In this section, we conduct a Monte Carlo simulation to compare the performance of our proposed statistics (denoted by K-S) with the two statistics introduced by Davidson and Duclos [
10] (denoted by DD) and Barrett and Donald [
5] (denoted by BD), respectively. Let
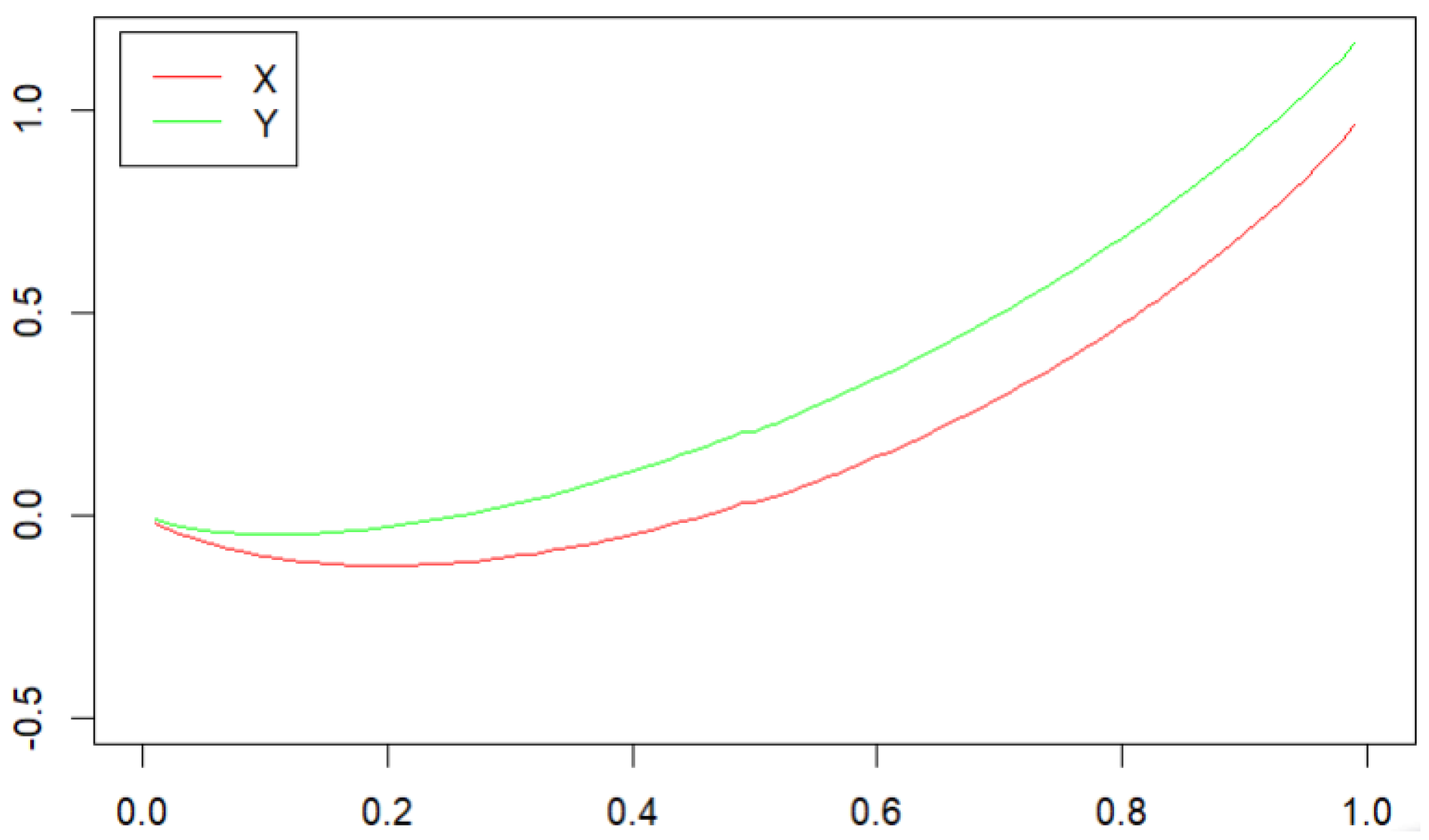
and
be the observations drawn from the independent populations
X and
Y, respectively. In
Section 4.1, we give a brief introduction of these two statistics.
4.2. Simulations
Next, we make a comparison of the powers of the DD test and BD test with our test by using the R language. To this end, we used the bootstrap method in
Section 3.4 to obtain
p-values of our tests. The method of obtaining the
p-values of BD test is similar to ours. Besides, to approximate the supremum of the statistics, we applied the function gridSearch() in the Package NMOF to achieve it. For the approximated
p-values of the DD test, we borrowed them from Bai et al. [
26] and Bai et al. [
27].
Based on the approximated p-values, we performed R-times Monte Carlo simulations to obtain the rejection rates. For each simulation, we assumed that X and Y are two normally distributed populations, i.e., and , and the following four different cases were considered in the process of the simulations.
Case 1: and . In this case, X and Y have the same distribution. The rejection rates ought to have a relative frequency that is close to the nominal significance level .
Case 2: and . In this case, it is easy to verify that and .
Case 3: and . In this case, we have , but we cannot say that .
Case 4: and . Both and should be rejected. The rejection rates of this case should converge to 1 as the sample size increases.
In each case, to balance the time and accuracy of the simulation results, the experimental replication, bootstrap replication, and sample size were selected as
. To improve the speed and efficiency of the simulation, we exerted several functions in the Package Parallel to conduct parallel computing. The simulation results are listed in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6.
For Case 1, we can easily find from
Table 1,
Table 2 and
Table 3 that the rejection rates of our K-S test are more robust than the DD test when
and
. As for
, the rejection rates of our K-S test are a little higher than the nominal level when
is smaller than 200. But, they decrease to 0.1 when the sample size increases. However, the fluctuations of the rejection rates of the DD test are still large when the sample size increases to 400. For the BD test, the fluctuations of their rejection rates are greater than our K-S test at any significance level.
For Case 2, we see from
Table 1,
Table 2 and
Table 3 that the rejection rates of all tests equal approximately zero, as they are supposed to be. Moreover, the rejection rate of our K-S test and BD test of each sample size is closer to zero than the DD test. This means that our K-S test and the BD test outperform the DD test. Meanwhile, the performance of our proposed K-S test is not inferior to the BD test.
The rejection rates of Cases 3 and 4 are supposed to increase to 1 as
increases. This can be easily seen from
Table 1,
Table 2 and
Table 3. As the sample size gradually increased, all three tests demonstrated great power performance and were consistent with our expectations.
Then, we analyzed the simulation results of SSD experiments. From
Table 4,
Table 5 and
Table 6, it is easily found that the rejection rates of our K-S test in Case 1 are more robust than the DD test and the BD test for all three nominal levels. In Case 2, when
and
, the rejection rates of our K-S test and the BD test decrease to zero rapidly and are lower than the DD test in almost every sample size. When
, even the rejection rates of the DD test and the BD test decline to a lower level than our K-S test as
reaches 200. As the sample size continues to expand, the rejection rates of the DD test demonstrate a remarkable rebound phenomenon. But, for our K-S test, the rejection rates drop to zero steadily. Meanwhile, the convergence rate is also faster than the BD test. Unlike the FSD experiment, the rejection rates in Case 3 converge to zero eventually. The rejection rates of three tests show a great performance in both Cases 3 and 4.
According to the above simulation results, we can conclude that three tests have different performances in Cases 1 and 2. Our K-S test performs better than the DD test and the BD test when the two distributions are identical. In Case 2, when the dominance relationship is , the performance of our K-S test and the BD test is better than the DD test. Moreover, when , we find that the speed of the rejection rate converging to zero in our K-S test is faster than that in the BD test when we test the SSD relationship in Case 2. In Cases 3 and 4, all three tests demonstrate great effects. Therefore, on the whole, our proposed K-S tests are better than the other two tests.




{kind=link}
{kind=link}
{kind=link}
{kind=link}