Abstract
In this paper, we propose a global numerical method for approximating Caputo fractional derivatives of order , with The numerical procedure is based on approximating by the m-th derivative of a Lagrange polynomial, interpolating f at Jacobi zeros and some additional nodes suitably chosen to have corresponding logarithmically diverging Lebsegue constants. Error estimates in a uniform norm are provided, showing that the rate of convergence is related to the smoothness of the function f according to the best polynomial approximation error and depending on order . As an application, we approximate the solution of a Volterra integral equation, which is equivalent in some sense to the Bagley–Torvik initial value problem, using a Nyström-type method. Finally, some numerical tests are presented to assess the performance of the proposed procedure.
Keywords:
Caputo’s derivatives; Lagrange interpolation; Jacobi polynomials; product integration rules; fractional differential equations MSC:
26A33; 34K37; 41A05; 45D05
1. Introduction
The paper considers the numerical evaluation of Caputo fractional derivatives of order of a given function f, i.e.,
Fixing the case , the numerical procedure is based on approximating , where the polynomial interpolates f at the zeros of the n-th orthogonal polynomial with respect to the Jacobi weight and additional nodes. According to the “additional method nodes” [1], the latter are chosen in such a way that the norm of the operator diverges as .
Fractional calculus has a long history, but only over the last few decades has its usefulness in applications become more evident. Indeed, fractional derivatives have been occurring more and more frequently in many physical and engineering problems, including diffusion processes [2,3,4,5], signal processing [6], and modeling of viscoelastic materials [7,8,9,10]. For this reason, efficient and reliable techniques for computing are needed. Several textbooks and papers (see, e.g., [4,11,12,13,14,15,16,17]) have been published dealing with various aspects of fractional calculus, ranging from its history to analytical and numerical results to possible applications. In addition, several papers dealing with numerical methods for solving differential equations of fractional order are available in the literature; among others, we mention [18,19,20,21,22,23,24,25,26] and the references therein. In particular, accurate classification and description of some numerical approximations proposed for the most frequently utilized fractional integrals and derivatives have been presented in [12,27].
One of the main advantages of the global approach we discuss here is the rate of convergence, which is related to the smoothness of the function f according to the best polynomial approximation error and depending on the order . Such estimates improve upon those stated in [13], and allow us to obtain finer results with fewer function evaluations than those required by local piecewise approximants (see, e.g., [28]). Furthermore, for any fractional derivative, the majority of methods for evaluating different functions, i.e., those at the Jacobi zeros, remain unchanged regardless of the fractional order .
As an application of the above-described numerical procedure, we propose a new Nyström-type method for solving the Bagley–Torvik initial value problem [7,8] and approximating the solution of the equivalent Volterra integral equation. We prove the convergence of the Nyström method, providing error estimates in the uniform norm. Such a numerical method leads to solving a system of linear equations with a dimension that is just the number of the function’s evaluations.
The rest of this paper is outlined as follows: Section 2 contains some basic definitions and preliminary results about the polynomial tool that we employ and a few properties of the fractional derivatives useful for our aims; Section 3 describes the method that we propose, along with error estimates, computational details, and some numerical tests; Section 4 is dedicated to the application of the introduced numerical scheme to approximate the solution of the Bagley–Torvik initial value problem, along with error estimates and some numerical tests; finally, Section 5 states the proofs of the main results.
2. Preliminary Results
In the sequelae, we denote by any positive constant having different meanings at different occurrences. The notation is used to underline that does not depend on . Moreover, where are quantities depending on some parameters, writing should be understood as indicating the existence of a constant such that Finally, is used to denote the space of algebraic polynomials of degree less than or equal to n.
2.1. Function Spaces
For any , is the space of all continuous functions, and is equipped with the uniform norm Let be the best polynomial approximation error in , i.e.,
and characterizing , i.e.,
As usual, for any integer , denotes the space of at least q times differentiable functions such that the q-th derivative , and is equipped with the norm
We use to denote the ordinary modulus of continuity of f, recalling the following Jackson inequality (see e.g., (5.1) in [29]):
The Hölder space on with is characterized as
For smoother functions, we recall that for any [30]
and that for (i.e., ) (see Section 5.1.5 in [29])
In what follows, in the case of we use the simpler notation and
2.2. Optimal Interpolation Processes
Consider the Jacobi weight and denote by the corresponding system of orthonormal polynomials with positive leading coefficients. Let be the roots of and let be the Christoffel numbers
For a given function , let be the Lagrange polynomial interpolating f at the zeros of i.e.,
and also
Denoting by the norm of the operator , i.e., the n-th Lebesgue constant, it is well known (see, e.g., Chapter 4 in [31]) that growing at least as plays an essential role in the study of the convergence of the Lagrange polynomial, as
In view of a classical result by Szëgo, the following behavior arises:
For instance, the Lebesgue constants related to the Legendre weight () or the Chebyshev weight of the second kind () algebraically diverge, as .
On the other hand, in [1] it was proved that by suitably modifying the above interpolation process, the corresponding Lebesgue constants also behave as in the case of or .
To describe the modified process, given two positive integers r and s, let
and set
Let be the polynomial interpolating f at the nodes , i.e.,
The following result proved in [1] shows how the sequence can be a useful tool for simultaneously approximating f and its derivatives in the uniform norm.
Theorem 1.
Remark 1.
For any , under assumptions (6), the following estimate holds [1]:
Remark 3.
The procedure described above is known as the ”method of additional nodes”, and has been used by several authors in different contexts. The sequence was introduced in [1] in the natural interval , where the Jacobi zeros are, for the simultaneous approximation of f and its derivatives in the uniform norm. The case of has been treated in [32]. For a short history of the additional nodes method, the interested reader can consult [31] (p. 264). We highlight that the previous interpolation process is very useful for simultaneously approximating the function f and its derivatives by using only the samples of f at the points
2.3. Computational Details
The interpolating polynomial can be represented as
equivalently, setting
it takes the form
To compute the derivatives of the polynomials in (9), we can set
by the Leibnitz rule derivative to easily obtain
In the special case with and selecting , the polynomial in (10) takes the form
and
where
and denotes Euler’s Gamma function.
We conclude by recalling that are related to the zeros and Christoffel numbers , which are defined in with respect to the weight through the relations
In addition, are computed by the Golub and Welsch algorithm [33]. Relying on a modification of the QR–method, this yields the nodes and weights by computing the eigenvalues of the Jacobi matrix and the first row of the associated eigenvector matrix.
2.4. Caputo Fractional Derivatives
We recall the definition of Caputo’s fractional derivative of order With [15], it is defined as
where
is the Riemann–Liouville fractional integral operator of order . From this definition, it follows that
For , Caputo’s fractional derivative is defined as
In what follows, we will consider the case of functions for fixed .
For , it is known that the operator is linear and bounded and that is compact (see, e.g., [19,34,35,36]; see also [37] (Lemma 6.2)). As a consequence, taking into account definition (15) of , it follows that, for any ,
3. Approximation of Caputo Fractional Derivatives
In this section, we describe the proposed method for numerically evaluating under the assumption for the case of With as defined in (9), in view of the “fine” results about the simultaneous approximation evidenced by (7) and (8), we propose using to obtain
By the Gauss–Jacobi rule of order with respect to the weight , with and , as the corresponding knots and Christoffel numbers, respectively, we obtain
and hence
where
Now, we state a result dealing with the convergence of the proposed rule and providing some upper bounds of the quadrature error.
Theorem 2.
Theorem 2 ensures that the rule uniformly converges to with a rate depending on the smoothness of f and on , with as the order of the fractional derivative.
Remark 4.
In [13], the authors proposed approximating using the m-th derivative of the Gauss–Lobatto zeros-based interpolating polynomial , which in this case coincides with the polynomial . However, the final error estimate that they derived for (see Remark 5.2 in [13]) was
which is certainly worse than the estimates established in Theorem 2.
In addition, it seems that in [13] the interpolating polynomial is always based on the Jacobi–Lobatto nodes, irrespective of the parameters of the Jacobi weight and fractional derivative order α. The latter of these determines the order m of the Lagrange derivative; consequently, the corresponding Lebesgue constants diverge algebraically, as the conditions on in (6) ensuring are necessary (see Theorem 4.2.4 in [31]). For example, in the case of , the previous approach leads to the approximation with final error
Unlike [13], we propose to approximate with error
Next, we highlight some advantages of using the proposed numerical approach through two cases that occur in different applications. Both cases involve multi-term Caputo fractional derivatives for which the calculation can be carried out based on knowledge of samples of f at nodes .
- Case I. In this first case, we evaluate
Taking (12) into account, we have
Examples of this multi-term structure in FDEs can be found, for instance, in [11,38].
- Case II. Considering
Remark 5.
We conclude this section by observing that in the case where it is necessary to approximate while letting , we can approximate for any by
3.1. Computational Cost
In this section, we provide a short discussion on the computational effort of the proposed procedure in terms of the number of long operations (l.o.) employed to evaluate We observe that for a fixed y, the computational effort depends on the terms in (20). Setting , in order to evaluate l.o. are needed. Moreover, with as defined in (11), the evaluation of for requires l.o. As a consequence, from (12) we can deduce that the computation of can be performed in l.o. We point out that despite this computational cost appearing quite large, the number of function evaluations is always n. In this sense, the proposed method is radically different from methods using graded mesh local approximants, for which the computational cost is lower but the number of function evaluations is variable, in particular becoming higher for values of y that are “closer” to the origin.
3.2. Numerical Tests for Evaluating
Now, we propose two numerical tests to assess the performance of the above-discussed approximation method. We compare the spectral method proposed in [13]; Example 1 can also be found in [22,24], with both papers proposing local approximation schemes. In [24], the method is based on compound trapezoidal rules, while in [22] the approximations involve piecewise quadratic and cubic polynomials. Denoting by
the absolute error at the point , let
where is a sufficiently dense set of equispaced points in . In both tests, we provide the maximum absolute errors for and the numerical values for selected points attained by , along with the corresponding pointwise errors.
We point out that here, as in the successive tests, all computations are performed in double precision arithmetic () using Wolfram Mathematica 14.0.
Example 1.

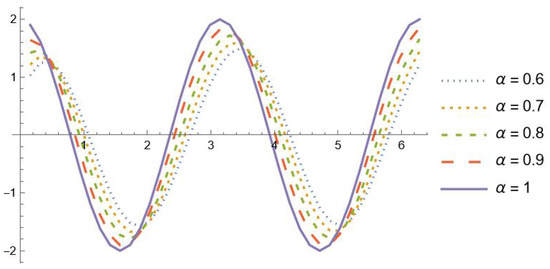
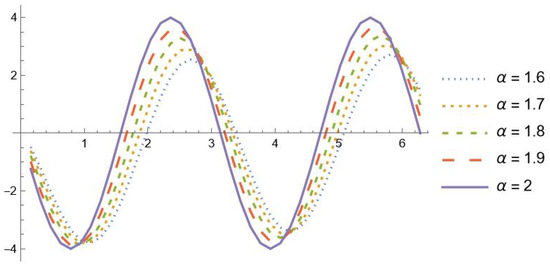
For it is known that
where is the generalized Mittag-Leffler function. We point out that the required Mittag-Leffler functions were computed using the Wolfram Mathematica function Table 1 shows the maximum absolute errors obtained when approximating for different choices of and for . Comparing the results with those stated in Table 4 in [13], it can be seen that our procedure is increasingly fast and accurate as α increases.
Table 1.
.
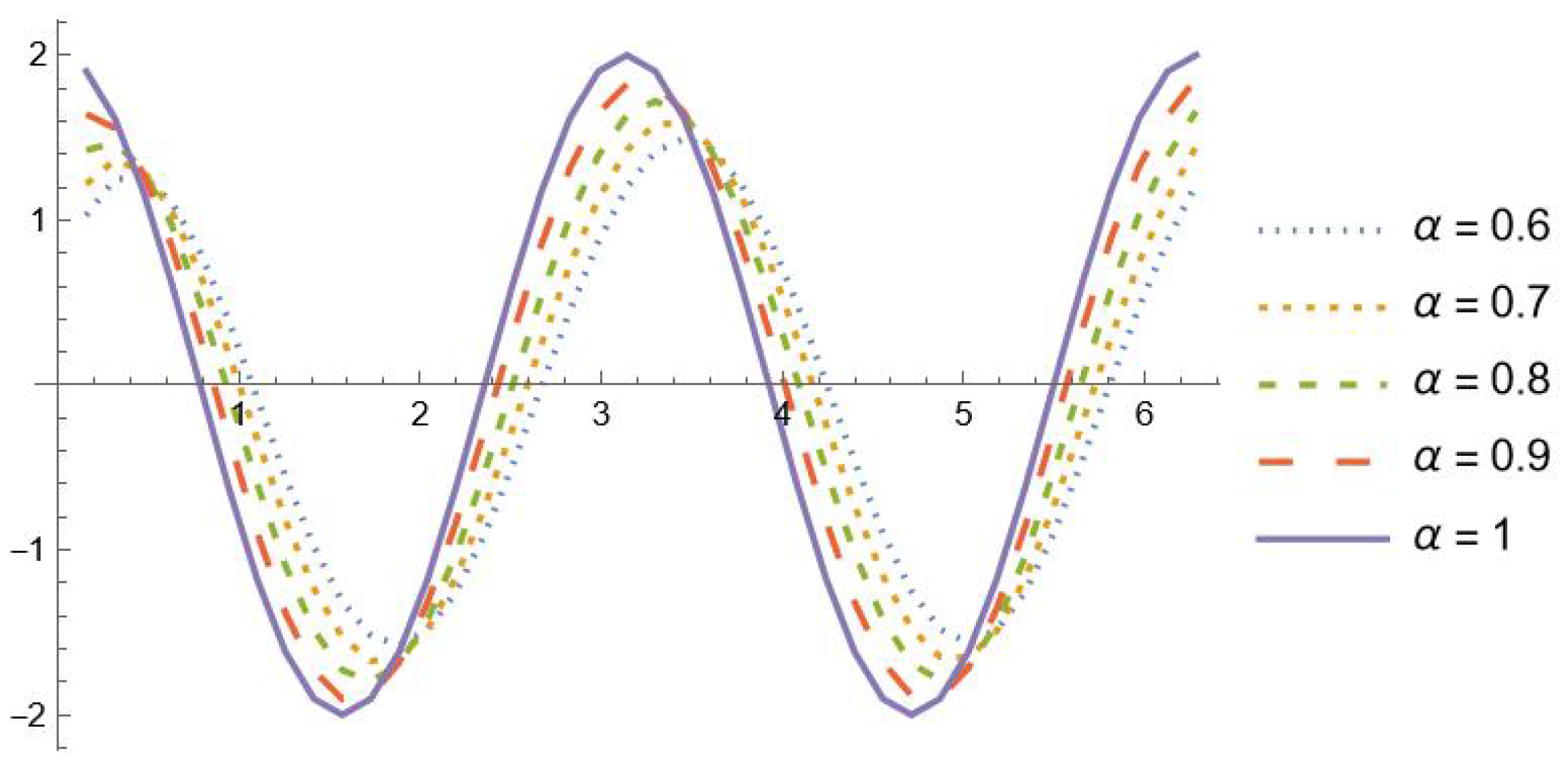
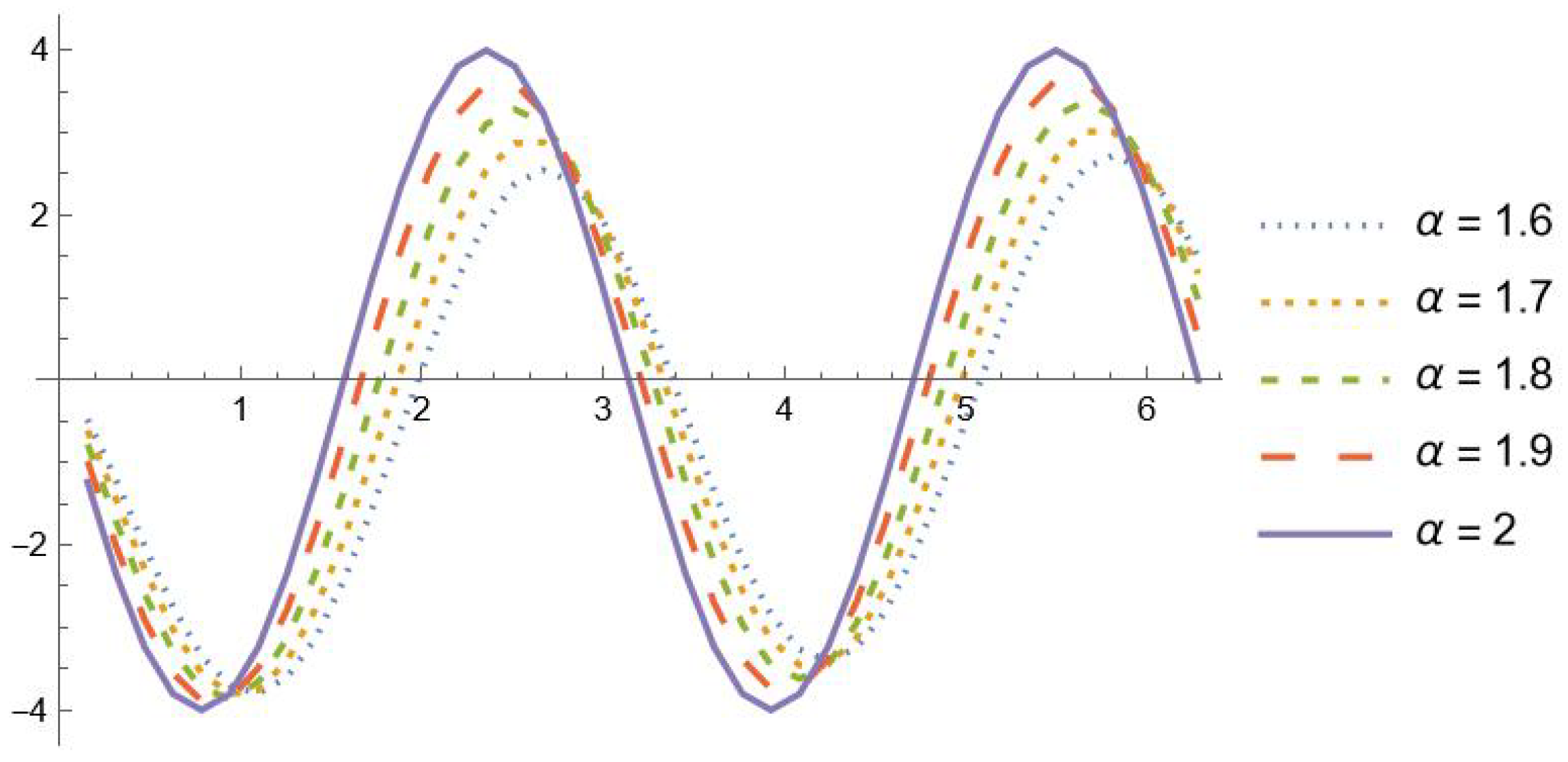
Moreover, Table 2 reports the maximum absolute errors obtained when approximating in the interval . Note that the precision is attained even in a wider range, though with a slightly greater number of interpolation nodes. In Figure 1 and Figure 2, the graphs of , and with are shown in the interval . It is evident that the fractional derivatives , , tend to for
Table 2.
.
Figure 1.
, , with .
Figure 2.
, , with .
Finally, Table 3 reports the approximate values achieved by simultaneously approximating for . Here, the exact values computed using (23) are
A comparison with the results in [24] (Tables 3.1 and 3.2) and [22] (Tables 11 and 12) shows that our procedure is more accurate and efficient.
Table 3.
.
Example 2.
For , the analytical form of the Caputo fractional derivative is
Table 4 shows the approximations of with in the interval for different choices of α. The obtained results are again better than those in [13] (second row of Table 1), in particular for larger values of α.
Table 4.
.
4. Application to the Bagley–Torvik IVP
In this section, we show how the procedure introduced in the previous section can be used to construct a Nyström-type method for solving the Volterra integral equation equivalent to the Bagley–Torvik IVP.
In [7,8], Bagley and Torvik studied the motion of a rigid plate immersed in an infinite Newtonian fluid. They proved that the displacement u of the plate at time t is described by the equation
where is the Caputo fractional derivative of order , h is the force applied to the plate, and T is the fixed maximum observation time. The quantities are connected with the mass and area S of the plate as well as with the stiffness constant K, fluidity , and fluid viscosity by the following relations:
Assuming that we know the initial displacement and velocity at the initial time , the following Bagley–Torvik IVP is deduced:
The following theorem stating the existence and uniqueness of the solution of Problem (25) in the space was proved in [39].
Theorem 3.
If then the Bagley–Torvik IVP admits a unique solution
As previously stated, our numerical method consists in approximating the solutions of a second kind Volterra integral equation (VIE) that is equivalent to the IVP problem (25). The next lemma introduces the VIE and establishes the equivalence between its solutions and the solutions of (25) in the space , where if and only if exists for a.e. with and such that
Lemma 1.
Remark 6.
If , then the equivalence stated in Lemma 1 holds true in the space .
With the change of variable the integral Equation (26) becomes
where , , , and . After determining f in (27), u in (26) (or, equivalently, the solution of the Bagley–Torvik IVP (25)) can be computed through
Letting
and denoting the identity operator by I, Equation (27) can be written as
Supported by Theorem 3 and Remark 6, we study the above equation in the space , proving the following theorem about its unisolvence.
Theorem 4.
If in , then Equation (29) admits a unique solution for any . Moreover, if , then f belongs to as well.
Remark 7.
Under the assumption that , the function , as
Now, we propose a Nyström-type method based on the approximation of by
where is defined in (18) with . In addition, we approximate by
where we lighten the notation by denoting the interpolating polynomial based on the zeros of simply by .
Hence, we obtain the following finite dimensional equation:
In view of (9) and (19), we have
The integrals can be exactly computed by the Gauss–Jacobi cubature rule of order N with respect to the bivariate weight function , i.e.,
We point out that the cubature formula is exact for any polynomial of degree separately in each variable (see, e.g., [40]). Moreover, from (9) we obtain
where the integrals can be exactly computed by the N-Gauss–Jacobi rule with with respect to the weight function , obtaining
Hence, taking into account the initial condition , we obtain
and
As a consequence, Equation (32) becomes
and by collocation at we obtain the equivalent linear system of order :
in the unknowns
If is a solution of the linear system in (33), then, letting , the Nyström interpolant
is a solution of the discrete Equation (32) and vice versa.
In the next theorem, we provide sufficient conditions assuring the convergence of the proposed method along with estimates of the error depending on the smoothness of the unknown solution.
Theorem 5.
Assuming that in , the inverses of the operators exist and are uniformly bounded and . Then, for sufficiently large n (say, ), the Nyström interpolating functions converge to the exact solution f of the VIE (29) and
Moreover, if , then
Here, the constants in “” are independent of n.
Coming back to the Bagley–Torvik IVP from Theorem 5 and Remark 7, it is easy to deduce the following result.
Corollary 1.
Under the assumptions of the previous theorem, if for all sufficiently large n (say, ), then the sequence , with converges to the exact solution u of the Bagley–Torvik IVP and
Numerical Tests on the Bagley–Torvik IVP
We now propose some numerical tests confirming the effectiveness of the method described in Section 4 and the approximation proposed in Section 3 for Caputo fractional derivatives. In the following examples,
is the maximum absolute error computed over a sufficiently large set of equispaced points in i.e.,
In Example 5, we make a comparison with the method proposed in [13].
Example 3.
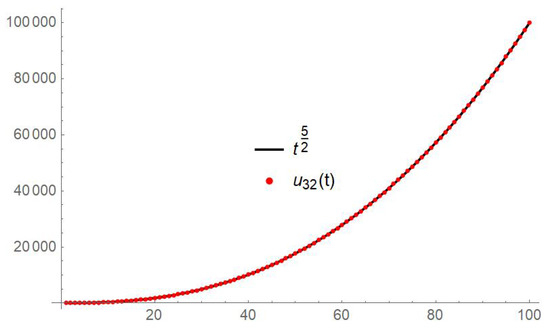
Consider the following Bagley–Torvik IVP:
If we choose , then the exact solution is . Table 5 reports the values of the approximant for . As can be seen, according to our theoretical expectations it is necessary to increase n in order to attain exact decimal digits. Figure 3 compares the graphs of the exact solution and its approximation in the interval
Table 5.
Example 3.
Figure 3.
Example 3.
Example 4.
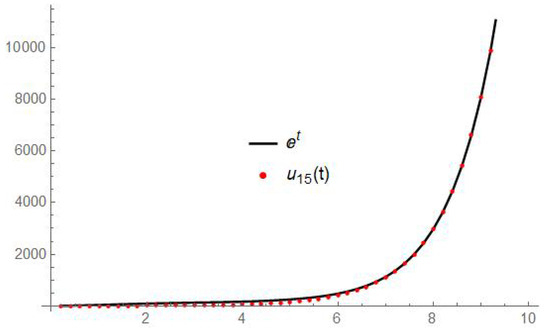
Let us consider
with , where is the incomplete Gamma function. The exact solution is . In this case, we expect very fast convergence, with being very smooth. This is confirmed by the numerical results presented in Table 6. The graphs of the exact solution and its approximation are shown in Figure 4.
Table 6.
Example 4.
Figure 4.
Example 4.
Example 5.
We take the following IVP:
with such that . Again, in this case the solution is very smooth, and, as shown in Table 7, the convergence is very fast.
Table 7.
Example 5.
This example was also considered in [13] (Example 6.3). We point out that they used a procedure quite different from the one that we propose in Section 4: they numerically solved the IVP (25) directly without considering the equivalent VIE (26). Comparing the results in [13] (Table 7) with those in Table 7, it can be observed that our Nyström method is faster for any choice of ω.
5. Proofs
Proof of Lemma 1.
Let be a solution of (25). Letting , (25) becomes
We first recall that, by definition, for (see [36] (Definition 2.4)). Then, under the assumption , we deduce ; using the fundamental theorem of calculus together with the initial conditions, we obtain
and
As it is well-known that [41]
we deduce
i.e., (26), recalling the expression of . Thus, u is also a solution of (26).
Proof of Theorem 4.
If we prove that the operators are compact, then under the assumption in the unisolvence in of (29) for any follows by Fredholm’s alternative theorem.
We first prove that the operator is continuous. We have
Moreover, taking into account that
it is easily seen that
Then,
i.e., is continuous. Now, because is compactly embedded in (for example, see [42] (Lemma 3.2)), from the continuity of the operator we deduce the compactness of the operator .
To prove the compactness of the operator , we first note that it can be written as the composition of the following operators: , and , i.e.,
From the continuity of and and the compactness of , we deduce the compactness of .
6. Conclusions
In this work, we have developed a global method for numerically evaluating fractional derivatives of f of order . The interpolating process is essentially based on Jacobi zeros, and makes use of the additional nodes method [1] to approximate the m-th derivative of f by the m-th derivative of the interpolating polynomial. Error estimates are provided in spaces of q times differentiable functions with , and some numerical tests are presented to confirm the theoretical estimates. As an application, the proposed method is implemented to approximate the solution of the VIE equivalent to the Bagley–Torvik IVP. We also present a detailed error analysis for the Nyström-type method proposed for the VIE. The efficiency of our numerical approach for approximating fractional derivatives is tested both directly through numerical tests and indirectly through implementation of the Nyström method, with the numerical experimentation confirming the theoretical results. From the implementation point of view, we show how to take advantage of simultaneous approximation; in approximating more than one , it is sometimes the case that the required number of function evaluations is the same, while at other times it may be slightly more depending on the number of additional nodes. Finally, the dependence of the errors on the best polynomial approximation assures fast theoretical convergence, allowing finer results to be obtained with a lower number of interpolation nodes.
Author Contributions
Conceptualization, D.O. and M.C.D.B.; Methodology, D.O. and M.C.D.B.; Investigation, D.O. and M.C.D.B.; Data curation, D.O. and M.C.D.B.; Funding acquisition, D.O. and M.C.D.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by EU grant number P20229RMLB.
Data Availability Statement
Data are contained within the article.
Acknowledgments
The authors are grateful to the anonymous referees for their helpful suggestions. The authors are supported by University of Basilicata (local funds) and by PRIN 2022 PNRR project no. P20229RMLB, financed by the European Union—NextGeneration EU and the Italian Ministry of University and Research (MUR). This research has been accomplished within RITA (Research ITalian network on Approximation) and the UMI Group TAA (Approximation Theory and Applications).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Mastroianni, G. Uniform convergence of derivatives of Lagrange interpolation. J. Comput. Appl. Math. 1992, 43, 37–51. [Google Scholar] [CrossRef]
- Morgado, M.L.; Lima, P.M.; Mendes, M. Numerical Solution of the Time Fractional Cable Equation. In Springer Proceedings in Mathematics and Statistics, Proceedings of the ICDDEA 2019, Lisbon, Portugal, 1–5 July 2019; Springer: Cham, Switzerland, 2020; Volume 333, pp. 603–619. [Google Scholar]
- Morgado, M.L.; Rebelo, M.; Ferrás, L.L.; Ford, N.J. Numerical solution for diffusion equations with distributed order in time using a Chebyshev collocation method. Appl. Numer. Math. 2017, 114, 108–123. [Google Scholar] [CrossRef]
- Oldham, K.B.; Spanier, J. The Fractional Calculus; Academic Press: New York, NY, USA; London, UK, 1974. [Google Scholar]
- Olmstead, W.E.; Handelsman, R.A. Diffusion in a semi-infinite region with nonlinear surface dissipation. SIAM Rev. 1976, 18, 275–291. [Google Scholar] [CrossRef]
- Marks, R.J., II; Hall, M.W. Differintegral interpolation from a bandlimited signal’s samples. IEEE Trans. Acoust. 1981, 29, 872–877. [Google Scholar] [CrossRef]
- Bagley, R.L.; Torvik, P.J. A theoretical basis for the application of fractional calculus to viscoelasticity. J. Rheol. 1983, 27, 201–210. [Google Scholar] [CrossRef]
- Bagley, R.L.; Torvik, P.J. On the appearance of the fractional derivative in the behavior of real materials. ASME J. Appl. Mech. 1984, 51, 294–298. [Google Scholar]
- Caputo, M. Linear models of dissipation whose Q is almost frequency independent—II. Geophys. R. Astr. Soc. 1967, 13, 529–539. [Google Scholar] [CrossRef]
- Caputo, M.; Mainardi, F. Linear models of dissipation in anelastic solids. Rivista Nuovo C. 1971, 1, 161–198. [Google Scholar] [CrossRef]
- Diethelm, K. The Analysis of Fractional Differential Equations; Springer: Heidelberg, Germany; Dordrecht, The Netherlands; London, UK; New York, NY, USA, 2010. [Google Scholar]
- Diethelm, K.; Ford, N.J.; Freed, A.D.; Luchko, Y. Algorithms for the fractional calculus: A selection of numerical methods. Comput. Methods Appl. Mech. Eng. 2005, 194, 743–773. [Google Scholar] [CrossRef]
- Li, C.P.; Zeng, F.H.; Liu, F.W. Spectral approximations to the fractional integral and derivative. Fract. Calc. Appl. Anal. 2012, 15, 383–406. [Google Scholar] [CrossRef]
- Miller, K.S.; Ross, B. An Introduction to the Fractional Calculus and Fractional Differential Equations; A Wiley-Interscience Publication; John Wiley & Sons Inc.: New York, NY, USA, 1993. [Google Scholar]
- Podlubny, I. Fractional Differential Equations; Academic Press: San Diego, CA, USA, 1999. [Google Scholar]
- Samko, S.; Kilbas, A.; Marichev, O. Fractional Integrals and Derivatives: Theory and Applications; Gordon and Breach Science Publishers: Yverdon, Switzerland, 1993. [Google Scholar]
- Cichoń, M.; Salem, H.A.H.; Shammakh, W. On the Equivalence between Differential and Integral Forms of Caputo-Type Fractional Problems on Hölder Spaces. Mathematics 2024, 12, 2631. [Google Scholar] [CrossRef]
- Brestovanska, E.; Medved, M. Asymptotic behavior of solutions to second-order differential equations with fractional derivative perturbations. Electron. J. Differ. Equ. 2014, 201, 1–10. [Google Scholar]
- Brunner, H.; Pedas, A.; Vainikko, G. Piecewise polynomial collocation methods for linear Volterra integro-differential equations with weakly singular kernels. SIAM J. Numer. Anal. 2001, 39, 957–982. [Google Scholar] [CrossRef]
- Diethelm, K.; Ford, N.J. Numerical Solution of the Bagley-Torvik equations. BIT 2002, 42, 490–507. [Google Scholar] [CrossRef]
- Kolk, M.; Pedas, A.; Tamme, E. Modified spline collocation for linear fractional differential equations. J. Comput. Appl. Math. 2015, 283, 28–40. [Google Scholar] [CrossRef]
- Kumar, K.; Pandey, R.K.; Sharma, S. Approximations of fractional integrals and Caputo derivatives with application in solving Abel’s integral equations. J. King Saud Univ. Sci. 2019, 31, 692–700. [Google Scholar] [CrossRef]
- Naber, M. Linear fractionally damped oscillator, Hindawi Publishing Corporation. Int. J. Differ. Equ. 2010, 2010, 197020. [Google Scholar]
- Odibat, Z. Approximations of fractional integrals and Caputo fractional derivatives. Appl. Math. Comput. 2006, 178, 527–533. [Google Scholar] [CrossRef]
- Saha Ray, S.; Bera, R.K. Analytical solution of the Bagley-Torvik equation by Adomian decomposition method. Appl. Math. Comput. 2005, 168, 398–410. [Google Scholar]
- Rehman, M.; Khan, R.A. A numerical method for solving boundary value problems for fractional differential equations. Appl. Math. Model. 2012, 36, 894–907. [Google Scholar] [CrossRef]
- Cai, M.; Li, C. Numerical Approaches to Fractional Integrals and Derivatives: A Review. Mathematics 2020, 8, 43. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, Z.; Liao, H. Finite difference methods for the time fractional diffusione quation on non-uniform meshes. J. Comput. Phys. 2014, 265, 195–210. [Google Scholar] [CrossRef]
- Timan, A.F. Theory of Approximation of Functions of Real Variable; Dover: New York, NY, USA, 1994. [Google Scholar]
- Rivlin, T.J. An Introduction to the Approximation of Functions; Dover Publications, Inc.: New York, NY, USA, 1969. [Google Scholar]
- Mastroianni, G.; Milovanović, G.V. Interpolation Processes: Basic Theory and Applications; Series: Springer Monographs in Mathematics; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Szabados, J. On the convergence of the derivatives of projection operators. Analysis 1987, 7, 349–357. [Google Scholar] [CrossRef]
- Golub, G.H.; Welsch, J.H. Calculation of Gauss quadrature rules. Math. Comput. 1969, 23, 221–230. [Google Scholar] [CrossRef]
- Webb, J.R.L. A fractional Gronwall inequality and the asymptotic behaviour of global solutions of Caputo fractional problems. Electron. J. Differ. Equ. 2021, 2021, 1–22. [Google Scholar] [CrossRef]
- Rafeiro, H.; Samko, S. Fractional integrals and derivatives: Mapping properties. Fract. Calc. Appl. Anal. 2016, 19, 580–607. [Google Scholar]
- Webb, J.R.L.; Lan, K. Fractional differential equations of Bagley-Torvik and Langevin type. Fract. Calc. Appl. Anal. 2024, 27, 1639–1669. [Google Scholar] [CrossRef]
- Fermo, L.; Occorsio, D. Weakly singular linear Volterra integral equations: A Nyström method in weighted spaces of continuous functions. J. Comput. Appl. Math. 2022, 406, 114001. [Google Scholar] [CrossRef]
- Doha, E.H.; Bhrawy, A.H.; Ezz-Eldien, S.S. Efficient Chebyshev spectral methods for solving multi-term fractional orders differential equations. Appl. Math. Model. 2011, 35, 5662–5672. [Google Scholar] [CrossRef]
- Luchko, Y.; Gorenflo, R. An operational method for solving fractional differential equations with the Caputo derivatives. Acta Math. Vietnam. 1999, 24, 207–233. [Google Scholar]
- Occorsio, D.; Russo, M.G. Numerical methods for Fredholm integral equations on the square. Appl. Math. Comput. 2011, 218, 2318–2333. [Google Scholar] [CrossRef]
- Tricomi, F.G. Integral Equations; Interscience Publishers, Inc.: London, UK; New York, NY, USA, 1957. [Google Scholar]
- Junghanns, P.; Luther, U. Cauchy singular integral equations in spaces of continuous functions and methods for their numerical solution. J. Comp. Appl. Math. 1997, 77, 201–237. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).