
Quantum-Inspired Attention-Based Semantic Dependency Fusion Model for Aspect-Based Sentiment Analysis

Abstract
1. Introduction
- We propose a quantum embedding module to build complex semantic systems and, for the first time, quantify inter-word relations in terms of quantum coherence.
- We propose a quantum cross-attention mechanism that emphasizes specific combinations of qubit or quantum states with dependencies, aiming to enhance the efficiency of feature fusion in text and its associated dependencies.
- Through numerous experiments on the ABSA task, we demonstrate the effectiveness of QEDFM. Additionally, visualization experiments for the quantum embedding module offer an intuitive understanding of this coding approach. The relative entropy of coherence experiments further enhance the model’s interpretability.
2. Related Work
3. Materials and Methods
3.1. Preliminaries on Quantum Theory
3.1.1. Quantum State
3.1.2. Quantum Evolution
3.1.3. Quantum Coherence
3.1.4. Quantum Measurement
3.2. Methodology
3.2.1. Sequence Preprocessing
3.2.2. Embedding Model
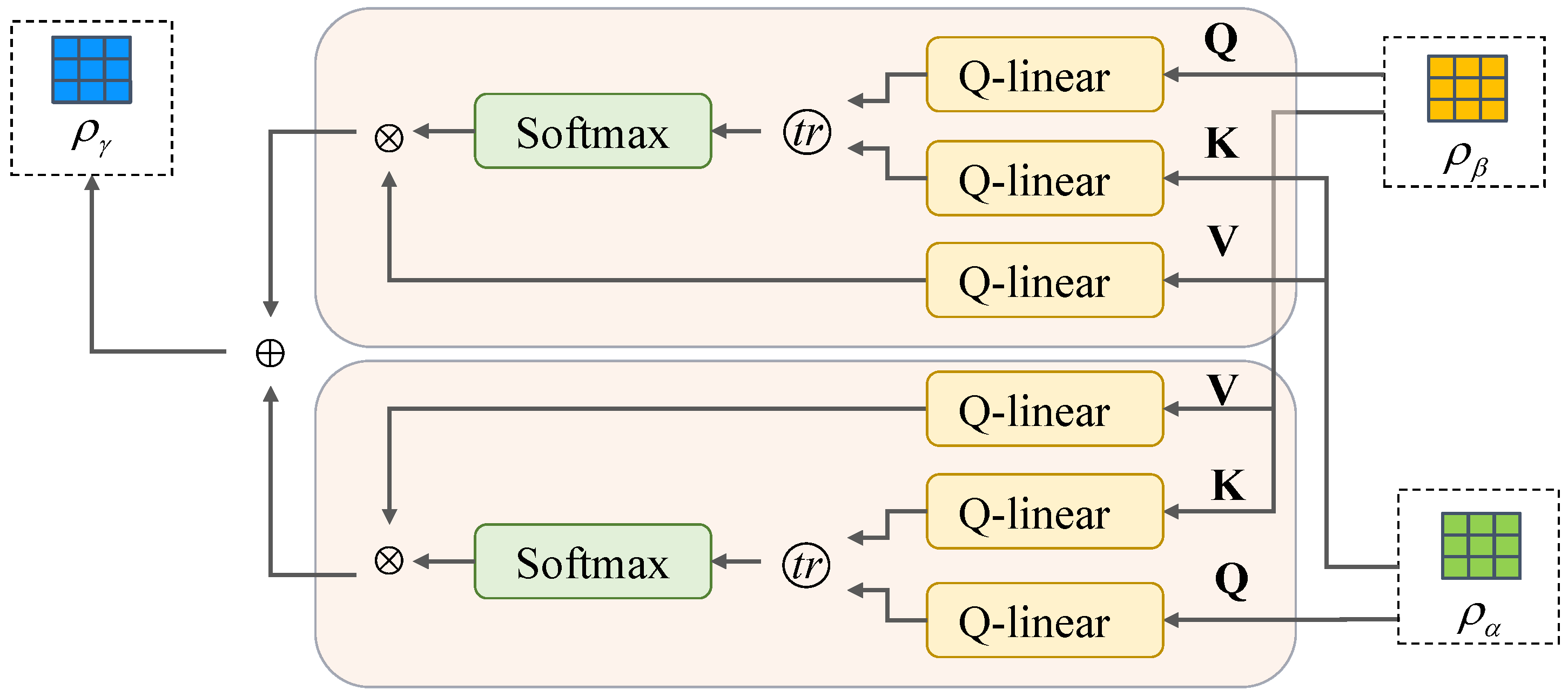
3.2.3. Dependency Fusion Module
3.2.4. Sentiment Classification
3.3. Datasets
4. Results
4.1. Baselines
4.2. Main Results
4.3. Ablation Experiment
4.4. Case Study
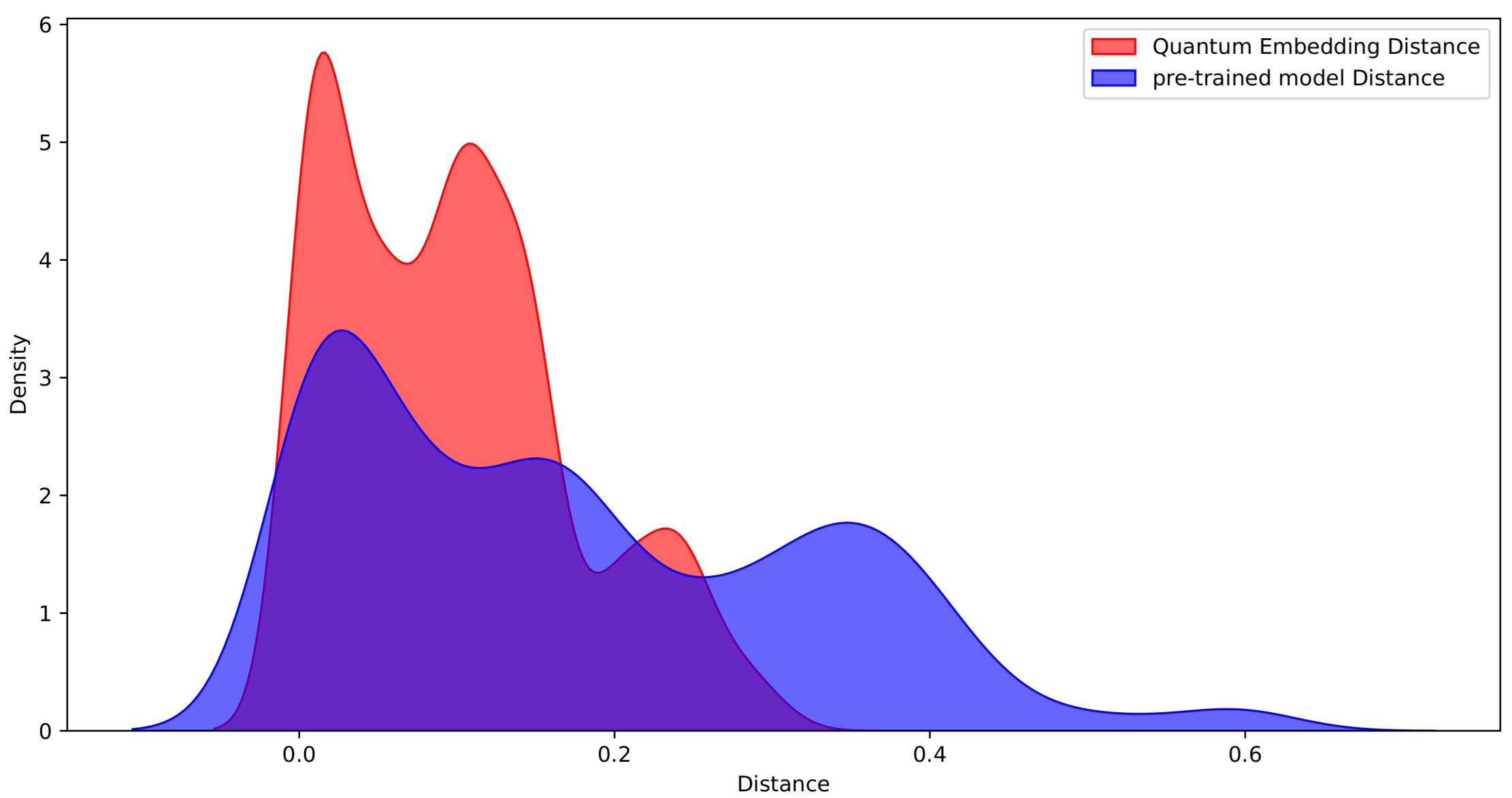
4.5. Post Hoc Interpretability
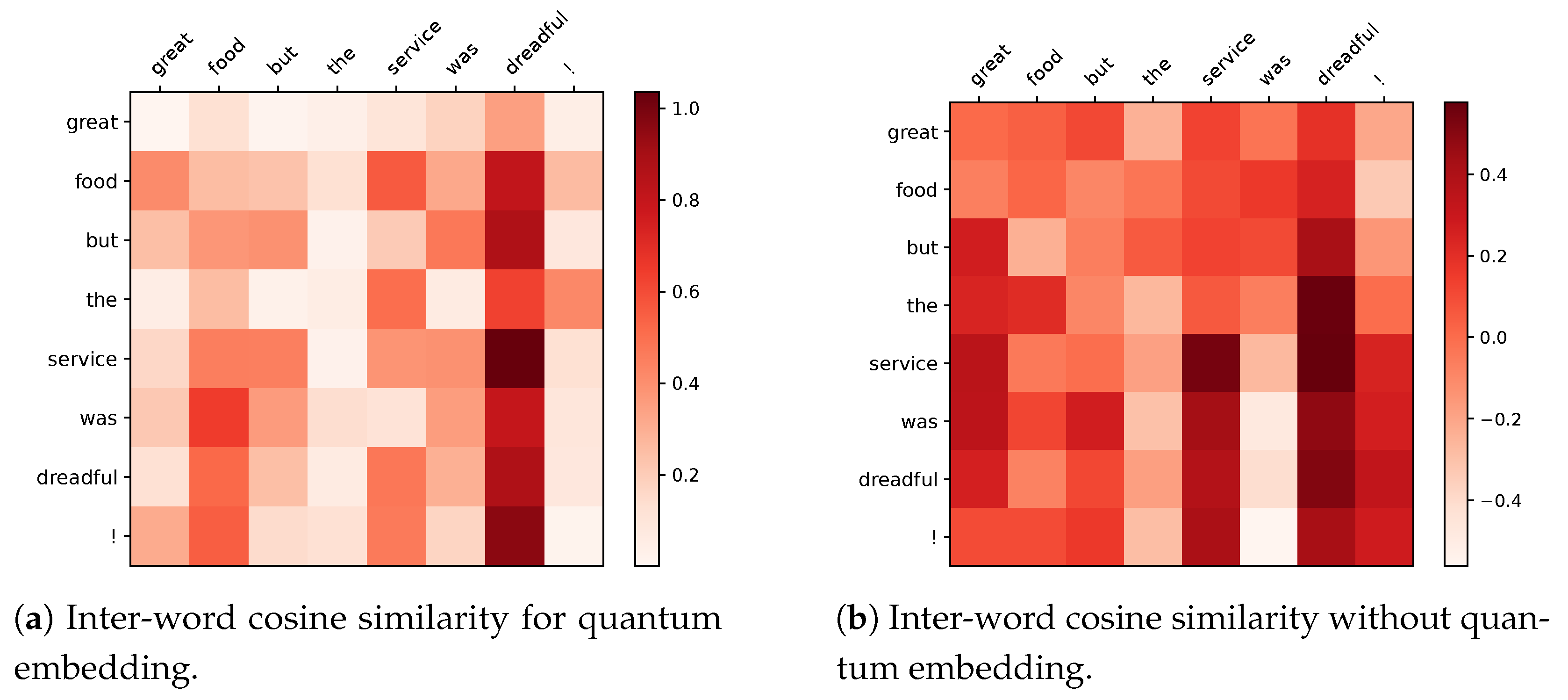
4.6. Visualization
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tang, D.; Qin, B.; Liu, T. Aspect Level Sentiment Classification with Deep Memory Network. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 214–224. [Google Scholar]
- Zhang, C.; Li, Q.; Song, D. Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4568–4578. [Google Scholar]
- Sun, K.; Zhang, R.; Mensah, S.; Mao, Y.; Liu, X. Aspect-level sentiment analysis via convolution over dependency tree. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5679–5688. [Google Scholar]
- Li, Q.; Wang, B.; Melucci, M. CNM: An Interpretable Complex-valued Network for Matching. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4139–4148. [Google Scholar]
- Chen, Y.; Pan, Y.; Dong, D. Quantum language model with entanglement embedding for question answering. IEEE Trans. Cybern. 2021, 53, 3467–3478. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Qiu, D.; Yan, R. A quantum entanglement-based approach for computing sentence similarity. IEEE Access 2020, 8, 174265–174278. [Google Scholar] [CrossRef]
- Zhou, J.; Huang, J.X.; Chen, Q.; Hu, Q.V.; Wang, T.; He, L. Deep learning for aspect-level sentiment classification: Survey, vision, and challenges. IEEE Access 2019, 7, 78454–78483. [Google Scholar] [CrossRef]
- Liu, H.; Chatterjee, I.; Zhou, M.; Lu, X.S.; Abusorrah, A. Aspect-based sentiment analysis: A survey of deep learning methods. IEEE Trans. Comput. Soc. Syst. 2020, 7, 1358–1375. [Google Scholar] [CrossRef]
- Vo, D.T.; Zhang, Y. Target-dependent twitter sentiment classification with rich automatic features. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Spain, 25–31 July 2015; pp. 1347–1353. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for aspect-level sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Guangzhou, China, 18–20 June 2016; pp. 606–615. [Google Scholar]
- Xu, H.; Liu, B.; Shu, L.; Yu, P. BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1. [Google Scholar]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational Graph Attention Network for Aspect-based Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3229–3238. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. arXiv 2018, arXiv:1710.10903. [Google Scholar]
- Tang, H.; Ji, D.; Li, C.; Zhou, Q. Dependency graph enhanced dual-transformer structure for aspect-based sentiment classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6578–6588. [Google Scholar]
- Tian, Y.; Chen, G.; Song, Y. Aspect-based sentiment analysis with type-aware graph convolutional networks and layer ensemble. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 2910–2922. [Google Scholar]
- Xiao, Z.; Wu, J.; Chen, Q.; Deng, C. BERT4GCN: Using BERT Intermediate Layers to Augment GCN for Aspect-based Sentiment Classification. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; pp. 9193–9200. [Google Scholar]
- Zhang, Z.; Zhou, Z.; Wang, Y. SSEGCN: Syntactic and semantic enhanced graph convolutional network for aspect-based sentiment analysis. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 4916–4925. [Google Scholar]
- Feng, S.; Wang, B.; Yang, Z.; Ouyang, J. Aspect-based sentiment analysis with attention-assisted graph and variational sentence representation. Knowl.-Based Syst. 2022, 258, 109975. [Google Scholar] [CrossRef]
- Zhao, G.; Luo, Y.; Chen, Q.; Qian, X. Aspect-based sentiment analysis via multitask learning for online reviews. Knowl.-Based Syst. 2023, 264, 110326. [Google Scholar] [CrossRef]
- Jiang, X.; Ren, B.; Wu, Q.; Wang, W.; Li, H. DCASAM: Advancing aspect-based sentiment analysis through a deep context-aware sentiment analysis model. Complex Intell. Syst. 2024, 10, 7907–7926. [Google Scholar] [CrossRef]
- Sordoni, A.; Nie, J.Y.; Bengio, Y. Modeling term dependencies with quantum language models for IR. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 653–662. [Google Scholar]
- Li, S.; Hou, Y. Quantum-inspired model based on convolutional neural network for sentiment analysis. In Proceedings of the 2021 4th International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 28–31 May 2021; pp. 347–351. [Google Scholar]
- Gkoumas, D.; Li, Q.; Dehdashti, S.; Melucci, M.; Yu, Y.; Song, D. Quantum Cognitively Motivated Decision Fusion for Video Sentiment Analysis. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, AAAI 2021, Online, 2–9 February 2021; pp. 827–835. [Google Scholar]
- Zhao, Q.; Hou, C.; Xu, R. Quantum-Inspired Complex-Valued Language Models for Aspect-Based Sentiment Classification. Entropy 2022, 24, 621. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Wan, H.; Qi, K. QPEN: Quantum projection and quantum entanglement enhanced network for cross-lingual aspect-based sentiment analysis. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 19670–19678. [Google Scholar]
- Khrennikov, A. Ubiquitous Quantum Structure; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Alodjants, A.; Tsarev, D.; Avdyushina, A.; Khrennikov, A.Y.; Boukhanovsky, A. Quantum-inspired modeling of distributed intelligence systems with artificial intelligent agents self-organization. Sci. Rep. 2024, 14, 15438. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Busemeyer, J. Quantum Models of Cognition and Decision; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Baumgratz, T.; Cramer, M.; Plenio, M.B. Quantifying coherence. Phys. Rev. Lett. 2014, 113, 140401. [Google Scholar] [CrossRef] [PubMed]
- Fell, L.; Dehdashti, S.; Bruza, P.; Moreira, C. An Experimental Protocol to Derive and Validate a Quantum Model of Decision-Making. In Proceedings of the Annual Meeting of the Cognitive Science Society, Montreal, QC, Canada, 24–27 July 2019; Volume 41. [Google Scholar]
- Halmos, P.R. Finite-Dimensional Vector Spaces; Courier Dover Publications: Garden City, UK, 2017. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the naacL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, p. 2. [Google Scholar]
- Balkır, E. Using Density Matrices in a Compositional Distributional Model of Meaning. Master’s Thesis, University of Oxford, Oxford, UK, 2014. [Google Scholar]
- Zhang, P.; Niu, J.; Su, Z.; Wang, B.; Ma, L.; Song, D. End-to-end quantum-like language models with application to question answering. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, AAAI 2018, New Orleans, LA, USA, 2–7 February 2018; pp. 5666–5673. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. SemEval-2014 Task 4: Aspect Based Sentiment Analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014); Nakov, P., Zesch, T., Eds.; Association for Computational Linguistics: Dublin, Ireland, 2014; pp. 27–35. [Google Scholar] [CrossRef]
- Dong, L.; Wei, F.; Tan, C.; Tang, D.; Zhou, M.; Xu, K. Adaptive recursive neural network for target-dependent twitter sentiment classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 13–15 June 2014; pp. 49–54. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train Data | Test Data | |||||
|---|---|---|---|---|---|---|
| Domain | #Pos | #Neg | #Neu | #Pos | #Neg | #Neu |
| RESTAURANT | 2159 | 800 | 632 | 730 | 195 | 196 |
| LAPTOP | 980 | 858 | 454 | 340 | 128 | 171 |
| 1567 | 1563 | 3127 | 174 | 174 | 346 | |
| Models | Restaurant | Laptop | ||||
|---|---|---|---|---|---|---|
| Acc. | F1 | Acc. | F1 | Acc. | F1 | |
| BERT † | 85.97 | 80.09 | 79.91 | 76.00 | 75.92 | 75.18 |
| BERT-PT | 84.95 | 76.96 | 78.07 | 75.08 | - | - |
| R-GAT+BERT | 86.60 | 81.35 | 78.21 | 74.07 | 76.15 | 74.88 |
| DGEDT+BERT | 86.30 | 80.00 | 79.80 | 75.60 | 77.90 | 75.40 |
| BERT4GCN | 84.75 | 77.11 | 77.49 | 73.01 | 74.73 | 73.76 |
| TGCN+BERT | 86.16 | 79.95 | 80.88 | 77.03 | 76.45 | 75.25 |
| SSEGCN+BERT † | 86.15 | 79.96 | 79.75 | 76.38 | 77.70 | 76.36 |
| AG-VSR+BERT | 86.34 | 80.88 | 79.92 | 75.85 | 76.45 | 75.04 |
| C-BERT | 86.70 | 81.41 | 79.94 | 76.35 | 75.29 | 73.80 |
| MHA+RGAT+BERT-ATE-APC † | 86.88 | 81.16 | 80.56 | 77.00 | 76.59 | 74.67 |
| DCASAM | 86.70 | 81.19 | 80.56 | 77.00 | 76.88 | 75.25 |
| QEDFM | 87.31 | 81.88 | 80.85 | 78.35 | 77.40 | 76.45 |
| Models | Accuracy (Acc.) | F1 Score (F1) |
|---|---|---|
| QE-QCA | 87.31 | 81.88 |
| QE-QA | 86.77 | 81.79 |
| QE | 86.59 | 81.54 |
| w/o any | 85.52 | 79.66 |
| Sentence | R-GAT | SSEGCN | QEDFM | True Label |
|---|---|---|---|---|
| Great food but the service was dreadful! | N-N | P-N | P-O | P-O |
| Can you buy any laptop that matches the quality of a MacBook? | P | O | P | P |
| Biggest complaint is Windows 8. | O | N | N | N |
| Try the rose roll (not on menu). | P-N | P-O | P-O | P-O |
| Type | Word Combinations |
|---|---|
| Most relative in Laptop | (the, thunder), (the, process), (ease, of), (after, all), (the, mac) |
| Least relative in Laptop | (to, be), (there, are), (are, a), (it, is), (is, a) |
| Most relative in Restaurant | (not, only), (tells, us), (ask, for), (my, friend), (thick, fries) |
| Least relative in Restaurant | (it, was), (is, a), (there, was), (of, the), (has, a) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, C.; Wang, X.; Tang, J.; Wang, Y.; Shao, L.; Gao, Q. Quantum-Inspired Attention-Based Semantic Dependency Fusion Model for Aspect-Based Sentiment Analysis. Axioms 2025, 14, 525. https://doi.org/10.3390/axioms14070525
Xu C, Wang X, Tang J, Wang Y, Shao L, Gao Q. Quantum-Inspired Attention-Based Semantic Dependency Fusion Model for Aspect-Based Sentiment Analysis. Axioms. 2025; 14(7):525. https://doi.org/10.3390/axioms14070525
Chicago/Turabian StyleXu, Chenyang, Xihan Wang, Jiacheng Tang, Yihang Wang, Lianhe Shao, and Quanli Gao. 2025. "Quantum-Inspired Attention-Based Semantic Dependency Fusion Model for Aspect-Based Sentiment Analysis" Axioms 14, no. 7: 525. https://doi.org/10.3390/axioms14070525
APA StyleXu, C., Wang, X., Tang, J., Wang, Y., Shao, L., & Gao, Q. (2025). Quantum-Inspired Attention-Based Semantic Dependency Fusion Model for Aspect-Based Sentiment Analysis. Axioms, 14(7), 525. https://doi.org/10.3390/axioms14070525