Abstract
The use of life distributions has increased over the past decade, receiving particular attention in recent years, both from a practical and theoretical point of view. Life distributions can be used in a number of applied fields, such as medicine, biology, public health, epidemiology, engineering, economics, and demography. This paper presents and investigates a new life distribution. The proposed model shows favorable characteristics in terms of reliability theory, which makes it competitive against other commonly used life distributions, such as the exponential, gamma, and Weibull distributions. The methods of maximum likelihood and moments are used to estimate the parameters of the proposed model. Additionally, real-life data drawn from different fields are used to illustrate the usefulness of the new distribution. Further, the R programming language is used to perform all computations and produce all graphs.
Keywords:
life distribution; reliability; exponential distribution; uniform distribution; estimation; stochastic order; maximum likelihood method; the method of moments MSC:
60E05; 62F10; 62N05; 62P10; 65C20
1. Introduction
The use of life distribution models increased in the late 20th century, mainly because they proved to be flexible for use with a wide variety of random phenomena, and because of rapid innovations in computing power. The statistical analysis of lifetime data, sometimes referred to as survival time or failure time data, is important in many fields, including in biomedicine, engineering, social sciences, medicine, biology, public health, epidemiology, engineering, economics, and demography [1]. In the 1970s, interest in life distribution grew quickly in terms of theory, methodology, and application, and from the 1980s onwards, software programs for lifetime data analysis became readily accessible. Indeed, new features and packages are now added on a regular basis [1].
One of the most important theories associated with life distribution models is reliability theory, which was conceived in the late 1940s and early 1950s [2]. Reliability theory concerns the study of the lifespan of the components of equipment or systems, as well as their failure or non-failure rates over time. Indeed, reliability theory is an important part of statistical research about reliability [2]. Further, ordering distributions and log concavity properties, especially among lifetime distributions, have a significant impact on the statistical literature, particularly when it comes to reliability theorem and its applications [3]. For example, an extensive discussion on the ordering of different life distributions is presented in [4,5]. Also, a discussion about the log-concavity for several life distributions, including extreme-value, exponential, Weibull, power function, gamma, log-normal, Student’s t, and more, is seen in [6]. The log-concavity property of a life distribution has practical applications in economics, social sciences, information theory, and optimization. The field of information economics especially deals with the assumption that the log of the cumulative distribution function is a concave function. Moreover, the log-concavity of survival functions is crucial in reliability theory, since it corresponds to an increasing or decreasing failure rate. Fortunately, most of life distributions have a concave cumulative function.
In the 1930s and 1940s, univariate life distributions were commonly used in the field of statistics, but serious research about these distribution only really began in about 1950 [1]. Among the univariate models, a few distributions occupy a central position because of their usefulness in a wide range of situations. The most popular life distributions used are exponential, Weibull, log-normal, log-logistic, and gamma distributions. In 1939, the Weibull distribution began to be used to test the strength or fatigue life of materials [2]. Later, in 1956 and 1959, the Weibull distribution was employed in reliability theory, and in medicine in 1966 [1]. In recent years, the Weibull distribution has become increasingly popular for analyzing lifetime data, because it is considerably easier to manage, at least computationally, than gamma distribution, in the presence of censoring. Nevertheless, one disadvantage of using the Weibull distribution is that maximum likelihood (ML) estimator distribution reveals a slower asymptotic convergence to normality; indeed, unless the sample size is sufficiently high, it is probable that the majority of asymptotic inferences will be inaccurate. The Weibull distribution also lacks any ordering properties, in contrast to gamma distribution, for example [7].
Gamma distribution has been used for many years, and its use demonstrates a number of positive features [4]. Gamma distribution enables considerable amounts of flexibility for analyzing positive real-world data, especially life data. It has an increasing and decreasing failure rate based on shape parameter, giving it an advantage over exponential distribution, which shows constant failure rates. Another interesting feature of gamma distribution is that when the scale parameter remains constant, it shows likelihood ratio ordering, with regard to shape parameter. Also, gamma distribution can be used in areas other than lifetime distributions. For example, [8,9,10] examine gamma distribution in relation to failure times. However, if the shape parameter is not an integer, the distribution function, or survival function, cannot be defined in a closed form, which is a significant disadvantage of gamma distribution. As a result, gamma distribution is used less than Weibull distribution, which has a reasonable distribution function, survival function, and hazard function [7].
Exponential distribution is used extensively to model lifetime data, both in theory and in practice [3]. It is highly amenable to statistical studies, because it contains just one parameter, and is simple to describe. Also, in comparison to alternative life data distributions, such as Weibull distribution, it has a constant hazard rate function. A significant amount of statistical analysis and life data modeling is undertaken using exponential distribution, especially in relation to reliability, and, therefore, it is a well-established model [1]. Even though distributions such as Weibull have gained popularity, reliability engineers tend to favor exponential distribution. For example, in [11], exponential distribution is linked to reliability theory, and [12] uses exponential distribution to model medical survival statistics. The exponential model produces useful results [13], and, therefore, it is not surprising that it is still used frequently.
The motivation for this study is from the increasing popularity of lifetime data applications. The standard life distributions, such as exponential, gamma, Weibull, and others, have good properties and can model a variety of data. However, there are real-life data where such common life distributions fail to give a good fit. Hence there is a need to develop new distributions that demonstrate superior performance. The goal of this paper is to devise a novel life data distribution which performs better than current popular models, such as exponential, gamma, Weibull, etc. In addition, the objective of this study is to provide a novel life distribution that possesses favorable characteristics, particularly in reliability theory, such as ordering distribution and log concavity properties. These properties make the proposed distribution very desired for a wide range of applications across various fields. As a result, a new lifetime distribution is proposed and investigated that is referred to as uniformly shifted exponential distribution (USED). It results from the convolution of exponential and uniform distributions. The current study examines the structural characteristics of the new distribution model, including its distribution function, survival function, hazard function, and stochastic ordering. The new distribution is capable of modeling data with an increasing failure rate, and the shape of the failure rate function remains constant. The value of the new distribution is demonstrated by means of application to a real-world dataset. The rest of the paper unfolds as follows: Section 2 presents the theory behind the new model and outlines its most important statistical properties. Section 3 discusses the parameter estimations of the new model and presents a simulation study. Section 4 details real-life data applications. Finally, Section 5 concludes the paper.
2. Uniformly Shifted Exponential Distribution (USED)
In this section, uniformly shifted exponential distribution (USED) is introduced. The probability density function (pdf), cumulative distribution function, survival function, and failure rate function of the USED can be derived as follows:
If we consider that is a random variable and has exponential distribution with the rate parameter , denoted by , and is an independent random variable, which has uniform distribution on the interval (, then the random variable has the following probability density function:
Here, for and 0 for .
Definition 1.
The random variable
is said to have uniformly shifted exponential distribution with the parameters
and
( if its pdf is given by (1).
Additionally, the properties outlined below can be derived from Definition 1:
Proposition 1.
If
, then the cumulative distribution function (cdf), the survival function (sf), and the failure rate function (fr), respectively, can be given as follows:
and
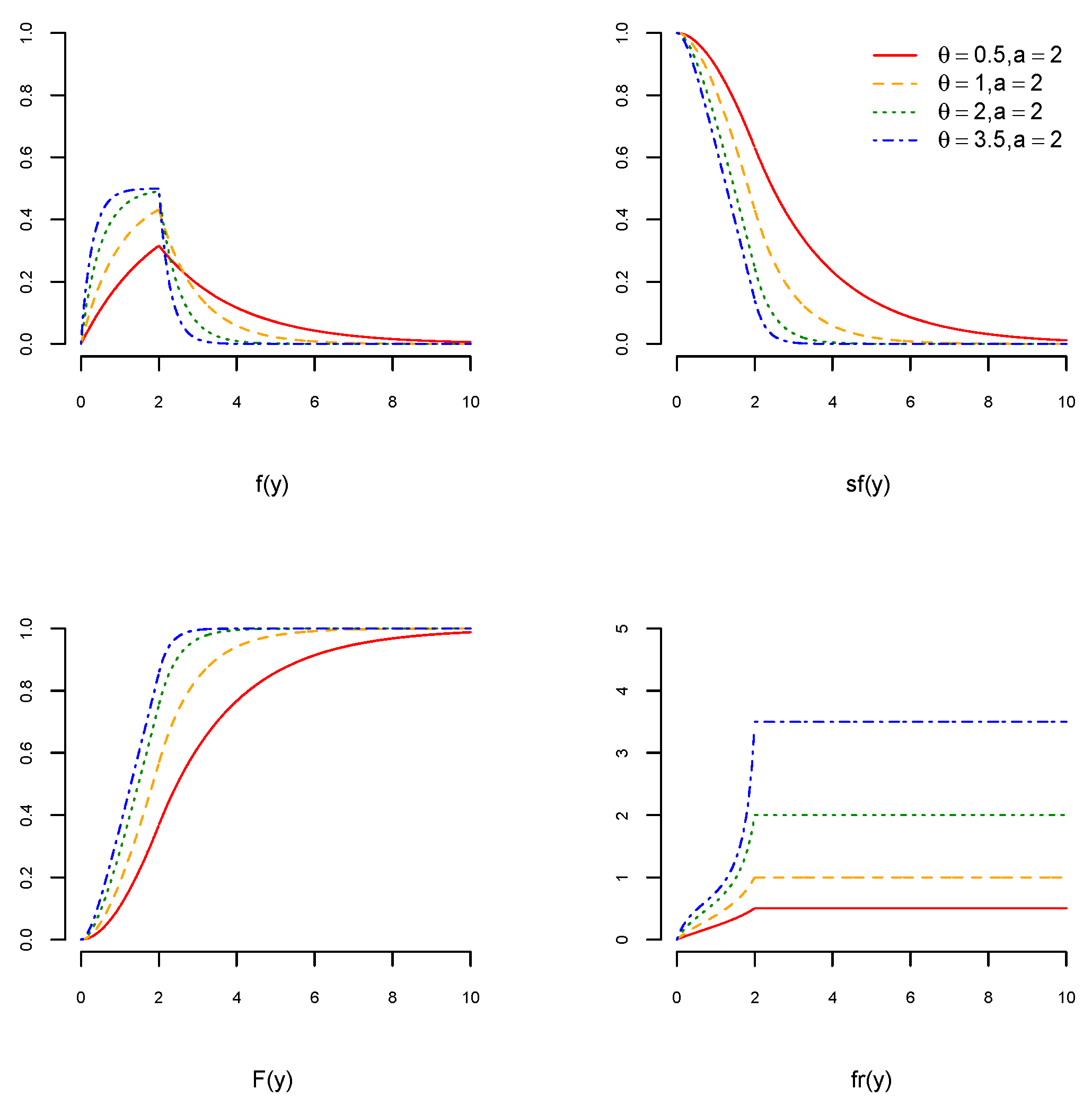
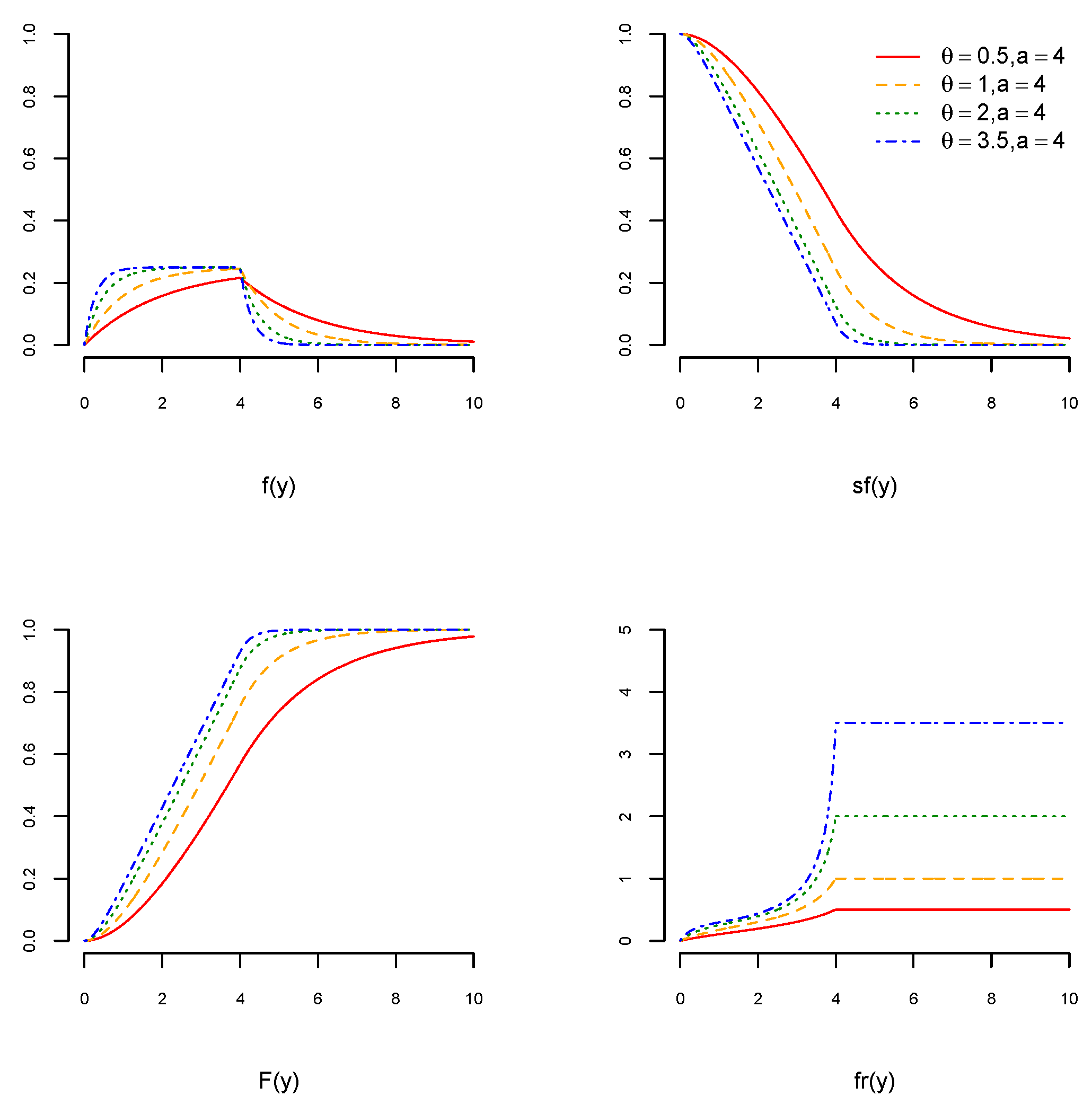
Here, fr remains constant when is greater than . Figure 1, Figure 2 and Figure 3 visualize the graphs of pdf, cdf, sf, and fr of the USED for different values of and We can see in Figure 1, Figure 2 and Figure 3 (top left) that the pdfs of the USED are skewed to the right. For , the pdfs of the USED become more concave, and for , they become less convex. Figure 1, Figure 2 and Figure 3 (bottom right) show that the fr of the USED remains constant when and it increases for .
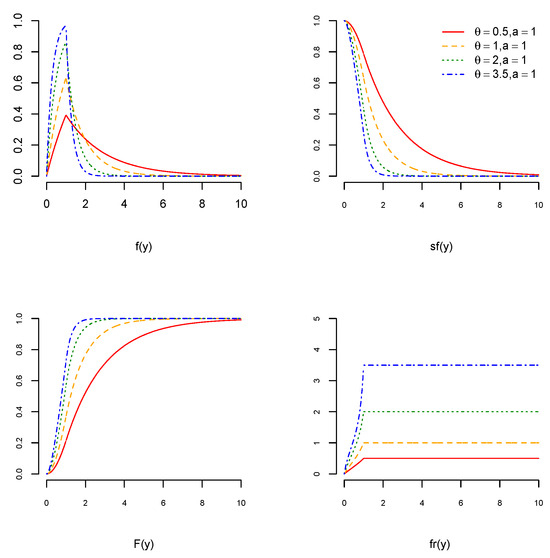
Figure 1.
The pdf of the USED (top left), the cdf of the USED (bottom left), the sf of the USED (top right), and the fr of the USED (bottom right) when and for and 3.5.
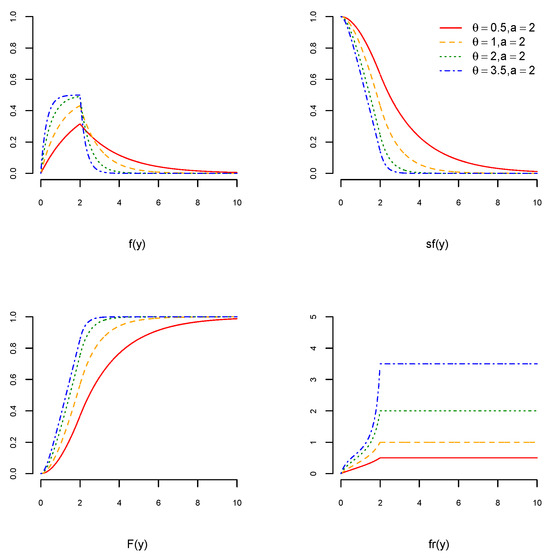
Figure 2.
The pdf of the USED (top left), the cdf of the USED (bottom left), the sf of the USED (top right), and the fr of the USED (bottom right) when and for and 3.5.
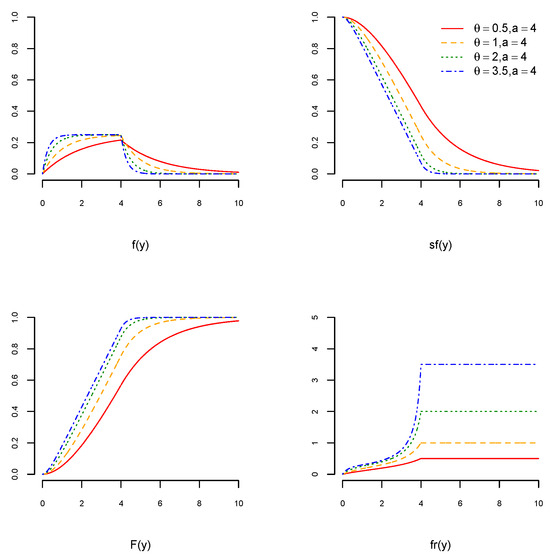
Figure 3.
The pdf of the USED (top left), the cdf of the USED (bottom left), the sf of the USED (top right), and the fr of the USED (bottom right) when and for , and 3.5.
Remark 1.
If we re-parametrize the USED, and set
, then the following applies:
Note that
which is USED (1, ), and, hence, can be viewed as a scale parameter.
2.1. Statistical Properties
This section reviews the statistical results relating to moments associated with the USED. Further, stochastic orders are addressed, and the properties of the USED as they relate to reliability theory are discussed.
2.1.1. The Moments of the USED
Proposition 2.
If
, then the non-central moments of order n ( can be given as follows:
Proof.
From the definition of the non-central moments, we obtain the following:
This delivers the desired outcome.□
From Proposition 2, the mean and the variance of the USED can be defined as follows:
Corollary 1.
The mean
and the variance
of the USED, respectively, are
and
Proposition 3.
Proof.
From Corollary 1, we obtain the following:
Then,
Here, . This is clearly non-negative, with a zero value when . This completes the proof. □
2.1.2. Reliability and Stochastic Order
Log-concavity probability distributions play a vital role in many applications, such as reliability theory, labor economics, monopoly theory, mechanism design theory, political science, and law, among others. See [6] for more details. The log-concave function of the USED can be defined as follows:
Definition 2.
A function f is said to be log-concave for the interval
if the function
is a concave function of
Due to the fact that the USED is a convolution of two log-concave distributions, which are uniform and exponential distributions, its pdf is log concave and, thus, it is strongly unimodal [14]. The log-concavity of the pdfs implies that the cdfs and sfs are, likewise, log-concaves [6]. This means that the USED incorporates an increasing failure rate function (IFR) [5]. The log-concavity and IFR are two critical features in reliability theory which give the USED its value in reliability applications.
Many different stochastic orderings are used by statistical researchers. The four most popular ones are the likelihood ratio (, hazard rate (, stochastic ordering (, and variability ordering (. Likelihood ratio ordering is the strongest order, in the sense that it implies the other three orderings. For more detail, see, for example [5]. The definition of the likelihood ratio can be given as follows:
Definition 3.
Let
and
be two random variables with corresponding pdfs, namely
and
, such that
decreases
in x on the union of the supports of
and
. Then,
can be said to be smaller than
in the likelihood ratio order (denoted by
).
Many classes of probability distributions, such as exponential and Poisson models, are likelihood-ordered with respect to their parameters. The USED shows favorable stochastic orders, as stated in the following proposition:
Proposition 4.
If
and
, then
for
Proof.
It can be observed that with are independent and identical to . In addition, it is known that and has log-concave density [15,16]. Therefore, , which completes the proof. □
Proposition 5.
If
and
, then
for
Proof.
Let , where is independent and identical to . Here, the union of the support points of the two uniform distributions is . Thus, if we denote as the pdf of , we obtain the following:
The above decreases in . Therefore, according to Definition 2, we obtain . It can be seen that the exponential distribution has a log-concave pdf, and therefore, an argument similar to that used to prove Proposition 4 offers the required result. □
3. Parameter Estimation and Simulation
This section presents the parameter estimation and a simulation study, both of which are important steps for understanding and evaluating the proposed model. For the parameter estimation, classical methods of estimation were used, namely, the maximum likelihood (ML) method and the method of moments (MM). In addition, a simulation was conducted to gain insight into the results obtained. The statistical programming language R (R core Team) was used to calculate the ML and MM estimates. It is worth mentioning here that two cases were considered and examined in order to obtain the USED parameters, when parameter is known and unknown.
3.1. Parameter Estimation
3.1.1. Maximum Likelihood Estimation (ML)
As demonstrated in many studies undertaken in the field of statistics, ML is one of the most widely used parametric estimation methods. In ML, estimation is driven by the maximization of the likelihood function (L), which frequently satisfies regularity conditions. In the context of the current study, let be a random sample of size from the USED, with the unknown parameters and , and be the observed values. Here, is given as follows:
Here, for and 0 for . is the number of observed values that satisfy , and refers to the number of observed values for which , where .
It is worth noting that is differentiable at all except at The ML estimators of and are the values that maximize the log likelihood function (, which are denoted as and , respectively. The corresponding can be defined as follows:
Below, two cases relating to the USED parameters are discussed:
- (a)
- Case 1: the parameter is known:
In this case, the ML estimate is obtained by differentiating the function in (8) with respect to and solving the following score function:
Since the closed-form expression for the ML estimate cannot be found by solving (9), a nonlinear optimization algorithm is required.
- (b)
- Case 2: the parameter is unknown
In this case, the ML estimates and cannot be calculated by differentiating (8) with respect to and because the function is not differentiable with respect to As a result, a mathematical method developed by Nelder and Mead [17] was used to obtain the ML estimates and . This method is robust and performs effectively with respect to non-differentiable functions. Further details can be found in [17].
3.1.2. The Method of Moments (MM)
Another well-known parametric estimation technique is the MM, which involves replacing population moments with sample moments to drive the estimators. In the current study for MM, two cases of the parameter were addressed as follows:
- (a)
- Case 1: the parameter is known:
The following equation was considered in order to estimate the parameter as follows:
The following equation is the MM estimate of :
- (b)
- Case 2: the parameter is unknown.
The MM estimates and can be obtained by solving the coupled equations below:
and
By using the above equations, we obtain the following equations:
and
Using (14), the condition for a real solution can be given as follows:
If (15) offers a real solution, it is possible to discriminate between two situations: the first is where one of the solutions is negative and will thus be rejected, and the second is as follows:
In the second situation, we have , and both solutions are positive. This is clear for the root , and for the root It should be noted that under the assumption , as .
Finally, a simulation analysis was conducted for the two scenarios = 2, = 1.5 and = 2, = 3.0, and the results revealed that the MM estimators were unreliable, as expected.
Therefore, for Case 2, when is unkown, the MM estimates were not included in the simulation study and the ML estimates were considered.
3.2. Simulation Study
This sub-section presents a numerical evaluation of the proposed parameter estimators. A simulation study was performed to examine the performance of the ML and MM estimates of the USED parameters and . A total of 1000 Monte Carlo replications with sample sizes of 20, 50, 200, and 1000 were considered. Random samples, such that USED (, ), were generated using one of the following Algorithms 1 and 2:
| Algorithm 1: |
|
| Algorithm 2: |
|
In practice, the two algorithms did not show a significant difference. Therefore, for simplicity, Algorithm 1 was performed. The mean square error (MSE) of the estimated parameters and the associated bias were used as assessment criteria, with the following formula:
Here, is the estimate of at the i-th replication, and
Table 1, Table 2, Table 3 and Table 4 show the MSE and bias of when is known. In general, the MSE of the ML estimates were less than the MSE of the MM estimates, especially for small sample size such as = 20, and large values of and . In addition, the bias of the ML estimates was smaller than the bias of the MM estimates in most cases, indicating that the ML estimation of the USED parameters yielded good precision, as expected. Table 1, Table 2, Table 3 and Table 4 show that all estimates are asymptotically unbiased, because as increases with the bias approaching 0, the MSEs decrease to 0.

Table 1.
MSE and bias for the USED estimates by ML and MM, when = 1 with = 0.5, 1, 2, and 3.5 and n = 20, 50, 200, and 1000.
Table 2.
MSE and bias for the USED estimates by ML and MM, when = 2 with = 0.5, 1, 2, and 3.5 and n = 20, 50, 200, and 1000.
Table 3.
MSE and bias for the USED estimates by ML and MM, when = 4 with = 0.5, 1, 2, 3.5, and n = 20, 50, 200, and 1000.
Table 4.
MSE and bias for the USED estimates by ML and MM, when = 10 with = 0.5, 1, 2, 3.5, and n = 20, 50, 200, and 1000.
It can be observed that as and increase, the MSE and the bias of both the ML and MM estimates increase, which offers the insight that the USED is adequate to fit data with small s and s.
The MSE and bias of and when is unknown are shown in Table 5, Table 6, Table 7 and Table 8, from which it can be seen that the MSE of the ML estimates and decreases as increases. This proves that the estimates are consistent. Furthermore, the effect of and on the ML estimates and is that the MSEs and biases become bigger for large values of and , as in the case when is known, which leads to the same conclusion.
Table 5.
MSE and bias for the USED estimates by ML, when is unknown with = 0.5, 1, 2, 3.5, and n = 20, 50, 200, and 1000.
Table 6.
MSE and bias for the USED estimates by ML, when is unknown with = 0.5, 1, 2, 3.5, and n = 20, 50, 200, and 1000.
Table 7.
MSE and bias for the USED estimates by ML, when is unknown with = 0.5, 1, 2, 3.5, and n = 20, 50, 200, and 1000.
Table 8.
MSE and bias for the USED estimates by ML, when is unknown with = 0.5, 1, 2, 3.5, and n = 20, 50, 200, and 1000.
4. Applications
This section presents a comparison of the USED with other competing models, in order to demonstrate the practical effectiveness of the USED. Its real-life applications are analyzed to evaluate the performance of the USED. The comparison of the fitted models is based on conventional metrics, namely, the Akaike information criterion (AIC), the Bayesian information criterion (BIC), and the function . In practical terms, the formulas for the AIC and BIC can be given, respectively, as follows:
and
Here, is the estimation of the log likelihood and is the number of parameters.
4.1. Eruption Data for the Kiama Blowhole
The Kiama Blowhole is a popular tourist destination located approximately 120 km south of Sydney, in Australia. The waiting times between the Kiama Blowhole’s 65 successive eruptions comprise the data used to test the USED model proposed in the current study. Kiama Blowhole eruptions are caused by rising ocean levels, which forces water into a hole behind a cliff, which then erupts through an exit, drowning everything in its path. From 12 July 1998, a digital watch was employed to track the time between eruptions over a 1340 h period. These data are used by [18] to test the performance of the Harris extended exponential distribution (HEED), which is compared to other models, such as the exponentiated Weibull model, the Marshall–Olkin extended exponential model, the exponentiated exponential model, and Weibull and gamma distributions. The study in [18] claims that the HEED is better than its competing models for fitting data based on the AIC and BIC. In [18], the pdf of the HEED is expressed as follows:
For the current study, the USED was fitted to the same data and compared with the models used in [18]. Table 9 summarizes the fittings results for the USED and HEED. The results are shown in terms of the number of parameters used, and according to the AIC, BIC, and . The results show that the USED is better than the HEED for fitting the real data based on the BIC and AIC, and better than the other models, namely, exponential, gamma, and Weibull distributions, according to the AIC, BIC, and .
Table 9.
The ML-estimated fitting parameters of the waiting times of eruptions of the Kiama Blowhole, using the exponential, gamma, Weibull, USED, and HEED models, along with their goodness-of-fit.
4.2. The Waiting Times for Bank Customers
The data used here relate to the amount of time in minutes 100 customers wait to be served at the branch of a bank. The study [19] uses these data to investigate how well the Lindley distribution fits the data in comparison to exponential distribution. According to the and the P-P plot and Q-Q plot, [19] indicates that the Lindley distribution fits the data better than the other models used. The current study examines the AIC, BIC, and for the USED against traditional life distributions, including the Lindley distribution. The findings for data fitting for the USED, exponential, gamma, Weibull, and Lindley models are summarized in Table 10. Based on the AIC and only, the results demonstrate that the USED fits real data better than the Lindley distribution. In addition, the USED is better than all other models when taking into account every criterion.
Table 10.
The ML-estimated fitting parameters of the waiting times for bank customers, using the USED, exponential, gamma, Weibull, and Lindley models, along with their goodness-of-fit.
4.3. Students’ Scores in Mathematics
One of the most well-known technical institutions in India, the Indian Institute of Technology Kanpur, provides the data used here. The Joint Entrance Examination (JEE) is used for first-year admissions to various disciplines. Every year, about 450 students enroll for their first year at the institute. However, students have the option of selecting a slow-paced program, because, often, the work is extremely challenging and competitive. All courses are required to be completed by all students in their first year. By the first mid-term exam, students may choose to enroll in a slow-paced program if they receive a sub-par grade in a particular subject; this mark varies from subject to subject and is not fixed each year. The following data comprise the final exam scores for students who studied mathematics at a slow pace in 2003:
29, 25, 50, 15, 13, 27, 15, 18, 7, 7, 8, 19, 12, 18, 5, 21, 15, 86, 21, 15, 14, 39, 15, 14, 70, 44, 6, 23, 58, 19, 50, 23, 11, 6, 34, 18, 28, 34, 12, 37, 4, 60, 20, 23, 40, 65, 19, 31.
The study [20] uses these data to investigate whether or not the weighted exponential distribution (WE) better fits the data in comparison to the Weibull, gamma, and extended exponential distributions. According to [20], the and the Kolmogorov–Smirnov test statistic (KS) indicate that the WE distribution fits the data better than the exponential distribution. For the current study, the fitting results for the exponential, gamma, Weibull, USED, and WE models are summarized in Table 11. According to the findings, the USED fits the real data more accurately than any other model when considering the AIC, BIC, and .
Table 11.
The ML-estimated fitting parameters of the students’ scores in mathematics, using the USED, exponential, gamma, Weibull, and WE models, along with their goodness-of-fit.
4.4. Daily Ozone Measurements in New York
The data presented here are the daily ozone measurements in New York from May to September in 1973. In [21], the α-power transformed generalized exponential distribution (αPTGE) is compared to the modified Weibull, exponential Weibull, and extended generalized gamma distributions for fitting data. The study [21] finds that the αPTGE distribution performs better than other distributions based on the , KS test, Q-Q plot, and AIC. Table 12 presents the fitting results for the USED, exponential, gamma, Weibull, and αPTGE models. The USED outperforms all other models for fitting real data based on the AIC, BIC, and .
Table 12.
The ML-estimated fitting parameters of the daily ozone data set, using the USED, exponential, gamma, Weibull, and αPTGE models, along with their goodness-of-fit.
5. Conclusions
This paper outlined a new life distribution called the uniformly shifted exponential distribution (USED). The main advantage of the USED is its increased survival function. This advantage is valuable for fitting different kinds of real-life data. The statistical properties of the USED were outlined, and some properties of this model were proven, to show that the USED variables can be stochastically ordered. Estimation for the USED was achieved using the ML method and the MM, with different parameters. In the simulation, the ML method offered good performance for estimation when placed in comparison to the MM. Real data were used to examine the performance of the USED for fitting lifetime data, in comparison with other models. The applications show the superiority of the proposed distribution in comparison with the other models. This implies that among the common life distributions, the USED can be used as an effective alternative distribution for modeling lifetime data. Finally, although the USED was applied using data sets, the model can be generalized and utilized in other areas of research.
Author Contributions
Conceptualization, A.A.A.; methodology, A.A.A.; software, N.Q.; validation, A.A.A. and N.Q.; formal analysis, A.A.A. and N.Q.; investigation, A.A.A. and N.Q.; resources, A.A.A. and N.Q.; data curation, A.A.A. and N.Q.; writing—original draft preparation, A.A.A. and N.Q.; writing—review and editing, A.A.A. and N.Q.; visualization, N.Q.; supervision, A.A.A.; project administration, A.A.A.; funding acquisition, N.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Princess Nourah bint Abdulrahman University Researchers Support Project (project number PNURSP2024R376), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Data Availability Statement
We make use of publicly available data in this study.
Acknowledgments
The authors gratefully acknowledge Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R376), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia for the financial support for this project.
Conflicts of Interest
The funders had no role in the design of the study; in the collection, analyses, or interpretation of the data; in the writing of the manuscript; or in the decision to publish the results.
References
- Lawless, J.F. Statistical Models and Methods for Lifetime Data; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Lawless, J. Statistical methods in reliability. Technometrics 1983, 25, 305–316. [Google Scholar] [CrossRef]
- Marshall, A.W.; Olkin, I. Life Distributions; Springer: Berlin/Heidelberg, Germany, 2007; Volume 13. [Google Scholar]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions, Volume 2; John Wiley & Sons: Hoboken, NJ, USA, 1995; Volume 289. [Google Scholar]
- Shaked, M.; Shanthikumar, J.G. Stochastic Orders; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Bagnoli, M.; Bergstrom, T. Log-concave probability and its applications. In Rationality and Equilibrium: A Symposium in Honor of Marcel K. Richter; Springer: Berlin/Heidelberg, Germany, 2006; pp. 217–241. [Google Scholar]
- Gupta, R.D.; Kundu, D. Exponentiated exponential family: An alternative to gamma and Weibull distributions. Biometr. J. J. Math. Methods Biosci. 2001, 43, 117–130. [Google Scholar] [CrossRef]
- Alexander, G. The Use of the Gamma Distribution in Estimating Regulated Output from Storage; State Rivers and Water Supply Commission: Melbourne, Australia, 1961. [Google Scholar]
- Epstein, B. Statistical Assessment of the Life Characteristic (A Bibliographic Guide). J. R. Stat. Soc. Ser. C Appl. Stat. 2018, 13, 56. [Google Scholar] [CrossRef]
- Cox, D.R. Renewal Theory; Chapman and Hall: Boca Raton, FL, USA, 1962. [Google Scholar]
- Davis, D. An analysis of some failure data. J. Am. Stat. Assoc. 1952, 47, 113–150. [Google Scholar] [CrossRef]
- Feigl, P.; Zelen, M. Estimation of exponential survival probabilities with concomitant information. Biometrics 1965, 21, 826–838. [Google Scholar] [CrossRef] [PubMed]
- Balakrishnan, K. Exponential Distribution: Theory, Methods and Applications; Routledge: London, UK, 2019. [Google Scholar]
- Merkle, M. Convolutions of Logarithmically Concave Functions; Publikacije Elektrotehničkog Fakulteta; Serija Matematika: Belgrade, Serbia, 1998; pp. 113–117. [Google Scholar]
- An, M.Y. Log-Concave Probability Distributions: Theory and Statistical Testing; Duke University Dept of Economics Working Paper; Duke University: Durham, NC, USA, 1997. [Google Scholar]
- Borzadaran, G.M.; Borzadaran, H.M. Log-concavity property for some well-known distributions. Surv. Math. Its Appl. 2011, 6, 203–219. [Google Scholar]
- Ja, N. A simplex algorithm for function minimization. Comput. J. 1965, 7, 308–313. [Google Scholar]
- Pinho, L.G.B.; Cordeiro, G.M.; Nobre, J.S. The Harris extended exponential distribution. Commun. Stat.-Theory Methods 2015, 44, 3486–3502. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Atieh, B.; Nadarajah, S. Lindley distribution and its application. Math. Comput. Simul. 2008, 78, 493–506. [Google Scholar] [CrossRef]
- Gupta, R.D.; Kundu, D. A new class of weighted exponential distributions. Statistics 2009, 43, 621–634. [Google Scholar] [CrossRef]
- Vilca, F.; Santana, L.; Leiva, V.; Balakrishnan, N. Estimation of extreme percentiles in Birnbaum–Saunders distributions. Comput. Stat. Data Anal. 2011, 55, 1665–1678. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).