
A Binary-State Continuous-Time Markov Chain Model for Offshoring and Reshoring



Abstract
1. Introduction
2. The Model
2.1. The Microscopic Model
2.2. The Macroscopic Model
- What is the trade-off between offshoring costs (described by parameters and ) and the different production costs in the two countries (described by parameters and )?
- How can the North country use the incentives described by the parameter to avoid the phenomenon of offshoring, and what is the impact of this type of incentives on the evolution over time of the quantity that is related to the proportion of companies that have offshored their production?
3. The HJB Equation and the Evolution of
4. Offshoring without Incentives
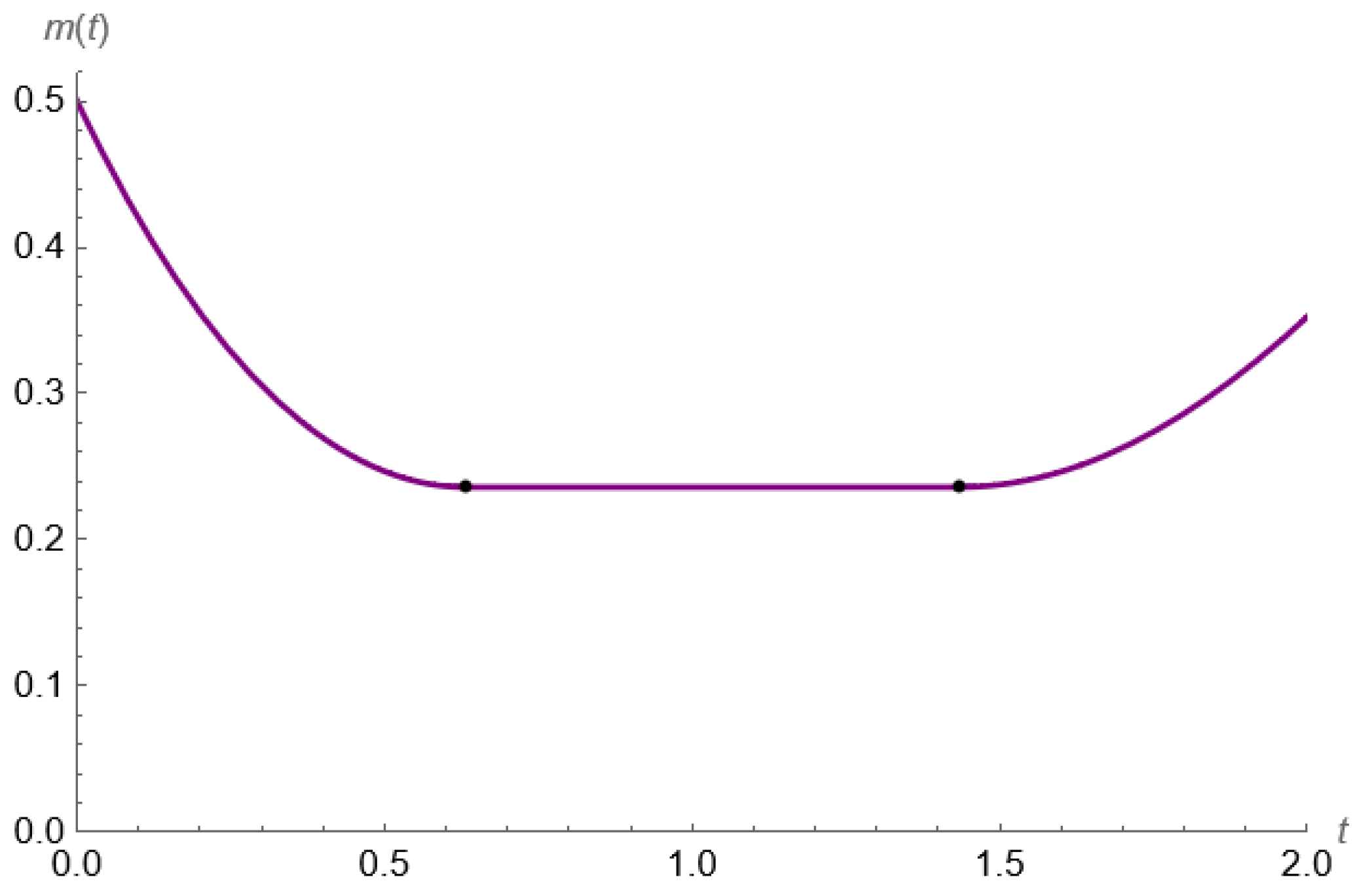
4.1. Technical Analysis
4.2. Interpretation of the Results
5. Offshoring and Reshoring in Presence of Relocalization Incentives
5.1. Technical Analysis
5.1.1. Low Incentives:
5.1.2. High Incentives:
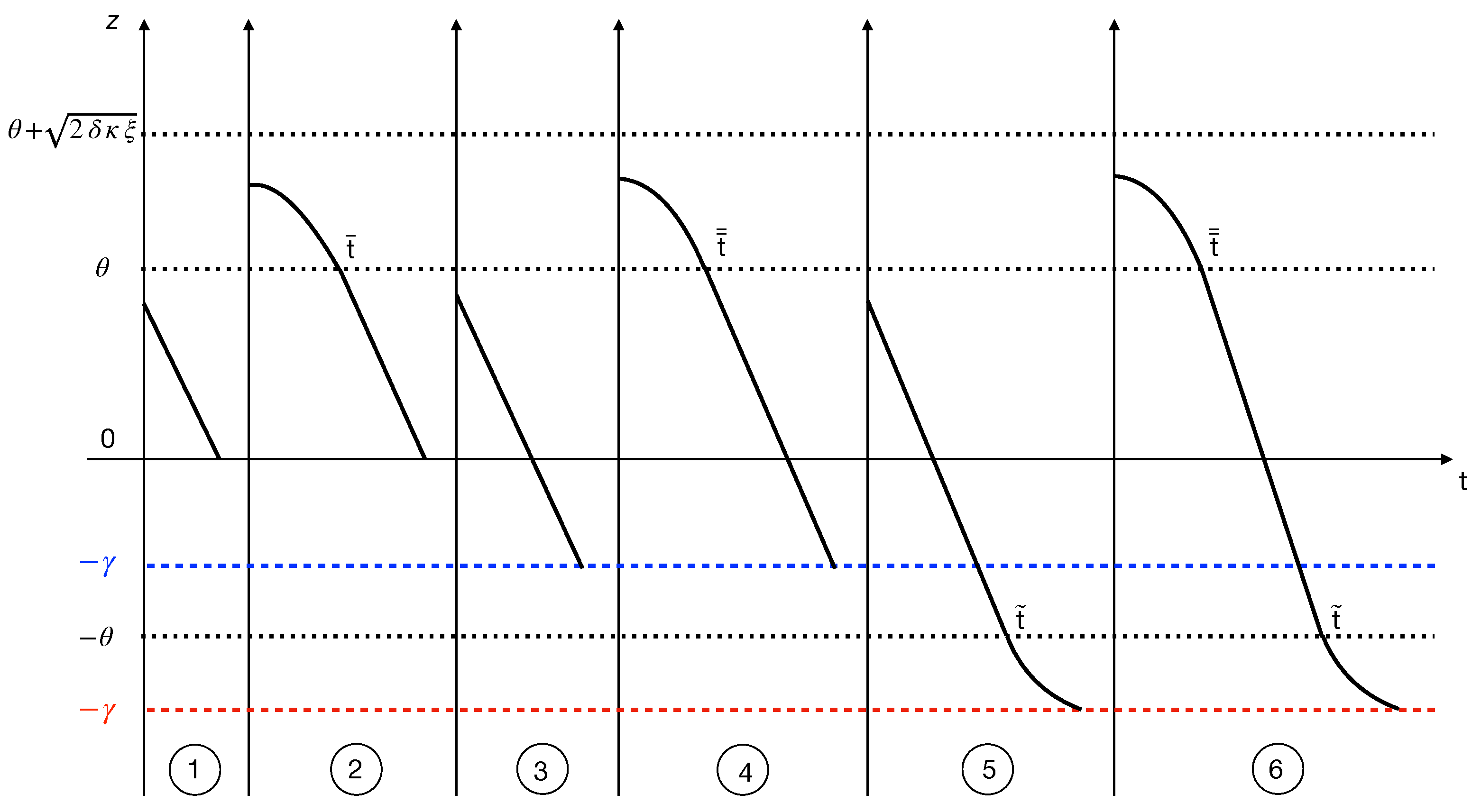
5.2. Interpretation of the Results
- ➀
- In this case, there is no offshoring because the marginal cost is greater than the savings obtained from production costs; see Equation (24).
- ➁
- Initially, the offshoring phenomenon is present, but it stops in the second part of the programming interval because the savings in production no longer justify the transaction cost; see Equation (25).
- ➂
- Even in the presence of incentives from the North country, there is neither offshoring nor reshoring because the transaction costs are too high compared to other parameters; see Equation (31).
- ➃
- In this situation, incentives from the North country are too weak, and only the offshoring phenomenon occurs in the first part of the programming interval; see Equation (32).
- ➄
- The presence of incentives from the North country is sufficiently intense to allow the reshoring phenomenon in the last part of the programming interval (eventually, in the whole programming interval if ). See Equation (38).
- ➅
- This is the most informative situation: offshoring occurs in the first part of the programming interval when there is enough time to take advantage of the low production costs in the South country; reshoring, on the other hand, occurs at the end of the programming interval and is stimulated by sufficiently high incentives paid by the North country; see Equations (38)–(40).
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schwörer, T. Offshoring, domestic outsourcing and productivity: Evidence for a number of European countries. Rev. World Econ. 2013, 149, 131–149. [Google Scholar] [CrossRef]
- Metters, R.; Verma, R. History of offshoring knowledge services. J. Oper. Manag. 2008, 26, 141–147. [Google Scholar] [CrossRef]
- Wang, Z.; Cheng, F.; Chen, J.; Yao, D. Offshoring or reshoring: The impact of tax regulations on operations strategies. Ann. Oper. Res. 2023, 326, 317–339. [Google Scholar] [CrossRef]
- Fratocchi, L.; Di Mauro, C.; Barbieri, P.; Nassimbeni, G.; Zanoni, A. When manufacturing moves back: Concepts and questions. J. Purch. Supply Manag. 2014, 20, 54–59. [Google Scholar] [CrossRef]
- Kudrenko, I. The new era of American manufacturing: Evaluating the risks and rewards of reshoring. E3S Web Conf. 2024, 471, 050250. [Google Scholar] [CrossRef]
- Robinson, P.K.; Hsieh, L. Reshoring: A strategic renewal of luxury clothing supply chains. Oper. Manag. Res. 2016, 9, 89–101. [Google Scholar] [CrossRef]
- Crawford, N. The Green Transition and European Industry. Survival 2024, 66, 99–124. [Google Scholar] [CrossRef]
- Saito, Y. A North-South model of outsourcing and growth. Rev. Dev. Econ. 2018, 22, 16–35. [Google Scholar] [CrossRef]
- Gomes, D.A.; Velho, R.M.; Wolfram, M.-T. Socio-economic applications of finite state mean field games. Philos. Trans. R. Soc. A 2014, 372, 20130405. [Google Scholar] [CrossRef]
- Gomes, D.A.; Mohr, J.; Souza, R.R. Continuous Time Finite State Mean Field Games. Appl. Math. Optim. 2013, 68, 99–143. [Google Scholar] [CrossRef]
- Brambilla, C.; Grosset, L.; Sartori, E. Continuous-Time Markov Decision Problems with Binary State. WSEAS Trans. Math. 2023, 22, 139–142. [Google Scholar] [CrossRef]
- Cecchin, A.; Dai Pra, P.; Fischer, M.; Pelino, G. On the Convergence Problem in Mean Field Games: A Two State Model without Uniqueness. SIAM J. Control Optim. 2019, 57, 2443–2466. [Google Scholar] [CrossRef]
- Huang, J.J.; Chen, C.Y. Integrating the Coupled Markov Chain and Fuzzy Analytic Hierarchy Process Model for Dynamic Decision Making. Axioms 2024, 13, 95. [Google Scholar] [CrossRef]
- Dai Pra, P.; Sartori, E.; Tolotti, M. Climb on the Bandwagon: Consensus and Periodicity in a Lifetime Utility Model with Strategic Interactions. Dyn. Games Appl. 2019, 9, 1061–1075. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, X.; Zhang, J. Optimal Investment Strategy for DC Pension Plan with Deposit Loan Spread under the CEV Model. Axioms 2022, 11, 382. [Google Scholar] [CrossRef]
- Brémaud, P. Markov Chains: Gibbs Fields, Monte Carlo Simulation and Queues; Springer Nature: Cham, Switzerland, 2020. [Google Scholar]
- Chen, L.; Hu, B. Is Reshoring Better Than Offshoring? The Effect of Offshore Supply Dependence. Manuf. Serv. Oper. Manag. 2017, 19, 166–184. [Google Scholar] [CrossRef]
- Yang, H.; Ou, J.; Chen, X. Impact of tariffs and production cost on a multinational firm’s incentive for backshoring under competition. Omega 2021, 105, 102500. [Google Scholar] [CrossRef]
- Pearce, J.A. Why domestic outsourcing is leading America’s reemergence in global manufacturing. Bus. Horiz. 2014, 57, 27–36. [Google Scholar] [CrossRef]
- Miao, L.; Li, S.; Wu, X.; Liu, B. Mean-Field Stackelberg Game-Based Security Defense and Resource Optimization in Edge Computing. Appl. Sci. 2024, 14, 3538. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| State at Time t | Instantaneous Profit | State at Time T | Final Incentive |
|---|---|---|---|
| 0 | |||
| Variables | Description |
| production State of the representative player (state function) | |
| transition rate of the representative player (control function) | |
| Parameters | Description |
| T | fixed final time |
| instantaneous demand for the product | |
| selling price for one unit of goods | |
| unit production cost in the South country | |
| additional production cost in the North country | |
| , | quadratic and linear activation costs of the transition rate |
| final incentive |
| T | ||||
|---|---|---|---|---|
| + | − | + | + |
| T | |||||
|---|---|---|---|---|---|
| + | − | + | + | − | |
| + | + | + | + | − |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brambilla, C.; Grosset, L.; Sartori, E. A Binary-State Continuous-Time Markov Chain Model for Offshoring and Reshoring. Axioms 2024, 13, 300. https://doi.org/10.3390/axioms13050300
Brambilla C, Grosset L, Sartori E. A Binary-State Continuous-Time Markov Chain Model for Offshoring and Reshoring. Axioms. 2024; 13(5):300. https://doi.org/10.3390/axioms13050300
Chicago/Turabian StyleBrambilla, Chiara, Luca Grosset, and Elena Sartori. 2024. "A Binary-State Continuous-Time Markov Chain Model for Offshoring and Reshoring" Axioms 13, no. 5: 300. https://doi.org/10.3390/axioms13050300
APA StyleBrambilla, C., Grosset, L., & Sartori, E. (2024). A Binary-State Continuous-Time Markov Chain Model for Offshoring and Reshoring. Axioms, 13(5), 300. https://doi.org/10.3390/axioms13050300