1. Introduction
In recent years, schemes to approximate infinite linear programs have become very important in theory. The authors of [
1] showed that under suitable assumptions, the program’s optimum value can be approximated by the values of finite-dimensional linear programs and that every accumulation point of a sequence of optimal solutions for the approximating programs is an optimal solution for the original problem. In particular, in [
2] the authors studied the Monge–Kantorovich mass transfer (MT) problem on metric spaces. They considered conditions under the MT problem as solvable and, furthermore, that an optimal solution can be obtained as the weak limit of a sequence of optimal solutions to suitably approximate MT problems.
Moreover, in [
3], the authors presented a numerical approximation for the value of the mass transfer (MT) problem on compact metric spaces. A sequence of transportation problems was built, and it proved that the value of the MT problem is a limit of the optimal values of these problems. Moreover, they gave an error bound for the numerical approximation. A generalization of this scheme of approximation was presented in [
4,
5]. They proposed an approximation scheme for the Monge–Kantorovich (MK) mass transfer problem on compact spaces that consisted of reducing to solve a sequence of finite transport problems. The method presented in that work uses a metaheuristic algorithm inspired by a scatter search in order to reduce the dimensionality of each transport problem. Finally, they provided some examples of that method.
On the other hand, the authors of [
6] provided orthonormal bases for
that have properties that are similar to those enjoyed by the classical Haar basis for
. For example, each basis consists of appropriate dilates and translates of a finite collection of “piecewise constant” functions. The construction is based on the notion of multiresolution analysis and reveals an interesting connection between the theory of compactly supported wavelet bases and the theory of self-similar tilings. Recent applications of the wavelet filter methodology have been used in various problems arising in communication systems and detection of thermal defects (see, for example, [
7,
8], respectively).
In [
9], the authors gave a scheme to approximate the MK problem based on the symmetries of the underlying spaces. They took a Haar-type MRA constructed according to the geometry of the spaces. Thus, they applied the Haar-type MRA based on symmetries to the MK problem and obtained a sequence-of-transport problem that approximates the original MK problem for each MRA space. Note that in the case of Haar’s classical wavelet, this methodology coincides with the methods presented in [
2,
3].
It is important to note that various scientific problems are modeled through the Monge–Kantorovich approach; therefore, providing new efficient methodologies to find approximations of such problems turns out to be very useful. Within the applications of problems whose solutions are the Monge–Kantorovich problem are found: the use of the transport problem for the analysis of elastic image registration (see, for example, [
10,
11,
12]). Other optimization problems related to this topic and differential equation tools can be found in recent works such as [
13,
14].
The main goal of this paper is to present a scheme of approximation of the MK problem based on wavelet analysis in which we use wavelet filters to split the original problem. That is, we apply the filter to the discrete cost function in level j, which results in a cost function of level and three components of wavelet analysis. Using the information of the cost function given by the low-pass filter, which belongs to level , we construct a solution of the MK problem for that level , and using the additional information, the other three components of wavelet analysis are extended to , which is a solution to level j, where the projection of to level is . Finally, we make a local analysis of the solution to obtain an improved solution based on the type of points of that solution (we have two type of points that are defined in the base in the connectedness of the solution).
This work has three non-introductory sections. In the first of them we present the Haar multiresolution analysis (MRA) in one and two dimensions. Next, we relate this to the absolutely continuous measures over a compact in . We finish with the definition of the Monge–Kantorovich mass transfer problem and its relation to the MRA.
In the second section, we define a proximity criterion for the components of the support of the simple solutions of the problem and study in detail the problem of, given a solution at level of resolution for the problem, construct a feasible solution for the problem at level of resolution j such that it is a refinement of the solution with lees resolution.
On the other hand, in the third section we present a methodological proposal to solve the problem such that it can be summarized in a simple algorithm of six steps:
- Step 1.
We consider a discretization of the cost function for the level j, denoted by .
- Step 2.
We apply the wavelet transform to ; we obtain the low-pass component and three high-pass components, denoted by , and , respectively.
- Step 3.
Using
and the methodology of [
3,
4,
9], we obtain a solution
for
associated with this cost function.
- Step 4.
We classify the points of the support of the solution by proximity criteria as points of Type I or Type II.
- Step 5.
Using the solution , the information of the high-pass components and Lemma 1, we obtain a feasible solution for the level j, which is denoted by . This feasible solution has the property that its projection to the level is equal to ; moreover, the support of is contained in the support of .
- Step 6.
The classification of the points of induce classification of the points in by contention in the support. Over the points of Type I of the solution , we do not move those points. For the points of Type II, we apply a permutation to the solution over the two points that better improves the solution, and we repeat the process with the rest of the points.
Finally, we present a series of examples that use the proposed methodology based on wavelet analysis and compare their results with those obtained applying the methodology of [
3,
4,
9].
3. Technical Results
In this section, we present a series of results that ensure the good behavior of the methodological proposal of the next section. In order to do this, we start by assuming an
problem with cost function
, base sets
and measure restrictions
. In other words, we consider the problem of moving a uniform distribution to a uniform one with the minimum movement cost. Since in applications we work with discretized problems, then as a result of applying the MRA on
, we have that our objective is to solve:
where
is the portion of the initial value
in the position
of the
x-axis allocated to the position
of the
y-axis. We call
j-discrete unit square the grid formed by the squares
(see (
20)), dividing the set
in
blocks, in a such way that each one is identified with the point
. We suppose that there is a simple solution
for (
40). That is,
is a feasible solution such that, given
with
, it necessarily holds that
for each
and
for each
. Geometrically, if the measure
is plotted as a discrete heat map in the
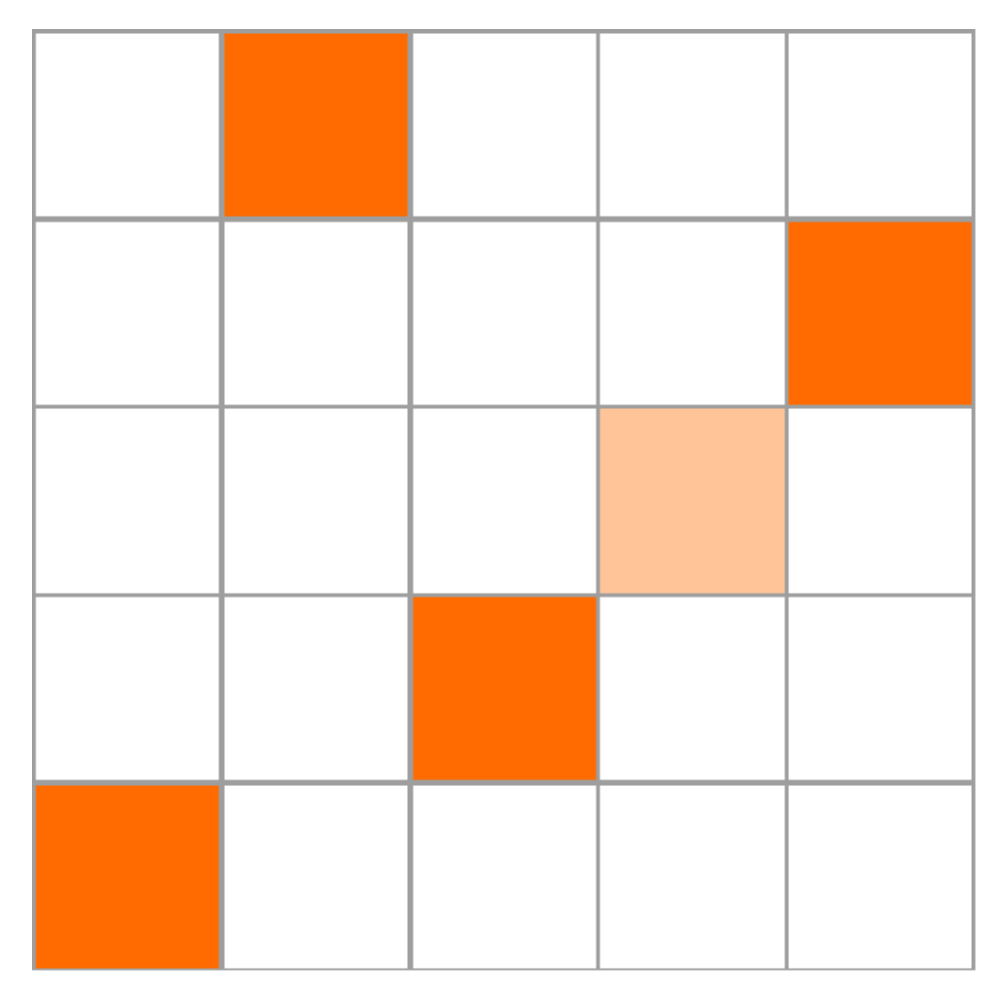
j-discrete unit square, then no color element in the plot has another color element in its same row and column, as can be seen in
Figure 2.
Definition 1. We define a proximity criteria in the j-discrete unit square as follows: is a neighbor of if In
Figure 2, we plot the support of the hypothetical simple solution
. Hence, the neighbors of the position in the middle of the cross are those that touch the yellow stripes. Then in this example, the middle point has four neighbors.
Figure 2.
Support of and the proximity criteria.
Figure 2.
Support of and the proximity criteria.
With this in mind, we can classify the points in as follows.
Definition 2. We say that is a border point if or equals 0 or 1; otherwise, we call it an interior point. It is clear that a border point has at least one neighbor and at most three, whereas an interior point has at least two neighbors and at most four. Hence, we can partition into two sets as follows.
The set of the points of Type I is given byand the set of the points of Type II is given by Intuitively, the set
is composed of well-controlled points, whereas the set
has the points that admit permutations between them, since, as we will see in the next section, in the proposed algorithm they will be permuted. See
Figure 3 and
Figure 4. Naturally, since
is a feasible solution for (
40), then given elements
and for
permutations
over
, the measure
defined by
is a feasible solution.
Figure 3.
Classification of the points in : Type I points.
Figure 3.
Classification of the points in : Type I points.
Figure 4.
Classification of the points in : Type II points.
Figure 4.
Classification of the points in : Type II points.
Refining Projections
In this subsection, we study the problem of improving an optimal solution
for (
40) on level
to a feasible solution
for the next level
j. Let
be an optimal solution for level
. Then we are looking for
such that:
As described in the previous section, the measure
can be decomposed in
where
From the geometric point of view, the projections
are formed from differences of characteristic functions, as we mentioned in
Section 2.2. So we have the following result:
Lemma 1. Let and be an optimal solution for (40) at level . Then for each positive measure such that and , it necessarily holds thatfor each Lebesgue measurable set and each . Therefore, the support of is contained in the support of . Proof. We only make the proof for the case
, since the other two are very similar. To simplify the notation, we use the symbols
and
as measures or functions in the respective subspace of
. Since when setting a level
all the measures in question are constant in pairs of rectangles dividing
, as we prove in
Section 2.2, then it is enough to prove that (
65) is valid on this rectangles. Let
and
as in (
22). Then for
, we have that
Now we will calculate each one of the expectations separately. By (
17), (
18) and (
25), we have that
and
Then for
and by (
15), (
16) and (
22), we have that
where
and
where
. Similarly, but using (
23) and (
24), we can prove that
and
Now, we will make an analogous argument for the case
. Hence,
and
Thus,
and by (
54), (
55), (
59) and (
60), we have that
and
Therefore, it follows from (
58), (
61), (
62), (
63) and the fact that
is a positive measure, that
From which we conclude that
implies
. Similarly, it can be shown that
implies
for
; for this, analogous proofs are carried out, with the difference being that for
, the sets to be considered are
and
as in (
23), whereas
and
as in (
24) are the respective sets when
. □
We have proved that if it is intended to go back to the preimage of the projection of the approximation operator
from a level
to a level
j, the support of the level
delimits that of the
j level. Now, we will prove that for every measure
that satisfies (
45) and (
46), it necessarily holds that
.
Lemma 2. Let and be an optimal simple solution for (40) at level . Then for each feasible solution to (40) at level j such that and . It necessarily holds that Proof. In order to perform this proof, we use the restrictions of the
problem (
40), which in turn, are related to the marginal measures. Therefore, we will only complete the proof for one of the projections, since the other is analogous. From the linearity of the Radon–Nikodym derivative, it follows that
Let
and
. Thus, by (
39) and (
66), we have that
That is, we are evaluating feasible solutions on rectangles whose height is half the size of the squares with which they are discretized at the
j level of the Haar MRA. Now, we will develop in detail (
66) evaluated on
. Since
is a simple solution, we call
the only number such that
, where
is defined as in (
20). With the aim of simplifying the notation, we define
. By (
16) and (
25), we have that
By the way
was defined, necessarily in the last equality it must be fulfilled that one of the terms in the expectation is equal to 0. Hence, it is fulfilled that
By a similar argument, it can be proved that
and
Then from (
66) to (
71), it follows that
Therefore, . In a similar way, we can prove that . □
Suppose we have a simple optimal solution
for the
problem discretized through the Haar MRA at level
and that we are interested in refining that solution to the next level
j. By Lemmas 1 and 2, any
that satisfies (
45) has its support contained in the support of
and has components
. Then the problem of constructing a feasible solution
such that it refines
is reduced to construct
which is equivalent to chosing for each
a value
such that
By Lemma 1 for each
, it is fulfilled that
Therefore, the choice of
is restricted to a compact collection, and since
is a solution of the linear program (
40), then
Thus, the sign of
must be such that it minimizes
. That is,
4. Methodological Proposal
In this section, we show through examples a process that builds solutions to the
problem with a reduced number of operations. First, we consider the
problem with cost function
defined by
and homogeneous restrictions
over
. So that the algorithm can be graphically appreciated, we take a small level of discretization, namely
. Thus, in the Haar MRA over
at level
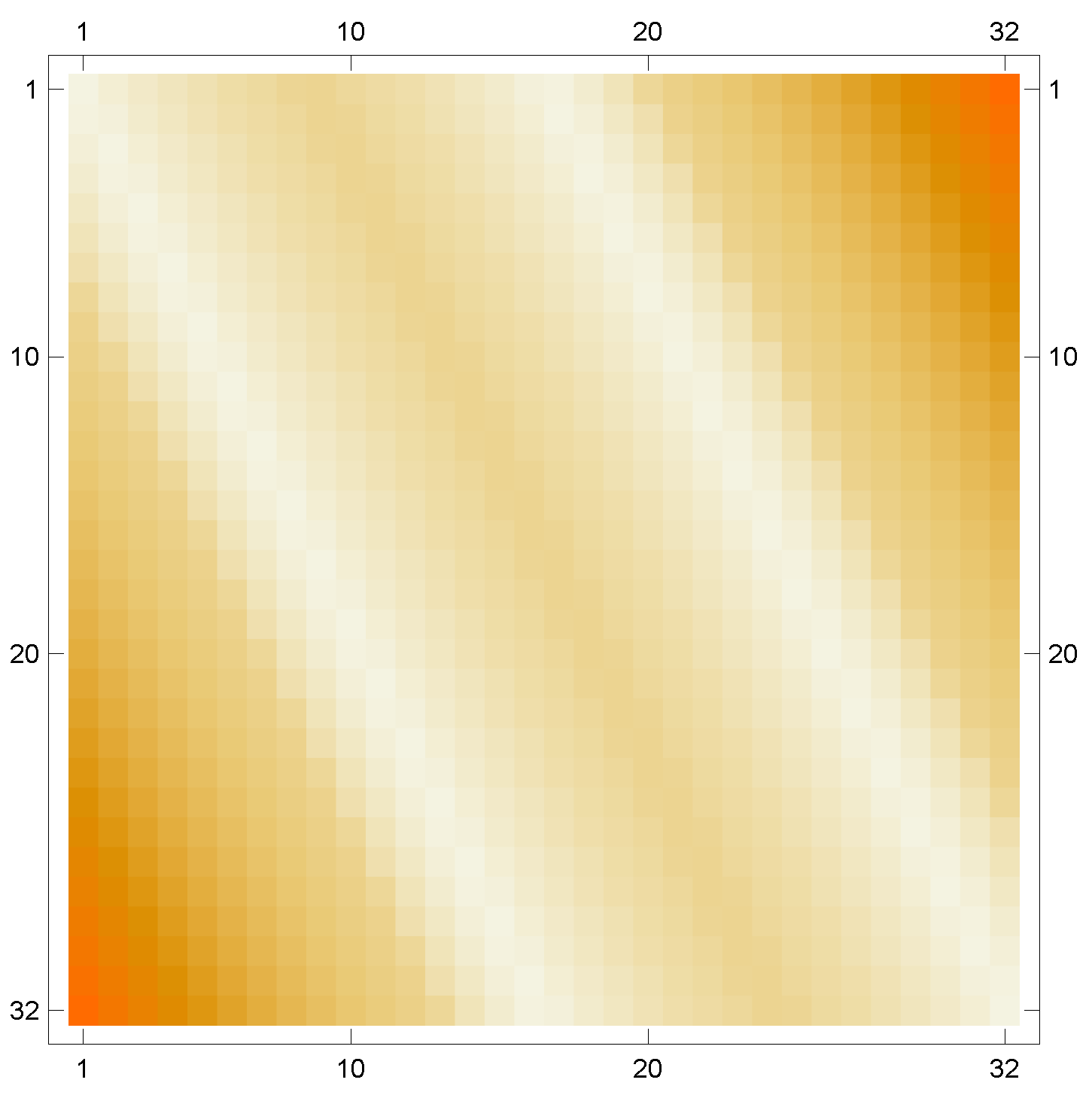
, the cost function has the form shown in
Figure 5, which can be stored in a vector of size
.
Figure 5.
Step 1. Discretization of the cost function to the level j, which is denoted by . In particular, the cost function is for lever .
Figure 5.
Step 1. Discretization of the cost function to the level j, which is denoted by . In particular, the cost function is for lever .
Step 2. Filtering the original discrete function using the high-pass filter, which yield three discrete functions denoted by
,
and
, that functions correspond to
Figure 7,
Figure 8 and
Figure 9, respectively, each describing local changes in the original discrete function. It is then low-pass filtered to produce the approximate discrete function
, which is given by
Figure 6.
Figure 6.
.
Figure 6.
.
Figure 7.
.
Figure 7.
.
Figure 8.
.
Figure 8.
.
Figure 9.
.
Figure 9.
.
We then solve the
problem for the level
. That is, we find a measure
that is an optimal solution for the
problem with cost function
. Such data can be stored in a vector of size
; see
Figure 10. For each entry
k, the formal application that plots this vector in a square is defined by
, where
and
.
Since the measure
is an optimal simple solution for the
problem, then we can represent its support in a simple way, as we show below:
where
is the square in (
20). Next, we split each block
into four parts as in (
24); see
Figure 11.
From the technical point of view, in the discretization at level
, we have a grid of
squares that we call
and identify with the points
. Thus, we refine to a grid of
, splitting each square into four, which in the new grid are determined by points
see
Figure 12.
As we prove in Lemma 1, any feasible solution
that refines
has its support contained in
. Therefore, we must only deal with the region delimited by the support of
. By Lemma 2, in order to construct the solution
, we only need to determine the values
corresponding to the coefficients of the wavelet part
; however, by (
77) and (
78), those values are well determined and satisfy that when added with the scaling part
, the result is a scalar multiple of a characteristic function. For example if the square
has scaling part coefficient
, then we choose
. Hence, by (
21) and (
25), we have that
Thus, from an operational point of view, we only need to chose between two options of supporting each division of square
, as we illustrate in
Figure 13 and
Figure 14.
This coincides with our geometric intuition. Hence, the resulting feasible solution
has its support contained in
, and its weight within each square
is presented in a diagonal within that block; see
Figure 15. Finally, we can improve
by observing the way the filtering process acts. To do this, we apply the proximity criteria (
41) and split the support of
into points of Type I and II. In
Figure 16, we identify the points of Type I and II of solution
, whereas in
Figure 15, we do the same but for
.
Intuitively, the division of the support into points of Type I and II allows us to classify the points so that they have an identity function form and, consequently, that come from the discretization of a continuous function—points of Type I—and in points that come from the discretization of a discontinuous function—points of Type II. Thus, the points of Type I are located in such a way that they generate a desired solution, and therefore it is not convenient to move them, whereas Type II points are free to be changed as this does not lead to the destruction of a continuous structure in the solution. As we mentioned in the previous section, each permutation of rows or columns of one weighted element
with another
constructs a feasible solution; see (
44). Thus, as a heuristic technique to improve the solution, we check the values
associated with each solution
obtained by permuting rows or columns of points of Type II of the solution
. We call
the solution for which its permutation gives it the best performance. See
Figure 17.
Figure 15.
Step 5. Using the solution
which is given by
Figure 10, the information of the high-pass components (
Figure 7,
Figure 8 and
Figure 9) and Lemma 1, we obtain a feasible solution for Level 6, which is denoted by
.
Figure 15.
Step 5. Using the solution
which is given by
Figure 10, the information of the high-pass components (
Figure 7,
Figure 8 and
Figure 9) and Lemma 1, we obtain a feasible solution for Level 6, which is denoted by
.
Figure 16.
Step 4. We classify the points of the support of the solution
by proximity criteria as points of Type I
■ or Type II
■ (the measure
corresponds to
Figure 10).
Figure 16.
Step 4. We classify the points of the support of the solution
by proximity criteria as points of Type I
■ or Type II
■ (the measure
corresponds to
Figure 10).
Finally, we present
Table 1 that compare the solutions of the
problem, in which
is the value associated with the optimal solution
at level of discretization
,
is the value associated with an optimal solution
at level of discretization
, and
is the value associated with the solution
obtained by the heuristic method described in the previous paragraph.
Figure 17.
Step 6. Classification of the points of induces classification of the points in by contention in the support. Over the points of Type I of the solution , we do not move those points. For the points of Type II, we apply a permutation to the solution over the two points that improve the solution and repeat the process with the rest of the points.
Figure 17.
Step 6. Classification of the points of induces classification of the points in by contention in the support. Over the points of Type I of the solution , we do not move those points. For the points of Type II, we apply a permutation to the solution over the two points that improve the solution and repeat the process with the rest of the points.
6. Conclusions and Future Work
Note that with the methodology of [
3,
4,
9], the authors obtain a solution of
. For this, they need to resolve a transport problem with
variables. We call this methodology an exhaustive method. For our methodology, in Step 3, we need to resolve a transport problem with
variables, and the other steps of the methodology are methods of classification, ordering and filtering; with
data for classification and ordering and
data for filtering, it is clear that this method requires fewer operations to resolve transport problems.
In summary, we have the following table comparing the results of solving the examples more often used in the literature with our methodology versus the exhaustive method (using all variables).
| Cost Function | | | Error |
| | | |
| | | |
| | | |
| | | |
| Cost Function | | | Error |
| | | |
| | | |
| | | |
| | | |
| Cost Function | | | Error |
| | | |
| | | |
| | | |
| | | |
Note that our method always improves the solution of the level and for some examples give an exact solution; we use Mathematica© and basic computer equipment for programming this methodology, and maybe we can improve the results with software focused on numerical calculus and better computer equipment. It is also important to mention that the methodology presented in this work has some weaknesses. In our computational experiments, we noticed that if we did not start with a sufficient amount of information, then the methodology tended to give very distant results. In other words, if the initial level of discretization was not fine enough, then because the algorithm lowers the resolution level when executed, such loss of information generates poor performance. However, when starting with an adequate level of discretization, experimentally it can be observed that the distribution of the solutions for the discretized problems, as well as the respective optimal values, have stable behavior with a clear trend. The question that arises naturally is: “In practice, what are the parameters that determine good or bad behavior of the algorithm?” Clearly, if the cost function is fixed and we rule out the possible technical problems associated with programming and computing power, the only remaining parameter is the initial refinement level at which the algorithm is going to work—that is, the level j. However, if we reflect more deeply on the reasons why there is a practical threshold beyond which at a certain level of discretization the algorithm has stable behavior, we only have as a possible causes the level of information of the cost function that captures the MR analysis. In other words, if the oscillation of the cost function at a certain level of resolution is well determined by MR analysis, then the algorithm will have good performance.
The approach presented in this paper is far from exhaustive and, on the contrary, opens the possibility for a number of new proposals for approximating solutions to the MK problem. The above is due to the fact that in the work [
9], it was proven that discretization of the MK problem can be performed from any MR analysis over
. Therefore, the possibility of implementing other types of discretions remains open. In principle, as we mentioned in the previous paragraph, the most natural thing is to expect better performance if the nature of the cost function and the types of symmetric geometric structures that it induces in space are studied in order to use an MR analysis that fits this information and therefore has more efficient performance.



 ,
, 



































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}