation learning. The overall structure is shown in Figure 2.
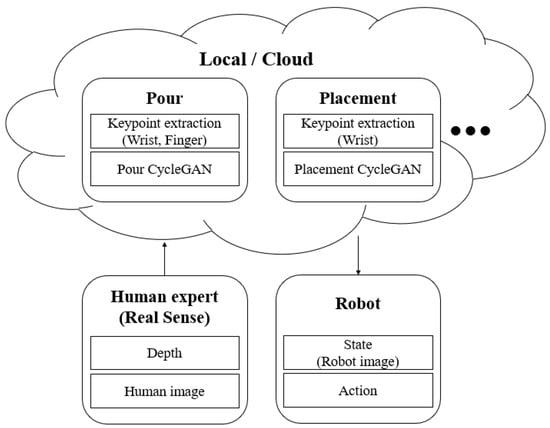
Figure 2.
The system structure.
4. Experiment
Herein, we introduce the experimental setup and report the results obtained. We aimed to test the following questions: (1) Can our architecture imitate the manual demonstration of the above simple architecture to complete the task? (2) Does it have certain robustness?
The hardware devices used in this study were a Franka Emika Panda, an Intel Realsense D435 camera, and a personal computer with processor: Intel core I7-9700K CPU@3.6Ghz × 8, memory 31.3 GiB, graphics processor RTX2080ti 12 G. The software environment comprised OS-Linux (Ubuntu 20.04), Python 3.8.5, Pytorch 1.1.1, CUDA 11.2, and GPU-driver 4460.32. In this study, the Franka Emika Panda arm was used in the virtual environment. Since there was no need to use any additional communication protocol settings in the virtual environment, the arms were controlled by the API provided by the virtual environment as a control method.
To verify the above-mentioned architecture of the system, we first collected the data required for the task based on the developer’s assumptions, trained the keypoint tracking model and image conversion model, and then provided demonstration actions from the user’s standpoint. Then, we went through the previous training. A good tracking model and image conversion model generated data and finally validated the feasibility of the architecture in different simulation learning experiments.
We set up our experimental environment for evaluation in the simulation pybullet environment. We evaluated two tasks: placement and pouring things.
- (1)
- The placement experiment is mainly aimed at assessing common placement actions in a family to perform a task. It is different from the common moving and pushing experiments in reinforcement learning and imitation learning. The robot is in the condition of picking up objects (this experiment used a black USB). The robot must place it in the target area. Its starting point and the height of the target point are not consistent. Therefore, simple movement in the X and Y directions cannot achieve the task. Therefore, the entire action space is three-dimensional rather than two-dimensional.
- (2)
- The task of pouring things is also a common action in home tasks. The robot must move to the container and start to rotate to pour the liquid and objects in the container into the container without too much offset; otherwise it will pour it all out of the vessel. We also placed the vessel on a platform with a height different from the initial position to make it more difficult. The pouring task is different from the placement task. In addition to the three-direction movement of the end effector (X, Y, Z), it also adds the rotation angle of the gripper θ.
In the training phase, the robot only received 256 × 256 × 3 RBG images as observation results. The robot was controlled by the operating space controller in the three-dimensional position of the end effector. We also assumed and fixed the initial posture of the robot arm and the initial position of the object and target.
4.1. Keypoint Detection
Placement task. To use keypoint tracking to supplement the lack of motion data, we believed that if the position and posture of the end effector of the robotic arm relative to the world coordinate can be known, then the subsequent joint values of the robotic arm can be reversed using inverse kinematics, and there is no need to perform the conversion for the joints of the human arm. In other words, the position and posture of the end effector can best express its movement, and the position where the human hand can best express its position is the wrist. When the relative gripping posture of the object is the same, the distance required to move to the target point is the same; thus, the use of tracking the position change of the keypoints of the wrist can make up for the lack of motion data.
For keypoint training data, we collected not only in the environment where the task was placed but also in an environment with complex scenes. The collected information was also added to the data augmentation during training. In order that the trained model could be directly used on other task models in the future, the training data was not limited to the fixed wrist posture in the placement experiment but also to train data from various other angles, as shown in Figure 3. There were a total of 160 wrist training materials, 10 of which were randomly selected as test materials, and 150 generations were trained. The training results are shown in Figure 4; Figure 4a is the mean square error (MSE) loss graph of the heat map regression, Figure 4b is the MSE loss graph of the image coordinates converted from the heat map, and Figure 4c is the accuracy of the test and training data. The accuracy of the test data here was higher than that of the training data because the training data was augmented (flip, blur, etc.), and the test data was based on the original image. In addition, the performance of the pybullet-based validation set complied with the mainstream virtual environment (other available but costly protocols are Gazebo and Mujoco) on artificial intelligence (AI) supporting quality objects and material characteristics, therefore rendering higher accuracy than the training set.

Figure 3.
Wrist data collection.
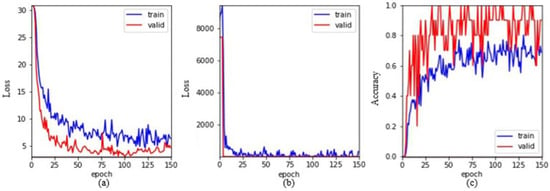
Figure 4.
Wrist keypoint training. (a) The mean square error (MSE) loss graph of the heat map regression. (b) The MSE loss graph of the image coordinates converted from the heat map. (c) The accuracy of the test and training data.
The trained model was applied to the demonstration data, and the experiment was placed for a total of 20 demonstrations, with the frequency of the camera being 20 Hz. Since the demonstration data did not require real-time tracking, the demonstration was not processed in real-time when the camera was shooting, and the fps was not in the evaluation range of this study. The stored keypoints were the output, and their movement value was taken, and the total combined movement value was compared with the actual set distance (20 cm, 20 cm, 0 cm), and its value is listed in Table 1; the blue number was the average value. The coordinate error of the model projected to the real 3D key point under correct detection was set at 1.8 cm.

Table 1.
The total average of the target distance and the action generated by the keypoint.
The results show that none of our motion data is too far away from the target point, proving the correctness of motion data generated by our keypoint tracking. In addition to the actual target point error, the error also includes the keypoint prediction error and the error of the camera placement, as well as whether the action space is parallel and whether the camera is placed horizontally. We expect that ordinary people can easily set up an environmental depth camera at home, as they only use the naked eye to correct the camera without using tools such as horizontal movement. Thus, the data set was not collected at the same time and was re-adjusted with the naked eye every time. The Z direction in the data shows that the Z value of the camera is affected because the placement of the camera was not completely horizontal to the horizon, but the error does not affect it significantly.
Pouring task. If a single-sided camera is used for keypoint detection, like the placement task, there is the problem of occlusion. But in the placement task, a camera is also placed on the front, so the front camera can be used for keypoint detection. To use keypoint tracking to make up for the lack of rotation motion data, the grasp of the hand to the index finger is limited, and the thumb must be parallel and face the camera frontally so that the keypoints of the index finger and thumb can be used to infer the relationship between the index finger and the thumb. The angle of the camera’s horizontal axis can make up for the lack of rotation motion data, while the motion data in the three XYZ directions follow the model trained when placing the task to track the keypoints.
The keypoint training data, as with the placement task, is not only collected in the placement task environment but also in the environment with complex scenes and adds training data from various other angles. To increase the robustness and versatility of the model, we also collected information about grasping different objects. When rotating, the object is not guaranteed to always stay parallel to the camera, so images that are not completely parallel to the camera were also added to the training data. The parameter setting of training was compared with the setting of the placement task, and the training result is shown in Figure 5.
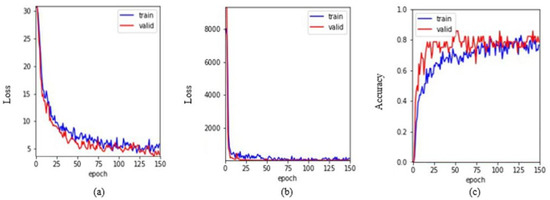
Figure 5.
Finger rotation keypoint training. (a) The MSE loss graph of the heat map regression. (b) The MSE loss graph of the image coordinates converted from the heat map. (c) The accuracy of the test and training data.
The trained model was applied to the demonstration data, and the pouring task was demonstrated for a total of 30 times, and the rest of the camera and other settings remained the same as in the placement experiment. The stored keypoints were received as output, and their movement value was taken. The difference from the placement experiment is that the pouring experiment added the rotation data. For the rotation data, we did not use the absolute angle as the action value, but it was the same as the translation value. The relative rotation angle between detections was used as the action value. For the relative relationship between the two keypoints of the finger (Figure 6), the blue represents the thumb and the red represents the index finger. To calculate the rotation angle, a tan was used to convert () into a real angle. However, with the calculation of the relative relationship, the angle must be converted again, as shown in Table 2.
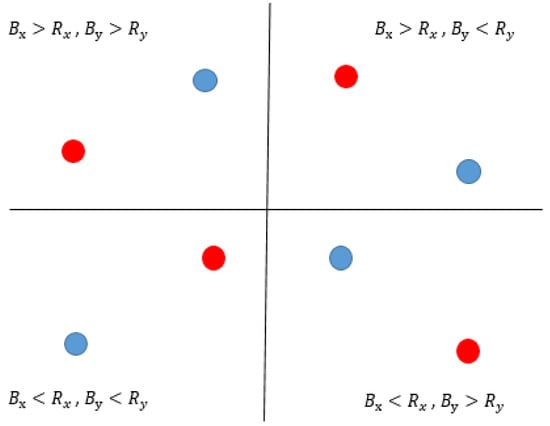
Figure 6.
Relative relationship between fingers. The blue dot represents the thumb and the red one represents the index finger.
Table 2.
Finger angle conversion table.
4.2. Cycle Generative Adversarial Networks
CycleGAN trains a total of 100 epochs and stores parameters every ten epochs, but CycleGAN is not trained as many times as possible. Since CycleGAN is based on GAN, it may cause the generator to over-converge, causing the generator to ignore the source domain image. No matter how long the duration, the same image is always generated, regardless of whether the human hand image is converted to the robot hand in any posture. Therefore, after comparison, we finally selected the best 50 epochs for useful parameters.
The reference arrangement of the image of the human hand and the generated robotic arm is demonstrated in Figure 7; the results show a good effect of CycleGAN. In addition to transforming the human hand style to a robotic arm, its structure and image space position can be smoothly converted from a human hand to a robotic hand, even if there are occasional incompletely converted color blocks in the surrounding area. But this does not affect the feature extraction of subsequent training.
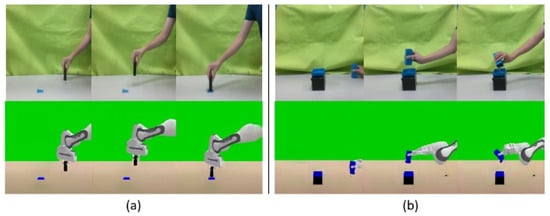
Figure 7.
Demonstration image and CycleGAN result. (a) Relatively vertical human hand data. (b) Relatively horizontal human hand data.
4.3. Behavior Cloning
Placement tasks. The most basic behavioral cloning is used as the architecture of imitation learning. The agent architecture in behavioral cloning is set to an EfficentNet plus three fully connected layers. The model is shown in Figure 8. The live function of the fully connected layer is Relu, and the output activation function is tanh so that the output can be limited to the (−1, 1) interval, and the output action is finally normalized according to the set maximum and minimum action values.
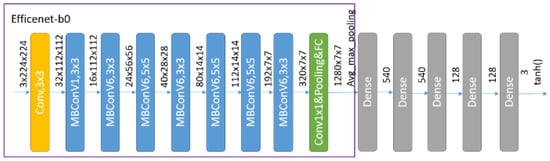
Figure 8.
Behavior clone model.
To test the efficiency of the data, 10 demonstration data were first selected as the demonstration learning data used for training. As a result, it was completely impossible to train. When the arm moved the USB above the target point, the output of the X and Y directions decreased. But the Z direction was not increased, so the USB could be lowered and placed on the target platform. Behavioral cloning is prone to state shifts due to unwatched states, and the accumulation of these shifts results in a final trajectory that is far from the desired trajectory, so we added the amount of data to 20 demonstration data. From the results, the USB path had slight improvement, but the distance from the target platform was still offset, and the downward movement was not made.
It was speculated that taking the side image as the observation value was not enough to predict the current system state, so we added a frontal environmental camera and used the same data collection method as the side environmental camera to perform image conversion (Figure 9). The only difference was that using the frontal environmental camera did not require keypoint tracking. The 10 repetitions of demonstration data were used for training, yet the number of successes did not improve. However, from the process perspective, the movement and position of the USB drop improved more significantly than in the single-view situation. After increasing number of the demonstration data to 20, the success rate rose sharply from that of the training process, and the downward movement of the USB became very obvious within the set target platform. The training results are shown in Figure 10, wherein Figure 10a shows the 10 training data, while Figure 10b shows the training process using 20 data. We only gave a reward for detection when we succeeded and considered one peak in the picture as one success. Obviously, the case with 20 data had 10 times the successful peaks better than the case using 10 data.

Figure 9.
The results of cycle generative adversarial networks from the frontal environmental camera for a placement task behavior clone.
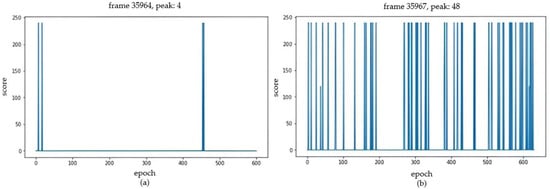
Figure 10.
Placement task behavior clone training. (a) Training process using 10 data. (b) Training process using 20 data.
Pouring task. Use the same behavioral cloning agent (EfficentNet plus three fully connected layers) as the main model as in the placement experiment, the output action increased and became (X, Y, Z, θ) four-dimensional output. To test the sample efficiency of the data, the first 20 demonstration materials were selected as the demonstration learning materials for training. The number of successes was only one (one peak), as shown in Figure 11a. The path deviation of the arm was much larger than that of the placement experiment, and the object was poured out of the tray. Therefore, we added 30 repetitions to the demonstration data, and the number of times the agent successfully completed the action greatly increased to more than one hundred peaks, making the training successful, as shown in Figure 11b.
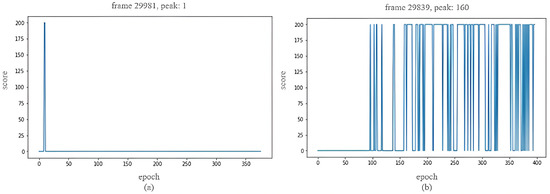
Figure 11.
Pouring task behavior clone training. (a) One peak. (b) Multiple peaks.
4.4. Soft Q-Function (Q) Imitation Learning
Placement task. We used the same 20 demonstration data as the aforementioned imitation learning to learn, gave the demonstration data a constant reward of 1, and used the reinforcement learning method of the soft actor–critic (SAC) to achieve SQIL. Initially, only the basic SAC was used, and the actor and critic did not share the same convolutional layer but were independent of each other. The model cannot use sparse reward signals to train the model to obtain latent dynamics from high-dimensional images, and poor sample efficiency requires a large amount of interactive training data, which can easily lead to poor performance. The way to solve this problem is to add an autoencoder that can reconstruct the image. We referred to an earlier method [27] to add an autoencoder to the SAC and let the actor and the critic use the same autoencoder extracted by the encoder feature. The model update was different from the original SAC in [28] to prevent the non-stationary gradient from the actor from causing poor agent performance, so the actor’s gradient update to the convolutional network was frozen, and only the gradient of the critic and the decoder was propagated. As with the behavioral clone setting, the SQIL still maintained the reward, which was greater than 0 to represent success, and the training was stopped when the success rate exceeded 75% in the prior 10 repetitions, and the update frequency was set to update every step. Figure 12 shows that it started to converge after about 65 interactions, and the success rate increased sharply. After 82 interactions (about 11,599 steps), the target success rate was reached, and training was stopped.
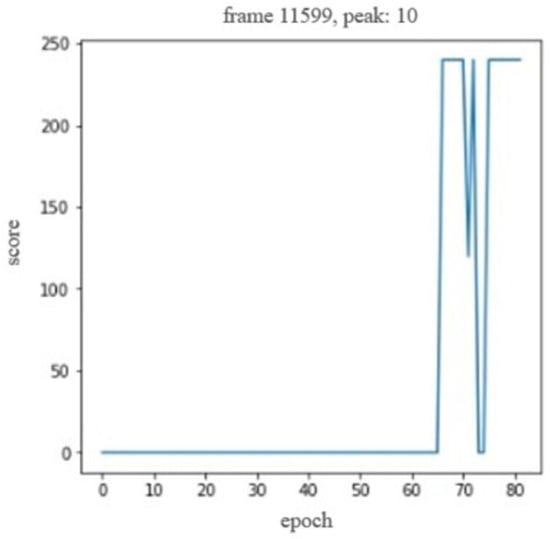
Figure 12.
Soft Q-function (Q) imitation learning training graph for a placement task.
Pouring task. The training model remained the same as the placement task; only the output dimension and movement were adjusted. Training data refers to the direct use of the same data as behavioral cloning. The training results are shown in Figure 13. Due to the randomness of SAC, training for pouring tasks with higher action dimensions was not faster than behavioral cloning, and it was easy to converge on a sub-optimal strategy, causing the arm to only hover on the stage.
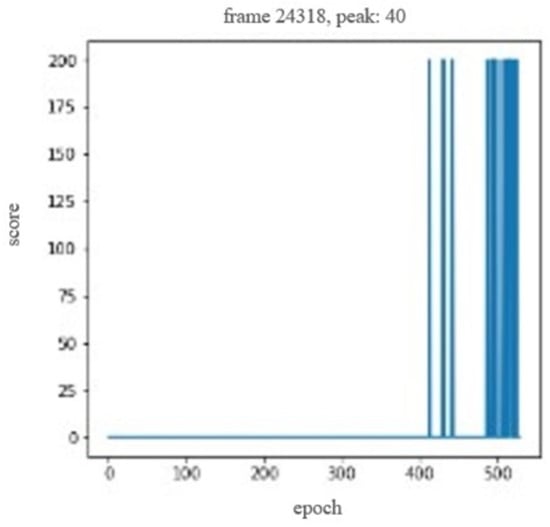
Figure 13.
Soft Q-function (Q) imitation learning training graph for a pouring task.
4.5. Robust Test
Placement task. In the training process, the average number of successes of nearly ten interactions was taken during each interaction with the environment as the basis for comparison, and the model parameters with the highest success rate for ten repetitions were stored as the test. In the placement task, considering that the initial position of the item placed under actual conditions cannot be completely consistent, so to test that the model trained by this method had certain robustness to the change in the starting position, we made three sets of initial deviations. For experiments within (±0, ±0, ±0), (±3, ±3, +3), (±5, ±5, +5) cm, each experiment performed 100 actions, and the results are shown in Table 3.
Table 3.
Placement task robustness test.
The test results prove that, even if the initial position has a certain degree of error, the trained model can still slightly correct the position of the arm so that the arm can reach the position as expected, suggesting that the trained strategy network maintains a certain degree of robustness. SQIL encourages the agent to return to the expert demonstration trajectory during training; therefore, it can pull back the expert trajectory in the case of large deviations from the initial point, which is more robust than the behavioral cloning of the greedy method.
Pouring task. In the training process, the average number of successes of nearly five times was taken as the basis for comparison, and the model parameters with the highest success rate of the five repetitions were stored for testing. In the pouring task, considering that the initial position of the cup grip under actual conditions cannot be completely consistent, so to test that the model trained by this method had certain robustness to the change in the starting position, we made three sets of initial deviations. For experiments within (±0, ±0, ±0), (±3, ±3, +3), (±5, ±5, +5) cm, each experiment performed 100 actions. The results are presented in Table 4. The success rate of the test results proves that even with a certain degree of error in the initial position, the trained model can still slightly correct the position of the arm so that the arm reaches the position as expected and pours the objects into the cup into the tray. Such an experiment represents the strategy network after training to maintain a certain degree of robustness.
Table 4.
Pouring task robustness test.
4.6. Comparison with Other Algorithms
To depict the advantages of our framework fairly, we implemented a classifier-based reward learning method in a similar fashion to so-called RL with active queries (RAQ) [28] as a benchmark. For comparison, we applied our SQIL to the same control model described earlier [28]. For each task, we directly gave the real robot image instead of the robot image after image conversion and used the classifier to pre-train the target image with positive labels and the remaining images with negative labels. The logarithmic reward function was given by the classifier during the training. In the placement task, we gave 248 positive and negative sample images and 120 for the pouring task. The RAQ needed to actively ask the user whether the image with the highest score in the register was completed or not during training; therefore, we referred to the parameter in RAQ and set it to be asked once at 500 time-steps. After that, our method and the baseline reinforcement learning method were also compared in the updated benchmark at 50 k time steps on the success rates. Results are listed in Table 5.
Table 5.
Comparison table with reinforcement learning realized by RL with active queries.
The results show that our method obviously outperformed the reinforcement learning method that requires a large amount of interactive data, especially in a high-dimensional environment with complex actions (pouring water task). Our method has more advantages, and it is expressed according to the training data we placed in the experiment. We could train by updating the 20 k time steps, while the reinforcement learning method requiring a lot of interactions within the environment approached the restricted 50 k time steps. The amounts of demonstration data were as efficient as possible, requiring 20 sets for pick and place and 30 sets for pouring water. To prove our improvement in sample efficiency compared with other based techniques, we performed experiments in alignment with quantitative approaches in [14,18,28], as shown in Table 6.
Table 6.
Difference between our proposed method and other based techniques in terms of comparison strategy.
5. Conclusions
To summarize, a simple depth camera was set to track the mapping changes of keypoints and achieved the task of letting the robot learn from humans after behavioral cloning training through viewing. The operation did not require prior knowledge about the robot.
The tracking of keypoints did not require the installation of any sensors on the body. The operator did not need vision-related knowledge of calibration to secure the accuracy of the camera, not relying on tools such as level gauges either. From the results, the motion data generated by the keypoint tracking in this method were as accurate as possible.
The method of image conversion overcame the problem of morphological differences. Although images from two source domains were required, the feature of not having to pair them allowed the use of previously collected data for future tasks. The demonstration data obtained through the proposed method accomplished the simplest behavioral cloning simulation learning by successfully involving the minimum data volume of 20 sets, which attested to the efficiency of the method.
For the observation problems caused by the different types between humans and manipulators, the current mainstream is the image-to-image conversion that requires a large amount of data sets for training for both sides; nonetheless, effectiveness is not guaranteed. In the future, possible improvements may involve the extraction of convolutional neural networks and the characteristics of CycleGAN to overlap the distribution of features extracted in the same state.
This research proposed the feature tracking of the human wrist and the feature tracking of the two points of the finger. The action data generated by keypoint tracking is converted from image and depth. Although the environmental camera is easy to set up and low in cost, the places where the robot can be used are still limited. If it is to be extended to the home market, the depth camera on the robot is expected to be used to observe human movements and through the first-person perspective during training.
The existing robots are mostly industrial robots and collaborative robots. In the future, as research in this area increases, a special household robot or personal robot may be developed to address these problems to solve the motion and shape problems caused by different structures.
The salient limitations of this study are listed as follows. If the keypoint is occluded, the misjudgment of the depth information will occur, resulting in incorrect subsequent action data. Therefore, the keypoints of this study must be under the conditions wherein no unoccluded area exists. Research concerning the keypoints of the human hand is ongoing for the improvement in the occlusion problem for more complex tasks.
Although image processing can convert the shape of a human hand into a mechanical arm, if the profile difference is too high, such as a large industrial arm versus a human hand, the conversion may fail due to the extreme difference in profile. Therefore, the recommended options fall into collaborative or dual-arm robots such as UR5, Sawyer, and Baxter.
Author Contributions
Conceptualization, Y.-T.A.S.; formal analysis, P.-Y.W.; resources, J.-T.H.; writing—review & editing, H.-C.L., J.-T.H. and Y.-T.A.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest. To the best of our knowledge, the named authors have no conflict of interest, financial or otherwise.
References
- Fu, H.; Zhang, J.; Zhang, Q.; Bao, C.; Huang, Y.; Xu, W.; Lu, C. RoboTube: Learning Household Manipulation from Human Videos with Simulated Twin Environments. In Proceedings of the Presented at the Workshop on Learning from Diverse, Offline Data, Auckland, New Zealand, 14–18 December 2022; Available online: https://openreview.net/forum?id=SYUEnQtK85o (accessed on 13 September 2022).
- Yang, J.; Zhang, J.; Settle, C.; Rai, A.; Antonova, R.; Bohg, J. Learning Periodic Tasks from Human Demonstrations. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 8658–8665. Available online: https://ieeexplore.ieee.org/abstract/document/9812402/ (accessed on 12 July 2022).
- Kim, H.; Ohmura, Y.; Nagakubo, A.; Kuniyoshi, Y. Training Robots without Robots: Deep Imitation Learning for Master-to-Robot Policy Transfer. arXiv 2022, arXiv:2202.09574. [Google Scholar]
- Bahl, S.; Gupta, A.; Pathak, D. Human-to-Robot Imitation in the Wild. arXiv 2022, arXiv:2207.09450. [Google Scholar]
- Li, J.; Lu, T.; Cao, X.; Cai, Y.; Wang, S. Meta-Imitation Learning by Watching Video Demonstrations. In Proceedings of the Tenth International Conference on Learning Representations, Online, 25–29 April 2022; Available online: https://openreview.net/forum?id=KTPuIsx4pmo (accessed on 9 May 2022).
- Ho, J.; Ermon, S. Generative adversarial imitation learning. In Advances in Neural Information Processing Systems 29, Proceedings of the Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2017; pp. 4565–4573. Available online: https://proceedings.neurips.cc/paper/2016/hash/cc7e2b878868cbae992d1fb743995d8f-Abstract.html (accessed on 1 August 2022).
- Zhang, T.; McCarthy, Z.; Jow, O.; Lee, D.; Chen, X.; Goldberg, K.; Abbeel, P. Deep imitation learning for complex manipulation tasks from virtual reality teleoperation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 5628–5635. Available online: https://ieeexplore.ieee.org/abstract/document/8461249/?casa_token=q90l5s-eeeQAAAAA:fk4MUKdlIXpIQZvO2TKZvIalmnG2OkMjt7rNL1T_jxe1jbO6r9uqX2IK5yBOhf2880XorBC6ZsE (accessed on 13 September 2018).
- Liu, Y.; Romeres, D.; Jha, D.K.; Nikovski, D. Understanding multi-modal perception using behavioral cloning for peg-in-a-hole insertion tasks. arXiv 2020, arXiv:2007.11646. [Google Scholar]
- Gubbi, S.; Kolathaya, S.; Amrutur, B. Imitation learning for high precision peg-in-hole tasks. In Proceedings of the 2020 6th International Conference on Control, Automation and Robotics (ICCAR), Singapore, 20–23 April 2020; pp. 368–372. Available online: https://ieeexplore.ieee.org/abstract/document/9108072/?casa_token=Yn05LGs5PX0AAAAA:6g-EugX-DAkYxQXw_5pay1227hG083KCW97SOnwkpDx5vepdqi28R-yYrkLlOcz1WVr_2MGJnfo (accessed on 4 June 2020).
- Ackerman, E. Toyota Research Demonstrates Ceiling-Mounted Home Robot. Available online: https://spectrum.ieee.org/automaton/robotics/home-robots/toyota-research-ceiling-mounted-home-robot (accessed on 30 September 2020).
- Torabi, F.; Warnell, G.; Stone, P. Behavioral cloning from observation. arXiv 2018, arXiv:1805.01954. [Google Scholar]
- Smith, L.; Dhawan, N.; Zhang, M.; Abbeel, P.; Levine, S. Avid: Learning multi-stage tasks via pixel-level translation of human videos. arXiv 2019, arXiv:1912.04443. [Google Scholar]
- Xiong, H.; Li, Q.; Chen, Y.C.; Bharadhwaj, H.; Sinha, S.; Garg, A. Learning by watching: Physical imitation of manipulation skills from human videos. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 7827–7834. Available online: https://ieeexplore.ieee.org/abstract/document/9636080/?casa_token=jmPBrgTdhfQAAAAA:qlJsNC5AuUu8Y2ss6jsIVPRNSWARvlglAz3hisizTQw-bwse0EsSo9J2H0VHwHcElql3-fYZ-Gk (accessed on 16 December 2021).
- Sharma, P.; Pathak, D.; Gupta, A. Third-person visual imitation learning via decoupled hierarchical controller. In Advances in Neural Information Processing Systems 32, Proceedings of the 33rd Conference on Neural Information Processing Systems 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2020; pp. 2593–2603. Available online: https://proceedings.neurips.cc/paper/2019/hash/8a146f1a3da4700cbf03cdc55e2daae6-Abstract.html (accessed on 1 August 2022).
- Schmeckpeper, K.; Rybkin, O.; Daniilidis, K.; Levine, S.; Finn, C. Reinforcement learning with videos: Combining offline observations with interaction. arXiv 2020, arXiv:2011.06507. [Google Scholar]
- Lu, Y.; Fu, J.; Li, X.; Zhou, W.; Liu, S.; Zhang, X.; Chen, Z. RTN: Reinforced Transformer Network for Coronary CT Angiography Vessel-level Image Quality Assessment. arXiv 2022, arXiv:2207.06177. [Google Scholar]
- Hawke, J.; Shen, R.; Gurau, C.; Sharma, S.; Reda, D.; Nikolov, N.; Kndall, A. Urban driving with conditional imitation learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 251–257. Available online: https://ieeexplore.ieee.org/abstract/document/9197408/ (accessed on 1 August 2022).
- Jang, E.; Irpan, A.; Khansari, M.; Kappler, D.; Ebert, F.; Lynch, C.; Levine, S.; Finn, C. Bc-z: Zero-shot task generalization with robotic imitation learning. In Proceedings of the 2022 Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022; pp. 991–1002. Available online: https://openreview.net/forum?id=8kbp23tSGYv (accessed on 1 August 2022).
- Wen, B.; Lian, W.; Bekris, K.; Schaal, S. You only demonstrate once: Category-level manipulation from single visual demonstration. arXiv 2022, arXiv:2201.12716. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. Available online: http://openaccess.thecvf.com/content_iccv_2017/html/Zhu_Unpaired_Image-To-Image_Translation_ICCV_2017_paper.html (accessed on 24 August 2020).
- Bain, M.; Sammut, C. A framework for behavioural cloning. In Machine Intelligence 15: Intelligent Agents; Furukawa, K., Michie, D., Muggleton, S., Eds.; Oxford University Press: Oxford, UK, 1999; pp. 103–129. Available online: http://www.cse.unsw.edu.au/~claude/papers/MI15.pdf (accessed on 30 July 2001).
- Reddy, S.; Dragan, A.D.; Levine, S. SQIL: Imitation learning via regularized behavioral cloning. arXiv 2019, arXiv:1905.11108. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. Available online: http://proceedings.mlr.press/v97/tan19a.html (accessed on 16 May 2019).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. Available online: https://openaccess.thecvf.com/content_cvpr_2018/papers/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.pdf (accessed on 21 March 2019).
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. Available online: https://openaccess.thecvf.com/content_cvpr_2018/papers/Hu_Squeeze-and-Excitation_Networks_CVPR_2018_paper.pdf (accessed on 16 May 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. Available online: https://openaccess.thecvf.com/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf (accessed on 1 August 2022).
- Yarats, D.; Zhang, A.; Kostrikov, I.; Amos, B.; Pineau, J.; Fergus, R. Improving sample efficiency in model-free reinforcement learning from images. In Proceedings of the 2021 AAAI Conference on Artificial Intelligence, Online, 2–9 January 2021; Volume 35, pp. 10674–10681. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/17276 (accessed on 18 May 2021).
- Singh, A.; Yang, L.; Hartikainen, K.; Finn, C.; Levine, S. End-to-end robotic reinforcement learning without reward engineering. arXiv 2019, arXiv:1904.0785. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).