

Heuristic Ensemble Construction Methods of Automatically Designed Dispatching Rules for the Unrelated Machines Environment


Abstract
1. Introduction
2. Literature Review
3. Background
3.1. The Unrelated Machines Scheduling Problem
| Algorithm 1 SGS used by generated DRs |
|
3.2. Automated Design of DRs with GP
| Algorithm 2 Standard steady state GP algorithm |
|
3.3. Ensemble Learning for Automatically Designed DRs
4. Deterministic Ensemble Construction Methods
4.1. Fitness-Based Ensemble Construction
| Algorithm 3 Outline of the fitness-based heuristic |
Input: k—ensemble size, R—set of DRs, —fitness of rule r on instance i in dataset D Output: E—the constructed ensemble
|
4.2. Optimal Count Heuristic
| Algorithm 4 Outline of the optimal count heuristic |
Input: k—ensemble size, R—set of DRs, —fitness of rule r on instance i in dataset D Output: E—the constructed ensemble
|
4.3. Optimal Unique Count Heuristic
4.4. Remaining Optimal Count Heuristic
| Algorithm 5 Outline of the optimal unique count heuristic |
Input: k—ensemble size, R—set of DRs, —fitness of rule r on instance i in dataset D Output: E—the constructed ensemble
|
| Algorithm 6 Outline of the remaining optimal count heuristic |
Input: k—ensemble size, R—set of DRs, —fitness of rule r on instance i in dataset D Output: E—the constructed ensemble
|
4.5. Fitness Coverage Heuristic
| Algorithm 7 Outline of the fitness coverage heuristic |
Input: k—ensemble size, R—set of DRs, —fitness of rule r on instance i in dataset D Output: E—the constructed ensemble
|
4.6. Remaining Fitness Heuristic
4.7. Weighted Fitness Heuristic
| Algorithm 8 Outline of the remaining fitness heuristic |
Input: k—ensemble size, R—set of DRs, —fitness of rule r on instance i in dataset D Output: E—the constructed ensemble
|
| Algorithm 9 Outline of the weighted fitness heuristic |
Input: k—ensemble size, R—set of DRs, —fitness of rule r on instance i in dataset D Output: E—the constructed ensemble
|
4.8. Adjusted Fitness Heuristic
| Algorithm 10 Outline of the adjusted fitness heuristic |
Input: k—ensemble size, R—set of DRs, —fitness of rule r on instance i in dataset D Output: E—the constructed ensemble
|
4.9. Standard Deviation Heuristic
4.10. Optimal Match Based Heuristic
| Algorithm 11 Outline of the standard deviation heuristic |
Input: k—ensemble size, R—set of DRs, —fitness of rule r on instance i in dataset D Output: E—the constructed ensemble
|
| Algorithm 12 Outline of the optimal match-based heuristic |
Input: k—ensemble size, R—set of DRs, —fitness of rule r on instance i in dataset D Output: E—the constructed ensemble
|
5. Experimental Analysis
5.1. Experimental Setup
5.2. Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, L.; Wang, S. Exact and heuristic methods to solve the parallel machine scheduling problem with multi-processor tasks. Int. J. Prod. Econ. 2018, 201, 26–40. [Google Scholar] [CrossRef]
- Gedik, R.; Kalathia, D.; Egilmez, G.; Kirac, E. A constraint programming approach for solving unrelated parallel machine scheduling problem. Comput. Ind. Eng. 2018, 121, 139–149. [Google Scholar] [CrossRef]
- Yu, L.; Shih, H.M.; Pfund, M.; Carlyle, W.M.; Fowler, J.W. Scheduling of unrelated parallel machines: An application to PWB manufacturing. IIE Trans. 2002, 34, 921–931. [Google Scholar] [CrossRef]
- Pinedo, M.L. Scheduling; Springer: New York, NY, USA, 2012. [Google Scholar] [CrossRef]
- Hart, E.; Ross, P.; Corne, D. Evolutionary Scheduling: A Review. Genet. Program. Evolvable Mach. 2005, 6, 191–220. [Google Scholar] [CrossRef]
- Đurasević, M.; Jakobović, D. Heuristic and metaheuristic methods for the parallel unrelated machines scheduling problem: A survey. Artif. Intell. Rev. 2022, 56, 3181–3289. [Google Scholar] [CrossRef]
- Ðurasević, M.; Jakobović, D. A survey of dispatching rules for the dynamic unrelated machines environment. Expert Syst. Appl. 2018, 113, 555–569. [Google Scholar] [CrossRef]
- Burke, E.K.; Hyde, M.R.; Kendall, G.; Ochoa, G.; Ozcan, E.; Woodward, J.R. Exploring Hyper-heuristic Methodologies with Genetic Programming. Comput. Intell. 2009, 1, 177–201. [Google Scholar] [CrossRef]
- Burke, E.K.; Gendreau, M.; Hyde, M.; Kendall, G.; Ochoa, G.; Özcan, E.; Qu, R. Hyper-heuristics: A survey of the state of the art. J. Oper. Res. Soc. 2013, 64, 1695–1724. [Google Scholar] [CrossRef]
- Branke, J.; Nguyen, S.; Pickardt, C.W.; Zhang, M. Automated Design of Production Scheduling Heuristics: A Review. IEEE Trans. Evol. Comput. 2016, 20, 110–124. [Google Scholar] [CrossRef]
- Nguyen, S.; Mei, Y.; Zhang, M. Genetic programming for production scheduling: A survey with a unified framework. Complex Intell. Syst. 2017, 3, 41–66. [Google Scholar] [CrossRef]
- Duflo, G.; Kieffer, E.; Brust, M.R.; Danoy, G.; Bouvry, P. A GP Hyper-Heuristic Approach for Generating TSP Heuristics. In Proceedings of the 2019 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Rio de Janeiro, Brazil, 20–24 May 2019; pp. 521–529. [Google Scholar] [CrossRef]
- Gil-Gala, F.J.; Durasević, M.; Sierra, M.R.; Varela, R. Evolving ensembles of heuristics for the travelling salesman problem. Nat. Comput. 2023, 22, 671–684. [Google Scholar] [CrossRef]
- Jacobsen-Grocott, J.; Mei, Y.; Chen, G.; Zhang, M. Evolving heuristics for Dynamic Vehicle Routing with Time Windows using genetic programming. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), San Sebastián, Spain, 5–8 June 2017; pp. 1948–1955. [Google Scholar] [CrossRef]
- Wang, S.; Mei, Y.; Park, J.; Zhang, M. Evolving Ensembles of Routing Policies using Genetic Programming for Uncertain Capacitated Arc Routing Problem. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 1628–1635. [Google Scholar] [CrossRef]
- Đurasević, M.; Đumić, M. Automated design of heuristics for the container relocation problem using genetic programming. Appl. Soft Comput. 2022, 130, 109696. [Google Scholar] [CrossRef]
- Burke, E.K.; Hyde, M.R.; Kendall, G. Evolving Bin Packing Heuristics with Genetic Programming. In Parallel Problem Solving from Nature—PPSN IX; Springer: Berlin/Heidelberg, Germany, 2006; pp. 860–869. [Google Scholar] [CrossRef]
- Burke, E.K.; Hyde, M.R.; Kendall, G.; Woodward, J. Automating the Packing Heuristic Design Process with Genetic Programming. Evol. Comput. 2012, 20, 63–89. [Google Scholar] [CrossRef] [PubMed]
- Park, J.; Nguyen, S.; Zhang, M.; Johnston, M. Evolving Ensembles of Dispatching Rules Using Genetic Programming for Job Shop Scheduling. In Proceedings of the Genetic Programming, Copenhagen, Denmark, 8–10 April 2015; Machado, P., Heywood, M.I., McDermott, J., Castelli, M., García-Sánchez, P., Burelli, P., Risi, S., Sim, K., Eds.; Springer: Cham, Swizterland, 2015; pp. 92–104. [Google Scholar]
- Đurasević, M.; Jakobović, D. Comparison of ensemble learning methods for creating ensembles of dispatching rules for the unrelated machines environment. Genet. Program. Evolvable Mach. 2017, 19, 53–92. [Google Scholar] [CrossRef]
- Miyashita, K. Job-Shop Scheduling with Genetic Programming. In Proceedings of the 2nd Annual Conference on Genetic and Evolutionary Computation, GECCO’00, San Francisco, CA, USA, 10–12 July 2000; pp. 505–512. [Google Scholar]
- Dimopoulos, C.; Zalzala, A. Investigating the use of genetic programming for a classic one-machine scheduling problem. Adv. Eng. Softw. 2001, 32, 489–498. [Google Scholar] [CrossRef]
- Zhang, F.; Mei, Y.; Nguyen, S.; Zhang, M. Survey on Genetic Programming and Machine Learning Techniques for Heuristic Design in Job Shop Scheduling. IEEE Trans. Evol. Comput. 2023, 1. [Google Scholar] [CrossRef]
- Nguyen, S.; Zhang, M.; Johnston, M.; Tan, K.C. A Computational Study of Representations in Genetic Programming to Evolve Dispatching Rules for the Job Shop Scheduling Problem. IEEE Trans. Evol. Comput. 2013, 17, 621–639. [Google Scholar] [CrossRef]
- Branke, J.; Hildebrandt, T.; Scholz-Reiter, B. Hyper-heuristic Evolution of Dispatching Rules: A Comparison of Rule Representations. Evol. Comput. 2015, 23, 249–277. [Google Scholar] [CrossRef]
- Nguyen, S.; Zhang, M.; Johnston, M.; Tan, K.C. Dynamic Multi-objective Job Shop Scheduling: A Genetic Programming Approach. In Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2013; pp. 251–282. [Google Scholar] [CrossRef]
- Nguyen, S.; Zhang, M.; Tan, K.C. Enhancing genetic programming based hyper-heuristics for dynamic multi-objective job shop scheduling problems. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), Sendai, Japan, 25–28 May 2015; pp. 2781–2788. [Google Scholar] [CrossRef]
- Masood, A.; Mei, Y.; Chen, G.; Zhang, M. Many-objective genetic programming for job-shop scheduling. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 209–216. [Google Scholar] [CrossRef]
- Đurasević, M.; Jakobović, D. Evolving dispatching rules for optimising many-objective criteria in the unrelated machines environment. Genet. Program. Evolvable Mach. 2017, 19, 9–51. [Google Scholar] [CrossRef]
- Zhang, F.; Mei, Y.; Nguyen, S.; Tan, K.C.; Zhang, M. Multitask Genetic Programming-Based Generative Hyperheuristics: A Case Study in Dynamic Scheduling. IEEE Trans. Cybern. 2021, 52, 10515–10528. [Google Scholar] [CrossRef]
- Zhang, F.; Mei, Y.; Nguyen, S.; Zhang, M.; Tan, K.C. Surrogate-Assisted Evolutionary Multitask Genetic Programming for Dynamic Flexible Job Shop Scheduling. IEEE Trans. Evol. Comput. 2021, 25, 651–665. [Google Scholar] [CrossRef]
- Nguyen, S.; Zhang, M.; Tan, K.C. Surrogate-Assisted Genetic Programming with Simplified Models for Automated Design of Dispatching Rules. IEEE Trans. Cybern. 2017, 47, 2951–2965. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Mei, Y.; Nguyen, S.; Zhang, M. Collaborative Multifidelity-Based Surrogate Models for Genetic Programming in Dynamic Flexible Job Shop Scheduling. IEEE Trans. Cybern. 2021, 52, 8142–8156. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Mei, Y.; Nguyen, S.; Zhang, M. Evolving Scheduling Heuristics via Genetic Programming with Feature Selection in Dynamic Flexible Job-Shop Scheduling. IEEE Trans. Cybern. 2021, 51, 1797–1811. [Google Scholar] [CrossRef]
- Gil-Gala, F.J.; Sierra, M.R.; Mencía, C.; Varela, R. Genetic programming with local search to evolve priority rules for scheduling jobs on a machine with time-varying capacity. Swarm Evol. Comput. 2021, 66, 100944. [Google Scholar] [CrossRef]
- Zhang, F.; Mei, Y.; Nguyen, S.; Zhang, M. Guided Subtree Selection for Genetic Operators in Genetic Programming for Dynamic Flexible Job Shop Scheduling. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 262–278. [Google Scholar] [CrossRef]
- Zhang, F.; Mei, Y.; Zhang, M. A Two-Stage Genetic Programming Hyper-Heuristic Approach with Feature Selection for Dynamic Flexible Job Shop Scheduling. In Proceedings of the Genetic and Evolutionary Computation Conference, GECCO ’19, Prague, Czech Republic, 13–17 July 2019; ACM: New York, NY, USA, 2019; pp. 347–355. [Google Scholar] [CrossRef]
- Park, J.; Mei, Y.; Nguyen, S.; Chen, G.; Johnston, M.; Zhang, M. Genetic Programming Based Hyper-heuristics for Dynamic Job Shop Scheduling: Cooperative Coevolutionary Approaches. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 115–132. [Google Scholar] [CrossRef]
- Hart, E.; Sim, K. On the Life-Long Learning Capabilities of a NELLI*: A Hyper-Heuristic Optimisation System. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 282–291. [Google Scholar] [CrossRef]
- Hart, E.; Sim, K. A Hyper-Heuristic Ensemble Method for Static Job-Shop Scheduling. Evol. Comput. 2016, 24, 609–635. [Google Scholar] [CrossRef]
- Park, J.; Mei, Y.; Nguyen, S.; Chen, G.; Zhang, M. An Investigation of Ensemble Combination Schemes for Genetic Programming based Hyper-heuristic Approaches to Dynamic Job Shop Scheduling. Appl. Soft Comput. 2017, 63. [Google Scholar] [CrossRef]
- Đurasević, M.; Jakobović, D. Creating dispatching rules by simple ensemble combination. J. Heuristics 2019, 25, 959–1013. [Google Scholar] [CrossRef]
- Đumić, M.; Jakobović, D. Ensembles of priority rules for resource constrained project scheduling problem. Appl. Soft Comput. 2021, 110, 107606. [Google Scholar] [CrossRef]
- Gil-Gala, F.J.; Varela, R. Genetic Algorithm to Evolve Ensembles of Rules for On-Line Scheduling on Single Machine with Variable Capacity. In From Bioinspired Systems and Biomedical Applications to Machine Learning; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 223–233. [Google Scholar] [CrossRef]
- Gil-Gala, F.J.; Sierra, M.R.; Mencía, C.; Varela, R. Combining hyper-heuristics to evolve ensembles of priority rules for on-line scheduling. Nat. Comput. 2020, 21, 553–563. [Google Scholar] [CrossRef]
- Gil-Gala, F.J.; Mencía, C.; Sierra, M.R.; Varela, R. Learning ensembles of priority rules for online scheduling by hybrid evolutionary algorithms. Integr. Comput.-Aided Eng. 2020, 28, 65–80. [Google Scholar] [CrossRef]
- Gil-Gala, F.J.; Đurasević, M.; Varela, R.; Jakobović, D. Ensembles of priority rules to solve one machine scheduling problem in real-time. Inf. Sci. 2023, 634, 340–358. [Google Scholar] [CrossRef]
- Đurasević, M.; Gil-Gala, F.J.; Planinić, L.; Jakobović, D. Collaboration methods for ensembles of dispatching rules for the dynamic unrelated machines environment. Eng. Appl. Artif. Intell. 2023, 122, 106096. [Google Scholar] [CrossRef]
- Đurasević, M.; Gil-Gala, F.J.; Jakobović, D. Constructing ensembles of dispatching rules for multi-objective tasks in the unrelated machines environment. Integr. Comput.-Aided Eng. 2023, 30, 275–292. [Google Scholar] [CrossRef]
- Đurasević, M.; Gil-Gala, F.J.; Jakobović, D.; Coello, C.A.C. Combining single objective dispatching rules into multi-objective ensembles for the dynamic unrelated machines environment. Swarm Evol. Comput. 2023, 80, 101318. [Google Scholar] [CrossRef]
- Wang, S.; Mei, Y.; Zhang, M. Novel ensemble genetic programming hyper-heuristics for uncertain capacitated arc routing problem. In Proceedings of the Genetic and Evolutionary Computation Conference, GECCO ’19, Prague, Czech Republic, 13–17 July 2019; ACM: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Leung, J.Y.T. (Ed.) Handbook of Scheduling; Chapman & Hall/CRC Computer and Information Science Series; Chapman & Hall/CRC: Philadelphia, PA, USA, 2004. [Google Scholar]
- Graham, R.; Lawler, E.; Lenstra, J.; Kan, A. Optimization and Approximation in Deterministic Sequencing and Scheduling: A Survey. In Annals of Discrete Mathematics; Hammer, P., Johnson, E., Korte, B., Eds.; Discrete Optimization II; Elsevier: Amsterdam, The Netherlands, 1979; Volume 5, pp. 287–326. [Google Scholar] [CrossRef]
- Koza, J.R. Genetic Programming; Complex Adaptive Systems, Bradford Books: Cambridge, MA, USA, 1992. [Google Scholar]
- Poli, R.; Langdon, W.B.; McPhee, N.F. A Field Guide to Genetic Programming; Lulu Enterprises, Ltd.: Egham, UK, 2008. [Google Scholar]
- Koza, J.R. Human-competitive results produced by genetic programming. Genet. Program. Evolvable Mach. 2010, 11, 251–284. [Google Scholar] [CrossRef]
- Mitchell, M. An Introduction to Genetic Algorithms; Complex Adaptive Systems, Bradford Books: Cambridge, MA, USA, 1998. [Google Scholar]
- Đurasević, M.; Jakobović, D.; Knežević, K. Adaptive scheduling on unrelated machines with genetic programming. Appl. Soft Comput. 2016, 48, 419–430. [Google Scholar] [CrossRef]
- Lee, Y.H.; Pinedo, M. Scheduling jobs on parallel machines with sequence-dependent setup times. Eur. J. Oper. Res. 1997, 100, 464–474. [Google Scholar] [CrossRef]
- Iba, H. Bagging, Boosting, and Bloating in Genetic Programming. In Proceedings of the 1st Annual Conference on Genetic and Evolutionary Computation—Volume 2, GECCO’99, Orlando, FL, USA, 13–17 July 1999; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 1999; pp. 1053–1060. [Google Scholar]
- Paris, G.; Robilliard, D.; Fonlupt, C. Applying Boosting Techniques to Genetic Programming. In Proceedings of the Artificial Evolution: 5th International Conference, Evolution Artificielle, EA 2001, Le Creusot, France, 29–31 October 2001; Volume 2310, pp. 267–278. [Google Scholar] [CrossRef]
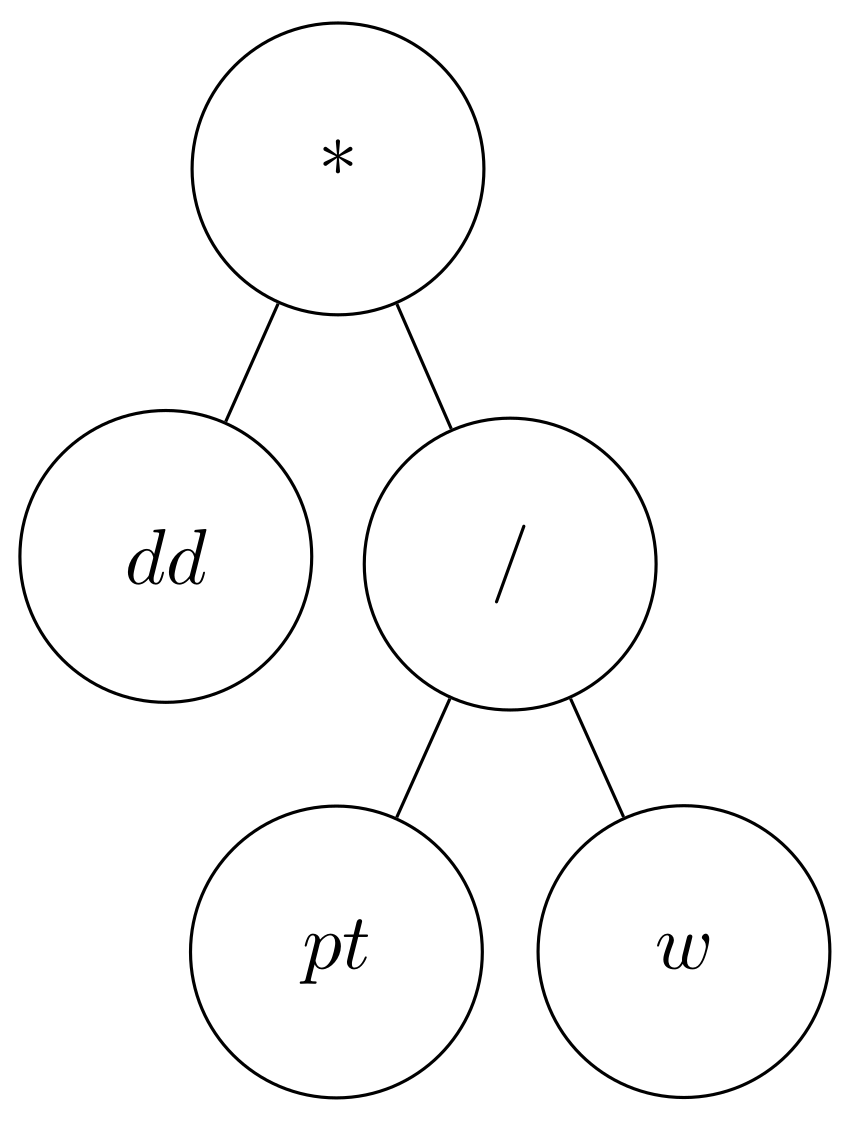


{kind=link}
{kind=link}
| Terminal | Description |
|---|---|
| processing time of job j on machine i | |
| minimal processing time (MPT) of job j | |
| average processing time of job j across all machines | |
| time until machine with the MPT for job j becomes available | |
| time until machine i becomes available | |
| time which job j spent in the system | |
| time until which job j has to finish with its execution | |
| w | weight of job j () |
| slack of job j, |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|
| ATC | 16.63 | ||||||||
| DR | 16.09 | ||||||||
| BagGP | 16.28 | 16.11 | 16.05 | 16.04 | 16.05 | 16.00 | 16.00 | 16.02 | 16.07 |
| BoostGP | 15.82 | 15.76 | 15.87 | 15.89 | 15.89 | 15.85 | 15.86 | 15.86 | 15.89 |
| MGA | 15.66 | 15.46 | 15.49 | 15.48 | 15.47 | 15.46 | 15.45 | 15.45 | 15.77 |
| SEC | 15.68 | 15.68 | 15.65 | 15.52 | 15.43 | 15.29 | 15.38 | 15.32 | 15.34 |
| FBH (3) | 16.09 | 15.53 | 15.05 | 15.07 | 15.13 | 14.95 | 14.92 | 14.91 | 14.99 |
| OCH (4) | 15.55 | 16.07 | 15.99 | 16.01 | 15.95 | 15.86 | 15.91 | 15.93 | 16.21 |
| OUCH (5) | 15.70 | 15.65 | 15.38 | 16.48 | 16.82 | 16.17 | 16.86 | 16.89 | 15.79 |
| ROCH (6) | 15.27 | 15.15 | 15.12 | 15.10 | 15.28 | 15.31 | 14.90 | 15.38 | 15.90 |
| FCH (7) | 15.55 | 15.16 | 15.27 | 15.11 | 15.40 | 15.48 | 15.45 | 15.60 | 15.59 |
| RFH (8) | 15.55 | 15.52 | 15.91 | 15.31 | 15.29 | 15.32 | 15.29 | 15.45 | 15.88 |
| WFH (9) | 16.09 | 14.94 | 15.12 | 14.94 | 15.01 | 15.01 | 15.02 | 15.02 | 15.02 |
| AFH (10) | 15.27 | 15.32 | 15.48 | 15.45 | 15.31 | 15.44 | 15.43 | 15.47 | 15.38 |
| SDH (11) | 15.46 | 15.73 | 15.48 | 15.84 | 15.57 | 15.66 | 15.66 | 15.66 | 15.67 |
| OMBH (12) | 15.95 | 15.38 | 16.00 | 15.60 | 15.67 | 15.68 | 15.68 | 15.68 | 15.70 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|
| ATC | 16.63 | ||||||||
| DRs | 16.09 | ||||||||
| BagGP | 16.38 | 15.81 | 15.82 | 15.70 | 15.68 | 15.58 | 15.65 | 15.58 | 15.57 |
| BoostGP | 16.02 | 15.72 | 15.67 | 15.50 | 15.64 | 15.56 | 15.68 | 15.53 | 15.55 |
| MGA | 15.59 | 15.54 | 15.79 | 15.51 | 15.53 | 15.51 | 15.59 | 15.50 | 15.50 |
| SEC | 15.76 | 15.60 | 15.67 | 15.67 | 15.64 | 15.55 | 15.57 | 15.52 | 15.55 |
| FBH (3) | 15.73 | 15.80 | 15.80 | 15.87 | 15.80 | 15.66 | 15.51 | 15.74 | 15.52 |
| OCH (4) | 15.43 | 15.71 | 15.52 | 15.74 | 15.71 | 15.60 | 15.65 | 15.46 | 15.50 |
| OUCH (5) | 15.73 | 15.61 | 15.64 | 15.20 | 15.21 | 15.11 | 15.27 | 15.67 | 15.69 |
| ROCH (6) | 16.17 | 15.46 | 15.49 | 15.29 | 15.34 | 15.32 | 15.50 | 15.49 | 15.58 |
| FCH (7) | 15.62 | 15.73 | 15.56 | 15.24 | 15.08 | 15.89 | 15.42 | 15.77 | 15.45 |
| RFH (8) | 15.62 | 15.53 | 15.24 | 15.67 | 15.71 | 15.59 | 15.56 | 15.31 | 15.58 |
| WFH (9) | 15.73 | 15.52 | 15.29 | 15.33 | 15.57 | 16.03 | 15.26 | 15.94 | 16.23 |
| AFH (10) | 16.17 | 15.64 | 15.54 | 15.39 | 15.53 | 15.59 | 15.40 | 15.75 | 15.61 |
| SDH (11) | 16.65 | 16.14 | 16.04 | 15.75 | 15.81 | 15.96 | 15.98 | 15.87 | 15.90 |
| OMBH (12) | 16.01 | 15.88 | 16.10 | 15.77 | 16.44 | 15.62 | 16.02 | 15.52 | 15.95 |
| Sum | Vote | Both | ||||||
|---|---|---|---|---|---|---|---|---|
| # | Avg. Rank | Tot. Rank | # | Avg. Rank | Tot. Rank | Avg. Rank | Tot. Rank | |
| FBH (3) | 7 | 2.89 | 2 | 1 | 6.67 | 8 | 4.78 | 6 |
| OCH (4) | 1 | 8.67 | 10 | 4 | 4.56 | 5 | 6.61 | 8 |
| OUCH (5) | 1 | 8.56 | 9 | 5 | 3.67 | 2 | 6.11 | 7 |
| ROCH (6) | 6 | 3 | 3 | 7 | 3.55 | 1 | 3.28 | 1 |
| FCH (7) | 5 | 4.78 | 5 | 5 | 4.33 | 4 | 4.56 | 4 |
| RFH (8) | 4 | 5.22 | 6 | 4 | 3.67 | 2 | 4.44 | 3 |
| WFH (9) | 8 | 2.56 | 1 | 4 | 5.33 | 7 | 3.94 | 2 |
| AFH (10) | 5 | 4.44 | 4 | 4 | 5.11 | 6 | 4.78 | 5 |
| SDH ¨(11) | 2 | 6.56 | 7 | 0 | 9 | 10 | 7.78 | 9 |
| OMBH (12) | 1 | 7.56 | 8 | 0 | 8.22 | 9 | 7.89 | 10 |
| DR Index | Fitness | # Optimal | # Unique Optimal |
|---|---|---|---|
| 1 | 14.494 | 37 | 1 |
| 3 | 14.3753 | 36 | 1 |
| 13 | 14.6812 | 37 | 0 |
| 20 | 14.297 | 37 | 3 |
| 24 | 14.3575 | 35 | 1 |
| 27 | 14.5239 | 38 | 0 |
| 29 | 14.7101 | 37 | 1 |
| 32 | 14.6285 | 37 | 1 |
| 43 | 14.43 7 | 35 | 1 |
| Average | 14.5969 | 35.14 | 0.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Đurasević, M.; Jakobović, D. Heuristic Ensemble Construction Methods of Automatically Designed Dispatching Rules for the Unrelated Machines Environment. Axioms 2024, 13, 37. https://doi.org/10.3390/axioms13010037
Đurasević M, Jakobović D. Heuristic Ensemble Construction Methods of Automatically Designed Dispatching Rules for the Unrelated Machines Environment. Axioms. 2024; 13(1):37. https://doi.org/10.3390/axioms13010037
Chicago/Turabian StyleĐurasević, Marko, and Domagoj Jakobović. 2024. "Heuristic Ensemble Construction Methods of Automatically Designed Dispatching Rules for the Unrelated Machines Environment" Axioms 13, no. 1: 37. https://doi.org/10.3390/axioms13010037
APA StyleĐurasević, M., & Jakobović, D. (2024). Heuristic Ensemble Construction Methods of Automatically Designed Dispatching Rules for the Unrelated Machines Environment. Axioms, 13(1), 37. https://doi.org/10.3390/axioms13010037