1. Introduction
Currently, the spatial correlation of data has a potential impact on financial risk management. Indeed, with the rapid development of internet technology, investors are increasingly interested in international financial assets, which requires taking into account the spatial dependence of international stock markets. Of course, unlike standard spatial data analysis, the spatial correlation in spatio-financial time series data is not necessarily measured by the geographic coordinates of the stock markets. This is the principal motivation for introducing a financial risk metric to cover the spatial component of risk management. Recall that spatial data cannot be treated as independent (see [
1,
2], among others). In practice, the challenging issue of spatial data analysis comes from the fact that points are in multi-dimensional space without linear order.
Statistical analysis of spatial data has become widely developed in the last decade. Concerning the nonparametric approach, the first results were obtained by the author of [
3], who obtained the asymptotic normality for the density kernel estimator. The regression function was studied in [
4,
5], in which the authors employed an estimator from the Nadaraya–Watson weights techniques. We refer to [
6] for the nonparametric kernel estimator for the variogram, considering Nadaraya–Watson weights. Ref. [
7] investigated the local linear estimation for the regression function (see also [
8] for the spatial auto-regression model) and proved the uniform convergence of the constructed estimator. Their convergence rate is optimal according to the
-norm. In [
9], we found an alternative local linear estimator of the spatial regression, which was obtained using the least absolute deviation. In this cited work, the authors have derived the asymptotic normality of their estimator. We return to [
10] for estimation using the nearest neighbor method. In functional statistics, the authors of [
11] have constructed an estimator using the spatiotemporal process. They proved the almost complete convergence (a.co.) of their estimator when the input variable is a continuous time process. The spatial quantile regression was estimated by [
12]. Their estimator was constructed by inverting the estimator of the cumulative distribution function. For a more bibliographic discussion of spatio-functional data analysis, we refer the reader to [
13,
14,
15,
16].
The second important component of this study is the shortfall function (ES). This is a risk management model and was created by [
17]. The principal motivation of the expected shortfall function as a risk metric is its coherency property. The estimation of the ES model is performed using multiple algorithms such as parametric, nonparametric, or semi-parametric approaches. The recent advances and references on the parametric approaches can be found in [
18,
19,
20]. While the nonparametric estimation was developed by [
21], we also cite [
22] for the functional Nadaraya–Watson estimator of the functional expected shortfall regression (FESR), in which the authors studied the asymptotic properties of FESR under the mixing assumption. The weak dependence case was treated by the authors of [
23], who almost established complete consistency of the kernel estimator of the FESR using the quasi-associated structure. We point out that in previous studies, the expected loss in FSER is defined through the Value at Risk (VaR)-level, the so-called FSER-VaR. In this work, we introduce an alternative risk threshold defined by the expectile regression, the so-called FSER-expectile. The expectile regression is an alternative risk metric based on tail expectation, unlike the VaR function, which is based on tail frequency. For this reason, the use of the expectile instead of the VaR function is more informative because it is more sensitive to outliers. This feature increases its ability to fit the financial risk located in the extreme values. In recent years, the expectile model has gained popularity in risk analysis (see, for instance, [
24,
25,
26,
27] for more motivations for these models). Although previous studies focus on the unconditional models, in this paper, we focus on the regression case. This version of the expectile has been studied in multivariate statistics by many authors. The first results date back to [
28]. In the last decade, multivariate expectile regression has been employed for many statistical issues, including additive models [
29], neural network models [
30], and machine learning models [
27]. However, financial risk analysis seems to be the principal applied area of the expectile regression model. In this context, ref. [
31] proposes an estimation of the value at risk (VaR) using an expectile model. Ref. [
32] presents different approaches used to preserve the coherence properties of multivariate expectiles. The same authors in [
33] established the asymptotic behavior of the multivariate expectiles for the Fréchet model. The treatment of the functional case was recently considered in [
13], in which the authors considered expectile regression (ER) with a functional covariate. They constructed an estimator of the functional ER using the nonparametric kernel approach. An alternative approach was studied by the authors of [
34] using the functional parametric ER. The authors employed a Hilbert structure using a reproducing kernel. More recent advances in functional expectile regression can be found in [
15] and the references therein. We may return to [
35,
36,
37] for more recent development in FTSA.
As discussed below, the main purpose of the present paper is to introduce a new risk metric based on the expectile shortfall regression. The developed risk metric has many advantages over the old shortfall model. These advantages are because the expectile is elicitable and coherent, unlike the VaR, and additionally, it is more sensitive to the magnitude of the tail, unlike the VaR function. Thus, the expectile shortfall with expectile (ESE) is more efficient than the standard shortfall. In this paper, we consider a more complex functional structure based on the spatial correlation. The spatial correlation is more general than the standard functional time series structure. It allows for controlling the spatial interaction of the data, which is more interactive in risk management. Furthermore, the principal outcomes of this work are the construction of a computational estimator and the establishment of its asymptotic properties using spatial dependence. The practical use of this risk metric is evaluated using simulated and real data. To the best of our knowledge, spatial expected shortfall regression has not yet been fully explored, and this is the first study in this direction.
This paper is organized as follows: We present our model as well as its spatial estimator in the next section.
Section 2 is dedicated to introducing the spatio-functional time series framework. The almost complete convergence of the constructed estimator is shown in
Section 3.
Section 4 is devoted to examining the easy implementation of the estimator using simulated data. In
Section 5, we apply our model to analyze the extreme values in environmental time series data. Some concluding remarks, as well as some future prospects, are discussed in
Section 6. Finally, the proofs of the auxiliary results are given in
Appendix A.
2. Model and Estimator
Consider
,
,
, a stationary spatial process defined on a probability space
and valued
.
is a semi-metric space with
d denoting the corresponding semi-metric. A point
will be referred to as a site and is defined by the components
. In this work, we focus on increasing domain asymptotic, where the underlining process,
, is observed over a rectangular domain
,
. Therefore, the index-vector
means
and
for all
such that
and for a given constant
C such that
. This kind of design is known as an asymptotically increasing domain, which allows the area of observations to become larger without large distances between the sites. Moreover, for
, we set
. The spectral structure of the functional random field
, is controlled through the following mixing condition:
where
(respectively,
) means the Borel
-field generated by
(respectively,
), Card
(respectively, Card
) is the cardinality of
(respectively,
), dist
is the Euclidean distance between
and
and
is a symmetric positive function nondecreasing in each variable, such that
Note that condition (2) can be replaced by
Both conditions (2) and (4) are used in Tran [
3] and Carbon et al. [
8], and are satisfied by many spatial models (see [
38] for some examples). It should be noted that if
then
is called a strongly mixing process.
Throughout this paper, for a fixed point , we denote by for a given neighborhood of . We assume that ’s have the same distribution as . We put , the conditional distribution of B given , and we assume the regular version of this conditional distribution exists for any . Additionally, we suppose that has a continuous density with respect to Lebesgue’s measure over .
Recall that the standard FESR regression is defined
where
is the conditional quantile of order
. Clearly, it is defined through the tail quantile, which is frequency-tail. Alternatively, it would be more interesting to evaluate this metric using the expectation tail. To do that, we introduce the FESR-expectile defined
where
is
where
is the indicator function of the set
. It should be noted that the replacement of
by
is important in practice, as it permits remedying the lack of risk insensitivity of
to the extreme values.
Now, to estimate
using the kernel estimator, we consider
, a measurable function,
a positive sequence of real numbers tending to zero as
tends to infinity, and we estimate the FESR-expectile by
where
is the kernel estimator of
, defined as the solution of
with
where
We refer to [
13] for more discussion on the construction of the estimator
. While the estimator
is constructed using similar ideas to those used for classical regression [
39], it is clear that the choice of the parameter
r is primordial in this smoothing approach. It is crucial for the estimation of
as well as for
. Motivated by the strong relationship between the expectile and the mean squared error (MSE), the MSE-based cross-validation criterion is an appropriate rule with which to address this issue. The latter is common in nonparametric functional data analysis:
The popularity of this approach comes from its easy implementation in real data analysis, using the fact that the conditional mean
is associated with
with
.
4. Simulated Data
In this section, we aim to evaluate the impact of the spatial dependency on the finite-sample performance of the spatio-functional expectile shortfall estimator. In order to highlight the main feature of our procedure, we compare its sensitivity to the volatility of the data in two situations (homoscedastic and heteroscedastic cases). For this purpose, we generate the data from the following regression relationship
where
is a Gaussian random field that has an exponential covariogram function,
Now, in order to fit the financial risk management context, we draw the spatio-functional input variables using a spatial ARCH process. This consideration allows us to simulate the spatial interaction in the co-movement of stock markets. Indeed, let
, the log-return of a financial asset at time
t on the stock market
, be generated by a spatial ARCH process
where
is a sequence of random variables that are independent in
t and identically distributed with zero mean, unit variance, and constant covariance matrix
C. The conditional variance
is defined by
where
is a known Spatial Weight Matrix (SWM). In fact, this kind of spatio-functional process is obtained using the routine code
sim.spARCH in the
R-package
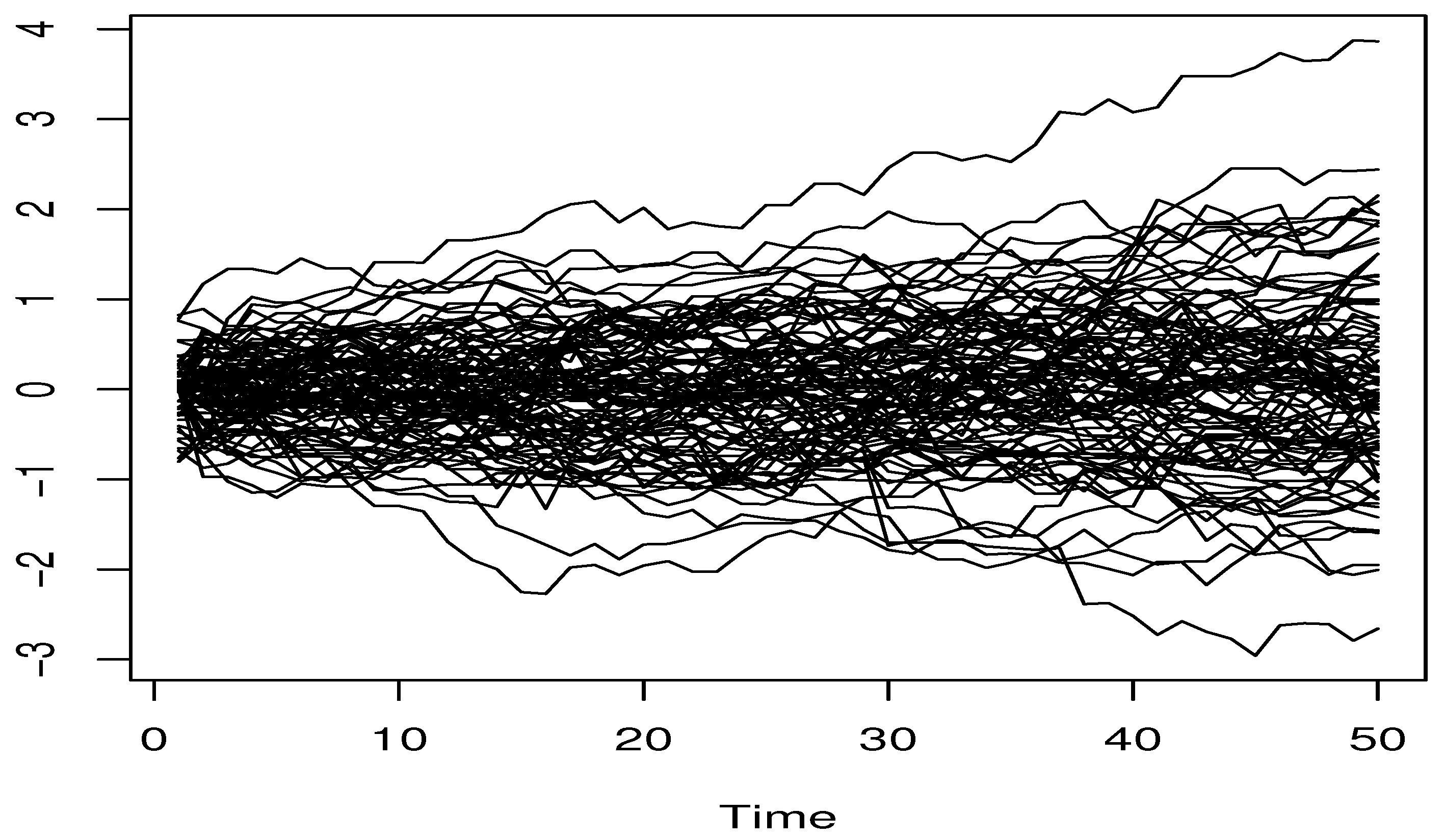
spGARCH. A sample of the functional co-variate is plotted in
Figure 1.
Recall that the principal feature of the FESR-expectile is its high sensitivity to the outliers. To measure the impact of this characteristic, we use the routine code
ODM in the R-Package
OutlierDM to detect the number of outliers in each model. It appears that the first model contains
versus
for the second one. On the other hand, the spatial-heterogeneity of the data constitutes a second principal issue of our study. The latter is controlled through the parameters
,
and the spatial weight matrix
. So, we calculate
for various values of the mentioned parameters.
Now, for this empirical study, we choose the smoothing parameter r via the local mean square cross-validation method as in (6). In the sense that the optimization of the mean square rule is performed over a discrete set defined by the -distance from the location point. The integer number k is obtained from . For the kernel , we use the -kernel. Finally, the metric is chosen according to the nature of the functional variable and its smoothing property. It appears that the principal component (pca) metric is more suitable for this type of discontinuous functional regressor.
The simulation results are given in
Table 1.
We observe that the behavior of the estimator is strongly affected by the different parameters of this study, such as the rate of the outliers and the spatial dependency degree. The high variability of the error between these different situations highlights the importance of the FESR- expectile as a risk-metric. In particular, the MSE varies between and with respect to the spatial level, while the horizontal variability, which describes the sensitivity to the outliers rate, ranges between and . These results incorporate the theoretical study, where the convergence rate is strongly affected by the local dependency of the spatio-functional data. In the sense that the computational part proves that the performance of the estimator is strongly impacted by the degree of spatial correlation of the data. Such a conclusion highlights the importance of the expectile-based-shortfall. The latter is very sensitive to the variability or deviation of the data, allowing more reliability in risk detection. This feature makes the expectile-based-shortfall more appropriate as a risk metric than the standard expected shortfall. We point out that the standard expected shortfall is based on the quantile, which is a robust model with low sensitivity to the variability in the risk analysis, because the risk is often located in the extremes. Such a characteristic is not beneficial in risk analysis. Finally, we can say that the estimator is very easy to implement and has good performance according to the nature of the treated data.
5. Real Data Application
After demonstrating the straightforward implementation of the estimator in the last section, we now focus on the applicability of our model to real spatial time series data. More specifically, we compare the performance of the new FESR-expectile
to the classical one
where
and
In the previous section, we evaluated the impact of spatial correlation using the ARCH model, which is well-solicited as an appropriate method for fitting the financial time series data. Alternatively, in this part, we employ the FESR-expectile model for another area, specifically in the environmental domain. This application emphasizes the importance and versatility of the FESR model. The environmental domain is a particularly relevant area for risk management, as air quality significantly affects the quality of life. Moreover, the extreme values models have usually been employed to model the risk in this area. Here, we aim to compare the efficiency of the FESR- expectile
with the FESR-VaR
in terms of risk prevention in air quality domain. For this goal, we analyze the air quality data used by [
42], which concerns the ozone concentration in Beijing. These data are available on the website
https://dataverse.harvard.edu/dataverse/beijing-air (accessed on 8 August 2024). Furthermore, there are many indices of air quality, such as Ozone (O
3), Particulate Matter (PM2.5 and PM10), Nitrogen Dioxide (NO
2), Carbon, and Sulfur Dioxide (SO
2). However, in this section, we concentrate on the ozone quantity (O
3) and sulfur dioxide (SO
2). Recall that the (SO
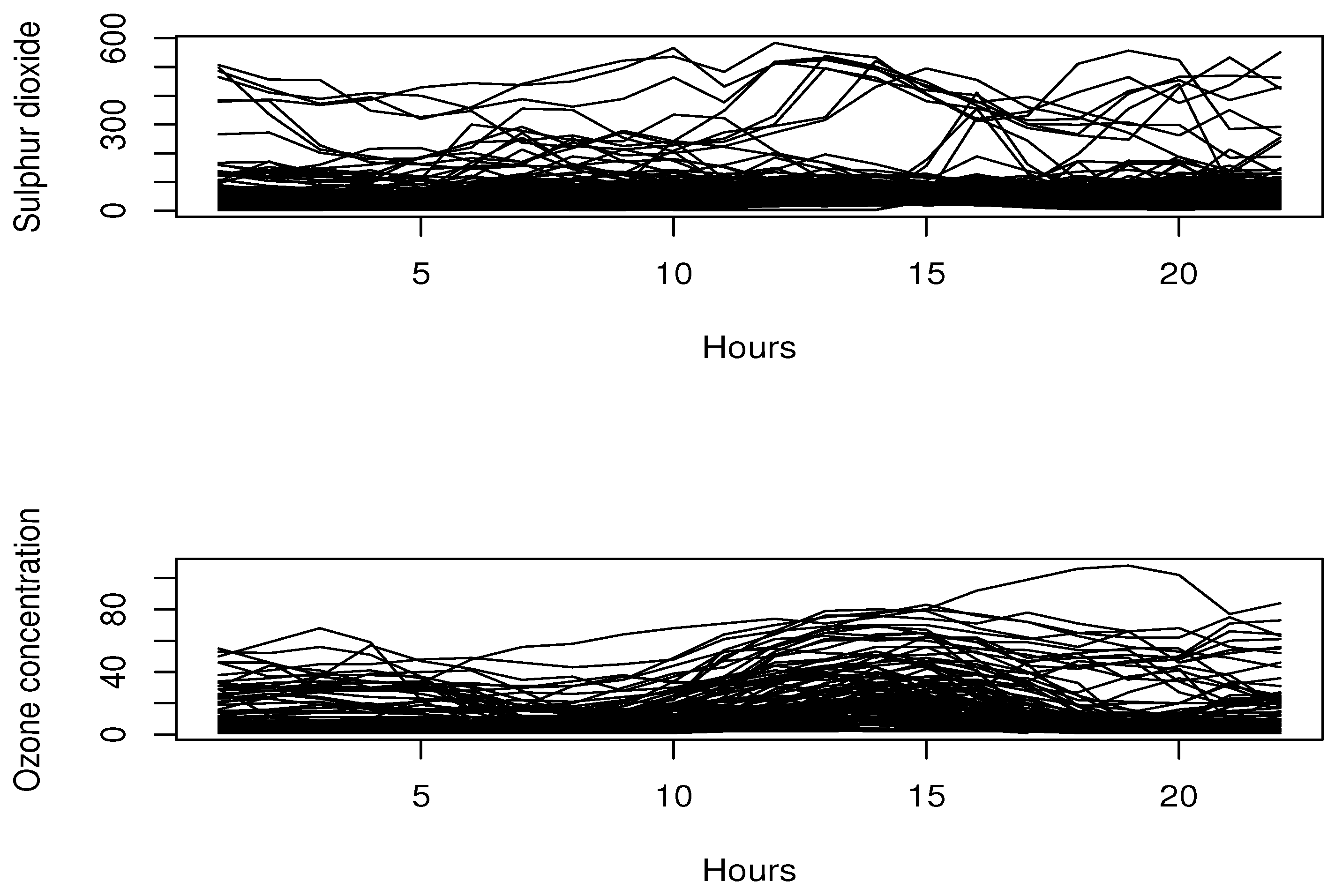
2) and the ultraviolet rays have a significant impact on the stratospheric ozone. Specifically, we collect the data from 120 monitoring stations in Beijing and we define
as the daily curve of SO
2 at the station
(on 30 December 2016). The response variable
represents the total ozone measured the day before at the same station
. The daily curves for the sulphur dioxide are shown in
Figure 2.
Now, in order to explore the spatial correlation of the data, we follow the same strategy considered by [
43]. This strategy permits us to estimate the spatial trend using the classical regression as follows. Indeed, we define
Therefore, before computing the estimators
and
, we start by estimating the statistics
. The latter is estimated by
where
and
are the kernel estimators of the functions
and
which are
where
are kernel functions. Such estimators are obtained using the routine code
npreg in the
R-package
np with
being the quadratic kernel. This step is fundamental for spatio-functional data analysis and is referred to as the detrending step. To highlight the potential impact of spatial correlation, we compare our expected shortfall to the standard one in both cases: with or without detrending. Specifically, the estimation with detrending is calculated by
, while in the other case (without detrending), we use the initial observation
to compute the estimators.
Furthermore, to calculate both estimators, we follow the same procedures used in the simulation section. In other words, we use the
quadratic kernel and the pca-metric, along with local cross-validation for the bandwidth parameter. The efficiency of both estimators is evaluated by computing
where
represents
or
. The values of
are evaluated as a function of
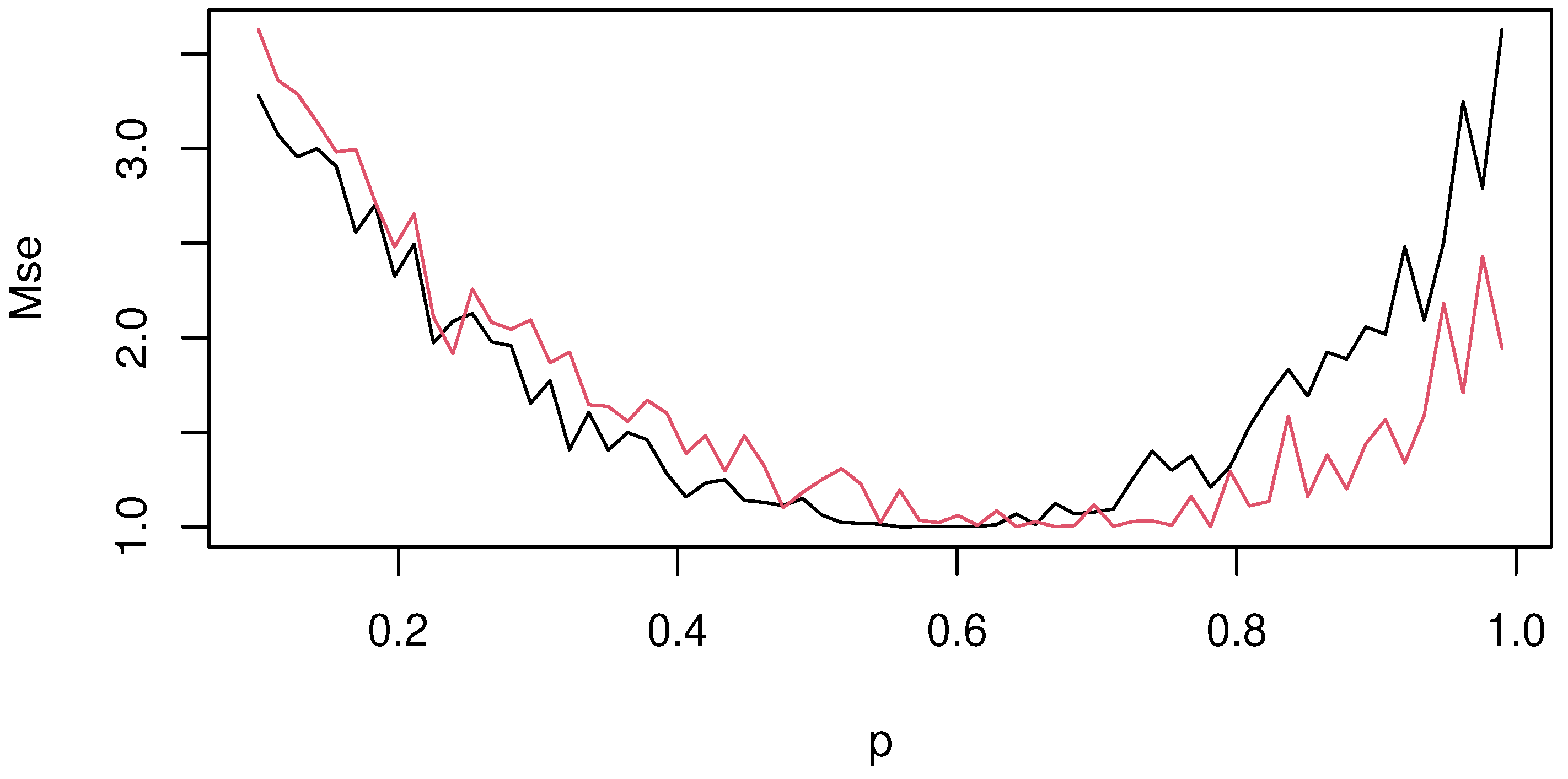
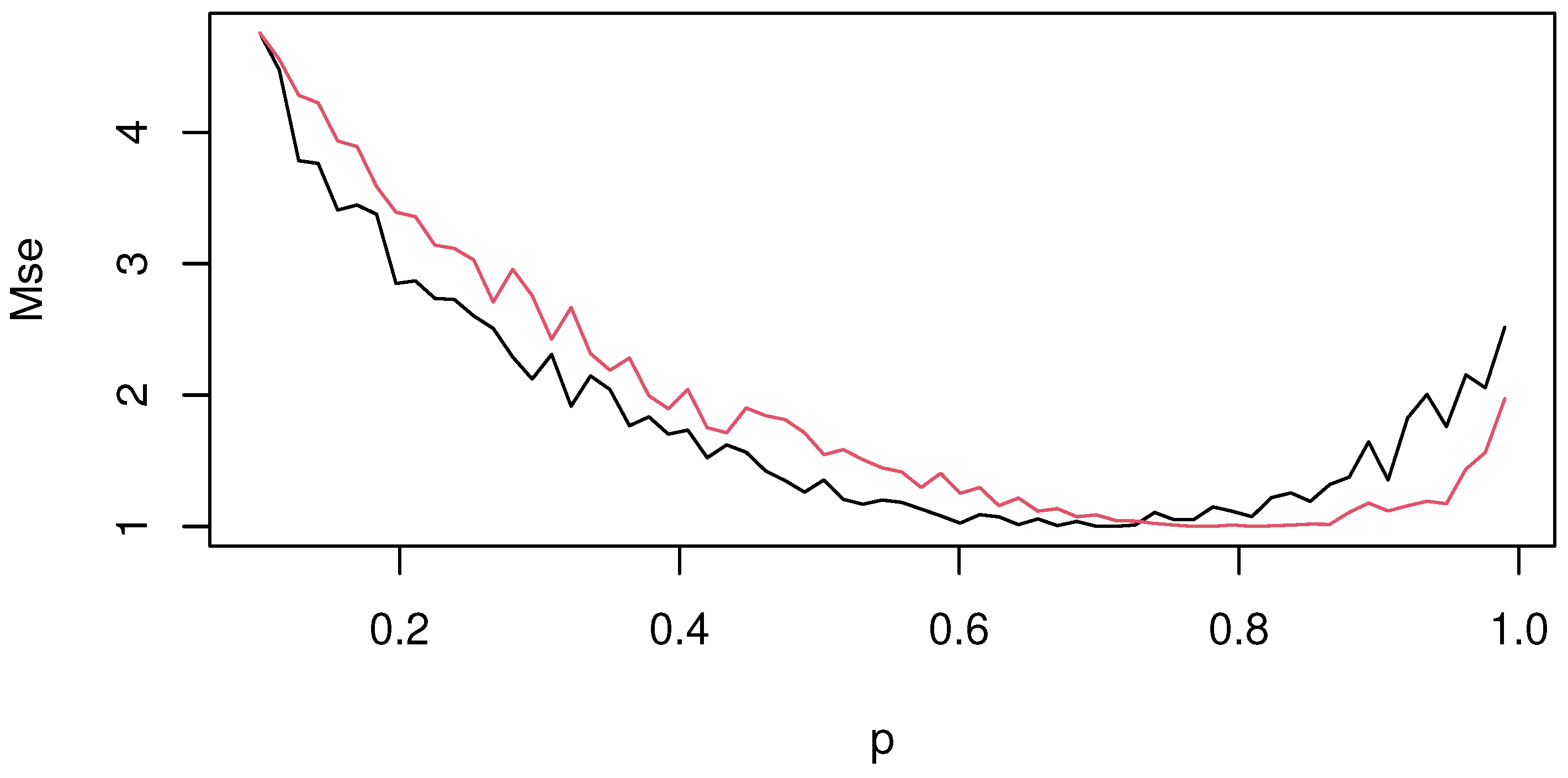
. In
Figure 3 and
Figure 4, we show the values of
of both estimators
(black line) and
(red line) in both cases (with detrending and without detrending step—see
Figure 3 and
Figure 4).
The graphs show the superiority of the FESR-expectile regression over the FESR-quantile model. This statement can be confirmed by the position of the black line, which is under the red line in most cases. These results show that the FESR-expectile detects the excessive level of ozone concentration more effectively, even in cases of high variability. This feature is not surprising. The slow variability of the VaR level is due to the robustness of the quantile regression, which reduces its sensitivity to extreme values. Additionally, this advantage seems to be more significant in the detrending step compared to the non-detrending case. This statement can be confirmed using the cover test developed by Bayer and Dimitriadis [
44]. This test allows us to examine the goodness-of-fit of our approach. The proposed test is an alternative approach to the procedure introduced by [
45] for forecasting. Since the risk prediction differs significantly from standard prediction, we have opted to examine the feasibility of our risk-metric using the Bayer–Dimitriadis test. Specifically, we compare both functional approaches
and
using the routine code esr-backtest from the R-package esrback. We have employed this code with
. Unsurprisingly, the obtained results confirm that both models are significantly good for this risk management issue. Typically, the cover-test gives a
p-value of
equal to 0.001, compared to 0.004 for the model
.




{kind=link}
{kind=link}
{kind=link}
{kind=link}