1. Introduction
Stochastic production planning lies at the intersection of optimal control, stochastic processes, and operations research. Over the last four decades, researchers have developed an array of methodologies to tackle the inherent uncertainty in production and inventory systems. The seminal work of Bensoussan et al. [
1] established the foundations for production optimization under probabilistic constraints. Cadenillas et al. then introduced regime-switching dynamics to reflect business cycle effects on demand [
2], and extended this framework to include production constraints [
3]. Dong et al. [
4] demonstrated the importance of regime shifts in microgrid energy management, while Gharbi and Kenne [
5] focused on multi-product manufacturing environments.
Building on elliptic PDE techniques, Covei et al. [
6] derived explicit radially symmetric solutions for infinite-horizon regime-switching problems, proving uniqueness and convexity. Subsequent works [
7,
8] refined numerical implementations and parabolic PDE analyses. More recently, Ghosh et al. [
9] and Borhan et al. [
10] applied switching diffusion controls to complex engineering systems, and Hu et al. [
11] developed a
K convex multi-cycle supply network model with interdependent demand shocks.
Motivated by economic cycles that abruptly alter production and holding costs, we study a stochastic production planning model in which a
dimensional Brownian motion
captures continuous demand fluctuations, and an independent, finite-state continuous-time homogeneous Markov chain
with the generator
models regime-switches (e.g., growth vs. recession). The chain has
stationary (time homogeneous) transition rates, so that regime-switching events occur at exponential times independent of the Brownian paths.
Under each regime
, cost and volatility parameters
remain constant until the next jump of
. This regime-switching structure reflects real-world scenarios in which economic cycles or policy shifts cause sudden parameter changes. The manager’s goal is to choose production rates
to minimize
where
evolves by
and
is the first exit time from a given inventory ball of radius
.
Our contributions are threefold:
We derive the coupled elliptic Hamilton–Jacobi–Bellman (HJB) equations for the regime-dependent value functions ; prove the existence, uniqueness, and convexity of the solution via a logarithmic transform and monotone iteration; and obtain an explicit radially symmetric bound.
We clarify and exploit the independence and stationarity of the Markov chain transitions; regime changes occur at exponential times independently of Brownian noise, ensuring no mixed diffusion jump terms and greatly simplifying both analysis and numerics.
We implement a fully integrated numerical pipeline solving the transformed PDEs, recovering the optimal feedback control, and simulating the controlled SDE, thereby illustrating sensitivity and model risk analyses under realistic economic scenarios.
The remainder of this paper is organized as follows:
Section 2 introduces the mathematical formulation of the model and its objectives.
Section 3 explains the methodology, including the derivation of the HJB equations and the existence of a solution.
Section 4 focuses on the optimal control of the problem at hand.
Section 5 provides a discussion on sensitivity analysis, model examination, and visualization of the results.
Section 6 proposes future research directions.
Section 7 concludes with the final observations, and
Appendix A concludes with a rigorous proof of the key technical result, a detailed presentation of the numerical algorithm implementing our main theorems, and the complete Python (version 3.13.1) code for these computations.
2. Theoretical Framework
In this section, we present the mathematical formulation of the stochastic production planning problem with regime-switching. The model incorporates random demand, regime-dependent parameters, and production controls, as described below.
2.1. Problem Formulation
This paper addresses a stochastic production planning problem involving types of goods stored in inventory with the objective of minimizing production and inventory costs over time under regime-switching economic parameters. The overall criterion is based on a quadratic cost functional that represents the production and holding costs (adjusted for stochastic demand), with production ceasing when inventory levels exceed a given threshold . In our model, regimes are characterized by a Markov chain that captures probabilistic transitions between states, and a D-dimensional Brownian motion models stochastic fluctuations in demand.
The stochastic dynamics of the inventory levels are governed by
where
is the deterministic production rate,
is an Itô process in
,
is the regime-dependent volatility, and
is a Markov chain representing economic regimes (here with two states, but the methodology extends seamlessly to scenarios involving any number of states).
The cost functional is defined as
subject to the dynamics in (
1) and the stopping time
, which stops production when the inventory exceeds the threshold
.
2.2. Regime-Switching and Dynamics
We consider a probability space
together with a standard
-valued Brownian motion
and an observable finite-state continuous-time homogeneous Markov chain, with states
We denote by
the
P-augmentation of the filtration
generated by the Brownian motion and the Markov chain, where
The manager of a firm wants to control the inventory of a given item. We assume a stochastic production environment driven by two sources of randomness:
Markov Chain: A continuous-time homogeneous Markov chain , with states , represents economic regimes. These regimes may correspond to scenarios such as economic growth () or recession ().
Brownian Motion: A D-dimensional Brownian motion models stochastic demand fluctuations in inventory levels.
We also assume that
and
w are independent (i.e., HJB system has no “mixed” terms; see [
12]), and that the Markov chain
has a strongly irreducible generator, which is given by
where
and
. In this case,
and
is explicitly described by the integral form
where
is a martingale with respect to
.
2.3. Inventory Dynamics and State Variables
Let
denote the inventory levels of good
i at time
t, adjusted for demand, and let
denote the production rate (control variable) for good
i at time
t under regime
. The stochastic dynamics of the inventory are governed by
where
is the regime-dependent volatility,
is the
i-th component of a
D-dimensional Brownian motion,
is a Markov chain representing economic regimes, and
denotes the initial inventory level of good
i.
2.4. Objective Function
The objective of the stochastic production planning problem is to minimize the total expected cost incurred over time. These costs include both production costs and inventory holding costs, adjusted for regime-switching dynamics and exponential discounting. This is formalized through the following components.
2.4.1. Production Costs
The cost associated with the production rate
for good
i is quadratic and regime-dependent. The quadratic form ensures tractability in optimization and is expressed as
where
represents the net production rate (actual production minus demand).
2.4.2. Inventory Costs
The holding cost for storing the inventory is modeled as a convex function of the inventory levels. It accounts for regime-switching parameters and is given by
where
represents regime-dependent holding costs. The convexity of
reflects the increasing marginal cost of holding excess inventory.
2.4.3. Discount Factor
To account for the time value of money, the costs are exponentially discounted with a regime-dependent discount rate . The discount factor ensures that costs incurred in the future are valued less than those incurred immediately.
2.4.4. Cost Functional
The factory aims to minimize production and inventory costs, subject to the stochastic dynamics (
2) described above. The total cost functional—combining production costs, inventory costs, and exponential discounting—is given by
where
is the production rate for good
i at time
t under regime
;
is the quadratic production cost for good
i;
is the regime-dependent production costs, modeled as quadratic functions of the production rate;
represents the inventory levels of goods, adjusted for demand;
represents the regime-dependent inventory holding costs (holding cost, modeled as convex functions
and
); and
is the regime-dependent discount rate for exponential discounting.
The stopping time
is defined as the moment when the inventory exceeds an exogenous threshold
R, i.e.,
where
stands for the Euclidian norm.
3. Optimization Problem
The primary objective of the stochastic production planning problem is to minimize the total expected cost, which comprises both production and inventory holding costs, subject to the constraints of stochastic inventory dynamics and regime-switching parameters. This optimization problem is formulated as follows.
3.1. Optimization Objective
The objective is to determine the optimal production rates
, …,
that minimize the total cost functional
J, while satisfying the stochastic inventory dynamics. Mathematically, this is expressed as
subject to the inventory dynamics:
The optimization problem is solved over a finite horizon, up to the stopping time , and incorporates the effects of regime-switching. The constraints ensure that the optimization respects the stochastic nature of the inventory dynamics and the stopping criterion at .
3.2. Hamilton–Jacobi–Bellman Equations
To solve the optimization problem, we employ the value function approach. The value function is defined as
The HJB equations for the value functions
and
, corresponding to the two regimes
and
, are given by
with the following boundary conditions:
Here, are regime-dependent parameters, is the Laplacian of (sum of second-order partial derivatives), is the open ball in () of radius , and and are the holding cost functions in regimes 1 and 2, respectively.
Assumptions
To ensure mathematical tractability, we impose the following assumptions:
and are continuous, convex functions satisfying , ;
and , ensuring non-degenerate stochastic dynamics;
Boundary conditions: when , .
The hypotheses on
and
are chosen so that
and so that the running cost
is convex in
. Together, these conditions guarantee that each value–function
is convex in
y.
This formulation provides the mathematical foundation for deriving the Hamilton–Jacobi–Bellman equations and solving the optimization problem.
The computational goal is to approximate the value functions and using numerical techniques that guarantee convergence and stability.
The next section focuses on the methodology used to obtain the solutions.
3.3. Transformation and Simplification
To simplify the PDE system (
4), we apply a change in variables:
which removes the gradient terms and transforms the PDE system into
with the following boundary conditions:
This transformation reduces the complexity of the system and facilitates numerical computation.
3.4. Existence and Uniqueness of Solutions
The solution’s computation involved specific parameters that had to be determined in an approximately exact form. In the paper [
8], we established only the existence of these parameters. Therefore, it becomes essential to provide a proof of the results that will facilitate our computational technique. Consequently, to facilitate the implementation of our main results, we state the following practical lemma; its proof can be found in
Appendix A.1.
Lemma 1. For any , and , there exist unique such that We are now ready to adapt the proof of the theorem in [
8], integrating the necessary steps to address the numerical implications.
Theorem 1. Let be the unique solutions of the nonlinear system (6): The system of Equation (4) has a unique positive convex solution with value functions and such that Proof. Our constructive approach aims to develop a computational scheme for numerical approximations of the solution. Since the system (
4) is equivalent to (
5), we will focus on the latter. The approach involves four key steps.
The main problem reduces to constructing functions
as sub-solutions (and
as super-solutions) for the system (
5) that satisfy the following inequalities:
(and similarly for the inequalities with ≤). For sub-solutions, choose
where
are solutions of (
6). For super-solutions, choose
Clearly,
Step 2: Approximation Scheme.
Construct sequences
via monotone Picard iterations, starting with
Define the iteration
where for
the functions
are defined by
Since
(respectively,
) is a continuous function with respect to the first variable in
and continuously differentiable with respect to the second and third in
respectively,
this allows us to choose
such that
respectively
for every
with
respectively, for every
with
to ensure monotonicity
via mathematical induction and the maximum principle.
The sequences
converge monotonically to bounded limits:
Standard bootstrap arguments ensure that
and
solves (
5) with
Uniqueness follows from the maximum principle, i.e., any two positive solutions and coincide.
- Step 4:
Since
J is convex in
, the state equation is affine in
p, and
grows at most quadratically and is continuous, it then follows that the function
is convex on
(see [
8]).
□
4. Optimal Control
The optimal control represents the production rate policy that minimizes the total expected cost functional. It is derived using the Hamilton–Jacobi–Bellman (HJB) equations and is directly related to the gradients of the value functions. Below, we delve deeper into its formulation and derivation.
4.1. Optimal Production Policy
By differentiating the HJB equations with respect to the inventory levels , we obtain the gradient terms that define the optimal control.
Hence, for each economic good
, the optimal production rate
is given by
where
is the value function corresponding to regime
and
denotes the partial derivative of the value function with respect to the inventory level of good
i.
This result is obtained by solving the first-order optimality condition derived from the HJB equations.
Economic Interpretation
The negative gradient of the value function implies that the optimal production rate decreases as the marginal cost of inventory increases. Intuitively, higher inventory levels (positive gradient) lead to a reduction in production to avoid excess costs, and lower inventory levels (negative gradient) necessitate an increase in production to meet anticipated demand.
4.2. Verification of Optimality
The verification of optimality establishes that the control , derived from the Hamilton–Jacobi–Bellman (HJB) equations, is indeed the optimal control that minimizes the cost functional. This involves proving the supermartingale property of the value function for all admissible controls and the martingale property for the optimal control.
4.2.1. The Stochastic Process
To verify that
is indeed the optimal control, we use the supermartingale and martingale properties of the value function
. Let the stochastic process
be defined as
where
is the value function for regime
,
are the production rates (control variables),
is the holding cost function, and
is the regime-dependent discount rate.
Using Itô’s lemma, the time derivative of
satisfies
where
is a martingale term, and
represents the generator of the Markov-modulated diffusion (here, the Laplacian operator).
4.2.2. Supermartingale and Martingale Properties
For the admissible controls
,
is a supermartingale because
satisfies the following HJB inequality:
For the optimal control
,
is a martingale because
satisfies the equality condition:
The optimal control ensures that is a martingale, while any other control results in being a supermartingale. This validates the optimality of .
4.2.3. Boundary Conditions and Optimality
The boundary condition
where
is the ball of radius
R, which ensures that
vanishes at the stopping time
. Thus, for
, the contribution to the cost functional ceases, confirming the proper termination of production when inventory exceeds the threshold
R.
The optimality of is formalized through the following theorem:
Theorem 2. Let be the stochastic process defined in (10). The control , derived from the HJB equations, minimizes the cost functional and satisfies Proof. For
under the admissible control
,
since
is a supermartingale.
For
under the optimal control
,
since
is a martingale.
From the boundary condition
, it follows that
Thus, the control minimizes the cost functional and satisfies the optimality condition.
□
4.2.4. Theoretical Properties of the Optimal Control and Inventory
Process
The theoretical properties of the optimal control are as follows: the optimal control is Lipschitz continuous in y, ensuring stability in production rates under small changes in inventory levels; the control policy is adaptive, responding dynamically to regime changes governed by the Markov chain ; and the quadratic nature of the cost functional guarantees uniqueness of the optimal control.
The inventory process is modeled by the stochastic differential equation (SDE)
where the economic regime
takes the values
with the following transitions:
In the simulation, one uses a time step
and performs the following update:
where
is an independent standard normal random variable. The optimal control is obtained by interpolating the computed value function gradients:
where
and
solve the coupled HJB system in each regime.
The simulation by Euler–Maruyama is executed until the stopping time
at which point the production is halted.
5. Sensitivity, Model Analysis, and Visualization
The proof of the results in this section is detailed in reference [
8], and thus, the specifics are excluded here. The data are presented for its visualization in accordance with the results, showcasing the strength of the mathematical conclusions and numerical implementation.
5.1. Sensitivity Analysis
The sensitivity analysis shows the following impacts:
Theorem 3. If and , for all , then higher volatility () increases the following value function: Theorem 4. If and , for all , then higher discount rates () decrease the value function Theorem 5. If and , then higher holding costs () increase the value function 5.2. Model Comparisons
For models with and without regime-switching, we have
Theorem 6. If , , and , for all , thenwhere and correspond to the value functions of a model without regime-switching. 5.3. Visualization of the Solution in the Case
In this section, we connect our theoretical results (Theorems 3–6) with concrete numerical experiments in the case
. We first present a compact tabular summary of the sensitivity analysis statements, then illustrate the transformed solutions and value functions, and finally show the time dynamics of the optimal control and inventory. All plots were generated with the annotated Python code in
Appendix A.3, which can be adapted to other parameter choices so long as the monotonicity and convergence assumptions remain valid.
5.3.1. Summary of Sensitivity Results
Table 1 collects the four main sensitivity comparisons of
Section 5.1, restating the impact of parameter changes on the regime-dependent value functions.
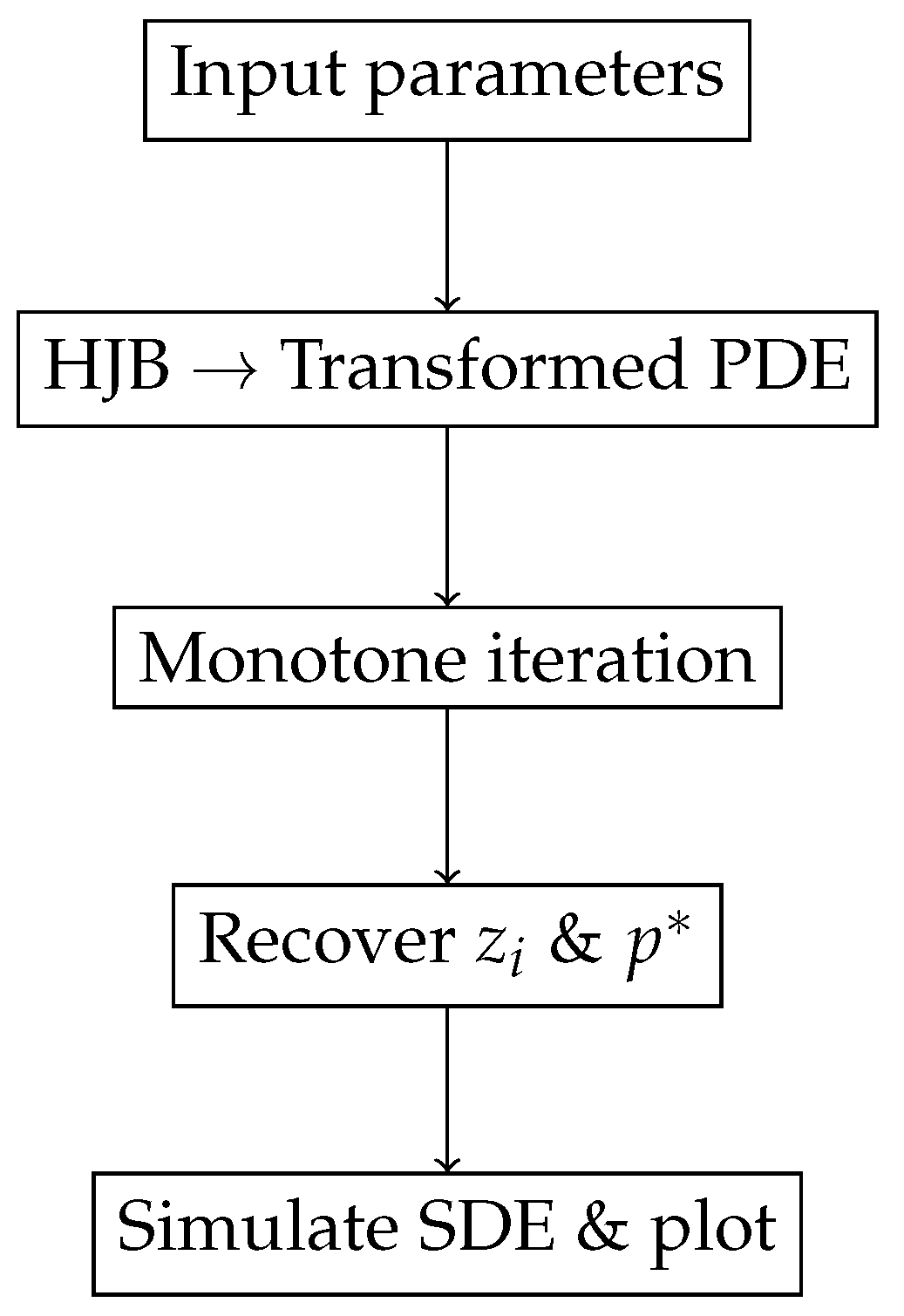
Next, we give a concise workflow diagram, which summarize the sensitivity statements in tabular form.
5.3.2. Workflow Overview
Model specification ().
HJB PDE derivation and logarithmic transform .
Monotone iteration (Picard) for on .
Back-transform to obtain , and compute feedback law .
Simulate inventory SDE under optimal control and regime-switching.
Figure 1 depicts the end-to-end computational pipeline:
We now present four detailed case studies “one per theorem” each with its own parameter table, plots, and discussion of practical relevance.
5.3.3. Case Study: Volatility Variation (Theorem 3)
To connect our theoretical model with practical applications (see [
4]), we vary certain parameters that typically arise in real-world problems.
Table 2 lists these inputs.
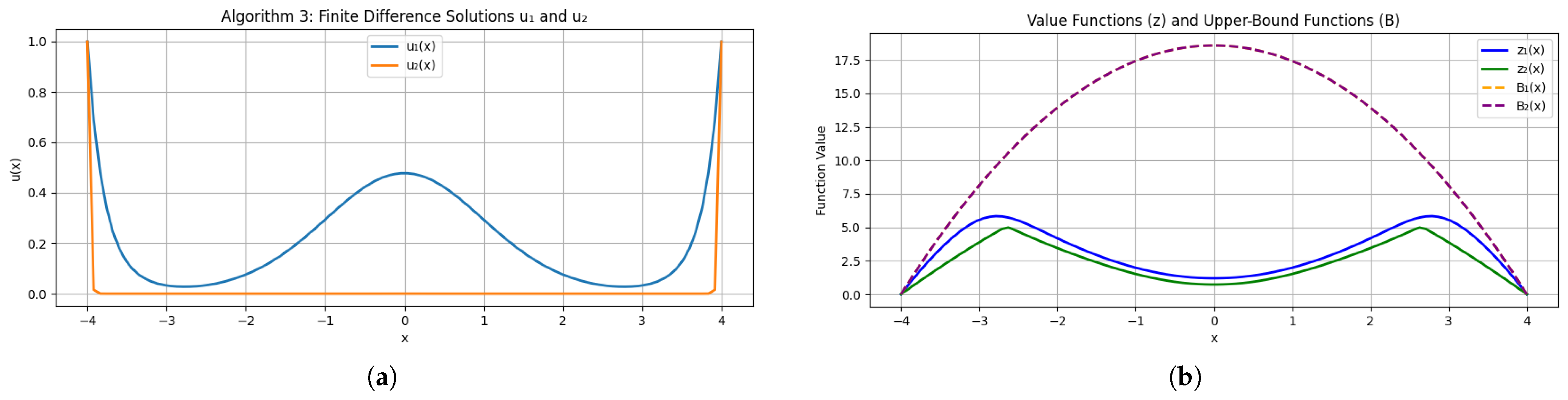
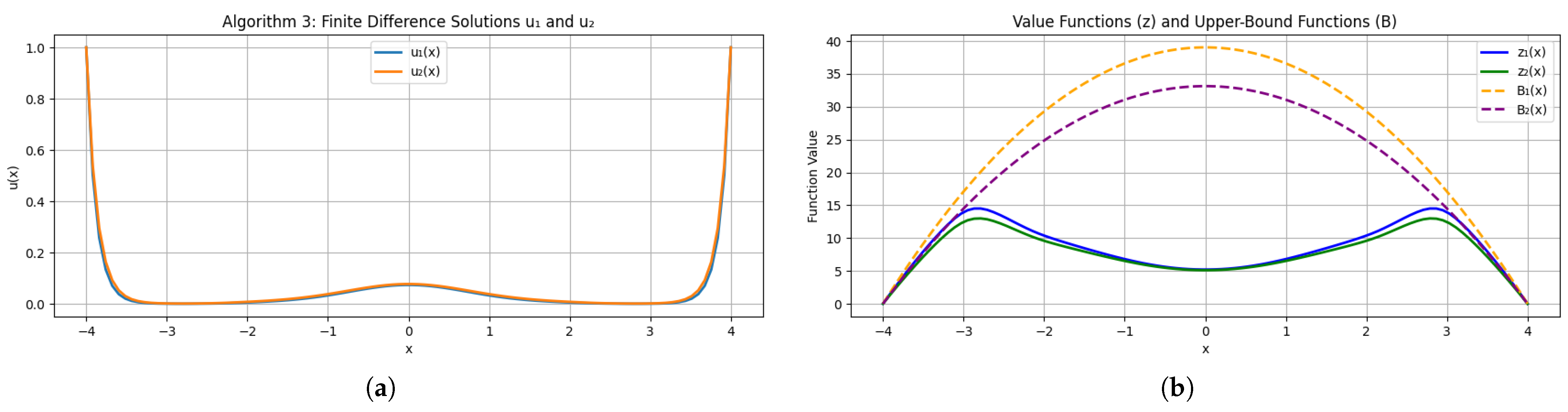
Figure 2a,b show the numerically computed transformed solutions
(so that
) alongside the regime-dependent value functions.
This choice satisfies the hypotheses of Theorem 3 and ensures that volatility differences dominate the ordering of and .
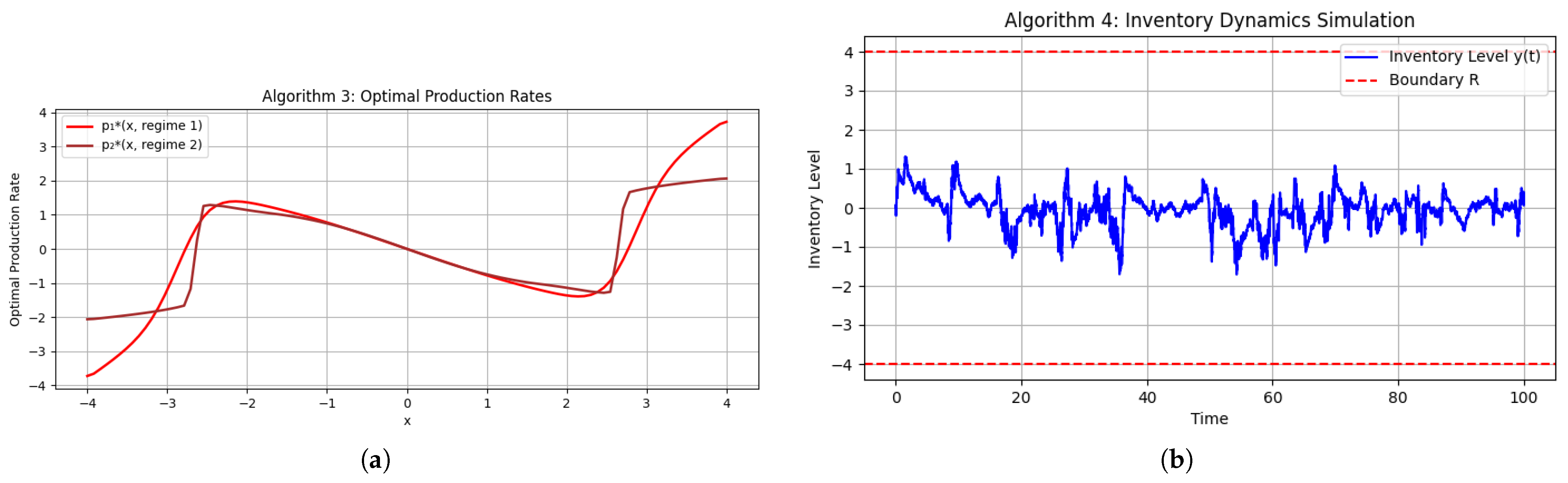
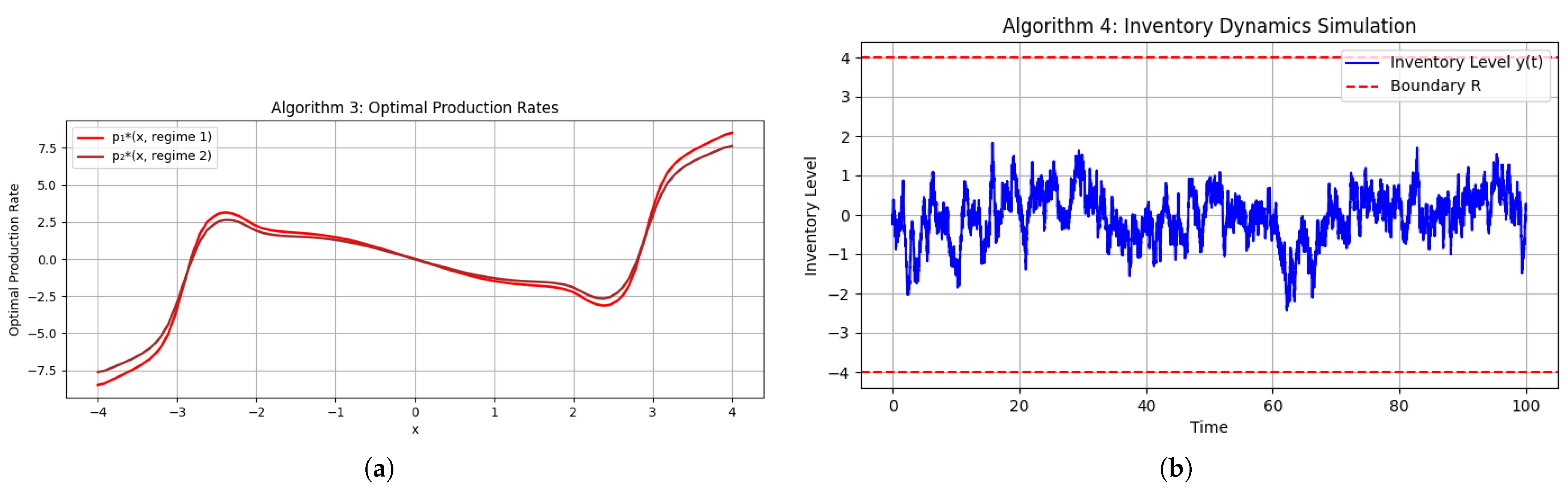
Figure 3a,b display a sample path under one realization of the regime-switching process.
Interpretation
In a microgrid context, and model drift and renewable generation uncertainty, while penalizes inventory deviations. Theorem 3 predicts when , confirmed by both the static profiles and dynamic simulation. The negative and ensure convexity and damping in the transformed PDEs (see Lemma 1 and Theorem 1).
5.3.4. Case Study: Discount Rate Variation (Theorem 4)
To illustrate Theorem 4, we choose parameters motivated by a multi-product, multi-machine manufacturing setting [
5] (
Table 3).
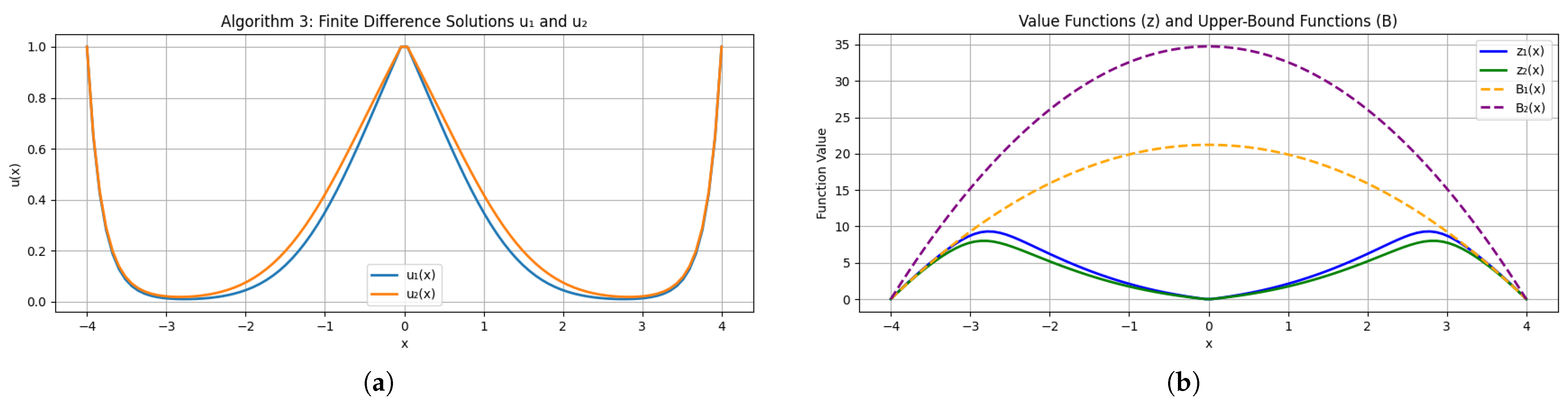
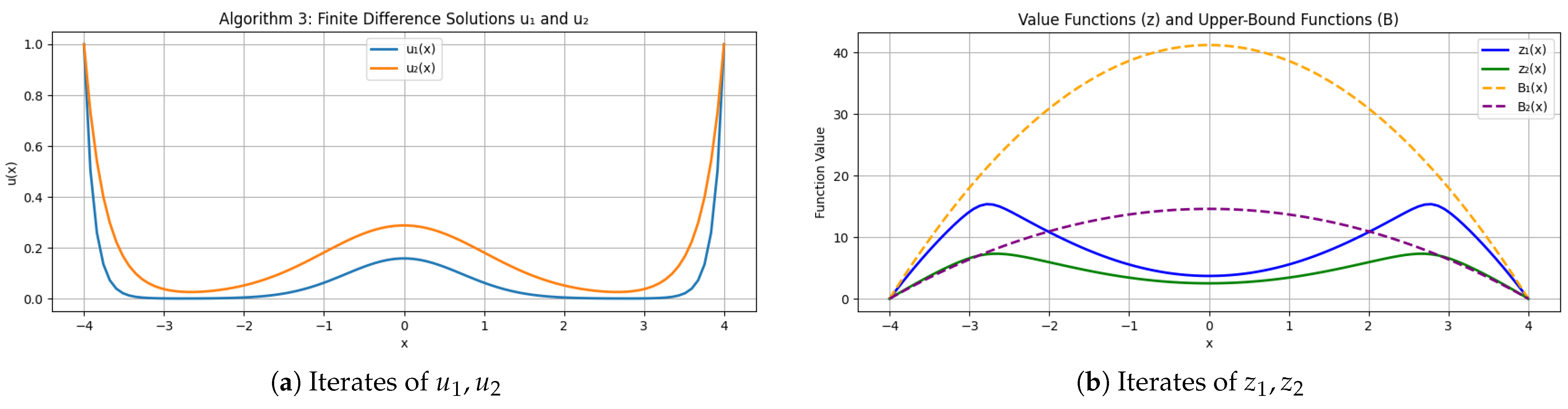
Figure 4a,b plot the transformed variables
,
and the resulting value functions
,
along a radial slice in
.
Notice
throughout, confirming the result in Theorem 4 (
Figure 5).
Interpretation
The lower discount rate in regime 1 increases the present value of future costs, driving above in line with Theorem 4. The parameters and reflect the distinct operational regimes and production dynamics, while the equal volatilities () capture the uncertainty inherent in the system. The quadratic cost functions impose a steep penalty on deviations, thereby driving the system to minimize inventory surplus and backlogs. These values serve as damping and sensitivity factors in the PDE framework and validate the stability and accuracy of our numerical scheme.
5.3.5. Case Study: Holding Cost Variation (Theorem 5)
To validate Theorem 5, we adopt parameters for a flexible manufacturing system [
9] (
Table 4).
Figure 6a,b show the transformed solutions and value functions, demonstrating
as
.
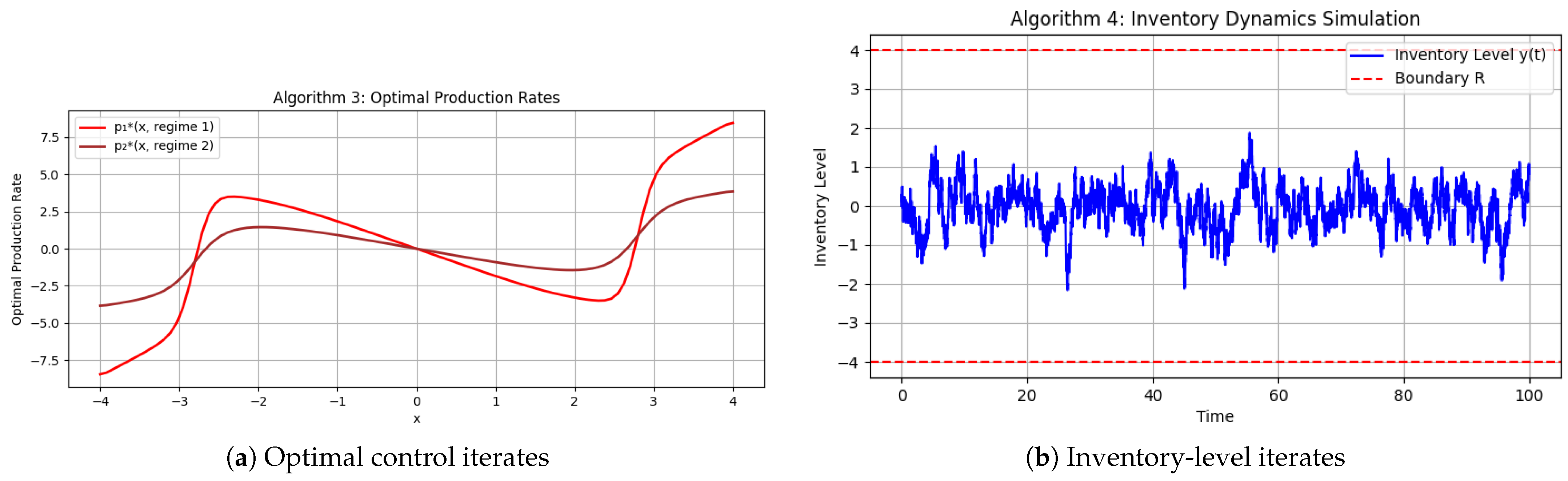
Next, we characterize the time evolution of the optimal production rate and inventory level under varying holding cost regimes (
Figure 7).
Interpretation
The steeper penalty in regime 1 elevates over , in full agreement with Theorem 5. These parameters model a production environment where the drift coefficients and switching intensities reflect dynamic operational regimes, while and capture the production capacities and uncertainties inherent in the system. The quadratic cost functions and impose steeper penalties for deviations in production levels, thereby promoting a robust control strategy.
5.3.6. Case Study 4: Automotive Manufacturing (Theorem 6)
We adopt a parameter set inspired by modern automotive production, “e.g., companies like Dacia from România” where planning must react to volatile demand and supply chain risks.
This case study shows how to choose and interpret each model parameter in practice and how the two regimes arise in an automotive production context (e.g., Dacia Logan at Mioveni România).
Regime Interpretation
We assume two operational regimes driven by market and supply chain conditions:
Regime 1 (High Demand) : On average 1.7 months until demand cools; : large volatility from rush orders; : lower discounting of near-term costs; : steep holding cost penalty to curb overstocking.
Regime 2 (Low Demand) : On average 1.1 months until demand rebounds; : stable production; : higher discounting of distant costs; : mild inventory penalty to maintain minimal safety stock.
Interpreting the Transition Rate
In our two-state Markov model, the time spent in regime 1 (high demand) is exponentially distributed with rate parameter
. By standard properties of the exponential law, the expected sojourn time in regime 1 is
Thus, once the system enters the high-demand regime, it will, on average, remain there for about months before switching back to the low-demand regime. This interpretation allows practitioners to translate the abstract rate directly into a familiar planning horizon—about seven weeks of sustained peak conditions under regime 1.
Table 5 displays the concrete numbers.
Numerical Implementation
Solve the transformed PDE system (
5) on the ball
by
monotone Picard iteration, initializing with the super solution
.
Back-transform to obtain the following value functions:
where
are the unique roots from Lemma 1.
Compute the feedback control
(Optional) Validate by simulating
Euler–Maruyama paths of
until
.
Convergence and Interpretation
Executing the Python script in
Appendix A.3 yields the following figures.
Rapid, uniform convergence of at all grid nodes, as predicted by Theorem 6.
Regime-tailored controls: During high demand ( large; small), the policy pre-emptively ramps production; during low demand, it throttles output to preserve cash.
Theoretical bounds: The computed lie strictly between the bounded limits that underlie the existence of a proof.
By following this parameter selection recipe and interpreting each , , , and in business terms, we consider that any practitioner can instantiate Theorems 3–6 for their own two-regime production inventory problem.
5.3.7. Implementation Notes
The full Python code (
Appendix A.3) is annotated step by step: each function call is commented to clarify mesh setup, PDE discretization, monotone iteration, and post-processing. For the above examples, the annotated Python routine prints the nonlinear solver settings and the convergence statistics compiled in
Table 6.
The negative and guarantee convexity and damping in the transformed PDEs, while rapid global convergence confirms the method’s suitability for real-time production planning under uncertainty.
5.3.8. Discussion and Practical Insights
Across all four experiments, the empirical ordering of agree with our theorems; this convergence demonstrates robustness, and in automotive production planning, rapidly changing regimes (peak/off peak, supply shocks) can be managed by our regime-switching feedback law , ensuring inventory targets are met with minimal cost.
Future work should extend to non-quadratic costs, correlated Brownian motions (see [
12], for the resulting system), and higher-dimensional product portfolios.
Remark 1. It is important to highlight that specific parameters require algorithmic application, each with an associated margin of error. In all the above considered scenarios, our theoretical results establish thatwhere the inequalities serve as a foundational guideline. In cases where these conditions are violated, the initial data must undergo adjustments to ensure the value functions align with (11). With the parameters explicitly defined, updating the Python code becomes easier; we only need to adjust these values directly when model parameters change, rather than re-running iterative numerical solvers. 6. Some Future Directions
Building on our stochastic production planning framework with regime-switching, we outline four concise avenues for future work:
Alternative Convex Loss Functions. Replace the quadratic cost functional by other convex penalties (e.g., logarithmic or exponential) to better reflect industry-specific cost structures. Such non-quadratic losses introduce nonlinear terms into the HJB system, calling for novel analytical approximations or specialized numerical schemes.
Correlated Brownian Motions. Allow nonzero correlations among the Brownian drivers to model interdependencies across product demands. The ensuing mixed-derivative terms in the coupled PDEs increase both theoretical complexity and computational burden, and yield a richer and more realistic description of cross-good risk.
Geometric Inventory Dynamics. Model inventory levels via geometric Brownian motion to enforce non-negativity. The multiplicative noise and drift require a logarithmic change of variables and adaptive discretization (e.g., mesh refinement or implicit solvers) to maintain stability and accuracy.
Real-Time Regime Detection. Integrate machine learning techniques (e.g., online change point detection, hidden Markov model inference) to identify economic regime shifts on the fly. Coupling an ML-based detector with the control law promises faster adaptation and enhanced robustness to structural breaks.
7. Conclusions
The production planning problem is solved using a value function approach, where the optimal production policy is characterized by a system of elliptic PDEs. This paper aims to bridge the gap between theoretical modeling and practical implementation, providing robust tools for stochastic production planning under regime-switching parameters. The regime-switching framework provides actionable insights for managerial decision-making, policy analysis, and operational optimization.
The contributions of this study include a derivation of the Hamilton–Jacobi–Bellman (HJB) equations and their transformation into an elliptic PDE system; the development of a monotone iteration scheme to approximate solutions, enabling quantitative analysis of production policies; an investigation of the impacts of volatility, holding costs, and discount rates on the value functions; and a comparison of models with and without regime-switching, highlighting the conservative and balanced predictions of regime-switching models.
By adapting production strategies to economic cycles, minimizing costs, and mitigating risks, the model enhances practical applicability in industries such as automotive manufacturing, energy systems, and retail.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}