Abstract
This paper discusses the multi-player non-cooperative game of nonlinear stochastic time-varying systems described by Itô-type differential equations in a finite time interval. Multi-player non-cooperative game problems are represented by multi-objective Pareto (MOP) control problems to describe the fact that each player has their own goals. By applying Hamilton–Jacobi inequalities (HJIs), the criterion of upper bounds of the MOP boundary is obtained for nonlinear stochastic systems, and the corresponding strategies are designed for such games, so the MOP problem is transformed into a HJI-constrained MOP problem. In order to overcome the difficulty of solving HJIs, a global linearization method is proposed to approximate the nonlinear systems. By the proposed global linearization method, multi-player non-cooperative game problems are transformed into Riccati equation-constrained MOP problems, and the approximate solutions of HJI-constrained MOP problems are obtained. Finally, a practical example is given to illustrate the effectiveness of the proposed method.
Keywords:
multi-player non-cooperative game; stochastic system; time-varying system; Hamilton–Jacobi equation MSC:
93E20
1. Introduction
Non-cooperative games are widely applied in various fields of natural and social sciences, such as economics, finance, and engineering technology [1,2,3]. Compared to cooperative games, the behavior and decision making of participants in non-cooperative games are independent of each other. Under proper conditions, there exists a Nash equilibrium point in the non-cooperative games [4]. To resolve the problem of multiple Nash equilibria for non-cooperative games, the concept of Pareto undominated Nash equilibrium is raised and is studied by many researchers. For example, by combining the subset of non-cooperative players with that of aggregate ones, Goldman and Shier proposed weaker conditions to solve the equilibrium-point solutions of the game and given the approximate versions to obtain the equilibrium points [5]. Using a modified fixed point theorem, Zhao, Hong and Li achieved an existence theorem of extended Nash equilibria of the nonmonetized noncooperative game [6]. Ye and Hu employed an extremum-seeking method to non-cooperative games and offered a non-model-based seeking scheme to achieve the time-varying Nash equilibrium [7]. Using the Hamilton–Jacobi–Bellman equations, Aduba and Won proposed the necessary and sufficient conditions for the Nash equilibrium solution of nonzero-sum dynamic statistical Nash games with N-player m-th cost cumulant optimization [8]. Bressan and Nguyen studied a kind of non-cooperative game in the case of infinite time horizon with exponentially discounted quadratic costs [9]. Dianetti and Ferrari established the existence of Nash equilibria for a class of N-player stochastic games with a monotone-follower type, in which the Markovian setting is not necessary and the approximation of the equilibrium values is also provided [10]. Furthermore, theories of non-cooperative or cooperative games such as vector-valued games [11], a Pareto undominated mixed-strategy [2], Nash–Stackelberg–Nash games [12] and multio-bjective games [13] have also been developed, and many excellent results have been obtained.
In practice, many economic, financial, biological or engineering systems can be described by ordinary differential equations [14,15,16,17,18] and stochastic differential equations [19,20,21,22,23,24,25] in continuous time and by difference equations [26,27,28] in a discrete-time case. For example, in order to demonstrate the interplay among interest rate, investment demand and price, the following ordinary different equation are proposed:
where is the interest rate of the financial market, is the investment demand of market participants, and is the reasonable market price. By solving the following equation,
it’s easy to find that one of the equilibria of System (1) is
In the real word, the equilibrium points of an economic systems or financial systems are changing at different times, which implies that parameters and c in System (1) change over time. Moreover, taking into account inherent stochastic fluctuations and external disturbances, the following stochastic dynamic system is constructed in reference [23]:
where denotes strategies (), is the exogenous disturbance, is the one-dimensional standard Brownian motion. In this model, the influence of government control strategy, investment strategy of bank consortium and investment strategy of the public on the stability of the financial system are considered to obtain the non-cooperative investment strategies for financial markets. According to the global linearization technique [20,29], the multi-objective problem (MOP) with the Hamilton–Jacobi inequality (HJI) constraint is transformed into MOP with an equivalent Linear matrix inequality (LMI) constraint to solve the non-cooperative game problems discussed in [23] in which the financial systems are described by time-invariant stochastic differential equations. These results are based on the help of Riccati equations or Riccati inequalities for linear systems [30,31].
Against the above -mentioned background, the time-varying systems are used to describe such systems as follows:
So conditions such as Hamilton–Jacobi equations or inequalities and Riccati equations for corresponding non-cooperative games of time-varying systems are also different from those of the time-invariant ones, which needs further study. This paper follows the line of [23] to discuss the non-cooperative games for nonlinear stochastic time-varying systems, and, in comparison to [23], this paper has the following novelty and innovation: (1) The systems discussed in this paper have more general forms which consider the time-varying case. (2) Because the Riccati equations, the Hamilton-Jacobi equations and matrices used in this paper are in the time-varying form, the global linear methods are more complex than the methods given by [23]. This paper is organized as follows: In Section 2, some theories of stochastic differential equations are reviewed, and the non-cooperative games for stochastic time-varying systems are described. In Section 3, the multi-party non-cooperative investment strategies for nonlinear time-varying stochastic financial systems are designed with the help of solving Hamilton–Jacobi inequalities for nonlinear systems and Riccati equations for linear systems. In Section 4, a global linearization method for a nonlinear stochastic financial system with time-varying parameters is proposed, which transforms an HJI-constrained MOP to an LMI-constrained MOP. In Section 5, a practical financial example is illustrated to verify the effectiveness of the proposed method.
Notations: : finite time interval , ; : dimension of vector v; or : transport of matrix A or vector x; : Euclidean norm of vector x; : expectation of random variable X; : symmetric real matrix A is a (semi-) positive definite matrix.
2. Preliminary
Suppose is a complete probability space. An economic or financial system with m-person decision makers can be described by the following time-varying stochastic differential equations:
where , , , , denotes the state vector of economic or financial system, denotes the ith agent’s strategies or policies, is the external disturbance, is a one-dimensional normal Brownian motion.
The goal of the ith agent is to maximize their profit returns or to minimize their return risk. The ith agent’s game strategy is decided under the background of the strategies of other agents with which are unknown to the ith agent. Since external disturbance also plays an important role and is not available to every participant including the ith agent, its impact on the financial system must be considered from the worst case. Each agent tends to minimize the worst-case effects of external distractions.
In a non-cooperative financial system, for the ith agent, it is difficult to obtain all other strategies and external distractions. Thus, each game strategy of an ith player tries to minimize the worst case effects of both a combination of competitive strategies and external distractions to achieve the desired target, . So the goals of the ith agent can be modeled by
where , and are weight matrices.
So the m-agent noncooperative game strategy of multi-objective Pareto problems (5)–(6) or (7)–(8) can be seen as a Nash equilibrium if and only if [4]
where is the Pareto boundary of multi-objective problems (MOPs) (5) and (6), i.e.,
Because stochastic Systems (5) and (8) are presented by Itô-type differential equations, the existence and uniqueness of solutions of such systems can be obtained by the following Lemma 1.
Lemma 1.
Suppose the Itô-type stochastic differential equations (SDEs) driven by a one-dimensional Brownian motion are given by
Coefficients and satisfy Lipschitzian conditions
and
for some constant and . Then, SDE (11) exists as a unique solution.
The following Itô formula of SDEs will be used in the proofs of our main results.
Lemma 2.
Suppose and is the solution of SDE (11), then the following Itô formula is obtained:
where and are first-order partial derivatives w.r.t. t and x, respectively, with
and is the second-order partial derivatives w.r.t. x defined as
3. Multi-Party Non-Cooperative Investment Strategies for Time-Varying Stochastic Financial Systems
To simplify the calculation, we let the desired target . So the solutions of (5) of (8) are equivalent, i.e., . The MOP problems of (5)–(6) and (7)–(8) convert to the following multi-objective problem:
subject to
In System (14), is the equilibrium point. Namely, only the stabilization issue is considered in traditional non-cooperative game strategies. In order to obtain the MOP solution and strategies , for every i, we first offer as the upper bound of , i.e., with . So the following inequality can be obtained when :
So, for every and , there exists
which equals to
Let
Then, is the upper bound of with if and only if, for every and v, there exists
Theorem 1.
Proof.
Applying the Itô formula to , we obtain
Integrating on , then taking expectation on both sides, we obtain
Since , we have
So
Completing the square w.r.t. , and , respectively, on the integral part of the right side, we have
where notation with and . Keeping Hamilton–Jacobi inequality (16), when , for every and v, we obtain
So is an upper bound of of MOP problems (13)–(14). □
We let
then, the Pareto boundary of MOP (13) and (14) can be obtained by following form:
So the MOP problems of (13) for nonlinear System (14) can be transformed to an HJI-constraint MOP,
Now, a linear stochastic system is considered, which is given as the following:
with multi-objective Problem (13); then, the results of Theorem 1 described by the Hamilton equation can be obtained as the following proposition with a Riccati equation form.
Proposition 1.
Proof.
4. The Global Linearization Method for a Nonlinear Stochastic Financial System with Time-Varying Parameters
Generally, it is difficult to solve HJIs (16). In this section, a global linearization method is proposed to obtain an approximate solution of multi-objective Problem (14) with the constrain of nonlinear stochastic financial System (14). We suppose the global linearized systems of a nonlinear stochastic financial system in (14) are bounded by a polytope given as follows:
The state trajectory of a nonlinear financial system of (14) can be represented by the combination of state trajectories of the following local linearized systems derived from the vertices of the polytope in (23):
According to the global linearization theory [29], the trajectory of the shifted financial system in (14) can be represented by a convex combination of the trajectories of these local linearized financial systems in (24) as follows:
where denotes the interpolation functions defined as
In practice, we can replace the trajectory of the nonlinear stochastic financial system in (14) by the trajectory of the interpolated financial system in (25).
Proposition 2.
Remark 2.
Compared to the Riccati equations constructed in [23], the Riccati equations (26) appllied in Proposition 2 are all given by ordinary differential equations with time-varying forms other than algebra equations proposed in [23].
Using J local linear financial systems in (24) to interpolate nonlinear stochastic financial System (14), the HJI-constraint MOP of a time-varying nonlinear financial system in (16) is transformed into the following Riccati equation-constraint MOP:
Remark 3.
The following steps can help us to obtain the values of :
Step 1: Take a positive as an initial value.
Step 2: For a given , solve Riccati equations (26).
Step 3: If Riccati equations (26) have a solution for , take another positive smaller than , i.e., ; else, take larger than , i.e., .
Step 4: Update value by ; repeat Steps 1 to 4.
Step 5: Continue until for , the Riccati equations of (26) have solutions but the ones of do not, and the error between and is lesser than the given accuracy , i.e., . Take as the approximation of Pareto boundary .
5. Examples and Simulations
Inherent random fluctuations and external disturbances of actual environmental conditions and investors’ investment strategies play a very important role in the financial system in real life. In this example, let Wiener process represent the inherent random fluctuations, let represent external disturbance. The financial model is described by the following Itô-type stochastic differential equations:
where is the Wiener process, represents the corresponding external interference, , and denote the investment strategies of government, bank consortium and public, respectively.
The goal of the multi-objective problem for System (31) is given by the following:
Take the coefficients in global linearization System (25) corresponding to nonlinear System (31) with the following forms:
where , , and . and are the weighted matrices of and , respectively.
Figure 1a illustrates the performance of points , where and are the upper bounds of and , respectively. In order to display the upper bound and the Pareto boundary more clearly, Figure 1b–d show the pairwise relationships between and with their Pareto boundaries and .
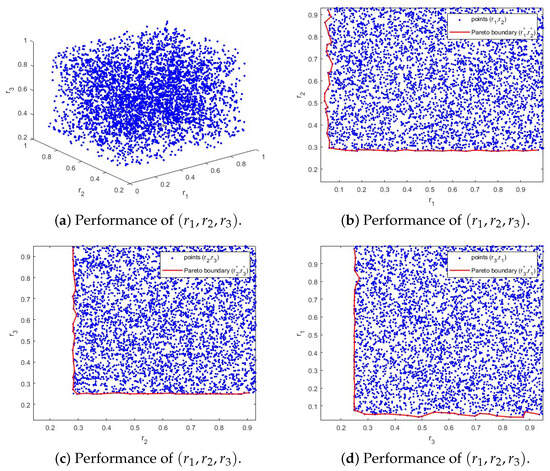
Figure 1.
Performance of and Pareto boundary of , , .
Figure 2 shows the surface of the Pareto boundary, which verifies the relationships between and described by (33).
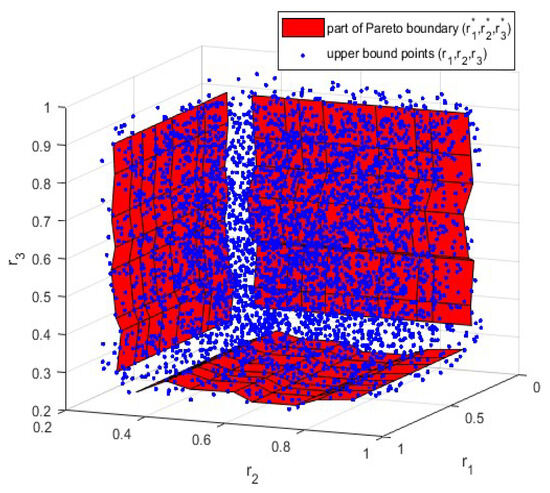
Figure 2.
Performance of Pareto boundary .
Figure 3 shows the profile of Brownian motion , and Figure 4 illustrates the trajectories of , and in System (31) driven by a Brownian motion. Figure 5 illustrates trajectories of , and , and they represent the investment strategies of government, bank consortium and public, respectively.
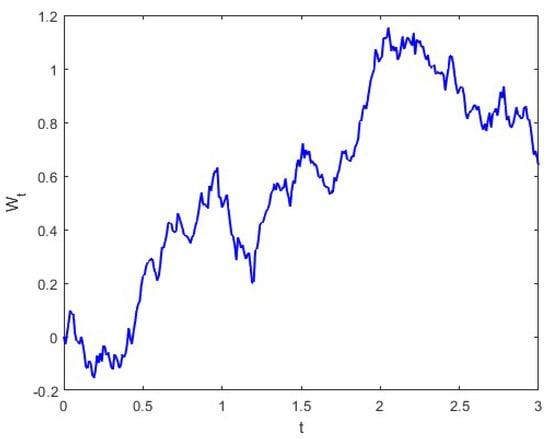
Figure 3.
Profiles of Brownian motion.
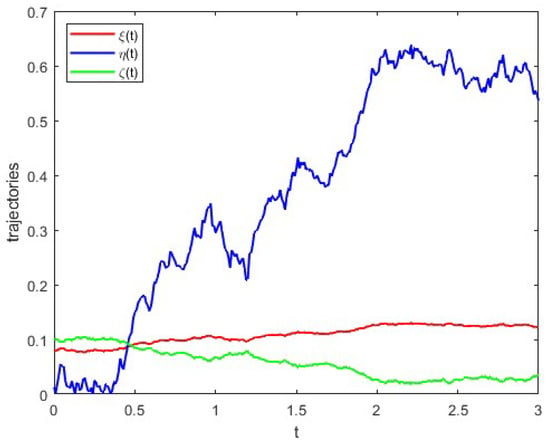
Figure 4.
Trajectories of , and .
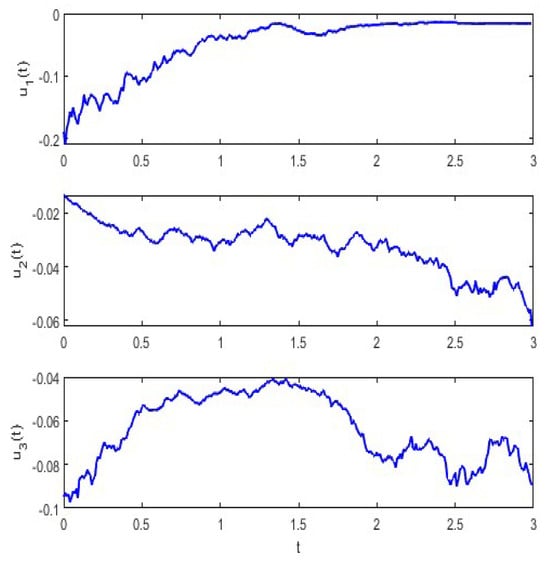
Figure 5.
Trajectories of controllers , and .
6. Conclusions
The non-cooperative game strategy for a nonlinear stochastic time-varying parameter financial system is studied. The proposed non-cooperative game is robust enough to achieve the desired goal of each player. Different from the traditional iterative method, it can be solved by all participants at the same time, and can realize the Nash equilibrium solution. When the value of a parameter in the system changes with time, the entire property changes with time. Finally, a practical example of investment and international capital flow is given to verify the performance of the proposed non-cooperative game strategy design for nonlinear stochastic time-varying parameter systems with continuous fluctuations.
Author Contributions
Conceptualization, R.Z. and X.L.; methodology, X.L. and T.Z.; software, X.L. and R.Z.; validation, X.L. and M.L.; formal analysis, M.L., X.L. and W.Z.; investigation, W.Z.; resources, X.L. and T.Z.; data curation, X.L.; writing—original draft preparation, X.L. and T.Z.; writing—review and editing, X.L. and R.Z.; visualization, W.Z.; supervision, W.Z.; project administration, X.L.; funding acquisition, X.L. and W.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant numbers 62273212, 62373229; the Natural Science Foundation of Shandong Province of China, grant numbers ZR2020MF062, ZR2021MF052.
Data Availability Statement
Data is contained within the article.
Acknowledgments
We thank the anonymous reviewers for their constructive suggestions to improve the quality of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Reny, P.J. Nash equilibrium in discontinuous games. Annu. Rev. Econ. 2020, 12, 439–470. [Google Scholar] [CrossRef]
- Fu, H.F. On the existence of Pareto undominated mixed-strategy Nash equilibrium in normal-form games with infinite actions. Econ. Lett. 2021, 201, 109771. [Google Scholar] [CrossRef]
- Poveda, J.I.; Krstic, M.; Basar, T. Fixed-time Nash equilibrium seeking in time-varying networks. IEEE Trans. Autom. Control 2023, 68, 1954–1969. [Google Scholar] [CrossRef]
- Nash, J. Non-cooperative games. Ann. Math. 1951, 54, 286–295. [Google Scholar] [CrossRef]
- Goldman, A.J.; Shier, D.R. Player aggregation in noncooperative games. J. Res. Natl. Bur. Stand. 1980, 86, 391–396. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.X.; Hong, S.H.; Li, C.H. Existence of extended Nash equilibriums of nonmonetized noncooperative games. Fixed Point Theory Appl. 2015, 2015, 65. [Google Scholar] [CrossRef]
- Ye, M.J.; Hu, G.Q. Distributed seeking of time-varying Nash equilibrium for non-cooperative games. IEEE Trans. Autom. Control 2015, 60, 3000–3005. [Google Scholar] [CrossRef]
- Aduba, C.; Won, C.H. N-player statistical Nash game control: m-th cost cumulant optimization. IEEE Trans. Autom. Control 2016, 61, 2688–2694. [Google Scholar] [CrossRef]
- Bressan, A.; Nguyen, K.T. Stability of feedback solutions for infinite horizon noncooperative differential games. Dyn. Games Appl. 2018, 8, 42–78. [Google Scholar] [CrossRef]
- Dianetti, J.; Ferrari, G. Nonzero-sum submodular monotone-follower games: Existence and approximation of Nash equilibria. SIAM J. Control Optim. 2020, 58, 1257–1288. [Google Scholar] [CrossRef]
- Zhang, Y.; Chang, S.S.; Chen, T. Existence and generic stability of strong noncooperative equilibria of vector-valued games. Mathematics 2022, 9, 3158. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Liu, F.; Wang, Z.J.; Chen, Y.; Feng, S.L.; Wu, Q.W.; Hou, Y.H. On Nash-Stackelberg-Nash games under decision-dependent uncertainties: Model and equilibrium. Automatica 2022, 142, 110401. [Google Scholar] [CrossRef]
- Setiawan, R.; Salmah; Endrayanto, I.; Indarsih. Analysis of the n-person noncooperative supermodular multiobjective games. Oper. Res. Lett. 2023, 51, 278–284. [Google Scholar] [CrossRef]
- Ma, J.H.; Chen, Y.S. Study for the bifurcation topological structureand the global complicated character of a kind of nonlinear financesystem. Appl. Math. Mech. 2001, 22, 1240–1251. [Google Scholar] [CrossRef]
- Cont, R.; Tankov, P. Financial Modelling with Jump Processes; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Wang, L. Dynamic model of stock prices based on technical tradingrules—Part I: The models. IEEE Trans. Fuzzy Syst. 2015, 23, 787–801. [Google Scholar] [CrossRef]
- Wang, L. Dynamical model of stock prices based on technical trading rules—Part II: Analysis of the model. IEEE Trans. Fuzzy Syst. 2015, 23, 1127–1141. [Google Scholar] [CrossRef]
- Wang, L. Dynamic model of stock prices based on technical tradingrules—Part III: Application to Hong Kong stocks. IEEE Trans. Fuzzy Syst. 2015, 23, 1680–1697. [Google Scholar] [CrossRef]
- Stoyanov, J. Stochastic financial models. J. Roy. Stat. Soc. A (Stat. Soc.) 2001, 174, 510–511. [Google Scholar] [CrossRef]
- Chen, B.S.; Chen, W.H.; Wu, H.L. Robust H2/H∞ global linearization filter design for nonlinear stochastic systems. IEEE Trans. Circuits Syst. 2009, 56, 1441–1454. [Google Scholar] [CrossRef]
- Wu, C.F.; Chen, B.S.; Zhang, W. Multiobjective investment policy for a nonlinear stochastic financial system: A fuzzy approach. IEEE Trans. Fuzzy Syst. 2017, 25, 460–474. [Google Scholar] [CrossRef]
- Chen, B.S.; Yeh, C.H. Stochastic noncooperative and cooperative evolutionary game strategies of a population of biological network under natural selection. Bio. Syst. 2017, 162, 90–118. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.S.; Chen, W.Y.; Young, C.T.; Yan, Z. Noncooperative game strategy in cyber-financial systems with Wiener and Poisson random fluctuations: LMIs-constrained MOEA approach. IEEE Trans. Cybern. 2018, 48, 3323–3336. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.S.; Lee, M.Y. Noncooperative and cooperative strategy designs for nonlinear stochastic jump diffusion systems with external disturbance: T-S fuzzy approach. IEEE Trans. Fuzzy Syst. 2020, 28, 2437–2451. [Google Scholar] [CrossRef]
- Tan, C.; Zhang, S.; Wong, W.; Zhang, Z. Feedback stabilization of uncertain networked control systems over delayed and fading channels. IEEE Trans. Control Netw. Syst. 2021, 8, 260–268. [Google Scholar] [CrossRef]
- Tan, C.; Yang, L.; Zhang, F.; Zhang, Z.; Wong, W. Stabilization of discrete time stochastic system with input delay and control dependent noise. Syst. Control Lett. 2019, 123, 62–68. [Google Scholar] [CrossRef]
- Zhang, T.; Deng, F.; Sun, Y.; Shi, P. Fault estimation and fault-tolerant control for linear discrete time-varying stochastic systems. Sci. China Inf. Sci. 2021, 64, 200201. [Google Scholar] [CrossRef]
- Jiang, X.; Zhao, D. Event-triggered fault detection for nonlinear discrete-time switched stochastic systems: A convex function method. Sci. China Inf. Sci. 2021, 64, 200204. [Google Scholar] [CrossRef]
- Boyd, S.; El Ghaoui, L.; Feron, E.; Balakrishnan, V. Linear Matrix Inequalities in System and Control Theory; SIAM: Philadelphia, PA, USA, 1994. [Google Scholar]
- Tan, C.; Yang, L.; Wong, W. Learning based control policy and regret analysis for online quadratic optimization with asymmetric information structure. IEEE Trans. Cybern. 2022, 52, 4797–4810. [Google Scholar] [CrossRef]
- Tan, C.; Zhang, H.; Wong, W. Delay-dependent algebraic Riccati equation to stabilization of networked control systems: Continuous-time case. IEEE Trans. Cybern. 2018, 48, 2783–2794. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).