
Conditioning Theory for


Abstract
1. Introduction
2. Preliminaries
3. Condition Numbers for -Weighted Pseudoinverse
4. Condition Numbers for -Weighted Least Squares Problem
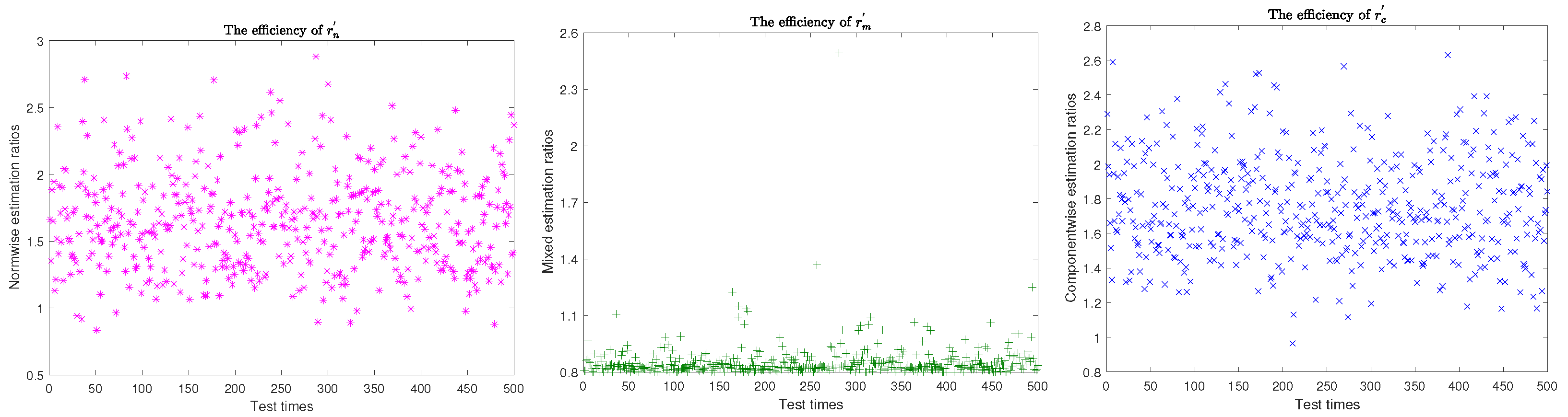
5. Numerical Experiments
- Generate matrices with each entry in and orthonormalize the following matrixto obtain by modified Gram-Schmidt orthogonalization process. Each can be converted into the corresponding matrices by applying the unvec operation.
- Let . The Wallis factor approximate and by
- Here, for any vector . Where the power operation is applied at each entry of and with . Where the square operation is applied to each entry of and the square root is also applied componentwise.
- Estimate the normwise condition number (33) bywhere .
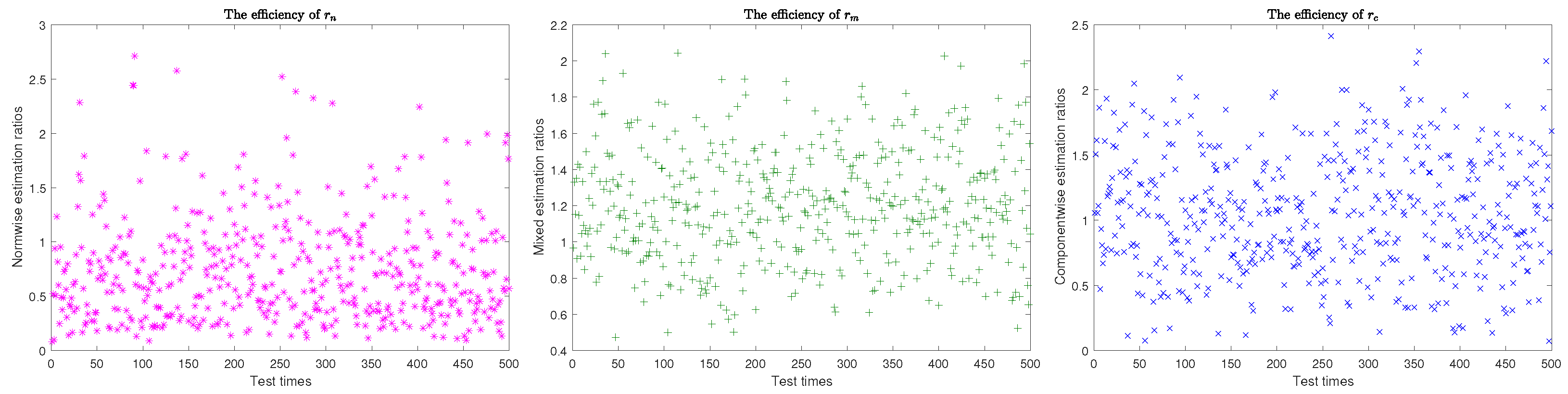
- Generate matrices with each entry in and orthonormalize the following matrixto obtain by modified Gram-Schmidt orthogonalization process. Each can be converted into the corresponding matrices by applying the unvec operation. Let be the matrix multiplied by componentwise.
- Let . Approximate and by (38).
- For calculate by (39). Compute the absolute condition vector
- Estimate the mixed and componentwise condition estimations and as follows:
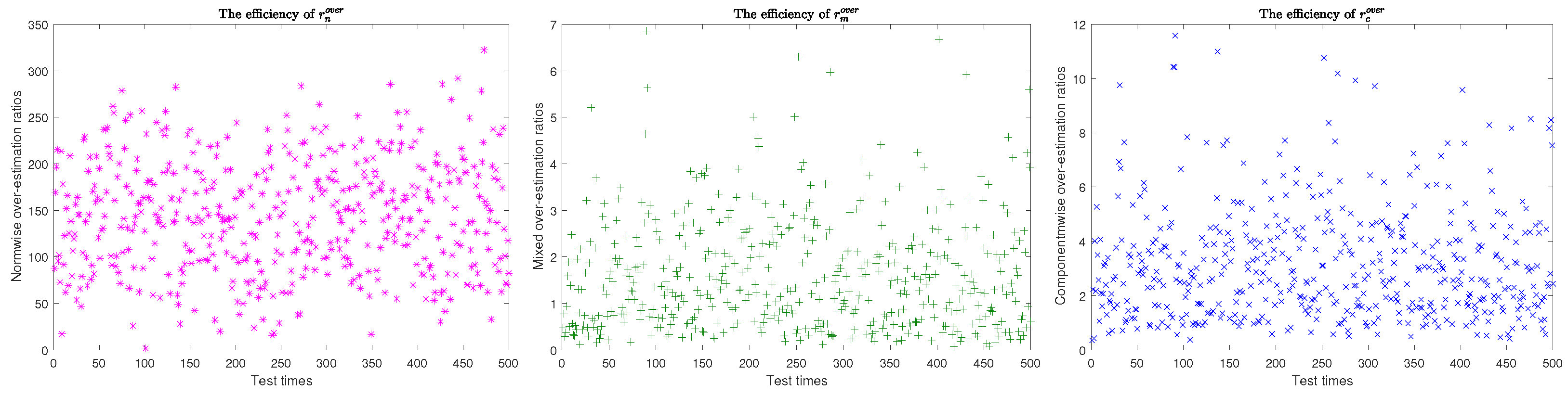
- Generate matrices with entries in where To orthonormalize the below matrixto obtain an orthonormal matrix by using modified Gram-Schmidt orthogonalization technique. Where can be converted into the corresponding matrices by applying the unvec operation.
- Let . Approximate and by using (38).
- For compute from (31)Using the approximations for and , estimate the absolute condition vector
- Estimate the normwise condition estimation as follows:
- Compute the mixed condition estimation and componentwise condition estimation as follows:
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nashed, M.Z. Generalized Inverses and Applications: Proceedings of an Advanced Seminar Sponsored by the Mathematics Research Center, The University of Wisconsin-Madison, New York, NY, USA, 8–10 October 1973; Academic Press, Inc.: Cambridge, MA, USA, 1976; pp. 8–10. [Google Scholar]
- Qiao, S.; Wei, Y.; Zhang, X. Computing Time-Varying ML-Weighted Pseudoinverse by the Zhang Neural Networks. Numer. Funct. Anal. Optim. 2020, 41, 1672–1693. [Google Scholar] [CrossRef]
- Eldén, L. A weighted pseudoinverse, generalized singular values, and constrained least squares problems. BIT 1982, 22, 487–502. [Google Scholar] [CrossRef]
- Galba, E.F.; Neka, V.S.; Sergienko, I.V. Weighted pseudoinverses and weighted normal pseudosolutions with singular weights. Comput. Math. Math. Phys. 2009, 49, 1281–1363. [Google Scholar] [CrossRef]
- Rubini, L.; Cancelliere, R.; Gallinari, P.; Grosso, A.; Raiti, A. Computational experience with pseudoinversion-based training of neural networks using random projection matrices. In Artificial Intelligence: Methodology, Systems, and Applications; Gennady, A., Hitzler, P., Krisnadhi, A., Kuznetsov, S.O., Eds.; Springer International Publishing: New York, NY, USA, 2014; pp. 236–245. [Google Scholar]
- Wang, X.; Wei, Y.; Stanimirovic, P.S. Complex neural network models for time-varying Drazin inverse. Neural Comput. 2016, 28, 2790–2824. [Google Scholar] [CrossRef]
- Zivkovic, I.S.; Stanimirovic, P.S.; Wei, Y. Recurrent neural network for computing outer inverse. Neural Comput. 2016, 28, 970–998. [Google Scholar] [CrossRef]
- Wei, M.; Zhang, B. Structures and uniqueness conditions of MK-weighted pseudoinverses. BIT 1994, 34, 437–450. [Google Scholar] [CrossRef]
- Eldén, L. Perturbation theory for the least squares problem with equality constraints. SIAM J. Numer. Anal. 1980, 17, 338–350. [Google Scholar] [CrossRef]
- Björck, Å. Numerical Methods for Least Squares Problems; SIAM: Philadelphia, PA, USA, 1996. [Google Scholar]
- Wei, M. Perturbation theory for rank-deficient equality constrained least squares problem. SIAM J. Numer. Anal. 1992, 29, 1462–1481. [Google Scholar] [CrossRef]
- Cox, A.J.; Higham, N.J. Accuracy and stability of the null space method for solving the equality constrained least squares problem. BIT 1999, 39, 34–50. [Google Scholar] [CrossRef]
- Li, H.; Wang, S. Partial condition number for the equality constrained linear least squares problem. Calcolo 2017, 54, 1121–1146. [Google Scholar] [CrossRef]
- Diao, H. Condition numbers for a linear function of the solution of the linear least squares problem with equality constraints. J. Comput. Appl. Math. 2018, 344, 640–656. [Google Scholar] [CrossRef]
- Björck, Å.; Higham, N.J.; Harikrishna, P. The equality constrained indefinite least squares problem: Theory and algorithms. BIT Numer. Math. 2003, 43, 505–517. [Google Scholar]
- Cucker, F.; Diao, H.; Wei, Y. On mixed and componentwise condition numbers for Moore Penrose inverse and linear least squares problems. Math Comp. 2007, 76, 947–963. [Google Scholar] [CrossRef]
- Wei, M. Algebraic properties of the rank-deficient equality-constrained and weighted least squares problem. Linear Algebra Appl. 1992, 161, 27–43. [Google Scholar] [CrossRef]
- Gulliksson, M.E.; Wedin, P.A.; Wei, Y. Perturbation identities for regularized Tikhonov inverses and weighted pseudoinverses. BIT 2000, 40, 513–523. [Google Scholar] [CrossRef]
- Samar, M.; Li, H.; Wei, Y. Condition numbers for the K-weighted pseudoinverse and their statistical estimation. Linear Multilinear Algebra 2021, 69, 752–770. [Google Scholar] [CrossRef]
- Samar, M.; Zhu, X.; Shakoor, A. Conditioning theory for Generalized inverse and their estimations. Mathematics 2023, 11, 2111. [Google Scholar] [CrossRef]
- Rice, J. A theory of condition. SIAM J. Numer. Anal. 1966, 3, 287–310. [Google Scholar] [CrossRef]
- Gohberg, I.; Koltracht, I. Mixed, componentwise, and structured condition numbers. SIAM J. Matrix Anal. Appl. 1993, 14, 688–704. [Google Scholar] [CrossRef]
- Kenney, C.S.; Laub, A.J. Small-sample statistical condition estimates for general matrix functions. SIAM J. Sci. Comput. 1994, 15, 36–61. [Google Scholar] [CrossRef]
- Xie, Z.; Li, W.; Jin, X. On condition numbers for the canonical generalized polar decomposition of real matrices. Electron. J. Linear Algebra. 2013, 26, 842–857. [Google Scholar] [CrossRef]
- Horn, R.A.; Johnson, C.R. Topics in Matrix Analysis; Cambridge University Press: New York, NY, USA, 1991. [Google Scholar]
- Magnus, J.R.; Neudecker, H. Matrix Differential Calculus with Applications in Statistics and Econometrics, 3rd ed.; John Wiley and Sons: Chichester, NH, USA, 2007. [Google Scholar]
- Diao, H.; Xiang, H.; Wei, Y. Mixed, componentwise condition numbers and small sample statistical condition estimation of Sylvester equations. Numer. Linear Algebra Appl. 2012, 19, 639–654. [Google Scholar] [CrossRef]
- Baboulin, M.; Gratton, S.; Lacroix, R.; Laub, A.J. Statistical estimates for the conditioning of linear least squares problems. Lect. Notes Comput. Sci. 2014, 8384, 124–133. [Google Scholar]
- Samar, M. A condition analysis of the constrained and weighted least squares problem using dual norms and their statistical estimation. Taiwan. J. Math. 2021, 25, 717–741. [Google Scholar] [CrossRef]
- Li, H.; Wang, S. On the partial condition numbers for the indefinite least squares problem. Appl. Numer. Math. 2018, 123, 200–220. [Google Scholar] [CrossRef]
- Samar, M.; Zhu, X. Structured conditioning theory for the total least squares problem with linear equality constraint and their estimation. AIMS Math. 2023, 8, 11350–11372. [Google Scholar] [CrossRef]
- Diao, H.; Wei, Y.; Xie, P. Small sample statistical condition estimation for the total least squares problem. Numer. Algor. 2017, 75, 435–455. [Google Scholar] [CrossRef]
- Samar, M.; Lin, F. Perturbation and condition numbers for the Tikhonov regularization of total least squares problem and their statistical estimation. J. Comput. Appl. Math. 2022, 411, 114230. [Google Scholar] [CrossRef]
- Diao, H.; Wei, Y.; Qiao, S. Structured condition numbers of structured Tikhonov regularization problem and their estimations. J. Comput. Appl. Math. 2016, 308, 276–300. [Google Scholar] [CrossRef]
- Higham, N.J. Accuracy and Stability of Numerical Algorithms, 2nd ed.; SIAM: Philadelphia, PA, USA, 2002. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| 20, 10, 5, 15 | 1.1022e+01 | 2.7522e+01 | 5.7654e+02 | 3.1027e+00 | 5.3832e+00 | 5.2416e+01 | 4.2054e+00 | 5.4372e+00 | 6.2721e+01 | |
| 2.2053e+01 | 3.2618e+01 | 7.1865e+02 | 2.3128e+00 | 3.4752e+00 | 2.3096e+01 | 2.5062e+00 | 3.6543e+00 | 3.6092e+01 | ||
| 3.1054e+01 | 4.2065e+01 | 2.6211.e+03 | 2.5201e+00 | 3.7032e+00 | 3.1965e+02 | 2.7084e+00 | 3.8033e+00 | 4.0544e+02 | ||
| 3.1054e+01 | 4.2065e+01 | 2.6211.e+03 | 2.5201e+00 | 3.7032e+00 | 3.1965e+02 | 2.7084e+00 | 3.8033e+00 | 4.0544e+02 | ||
| 60, 40, 30, 50 | 4.4034e+01 | 5.6652e+01 | 5.1977e+03 | 3.8402e+00 | 6.0328e+00 | 8.6047e+01 | 5.1054e+00 | 7.3590e+00 | 8.9076e+01 | |
| 4.7901e+01 | 5.9084e+01 | 7.4710e+03 | 2.8033e+00 | 3.2228e+00 | 6.3722e+01 | 3.1560e+00 | 4.3805e+00 | 7.6943e+01 | ||
| 2.1642e+02 | 3.7611e+02 | 1.3179e+04 | 2.8764e+00 | 4.3502e+00 | 4.0644e+02 | 4.1232e+00 | 5.4653e+00 | 5.3772e+02 | ||
| 2.1642e+02 | 3.7611e+02 | 1.3179e+04 | 2.8764e+00 | 4.3502e+00 | 4.0644e+02 | 4.1232e+00 | 5.4653e+00 | 5.3772e+02 | ||
| 100, 60, 40, 80 | 1.6543e+02 | 2.4638e+02 | 3.0643e+04 | 4.3222e+00 | 6.1108e+00 | 4.0644e+02 | 5.7642e+00 | 7.4544e+00 | 5.3632e+02 | |
| 1.2324e+02 | 2.3207e+02 | 4.2501e+04 | 3.6233e+00 | 5.2326e+00 | 2.5489e+02 | 5.3562e+00 | 6.6533e+00 | 3.6471e+02 | ||
| 2.5434e+02 | 3.2455e+02 | 6.5731e+04 | 3.2064e+00 | 4.5211e+00 | 5.7654e+02 | 4.8659e+00 | 5.7532e+00 | 6.5703e+02 | ||
| 2.5434e+02 | 3.2455e+02 | 6.5731e+04 | 3.2064e+00 | 4.5211e+00 | 5.7654e+02 | 4.8659e+00 | 5.7532e+00 | 6.5703e+02 | ||
| 200, 100, 50, 150 | 2.0331e+02 | 4.2224e+02 | 7.1023e+04 | 4.7532e+00 | 7.0665e+00 | 3.2052e+03 | 6.7051e+00 | 7.8066e+00 | 4.6281e+03 | |
| 2.2053e+02 | 3.2618e+02 | 7.4533e+04 | 4.1054e+00 | 6.2350e+00 | 1.2411e+03 | 6.0462e+00 | 7.1102e+00 | 2.7403e+03 | ||
| 4.1326e+02 | 6.7651e+02 | 9.2016e+04 | 3.6325e+00 | 5.3824e+00 | 4.5341e+03 | 5.1632e+00 | 6.5032e+00 | 7.2305e+03 | ||
| 4.1326e+02 | 6.7651e+02 | 9.2016e+04 | 3.6325e+00 | 5.3824e+00 | 4.53414e+03 | 5.1632e+00 | 6.5032e+00 | 7.2305e+03 |
| 30, 20, 10, 15 | 1.5301e+01 | 3.3711e+01 | 4.3502e+03 | 3.1081e+00 | 4.5121e+00 | 1.7609e+02 | 4.1428e+00 | 5.1213e+00 | 2.3461e+02 | |
| 3.7103e+03 | 4.1046e+03 | 1.2353e+05 | 4.1311e+00 | 5.4115e+00 | 3.0554e+02 | 5.4401e+00 | 6.5041e+00 | 4.5530e+02 | ||
| 4.0511e+03 | 5.6105e+03 | 1.8619e+05 | 4.1781e+00 | 5.5733e+00 | 3.6102e+02 | 5.6505e+00 | 6.7504e+00 | 4.7082e+02 | ||
| 5.0171e+03 | 6.4115e+03 | 5.4632e+05 | 5.3161e+00 | 6.4132e+00 | 4.3011e+02 | 6.1865e+00 | 7.1805e+00 | 5.0122e+02 | ||
| 6.3304e+04 | 7.8651e+04 | 5.7011e+05 | 6.6701e+00 | 7.3101e+00 | 4.6750e+02 | 7.5311e+00 | 7.6541e+00 | 5.3443e+02 | ||
| 90, 60, 30, 45 | 4.0314e+01 | 5.1011e+01 | 5.0754e+03 | 3.1011e+00 | 4.1041e+00 | 6.3560e+02 | 4.1566e+00 | 5.1108e+00 | 9.8642e+02 | |
| 1.1135e+03 | 3.1103e+03 | 3.1398e+05 | 3.3671e+00 | 4.5781e+00 | 1.4567e+03 | 4.1401e+00 | 5.0713e+00 | 3.5567e+03 | ||
| 4.5311e+03 | 5.7611e+03 | 3.5743e+05 | 3.4122e+00 | 4.7551e+00 | 1.6091e+03 | 4.4311e+00 | 5.7141e+00 | 3.8110e+03 | ||
| 6.1351e+03 | 7.3450e+03 | 6.5865e+05 | 4.0167e+00 | 5.3502e+00 | 2.4113e+03 | 5.1104e+00 | 6.0511e+00 | 4.5225e+03 | ||
| 3.6111e+04 | 4.7661e+04 | 6.8952e+05 | 4.6311e+00 | 5.6215e+00 | 2.7840e+03 | 5.3054e+00 | 6.4403e+00 | 4.8203e+03 | ||
| 120, 80, 40, 60 | 3.3401e+01 | 4.5611e+01 | 7.1209e+03 | 1.7101e+00 | 3.8115e+00 | 8.3411e+02 | 3.6411e+00 | 4.7110e+00 | 9.7438e+03 | |
| 1.7611e+03 | 1.1403e+03 | 6.3689e+05 | 1.4471e+00 | 1.5171e+00 | 3.4229e+03 | 1.3544e+00 | 3.4811e+00 | 6.0431e+03 | ||
| 3.4511e+03 | 5.0411e+03 | 6.7754e+05 | 1.6331e+00 | 1.7813e+00 | 3.9810e+03 | 3.5886e+00 | 4.7805e+00 | 6.4332e+03 | ||
| 5.1014e+03 | 6.1331e+03 | 8.2306e+05 | 1.8041e+00 | 1.8866e+00 | 5.4240e+03 | 4.0113e+00 | 5.1531e+00 | 7.3552e+03 | ||
| 1.7411e+04 | 3.3811e+04 | 8.6435e+05 | 3.7316e+00 | 4.8031e+00 | 5.6708e+03 | 4.1108e+00 | 5.8611e+00 | 7.6622e+03 | ||
| 150, 100, 50, 75 | 3.1517e+01 | 4.3401e+01 | 9.0654e+03 | 1.5113e+00 | 3.6305e+00 | 4.7622e+03 | 3.1077e+00 | 4.1765e+00 | 5.1108e+03 | |
| 1.6311e+03 | 1.1451e+03 | 8.6422e+05 | 1.1411e+00 | 1.4134e+00 | 6.3005e+03 | 1.1711e+00 | 3.3086e+00 | 8.5994e+03 | ||
| 3.0558e+03 | 4.7550e+03 | 8.8043e+05 | 1.4770e+00 | 1.6511e+00 | 6.9021e+03 | 3.1341e+00 | 4.5311e+00 | 8.7043e+03 | ||
| 5.0141e+03 | 5.8301e+03 | 9.4660e+05 | 1.0111e+00 | 1.7001e+00 | 8.2765e+03 | 3.7661e+00 | 5.0111e+00 | 9.0492e+03 | ||
| 1.5431e+04 | 3.0801e+04 | 9.7034e+05 | 3.1314e+00 | 4.6441e+00 | 8.8211e+03 | 4.1055e+00 | 5.7101e+00 | 9.8955e+03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samar, M.; Zhu, X.; Xu, H.
Conditioning Theory for
Samar M, Zhu X, Xu H.
Conditioning Theory for
Samar, Mahvish, Xinzhong Zhu, and Huiying Xu.
2024. "Conditioning Theory for
Samar, M., Zhu, X., & Xu, H.
(2024). Conditioning Theory for