1. Introduction
Consider the linear system of equations
where
is a large, symmetric, nonsingular, and indefinite matrix and
and
are real vectors. Such systems arise in various areas of applied mathematics and engineering. When
A is too large to make its factorization feasible or attractive, an iterative solution method has to be employed. Among the most well-known iterative methods for solving linear systems of the kind (
1) are MINRES or SYMMLQ by Paige and Saunders (see [
1,
2]). However, none of these methods allow for easy estimation of the error in the computed iterates. This can make it difficult to decide when to terminate the iterations.
For a symmetric, positive definite matrix
A, the conjugate gradient method is typically used to solve (
1). Various techniques are available to estimate the
A-norm of the error in the iterates determined by the conjugate gradient method. These techniques leverage the relationship between the conjugate gradient method and Gauss-type quadrature rules applied to integrate the function
. The quadrature rules are determined with respect to an implicitly defined non-negative measure defined by the matrix
A, the right-hand side
, and the initial iterate
(see, for example, Almutairi et al. [
3], Golub and Meurant [
4,
5], Meurant and Tichý [
6] and references therein).
Error estimation of iterates in cases where the matrix
A is nonsingular, symmetric, and indefinite has not received much attention in the literature. We observe that the application of
A-norm estimates of the error in the iterates is meaningful when
A is symmetric and positive definite [
7]. However, this is not the case when
A is symmetric and indefinite. In this paper, we estimate the Euclidean norm of the error for each iterate produced by an iterative method, which is described below.
In their work, Calvetti et al. [
8] introduced a Krylov subspace method for the iterative solution of (
1). They proposed estimating the Euclidean norm of the error in the iterates generated by their method using pairs of associated Gauss and anti-Gauss quadrature rules. However, the quality of the error norm estimates determined in this manner is mixed. Examples of computed results demonstrate that some error norm estimates are significantly exaggerated compared to the actual error norm in the iterates.
This paper presents novel methods for calculating the Euclidean norm of the error in the iterates computed using the iterative method described in
Section 2 and [
8]. In particular, the anti-Gauss rule used in [
8] is replaced by other quadrature rules.
For notational simplicity, we start with the initial approximate solution
. Consequently, the
kth approximate solution
determined by the iterative method discussed in this paper lives in the Krylov subspace:
i.e.,
for a suitable iteration polynomial
in
, where
is the set of all polynomials of degree less than or equal to
. We require that the iteration polynomials satisfy
Then
fulfills condition (
4) for a polynomial
.
We introduce the residual error related to
as
and let
denote the solution of (
1). Then the error
in
can be expressed as
Equations (
6) and (
7) yield
where the superscript
t denotes transposition. We may calculate the Euclidean norm of the vector
by using the terms found on the right-hand side of Equation (
8). It is straightforward to compute the term
, and using (
5), the expression
can be calculated as
Hence, the expression
can be evaluated without using
. The iterative method has to be chosen so that recursion formulas for the polynomials
,
easily can be computed. Finally, we have to estimate
, which by setting
, can be written as the following matrix functional
We use Gauss-type quadrature rules determined by the recurrence coefficients of the iterative method to approximate (
9).
The structure of this paper is as follows.
Section 2 outlines the iterative Krylov subspace method employed for the solution of (
1). This method was discussed in [
8]. We review the method for the convenience of the reader. Our presentation differs from that in [
8]. The iterative method is designed to facilitate the evaluation of the last two terms on the right-hand side of (
8).
Section 3 explores various Gauss-type quadrature rules that are employed to estimate the first term on the right-hand side of (
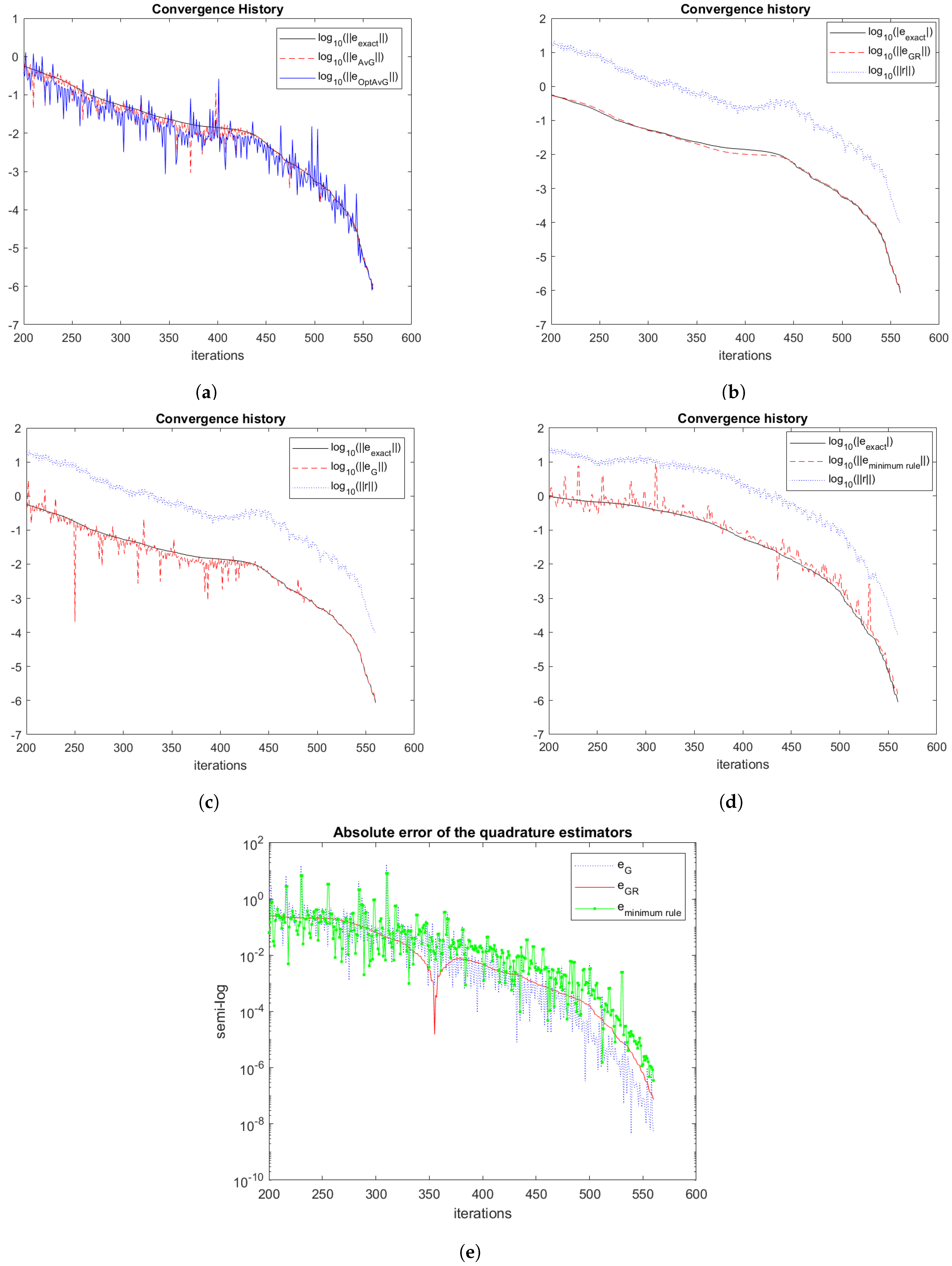
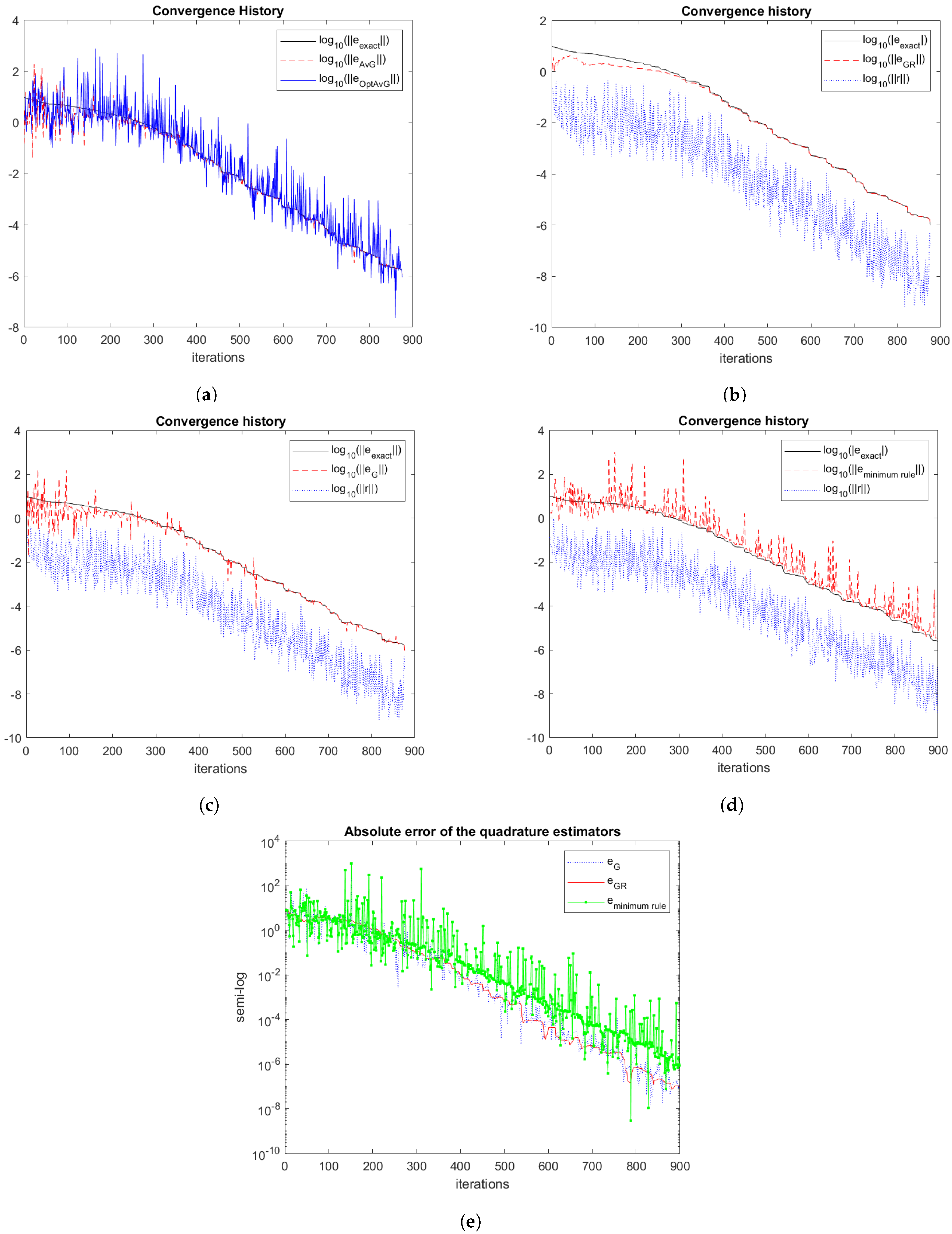
8). The quadrature rules used in this study include three kinds of Gauss-type rules, namely averaged and optimally averaged rules by Laurie [
9] and Spalević [
10], respectively, as well as Gauss-Radau rules with a fixed quadrature node at the origin. Additionally, we describe how to update the quadrature rules cost-effectively as the number of iterations grows. This section improves on the quadrature rules considered in [
8].
Section 4 describes the use of these quadrature rules to estimate the Euclidean norm of the errors
,
.
Section 5 provides three computed examples and
Section 6 contains concluding remarks.
The iterates determined by an iterative method often converge significantly faster when a suitable preconditioner is applied (see, e.g., Saad [
11] for discussions and examples of preconditioners). We assume that the system (
1) is preconditioned when this is appropriate.
2. The Iterative Scheme
This section revisits the iterative method considered in [
8] for solving linear systems of Equation (
1) with a nonsingular, symmetric, and indefinite matrix
A. We begin by discussing some fundamental properties of the method. Subsequently, we describe updating formulas for the approximate solutions
. This method can be seen as a variation of the SYMMLQ scheme discussed in [
1,
12].
It is convenient to introduce the spectral factorization of the coefficient matrix (
1),
where
is a diagonal matrix with diagonal elements
and the matrix
is orthogonal. The spectral factorization is used for the description of the iterative method but does not have to be computed for the solution of (
1). Defining
, the functional (
9) can be written as
where the measure
has jump discontinuities at the eigenvalues
of
A.
Our iterative method is based on the Lanczos algorithm. Let
denote the identity matrix. By applying
steps of the Lanczos process to
A with initial vector
, the following Lanczos decomposition is obtained:
where
and
are such that
,
, and
Additionally,
is a symmetric, tridiagonal
matrix,
denotes the
kth column of the identity matrix, and
represents the Euclidean vector norm. The columns of the matrix
span the Krylov subspace (
2), i.e.,
It is assumed that all subdiagonal entries of
are nonvanishing; otherwise, the recursion formulas of the Lanczos process break down, and the solution of (
1) can be formulated as a linear combination of the vectors
that are available at the time of breakdown. The recursion relation for the columns of
is established by Equation (
11) and, in conjunction with (
12), shows that
for certain polynomials
of degree
j.
Theorem 1. The polynomials determined by (14) are orthonormal with respect to the inner productinduced by the operator . Proof. We have
because the columns
,
, of the matrix
are orthogonal and of unit norm (see (
11)). □
We also use the related decomposition to (
11):
where
is the leading submatrix of
of order
.
We use the QR factorization for
, that is,
where
and the matrix
is upper triangular. Similarly, we introduce the factorization
where the
matrix
is the leading submatrix of
and
is the leading submatrix of
.
Theorem 2. Combine the QR factorization (17) with the Lanczos decomposition (11). This defines a new iterative process with iteration polynomials that comply with (4). Proof. Let
. By applying the QR factorization (
17) within the Lanczos decomposition (
11), we obtain
Multiplying (
19) by
from the right-hand side, letting
, and defining
, we obtain
The column vectors of the matrix expressed as
are orthonormal, and the matrix
is symmetric and tridiagonal. To expose the relation between the first column
of
and the first column
of
, we multiply (
19) by
from the right. This yields
which simplifies to
where
. For a suitable choice of the sign of
, we have
Since
is tridiagonal, the orthogonal matrix
in the QR factorization (
17) has upper Hessenberg form. As a result, only the last two entries of the vector expressed as
are non-zero. Hence, the decomposition (
20) differs from a Lanczos decomposition by potentially having non-zero entries in the last two columns of the matrix
.
Suppose that the matrix
consists of the first
columns of
. Then,
where
is defined by Equation (
18). Typically,
; additional details can be found in
Section 4. When the last column is removed from each term in (
20), the following decomposition results:
In (
23), the matrix
is the
leading submatrix of
. Furthermore,
, and
. As a result, according to (
21), we have that (
23) is a Lanczos decomposition with the starting vector
of
proportional to the vector
. Similarly to (
13), we have
To determine the iteration polynomials (
3) and the corresponding approximate solutions
of (
3), we impose the following requirement for certain vectors
:
It follows from (
24) that any polynomial
determined by (
25) fulfills (
4). This completes the proof. □
Remark 1. We chose in (25) and, thereby, in in a manner that guarantees the residual error (6) for the approximate solution of (1) satisfies the Petrov-Galerkin condition, i.e.,which, according to (12) and the factorization (22), simplifies to Remark 2. Replacing the matrix in (26) with recovers the SYMMLQ method [1]. However, the iteration polynomial associated with the SYMMLQ method typically does not satisfy condition (4). Our method implements a QR factorization of matrix , akin to the SYMMLQ method implementation by Fischer ([12], Section 6.5). In contrast, Paige and Saunders’ [1] implementation of the SYMMLQ method relies on an LQ factorization of . Remark 3. Equation (26) shows that the iterative method is a Petrov-Galerkin method. In each step of the method, the dimension of the solution subspace (24) is increased by one, and the residual error is required to be orthogonal to the subspace , cf. (
13)
. This secures convergence of the iterates (25) to the solution of (1) as k increases. Using Theorems 1 and 2, along with Remark 1, we can simplify the right-hand side of (
7). First, using (
16) and (
18), we obtain
Subsequently, by substituting (
28) into (
27), we obtain
We can evaluate
by forward substitution using (
29). The rest of this section focuses on evaluating the right-hand side of (
8).
Section 4 presents iterative formulas to efficiently update the approximate solutions
. The remainder of this section discusses the evaluation of the right-hand side of (
8). From (
24) and (
25), it can be deduced that
lives in
. Consequently, there is a vector
such that
Using the decomposition (
16), the
kth iterate generated by our iterative method can be written as
Furthermore, according to (
22) and (
25), we have
Multiplying (
31) by
from the left and using (
18) yields
By successively applying (
12), (
29), (
30), and (
32), we obtain
According to (
25), it follows that
. Combining this with (
33) shows that Equation (
8) can be represented as
The term
can easily be computed using (
29).
Section 3 describes several Gauss-type quadrature rules that are applied to compute estimates of
in
Section 4.
3. Quadrature Rules
This section considers the approximation of integrals like
by Gauss-type quadrature rules, where
and
denotes a non-negative measure with an infinite number of support points such that all moments
exist, for
. In this section, we assume that
. Let
denote an
n-node quadrature rule to approximate (
34). Then
where
is the remainder term. This term vanishes for all polynomials in
for some non-negative integer
d. The value of
d is referred to as the degree of precision of the quadrature rule. It is well known that the maximum value of
d for an
n-node quadrature rule is
. This value is achieved by the
n-node Gauss rule (see, e.g., [
13] for a proof). The latter rule can be written as
The nodes
,
, are the eigenvalues of the matrix
and the weights
are the square of the first elements of normalized eigenvectors.
The entries
and
of
are obtained from the recursion formula for the sequence of monic orthogonal polynomials
associated with the inner product (
15):
where
and
. The values of
and
in (
37) can be determined from the following formulas (see, e.g., Gautschi [
13] for details):
They also can be computed by the Lanczos process, which is presented in Algorithm 1.
| Algorithm 1: The Lanczos algorithm. |
![Axioms 14 00179 i001]() |
It is straightforward to demonstrate that
where
.
We are interested in measures
with support in two real intervals
and
, where
. The following result sheds light on how the nodes of the Gauss rule (
35) are allocated for such measures.
Theorem 3. Let be a non-negative measure with support on the union of bounded real intervals and , where . Then, the Gauss rule (35) has at most one node in the open interval . Proof. The result follows from [
14] (Theorem 3.41.1). □
The following subsection reviews some Gauss-type quadrature rules that are used to estimate the error in approximate solutions
of (
1) that are generated by the iterative method proposed in
Section 2.
Selected Gauss-Type Quadrature Rules
In [
9], Laurie presented
anti-Gauss quadrature rules. A recent analysis of anti-Gauss rules was also carried out by Díaz de Alba et al. [
15]. Related investigations can be found in [
16,
17]. The
-point anti-Gauss rule
, which is associated with the Gauss rule (
35), is defined by the property
The following tridiagonal matrix is used to determine the rule
:
Similarly to (
38), we have
Moreover,
Further, Laurie [
9] introduced the
averaged Gauss quadrature rule associated with
. It has
nodes and is given by
The property (
39) suggests that the quadrature error for
is smaller than the error for
. Indeed, it follows from (
39) that the degree of precision of
is no less than
. This implies that the difference
can be used to estimate the quadrature error
Computed results in [
18] illustrate that for numerous integrands and various values of
n, the difference (
41) provides fairly accurate approximation of the quadrature error (
42). The accuracy of these estimates depends both on the integrand and the value of
n.
In [
10], Spalević presented
optimal averaged Gauss quadrature rules, which usually have a higher degree of precision than averaged Gauss rules with the same number of nodes. The symmetric tridiagonal matrix for the optimal averaged Gauss quadrature rule
with
nodes is defined as follows. Introduce the reverse matrix of
, which is given by
as well as the concatenated matrix
The nodes of the rule
are the eigenvalues, and the weights are the squared first components of normalized eigenvectors of the matrix
. It is worth noting that
n of the nodes of
agree with the nodes of
. Similarly to Equation (
38), we have
The degree of precision for this quadrature rule is at least
. Analyses of the degree of precision of the rules
and the location of their largest and smallest nodes for several measures for which explicit expressions for coefficients
and
are known can be found in [
19] and references therein. An estimate of the quadrature error in the Gauss rule (
35) is given by
Numerical examples provided in [
18] show this estimate to be quite accurate for a wide range of integrands. As the rule
typically has strictly higher degree of precision than Laurie’s averaged Gauss rule (
40), we expect the quadrature error estimate (
43) to generally be more accurate than the estimate (
41), particularly for integrands with high-order differentiability.
In the computations, we use the representation
where
with
and
.
We finally consider the
Gauss-Radau quadrature rule , which has
nodes, with one node anchored at 0. This rule can be written as
To maximize the degree of precision, which is
, the
n nodes
,
, are suitably chosen. The rule
can be expressed as
where
and the entry
is chosen so that
has an eigenvalue at the origin. Details on how to determine
are provided by Gautschi [
13,
20] and Golub [
21].
Theorem 4. Let the nodes of the rule (44) and the nodes of the rule (35) be ordered according to increasing magnitude. Then and Proof. The last subdiagonal entry of the matrix (
45) is non-vanishing since the measure
in (
34) has infinitely many support points. By the Cauchy interlacing theorem, the eigenvalues of the leading principal
submatrix (
36) of the symmetric tridiagonal
matrix (
45) strictly interlace the eigenvalues of the latter. Since one of the eigenvalues of (
45) vanishes, the theorem follows. □
The measure
has no support at the origin. We therefore apply the Gauss-Radau rules with
in (
44).
Finally, we compute error-norm estimates by using the “minimum rule”:
It typically has
distinct nodes. This rule is justified by the observation that the rules
and
sometimes overestimate the error norm.
4. Error-Norm Estimation
This section outlines how the quadrature rules discussed in the previous section can be used to estimate the Euclidean norm of the error in the iterates
,
, determined by the iterative method described in
Section 2. The initial iterate is assumed to be
. Then the iterate
lives in the Krylov subspace (cf. (
24) and (
25)),
The residual corresponding to the iterate
is defined in (
6). We use the relation (
7) to obtain the Euclidean norm of the error, cf. (
8). Our task is to estimate the first term in the right-hand side of (
8). In this section, the measure is defined by (
10). In particular, the measure has support in intervals on the negative and positive real axis. These intervals exclude an interval around the origin.
We turn to the computation of the iterates
described by (
25). The computations can be structured in such a way that only a few
m-vectors need to be stored. Let the
real matrix
be given by (
36) with
, i.e.,
Based on the discussion following Equation (
12), we may assume that the
are nonzero. This ensures that the eigenvalues of
are distinct. We can compute the QR factorization (
17) of
by applying a sequence of
Givens rotations to
,
This yields an orthogonal matrix
and an upper triangular matrix
given by
For a discussion on Givens rotations, see, e.g., ([
2], Chapter 5). In our iterative method, the matrix
is not explicitly formed; instead, we use the representation in (
49). Since
is tridiagonal, the upper triangular matrix
has nonzero entries solely on the diagonal and the two adjacent superdiagonals.
Application of
k steps of the Lanczos process to the matrix
A with initial vector
results in the matrix
, as shown in (
47). By performing one more step, analogous to (
11), we obtain the following Lanczos decomposition:
We observe that the last subdiagonal element of the symmetric tridiagonal matrix
can be calculated as
right after the
kth Lanczos step is completed. This is convenient when evaluating the tridiagonal matrices (
45) associated with Gauss-Radau quadrature rules.
We can express the matrix
in terms of its QR factorization as follows:
whose factors can be computed from
and
in a straightforward manner. Indeed, we have
wherein
is a
real orthogonal matrix;
is a
real matrix;
is defined by (
48); and
is a real
matrix, which is made up of the first
k columns of
.
We express the matrices in terms of their columns to derive updating formulas for the computation of the triangular matrix
in (
51) from
in (
49):
A comparison between (
17) and (
51) yields the following results:
and
Thus, the elements of all the matrices can be calculated in just arithmetic floating-point operations (flops).
As defined by (
18), the matrix expressed as
is the leading principal submatrix of
of order
k, and differs from
only in its last diagonal entry. From Equation (
53) and the fact that
is nonzero, it follows that
. When
is nonsingular, we obtain that
. Here we assume that the diagonal entries of the upper triangular matrix in all QR factorizations are non-negative.
We turn to the computation of the columns of the matrix
, that is,
from columns of
, where
is obtained by the modified Lanczos scheme (
50), see Algorithm 1, and
is determined by (
52). Substituting (
52) into the right-hand side of (
54) yields
As a result, the initial columns of the matrix correspond to those of . The columns and in are linear combinations obtained from the last columns of both and .
Given the solution
of the linear system (
29) and considering that
is upper triangular, with
as the leading principal submatrix of order
, the computation of the solution
of
is inexpensive. We find that
Note that the computation of
from
only requires the last column of the matrix
.
We are now in a position to compute
from
. Using Equations (
25) and (
55), we obtain
Note that only the last few columns of
and
are required to update the iterate
.
Algorithm 1 shows pseudo-code for computing the nontrivial elements of the matrix
in (
36) and the matrix
in (
50). Each iteration requires the evaluation of one matrix-vector product with the matrix
A and a few operations with
m-vectors. The latter only require
flops.






{kind=link}
{kind=link}
{kind=link}