1. Introduction
Progress in science and technology has resulted in the creation of exceptionally durable and intricate products, like silicone seals, computers, missiles, and LEDs. Reliability is crucial for sustaining product quality, leading firms to invest significantly in testing and design. Nevertheless, for exceptionally reliable goods, their prolonged lifespans frequently provide minimal or no failures during regular testing under typical conditions. Conventional life-testing methodologies encounter difficulties in managing such situations.
In conventional life testing and reliability trials, acquiring adequate failure data can be difficult, particularly for highly dependable items with extended lifespans. Under typical circumstances, assessments performed within restricted durations frequently provide fewer failures. Accelerated life testing (ALT) is frequently employed to tackle this issue. ALT exposes products to heightened stress conditions, including enhanced humidity, temperature, pressure, voltage, or vibration, to expedite breakdown occurrences. The resultant failure statistics are subsequently evaluated to assess the product’s lifespan characteristics under standard operating settings. ALT can be executed by multiple methodologies, including continual stress, step stress, and progressive stress techniques, as articulated by Nelson [
1]. To tackle this difficulty, ALT is utilized, wherein items are exposed to elevated stress conditions (e.g., temperature, voltage) to precipitate premature failures. This allows producers to forecast product longevity under standard usage conditions. Alternative methods encompass the following:
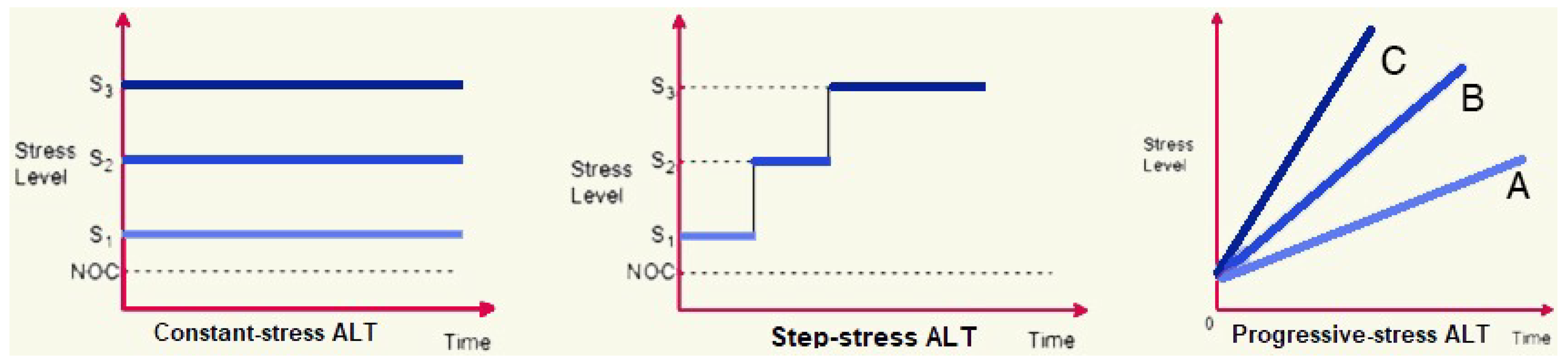
Constant stress: applies a steady and unchanging high level of stress during the entire test.
Step-stress: increases the stress level incrementally in distinct stages.
Progressive stress: gradually raises the stress level in a continuous manner over time.
Refer to Nelson [
1] for fundamental notions regarding ALT. ALT optimizes testing productivity, lowers costs, and improves product design by delivering critical failure data within reduced timescales.
Figure 1 delineates the distinctions among ALT approaches.
1.1. Constant-Stress ALT
In constant-stress accelerated life testing, test units are exposed to a consistently high-stress environment until either all units fail or a specified stopping criterion is met. Notable contributions in this area are included in
Table 1.
1.2. Step-Stress ALT
Step-stress ALT entails the incremental augmentation of stress at predefined intervals or following a specified number of failures. This approach is extensively documented in the literature, with significant contributions including in
Table 2.
1.3. Progressive-Stress ALT
Progressive stress ALT has a distinctive methodology in contrast to constant and step-stress techniques by progressively escalating stress levels over time. An illustrative instance is the ramp stress test, characterized by a linear increase in stress. Researchers have investigated multiple facets of this approach, with significant contributions included in
Table 3.
These studies illustrate ALT’s efficacy in tackling issues associated with highly reliable goods, offering insights into statistical models, optimal test designs, and sophisticated failure analysis methodologies.
Censored data are frequently utilized in research about dependability and life testing. Investigators must collect data using censored samples due to considerations such as the preservation of operational experimental equipment for future utilization, the minimization of overall testing duration, and financial constraints. Time-censoring (type I) and failure-censoring (type II) are the two predominant censoring strategies employed in life-testing and reliability studies (see the work by Bain and Engelhardt for further details [
18]). These approaches lack sufficient flexibility to permit the removal of units from the experiment at any time other than the final point.
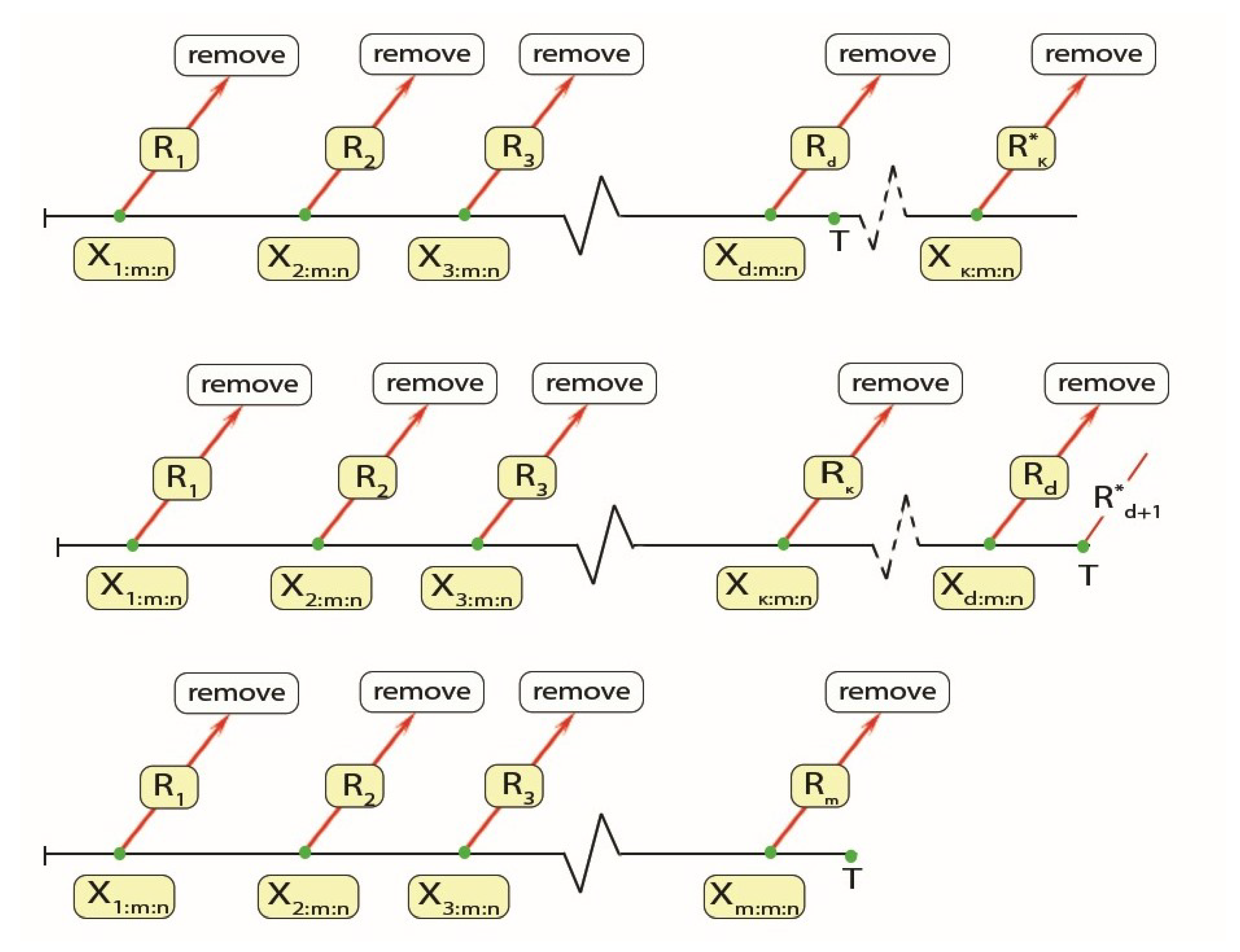
The progressive type-II censoring scheme (PTII) is a commonly employed technique in reliability and survival analysis, frequently favored over the conventional type-II censoring scheme due to its versatility in practical applications, including industrial and medical research. In contrast to the traditional methodology, PTII allows for the extraction of functioning units throughout the experiment rather than at its completion [
19]. In PTII, let
m represent the number of units out of
n that are designated to fail during a life test. A specified sequence
determines the number of units extracted following each failure. Upon the initial failure occurring at time
,
remaining units are deleted arbitrarily. Likewise, following the second failure at
,
supplementary units are extracted. The procedure persists until the
m-th failure at
, at which point all
remaining units are eliminated, therefore ending the test. This method has been thoroughly examined; nonetheless, it has a significant limitation: if the units exhibit great reliability, the time of the experiment may become unduly prolonged.
Kundu and Joarder [
20] proposed the progressive hybrid censoring scheme to overcome this issue, wherein the test concludes at
, with
T representing a preset maximum duration. Nonetheless, the progressive hybrid censoring scheme encounters difficulties when only a few failures transpire before
T, resulting in constrained or inaccurate parameter estimates. To address these issues, Cho et al. [
21] introduced the GPHC scheme (GPHCS). This technique guarantees a minimal occurrence of failures, hence enhancing the precision of parameter estimates. Under GPHCS, the number of failures and their respective lifespan are pre-established, optimizing test length and expense. The experiment finishes at
, with
k,
m, and
being predetermined, as referenced in [
20]. The observations are classified into three categories:
Case I: if ,
Case II: if ,
Case III: if ,
Figure 2 illustrates a schematic illustration of the generalized progressive hybrid censoring scheme.
GPHCS was utilized by Koley and Kundu [
22] to develop a new dialogue regarding censored samples within the context of conflicting hazard models. Maswadah [
23] enhanced maximum likelihood estimation for the shape-scale family utilizing GPHCS. Salem et al. [
24] presented the combined type II of GPHCS. Abdelwahab et al. [
25] examined classical and Bayesian inference for lifespan distribution utilizing GPHCS. Mohie El-Din et al. [
26] derived predictions of lives under GPHCS. Mahto et al. [
27] formulated a partially observable competitive risk model inside the framework of GPHSC. Zhu derived reliability inference for the multi-component stress–strength model under GPHCS. Wang et al. [
16] examined the reliance of competing risks on partially observed failure reasons derived from a bivariate distribution under GPHCS. Çetinkaya [
28] examined the inference of P(X > Y) within the framework of GPHCS. Shi et al. [
29] presented a reliability analysis of the J-out-of-N system under GPHCS.
Research on progressive-stress ALT is always advancing, integrating various statistical models and censoring methodologies. Abdel-Hamid and Al-Hussaini [
30] integrated progressive stress with finite mixture distributions, Bayesian analysis, and progressive censoring for multiple lifespan distributions. Abdel-Hamid and Al-Hussaini [
31] investigated inference for Weibull distributions in the context of PTII filtering. Recent studies employing progressive-stress ALT with censoring methodologies encompass the works of Mohie et al. [
32], Zhuang [
33], Mahto [
34], Abushal [
35], Ismail [
36], Hussam [
37], and Alotaibi [
38].
The GPHCS has demonstrated its efficacy as a valuable instrument for studying censored data in ALTs, especially within models such as competing risks and step-stress models. Nonetheless, a notable deficiency is present in the implementation of GPHC under Progressive Stress ALT models, which entail incrementally escalating stress levels during the assessment. The majority of current research, including that by Wang et al. [
39] and Pandey et al. [
40], concentrates on constant or step-stress models, neglecting the complexity associated with progressive stress scenarios.
The present study seeks to address this deficiency by modifying and expanding the GPHC methodology for PSALT models. The objective is to deliver a more adaptable and precise analytical instrument capable of managing censored data resulting from incremental stress, thereby enhancing the accuracy of forecasts in progressive life-testing contexts. This study identifies a significant deficiency in the literature and facilitates the development of more accurate models for accelerated life testing.
2. Test Assumptions
2.1. Generalized Kavya–Manoharan Exponential Distribution
To provide more leeway for modeling lifetime data, the generalized Kavya–Manoharan exponential (GKME) distribution was created as an expansion of the exponential distribution. Developed by Mahran et al. [
41], this distribution incorporates a shape parameter,
, which, when coupled with the principal scale parameter
, permits a more precise representation of actual data, particularly in cases where classical models are inadequate. There is a PDF for the GKME distribution, and it is found by
The cumulative distribution function (CDF) of the GKME distribution is given by
2.2. Assumption: Progressive-Stress ALT
Lifetimes of units follow .
We have stress function , .
The depends upon t.
We also have , where and are to be estimated.
Linear cumulative exposure model (LCEM) is considered for modeling the effect of stress change, for more details, see Nelson [
1].
Under consideration of LCEM, the CDF under progressive-stress
is expressed as
where
denotes the CDF of the lifetime distribution at stress level
i,
, while s is the total number of progressive stress levels, and
where
is the time-dependent degradation rate function associated with the
i-th stress level.
Then, by setting the value of the scale parameter
, we have the CDF for the
i-th progressive stress given as
where
is vector of parameter as
, and the corresponding PDF is given by
2.3. Algorithm: GPHCS
Input:
Distribution election: the GKME distribution is chosen for this study.
Number of units: n.
Predefined time: .
Failure counts: k and m where .
Censoring plan: a sequence such that .
Procedure:
- (a)
Deploy n units for life testing.
- (b)
Simulate lifetimes based on the GKME distribution with CDF
, using PTII methodology [
42].
Assign values for .
For given values of n, m, and (), generate a PTII sample:
Draw as independent samples from a uniform distribution.
Invert the GKME distribution to determine
The resulting values represent PTII order statistics from the GKME distribution.
- (c)
Set the failure time threshold as
where
- (d)
Determine the number of failures for different cases:
Here, is an indicator variable used to distinguish the termination mechanism of the test. It equals 1 when the experiment ends due to the pre-specified time T (i.e., time-censoring), and 0 when it ends due to the occurrence of m failures.
Output: The observed failure times , where the following is true:
- (a)
If , then .
- (b)
If , then d represents the number of failures before T.
- (c)
If , then .
3. Estimation Methods
In this section, we utilize the maximum likelihood estimation method based on PSALT to estimate the model parameters , , and . A concise explanation of GPHCS under PSALT is provided. Consider s stress levels, where items are subjected to testing at each level, with . Additionally, the observed items, denoted as , , and , for , follow predefined censoring schemes at failure times , for .
During the first failure at the
ith stress level,
surviving units are removed from the experiment. Similarly, at the second failure in the
ith stress level,
surviving units are withdrawn from the remaining
units. Finally, at the
th failure, all the remaining units, calculated as
, are withdrawn, bringing the experiment to an end. Refer to
Figure 2 for illustration.
Let the observed GPHCS data under the progressive-stress level
, for
be represented by
. Here,
and
. The corresponding likelihood function with vector parameter
is then expressed as follows:
where
is constant and does not depend on parameters
, the
can be define as
.
Using Equations (
3) and (
4) in (
5), the likelihood function of the QXG distribution under GPHCS within the framework of the PSALT model is derived as
hence, the log-likelihood function, excluding the constant term
, is expressed as
3.1. Newton–Raphson Algorithm
The likelihood equations are obtained by taking the first partial derivatives of the log-likelihood function in (
7) with respect to
,
, and
, expressed as
and
where
,
, and
.
The maximum likelihood estimates of the unknown parameters
,
, and
are determined by solving the three Equations (
8)–(
10) by setting them to zero. Since these equations are nonlinear, a numerical method is employed to compute the estimates, such as the Newton–Raphson (NR) algorithm. The NR algorithm begins with an initial estimate
and iteratively improves the estimates through the following update formula:
Here,
denotes the vector of unknown parameters,
corresponds to the vector of first-order derivatives, and
represents the Hessian matrix of second-order derivatives:
3.2. Asymptotic Confidence Interval
In this subsection, approximate confidence intervals for the parameters are derived using the asymptotic distribution of the MLEs of
. The asymptotic distribution of the MLEs for
is expressed as
where
represents the variance–covariance matrix of the parameters
. The elements of the
matrix
denoted as
for
for
, can be approximated by
. Accordingly, an approximate
confidence interval for the parameter
is given by
where
,
, and
.
The following section explores the incorporation of prior knowledge into the analysis to achieve improved results.
4. Bayesian Estimation
In this section, we introduce Bayesian estimates that address the GKME parameter uncertainty by considering a joint prior distribution formulated before collecting failure data. Utilizing prior knowledge in the analysis, the Bayesian approach proves valuable in reliability assessment. Through the squared error loss function (SELF) and entropy loss function (ELF), we derive Bayesian estimates (BEs) for the unidentified parameters
and
. These parameters are assumed to be independent and to adhere to gamma prior distributions as follows:
It is presumed that all hyper-parameters
and
have positive values and are given.
The posterior distribution of parameters
, and
, denoted as
, can be calculated by combining the likelihood function from Equation (
6) with the prior distributions outlined in Equation (
11).
Equation (
12) represents the joint posterior distribution of the parameters
,
, and
. It is derived by applying Bayes’ theorem, where the posterior is proportional to the product of the likelihood function (Equation (
6)) and the prior distributions (Equation (
11)), normalized by the marginal likelihood (i.e., the integral of the numerator over the parameter space).
The SELF is commonly used, as it is a symmetrical loss function that assigns the same penalties to both overestimation and underestimation. When an estimator
,
and
is used to estimate the parameter
,
, and
, the SELF is defined as
,
, and
. Thus, the Bayesian estimation of any function involving
,
, and
, such as
within the SELF framework, can be determined as
The ELF is the predominant choice for an asymmetric loss function, widely recognized as more comprehensive. The Bayesian estimate
under the ELF function can be calculated as follows:
4.1. Markov Chain Monte Carlo
Equation (
13) offers an expectation that can be solved through various integrals, but obtaining these multiple integrals mathematically is not feasible. Hence, to generate samples from the joint posterior density function in Equation (
12), the MCMC method is employed. This involves incorporating the Gibbs sampling step within the Metropolis–Hastings (M–H) sampler procedure. In statistics, two commonly utilized MCMC techniques are the M–H and Gibbs sampling methods. The joint posterior density function of
and
is given by the following equation:
The joint posterior distribution of
, and
in Equation (
15) does not follow conventional patterns, thus requiring the utilization of the M–H sampler for MCMC implementation. The “coda” package in R 4.3.0 software is a suitable tool for applying the M–H algorithm within Gibbs sampling.
and
The posterior density functions of
, and
cannot be simplified analytically to any established distribution, as demonstrated in Equations (
16)–(
18). Consequently, the M–H method is considered the most effective approach for addressing this challenge. For additional details, please refer to citations [
43,
44,
45,
46]. The subsequent section outlines the sampling technique employed in the M–H algorithm, utilizing a normal proposal distribution:
Initialize the starting values as , and .
Set the counter i to 1.
Generate , and from normal distributions , and , respectively.
Determine , and .
Generate random samples , and from a uniform distribution .
If both , and are less than , and respectively, set , and ; otherwise, set , and .
Increment i by .
Repeat steps 3–7 H times to obtain , and for .
4.2. Hyper-Parameters Determination
The determination of the hyper-parameters relies on informative priors, which are obtained from the MLEs of
by setting the mean and variance of
equal to those of the specified priors (Gamma priors). Here,
, where
k represents the number of available samples from the GKME distribution (Dey et al. [
47]). By setting the moments of
equal to the moments of the gamma priors, we obtain the following equations:
By resolving the mentioned set of equations, the estimated hyper-parameters can be represented as follows:
5. Simulation
A Monte Carlo simulation is conducted to assess the efficacy of the approaches outlined in this research. The maximum likelihood estimates (MLEs) and Bayesian estimates are evaluated based on their relative absolute bias (RAB) and mean squared errors (MSEs). Furthermore, the asymptotic confidence intervals (ACI) and highest posterior density (HPD) intervals are evaluated based on their mean interval lengths and coverage probabilities. The simulation study encompasses distinct progressive-stress ALTs: the initial test is a straightforward ramp-stress ALT, including two stress levels (
). Additionally, two censoring strategies are examined by binomial random removal. Assume that the elimination of a single unit from the life test is independent of the other units, with each unit possessing an identical probability
p of being removed. Thus, the quantity of units eliminated at each failure time adheres to a binomial distribution, articulated as
and
where
and
corresponds to the different stress levels.
Furthermore, assume that
is independent of
for every stress level. Under these assumptions, the joint likelihood function with binomial removal can be formulated as follows:
Substituting (
20) and (
21) into (
22), we obtain
In all examined instances, we have assumed and without loss of generality. Samples were produced for designated values of each stress level n, where I is ( = 10, = 10), II is ( = 30, = 30), , and alongside a predetermined sampling protocol. The true values of the parameters , , and are assumed as follows: Case 1: , and ; Case 2: , and ; Case 3: , and ; Case 4: , and .
In Bayesian estimation, it is customary to omit a segment of the initial samples as a burn-in period to confirm that the Markov chain has converged to the appropriate stationary distribution. Our methodology involves generating a total of M–H samples, with the initial samples eliminated as burn-in. The residual samples can thereafter be utilized to formulate point estimates and interval estimates for , , and .
In the ramp-stress ALT, the ramp stresses are established at
and
. The simulation outcomes, derived from 5000 samples, are included in
Table 4,
Table 5,
Table 6 and
Table 7:
Bayesian estimates (SELF, ELF I, ELF II) consistently show lower bias and MSE compared with MLE, indicating higher accuracy and stability. Example: For , Bayesian MSE (e.g., 0.1238 under SELF) is much smaller than MLE MSE (0.5262).
Bayesian approaches, especially under SELF, provide tighter confidence intervals, as seen from smaller standard errors.
MLE tends to have higher variability, particularly for smaller sample sizes or extreme parameter values.
Results remain robust across varying hyperparameters () and censoring schemes ().
Bayesian methods adapt better to censored data (common in reliability studies).
Bayesian methods provide smoother and more conservative reliability curves.
The Bayesian framework (SELF, ELF I, ELF II) consistently outperforms MLE in estimating GKME distribution parameters for sodium–sulfur battery failure data. It offers lower bias, smaller MSE, and greater robustness, especially in scenarios with censored or limited data. These findings suggest that Bayesian methods are preferable for reliability modeling, ensuring more precise and interpretable results for failure time analysis.
6. Application of Real Data
In this section, two real-world data sets are discussed. The first data set involves times to failure and censored times (in hours) collected under two different temperature levels, specifically 170 °C and 200 °C. These data were obtained from accelerated life testing of metal–oxide–semiconductor integrated circuits. The second data set contains lifetimes (in cycles) for sodium–sulfur batteries, which were used to assess performance and reliability under ALT operating conditions.
6.1. Data Set I
Accelerated failure data with covariates were reported for time-dependent dielectric breakdown of metal–oxide–semiconductor (MOS) integrated circuits. The tests were conducted under elevated temperature conditions to accelerate failure mechanisms, with temperature serving as the stress variable (or covariate). The goal was to estimate dielectric reliability and hazard functions at normal operating conditions using data collected under stress. Specifically, the tests were performed at three elevated temperatures: 170 °C, 200 °C, and 250 °C. However, in our study, we considered only the data corresponding to the temperature levels of 170 °C and 200 °C. These data, originally reported by Elsayed and Chan [
48] and also referenced in Pham [
49], can be used to evaluate failure time models with parameters dependent on temperature; see
Table 8. The nominal electric field was kept constant across all temperature levels.
Table 9 provides likelihood estimates for parameters (
,
,
) and statistical measures (AIC, BIC, KSD, ADS, CVMS) under a times-to-failure data set at two temperatures (170 °C and 200 °C). The estimates reveal how temperature influences the model parameters, with higher temperatures generally reducing
and
, suggesting accelerated degradation. The AIC and BIC values are lower at 200 °C, indicating a better model fit, while the KSD, ADS, and CVMS metrics (with their
p-values, PVKS, PVAD, PVCVM) assess goodness-of-fit, showing weaker evidence against the model at 200 °C. Standard errors (StEr) highlight parameter uncertainty, which is notably higher for
and
at 200 °C. This table is critical for reliability analysis, demonstrating temperature-dependent failure patterns, fitting, and model robustness.
Figure 3 and
Figure 4 present the fitting results of variable I and II, respectively, for a times-to-failure data set. The visual representation likely illustrates how well a GKME model aligns with the observed failure times, highlighting trends, deviations, or goodness-of-fit metrics. Such analyses are crucial in reliability engineering or survival analysis, as they help validate predictive models and inform decision-making regarding maintenance, risk assessment, or product lifespan about GKME distribution.
Table 10 compares MLE and Bayesian estimates (under SELF and ELF) for parameters
,
, and
in a times-to-failure model, evaluated across different hyperparameter pairs
and probabilities
. The Bayesian estimates generally exhibit smaller standard errors (StEr) than MLEs, suggesting improved precision, particularly for
and
. For instance, at
and
, the StEr for
drops from 0.0949 (MLE) to 0.0499 (Bayes). The ELFI and ELFII estimates align closely with Bayesian results, reinforcing robustness. Notably,
estimates are extremely small, with MLEs showing higher variability (e.g., StEr of 6.01 × 10
−5 vs. 3.10 × 10
−7 for Bayes). This table highlights the trade-offs between frequentist and Bayesian approaches, with the latter offering more stable estimates, especially for sparse or uncertain data scenarios. Such insights are vital for reliability modeling and decision-making under uncertainty.
Table 11 compares MLE and Bayesian estimates (SELF, ELFI, ELFII) for reliability measures (R, H) across different parameter sets. Bayesian methods generally yield more stable estimates, with ELFI/ELFII closely aligning. Notably, at (17, 17) and
p = 0.2, all methods agree (R = 0.13, H = 0.66–0.67), while greater divergence occurs at
p = 0.9, suggesting sensitivity to non-informative prior assumptions. The table highlights Bayesian approaches’ utility in reliability analysis, especially for uncertainty quantification.
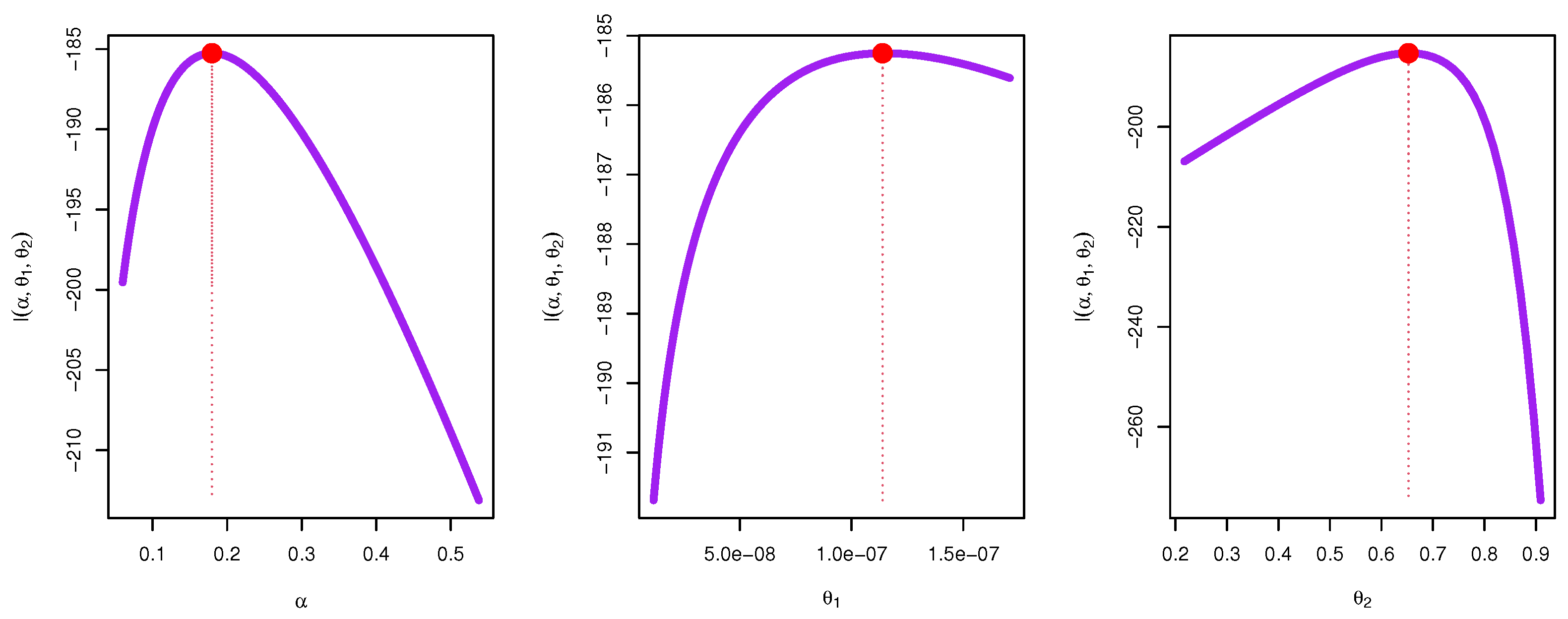
Figure 5 shows the likelihood profiles for model parameters, highlighting peak values, MLEs, and their precision. Steeper curves indicate more reliable estimates, aiding model validation in reliability studies.
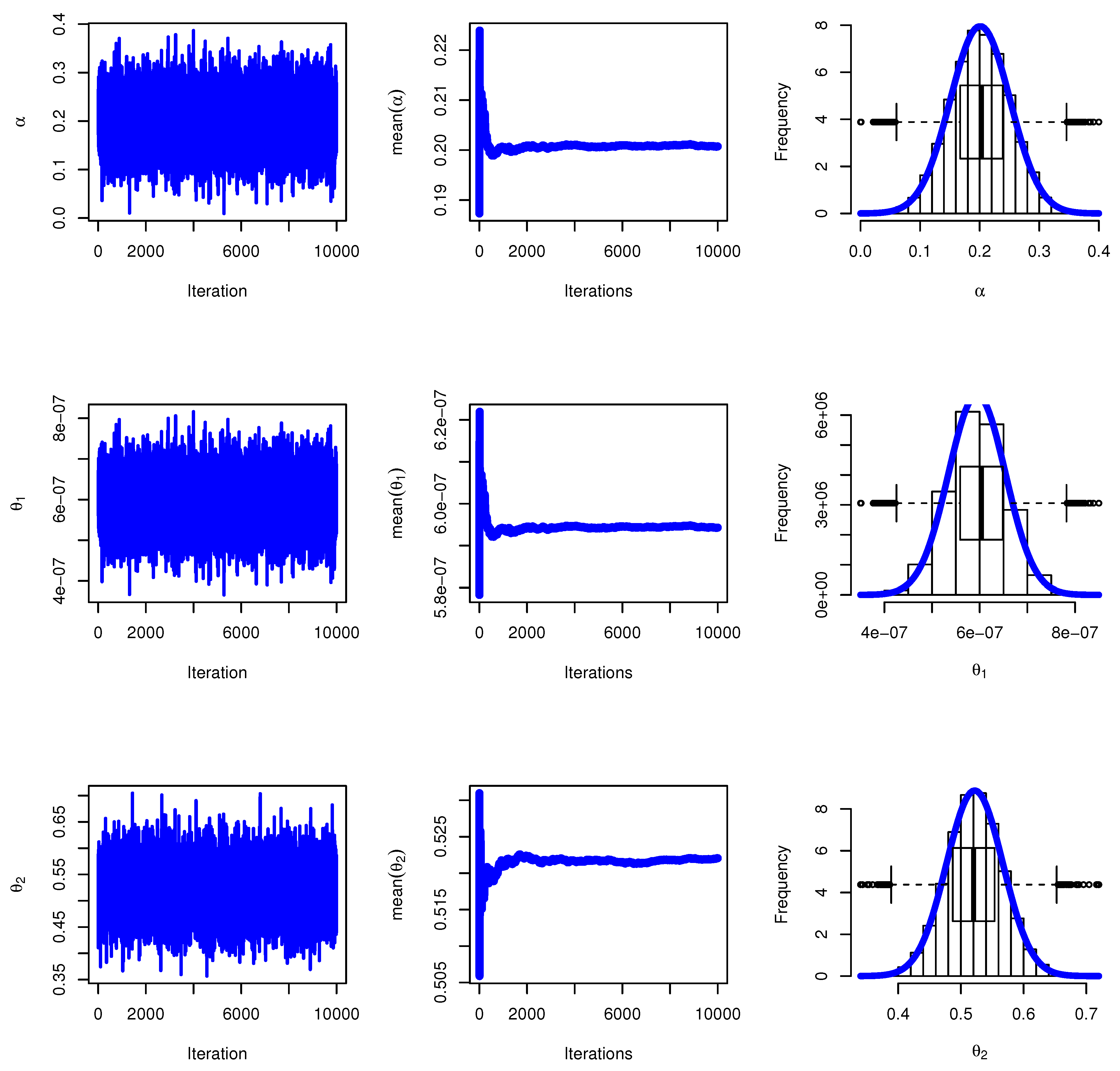
Figure 6 displays MCMC trace plots and posterior distributions for model parameters in a times-to-failure analysis. The trace plots (left) show stable chains with good mixing, indicating convergence, while the posterior densities with normal curves (right) reveal well-identified parameter estimates.
6.2. Data Set II
Ansell and Ansell [
50] examined the data set presented in
Table 12 as part of their evaluation of sodium–sulfur battery performance. The data set includes battery lifetimes (measured in cycles) from two different batches. The first batch contained 15 batteries, with four lifetimes being right-censored—these represent the four highest values, all recorded as the same. The second batch consisted of 20 batteries, with only one right-censored lifetime, which is not the highest value in that group. The primary goal of the analysis was to determine whether there was a performance difference between the two batches of batteries. Let these data be considered as an ALT data example, where the first stress factor is temperature. Batteries are typically exposed to elevated temperatures to accelerate their failure mechanisms. The natural use condition is assumed to be 170 °C, while under accelerated stress, the temperature was increased to 200 °C.
Table 13 shows the parameter estimates and goodness-of-fit statistics for the GKME distribution applied to sodium–sulfur battery lifetime data across two batches. Batch 1 has higher shape (
) and scale (
) parameter estimates compared with Batch 2 (
,
), suggesting differences in failure patterns. Both batches exhibit strong model fit, as indicated by high
p-values in KSD, ADS, and CVMS tests (all > 0.63), with Batch 1 showing slightly better performance (lower AIC/BIC). The results support the GKME distribution’s suitability for modeling battery lifetimes, though Batch 2’s larger standard errors imply less precision in its estimates.
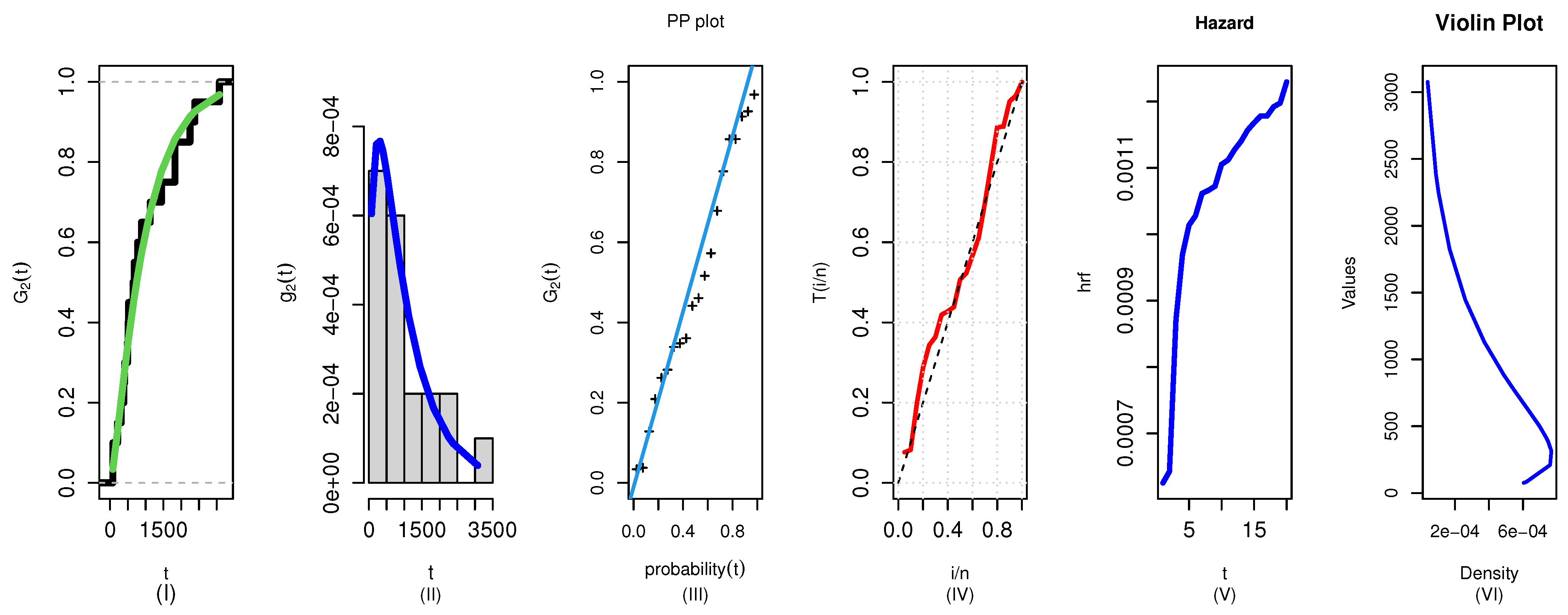
Figure 7 and
Figure 8 visually assess the fit of the GKME distribution to the battery lifetime data for two variables. Variable I (
Figure 7) and Variable II (
Figure 8) likely show how well the theoretical curves align with the empirical data, such as through Q–Q plots or density overlays. The close agreement between the modeled and observed values would support the earlier statistical results (
Table 13), confirming the GKME distribution’s effectiveness in capturing the failure patterns of sodium–sulfur batteries. Without the exact images, the figures presumably reinforce the high
p-values and low AIC/BIC scores, indicating a robust fit.
Figure 9 displays the likelihood profiles for the GKME distribution parameters fitted to the sodium–sulfur battery lifetime data. The curves likely show how the log-likelihood function varies with changes in parameters like
,
, and
, with peaks indicating MLEs. A well-defined peak would confirm precise parameter estimation, while flat or multi-peaked profiles might suggest identifiability issues of estimates.
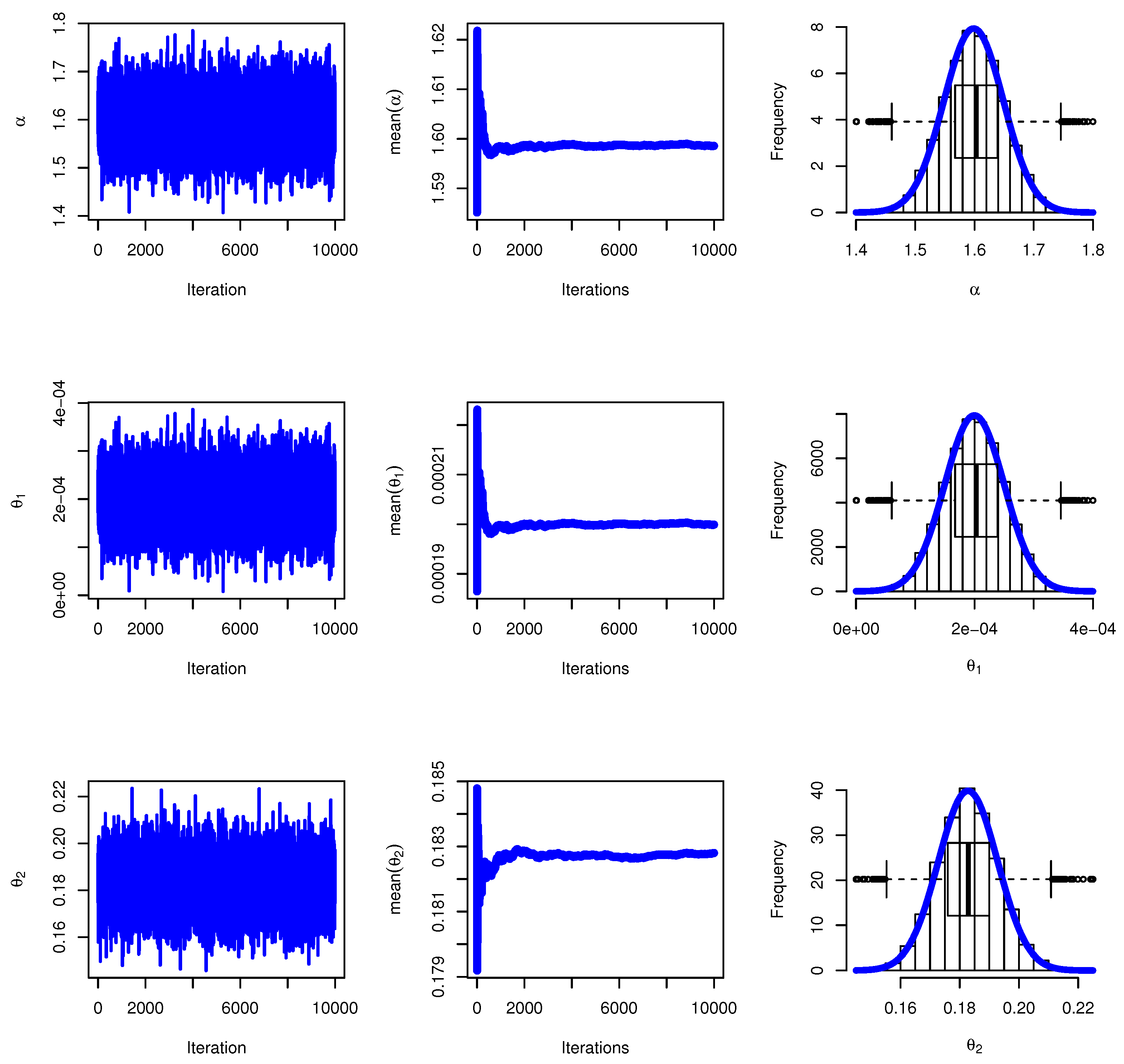
Figure 10 presents the MCMC diagnostic plots for the GKME distribution parameters applied to the sodium–sulfur battery lifetime data. These plots likely include trace plots (showing convergence of chains) and density plots (depicting posterior distributions) for parameters like
,
, and
. Well-mixed, stationary trace plots and smooth, unimodal density curves would indicate robust Bayesian estimation, supporting the reliability of the model.
Table 14 compares MLEs and Bayesian estimates (under squared error loss function, SELF, and two other loss functions, ELF I and II) for the GKME distribution parameters (
,
,
) fitted to sodium–sulfur battery failure data. The MLE and Bayesian estimates are notably close, with minor deviations (e.g.,
vs.
for
), suggesting robustness in parameter estimation. The Bayesian standard errors (StEr) are significantly smaller (e.g.,
vs.
for
), highlighting the precision of the Bayesian approach. This alignment reinforces the reliability of the GKME model for analyzing battery lifetimes, with both methods yielding consistent results.
Table 15 presents reliability measures (R) and hazard rates (H) derived from both MLEs and Bayesian methods (SELF, ELF I, ELF II) for the GKME model applied to sodium–sulfur battery failure data. The results, consistent with
Table 14 parameter estimates, show close agreement between MLE and Bayesian approaches (e.g., R = 0.203 for
), with minor variations (e.g., R = 0.2914 vs. 0.2721 for
). This alignment confirms the model’s robustness in predicting reliability, while the Bayesian estimates exhibit slightly lower hazard rates (H), suggesting a more conservative assessment of failure risk. The findings reinforce the GKME distribution’s utility for reliability analysis in battery lifetime studies.
7. Conclusions
This study examines progressive-stress ALT for the lifespan GKME distribution based on a generalized progressive hybrid censoring framework, illustrating the recommended methodologies with a real example. MLE and Bayesian estimates of the parameters were obtained for several sample sizes and two binomial parameter configurations for random elimination, with their efficacy evaluated using mean squared errors. The results of the simulation exercise demonstrate that Bayesian point estimates and the highest posterior density credible intervals surpass traditional point estimates derived from bootstrap methods. This pattern was likewise evident in two empirical data studies. The analysis, utilizing statistical metrics including AIC, BIC, KSD, and p-values, indicates that the GKME distribution derived from progressive-stress ALT surpasses the competing models.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}