

On the Conflation of Poisson and Logarithmic Distributions with Applications


Abstract
1. Introduction
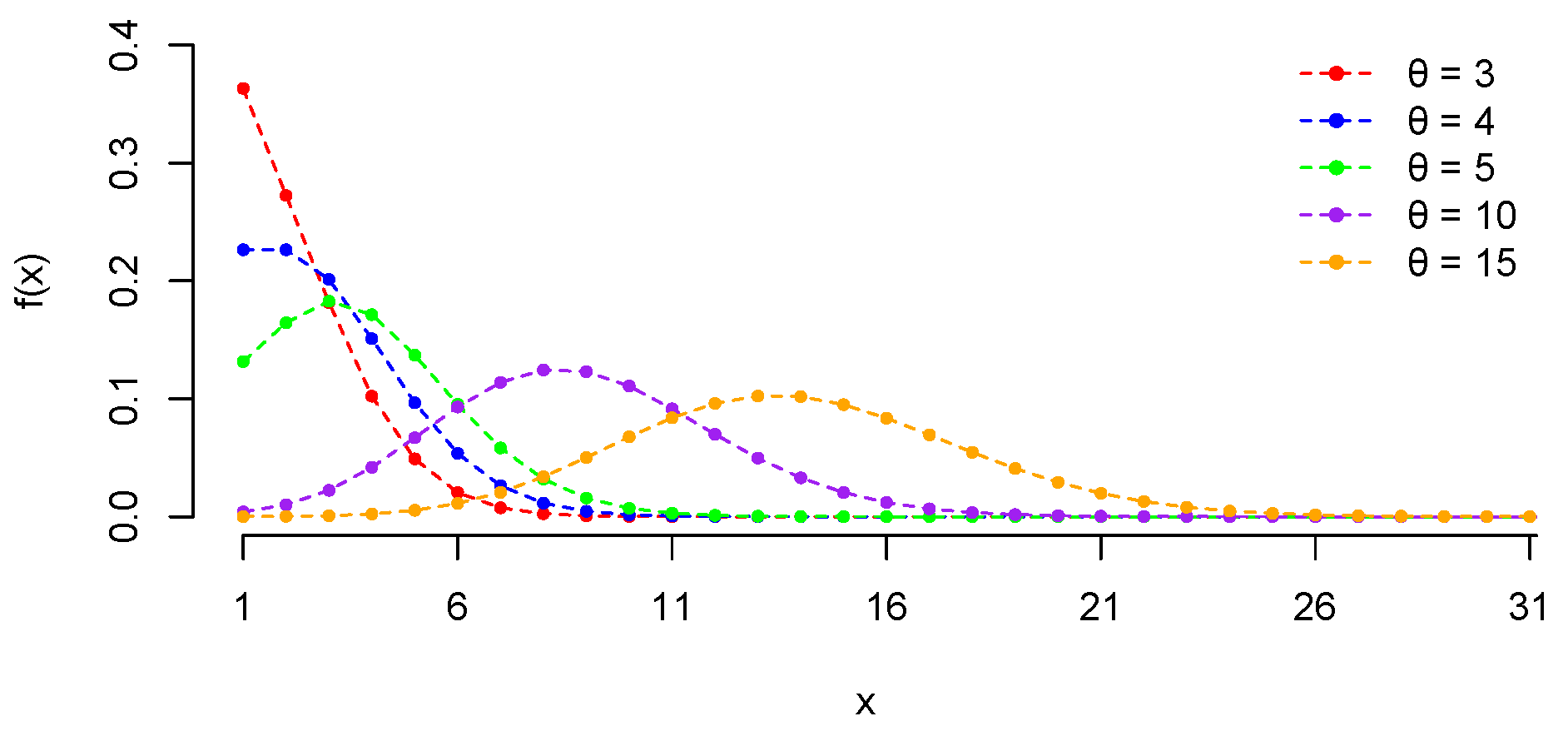
2. Conflated Poisson Logarithmic Distributions
3. Some Statistical Properties
3.1. Moments and Probability-Generating Functions
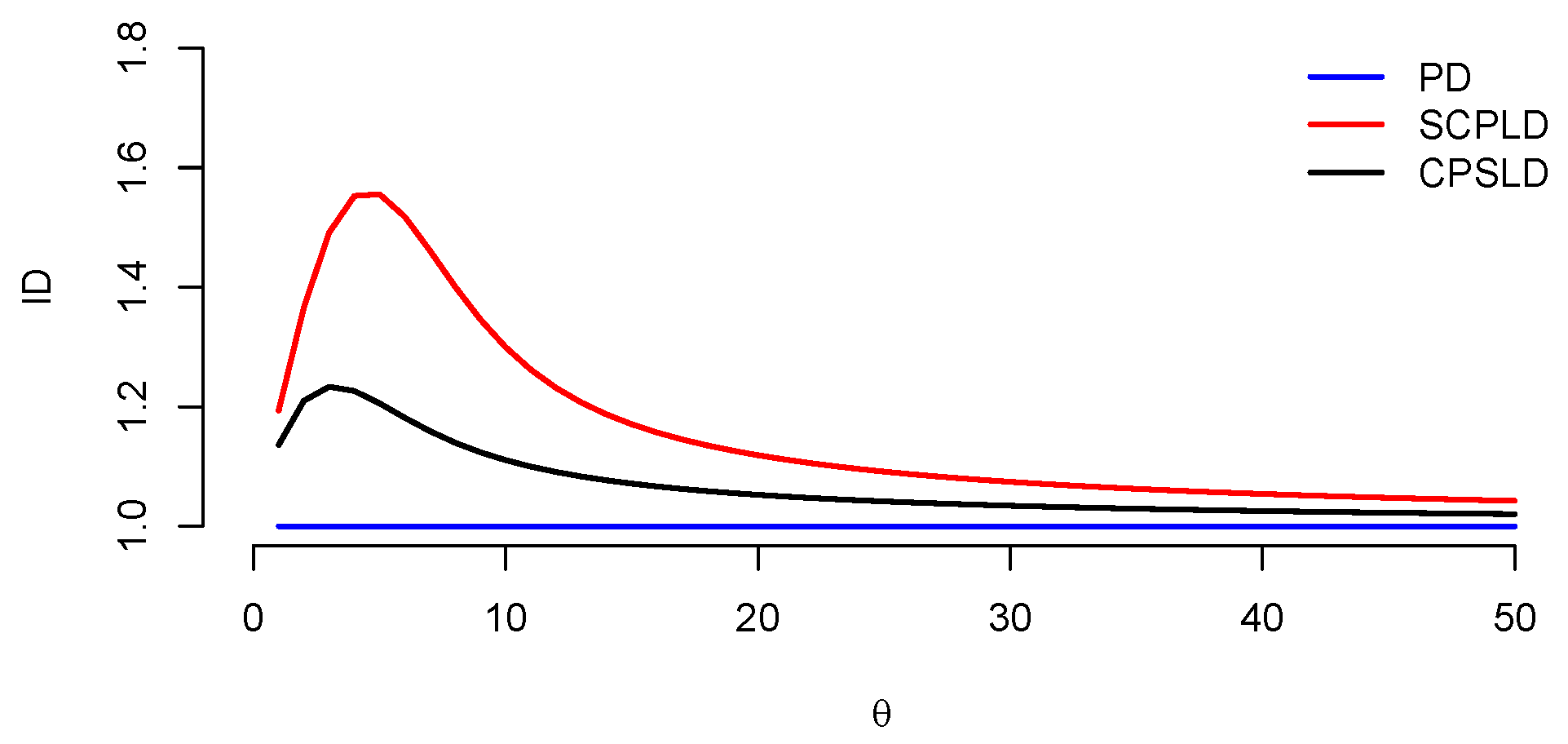
3.2. Index of Dispersion
3.3. Unimodality
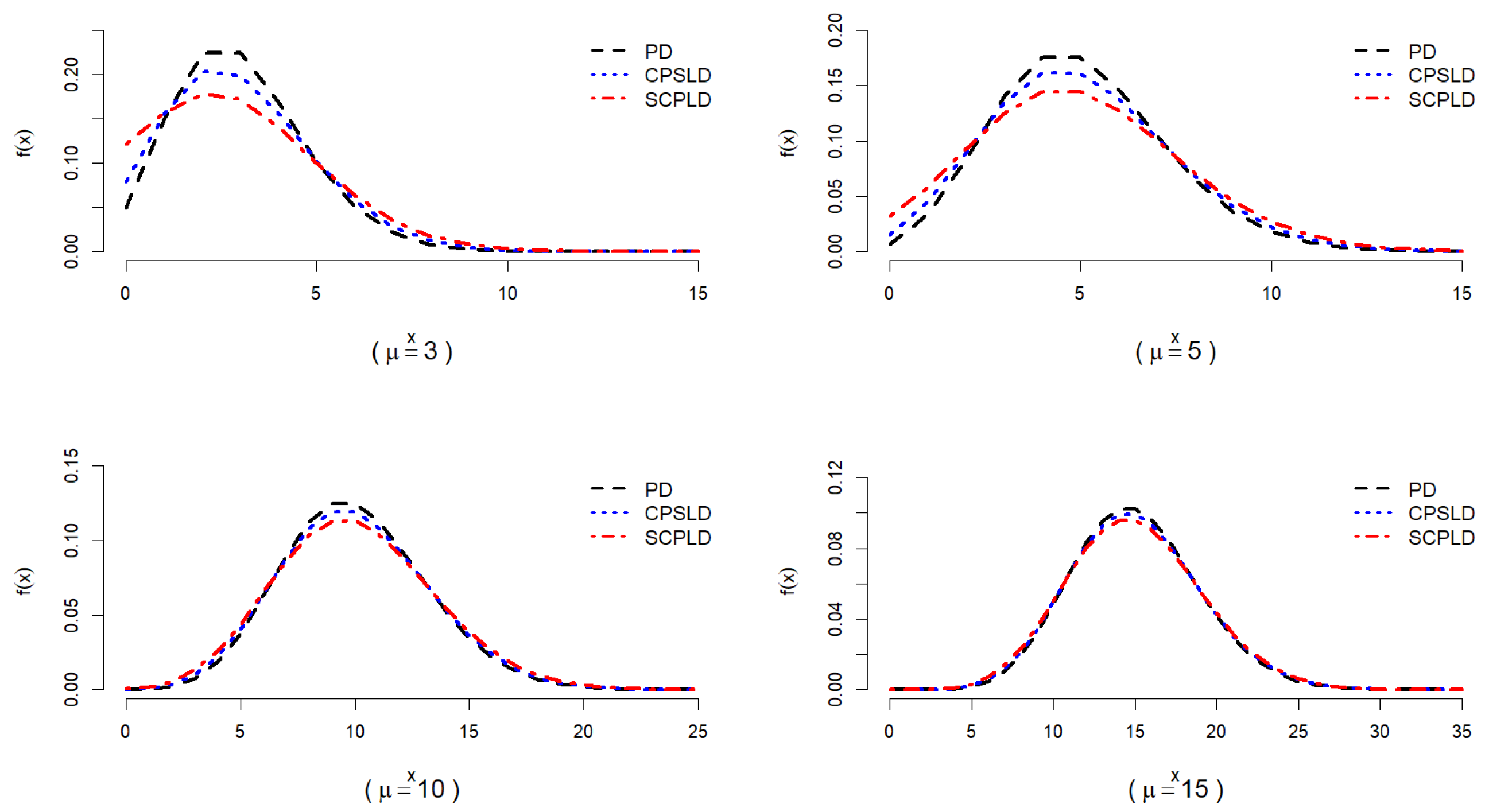
3.4. Stochastic Ordering
4. Parametric Estimation and Simulation Study
4.1. Estimation Study of CPLD
4.2. Simulation Study for CPLD
- Choose the value and the sample size n.
- Generate n random samples such that .
- Maximize Equation (6) to find the ML estimate for numerically.
- Repeat steps 2 to 3 for times to calculate the following:
- The absolute bias of the simulated estimates is defined as
- The average of the mean squared error of the simulated estimates is defined as
- As the sample size n increases, the estimates values () converge to the true value .
- The absolute bias decreases with the increase in sample size n, indicating that the estimates tend to be unbiased estimates.
- The MSE significantly decreases with the increase in sample size n that makes the ML estimates more accurate.
4.3. Estimation Study of CPSLD
4.4. Simulation Study for CPSLD
- In step 2, n random samples were obtained from the CPSLD.
- In step 3, the score function used is presented in Equation (9).
- The simulation results are shown in Table 2 below.
5. Applications
5.1. Number of Eggs per Flower Head
5.2. Number of European Corn Borers
5.3. Number of Micronuclei Counted Using Cytochalasin B Method After 4 Gy Irradiation Exposure
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Greenwood, M.; Yule, G.U. An inquiry into the nature of frequency distributions representative of multiple happenings with particular reference to the occurrence of multiple attacks of disease or of repeated accidents. J. R. Stat. Soc. 1920, 83, 255–279. [Google Scholar] [CrossRef]
- Sankaran, M. The Discrete Poisson-Lindley Distribution. Biometrics 1970, 26, 145–149. [Google Scholar] [CrossRef]
- Shanker, R.; Fesshaye, H.; Tesfazghi, T. On Poisson-Akash distribution and its applications. Biom. Biostat. Int. J. 2016, 3, 146–153. [Google Scholar] [CrossRef]
- Shanker, R.; Fesshaye, H.; Shanker, R.; Leonida, T.A.; Sium, S. On discrete Poisson-Shanker distribution and its applications. Biom. Biostat. Int. J. 2017, 5, 00121. [Google Scholar] [CrossRef]
- Conway, R.W.; Maxwell, W.L. Network dispatching by the shortest-operation discipline. Oper. Res. 1962, 10, 51–73. [Google Scholar] [CrossRef]
- Shmueli, G.; Minka, T.P.; Kadane, J.B.; Borle, S.; Boatwright, P. A useful distribution for fitting discrete data: Revival of the Conway–Maxwell–Poisson distribution. J. R. Stat. Soc. Ser. C Appl. Stat. 2005, 54, 127–142. [Google Scholar] [CrossRef]
- Fisher, R.A. The effect of methods of ascertainment upon the estimation of frequencies. Ann. Eugen. 1934, 6, 13–25. [Google Scholar] [CrossRef]
- Rao, C.R. On discrete distributions arising out of methods of ascertainment. Sankhyā Indian J. Stat. Ser. A 1965, 27, 311–324. [Google Scholar]
- Johnson, N.L.; Kemp, A.W.; Kotz, S. Univariate Discrete Distributions, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar] [CrossRef]
- Hill, T. Conflations of probability distributions. Trans. Am. Math. Soc. 2011, 363, 3351–3372. [Google Scholar] [CrossRef]
- Alqefari, A.A.; Alzaid, A.A.; Qarmalah, N. On the Conflation of Negative Binomial and Logarithmic Distributions. Axioms 2024, 13, 707. [Google Scholar] [CrossRef]
- Abramowitz, M.; Stegun, I.A. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables, 10th ed.; US Government Printing Office: Washington, DC, USA, 1968. [Google Scholar]
- Butler, R.J.; McDonald, J.B. Using incomplete moments to measure inequality. J. Econom. 1989, 42, 109–119. [Google Scholar] [CrossRef]
- Winkler, R.L.; Roodman, G.M.; Britney, R.R. The determination of partial moments. Manag. Sci. 1972, 19, 290–296. [Google Scholar] [CrossRef]
- Karlin, S. Total Positivity; Stanford University Press: Redwood City, CA, USA, 1968. [Google Scholar]
- Barlow, R.E.; Proschan, F. Statistical Theory of Reliability and Life Testing: Probability Models; Holt, Rinehart and Winston: New York, NY, USA, 1975. [Google Scholar]
- Sellers, K.F. The Conway-Maxwell-Poisson Distribution, 1st ed.; Cambridge University Press: Shaftesbury Road, UK, 2023. [Google Scholar] [CrossRef]
- Bagnoli, M.; Bergstrom, T.C. Log-concave probability and its applications. Econ. Theory 2005, 26, 445–469. [Google Scholar] [CrossRef]
- Bertin, E.M.; Cuculescu, I.; Theodorescu, R. Unimodality of Probability Measures, 1st ed.; Springer: Dordrecht, The Netherlands, 2013. [Google Scholar] [CrossRef]
- Shaked, M.; Shanthikumar, J.G. Stochastic Orders, 1st ed.; Springer: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Dennis, J.E., Jr.; Schnabel, R.B. Numerical Methods for Unconstrained Optimization and Nonlinear Equations; SIAM: Philadelphia, PA, USA, 1996. [Google Scholar]
- Shanker, R.; Hagos, F.; Sujatha, S.; Abrehe, Y. On zero-truncation of Poisson and Poisson-Lindley distributions and their applications. Biom. Biostat. Int. J. 2015, 2, 1–14. [Google Scholar] [CrossRef]
- McGuire, J.U.; Brindley, T.A.; Bancroft, T.A. The distribution of European corn borer larvae Pyrausta nubilalis (Hbn.), in field corn. Biometrics 1957, 13, 65–78. [Google Scholar] [CrossRef]
- Aijaz, A.; Qurat ul Ain, S.; Afaq, A.; Tripathi, R. Poisson area-biased Ailamujia Distribution and its applications in environmental and medical sciences. Stat. Transit. New Ser. 2022, 23, 167–184. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| n | |Bias| | MSE | ||
|---|---|---|---|---|
| 10 | 0.4846 | 0.0154 | 0.0394 | |
| 20 | 0.4916 | 0.0083 | 0.0079 | |
| 50 | 0.5 | 0.4939 | 0.0061 | 0.0042 |
| 100 | 0.4966 | 0.0034 | 0.00203 | |
| 500 | 0.4986 | 0.0014 | 0.0016 | |
| 10 | 0.9976 | 0.0024 | 0.0536 | |
| 20 | 0.9998 | 0.0002 | 0.0045 | |
| 50 | 1 | 1.0001 | 0.0001 | 0.0003 |
| 100 | 0.9998 | 0.0001 | 0.0002 | |
| 500 | 0.9999 | 0.00008 | 0.0001 | |
| 10 | 5.0088 | 0.0088 | 0.1111 | |
| 20 | 4.9997 | 0.0003 | 0.0112 | |
| 50 | 5 | 5.0001 | 0.0001 | 0.0008 |
| 100 | 4.9999 | 0.00003 | 0.0002 | |
| 500 | 4.9999 | 0.00001 | 0.00001 |
| n | |Bias| | MSE | ||
|---|---|---|---|---|
| 10 | 0.4805 | 0.0195 | 0.0884 | |
| 20 | 0.4873 | 0.0126 | 0.0407 | |
| 50 | 0.5 | 0.5022 | 0.0022 | 0.0176 |
| 100 | 0.4980 | 0.0019 | 0.0086 | |
| 500 | 0.4993 | 0.0007 | 0.0014 | |
| 10 | 1.0028 | 0.0028 | 0.1525 | |
| 20 | 0.9981 | 0.0019 | 0.0073 | |
| 50 | 1 | 0.9985 | 0.0014 | 0.0065 |
| 100 | 1.0011 | 0.0011 | 0.0051 | |
| 500 | 0.9996 | 0.0004 | 0.0025 | |
| 10 | 4.9892 | 0.0107 | 0.1756 | |
| 20 | 4.9911 | 0.0089 | 0.0255 | |
| 50 | 5 | 4.9994 | 0.0006 | 0.0177 |
| 100 | 5.0003 | 0.0003 | 0.0005 | |
| 500 | 5.00005 | 0.00005 | 0.00008 |
| X | OF 1 | ZTPD | ZTPLiD | CNBLD | CPLD |
|---|---|---|---|---|---|
| 1 | 22 | 15.28 | 26.78 | 21.42 | 19.92 |
| 2 | 18 | 21.86 | 19.77 | 19.79 | 19.92 |
| 3 | 18 | 20.84 | 13.94 | 16.81 | 17.71 |
| 4 | 11 | 14.90 | 9.53 | 12.45 | 13.28 |
| 5 | 9 | 8.53 | 6.37 | 8.12 | 8.50 |
| 6 | 6 | 4.06 | 4.19 | 4.73 | 4.72 |
| 7 | 3 | 1.66 | 2.72 | 2.51 | 2.31 |
| 8 | 0 | 0.59 | 1.74 | 1.22 | 1.02 |
| 9 | 1 | 0.19 | 1.11 | 0.55 | 0.40 |
| Total | 88 | ||||
| ML | |||||
| AIC | 335.09 | 336.76 | 331.93 | 329.93 | |
| BIC | 337.57 | 339.24 | 336.89 | 332.41 | |
| X | OF 1 | NB | NTA | PB |
|---|---|---|---|---|
| 0 | 188 | 185.79 | 187.99 | 197.02 |
| 1 | 83 | 89.28 | 85.02 | 84.34 |
| 2 | 36 | 32.99 | 34.52 | 37.45 |
| 3 | 14 | 10.97 | 11.65 | 11.17 |
| 4 | 2 | 3.45 | 3.51 | 3.11 |
| 5 | 1 | 1.52 | 1.30 | 0.91 |
| Total | 88 | |||
| 2.36 | 1.28 | 1.06 | ||
| p-value | 0.505 | 0.735 | 0.785 | |
| d.f | 3 | |||
| X | OF 1 | PD | PLiD | PAD | SCPLD | CPSLD |
|---|---|---|---|---|---|---|
| 0 | 188 | 169.46 | 194.05 | 197.53 | 187.47 | 177.94 |
| 1 | 83 | 109.83 | 79.53 | 75.72 | 85.47 | 97.77 |
| 2 | 36 | 35.59 | 31.32 | 30.23 | 34.64 | 35.81 |
| 3 | 14 | 7.69 | 11.99 | 12.26 | 11.84 | 9.84 |
| 4 | 2 | 1.25 | 4.50 | 4.97 | 3.46 | 2.16 |
| 5 | 1 | 0.18 | 2.61 | 3.29 | 1.12 | 0.46 |
| Total | 324 | |||||
| ML() | 0.65 | 2.04 | 2.09 | 1.82 | 1.10 | |
| −2log ℓ | 724.49 | 714.09 | 716.74 | 710.54 | 714.08 | |
| AIC | 726.49 | 716.09 | 718.74 | 712.54 | 716.07 | |
| BIC | 730.27 | 719.88 | 722.52 | 716.32 | 719.86 | |
| 15.4056 | 1.2719 | 2.8647 | 0.1472 | 4.4469 | ||
| p-value | 0.0005 | 0.5294 | 0.2387 | 0.9290 | 0.1082 | |
| d.f | 2 | |||||
| X | OF 1 | PD | PLiD | PAiD | PABAD | PSBAD | PSD | SCPLD | CPSLD |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1974 | 1816.01 | 2396.79 | 2412.91 | 2027.28 | 2089.44 | 2398.31 | 2031.23 | 2010.23 |
| 1 | 1674 | 1839.97 | 1300.33 | 1256.24 | 1638.94 | 1582.51 | 1288.41 | 1600.37 | 1619.55 |
| 2 | 869 | 932.12 | 668.81 | 664.62 | 828.12 | 799.09 | 665.14 | 857.57 | 869.87 |
| 3 | 342 | 314.81 | 332.15 | 343.20 | 334.74 | 336.23 | 334.03 | 351.47 | 350.41 |
| 4 | 102 | 79.74 | 160.91 | 171.34 | 118.39 | 127.33 | 164.38 | 117.47 | 112.92 |
| 5 | 26 | 16.16 | 76.52 | 82.79 | 38.29 | 45.01 | 79.65 | 33.34 | 30.33 |
| 6 | 13 | 2.73 | 35.87 | 38.88 | 11.61 | 15.15 | 38.12 | 8.26 | 6.98 |
| 7 | 2 | 0.39 | 30.59 | 17.81 | 3.35 | 4.92 | 33.93 | 2.27 | 1.70 |
| Total | 5002 | ||||||||
| ML() | 1.01319 | 1.3873 | 1.7323 | 1.9739 | 1.4804 | 1.3197 | 2.5160 | 1.6113 | |
| −2log ℓ | 13,535.82 | 13,836.73 | 13,895.01 | 6740.37 | 6752.8 | 6931.20 | 13,478.64 | 13,475.52 | |
| AIC | 13,537.82 | 13,838.73 | 13,897.01 | 13,482.3 | 13,507.2 | 13,862.41 | 13,480.64 | 13,477.52 | |
| BIC | 13,544.34 | 13,845.25 | 13,903.53 | 13,489.5 | 13,514.3 | 13,864.41 | 13,487.15 | 13,484.04 | |
| 92.7039 | 336.95 | 379.28 | 11.25 | 32.98 | 358.14 | 10.9582 | 8.9499 | ||
| p-value | ≈0 | ≈0 | ≈0 | 0.128 | ≈0 | ≈0 | 0.0522 | 0.1111 | |
| d.f | 5 | ||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzaid, A.A.; Alqefari, A.A.; Qarmalah, N. On the Conflation of Poisson and Logarithmic Distributions with Applications. Axioms 2025, 14, 518. https://doi.org/10.3390/axioms14070518
Alzaid AA, Alqefari AA, Qarmalah N. On the Conflation of Poisson and Logarithmic Distributions with Applications. Axioms. 2025; 14(7):518. https://doi.org/10.3390/axioms14070518
Chicago/Turabian StyleAlzaid, Abdulhamid A., Anfal A. Alqefari, and Najla Qarmalah. 2025. "On the Conflation of Poisson and Logarithmic Distributions with Applications" Axioms 14, no. 7: 518. https://doi.org/10.3390/axioms14070518
APA StyleAlzaid, A. A., Alqefari, A. A., & Qarmalah, N. (2025). On the Conflation of Poisson and Logarithmic Distributions with Applications. Axioms, 14(7), 518. https://doi.org/10.3390/axioms14070518