Abstract
In this article, we consider the nonparametric inference for the time-varying coefficient double-threshold generalized autoregressive conditional heteroscedastic models. The quasi-maximum exponential likelihood estimators (QMELEs) of the model’s parameters and the asymptotic properties of the estimators are obtained. The simulation study implies that the distribution of the estimators is asymptotically normal. A real data application to stock returns is given. Both the simulations and real data example imply that the model and the QMELE are proper, compatible and accurately fit the financial time series data of the Nikkei 225.
Keywords:
time-varying coefficient; threshold model; QMELE; asymptotic properties; financial time series; explanatory variables MSC:
62P20; 62F99
1. Introduction
The random coefficient autoregressive (RCA) model proposed by [1] is a nonlinear time series models that is widely used when analyzing data generated on economics and finance. The RCA model incorporates a random variable in its autoregressive coefficient part, and thus makes the model able to capture the random influential factors. Refs. [2,3,4,5] studied various problems of inference for non-linear time-series models, including random coefficient models. Subsequently, ref. [6] proposed the generalized random coefficient autoregressive (GRCA) model. Refs. [7,8] studied properties of the RCA model with order 1 (the RCA(1) model). Ref. [9] studied the RCA model with GARCH innovations and its properties.
When analyzing the economic and financial time series, researchers found that the data frequently exhibit apparent evidence of asymmetry. For example, when the stock price is rising (in a bull market), the return yield (volatility) is different from the relevant yield when the price is falling (in a bear market). Refs. [10,11] proposed the threshold autoregressive model (TAR) to capture the asymmetric features shown in the financial time series. By using the threshold variable, the TAR model set up several different regimes with different parameters to describe asymmetric phenomena. Since [12] proposed the autoregressive conditional heteroscedastic (ARCH) model and [13] extended the ARCH models to the generalized autoregressive conditional heteroscedastic (GARCH) models, ref. [14] implied that the asymmetric volatility is exhibited in financial series data obtained from the stock market. Ref. [15] extended the TAR model to the model with conditional heteroscedasticity, which is the self-exciting threshold autoregressive ARCH (SETAR-ARCH) model. Then, ref. [16] proposed the double-threshold autoregressive conditional heteroscedastic (DTARCH) model, which captures asymmetry in the conditional mean and conditional variance at the same time, and used their model to analyze the Hang Seng Index return series in Hong Kong. Ref. [17] extended the DTARCH model to the DTGARCH model and used it to investigate the French Franc/Deutschmark exchange rates. Based on these achievements, several researchers conducted further studies of applications of this model in finance and economics, e.g., [18,19,20,21,22].
In the literature related to the RCA model, the random coefficient is usually affected by an independent and identically distributed random variable. In [1], the random coefficient part is influenced by a white noise sequence. However, in practical application, the random coefficients may depend on some observed data and external factors. For instance, when analyzing the stock data, the return of yield at time t should be influenced by the one at time and some factors external to the stock market. Ref. [23] proposed the smooth transition autoregressive (STAR) model, and the autoregressive parameters of STAR model incorporated the influence of the observations. Then, ref. [24] used the smooth transition autoregressive (STAR) model to analyze the data of industrial production in West Germany. Since then, STAR models have widely been used in economics and finance. When analyzing the economic and financial data, the models are not only affected by observations but also some external factors. Therefore, incorporating the observations and explanatory variables in the model and influencing the model through the random coefficient part are considered. Refs. [25,26,27] proposed several integer-valued autoregressive models, in which the random coefficients were influenced by observations or explanatory variables. Motivated by the above literature, which shows different approaches of constructing time series models, we incorporate observations and explanatory variables into the autoregressive coefficient part, and investigate a time-varying coefficient double-threshold generalized autoregressive conditional heteroscedastic (TVCDT-GARCH) model.
Ref. [28] studied the estimation of the random coefficient AR(1) processes based on the least squares estimator. Ref. [8] studied the model parameter estimation of the RCA(1) model, and [9] discussed the RCA models with GARCH innovations and its parameter-estimation problem. Ref. [29] found that some parameters of the nonstationary RCA model cannot be estimated using quasi-maximum likelihood estimation (QMLE); then, ref. [30] presented the quasi-likelihood estimation for the stationary and nonstationary process of RCA(1) model. In general, when solving the problem related to the model parameter estimation of the G/ARCH type model, the QMLE is an approach that is frequently used and is discussed by several researchers, such as [31,32,33,34]. However, QMLE requires a finite fourth moment for the error term. Due to the heavy-tailed features of financial time series, this requirement is not easily satisfied in many practical applications, especially in economics and finance. Ref. [35] studied the models with heavy-tailed errors and showed that QMLE is not asymptotically normal. Then, ref. [36] proposed the quasi-maximum exponential likelihood estimators (QMELE) for the ARMA-GARCH model under a fractional moment condition of the error term without specification of the distribution of the error term. Consequently, QMELE exhibits superior performance when dealing with heavy-tailed data in practical applications. These considerations motivate us to study the QMELE of the TVCDT-GARCH model.
As financial data usually involve non-normality and fat tails, the double exponential distribution is better than the normal distribution for characterizing heavy-tailed data. Compared with traditional QMLE, the QMELE is a better approach to esimate model parameters. The time-varying coefficients of our model incorporate not only the information of observations but also the information of external factors. Hence, by using QMELE, we investigate inference for TVCDT-GARCH models, which provides practitioners with an attractive modeling alternative for fitting financial data.
The rest of this paper is organized as follows. In Section 2, we discuss the model, parameter estimation and the asymptotic results. Section 3 shows the results from some simulation studies. In Section 4, we use our results to analyze the real data of the Nikkei 225. Section 5 provides our conclusions and some extensions for further research. We put the proofs in Appendix A.
2. Model and Estimation
Ref. [1] proposed the classic random coefficient autoregressive (RCA) model as the following:
where are independent and identically distributed pairs of random variables and satisfy
Although the RCA models are widely used in biology, economics and finance, and studied in the literature, there are some drawbacks that can be improved. For instance, when analyzing stock data, the return of yield at time t should be influenced by the one at time and some external factors; however, in the RCA model, the random coefficient is only affected by the random variable . Based on the discussion above, we consider the following time-varying coefficient double threshold GARCH (TVCDT-GARCH) model:
where
where represents observations of explanatory variables, is a stationary sequence, , , and d are positive integers, are independent and identically distributed noise with , and r is a threshold parameter. Let be the model parameters with true value , where and . The parameter space is , where , , , , . For the sake of representation, let denote the parameters in our model, except the threshold parameter r; then, . Assume that and are compact, and is an interior point of . We consider the following function:
where and . We look for , the minimizer of on , where
is called the QMELE of . To estimate , we have to fix the threshold parameter r, then minimize on and finally derive its minimizer . In what follows, we assume that r is already known.
In the circumstances that r is unknown, we can use several methods to estimate the threshold parameter, such as the single grid search (SGS) algorithm (e.g., [37,38,39]) and the nested sub-sample search (NeSS) algorithm ([40]), etc. Researchers then can choose a proper method to locate the threshold parameter. Using the optimization algorithms to optimize the log-likelihood function is an alternative procedure to obtain the threshold parameter. Whether this estimator is proper or not requires judgement. We use the SGS method to estimate the threshold parameter r in our estimation process. When r is fixed, we can calculate the AIC of the model, and the optimal r is the one with the minimum model AIC. Using the SGS method, we search for r over the range of the 20th to the 80th percentile of the sample data with a search step size of 0.01 (1%), and then we obtain the estimated threshold that corresponds to the minimum model AIC.
Remark 1.
The least absolute deviation (LAD) estimation can also relax the requirement of the moment condition. However, we do not use the LAD method to estimate the parameters of our model. Remark 2.2 in [41] gives a detailed description, and thus we will not consider the LAD method henceforward.
Next, we discuss the asymptotic properties of our estimators. Let , and . We need the following assumptions.
Assumption 1.
satisfying Equation (1) is strictly stationary and ergodic. The parameter space Θ is compact. , , , for , and .
Assumption 2.
For each , and have no common root, , , and we let , if . A similar condition holds for , and .
Assumption 3.
has a nondegenerate distribution with . is independent and identically distributed with median 0, ; its density function is continuous and satisfies , , and .
Assumption 4.
for any , where .
Assumption 5.
, , , and is a stationary sequence and independent of .
Remark 2.
For the time-varying coefficients part, we notice that , , . With Assumptions 1–5 and similarly to Proposition 1.1 in [42], the parameters of the autoregressive part fit the strictly stationary and ergodic solution condition. Our model is a two-regime threshold model that can be seen as a special case of [43] that then combines the corresponding results of Theorem 1 in [43] with the restrictions on the parameters of the variance part: , , , . We can guarantee the stationarity of our model.
For the sake of clarity, let denote the minimizer of on for fixed r. The following theorem gives the strong consistency of .
Theorem 1.
Suppose has a zero median with . If Assumptions 1–5 hold, then a.s., as .
To investigate the rate of convergence of , we rewrite the log-likelihood function as follows: , where . Let ; then, is the minimizer of for fixed r. Note that
and
where
Now we divide into three parts:
where
Let ; using the equality
we have
, where ,
and lies between and . Let , and note that ; then, we have
where
By Taylor’s expansion, we have
where
and lies between and . We need three lemmas.
Lemma 1.
Let for i = 1, 2. If Assumptions 1–5 hold, then
where
Lemma 2.
If Assumptions 1–5 hold, then for any sequence of random variables such that , it follows that, for i = 1, 2,
where
Lemma 3.
If Assumptions 1–5 hold, then
Then, we can establish the asymptotic normality of .
Theorem 2.
If Assumptions 1–5 hold, then
(1) as ,
(2) as ,
where and with ,
for .
The proofs of Lemmas and Theorems are given in Appendix A.
When we analyze the real data of the Nikkei 225, we calculate the asymptotic standard deviation using , where and . For , and are estimated by
where
We can obtain from the following function:
where is the kernel function and is the bandwidth. In the simulation study, we choose the normal kernel function and a same bandwidth with [44], , where s is the sample standard deviation. By replacing the true value with our estimator in theoretical asymptotic variance, we obtain the consistent asymptotic variance estimation. Researchers can flexibly use the results above to work on the studies they are interested in, such as constructing confidence intervals or test procedure to study some statistical test problems, based on their own requirements.
3. Simulation Studies
In this section, we compare the estimation performance results of QMELE and QMLE under the circumstances that the error terms follow different distributions. The data-generating processes (DGPs) are as follows.
:
:
where , .
The data of these DGPs can be generated by transforming the time-varying coefficient part into the equation of observations or explanatory variables, and these generating processes do not need the support of any complicated algorithm. We let , and to ensure in these DGPs, and replicate 1000 times in each process. Table 1 and Table 2 present the simulation results for and respectively. In these tables, SD and ASD are the standard deviation and asymptotic standard deviation of the estimators, and bias equals the difference between the average of each estimator and the corresponding true value of the parameter. The ASDs of the parameter estimators of QMELE are calculated via and , which we demonstrated in Section 2.

Table 1.
Estimation performance results of (QMELE vs. standard QMLE ).
Table 2.
Estimation performance results of (QMELE vs. Standard QMLE ).
From Table 1 and Table 2, we can see that when the sample size n increases, the mean of QMELE gets closer to the corresponding true values, regardless of the distribution of . As n increases, all of the bias, SD and ASD decrease. The simulation results imply that when follows the normal distribution, the estimation results of standard QMLE are relatively normal but display greater biases than the corresponding results of QMELE. When follows the Laplace distribution and the T-distribution, the performance of the standard QMLE is not desirable; inversely, QMELE has much better performance.
From the simulation results, we can clearly see that when the error terms follow different distributions, the QMELE are consistent and perform much better than standard QMLE. Especially when the distribution of the error term is not normal, the QMELE provides more precise results and shows obvious advantages.
4. Real Data Example
In this section, we provide our analysis of a real data set of the Nikkei 225 in the Japanese stock market. The original data express the closing price on each trading day from 1 May 2014 to 1 April 2019, and there are 1208 valid observations. The explanatory variable is the corresponding daily volume (). Figure 1a presents the the original data of the closing price on each trading day, which we denote as . Figure 1b shows the rescaled 100 times log return, which we denote as : .
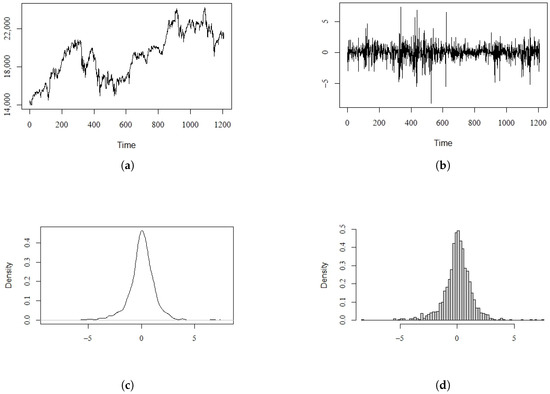
Figure 1.
The data of the Nikkei 225. (a) Original closing price. (b) 100 times log return. (c) Density plots of log return. (d) Frequency histogram of log return.
Figure 1c,d present the density plots and the histogram of the log return, respectively. From these two nonparametric plots, we can see that the log return data exhibit the characteristics of non-normality and fat tails.
In order to estimate the tail index of , we use the Hill’s estimator as follows:
where , and is the ith order statistic of . From Figure 2, we can clearly see that when , . Thus, the tail index of lies between 1 and 2, which means . Since this result does not satisfy the assumption of the asymptotic normality of QMLE, we use the QMELE to estimate the model parameters. First, we need to determine d and locate the threshold parameter r. Following several studies that analyze the stock return series (Chen et al., 2006 [18]; Yang and Chang, 2008 [19]; Chen et al. 2016 [22]), we believe that is an appropriate choice. By using the SGS method, we obtain and the fitted model
where the standard errors are given in parentheses. The estimated value of is 1.0238, which is very close to 1. Figure 3 shows the density histogram and density plots of . We can see that the distribution of is asymmetric and heavy tailed and very similar to a double exponential distribution. This evidence determines the choice of using QMELE to fit these Nikkei 225 log return data. Figure 4 shows the diagnostic checking plots for our fitted model. The estimated residuals indicate that the series is stationary. In addition, the histogram plot implies that the standardized residuals are approximately normal, which reveals that our fitted model is suitable. As a comparison, we present the DT-GARCH fitted model of the same data, which is as follows:
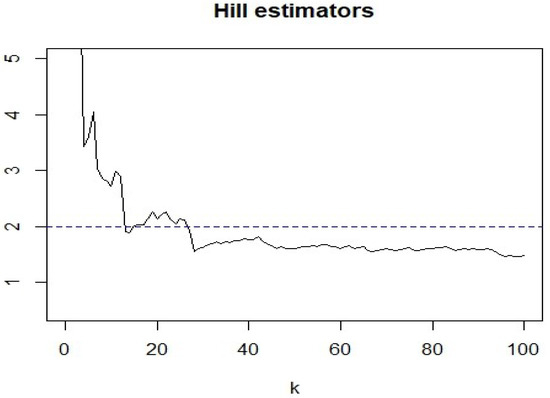
Figure 2.
The Hill’s estimators of .
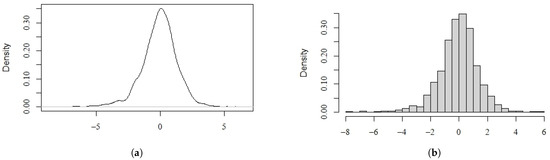
Figure 3.
The frequency histogram and density plots of . (a) Density plots. (b) Frequency histogram.
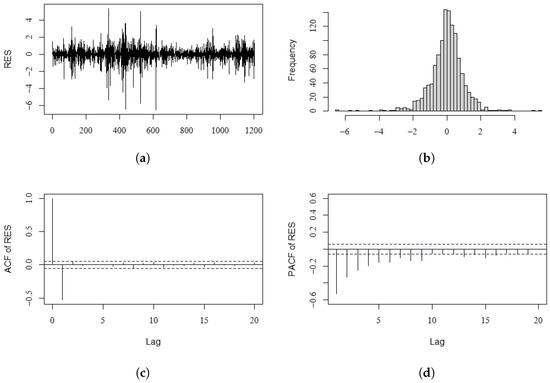
Figure 4.
Diagnostic checking plots for the Nikkei 225 (log return) data. (a) Standardized residuals; (b) histogram of standardized residuals; (c) ACF plot of residuals; (d) PACF plot of residuals.
Table 3 displays the AIC of these two fitted models, from which we can see that the AIC of the TVCDT-GARCH model is smaller than the one of the DT-GARCH model.
Table 3.
AIC of two fitted models.
In conclusion, the real data application reveals that the TVCDT-GARCH model is better than the DT-GARCH model, and the QMELE is proper, compatible, and more accurate than the traditional QMLE. This is not surprising, so in the TVCDT-GARCH model, we consider the influence of the explanatory variable (daily volume). Thus, the model contains more information and can fit the real data better than the DT-GARCH model. Futhermore, the distribution of exhibits asymmetric and heavy-tailed features, which is a frequent phenomenon involving financial time series, so we think that using QMELE in parameter-estimation procedures is a pragmatic alternative for practitioners.
5. Conclusions
In this article, we studied the use of the quasi-maximum exponential likelihood estimators (QMELE) to fit the TVCDT-GARCH model. We presented the consistency and the asymptotic normality of the QMELE for the model parameters. The simulation study provided the performance of these estimators. The application of the Nikkei 225 log return series revealed that the TVCDT-GARCH model is appropriate and feasible for analyzing the data, and QMELE provides researchers with a better approach than traditional QMLEs. For further study, the explanatory variables may be developed to higher dimensions, and the models may involve multiple threshold parameters under certain circumstances. These discussions will help us to extend our research in the future.
Author Contributions
Conceptualization, T.Z., L.F., D.W. and Z.Y.; methodology, T.Z. and D.W.; software, T.Z.; validation, T.Z., L.F., D.W. and Z.Y.; formal analysis, T.Z., L.F., D.W. and Z.Y.; investigation, T.Z., L.F., D.W. and Z.Y.; resources, L.F. and D.W.; data curation, T.Z. and D.W.; writing—original draft preparation, T.Z.; writing—review and editing, T.Z., L.F., D.W. and Z.Y.; visualization, T.Z.; supervision, L.F. and D.W.; project administration, L.F., D.W. and Z.Y.; funding acquisition, D.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China (No. 12271231, 12001229, 11901053), the National Social Science Foundation of China (No. 21BTJ043, No. 20BTJ056), and the Social Science Foundation of Liaoning Province (No. L22ZD065).
Data Availability Statement
Data are available on the website: hk.finance.yahoo.com, accessed on 1 January 2023.
Acknowledgments
We gratefully acknowledge the anonymous reviewers and editors for their insightful comments on and suggestions for this paper.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ACF | Autocorrelation Function Plot |
| PACF | Partial Autocorrelation Function Plot |
Appendix A
We need Lemma A1 and Lemma A2 for our proofs; hence, we list two lemmas below.
Lemma A1.
Let , where . If Assumptions (1)–(4) hold, then there exist constants C and such that the following holds uniformly in Θ:
Lemma A2.
For any , let be an open neighborhood of with radius . If Assumptions (1)–(4) hold, then we have the following:
(a) ;
(b) has an unique minimum at ;
(c) as .
Lemma A1 is taken from Lemma A2 in [45] and Lemma A1 of [36]. Lemma 1 is straightforward and follows from the central limit theorem for a martingale difference sequence. For Lemma 2, by letting in Lemmas 2.2 and 2.3 of [36], we can directly obtain Lemma 2.2. The detailed proofs of Lemma A2, Lemma 3, Theorem 1 and Theorem 2 can be found in the appendix of [41], and, hence, we omit the proofs of these lemmas and theorems.
References
- Nicholls, D.F.; Quinn, B.G. Random Coefficient Autoregressive Models: An Introduction; Springer: New York, NY, USA, 1982. [Google Scholar]
- Tjostheim, D. Estimation in nonlinear time series models. Stoch. Process. Their Appl. 1986, 21, 251–273. [Google Scholar] [CrossRef]
- Kim, Y.W.; Basawa, I.V. Empirical Bayes estimation for first order autoregressive processes. Aust. J. Stat. 1992, 34, 105–114. [Google Scholar] [CrossRef]
- Hwang, S.Y.; Basawa, I.V. Asymptotic optimal inference for a class of nonlinear time series models. Stoch. Process. Their Appl. 1993, 46, 91–113. [Google Scholar] [CrossRef]
- Hwang, S.Y.; Basawa, I.V. Large sample inference for conditional exponential families with applications to nonlinear time series. J. Stat. Plan. Inference 1994, 38, 141–157. [Google Scholar] [CrossRef]
- Hwang, S.Y.; Basawa, I.V. Parameter estimation for generalized random coefficient autoregressive processes. J. Stat. Plan. Inference 1998, 68, 323–337. [Google Scholar] [CrossRef]
- Aue, A. Strong approximation for RCA(1) time series with applications. Stat. Probab. Lett. 2004, 68, 369–382. [Google Scholar] [CrossRef]
- Aue, A.; Horvath, L.; Steinebach, J. Estimation in Random Coefficient Autoregressive Models. J. Time Ser. Anal. 2006, 27, 61–76. [Google Scholar] [CrossRef]
- Thavaneswaran, A.; Appadoo, S.S.; Ghahramani, M. RCA models with GARCH innovations. Appl. Math. Lett. 2009, 22, 110–114. [Google Scholar] [CrossRef]
- Tong, H. On a Threshold Model; Sijhoff & Noordhoff: Amsterdam, The Netherlands, 1978. [Google Scholar]
- Tong, H.; Lim, K.S. Threshold autoregression, limit cycles and cyclical data. J. R. Stat. Soc. Ser. B (Methodol.) 1980, 42, 245–268. [Google Scholar] [CrossRef]
- Engle, R.F. Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef]
- Karpoff, J.M. The Relation between Price Changes and Trading Volume: A Survey. J. Financ. Quant. Anal. 1987, 22, 109–126. [Google Scholar] [CrossRef]
- Tong, H. Non-Linear Time Series: A Dynamical System Approach; Oxford University Press: Oxford, UK, 1990. [Google Scholar]
- Li, C.W.; Li, W.K. On a Double-Threshold Autoregressive Heteroscedastic Time Series Model. J. Appl. Econometr. 1996, 11, 253–274. [Google Scholar] [CrossRef]
- Brooks, C. A Double-threshold GARCH Model for the French Franc/Deutschmark exchange rate. J. Forecast. 2001, 20, 135–143. [Google Scholar] [CrossRef]
- Chen, C.W.S.; Yang, M.J.; Gerlach, R.; Jim, L.H. The asymmetric reactions of mean and volatility of stock returns to domestic and international information based on a four-regime double-threshold GARCH model. Phys. Stat. Mech. Appl. 2006, 366, 401–418. [Google Scholar] [CrossRef]
- Yang, Y.L.; Chang, C.L. A double-threshold GARCH model of stock market and currency shocks on stock returns. Math. Comput. Simul. 2008, 79, 458–474. [Google Scholar] [CrossRef]
- Chen, C.W.S.; Gerlach, R. Semi-parametric quantile estimation for double threshold autoregressive models with heteroskedasticity. Comput. Stat. 2013, 28, 1103–1131. [Google Scholar] [CrossRef]
- Chen, C.W.S.; Chen, M.; Chen, H. Pairs Trading via Three-Regime Threshold Autoregressive GARCH Models. In Proceedings of the 7th International Conference of the Thailand Econometric Society, TES 2014, Chiang Mai, Thailand, 8–10 January 2014; pp. 127–140. [Google Scholar]
- Chen, C.W.S.; So, M.K.P.; Chiang, T.C. Evidence of Stock Returns and Abnormal Trading Volume: A Threshold Quantile Regression Approach. Jpn. Econ. Rev. 2016, 67, 96–124. [Google Scholar] [CrossRef]
- Luukkonen, R.; Saikkonen, P.; Teräsvirta, T. Testing linearity against smooth transition autoregressive models. Biometrika 1988, 75, 491–499. [Google Scholar] [CrossRef]
- Teräsvirta, T. Specification, estimation, and evaluation of smooth transition autoregressive models. J. Am. Stat. Assoc. 1994, 89, 208–218. [Google Scholar]
- Zheng, H.T.; Basawa, I.V. First-order observation-driven integer-valued autoregressive processes. Stat. Probab. Lett. 2008, 78, 1–9. [Google Scholar] [CrossRef]
- Yu, M.J.; Wang, D.H.; Yang, K. A class of observation-driven random coefficient INAR(1) processes based on negative binomial thinning. J. Korean Stat. Soc. 2019, 48, 248–264. [Google Scholar] [CrossRef]
- Yang, K.; Li, H.; Wang, D.H.; Zhang, C.H. Random coefficients integer-valued threshold autoregressive processes driven by logistic regression. AStA Adv. Stat. Anal. 2021, 105, 533–557. [Google Scholar] [CrossRef]
- Hwang, S.Y.; Basawa, I.V. Explosive Random Coefficient AR(1) Processes and Related Asymptotics for Least Squares Estimation. J. Time Ser. Anal. 2005, 26, 807–824. [Google Scholar] [CrossRef]
- Berkes, I.; Horvath, L.; Ling, S.Q. Estimation in nonstationary random coefficient autoregressive models. J. Time Ser. Anal. 2009, 30, 395–416. [Google Scholar] [CrossRef]
- Aue, A.; Horvath, L. Quasi-likelihood estimation in stationary and nonstationary autoregressive models with random coefficients. Stat. Sin. 2011, 21, 973–999. [Google Scholar]
- Weiss, A. Asymptotic theory for ARCH models: Estimation and testing. Econom. Theory 1986, 2, 107–131. [Google Scholar] [CrossRef]
- Engle, R.F.; Bollerslev, T. Modelling the persistence of conditional variances. Econom. Rev. 1986, 5, 1–50. [Google Scholar] [CrossRef]
- Berkes, I.; Horvath, L.; Kokoszka, P. GARCH processes: Structure and estimation. Bernoulli 2003, 9, 201–227. [Google Scholar] [CrossRef]
- Francq, C.; Zokaian, J.M. Maximum Likelihood Estimation of Pure GARCH and ARMA-GARCH Processes. Bernoulli 2004, 10, 605–637. [Google Scholar] [CrossRef]
- Hall, P.; Yao, Q. Inference in ARCH and GARCH models with heavy-tailed errors. Econometrica 2003, 71, 285–317. [Google Scholar] [CrossRef]
- Zhu, K.; Ling, S.Q. Global self-weighted and local quasi-maximum exponential likelihood estimators for ARMA-GARCH/IGARCH models. Ann. Stat. 2011, 39, 2131–2163. [Google Scholar] [CrossRef]
- Tsay, R.S. Testing and modeling threshold autoregressive processes. J. Am. Stat. Assoc. 1989, 84, 231–240. [Google Scholar] [CrossRef]
- Li, D.; Ling, S.Q. On the least squares estimation of multiple-regime threshold autoregressive models. J. Econom. 2012, 167, 240–253. [Google Scholar] [CrossRef]
- Yu, P. Likelihood estimation and inference in threshold regression. J. Econom. 2012, 167, 274–294. [Google Scholar] [CrossRef]
- Li, D.; Tong, H. Nested sub-sample search algorithm for estimation of threshold models. Stat. Sin. 2016, 26, 1543–1554. [Google Scholar] [CrossRef]
- Zhang, T.W.; Wang, D.H.; Yang, K. Quasi-maximum exponential likelihood estimation for double-threshold GARCH models. Can. J. Stat. 2021, 49, 1152–1178. [Google Scholar] [CrossRef]
- Sheng, D.S.; Wang, D.H.; Kang, Y. A new RCAR(1) model based on explanatory variables and observations. Commun. Stat.-Theory Methods 2022. [Google Scholar] [CrossRef]
- Li, G.D.; Guan, B.; Li, W.K.; Yu, P.L.H. Hysteretic autoregressive time series models. Biometrika 2015, 102, 717–723. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman and Hall: New York, NY, USA, 1986. [Google Scholar]
- Ling, S.Q. Self-weighted and local quasi-maximum likelihood estimators for ARMA-GARCH/IGARCH models. J. Econom. 2007, 140, 849–873. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).